
Abstract
In mobile ad hoc networks (MANETs), traditional routing protocols send packets along pre-determined paths which are vulnerable in dealing with unreliable and unpredictable wireless medium. The main difference between the opportunistic routing and the traditional routing is that the former can employ several lossy broadcast links to support a reliable transmission. In order to improve the performance of opportunistic routing, nowadays, the tendency is to blend the idea of stable routing into opportunistic routing algorithms more or less. Just based on this ideology, this paper presents a stable ideology-based opportunistic routing (SIOR) for MANETs. Different from the existing protocols for MANETs, in SIOR, the stable ideology is infused into every step. In this paper, SIOR is described in detail around three issues of opportunistic routing. The first issue is how to select the forwarders among the neighbors; the second one is how to communicate among these forwarders to select a relay; the last one is how and when to relay the packets. The novel contribution of this paper is in dealing with the third issue. The ultimate target is to adapt SIOR to the mobility of MANETs. And then, the theory analysis is depicted on the basis of probability theory to compare SIOR with several relevant mechanisms. Finally, we have implemented simulation experiments. The simulation results show SIOR has prominent performance than other relevant protocols.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
Ad hoc networks have become a very active research field in the past twenty years. Routing in ad hoc networks is more challenging than in wired networks. Due to the mobility of the intermediate nodes, it is very hard to establish a stationary path between the source and the destination; thus, scholars have developed lots of routing algorithms for ad hoc networks.
A great number of routing protocols based on traditional routing techniques were proposed in early stage, e.g., DSR [14], AODV [1]. These protocols attempt to optimize different metrics. In general, they choose a path from the source to the destination prior to forwarding data packets in ad hoc networks and then transmit data packets via the predetermined route.
With the popularity of global positioning system (GPS), geographic routing algorithms have been proposed, e.g., the representative protocols LAR [17] and GPSR [15]. In geographic routing, a forwarding node can learn about its own, its neighbors, and the destination location information; thus, a packet can be effectively forwarded towards the destination.
In order to further improve the performance of packet transmissions, a concept of stable routing is proposed in recent years. The main goal of stable routing is to strengthen the stability of the route by backup nodes or backup paths along the primary path. GBR [27] considers both route length and link lifetime to achieve high routing stability. In GBR, the primary path is constructed mainly based on the greedy forwarding mechanism [15], whereas the local-backup path for each link is established according to a contention-based mechanism on the basis of link lifetime. ARMBR [28] creates the main route by flooding RREQ messages and unicasting RREP messages. The backup links are constructed as data packets are transmitted. In B2RP [8], the geographic information, bit error rate (BER) of the links and 2-hop routing information were synthesized to elaborate a most durable routing path between the source node and the destination node.
To exploit the broadcast nature and spatial diversity of the wireless medium to improve the packet forwarding efficiency, many researchers concentrate on the concept of opportunistic routing [2]. The main idea of opportunistic routing is that, instead of pre-selecting a single specific node as the next-hop to forward packets, multiple nodes can potentially serve as the next-hop forwarders, that is, in the opportunistic routing mechanism, there is not specific next-hop node. Once the current node transmits a packet via a single-hop broadcast, all the candidate nodes that receive the packet successfully will coordinate with each other to determine which one or ones would actually relay the packet according to some criteria, e.g., only the one that is closest to the destination will implement the forwarding while the rest will simply drop the packet even if they have successfully received it. As a result, opportunistic routing can take advantage of the potentially numerous, yet unreliable wireless links in the network [13]. In short, opportunistic routing is conceptually composed of three steps: (1) Broadcasting a data packet to relay candidates, (2) Choosing the best relay by a coordination mechanism, (3) Relaying the data packet towards the destination. Fig. 1 illustrates the principle of opportunistic routing. The digits along each edge indicate the sequence of events.

Opportunistic routing implementation steps. In order to illustrate the principle of opportunistic routing distinctly, the three nodes a, b and c are located in the most favorable position towards the destination
Compared with traditional routing, opportunistic routing has the following advantages: (1) Opportunistic routing can make full use of the intermediate nodes to transmit as far as possible. An experiment in [2] has shown opportunistic routing outperforms traditional routing when loss rates of links are high. (2) Opportunistic routing increases transmission range. Opportunistic routing takes into account all possible links, within one transmission range, including good quality short-ranged links and poor quality long-ranged links. Both theoretical analyses [20, 29] and experiment results [6, 22] have shown opportunistic routing has potential to perform better than traditional routing. During the same period, [18] discussed opportunistic routing deeply in terms of its merits and drawbacks, and then concluded that opportunistic routing is a promising direction to improve the performance of wireless networks.
In this paper, we propose an opportunistic routing mechanism SIOR for MANETs. In MANETs, due to the mobility of all nodes, traditional routing mechanisms have to spend many overheads to construct routes from the source to the destination and maintain the fragile routes. However, aided by geographic information, SIOR exploits the intrinsic properties of MANETs to reduce the effect coming from nodes’ mobility as far as possible. Different from the existing opportunistic routing schemes for MANETs, the stable ideology is infused into every step of SIOR: in the candidate selection stage, firstly, SIOR selects candidates within the reuleaux triangle towards the destination, which guarantee that all the candidates can communicate with each other; in the candidate communication phase, secondly, instead of pre-setting the priority of intermediate forwarding nodes, SIOR schedules the relaying sequence according to the instant geographic positions of the intermediate nodes, which adapts SIOR to the mobility of nodes and avoid the overheads of routing maintenance; in the relaying stage at every hop, lastly, SIOR employs multiple intermediate candidates to collect enough packets in a batch as far as possible, and then the batch fragment is relayed by a relay agent (RA) towards the destination. The former two steps have been studied sufficiently in the existing literatures, and many approaches have been put forward. However, there are few developments in the third step, which is nearly a blank field. The novel contribution of SIOR is just in the third step, in each hop, which not only exploits the spatial diversity but also makes use of the multiple candidates as backup nodes, which are seldom utilized in the existing opportunistic routing solution, i.e., in the third step, SIOR absorbs the advantage of stable routing. Meanwhile, collected by RA, the multiple duplicated packets are deleted and the redundant transmissions to the next hop are avoided. Compared with the existing opportunistic routing schemes designed for MANETs, SIOR shows its superiority in accommodating the mobility of MANETs.
The remainder of this paper is organized as follows. In the next section, we summarize the related works. The SIOR principle is described in details in Sect. 3. In Sect. 4 the theoretical analysis is depicted. The results of performance evaluation are presented in Sect. 5. Finally, conclusions and our future works are proposed in Sect. 6.
2 Related Works
The first opportunistic routing was presented by Biswas and Morris. The mechanism, named extreme opportunistic routing (ExOR) protocol [2], was developed for wireless mesh networks. ExOR selects the forwarders based on simulation with available nodes prioritized using a metric expected transmission cost (ETX) [7]. The metric is the average number of retransmissions needed to forward a packet over a link using the packet delivery ratio of the link. ETX of a node in ExOR can be considered as the logical distance of the node from the destination.
Since then, many scholars proposed a lot of opportunistic routing protocols that focus on how to improve the performance of opportunistic routing in wireless networks. To reach the goal, there are two common key techniques to be addressed: One is the candidate selection among the intermediate nodes from the source to the destination; the other is the coordination methods among these candidates.
2.1 Candidate Selection
In order to achieve a theoretical model for opportunistic routing in ad hoc networks, Angela Sara Cacciapuoti etc derived a closed-form expression of the average number of data-link transmissions needed to successfully deliver a packet [3]. However, during the procedure of derivation, the candidate priority is based on the adopted routing metric [Expected Transmission Count (ETX), geographic distance, etc]. Thus, the issue of candidate selection is still leaved to specific opportunistic routing. In [19], Mingming Lu and Jie Wu designed an opportunistic routing algebra to model opportunistic routing. In the opportunistic routing algebra, all the possible candidate paths between the specific source-destination pair are regarded as a tree. Only one candidate path will be selected as the actual forwarding path. The path selection is dynamic and dependent on the instantaneous channel conditions and node availability, that is to say, the candidate selection is also dynamic according to the instantaneous situation.
The least-cost anypath routing (LCAR) [9] designed by Dubois-Ferrière etc., which chooses anypath and not the shortest path in order to reduce retransmissions. A node selects its forwarder list (selector node) by considering all possible subsets of its neighbor set and then compute the relay cost from each of the subset to the destination. The total cost, from the selector node to the destination through a subset, is the sum of the relay set cost and the cost to the set from the selector. The subset which results in the minimum total cost of the selector is selected as its relay set. The main issue with this approach is that while selecting the relay set, it does not consider the connectivity between the member nodes of the set. To address the issue effectively, Arka Prokash Mazumdar and Ashok Singh Sairam elaborates a scheme to minimize redundant transmissions. The authors analyse the classical opportunistic routing protocols like ExOR and draw a conclusion that duplicate packet transmissions occur if a lower priority forwarder can’t hear the transmission of its adjacent higher priority forwarder. Based on the result, the authors proposed a protocol TOAR [21], which optimizes the forwarder list by constructing a full path tree and systematically pruning nodes of the tree. Empirical results show TOAR significantly reduces the number of duplicate transmissions. To further improve the efficiency of candidate selection, a concept maximum progress distances (MPD) [5] was proposed. Based on the concept, the authors reach an analytical model that can compute the optimal position of these nodes, such that the advancement towards the destination is maximized. Aided by experiments, the authors conclude whether the first two candidates locate their optimal positions is the most critical aspect in order to minimize the expected number of transmissions.
Those candidate selection approaches mentioned above are designed for static scenarios. In order to choose optimal candidates in dynamic networks, many scholars try every means to design various algorithms. Zhen et al. [30] put forward an algorithm PORM to choose the proper candidates by Request to send/clear to send (RTS/CTS) mechanism. PORM works on the basis of modified DSR. It uses the control messages of DSR not to build the end-to-end path, but to select the proper forwarder nodes. After that, PORM sorts those forwarders in priority order according to the distance between them to the destination or to the source. In order to improve the routing performance for MANETs, Tahooni et al. [23] depicted an enhanced mobility-based opportunistic routing protocol (EMOR). In EMOR, candidates are selected based on its predicted position, predicted link delivery probability and predicted geographic progress. The simulation results show that delivery ratio and number of expected transmission are very superior.
Likewise, SIOR is also developed for MANETs. Therefor, the candidate selection is also an issue. Assimilating the strong points of the algorithms above, we elaborated an approach to select the candidates based on geographic information, which not only adapt to MANETs but also can avoid duplicated transmissions effectively.
2.2 Coordination Methods [12]
After the selection of candidates, the other crucial issue is the coordination among these candidates. A good coordination method can select the best relay without duplicate transmissions while using the smallest overhead (in terms of time and/or control overhead). Existing coordination methods are mainly divided into three groups based on the mechanism used: timer, token, and network coding.
2.2.1 Timer-Based Coordination
Timer-based coordination is the most straightforward approach and easy to implement, but it may result in a few duplicate transmissions. To pick out the best relay from a candidate list, candidates in timer-based coordination method [2, 22, 23] are delayed based on a predefined candidate order before responding. The first one to respond is then selected as the next relay. The general coordination method behaviors of timer-based are as follows. All candidates are pre-ordered based on a predefined metric. The order is generated by either the source (global candidate order) or intermediate relay (local candidate order), and encapsulated in the packet header. After a data packet is broadcast, candidates will respond in order, i.e., ith priority candidate will respond at the ith time slot. A candidate responds at its turn only when it does not hear any responses from its neighbors.
2.2.2 Token-Based Coordination
Token-based coordination is first proposed in [11]. In the coordination, only the token holder can forward packets and duplicate transmissions are thoroughly prevented but at the cost of extra control packets. The procedure is summarized as follows: a relay collects overheard packets and forwards them only when it receives a token. Tokens are passed along “connected candidates”, where candidates are ordered in the way such that the ith candidate can hear the \((i+1)th\) candidate. Tokens are generated from the destination and flow from high priority relays (close to the destination) to low priority relays (close to the source).
2.2.3 Network Coding
Katti et al. [16] introduced a concept of network coding in wireless communication. When coordination by coding packets is combined with opportunistic routing, duplicate transmissions can be avoided. A general concept of network coding applied with opportunistic routing is as follows: When packets are transmitted from a source to a destination, the flow is divided into batches to code and decode. A batch contains several native packets, which are original packets without coding. Then, the source broadcasts random linear combinations of native packets, and relays forward the linear combinations of received coded packets to the destination. Coded packets are decoded only when the destination collects enough linearly independent coded packets (e.g., if there are m native packets in the batch, and the destination has received n coded packets, where \(n \ge m\)). Finally, native packets can be recovered by Gaussian elimination.
2.2.4 Novel Coordination Approaches
All of the coordination mechanisms above serve for mesh networks or sensor networks, i.e., the nodes are static. Aimed at accommodating mobile nodes, Cooperative Opportunistic Routing in Mobile Ad hoc Networks (CORMAN) was developed by Wang et al. [25]. It is supported by an underlying routing protocol Proactive Source Routing (PSR) [24, 26], which provides each node with the complete routing information to all other nodes in a network. Based on PSR, there are two means to enhance packet delivery rate, which are named as large-scale live update and small-scale retransmission. As packets are transmitted in the network, aided by large-scale live update, the nodes listed as forwarders can modify the forwarder list if any topology change has been observed in the network. Assisted by small-scale retransmission, as well as, those nodes that are not listed as forwarders can also retransmit data if it turns out to be helpful. However, this mechanism incurs a slight overhead than ExOR by including shorter forwarder lists in data packets.
Based on geographic information, taking advantage of the real-time nodes’ position information, SIOR applies timer-based coordination to furthest reduce useless forwarding among those candidates, which not only can decrease transmission overhead but also suit to mobile scenarios.
3 SIOR Principle
In this section, we describe SIOR principle in every aspect in details.
3.1 Network Model
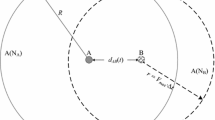
We assume all nodes are uniformly and randomly distributed in a two-dimensional space. Each node has a single channel and the same transmission range R. All communication links are bidirectional. Each node knows itself position information through a mechanism, e.g., GPS. All nodes, except the source and the destination, are mobile at random speeds and in any directions. Figure 2 is the network scene at certain instant.

Moving nodes between the source and the destination
3.2 General Idea
The source S will send a mass of packets to the destination D. All the packets are divided into several groups and transmitted in batch. Firstly, the source S transmits the first batch destined to D. All of the nodes within its transmission range can receive some packets of the batch more or less. Only the nodes located in the forwarding area accept these packets and others drop it simply. As exampled in Fig. 3, node a, b, c, d and e accept the packets from S while node f and g abandon it. Secondly, one of these nodes within the forwarding area is selected as RA according to some metrics and the rest serve as relay members (RMs) from S to RA. Thirdly, RA informs RMs that there are some packets it has not received in the same group. And then, RMs relay packets to RA in the order of priority. Finally, it reaches an opportune instant for RA to suppress RMs’ forwarding. Acting like S, RA starts a new iteration to transmit the same batch (or batch fragment) towards D.

Nodes and reuleaux triangle
3.3 Packet Header Fields
The source S begins by preparing a batch of packets for transmission. First, S prepends the SIOR header to each packet. The meaning and function of some key fields are listed as below.
- PackTyp::
-
The packet type. In SIOR, there are many types of packets. The packets including data: the source broadcasts to RMs; the RMs relay to RA. The others not encapsulating data: RMs compete for acting as RA; RA broadcasts to RMs; RA requests RMs for data packets; RA suppresses RMs for it has already received all packets in the batch; the destination replies to the source.
- SouIP, RAIP and DesIP::
-
the source IP address, the relay agent IP address and the destination IP address respectively.
- SouXco, RAXco and DesXco::
-
the source, the relay agent and the destination X-axis coordinates respectively.
- SouYco, RAYco and DesYco::
-
the source, the relay agent and the destination Y-axis coordinates respectively. These coordinate values are used by those nodes which have received the packet to judge whether it is in the forwarding area or not.
- BatchID::
-
the batch identifier (ID) of the packet belongs to. In the memory of each receiving node, there are buffers associated with each batch ID.
- PktNum::
-
the current packet’s offset in the batch. This offset corresponds to the PackMap entry for the packet. The value of this field is used to estimate the transmission end of this batch when one RM can’t receive the last packet in this batch.
- BatchSz::
-
the total number of packets in this batch.
- FragNum::
-
the current packet’s offset within the batch fragment.
- FragSz::
-
the size of the current batch fragment (in packets).
- NumofRA::
-
the number of RA by which this batch fragment has passed. The value is used by the destination when it estimates the transmission opportunity to send a reply to the source.
- PackMap::
-
the map of packets in the batch or batch fragment. The value of each entry in the PackMap is either one or zero, which indicates the corresponding packet is in the batch (or batch fragment) or not; so the space needed is equal to the value of field BatchSz in bits. In the packet transmission phase, the source or RA utilizes this map to show which packets are sent out in the batch (or batch fragment). In order to record which data packets are received or not, each RM keeps a packet map in its memory as well and updates it timely when receiving a new data packet. Obviously, these two packet maps are not identical. In the reply stage, RA employs the packet map buffered in its memory to inform RMs which packets it has already received or not.
3.4 Selection of Forwarding Area
As mentioned in Sect. 2, in geographic routing, which nodes are qualified to forward packets among those intermediate ones is a key issue, i.e., how to select forwarding area. There are three different forwarding areas analysed in [10]. According to SIOR’s principle, the forwarding area should meet two conditions: the forwarding area contains as many nodes as possible; all the nodes in the forwarding area can overhear each other. Therefore, the reuleaux triangle is the best option under the assumption about the radio signal that there aren’t fading and multipath and so on. As illustrated in Fig. 4, r is the greatest possible transmission distance of nodes, which is also the radius of the three arcs to form the reuleaux triangle. In theory, any two nodes in the reuleaux triangle can overhear each other. As a result, this scheme can reduce redundant transmissions as far as possible. All nodes in the reuleaux triangle may serve as RMs for S. Meanwhile, RA is chosen from these RMs.

Selection area of candidates
3.5 Selection Conditions of RA
In the forwarding procedure from the source to the destination, RAs play an important role as mentioned in Sect. 3.2. RAs collect all packets in the same batch that have been accepted by RMs as best as it can and transmit these packets towards the destination. Which RM can perform the task in the reuleaux triangle? The RM selected as RA must meet two conditions. One is that the RM has received at least one packet in the batch successfully; the other is that the projection of the straight line from the RM to the source (or the previous RA) on the line S-D (or RA-D) is the longest. As shown in Fig. 3, if e received at least one packet from S successfully, it can act as RA; otherwise, d is considered.
3.6 Selection Procedure of RMs and RA
When the source S sends a batch of packets destined to the destination D, in Fig. 4, all nodes in its transmission range can receive packets more or less. Firstly, each node should judge whether itself locates in the reuleaux triangle by calculating the distance to the three points S, A and B respectively: let the node is N and \(dis(N-S)\) represents the distance between node N and node S, likewise \(dis(N-A)\) and \(dis(N-B)\), if \(dis(N-S)\le r \bigwedge dis(N-A)\le r \bigwedge dis(N-B)\le r\), then node N is located in the reuleaux triangle, where the coordinate values of node S, A and B are (0, 0), \((0.866\times r, 0.5\times r)\) and \((0.866\times r, -0.5\times r)\) (in practice, the coordinate values can be obtained by coordinate translation) respectively. If it is in the reuleaux triangle, it pushes these packets to a buffer associated with the batch ID and becomes a RM from S to D; otherwise it drops the packets simply. At the end of the tranmission of the batch, every RM estimates its waiting interval time by Eq. (1) to compete with other RMs for playing the role of RA by broadcasting a notification, where p is the projection of the straight-line distance to the source (or the previous RA) on the line S-D (or RA-D); r is the transmission range; \(T_c\) and \(T0_c\) are system constants of time interval. According to Fig. 4, within the reuleaux triangle for any RM, \(p\le r\). Only when the destination D calculates \(t_c\), \(T_c\) and \(T0_c\) are set to zero (the destination D locates in the reuleaux triangle). As a consequence, the closest RM to the destination broadcasts the notification at the first time. Upon receiving the notification, all of the other RMs suppress its broadcasting of the same notification. In the next step, RMs will send some packets to RA, which have not been received by RA due to the lossy links.
However, there may be an extreme case that no RM lies in the reuleaux triangle. Assume there are only f and g in Fig. 3 within the S transmission range, which can be perceived by S for it can’t overhear any notification broadcast by certain RM for becoming RA. On this occasion, S adopts greedy forwarding [15] to transmit the batch of packets to g. This situation is small probability event, thus it isn’t discussed in the following part.
3.7 Communications Between RA and RMs
In the reuleaux triangle, RA may be the one that accepted the least of packets for it is the farthest one from the source (or the previous RA); however, some of the RMs may receive greater majority packets from the source (or the previous RA) successfully. In order to take advantage of the spatial diversity of the wireless medium, RA can get the lost packets from RMs by following the procedure below.
RA informs all RMs that which packets it has not received by broadcasting packet map to them. For example, the source S has sent out 64 packets towards the destination, and RA only received 2 packets. Then, RA broadcasts a packet map to RMs as shown in Fig. 5b. Figure 5a is the packet map encapsulated in the packets transmitted by the source with all entries filled with 1, which means all packets are sent out successfully; whereas in Fig. 5b, there are only two entries filled with 1 and the remaining are 0, which means RA has only successfully received two packets from the source S. Upon receiving the packet map from RA, all of the RMs estimate its waiting time to reply RA by Eq. (2)
where p and r are same as Eq. (1); \(T_r\) and \(T0_r\) are system constants of time interval. The RM with the shortest waiting time checks its buffer associated with the same batch ID to find out which packets that haven’t been received by RA and relays these packets (batch fragment) to RA; meanwhile, to avoid reduplicate transmission, the RM records this transmission by keeping the batch ID and the IP address of the RA. Besides RA, other RMs in the reuleaux triangle can receive the batch fragment as well. They cancel their forwarding to RA and selectively accept those packets that have not received from the source S(or previous RA) before. RA accepts some packets in the batch fragment successfully and there are still others can’t be received. Repeatedly, RA broadcasts a second packet map as shown in Fig. 5c. And then, the RM with the second shortest waiting time replies just like the former. Successively, the rest of RMs response to RA in the priority ordered by distance from the near to the distant from the source. If one of the conditions below is met, RA broadcasts a suppression packet to all RMs: (1) RA has already received all of the packets in the batch; (2) The timer expires. Since the RA broadcasts every packet map, it sets a timer to avoid indefinite waiting. The waiting interval denoted as \(T_{wait}\) is several times of \(T_{pack}\) which represents a unit time when a packet is sent out from MAC layer till it is received by the receiver application layer [2]. Upon receiving the suppression packet, all RMs flush its buffer associated with the corresponding batch. And then, RA serves as the source to forward the batch (or batch fragment) towards the destination. Different from the previous packets sent by the source, the fields RAIP, RAXco and RAYco of these packets relayed by RA are filled with relevant information.

The field PackMaps in SIOR packet header at different stage. a The packet map sent out by source S in each packet, b the packet map broadcast by RA at the first time, c the packet map broadcast by RA at the second time
3.8 Response from D to S
As shown in Fig. 3, when the batch (or batch fragment) reaches the reuleaux triangle where the destination locates, to avoid the competition for becoming RA among them, the destination broadcasts a suppression message to other RMs once the batch transmission ends. Just like RA communicates with RMs, the destination replaces RA and performs its task as well. After the destination meets one of the two conditions mentioned in Sect. 3.7, it informs the RMs and makes a response to the source. The content of the response includes the batch ID and the packet map, which notify the source that which packets of the batch have been received by the destination. The response packet is very short and simple; so it is relayed by the greedy forwarding mechanism proposed in [15]. After receiving the response, the source sends the unreceived packets to the destination in the next batch. The response packet may be lost as well due to the lossy links between the source and the destination. To avoid indefinite waiting, the destination sets a timer when it sends out the response. The duration time is estimated by Eq. (3).
where K is the system coefficient correlated with RMs motion velocity; n is the value of the field NumofRA of the received packet; \(T_{pack}\) is the unit time.
3.9 An Example of Communications Between RA and RMs
In this section, to further explain the opportunity forwarding mechanism aided by packet map, we examine one simulative implementation in the scene of Fig. 3.
The source S sends a batch to the destination D, which includes 64 packets. The PackMap fields of these packets are same as Fig. 5a, which means all the packets of this batch are sent out by S. The neighbors of S may receive some packets of this batch more or less. Only those neighbors locating in the reuleaux triangle accept these packets. Just as in Fig. 3, only node a, b, c, d and e accept packets from S. Each neighbor in the reuleaux triangle not always receives all packets from S due to the lossy links. If it only receives one packet from S, the neighbor becomes a RM from S to D. At the end of this batch transmission, the packet maps cached in these RMs are updated as shown in Fig. 6. RMs can estimate the end time of this batch by means of Eq. (4), if it didn’t receive the last packet of this batch.
where BatchSz and PktNum are the field values of the last received packet; \(T_{pack}\) is the unit time which is set to 15 milliseconds [2]. \(t_{last}\) is the time when this RM receives the nth packet in this batch (n is the value of field PktNum). At the end of this batch, all RMs compete for becoming the RA by means of Eq. (1), where \(T0_c\) is set to 30 milliseconds and \(T_c\) is set to 15 milliseconds. Node e has received two packets from S and becomes RA after the competition. And then, it broadcasts its packet map just like Fig. 6e, which tells other RMs that it has only received two packets from S.

The packet maps in the memory of each RM after S transmits a batch of packets. a The packet map in the memory of a, b the packet map in the memory of b, c the packet map in the memory of c, d the packet map in the memory of d, e the packet map in the memory of e
Upon receiving the packet map from e, all RMs estimate its waiting time by Eq. (2). As a result, a sends the batch fragment to e and records this forwarding. The batch fragment includes packets that have not been received by node e. The packet map of this batch fragment is shown in Fig. 7. Node b, c, d and e selectively accept packets from the batch fragment. Figure 8 exhibits the results after a relays the batch fragment.

The packet map sent by a to e

The packet maps in the memory of each RM after a relays its batch fragment. a The packet map in the memory of b after a relays its batch fragment, b the packet map in the memory of c after a relays its batch fragment, c the packet map in the memory of d after a relays its batch fragment, d the packet map in the memory of e after a relays its batch fragment
In the next round, e broadcasts its packet map once again. The RMs a, b, c and d can receive it. a checks its buffer and learns that it has already replied the same request; thus it ignores this message. As a consequence, node b sends a second batch fragment including packets that node e hasn’t received from S and a. The packet map of this batch fragment sent by b is shown in Fig. 9. Meanwhile, node c and d selectively accept packets from this batch fragment (Fig.10).

The packet map sent by b to e

The packet maps in the memory of each RM after b relays its batch fragment. a The packet map in the memory of c after b relays its batch fragment, b the packet map in the memory of d after b relays its batch fragment, c The packet map in the memory of e after b relays its batch fragment
In the third round, e broadcasts its packet map to c and d. And then, c sends its batch fragment including packets that e hasn’t received from S, a and b. The packet map encapsulated in these packets is shown in Fig. 11.

The packet map sent by c to e
After c transmits this batch fragment, d and e can receive some packets that they haven’t received before. The packet maps cached in their memories are updated as Fig. 12.

The packet maps in the memory of each RM after c relays its batch fragment. a The packet map in the memory of d after c relays its batch fragment, b the packet map in the memory of e after c relays its batch fragment
In the last round, e broadcasts its packet map to d, and then d replys a batch fragment to e. The packet map sent along with data packets by d is shown in Fig. 13. In this round, e receives all packets from d for they are very close. The packet map updated in e is shown in Fig. 14. Now, e receives all packets in the batch sent by source S after the four relays performed by a, b, c and d. As RA, e broadcasts a suppression message to RMs. And then, RMs clear away its buffers associated with this batch. In the next step, e will serve as source S to transmit the batch towards the destination D.

The packet map sent by d to e

The packet map in the memory of e after d relays its batch fragment
4 Theoretical Analysis
In this section, we analyse SIOR in terms of transmission efficiency by probability theory, using Fig. 3 as an example, and then compare it with other three routing mechanisms developed for MANETs as well.
Let \(p_1\), \(p_2\), \(p_3\), \(p_4\) and \(p_5\) be the delivery probability from S to nodes e, d, c, b and a respectively. Meanwhile, the projections of lines Se, Sd, Sc, Sb and Sa are denoted as \(d_1\), \(d_2\), \(d_3\), \(d_4\) and \(d_5\) respectively. \(\Delta _{SIOR}\) represents the random variable equal to the reached distance after one transmission shot of a packet from S. Such that the efficiency of one transmission shot is \(E[\Delta _{SIOR}]\). According to the detailed depiction about the principle of SIOR in Sect. 3, we can get Eq. (5).
That is to say, the packet will be progressed a distance \(d_1\) if the farthest RM receives it, or a distance \(d_i,(i=2,3,4,5)\), if ith RM receives it.
Let \(\Delta _{PORM}\) denotes the transmission efficiency of PORM discussed in Sect. 2. The forwarder list of PORM is the subset of RMs by studying its candidate selection procedure, thus \(E[\Delta _{SIOR}]>E[\Delta _{PORM}]\).
In EMOR, those nodes outside of the reuleaux triangle are taken into account as candidates. Therefor, the forwarding nodes in EMOR is a little more than those in SIOR. Superficially, the efficiency of one transmission shot is greater than that of SIOR according to both Eq. (5) and the Eq. (5) in [23]. Because they aren’t located in the reuleaux triangle, they can’t be coordinated with some of the forwarding nodes, which will result in duplicated transmissions and waste the valuable wireless channel bandwidth. Consequently, the routing performance of EMOR is affected by them outside of the reuleaux triangle.
Besides PORM and EMOR, CORMAN is also designed for MANETs. Furthermore, the general idea of CORMAN is very similar to SIOR. In CORMAN, the large scale live update is used for renewing the beforehand determined route. Meanwhile, the small scale retransmission is employed to retransmit the missed packets. if there are multiple nodes between two forwarders in the route, only the one which is closest to the midpoint of the line segment between the two forwarders is selected as relay node. In Fig. 3, e.g., only node b is selected to relay the missed packets from node S to node e. Obviously, the transmission efficiency of CORMAN is less than that of SIOR as well.
5 Performance Evaluation
In order to verify the excellent performance of SIOR, in this section, we compare its performance with that of other several protocols. There are many opportunistic routing mechanisms mentioned in Sect. 2. However, only PORM [30], EMOR [23] and CORMAN [25] were designed for MANETs. Thus, they are comparable with SIOR. In this section, the four routing schemes are compared in terms of opportunistic routing characteristics.
5.1 Simulation Setup
These simulations were implemented in a \(2000\,\mathrm{m}\times 2000\,\mathrm{m}\) network area on the platform NS-2. IEEE 802.11b distributed coordination function (DCF) with the RTS/CTS mechanism was used as the MAC layer protocol. The radio interface was modeled as a shared-media radio with a nominal bit rate of 2 Mbps. The UDP protocol was used as the transport layer. There was only one source-destination pair in the network. The source and the destination were fixed at the both ends of the simulation area. The source sent 64MB data to the destination and each packet encapsulated 1KB data. The motion velocity of these nodes in these scenarios varied from 0.5 to \(3\,\mathrm{m/s}\), which was used to evaluate the performance of different mechanisms under different node motion speeds. We chose the random walk model in these simulations since it can mimic a pedestrian behavior; therefore, the node speed wasn’t too fast. The nodes’ transmission ranges were set to \(250\,\mathrm{m}\). The number of nodes in these scenarios was varied from 200 to 600 to verify the influence from the node density. The results, except the proportions of transmissions of different location nodes, are averaged over 50 simulation runs and given with a 95% confidence interval.
The values of system parameters in Eqs. (1), (2), (3) and (4) are listed as follows: \(T_{pack}=15\) milliseconds, \(T_c=T_r=T_{pack}\), \(T0_c=T0_r=2\times T_{pack}\), \(T_{wait}=3\times T_{pack}\) and the coefficient \(K=2\). The default values of the system parameters of other three protocols were adopted.
5.2 Influence from the Size of Packet Batch
SIOR works for packet batch. Hence, we discuss firstly the size of packet batch influence on the performance. To avoid the effect come from node density to the greatest extent, we set the node number as 600. Figure 15 demonstrates the duration time to transmit 64MB data under varying sizes of packet batches while node motion velocity is set to 0.5, 1.0, 1.5, 2.0, 2.5, \(3.0\,\mathrm{m/s}\) respectively. The general tendency of duration time is decline as the size of packet batch increases. That is because the usage rate of links is raised as the size of packet batch ascends. As the size of packet batch increases, on the one hand the usage rate of links grows; however, the RMs and RAs are mobile in the networks, thus the longer the forwarding time last, the more difficult the transmission of a packet batch can be completed, i.e., the duration time of each batch goes up rapidly as the size of packet batch boosts. As an integrated result, the average duration time of forwarding a packet essentially unchanged; so the duration time reaches a constant while the size of packet batch is around 1024. In Fig. 15, another significant result is that the duration time grows as the node motion velocity rises. The reason is that the stability of links between RMs and RA declines as the node mobility is boosted.

Duration time versus varying sizes of packet batches under different node motion velocity
5.3 Proportions of Transmissions of Different Location Nodes
In this simulation, the source S transmits 256 packets to the destination D by the four routing schemes SIOR, PORM, EMOR and CORMAN respectively. In order to avoid the effect of nodes’ mobility and density as far as possible, the node motion velocity is set to \(0.5\,\mathrm{m/s}\) and 600 nodes distributed randomly in the network area. In the transmitting procedure of the packets, the more extensive the participators distribute, the more stable the scheme is [4]. Hence, the goal of this experiment is to survey the proportions of transmissions conducted by different location nodes in one execution. Figure 16 shows the forwarding node distribution and the proportions of transmissions implemented by these nodes of the four routing protocols in one simulation.

The forwarding nodes’ distribution and its transmissions
The most obvious difference among these four histograms is that the widest range of forwarding node locations is EMOR, whereas the most limiting range is CORMAN. The other distinction in these histograms is that the numbers of the received packets by the four destination nodes are different, which is indicated by the last pillar in each histogram. In EMOR, those nodes whose geographic progresses exceed zero are chosen as candidates. Therefore, the number of intermediate forwarding nodes is greater than that of SIOR. Furthermore, those intermediate forwarding nodes are selected based on the predicted link delivery probability, the number of the neighboring nodes and the predicted position using the motion velocity of the nodes. Thus, some of those nodes may become invalid while forwarding packets, which results in the received packets by the destination node are less than that of SIOR. In SIOR, the RMs are chosen according to the instant geographic information. Moreover, all RMs in each hop can overhear each other for they locate in a reuleaux triangle. So, the destination in SIOR receives the most packets. In CORMAN, only one intermediate node is selected as relay node between two candidates determined beforehand, regardless of there are multiple ones. Hence, the number of intermediate forwarding nodes of CORMAN is the smallest in the four schemes, likewise, which leads to the destination node receives the least packets. In order to avoid broadcast storm, however, PORM limits RREQ forwarding times to reduce the forwarding nodes; hence the forwarder list is limited. That is to say, some useful intermediate nodes don’t be employed to relay packets.
5.4 The Average Number of Forwarding Nodes
Just like the simulations above, the source S transmitted 256 packets to the destination D by the four routing mechanisms SIOR, PORM, EMOR and CORMAN respectively. In order to avoid the effect of nodes’ density as far as possible, there are 600 nodes distributed randomly in the network area. We aimed at observing the average number of forwarding nodes in a single transmission under varying node motion velocity. The results were indicated in Fig. 17.

The average number of forwarding nodes versus node motion velocity
The primary impression is that the average number of forwarding nodes increases as the node motion velocity rises. The cause is that the node mobility leads to the change of forwarding nodes. Secondly, the average numbers of forwarding nodes of SIOR and CORMAN are less than those of PORM and EMOR, which results from batch transmission application in the formers. The average number of forwarding nodes of CORMAN is less than that of SIOR. The main reason is that CORMAN only uses one intermediate relay in small scale retransmission. Meanwhile, as the node motion velocity goes up, the gap between CORMAN and SIOR enlarges, which is caused by the process of route construction. In CORMAN, the route is established by proactive source routing. Therefore, the route becomes fragile as the node motion velocity ascends. Consequently, the route may break, and the batch transmission failed. However, the same situation doesn’t occur in SIOR.
Different from SIOR and CORMAN, PORM and EMOR send a single packet in each transmission. In PORM, the forwarding list is created on the basis of modified DSR. And then, all the forwarding nodes are ordered from the destination side and the source side respectively. Finally, all the forwarding nodes are roughly sorted in priority order according to the number of hops to the destination. Aided by geographic position information, EMOR also sorts its candidates. However, EMOR orders those candidates based on the link delivery probability, the number of neighboring nodes and the predicted position of the candidates. Clearly, the ordering approach of EMOR is more accurate than that of PORM. Therefore, the routes established by EMOR are more reliable than that by PORM. Consequently, there are more nodes to forward packets in EMOR than that in PORM. And the gap can be amplified as the node motion velocity ascends. All the above are reflected by the two curves in Fig. 17.
5.5 The Effect of Node Motion Velocity
In this experiment, there are 600 nodes distributed randomly in the network area. The source sends 64M data to the destination. A batch includes 1024 packets in SIOR. The duration time of these four protocols are showed in Fig. 18. As node motion velocity is \(0.5\,\mathrm{m/s}\), the duration time of these four schemes only has little difference due to their elaborate design. However, as node motion velocity goes up, the difference is obvious.

Duration time versus node motion velocity
SIOR and EMOR are based on geographic information. Thus, the effects on their duration time from node motion velocity are less than those of PORM and CORMAN. In EMOR, some metrics are predicted as it constructs routes, whereas, SIOR is on the basis of real-time information while transmitting packets. Therefore, the reliability of EMOR is inferior to that of SIOR. As the node motion velocity rises, the forecast accuracy is decline, which results in the difference between them goes up.
PORM and CORMAN establish routes in advance by means of other routing protocols; Nevertheless, CORMAN transmits packets in batch. While the node motion velocity is slow, as a result, the duration time of CORMAN is less than that of PORM, which forwards a single packet in each transmission. When the node motion velocity exceed \(1.6\,\mathrm{m/s}\), the circumstance is reversed. The main contributor is that PORM employs multiple intermediate nodes as relays within one hop and CORMAN makes use of only one intermediate node. That is to say, the stabilizing measure of PORM is better than that of CORMAN.
6 Conclusion and Future Work
In this paper, an opportunistic routing protocol SIOR for MANETs has been proposed. Our mechanism aims to provide more superior QoS than the existing ones under the unstable wireless scenarios.
How to reduce the unnecessary retransmissions is a key issue in opportunistic routing. In SIOR, we addressed the problem skillfully by adopting reuleaux triangle as the selection area of RMs, where all the RMs can overhear each other in theory. And then, from the source, one most distant RM is chosen as RA to determine the forwarding direction of the packet batch. In the reuleaux triangle, there are multiple RMs and one RA. In order to collect more packets from RMs as far as possible, RA communicates with RMs by packet map in which one packet only occupies one bit space. Compared with the existing opportunistic routing protocols, e.g., PORM, EMOR, CORMAN, the overhead of SIOR is very low. After RA collects enough packets or there isn’t RM to relay packets to it, it acts as the source to send the batch fragment towards the destination. The RMs work just like those backup nodes in most stable routing protocols. To explain the operating principle of packet map detailedly, a simple example of communication between RA and each RM is illustrated as well. In SIOR, batch forwarding and multiple RMs are adopted at the same time. In other words, it assimilates the essences both of opportunistic routing and stable routing. Accordingly, on the basis of transmission efficiency, the theory analysis confirms SIOR is superior compared with the existing relevant opportunistic routing mechanisms. In performance evaluation section, we studied the influence from the size of packet batch firstly; and then, we come to a conclusion that SIOR reached its optimum performance when the size of packet batch is around 1024. Based on this conclusion, we compared SIOR with other three opportunistic routing protocols in terms of the proportions of transmissions of different location nodes, the average number of forwarding nodes and the effect of node motion velocity. The results show SIOR has excellent performance than other relevant protocols. We hop our works can serve as a modest spur to induce those researchers who share the same topic with us to come forward with their valuable contributions
In our future work, we will conduct extensively simulations and rigorous analysis to verify the performance of SIOR under real environment. In addition, we will integrate this mechanism with QoS assurance for further study, and then devise a high-performance routing protocol for MANETs.
References
Ad, M., Perkins, C. E., & Das, S. R. (2000). Ad hoc on-demand distance vector (AODV) routing. In IETF RFC (p. 90).
Biswas, S., & Morris, R. (2005). ExOR: opportunistic multi-hop routing for wireless networks. In ACM SIGCOMM computer communication review (Vol. 35, pp. 133–144), ACM.
Cacciapuoti, A. S., Caleffi, M., & Paura, L. (2009). A theoretical model for opportunistic routing in ad hoc networks. In International conference on ultra modern telecommunications and workshops (pp. 1–7).
Cacciapuoti, A. S., Caleffi, M., & Paura, L. (2010). Optimal constrained candidate selection for opportunistic routing. In Global telecommunications conference (pp. 1–5).
Cerdà-Alabern, L., Darehshoorzadeh, A., & Pla, V. (2013). Optimum node placement in wireless opportunistic routing networks. Ad Hoc Networks, 11(8), 2273–2287.
Chachulski, S., Jennings, M., Katti, S., & Katabi, D. (2007). Trading structure for randomness in wireless opportunistic routing (vol. 37), ACM.
De Couto, D. S., Aguayo, D., Bicket, J., & Morris, R. (2005). A high-throughput path metric for multi-hop wireless routing. Wireless Networks, 11(4), 419–434.
Ding, Y., Xu, M., Tian, Y., Li, H., & Liu, B. (2016). A BER and 2-hop routing information-based stable geographical routing protocol in manets for multimedia applications. Wireless Personal Communications, 90(1), 3–32.
Dubois-Ferrière, H., Grossglauser, M., & Vetterli, M. (2011). Valuable detours: Least-cost anypath routing. IEEE/ACM Transactions on Networking, 19(2), 333–346.
Heissenbüttel, M., Braun, T., Bernoulli, T., & WäLchli, M. (2004). BLR: beacon-less routing algorithm for mobile ad hoc networks. Computer Communications, 27(11), 1076–1086.
Hsu, C. J., Liu, H. I., & Seah, W. (2009). Economy: A duplicate free opportunistic routing. In Proceedings of the 6th international conference on mobile technology, application & systems (p. 17). ACM.
Hsu, C. J., Liu, H. I., & Seah, W. K. G. (2011). Opportunistic routing—A review and the challenges ahead. Computer Networks, 55(15), 3592–3603.
Jie, Z., Huang, C., Xu, L., Wang, B., Yang, W., & Chen, X. (2013). Opportunistic unicast and multicast routing protocol for vanet. Journal of Software Engineering and Applications, 06(6), 319–327.
Johnson, D. B., & Maltz, D. A. (1996). Dynamic source routing in ad hoc wireless networks. In Mobile computing (pp. 153–181). Springer.
Karp, B., & Kung, H. T. (2000). GPSR: Greedy perimeter stateless routing for wireless networks. In Proceedings of the 6th annual international conference on Mobile computing and networking (pp. 243–254). ACM.
Katti, S., Rahul, H., Hu, W., Katabi, D., Médard, M., & Crowcroft, J. (2006). XORs in the air: Practical wireless network coding. In: ACM SIGCOMM computer communication review (Vol. 36, pp. 243–254). ACM.
Ko, Y. B., & Vaidya, N. H. (2000). Location-aided routing (LAR) in mobile ad hoc networks. Wireless Networks, 6(4), 307–321.
Liu, H., Zhang, B., Mouftah, H., Shen, X., & Ma, J. (2009). Opportunistic routing for wireless ad hoc and sensor networks: Present and future directions. IEEE Communications Magazine, 47(12), 103–109.
Lu, M., & Wu, J. (2009). Opportunistic routing algebra and its applications. In INFOCOM (pp. 2374–2382).
Luk, C. P., Lau, W. C., & Yue, O. C. (2008). An analysis of opportunistic routing in wireless mesh network. In IEEE international conference on communications, 2008. ICC’08 (pp. 2877–2883), IEEE.
Mazumdar, A. P., & Sairam, A. S. (2013). TOAR: Transmission-aware opportunistic ad hoc routing protocol. EURASIP Journal on Wireless Communications and Networking, 2013(1), 1–19.
Rozner, E., Seshadri, J., Mehta, Y., & Qiu, L. (2009). SOAR: Simple opportunistic adaptive routing protocol for wireless mesh networks. IEEE Transactions on Mobile Computing, 8(12), 1622–1635.
Tahooni, M., Darehshoorzadeh, A., & Boukerche, A. (2014). Mobility-based opportunistic routing for mobile ad-hoc networks. In: ACM symposium on performance evaluation of wireless ad hoc, sensor, ubiquitous networks (pp. 9–16).
Wang, Z., Chen, Y., & Li, C. (2011). A new loop-free proactive source routing scheme for opportunistic data forwarding in wireless networks. IEEE Communications Letters, 15(11), 1184–1186.
Wang, Z., Chen, Y., & Li, C. (2012). CORMAN: A novel cooperative opportunistic routing scheme in mobile ad hoc networks. IEEE Journal on Selected Areas in Communications, 30(2), 289–296.
Wang, Z., Li, C., & Chen, Y. (2011). PSR: Proactive source routing in mobile ad hoc networks. In IEEE Communications society (pp. 1–6).
Yang, W., Yang, X., Yang, S., & Yang, D. (2011). A greedy-based stable multi-path routing protocol in mobile ad hoc networks. Ad Hoc Networks, 9(4), 662–674.
Yu, K. M., Yu, C. W., & Yan, S. F. (2011). An ad hoc routing protocol with multiple backup routes. Wireless Personal Communications, 57(4), 533–551.
Zeng, K., Lou, W., & Zhai, H. (2008). Capacity of opportunistic routing in multi-rate and multi-hop wireless networks. IEEE Transactions on Wireless Communications, 7(12), 5118–5128.
Zhen, Y., Wu, M. Q., Su, J. F., Xu, C. X., et al. (2010). A priority based opportunistic routing mechanism for real-time voice service in mobile ad hoc networks. Wireless personal communications, 55(4), 501–523.
Acknowledgements
The authors wish to thank the reviewers and the editors for their valuable suggestions and comments that will help us to improve the quality of this paper.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article

Cite this article
Ding, Yz., Li, Yc., Xu, Yc. et al. An Opportunistic Routing Protocol for Mobile Ad Hoc Networks Based on Stable Ideology. Wireless Pers Commun 97, 309–331 (2017). https://doi.org/10.1007/s11277-017-4506-7
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11277-017-4506-7