
Abstract
The development of a system to recognize the speeches of standard speakers has been in practice for many decades. Research development is still progressing to implement a strategy to identify the speeches uttered by people with hearing impairment/Autism spectrum disorder/dysarthria. This work includes various speech enhancement techniques to increase the intelligibility of spoken utterances. This system uses perceptual features and different modelling techniques for developing a dysarthric speech recognition system. Perceptual features are extracted from raw speeches, and intelligibility-enhanced spoken utterances and models are created. The design features extracted from the test utterances are given to the models, and based on the classifier used, the test utterance is identified to be associated with the model. An Implementation of speech enhancement techniques would facilitate better accuracy. Decision-level fusion classification on integrating features, models, and speech enhancement techniques has provided overall accuracy of 81% for recognizing isolated digits spoken by a few dysarthric speakers. Better accuracy can be ensured for the database containing more utterances from many dysarthric speakers. This system would help caretakers understand the speeches uttered by persons affected with dysarthria to provide the necessary assistance.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
Speech production is a mechanism in which speech is considered an output of a vocal tract system excited by vocal cords' vibration due to airflow from the lungs. Articulators in the vocal tract and muscles move in response to the neural signals for producing speech. Muscles in the vocal tract are weak in delivering speech for persons with dysarthria. Dysarthria refers to multiple neurogenic disorders with irregularities in speech. It is measured in the articulator movements' strength, speed, range, tone, and precision. Dysarthric patients may struggle to control the articulatory mechanisms in producing normal sounds. Dysarthric persons may be easily identified by listening to their way of creating speech. They may utter unclear, slurred, random, rapid, slow, and weak speeches. They may have difficulty controlling the facial muscles and articulators for speech production. Stroke and injury or tumour in the brain influence dysarthric patients' neurological defects. It may also be caused by facial paralysis or tongue and weakness in throat muscles.
Speech-language pathologists treat dysarthric patients and administer remedial measures to improve their speaking abilities. It is suggested that dysarthric patients' communication abilities could improve by increasing lip and tongue movement, strengthening the speech muscles, reducing the rate of uttering speech, and doing regular voice-related exercises. Converting thoughts into speech sounds includes articulators in the vocal tract system [1]. Speech is an output of the linear time-varying vocal tract system excited by quasi-periodic air pulses due to vocal cords' vibration for voiced sounds and noise for unvoiced sounds. Dysarthria is a speech disorder caused due to the lack of ability to control articulators. Speech impairment affects every activity and makes these people's lives miserable.
Dysarthria makes coordinating the nerves and articulators used for speech production difficult. Articulation of various speech sounds will get perturbed by the uncontrolled behaviour of the nerves used for speech production. The speed at which dysarthric people utter speeches is relatively slow compared to standard speakers. Due to the lack of control of muscular activity, it is difficult for patients with dysarthria to control speech parameters such as loudness, speed, pacing, breath, rhythm, and voice quality. Due to cerebral palsy, the system is proposed to recognize persons' speeches with an articulation disorder [2]. The acoustic and language models are constituent components of the speech recognition system.
An acoustic model may be specific to persons with dysarthria, but a language model may be universal irrespective of any category of speakers. A speech recognition system [3] is developed to assess the severity of dysarthric people's problems. The Partial Least Square based Voice conversion (VC) method [4] is used for dysarthric people. Healthy speeches are transformed into dysarthric utterances for data augmentation [5], and large-scale machine-learning models are used for classification.
Convolutional bottleneck networks [6] are used for speech recognition. Two hybrid speech recognition systems (DNN-HMM and GMM-HMM) [7] have been developed for speech recognition, with a 13% improvement in word error rate. The system's efficiency for dysarthric persons has been improved using rhythm knowledge [8]. The connectionist approach assesses the severity of the dysarthria, and the Hidden Markov Model is used to recognize speaker-dependent dysarthric speech. System [9] is developed to convert physically disabled persons' spoken utterances into intelligible utterances to understand better. The transformations are based on the movement of articulators for speech production. Non-negative matrix factorization [10] is used for voice conversion, which is better than GMM-based voice conversion.
Augmentation of acoustic models with articulatory information [11] shows improved recognition of the speech of dysarthric speakers. This integration is done by suiting the dysarthric speakers. Deep learning neural networks [12] are used to predict the severity of the problem concerned with dysarthric speakers. Dysarthric speeches are modified based on temporal and spectral factors [13] to improve the intelligibility of the speeches uttered by dysarthric speakers. A speech recognition system [14] is developed for dysarthric speakers using Hidden Markov Models, and the severity of the problems associated with their speeches being uttered is evaluated. Speech enhancement techniques [15,16,17,18,19,20,21] are described. A description of the UA- speech database [22] is given. A speech recognition system [23] is developed for hearing impaired. The unsupervised learning method has been developed [24] to assess the auditory systems for speech recognition, which do not need a specific transcription of training data.
The dysarthric speech classification from coded telephone speech was developed [25, 26]. This feature is extracted using the deep neural network-based glottal inverse filtering method. Furthermore, an algorithm is proposed for syllable boundary and repletion of syllable detection [27] in dysarthric speech. Acoustic speech parameters [28] are analyzed for patients with Parkinson's disease. Speech patterns are analyzed to study the speaking characteristics of dysarthric speakers, and speech recognition systems [29,30,31,32,33,34] are developed. Variational mode decomposition with wavelet thresholding is used for speech enhancement. CNNs [35] classify dysarthric speeches on the UA-speech database. Speaker-independent dysarthric speech assessment [36] systems are developed. Deep neural network architectures [37] are used for analyzing the speeches of a dysarthric speaker. Empirical mode decomposition and Hurst-based mode selection (EMDH), along with deep learning architecture using a convolutional neural network (CNN) [38], are used to improve the recognition of dysarthric speech. The diversity of the speech patterns [39] of dysarthric speakers is characterized using clinical perspective and speech analytics. Dysarthric speeches are synthesized using text–into–speech (TTS) conversion systems [40] to improve the accuracy of dysarthric speech recognition.
Deep-belief-neural networks [41] are used for dysarthric speech recognition. Dysarthric speeches are augmented [42] using more training data to improve accuracy. The TORGO dataset uses transfer learning-based convolutional neural networks (CNN) [43] for dysarthric speech recognition. Variational mode decomposition with wavelet thresholding is used for speech enhancement. CNNs [35] classify dysarthric speeches on the UA-speech database. Dysarthric speech recognition [44] uses features and models on the UA-speech database. Speech emotion recognition [45] is done using CNNs. Detection of dysarthric speech [46] is done using CNNs. Automatic assessment of dysarthric speech intelligibility [47] is done using deep learning techniques. Deep-learning-based acoustic feature representation [48] is done for dysarthric speech recognition [49,50,51,52]. Audio-visual features are considered [49] for dysarthric speech recognition. A dysarthric isolated digit recognition system with speech enhancement techniques has been developed [50]. This work emphasizes using speech enhancement techniques to improve the intelligibility of the speeches uttered by dysarthric speakers to establish a robust speech recognition system for dysarthria. It also emphasizes using different spectral features and machine learning techniques to produce the speech recognition system.
In this work on speaker-independent dysarthric speech recognition, Sect. 2 describes the database used, analysis of dysarthric speeches in time and frequency domains, implementation of speech enhancement techniques, Feature extraction procedures, modelling techniques and testing procedures. Section 3 depicts the system's experimental, subjective comparison between experimental and emotional, and statistical validation results. Finally, Sect. 4 summarises the dysarthric speech recognition system's outcome by applying speech enhancement techniques, features, models and testing procedures of different modelling techniques.
2 Preliminaries
2.1 Dysarthric Speech Database
The dysarthric dataset [22] considered in this work contains speech utterances from 6 speakers (M01, M04, M07, M09, F03, F05) in the age group 18–51 for each isolated digit. As per the database description, M01, M04, M07, M09, and F03 are low speech intelligibility. F05 is a speaker with high speech intelligibility. Subjective analysis done on the speeches of F05 by hearing would also indicate the clarity of the spoken utterance, and her speeches are similar to that of standard speakers. The listeners can easily understand and recognize the speech recordings of F05. However, these speakers are spastic and athetoid and persons who use wheelchairs. Speech intelligibility is measured in the average score in word transcription tasks. Few utterances are recorded from these speakers because it is difficult to understand and reciprocate the word transcriptions correctly. So, it isn't easy to increase the robustness of the dysarthric speech recognition system.
2.2 Analysis – Dysarthric Speech
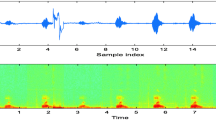
It is fascinating to characterize the speech uttered by dysarthric speakers. There are many differences between dysarthric speakers in pronouncing words/sentences. This fact necessitates the provision of an extensive database for recognizing the words uttered by them. It is understood that their speeches are highly distorted, and subjective identification of utterances becomes difficult. On average, dysarthric and regular speakers' speeches are different in style, slang, and place of articulation. Figure 1 indicates the characteristics of the speech uttered by the dysarthric person in terms of signal variations and its spectrogram for the isolated digit "one".

Speech signal and spectrogram – Dysarthricspeaker (M09)—Digit "One."
Signal representation and spectrogram are shown in Fig. 2, which depict another dysarthric person's characteristics for uttering the word "one". The same word they spoke at different instants may have differences in amplitude and spectral energy. Since dysarthric speakers' speeches are indistinct, it is more imperative for better accuracy in recognizing dysarthric speakers' speeches.

Speech signal and spectrogram – Dysarthric speaker (M07)—Digit "One"
2.3 Implementation of Speaker Independent Speech Recognition System
The speaker-dependent and independent speech recognition systems are implemented to recognize the isolated words /isolated digits/continuous sentences/spontaneous sentences uttered by speakers. A speaker-dependent system is developed using a set of speech utterances spoken by all the speakers for training and the remaining set of phrases spoken by the same speakers for testing. Speaker independent speech recognition system facilitates the use of utterances spoken by some of the enrolled speakers for training and other enrolled subjects' utterances for testing.
Feature extraction and modelling are the two stages constituting the training phase. The feature extraction stage facilitates the extraction of speech-specific robust features. Then, these features are applied to the modelling techniques for creating templates specific to speeches. The testing phase dwells upon using test feature vectors in the models designed to recognize the spoken utterance. The word is finally recognized as associated with the pertinent model based on matching. So, it is imperative to have a proper notion of robust feature selection, modelling techniques, and implementing the appropriate testing procedure. It is also essential to use techniques to improve the lucidity of dysarthric speakers' distorted speeches so that the system's accuracy can be reasonably enhanced.
2.4 Speech Enhancement Techniques
In noisy practical environments, background noise sources often degrade speech clarity. So, it is required to use efficient speech enhancement techniques to improve the clarity of the speech. The noisy speech is represented by the Eq. (1)
\({x}_{n}\left(m\right)\) – Clean speech signal.
\({d}_{n}\left(m\right)\) – Noise signal.
2.4.1 Single-channel online enhancement of speech [15]
Background noises and reverberation affect the voice-based interaction between people. Speech enhancement techniques are used to improve the quality of the speech for better speech recognition. Online speech enhancement technique based on the all-pole model enhances speech quality. It is implemented using reverberation power and a hidden Markov model for removing noise superimposed with speech. Statistical parameters are estimated from the speech and noise, and analysis is performed by taking a short-time Fourier transform (STFT) with filters spaced in the MEL scale; spectral gain is derived.
Figure 3 indicates the speech enhancement process in the STFT domain. System parameters and signal powers are estimated using the MEL-spaced sub-bands. Then, the transformation of the power spectrum is done by using filters spaced in the Mel scale.

Speech enhancement using a single-channel online enhancement technique
Consider noisy speech signals as \({{\text{Y}}}_{{\text{n}}}\left({\text{m}}\right)\). STFT is taken on \({{\text{Y}}}_{{\text{n}}}\left({\text{m}}\right)\) and coefficients are computed as in (2)
k – STFT frequency bin. \(n\) – Time frame index. w(n) – Hamming Window sequence.
A power-domain filter bank is applied to compute the power in k Mel-spaced sub-bands as in (3)
\({a}_{F,k}\) – Frequency response of the triangular filters.
HMM model is used to define the clean speech with an input probability distribution, state transition probabilities, and output observation probability distribution as in (4)
\({{\text{H}}}_{{\text{m}}}\) is an HMM model including the reverberation \({{\text{R}}}_{{\text{m}}}\) and noise parameters \({{\text{d}}}_{{\text{m}}}\) for all subbands in a single state vector. Noise removal and improvement in intelligibility from noisy speech are made in the STFT domain. Figure 4 indicates the signals before and after applying the online speech enhancement algorithm on dysarthric speech.

Illustration of online speech enhancement algorithm
2.4.2 Speech Enhancement Using a Minimum Mean Square Error (MSE) LogSpectral Amplitude Estimator [16]
Minimizing MSE of the log spectra of the difference between the original signal's short-time spectral amplitude and the estimated signal is performed by the short-time spectral amplitude (STSA) estimator. The magnitude and phase response of the noisy, noise and clean speech signal is expressed in the frequency domain.
As \({Y}_{k}={R}_{k}{e}^{j{\gamma }_{k}}\), \({D}_{k}={B}_{k}{e}^{j{\beta }_{k}}\) and \({X}_{k}={A}_{k}{e}^{j{\alpha }_{k}}\)
The short-time spectral amplitude estimator \(\widehat{{{\text{A}}}_{{\text{k}}}}\), for minimizing the distortion measure is defined as in (5)
The expected value of \(\widehat{{A}_{k}}\) given \({Y}_{k}\) equal to the expected value of \({A}_{k}\) given \({Y}_{k}\) as in (6)
MSE of log power spectra is calculated as in (7)
\({\widehat{{A}_{k}}}^{2}\) Denote the estimator of \(\overline{{A}_{k}}\) as in (8)
\(E[{\text{ln}}{A}_{k}|{Y}_{k}]\) is computed by utilizing the moment-generating function of \({\text{ln}}{A}_{k}\) given \({Y}_{k}\).
Let \({Z}_{k}={\text{ln}}{A}_{k}\), and \({\varphi }_{{Z}_{k|{Y}_{k}}(\mu )}\) of \({Z}_{k}\) given \({Y}_{k}\) Be the moment generating function, and it is defined as in (9)
\(E\{[{\text{ln}}{A}_{k}|{Y}_{k}]\)} is obtained from \({\varphi }_{{Z}_{k|{Y}_{k}}(\mu )}\) by using (10)
The STSA estimator is as in (11)
Figure 5 indicates the speech enhancement process using a log spectral amplitude estimator.

Illustration of speech enhancement by log spectral amplitude estimator
2.4.3 Speech Enhancement by Using Minimum Mean-Square Error Short-Time Spectral Amplitude Estimator [17]
The signal \({\text{x}}\left({\text{t}}\right),\) noise \({\text{n}}\left({\text{t}}\right),\) and the noisy observations \({\text{y}}\left({\text{t}}\right)\) are expressed in the frequency domain as \({{\text{D}}}_{{\text{k}}}\) and \({{\text{Y}}}_{{\text{k}}}\). The \({{\text{Y}}}_{{\text{k}}}\) in the interval [0 T] is defined as in (12)
The spectral components are uncorrelated to each other; The MMSE estimator. \(\widehat{{{\text{A}}}_{{\text{k}}}}\) of \({{\text{A}}}_{{\text{k}}}\) given \({{\text{Y}}}_{{\text{k}}}\) is obtained as in (13) and (14)
\(E\{.\}\) – denotes Expectation operation
\(p\left(.\right)\)- Probability density function.
\(p\left({Y}_{k}|{a}_{k} , {\alpha }_{k}\right)\) is given by (15)
\(p\left({a}_{k},{\alpha }_{k}\right)\) is given by (16)
\({\lambda }_{d}\left(k\right)\), \({\lambda }_{x}\left(k\right)\) are the variances of the \(kth s\) pectral component of the noise and the speech.
Substituting \(p\left({a}_{k},{\alpha }_{k}\right)\) in Eqs. (17) and (18)
\(\Gamma \left(.\right)\) Denotes the gamma function.
\({I}_{0}\left(.\right) , {I}_{1}\left(.\right)\) Denotes the modified Bessel functions of zero and first order, respectively, with parameters as in Eqs. (19–21)
\({\epsilon }_{k}\) and \({\gamma }_{k}\) – a priori and a posteriori signal-to-noise ratios.
Figure 6 depicts the speech enhancement process by a short-time spectral amplitude estimator.

Illustration of speech enhancement by short-time spectral amplitude estimator
2.4.4 Wavelet denoising for Speech Enhancement [18]
The wavelet denoising technique suppresses noise from noisy speech to obtain clean speech. First, wavelet packet transform decomposes noisy speech into approximation and detail coefficients. Then, the threshold is fixed and applied to the final level sub-band coefficients to minimize the noise propositions. Figure 7 shows the wavelet-based enhancing quality of speech. Finally, Enhanced speech is obtained by upsampling and interpolating the modified detail and approximation coefficients.

Speech enhancement using Wavelet denoising technique
Figure 8 demonstrates the speech enhancement process by using wavelets.

Illustration of speech enhancement process by wavelets
2.4.5 Probabilistic Geometric Approach (PGA) to spectral subtraction based Speech Enhancement [19]
A confidence parameter of noise estimation is introduced in the gain function, which removes the noise efficiently and prevents speech distortion. The schematic shown in Fig. 9 depicts the PGA-based speech enhancement technique modules.

Speech enhancement using Probabilistic Geometric Approach
The equation represents the STFT of noisy speech as in (22)
\(n\) – frame number.
The STFT of \({{\text{y}}}_{{\text{n}}}\left({\text{m}}\right)\) is represented as in (23)
From the basic rule of spectral subtraction, the Eq. (23) can be written as (24)

This equation can also be written as (25)
\({H}_{n(PGA)}\left(k\right)\) – gain function of the nth frame. \({X}_{n}\left(k\right)\), \({Y}_{n}\left(k\right)\) and \({D}_{n}\left(k\right)\) can be expressed in polar form as
\(\rho\) – is a constant dependent on posterior and a priori SNRs.
\({a}_{x}\), \({a}_{y}\) and \({a}_{d}\) are the magnitude response of clean, noisy and noise signals.
\({\theta }_{x}\), \({\theta }_{y}\) and \({\theta }_{d}\) are the phase response of clean, noisy and noise signals.
The gain function \({H}_{n(PGA)}\left(k\right)\) can be defined as in (26)
The unchanged phase spectrum and compensated magnitude spectrum are combined to produce an enhanced speech by using the formula in (27)

Figure 10 indicates the effect of the probabilistic geometric approach in enhancing the speech uttered by the dysarthric speaker.

Illustration of speech enhancement by a probabilistic geometric approach
2.4.6 The Geometric Approach to Spectral Subtraction-Based Speech Enhancement [20]
Noise present in speech is effectively reduced by spectral subtraction. The spectral subtraction method removes the noise based on the assumption that the noise is uncorrelated with any other system signal. Figure 11 gives a detailed description of the blocks used for geometric approach-based speech enhancement.

Geometric approach to spectral Subtraction for speech enhancement
This equation to compute signal spectrum is as in (28)
\({H}_{n(GA)}\left(k\right)\) – gain function of the Geometric approach of the nth frame.
The magnitude and phase response of the noisy, noise and clean speech are related as in (29)
The triangle shown in Fig. 12 depicts the phase spectra of the noisy speech and clean speech and noise signals.

Geometric representation of noisy speech, clean speech and noise spectra
In Fig. 12, Eqs. (30) give the trigonometric relations for magnitude and phase spectra of noisy speech, clean speech and noise signals.
Taking square of both sides
It can be written as in (30)
The gain function is defined as in (31)
Using cosine rules in triangle ABC, Eqs. (32) and (33) are used
Dividing both numerator and denominator of the equation by \({{a}_{D}}^{2}\) as in (34) and (35)
\(\Upsilon\) – A posteriori SNR.
\(\varepsilon\)– A priori SNR.
The gain function can be written as in (36)
Enhanced speech is obtained by combining an unchanged phase spectrum with compensated magnitude spectrum, as in (37)

Figure 13 illustrates the speech enhancement process by the geometric approach applied to the dysarthric speaker's speech.

Effect of speech enhancement process by a geometric approach
2.4.7 Phase Spectrum Compensation Based Speech Enhancement [21]
This method combines the modified phase response with a magnitude response to get the changed frequency response for the noisy speech. Analyzing the relation between the spectral and time domains during the synthesis process makes it possible to cancel out the high-frequency components, thus producing a signal with a reduced noise component. The STFT of the noisy signal is computed as in (38)
The compensated short-time phase spectrum is computed by using the Eqs. (39) and (40)
The process obtains phase spectrum compensation function as in Eq. (39)
\(\left|{D}_{n}(k)\right|\) Defines magnitude response of the noise signal.
\(\lambda\)– Constant.
The anti-symmetry function \(\psi (k)\) is defined as in (40)
Multiplication of symmetric magnitude spectra of the noise signal with anti-symmetric function \(\uppsi \left({\text{k}}\right)\) produces an anti-symmetric \({\wedge }_{{\text{n}}}\left({\text{k}}\right)\). Noise cancellation is made during the synthesis process by utilization of the anti-symmetry property of the phase spectrum compensation function. The complex spectrum of noisy speech is computed as in Eq. (41)
The compensated phase spectrum of the noisy signal is derived as in Eq. (42)
Recombination of the compensated phase response with the magnitude response of the noisy signal is done to get the modified spectrum, from which enhanced speech is derived by performing inverse transform as in (44) on the modified spectral response given in (43).
Figure 14 indicates the performance of the speech enhancement technique by phase compensation. Figure 15 depicts the variation in the distribution of samples for each speech enhancement technique by performing histogram equalization.

Illustration of speech enhancement by phase spectrum compensation technique

Histogram equalization – (1) Original speech (2–8) Enhanced speech using speech enhancement techniques
2.5 Feature Extraction
PLP extraction is based on the principle of how the human ear perceives sounds [1]. The PLP extraction method is similar to the linear prediction coefficient method, except its spectral characteristics are changed based on the human auditory system. Perceptual features with filters spaced in BARK, ERB, and MEL scales are extracted from the pre-processed speech using the techniques shown in Fig. 16. The FFT technique obtains the pre-processed signal's power spectrum; the auditory spectrum is obtained by multiplying the signal's power spectrum. The squared magnitude spectrum of the filters is spaced in different frequency scales. Cube root compression and Loudness equalization simulate the human ear's power law of hearing perception. Finally, the inverse transform is performed to obtain the signal, from which cepstral coefficients are derived using LPC and Cepstral analyses.

Procedure—Perceptual features extraction
i Procedural steps used for PLPC, MF-PLPC and ERB-PLPC extraction are summarised as follows.
1 Computation of power spectrum on pre-processed speech segment.
2 Critical band analysis uses 21, 47 and 35 critical bands in BARK, Mel, and ERB frequency scales at 16 kHz as sampling frequency. The magnitude response of the filter banks spaced in the MEL scale, BARK scale and ERB scale are shown in Figs. 17, 18 and 19. Frequency in Hz and other frequency scales, namely MEL, BARK and ERB, are related as in (45), (46) and (47).

Magnitude response of critical bands in the BARK scale

Magnitude response of the critical bands in the MEL scale

Magnitude response of the critical bands in the ERB scale
3 Hearing's power law is stimulated by hearing, loudness equalization, and cube root compression. Loudness equalization is done by pre-emphasis filter to weight the filter-bank outputs to simulate the sensitivity of ears to perceive sounds as in (48).
Transformation of equalized values is done by a power law of hearing (i.e.) raising the power by 0.33. It is represented in (49)
4 IFFT is performed on L (\(\omega\)).
5 The Levinson-Durbin procedure computes the LP coefficient.
6 LP coefficients are converted into PLP, MFPLP and ERBPLP Cepstral coefficients.
2.6 Implementation of Template Creation Module
For a speech recognition system, templates are created to act as a representative model pertinent to speeches to be recognized. VQ-based or fuzzy-based clustering technique forms the low dimensional cluster set from the high dimensional training set among the many modelling techniques. They include M cluster centroids for contemplating the speech model from the training data of high dimension. This process is done by computing the Euclidean distance between the training set and initial cluster centroids. These cluster centroids are updated for iterations, and finally, the cluster set formed in pertinent speech represents the training set of feature vectors. For testing, Euclidean distance is computed between test vectors and cluster set, and cluster centroid, which produces minimum distance, is restored. All the test speech features and minimum distances are calculated and stored as a model value. This process is implemented for all models. Finally, a model is selected for the test speech to compare the minimum of model values. MHMM modelling technique facilitates the expectation–maximization procedure to generate templates containing maximum likelihood parameters. The testing procedure for MHMM enables the application of test features to the models, and log-likelihood values are computed. The model associated with the test speech has the most considerable log-likelihood value.
3 Experimental Evaluation – Results and Discussion
The dysarthric speech recognition system is evaluated based on perceptual features and various modelling techniques. Different speech enhancement techniques applied to distorted dysarthric speeches would enable the system to enhance performance. This speech recognition system encompasses training and testing phases. During training, speeches are concatenated, and conventional pre-processing techniques are applied to the speech data. After the pre-processing, extraction of perceptual features is performed, followed by using features for creating templates. Test speeches undergo pre-processing during testing, and perceptual features are extracted. These features are applied to all speech templates, and based on the classifier used; speech is identified to be associated with pertinent speech templates. Recognition accuracy/word error rate is used as a performance metric for evaluating the system. Finally, speech enhancement techniques are applied to raw training and test speeches, and the system's performance is assessed. The implementation uses the decision-level fusion of speech enhancement techniques, features, and modelling techniques to classify the pertinent dysarthric speech. Features extracted from test segments are applied to the models, and the model index based on the classifier used is derived. This process is repeated for all test segments. Finally, a decision-level fusion of correct indices about the modelling techniques is done to augment the system's performance. The decision-level fusion classifier is depicted in Fig. 20.

Decision-level fusion classifier
This decision-level fusion classifier classifies the pertinent speech based on the correct classification of features, modelling techniques, and speech enhancement techniques. Table 1 indicates the system's performance with a decision-level fusion of elements and models by taking speeches with and without speech enhancement techniques. The overall accuracy for ten digits in Fig. 21 shows the system's evaluation for recognizing dysarthric speeches against speech enhancement techniques with a decision-level fusion of results on features and models. Individual accuracy for some isolated digits is 100%, with overall accuracy for the decision-level fusion of influences of the features, models, and speech enhancement techniques at 80.2%.

Performance of the dysarthric speech recognition system –dysarthric speaker F03 (6% speech intelligibility)
Individual accuracy for some isolated digits is low because the testing is done with utterances of a dysarthric speaker with only 6% speech intelligibility. Training the models with many feature vectors can enhance the system's accuracy. The system has not provided good accuracy because it is tested for the female speaker with only 6% speech intelligibility. Decision-level fusion of results of features and models has provided a better overall accuracy of 43%, with an application of phase spectrum compensation as a speech enhancement technique. It is 12% more than the system without using a speech enhancement mechanism. So, the system's accuracy depends on features, models, speech enhancement techniques, and the test set of spoken utterances. However, the system is trained for speech utterances at all intelligibility levels. Therefore, obtaining better accuracy for speakers with very low intelligibility is difficult.
Table 2 gives the individual performance of the isolated digit recognition system for dysarthric speakers with 95% speech intelligibility by considering the perceptual features and vector quantization (VQ) models. Results show that the system provides excellent accuracy if the features and models are tested for speaker F05, diagnosed with 95% speech intelligibility. She is almost like an average speaker, and testing done using her speech utterances for all isolated digits provides exemplary accuracy. So, the speech utterances applied for evaluation must be acceptable, and the distortion level must be low.
3.1 Statistical Analysis and Validation of Experimental Results
The system's performance is statistically analyzed [23] to validate the perceptual features, models and speech enhancement techniques for recognizing dysarthric speakers' speeches. Table 3 indicates the usage of χ2 a statistical distribution tool to analyze the experimental result. The number of test segments for concatenated test speech uttered by the dysarthric speaker in a pertinent digit is probable frequency. The actual frequency is the number of correctly identified test speech segments for each digit. Ten isolated digits are taken as ten attributes. Since the sample size is 100, χ2distribution is applied to statistically analyze the choice of features, models and speech enhancement techniques. Hence, the rule of hypothesis based on χ2distribution is framed as below:
H0: Rejection rate is greater than or equal to 10%
H1: Rejection rate is less than 10%
The individual χ2test is applied at a 10% significance level, and the degree of freedom is considered nine χ20.1 = 21.66. Concerning the χ2 table, the H0 hypothesis is accepted. Table 4 indicates the system's statistical analysis for F05 speakers with perceptual features and clustering as a modelling technique with the hypothesis set below.
H1: Digit recognition rate is \(\ge \,95\%\)
H0: Digit recognition rate is \(< 95\%\)
The individual χ2 test is applied at a 5% significance level, and the degree of freedom is considered nine χ20.05 = 16.919. The χ2 table's calculated values are much less than the table value. Hence, the H1 hypothesis is accepted. Subjective analysis is done to supplement the experimental dysarthric speech recognition system. Four average persons are asked to recognize the speeches uttered by dysarthric speakers. They are informed to listen to the isolated digits spoken by F03 and F05 dysarthric speakers. Tables 5 and 6 indicate the subjective analysis results for recognizing the numbers uttered by dysarthric speakers. Figure 22 and 23 show the comparative analysis between the experimental and manual assessment for identifying isolated digits spoken by F03 and F05 dysarthric speakers. The practical and subjective analysis would yield low accuracy since the F03 dysarthric speaker has 6% speech intelligibility. The experimental study is better than manual recognition for all the digits except 'zero'. It reveals that ensuring better performance for dysarthric speech recognition has been challenging. The comparative analysis in Fig. 23 indicates that the subjective assessment has yielded slightly better accuracy than the experimental assessment. F05 is a dysarthric female speaker with 95% speech intelligibility, so the accuracy of the decision-level practical classification and subjective analysis is very high. It is revealed that accuracy is directly proportional to the speakers' intelligibility level of the speeches uttered. In this work, speech enhancement techniques are implemented for improvement.

Comparative analysis – Experimental and subjective assessment – F03 dysarthric speaker (6% speech intelligibility)

Comparative analysis – Experimental and subjective assessment – F05 dysarthric speaker (95% speech intelligibility)
Since the speeches of F03 speakers with 6% speech intelligibility are highly distorted and disordered, it is cumbersome to ensure better accuracy. There are significant variations in style, difficulty level and pronunciation of words in the speeches of these speakers. However, if the speech intelligibility is good, their speeches can be classified without ambiguity. Adapting better speech enhancement mechanisms, features, and models would be a promising solution for ensuring better accuracy for speech-impaired whose impairment level is high. Table 7 depicts the comparative analysis between the existing works and our proposed work.
4 Conclusion
Since the speeches uttered by dysarthric people are severely distorted and degraded, it has become essential to improve the intelligibility of dysarthric spoken utterances. Subjective analysis of recognizing dysarthric spoken words reveals that human manual recognition is complex, especially those uttered by speakers with low speech intelligibility. The system uses perceptual features, speech enhancement techniques and statistical modelling methods. The proposed decision-level fusion system comprising features, models and speech enhancement techniques could improve accuracy for recognizing isolated digits uttered by dysarthric speakers. Accuracy is 81% for the decision-level fusion classifier for identifying numbers spoken by the dysarthric speaker with 6% speech intelligibility. However, this system has provided 99% accuracy in recognizing the isolated digits uttered by the dysarthric speaker with 95% speech intelligibility. Experimental results surpass the manual recognition of numbers uttered by a speaker with deficient speech intelligibility. However, manual credit has 100% accuracy for recognizing isolated digits spoken by a dysarthric speaker with 95% speech intelligibility. This system would provide accuracy if the system is trained using the database containing a more significant number of utterances spoken by more dysarthric speakers. This system can act as a translator for caretakers to understand dysarthric speakers' speeches to provide them with the necessary assistance. A robust speech translator may be designed to convert unintelligent spoken utterances into intelligible ones and interpret speeches uttered by dysarthric speakers that can be understandable. This work emphasizes the need for more efficient speech enhancement techniques to improve speech quality. It is proposed to strengthen the selection of features, speech enhancement and modelling techniques for the system's performance improvement.
Data Availability
The datasets generated during and analyzed during the current study are available from the corresponding author upon reasonable request.
References
Cespedes-Simangas, L., Uribe-Obregon, C., & Cabanillas-Carbonell, M. (2021). Analysis of speech therapy systems for children with physical disabilities and speech disorders: A systematic review. European Journal of Molecular & Clinical Medicine, 8(3), 2287–2301.
Takashima, Y., Takiguchi, T., & Ariki, Y. (2019). End-to-end dysarthric speech recognition using multiple databases. In ICASSP 2019–2019 IIEEE international conference on acoustics, speech and signal processing (ICASSP), IEEE, pp 6395–6399
Thoppil, M. G., Kumar, C. S., Kumar, A., & Amose, J. (2017). Speech signal analysis and pattern recognition in diagnosis of dysarthria. Annals of Indian Academy of Neurology, 20(4), 352.
Aihara, R., Takiguchi, T., & Ariki, Y. (2017). Phoneme-discriminative features for dysarthric speech conversion. In Interspeech, pp 3374–3378
Jiao, Y., Tu, M., Berisha, V., & Liss, J. (2018). Simulating dysarthric speech for training data augmentation in clinical speech applications. In 2018 IEEE international conference on acoustics, speech and signal processing (ICASSP), IEEE, pp 6009–6013
Takashima, Y., Nakashika, T., Takiguchi, T., & Ariki, Y. (2015). Feature extraction using pre-trained convolutive bottleneck nets for dysarthric speech recognition. In 2015 23rd European Signal Processing Conference (EUSIPCO), IEEE, pp 1411–1415
Espana-Bonet, C., & Fonollosa, J. A. (2016). Automatic speech recognition with deep neural networks for impaired speech. In Advances in Speech and Language Technologies for Iberian Languages: Third International Conference, IberSPEECH 2016, Lisbon, Portugal, November 23–25, 2016, Proceedings 3, Springer International Publishing, pp 97–107
Selouani, S. A., Dahmani, H., Amami, R., & Hamam, H. (2012). Using speech rhythm knowledge to improve dysarthric speech recognition. International Journal of Speech Technology, 15, 57–64.
Rudzicz, F. (2013). Adjusting dysarthric speech signals to be more intelligible. Computer Speech & Language, 27(6), 1163–1177.
Aihara, R., Takashima, R., Takiguchi, T., & Ariki, Y. (2014). A preliminary demonstration of exemplar-based voice conversion for articulation disorders using an individuality-preserving dictionary. EURASIP Journal on Audio, Speech, and Music Processing, 2014(1), 1–10.
Rudzicz, F. (2010). Articulatory knowledge in the recognition of dysarthric speech. IEEE Transactions on Audio, Speech, and Language Processing, 19(4), 947–960.
Tu, M., Berisha, V., & Liss, J. (2017). Interpretable objective assessment of dysarthric speech based on deep neural networks. In Interspeech, pp 1849–1853
Rudzicz, F. (2011). Acoustic transformations to improve the intelligibility of dysarthric speech. In Proceedings of the Second Workshop on Speech and Language Processing for Assistive Technologies, pp 11–21
Lee, S. H., Kim, M., Seo, H. G., Oh, B. M., Lee, G., & Leigh, J. H. (2019). Assessment of dysarthria using one-word speech recognition with hidden markov models. Journal of Korean Medical Science, 34(13), 108.
Doire, C. S., Brookes, M., Naylor, P. A., Hicks, C. M., Betts, D., Dmour, M. A., & Jensen, S. H. (2016). Single-channel online enhancement of speech corrupted by reverberation and noise. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 25(3), 572–587.
Ephraim, Y., & Malah, D. (1985). Speech enhancement using a minimum mean-square error log-spectral amplitude estimator. IEEE Transactions on Acoustics, Speech, and Signal Processing, 33(2), 443–445.
Ephraim, Y., & Malah, D. (1984). Speech enhancement using a minimum-mean square error short-time spectral amplitude estimator. IEEE Transactions on Acoustics, Speech, and Signal Processing, 32(6), 1109–1121.
Lallouani, A., Gabrea, M., & Gargour, C. S. (2004). Wavelet based speech enhancement using two different threshold-based denoising algorithms. In Canadian Conference on Electrical and Computer Engineering 2004 (IEEE Cat. No. 04CH37513), IEEE, vol. 1, pp 315–318
Islam, M. T., Shahnaz, C., Zhu, W. P., & Ahmad, M. O. (2018). Enhancement of noisy speech with low speech distortion based on probabilistic geometric spectral subtraction. arXiv preprint arXiv:1802.05125.
Lu, Y., & Loizou, P. C. (2008). A geometric approach to spectral subtraction. Speech communication, 50(6), 453–466.
Stark, A. P., Wójcicki, K. K., Lyons, J. G., & Paliwal, K. K. (2008). Noise driven short-time phase spectrum compensation procedure for speech enhancement. In Ninth Annual Conference of the International Speech Communication Association
Kim, H., Hasegawa-Johnson, M., Perlman, A., Gunderson, J., Huang, T. S., Watkin, K., & Frame, S. (2008). Dysarthric speech database for universal access research. In Ninth Annual Conference of the International Speech Communication Association
Arunachalam, R. (2019). A strategic approach to recognize the speech of the children with hearing impairment: Different sets of features and models. Multimedia Tools and Applications, 78, 20787–20808.
Despotovic, V., Walter, O., & Haeb-Umbach, R. (2018). Machine learning techniques for semantic analysis of dysarthric speech: An experimental study. Speech Communication, 99, 242–251.
Narendra, N. P., & Alku, P. (2019). Dysarthric speech classification from coded telephone speech using glottal features. Speech Communication, 110, 47–55.
Narendra, N. P., & Alku, P. (2021). Automatic assessment of intelligibility in speakers with dysarthria from coded telephone speech using glottal features. Computer Speech & Language, 65, 101117.
Diwakar, G., & Karjigi, V. (2020). Improving speech to text alignment based on repetition detection for dysarthric speech. Circuits, Systems, and Signal Processing, 39, 5543–5567.
Cavallieri, F., Budriesi, C., Gessani, A., Contardi, S., Fioravanti, V., Menozzi, E., & Antonelli, F. (2021). Dopaminergic treatment effects on dysarthric speech: Acoustic analysis in a cohort of patients with advanced Parkinson’s disease. Frontiers in Neurology, 11, 616062.
Hirsch, M. E., Lansford, K. L., Barrett, T. S., & Borrie, S. A. (2021). Generalized learning of dysarthric speech between male and female talkers. Journal of Speech, Language, and Hearing Research, 64(2), 444–451.
Hu, A., Phadnis, D., & Shahamiri, S. R. (2021). Generating synthetic dysarthric speech to overcome dysarthria acoustic data scarcity. Journal of Ambient Intelligence and Humanized Computing, 14, 1–18.
Kodrasi, I. (2021). Temporal envelope and fine structure cues for dysarthric speech detection using CNNs. IEEE Signal Processing Letters, 28, 1853–1857.
Liu, S., Geng, M., Hu, S., Xie, X., Cui, M., Yu, J., & Meng, H. (2021). Recent progress in the CUHK dysarthric speech recognition system. IEEE ACM Transactions on Audio, Speech, and Language Processing, 29, 2267–2281.
Liu, Y., Penttilä, N., Ihalainen, T., Lintula, J., Convey, R., & Räsänen, O. (2021). Language-independent approach for automatic computation of vowel articulation features in dysarthric speech assessment. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 29, 2228–2243.
Dhanalakshmi, M., Nagarajan, T., & Vijayalakshmi, P. (2021). Significant sensors and parameters in assessment of dysarthric speech. Sensor Review, 41(3), 271–286.
Rajeswari, R., Devi, T., & Shalini, S. (2022). Dysarthric speech recognition using variational mode decomposition and convolutional neural networks. Wireless Personal Communications, 122(1), 293–307.
Tripathi, A., Bhosale, S., & Kopparapu, S. K. (2021). Automatic speaker independent dysarthric speech intelligibility assessment system. Computer Speech & Language, 69, 101213.
Zaidi, B. F., Selouani, S. A., Boudraa, M., & Sidi Yakoub, M. (2021). Deep neural network architectures for dysarthric speech analysis and recognition. Neural Computing and Applications, 33, 9089–9108.
Sidi Yakoub, M., Selouani, S. A., Zaidi, B. F., & Bouchair, A. (2020). Improving dysarthric speech recognition using empirical mode decomposition and convolutional neural network. EURASIP Journal on Audio, Speech, and Music Processing, 2020(1), 1–7.
Rowe, H. P., Gutz, S. E., Maffei, M. F., Tomanek, K., & Green, J. R. (2022). Characterizing dysarthria diversity for automatic speech recognition: A tutorial from the clinical perspective. Frontiers in Computer Science, 4, 770210.
Soleymanpour, M., Johnson, M. T., Soleymanpour, R., & Berry, J. (2022). Synthesizing dysarthric speech using multi-talker TTS for dysarthric speech recognition. arXiv preprint arXiv:2201.11571.
Ren, J., & Liu, M. (2017). An automatic dysarthric speech recognition approach using deep neural networks. International Journal of Advanced Computer Science and Applications. https://doi.org/10.14569/IJACSA.2017.081207
Harvill, J., Issa, D., Hasegawa-Johnson, M., & Yoo, C. (2021). Synthesis of new words for improved dysarthric speech recognition on an expanded vocabulary. In ICASSP 2021–2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), IEEE, pp 6428–6432
Sekhar, S. M., Kashyap, G., Bhansali, A., & Singh, K. (2022). Dysarthric-speech detection using transfer learning with convolutional neural networks. ICT Express, 8(1), 61–64.
Shahamiri, S. R. (2021). Speech vision: An end-to-end deep learning-based dysarthric automatic speech recognition system. IEEE Transactions on Neural Systems and Rehabilitation Engineering, 29, 852–861.
Ullah, R., Asif, M., Shah, W. A., Anjam, F., Ullah, I., Khurshaid, T., & Alibakhshikenari, M. (2023). Speech emotion recognition using convolution neural networks and multi-head convolutional transformer. Sensors, 23(13), 6212.
Shih, D. H., Liao, C. H., Wu, T. W., Xu, X. Y., & Shih, M. H. (2022). Dysarthria speech detection using convolutional neural networks with gated recurrent unit. In Healthcare, 10(10), 1956.
Hall, K., Huang, A., & Shahamiri, S. R. (2023). An investigation to identify optimal setup for automated assessment of dysarthric intelligibility using deep learning technologies. Cognitive Computation, 15(1), 146–158.
Latha, M., Shivakumar, M., Manjula, G., Hemakumar, M., & Kumar, M. K. (2023). Deep learning-based acoustic feature representations for dysarthric speech recognition. SN Computer Science, 4(3), 272.
Yu, C., Su, X., & Qian, Z. (2023). Multi-stage audio-visual fusion for dysarthric speech recognition with pre-trained models. IEEE Transactions on Neural Systems and Rehabilitation Engineering, 31, 1912–1921.
Revathi, A., Sasikaladevi, N., & Arunprasanth, D. (2022). Development of CNN-based robust dysarthric isolated digit recognition system by enhancing speech intelligibility. Research on Biomedical Engineering, 38(4), 1067–1079.
Almadhor, A., Irfan, R., Gao, J., Saleem, N., Rauf, H. T., & Kadry, S. (2023). E2E-DASR: End-to-end deep learning-based dysarthric automatic speech recognition. Expert Systems with Applications, 222, 119797.
Jolad, B., & Khanai, R. (2023). An approach for speech enhancement with dysarthric speech recognition using optimization based machine learning frameworks. International Journal of Speech Technology, 26, 287–305.
Acknowledgements
The authors thank the Department of Science & Technology, New Delhi, for the FIST funding (SR/FST/ET-I/2018/221(C). Furthermore, the authors also wish to thank the Intrusion Detection Lab at the School of Electrical & Electronics Engineering, SASTRA Deemed University, for providing infrastructural support to carry out this research work.
Funding
FIST funding (SR/FST/ET-I/2018/221(C).
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors have no relevant conflicts of interest to disclose.
Ethical Approval
This article contains no studies with human participants or animals performed by authors.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Revathi, A., Sasikaladevi, N., Arunprasanth, D. et al. A Strategic Approach for Robust Dysarthric Speech Recognition. Wireless Pers Commun 134, 2315–2346 (2024). https://doi.org/10.1007/s11277-024-11029-y
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11277-024-11029-y