
Abstract
With expanding realms of Internet of Things (IoT), researchers have started venturing into designing such algorithms for Wireless Sensor Networks (WSN) that support IoT network requirements. However, collaborating a sensor network into Internet of Things applicability faces surging data flow amidst which the senor network is expected to provide reliable data over extended span. Amidst variant techniques like routing, data aggregation, packet scheduling etc. which can be improvised upon, clustering has been a widespread energy efficient technique that primarily shortens distances in large-scale networks while also bring down commuting packets over improved connectivity. Therefore, utilizing clustering to incorporate WSN enabled IoT (WSN-IoT) standards becomes the primary focus of this paper. Heuristic based clustering algorithm termed as Prolong—Lines of Uniformity based Energy Threshold protocol (P-LUET) has been proposed that focusses on expanding the stable operating period of WSN-IoT. This algorithm is based on certain measures of WSN-IoT’s per unit, that is, residual energy, cartesian coordinate based location, shadow distance from the Sink Node, and density within the field. The parameters are employed such that they help combat hotspot issue, cluster overlapping, and network connectivity. A cluster-based conditional gridding Voronoi structure has also been consolidated that enables multi-hop communication. P-LUET algorithm is thoroughly analysed through comparisons with the existing approaches. Furthermore, analysis on P-LUET has also been carried on scenarios that are based on heterogeneity synthesis and b, c parameters.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
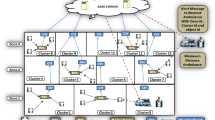
Wireless Sensor Network—enabled Internet of Things (WSN-IoT) (Fig. 1) is an innovation in the midst of numerous advances in micro sensors, VLSI and wireless communication based technologies [1]. Apart from applications relating to environment, home, healthcare, security, infiltration detection across LoC, military, industrial process control, civil, kindergartens etc. [2]–[5], WSN also adds benefit in IoT infrastructure by allowing researchers to realise a dynamic and robust paradigm [6, 7]. WSN’s autonomous energy-efficient resilient traits, dynamic network size, energy-heterogeneity, functionality of quality of service (QoS) allows it to dominate data collection task for any IoT framework [8,9,10]. Several real-time WSN-IoT applications are WaIoT—no flooding system based on IoT [11], Smart IoT-Connected Railways by SADEL, AAEON and Intel [12], Bosch Early Warning System [13], Intelligent Manufacturing by NEXCOM and Intel IoT Gateway [14] etc.

Wireless Sensor Network (WSN-IoT) scenario enabled with Internet of Things (IoT)
As WSN ventures into IoT, it efficiently uses machine-to-machine connectivity to gather field data and make it accessible anywhere [15, 16]. WSN-IoT has innovated its services to serve many applications like smart home, smart city, smart industries, smart health care, smart environment, smart transportation and many more. And therefore, with such advances, the need for efficiency infiltrated. It demanded an improvement in efficient acquiring of data monitored by IoT end devices scattered within the field area. These end devices, which hold limited energy resources and loose major battery power during a communication, have to comply with the constraints even while fulfilling the efficiency attainment demand. The WSN-IoT architectural framework follows a two-layered hierarchy of sensing layer and IoT layer as can be seen from Fig. 2. With the WSN mainly required for acquiring field data or any other environment data, it is contained in the sensing layer of the architectural framework that consist of numerous randomly deployed ID-enabled (not necessarily connected to internet and are alternatively known as sensor nodes) or IP-enabled end devices. These end-devices are equipped with one or more micro-sensors dependent of the kind of IoT application like smart homes can use IR, proximity, motion, and video sensors to detect any intrusion, smart city can use acoustic, temperature and seismic sensors to detect any natural calamity, smart industries can use gas, pollutant, and humidity sensors to prevent any industrial damage etc. [17,18,19,20]. The end-devices are connected to one or more static/mobile IoT hub in the IoT layer that performs the essential function of a Sink Node SN (or a Base Station BS) and allows to access the retrieved data from the field from anywhere across the globe. The IoT hub can either lie in the field surrounding the phenomenon or may lie outside it. A flat routing arrangement between the end-devices and the IoT hub resonates a computational complexity of \(O\left( {n_{ini}^{2} } \right)\) where \(n_{ini}\) is the initial arrangement count of a WSN which clearly describes an unstable operation as the population rises as can also be graphically seen from Fig. 3 [21]. Therefore, in order to enhance the scope of research in this domain, a need to prompt efficient connectivity among these IoT end-devices and with the IoT hub arises. Among the various ways of achieving an improved connectivity through minimal communication, the prominently used methods are as follows.
-
Efficient grouping of the IoT end-devices.
-
Strategically defining the commuting hop between these end-devices and their corresponding IoT-hub(s) such that efficiency improves over nominal computational complexity [22].

WSN-IoT architectural framework

Computational Complexity of flat-routed WSN-IoT
Grouping of the end-devices within a WSN either follows a Voronoi structure or a non-Voronoi structure. The most common domain of grouping has been embarked upon by employing Voronoi structure which either adopts a distributed clustering strategy or randomness-based strategy or an adaptive clustering strategy and have a basic purpose of averting transmittal of spatially correlated sensed data [23]. Clustering of IoT end devices successfully carries out the task of acquiring data from the field over reduced communication and the corresponding overhead. Clustering involves choosing one or more heads amongst the network population to other end-devices that primarily have the job of communicating with the IoT hub. These heads are popularly termed as cluster heads (CHs) which become the intermediator for the sensing layer. However, for efficient operation, there is a constant need to keep researching and innovating various CH-selection techniques that are based on certain characteristic measures of the network or of its end-devices. However, this operation is quite a challenging task as choosing an optimal set of CHs in every round of network life is an NP-hard problem where round is one cycle of sensing, data acquisition and communication to IoT hub.
An ordinary WSN-IoT consists of hundreds or probably thousands of end-devices with fewer enacting the role of a CH. With limited energy resources and communication range, there is a possibility that a fewer section of network population (known as isolated devices) faces no connectivity with any CH of the running round causing them to commute directly with the IoT hub. As long-distance communication leads to greater energy drainage, greater isolated nodes leads to reduced network efficiency. This issue is mostly observed in environments requiring large networks. WSN-IoT may also sometimes tend to face overlapping clusters in densely populated areas that further raise the chances of facing device isolation in the other parts of the network. This may add as a disadvantage to the device isolation. Another arrogant design concern of large-scale clustered WSN-IoT is hotspot issue that hinders lifespan of the devices closer to the IoT hub that may hold a higher probability of being chosen as a CH owing to their vicinity with the IoT hub. This concern can be projected through right measures for CH selection and/or communication pattern for all the devices. An appropriate algorithm that optimally defines such set of nodes as CH that help overcome or partially overcome these issues becomes the need of the hour solution for WSN-IoT.
1.1 Major Contributions
The prominent focus of the proposed Prolong-LUET algorithm is on prolonging the stability period of the LUET (Lines of Uniformity based Enhanced Threshold) protocol [24] (which is our previous work) in a WSN-IoT environment. The main contributions addressed in this work are stated below.
-
a.
Apart from incorporating vicinity to the Lines of Uniformity LoU in a field, algorithm also requires the end-devices to calculate their shadow distance from their IoT hub based on this vicinity parameter to alternate the perception of obtaining the annulus ring.
-
b.
With the IoT hub considered within the field limits, concentric rings around it define a weight for every end-device in such a way that it helps overcome the hotspot issue.
-
c.
CH selection is based on a rank value that additionally depends on the device density and its residual energy apart from its shadow distance and weight value.
-
d.
Conditional gridding for a partial lifetime is adopted within algorithm to help overcome overlapping clusters to a certain limit.
-
e.
Conditional multi-hop communication has been adopted.
-
f.
Simulation results assess the dominance of P-LUET over the existing state-of-the-art clustering algorithms while also accessing the P-LUET performance on scenarios based on heterogeneous sensitivity and b, c parameters.
1.2 Methodology Workflow
The rest of the manuscript is coordinated as follows. Section 2 elaborates the shift in the concerned research domain of design of CH list from homogeneity to heterogeneity to improvisation in probability definitions within threshold function values to indulgence of heuristic metrics to meta-heuristic based schemes to being efficiently available for IoT incorporation and the motivation for the proposed work. Section 3 presents the preliminary notations for the opted WSN-IoT scenario. Section 4 describes the proposed methodology, and the simulation results and their analysis is given in Sect. 5. Finally, Sect. 6 concludes the paper.
2 Related Work
The main goal of the proposed algorithm is to prolong stability period over improved energy efficiency during the design of a CH-selection based clusters in sensing layer of WSN-IoT architectural framework. In practise there is a need to integrate IoT end devices with the IoT cloud for any real application. This can be achieved either via adding a few IP-enabled end-devices among the other ID-enabled end-devices or via connecting an IP-enabled IoT hub with the locally connected ID-enabled end-devices. As pointed out earlier, due to the constrained resources of an end-device (ID-/IP-enabled), there is a need to perform grouping which could either be grid-based or clustering-based. Therefore, popular network topologies have been based on a grid structure or on a clustered strategy. The approach of clustering was first used in Low Energy Adaptive Clustering Hierarchy protocol (LEACH) [25] for a homogeneous environment that divided every round of lifetime into setup phase and steady state phase. Setup phase involved CH election based on a probabilistic fitness function \(P_{opt}\) and setup of a cluster layout while a steady state phase observed uploading of data from non-CH nodes to their corresponding CH where after removal of data redundancy, aggregated data is forwarded to network’s SN by these CHs. However, despite shortened commuting distances, slower power depletion, longer life, the randomness-based protocol faces reduced connectivity coverage due to non-uniform CH distribution which brings down the overall efficiency of a CH selection procedure. Thereafter, many heuristic/meta-heuristic approaches were proposed to optimize the CH-selection. Energy-homogeneity could not be relied upon for real-time applications as it contrasts with the environment dynamicity and observed unreliable stability-lifetime relationship. Later, to allow deployment of WSN in a real-time environment, energy heterogeneity was introduced through SEP protocol [26] that replaced \(P_{opt}\) with weighted election probabilities for a two-level (\(:2\)) heterogeneity while an enhancement to a three-level (\(:3\)) heterogeneity was introduced in EEHC protocol [27]. Both the protocols considered sub-epochs for the heterogeneous end-devices of the WSN. However, the issue of non-uniform CH distribution was still not addressed. Apart from transforming sub-epochs, the dynamicity in the environment also required nodes to adapt their epoch duration according to their energy usage pattern. This led to the discovery of DEEC protocol [28] that adhered to the shortcomings and included an energy parameter (ratio of residual and average energy) in the weighted probability function of SEP, \(P_{wgt} = \left\{ {P_{nrm:2} ,{ }P_{adv:2} } \right\}\). The same concept was applied on three-level heterogeneity in EDEEC protocol [29] on weighted probability functions for normal, advanced and super-advanced devices (\(P_{nrm:3}\), \(P_{adv:3}\) and \(P_{sadv:3}\)) as can be seen from Eqs. (1–3), respectively.
Improved epoch sure enough introduced dynamicity, however, it also observed a higher sub-epoch for the super-advanced (or advanced) end-devices leading to their early decay. Therefore, DDEEC protocol [30] made use of a threshold residual energy \(Th_{res}\) parameter, \(E_{i} \left( {0.7} \right)\) that lets both the end-devices to switch to a common probability function in a two-level heterogeneous network as shown in Eq. (4).
A similar \(Th_{res}\) parameter was used for three-level heterogeneity network in EDDEEC protocol [31]. In order to extend dynamicity, an n-level heterogeneity based hetDEEC protocol [32] was proposed that could be applied on 1/2/3-level heterogeneous network model just by varying a Θ parameter. Along the research journey, many heuristic based CH-selection approaches have been proposed that aimed at improving certain sensor network characteristics which could be implied via network’s certain performance metrics. ATEER [33] adopted three-level heterogeneous network that utilized \(P_{nrm:3}\), \(P_{adv:3}\) and \(P_{sadv:3}\) for CH election. Along with TEEN for intra-cluster communication and CDMA for inter-cluster communication, ATEER successfully improved network’s lifetime as compared to EEHC, DEEC, EDDEEC. However, ATEER mainly hybridised the existing protocols, yet despite unbalanced energy consumption due to TEEN implementation, it employed average energy estimate value for CH selection in every round leading to inappropriate results. Incompetence towards solving the isolated node value, ATEER may face an early death and hence, early energy hole issue causing the network to lose probable important data. Apart from improvising CH selection technique, protocol may also focus on working on data fusion at the CH. One such algorithm [34] outperformed SEP and was proposed for a two-level heterogeneous network with a threshold function. It comparatively enhanced results by additionally betting the cluster design upon residual energy of an end-device i, \(E_{i}\), its initial energy, \(E_{initial}\), its distance from the SN, \(d_{i}\) and distance of SN from network’s farthest alive device, \(d_{max}\). However, this operation requires the network to keep a track of the farthest alive node which adds to network’s additional overhead hindering its efficiency. Therefore, distance computation dependency upon a dynamic network characteristic limits algorithm’s application in a real-time scenario. PSEP protocol [35] infused the research domain with a new CH selecting policy to prolong the stability period of uniformly-distributed fog-supported WSNs. It incorporated two-tier heterogeneous settings and neighbour density-based data fusion that enabled prolonged stable time interval as compared to SEP. However, it either requires spending additional power in accumulating past energy usage of all network devices or requires keeping memory to save energy levels to avoid overhead. In both scenarios, end-devices face energy or memory constraints in real environments bring the network a disadvantage. This protocol tends to keep a higher probability rate for normal nodes due to their greater population compared to the other category nodes, however, this tends to unbalance energy consumption leading to an early death in normal nodes despite prolonging stability period compared to SEP. This unbalanced energy consumption may directly impact calculation of average energy that otherwise is responsible for \(P_{adv:2}\) computation. Another disadvantage that affects its average energy computation is its applicability domain i.e., precisely critical IoT scenarios. EDCF technique [36] for two-level heterogeneous system aims at improving its energy structure while also enhancing its lifespan. Based on the total initial energy of the network and residual energy of individual network devices, this technique incorporates a new threshold function formula. However, depending solely on energy parameter for CH selection, overlooks the need of some important network characteristics that require a researcher’s eye. Some of them are a device’s location, its device-vicinity degree, its SN vicinity etc. that greatly impact network’s situation in terms of hotspot issue, overlapping clusters etc. Gradually, a shift in research domain of WSN was observed such that clustering algorithms supporting the IoT environment were birthed and a new term WSN-enabled IoT (WSN-IoT) was born. IoT was observed to base on continuous or query systems that intended on satisfying the requests from local/distant end-users. These requests mostly required WSN to sense and transmit proclaimed data from their deployed environment. Having to serve frequent requests meant constant data transfer over the channel, thereby, largely affecting network’s efficiency. Therefore, researchers focussed on grouping algorithms that could improve efficiency. Both grid-based and cluster-based algorithms were proposed. A grid-based algorithm, namely energy efficient hierarchical clustering index tree (ECH-tree) technique [37] was developed to answer continuous queries from the end-users. This time-correlated region query technique segregated the IoT end-devices into even grids before assigning a clustering index tree to organize these grids cells. The assigned index allows clustering of sub grid regions ensuring reduced redundant data with upper-level sub-regions holding lesser dead space. However, apart from serving a network’s efficacy, the researchers noticed that pertaining to real-time scenario, it was important for algorithms to serve for longer stability periods as loss of any single device may make the data comparatively less reliable. Dynamic partitioning into grid cells was proposed in virtual uneven grid-based routing protocol, VUGR [38] that directed towards honouring improved stable lifespan. The uneven gridding was based on the energy resources of end-devices which helped overcome hotspot issue of WSN-IoT. The protocol assigned three roles among the end-devices, namely, regular nodes, main cell-headers, assistant cell-headers apart from utilizing a mobile SN. The grids fulfilling the hard energy criteria is known to elect a main cell header while the grid that fails is broken down into smaller grids beheaded by assistance cell-headers. With a mobile sink, a hotspot issue is curbed, however, it adds to the delay while a query has to be reported back. Also, this strategy has been applied using homogeneous environment that makes it less feasible within the real-world dynamics. Utilizing the standard IoT standards, a pragmatic architectural framework was introduced in [22] where in two approaches, clustering based and gridding based were introduced. They primarily focussed on improving the network lifespan using either of the two approaches where heuristic based clustering approach utilizes neighbour count and residual energy of IP and ID enabled end-devices, while the grid-based approach utilizes location information of ID-enabled end-devices only. Although improved communication is achieved yet an algorithm is required that utilizes all the parameters together and yet showcase an improved stable period. A homogeneous scenario incorporates a clustering algorithm that savours initial and residual energy of an end device to reach optimal CHs [39]. However, a random CH election in the first round before the energy-based selection in the consecutive rounds, may cause a derange partition, thereby snubbing the movement and degree of wireless mobile nodes, WMNs. An evolutionary algorithm namely, memetic algorithm (memA) has been introduced into WSN (also inhabited with WMNs) clustering [21] to lower down the probability of early convergence. In order to achieve dynamic load balancing, memA supports in reaching an optimal CH set (if and when required) as early as possible. However, there are more network characteristics that need to be addressed to. A proficient bee-colony clustering protocol (PBC-CP)—based on artificial bee colony (ABC) algorithm [40], utilizes energy, degree, and distance from SN of WMNs for selection of head nodes. Despite appropriate parameter utilization, the non-involvement of mobility metric for CH selection, may lead nodes with varied mobility as compared to that of its neighbours to be chosen as CHs. No concurrence in mobility with its neighbours may lead to frequent re-clustering as the untimely topology change in chosen CHs’ vicinity causes unstable clustering.
2.1 Motivation
Over a long reign, clustering algorithms have been prioritized to enhance network’s efficacy and stable lifespan, while also indulging individually into other design constraints due to clustering i.e., hotspot issue or cluster connectivity or energy hole or cluster overlapping, etc. However, a need for a technique that addresses multiple issues arises as sensors networks are being conglomerated with the Internet. IoT designs cater to real-world dynamics that rarely observe homogeneous environment, hence, WSNs deployed with energy heterogeneity are considered more feasible. Therefore, venturing completely into heterogeneous environment is a gradual yet essential requirement for any WSN-IoT. As energy heterogeneity is catered to in sensor networks, primarily energy-based CH selection strategies are focussed upon. However, for an overall optimized CH list, it is necessary to also cater to other characteristics of the end-devices actively such as, information about its vicinity, its location within the field etc. Literature also observed various grid-based and clustering based Voronoi schemes, however, either have their own disadvantages. Where clustering schemes may introduce cluster overlapping in case of unmanned CH selections when the node population is denser, static grid schemes may hamper network’s efficiency as the node count decreases. Hence, a need also arises to design an algorithm that successfully captures the individual benefits of either of the schemes and strategically convenes a technique. Therefore, from the survey, it can be observed that there is a shift in research domain within design of clustering algorithms. In order to ply with one design constraint i.e., network connectivity apart from network’s efficiency and lifetime, LUET [24] has been proposed in our previous work. In LUET, a novel concept of Lines of Uniformity LoU has been introduced that manages to lower down the average isolated node ratio within the network thereby improving its connectivity. However, it lacks in overpowering the other primary constraints of a WSN-IoT i.e., hotspot issue or cluster overlapping or energy hole due to early first device death—FDD. Therefore, this work further enhances the LUET protocol in terms of its stable region.
3 Preliminary Notations
3.1 Assumptions
The proposed network model for P-LUET algorithm follows a few basic assumptions as follows:
-
After deployment, all end devices are static in position within the field and are ID-enabled.
-
Every end device has alike processing—communication functionalities, however, they are energy-heterogeneous.
-
The field is governed by a single static IoT hub in the centre of the field that acts as a sink end-device for the IoT end devices and does not face any memory, energy, or computation constraint.
-
Energy depletion is the only potential cause considered for an end-device’s failure.
-
No obstacles from external environment hamper the operation of the network laid in the field.
-
Every end-device holds an aggregation capability which allows it to compress redundant information into one useful packet while performing the CH duty.
-
Received Signal Strength Indicator (RSSI) at an end-device allows it to estimate its relative distance from any other entity matching its radio standards.
-
Every end-device is aware of its own location and the field dimensions through a positioning system or an energy-efficient positioning algorithm.
3.2 Network Topology
This section describes the three-grade energy-heterogeneous network model assumed for a WSN-IoT. The reason behind using a heterogeneous model is that deployment for real-time scenarios suffer dynamicity requiring a network to be capable enough to handle energy-heterogeneity. The proposed network is patterned as a square field \(\left( {{\mathbf{\mathcal{M}}} \times {\mathbf{\mathcal{M}}}} \right)\) of \({\fancyscript{n}}_{ini} ,\left( { {\fancyscript{n}}_{ini} \in {\mathbb{N}}} \right)\) end-devices dispersed haphazardly yet uniformly with fixed locations after deployment. The end-devices (alternatively termed as sensors in this work) are presumptuously based on three-level energy heterogeneity and can be classified as normal nrm, advanced adv, and super-advanced sadv. Note that if \({\mathbf{\rm E}}_{{o}}\) is considered the initial energy of a single normal device then the initial energy of advanced and super-advanced device is \({\mathbf{\rm E}}_{{o}} \left( {1 + {a}} \right)\) and \({\mathbf{\rm E}}_{{o}} \left( {1 + {s}} \right)\), respectively. The advanced and super-advanced end-devices are equipped with \({a}\) and \({s}\) times more energy than that of normal end-devices, respectively. Advanced end-devices are considered \({m}_{a}\) fraction of the total end-devices and super-advanced end-devices are considered \({m}_{{s}}\) fraction of advanced end-devices. The total initial energy of the network can be calculated as shown in Eq. (5).
The clustering hierarchy has been applied on this network model that leads the WSN-IoT to be segregated into several clusters, assuming that the IoT Hub is situated in the centre of the network. There are two tiers of communication in the clustered WSN-IoT, namely, sensors to their individual CHs, CHs to network’s IoT Hub. The CHs execute aggregation to remove any existing correlated redundant data before forwarding any data to the IoT Hub. Removing redundancy reduces communication overhead and supports improving efficiency.
3.3 Optimal Clustering
The location of the IoT Hub (SN) is known to every sensor of the network. Therefore, average distance between any sensor \(i\) enacting the CH duty and the IoT Hub can be estimated using Eq. (6).
In order to prevent non-essential formation of clusters within the network which may lead to network instability in terms of exponential increase in network energy consumption, clusters need to be created in optimal count. Communication channel incorporates a channel model dependent upon the commuting distance between any two entities. As a common reference, a threshold distance \(d_{0}\) is assumed. If the distance between the two entities is less than \(d_{0}\), it assumes a free-space channel model, \(fs\), while otherwise multi-path channel, \(mp\), model is assumed for communication. Therefore, computation of \(d_{0}\) (\(d_{0} = \sqrt {\frac{{E_{fs} }}{{E_{mp} }}}\), that amounts to \(87.7\) meters in this case) is based on the transmit free-space amplifier energy \(E_{fs} = 10 pJ / bit/m^{2}\) and \(E_{mp} = 0.0013 pJ / bit/m^{2}\) for both the channel models. Optimum number of CH count \(k_{opt}\) and the optimum probability value \(P_{opt} { }\) can, therefore, be calculated utilizing Eqs. (7) and (8) dependent upon the distance of significant number of end-devices from their IoT Hub \(d_{i:hub}^{^{\prime}}\) with respect to \(d_{0}\) [26].
4 Methodology of P-LUET algorithm
P-LUET algorithm has been proposed to address the needs of the current research scenario mentioned in the Motivation Sect. 2.1. It is named as P-LUET in order to justify the prolonged stability period. The basic procedure of the CH-selection in P-LUET is similar to the selection procedure in SEP which asks of every end-device to compute its threshold value, \(Th_{CH}\), based on some pre-defined parameters so as to compare it with its generated random number. A higher \(Th_{CH}\) makes a significant criterion for the CH selection eligibility process.
4.1 End-Device Initialization
Before the onset of network’s round-time operation, every end-device uses a buffer time to compute its necessary parameters which is termed as initialisation phase. To compute its eligibility for the CH role, every end-device initializes pre-computation with using its location on a visualized 2-dimensional (2-D) field platform to calculate its proximity to network’s ‘lines of uniformity’ (LoU), its tier distance away from SN and the corresponding weight value, its initial vicinity density, and its region concurrence.
4.1.1 Proximity to LoU, \(d_{ \bot } \left( i \right)\).
Any geometric polygon has a circumradius and an inradius where circumradius is the smallest radius of the sphere into which the geometric polygon can fit in while inradius is the largest radius of the sphere which can completely fit inside the geometric polygon. Compared to the incircle with a radius \(r\), polygon’s circumcircle with a radius \(R\) contains every point of the polygon within the circle as can be seen from Fig. 4. The term ‘lines of uniformity’ is given to the two-line segments individually connecting the opposite edges of the field (any polygon, in this case square) which are popularly also known as field diagonals. These line segments intersect at the centre of the field and individually have a length of \(d\) (\(d = 2R;d = 2\surd 2r\)). Considering the SN at the centre of the field with omni-directional connectivity, its spherical connectivity coverage should have a radiation reach of \(d/2 = R{ }\left( { = \surd 2r} \right)\) to cover the entire network population. Therefore, the lines of uniformity sweeping through the entire polygon network are considered since they have a greater coverage spread around the SN.

Polygon with its circumcircle and incircle
The lines of uniformity for the field of dimensions, 300 m in length and 300 m in width, are \(x - y = 0\) and \(x + y - 300 = 0\). These lines intersect at the polygon field centre where the SN is placed. This polygon field has \({\fancyscript{n}}_{ini}\) haphazardly scattered end-devices with coordinates as \(\left( {x_{i} , y_{i} } \right) = \left[ {\left( {x_{1} ,y_{1} } \right),\left( {x_{2} ,y_{2} } \right),\left( {x_{3} ,y_{3} } \right), \ldots \left( {x_{{ {\fancyscript{n}}_{ini} }} ,y_{{ {\fancyscript{n}}_{ini} }} } \right)} \right]\). Each end-device calculates its proximity to both the lines of uniformity \(D_{1} \left( i \right),{ }D_{2} \left( i \right)\) using Eqs. (9) and (10) where the primary proximity is known to be from the closer LoU. The primary proximity \(d_{ \bot } \left( i \right)\) is therefore obtained from \(d_{ \bot } \left( i \right) = \min { }\left\{ {D_{1} \left( i \right){ },{ }D_{2} \left( i \right)} \right\}\) while the secondary proximity is discarded by the end-device as stated in [24].
4.1.2 Concentric Tiers, \({\mathcal{R}}_{b}\) encircling IoT Hub.
P-LUET algorithm considers two concentric circles, \(n = \left\{ {1,2} \right\} ,\forall n \in n_{max}\) within the polygon field with IoT Hub as their common centre and different radii, \(t_{n}\). To compute both the tier radii in the field of dimensions, 300 by 300 m (pertaining to a large-scale sensing layer), \(R\) (\(= d/2\)) defining the distance of the IoT Hub from the farthest point in the field is utilized as can be seen from Fig. 5. The equation of the concentric tiers for P-LUET, can be exhibited as \(\left( {x - 150} \right)^{2} + \left( {y - 150} \right)^{2} = t_{n}\). The radius of the outer tier \(t_{2}\) and the inner tier \(t_{1}\) can be calculated from \(t_{2} = R - \left( {R/3} \right)\) and \(t_{1} = t_{2} - d_{0}\), respectively. Utilizing the tier radii distance \(t_{n} { },{ }\forall n = \left\{ {1,2} \right\}\), every end-device \(i\) computes its annulus ring \({\mathcal{R}}_{t} \left( i \right){ },{ }\forall t = \left\{ {1,2,3} \right\}\) based on its shadow distance from the IoT Hub \(d_{tier} \left( i \right)\) with respect to its primary proximity value \(d_{ \bot } \left( {\text{i}} \right)\) as can be understood from Fig. 5. Based on \({\mathcal{R}}_{t} \left( i \right){ },{ }\forall t = \left\{ {1,2,3} \right\}\) value, considering the global solution, a weight value \(_{i}^{t} W{ },{ }\forall t = \left\{ {1,2,3} \right\}\) is self-assigned by the end-device or sensor \(i\). The corresponding computations have been explained below.

Concentric tiers within the field
Computation of sensor’s (\({\varvec{i}}\)) Annulus Ring \({\mathbf{\mathcal{R}}}_{{\varvec{t}}} \left( {\varvec{i}} \right),\;\;\forall {\varvec{t}} = \left\{ {1,2,3} \right\}\) |
|---|
Sensor \({\varvec{i}}\) computes \({\varvec{d}}_{{{\varvec{i}}:{\varvec{hub}}}} \left( {\varvec{i}} \right) = \sqrt {\left( {{\varvec{x}}_{{\varvec{i}}} - {\varvec{x}}_{{{\varvec{hub}}}} } \right)^{2} + \left( {{\varvec{y}}_{{\varvec{i}}} - {\varvec{y}}_{{{\varvec{hub}}}} } \right)^{2} }\), \(\exists \left( {{\varvec{x}}_{{\varvec{i}}} ,{\varvec{y}}_{{\varvec{i}}} } \right),\left( {{\varvec{x}}_{{{\varvec{hub}}}} ,{\varvec{y}}_{{{\varvec{hub}}}} } \right)\) cartesian coordinates of \({\varvec{i}}\), IoT Hub, respectively |
Sensor \({\varvec{i}}\) computes \({\varvec{d}}_{{{\varvec{tier}}}} \left( {\varvec{i}} \right) = \sqrt {{\varvec{d}}_{{{\varvec{i}}:{\varvec{hub}}}} \left( {\varvec{i}} \right)^{2} - {\varvec{d}}_{ \bot } \left( {\varvec{i}} \right)^{2} }\), where \({\varvec{d}}_{{{\varvec{i}}:{\varvec{hub}}}} \left( {\varvec{i}} \right)\) is the direct distance of \({\varvec{i}}\) from the IoT Hub |
\({\varvec{d}}_{{{\varvec{tier}}}} \left( {\varvec{i}} \right)\) is computed \(\because\) the annulus ring \({\mathbf{\mathcal{R}}}_{{\varvec{t}}} \left( {\varvec{i}} \right),\;\;\forall {\varvec{t}} = \left\{ {1,2,3} \right\}\) determination is based on the common parameter, \({\varvec{R}}\) with respect to IoT Hub |
\({\varvec{for}} \left( {{\mathbf{\mathcal{R}}}_{{\varvec{t}}} \left( {\varvec{i}} \right) , \forall {\varvec{t}} = 1,3} \right)\), sensor \({\varvec{i}}\) assumes \({\varvec{d}}_{{{\varvec{tier}}}} \left( {\varvec{i}} \right) = {\varvec{d}}_{{{\varvec{i}}:{\varvec{hub}}}} \left( {\varvec{i}} \right)\) |
\(\because\) sensor \({\varvec{i}}\) in \({\mathbf{\mathcal{R}}}_{1}\) will have a near approximate \({\varvec{d}}_{{{\varvec{tier}}}} \left( {\varvec{i}} \right) \cong {\varvec{d}}_{{{\varvec{i}}:{\varvec{hub}}}} \left( {\varvec{i}} \right)\) value and \({\varvec{Area}}\left( {{\mathbf{\mathcal{R}}}_{3} } \right) < {\varvec{\pi}}\left( {{\varvec{R}}^{2} - ({\varvec{t}}_{2} )^{2} } \right)\) which causes \({\varvec{i}}\) in \({\mathbf{\mathcal{R}}}_{3}\) to have disproportionate chances of CH selection contingency |
\({if }({\mathbf{\mathcal{R}}}_{{\varvec{t}}} \left( {\varvec{i}} \right) = = {\mathbf{\mathcal{R}}}_{1} ){ then }_{{\varvec{i}}}^{1} {\varvec{W}} = 2\) \({if }({\mathbf{\mathcal{R}}}_{{\varvec{t}}} \left( {\varvec{i}} \right) = = {\mathbf{\mathcal{R}}}_{2} ){ then }_{{\varvec{i}}}^{2} {\varvec{W}} = 3\) \({if }({\mathbf{\mathcal{R}}}_{{\varvec{t}}} \left( {\varvec{i}} \right) = = {\mathbf{\mathcal{R}}}_{3} ){ then }_{{\varvec{i}}}^{3} {\varvec{W}} = 1\) |
\(_{{\varvec{i}}}^{2} {\varvec{W}} > _{{\varvec{i}}}^{1} {\varvec{W}}\) to overcome hotspot problem and \(_{{\varvec{i}}}^{2} {\varvec{W}} > > _{{\varvec{i}}}^{3} {\varvec{W}}\) to overcome high energy consumption due to direct inter-cluster communication which could result from high CH selection probability of sensors in \({\mathbf{\mathcal{R}}}_{3}\) |
4.1.3 Initial Vicinity Density, \(\partial_{{\varvec{i}}}\).
The initial vicinity density allows to determine an end-device \(i\)’s degree of accessibility within the network during its tenure of performing CH duty. This degree is estimated based on the effective distance of \(i\) with its neighbours within its threshold range (which could possibly be \(k_{nei}\) in count), \(d_{i:j} { },\forall j = \left\{ {1,2,3, \ldots ,k_{nei} } \right\}\). As can be referred from [41], the vicinity density \(\partial_{i}\) for a sensor \(i\) in a network of population \(\aleph\) can be inferred from the following Eqs. (11–12). While based on \(d_{0}\) value, average \(\partial^{^{\prime}}\) value can be estimated as given in Eq. (13).
4.1.4 Region Concurrence for Large-Scale WSN, \({\fancyscript{g}}\)
The P-LUET algorithm grids the large-scale deployment field into uniform regions of equal size. The number of virtual grids \({\fancyscript{g}}\) is conditionally determined by the initial count of the end-device population \({\fancyscript{n}}_{ini}\) and the current alive end-devices \(A_{\aleph } = \left[ {0, {\fancyscript{n}}_{ini} } \right]\) as can be adhered from the Eq. (14) below. The network field is presumed to be virtually divided into \(k_{opt}\) grids as can be seen in Fig. 6 if \(\left( {0.75 {\fancyscript{n}}_{ini} \times P_{opt} < A_{\aleph } \times P_{opt} \le {\fancyscript{n}}_{ini} \times P_{opt} } \right)\) condition is fulfilled and is considered as one whole field without any grid for \((A_{\aleph } \times P_{opt} \le 0.75 {\fancyscript{n}}_{ini} \times P_{opt} )\) condition. The CH selection does not adhere to the selection of an end-device \(i\) near the centre of these regions since the random end-device deployment may cause a shift in the centroid due to varied density composite within every region. The proposed gridding analogy for a partial lifetime allows P-LUET algorithm to overcome overlapping to a certain extent until the network has comparatively dense deployment.

Virtual grids in the large-scale network. {subjective to the scenario when \(size_{WSN}\) is \(\left( {300,300} \right)\), \(k_{opt} = 8\), \(A_{\aleph } = 85\), \({\fancyscript{n}}_{ini} = 100\)}
After virtual grid partition, every end-device \(i\) assigns itself a grid region \(G_{k} { },\;\;\forall k = \left\{ {1, \ldots ,{\fancyscript{g}}} \right\}\) based on its cartesian coordinate based location information \(\left( {x_{i} ,y_{i} } \right)\).
4.2 Likelihood of CH Choice
The assumed topology adopted for configuring P-LUET algorithm follows three-level energy heterogeneity. The resultant total energy of the network amounts to \({\text{E}}_{T} = \left( {1 + m_{a} \left( {a + sm_{s} } \right)} \right) {\fancyscript{n}}_{ini} {\text{E}}_{o}\) showcasing \(m_{a} \left( {a + sm_{s} } \right)\) gain value in the total energy of similar network using homogeneous energy setting. Therefore, due to the additional gained network energy, the resultant heterogeneous epoch of the network correspondingly changes to \(\left( {1 + m_{a} \left( {a + sm_{s} } \right)} \right) \times \left( {{\raise0.7ex\hbox{$1$} \!\mathord{\left/ {\vphantom {1 {P_{opt} }}}\right.\kern-\nulldelimiterspace} \!\lower0.7ex\hbox{${P_{opt} }$}}} \right)\). However, due to resource-variability amongst the end-device population in a heterogeneous sensor network, every end-device type (\(nrm/adv/sadv\)) has its individual sub-epoch within the heterogeneous epoch to achieve an unbiased threshold assignment. Therefore, if \(nrm\) can perform the CH duty once in the heterogeneous epoch, \(adv\) can perform the CH duty \(\left( {1 + a} \right)\) times in the same epoch owing to the additional \(a\) times energy while \(sadv\) can perform the CH duty \(\left( {1 + s} \right)\) times in the same epoch owing to the additional \(s\) times energy. This leads the algorithm to assign an energy-based weight to their individual election probabilities (likelihood of choice in lieu of every single elected CH), giving birth to the term weighted probability \(P_{wgt}\). In this work, the \(P_{wgt}\) term assignment for \(nrm\) is assumed as \(P_{n}\), for \(adv\) is assumed as \(P_{a}\), and for \(sadv\) is assumed as \(P_{s}\). Hence, an average count of \(nrm\) enacting as CHs per round per heterogeneous epoch is \(P_{n} {\fancyscript{n}}_{ini} \left( {1 - m_{a} } \right)\), \(P_{a} {\fancyscript{n}}_{ini} m_{a} \left( {1 - m_{s} } \right)\) is the an average count of \(adv\) enacting as CHs per round per heterogeneous epoch, and an average number of \(sadv\) enacting as CHs per round per heterogeneous epoch is \(P_{s} {\fancyscript{n}}_{ini} m_{a} m_{s}\) while the total average number of CHs per round per epoch stays \(P_{opt} {\fancyscript{n}}_{ini}\). Thus, the total average CH count per round per epoch can be stated as below in Eq. (15) [42].
However, apart from the initial energy resources, \(P_{wgt}\) in [42] is oblivious to end-devices’ other fixed/adaptive parametric measures which affect any end-device’s individual capacity to be assigned the role of a CH. These measures are subjective to overcoming specified challenges in achieving the desired Quality-of-Service QoS in clustering. In this work, P-LUET assigns a rank value \(rank\left( i \right)\) defined in Eq. (16) to the individual probabilities of the end-device population \(P_{wgt}\) as shown in Eq. (17). This rank value is based on a few static end-device’s parametric measures like \(i\)’s primary proximity to \(LoU\) \(d_{ \bot } \left( i \right)\), its annulus ring association to the IoT Hub and the corresponding weight value \({\mathcal{R}}_{t} \left( i \right),_{i}^{t} W{ },{ }\forall t = \left\{ {1,2,3} \right\}\), its shadow distance from the IoT Hub \(d_{tier} \left( i \right)\), and the degree of its vicinity density during WSN-IoT’s stable life span \(\partial_{i}\). Under dynamic environment requirements, an end-device \(i\) may have disproportionate energy consumption making it a necessary inclusion in the \(P_{wgt}\) computation. Therefore, an additional parameter defining the proportionate change in end-device’s energy resources is adopted in computing the \(P_{wgt}\) of the end-device.
Iterative CH-reaffiliation rate snubs end-devices of their battery power. With a higher rate in \(adv/sadv\) of being chosen for duty as compared to \(nrm\), P-LUET utilizes the concept of threshold energy, \(E_{th} = b{\text{E}}_{ini} \forall b = \left[ {0,1} \right]\), as proposed in DDEEC [30], that lets the end-devices to switch to a common probability function \(P\left( i \right)\) as can be understood from Eq. (17).
4.3 Ranked Threshold computation for CH selection
The threshold value has been denoted as \(Th_{CH}\) in the current work that corresponds to \(Th_{CH} \left( {i \in nrm} \right)\) for \(nrm\) end-devices, \(Th_{CH} \left( {i \in adv} \right)\) for \(adv\) end-devices, \(Th_{CH} \left( {i \in sadv} \right)\) for \(sadv\) end-devices, and \(Th_{CH} \left( i \right)\) for any device type (if \({\text{E}}_{res} \le E_{o}\)) to be shortlisted for the tentative CH list. Upon utilizing calculated \(P_{wgt}\) values from Eq. (17), the respective threshold value functions can be demonstrated as given in Eqs. (18–21).
The \(Th_{CH} \left( {i \in nrm} \right)\) is applied to \({\fancyscript{n}}_{ini} \left( {1 - m_{a} } \right)\) normal end-devices for the current \(l\) th round. However, end-devices in \(nrm\) category have to belong to a set \(G_{l}^{^{\prime}}\) which have not played the CH role in the last \({\raise0.7ex\hbox{$1$} \!\mathord{\left/ {\vphantom {1 {P_{n} \left( i \right)}}}\right.\kern-\nulldelimiterspace} \!\lower0.7ex\hbox{${P_{n} \left( i \right)}$}}\) rounds of the heterogeneous epoch. Therefore, for P-LUET algorithm, the average count of \(i \in nrm\) playing the CH role in a round per epoch stays \(\cong P_{n} {\fancyscript{n}}_{ini} \left( {1 - m_{a} } \right)\), and \(\left( {1 + m_{a} \left( {a + sm_{s} } \right)} \right) \times \left( {{\raise0.7ex\hbox{$1$} \!\mathord{\left/ {\vphantom {1 {P_{opt} }}}\right.\kern-\nulldelimiterspace} \!\lower0.7ex\hbox{${P_{opt} }$}}} \right)\) becomes the rate of being selected for the CH role per epoch and per \(\left[ {rank\left( i \right){\text{E}}_{ini} } \right]/{\text{E}}_{res}\).
The \(Th_{CH} \left( {i \in adv} \right)\) is applied to \({\fancyscript{n}}_{ini} m_{a} \left( {1 - m_{s} } \right)\) advanced end-devices for the current \(l\) th round. However, end-devices in \(adv\) category have to belong to a set \(G_{l}^{^{\prime\prime}}\) which have not played the CH role in the last \({\raise0.7ex\hbox{$1$} \!\mathord{\left/ {\vphantom {1 {P_{a} \left( i \right)}}}\right.\kern-\nulldelimiterspace} \!\lower0.7ex\hbox{${P_{a} \left( i \right)}$}}\) rounds of the heterogeneous epoch. Therefore, for P-LUET algorithm, the average count of \(i \in adv\) playing the CH role in a round per epoch stays \(\cong P_{a} {\fancyscript{n}}_{ini} m_{a} \left( {1 - m_{s} } \right)\), and \(\left( {1 + m_{a} \left( {a + sm_{s} } \right)} \right) \times \left( {{\raise0.7ex\hbox{$1$} \!\mathord{\left/ {\vphantom {1 {\left( {1 + a} \right)P_{opt} }}}\right.\kern-\nulldelimiterspace} \!\lower0.7ex\hbox{${\left( {1 + a} \right)P_{opt} }$}}} \right)\) becomes the rate of being selected for the CH role per epoch and per \(\left[ {rank\left( i \right){\text{E}}_{ini} } \right]/{\text{E}}_{res}\).
The \(Th_{CH} \left( {i \in sadv} \right)\) is applied to \({\fancyscript{n}}_{ini} m_{a} m_{s}\) super-advanced end-devices for the current \(l\) th round. However, end-devices in \(sadv\) category have to belong to a set \(G_{l}^{^{\prime\prime\prime}}\) which have not played the CH role in the last \({\raise0.7ex\hbox{$1$} \!\mathord{\left/ {\vphantom {1 {P_{s} \left( i \right)}}}\right.\kern-\nulldelimiterspace} \!\lower0.7ex\hbox{${P_{s} \left( i \right)}$}}\) rounds of the heterogeneous epoch. Therefore, for P-LUET algorithm, the average count of \(i \in sadv\) playing the CH role in a round per epoch stays \(\cong P_{s} {\fancyscript{n}}_{ini} m_{a} m_{s}\), and \(\left( {1 + m_{a} \left( {a + sm_{s} } \right)} \right) \times \left( {{\raise0.7ex\hbox{$1$} \!\mathord{\left/ {\vphantom {1 {\left( {1 + s} \right)P_{opt} }}}\right.\kern-\nulldelimiterspace} \!\lower0.7ex\hbox{${\left( {1 + s} \right)P_{opt} }$}}} \right)\) becomes the rate of being selected for the CH role per epoch and per \(\left[ {rank\left( i \right){\text{E}}_{ini} } \right]/{\text{E}}_{res}\).
The \(Th_{CH} \left( i \right)\) is applied to \(nrm/adv/sadv\) for the current \(l\) th round if they satisfy \({\text{E}}_{res} \le E_{th}\) condition. However, end-devices have to belong to a set \(G_{l}\) which have not played the CH role in the last \({\raise0.7ex\hbox{$1$} \!\mathord{\left/ {\vphantom {1 {P\left( i \right)}}}\right.\kern-\nulldelimiterspace} \!\lower0.7ex\hbox{${P\left( i \right)}$}}\) rounds of the heterogeneous epoch. Therefore, for P-LUET algorithm, \(\left( {1 + m_{a} \left( {a + sm_{s} } \right)} \right) \times \left( {{\raise0.7ex\hbox{$1$} \!\mathord{\left/ {\vphantom {1 {\left( {1 + s} \right)P_{opt} }}}\right.\kern-\nulldelimiterspace} \!\lower0.7ex\hbox{${\left( {1 + s} \right)P_{opt} }$}}} \right)\) becomes the common rate for all end devices to be selected for the CH role per epoch and per \({\text{E}}_{avg} /{\text{E}}_{ini}\).
Henceforth, upon computed \(Th_{CH}\) evaluation with respect to a randomly generated number \(rand()\) by the eligible end-device population in WSN-IoT, \(P_{opt} {\fancyscript{n}}_{ini}\) (as derived from Eq. (15)) end-devices are chosen randomly from the tentative list \(list_{l}^{tCH}\) as the final CHs \(list_{l}^{CH}\) of the network for the \(l\) th round. However, the choice of final CHs is based upon the validation of the condition for the region concurrence. If the network fulfils the condition \(0.75 {\fancyscript{n}}_{ini} \times P_{opt} < A_{\aleph } \times P_{opt} \le {\fancyscript{n}}_{ini} \times P_{opt}\), the end-devices assume \({\fancyscript{g}} = k_{opt}\) virtual grids in the network. Based on the location information, end-devices from \(list_{l}^{tCH}\) move to \(list_{l}^{CH}\) only if its corresponding region \(G_{k} { },\;\;\forall k = \left\{ {1, \ldots ,{\fancyscript{g}}} \right\}\) has yet to choose a CH. Every grid region will primarily be headed by one CH. After CHs have been chosen per grid, the rest of the end-devices \(i \notin list_{l}^{CH}\) associate themselves with the CH of their corresponding region \(G_{k}\). This greatly reduces the overhead exchange during the association confirmation process in case of multiple advertisement messages received by the non-CH end-devices. Since, the regions are clearly demarcated, the cluster overlapping is also reduced, thereby improving the cluster coverage, and further enhancing the network efficiency by \(\approx 6.7\%\) as can be seen from Fig. 7. The energy efficiency of P-LUET, \(\varepsilon_{p - luet}\) is proportional to the amount of network data \(T^{net}\) propagated by consuming a certain energy \(E_{used}\) to withstand surging data flow from the IoT Hub as given in (22) and as stated in [43].

\(\varepsilon_{p - luet}\) implying the effect of \( {\fancyscript{g}}\)
As soon as the new condition \(A_{\aleph } \times P_{opt} \le 0.75 {\fancyscript{n}}_{ini} \times P_{opt}\) turns true, the virtual gridding concept is discarded by the end-device population and thereafter, random \(k_{opt}\) end-devices are chosen as CHs from \(list_{l}^{tCH}\). Thereby, end-devices \(i \notin list_{l}^{CH}\) either associate to their closest CH and be known as member \(i^{CM}\) to that CH or be known as isolated end-devices \(i^{IN}\) that communicate directly with the IoT Hub.
4.4 \({\fancyscript{g}}\)-based Conditional Multi-Hop Inter-Cluster Communication
In this subsection, the inter-cluster communication model has been discussed. The inter-cluster communication model is based on the condition validation for \({\fancyscript{g}}\). If the condition \(\left( {0.75 {\fancyscript{n}}_{ini} \times P_{opt} < A_{\aleph } \times P_{opt} \le {\fancyscript{n}}_{ini} \times P_{opt} } \right)\) holds true for the network, the end-devices \(i^{CH} { },{ }\forall i \in list_{l}^{CH}\) compare their distance from their IoT Hub with their distance from CH \(j^{CH} ,{ }\forall j \in list_{l}^{CH} ,G_{k} \left( i \right) \ne G_{k} \left( j \right),{ }i \ne j\) in its adjoining grid region as shown in the following Eqs. (23–24).
The proposed model focusses on minimizing the communication cost during the data uploading from the CHs overlooking farther grid regions since energy usage \(E_{R} \left( {size} \right)/E_{T} \left( {size,d} \right)\) varies either proportionally to the length of the information to be imparted size or also the commuting distance \(d\) as can be understood from Eqs. (25–26). In an attempt to save energy consumption, network savours prolonged aliveness \(NL_{p - luet}\) with end-devices showcasing longer lingering vitality. As can be observed from Fig. 8, a P-LUET incorporated WSN-IoT spans longest period if conditional gridding is employed with multi-hop communication while showcases the lowest span count on employing grids without multi-hop communication. In the abstinence of conditional grid structure, CH list is not chosen to bound to the grid coordinates, thereby, bearing higher probability of being chosen in context to the IoT Hub location. Therefore, after selection of a desired CH count that successfully qualify the algorithm specifications, as the data gets uploaded to these CHs from their respective members, the minimum distance path to the IoT Hub is computed that defines whether a multi-hop model or a single-hop model has to be presumed. However, as the previously mentioned condition turns false over the net-life’s course, with a new condition turning true i.e., \(A_{\aleph } \times P_{opt} \le 0.75 {\fancyscript{n}}_{ini} \times P_{opt}\), the end-devices that are supposedly chosen for performing CH duty henceforth are selected randomly throughout the network. The CH count is based on the optimal count of clusters \(k_{opt}\) required for an efficient network operation. Under this condition, every end-device enacting as a CH, \(i^{CH} { },{ }\forall i \in list_{l}^{CH}\), transmits its aggregated data directly to the IoT Hub. The energy expended in the electronic circuitry of an end-device that supports transmission or reception of information can be known as \(E_{elec}\).

\(NL_{p - luet}\) implying the effect of \({\fancyscript{g}}\) and multi-hop communication model
4.5 Some Explicit Remarks About P-LUET Algorithm
The quoted algorithm points at the significant steps of P-LUET. Specifically, the proposed algorithm focusses on defining the set \(list_{l}^{CH}\) for every \(l\)-th round. \(Lines{ }2 - 3\) attempt to establish end-device deployment and thereafter, network configuration. \(Line{ }4\) starts a loop for initialization on every end-device which means every end-device \(i\) individually computes \(d_{ \bot } \left( i \right)\), \({\mathcal{R}}_{t} \left( i \right),_{i}^{t} W{ },{ }\forall t = \left\{ {1,2,3} \right\}\), \(d_{tier} \left( i \right)\), and \(\partial_{i}\). Note that distance computations are based on the Euclidean distance computed between any two desired entities of the network. Using these static location-based parameters and an adaptive resource-based parameter \({\text{\rm E}}_{res}\), every end-device \(i\) calculates \(P_{wgt}\)-based \(Th_{CH}\) value via \(line{ }8\) for every \(l\)-th round. \(Lines{ }10 - 19\) and \(lines{ }22 - 32\) show routing plan from the end-devices \(i \notin list_{l}^{CH}\) to the root centre of WSN-IoT (i.e., IoT Hub) for the g-based conditions mentioned in Eq. (14). \(Line{ }35\) defines the end condition for the algorithm operational process.
4.6 MAC Scheme Adopted Within a P-LUET Cluster
P-LUET opts for Time Division Multiple Access (TDMA)/ Code Division Multiple Access (CDMA) within a cluster/ network to abridge congestion within the network during intra-cluster/ inter-cluster data transfer. For the sake, the network operation is divided into two time-stages, Setup Stage and Steady State Stage. Where Setup Stage broadly involves CH selection process within the network, Steady State Stage involves transmitting data from the source end-devices to the IoT Hub of the network either directly or via the chosen CHs.
As the network initialises, it enters the setup stage where upon obtaining \(Th_{CH} > rand()\), and being chosen as a CH \(i^{CH}\), the end-device \(i\) broadcasts its address via an advertisement packet \(ADV\) in its vicinity range. Every \(j \notin list_{l}^{CH}\) may receive one or more broadcasted \(ADV\) from its neighbourhood. It associates itself to the nearest \(i^{CH}\) (that source of \(ADV\) which is the highest on the \(RSSI\) comparison list in \(j\)) or the only \(i^{CH}\) through an acknowledgment packet \(ACK\) containing its own address. After all the \(i^{CH}\) setup their clusters, the steady state stage initiates in which end-devices \(j \notin list_{l}^{CH}\) sense and upload data to their respective \(i^{CH} \in list_{l}^{CH}\) by opting TDMA which after aggregating the received data, opt for CDMA to transmit this aggregated data to the IoT Hub. During the setup phase, the network may contain a few \(j \notin list_{l}^{CH}\) that do not receive \(ADV\) from any chosen \(i^{CH} \in list_{l}^{CH}\) and end up getting known as isolated or disconnected end-devices. These end-devices transmit their data directly to the IoT Hub during the following steady state stage. After a time that is planned prior to the network setup, the network enters another round of CH selection i.e., the Setup Stage and its corresponding steady state stage. This repeats until the last alive end-device is drained completely of its energy resources. The opting of TDMA/CDMA allows congestion-free hierarchy via clustering on several levels within the network, leading to improved energy structure for a heterogeneous environment.

4.7 Time Complexity Analysis of P-LUET
Time complexity (or computation complexity) can be described as the amount of work microcontroller \(\mu c\) has to perform as the input data increases (approaching to \(\infty\)) and is computed based on the Big \({\text{O}}\) notation that describes the worst-case diversified computational scenario of an algorithm.
In P-LUET, it can be observed that the convergence rate to reach an optimum solution is a constant value for every end-device for every iteration (in this case it is known as a round of the lifetime). Since P-LUET follows a distributed clustering strategy, every end-device in the network is known to execute the algorithm independently to determine its decision towards CH selection. These decisions are independent of status of the end-device’s neighbours or the end-device population within the network and only depend on an end-device’s current energy status apart from its static computed metrics. Therefore, the implementation complexity for CH selection can be given as \(0\left( 1 \right)\) (Fig. 9).

Computational Complexity of intra-cluster communication in WSN-IoT
However, for the initial phase of the operation when the condition \(0.75 {\fancyscript{n}}_{ini} \times P_{opt} < A_{\aleph } \times P_{opt} \le {\fancyscript{n}}_{ini} \times P_{opt}\) holds true, the network opts for static graph theoretical communication model between CHs and the IoT Hub while throughout the operation source devices follow multi-hop communication model. The diversity \(g\left( V \right)\) for computational analysis of the conditionally adopted grid network has been taken as \(\log \left( {2^{{ {\fancyscript{n}}_{ini} }} } \right) = {\fancyscript{n}}_{ini}\) wherein network either follows single-hop communication between IoT Hub and CHs of its vicinity grids or a two-tier multi-hop communication from far away CHs and IoT Hub. Therefore, this selective multi-hop communication among CHs introduces a stronger efficient connectivity at the cost of additional \(O\left( {g\left( V \right)} \right) = O\left( { {\fancyscript{n}}_{ini} } \right)\) factor in the algorithm’s implementation complexity (Fig. 10) and fulfils the property of each CH communicating successfully at least once i.e., \({\Psi }_{min}\).

Computational Complexity of inter-cluster communication in WSN-IoT
5 Simulation of Results and Analysis
For the purpose of P-LUET algorithm analysis, \(NS{ }2.35\) has been used as the simulator that runs on a system with Windows 10 operating system. The system is i7-8750H CPU with 16 GB RAM and the processor operates at 2.20 GHz. The basic simulation environment consists of a network of haphazardly deployed 100 end-devices in a field of dimensions \(300 \times 300{ }m^{2}\). Each end-device has an optimal probability \(P_{opt}\) of 0.08 as computed from Eq. (7) and a maximum capacity of carrying 4000bits of data. The energy heterogeneity metrics of the basic simulation environment have been listed in Table 1.
5.1 Performance Metrics
5.1.1 Stability Period, \({\varvec{\tau}}_{{{\varvec{fdd}}}}\).
It can be defined as the vitality period until the death of first end-device. It can alternatively be termed as reliable period despite high correlation, since field contains no energy hole which means every end-device actively participates in reading the environment. There are many critical smart applications like IoT-based health monitoring of a critical patient, or battlefield surveillance etc. that require to keep a regular check on every characteristic of the environment. Such applications may deploy end-devices with a sole purpose of updating about their respective functionality. Hence, death of any single end-device in these applications can turn detrimental owing to loss of a functionality. For example, in battlefield surveillance, loss of any end-device may result in loss of coverage of a crucial surveillance area, which may lead to minacious consequences. Hence, this metric plays a dominant role in guaranteeing acceptable performance of any protocol.
5.1.2 Unreliable Period, \({\varvec{\sigma}}_{{{\varvec{W}}/{\varvec{I}}}}\).
Network lifetime \(NL_{W/I}\) can be defined as the period until the network’s last alive device survives. Although, the last node is alive and transmitting data, the received data cannot be considered reliable as it fails to represent enough for the network. Hence, as soon as the first device dies, the network loses information about the area which was initially sensed by the dead device. Therefore, after first device death (FDD), the rest of the population may keep transmitting data, however, the data will be termed as unreliable. Hence, the corresponding unreliable period can be calculated as: \(\sigma_{W/I} = NL_{W/I} - \tau_{fdd}\).
5.1.3 Energy Efficiency, \({\varvec{\varepsilon}}_{{{\varvec{W}}/{\varvec{I}}}}\).
As stated, before in Sect. 4.3, energy efficiency, \(\varepsilon_{W/I}\) is proportional to the network throughput \(T^{net}\) while inversely proportional to the energy consumption \(E_{used}\) and can be computed as \(\varepsilon_{W/I} = T^{net} /E_{used}\) [43]. A higher \(\varepsilon_{W/I}\) defines algorithm’s improved capability of withstanding surging data flow from the IoT Hub while balancing devices’ energy-constrained resources.
5.1.4 Network Throughput, \({\varvec{T}}^{{{\varvec{net}}}}\).
Despite varyingly known in the literature, its inherent definition stays the same i.e., the total number of packets that can be transmitted successfully to the IoT Hub. Therefore, however differently this term may be defined in various literatures, yet the above stated remains the widely accepted definition amongst all the researchers.
5.1.5 Probability of Device Isolation, \({\mathbb{P}}\left( {{\varvec{iso}}} \right)\).
Imbalanced CH-selection could isolate certain end-devices from the chosen head list \(list_{l}^{CH}\) in the \(l\)-th round and resultantly the count of isolated nodes per round is taken as \(\alpha_{iso}\). As a result, these devices resort to direct-transmission with the IoT Hub irrespective of its location. However, a direct communication with the IoT Hub leads to a computational complexity of \(O\left( { {\fancyscript{n}}_{ini}^{2} } \right)\) that leads to exuberant energy-usage as depleted-energy increases proportionally-bifold with distance from the IoT Hub. Therefore, probability of end-device isolation \({\mathbb{P}}\left( {iso} \right)\) in every \(l\)-th round also comes across as a performance metric that can be computed as \({\mathbb{P}}\left( {iso} \right)_{l} = \frac{{\# \alpha_{iso} }}{{\# A_{\aleph } }}\) [44].
5.2 Numerical Results
In the following, the performance of the P-LUET algorithm has been compared with the aforementioned state-of-the-art algorithms while is also tested under varied network settings.
5.2.1 Comparative Analysis with Respect to State-of-that-Art Clustering Algorithms
The proposed algorithm is run through basic simulation environment as mentioned earlier with the aforementioned algorithms ([24, 33,34,35,36]) and is evaluated based on longevity metrics (\(NL_{W/I} ;{ }\tau_{fdd} ;{ }\sigma_{W/I}\)), \(\varepsilon_{W/I}\), \(T^{net}\), and \(\% {\mathbb{P}}( iso)\) w.r.t. these algorithms. Figure 11 exhibits the overall life pace of the algorithms involved from where it can be observed that EDCF [36] showcases a higher exponential fall rate in \(A_{\aleph }\) as compared to the other algorithms, P-SEP [35] follows a gradual exponential fall rate during its major portion of the \(\sigma_{W/I}\). Although, [35] may showcase an improved pace over certain period, it fails to maintain this pace until the end delivering a shorter \(NL_{W/I}\). Other algorithms ATEER [33], Improved clustering algorithm [34] and LUET [24] deliver similar life pace characteristics as that of P-LUET algorithm with a constant pace throughout the journey delivering no sudden fall rate \(\left( {1 - 0.01A_{\aleph } } \right)\). However, in an IoT environment, where queries suggest data proclaimed by every end-device of the network for reliable despite redundant data. In such cases it is important to determine the stability period of the network incorporated with the designed algorithm. Under such scenario, through Fig. 12 it can be observed that P-LUET demonstrates longer \(\tau_{fdd}\) while P-SEP delivers shortest \(\tau_{fdd}\). Therefore, despite improved life pace over \(\sigma_{W/I}\), P-SEP delivers the shortest \(\tau_{fdd}\) compared to the aforementioned algorithms. With a strong direction towards enhancing \(\tau_{fdd}\) of LUET, it can be clearly observed from Table 4 that P-LUET shows an improvement factor \(\tilde{\alpha }\) of 0.187. This can be understood as a resultant of upholding CH election operation that not only works on one design constraint, however, additionally supports overcoming hotspot issue and cluster overlapping apart from poor network connectivity.

Comparative life pace; \((A_{\aleph } \in \left[ {0,100} \right] vs l, {\mathcal{M}}^{2} = \left( {300} \right)^{2} )\)

\(\tau_{fdd}\)- analysis; \((A_{\aleph } \in \left[ {95,100} \right] vs l, {\mathcal{M}}^{2} = \left( {300} \right)^{2} )\)
It can also be observed from Table 2 that P-LUET successfully upgrades \(\tau_{fdd}\)-based \(\tilde{\alpha }\) value by \(\in \left[ {0.011,0.192} \right]\) defining longer \(\tau_{fdd}\) making it more suitable within a query-based or continuous-monitoring-based IoT environment than the other established algorithms. The main disadvantages towards lower \(\tau_{fdd}\) observed in established algorithms apart from [24] can be briefed as non-consideration of device location w.r.t. the IoT Hub of the network in [33, 36], large overhead due to dependency on a dynamic location entitiy in [34], higher probability rate of normal devices due to comparatively large population in [35], no direction towards towing the CH selection to devices that help improve the network connectivity without enhancing its overhead in [33,34,35,36]. It can also be observed that P-LUET incorporated WSN-IoT delivers greater \(NL_{W/I}\) by \(\tilde{\alpha }\) factor ranging from \(\left[ {0.001 - 0.139} \right]\) which has been clearly depicted graphically in Fig. 13. Although [33] may deliver longer \(NL_{W/I}\) by \(\tilde{\alpha }\) factor of 0.011, yet due to smaller \(\tau_{fdd}\), it faces longer \(\sigma_{W/I}\) compared to the proposed algorithm as can be evaluated from Table 3.

\(NL_{W/I}\)- analysis; \((A_{\aleph } \in \left[ {0,5} \right] vs l, {\mathcal{M}}^{2} = \left( {300} \right)^{2} )\)
Observations defined in Table 3, clearly mark P-LUET as the most efficiently suitable algorithm to be considered for deployment in a WSN-IoT framework. Observations in Table 5 calibrated as per longevity parameters and throughput along with energy helps realise the energy utilization in either of the algorithms. Drawing the inferences from Table 4, the synthesized data has been utilized to reach a consensus stating that P-LUET can effectively serve an IoT-framework.
Thereafter, Tables 6 and 7 have been described that individually showcase P-LUET’s energy credibility and channel utilization capability over randomly chosen round counts w.r.t. aforementioned state-of-the-art clustering algorithms. From Table 6, it can be observed that [24, 35, 36] loose energy earliest than [33, 34] and P-LUET. It can also be observed that despite holding more residual energy at the defined round (1100, 1800) than P-LUET, [35] showcases a poor channel utilization capacity during those round counts as can be confirmed from Table 7. P-LUET displays a better or similar channel utilization capacity compared to [24, 33,34,35,36] for round counts 500, 1100, 1800 and a better channel capacity compared to [24, 33, 34, 36] for round counts 2600, 3400, 4000, 4600, 5100. [35]’s channel capacity improves over latter round counts compared to P-LUET, however, over unreliable session of WSN-IoT lifetime which holds minimal importance in IoT architecture.
As an extension of LUET, P-LUET also helps in improving the network connectivity by working on keeping the \({\mathbb{P}}\left( {iso} \right)\) lower as was obtained in LUET. To further enhance this characteristic of the network, P-LUET introduces conditional gridding that allows devices to be connected to one device acting as a CH within its local grid until the condition \(\left( {0.75 {\fancyscript{n}}_{ini} \times P_{opt} < A_{\aleph } \times P_{opt} \le {\fancyscript{n}}_{ini} \times P_{opt} } \right)\) is fulfilled. As can be seen from Fig. 14, unlike [35, 36] that has a few cases of higher \({\%}{\mathbb{P}}\left( {iso} \right)\) until round count 1700, P-LUET’s \({\%}{\mathbb{P}}\left( {iso} \right)\) spread is on a lower front. Moving ahead in lifetime, P-LUET’s \({\%}{\mathbb{P}}\left( {iso} \right)\) spread can be seen rising than its spread in the previous round range yet it falls on the lower front compared to the spread for [33, 35, 36] despite a fall in \(A_{\aleph }\).

\(\% {\mathbb{P}}\left( {iso} \right)\)- analysis; \(\left( {\% {\mathbb{P}}\left( {iso} \right) \in \left[ {0,100} \right] vs l, {\mathcal{M}}^{2} = \left( {300} \right)^{2} } \right)\)
5.2.2 Assessment based on varied assumptions on P-LUET
In this section the performance of P-LUET is tested under varying assumptions to further understand the liability of employing P-LUET. As understood from the literature, a heterogeneous network is supposedly assumed to lay devices with an additional Δ times energy to enhance network’s capability. However, varying the individual device capabilities without affecting the overall network resources can also be known as heterogeneity sensitivity. Therefore, in the first assumption, while keeping the total energy of the network same \({\text{E}}_{T} = 100J\), varying scenarios have been considered on how this energy can be individually varied among devices. Under such presumption, 4 cases can be obtained. The first case is keeping the initial device count of the network \({n}_{ini} = 100\) and increasing the energy of every device \({\text{E}}_{ini}\) from \(0.5 \to 1.0{ }J\); the second case is keeping \({\text{E}}_{ini} = 0.5J\) as is the energy of normal nodes in the basic pre-analysed environment and adding more devices of same \(E_{o}\) to the network; the third case is the two-level energy heterogeneity with two kinds of devices: normal and advanced devices where advanced devices hold \(a^{^{\prime}} = 2\) times more \(E_{o}\) and are \(m_{a}^{^{\prime}} = 0.5\) fraction of total nodes; the fourth case is the basic three-level heterogeneous scenario analysed in the previous section.
The observations from the Table 8 direct the analysis towards accepting Case 4 for the needful environment. Additionally, Fig. 15 graphically demonstrates the improved efficiency compared to the other cases while also showcases the FDD round graph for all the cases. Pertaining to the high \({\text{E}}_{ini}\) value in Case 1, it demonstrates a much longer \(\tau_{fdd}\). However, considering it unfair for initial performance evaluation and bypassing it for valuation, Case 4 wins the race among the rest of the cases as clearly, it has the longest \(\tau_{fdd}\).

Analysis based on heterogeneity sensitivity
\(E_{th}\) plays an important role in defining \(P_{wgt}\) of an end-device for being chosen as the CH. The \(E_{th}\) value is greatly influenced by \(b\) parameter as \(E_{th} = b{\text{E}}_{ini}\) while upon successful fulfilment of this condition, \(P_{wgt}\) value is greatly influenced by \(c\) parameters. Hence, it is important to understand the effect of these parameters on the performance evaluation. Therefore, in the second assumption, both the discrete parameters have been varied individually from \(\left[ {0.1,1.0} \right]\) while the algorithm’s FDD has been noted. Focussing on the \(b\) parameter, it can be observed from Fig. 16a that at \(b = \{ 0.1, 0.4, 0.5, 0.7, 0.8\)}, a higher FDD has been observed depicting them as the probable optimal values of \(b\). Upon Fig. 16b analysis for values \(b = \{ 0.1, 0.4, 0.5, 0.7, 0.8\)}, it can be observed that \(b = \{ 0.7, 0.8\)} derive the network for a longer duration picking themselves as the most near optimal points if only longevity is considered. However, the proposed algorithm also focusses on improved network connectivity and thereby reduced device isolation within the network. However, among the chosen probable \(b\) values, \(b = 0.7\) provides the minimum isolation among the devices (as can be verified from Fig. 16c) making it the most apt value. Thereafter, stabilizing \(b\) value in the \(E_{th} = b{\text{E}}_{ini}\) metric, \(c\) value is analysed for \(P_{wgt}\) computation. For the very purpose, \(c\) is varied from \(\left[ {0.01,1.0} \right]\) to understand its presence. It can be observed from Fig. 16d that at smaller values of \(c\), the network celebrates a longer \(\tau_{fdd}\) while the network behaves vice-versa as c value increases. As clearly briefed in [30], \(c\) is that reel positive number that influences the CH count through the \(P_{wgt}\) computation. It is because a higher \(c\) results in comparatively a higher \(P_{wgt}\) outputting a smaller epoch for all the devices barring them to adapt as per each residual constraints. This may result in higher CH count with most nodes communicating directly with their IoT Hub which becomes the cause of early FDD. A value of 0 is avoided for parameter \(c\) as it would result in \(P_{wgt} = 0\) which again leads to a direct communication of all end-devices with the IoT Hub of the network. Therefore, from Fig. 16d, it can be inferred that \(c = \{ 0.1, 0.2\)} are considered the best possible options for consideration.

Analysis based on b and c parameters
6 Conclusion
Exhaustive research critically analyses P-LUET algorithm w.r.t. the state-of-the-art clustering algorithms for their suitability in an IoT framework. The need of modification arises from the need to overcome hotspot issue and cluster overlapping. This algorithm has introduced the concept of annulus ring-based weight value (\({\mathcal{R}}_{b}\)-based \(_{i}^{3} W\)) and conditional region concurrence (\({\fancyscript{g}}\)) to help overcome these issues. This algorithm successfully improves the stability period (\(\tau_{fdd}\)) of LUET by 18.7%. As it is an extension of the previous work, P-LUET is expected to better the network connectivity by utilizing the lines of uniformity concept. Apart from showcasing improved efficiency of 12.8% over \(\tau_{fdd}\) and a stronger connectivity, it also delivers a longer life of about 5506 rounds and a higher network throughput of 279,798 data packets. P-LUET has also been evaluated on scenarios of heterogeneous sensitivity and \(b,c\) parameters. Our work considers Constant Bit Rate (CBR) for the network. However, with the upcoming increase in the multimedia applications of IoT scenario, it is important that the network is equipped with Variable Bit Rate (VBR) that allows the sender to transmit data at a varying speed. Hence, this algorithm can be improved by considering VBR instead of CBR. The ID-enabled end devices can be replaced with IP-enabled devices to uplift the algorithm’s suitability within a scenario. The impact of the algorithm can be studied on other WSN-IoT metrics like latency, packet delivery ratio and QoS in future. This algorithm can also be tested and made suitable for varying scalable network scenarios.
Availability of data and material
The datasets generated during and/or analysed during the current study are available from the corresponding author on reasonable request.
Code availability
The code of the algorithm has been run in Network Simulator 2.35.
References
Ebadi, S. (2012). A multihop clustering algorithm for energy saving in wireless sensor networks. International Scholarly Research Notices, 2012, 1–4. https://doi.org/10.5402/2012/817895.
Yu, Y., Prasanna, V. K., Krishnamachari, B. (2006). Information processing and routing in wireless sensor networks. World Scientific Publishing Co. Pte. Ltd. https://doi.org/10.1142/6288.
Boujelben, M., & Youssef, H. (2008). Survey on pre shared key in WSN. In International conference on wireless and mobile computing (pp. 532–537).
Ahmad, T., Haque, M., & Khan, A. K. (2019). An energy-efficient cluster head selection using artificial bees colony optimization for wireless sensor networks. Advances in Nature-Inspired Computing and Applications. https://doi.org/10.1007/978-3-319-96451-5_8.
Al-Karaki, J. N., & Kamal, A. E. (2004). Routing techniques in wireless sensor networks: a survey. IEEE Wireless Communications, 11(6), 6–28. https://doi.org/10.1109/MWC.2004.1368893.
Al-Turjman, F. (2016). Impact of user’s habits on smartphones’ sensors: An overview. In: Proceedings of the 2016 HONET-ICT. https://doi.org/10.1109/HONET.2016.7753422.
Al-Turjman, F. M., Al-Fagih, A. E., Hassanein, H. S. (2012). A novel cost-effective architecture and deployment strategy for integrated RFID and WSN systems. In: Proceedings of the 2012 international conference on computing, networking and communications (ICNC) (pp. 835–839). https://doi.org/10.1109/ICCNC.2012.6167542.
Al-Turjman, F. (2016). Hybrid approach for mobile couriers election in smart-cities. In: Proceedings of the 2016 IEEE 41st conference on local computer networks (LCN) (pp. 507–510). https://doi.org/10.1109/LCN.2016.79.
Behera, T. M., Mohapatra, S. K., Samal, U. C., Khan, M. S., Daneshmand, M., & Gandomi, A. H. (2019). Residual energy based cluster-head selection in WSNs for IoT application.
Gubbi, J., Buyya, R., & Marusic, S. (2013). Internet of things (IoT): a vision, architectural elements, and future directions. Future Generation Computer Systems, 29(7), 1645–1660. https://doi.org/10.1016/j.future.2013.01.010.
‘WaIoT Intelligent no flooding system’. [Online]. https://www.waiot.eu/index.php.
Atom, I., & Processor, E. (1991). Smart IoT-connected rail passenger infotainment solution by SADEL. https://www.intel.in/content/www/in/en/internet-of-things/case-studies/smart-connected-railways-study.html.
The Institution of Engineering and Technology, India IOT Panel. IoT Case Studies from India. http://theiet.in/iot-case-studies-india.
Summary, E. Bringing intelligence to manufacturing with the internet of things (IoT). https://www.intel.sg/content/dam/www/program/embedded/internet-of-things/blueprints/iot-nexcom-bringingintelligence-to-manufacturing-blueprint.pd.
Kumar, J. S., & Patel, D. R. (2014). A survey on the internet of things: security and privacy issues. International Journal of Computer Applications, 90(11), 20–26. https://doi.org/10.5120/15764-4454.
Salem, A. O. A., & Shudifat, N. (2019). Enhanced LEACH protocol for increasing a lifetime of WSNs. Personal and Ubiquitous Computing, 23, 901–907. https://doi.org/10.1007/s00779-019-01205-4.
Teja, R. ‘Different Types of Sensors-Electronics Hub’. [Online]. https://www.electronicshub.org/different-types-sensors/.
Heinzelman, W. R., Chandrakasan, A., & Balakrishnan, H. (2000). Energy-efficient communication protocol for wireless microsensor networks. Hawaii International Conference on System Sciences. https://doi.org/10.1109/HICSS.2000.926982.
Akyildiz, I. F., Melodia, T., & Chowdhury, K. R. (2007). A survey on wireless multimedia sensor networks. Computer Networks, 51(4), 921–960. https://doi.org/10.1016/j.comnet.2006.10.002.
Lodhi, A. K., & Sattar, S. A. (2019). Cluster head selection by optimized ability to restrict packet drop in wireless sensor networks. Soft Computing in Data Analytics, 758, 453–461. https://doi.org/10.1007/978-981-13-0514-6_45.
Ahmad, M., Shah, B., Ullah, A., Moreira, F., Alfandi, O., Ali, G., & Hameed, A. (2021). Optimal clustering in wireless sensor networks for the internet of things based on memetic algorithm: memeWSN. Wireless Communications and Mobile Computing. https://doi.org/10.1155/2021/8875950.
Kumar, J. S., & Zaveri, M. A. (2018). Clustering approaches for pragmatic two-layer IoT architecture. Wireless Communications and Mobile Computing. https://doi.org/10.1155/2018/8739203.
Al-Humidi, N., & Chowdhary, G. V. (2019). Energy-aware approach for routing protocol by using centralized control clustering algorithm in wireless sensor networks. Computing, Communication and Signal Processing, 810, 261–274. https://doi.org/10.1007/978-981-13-1513-8_28.
Sood, T., & Sharma, K. (2020). LUET: a novel lines-of-uniformity based clustering protocol for heterogeneous-WSN for multiple-applications. Journal of King Saud University: Computer and Information Sciences. https://doi.org/10.1016/j.jksuci.2020.09.016.
Heinzelman, W. B., Chandrakasan, A. P., & Balakrishnan, H. (2002). An application-specific protocol architecture for wireless microsensor networks. IEEE Transactions on Wireless Communications, 1(4), 660–670. https://doi.org/10.1109/TWC.2002.804190.
Smaragdakis, G., Matta, I., & Bestavros, A. (2004). SEP: A stable election protocol for clustered heterogeneous wireless sensor networks. Second international workshop on sensor and actor network protocols and applications (SANPA 2004) (pp. 1–11).
Kumar, D., Aseri, T. C., & Patel, R. B. (2009). EEHC : energy efficient heterogeneous clustered scheme for wireless sensor networks. Computer Communications, 32(4), 662–667. https://doi.org/10.1016/j.comcom.2008.11.025.
Qing, L., Zhu, Q., & Wang, M. (2006). Design of a distributed energy-efficient clustering algorithm for heterogeneous wireless sensor networks. Computer Communications, 29(12), 2230–2237. https://doi.org/10.1016/j.comcom.2006.02.017.
Saini, P., & Sharma, A. K. (2010). E-DEEC-enhanced distributed energy efficient clustering scheme for heterogeneous WSN. In: Proceedings of the 2010 First International Conference On Parallel, Distributed and Grid Computing (PDGC 2010) (pp. 205–210). https://doi.org/10.1109/PDGC.2010.5679898.
Elbhiri, B., Saadane, R., Elfldhi, S., & Aboutajdine, D. (2010). Developed distributed energy-efficient clustering (DDEEC) for heterogeneous wireless sensor networks. In: Proceedings of the 2010 5th international symposium on I/V communications and mobile network (pp. 1–4). https://doi.org/10.1109/ISVC.2010.5656252.
Javaid, N., Qureshi, T. N., Khan, A. H., Iqbal, A., Akhtar, E., & Ishfaq M. (2013). EDDEEC: Enhanced developed distributed energy-efficient clustering for heterogeneouswireless sensor networks. International workshop on body area sensor networks (BASNet-2013) in conjunction with 4th international conference on ambient systems, networks and technologies (ANT 2013) 19 (pp. 914–919).
Singh, S., Malik, A., & Kumar, R. (2017). Engineering science and technology, an international journal energy efficient heterogeneous DEEC protocol for enhancing lifetime in WSNs. Engineering Science and Technology, an International Journal, 20(1), 345–353. https://doi.org/10.1016/j.jestch.2016.08.009.
Singh, R., & Verma, A. K. (2017). Energy efficient cross layer based adaptive threshold routing protocol for WSN. AEU International Journal of Electronics and Communications, 72, 166–173. https://doi.org/10.1016/j.aeue.2016.12.001.
Wu, W., Xiong, N., & Wu, C. (2017). Improved clustering algorithm based on energy consumption in wireless sensor networks. The Institution of Engineering and Technologu, IET Networks, 6(3), 47–68. https://doi.org/10.1049/iet-net.2016.0115.
Naranjo, P. G. V., Shojafar, M., Mostafaei, H., Pooranian, Z., & Baccarelli, E. (2017). P-SEP: a prolong stable election routing algorithm for energy-limited heterogeneous fog-supported wireless sensor networks. The Journal of Supercomputing, 73, 733–755. https://doi.org/10.1007/s11227-016-1785-9.
Priyadarshi, R., Rawat, P., & Nath, V. (2019). Energy dependent cluster formation in heterogeneous wireless sensor network. Microsystem Technologies, 25, 2313–2321. https://doi.org/10.1007/s00542-018-4116-7.
Tang, J., Zhou, Z., Niu, J., & Wang, Q. (2014). An energy efficient hierarchical clustering index tree for facilitating time-correlated region queries in the Internet of Things. Journal of Network and Computer Applications, 40, 1–11. https://doi.org/10.1016/j.jnca.2013.07.009.
Liu, X., & Liu, Q. (2018). A virtual uneven grid-based routing protocol for mobile sink-based WSNs in a smart home system. Personal and Ubiquitous Computing, 22, 111–120. https://doi.org/10.1007/s00779-017-1093-2.
Behera, T. M., Mohapatra, S. K., Samal, U. C., Khan, M. S., Daneshmand, M., & Gandomi, A. H. (2019). Residual energy-based cluster-head selection in WSNs for IoT application. IEEE Internet of Things Journal, 6(3), 5132–5139. https://doi.org/10.1109/JIOT.2019.2897119.
Pathak, A. (2020). A proficient bee colony-clustering protocol to prolong lifetime of wireless sensor networks. Journal of Computer Networks and Communications. https://doi.org/10.1155/2020/1236187.
Verma, S., Sood, N., & Sharma, A. K. (2019). Genetic algorithm-based optimized cluster head selection for single and multiple data sinks in heterogeneous wireless sensor network. Applied Soft Computing. https://doi.org/10.1016/j.asoc.2019.105788.
Kumar, D., Aseri, T. C., & Patel, R. B. (2009). EEHC: energy efficient heterogeneous clustered scheme for wireless sensor networks. Computer Communications, 32(4), 662–667. https://doi.org/10.1016/j.comcom.2008.11.025.
Iqbal, A., & Lee, T. J. (2019). GWINs: group-based medium access for large-scale wireless powered IoT networks. IEEE Access, 7, 172913–172927. https://doi.org/10.1109/ACCESS.2019.2956029.
Wang, Q., Dai, H. N., Zheng, Z., Imran, M., & Vasilakos, A. V. (2017). On connectivity of wireless sensor networks with directional antennas. Sensors (Basel). https://doi.org/10.3390/s17010134.
Funding
No funding was received to assist with the preparation of this manuscript.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors have no conflicts of interest to declare that are relevant to the content of this article.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Sood, T., Sharma, K. P-LUET: A Prolong Lines of Uniformity Based Enhanced Threshold Algorithm for Heterogeneous Wireless Sensor Network Enabled Internet of Things Framework. Wireless Pers Commun 120, 2935–2970 (2021). https://doi.org/10.1007/s11277-021-08593-y
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11277-021-08593-y