
Abstract
Cardiovascular disease (CVD) is among one of the notable menaces to society worldwide. CVD causes the highest number of deaths each year making it one of the most life-threatening diseases across the globe. Most deaths from CVD are sudden therefore patients do not have a chance to get medical assistance in time. Consequently, an immense need for a smart real-time system arises that can be used to monitor heart patients’ activities affecting their cardiac health. This system acts as a life-saving tool during serious health emergencies. Data analysis in real-time will proves to be a substantial enhancement in innovative healthcare practices, by which in the near future we can develop an effective, faster, and smarter diagnosis system for doctors. If we talk about real-time data monitoring possibilities, Internet of Things (IoT) empowered systems can provide one of the better solutions. IoT-enabled intelligent healthcare system include a variety of applications, such as Blood Pressure (BP) check, Heart Rate (HR) monitoring, Electrocardiography (ECG) observation, etc. This paper recommends an IoT-enabled ECG monitoring system for data generation (with the help of Node MCU ESP32 and heart rate sensor AD8232) and an intelligent hybrid classification model for data classification. The dataset used has two classes where class 1 represents healthy patients and class 2 represents cardiac ill patients. A comparison among state-of-the-art algorithms and recommended hybrid models has been carried out to establish the accurateness and suitableness of our recommended model. The recommended model attains the highest accuracy of 99.7% under different validation criteria among all the state-of-the-art algorithms, i.e. Adaboost (91.88%), Bagging (92.40%), random forest (92.48%), K-Nearest Neighbor (92.38%), and support vector machine (91.98%). The recommended hybrid model not only handles the complexities of class imbalance for electrocardiogram datasets but will also help in building intelligent and accurate IoT-enabled healthcare systems.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
According to the World Health Organization (WHO), the approximate count of patients deceased because of cardiovascular disease (CVD) is nearly 17.9 million, accounting for close to 31% of all fatalities [1, 2]. CVD includes various underline diseases, such as raised blood pressure (hypertension), coronary heart disease (heart attack), peripheral artery disease, rheumatic heart disease, cerebrovascular disease (stroke), deep vein thrombosis, heart failure, pulmonary embolism and congenital heart disease [3]. Of these diseases, approximately 85% of deaths are caused by stroke and heart attack. As per the WHO’s reports, by 2030, about 23.6 million individuals will die due to CVDs, i.e. primarily from stroke and heart disease [4, 5]. Thus, there is an immense need for continuous monitoring of some essential parameters of the human body, which are critical and should be exhaustively monitored in real-time paradigms.
The enormous growth in the field of Internet of Things (IoT) has facilitated Information Technology (IT) to new heights [6,7,8,9,10]. Rapid development in the empire of IoT-based applications areas makes IoT a rising technology. In the current viewpoints, approximate all the application domains the IoT is getting involved and actively participating in the journey towards a smarter world [11,12,13]. In the healthcare domain, the traditional procedure was being followed by the patients but after the emergence of IoT in healthcare, the e-health or smart health concept has come into the picture [14,15,16,17,18]. Resultant, a variety of smart devices are being developed for enabling services such as remote monitoring of the patients, unleashing patients' healthy and safe, and empowering doctors to verbalize superlative care [19,20,21]. This technological advancement will not only reduce the medical overhead but also enable in-time support of the patients at remote locations [14,15,16,17,18]. It also plays a major role in decreasing the total expenditure by minimizing the span of hospital stay with improved treatment outcomes.
In the classification problem, the data with unbalanced nature is one of the biggest issues, and as far as the healthcare domain is concerned it even became more crucial because the medications are totally dependent upon the classification outcome [22,23,24,25,26]. Therefore, in the healthcare domain, the classification of unbalanced datasets is an emerging area of research. Over time a number of researchers have not only suggested their viewpoints in the form of algorithms and theoretical approaches [27, 28] but also developed various class-balancing solutions in the form of hybrid paradigms [29, 30]. As far as data balancing techniques are concerned, two types of data balancing techniques are being widely used where the first is under-sampling and the other is over-sampling [31, 32]. In the under-sampling approach, the class balancing is done by eliminating the data samples from the majority class, whereas, in the over-sampling approach, the class balancing is done by adding up artificial samples to the minority class.
Individuals' well-being is one of the crucial tasks and it becomes more complex when we are dealing with one of the deadliest diseases, i.e. CVD in real-time scenarios. Consequently, there is a need for algorithmic approaches that would play an essential role in reducing the total risk of CVD through its efficient classification. Keeping these constraints in our mind, we begin the experimental examination with basic classification models that are less accurate and not capable enough to deal with the class imbalance problems. After several trials, we found that the proposed intelligent hybrid classification model is well suited for classifying the imbalanced Electrocardiogram datasets.
The main contributions of the paper are:
-
To establish an IoT-enabled ECG monitoring system for data generation with the help of Node MCU ESP32 and heart rate sensor AD8232.
-
To propose an intelligent hybrid classification model having the capability of handling the complexities of class imbalance with more accurate results.
The characterization of this paper is as follows: Section two presents a short description of current literature based on algorithmic approaches for the classification of ECG Dataset. In section three, a brief discussion of the methods and materials such as dataset generation and description, proposed epistemology and statistical measures have been presented. The statistical measure-based classification results have been shown in section four. The deeper insights into the classification results have been presented in section five. Section six incorporates the closing remarks along with future routes of the work.
2 Related work
Massive growth in the field of Information technology encourages research to explore the dimensions of recent technologies. It also motivates researchers and groups to build a technological solution for human well-being. In a couple of years, various development not only in the algorithmic perspective but also in system design has been seen [33,34,35,36,37]. If we talk about the healthcare domain, a lot of possibilities are still available, which will catalyze the idea of a smart world. Cardiovascular disease (CVD) is a crucial disease among various life-threatening diseases across the globe, it has gotten the attention of researchers to work on and give their contributions to social well-being. From time to time various algorithmic solutions to the ECG dataset have been suggested but there is still plenty of scope for improvements [38,39,40,41,42,43,44,45,46,47,48,49,50,51,52,53,54,55,56,57,58,59,60,61,62,63]. The quick insights of the current research on ECG datasets are shown in Table 1.
3 Materials and methods
This section introduces the material and methodology that has been used to carry out the experimental evaluation. This section is divided into five subsections, where, the first subsection refers to the hardware setup for ECG data generation. In the second subsection, the dataset description has been presented. The model setup for the classification task has been discussed in subsection three. In the fourth subsection, the recommended model has been introduced. Statistical measures for the validation of the classification model have been presented in the last subsection five.
3.1 Hardware setup for ECG data generation
In order to generate the ECG data, we made a setup that mainly consists of a node MCU (ESP32) and a heart sensor (AD8232). In Fig. 1a the graphical representation of the hardware setup has been shown, whereas the nine electrode placement (E1—Fourth intercostal space (at the right sternal border), E2—Fourth intercostal space (at the left sternal border), E3—Intermediate between leads E2 and E4, E4—Fifth intercostal space (at the midclavicular line), E5—Left anterior axillary line (as the same horizontal plane of E4), E6—Left mid axillary line (as the same horizontal plane of E4 and E5), E7—Right arm (inner wrist), E8—Left arm (inner wrist), and E9—Right side of stomach) the human body is shown in Fig. 1b.

Hardware setup for ECG data generation (a) Hardware setup (b) Electrode placement
In Table 2, the pin connection among node MCU (ESP32) and heart sensor (AD8232) for the ECG data generation have been shown.
The data has been generated in real-time and stored in cloud storage (Ubidots) over a TCP connection with the help of the HTTP POST command. The generated data is transferred in real-time to the cloud storage by using a Wi-Fi connection. The working steps of the hardware setup have been shown in Fig. 2. The functioning of this hardware setup is as follows:
-
First of all, the connection between the heart sensor (AD8232) and node MCU (ESP32) is established.
-
In the second step, the electrode placement to the human body is performed.
-
In the third step, the generated data is visualized on the serial monitor.
-
In the fourth step, this generated data is transferred into cloud storage with the help of the ESP32 Wi-Fi module.
-
In the last step after this ECG data is extracted from the cloud medium to the local machine for performing further investigation

Working steps of the hardware setup
3.2 Dataset description
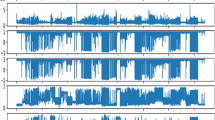
For the experimental analysis, the ECG data have been used, which is generated through Node MCU (ESP32) and heart rate sensor (AD8232). Nine sensors (E1–E9) are placed at different body locations and their corresponding readings are observed. This exercise has performed on the 50 volunteer participants over a time span of 150 s. For every second, a tuple consisting of nine attributes is generated by the system and uploaded to the server (Ubidots) over a TCP connection with the help of the HTTP POST command. The generated stream of data is transferred in real-time to the cloud storage by using a Wi-Fi connection. This ECG data has been extracted from the cloud to a local/native machine for evaluation purposes. Based on the current health of the volunteer this dataset has been classified into the two-class where class 1 denotes healthy patients and class 2 represents the cardiac ill patient. This dataset is consisting of 1700 instances of 10 attributes. The visualization of the ECG dataset (nine channels with class level) and their co-relation are presented in respective Fig. 3a, b.

Dataset description (a) Visualization of the ECG dataset (b) Co-relation coefficient matrix
The class-based partitioning of the ECG dataset over nine attributes is shown in Table 3, which consists of the attribute’s illustration with the help of range (min and max), means, and standard deviation.
3.3 Model setup
The classification model setup for the experimental analysis of the ECG dataset has been shown in Fig. 4. This setup is comprised of five essential steps. In step one, the ECG data is given as input to the model. In step two, the data preprocessing for the exclusion of unusual objects and missing values has been performed. Step three is consisting of the classification task where the processed data is given out as an input to the classification algorithms (i.e. K-Nearest Neighbor (KNN), support vector machine (SVM), random forest (RF), Adaboost (ADB), and Bagging (BAG)). Performance estimation of the classification algorithm is measured in step four and based on these classification results the identification of the best classification model is identified in step five. All the experimental evaluation has been executed using various evaluation criteria, i.e. 2, 3, 5, and 10-fold on a Dell workstation with a 64-bit Intel Xeon processor running at 3.60 GHz and 32 GB of RAM. Python has been used to implement each of the algorithms being used in the simulation.

Classification model setup
3.4 Proposed hybrid classification model
The workflow of the recommended hybrid model is presented in Fig. 5. The recommended hybrid classification model is composed of several steps are:
-
Step I The raw data is given out as input to the recommended model.
-
Step II The pre-processing task on the raw ECG dataset is performed to eliminate the missing values and unusual objects from the dataset.
-
Step III Class balancing has been achieved using SMOTE (Synthetic Minority Oversampling Technique) and which gives a new balanced dataset as output.
-
Step IV This new balanced dataset has been given out as an input to the hyper-tuned random forest algorithms under the various evaluation criteria, i.e. 2, 3, 5, and 10-fold.
-
Step V The statistical parameters (i.e., accuracy, recall, precision, and f1-score) based on performance evaluation on the hybrid classification model have been performed.

Work-flow of the proposed hybrid model
3.4.1 Class balancing using SMOTE
Class balancing is one of the critical matters which should be effectively handled while making the classification. Suppose, we have a binary classification problem where one class holds the majority of samples and the other one has very few data samples. Thus, making the classification based on imbalanced data may give biased results toward the majority class because while making the classification model the majority class contribution will be more as compared to the minority class. Resultantly, the correctness of the classification model will be sacrificed. Therefore, in dealing with the class imbalance problem we have used a SMOTE algorithm which was introduced by Chawla et al. in the year 2002 [64, 65]. The basic principle of this algorithm is to make the class balance by generating artificial samples in the minority class. It uses the k-nearest neighbors (NNs) concept to generate random synthetic samples. The SMOTE-based class balancing result has been shown in Table 4, which contains class-wise distribution with the various SMOTE percentage (i.e. 0, 50, 150, 250, 350, 450, 550, and 650).
The pseudocode of the SMOTE algorithm to solve the class imbalance issue of the ECG dataset is represented in Algorithm 1.

3.4.2 Hyper-tuned random forest algorithm
The Random forest (RF) algorithm is among the extensively used classification algorithms [66, 67]. Due to its extensive nature, it can be applicable in roughly all application areas. The reason for picking up this algorithm in classification is its extensive coverage and well-established nature. The best parameter for this classification algorithm is achieved by the hyper-tuning selection criteria. The best hyperparameter is used in the recommended hybrid paradigms. The pseudocode of the hyper-tuned random forest model for the classification of the ECG dataset has been represented in Algorithm 2.

The classification hyperparameters (i.e., min_samples_split, n_estimators, max_features, min_samples_leaf, bootstrap, max_depth) with the various selection criteria and best hyper-parameter settings used for tuning purposes have been presented in Table 5.
3.5 Statistical analysis
For the validation of the classification results, four statistical measures, i.e., accuracy, f1-score, precision, and recall have been used. These statistical measures play an essential role in establishing the accurateness and suitableness of the classification model [68]. Statistical measures with their respective mathematical formulation have been shown in Table 6.
4 Result
An accurate model identification in the IoT-enabled smart healthcare environment is among the arduous but innovative tasks. The work primarily aims to create an intelligent hybrid classification model which is proficient in dealing with the class imbalance issue with greater exactness and will play a key role in building the robotics solution for communal well-being. Results are obtained by comparison of five state-of-the-art models namely, ADB, BAG, RF, KNN, and SVM with the proposed model which is also shown in Fig. 6.

Classification models a quick look
To find out the effectiveness of the recommended model, a deep assessment among the five state-of-the-art models under the various evaluation criteria (2, 3, 5, and 10-fold) has been conducted. The validation of the classification results is calculated using four performance measures (namely, accuracy, recall, f1-score, and precision).
The dataset used has two classes where class 1 represents healthy patients and class 2 represents cardiac ill patients. From the empirical evaluation, it is clear that the recommended hybrid model obtained the top accuracy throughout the experiment under various validation measures over the other well-established classification models. The statistical measures-based experimental result is shown in Table 7.
5 Discussion
For the experimental analysis, the ECG data have been used, which has been generated through the heart rate sensor (AD8232) and Node MCU (ESP32). To perform the evaluation this ECG data is been transferred from the cloud to the local machine. This dataset is classified into the two-class, where class 1 denotes healthy patients and class 2 represents the cardiac ill patient. The paper presents a comparison of five state-of-the-art models namely, ADB, BAG, RF, KNN, and SVM with the proposed model. Evaluation is performed against four statistical metrics namely, accuracy, precision, recall, and f1-score. The class-wise visualization of classification results with the help of four statistical measures under various validation criteria using cross-validation policy having 2, 3, 5, and 10-fold is shown in Figs. 7a, b, c, and 8a, b, c, respectively. Figure 9 presents the average accuracy of models during the experimental period.

Classification result of class 1 (a) f1-Score (b) Recall (c) Precision

Classification result of class 2 (a) f1-Score (b) Recall (c) Precision

Results of classification models
The empirical evaluation shows that the recommended hybrid model is proficient to handle the complexities of class imbalance in the ECG dataset with enhanced performance for both classes, which will give support in building the IoT-enabled smart and accurate healthcare system. A comparison among state-of-the-art algorithms and recommended hybrid models has been carried out to establish the accurateness and suitableness of our recommended model. The recommended model attains the highest accuracy of 99.7% under different validation criteria among all the state-of-the-art algorithms, i.e. Adaboost (91.88%), Bagging (92.40%), random forest (92.48%), K-Nearest Neighbor (92.38%), and support vector machine (91.98%). The recommended hybrid model not only handles the complexities of class imbalance for electrocardiogram datasets but will also help in building intelligent and accurate IoT-enabled healthcare systems.
The dataset has been generated by 50 volunteer participants which are suitable for binary classification problems and are not suitable to cover all types of heart diseases (i.e. for multiclass classification problems). Therefore, in the future this work will be expanded from the data (for adding more feasible attributes) and algorithmic point of view. We will also try to make this problem a multiclass classification problem by generating data related to different types of Cardiovascular diseases.
6 Conclusion
Cardiovascular diseases (CVD) are one of the biggest hazards to human society across the globe. Hence, there is an immense requirement for real-time observation and analysis of cardiac health. Identification of the correct model in IoT-enabled smart healthcare paradigms is an arduous but innovative task. IoT-enabled intelligent healthcare systems include numerous applications like Blood Pressure (BP) check, Heart Rate (HR) monitoring, Electrocardiography (ECG) observation, etc. This paper recommends an IoT-enabled ECG monitoring system for data generation (with the help of Node MCU ESP32 and heart rate sensor AD8232) and an intelligent hybrid classification model. The key intention of this study is to give a smart hybrid classification model for dealing with class imbalance problem with greater exactness and which will play a key role in building the robotics solution for communal well-being. The dataset used has two classes where class 1 represents healthy patients and class 2 represents cardiac ill patients. A rigorous comparison based on various evaluation criteria (2, 3, 5, and 10-fold) among state-of-the-art algorithms and recommended hybrid models have been carried out to establish the accurateness and suitableness of our recommended model. The recommended model attains the highest accuracy of 99.7% throughout the experiment under different validation criteria among all the state-of-the-art algorithms, i.e. Adaboost (91.88%), Bagging (92.40%), random forest (92.48%), K-Nearest Neighbor (92.38%), and SVM (91.98%). The recommended hybrid model not only handles the complexities of class imbalance for electrocardiogram datasets but will also help in building intelligent and accurate IoT-enabled healthcare systems. Thus, accurate classification of cardiovascular health through our recommended model would be useful for improving the lifestyle of cardiac patients. This will not only allow patients to be treated from the comfort of their homes but will also reduce the need for hospital visits and reduce the overall expenditure on hospital visits. Furthermore, it would also help in enhancing the capabilities of effective emergency response to any medical emergency.
In the future, this work will be expanded from the data and algorithmic point of view. We will also try to make this problem a multiclass classification problem by generating data related to different types of cardiovascular diseases. Thus, we can not only detect different types of heart diseases but also classify them correctly. After this, we will try to build wearable devices in the form of a band or chest belt or undergarment which will be a complete cloud-based framework.
References
Cardiovascular diseases (CVDs). Available online: https://www.who.int/news-room/fact-sheets/detail/cardiovascular-diseases-(cvds) (accessed on 15 August 2020)
Foley RN, Parfrey PS, Sarnak MJ (1998) Clinical epidemiology of cardiovascular disease in chronic renal disease. Am J Kidney Dis 32(5):S112–S119
Lakka HM, Laaksonen DE, Lakka TA, Niskanen LK, Kumpusalo E, Tuomilehto J, Salonen JT (2002) The metabolic syndrome and total and cardiovascular disease mortality in middle-aged men. JAMA 288(21):2709–2716
Anderson KM, Odell PM, Wilson PW, Kannel WB (1991) Cardiovascular disease risk profiles. Am Heart J 121(1):293–298
Bonow RO, Smaha LA, Smith SC Jr, Mensah GA, Lenfant C (2002) World Heart Day 2002: the international burden of cardiovascular disease: responding to the emerging global epidemic. Circulation 106(13):1602–1605
Ahmed E, Yaqoob I, Gani A, Imran M, Guizani M (2016) Internet-of-things-based smart environments: state of the art, taxonomy, and open research challenges. IEEE Wirel Commun 23(5):10–16
Fortino G and Trunfio P (Eds) (2014) Internet of things based on smart objects: Technology, middleware and applications. Springer Science & Business Media.
Ketu S, Mishra PK (2022) Hybrid classification model for eye state detection using electroencephalogram signals. Cogn Neurodyn 16(1):73–90
Ketu S, Mishra PK (2021) Cloud, fog and mist computing in IoT: an indication of emerging opportunities. IETE Tech Rev 36:1–12
Ketu S, Mishra PK (2022) A contemporary survey on IoT based smart cities: architecture, applications, and open issues. Wirel Pers Commun 69:1–49
Gubbi J, Buyya R, Marusic S, Palaniswami M (2013) Internet of things (IoT): a vision, architectural elements, and future directions. Futur Gener Comput Syst 29(7):1645–1660
Chui KT, Alhalabi W, Pang SSH, Pablos POD, Liu RW, Zhao M (2017) Disease diagnosis in smart healthcare: innovation, technologies and applications. Sustainability 9(12):2309
Ketu S, and Mishra PK (2020) Performance analysis of machine learning algorithms for iot-based human activity recognition. In Advances in electrical and computer technologies (pp. 579–591). Springer, Singapore.
Datta SK, Gyrard A, Bonnet C and Boudaoud K (2015) oneM2M architecture based user centric IoT application development. In 2015 3rd International Conference on Future Internet of Things and Cloud (pp. 100–107). IEEE.
Al Mamun MA, Yuce MR (2019) Sensors and systems for wearable environmental monitoring toward iot-enabled applications: a review. IEEE Sens J 19(18):7771–7788
Baker SB, Xiang W, Atkinson I (2017) Internet of things for smart healthcare: technologies, challenges, and opportunities. IEEE Access 5:26521–26544
Tian S, Yang W, Le Grange JM, Wang P, Huang W, Ye Z (2019) Smart healthcare: making medical care more intelligent. Global Health J 3(3):62–65
Ghazal TM, Hasan MK, Alshurideh MT, Alzoubi HM, Ahmad M, Akbar SS, Akour IA (2021) IoT for smart cities: Machine learning approaches in smart healthcare—a review. Futur Internet 13(8):218
Kalarthi ZM (2016) A review paper on smart health care system using internet of things. Int J Res Eng Technol 5(03):8084
He D, Ye R, Chan S, Guizani M, Xu Y (2018) Privacy in the internet of things for smart healthcare. IEEE Commun Mag 56(4):38–44
Ketu S, Mishra PK (2021) Internet of healthcare things: a contemporary survey. J Netw Comput Appl 192:103179
Algarni A (2019) A survey and classification of security and privacy research in smart healthcare systems. IEEE Access 7:101879–101894
Lee I, Lee K (2015) The internet of things (IoT): applications, investments, and challenges for enterprises. Bus Horiz 58(4):431–440
Ketu S, Mishra PK (2022) Empirical analysis of machine learning algorithms on imbalance electrocardiogram based arrhythmia dataset for heart disease detection. Arab J Sci Eng 47(2):1447–1469
Ketu S, Mishra PK (2021) Scalable kernel-based SVM classification algorithm on imbalance air quality data for proficient healthcare. Complex Intell Syst 7(5):2597–2615
Ketu S (2022) Spatial air quality index and air pollutant concentration prediction using linear regression based recursive feature elimination with random forest regression (RFERF): a case study in India. Nat Hazards 114(2):2109–2138
Ngu AH, Gutierrez M, Metsis V, Nepal S, Sheng QZ (2016) IoT middleware: a survey on issues and enabling technologies. IEEE Internet Things J 4(1):1–20
Pramanik MI, Lau RY, Demirkan H, Azad MAK (2017) Smart health: big data enabled health paradigm within smart cities. Expert Syst Appl 87:370–383
Patel KK, Patel SM (2016) Internet of things-IOT: definition, characteristics, architecture, enabling technologies, application & future challenges. Int J Eng Sci Comput 6(5):10
Lima LE, Kimura BYL, Rosset V (2019) Experimental environments for the internet of things: a review. IEEE Sens J 19(9):3203–3211
Drummond C, and Holte RC (2003). C4. 5, class imbalance, and cost sensitivity: why under-sampling beats over-sampling. In Workshop on learning from imbalanced datasets II (Vol. 11, pp. 1–8). Washington DC, Citeseer.
Liu AC (2004) The effect of oversampling and undersampling on classifying imbalanced text datasets. The University of Texas, Austin.
Majumder BD, Roy JK, Padhee S (2018) Recent advances in multifunctional sensing technology on a perspective of multi-sensor system: a review. IEEE Sens J 19(4):1204–1214
Nag A, Mukhopadhyay SC, Kosel J (2017) Wearable flexible sensors: a review. IEEE Sens J 17(13):3949–3960
Belhaj Mohamed M, Meddeb-Makhlouf A, Fakhfakh A, Kanoun O (2021) Wireless body sensor networks with enhanced reliability by data aggregation based on machine learning algorithms. Adv Sens Biomed Appl 12:67–81
Belhaj Mohamed M, Meddeb-Makhlouf A, Fakhfakh A, Kanoun O (2022) Efficient data aggregation technique for medical wireless body sensor networks. Tm Tech Messen 89(5):328–342
Mohamed MB, Meddeb-Makhlouf A, Fakhfakh A, Kanoun O (2022) Secure and reliable ML-based disease detection for a medical wireless body sensor networks. Int J Biol Biomed Eng 16:196–206
Dolatabadi AD, Khadem SEZ, Asl BM (2017) Automated diagnosis of coronary artery disease (CAD) patients using optimized SVM. Comput Methods Programs Biomed 138:117–126
Tayefi M, Tajfard M, Saffar S, Hanachi P, Amirabadizadeh AR, Esmaeily H, Ghayour-Mobarhan M (2017) hs-CRP is strongly associated with coronary heart disease (CHD): a data mining approach using decision tree algorithm. Comput Methods Programs Biomed 141:105–109
Arabasadi Z, Alizadehsani R, Roshanzamir M, Moosaei H, Yarifard AA (2017) Computer aided decision making for heart disease detection using hybrid neural network-genetic algorithm. Comput Methods Programs Biomed 141:19–26
Mustaqeem A, Anwar SM, Khan AR, Majid M (2017) A statistical analysis based recommender model for heart disease patients. Int J Med Informatics 108:134–145
Boon KH, Khalil-Hani M, Malarvili MB (2018) Paroxysmal atrial fibrillation prediction based on HRV analysis and non-dominated sorting genetic algorithm III. Comput Methods Programs Biomed 153:171–184
Mahajan R, Viangteeravat T, Akbilgic O (2017) Improved detection of congestive heart failure via probabilistic symbolic pattern recognition and heart rate variability metrics. Int J Med Inf 108:55–63
Bozkurt B, Germanakis I, Stylianou Y (2018) A study of time-frequency features for CNN-based automatic heart sound classification for pathology detection. Comput Biol Med 100:132–143
Sudarshan VK, Acharya UR, Oh SL, Adam M, Tan JH, Chua CK, San Tan R (2017) Automated diagnosis of congestive heart failure using dual tree complex wavelet transform and statistical features extracted from 2 s of ECG signals. Comput Biol Med 83:48–58
Aborokbah MM, Al-Mutairi S, Sangaiah AK, Samuel OW (2018) Adaptive context aware decision computing paradigm for intensive health care delivery in smart cities—a case analysis. Sustain Cities Soc 41:919–924
Pławiak P (2018) Novel methodology of cardiac health recognition based on ECG signals and evolutionary-neural system. Exp Syst Appl 92:334–349
Miao F, Cai YP, Zhang YX, Fan XM, Li Y (2018) Predictive modeling of hospital mortality for patients with heart failure by using an improved random survival forest. IEEE Access 6:7244–7253
Tan JH, Hagiwara Y, Pang W, Lim I, Oh SL, Adam M, Acharya UR (2018) Application of stacked convolutional and long short-term memory network for accurate identification of CAD ECG signals. Comput Biol Med 94:19–26
Dominguez-Morales JP, Jimenez-Fernandez AF, Dominguez-Morales MJ, Jimenez-Moreno G (2017) Deep neural networks for the recognition and classification of heart murmurs using neuromorphic auditory sensors. IEEE Trans Biomed Circ Syst 12(1):24–34
Shaikh A, Al Reshan MS, Sulaiman A, Elmagzoub MA, AlYami S (2023) A fully automatic model for premature ventricular heartbeat arrhythmia classification using the internet of medical things. Biomed Signal Process Control 83:104697
Alfaras M, Soriano MC, Ortín S (2019) A fast machine learning model for ECG-based heartbeat classification and arrhythmia detection. Front Phys 7:103
Xie T, Li R, Shen S, Zhang X, Zhou B, Wang Z (2019) Intelligent analysis of premature ventricular contraction based on features and random forest. J Healthc Eng 21:5787586
Raj S, Ray KC (2018) Sparse representation of ECG signals for automated recognition of cardiac arrhythmias. Exp Syst Appl 105:49–64
Siavashi A and Majidi M (2021) Sensing, wireless transmission, and smart processing of heart signals. In 2021 5th International Conference on Internet of Things and Applications (IoT) (pp. 1–6). IEEE.
Zhang H, Zhu L, Nathan V, Kuang J, Kim J, Gao JA, Olgin J (2021) Towards early detection and burden estimation of atrial fibrillation in an ambulatory free-living environment. Proc ACM Interact Mob Wearable Ubiquitous Technol 5(2):1–19
Kwon JM, Jo YY, Lee SY, Kang S, Lim SY, Lee MS, Kim KH (2022) Artificial intelligence-enhanced smartwatch ECG for heart failure-reduced ejection fraction detection by generating 12-lead ECG. Diagnostics 12(3):654
Baraeinejad B, Shayan MF, Vazifeh AR, Rashidi D, Hamedani MS, Tavolinejad H, Fakharzadeh M (2022) Design and implementation of an ultralow-power ECG patch and smart cloud-based platform. IEEE Trans Instrum Meas 71:1–11
Shrestha AP and Yu CH (2022) ECG data analysis with IoT and machine learning. In 2022 IEEE 12th Annual Computing and Communication Workshop and Conference (CCWC) (pp. 0323–0327). IEEE.
Muthu Ganesh V, Nithiyanantham J (2022) Heuristic-based channel selection with enhanced deep learning for heart disease prediction under WBAN. Comput Methods Biomech Biomed Engin 25(13):1429–1448
Sheeba A, Padmakala S, Subasini CA, Karuppiah SP (2022) MKELM: mixed kernel extreme learning machine using BMDA optimization for web services based heart disease prediction in smart healthcare. Comput Methods Biomech Biomed Engin 25(10):1180–1194
Jansi Rani SV, Chandran KS, Ranganathan A, Chandrasekharan M, Janani B, Deepsheka G (2022) Smart wearable model for predicting heart disease using machine learning: wearable to predict heart risk. J Ambient Intell Hum Comput 13(9):4321–4332
Manimurugan S, Almutairi S, Aborokbah MM, Narmatha C, Ganesan S, Chilamkurti N, Almoamari H (2022) Two-stage classification model for the prediction of heart disease using IoMT and artificial intelligence. Sensors 22(2):476
Chawla NV, Bowyer KW, Hall LO, Kegelmeyer WP (2002) SMOTE: synthetic minority over-sampling technique. J Artif Intell Res 16:321–357
Fernández A, Garcia S, Herrera F, Chawla NV (2018) SMOTE for learning from imbalanced data: progress and challenges, marking the 15-year anniversary. J Artif Intell Res 61:863–905
Biau G, Scornet E (2016) A random forest guided tour. TEST 25(2):197–227
Liaw A, Wiener M (2002) Classification and regression by random forest. R News 2(3):18–22
Goutte C and Gaussier E (2005) A probabilistic interpretation of precision, recall and F-score, with implication for evaluation. In European Conference on Information Retrieval (pp. 345–359). Springer, Berlin.
Author information
Authors and Affiliations
Contributions
S.K.: Conceptualization, methodology, writing—original draft preparation, visualization, investigation. P.K.M.: Supervision.
Corresponding author
Ethics declarations
Conflict of interest
The authors declare no competing interests.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Ketu, S., Mishra, P.K. An intelligent hybrid classification model for heart disease detection using imbalanced electrocardiogram signals. J Supercomput 80, 4286–4308 (2024). https://doi.org/10.1007/s11227-023-05583-8
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11227-023-05583-8