
Abstract
A radio frequency identification system can establish a communication between tags and readers through a wireless connection. Due to the optimized coverage of the environment, the readers are placed close to each other in this system and hence it is called dense reader environment. The very property of such an environment leads to increase in the probability of occurrence of reader-to-reader and reader-to-tag collisions which consequently come up with decrease in performance of the network. To solve this problem, many various protocols have been proposed of which centralized ones provide higher throughput. Our proposed method can reduce reader-to-reader collision through combining TDMA and FDMA mechanisms and benefiting from sift probability function and fairness. Furthermore, we found that distance comparison between two readers can reduce reader-to-tag collision as well. Our simulations indicate that the proposed method provides better throughput, average waiting time and fairness than existing ones. Our method also supports the mobility of the readers.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
A radio frequency identification system identifies tagged objects via near/far-field wireless communication. Some of the advantages of this system are rapid identification, long transmission range and data storage, and it can be used in many applications such as supply chain management, traces of objects or animals and medical care to name a few [20, 22]. A radio frequency identification system has two components: readers and tags [4]. In some cases, RFID systems can be combined with wireless sensor networks. A number of articles such as [12, 27, 29] have presented a promising platform for wireless rechargeable sensor networks through such combinations, which complete the sensing and computation capabilities of traditional RFID tags. These methods seek to reduce charging delays.
Tags are small electrical components which are physically installed on the objects to contain necessary information. Roughly speaking, tags can be divided into three categories [21, 24]: active, semi-active, and passive tags. Passive tags do not have any explicit power supply and receive their required energy from readers’ wave transmissions and directly respond to them. In contrast, active tags possess a power supply and carry out all tasks via the provided power supply [22]. In the mid of this spectrum, semi-active tags also have a power supply but it is used only for internal tasks; whilst the received energy from readers’ wave transmissions are utilized for responding to readers. In a radio frequency identification system, passive tags are mainly used since they are economically affordable, but their interrogation range is short [2].
Readers are small electrical components that explore their surrounding and identify the tags via transmitting waves. Every reader has two ranges: reading range and interference range [19]. The maximum distance from which a reader can read surrounding tags is called the reading range, and the maximum distance from which the emitted waves of a reader interfere those of other readers in the environment is called the interference range. The surrounding readers which are in the interference range of a specific reader are known as its neighbors. Note that the maximum distance between these two ranges is correlated with the reader transmission power [14].
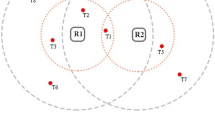
As you can see in Fig. 1, a reader identifies surrounding tags and retrieves their information through a reader-to-tag identification protocol. The information are collected, stored and finally are sent to a central server via a wireless or wired communication [13, 24]. In some environments, a single reader may not be sufficient to cover a target area, and thus aggregation of several readers in the RFID system come to be necessary. An environment in which multiple readers are required is called dense reader environment (DRE) [5].

RFID network Structure
To optimally cover an environment, the readers are placed close to each other, and therefore for any reader there may exist several other readers and tags in the interference range, causing collisions between them. These collisions imply failure in recognizing tags and inevitably decrease the performance of the system. Thus, one of the main goals of hot researches in practical applications of RFID systems is to find a solution for collision problem. The simultaneous transmission between readers causes collision. This collision is solved in the mac layer [29]. In dense reader environments, three types of collisions may occur [25]:
-
1.
Tag-to-tag collision It occurs when multiple tags in a reader’s range simultaneously respond to the reader. In Fig. 2(a), T1, T2 and T3 tags simultaneously communicate with R2 and the collision happens [26].
Fig. 2 
a Tag-to-tag collision, b reader-to-tag collision, c reader-to-reader collision
-
2.
Reader-to-tag collision It occurs when two or more readers try to read a specific tag because of an overlap in their reading ranges. In Fig. 2(b), when R1 and R2 simultaneously read T1, the collision happens. As depicted in Fig. 2(b), T1 is within the reading range for both readers [10, 17].
-
3.
Reader-to-reader collision It happens when the signal emitted by one reader interferes with the reception system of the others. In Fig. 2(c), R1 interference range affects R2 reading range and hence R2 cannot read T1 [17, 23].

In this paper, we propose a centralized method which uses multi-channels to permit simultaneous communications between readers and tags. In addition, every reader uses sift probability distribution function to select a time slot number [18]. In our method, a solution is suggested which encourages fairness between readers as well. As a side effect of using multi-channels, numbers of reader-to-tag collisions tend to increase. Therefore, a solution is also provided which can hopefully reduce the number of reader-to-tag collisions.
The rest of this paper is organized as follows. Section 2 reviews the related work. Section 3 contains the details for our novel proposed algorithm. Section 4 evaluates the results of the proposed algorithm under different scenarios. We present the conclusion of our work and future work in Sect. 5.
2 Related work
Existing protocols in RFID systems can be categorized into two main groups: distributed and centralized protocols. In the distributed ones, the functionality of the reader is not dependent on a central server for obtaining resources and thus independently operates. On the contrary, in the centralized one, a central server communicates with readers through a wired or wireless communication network. The central server is responsible for managing the readers and sharing the resources in the network. In following, the most important protocols based on these two mechanisms are presented [3].
2.1 Distributed protocol
In DCS protocol, each round consists of time slots within which readers communicate with each other. First, each reader selects one random number as its time slot number. When more than one reader selects the same time slot, a reader collision occurs. If so, the reader randomly selects a new time slot and its number is reported to the neighbors as a part of the kick message in the next round. When the neighbors receive this message, they compare it with their own time slots numbers. If the numbers are equal, they will randomly change their time slot numbers [31]. This method does not require central controller. In this protocol, there is no synchronization between readers but there should exist a synchronizer for time slots to determine the start time slot for all readers. It is noteworthy that this method does not require additional hardware and control channel [15].
In DCS, all pairs of the collided readers must change their colors after any collision, and this behavior often causes other collisions again. In PDCS, which is based on DCS, each reader changes its own time slot number with probability P after collision and the optimal value for this probability has been estimated to be 70%. Here, readers use multiple channels for communicating with tags [15].
As another extension of DCS, in Colorwave protocol a round consists of several varying time slots. Each reader independently manages the number of time slots in each round and readers use two pairs of thresholds to change this number. They broadcast the change in the number of time slots to their neighbors through transmitting a kick message. Subsequently, when the neighbors receive this message, they estimate the percentage of their own successful reads and change their number of time slots according to their pair thresholds, if necessary [30]. Note that readers must be synchronous in this protocol. Moreover, finding the least number of time slots lead to much communications among the readers. Compared to the DCS, this protocol has more overhead and requires additional signals to change the color. It is less efficient in the early stages of transmission and its configuration is more appropriate as the number of time slots is variable. In addition to the DCS requirements, this protocol needs to manage the kick messages. Additionally, readers with varying number of different time slots may cause collision [15].
In LBT protocol, readers first listen to the channel, and if the channel is free, they use it for communication with the tag. Here, multiple channels can be used to communicate with a tag. There is no solution to avoid collision [6].
In pulse protocol, readers periodically communicate with the tags. They first wait for a period of tmin length and then start the competition. They watch the control channel for a short time, and if the channel is empty, readers send a kick to stop other competitors for the rest of the time and begin to read. If the channel is busy, they wait and listen to channel again. If the reader receives a kick during the competition or reading phase, it does not continue the process and awaits the competition again [1]. Pulse protocol asks for more requirements compared to DCS and Colorwave. It spends so much energy for information transmission in control channels but improves the fairness. In this method, a kick message must be sent before any transmission which causes delay. Lastly, sending kicks periodically causes overhead [30].
2.2 Centralized protocol
A central server is available to manage readers through broadcasting the arrangement command (AC) message in NFRA protocol. This message introduces the start time of each round and the number of time slots from 1 to maximum number (MN). Any reader that receives the AC message, generate a random number as the time slot number for itself. Then, the server broadcasts an ordering command (OC) message to all readers. The OC message contains the current time slot number. Each reader then compares its random number with the value in the OC message; If they are the same, the reader broadcasts beacons with short transmission range to find out whether a collision occurs or not. After the beacon frames, if some readers do not detect any collision, they will send overriding frame (OF) message to the neighboring readers. The OF message prevents neighbors from receiving the next OC message from the server and they must sleep until a new round [7]. This method has heavy requirements. The aim of this protocol is to increase fairness and reduce reader-to-reader collision, however it intrinsically selects the readers with less number of neighbors in each round and consequently this behavior hinders fairness. On the other hand, this protocol uses uniform probability distribution to select random numbers and accordingly the probability of collision between readers follows uniform probability distribution [9].
GDRA protocol is a new protocol based on NFRA which minimizes reader-to-reader collision. This protocol manages frequencies, considers time slots as resources and achieves better performance than NFRA. Moreover, it can be implemented without any additional hardware in a real DRE. Readers randomly select one of the four frequencies recommended in the EPC [8] and ETSI [16] standards. When the reader gets its turn for reading, if the channel is busy in the current time slot, it leaves competition, randomly selects another channel and waits for the start of the next round, however if the channel is empty, reader can communicate with the tag [4].
On the network shown in Fig. 3, we apply NFRA protocol, and as you can see in Fig. 4, R3 and R5 readers are able to communicate with the tags. R1 and R2 readers and R6 and R7 readers are experiencing beacon collision and R4 reader cannot do anything and must wait until the next round due to receiving OF packet on this round.

Example of network

Example of NFRA procedure
3 Proposed algorithm
In this paper we aim at introducing a novel protocol to reduce the reader collisions. In so doing, we take both reader-to-reader and reader-to-tag collisions under consideration and present a fairness reader collision avoidance protocol (FRCA). FRCA1 method solves the problem of reader-to-reader collision while FRCA2 tackles the problem of reader-to-tag collision.
3.1 FRCA1
In this method, like NFRA protocol, the communication between the server and readers is addressed. At the beginning of each round, the server broadcasts a Start Order (SO) message to all readers. The message introduces an active range for time slots [i.e. from 1 to maximum number (MN)] and another accrue range for channel number (i.e. from 1 to F). Then, the readers generate a random value for channel number and another one for time slot number from uniform distribution and sift distribution functions, respectively. Next, the server broadcasts an Elect Order (EO) message to all readers which contains the current time slot number. The readers then compare their time slot numbers with the value in the EO message; If they are not the same, the reader waits until a new round, but if they are the same, the readers broadcast beacons to determine whether a collision occurs or not. If there exist some readers with equal time slot and channel numbers, beacon collision occurs. If the beacon collision occurs only between two readers, the reader for which the number of successful transmissions (the number of communications with a tag in the last recent rounds) is smaller can occupy the channel and communicate with the tags. Conversely, the reader for which the number of successful transmissions is larger should wait until a new round. However, if the number of collided readers is more than two, all of them must wait until the start of a new round. In this method, each reader stores the number of its own successful transmissions and sends it to competing readers through the beacon message, and after each successful transmission, adds one unit to the number.
In brief, our proposed FRCA1 method is able to improve performance and give better fairness, thanks to combination of TDMA and FDMA mechanisms. Since the readers simultaneously work in different frequencies, they do not receive any signal from each other and thus it reduces the number of reader-to-reader collisions. Subsequently, the number of successful transmissions increases.
3.2 FRCA2
In FRCA1 approach, the number of reader-to-tag collisions tend to increase since many readers can simultaneously communicate with the tags. Additionally, two neighbors are able to read the tags located in their overlapping reading range, and thus reader-to-tag collision may occur. To solve this problem, we suggest FRCA2 method.
In FRCA2, all neighboring readers which are up for read should compete with each other. If only two readers have the aforesaid conditions and distance between them is less than two times of the reading range, then the reader for which its number of successful transmissions is less than that of the other will take the channel, and the loser reader must wait until the next round. Conversely, if the distance between the two neighboring readers is larger than two times of the reading range, the reader with less successful transmissions can read in this time slot, while the reader with more successful transmissions must randomly select a new channel and compete in the next time slot (i.e. adds one unit to its time slot number).
If the number of neighboring readers which are up for read is larger than two, and the distance between them is less than two times of the reading range, all the competing readers must wait until the next round. Conversely, if the distance between them is larger than two times of the reading range, they randomly select a new channel and again compete in the next time slot (i.e. add one unit to their time slot numbers).
FRCA2 method efficiently solves the problems associated with FRCA1, i.e. reader-to-tag collision. For the network depicted in Fig. 3, we apply FRCA1 and FRCA2 protocols, and the results are observable in Figs. 5 and 6.

Example of FRCA1 procedure

Example of FRCA2 procedure
As shown in Fig. 5, applying FRCA1 protocol leads to the following results: R1, R2, R4 and R6 readers are able to read to tags. R3 reader must wait until the start of the new round since the channel is busy. R6 and R7 readers encounter a collision, and their number of successful transmissions (S) are examined. Because the number of successful transmissions for R6 reader is less than that of R7 (S7 > S6), R6 is able to communicate with the tags in this round.
Similarly, the results of applying FRCA2 protocol are depicted in Fig. 6: R2 and R6 readers are able to read. For all readers which could read in FRCA1 protocol, if they are neighbors and the distance between them is less than two times of the reading range, only the ones are able to read for which the number of successful transmissions is less than those of others. This is why the number of successful transmissions of readers has decreased but the number of reader-to-tag collisions have improved in this method compared to the FRCA1 method. The number of successful transmissions for R2 and R6 readers are less than those of R1 and R4 readers, respectively, and hence R2 and R6 are able to read. As in FRCA1, rest of the readers are not able to read.
The following pseudo code (FRCA1 pseudo code) is written for each reader. In lines 2–3, the value for channel number (F) and time slot number are randomly selected from random function and sift distribution function, respectively. In lines 8–15, if only two readers encounter the collision, a competition will start between them based on the number of their successful transmissions. In lines 16–21, if more than two readers encounter the collision, all competing readers will wait for start of a new round.
FRCA1 pseudo code:

The following pseudo code (FRCA2 pseudo code) is also written for each reader. Consider the pseudo code of FRCA1; if we replace the lines 13–19 with the code described below, the pseudo code of FRCA2 method is obtained. This new function states that any reader which has succeeded to directly communicate with the tags, cannot do so now on and it must compete with all other readers which have had successful communications with the tags. In the following reading function, this competition among neighbors can be seen.
Reading pseudo code:

In lines 2–8, if only two readers are able to read and they are also neighbors, the distance between them is calculated. If the distance is less than two times of the reading range, the reader with less number of successful transmissions can read and the other reader must wait until start of a new round. Lines 9–17, if there exists only two readers, the same distance computation is carried out between the successful reader and its neighbor. If the distance between them is larger than two times of the reading range, the reader with less number of successful transmissions can use the channel and the loser reader must randomly select a new channel and compete in the next time slot (i.e. add one unit to its time slot numbers). In line 19–25, there are more than two readers in the network and the distance between successful and neighboring readers are again computed. In this case, if the distance between them is less than two times of the reading range, all competing readers must wait until start of a new round, but if the distance is larger than two times, they must randomly select a new channel and compete in the next time slot (i.e. add one unit to their time slot numbers).
The FRCA1 and FRCA2 methods, in comparison with the NFRA method, use multiple channels. This issue causes the readers to simultaneously communicate with tags in different frequencies, reducing the number of reader-to-reader collisions. On the other hand, NFRA uses the uniform probability function for selecting time slot number, but the FRCA1 and FRCA2 methods use the sift distribution function which reduces the probability of readers choosing the same time slot number. FRCA1 and FRCA2 methods provide more fairness, because if collision occurs between two readers, the reader for which the number of successful transmissions is smaller, can occupy the channel. In the FRCA1 and GDRA methods, the number of reader-to-tag collision tends to increase since many readers can simultaneously communicate with the tags. FRCA2 has solved this problem by considering the distance between neighboring readers.
3.3 Sift distribution function
When readers select a random value for time slot numbers from uniform probability distribution function, the probability of occurrence of collision in each time slot is the same for all competing readers. Competing readers are known as the ones who are located in the interference range of each other and are working in the same channel. In CSMA/p* [28] protocol, the readers use a non-uniform probability distribution p* for random selection of competing slots. The probability distribution function p* is defined as formula 1. This distribution reduces the collisions between competing readers and increases the probability of selecting a time slot only by an individual reader.
Given formula 2, f K−k (R) is a recursive function for 1 ≤ k ≤ K:
For 2 ≤ k, R ≥ 2 and f 1(R) = 0.
In a dense RFID system, each reader needs to compute the number of its own neighbors. However, if the reader does not know the number of neighbors, it uses sift probability distribution function (p k ) to select a random value for this variable [16]. p k is defined in formula 3:
Formula 3 holds for 1 ≤ k ≤ K, 0 < α < 1 and α = M −1/K−1; where M is the maximum number of competing readers [16]. When M = 1 and α = 1, the formula 4 corresponds to a uniform probability distribution function:
In sift probability distribution function, the probability of selecting higher time slots will increase. With this approach, the probability of selecting lower time slots by only an individual reader will increase [16]. This reader quickly wins the competition. In the sift probability distribution function the probability of winning the competition in presence of R neighbors for a reader is computed by formula 5:
3.4 Distance between readers
Figure 7 shows that the readers with overlapping interference range receive the emitted signals by each other. Given the strength of the received signals, the distance between two readers with overlapping interference range can be computed by formula 6:
where D is the distance between R1 and R2 readers, α is path loss exponent, P r is reader transmission power, G r is reader antenna gain, K 0 is the coefficient of channel path loss and power ratio in the bandwidth, and I r denotes the total interference that the reader receives [32].

Two readers with distance D from each other
4 Simulation and evaluation
In this section, we present the results obtained from simulating and evaluating our proposed method. All protocols are evaluated based on the following metrics: throughput, average waiting time and fairness. Throughput is defined as the total number of reads in a time unit [14]. Average waiting time is defined as the average of waiting time for all readers to read the tags [14].
We benefit from R2RIS simulator [11] to show that our proposed protocol has improved throughput, average waiting time and fairness compared to other protocols. We broadcast some tag variables in the simulator to compute the number of reader-to-tag collisions, improving them, and analyze their effect in the throughput. Then, the throughput is anew re-computed with effects of reader-to-reader and reader-to-tag collisions.
In this simulation, we use the protocols introduced in Sect. 2 to compare our method with existing ones. The simulation parameters for existing protocols and the proposed method are reported in Table 1. Other required parameters were kept equal to those in [7].
In this study, five scenarios were defined. In the first scenario, we compare the proposed methods, i.e. FRCA1 and FRCA2 with GDRA, PDCS, NFRA, Colorwave and Pulse protocols in a 100 × 100 m environment with 25, 50, 75 and 100 readers while the value of MN (maximum number for time slot) is 32 and the number of channels for GDRA, FRCA1, FRCA2 and PDCS is 4 and the number of channels for NFRA, Colorwave and pulse is 1 and interference range is 100 m and reading range is 10 m. Results are shown in throughput chart and average waiting time chart. Shown in Fig. 8, the throughputs of FRCA1 and FRCA2 protocols are better than those of others. Furthermore, the throughput of FRCA1 protocol is better than that of FRCA2. The reason is that in FRCA2, the readers for which the distance between them was shorter than two times of the reading range were suppressed to avoid reader-to-tag collision. Hence, the number of successful reads in this method appeared to be less. Figure 9 shows that average waiting time of FRCA1 and FRCA2 protocols are very close to each other while a marginal improvement against other methods is witnessed.

Throughput of the evaluate condition in scenario 1

Average waiting time of the evaluate condition in scenario 1
In the second scenario, we compare the proposed methods with GDRA, PDCS, NFRA, Colorwave and Pulse protocols in a 100 × 100 m environment with 25, 50, 75 and 100 readers while the value of MN is 32 and the number of channels for GDRA, FRCA1, FRCA2 and PDCS is 4 and the number of channels for NFRA, Colorwave and pulse is 1 and interference range is 100 m and reading range is 10 m. The result is depicted in Fig. 10. Regarding fairness, our proposed methods outperform centralized protocols.

Fairness of the evaluate condition in scenario 2
In the third scenario, we carry out the comparison with GDRA centralized protocols in a 100 × 100 m environment with 20, 30, 40, 50, 60, 70, 80, 90 and 100 readers while the value of MN is 32 and the number of channels for GDRA, FRCA1 and FRCA2 is 4 and interference range is 60 m and reading range is 2 m and the number of tags is 100. Figure 11 shows the results. Compared to FRCA1 protocol, FRCA2 protocol turns to have less number of reader-to-tag collisions.

Reader-to-tag collision of the evaluate condition in scenario 3
In the fourth scenario, we compare our proposed methods with GDRA centralized protocols in a 100 × 100 m environment with 50 readers while the value of MN is 32 and the number of channels for GDRA, FRCA1 and FRCA2 is 4 and interference range is 100 m and reading range is 10 m with 10, 20, 30, 40, 50, 60, 70, 80, 90 and 100 tags. Result is depicted in Fig. 12. Throughput does not change dramatically with increasing the number of tags. It is also seen that different number of tags does not affect throughput while the number of readers change.

Throughput of the evaluate condition in scenario 4
In the fifth scenario, we analyze FRCA1 protocol with different number of channels in a 100 × 100 m environment with 50 readers while MN is 32 and interference range is 100 m and reading range is 10 m. Depicted in Fig. 13, throughput increases as far as the number of channels is equal to the number of readers, and throughput remains constant thereafter.

Throughput of the evaluate condition in scenario 5
5 Conclusion and future work
In this paper, we presented two FRCA1 and FRCA2 protocols which are able to reduce reader collisions. In FRCA1 protocol, we suggested a solution that reduces reader-to-reader collisions and in FRCA2 protocol the aim of our solution was to reduce reader-to-tag collisions. FRCA1 protocol is composed of combination of TDMA and FDMA mechanisms and uses sift probability distribution function and fairness to reduce reader-to-reader collisions. Furthermore, FRCA2 protocol could reduce reader-to-tag collisions through comparing the distance between two readers. These protocols provided better throughput and average waiting time and fairness compared to the existing protocols. For further work, one can suggest to use a non-uniform probability function for channel selection instead of a uniform one. Therefore, the selected numbers by readers will not be equal.
References
Birari, S. M., & Iyer, S. (2005). PULSE: A MAC protocol for RFID networks. International Conference on Embedded and Ubiquitous Computing, 3823, 1036–1046.
Bueno-Delgado, M. V., Egea-Lopez, E., Vales-Alonso, J., & Garcia-Haro, J. (2009). Radio-frequency identification technology. In Handbook of enterprise integration (pp. 429–466).
Bueno-Delgado, M., et al. (2010). A comparative study of RFID schedulers in dense reader environments. In 2010 IEEE international conference on industrial technology (ICIT) (pp. 1373–1378). IEEE.
Bueno-Delgado, M. V., et al. (2013). A geometric distribution reader anti-collision protocol for RFID dense reader environments. IEEE Transactions on Automation Science and Engineering, 10(2), 296–306.
Bueno-Delgado, M. V., & Pavon-Marino, P. (2013). A centralized and aligned scheduler for passive RFID dense reader environments working under EPCglobal standard. Simulation Modelling Practice and Theory, 34, 172–185.
CEPT, U. (2005). Electromagnetic compatibility and radio spectrum matters (ERM); Radio frequency identification equipment operating in the band 865 MHz to 868 MHz with power levels up to 2 W; Part 1: Technical requirements and methods of measurement [Internet], Internet.
Eom, J.-B., et al. (2009). An efficient reader anticollision algorithm in dense RFID networks with mobile RFID readers. IEEE Transactions on Industrial Electronics, 56(7), 2326–2336.
ETSI, E. 302 208-1 Version 1.4. 1 2011.
Ferrero, R., et al. (2010). Fair anti-collision protocol in dense RFID networks. In 3rd international EURASIP workshop on RFID technology (EURASIP-RFID 2010) (pp. 101–105). Citeseer.
Ferrero, R., et al. (2014). Improving Colorwave with the probabilistic approach for reader-to-reader anti-collision TDMA protocols. Wireless Networks, 20(3), 397–409.
Ferrero, R., et al. (2013). Simulating reader-to-reader interference in RFID systems. In 2013 27th international conference on advanced information networking and applications workshops (WAINA) (pp. 1063–1069). IEEE.
Fu, L., et al. (2016). Optimal charging in wireless rechargeable sensor networks. IEEE Transactions on Vehicular Technology, 65(1), 278–291.
Galiotto, C., et al. (2012). Low access delay anti-collision algorithm for readers in passive RFID systems. Wireless Personal Communications, 64(1), 169–183.
Gandino, F., et al. (2009). Introducing probability in RFID reader-to-reader anti-collision. In Eighth IEEE international symposium on network computing and applications, 2009. NCA 2009 (pp. 250–257). IEEE.
Gandino, F., et al. (2011). Probabilistic DCS: An RFID reader-to-reader anti-collision protocol. Journal of Network and Computer Application, 34(3), 821–832.
Global, E. (2008). EPC radio-frequency identity protocols class-1 generation-2 UHF RFID protocol for communications at 860 MHz–960 MHz, version.
Golsorkhtabaramiri, M., et al. (2015). A reader anti-collision protocol for RFID-enhanced wireless sensor networks. Wireless Personal Communications, 81(2), 893–905.
Jamieson, K., et al. (2006). Sift: A MAC protocol for event-driven wireless sensor networks. In European workshop on wireless sensor networks (pp. 260–275). Springer.
Jiang, X., Liu, Y., Leng, Y., Liu, J., & Gan, Z. (2012). An efficient and secure RFID-based online monitoring system architecture for enterprise asset management. Journal of Convergence Information Technology, 7(21), 220–227.
Joshi, G. P., & Kim, S. W. (2008). Survey, nomenclature and comparison of reader anti-collision protocols in RFID. IETE Technical Review, 25(5), 234–243.
Klair, D., et al. (2009). On the energy consumption of pure and slotted aloha based RFID anti-collision protocols. Computer Communications, 32(5), 961–973.
Klair, D. K., et al. (2010). A survey and tutorial of RFID anti-collision protocols. IEEE Communications Surveys and Tutorials, 12(3), 400–421.
Leong, K. S., et al. (2005). The reader collision problem in RFID systems. In 2005 IEEE international symposium on microwave, antenna, propagation and EMC technologies for wireless communications (Vol. 1, pp. 658–661). IEEE.
Nawaz, F., & Jeoti, V. (2015). NFRA-C, neighbor friendly reader to reader anti-collision protocol with counters for dense reader environments. Journal of Network and Computer Applications, 49, 60–67.
Safa, H., et al. (2015). A distributed multi-channel reader anti-collision algorithm for RFID environments. Computer Communications, 64, 44–56.
Shih, D. H., Sun, P. L., Yen, D. C., & Huang, S. M. (2006). Taxonomy and survey of RFID anti-collision protocols. Computer Communications, 29(11), 2150–2166.
Shu, Y., et al. (2015). TOC: Localizing wireless rechargeable sensors with time of charge. ACM Transactions on Sensor Networks (TOSN), 11(3), 44.
Tay, Y., et al. (2004). Collision-minimizing CSMA and its applications to wireless sensor networks. IEEE Journal on Selected Areas in Communications, 22(6), 1048–1057.
Tian, Y., Cheng, P., He, L., Gu, Y., & Chen, J. (2016). Achieving collision-free communication by time of charge in WRSN. Mobile Networks and Applications, 21(3), 414–424.
Waldrop, J., et al. (2003). Colorwave: A MAC for RFID reader networks. Wireless Communications and Networking, 2003. WCNC 2003. 2003 IEEE (Vol. 3, pp. 1701–1704). IEEE.
Waldrop, J., et al. (2003). Colorwave: an anticollision algorithm for the reader collision problem. Communications, 2003. ICC’03. IEEE International Conference on, IEEE, 2, 1206–1210.
Zhang, L., Ferrero, R., Gandino, F., & Rebaudengo, M. (2013, December). Simulation and evaluation of the interference models for RFID reader-to-reader collisions. In Proceedings of international conference on advances in mobile computing & multimedia (p. 209). ACM.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article

Cite this article
Rezaie, H., Golsorkhtabaramiri, M. A fair reader collision avoidance protocol for RFID dense reader environments. Wireless Netw 24, 1953–1964 (2018). https://doi.org/10.1007/s11276-017-1447-8
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11276-017-1447-8