
Abstract
This paper introduces a nonlinear integer programming model for the clustering problem in wireless sensor networks, with a threefold contribution. First, all factors that may influence the energy consumption of clustering protocols, such as cluster-heads selection and distribution, are considered implicitly in the model. Second, an innovative fitness function that directly maximizes the WSN lifetime is proposed. Finally, a global optimum of the whole network lifespan clustering schemes is targeted. The proposed model is then solved by a particle swarm optimization meta-heuristic based algorithm. This algorithm follows a centralized one-step off-line approach, in which the clustering schemes of the whole network lifetime and their associated durations are computed at the initialization of the network operations. The one-step approach is enabled by an energy prediction mechanism that allows to reduce the costs of the periodic network re-clustering. Simulation results show clear enhancement in network lifespan and number of received data packets as compared to some state-of-the-art clustering approaches.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
In the last few years, tremendous research works have been carried out towards smartening the environments by monitoring/controlling selected areas in real time [29, 36]. The outcome of these works can fuel several domains including military applications, healthcare, target tracking, etc., [26]. While these are diverse in domains and purposes, all of them rely on the collection of meaningful information, generally from a remote areas of interest. This is ensured by a collaborative infrastructure named Wireless Sensor Network (WSN), which is composed with a set of compact low power sensor nodes and one (or more) super node(s) called base station [2, 3], as illustrated in Fig. 1. The restriction in resources, predominantly energy, is the inherent characteristic of WSNs. The lifetime of the WSN strongly depends on the residual energy of the SNs, and it represents the principal performance criterion in most applications. Achieving a long lifespan in WSN is challenging, especially for densely and large-scale SNs deployment. It has been proved that the major part of node’ energy is dissipated in communication [34], and that the transmission power is proportional to the transmission range [22]. This motivates for the use of topology control techniques that limit the number of data packets circulating in the network and lessen the distances over which packets are transmitted. Clustering is one of such techniques that is widely used. It partitions the SNs into clusters with a particular node as cluster-head (CH) in each cluster. The other SNs of the cluster become members and send the sensed data to their CHs, which in turns forwards to the BS.
Numerous WSN clustering solutions have been proposed [1, 9, 28]. Each one deals with some clustering challenges to intuitively prolong the network lifetime. However, all the existing clustering solutions suffer from one or more of the following drawbacks. (i) In the set-up phase of every round, a high amount of information overhead (required for re-clustering) is exchanged between nodes or from nodes to the BS in centralized clustering, which causes waste of energy. (ii) Re-clustering schemes are calculated gradually and greedily. In fact, the scheme for round \(r+1\) is computed at the end of round r, with no consideration of the upcoming rounds’ schemes (\(i>r+1\)); which may lead to the local optimum problem. (iii) A constant round-time is used, or if modelled to change dynamically, the nodes are supposed to act as CH at one round and as non-CH in the other \((N/K-1)\) rounds (where N is the network size and K is the number of CHs in the network). This is not effective for topologies where some nodes are located in positions that are unsuitable for acting as CHs. (iv) The number of CHs is set to a predetermined parameter in every round. This could be inappropriate given the temporal variation in the energy state of the SNs. (v) In clustering protocols based on meta-heuristics, the proposed Fitness Functions attempt to prolong the network lifetime by optimizing either some factors related to energy (e.g., the node residual energy, the expected energy to be consumed if the SN is elected as CH, etc.), or some geospatial factors (e.g., the distance among SNs and from SNs to the BS). To our best knowledge, no existing solution considers direct maximization of the network lifetime in the clustering FF.
To address the aforementioned drawbacks, a new non-linear integer programming (NIP) formulation of the clustering problem is introduced in this paper. All the existing clustering solutions that focus on network lifetime try to prolong it, indirectly, by optimizing some factors such as the cluster heads selection and distribution, the clusters’ size, etc., which allows only achieving sub optimal solutions. However, we do not, explicitly, focus on any of these issues given that the ultimate objective is the network lifetime extension. The innovative idea in this paper is the formulation of a fitness function that intends to maximize the network lifetime directly. This way, all the overlapped energy-efficiency factors will be considered implicitly, as extending the network lifetime requires selecting the appropriate set of CHs, tuning the optimal rounds’ times, etc. Motivated by this, we propose a new original clustering approach in which the clustering schemes are modelled as square binary matrices and the rounds’ durations are represented by a vector. Based on this model, an appropriate clustering algorithm is used to find the optimal schemes and their durations that maximize a fitness function defined as the sum of all rounds’ durations, which represents the network lifetime. Moreover, the introduced NIP formulation enabes all the clustering schemes (of all rounds) and their respective durations to be calculated together by the BS. This provides the BS with a horizontal vision and enables it to target a global optimization and choosing schemes that increase the network lifespan, as a whole. Given the NP-hardness and the high complexity of the NIP problems [7], it is extremely difficult to find exact solutions. We therefore develop a centralized one-step off-line clustering algorithm based on the particle swarm optimization and an energy prediction mechanism to solve the proposed NIP. Energy prediction is also used to prevent the periodic re-clustering process while distributing the load evenly amongst the SNs. The main contributions of the proposed solution are summarized below:
-
An innovative fitness function that, directly, maximizes the WSN lifespan is introduced.
-
Values of all the factors influencing the energy efficiency of a clustering protocol are optimized dynamically in each round.
-
Global optimum of the whole network lifetime clustering schemes and their durations is targeted.
-
Re-clustering cost is mitigated while balancing the load between the SNs.
The rest of the paper is organized as follows. Sect. 2 presents some existing clustering protocols in WSNs. Section 3 describes the PSO meta-heuristic, as well as the network and energy models. Section 4 introduces the NIP formulation followed by the general functioning of the proposed clustering protocol and the proposed PSO-based algorithm. Section 5 discusses simulation results, and finally Sect. 6 draws conclusions and gives some perspectives. All the acronyms used throughout the paper are given in Table 1.

Wireless sensor network
2 Related Work
LEACH-C [13] is one of the earlier and canonical clustering approaches. In this protocol, the BS applies simulated annealing algorithm in order to select the CHs that allow reducing the energy dissipated by non-CH-nodes, while the FF enables minimizing the total sum of squared distances between all the non-CH-nodes and their closest CHs.
In TPSO-CR [7], the clustering and routing problems were modelled as linear programs and two algorithms based on PSO were introduced to resolve the proposed programs. The used FF targets the optimization of the energy consumption, the cluster quality, and the network coverage. ETPSO-CR [20] is an enhanced version of TPSO-CR that adopts an energy prediction mechanism, for the purpose of reducing the periodic network re-clustering costs. It also modifies the FF to permit the election of well distributed CHs and adapts the rounds’ durations to the CHs residual energy.
CGC [12] is a protocol that uses GA with a FF aiming to select as CHs the non-outlier SNs with residual energy higher than the network average energy and that optimize the total energy consumed in the network. CECP [11] also uses a GA with an objective function aiming to select as CHs the SNs that optimize the energy consumed in the network.
OSC [21] uses a one-step off-line cluster computation algorithm, where all the clustering schemes and their respective durations are calculated by the BS once at the network initialization by a greedy approach. OSC introduced a new weight function for selecting the set of CHs that minimizes energy consumption of CHs, and non-CH nodes as well. OSC also eliminated costs proportional to periodic online re-clustering by using an energy prediction model.
EBUC [14] was proposed to address the hot-spot problem associated to multi-hop WSN, as well as equitably distribute the energy consumption over the network. In EBUC, the network is subdivided into unequal sized clusters with small-size clusters near the BS. In such way, their CHs may save sufficient energy to guarantee the routing operation. For the creation of optimized unequal clusters, EBUC uses an algorithm based on PSO and introduces an energy-aware multi-hop routing algorithm between the CHs and the BS. This protocol uses an energy prediction method to estimate the SNs energy level at the starting of each round. EAUCA [6] also considers the energy hole problem and targets extending the network lifetime by creating unequal sized clusters. The unequal clustering is achieved by calculating the competition radius of the candidate CHs based on the SN remaining energy and its distance to the BS. The final CHs are then selected by considering both residual energy and degree of the SNs. To further energy preservation, EAUCA proposes a multi-hop routing algorithm between the CHs and the BS. Relay nodes are chosen in accordance with the SN remaining energy, degree, and distance to BS.
LEACH-CE [16] and HMM-PSO [10] proposed energy prediction techniques to reduce the periodic network re-clustering costs while distributing the load evenly amongst the SNs.
In order to prolong the FND and to optimize the use of the SNs’ energy, NARTC [24] and D-LEACH-F [4] proposed methods to model the rounds’ durations. In these methods, each SN takes on the role of CH at least once and acts as a member-node in the other \((N/K-1)\) rounds, where N is the size of the WSN and K is the desired number of CHs.
FL has been used in some recent solutions such as LPOBC [35], BMBWFL-HEED [31] and PS-SFLA [8]. LPOBC uses the lion pride optimizer algorithm and FL in the CHs selection phase. It also proposes the construction of a direct virtual backbone of CHs to facilitate data routing. BMBWFL-HEED makes use of the combination of the boosted mutation based black widow optimization along with the FL system to select the optimal set of CHs in the network. In PS-SFLA, authors focused on the optimal selection of the fuzzy input parameters and rule tuning for multi-hop clustering protocols in WSNs.
Along with energy optimization, some state-of-the-art clustering protocols consider other WSN aspects. For instance, the effect of the harsh external environment was considered in HDDS [19], which is an energy-efficient hierarchical protocol aiming at enhancing the network coverage and supporting the dynamic changes in the WSN topology.
All the reviewed clustering protocols suffer from at least one of the drawbacks previously presented in Sect. 1. LEACH-C, TPSO-CR, CGC, CECP, LPOBC, BMBWFL-HEED and HDDS have the advantage of using robust algorithms such as PSO or FL with energy-efficiency criteria to select the optimal set of CHs. Nevertheless, they suffer from re-clustering cost, fixed rounds’ times and non-optimal tuning of the CHs number in every round. ETPSO, OSC, LEACH-CE and HMM-PSO deal with the re-clustering cost and effectively minimize the energy consumption in the network through energy prediction mechanisms. However, they do not optimally set the number of CHs to be elected in every round. Moreover, LEACH-CE and HMM-PSO suffer from the fixed rounds’ durations. NARTC and D-LEACH-F have the advantage of modeling the round times (durations) but they elect the CHs randomly and create clusters with random sizes. The strong point of EBUC and EAUCA is the unequal clustering which balances the energy dissipation between the SNs. Nevertheless, the predefined number of CHs, the fixed rounds’ durations, and the re-clustering cost in EAUCA have negative impact on energy. Furthermore, in all the reviewed clustering protocols, re-clustering schemes are calculated gradually and protocols intend to maximize the network lifetime “indirectly” by considering some energy related criteria. This paper proposes a new energy-efficient clustering solution aiming at sorting out all the above-mentioned problems.
3 Background, Assumptions and Models
3.1 PSO
PSO is an artificial intelligence technique that can be used to find approximate solutions to extremely difficult maximization and minimization problems that cannot be solved numerically with accurate algorithms [15, 23]. It is a population-based optimization method derived from the social behavior of birds. The success of an individual in such method is not only affected by its own effort but also by the information shared by its neighbors. PSO keeps concurrently many candidate solutions (particles) and maximizes or minimizes an objective function through the estimation of all the particles’ fitness. Particles are featured by velocities and positions having at the start-up random values. The velocity, Ve, and position, X, are updated at each optimization iteration, t, for each particle, i. Equations 1 and 2 define the update formulas associated to velocity and position, respectively [23].
For ensuring convergence towards the global best solution during the running of the algorithm, each particle involves its best discoveries in the past, \(pbest_i\), as well as its best discoveries of the entire population, say gbest. w stands for a weight factor managing the velocity of the particle, \(c_1\) and \(c_2\) define the learning factors, while \(r_1\) , \(r_2\) are random numbers within the interval [0, 1].
The easiness of PSO implementation motivates its application in different fields of science to solve complex problems, including clustering in WSNs.
3.2 Network Model
In this paper we consider the same network model used in [21] where the network is represented by an undirected unit disk graph, \(G=(V, E, B)\). V is the set of nodes and E is the set of edges. \((u,v) \in E\) if u and v are within the communication range of each other. B is the BS, which is supposed to have no energy constraint. G models a network topology while considering a regular transmission range of nodes. Nonetheless, it is assumed that the SNs can communicate directly with the BS by boosting their power if required. Once deployed, the WSN is assumed stationary and the SNs are aware of their positions. Traffic is assumed periodic, i.e. all the SNs generate fixed-length data packets at a constant rate. Data aggregation is considered by every CH before transmitting the collected data to the BS. A clustering Scheme, S, is defined as a set of clusters, \(S=\{(CH_k, m_1, m_2, \cdots m_{\lambda })\}\), covering the WSN (the graph G). Each tuple \((CH_k, m_1, m_2, \cdots m_{\lambda })\) represents a cluster, k, with a CH, \(CH_k\), and \(\lambda\) members (\(m_1, m_2, \cdots m_{\lambda }\)). The set of all schemes for the whole WSN lifespan is then modelled by a vector, \(C^R\), of schemes, where R is the number of schemes (i.e. the number of rounds). In the rest of this paper, we will refer to the vector, \(C^R\), by a clustering configuration.
3.3 Energy Model
In this section, we present an energy consumption model allowing the BS to predict the remaining energy of all the nodes in the network to eliminate the periodic sending of such information from the SNs. During its life cycle, a SN spends its energy, principally, in [18]: (i) Sensing: energy is dissipated to activate the sensing circuit to retrieve the data from the environment, (ii) Processing: SNs are in charge of doing some simple treatments such as computation and data aggregation, which consume some of their energy to activate the processing units, and (iii) Radio communication: which is the most energy consuming. To permit the transmission and the reception of data packets, a considerable amount of energy is consumed.
In this paper, we consider the radio communication model illustrated in [13] and utilized in many state-of-the-art protocols, e.g., [17, 30] and [21]. In this model, transmission energy, \(E_{tx}\), is proportional to the data packet size, l, and the packet transmission distance, d. Equations 3 and 4 gives the formulas for calculating \(E_{tx}\) while considering both fs and mp carriers. This depends on the crossover distance, \(d_0\), separating the transmitter from the receiver. \(d_0\) is calculated by Eq. 5. The energy spent to receive a packet, \(E_{rx}\), is given by Eq. 6. \(E_{rx}\) is proportional to the data size only. \(E_{el}\) is the energy required for running the transmitter and receiver electronic circuitry. \(\epsilon _{fs}\) and \(\epsilon _{mp}\) are the amplification energy in the fs and mp models, respectively.
The approximate consumption of node, \(v_{i}\), in a round, r, depends on its status in that round, i.e., member versus CH. We consider the frame as the unit of time. In each frame, a member-SN senses and communicates data to its CH. The CH aggregates the data collected from its members and transmits it to the BS. The energy spent during a time frame by a member node, \(v_{m}\), and a CH, \(v_{h}\), are then calculated by Eqs. 7 and 8, respectively, where \(E_{sen}\) and \(E_{agr}\) are the energy dissipated in sensing and data aggregation, respectively, and \(\lambda _{h}\) is the cluster’ size of the CH \(v_{h}\). \(d_{{v_{m}}, {v_{h}}}\) represents the distance between the member \({v_{m}}\) and its CH \({v_{h}}\), and \(d_{{v_{h}}, B}\) is the distance from the CH \({v_{h}}\) to the BS. Accordingly, the consumed energy, \(E_{c_{v_{i}}}(r)\), of any node, \(v_{i}\), in a round, r, can be calculated by Eq. 9, where \(t_{r}\) is the round duration (in terms of frames).
4 Proposed Solution
4.1 Problem Formulation
Let N be the size of the network and R the upper bound of the possible number of rounds for the whole network lifetime. The variables of the optimization program are: i) t: a vector of size R, of integer variables representing the duration of rounds, i.e, \(t_r\) represents the duration of round r, ii) \(C^{R}, r=1\ldots R\): a vector of square matrices (of size \(N \times N\) each), where a matrix \(C^r\) represents the clustering scheme of the round r. Each matrix holds \(N^2\) binary (decision) variables, and \(C^r_{j,j}\) is set to 1 when the node j is designated as CH in the round r, and \(C^r_{i,j}\) (\(i \ne j\)) is set to 1 if node, i, is assigned to CH, j, in round r. Let \(IE_i\) denotes the initial energy of node i. The proposed NIP formulation is given as follows,
Subject to:
The objective function in Eq. 10 aims to maximize the network lifetime defined as the sum of all the rounds’ durations \(t_r\) (\(r=1\ldots R\)). Constraint of Eq. 11 is proposed to permit the creation of non-overlapped clusters and to force all the SNs to be part of these clusters. In fact, this constraint ensures that in each round, r, every SN, i, will be assigned to exactly one CH j. Constraint of Eq. 12 assures the assignment of SNs to only nodes designated as CHs in all the rounds r. In other words, if \(C_{j,j}^r = 0\) (i.e., j is not designated as CH in round r), then all SNs cannot be member of j, i.e., \(\forall i\), \(C_{i,j}^r\) is inevitably set to 0. Constraint of Eq. 13 verifies that the total sum of the energy spent by each SN, i, throughout all the rounds does not exceed its initial energy \(IE_i\). \(E_{sen}^1\) is the energy spent by a SN, i, for sensing in a time frame. \(\sum _{j=1, j \ne i}^N (E_{tx}^1(l,d_{i,j}) C_{i,j}^r)\) represents the energy required by a SN i to transmit its sensed data to its CH j. Obviously, if \(C_{i,j}^r = 0\) (i.e., SN i is not member of CH j in round r), then \(E_{tx}^1(l,d_{i,j})\) is eliminated. \((E_{tx}^1(l,d_{i, B}) + E_{agr}) C_{i,i}^r + E_{rx}^1 \sum _{j=1, j \ne i}^N C_{j,i}^r\) is the energy required by a SN i, if it is designated as CH in round r. \(E_{rx}^1 \sum _{j=1, j \ne i}^N C_{j,i}^r\) is the energy consumed by this CH i to receive data from its members. \((E_{agr} + E_{tx}^1(l,d_{i, B})) C_{i,i}^r\) is the energy of data aggregation and data transmission to the BS, B. This way, clustering schemes will be generated until the first node drains its energy which will intuitively optimize the FND metric (known as stable period). However, the proposed model permits to extend the WSN lifetime with respect to the three definitions FND, HND and LND, as it will be demonstrated in the simulation Sect. 5.
4.2 General Functioning of the Proposed Clustering Protocol
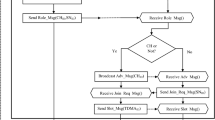
The clustering protocol we propose herein (called OPOC for “OPtimized One-step Clustering”) is dynamic, centralized and follows a one-step offline approach for the clustering schemes calculation. As for all dynamic clustering protocols, OPOC is carried out in rounds composed of two phases, (i) set-up phase, and (ii) steady state phase. The set-up phase of the proposed solution is different from all existing clustering protocols. In fact, in the set-up phase of the first round, clustering schemes for the whole network lifetime are generated together (along with theirs durations) in a one-step offline approach. To do this, the nodes communicate information about their location and residual energy to the BS. Then, BS calculates all clustering schemes and their durations by a PSO-based algorithm (details are given in the next subsection) and diffuses a message (SCHEME) containing the clustering scheme related to the first round, as well as its associated duration. Once this message received, every node will be informed whether it is elected as CH or to which cluster it is attributed. From the set-up phase of the second round, only the BS broadcats a (SCHEME) message carrying the clustering scheme for the incoming round that have been already computed. The steady state phase is similar to LEACH-C based protocols, in which every node gathers periodic data and sends it to its respective CH. The CHs accordingly aggregate the received data and forward it to the BS. The general functioning of OPOC is illustrated in Fig. 2.

General functioning of OPOC
4.3 PSO Based Clustering Algorithm
The proposed clustering algorithm of the OPOC protocol is based on the PSO meta-heuristic and uses the energy prediction mechanism presented in Sect. 3.3. The aim of this algorithm is to solve the NIP formulation presented in Sect. 4.1, following a one-step offline approach. The advantage of such approach is twofold. (i) Minimizing the cost of periodic network re-clustering. This is because nodes do not need to send energy information at the beginning of each round. (ii) Targeting a global optimization of the network lifetime by calculating all clustering schemes together. In fact, calculating clustering schemes progressively, i.e., the scheme for round \(r+1\) is determined at the end of round r without considering schemes of further rounds (\(i>r+1\)), cannot ensure the global optimum of the network lifetime. This is similar to the shortest path problem, where choosing the next edge with the minimum weight cannot led necessary to the shortest path. The FF of the PSO-based clustering algorithm is the objective function of the NIP model, given by Eq. 10, and the particle position is the vector of rounds’ durations.
In the following, a detailed description of the PSO-based clustering algorithm is given, which is also illustrated in Algorithm 1. This algorithm takes as inputs the graph G(V, E, B), the initial energy of nodes \(IE_i \in {\mathbb {R}}^N\), the number of rounds upper bound, R, the maximum number of configurations, \(\alpha\), the number of PSO iterations \(\beta\), the size of PSO population \(\gamma\), and the upper bound of the round duration \(\theta\). The optimal values of R, \(\alpha\), \(\beta\), \(\gamma\) and \(\theta\) are set empirically in the simulation phase. The first step of this algorithm consists in fixing PSO parameters (w, \(c_1\), \(c_2\)) according to [7]. The main loop (line 6 throughout 27), that will be repeated for a certain number of iterations \(\alpha\), searches the optimal clustering schemes along with theirs respective durations. In line 7, a clustering configuration \(C^R\) is generated randomly while respecting constraints of Eqs. 11 and 12 of the NIP model. In line 8, the energy required to satisfy the generated configuration for a single frame by every node is estimated using Eqs. 7 and 8 for member SNs and CHs, respectively. Thereafter, rounds’ durations corresponding to the generated clustering schemes are optimized using PSO as follows. A population, P, of, \(\gamma\), particles and their velocities are first initialized randomly (line 9). A particle, p, is defined by its position and velocity. The position of p, say \(T_p\), is a vector containing R values, where \(T_p[r]\) is the duration of the \(r^{th}\) round given by particle p. In the following we will refer to the particle p by its position \(T_p\). Note that a round with duration 0 means that the corresponding clustering scheme is not suitable (i.e, the clustering scheme will be eliminated). Therefore, the number of rounds will be variable. The velocity is used to change iteratively the particle position. For \(\beta\) iterations (loop in lines 10 throughout 25), and for each particle, the energy, \(E_{c_i}\), that would be consumed by every node, i, to execute the configuration, C, throughout the generated rounds’ durations, \(T_p\), is calculated using Eq. 9. The calculated \(E_{c_i}\) of all the nodes are used then to verify whether the solution (the particle) is valid or not. A valid solution is the one that satisfies constraint of Eq. 13 of the NIP model. If the solution is valid, the fitness of the particle \(T_p\) is calculated (line 15) using the FF of the proposed NIP (Eq. 10), and the best local fitness value, \(Pbest_p\), is updated accordingly. In line 19, the Global best fitness Gbest of the population is set to the maximum value of all the Pbest of the particles. After that, the velocity and the position of each valid particle are updated using Eqs. 2 and 1. Finally, the Gbest of the current configuration is compared with the \(Gbest\_conf\) of the previous iteration and the one with the highest value is saved as \(Gbest\_conf\) along with its corresponding configuration, \(C^R\), and rounds’ durations, \(T_p\), for the next iteration (line 25 throughout 28). The output of this algorithm are the optimal clustering schemes and their rounds’ durations.
This algorithm allows the generation of clustering schemes until the FND. According to the algorithm logic, it is possible that more than one node exhaust their energies simultaneously, while other nodes in the network will still have some remaining energy. For this, the algorithm described above (Algorithm 1) is executed in many iterations. At each iteration, nodes involved are those having minimum energy required for transmission. At the end of each iteration, the consumed energy required by each involved node to satisfy all the generated clustering schemes are calculated, and its remaining energy is estimated accordingly. Finally, those remaining energies are used as input in the next iteration of the algorithm execution, instead of the nodes initial energies \(IE_i\). All these iterations will take place at the network initialization in a one step approach to obtain clustering schemes of the whole network lifetime and their durations.

5 Simulation Study
The performance of the OPOC clustering protocol is evaluated by simulation and compared to the LEACH-C [13], TPSO-CR [7], OSC [21] and ETPSO-CR [20]. Simulations have been carried out with MATLAB [25] and NS3 [27]. MATLAB has been used to simulate the task of the BS, i.e. centralized calculation of clustering schemes and their durations, while NS3 has been used to simulate a WSN with a periodic traffic. Three network densities, respectively 100, 200, and 300 SNs have been considered. For each network density, various realistic network topologies generated with the GenSeN tool [5] were considered. The values of the remaining simulation parameters, as well as the PSO related parameters are summarized in Table 2 and Table 3, respectively.
The next subsections present and discuss the obtained results. The first one shows the variation of the round times and the number of elected CHs in WSNs clustered by the OPOC protocol. The second one compares LEACH-C, TPSO-CR, OSC, ETPSO-CR and OPOC with respect to three definitions of the network lifetime, namely: FND, HND and LND. In the third and firth subsections, the above-mentioned protocols are compared in terms of the number of alive nodes over time and the total number of packets received at the BS, respectively. Each point of the simulation results represented in the plots hereafter is the average of 25 simulation runs, with confidence interval error bars of \(95\%\).
5.1 Round Time and Number of CHs Variation
Like all clustering solutions, OPOC is inevitably impacted by the number of elected CHs in each round and the rounds’ durations. Figures 3a–c capture the number of CHs elected in some rounds operation of OPOC in WSNs of 100, 200 and 300 SNs, respectively. Likewise, an example of the round times variation in OPOC is also presented in Figs. 4a–c for networks of 100, 200 and 300 SNs, respectively. The figures demonstrate that values of the two parameters change independently from a round to another, which are in fact the values obtained by solving the proposed NIP program. Optimal setting of these values depends on several other parameters that fluctuate over time, such as the relative variation of the remaining energy (between nodes), the load of CHs in the generated clustering schemes, etc. Since the FF of the OPOC clustering protocol intends to maximize the network lifetime, optimal values to these factors are given in each round in such a way to prolong the network lifespan. The figures also show that the number of CHs selected in each round is proportional to the network size. The means of the CHs number for WSNs with 100, 200 and 300 SNs are 10.70, 21.92 and 34.73, respectively. For the rounds’ times, we notice that the networks of 100 and 200 SNs have high values with means of 100.62 and 144.39 frames, respectively. In more dense networks (of 300 SNs) rounds’ times values are relatively small, with a mean of 47.26. Note that the number of the generated CHs in each round and the rounds’ durations are also variable in OSC, contrary to LEACH-C and TPSO-CR that use a fixed number of CHs and a fixed round duration. In ETPSO-CR, the number of CHs is also fixed but the round times are variable.

Dynamic number of CHs in OPOC for in WSNs of 100, 200 and 300 nodes

Dynamic rounds’ durations in OPOC in WSNs of 100, 200 and 300 nodes
5.2 Network Lifetime
Figures 5, 6 and 7 compare the network lifetime of LEACH-C, TPSO-CR, ETPSO-CR, OSC and OPOC for networks of 100 SNs, 200 SNs, and 300 SNs, respectively, using three metrics: FND, HND and LND. The results show that OPOC clearly improves the network lifespan with respect to all the defined metrics. For instance, OPOC enhances the FND by an average (the average of the three network densities) of \(92,80\%\), \(84,16\%\), \(72,53\%\) and \(28,26\%\) over LEACH-C, TPSO-CR, ETPSO-CR and OSC, respectively. This improvement is due to the effectiveness of the proposed NIP and PSO-based algorithm with their innovative FF that maximizes directly the WSN lifetime, instead of only focusing on selecting the optimal set of CHs, which is the approach used in the other compared protocols. OSC and ETPSO-CR propose techniques to avoid the cost of periodic network re-clustering and to model the round times. However, other important parameters that greatly impact the energy efficiency of clustering protocols are not considered, such as the optimal number of CHs, the distribution of the CHs over the network, the size of the clusters, etc. In OPOC all these factors, and more, are considered implicitly. In fact, by modeling the clustering schemes as binary matrices and running an appropriate clustering algorithm in such a way to find the optimal schemes that maximize the FF (representing the network lifetime), all the factors influencing the energy effectiveness will have optimal values in each round. In another words, directly targeting the maximization of the network lifetime enables to avoid considering all the overlapped factors that influence the energy efficiency of clustering protocols. Moreover, the introduced NIP formulation allows all the clustering schemes (of all rounds) and their respective durations to be calculated together by the BS. This provides the BS with a horizontal vision and enables it to target a global optimization and choosing schemes that increase the network lifespan, as a whole. The clustering algorithm of OPOC also permits dynamic and optimized setting of the round durations by the PSO meta-heuristic. The elimination of re-clustering and thus of long range transmissions in every round contributes to further energy conservation. On the other hand, it can be observed from Fig. 7 that the HND value of OSC in 300 SNs networks is slightly higher than that obtained by OPOC. This is because OPOC aims principally at balancing the energy consumption in the network and hence extending the FND, known as stable period. This also explains why the improvement is more remarkable for the FND.

Network lifetime of 100 nodes WSNs

Network lifetime of 200 nodes WSNs

Network lifetime of 300 nodes WSNs
5.3 Number of Alive Nodes
In Figs. 8, 9 and 10, the number of surviving nodes is plotted versus time. The figures show that the decrease of this number is clearly prolonged by OPOC. The improvement with respect to this metric is due to the energy-efficient operations of OPOC, as explained previously. Notice that for networks of 200 SNs and 300 SNs the number of alive nodes in OSC is higher than in OPOC after the time of HND and when approaching the LND. Again, this is because the OPOC targets principally the FND. The number of alive nodes is generally more significant in the period prior FND than after it (when nodes start deplete energy). The obtained results confirm that OPOC allows to keep nodes alive all together for as long as possible.

Alive nodes versus time for 100 nodes WSNs

Alive nodes versus time for 200 nodes WSNs

Alive nodes versus time for 300 nodes WSNs
5.4 Total Number of Received Data at the BS
Figure 11 depicts the number of data packets received by the BS. Since OPOC widens the network lifetime by enabling nodes preserve their batteries for longer time compared to LEACH-C, TPSO-CR, ETPSO-CR and OSC, it was expected to reach higher number of data packets received at the BS. The results presented in this figure confirm this. It can be noted from the figure that OPOC improves the number of data packets received by the BS by an average of \(93,56\%\), \(84,92\%\), \(77,26\%\) and \(35,06\%\) over LEACH-C, TPSO-CR, ETPSO-CR, and OSC, respectively. In summary, the results demonstrate that the proposed solution globally optimizes the network lifetime, fairly distributes the energy consumption between nodes, and depletes evenly this consumption.

Number of received data Packet throughout the network lifetime
6 Conclusion and Perspectives
A new model for the clustering problem in WSNs has been proposed. It implicitly considers the parameters that may influence the energy effectiveness of clustering solutions such as the number and distribution of CHs, the cluster size, the round duration, etc. It further targets the search of clustering schemes that provide global optimization of the network lifespan. The model is a nonlinear integer program (NIP), which has been solved by a PSO meta-heuristic algorithm that we proposed. To the best of our knowledge, this is the first model for clustering in WSN that is based on an one-step off-line approach and targets a global optimization. The clustering algorithm is also the first that uses a FF that explicitly maximizes the network lifespan. Simulation results clearly show the improvement of the network lifetime and the number of data packets received at the BS, as compared to some state-of-the-art approaches.
Despite the enhanced results obtained by the OPOC protocol, it has few limitations that open some perspectives for future research. Firstly, OPOC does not feature fault-tolerance– similarly to all existing clustering protocols that are based on energy estimation. In fact, all the clustering schemes are calculated at the network initialization in OPOC. A node that has been designated as CH for a certain round may fail. An intuitive direction is the replacement of the failed CH by the nearest SN with the largest amount of remaining energy. The failure of a member-SN may be detected and reported to the BS by its CH if it does not receive data from this member within a predefined timeout. The BS can therefore designate the new CH and send an update message to the concerned SNs. Secondly, OPOC employs the first order radio model similarely to most of existing clustering protocols. Some sources of energy consumption in the SN such as overhearing, collision, idle listening, etc., are not considered in this model. Using a more practical energy consumption model is an interesting perspective. Further, OPOC considers periodic traffic applications, while several WSN applications are based on query-driven or event-driven traffic. Adapting the proposed solutions to such traffic paterns is an other perspective of this work. Moreover, the distributed version of the SCIP solver (Para-SCIP [32, 33]) can be used to obtain the exact optimal solution of the proposed NIP model (up to a certain scale to be determined). This should also be investigated.
References
Abbasi, A. A., & Younis, M. (2007). A survey on clustering algorithms for wireless sensor networks. Computer Communications, Network Coverage and Routing Schemes for Wireless Sensor Networks, 30(14–15), 2826–2841.
Akyildiz, I., Su, W., Sankarasubramaniam, Y., & Cayirci, E. (2002). Wireless sensor networks: A survey. Computer Networks, 38(4), 393–422.
Amutha, J., Sharma, S., & Nagar, J. (2020). WSN strategies based on sensors, deployment, sensing models, coverage and energy efficiency: Review, approaches and open issues. Wireless Personal Communications, 111, 1089–1115.
Azim, A., & Islam, M. M. (2009). A dynamic round-time based fixed low energy adaptive clustering hierarchy for wireless sensor networks. In IEEE 9th Malaysia International Conference on Communications (MICC) (pp. 922–926).
Camilo, T., Silva, J. S., Rodrigues, A., & Boavida, F. (2007). GENSEN: A Topology Generator for Real Wireless Sensor Networks Deployment (pp. 436–445). Springer.
Chauhan, V., & Soni, S. (2021). Energy aware unequal clustering algorithm with multi-hop routing via low degree relay nodes for wireless sensor networks. Journal of Ambient Intelligence and Humanized Computing.
Elhabyan, R. S., & Yagoub, M. C. (2015). Two-tier particle swarm optimization protocol for clustering and routing in wireless sensor network. Journal of Network and Computer Applications, 52, 116–128.
Fanian, F., Kuchaki Rafsanjani, M., & Borumand Saeid, A. (2021). Fuzzy multi-hop clustering protocol: Selection fuzzy input parameters and rule tuning for wsns. Applied Soft Computing, 99, 106923.
Fanian, F., & Rafsanjani, M. K. (2019). Cluster-based routing protocols in wireless sensor networks: A survey based on methodology. Journal of Network and Computer Applications, 142, 111–142.
Goudarzi, R., Jedari, B., & Sabaei, M. (2010). An efficient clustering algorithm using evolutionary hmm in wireless sensor networks. In IEEE/IFIP 8th international conference on embedded and ubiquitous computing (EUC) (pp. 403–409).
Hatamian, M., Ahmadpoor, S. S., Berenjian, S., Razeghi, B., & Barati, H. (2015). A centralized evolutionary clustering protocol for wireless sensor networks. In 6th International conference on computing, communication and networking technologies (ICCCNT) (pp. 1–6).
Hatamian, M., Barati, H., Movaghar, A., & Naghizadeh, A. (2016). Cgc: Centralized genetic-based clustering protocol for wireless sensor networks using onion approach. Telecommunication System, 62(4), 657–674.
Heinzelman, W. B., Chandrakasan, A. P., & Balakrishnan, H. (2002). An application-specific protocol architecture for wireless microsensor networks. IEEE Transactions on Wireless Communications, 1(4), 660–670.
JIANG, C. J., SHI, W. R., XIANG, M., & TANG, X. J. (2010). Energy-balanced unequal clustering protocol for wireless sensor networks. The Journal of China Universities of Posts and Telecommunications, 17(4), 94–99.
Kennedy, J., & Eberhart, R .C. (1995). Particle swarm optimization. In Proceedings of IEEE International Conference on Neural Networks (pp. 1942–1948).
Kim, J. M., Joo, H. K., Hong, S. S., Ahn, W. H., & Ryou, H. B. (2006). An efficient clustering scheme through estimate in centralized hierarchical routing protocol. 2006 International Conference on Hybrid Information Technology, 2, 145–152.
Li, J., & Liu, D. (2015). Dpso-based clustering routing algorithm for energy harvesting wireless sensor networks. In International Conference on Wireless Communications Signal Processing (WCSP) (pp. 1–5).
Ezhilarasi, V. K. M. (2018). A survey on energy and lifetime in wireless sensor networks. Computer Reviews Journal, 1(1), 30–51.
Mazumdar, N., Nag, A., & Nandi, S. (2021). Hdds: Hierarchical data dissemination strategy for energy optimization in dynamic wireless sensor network under harsh environments. Ad Hoc Networks, 111, 102348.
Merabtine, N., Djenouri, D., Zegour, D. E., Boumessaidia, B., & Boutahraoui, A. (2019). Balanced clustering approach with energy prediction and round-time adaptation in wireless sensor networks. International Journal of Communication Networks and Distributed Systems (IJCNDS), 22, 1.
Merabtine, N., Djenouri, D., Zegour, D. E., Lamini, E., Bellal, R., Ghaoui, I., & Dahlal, N. (2017). One-step clustering protocol for periodic traffic wireless sensor networks. In 26th Wireless and Optical Communication Conference, WOCC 2017 (pp. 1–6). Newark, NJ, USA, April 7–8, 2017.
Nilesh Modi Pramode Verma, B. T. (2016). advances in intelligent systems and computing. In Proceedings of International Conference on Communication and Networks comNet 2016. Springer.
Nor Azlina, A. A., & Mohamad Yusoff, A. (2011). Particle swarm optimization for constrained and multiobjective problems: A brief review. International Conference on Management and Artificial Intelligence IPEDR, 6, 146–150.
Pal, V., Singh, G., & Yadav, R. P. (2013). Network adaptive round-time clustering algorithm for wireless sensor networks. In International Conference on Advances in Computing, Communications and Informatics (ICACCI) (pp. 1299–1302).
Pócsová, J., Mojžišová, A., & Mikulszky, M. (2018). Matlab in engineering education. In 19th International Carpathian Control Conference (ICCC) (pp. 532–535).
Rawat, P., Singh, K. D., Chaouchi, H., & Bonnin, J. M. (2014). Wireless sensor networks: a survey on recent developments and potential synergies. The Journal of Supercomputing, 68(1), 1–48.
Riley, G. F., & Henderson, T. R. (2010). The ns-3 Network Simulato (pp. 15–34). Springer.
Rostami, A. S., Badkoobe, M., Mohanna, F., Keshavarz, H., Hosseinabadi, A. A. R., & Sangaiah, A. K. (2018). Survey on clustering in heterogeneous and homogeneous wireless sensor networks. The Journal of Supercomputing, 74(1), 277–323.
Senapati, B. R., Swain, R. R., & Khilar, P. M. (2020). Environmental monitoring under uncertainty using smart vehicular ad hoc network. In S. C. Satapathy, V. Bhateja, J. R. Mohanty, & S. K. Udgata (Eds.), Smart Intelligent Computing and Applications (pp. 229–238). Springer.
Sert, S. A., Bagci, H., & Yazici, A. (2015). Mofca: Multi-objective fuzzy clustering algorithm for wireless sensor networks. Applied Soft Computing, 30, 151–165.
Sheriba, S., & Rajesh, D. (2021). Energy-efficient clustering protocol for wsn based on improved black widow optimization and fuzzy logic. Telecommunication System
Shinano, Y., Achterberg, T., Berthold, T., Heinz, S., & Koch, T. (2012). Parascip: A parallel extension of scip. In C. Bischof, H. G. Hegering, W. E. Nagel, & G. Wittum (Eds.), Competence in High Performance Computing 2010 (pp. 135–148). Springer.
Shinano, Y., Achterberg, T., Berthold, T., Heinz, S., Koch, T., & Winkler, M. (2016). Solving open mip instances with parascip on supercomputers using up to 80,000 cores. In IEEE International Parallel and Distributed Processing Symposium (IPDPS) (pp. 770–779).
Sundararaman, B., Buy, U., & Kshemkalyani, A. D. (2005). Clock synchronization for wireless sensor networks: a survey. Ad hoc Networks, 3(3), 281–323.
Tabatabaei, S., Rajaei, A., & Rigi, A. M. (2019). A novel energy-aware clustering method via lion pride optimizer algorithm (LPO) and fuzzy logic in wireless sensor networks (wsns). Wireless Personal Communications, 108(3), 1803–1825.
Verma, S., Sood, N., & Sharma, A. (2018). Design of a novel routing architecture for harsh environment monitoring in heterogeneous wireless sensor network. IET Wireless Sensor Systems, 8, 1.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflicts of interest
All the authors declare that they have no conflict of interest.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Merabtine, N., Djenouri, D., Zegour, DE. et al. Towards Optimized One-Step Clustering Approach in Wireless Sensor Networks. Wireless Pers Commun 120, 1501–1523 (2021). https://doi.org/10.1007/s11277-021-08521-0
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11277-021-08521-0