
Abstract
Streamflow forecasting and predicting are significant concern for several applications of water resources and management including flood management, determination of river water potentials, environmental flow analysis, and agriculture and hydro-power generation. Forecasting and predicting of monthly streamflows are investigated by using three heuristic regression techniques, least square support vector regression (LSSVR), multivariate adaptive regression splines (MARS) and M5 Model Tree (M5-Tree). Data from four different stations, Besiri and Malabadi located in Turkey, Hit and Baghdad located in Iraq, are used in the analysis. Cross validation method is employed in the applications. In the first stage of the study, the heuristic regression models are compared with each other and multiple linear regression (MLR) in forecasting one month ahead streamflow of each station, individually. In the second stage, the models are evaluated and compared in predicting streamflow of one station using data of nearby station. The research investigated also the influence of the periodicity component (month number of the year) as an external sub-set in modeling long-term streamflow. In both stages, the comparison results indicate that the LSSVR model generally performs superior to the MARS, M5-Tree and MLR models. In addition, it is seen that adding periodicity as input to the models significantly increase their accuracy in forecasting and predicting monthly streamflows in both stages of the study.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
Understanding the complicated phenomena of streamflow plays a significant part in water resources management. More specifically, long-term streamflow forecasting (e.g., monthly river flow) is greatly crucial for hydro-power generation, appropriate reservoir operation, effective irrigation management decision and several other hydrological applications. Over the past couple decades, streamflow modeling has received a massive attention by hundreds of researchers. This is due to the fact that, the global climate changes have been influenced the hydrologic cycle that caused numerous of flood and drought events. According to the literature, river flow forecasting has been undertaken based on two main methodologies, physical based models and conceptual based models “e.g., data-driven techniques”. Physical models usually required more effort and various hydrological variables to simulate the elemental physical processes of the watershed (Costabile et al. 2012). Whereas, data-driven soft computing approaches have shown the capability to capture the non-linearity relationship between the predictors and predicted without advance knowledge with less inputs hydrological parameters (Ahmed and Sarma 2007; Afan et al. 2014; Singh and Cui 2015; Tigkas et al. 2016).
Classically, black box time series models have been applied for streamflow forecasting since 1970 by (Box and Jenkins). Based on the review researches, those parametric linear models such as Moving Average (MA), Auto Regressive Integrated Moving Average (ARIMA), and Multiple Linear Regression (MLR) have been used in almost all the hydrological variables (Abrahart and See 2000; Maier and Dandy 2000; Abrahart et al. 2010; Abrahart et al. 2012; Yaseen et al. 2015). However, they perform poorly in the conditions of highly non-stationary and non-linear real problems. Since 1990, artificial intelligence methods have been extensively utilized in a wide range of hydrological applications and more specifically for streamflow forecasting, such as artificial neural network (ANN), support vector machine (SVM), adaptive neuro fuzzy inference system (ANFIS), genetic algorithm (GA), and gene expression programming (GEP) (Nourani et al. 2014; Yaseen et al. 2015).
Most recently, three data driven approaches have been gained a remarkable emerging and potential in handling the complex nonlinear problems such as least square support vector regression (LSSVR), multivariate adaptive regression splines (MARS) and M5 Model Tree. Those forgoing approaches have been broadly used in solving hydrologic problems. LSSVR is the modified version of support vector repression (SVR) that can exclude the quadratic programming problems (Suykens and Vandewalle 1999 ). In addition, it avoids several shortcomings of other data-driven learning processes (e.g., local minima, time consumption and over-fitting) (Ji et al. 2014). LSSVR has received a positive successful application in the engineering field; for instance, bearing raceway prediction (Tao et al. 2008), prediction of effluent parameter of wastewater treatment plant (Huang et al. 2009), airframe wing-box estimation (Deng and Yeh 2010), power system stabilization (Pahasa and Ngamroo 2011), prediction of CO2 in reservoir (Shokrollahi et al. 2013), oil recovery and economic analysis (Kamari et al. 2014), and oil reservoir viscosity determination (Hemmati-Sarapardeh et al. 2014). In the hydrological context, there are a few studies have been conducted using LSSVR; for example, evapotranspiration prediction (Guo et al. 2011; Kisi 2013), daily water demand estimation (Hwang et al. 2012), sediment transport modeling (Kisi 2012), reservoir inflow modeling (Okkan and Ali Serbes 2013), and water pollution prediction (Kisi and Parmar 2016), authors concluded the outperformance of the LSSVR over the other data-driven used in their researches and recommended its applicability for other hydrological variables.
Multivariate adaptive regression splines is a relatively modern artificial intelligence approach that firstly proposed by (Friedman 1991). The main advantages of this method are the capacity to capture the natural complication of the data mapping in high-dimensional data patterns, quick and flexible model, and perform the forecasting of continuous and binary output variables accurately. In addition, this nonparametric statistical method is a flexible procedure that organize the relationship between the inputs and output variables with less including variable interactions (Leathwick et al. 2006). Previous studies of the MARS algorithm in water resources application include rainfall and temperature forecasting, sediment concentration estimation, water pollution prediction, freshwater distribution system modeling, and drought events river flow simulation (Sarangi and Bhattacharya 2005; Leathwick et al. 2006; Sotomayor 2010; Adamowski et al. 2012; Shortridge et al. 2015). Thus, in the current research, the best knowledge of the authors is to introduce the multivariate adaptive regression splines approach for forecasting and predicting monthly streamflow.
Another new data-driven technique is M5 Model tree. M5 model tree is a data mining approach that splits the data time series into subspace using divide-and-conquer method, which makes it possible to divide the multi-dimensional parameter space and generate the model automatically based on the overall quality criterion (Quinlan 1992). Recently, scholars researched the utility of the M5 model tree in different hydrological applications such as water level optimization (Bhattacharya and Solomatine 2005), precipitation-river flow modeling (Solomatine and Dulal 2003), evapotranspiration prediction (Pal and Deswal 2009), flood events forecasting (Solomatine and Xue 2004), and sedimentation estimation (Sarangi and Bhattacharya 2005). Those are a few studies effectively accomplished in the water resources sector using M5 model tree.
For the best knowledge of the authors, the major objectives of the current research are (i) investigate three different modern heuristic regression approaches (i.e., LSSVR, MARS and M5 model tree) for modeling long-term streamflow, (ii) compare their performance with one classical method such as MLR, (iii) in order to demonstrate the effectiveness, four rivers placed in two different region namely, Batman and Garzan Rivers located in Turkey, Euphrates and Tigris Rivers located in Iraq, have been used to perform the proposed models. In the first phase of the study, streamflow forecasting is demonstrated based on the same river flow data for the same river. Whereas the second phase, streamflow prediction is conducted for specific stream based on the nearby stream. Furthermore, the influence of periodicity on the forecasting and predicting performance was examined.
2 Theoretical Overview
2.1 Least Square Support Vector Regression
LSSVR is the extended version of support vector regression (SVR) model, modified by (Suykens and Vandewalle 1999 ). Based on the literature, the major drawback of SVR is time consumption that overcame by the improved version of LSSVR via excluding the quadratic programming problem. This enhancement would avoid several limitations (e.g., the local minima, the over-fitting problem). In addition, it may produce a stable solution to crack the quadratic programming problems (Xie et al. 2013; Ji et al. 2014). Statistically, the main principle knowledge of LSSVR is to accomplish the optimum mapping function between the inputs x and the output y. This process is conducted through non-linear relationship function with high-dimensional feature space. To attain the optimal solution, regression model into the high-dimensional feature space was developed to capture the non-linear regression function. Regression function can be formulated as follows:
where y is the obtained value in terms of x, w is the coefficient vector, φ is the mapping function, b is the bias term achieved by the minimizing the upper bound of the generalization error. According to the standard of minimizing the regularized risk, the regression function of LSSVR (Suykens and Vandewalle 1999) can be well-defined as:
That subject to the following constraints
Where γ is the regularization parameter which is control the minimization of the forecasting or prediction error and the function smoothness, while ξ is the training error for the inputs (x i ).
At this point, Lagrange Multiplier is utilized to derive solution for w and ξ using formula (2). The objective function obtained by changing the constraint problem into an unconstraint problem. The Lagrange function L written as follows:
where a i presents Lagrange Multipliers.
The Lagrangian theorem and Karush-Kuhn-Tucker (KKT) condition permit (Fletcher 1987) to achieve the following function:
K(x) denotes the kernel function that satisfies Mercer’s conditions; K(x, x i ) = (φ(x) . φ(x i )) that eliminate vector dot product operation in some feature space.
In the current research, radial basis function (kernel function) was used to in the regression solution. The formula can be defined as:
There are two parameters used for tuning LSSVR model, which are γ and σ2 (Cao et al. 2008). The current state-of-the-art of the authors is the utilization of LSSVR for streamflow forecasting and prediction. This is relying on the robustness of LSSVR model against the chaotic disturbances, complex non-linear and randomness problems. Furthermore, it’s utility to reduce the soft computing efforts comparatively to the classical approaches.
2.2 Multivariate Adaptive Regression Splines
MARS is a nonparametric regression model that was initially proposed by (Friedman 1991), which is utilized to forecast continuous numeric outcomes. The main feature of MARS algorithm is the forward and backward stepwise procedure that can controls and explains the complex nonlinear mapping between the inputs and output variables. The advantage of the backward stepwise procedure is to remove the unnecessary input candidates from the previous selected data set in order to enhance the forecasting accuracy. This function forecasts the new output Y according to the input variable X using either of the two basis functions, using a knot or value of variable that defines the inflection point along the inputs range (Sharda et al. 2006):
where the c parameter indicates the threshold value. There are two adjacent splines intersect at a knot, in order to maintain the continuity of the basis functions. The function is used in the forward and backward stepwise procedure to each input parameter is to identify the precise location of knots where the function value changes. Great to mention, MARS model is a data-driven process that gained popularity in time series analysis, most recently. In addition, it is even better to explore its capability to enhance river flow forecast models. Authors recommend the following references for the reader to refer for more comprehensive details of MARS model (Friedman 1991; Sharda et al. 2008; Zhang and Goh 2014).
2.3 M5 Model Tree
The complex time series problems can be comprehended by splitting the time space into a number of sub time space and build each category individually using linear regression model. M5 model tree algorithm is one of the new data mining method that divide the data space into smaller sub-spaces using divide and conquer procedure (Quinlan 1992). The fundamental concept of this model is the binary decision tree. The partition procedure follows the idea of a decision tree that has a regression function, which is able to forecast continuous numerical attribution. As shown in Fig. 1, M5 model tree perform its algorithm based on two stages, at the first stage time series data are divided into subset in order to initiate the decision tree. The splitting criterion for this model is relying on the standard deviation of the class values that reach a node as an amount of error at that node. Then after, computing the expected reduction in this error as a result of testing each attribute at that node (Solomatine and Dulal 2003; Pal and Deswal 2009). Now, the equation that compute the standard deviation reduction (SDR) can be expressed as:

The two stages of M5 model tree
The variables of the SDR formula explained are as follows; (i) sd represents the standard deviation, (ii) K denotes a set of examples that reaches the node, and (iii) the subset of examples that have the ith outcome of the potential set is represented as Ki. In the partition procedure, the first generation (child) nodes are less than the origin node in data’s standard deviation. As final step in first stage, M5 selects the split that maximizes the envisioned error reduction. Nevertheless, this separation usually produces a large diagram (tree) structure that need to be pruned subtrees using linear regression functions, which is representing the second stage of M5 modeling.
2.4 Multiple Linear Regression
There are several engineering applications involve exploring the relationship between two or more parameters. Regression analysis model is one of the popular statistical approach that is highly recommended for these kind of problems. Throughout the literature, streamflow forecasting has been undertaken using MLR model, due to the fact that this model comprises many regressors to deal with the time series data base. Theoretically, the relationship between the dependent variable (Y) “i.e., one-step-ahead streamflow” and the independent variables (Xi) “i.e., the preceding streamflow records” can be described as followed:
Where Y is the target output, Pi (i=0,…., n) are the regression coefficients, and Xi (i=0,…., n) are the input variables.
2.5 Model Performance Indicators
Hydrological applications usually are evaluated based on quantitative indicators. Legates and McCabe (1999) stated in their study that predictive models in the scope of hydrology recommended to be examined using “goodness-of-fit” for example determination coefficient (R) and minimum one of absolute error performance criteria (e.g., mean absolute error (MAE) and root mean square error (RMSE)). Thus, the proposed data-driven models were evaluated with respect to RMSE, MAE and R for each input combination. The statistic measure RMSE and MAE are formulated as follows:
where N is the number of the raw streamflow data, Q o is the actual (observed) flow values and Q f is the model output.
3 Cases Studies and Data Preparation
3.1 Turkey Region
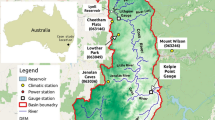
Average monthly intermittent streamflow data of two stations in the East-Anatolia region located in Southeast Turkey were used. The location of the stations was illustrated in Fig. 2a. In this study, the Besiri Station (Station No: 2603) on the Garzan Stream and Malabadi Station (Station No: 2612) on the Batman Stream, in the Firat-Dicle Basin of Turkey were used. The drainage areas at these sites are 2450 km2 for Besiri and 4105 km2 for Malabadi. In Turkey, the first largest basin is Firat (basin number 21) with an approximately 127,000 km2 of land zone. Dicle Basin (basin number 26) is the third largest basin with an almost 57,000 km2 of land zone. Rely on basin land area, the Firat basin is the largest, with a total yearly flow volume approximately 32 billion m3. The second one is Dicle Basin, with approximately 25 billion m3 (Kaygusuz 1999; Demirbas and Bakis 2003). Streamflow forecasting for this region is very important for many of the activities such as flood mitigation, management of water reservoirs, distribution of drinking water and management of water infrastructures and dam planning etc. The observed data are 35 years (420 months) long with an observation period between 1964 and 1999 for mentioned stations. The observed data were obtained from the report of the Turkish General Directorate of Electrical Power Resources Survey and Development Administration.

a The Large basins of Turkey and The Malabadi (2612), Besiri (2603) stations, b Hit and Baghdad stations which are located in Iraq region
3.2 Iraq Region
Another two stations were selected to apply in this study which are Hit station on the Euphrates River and Baghdad station on Tigris River in Iraq region, as shown in Fig. 2b. Hit and Baghdad stations are covered a drainage area approximately 264,100 km2 and 134,000 km2, respectively. The geographic position of the Hit and Baghdad stations areas are stretched between (33° 36' 23") N Latitude and (42° 50' 14") E Longitude, (33° 24' 34") N Latitude and (44° 20' 32") E Longitude. Euphrates and Tigris Rivers are the essential source of fresh water, socioeconomic development and the political stabilization in this region. Developing such accurate forecasting and predicting river flow modeling in particular long-term (e.g., monthly streamflow) are significantly important to provide a considerable economic benefit, improve the irrigation sector, and solve the water shortage problems. The monthly streamflow data records 38 years (456 months) between (1960-1997) for Hit and Baghdad stations between (1968-2005) were used for this application. The hydrological data were obtained from the descriptive research that was conducted by Saleh (2010).
3.3 Data Time Series Preparation
For all presented stations, streamflow data time series were splitted into four training/testing divisions in order to achieve the best effective model formulation. For both of the applications forecasting and predicting, three divisions of the data were utilized to train the models, while the fourth was used to validate (test) the models network. The testing data phase was changed in all application; therefore, four different scenarios were investigated. Table 1 indicated the statistical characteristics of each data set used in this study for all stations. Those statistical indicators included over all mean (Xmean), standard deviation (Sx), minimum and maximum flow records (Xmin and Xmax), skewness (Csx), and the antecedent values of auto-correlation coefficient.
4 Application and Analysis
The effectiveness of the proposed artificial intelligence approaches were examined upon actual streamflow data obtained from official organizations authorized for monitoring such river flows. In the first part of the current study, it was decided to prove the efficiency of the LSSVR, MARS and M5-Tree models to forecast one month ahead streamflow and compare the results with MLR model. In addition, the effect of the periodic time scale on the forecasting results was also explored. Whereas, the second part of the study is to investigate the applicability of the data-driven to predict monthly streamflow using inflow time series data belonging to the nearby river. Different input combinations based on the present and antecedent streamflow were used to model the forecasting and prediction. In other words, Qt indicates the streamflow at time t, the input variables are; (i) Qt, (ii) Qt, Qt-1, (iii) Qt, Qt-1 and Qt-2. This application section provides a comprehensive detailed discussion and analysis of the proposed methods. It should be remarked that the utilized river flow data for all rivers are continuous and do not experience any missing monitoring events data during the examination period.
4.1 Streamflow Forecasting
As mentioned in the previous section, the first scenario was undertaken to forecast monthly streamflow. For the purpose of how the statistical analysis will generalize an independent data set, each input combination was cross validated by partitioning the time series data into four sets. By recalling the main parameters of LSSVR model, different regularization constant and width of radial basis function kernel were tried to obtain the minimum RMSE indicator. Table 2 displayed the optimal LSSVR parameters models of each input combination for the testing phase. Tables 3, 4, 5, and 6 indicated the testing phase outcomes using LSSVR, MARS, M5 model tree and MLR models for the all stations (Besiri, Malabadi, Hit and Baghdad). According to the mean values of the performance indicators (e.g., RMSE and MAE) of the modeling, there is a remarkable difference can be observed in the results, which are the values of the root mean square error and mean absolute error. The Turkish rivers modeling showed low percentages of RMSE and MAE comparing the Iraq Rivers. This is due to the mean average flow of the rivers, Garzan and Batman Rivers are characterized by mean river flow 53.66 and 129.37 m3/s, respectively. While Euphrates and Tigris rivers are 750.06 and 838.84 m3/s, respectively.
Based on the mean performance of RMSE and MAE, Tables 3, 4, and 5) exhibited M3 as the best data set to forecast one month ahead for Besiri and Malabadi stations. This might be because M3 data set provides a knowledgeable pattern of flow in the training and testing phases of the models that could perform very well comparing to the other data sets. On the other hand, the worst data set was M1 for LSSVR, MARS and M5 model tree for all the investigated inputs combination. This can be expounded that LSSVR, MARS and M5 model tree could not explore the nature of the streamflow of the M1 data set in the training and testing periods. However, LSSVR results outperformed MARS and M5-Tree models and the outstanding outcome presented for M3 data set period for the input combination (iii). The optimal LSSVR model (M3 data set and input iii) increased the RMSE accuracy of the optimal MARS and M5-Tree models by 3.9 and 31.2 % for the Besiri and by 2.6 and 20.6 % for the Malabadi stations, respectively. It should be noted that there is also a significant difference between MARS and M5-Tree for the both stations. Euphrates and Tigris Rivers modeling were totally different with obvious fluctuation of the best performance results. The consistency of the Iraq rivers region modeling conclusion was diverse, various data sets with different inputs combination performed the remarkable results of the used intelligence approaches. Hit station modeling showed the best accuracy belonging to M2 with one lag time for the LSSVR and MARS models, while M5 model tree demonstrated the best results for the M1 with one lag as well (the input combination (i)). Baghdad station obtained its best application using the first data set (M1) with one antecedent value of flow to forecast one-month-ahead. The variance of the best results here is because of the phenomena that characterized Iraq climatology which is highly nonstationary and each approach dealt with the data base with different consistency. Here, the lowest standard indicators appeared for the fourth data set (M4) with respect to the all inputs combination. In general, it could be noticed that LSSVR provides the admirable forecasting modeling of streamflow over the other methods. The RMSE performance of the best MARS and M5-Tree models was increased using the best LSSVR model by 10.1 and 36.7 % for the Hit and by 3.3 and 17.8 % for the Baghdad stations, respectively. Similar to the previous application, here also a considerable difference exists between MARS and M5-Tree models.
Traditionally, MLR models were examined for the same data sets and the remarkable goodness in term of RMSE and MAE were selected for comparison purpose. MLR results presented in Table 6 for all the stations. There is an outstanding harmony with gained results regarding the data sets and the preceding input vectors comparing with LSSVR, MARS and M5 model methods. What is worth to be observed? There is a noteworthy enhancement in the application of LSSVR, MARS and M5-Tree model methods comparatively with MLR method. In order to describe this improvement in rational way, the percentages of the accuracy increment for the performance criteria have been calculated. The mean RMSE and MAE accuracies of the MLR model successfully increased using LSSVR model by 8.95-4.19 %, 12.8-8.08 %, -0.12-4.03 % and 13.56-10.03 % for Besiri, Malabadi, Hit and Baghdad stations, respectively.
The periodicity data component was also examined and evaluated for the forecasting modeling section. In fact, the main idea behind including this periodic sub data which is one year to forecast one month ahead, is to supply the modeling an external pattern of flow that might give a comprehensive knowledge and better accuracy of results. Table 7 displayed the results of the testing phase for periodic LSSVR model. Obviously, adding the periodicity component has increased the average LSSVR model performance accuracy in term of the RMSE and MAE by 20-23.21 %, 28.73-33.82 %, 2.20-5.91 % and 4.98-11.08 % for Besiri, Malabadi, Hit and Baghdad stations, respectively. By comparing Table 7 with 3, the periodic LSSVR indicates the same consistency of modeling accuracy with LSSVR for Besiri and Malabadi stations which are M3 the best model and M1 the worst model. In addition, Hit station gives the same combination of results M2 the best model and M4 the worst model. Whereas, Baghdad station presents different outcome the best testing data set was 1977-1986 (M3) and the worest testing data set was similar to the previous application od the LSSVR, 1968-1976 (M4).
Further assessment for the effectiveness of the utilized data-driven models, it seems reasonable to investigate the linear relationship between the observed and forecasted time series for the testing period. Scatter plots are illustrated in Figs. 3a, b belonging to Besiri and Malabadi stations, respectively. Those figures demonstrated the best models of LSSVR, MARS, M5 model tree, periodic LSSVR (P-LSSVR) and MLR models for M3 input combination. P-LSSVR has been found the best model displayed closed to the fit line comparing to the other models. Similarly, Fig. 3c, d showed the best fit line regression indicator regarding Hit and Baghdad stations. Hit station performed the best value of R for LSSVR model with M2 data set and input combination (i). However, it is evident based on Fig. 3c that there is a slight deviation between LSSVR model and MLR. Fig. 3d displayed the best fit line all the models for M1 and combination (i), except MLR method with combination (ii), for Baghdad station.

The observed and forecasted streamflows scatterplot by the LSSVR, MARS, M5-Tree, MLR and P-LSSVR, a the M3 data set-Beşiri station, b the M3 data set-Malabadi station c the M1 and M2 data sets–Hit station, and d the M1 data set - Baghdad station
Overall, LSSVR and MARS generally performed superior to M5-Tree and MLR models. The reason behind this may be the fact that the linear structure of the M5-Tree and MLR models prevents them from accurately modeling highly nonlinear streamflow process. Wang et al. 2009 compared the ability of autoregressive moving-average ARMA, ANN, ANFIS, genetic programming (GP) and SVM methods in forecasting monthly discharge time series and they obtained R of 0.786, 0.786, 0.801, 0.815 and 0.823 for the ARMA, ANN, ANFIS, GP and SVM, respectively. Rezaeian-Zadeh et al. 2013 predicted monthly discharges in a semi-arid region using ANN with different training algorithms and they found that the best ANN model trained with scaled conjugate gradient algorithm provided a correlation 0.78. Turan and Yurdusev 2014 used ANFIS and genetic fuzzy system (GFS) in predicting monthly river flows of Gediz Basin in Turkey and they obtained R of 0.84 and 0.85 for the best ANFIS and GFS models. It is clear from the presented tables “performance metrics” that the LSSVR and MARS models provided accurate results in forecasting monthly streamflow from the R 2 viewpoint.
4.2 Streamflow Predicting
In this section, streamflow’s prediction has been conducted using the LSSVR, MARS, M5 model tree, P-LSSVR and MLR based on nearby streamflow data for particular station. The significant of this kind of modeling is for the cases of missing river flow or the poor quality of discharge monitoring (e.g., upstream or downstream stations). For this kind of problem, streamflow prediction using nearby station can be highly useful to predict the missing data. In this study, the prediction was undertaken for the Turkish streams. This is for the reason that Garzan and Batman rivers have the same drainage hydrological features; so that, the prediction will be implemented in homogenous physical characteristics. Here also, the data base was cross-validated and divided into four divisions. With similar to the previous sub section application procedure, Table 8 expresses the optimal parameters of LSSVR model. For the scenario of predicting streamflow at Malabadi station (Batman River) using river flow data of Besiri station (Garzan River), Table 9 and 10 provided the modeling evaluators of LSSVR, MARS and M5 Tree models, respectively. According to the mean RMSE and MAE indicators, the highest score given by LSSVR and MARS models for M3 and input combination (iii) and (ii); in that order, while M5 Tree model score the best accuracy of M4 data set and two lagged times. Negatively, the three models gave the lowest accuracy scores for M1 data set. The best LSSVR model (M3 data set and input iii) increased the RMSE performance of the best MARS (M3 data set and input ii) and M5-Tree (M4 data set and input iii) models by 5.3 and 11.9 %, respectively. Comparison of the best explored model which is using LSSVR approach with MLR model (table 10), there were a positive improvement in the prediction scenario accuracies in term of mean RMSE and MAE by 37.04-29.95 %, respectively.
The effect of embedding the periodicity feature was tested for prediction phase. This was conducted for the best accurate model has been obtained in the forgoing applications, which is least square support vector regression model. Again, the ideal regularization constant and RBF kernel values are visualized in Table 11. The test results of P-LSSVR is exhibited in Table 12; however, the best average performances accuracies of P-LSSVR were gained from M3 data set, whereas the worst model from M1 and M2 with slight variation. To further visualize the effect of including the periodic component, the percentages of the prediction development between LSSVR and P-LSSVR in term of the mean RMSE and MAE were 22.50-24.17 %, respectively. Finally, the actual and predicted river flow for LSSVR, MARS, M5 model tree, MLR and P-LSSVR are illustrated in Fig. 4 of the best sophisticated data set. Clearly, it was found that the closet prediction model is P-LSSVR with R value 0.89.

The streamflow prediction of the Malabadi Station by LSSVR, MARS, M5-Tree, MLR and P-LSSVR using M3 data sets of Beşiri Station
5 Conclusion
As a matter of fact, streamflow modeling is a challenging task for the hydrology researchers. This is due to the chaotic disturbances, complex non-linear dynamics and randomness phenomena of this hydrological variable. In the current research, the potential of three heuristic regression models namely; LSSVR, MARS and M5 model tree were investigated in forecasting and predicting long-term streamflow. The application and analysis were numerically conducted based on four rivers flow, Batman and Garzan Rivers located in Turkey, Euphrates and Tigris Rivers located in Iraq. However, the findings are enumerated as follows.
-
(i)
LSSVR, MARS and M5 tree models outperformed the classical MLR method in both scenarios forecasting and predicting.
-
(ii)
In general, LSSVR indicated better forecasted and predicted accuracies for one-month-ahead over MARS and M5 model tree. Indeed, this is due to the capability of the novel application of least square support vector regression which is developed version of support vector regression via excluding the quadratic programming problem in addition to the skill to capture the complicated non-linear relationship.
-
(iii)
The periodic component feature was embedded and considered within the input combinations of the modeling, the results illustrated that adding this component data was remarkably helpful to provide a detailed intuition into the process of the forecasted and predicted monthly streamflow and improves the accuracy modeling for all the examined rivers.
References
Abrahart RJ, See L (2000) Comparing neural network and autoregressive moving average techniques for the provision of continuous river flow forecasts in two contrasting catchments. Hydrol Process 14:2157–2172. doi:10.1002/1099-1085(20000815/30)14:11/12<2157::AID-HYP57>3.0.CO;2-S
Abrahart RJ, See LM, Dawson CW, et al (2010) Nearly two decades of neural network hydrologic modeling. Adv Data-Based Approaches Hydrol Model Forecast NJ World Sci Publ 267–346.
Abrahart RJ, Anctil F, Coulibaly P, et al. (2012) Two decades of anarchy? Emerging themes and outstanding challenges for neural network river forecasting. Prog Phys Geogr 36:480–513. doi:10.1177/0309133312444943
Adamowski J, Chan HF, Prasher SO, Sharda VN (2012) Comparison of multivariate adaptive regression splines with coupled wavelet transform artificial neural networks for runoff forecasting in Himalayan micro-watersheds with limited data. J Hydroinf 14:731. doi:10.2166/hydro.2011.044
Afan HA, El-Shafie A, Yaseen ZM, et al. (2014) ANN Based Sediment Prediction Model Utilizing Different Input Scenarios. Water Resour Manag 29:1231–1245. doi:10.1007/s11269-014-0870-1
Ahmed JA, Sarma AK (2007) Artificial neural network model for synthetic streamflow generation. Water Resour Manag 21:1015–1029. doi:10.1007/s11269-006-9070-y
Bhattacharya B, Solomatine DP (2005) Neural networks and M5 model trees in modelling water level–discharge relationship. Neurocomputing 63:381–396. doi:10.1016/j.neucom.2004.04.016
Box GEP, Jenkins GM (1970) Time Series Analysis, Forecasting and Control, 1st editio. Holden-Day, San Francisco, CA
Cao SG, Liu YB, Wang YP (2008) A forecasting and forewarning model for methane hazard in working face of coal mine based on LS-SVM. J China Univ Min Technol 18:172–176. doi:10.1016/S1006-1266(08)60037-1
Costabile P, Costanzo C, Macchione F, Mercogliano P (2012) Two-dimensional model for overland flow simulations: A case study. Eur Water 38:13–23
Demirbas A, Bakis R (2003) Turkey’s water resources and hydropower potential. Energy Explor Exploit 21:405–414
Deng S, Yeh T-H (2010) Applying least squares support vector machines to the airframe wing-box structural design cost estimation. Expert Syst Appl 37:8417–8423
Fletcher R (1987) Practical methods of optimization. John Wiley & Sons.
Friedman JH (1991) Multivariate Adaptive Regression Splines. Ann Stat 19:1–67. doi:10.1214/aos/1176347963
Guo X, Sun X, Ma J (2011) Prediction of daily crop reference evapotranspiration (ET0) values through a least-squares support vector machine model. Hydrol Res 42:268
Hemmati-Sarapardeh A, Shokrollahi A, Tatar A, et al. (2014) Reservoir oil viscosity determination using a rigorous approach. Fuel 116:39–48. doi:10.1016/j.fuel.2013.07.072
Huang Z, Luo J, Li X, Zhou Y (2009) Prediction of effluent parameters of wastewater treatment plant based on improved least square support vector machine with PSO. In: Information Science and Engineering (ICISE), 2009 1st International Conference on. IEEE, pp 4058–4061
Hwang SH, Ham DH, Kim JH (2012) Forecasting performance of LS-SVM for nonlinear hydrological time series. KSCE J Civ Eng 16:870–882. doi:10.1007/s12205-012-1519-3
Ji Z, Wang B, Deng S, You Z (2014) Predicting dynamic deformation of retaining structure by LSSVR-based time series method. Neurocomputing 137:165–172. doi:10.1016/j.neucom.2013.03.073
Kamari A, Nikookar M, Sahranavard L, Mohammadi AH (2014) Efficient screening of enhanced oil recovery methods and predictive economic analysis. Neural Comput & Applic 25:815–824. doi:10.1007/s00521-014-1553-9
Kaygusuz K (1999) Hydropower potential in Turkey. Energy Sources 21:581–588
Kisi O (2012) Modeling discharge-suspended sediment relationship using least square support vector machine. J Hydrol 456-457:110–120. doi:10.1016/j.jhydrol.2012.06.019
Kisi O (2013) Least squares support vector machine for modeling daily reference evapotranspiration. Irrig Sci 31:611–619
Kisi O, Parmar KS (2016) Application of least square support vector machine and multivariate adaptive regression spline models in long term prediction of river water pollution. J Hydrol 534:104–112. doi:10.1016/j.jhydrol.2015.12.014
Leathwick JR, Elith J, Hastie T (2006) Comparative performance of generalized additive models and multivariate adaptive regression splines for statistical modelling of species distributions. Ecol Model 199:188–196. doi:10.1016/j.ecolmodel.2006.05.022
Legates DR, McCabe GJ Jr (1999) Evaluating the use of “goodness-of-fit” measures in hydrologic and hydroclimatic model validation. Water Resour Res 35:233–241
Maier HR, Dandy GC (2000) Neural networks for the prediction and forecasting of water resources variables: A review of modelling issues and applications. Environ Model Softw 15:101–124. doi:10.1016/S1364-8152(99)00007-9
Nourani V, Hosseini Baghanam A, Adamowski J, Kisi O (2014) Applications of hybrid wavelet-Artificial Intelligence models in hydrology: A review. J Hydrol 514:358–377. doi:10.1016/j.jhydrol.2014.03.057
Okkan U, Ali Serbes Z (2013) The combined use of wavelet transform and black box models in reservoir inflow modeling. J Hydrol Hydromechanics 61:112–119. doi:10.2478/johh-2013-0015
Pahasa J, Ngamroo I (2011) A heuristic training-based least squares support vector machines for power system stabilization by SMES. Expert Syst Appl 38:13987–13993
Pal M, Deswal S (2009) M5 model tree based modelling of reference evapotranspiration. Hydrol Process 23:1437–1443. doi:10.1002/Hyp.7266
Quinlan JR (1992) Learning with continuous classes. In Proceedings of the 5th Australian joint Conference on Artificial Intelligence (Vol. 92, pp. 343–348). http://sci2s.ugr.es/keel/pdf/algorithm/congreso/1992-Quinlan-AI.pdf
Rezaeian-Zadeh M, Tabari H, Abghari H (2013) Prediction of monthly discharge volume by different artificial neural network algorithms in semi-arid regions. Arab J Geosci 6:2529–2537. doi:10.1007/s12517-011-0517-y
Saleh DK (2010) Stream gage descriptions and streamflow statistics for sites in the Tigris River and Euphrates River basins, Iraq. US Department of the Interior, US Geological Survey
Sarangi A, Bhattacharya AK (2005) Comparison of Artificial Neural Network and regression models for sediment loss prediction from Banha watershed in India. Agric Water Manag 78:195–208. doi:10.1016/j.agwat.2005.02.001
Sharda VN, Patel RM, Prasher SO, et al. (2006) Modeling runoff from middle Himalayan watersheds employing artificial intelligence techniques. Agric Water Manag 83:233–242. doi:10.1016/j.agwat.2006.01.003
Sharda VN, Prasher SO, Patel RM, et al. (2008) Performance of Multivariate Adaptive Regression Splines (MARS) in predicting runoff in mid-Himalayan micro-watersheds with limited data. Hydrol Sci J-J Des Sci Hydrol 53:1165–1175. doi:10.1623/hysj.53.6.1165
Shokrollahi A, Arabloo M, Gharagheizi F, Mohammadi AH (2013) Intelligent model for prediction of CO2 - Reservoir oil minimum miscibility pressure. Fuel 112:375–384. doi:10.1016/j.fuel.2013.04.036
Shortridge JE, Guikema SD, Zaitchik BF (2015) Empirical streamflow simulation for water resource management in data-scarce seasonal watersheds. Hydrol Earth Syst Sci Discuss 12:11083–11127. doi:10.5194/hessd-12-11083-2015
Singh VP, Cui H (2015) Entropy Theory for Streamflow Forecasting. Environ Process 2:449–460. doi:10.1007/s40710-015-0080-8
Solomatine DP, Dulal KN (2003) Model trees as an alternative to neural networks in rainfall—runoff modelling. Hydrol Sci J 48:399–411. doi:10.1623/hysj.48.3.399.45291
Solomatine DP, Xue Y (2004) M5 Model Trees and Neural Networks: Application to Flood Forecasting in the Upper Reach of the Huai River in China. J Hydrol Eng 9:491–501. doi:10.1061/(ASCE)1084-0699(2004)9:6(491)
Sotomayor KAL (2010) Comparison of adaptive methods using multivariate regression splines ( MARS ) and artificial neural networks backpropagation ( ANNB ) for the forecast of rain and temperatures in the Mantaro river basin. 58–68.
Suykens JA, Vandewalle J (1999) Least Squares Support Vector Machine Classifiers. Neural Process Lett 9:293–300. doi:10.1023/A
Tao B, Xu W, Pang G, Ma N (2008) Prediction of bearing raceways superfinishing based on least squares support vector machines. In: Natural Computation, 2008. ICNC’08. Fourth International Conference on. IEEE, pp 125–129
Tigkas D, Christelis V, Tsakiris G (2016) Comparative Study of Evolutionary Algorithms for the Automatic Calibration of the Medbasin-D Conceptual Hydrological Model. Environ Process. doi:10.1007/s40710-016-0147-1
Turan ME, Yurdusev MA (2014) Predicting Monthly River Flows by Genetic Fuzzy Systems. Water Resour Manag 28:4685–4697. doi:10.1007/s11269-014-0767-z
Wang WC, Chau KW, Cheng CT, Qiu L (2009) A comparison of performance of several artificial intelligence methods for forecasting monthly discharge time series. J Hydrol 374:294–306. doi:10.1016/j.jhydrol.2009.06.019
Xie G, Wang S, Zhao Y, Lai KK (2013) Hybrid approaches based on LSSVR model for container throughput forecasting: A comparative study. Appl Soft Comput 13:2232–2241. doi:10.1016/j.asoc.2013.02.002
Yaseen ZM, El-shafie A, Jaafar O, et al. (2015) Artificial intelligence based models for stream-flow forecasting: 2000–2015. J Hydrol 530:829–844. doi:10.1016/j.jhydrol.2015.10.038
Zhang W, Goh ATC (2014) Multivariate adaptive regression splines and neural network models for prediction of pile drivability. Geosci Front 7:45–52. doi:10.1016/j.gsf.2014.10.003
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article

Cite this article
Yaseen, Z.M., Kisi, O. & Demir, V. Enhancing Long-Term Streamflow Forecasting and Predicting using Periodicity Data Component: Application of Artificial Intelligence. Water Resour Manage 30, 4125–4151 (2016). https://doi.org/10.1007/s11269-016-1408-5
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11269-016-1408-5