
Abstract
In recent years, the popularity of using data science for decision-making has grown significantly. This rise in popularity has led to a significant learning challenge known as concept drifting, primarily due to the increasing use of spatial and temporal data streaming applications. Concept drift can have highly negative consequences, leading to the degradation of models used in these applications. A new model called BOASWIN-XGBoost (Bayesian Optimized Adaptive Sliding Window and XGBoost) has been introduced in this work to handle concept drift. This model is designed explicitly for classifying streaming data and comprises three main procedures: pre-processing, concept drift detection, and classification. The BOASWIN-XGBoost model utilizes a method called Bayesian-Optimized Adaptive Sliding Window (BOASWIN) to identify the presence of concept drift in the streaming data. Additionally, it employs an optimized XGBoost (eXtreme Gradient Boosting) model for classification purposes. The hyperparameter tuning approach known as BO-TPE (Bayesian Optimization with Tree-structured Parzen Estimator) is employed to fine-tune the XGBoost model's parameters, thus enhancing the classifier's performance. Seven streaming datasets were used to evaluate the proposed approach's performance, including Agrawal_a, Agrawal_g, SEA_a, SEA_g, Hyperplane, Phishing, and Weather. The simulation results demonstrate that the suggested model achieves impressive accuracy values of 70.83%, 71.02%, 76.76%, 76.96%, 84.26%, 95.53%, and 78.35% on the corresponding datasets, affirming its superior performance in handling concept drift and classifying streaming data.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
In the modern digital age, numerous applications create enormous spatiotemporal data streams that must be instantly sorted and analyzed. For a variety of systems, the capacity to understand spatiotemporal data streams in real-time is essential. Processing enormous amounts of spatiotemporal data from various sources, including online traffic, social media, sensor networks, and others, is a significant challenge [1]. Because of this, storing a lot of data for analysis is impractical. Currently, the classification of this infinitely evolving data stream is being challenged by concept drifts. Concept drift is the process by which the spread of the data input or the association between the input and the desired label alters over time. Practically, there are three ways that concept drift can happen in a situation of stream learning: (a) "sudden/abrupt drift", where there is a total change in the distribution of data; (b) "gradual drift", where the current concept gradually shifts to another concept over time; and (c) "recurring drift", where the old concept reappears after a specific interval of time [2]. Figure 1 depicts the practical types of concept drifts.

Structural types of concept drift
Assuming a sample \(\left(X,Y\right)\) in the data stream has three potential classes \((Y=\left({y}_{1}, {y}_{2}, {y}_{3}\right))\), as shown in Fig. 2, and a two-dimensional feature vector \((X=\left({x}_{1}, {x}_{2}\right))\) as well. At time t, the samples exhibit a specific distribution \({P}_{t }(X, Y)\). Concept drift happens when \({P}_{t }\left(X, Y\right) \ne {P}_{t+1 }(X, Y)\) and the distribution changes at time t + 1. Concept drift, as mentioned above, can be caused by the three factors that correspond to the equation \({P}_{t}\left(X, Y\right)= {P}_{t}\left(X\right)* {P}_{t}\left(Y|X\right)\), virtual, real, and mixed drift [3], as shown in Fig. 2. Virtual drift occurs when the decision boundary \(({P}_{t}\left(Y|X\right)= {P}_{t+1}\left(Y|X\right))\) does not change but the feature vector distribution does, as seen in Fig. 2b, f, that is: \({P}_{t}\left(X\right)\ne {P}_{t+1}\left(X\right)\). Real drift on the other hand happens when the decision boundary shifts, as in Fig. 2c, g, where \({P}_{t}\left(Y|X\right) \ne {P}_{t+1}\left(Y|X\right)\), but the feature vector distribution does not change; that is: \({P}_{t}\left(X\right) = {P}_{t+1}\left(X\right)\). Finally, as seen in Fig. 2d, h, mixed drift happens when both the decision boundary change (\({P}_{t}\left(Y|X\right) \ne {P}_{t+1}\left(Y|X\right)\)) and the feature vector distribution change (\({P}_{t}\left(X\right) \ne {P}_{t+1}\left(X\right)\)) [4]. Figure 2a, e indicates the original nature of the dataset when the concept has not changed. Concept drift, a critical aspect in evolving data analysis, can be categorized in two ways based on alterations in the class prior probability denoted as P(Y). The first category, "FixedImb," as shown in Fig. 2, signifies concept drift characterized by a fixed imbalance ratio. In this scenario, the class prior probability P(Y) remains constant, while variations occur in the class-conditional probability P(X|Y). The second category, "VarImb," represents concept drift with a variable imbalance ratio. In VarImb, the class prior probability P(Y) changes, as visually represented in Fig. 2. It is important to note that the study did not specifically delve into the investigation of class imbalance but focused on the broader concept drift phenomenon.

Factors causing concept drift [4]
The learning model performs worse if the drifts are left unattended. Concept drift is the most challenging issue in real-time learning because it significantly affects the consistency of streaming spatiotemporal data classification [5]. As a result, real-time analytics on streaming or non-stationary spatiotemporal data have recently caught the attention of researchers [6]. Spatiotemporal data streams are data collections that flow continuously and alter as they enter a system. According to [7], data streams can be enormous, ordered promptly, changed quickly, and potentially endless in duration. Due to the periodic data changes on the streaming platform, the typical mining method needs to be upgraded [8].
Constructing models that can adjust to the online adaptive analytics for the anticipated and unanticipated variations in the spatiotemporal data is vital. The importance is because the traditional machine learning (ML) models cannot handle concept drift [3]. As a result, this research suggests an ML-based drift adaptive framework for spatiotemporal streaming data analytics, which deals with data that has both spatial and temporal dimensions.
The framework consists of a "Bayesian Optimization with Tree-structured Parzen Estimator (BO-TPE)" approach for model optimization, an eXtreme Gradient Boosting model (XGBoost) for learning spatiotemporal data, and a newly proposed method called Bayesian-Optimized Adaptive and Sliding Windowing (BOASWIN) for adaptation of concept drift. The effectiveness and efficiency of the suggested adaptive framework are assessed using seven open-source datasets. The following can be used to summarize the main article's contributions:
-
Novel Drift Adaptation Approach The paper introduces a novel method called "BOASWIN" to address the challenge of concept drift in spatiotemporal data. BOASWIN offers a fresh perspective by combining Bayesian optimization and sliding window techniques. This innovative approach not only detects changes in data distribution but also optimizes model parameters to adapt effectively.
-
Efficient Adaptive Framework The research presents an adaptive framework that combines "BO-TPE" for model optimization, an "XGBoost" for learning spatiotemporal data, and the BOASWIN method for concept drift adaptation. This framework offers offline and online learning functionalities, enhancing its efficiency for spatiotemporal data categorization use cases.
-
Experimental Evaluation The proposed approach is empirically evaluated using seven open-source datasets and compared against contemporary techniques. This evaluation provides evidence of the framework's effectiveness and efficiency in handling spatiotemporal data streams with varying patterns and concept drift.
While the proposed framework for spatiotemporal streaming data analytics presents several noteworthy contributions, some limitations deserve attention. Firstly, the size and complexity of the spatiotemporal datasets it encounters might influence the framework's effectiveness. Extensive experimentation on datasets with varying scales and dimensions is imperative to gauge their scalability accurately. Additionally, despite its efficiency, the framework may introduce some computational overhead when dealing with particularly large-scale data streams. Thus, further research should explore strategies to optimize its computational efficiency.
2 Related works
Various concept drift learning strategies have been developed recently to adjust to shifting concepts [9,10,11]. "Concept drift detectors" strive to spot changes in streams by either keeping an eye on the streams' distribution or the performance of a classifier concerning some standard, like accuracy. The Adaptive Sliding Window (ADWIN) [12, 13] is a standard method for assessing a classifier's prediction accuracy, and it works under the presumption that if a change in performance is seen, the concept has been altered [14]. ADWIN breaks a window W into two adaptive subwindows, analyses the underlying statistics, and utilizes W to detect distribution changes. If no change is discovered, the main window enlarges; if a difference in the statistics of the subwindows is discovered, it shrinks. Hoeffding Bound [14] allows for the recognition of the change. The "Drift Detection Method (DDM)" [15, 16], a well-liked model performance-based approach, establishes two thresholds—a warning level and a drift level—to track changes in the standard deviation and error rate of the model for drift detection [15].
In DDM, concept drift is a frequent phenomenon characterized by a significant increase in the model's overall error rate and standard deviation. Since a learner will only be changed when its performance significantly deteriorates, DDM is easy to use and can prevent unnecessary model modifications. While DDM is good at detecting abrupt drift, it frequently responds slowly to gradual drifts. The disadvantage happens because memory overflows result from storing many data samples to meet the drift level of a long, slow drift [17]. "Early drift detection method (EDDM)", a variation of DDM [18], examines the distance between two successive misclassifications rather than the total number of misclassifications. One benefit of this detector is its lack of an input parameter [6]. An incremental learning system called Online Passive-Aggressive (OPA) [19] adapts to drift by passively responding to accurate predictions and forcefully reacting to errors. The standard K-Nearest Neighbors (KNN) model for online data analytics has been improved by "Self-Adjusting Memory with KNN (SAM-KNN)" [20]. The SAM-KNN algorithm uses two memory modules to adjust to concept drift: Short-term memory (STM) for the present concept and long-term memory (LTM) for prior conceptions [20]. Lu et al. presented the chunk-based dynamic weighted majority to analyze data streams with concept drift, in which the chunk size was adaptively chosen using statistical hypothesis testing [5]. To increase the classification accuracy, Zhang et al. suggested a three-layer concept drift detection method [21]. A framework for drifting data stream classification that integrates data pre-processing and the dynamic ensemble selection approach is proposed. It uses stratified bagging to train base classifiers [22]. Concept drift detection is achieved using a cluster-based histogram, and segmentation loss minimization increases the method's sensitivity [11]. In [23], the selective ensemble technique suggests adopting a deep neural network to solve the concept drift problem. Shallow and deep features are merged in the depth unit to improve the convergence of the online deep learning model. A semi-supervised classification system was suggested by Din et al., where the micro-clusters were dynamically maintained to capture idea drift in data streams [24]. The diversified dual ensemble model is built for the drifting data stream, where the weights are updated dynamically and adaptively to identify gradual drift and rapid drift [25]. The aforementioned studies are successful at resolving concept drift, but based on this review, classifier performance received more focus than stream data distributions. As a result, in this research, we examine both classifier performance and streaming data distribution for better classifications.
3 Proposed model
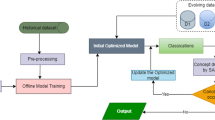
This study proposed an optimized adaptive sliding window with the XGBoost model called the BOASWIN-XGBoost model, which monitors the classifier's performance and regulates the streaming distribution of data into the classifier for improved classification. Figure 3 illustrates the three components of the suggested paradigm: pre-processing (stage 1), concept drift detection and classification. An initial XGBoost model is trained using the historical dataset. Additionally, Bayesian Optimization, a hyperparameter optimization (HPO) technique, is used to adjust the XGBoost model's hyperparameters to produce the optimized XGBoost model.

Proposed model framework
The suggested system will handle the data streams continuously produced throughout time. The next step in this method is processing (stage 3) the data streams using the initial XGBoost model obtained. Suppose concept drift (stage 2) is discovered in the new data streams using the proposed BOASWIN approach, fitting the current concept of the new data streams. In that case, the XGBoost model will be retrained on the new concept data samples obtained by the adaptive window of BOASWIN. The suggested system can adapt to the new data streams' ever-changing patterns to maintain correct classifications. The classifier's performance is monitored, and the distribution of data streams is also controlled.
3.1 XGBoost model
A powerful ensemble machine learning model built on decision trees is the eXtreme Gradient Boosting (XGBoost) model [26]. The XGBoost discussed in [27] was created using a GBDT (Gradient Boosting Decision Tree), and it was shown to have excellent convergence and generalization speed [28]. In [28], the XGBoost algorithm's goal function and optimization strategy were introduced. XGBoost's target function is given by Eq. 1 [29].
where \(L\left(\theta \right)=l\left({\widehat{y}}_{i},{y}_{i}\right)\) and \(\Omega \left(\theta \right)=\gamma {\text{T}}+\frac{1}{2}\lambda \Vert \mathcalligra{w}{||}^{2}\).
The objective function (\(Obj\left(\theta \right)\)) which is to be optimized is divided into two sections: \(L\left(\theta \right)\) and \(\Omega \left(\theta \right)\). θ corresponds to the formula's numerous parameters. The goal is to find the values of θ that minimize this function. The difference between the forecast \({\widehat{y}}_{i}\) and the target \({y}_{i}\) is measured by \(L\left(\theta \right)\), a differentiable convex loss function. The point is to demonstrate how to incorporate the facts into the framework [29]. Convex loss functions frequently employed, such as the mean square loss function in Eq. 2 and the logistic loss function shown in Eq. 3, can be employed in the above equation.
Complex models are penalized by the regularized term \(\Omega \left(\theta \right)\). \(\mathrm{T}\) is the number of leaves in the tree, and \(\gamma \) is the learning rate, which ranges from 0 to 1. When multiplied by \(\mathrm{T}\), it equals spanning tree pruning, which prevents overfitting. When compared to the classic GBDT algorithm, the XGBoost algorithm increases the term \(\frac{1}{2}\lambda \Vert \mathcalligra{w}{||}^{2}\). The regularized parameter is, while \(\mathcalligra{w}\) is the weight of the leaves. The value of this item can be increased to prevent the model from fitting and to improve its generalization capabilities. On the other hand, including model penalty items with functions as parameters leads to the failure of classical approaches to be optimized by the objective function in Eq. 1. As a result, we must assess if we can learn to obtain the aim \({y}_{i}\) as seen in Eq. 4 [29].
where, in the \(t\) iteration, \({S}_{t}\left({\mathrm{T}}_{i}\right)\) denotes the tree produced by instance \(i\), and n number of points.
The optimization target in each iteration is to build a tree design that minimizes the aimed function. Hence, when solving the square loss function, the objective function of Eq. 4 is optimal, but it becomes tricky when calculating other loss functions. As a result, Eq. 4 translates Eq. 5 using the two-order Taylor expansion, allowing further loss functions to be solved.
where \({g}_{i}={\partial }_{{\widehat{y}}^{\left(t-1\right)}}l\left({y}_{i},{\widehat{y}}^{\left(t-1\right)}\right)\) which is the 1st derivative of the error function and \({h}_{i}={\partial }_{{\widehat{y}}^{\left(t-1\right)}}^{2}l\left({y}_{i},{\widehat{y}}^{\left(t-1\right)}\right)\) is the 2nd derivative of the error function.
Because the tree model needs to find the best segmentation points and store them in several blocks, the algorithm ranks the eigenvalues based on the realization of XGBoost. This structure is reused in subsequent iterations, resulting in a significant reduction in computing complexity. Furthermore, the information gain of each feature must be determined during the node splitting process, which employs the greed algorithm, as shown in algorithm 1, allowing the calculation of information gain to be parallelized [28].

Split finding greed algorithm
Algorithm 1 utilizes a greedy approach as its fundamental strategy. Its primary concept involves an initial sorting of the data based on eigenvalues. Subsequently, it proceeds by iterating through each feature. It considers every possible value as a potential splitting point for each feature and computes the corresponding gain and loss. After evaluating all features in this manner, the algorithm identifies the most distinctive value for gain loss as the optimal splitting point. Within the algorithm, 'j' represents the index used to iterate through all eigen attribute values during the sorting process, while 'k' is employed to iterate through all samples.
3.2 Dynamic hyperparameter tuning
Dynamic hyperparameter tuning strategies are pivotal in ensuring that machine learning models maintain their effectiveness in changing data characteristics. These strategies enable models to adapt and optimize their hyperparameters to match evolving data distributions.
Dynamic hyperparameter tuning, as outlined in the literature [30], involves automatically adjusting hyperparameters during training and inference. One of the primary ways it achieves this is through a learning rate schedule. Learning rate scheduling dynamically adapts the learning rate based on performance metrics or predefined schedules. For instance, the learning rate may be reduced when the loss plateaus, allowing the model to fine-tune its parameters more delicately in response to data changes [31].
Another strategy involves early stopping, a widely recognized technique [32]. By monitoring a validation metric such as validation loss, the model's training can be halted when it begins to deteriorate, thereby preventing overfitting and ensuring that the model remains robust to variations in data characteristics. Adaptive optimizers like Adam and RMSprop [33] are also valuable in dynamic hyperparameter tuning. These optimizers adapt the learning rates for individual model parameters based on their gradients, allowing the model to navigate through varying data landscapes effectively.
Hyperparameter search methods, as discussed in research by Wu et al. [34], can continuously seek optimal hyperparameter configurations as data evolves. Techniques like Bayesian optimization or grid search can be employed to identify the best hyperparameters for the current data distribution, ensuring the model's adaptability. Ensemble models [35] and online learning [19] are further strategies for adapting models to changing data patterns by combining multiple models or incrementally updating the model with new data.
In summary, dynamic hyperparameter tuning strategies, backed by research in the field, provide the means for models to adapt their hyperparameters to continuously changing data characteristics. By incorporating these strategies, machine learning models can maintain their performance and relevance over time. They are well-suited for real-world applications where data is subject to fluctuations and shifts.
3.2.1 Bayesian optimization (BO)
BO [36] models were created to solve optimization issues. BO comprises two essential components: surrogate models for simulating the objective function and an acquisition function for measuring the value produced by the objective function's assessment at a new location [37]. These activities, exploration and exploitation occur during BO processes. Exploration is exploring previously unexplored areas, whereas exploitation is analyzing samples in the current zone where the global optimum is most likely. These activities should be balanced according to BO models [38]. "The Gaussian Process (GP)" and "The Tree Parzen Estimator (TPE)" are two popular models used as BO surrogate models [39, 40]. Based on the surrogate model used, BO models can be divided into BO-GP and BO-TPE models [41]. In this study, we adopted the BO-TPE due to the drawback of BO-GP, which restricts parallelizability due to its cubic computational complexity, O(n3). Among BO surrogate models, the Tree-structured Parzen Estimator (TPE) [40] is well-liked. BO-TPE creates two density functions, l(x) and g(x), that act as generative models for all processed data instead of deriving a prediction distribution for the objective function. As part of BO-TPE, the input data is divided into two groups (good and poor observations) depending on a predetermined threshold * that is modeled using standard Parzen windows (Eq. 6):
where y = f(x) represents the prediction for input data x, and D is the configuration search space.
Due to its capacity to optimize complex configurations with low computational complexity of O(nlogn), BO-TPE has demonstrated excellent performance when applied to a variety of machine learning applications [37, 38]. Furthermore, TPE can accurately handle conditional variables because it uses a tree structure to keep conditional dependencies [42]. Hence, we used the BO to optimize the proposed adaptative XGBoost and the adaptive sliding windows for effective concept drift handling in spatiotemporal data streams.
3.3 Bayesian optimized adaptive sliding window (BOASWIN)
As seen from the literature [13, 17], the adaptive sliding windows continue to grow large enough to detect a drift; however, this is a drawback. Since drifts like the gradual drift may occur unnoticed, this will give the classifier a wrong classification since the gradual drift is not detected promptly. To handle this challenge and check the distribution of the streams, we proposed BOASWIN. Here, our windows are made to be variables, giving room for close monitoring.
The BOASWIN approach is suggested in this study to provide reliable analytics. It is intended to detect concept drift and adapt to the continually changing data stream. BOASWIN was created based on synthesizing concepts from sliding and adaptable window-based methods, performance-based approaches, and window-based strategies. Two essential functions, "ConceptDriftAdaptation" and "HPO_BO-TPE," comprise the entire BOASWIN technique. With the help of the supplied hyperparameter settings, the "ConceptDriftAdaptation" function seeks to identify concept drift in streaming data and update the XGBoost model with fresh concept samples for drift adaptation. The "ConceptDriftAdaptation" function's hyperparameters are tuned and optimized using BO-TPE by the "HPO_BO-TPE" function. A sliding window (P) for concept drift detection and an adaptive window (Pmax) for storing new concept samples are the two different types of windows in BOASWIN. The concept drift detection method also uses two thresholds to indicate the drift level: α and the warning level: β.
Four parameters in the BOASWIN proposed method, α, β, P, and Pmax are the crucial hyperparameters that directly affect how well the BOASWIN model performs. Since BO is successful for both discrete and continuous hyperparameters, to which the hyperparameters of BOASWIN correspond, it is utilized to change these four hyperparameters to provide the optimal adaptive learner. We adopted the adaptive sliding window algorithm proposed in [43] [44] and modified it to achieve our goals. Hence, the algorithm for our proposed BOASWIN is given in algorithm 2.

Bayesian-optimized adaptive sliding window (BOASWIN)
4 Experimental analysis
Our experiment is carried out and analyzed using the River [45] library and Python 3.9. Our suggested approach, BOASWIN-XGBoost, is compared to seven cutting-edge models, including ADWIN, DDM, EDDM, OPA, SAM-KNN, SRP, and XGBoost. Here, we aim to assess a fair comparison between these models regarding how well they perform in the face of various types of concept drift.
4.1 Datasets used in the study
Where an actual drift genuinely is must be determined before we can evaluate a drift detector's performance using the various detection criteria. Only synthetic datasets make this possible. The scikit-multiflow framework enables the creation of various types of synthetic data to simulate the occurrence of drifts [46]. Table 1 includes specific details about the seven datasets that were used in this research.
Agrawal generator [47] has three categorical elements and six numeric attributes to describe the hypothetical loan applications. A perturbation factor for the numeric characteristics offsets the actual value and causes it to shift. It can provide ten functions to assess whether or not the loan should be granted. By altering the functions, the concept drift takes place.
SEA generator [48] is comprised of two classes, three numerical attributes produced at random, and noise for the third attribute. In the range [0,10], the numbers are created at random. Each instance is classified as class 1 if \({f}_{1}+{f}_{2} \le \theta \), where \({f}_{1}\) and \({f}_{2}\) are the first two characteristics, and is a threshold that generates several contexts, has a value of 8, 9, 7, or 9.5.
The weather dataset consists of over 9000 weather stations worldwide and has provided data to the US National Oceanic and Atmospheric Administration. Records go back to the 1930s and offer various weather patterns. Temperature, pressure, wind speed, and other variables are measured every day, along with indications for precipitation and other weather-related phenomena. We used the Offutt Air Force Base in Bellevue, Nebraska, as a representative real-world dataset for this experiment because of its vast period of 50 years (1949–1999) and a variety of weather patterns that make it a long-term precipitation classification/prediction drift challenge [49].
HyperPlane In this data set, the ideas that have gradually changed are calculated using the formula \(f\left(x\right)={\sum }_{i=1}^{d-1}{a}_{i}*\left(\left({x}_{i}+{x}_{i+1}\right)/{x}_{i}\right)\), where d = 10 is the dimension and ai is utilized to regulate the decision hyperplane [50].
The phishing dataset, distinguishing between dangerous and benign web pages, is taken from [51]. A typical classification problem was assumed to be represented by the digits dataset [51].
4.2 Results and discussion
BO automatically tunes the hyperparameters of the XGBoost and BOASWIN models to produce optimum versions. Table 2 displays the XGBoost and BOASWIN models' initial hyperparameter search range and discovered hyperparameter values for the seven datasets under consideration. After applying BO to create optimized models for spatiotemporal classifications, the proposed models were given the ideal hyperparameter values. Table 3 shows the default and optimized classification accuracy for the seven datasets used, in which the optimized were higher than the default.
4.2.1 Analysis of varying window size
As part of our goal to monitor the stream data distribution in the sliding windows, Table 4 shows the experiments carried out in this study with varying window sizes to see which sizes of these windows produced good results in the presence of concept drift. It was observed that moderate-sized windows produce good outputs regarding the classifier accuracy on the seven datasets used in this study. The bold values from Table 4 were the best parameters; hence, they were used to detect changes in the datasets used, and the results of the experiments are shown in Fig. 4.

Drift points detection graphs
4.2.2 Drift points
Drift points are those specific moments or data points where these changes become evident, often leading to the need for model adaptation or retraining. Identifying and monitoring drift points is crucial for maintaining model accuracy and effectiveness in applications that involve evolving data distributions. In Fig. 4, the dots indicate the change points in the datasets used. The blue lines representing our proposed model could track the point of drifts while maintaining a higher classification accuracy than the offline XGBoost model in red lines. The suggested accuracy of the BOASWIN + XGBoost model is compared in Table 5 to the cutting-edge drift adaptive techniques described in an earlier section.
4.2.3 Analysis of AGRAWAL dataset
Table 5 shows that the suggested adaptive model performs better than all previous techniques regarding accuracy on the seven datasets used in this study. Bold values show the best outcomes for each dataset in Table 5.
The proposed technique, implemented on the AGRAWAL_a dataset and illustrated in Fig. 5, attained the most excellent accuracy of 70.83% among all implemented models by adjusting to the sudden concept drift found in the dataset. The offline XGBoost model's accuracy is 70.53% without drift adaption, which is slightly less accurate. The accuracy ratings of the other six cutting-edge methods are also less accurate than those of our proposed strategy. Additionally, as shown in Fig. 6, our suggested model (BOASWIN + XGBoost) indicated as "OURs" beat other state-of-the-art models in terms of precision, recall, and f1-score (69.61%, 67.87%, and 68.73%, respectively).

Comparison of the accuracy of the AGR_a dataset using different drift adaption techniques

Comparison of the proposed model's precision, recall, and f1-score and other state-of-the-art models on the Agrawal_a dataset
There is a gradual drift on the AGRAWAL_g dataset. As seen in Fig. 7 and Table 5, the suggested technique attained the best accuracy of 71.02% by responding to the gradual drift identified. In comparison, the offline XGBoost model's accuracy reduces significantly to only 70.28% without drift adaptation. This places a focus on the advancement of our proposed drift adaption technique. The proposed technique is substantially more accurate than the other six examined methods, OPA, SAM-KNN, SRP, ADWIN, DDM and EDDM, with accuracy values of 50.32%, 53.71%, 67.15%, 67.78%, 67.18%, and 67.03% respectively. Figure 8 depicts our proposed model's precision, recall, and f1-score comparison with the models experimented with in this study. However, the proposed model was best in precision and f1-score with values of 69.47% and 69.00%, respectively, while the XGBoost model had the highest recall value of 69.83%.

Comparison of the accuracy of the AGRAWAL_g dataset using different drift adaption techniques

Comparison of the proposed model's precision, recall, and f1-score and other state-of-the-art models on the Agrawal_g dataset
The success of "BOASWIN + XGBoost" on the AGRAWAL datasets can be attributed to the synergistic combination of Bayesian optimization (BOASWIN) and the XGBoost model. While other methods struggle to adapt to concept drift adequately, the proposed approach optimizes model hyperparameters dynamically, ensuring robust performance even in changing data distributions.
4.2.4 Analysis of the SEA datasets
The suggested BOASWIN + XGBoost model's accuracy is compared on the SEA_a dataset, which contained sudden drift, and on the SEA_g dataset, which contained gradual drift. Figure 9 compares the proposed model outperforming the other models by adjusting to the sudden concept drift found in the dataset. Figure 10 compares the proposed model outperforming the others by adjusting to gradual drift in the SEA_g dataset. The proposed model attained the most remarkable accuracy of 76.76% on the SEA_a dataset in Fig. 9 and 76.96% on the SEA_g dataset in Fig. 10 among all implemented models. Figure 11 depicts our proposed model's precision, recall, and f1-score comparison with the models experimented with in this study. However, the proposed model was best in precision with a value of 76.81%, while the XGBoost model had the highest values of recall and f1-score of 80.05% and 76.82%, respectively.

Comparison of the accuracy of the SEA_a dataset using different drift adaption techniques

Comparison of the accuracy of the SEA_g dataset using different drift adaption techniques

Comparison of the proposed model's precision, recall, and f1-score and other state-of-the-art models on the SEA_a dataset
Figure 12 depicts our proposed model's precision, recall, and f1-score comparison with the other models experimented with in this study. The proposed BOASWIN + XGBoost model outperformed all the other models concerning precision and f1-score with the highest values of 76.93% and 76.86%, respectively, while the XGBoost model has the best recall value of 79.25%.

Comparison of the proposed model's precision, recall, and f1-score and other state-of-the-art models on the SEA_g dataset
4.2.5 Analysis of the HYPERPLANE dataset
A significant drift at the start of the HYP dataset test set contained sudden and reoccurring concept drift. As seen in Fig. 13, the suggested technique attained the best accuracy of 84.26% by responding to both the sudden and reoccurring drifts identified. In comparison, the offline XGBoost model's accuracy reduces significantly to only 74.66% without drift adaptation. The proposed technique is substantially more accurate than the other six examined methods, OPA, SAM-KNN, SRP, ADWIN, DDM and EDDM, with accuracy values of 81.95%, 75.59%, 76.62%, 79.59%, 78.26%, and 77.44% respectively. Figure 14 compares the precision, recall, and f1-score of our proposed model on the HYP dataset with the other models in this study. The proposed BOASWIN + XGBoost model outperformed all the other models concerning precision, recall, and f1-score with the highest values of 84.02%, 84.64%, and 84.33%, respectively.

Comparison of the accuracy of the HYP dataset using different drift adaption techniques

Comparison of the proposed model's precision, recall, and f1-score and other state-of-the-art models on the HYP dataset
4.2.6 Analysis of PHISHING and WEATHER datasets
The proposed BOASWIN + XGBoost model's accuracy is evaluated using the real-world datasets PHI and WET, which contain drifts. Using the PHI data set, Fig. 15 compares the performance of the suggested model with that of the competing models. Figure 16 compares the performance of the proposed model with that of the other models using the WET data set. The proposed model outperformed the other models by responding to changes detected in the PHI data set with an accuracy of 95.53%. The proposed model's accuracy score of 78.35% was the highest for the WET data set. Figure 17 compares the precision, recall, and f1-score of our suggested model on the PHI data set with the other models tested in this work. The proposed BOASWIN + XGBoost model outperformed all the other models concerning precision, recall, and f1-score with the highest values of 94.99%, 97.10%, and 96.03%, respectively.

Comparison of the accuracy of the PHI dataset using different drift adaption techniques

Comparison of the accuracy of the WET dataset using different drift adaption techniques

Comparison of the proposed model's precision, recall, and f1-score and other state-of-the-art models on the PHI dataset
Figure 18 compares our suggested model's precision, recall, and f1-score with the models tested in this study on the WET data set. However, the XGBoost model had the highest precision value of 73.69%, while the proposed model had the best recall and f1-score with values of 58.66% and 63.38%, respectively.

Comparison of the proposed model's precision, recall, and f1-score and other state-of-the-art models on the WET dataset
The results obtained from the proposed "BOASWIN + XGBoost" model exhibit significant implications for both false positives and false negatives in classification tasks. These implications stem from the model's performance in key metrics such as precision, recall, F1-score, and accuracy, directly influencing its ability to handle concept drift effectively.
Firstly, let's consider the effect of these results on false positives (Type I Errors). Precision, a critical metric, represents the ratio of true positives to the total predicted positives. When "BOASWIN + XGBoost" achieves higher precision than other models, it implies that the model correctly classifies positive instances while minimizing false positives. This outcome is paramount when false positives can have substantial consequences, such as in medical diagnosis or fraud detection. The model's superior precision suggests that it reduces the risk of falsely flagging instances as positive when they are, in fact, harmful.
On the other hand, the results also have a significant impact on false negatives (Type II Errors). Recall, another essential metric, quantifies the ratio of true positives to the total actual positives. When "BOASWIN + XGBoost" achieves higher recall, the model is proficient at capturing actual positive instances while reducing false negatives. In practical terms, the model is less likely to miss positive cases, leading to a lower rate of false negatives. This characteristic is especially critical in applications where missing positive instances can have severe consequences, such as in medical screenings or cybersecurity, where failing to detect diseases or security breaches can be detrimental.
Moreover, the F1-score, a metric that balances precision and recall, plays a pivotal role. A higher F1-score achieved by "BOASWIN + XGBoost" suggests an effective trade-off between reducing false positives and false negatives. This balance is crucial in real-world scenarios where both types of errors can have significant implications. The model's ability to maintain high precision and recall implies that it can adapt to concept drift without disproportionately increasing either false positives or false negatives, making it an invaluable choice for applications where balanced performance is paramount.
In conclusion, the performance results of "BOASWIN + XGBoost" on precision, recall, F1-score, and accuracy collectively indicate its capability to achieve a harmonious equilibrium between minimizing false positives and false negatives. This equilibrium is essential in diverse real-world settings where the consequences of classification errors can vary widely. The model's ability to maintain this balance while handling concept drift positions it as a robust and adaptable solution for applications demanding accurate and well-balanced classifications.
4.2.7 Analysis of the average time
As shown in Fig. 19 and Table 5, the suggested method for real-time learning is evaluated by calculating the average prediction time for each occurrence while considering time in spatiotemporal systems. OPA, SAM-KNN, SRP, ADWIN, DDM, and EDDM all have prediction times that are less than the suggested model, but their accuracy is substantially worse. Regarding the trade-off between accuracy and efficiency, the proposed method continues to outperform the methods in the presence of concept drift. The experimental findings demonstrate the potency and reliability of the suggested BOASWIN + XGBoost model for spatiotemporal streaming data analytics.

Comparison of the average execution time of all the models used on the seven experimented datasets
In the AGR_a and AGR_g datasets, most models exhibit relatively short processing times, ranging from 0.36 to 65.43 min. While OPA operates swiftly, SRP, DDM, and EDDM require the most extensive processing durations. However, BOASWIN-XGBoost stands out for its relatively longer processing times in these datasets, with 40.03 and 65.43 min, respectively.
Across the SEA_a and SEA_g datasets, OPA, SAM-KNN, and ADWIN consistently demonstrate minimal processing times within the 0.02–0.33 min range. Here, too, BOASWIN-XGBoost exhibits longer processing times, which can be attributed to its intricate algorithm and comprehensive approach to handling concept drift.
However, XGBoost and BOASWIN-XGBoost stand out for their relatively longer processing times, especially in the case of SEA_a, where XGBoost's duration is notably higher. OPA is the quickest in the HYPERPLANE dataset, taking only 0.07 min. In contrast, BOASWIN-XGBoost significantly extends the processing time to 25.73 min, suggesting it may not be ideal for real-time applications within this dataset. This extended processing time for BOASWIN-XGBoost can be attributed to the complexity of its algorithm, which likely involves advanced techniques to maintain high predictive accuracy in the face of concept drift.
In the PHISHING dataset, OPA boasts the fastest processing time at 0.007 min, while both XGBoost and BOASWIN-XGBoost require more extensive processing periods, with XGBoost notably exceeding the duration of OPA. Again, this longer processing time for BOASWIN-XGBoost reflects its thorough approach to concept drift handling.
Lastly, within the WEATHER dataset, OPA maintains its reputation as the swiftest, with a mere 0.004 min. BOASWIN-XGBoost necessitates more processing time but remains within reasonable limits at 2.32 min. The extended processing time for BOASWIN-XGBoost in various datasets can be attributed to its algorithm's complexity and the thoroughness with which it tackles concept drift, resulting in higher predictive accuracy but longer processing durations.
BOASWIN-XGBoost appears to excel for several reasons in the context of drift adaption techniques. First and foremost, it is crucial to recognize that its average time consumption does not solely determine the effectiveness of a drift adaption technique. Instead, it balances time efficiency and maintaining high predictive accuracy in the face of concept drift. BOASWIN-XGBoost appears to strike this balance effectively, as it consistently achieves competitive or even superior performance compared to other techniques.
One key factor contributing to the strong performance of BOASWIN-XGBoost is its adaptability. Concept drift, which occurs when the underlying data distribution changes over time, is a common challenge in many machine learning applications. BOASWIN-XGBoost possesses a robust mechanism for detecting and adapting to these changes efficiently, reflected in its high accuracy, precision, recall, and F1-score across diverse datasets.
In conclusion, the BOASWIN + XGBoost model's suitability in real-time or resource-constrained scenarios depends on the task's context and requirements. While it can be computationally expensive, its accuracy benefits should be balanced against available resources and decision urgency. Careful model selection, deployment optimizations, and hardware choices can make it viable in various applications.
5 Conclusion
In this research endeavor, we have delved into handling concept drift within non-stationary spatiotemporal data streams. This challenge has grown exponentially in significance with the proliferation of data-rich environments. Our novel approach, BOASWIN, which marries an adaptive XGBoost-based model with the BO-TPE hyperparameter optimization strategy, has emerged as a potent tool for spatiotemporal data analytics. The outcomes of our extensive experimentation, involving seven diverse datasets (AGR_a, AGR_g, SEA_a, SEA_g, HYP, PHI, and WET), have yielded insights of paramount importance. One of the paramount findings of our research is the remarkable and consistent superiority of our model's classification performance over a spectrum of state-of-the-art drift adaptation techniques. On dataset AGR_a, BOASWIN + XGBoost achieved an accuracy rate of 70.83%.
Similarly, on dataset AGR_g, the model demonstrated an accuracy rate of 71.02%. This trend of outperforming other techniques was maintained across datasets SEA_a (76.76%), SEA_g (76.96%), HYP (84.26%), PHI (95.5%), and WET (78.35%). These results underscore the model's effectiveness in maintaining high classification accuracy rates across all datasets examined. The adaptability of BOASWIN + XGBoost, which enables it to respond autonomously to evolving data patterns, emerges as a critical asset in this research. Not only does it enhance classification accuracy, but it also ensures that models remain pertinent in scenarios where data distributions undergo continuous and unpredictable changes. This adaptability is a testament to the model's practicality in real-world applications where dynamic data streams are the norm. The implications of our research extend far beyond academia, carrying profound significance for a wide array of practical applications. Fields such as environmental monitoring, urban planning, and disaster management stand to gain immensely from the availability of reliable and adaptive classification models. Our work represents a significant step in ensuring these domains can make informed decisions despite rapidly changing spatiotemporal data. As we chart our course into the future of spatiotemporal data analytics, we anticipate that our findings and limitations, as presented in section one, will catalyze the development of more resilient and effective solutions in handling concept drift within spatiotemporal data streams, thereby benefiting a multitude of applications and domains.
Availability of data and materials
The datasets generated during and analyzed during the current study are available from the corresponding author upon reasonable request.
References
Angbera A, Chan HY (2022) A novel true-real-time spatiotemporal data stream processing framework. Jordan J Comput Inf Technol (JJCIT) 8(3):256–270
Tanha J, Samadi N, Abdi Y, Razzaghi-asl N (2022) CPSSDS: conformal prediction for semi-supervised classification on data streams. Inf Sci 584:212–234. https://doi.org/10.1016/j.ins.2021.10.068
Lu J, Liu A, Dong F, Gu F, Gama J, Zhang G (2019) Learning under concept drift: a review. IEEE Trans Knowl Data Eng 31(12):2346–2363. https://doi.org/10.1109/TKDE.2018.2876857
Liu W, Zhang H, Ding Z, Liu Q, Zhu C (2021) A comprehensive active learning method for multiclass imbalanced data streams with concept drift. Knowl-Based Syst 215:106778. https://doi.org/10.1016/j.knosys.2021.106778
Yang L, Cheung Y-M, YanTang Y (2020) Adaptive chunk-based dynamic weighted majority for imbalanced data streams with concept drift. IEEE Trans Neural Netw Learn Syst 31(8):2764–2778. https://doi.org/10.1109/TNNLS.2019.2951814
Suárez-Cetrulo AL, Quintana D, Cervantes A (2022) A survey on machine learning for recurring concept drifting data streams. Expert Syst Appl. https://doi.org/10.1016/j.eswa.2022.118934
Gama J, Zliobaite I, Bifet A, Pechenizkiy M, Bouchachia A (2013) A survey on concept drift adaptation. ACM Comput Surv 1(1):35. https://doi.org/10.1145/0000000.0000000
Priya S, Uthra RA (2020) Comprehensive analysis for class imbalance data with concept drift using ensemble based classification. J Ambient Intell Humaniz Comput 12(5):4943–4956. https://doi.org/10.1007/s12652-020-01934-y
Liu A, Lu J, Liu F, Zhang G (2018) Accumulating regional density dissimilarity for concept drift detection in data streams. Pattern Recogn 76:256–272. https://doi.org/10.1016/j.patcog.2017.11.009
Liao G et al (2022) A novel semi-supervised classification approach for evolving data streams. Expert Syst Appl. https://doi.org/10.1016/j.eswa.2022.119273
Liu A, Lu J, Zhang G (2021) Concept drift detection via equal intensity k-means space partitioning. IEEE Trans Cybern 51(6):3198–3211. https://doi.org/10.1109/TCYB.2020.2983962
Bifet A, Gavaldà R (2007) Learning from time-changing data with adaptive windowing. In: Proceedings of the 7th SIAM International Conference on Data Mining, pp 443–448. https://doi.org/10.1137/1.9781611972771.42
Santos SGTC, Barros RSM, Gonçalves PM (2019) A differential evolution based method for tuning concept drift detectors in data streams. Inf Sci J 485:376–393
Raab C, Heusinger M, Schleif FM (2020) Reactive soft prototype computing for concept drift streams. Neurocomputing 416:340–351. https://doi.org/10.1016/j.neucom.2019.11.111
Gama J, Medas P, Castillo G, Rodrigues P (2004) Learning with drift detection. In: Lecture Notes in Computer Science (including Subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics), vol 3171, pp 286–295. https://doi.org/10.1007/978-3-540-28645-5_29
Yang L, Manias DM, Shami A (2021) PWPAE: an ensemble framework for concept drift adaptation in IoT data streams. In: 2021 IEEE Global Communications Conference, GLOBECOM 2021—Proceedings, pp 1–6. https://doi.org/10.1109/GLOBECOM46510.2021.9685338
Wares S, Isaacs J, Elyan E (2019) Data stream mining: methods and challenges for handling concept drift. SN Appl Sci 1(11):1–19. https://doi.org/10.1007/s42452-019-1433-0
Baena-Garcia M, Del Campo-Avila J, Fidalgo R, Bifet A, Gavalda R, Morales-bueno R (2006) Early drift detection method. In: 4th ECML PKDD International Workshop on Knowledge Discovery from Data Streams, vol 6, pp 77–86
Crammer K, Dekel O, Keshet J, Shalev-Shwartz S, Singer Y (2006) Online passive-aggressive algorithms. J Mach Learn Res 7:551–585
Losing V, Hammer B, Wersing H (2017) Self-adjusting memory: how to deal with diverse drift types. In: IJCAI International Joint Conference on Artificial Intelligence, October, pp 4899–4903. https://doi.org/10.24963/ijcai.2017/690
Zhang Y, Chu G, Li P, Hu X, Wu X (2017) Three-layer concept drifting detection in text data streams. Neurocomputing 260:393–403. https://doi.org/10.1016/j.neucom.2017.04.047
Zyblewski P, Sabourin R, Woźniak M (2021) Preprocessed dynamic classifier ensemble selection for highly imbalanced drifted data streams. Inf Fus 66:138–154. https://doi.org/10.1016/j.inffus.2020.09.004
Guo H, Zhang S, Wang W (2021) Selective ensemble-based online adaptive deep neural networks for streaming data with concept drift. Neural Netw 142:437–456. https://doi.org/10.1016/j.neunet.2021.06.027
UdDin S, Shao J, Kumar J, Ali W, Liu J, Ye Y (2020) Online reliable semi-supervised learning on evolving data streams. Inf Sci 525:153–171. https://doi.org/10.1016/j.ins.2020.03.052
Goel K, Batra S (2022) Dynamically adaptive and diverse dual ensemble learning approach for handling concept drift in data streams. Comput Intell 38(2):463–505
Yang L, Moubayed A, Hamieh I, Shami A (2019) Tree-based intelligent intrusion detection system in internet of vehicles. In: 2019 IEEE Global Communications Conference, GLOBECOM 2019—Proceedings, no. Ml. https://doi.org/10.1109/GLOBECOM38437.2019.9013892
Chen T, Guestrin C (2016) XGBoost: a scalable tree boosting system. In: Proceedings of the ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, vol 13–17-August, pp 785–794
Jiang Y, Tong G, Yin H, Xiong N (2019) A pedestrian detection method based on genetic algorithm for optimise XGBoost training parameters. IEEE Access 7:118310–118321. https://doi.org/10.1109/ACCESS.2019.2936454
Chen Z, Jiang F, ChengY, Gu X, Liu W, Peng J (2018) XGBoost classifier for DDoS attack detection and analysis in SDN-based cloud. In: Proceedings—2018 IEEE International Conference on Big Data and Smart Computing, BigComp 2018, pp 251–256. https://doi.org/10.1109/BigComp.2018.00044
Smith LN (2018) A disciplined approach to neural network hyper-parameters: part 1—learning rate, batch size, momentum, and weight decay, pp 1–21. http://arxiv.org/abs/1803.09820
Ruder S (2016) An overview of gradient descent optimization algorithms, pp 1–14. http://arxiv.org/abs/1609.04747
Prechelt L (1998) Early stopping—but when? Early stopping is not quite as simple, pp 55–69
Kingma DP, Ba JL (2015) Adam: a method for stochastic optimization. In: 3rd International Conference on Learning Representations, ICLR 2015—Conference Track Proceedings, pp 1–15
Wu J, Chen XY, Zhang H, Xiong LD, Lei H, Deng SH (2019) Hyperparameter optimization for machine learning models based on Bayesian optimization. J Electron Sci Technol 17(1):26–40. https://doi.org/10.11989/JEST.1674-862X.80904120
Caruana R, Ksikes A, Crew G (2014) Ensemble selection from libraries of models. In: Proceedings of the Twenty-First International Conference on Machine Learning. https://doi.org/10.1145/1015330.1015432
Snoek J, Larochelle H, Adams RP (2012) Practical Bayesian optimization of machine learning algorithms. Adv Neural Inf Process Syst 4:2951–2959
El Shawi R, Sakr S (2020) Automated machine learning: techniques and frameworks. In: Kutsche R-D, Zimanyi E (eds) Big Data Management and Analytics. Springer, Cham, pp 40–69
Yang L, Shami A (2020) On hyperparameter optimization of machine learning algorithms: theory and practice. Neurocomputing 415:295–316. https://doi.org/10.1016/j.neucom.2020.07.061
Seeger M (2004) Gaussian processes for machine learning University of California at Berkeley. Int J Neural Syst 14:69–109
Bergstra J, Bardenet R, Bengio Y, Kégl B (2011) Algorithms for hyper-parameter optimization. In: Advances in Neural Information Processing Systems, vol 24. https://proceedings.neurips.cc/paper/2011/file/86e8f7ab32cfd12577bc2619bc635690-Paper.pdf
Injadat M, Moubayed A, Nassif AB, Shami A (2021) Multi-stage optimized machine learning framework for network intrusion detection. IEEE Trans Netw Serv Manag 18(2):1803–1816. https://doi.org/10.1109/TNSM.2020.3014929
Yang L, Shami A (2022) IoT data analytics in dynamic environments: from an automated machine learning perspective. Eng Appl Artif Intell. https://doi.org/10.1016/j.engappai.2022.105366
Sun Y, Wang Z, Liu H, Du C, Yuan J (2016) Online ensemble using adaptive windowing for data streams with concept drift. Int J Distrib Sensor Netw. https://doi.org/10.1155/2016/4218973
Yang L, Shami A (2021) A lightweight concept drift detection and adaptation framework for IoT data streams. IEEE Internet Things Mag 4(2):96–101. https://doi.org/10.1109/iotm.0001.2100012
Montiel J et al (2021) River: machine learning for streaming data in python. J Mach Learn Res 22:1–8
López Lobo J (2020) Synthetic datasets for concept drift detection purposes. Harvard Dataverse. https://doi.org/10.7910/DVN/5OWRGB
Agrawal R, Swami A, Imielinski T (1993) Database mining: a performance perspective. IEEE Trans Knowl Data Eng 5(6):914–925. https://doi.org/10.1109/69.250074
Bifet A, Holmes G, Pfahringer B, Kirkby R, Gavaldà R (2009) New ensemble methods for evolving data streams. In: Proceedings of the ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, pp 139–147. https://doi.org/10.1145/1557019.1557041
Elwell R, Polikar R (2011) Incremental learning of concept drift in nonstationary environments. IEEE Trans Neural Netw 22(10):1517–1531. https://doi.org/10.1109/TNN.2011.2160459
Zhu X (2010) Stream Data Mining Repository. http://www.cse.fau.edu/~xqzhu/stream.html
Dua D, Graff C (2017) UCI Machine Learning Repository. http://archive.ics.uci.edu/ml.
Funding
No funding.
Author information
Authors and Affiliations
Contributions
AA wrote the manuscript and did all the analysis, while HYC supervised the study, and both went through the manuscript.
Corresponding author
Ethics declarations
Conflict of interest
No conflict of interest.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Angbera, A., Chan, H.Y. An adaptive XGBoost-based optimized sliding window for concept drift handling in non-stationary spatiotemporal data streams classifications. J Supercomput 80, 7781–7811 (2024). https://doi.org/10.1007/s11227-023-05729-8
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11227-023-05729-8