
Abstract
To turn General Circulation Models (GCMs) projection toward better assessment, it is crucial to employ a downscaling process to get more reliability of their outputs. The data-driven based downscaling techniques recently have been used widely, and predictor selection is usually considered as the main challenge in these methods. Hence, this study aims to examine the most common approaches of feature selection in the downscaling of daily rainfall in two different climates in Iran. So, the measured daily rainfall and National Centers for Environmental Prediction/National Center for Atmospheric Research (NCEP/NCAR) predictors were collected, and Support Vector Machine (SVM) was considered as downscaling methods. Also, a complete set of comparative tests considering all dimensions was employed to identify the best subset of predictors. Results indicated that the skill of various selection methods in different tests is significantly different. Despite a few partial superiorities viewed between selection models, they not presented an obvious distinction. However, regarding all related factors, it may be deduced that the Stepwise Regression Analysis (SRA) and Bayesian Model Averaging (BMA) are better than others. Also, the finding of this study showed that there are some weaknesses in the interpretation of SRA, so concerning this issue, it may be concluded that BMA has more reliable performance. Furthermore, results indicated that generally, the downscaling procedure has more accuracy in arid climate than cold-semi arid climate.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
The most reliable instrument to assess the variability of the climate components influenced by climate change impacts is the projection of General Circulation Models (GCMs) (Fayaz et al. 2020). GCMs simulate the variability of climate components such as wind direction, sea surface pressure, temperature, relative and specific humidity, divergence, and velocity in grid points with a large scale. Hence, their spatial resolution is very coarse and it limits their efficiency to reflect their simulation on a local scale.
To assess the impact of climate change, GCMs projections must be converted. The downscaling process, categorized into two statistical and dynamical approaches, is a method to gain GCMs outputs by converting coarse resolution data to finer resolution. The statistical techniques are performed based on a statistical relation among GCMs outputs as predictors and weather variables as predictants (Wood et al. 2004). The statistical downscaling has different categories (Bermúdez et al. 2020), in which the transfer functions have gained the attention of most hydrologists due to the widespread development of computational modeling. Some researchers such as Duhan and Pandey, (2015) and Flower et al., (2007) have stated that Transfer functions have various ranges of different black-box models such as Artificial Neural Network (ANN), Support Vector Machine (SVM), and K-Nearest Neighbors (KNN) and prepared platforms such as Statistical Downscaling Model (SDSM).
GCMs predictors and local predictant are considered as inputs and output components of transfer functions, respectively. In these downscaling methods, the most crucial step is to discover the most reliable predictors to establish a statistical relationship (Crawford et al. 2007). Many researchers consider a physical relation as a proper criterion while some of them express that behavior of rainfall is a consequence of one specific variable (Goyal and Ojha 2012), so they selected single ones or considered a set of predictors. Anyway, there is still an important question; which of the available predictors have the most competent for the downscaling procedure? Several researchers employed different methods such as Principal Component Analysis (PCA), Gamma test, Canonical Correlation Analysis (CCA), fuzzy clustering, Rapid Variable Elimination (RaVE), Entropy methods, and Independent Component Analysis (ICA) to select variables for downscaling (MoradiKhaneghahi et al. 2019; Ahmadi et al. 2015). For example, Najafi et al. (2011) used ICA to select predictors for downscaling of daily precipitation using the SVM method. Ben Alaya et al., (2015) employed PCA to reduce the dimension of predictors. Also, there are some studies that developed previous methods and presented novel approaches (Harpham and Wilby 2005; Fistikoglu and Okkan 2011; Sarhadi et al. 2017). In follow, it is tried to present a review and assessment of the most applied selection methods involved with downscaling literature. As a general consequence of the literature review, it is revealed that the strong correlation is a vital criterion for predictor selection (Wilby and Wigley 2000) so, the Correlation Analysis (CA) is usually used to discover best predictors (Pervez and Henebry 2014). For example, Chen et al. (2012) and Meenu et al. (2013) determined the required predictors by the CA method. There are several studies that their predictor selection was accomplished using Partial Correlation Analysis (PCA) (Liu et al. 2011). Nasseri and Zahraie (2013) used the PCA method to detect essential predictors for SDSM downscaling. The results of their study indicated that predictors such as relative humidity and velocity were the most realistic variables. The Stepwise Regression Analysis (SRA) is another common technique used in studies of assessment of climate change impacts. The fundamental logic behind SRA is trying to find the best fitting of a Multiple Linear Regression (MLR) in which the Sum of Square Error (SSE) be minimized. Currently, the application of SRA has been extended in various studies (Huth 1999; Chen et al. 2011; Hessami et al. 2008). For example, Hessami et al. (2008) apply SRA for choosing the best predictors for SDSM downscaling method to simulate extreme values. Literature assessment of feature selection methods indicates that SRA is one of the most applied methods, however it has some deficiencies. This method has defects when there are large numbers of predictors that have a strong correlation together. This case may cause a multi-colinearity issue in which estimated weights of predictors have not specific link to predictor accuracy. Interested readers are referred to Burnham et al. (2011) for more information about SRA’s drawback.
A Least Absolute Shrinkage and Selection Operator (LASSO) is an alternative to improve this problem (Tibshirani 1996). In this method, the Penalized Multiple Linear Regressions (PMLR) is replaced by conventional MLR. In the LASSO the sum of the predictors’ coefficient is embedded into the SSE function to shrinkage the total number of the predictors. While in SRA, the Fisher statistic limits the number of predictors. Despite the novelty plan, few downscaling studies employed LASSO as predictor selection in past. But, its application in recent years, is becoming more widespread (Long et al. 2019; Liu et al. 2019; He et al. 2019). For example, He et al. (2019) used LASSO to specify the best predictor in geopotential height at 500 hectoPascal (hPa) for downscaling monthly rainfall over the Yangtze River Valley in China.
Recently a number of studies have addressed Bayesian model averaging (BMA) applicability (e.g. Huang et al. 2019; Li et al. 2019). The major application of BMA is related to studies whose purpose is to improve the outputs of downscaling or enhance the projection of ensemble GCM (Zhang and Yan, 2015; Zhang et al. 2016a, 2016b; Pichuka and Maity 2018). For example, Zhang and Yan, (2015) employed CA as predictor selection and BMA was incorporated to downscale GCMs projection. Also, in a study by Su et al. (2019), BMA was applied for downscaling monthly precipitation in different stations of China (Heihe River basin HRB). Furthermore, Zhang et al. (2016a, 2016b) used BMA as a downscaling method to rebuild regional mean temperature. In Bayesian predictor selection, the superiority of variables is recognized based on Bayes’s theorem and that is defined based on probabilistic likelihood. Hence, the estimated weights are directly reflex the predictor accuracy, and it drives to more realistic results. In spite of BMA’s advantages, its application in climate change studies as feature selection remains unused and there is rare literature in this field. The study by Tareghian and Rasmussen (2013) is one of the rarest studies that was conducted to examine BMA’s applicability as predictor selection in the downscaling procedure. They introduced a quantile regression model for extreme precipitation downscaling in which BMA elected the best predictor. They examined results and found that the performance of the proposed plan is superior to common regression downscaling especially in summer precipitation in the Punjab state of India.
The presented literature review can properly describe some methodological deficiencies listed as follow: First, the performance assessment of all excited feature selection approaches in the downscaling process was neglected, as there are relatively few studies in this field. The studies by Hammami et al. (2012), Soleh et al. (2016), Yang et al. (2018), and Teegavarapu and Goly (2018) are well cases for the above explanation. For example, Hammami et al. (2012) aimed to compare just SRA and LASSO for downscaling, and examination of other exciting methods was dismissed. Also, in studies by Yang et al. (2018) and Teegavarapu and Goly (2018), the examination of two common approaches of correlation (CA and PCA) and regression (SRA) was investigated, while the analysis of the more recent approaches such as BMA and LASSO was ignored. As a consequence, there isn’t a specific study to investigate the performance of all predictor selection methods in the downscaling process.
Second, the most relevant studies attempted to examine the predictor selection methods alone in one climate pattern whilst the effect of predictor selection methods is likely mixed in different climates. Therefore, it can be concluded that the regional effects of the selection methods weren’t examined.
Third, On the other hand, due to the daily downscaling requires for large-scale computations, some researchers (Hammami et al. 2012; Yang et al. 2018) carried out the variable selection step on a daily scale, then they considered a monthly scale in the downscaling process to reduce computation time. However, the proposed solution has many defects, as it is proven that the same time scale should be considered in both the downscaling and the predictor selection.
This paper attempts to cover all mentioned deficiencies above and aims to perform a comprehensive examination to specify the skill of the various predictor selections approaches including correlation, regression, and maximum likelihood in downscaling of daily rainfall through high computation professional center. Furthermore, this study purposes to compare the effect of different selection methods in two diverse climates (arid-desert and semiarid-cold) in Iran.
The current manuscript is structured as follows, Section 2 describes case studies, feature selection methods, downscaling process, and assessment metric. Following this, Section 3 presents related results about selected predictors, discusses the performance of different selection methods. Finally, a summary of current work and a set of conclusions well as some suggestions for future work in this field are drawn in Section 4.
2 Material and Methods
2.1 Presented Work
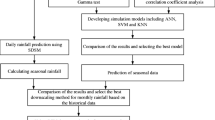
This section describes the steps of the current study. In the first step, the long-term data sets, including predictor variables and measured rainfall, were collected. Then, different selection methods such as CA, PCA, SRA, LASSO, and BMA chose the dominant atmospheric variables and entered them into SVM to simulate local rainfall. In the last, the effect of different selection methods for the downscaling process was investigated by a set of comparative tests.
2.2 Data Sets and Case Study
In this study, the all 26 National Centers for Environmental Prediction/National Center for Atmospheric Research (NCEP/NCAR) predictors obtained from Canadian Centre for Climate Modelling and Analysis (CCCMA) were captured for 1961–2005. The NCEP predictors and their explanation has been provided in Table 1. Also, the daily rainfall dataset (1960–2005) from Urmia and Birjand synoptic stations were used as observation data. Urmia is the center of Urmia province, located in the north-west of Iran (See Fig. 1). Annual rainfall and mean annual temperature are 330 mm and 8.9 °C, and the coordinate of this station is nearly 37o 32’ N latitude and 45o 05′ E longitude (Amirataee and Montaseri 2013). Birjand is the center of Southern Khorasan province with low annual precipitation and high mean annual temperature. Based on Emberger (1932) and De Martonne (1925) climate classification the categories of climate pattern of Urmia and Birjand can be evaluated as cold- semi-arid and arid.

Location of study area in the east and northwest of Iran
This study divided data into two parts of 1961–1990 as the training (70%) and 1991–2000 as the testing (30%). Due to the high computation and complexity of the daily simulation, a high-performance computing framework was designed in the High-Performance Computing (HPC) center at the University of Birjand to perform the downscaling process. Also, the Data preprocessing stage, including removing and replacing outliers and miss-data well as the stationary assumption was tested and verified.
2.3 Feature/Predictor Selection
In this study, each selection method ranked all 26 NCEP variables to pick up the first five ones as the dominant predictors. The structure of each selection method was described in the following:
2.3.1 CA
This method is used to obtain the strength of the mutual relationship between local rainfall and atmospheric predictors. The priority of predictors was calculated according to Pearson correlation as following:
Where, x, y (hereafter) represent predictor and local rainfall, while σ, μ, n are standard division, average and number of sample. Also, Rxy indicates correlation coefficient amongst x and y.
2.3.2 PCA
This test calculates the strength of correlation between one predictor and daily rainfall, while it removes the effect of other predictors as the following equations:
Where, Rxy, Rxz, and Ryz represent the correlation coefficient between x, y, and z. Also, Rxy,z denotes the partial correlation between x and y, while it removes the correlation of z.
2.3.3 SRA
This method has consecutive steps in which the p value of Fisher’s test determines the validation of the different combinations of predictors. The SAR has two kinds of algorithms: forward and backward. In the forward state, used in this study, the most correlated predictor is chosen first. Afterward, the model adds another predictor among the remaining based on Fisher’s tests as following:
Where, F denotes Fisher’s test, SSEp is SSE of current model, SSEp + i and \( {\sigma}_{p+1}^2 \) indicates SSE and variance of model when predictor i is considered respectively. When Fisher’s test value of predictor i, is more than the Fisher value limit of F-table, predictor i will add to the model.
2.3.4 Lasso
LASSO has two possible types: constrained and penalized. In the constrained case (Eq. 4), the summation of predictors’ coefficient must be minimized or equal to the shrinkage parameter (λ) while in the penalized case (Eq. 5), this summation is considered as a penalty and is backed by shrinkage parameter as the following;
Where, βand β0 are regressor coefficients and intercept of MLR. While, n and p are sample size and numper of predictors. In this study the Coordinate Descent Algorithm (CDA) was used to solve LASSO equations and identify a proper subset of variables. For more information see Schmidt, (2005).
2.3.5 BMA
BMA provides a weighted average of different models (here predictor) that their contribution (weights) is based on Bayesian’s theorem and probabilistic likelihood. Consider y as daily rainfall and atmospheric predictors as ensemble members ({Si, i = 1, 2, …, n}). BMA corrects the value of the members first ({Si, i = 1, 2, …, n} → {fi, i = 1, 2, …, K}). The probabilistic density of y based on total probability’s law can be presented as the following equation (Duan et al. 2007):
Where, p(fi|Y)is the posterior probability of model prediction fi and it indicates that how well ith member reflects the observed behaviors. Indeed this term is the weight of each predictor. Hence it can be expressed that wi = p(fi|Y) and consequently\( \sum \limits_{i=1}^K{w}_i=1 \). The term pi(y|fi, Y) is the conditional Probabilistic Density Function (PDF) of members. Based on the BMA procedure, this term can be mapped to a normal distribution that its average and variance are approximated by {fi, i = 1, 2, …, K} and σi. Therefore pi(y|fi, Y) was replaced by \( g\left(\left.y\right|{f}_i,{\sigma}_i^2\right) \) and final form of Eq. 6 can be written as following the equation:
Proper estimation of wi and σi can provide a good performance of BMA. Therefore, the BMA requires an optimization algorithm to estimate the parameter setθ = {wi, σi, i = 1, …, K}. This study employed the Expectation-Maximization (EM) algorithm as an optimization technique and maximum log-likelihood as a fitness function to find the best values of the parameter set. See Raftery et al. 2005 for more information.
2.4 Downscaling by SVM
Vapnik (1995) presented a new statistical learning method denominated SVM for regression simulation. Based on Cover’s law (Cover 1965) a linear function was employed to form a non-linear relation between input (x) and output (y) through the following equations:
Where, \( \hat{y} \) and φ(x) are model prediction and non-linear transformation function mapping set (x, y) to a higher feature space. Also, w and b are the model parameters representing weight and bias. To find these parameters, \( {\left|{y}_i-{\hat{y}}_i\right|}_{\varepsilon } \)is considered as ε-insensitive loss function based on Vapnik’s theorem:
Where, ξ indicates the deviation of model prediction (\( {\hat{y}}_i \)) from observed rainfall (yi). Based on Eq. (9), the lowest value ofξ is desired. To reach it, a cost function was considered to minimize deviation as the following:
Where, ξ represents more error thanε, while \( {\xi}_i^{\ast } \) denotes less error thanε. Also, C is a constant and positive coefficient to highlight deviation. Furthermore, the first term was imposed on the cost function to regularize the weights (w). The method of Lagrangian multipliers used to solve the above equation is the following:
Where, αiand \( {\alpha}_i^{\ast } \) are Lagrange coefficients, from which the weight can be evaluated as \( w=\sum \limits_{i=1}^n\left({\alpha}_i-{\alpha}_i^{\ast}\right)\varphi \left({x}_i\right) \).By substituting weight parameter back into Eq. (8), the SVM formulation can be obtained as following equation:
Where,K(xi, x)is the kernel function. This study employed a linear kernel due to its simplicity and quick run. Also, the values of εand penalty coefficient were evaluated by Ant Colony Optimization (ACO) algorithm, similar to other researches (Kashif Gill et al. 2007). Readers are referred to Tripathi et al. (2006) and Farzin et al. (2020) for more details about SVM formulation.
2.5 Performance Assessment
To examine the performance of different selection methods, it needs to employ a perfect set of comparative tests comprising all possible aspects explaining the rainfall pattern. Hence this study compared performance criteria RMSE, NSE, and R over the training and testing periods first. Then to give a more accurate examination, the assessment of descriptive statistics was performed. Also, to address the variability of measured and downscaled series, Interquartile Relative Fraction (IRF) and Absolute Cumulative Bias (ACB) were compared (Campozano et al. 2016.). Further, the comparison of probability distribution was carried out by the violin plot and Kolmogorov- Smirnov (KS) test. Finally, the analysis of the wet spells in the measured and simulated rainfall was performed. The following equations represent the formula of the RMSE, NSE, IRF, and ACB:
Where, Pm and Po are downscaled and observed rainfall, while \( {\overline{P}}_o \)and n are the average of the observation and sample size. The P25m and P25o denote the first modeled and measured quartiles, while P50m and P50o well as P75m and P75o represent the second and third ones. Also, KS calculates the maximum difference of CDFs based on the following equation:
Where F1(x) and F2(x) are the CDFs of actual and downscaled data set respectively, while D is the KS test statistic.
Furthermore, the contingency table event was employed to assess the performance of each selection method. This table contains four internal partitions computed based on the following plan: Hits: the count of true distinguishes of wet events, Correct negative: the count of true distinguishes of dry events (See Table. 2), Misses: the count of the observed wet days estimated as dry day, False alarm: the count of the observed dry days simulated as wet days. The Critical Success Index (CSI) was applied to quantify the precision of the distinguishing based on the following:
As shown, CSI takes zero in the worst case and it obtains one by contrast (Duan et al. 2019). Also, 1 mm.day−1 was considered as separator threshold of wet and dry days (Raje and Mujumdar 2011).
3 Results and Discussion
3.1 Predictor Selection
Table 3 presents the final predictor numbers adopted from Table 1 for both Urmia and birjand stations. In Urmia station, atmospheric precipitation (represented by * in Fig. 2) can be accounted as a dominant predictor. Also, the vorticity of wind at 500 hPa can be in the second place. Table 3 indicates that there is no significant difference between all selection methods in Birjand station. However, the specific humidity in surface and precipitation in 1000 hPa pressure level are the main predictors. Also, the meridional and vorticity of wind at 500 hPa pressure level take the second place. Fig. 3 is a Butterfly chart (Tornado diagram) that provides a quick view for different arrangements of final selected predictors in two stations as side by side at the same time. In this plot, the top three fields indicate the height of variables, while the remaining is related to variables type. As shown, the count of final predictors in both stations at the circulation category is more than other categories (i.e. surface, humidity, and temperature). Also, it may be inferred from Fig. 3 that the selection methods would prefer to choose the lower-level variables.

Radar chart frequency of selected predictors for Urmia (a) and Birjand (b) Stations

Butterfly chart in Urmia and Birjand stations
3.2 Performance Assessment
Tables 4 and 5 outline the performance criteria values for two stations Urmia and Birjand in the training and testing period. For all selection methods, the value of RMSE, R, and NSE at Birjand is consistently better than those in the Urmia site throughout the simulation period. Based on the obtained results for performance criteria, the accuracy of the downscaling procedure with SRA outperform (bolded values) others in both sites during training and testing periods.
Downscaled and observed descriptive statistics were presented in Table 6, and the best values were bolded. In this table, Std.Dev and CV denote the standard deviation and coefficient of variation, while KS and SC indicate kurtosis coefficient and Skewness Coefficient. It reveals that downscaling based on SRA has more accurate than others, although there is no obvious difference between estimated statistical components such as Std. Dev, CV, SC, IRF, and ACB by different methods.
Figure. 4 presents the violin plots of observation versus downscaled rainfall in the wet days. This plot exhibits both the frequency density and box plot. In this plot, the green boxes, white circles, and squares express, respectively, the limitation of 5 and 95th percentiles, median, and average. This figure indicates that there is an underestimation of rainfall in both stations and all selection methods. As shown, heavy rainfalls (more than 15 mm.day-1) have no density in all selection methods, whilst the frequency of these events in the observation is significant.

Violin plot between observation and downscaled rainfall in wet days based on different selection methods in Urmia (a) and Birjand (b) stations
Note that Fig. 4 shows the probability distribution form. The observation violin indicates that as rainfall increases, its density reduces smoothly. Whereas, some simulated violins have violated this pattern. For example, in the Urmia site (Fig. 4a) in the observation violin, the density of rainfall with 9 mm.day-1 is less than 8 or 7 mm.day-1, whilst the PCA violin shows the equal density for rainfalls ranged between 9 to 10.5 mm.day-1. Similar behavior is understood in the CA and LASSO violins. This point may be better realized in the Birjand station (Fig. 4b), where the LASSO violin confirms this matter. However, the style of BMA and SRA violins in the Urmia station, as well as the BMA and CA violin in the Birjand are closer to observation ones.
In this section, the comparison results of observed and downscaled CDF has been presented. The results strongly rejected the null hypothesis in which actual and downscaled rainfall come from identical distribution. But KS test statistic (D) was computed and compared for better examination between different methods (Fig. 5). According to D values, the downscaled rainfall using BMA predictors obtained the lowest D value, and consequently, it gained more similar to observation ones. The superiority of BMA to SRA has approved by Su et al. (2019).

KS test statistic for all selection methods in Urmia and Birjand stations
To better analyze, the scatter plot with Mean of Error (ME) for the observed and simulated rainfall was illustrated. Based on Fig. 6a, all selection methods downscaled the rainfall with an underestimation in the Urmia station. Also, this Figure indicates that the estimation of small rainfalls (less or equal to 5 mm) is better than larger. As shown, based on the ME, the underestimation in the Urmia station is varied between different methods, as the downscaling process based on the LASSO has the most bias (−3.87 mm) while the lowest bias is owned for the SRA (−3.11 mm). The same results may be received in the Birjand station, but it seems that, due to less ME, there is more accuracy in this station.

Comparison of downscaled and observed rainfall in wet days over testing period for Urmia (a) and Birjand (b) stations
The comparison of the simulated wet and dry spells was carried out, and the results were presented in Table 7. As the CSI indicates (last column in the table), the downscaled data for various selection methods is more accurate in the Birjand than Urmia. Considering the last rows, in the Urmia station, there are 703 and 4776 days for wet and dry events, respectively. Whilst the downscaled data for all selection methods contains an over- and under- forecast for wet and dry days. For example, the downscaling based on the CA, detected correctly 490 wet days while it made 213 false detections. Also, this procedure simulated 4218 dry days correctly, but it made a mistake 558 times in detecting of dry events. Although there isn’t a significant difference between CA, PCA, RSA, and BMA methods, the CA and PCA have acceptable act in both stations.
Figure 7 exhibits the observed and downscaled frequency of the wet spells with different duration (days) in both stations. This figure indicates that all selection methods simulated long-duration wet spells (more than 2 days) more than measured ones. This is while these methods had underestimated the daily rainfall (see Table 6 and Figs. 4 and 6). In contrast, these methods have better efficiency in the short-duration wet spells (less or equal to 2 days). Furthermore, form Fig. 7b, it can be derived that there is more consistency, particularly in the wet spells with length 2, 3, and 5 days, in the Birjand. It is obvious that the simulated wet spells in the Birjand station (with more arid climate and lower rainfall) are closer together.

Observed and downscaled frequency of wet spells at Urmia (a) and Birjand (b) stations
The obtained results from various tests have been summarized here. It can be understood that there is a great desire in all methods to select circulation and humidity variables located in the low-pressure levels. The selection methods frequently picked the meridional wind component and relative vorticity of true wind at 500 hPa well as surface precipitation in both stations.
Generally, the accuracy of downscaling based on all selection methods in the Urmia site is less than the Birjand. It is likely related to the inherent dynamic of rainfall in these two climate patterns. Since rainfall variation is significantly more in Urmia than Birjand, then it led to the rainfall process is more complicated.
As shown, the strengths and weaknesses of various selection methods are different in diverse comparison tests. For example, based on the comparative tests such as performance criteria and statistic components, the SRA- based downscaling rendered better results. This is while in other tests, including distributions comparison, the BMA-based downscaling is outperformed. Also, there is a similarity between methods in comparison to wet and dry spells at two sites. However, it can be declared that the SRA and BMA gained more accurate results than other methods. But, due to many drawbacks of SRA as reported in hard interpretation in the multi-collinearity case (Winkler 1989), it can be derived that BMA predictors are more reliable for downscaling. The BMA gives better information about selected predictors, as it presents a distribution instead of a single number. Also, the final BMA predictors have been selected based on maximum likelihood, so it has no problem even in multi-colinearity conditions.
4 Conclusion
This study has designed a framework in MATLAB to take three different approaches: correlation, regression, and maximum likelihood to select the most relevant predictors for downscaling procedure in the two different climates. Within the suggested plan, we employed Pearson and partial strategies in correlation fashion, stepwise, and penalized strategies in regression and Bayesian theorem as likelihood techniques. Also, the downscaling process was carried out using the SVM technique, and the comparison stage was done through many tests to find out the ability of each selections method.
The outcomes of different comparative tests indicated that generally, the accuracy of the downscaling process influenced by predictors selected by BMA and SRA outperformed other selection methods. Also, it should be noted that the BMA has some more advantages than SRA.
Finally, we present some limitations excited in this study to obtain a specific outlook and to overcome them for future studies. First, we employed default BMA to select the most influential predictors, while some presented version of BMA currently has more superiorities, and it leads to more reliable results. Second, the used algorithm in the LASSO method surely affects the performance estimate, while the current study used the default algorithm of LASSO (CDA). Therefore, it is worthy to note that which of an available algorithm can give a better estimation of daily rainfall in the downscaling procedure. Third, the current study included two climate types and examined the effect of predictor selection step in the various approaches, as for a reliable and good conclusion, more climate categories are required. Hence, it is worthy to more studies may be conducted to examine the Intercomparison of climate patterns and predictor selection methods.
Data Availability
The authors confirm that all data supporting the findings of this study are available from the corresponding author by request.
References
Ahmadi A, Han D, Kakaei Lafdani E, Moridi A (2015) Input selection for long-lead precipitation prediction using large-scale climate variables: a case study. J Hydroinf 17(1):114–129
Amirataee B, Montaseri M (2013) Evaluation of l-moment and ppcc method to determine the best regional distribution of monthly rainfall data: case study northwest of Iran. J Urban Environ Eng 7(2):247–252
Ben Alaya MA, Chebana F, Ouarda TB (2015) Probabilistic multisite statistical downscaling for daily precipitation using a Bernoulli–generalized pareto multivariate autoregressive model. J Clim 28(6):2349–2364
Bermúdez M, Cea L, Van U, Willems EP, Farfán JF, Puertas J (2020) A Robust Method to Update Local River Inundation Maps Using Global Climate Model Output and Weather Typing Based Statistical Downscaling. Water Resour Manag. https://doi.org/10.1007/s11269-020-02673-7
Burnham KP, Anderson DR, Huyvaert KP (2011) AIC model selection and multimodel inference in behavioral ecology: some background, observations, and comparisons. Behav Ecol Sociobiol 65(1):23–35
Campozano L, Tenelanda D, Sanchez E, Samaniego E, Feyen J (2016) Comparison of statistical downscaling methods for monthly total precipitation: case study for the paute river basin in southern Ecuador. Adv Meteorol 2016:1–13
Chen J, Brissette FP, Leconte R (2011) Uncertainty of downscaling method in quantifying the impact of climate change on hydrology. J Hydrol 401:190–202
Chen H, Xu CY, Guo SL (2012) Comparison and evaluation of multiple GCMs, statistical downscaling and hydrological models in the study of climate change impacts on runoff. J Hydrol 434:36–45
Cover TM (1965) Geometrical and statistical properties of systems of linear inequalities with applications in pattern recognition. IEEE Trans Electron Comput 3:326–334
Crawford T, Betts NL, Favis-Mortlock D (2007) GCM grid-box choice and predictor selection associated with statistical downscaling of daily precipitation over Northern Ireland. Clim Res 34(2):145–160
De Martonne E (1925) Traité de Géographie Physique, Vol I: Notions generales, climat, hydrographie. Geogr Rev 15(2):336–337
Duan Q, Ajami NK, Gao X, Sorooshian S (2007) Multi-model ensemble hydrologic prediction using Bayesian model averaging. Adv Water Resour 30(5):1371–1386
Duan Q, Pappenberger F, Wood A, Cloke HL, Schaake J (Eds.). (2019). Handbook of Hydrometeorological ensemble forecasting. Springer
Duhan D, Pandey A (2015) Statistical downscaling of temperature using three techniques in the Tons River basin in Central India. Theor Appl Climatol 121(3-4):605–622
Emberger L (1932) Sur une formule climatique et ses applications en botanique. La Météorologie 92:1–10
Farzin S, Chianeh FN, Anaraki MV, Mahmoudian F (2020) Introducing a framework for modeling of drug electrochemical removal from wastewater based on data mining algorithms, scatter interpolation method, and multi criteria decision analysis (DID). J Clean Prod: 122075
Fayaz N, Condon LE, Chandler DG (2020) Evaluating the sensitivity of projected reservoir reliability to the choice of climate projection: A case study of Bull Run Watershed, Portland, Oregon. Water Resour Manag: 1–19
Fistikoglu O, Okkan U (2011) Statistical downscaling of monthly precipitation using NCEP / NCAR reanalysis data for Tahtali River basin in Turkey. J Hydraul Eng 16:157–164
Fowler HJ, Blenkinsop S, Tebaldi C (2007) Linking climate change modelling to impacts studies: recent advances in downscaling techniques for hydrological modelling. International Journal of Climatology: A Journal of the Royal Meteorological Society 27(12):1547–1578
Goyal MK, Ojha CSP (2012) Downscaling of precipitation on a lake basin: evaluation of rule and decision tree induction algorithms. Hydrol Res 43(3):215–230
Hammami D, Lee TS, Ouarda TBMJ, Le J (2012) Predictor selection for downscaling GCMs data with LASSO. J Geophys Res-Atmos 117(17):1–11
Harpham C, Wilby RL (2005) Multi-site downscaling of heavy daily precipitation occurrence and amounts. J Hydrol 312(1):235–255
He RR, Chen Y, Huang Q, Kang Y (2019) LASSO as a tool for downscaling summer rainfall over the Yangtze River valley. Hydrol Sci J 64(1):92–104
Hessami M, Gachon P, Ouarda T, St-Hilaire A (2008) Automated regression-based statistical downscaling tool. Environ Model Softw 23:813–834
Huang H, Liang Z, Li B, Wang D, Hu Y, Li Y (2019) Combination of multiple data-driven models for long-term monthly runoff predictions based on Bayesian model averaging. Water Resour Manag 33(9):3321–3338
Huth R (1999) Statistical downscaling in Central Europe: evaluation of methods and potential predictors. Clim Res 13:91–101
Kashif Gill M, Kemblowski MW, McKee M (2007) Soil moisture data assimilation using support vector machines and ensemble Kalman filter 1. JAWRA J Am Water Resour Assoc 43(4):1004–1015
Li XQ, Chen J, Xu CY, Li L, Chen H (2019) Performance of post-processed methods in hydrological predictions evaluated by deterministic and probabilistic criteria. Water Resour Manag 33(9):3289–3302
Liu Z, Xu Z, Charles SP, Fu G, Liu L (2011) Evaluation of two statistical downscaling models for daily precipitation over an arid basin in China. Int J Climatol 31(13):2006–2020
Liu Y, Feng J, Shao Y, Li J (2019) Identify optimal predictors of statistical downscaling of summer daily precipitation in China from three-dimensional large-scale variables. Atmos Res 224:99–113
Long X, Guan H, Sinclair R, Batelaan O, Facelli JM, Andrew RL, Bestland E (2019) Response of vegetation cover to climate variability in protected and grazed arid rangelands of South Australia. J Arid Environ 161:64–71
Meenu R, Rehana S, Mujumdar PP (2013) Assessment of hydrologic impacts of climate change in Tunga-Bhadra river basin, India with HEC-HMS and SDSM. Hydrol Process 27(11):1572–1589
MoradiKhaneghahi M, Lee T, Singh VP (2019) Stepwise extreme learning machine for statistical downscaling of daily maximum and minimum temperature. Stoch Env Res Risk A 33(4–6):1035–1056
Najafi MR, Moradkhani H, Wherry SA (2011) Statistical downscaling of precipitation using machine learning with optimal predictor selection. J Hydrol Eng 16(8):650–664
Nasseri M, Zahraie B (2013) Performance assessment of different data mining methods in statistical downscaling of daily precipitation. J Hydrol 492:1–14
Pervez MS, Henebry GM (2014) Projections of the Ganges–Brahmaputra precipitation downscaled from GCMs predictors. J Hydrol 517:120–134
Pichuka S, Maity R (2018) Development of a time-varying downscaling model considering non-stationarity using a Bayesian approach. Int J Climatol 38(7):3157–3176
Raftery AE, Gneiting T, Balabdaoui F, Polakowski M (2005) Using Bayesian model averaging to calibrate forecast ensembles. Mon Weather Rev 133(5):1155–1174
Raje D, Mujumdar PP (2011) A comparison of three methods for downscaling daily precipitation in the Punjab region. Hydrol Process 25(23):3575–3589
Sarhadi A, Burn DH, Yang G, Ghodsi A (2017) Advances in projection of climate change impacts using supervised nonlinear dimensionality reduction techniques. Clim Dyn 48(3–4):1329–1351
Schmidt M (2005) Least squares optimization with L1-norm regularization. CS542B Project Report 504:195–221
Soleh AM, Wigena AH, Djuraidah A, Saefuddin A (2016) Gamma distribution linear modeling with statistical downscaling to predict extreme monthly rainfall in Indramayu. In 2016 12th International Conference on Mathematics, Statistics, and Their Applications (ICMSA). IEEE, pp 134–138
Su H, Xiong Z, Yan X, Dai X (2019) An evaluation of two statistical downscaling models for downscaling monthly precipitation in the Heihe River basin of China. Theor Appl Climatol 138(3-4):1913–1923
Tareghian R, Rasmussen PF (2013) Statistical downscaling of precipitation using quantile regression. J Hydrol 487:122–135
Teegavarapu RS, Goly A (2018) Optimal selection of predictor variables in statistical downscaling models of precipitation. Water Resour Manag 32(6):1969–1992
Tibshirani R (1996) Regression shrinkage and selection via the LASSO. J R Stat Soc Ser B 58(1):267–288
Tripathi S, Srinivas VV, Nanjundiah RS (2006) Downscaling of precipitation for climate change scenarios: a support vector machine approach. J Hydrol 330(3–4):621–640
Vapnik VN (1995) The nature of statistical learning theory. Springer Verlag, New York
Wilby RL, Dawson CW, Barrow EM (2002) SDSM—a decision support tool for the assessment of regional climate change impacts. Environ Model Softw 17(2):145–157
Winkler RL (1989) Combining forecasts: a philosophical basis and some current issues. Int J Forecast 5(4):605–609
Wood AW, Leung LR, Sridhar V, Lettenmaier DP (2004) Hydrologic implications of dynamical and statistical approaches to downscaling climate model outputs. Clim Chang 62:189–216
Yang C (2018) Performance comparison of three predictor selection methods for statistical downscaling of daily precipitation. Theor Appl Climatol. Volume and page
Yang C, Wang N, Wang S, Zhou L (2018) Performance comparison of three predictor selection methods for statistical downscaling of daily precipitation. Theor Appl Climatol 131(1-2):43–54
Zhang X, Yan X (2015) A new statistical precipitation downscaling method with Bayesian model averaging: a case study in China. Clim Dyn 45(9-10):2541–2555
Zhang X, Xiong Z, Zhang X, Shi Y, Liu J, Shao Q, Yan X (2016a) Using multi-model ensembles to improve the simulated effects of land use/cover change on temperature: a case study over Northeast China. Clim Dyn 46(3–4):765–778
Zhang X, Yan X, Chen Z (2016b) Reconstructed regional mean climate with Bayesian model averaging: a case study for temperature reconstruction in the Yunnan–Guizhou plateau, China. J Clim 29(14):5355–5361
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.
Author information
Authors and Affiliations
Contributions
All authors contributed to the study conception and design. Material preparation, data collection and analysis were performed by Jafarzadeh, Ahmad, Pourreza Bilondi, Mohsen, Khashei Siuki, Abbas, and Ramezani Moghadam, Javad. The first draft of the manuscript was written by Jafarzadeh, Ahmad and all authors commented on previous versions of the manuscript. All authors read and approved the final manuscript.
Corresponding author
Ethics declarations
Conflict of Interest
None.
Code Availability
The authors announce that there is no problem for sharing the used model and codes by make request to corresponding author.
Additional information
Publisher’s Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Jafarzadeh, A., Pourreza-Bilondi, M., Khashei Siuki, A. et al. Examination of Various Feature Selection Approaches for Daily Precipitation Downscaling in Different Climates. Water Resour Manage 35, 407–427 (2021). https://doi.org/10.1007/s11269-020-02701-6
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11269-020-02701-6