
Abstract
With the consistent growing maneuver and applications of mobile technologies, dynamic handling of queries related to information on electronic media (Broadcast Queries) plays a vital role. Broadcast Queries (BQs) consists of some authentic characteristics that are not addressed when compared to conventional spatial query processing. It is possible to achieve a considerable reduction in latency while maintaining the highest accuracy and scalability related to queries related to peer-to-peer allocation and thereby allows finishing queries with no interruption at a mobile congregation. In this paper, we propose a hybrid cache management algorithm in order to proficiently encourage accessing of data in ad hoc networks. The verification algorithm gathers the neighboring peer data items to provide the spatial query solutions. The network utilization in the network is related with the available bandwidth and the free space through efficient cache management. The hybrid cache management is combined with \(Cach{e}_{Data}\) and \(Cach{e}_{Path}\) techniques utilizing the concept of cache replacement policies with the motivation to further improve the performance of BQs. The experimental results indicate that the proposed scheme works well in reduction of query delay and also message complexity than the related techniques.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
1 Introduction
In mobile applications, broadcast query processing (BQ) [1] is mainly used in networks to signify a collection of queries that retrieve data based on the present locations of mobile users [2]. The query processing techniques are categorized to carry over challenges like the BQ can be represented in the form of real-time issues in mobile environments [3]. According to the position of its requester, the result of the query will be changed. By considering the location of the query issuer, caching and distribution of query results are considered. In wireless communication, the database is located in a centralized environment, by which it usually distributes data to the huge number of mobile users [4]. Accordingly, two parameters considered in BQ algorithms are bandwidth constraints and scalability [5]. If the user is in a moving state, there will be possibility of extended interval in data transmission. Then, the answer to BQ will lose their relevancy [6]. The answer will become meaningless if it is received later. This type of long delay in a high workload environment is an importance issue [7].
For the related methods, Constructing Optimal Clustering Architecture (COCA) [8] leads to flood cache, another method is COCA with Push based information [9]. Here, server repeatedly sends data to clients. This also leads to fill the cache of the client. In processing of BQs, wireless atmosphere and transmission parameters attached to a vital role in aggravating the approach [10]. The user creates an active server communication so that the communication is established in a smooth manner. The main problem is it could not able to stability to huge users, in order to interconnect within the network. A fee-based cellular-type network [11] was used to accomplish an equitable operating collection. Then, the exact location of the user is sent to the server [12]. The wireless broadcast model is the most progressive solution. It can provide the maximum boundless number of mobile hosts (MHs) in a huge area with an initial broadcaster. MHs may not suggest queries in this broadcast model [13]. To get the information as they needed, the broadcast channel is tuned. Therefore, the location of the user is not revealed and identified [14]. The main drawback of the broadcast methodology is that it does not allow data communication to be inter-connected in the entire network.
A mountable low-delay methodology [15] was given for processing Broadcast Queries in broadcast environments. This approach investigated peer-to-peer networks to exchange data between mobile clients [16]. The R-tree based spatial data structure [17] was used with K-nearest neighbor (KNN) algorithm [18] for effectively finding nearest mobile nodes but not to deal with cache path and forward the requests (our proposed algorithm supports). The Branch and Bound R-tree traversal algorithm [19] discovers the adjacent node, but does not support more numbers of pages accessed while the proposed algorithm does [20]. KNN [21] was given as an input to SBNN [22] and SBWQ [23] (sharing based window query), which is effective only in caching but the data does not deal with cache path [24]. The algorithm [25] was introduced with a space-filling curve index for server spatial data. For the purpose of superior locality, the Hilbert curve was selected. The order of broadcasting data packets is indicated in the index value. Others can be seen in [26,27,28,29].
The main issues of the existing approaches are that if the mobile user queries are about a nearest neighbor (NN) [30], the user would choose a similar result that attains with a lesser delay time instead of accurate result with high delay. The outputs of spatial elements frequently parade spatial position. For instance, if the mobile hosts are near, the results may overlap sufficiently [31]. If the delay is considered as a valid concern, the Peer-to-Peer method can be valuable. Using mobile cooperative caching [32], data can be shared between mobile clients. The existing cache management techniques have several disadvantages like the consistency maintenance, reduced amount of throughput, a highest number of delays, huge routing overheads, and restricted scalability of the caching management. The proposed hybrid technique has been constructed to overcome these issues. The main contributions of this paper are:
-
1.
We find the particular characteristics of Broadcast Queries, which enhance the improvement of efficient data sharing.
-
2.
We properly use a Peer-to-Peer sharing methodology to modify the present methodologies in giving answer on-air KNN queries and Window Queries.
-
3.
We calculate Broadcast Queries approach using a probabilistic of the hit ratio for exchanging including widespread simulation experiments.
-
4.
The proposed methodology maintains the availability of data to implement the accessed data elements in view of cache size.
-
5.
The proposed methodology increases the cache hit ratio by utilizing effective cache maintenance technique.
-
6.
To increase the effective utilization of data, the workload is constructed using cache reallocation strategy within the transmission area.
2 Data Broadcast on Wireless Networks
Commonly, mobile data accesses are approached by the concept of active communications that are recognized within mobile nodes. The server operates based on the requests under client demands. The server constantly transmits entire data through communication area, and data are filtered by the clients. The scalable method is one of the merits of the dynamic communication framework, but in broadcast model, high latency is ensured and the client has to hang around for the remaining broadcast cycle. A client ignores the packet which it wants. Data management on wireless transmission channels is made by analyzing information agents, which are usually transmitted by the server. The broadcast index structure is in the form of (1,m) indexing allocation method. Figure 1 shows that the entire index is transmitted and all 1/m is known as the fraction of the information file. Since in one cycle, the index is presented for ‘m’ times, it permits a mobile client to process with the index so that it may block the received data within the time period. If the arrival time is known, the function is to adjust it into the transmitter channel. In battery-based devices, this data bucket mechanism is important. The numbers are used to represent index value.

The Hilbert-curve-based index structure
In a wireless transmitter channel, the steps for retrieving data on general access protocol are:
-
Initial probe The broadcast of remaining index segment may be found by the client when tuning in to transmitter channel.
-
Searching index To extract needed data, the set of pointers in an index segments are tuned.
-
Retrieval of data When packets are arrived with a required data, needed information are downloaded from the channel.
No matter how equally the entire previous spatial access methods are made for databases, these previously mentioned techniques cannot be used in WBE. They support sequential data access only. For instance, Fig. 1 shows the grouping of nearby values, therefore they can be accessed within a short period.
2.1 Spatial Queries
The existing methodologies are based on 2 general methods of spatial data, called KNN queries and Window Queries [33]. In R-tree related spatial methods [34], DFS [35] are the common branch-and-bound methods to operating on Nearest Neighbor queries. Depth First Search repeatedly elaborates the participated nodes for probing adjacent nodes. For every node, Depth First Search processes the ordering metrics to eliminate unwanted nodes. At the time of reaching the leaf node, objects are recovered, adjacent nodes are modernized. Best First Search properly uses a queue to keep nodes to be updated using the routing technique.
2.2 Cooperative Caching
Distributed caching is a methodology to develop information recovery performance. By means of growing exploitation of Peer-to-Peer wireless communication technologies, P2P supportive caching becomes a well-organized allocation substitute. Mobile hosts interact among adjacent peers in a Peer-to-Peer model. The information’s are shared and communicated between remote sources. This caching mechanism gives more benefits in the mobile system such as developed access delay, minimized workload and avoids congestion.
2.3 Sharing-Based NN Queries
Figure 2 demonstrates the formation of an on-air KNN query related on the Hilbert curve. Initially, the entire on-air index is scanned and the k-nearer node is identified. Then, a minimal circle is drawn in center of q and the circle contains all k objects. The least k objects also enclosed within the MBR of the circle, which is called as a search range. Accordingly, data packets are received by q and all packets are covered by the transmitted objects. In Fig. 2, a lengthy recovery time is needed between the related packets 5 and 58. Another problem in the above algorithm is in the broadcast cycle the indexing information is replicated in double. In this search algorithm, the KNN search range is identified using the first scan, and then k objects are recovered in the search range using the second scan [36]. As a result, the query approaches to progress the communicated network.

Formation of neighbour node
3 Proposed Method
The novelty in the proposed approach is a verification algorithm which checks whether the neighboring peer data items are a part of spatial query solutions. Although if the demonstrated results are present within the solution set, the client query will wait till it got the answers of needed data packets. The partial answer produced from the KNN query is applied in many applications. It requires only short response time to get accurate results.
3.1 Verification of Nearest Neighbor
When the Mobile Host q SBNN, at first requests are broadcasted to all 1-hop peers to cache the spatial information, every single peer collects the request and precedes back the established cache management. After that, q joins checked area of entire responding peers. All are encircled by MBR and into a combined established framework (Fig. 3). MapOverlay algorithm is used to carry out the merging process. The Sharing-Based Adjacent node Verification method aims to check whether POI identified from nodes is a legal Nearest Neighbor of Mobile Host q. The data collected from peers q to j are denoted as \(\{p{e}_{1}, p{e}_{2}, \dots , p{e}_{n}\}\). Accordingly, joined verified area (MVR) is denoted using Eq. (1).

The shortest path construction
If the margin of MVR contains nodes, \(IE=\{{ie}_{1}, i{e}_{2}, . . ., {ie}_{k}\}\), and there are l POIs. Here O represents \(O =\{o{u}_{1}, o{u}_{2},\dots o{u}_{n}\}\) within the MVR. Let ek∈ IE being the edge, which have the small distance to q. The example is shown in Fig. 3. Until all requested packets are received from the broadcast channel, the client will wait to save the result quality. To forward on-air data set, the fractional output in H is used to shrink the necessary data packets.
Moreover, the resource utilization in network is based on the free space and the available bandwidth. Finally, the threshold value \(\delta\) is used to demonstrate the time for determining the cache management. The cache size in the network is fixed to be large in network resource utilization to demonstrate good performance. Access rate \({A}_{rate}\) is computed using Eq. (2)
where \({\mathrm{Total}}_{\mathrm{data}}\) demonstrates the total amount of data elements to access the cache data, and \({\mathrm{Time}}_{\mathrm{period}}\) refers to the required time period for accessing the data element.
3.2 Approximate Nearest Neighbor
This component is used to calculate the probability of ith nearest neighbor O of query in q. Using O, the nearest neighbor is found. The area is not covered by q’s adjacent peer cannot be verified by O. At the same time if POI is inside the area then O could not survive as q’s ith adjacent node. This region is called as O’s unverified region. The POIs are assumed to be a Poisson distributed and contains the square based values also.
3.3 System Network Model
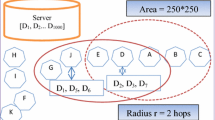
The MANET model is shown in Fig. 4. Wireless interfaces in the MANET must connect to some nodes in unfamiliar environment through wireless LANs. In the system, the node marked in red color \((Nod{e}_{11})\) is mentioned as a data center, which has the database for n data items such as \({d}_{1},\dots ,{d}_{n}\). This \(Nod{e}_{11}\) is a node used to connect all the remaining ones in a wired network. The databases related to all connected nodes are stored in \(Nod{e}_{11}\). The data requests in a MANET are transmitted to reach the destination. In ad hoc network, the messages are routed using a variety of routing algorithms. The parameters considered are query delay and bandwidth consumption. The aim is to reduce query delay and bandwidth. The total amount of hops within the adjacent node is established as small as possible to decrease the query delay. To achieve this goal, routing protocols are used with some limitations.

System network model
3.3.1 \({\varvec{C}}{\varvec{a}}{\varvec{c}}{\varvec{h}}{{\varvec{e}}}_{{\varvec{D}}{\varvec{a}}{\varvec{t}}{\varvec{a}}}\)
In \(Cach{e}_{Data}\), communicating data items \({d}_{i}\) are cached if they found that di has many data requests and also di has free space to cache data. The example in Fig. 4 shows that the nodes \(Nod{e}_{6}\) and \(Nod{e}_{7}\) request \({d}_{i}\) via Node_5. Requests from nodes \(Nod{e}_{3}\), \(Nod{e}_{4}\), or \(Nod{e}_{5}\) can be served by \(Nod{e}_{5}\) directly. More space is needed to save the \(Cach{e}_{Data}\). All requests came for \({d}_{i}\) is forwarded through the node \(Nod{e}_{3}\). The remaining nodes in the network model such as \(Nod{e}_{3}\), \(Nod{e}_{4}\) and \(Nod{e}_{5}\) are directly communicated by \({d}_{i}\). If all three nodes cache di at the same time, they waste more numbers of cache space. Some of the optimization techniques are applied in the proposed scheme. At the time of storing the path, the information along the path and node are not stored in the node. From the analysis, it is proved that there exists a significance enhancement in performance using cache Path and cache Data. It is also proved that cache path outperforms in tiny cache size and short data update.
3.4 Hybrid Cache Management Algorithm
A hybrid algorithm is proposed to improve the performance. It takes benefits of \(Cach{e}_{Data}\) and \(Cach{e}_{Path}\). Definitely, the \(Cach{e}_{Data}\) item and paths depend on certain criteria such as data element size \({s}_{i}\), TTL time \(TT{L}_{i}\), and the \({H}_{save}\). For a data item \({d}_{i}\), the sub sequent factors are used to identify whether to cache data or path.
-
If \({s}_{i}< \delta\)
-
Adopt \(Cach{e}_{Data}\) since the data item require minor part of the cache;
Otherwise
-
Adopt \(Cach{e}_{Path}\) since it is necessary to store the cache space. \(\delta\) demonstrates the threshold value.
-
-
If \(TT{L}_{i} < \delta,\)
-
\(Cach{e}_{Path}\) is not a valid option since the data member will be invalided shortly. There is possibility to select a wrong path Using \(Cach{e}_{Path}\). Hence, \(Cach{e}_{Data}\) should be adopted.
-
-
If \(TT{L}_{i}> \delta,\)
-
Adopt \(Cach{e}_{Path}\). \(\delta\) for TTL is assumed to be a system tuning metric which is demonstrated as TTL.
-
-
If \({H}_{save}> \delta,\)
-
\(Cach{e}_{Path}\) is a better option since large number of hops can be saved.
-
-
otherwise,
-
Adopt \(Cach{e}_{Data}\) to increase the performance. Threshold value TH is used in \(Cach{e}_{Path}\).
-
To increase the performance, optimal threshold values should be set.

The hybrid cache algorithm is proposed so that only overhead is identified to store a node id in the cache. In this scheme, data item \({d}_{i}\) and the path for di are also saved. To remove \({d}_{i}\), the cache replacement algorithm is used. Likewise, Cache path is also advanced to \(Cach{e}_{Data}\) over when \({d}_{i}\) permits. The parameter \(TT{L}_{i}\) and \(\delta\) play a significance role in the last performance because \(TT{L}_{i}\) resolves when forwarding the application to the data center for demanded data if it is not obtainable in the adjacent neighbor.
Figure 5 demonstrates the flowchart for cache management to construct the cache table and the cache node table. Initially, the cache management traces the node of local cache as per request from the data element of the particular node. If the data element is found in the cache, it will update the cache table and cache node table. If the data element is not found then it will send the request to every adjacent node in the network. The best route is generated to process the query and within the time period, the entire process will be completed. Every time the cache table is updated and the format of the cache table is illustrated in Fig. 6. For every data element, the available caching node is stored in the cache table for efficient formation of the MANET.

Flowchart for cache management

Cache table
4 Performance Evaluation
The simulation parameters are demonstrated in Table 1. Dissimilar speed values are utilized to implement the simulations. The threshold value for implementing the simulation is utilized to gather the performance in simulation environments. Moreover, the condition of the network is analyzed that the total amount of simulations is conducted in a MANET environment. The proposed hybrid cache management (HCM) methodology is compared with COCA (Constructing Optimal Clustering Architecture) [8], RMCC (Regionally Maintained Cooperative Caching) [37], ECM (Enhanced Cache Management) [38] with the performance metrics of Probability Density Function, End-to-End Delay, Total number of pages accessed, delay, transmission range, hit ratio, traffic overload and latency. The output results are created using NS2 simulator. Based on the proposed algorithm, the cache path and cache data are created. When the node 0 gives the request to data center, it caches data. If the node 0 again gives request to cache data, it analyzes and collects data. Rather than this, if any other node also requests the same data, node 1 gets the path id and responds to request. The proposed work is executed in various workloads and different metrics. The result of simulation is displayed in Fig. 7. It shows the performance evaluation. Figures 8 and 9 shows the ad hoc network system model which has totally seven nodes, in the seven nodes, one node behaves as a data center, and all the other nodes are connected in a peer to peer connection.

Wireless scenario

Ad hoc model

Route formation
From Fig. 10, it is noticed that the performance of the proposed HCM is better with the increased number of nodes. The stable path is delivered if the nodes are stationary between source and destination. Performance of related methodologies like COCA, RMCC and ECM decreases with increased number of nodes. The reason behind this is the loss of packets because of link breaks. If the total amount of nodes fixed between 20 and 35, HCM performs better than COCA, RMCC and ECM. HCM improves the PDF as it finds an alternate route to the endpoint, if there exists a link break.

Probability density fraction
In the simulation, the bandwidth assumed is 2 Mb/s with the frequency range is within 250 m. Figure 11 shows the End-to-End delay. If the number of nodes increases, the HCM does not create much of delay. Compared to COCA, RMCC and ECM, the HCM protocol gives better performance. When the graph is plotted between nodes 15 to 30, the ECM gives better result than COCA and RMCC. Whenever the increment for the number of nodes initially, the delay gets increased for all the compared methods. Later stage HCM reach concave point (indicates delay reduction) because HCM supports many nodes. When we compare COCA, RMCC and ECM with HCM, HCM produces low delay even when nodes are higher in count. Two concave spots are observed at 10 and 25 for blue and yellow line. One concave spot is observed at 10 for purple line. Finally, the HCM performs better in delay reduction and packet delivery. It is used as an underlying routing algorithm for our approach. The experiment on both real and synthetic data sets are analyzed and corresponding results are plotted (Fig. 12). From the results, we can understand the number of pages accessed is high in the hybrid cache algorithm even when increasing the number of neighbors (120).

End-to-end delay

Page access comparison
The experimental results in Fig. 13 show the comparison between COCA, RMCC and ECM with HCM with push-based information. We can see the delay percentage, which is reduced for hybrid cache management methodology.

Delay comparison
Figure 14 displays the comparison results instead of transmission range. Here, X axis shows the transmission range in meters, and Y axis shows the performance result in percentage. The above comparative analysis shows that the hybrid cache management technique gives better growth when the transmission range is increased. Compared to cache data and cache path, the hybrid cache gives better result. By considering the threshold level and data size, cache data are considered. Based on time of threshold and data item, the cache path is also considered. Whenever the cache size in the network increases, the latency gets reduced. Huge amount of cache size is used to keep the nodes that can access the local cache to guarantee the reduced amount of latency. Figure 15 demonstrates that the proposed methodology has good overall performance with the effective replacement methodology that relies on several realistic metrics to guarantee that the free cache size to save the time period in network simulations.

Transmission range experiments

Latency
The cache size increases in some order, the traffic overload is also increasing. The traffic overload could be reduced whenever the congestion is in minimized value. The traffic overload has the frequent level. Figure 16 demonstrates that the proposed methodology has reduced amount of traffic overload compared to the related methodology in the parameter called as the cache size.

Traffic overload
Whenever the total amount of nodes in the network is increasing frequently, every related methodology has an improving hit ratio, but the small difference in the values with others. The nodes are in increasing the cache hits are also in increasing order. Figure 17 demonstrates that the proposed methodology has good numbers of hit ratio compared to other related methodologies.

Hit ratio
According to the relative simplicity of the proposed technique, it has consumed minimized energy level whenever the total amount of nodes is increased, but the consumed energy for related techniques is very high and the energy consumption is demonstrated in Fig. 18.

Energy consumption
The throughput has been measured using the total amount of packets that are delivered within the specific time. During the cache miss, the data packets are requested and the process is slow whenever the limitation of the bandwidth and while there are lot of delays. Throughput is related to the latency and the proposed technique has the enhanced value than the related techniques which is demonstrated in Fig. 19.

Throughput
The collision and the mobility are the main reasons for packet drops in the network routing procedure. The utilization of the routes through the cache for the proposed technique will enhance the packet delivery. While comparing the proposed technique with other techniques, the smallest amount of packet drops has been happened. Figure 20 demonstrates that the proposed technique has utilized the threshold value for selecting the enhanced route for packet delivery than other techniques.

Packet loss ratio
The normalized routing overhead is the total amount of data packets are delivered within the specific time from one node to the end node. Every delivered packet is measured for every communication and this parameter is correlated to the total amount of routing changes while performing simulation. The control messages are measured, whenever the mobility is in the highest value, it produces the highest amount of overload. Figure 21 demonstrates the normalized routing overhead comparison.

Normalized routing overhead
Table 2 demonstrates the performance comparison with several metrics.
The complexity analysis of the cache management techniques has been observed in view of time and space complexity for the communication overhead. The scalability could be maintained through the path length that generate the overhead for the specific node \((\beta )\) with the functionality of \(|X|\) that is the set of nodes for providing active transmission. The arithmetic log for the specific node is measured as \(\beta =O({\mathrm{log}}^{2}|X|)\) bits per second. The space complexity for the active transmission is computed as \(O\left(\frac{1}{k}{\left|X\right|}^{2}\right)\). The time complexity is measured with the communication range as \(O\left(\frac{1}{X}\right)\).
5 Conclusion
In this paper, the mechanism of hybrid cache was applied to reduce the spatial query process latency by getting the data from adjacent peers. The proposed methodology aims to improve the cache management technique. In the initial stage, the data path is cached and the future requests are redirected to the nearby nodes. These nodes have the needed data in the data center. Using this innovation methodology, instead of accessing data in the data center, the data in the nearby nodes are accessed. In the further implementation of cache management rather than accessing data from data center, the data are served to intermediate nodes. Finally, Hybrid Cache management is combined to avoid the drawbacks of the existing works. Cache performance is improved using Cache Replacement polices. Based on the simulation result, we can identify that the query delays and the message complexity were significantly decreased compared to related works. The proposed work proves that the wireless broadcast channel is significantly accessed till 90%. Further studies will involve boosting up the methodology by advanced machine learning.
References
Zeeshan Hussain, S., & Ahmad, N. (2018). Minimizing broadcast expenses in clustered ad-hoc networks. Journal of King Saud University—Computer and Information Sciences, 30(1), 67–79.
Ali, H. A., Areed, M. F., & Elewely, D. I. (2018). An on-demand power and load-aware multi-path node-disjoint source routing scheme implementation using NS-2 for mobile ad-hoc networks. Simulation Modelling Practice and Theory, 80, 50–65.
Beckmann, N., Kriegel, H.-P., Schneider, R., & Seeger, B. (1990). The R*-tree: An efficient and robust access method for points and rectangles. In Proceedings of the ACM SIGMOD ’90 (pp. 322–331).
Harold Robinson, Y., & Rajaram, M. (2015). Energy-aware multipath routing scheme based on particle swarm optimization in mobile ad hoc networks. The Scientific World Journal, pp. 1–9.
Xiuwu, Yu., Feng, Z., Lixing, Z., & Qin, L. (2018). Novel data fusion algorithm based on event-driven and Dempster–Shafer evidence theory. Wireless Personal Communications, 100(4), 1377–1391.
Sahu, R. K., & Chaudhari, N. S. (2018). Energy reduction multipath routing protocol for MANET using recoil technique. Electronics, 7(5), 56.
Kumar, V. V., & Ramamoorthy, S. (2018). Secure adhoc on-demand multipath distance vector routing in MANET. In Proceedings of the International Conference on Computing and Communication Systems (pp. 49–63). Singapore: Springer.
Li, H., Liu, Y., Chen, W., Jia, W., Li, B., & Xiong, J. (2013). COCA: Constructing optimal clustering architecture to maximize sensor network lifetime. Computer Communications, 36(3), 256–268.
Chen, L., Lyu, D., Xu, Z., Long, H., & Chen, G. (2020). A content-location-aware public welfare activity information push system based on microblog. Information Processing and Management 57(1): Article 102137.
Chaudhry, R., & Tapaswi, S. (2018). Optimized power control and efficient energy conservation for topology management of MANET with an adaptive Gabriel graph. Computers and Electrical Engineering, 72, 1021–1036.
Ku, W. S., & Zimmermann, R. (2006). Location-based spatial queries with data sharing in mobile environments. In Proceedings of the 22nd IEEE international conference on data engineering (ICDE ’06) workshops (p. 14).
Harold, R. Y., Golden, J. E., Saravanan, K., Kumar, R., & Son, L. H. (2019). DRP: Dynamic routing protocol in wireless sensor networks. Wireless Personal Communications, 111, 1–15.
Kang, D., Kim, H. S., Joo, C., & Bahk, S. (2018). ORGMA: Reliable opportunistic routing with gradient forwarding for MANETs. Computer Networks, 131, 52–64.
Khamayseh, Y. M., Aljawarneh, S. A., & Asaad, A. E. (2018). Ensuring survivability against Black Hole Attacks in MANETS for preserving energy efficiency. Sustainable Computing: Informatics and Systems, 18, 90–100.
Saravanan, T., & Nithya, N. S. (2019). Modeling displacement and direction aware ad hoc on-demand distance vector routing standard for mobile ad hoc networks. Mobile Networks and Applications, 24, 1804–1813.
Sarkar, D., Choudhury, S., & Majumder, A. (2018). Enhanced-Ant-AODV for optimal route selection in mobile ad-hoc network. Journal of King Saud University-Computer and Information Sciences. https://doi.org/10.1016/j.jksuci.2018.08.013.
Sun, Z., Zhang, X., Ye, Y., Chu, X., & Liu, Z. (2019). A probabilistic approach towards an unbiased semi-supervised cluster tree. Knowledge-Based Systems. Available online 10 December 2019, Article 105306 (in press, journal pre-proof).
Han, Q., Liu, J., Shen, Z., Liu, J., & Gong, F. (February 2020). Vector partitioning quantization utilizing K-means clustering for physical layer secret key generation. Information Sciences, 512, 137–160.
Marendet, A., Goldsztejn, A., Chabert, G., & Jermann, C. (2020). A standard branch-and-bound approach for nonlinear semi-infinite problems. European Journal of Operational Research, 282(2), 438–452.
Bhvani, K., & Sasindrakumar, S. (2015). Traffic pattern discovery system for MANET. International Journal of Advanced Research Trends in Engineering and Technology, 2, 67–74.
Jamali, M. A. J. (2018). A multipath QoS multicast routing protocol based on link stability and route reliability in mobile ad-hoc networks. Journal of Ambient Intelligence and Humanized Computing. https://doi.org/10.1007/2Fs12652-017-0609-y.
Zimmermann, W.-S.K., & Wang, H. (2008). Location-based spatial query processing in wireless broadcast environments. IEEE Transactions on Mobile Computing, 7(6), 778–791.
Sasikala, K., Reka, R., & Prasath, M. A. (2014). Performance evaluation of improving network capacity with optimized cooperative (COCO) topology control scheme in MANETS. International Journal for Research in Emerging Science and Technology, 1(6), 58–64.
Harold Robinson, Y., Balaji, S., & Golden Julie, E. (2019). Design of a buffer enabled ad hoc on-demand multipath distance vector routing protocol for improving throughput in mobile ad hoc networks. Wireless Personal Communications, 106(4), 2053–2078.
Abu-EIN, A., & Nader, J. (2014). An enhanced AODV routing protocol for MANETs. International Journal of Computer Science Issues, 11(1), 196–206.
Dehghani, F., & Movahhedinia, N. (2018). CCN energy-delay aware cache management using quantized hopfield. Journal of Network and Systems Management, 26(4), 1058–1078.
Gao, G., & Li, R. (2019). Collaborative caching in P2P streaming networks. Journal of Network and Systems Management, 27(3), 815–836.
Aljeri, N., & Boukerche, A. (2019). A two-tier machine learning-based handover management scheme for intelligent vehicular networks. Ad Hoc Networks, 94, 101930.
Amiri, E., & Hooshmand, R. (2019). Improved AODV based on TOPSIS and fuzzy algorithms in vehicular ad-hoc networks. Wireless Personal Communications, 111, 1–15.
Jin, H., Xu, D., Zhao, C., & Liang, D. (2017). Information-centric mobile caching network frameworks and caching optimization: A survey. EURASIP Journal on Wireless Communications and Networking, 2017(1), 33.
Kanellopoulos, D. (2018). Congestion control for MANETs: An overview. ICT Express, 5, 77–83.
Harold Robinson, Y., Santhana Krishnan, R., Golden Julie, E., Kumar, R., Son, L. H., & Thong, P. H. (2019). Neighbor knowledge-based rebroadcast algorithm for minimizing the routing overhead in mobile ad-hoc networks. Ad Hoc Networks, 93, 101896.
Hamza, R., Muhammad, K., Lv, Z., & Titouna, F. (2017). Secure video summarization framework for personalized wireless capsule endoscopy. Pervasive and Mobile Computing, 41, 436–450.
Harold Robinson, Y., Balaji, S., & Golden Julie, E. (2019). FPSOEE: Fuzzy-enabled particle swarm optimization-based energy-efficient algorithm in mobile ad-hoc networks. Journal of Intelligent and Fuzzy Systems, 36(4), 3541–3553.
Usman, M., Jan, M. A., He, X., & Nanda, P. (2018). QASEC: A secured data communication scheme for mobile ad-hoc networks. Future Generation Computer Systems. https://doi.org/10.1016/j.future.2018.05.007.
Harold Robinson, Y., Balaji, S., & Golden Julie, E. (2019). PSOBLAP: Particle swarm optimization-based bandwidth and link availability prediction algorithm for multipath routing in mobile ad hoc networks. Wireless Personal Communications, 106(4), 2261–2289.
Chuang, P., Chen, Y., & Chen, H. (2013). Efficient cooperative caching in mobile ad-hoc networks. In Proceedings of the 2nd international conference on cloud-computing and super-computing CCSC 2013 (Vol. 2, pp.104–108).
Zam, A., & Movahedinia, N. (2013). Performance improvement of cache management in cluster based MANET. I.J. Computer Network and Information Security, 10(1), 24–29.
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Krishnan, C.G., Robinson, Y.H., Julie, E.G. et al. Hybrid Cache Management in Ad Hoc Networks. Wireless Pers Commun 118, 2843–2865 (2021). https://doi.org/10.1007/s11277-021-08158-z
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11277-021-08158-z