
Abstract
The widespread dissemination of fake news on social media brings adverse effects on the public and social development. Most existing techniques are limited to a single domain (e.g., medicine or politics) to identify fake news. However, many differences exist commonly across domains, such as word usage, which lead to those methods performing poorly in other domains. In the real world, social media releases millions of news pieces in diverse domains every day. Therefore, it is of significant practical importance to propose a fake news detection model that can be applied to multiple domains. In this paper, we propose a novel framework based on knowledge graphs (KG) for multi-domain fake news detection, named KG-MFEND. The model’s performance is enhanced by improving the BERT and integrating external knowledge to alleviate domain differences at the word level. Specifically, we construct a new KG that encompasses multi-domain knowledge and injects entity triples to build a sentence tree to enrich the news background knowledge. To solve the problem of embedding space and knowledge noise, we use the soft position and visible matrix in knowledge embedding. To reduce the influence of label noise, we add label smoothing to the training. Extensive experiments are conducted on real Chinese datasets. And the results show that KG-MFEND has a strong generalization capability in single, mixed, and multiple domains and outperforms the current state-of-the-art methods for multi-domain fake news detection.
Similar content being viewed by others



Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
In the information age, various social media platforms, such as Twitter, Facebook, and Sina Weibo, have set off a wave of information dissemination [1, 2]. Social media has facilitated users to obtain information, express viewpoints, and exchange personal opinions with others. However, it provides an ideal platform where anyone can become the creator and disseminator of information, which leads to the easy generation and rapid spread of fake news [3]. Fake news is harmful and poses a serious threat to individuals and society [4]. After the outbreak of COVID-19, a large amount of related fake news circulated through social media, causing great social panic. For example, the fake news that drinking cleaning products can cure diseases. Seriously, many people have lost their lives after being misled to believe it [5]. Due to the limitations of scientific knowledge, time, and space [6], it is a challenging task for the public to distinguish fake news from numerous online information. Therefore, developing efficient and automatic technologies to identify fake news on social media has become critical.
Many approaches have been proposed to detect fake news. Table 1 shows the most commonly used public datasets for fake news detection. We can find that most existing efforts are focused on a single domain, such as politics and entertainment [7], or detecting fake news in general (mixed domain). In practice, social media posts millions of pieces of information every day, covering different domains. Some features, such as word usage and semantic structure, vary from domain to domain, namely domain shift [8]. As shown in Fig. 1, we observe that words in politics like “China,” “country,” and “government” appear more frequently, while the most frequently used words in health are “vaccine,” “doctor,” “virus,” etc. The professional backgrounds and knowledge also range significantly across domains. In addition, identifying multi-domain fake news requires dealing with issues such as wider data diversity, higher unpredictability of data structures, and more data noise. Because of these limitations, most techniques fail to achieve acceptable results [9]. Therefore, studying multi-domain fake news detection has great potential for practical applications.

Word cloud map of the nine domains
A large number of high-quality structured subject-object triples from external knowledge bases (KBs) have been proven to be effective for fake news detection [16,17,18]. In this paper, we aim to alleviate the domain shift in multi-domain fake news detection at the word level using external knowledge. News pieces in different domains are also inherently correlated in word usage. As shown in Fig. 1, society-related terms appear in all domains, and the common words in politics are similar to society or science. Thus extracting entity knowledge from the knowledge graph (KG) containing multi-domain entity triples can make inferences based on domain-specific knowledge while providing other domain knowledge. However, we discover that the way to knowledge integration faces two problems that are not yet solved in fake news detection. (1) Heterogeneous embedding space: The embedding features of news text and the entities in KG are obtained in different ways, which results in the inconsistency of their existing spaces. (2) Knowledge Noise (KN) [19]: Because the training model can learn about other similar entities, introducing too much knowledge into news text may change the original meaning or even appear biased. In addition, existing methods rely too heavily on raw labels for classification. And ignoring the error label can greatly reduce the generalization ability of the model [20].
To address these problems, we propose a novel knowledge graph-based framework for multi-domain fake news detection, namely KG-MFEND. KG-MFEND introduces entity triples to construct the sentence trees and uses the soft position and visible matrix in the knowledge embedding process to avoid knowledge noise caused by excessive entity knowledge injection. First, we construct a new KG containing multiple domains and transform the original news content into knowledge-rich sentence trees. Then, we distinguish the vector space of entities and news by improving the embedding in the BERT model. Specifically, in position embedding, we use the soft position instead of the hard position to encode tokens in the sentence tree and use the visible matrix to the visibility of each mark. Next, KG-MFEND inputs the visible matrix together with the embedding vector into the mask-transformer module to obtain the final feature vector for classification. The main contributions of this paper can be summarized as follows:
-
We propose a novel knowledge-based multi-domain fake news detection framework, KG-MFEND. We aim to reduce the influence of domain shift at the word level. We construct a new KG covering common entity knowledge and domain-specific entity knowledge for shared domain information. In the training process, the model adopts label smoothing to reduce the influence of inevitable incorrect labels.
-
To solve the problem of embedding space and KN in knowledge embedding, our model uses the soft position and visible matrices to encode the sentence tree structure, which can selectively distinguish the embedding space of original text and knowledge entities and mitigate the knowledge noise problem of the injection of too many entities.
-
A large number of experiments have been conducted on real-world Chinese datasets, and the results verify that KG-MFEND outperforms state-of-the-art methods in the single domain, mixed domain, and multi-domain. Additionally, our model has good performance on future data.
The remainder of the paper can be summarized as follows: Sect. 2 briefly reviews the related work on fake news detection. In Sect. 3, we describe our proposed model in detail. Section 4 conducts a series of experiments on real Chinese datasets and discusses the experimental results. Finally, conclusions are drawn and future work is clarified in Sect. 5.
2 Related work
Fake news refers to inaccurate and unreliable information on the Internet that is deliberately fabricated with certain intentions [21]. In this section, we briefly review its relevant work from three perspectives: (1) fake news detection; (2) knowledge-based approaches; and (3) multi-domain learning.
2.1 Fake news detection
In recent years, fake news detection has drawn a lot of attention[22]. Existing techniques can be broadly categorized as content-based, user information-based, and propagation structure-based [23,24,25,26].
Content-based methods Content-based research is more conducive to discovering fake news early, which is still the most popular method [27]. To detect fake news automatically, Ma et al. [28] first proposed a recursive neural network (RvNN) by using content semantics to detect fake news. On this basis, Xing et al. [29] constructed a novel ViP-RNN model that combined RNN with CNN to capture a discriminative semantic representation of the news. Vo et al. [30] developed a text generation framework by generating responses with fact-checking to support or refute the original tweets. Social media posts were used as data streams by Zhou et al. [31], using reinforcement learning techniques for early detection.
User information-based methods Those methods focus on acquiring information from users’ social networks to infer user credibility [32]. Shelke et al. [33] defined a set of user features (such as registration age, description length, and follower count) and trained a deep learning framework to improve accuracy on real datasets. Starting at the participant level, Chen et al. [34] deeply mined the users’ feature vectors in the communication chain and integrated them into fake news detection.
Propagation-based methods Some studies have demonstrated that real and fake news have significantly different propagation networks. Ma et al. [35] introduced a recurrent neural network (RNN) for rumor detection by capturing content semantics and propagation structure. Considering the semantic structure and propagation paths, Bian et al. [36] proposed Bi-Directional Graph Convolutional Networks (Bi-GCN) to deal with both propagation and dispersion of rumors. Yuan et al. [37] explored a global–local attention network called GLAN to obtain local semantic relations and global structural information from source tweets and the relationship between posts and post users.
Although user information-based and propagation-based methods have had some success, they have the following limitations when it comes to acquiring additional users and propagation structure information [22]: (1) Data ethics issues: User information is personal and subject to relevant data protection laws; it must be obtained in reasonable and legal ways [38]. (2) Data acquisition difficulty: Researchers must strictly follow their propagation paths to capture relevant information. And it is more vulnerable to issues with missing data and data noise.
In contrast, content-based methods can directly determine fake news without auxiliary information. However, most of the existing content-based research has been conducted in general (a mixed dataset) or in a specific domain while performing poorly across domains. In this paper, we will look for a more effective and content-based approach to carry out multi-domain fake news detection work.
2.2 Knowledge-based methods
Knowledge-based methods can be used to analyze, research, and comprehend big data by leveraging a large amount of textual information [39]. Knowledge-based technology is also regarded as fact-checking [17], which can be divided into manual and automatic fact-checking. Manual fact-checking relies heavily on human experts to identify fake news, which is labor-intensive and time-consuming. In automatic fact-checking, fake news is detected by comparing knowledge extracted from news content with knowledge included in a built-in knowledge base or knowledge graph [40].
In recent years, automatic fact-checking based on knowledge graphs (KG) has developed rapidly in fake news detection. Pan et al. [17] first applied knowledge graphs to fake news detection. They classified fake news based on the comparative deviation between triples extracted from news content and external knowledge. Sicilia et al. [41] significantly improved the accuracy of fake news identification by utilizing a neural network model based on topic features and knowledge graphs. They are effective when applied to a single event, but news concerning newly developing events cannot be recognized.
To solve the problem, a novel direction of knowledge graph embedding has been proposed. Its key is to preserve the structural information while easing computation by embedding the item and relation in the knowledge graph into a continuous vector space [42]. Hu et al. [18] argued that both structured subject-predicate-object triplets and unstructured entity descriptions can provide valuable information, so the two types of embedding are used jointly with the gating function for fake news detection. Wang et al. [11] proposed a new multimodal perspective of fake news detection where they jointly modeled news text, knowledge concepts, and vision onto graphs to obtain multimodally enhanced semantic representations. Wang et al. [39] proposed a topic-dependent tree structure by obtaining topic knowledge about the news content as input to a graph neural network.
It should be emphasized that the entity embedding feature in the knowledge graph and the news text feature are obtained using separate methods, implying that the two should belong to a heterogeneous embedding space. Meanwhile, the fusion of news text with too many knowledge entities may generate noisy information, which affects the performance of the model. However, existing knowledge-based methods cannot meet these requirements. In this paper, we propose a new knowledge-based framework that uses soft positions and visible matrices to encode the sentence tree structure for fake news detection.
2.3 Multi-domain learning
Recent years have witnessed that multi-domain learning is effective in many applications [43,44,45], including fake news detection. Pennycook et al. [21] pointed out that most current fake news detection methods are usually limited to the domain or source, making it difficult to train data from other domains. Some work has attempted to validate the applicability of the model in different domains by using cross-domain datasets. Wang et al. [27] proposed an end-to-end model, SemSeq4FD, for early fake news detection. To demonstrate the ability of the model to generalize across domains, SemSeq4FD was trained on mixed datasets from society and entertainment to predict a single-domain dataset. But, it does not substantially explain the applicability of its model to multiple domains.
Therefore, it is essential to provide a technique for identifying fake news that can be reasonable, efficient, and generalizable to multi-domain datasets. Silva et al. [46] established a cross-domain learning model to learn the embedding features from the specific domain and the cross-domain, respectively. Then, two features are combined to identify fake news. Combining multi-domain features softly is preferable to decoupling domain-shared and domain-specific features roughly [45]. Nan et al. [4] proposed a multi-domain fake news detection model that uses nine expert networks (TextCNN) to obtain different domain representations of each news piece and then inputs them to a ”domain gate” to aggregate multiple features for classification. However, news domain labels are not absolute, meaning that a news article in a particular domain also has characteristics of other domains, such as the usage of words. From the word level, we construct a multi-domain KG as a multi-domain expert to provide the appropriate background knowledge by entity injection of domain features for multi-domain fake news detection.
3 Methodology
In this section, we first give the definition of the problem and then describe our proposed KG-MFEND in detail. The model includes three parts: (1) knowledge representation; (2) knowledge embedding; and (3) prediction. The whole architecture of the proposed model is shown in Fig. 2.

Overall framework of KG-MFEND
3.1 Problem statement
Let \(\underline{\underline{M}}\) be a dataset containing multi-domain news pieces on social media, \(M=\left\{ P_j\right\} _{j=1}^n\), where \(\textit{n}\) represents the number of news pieces. Each news item \(P_j\) is composed of a set of words, i.e., \(P_j=\left\{ w_{j 1}, w_{j 2}, \ldots , w_{j t}\right\}\). We will extract the entity Ej in \(P_j\), \(E j=\left\{ e_{j 1}, \ldots , e_{j m}\right\}\), where m denotes the number of entities. Following previous work, we consider fake news detection a binary classification task. Each piece of news has its fundamentally true label \(y \in \{0,1\}\), where 1 means that the news item is true and 0 denotes fake news. Fake news detection can be described as learning a detection function: \(f:(P, E) \rightarrow y\) to determine whether a given piece of news is fake. We aim to train a model that can effectively detect fake news in multiple domains.
3.2 Knowledge representation
In this section, we construct a multi-domain KG that includes general knowledge and professional background and introduce how to inject knowledge and convert it into the sentence tree. The whole process can be described as giving domain-specific news \(P_i=\) \(\left\{ w_{j 1}, w_{j 2}, \ldots , w_{j t}\right\}\) and a \(\textrm{KG}\), which is converted into \(P_j=\) \(\left\{ w_{j 1}, w_{j 2}, \ldots , w_{j m}\left\{ \left( \textrm{r}_{\textrm{m} 0}, \textrm{w}_{\textrm{im} 0}\right) \ldots \ldots ,\left( \textrm{r}_{\textrm{mk}}, \textrm{w}_{\textrm{imk}}\right) \right\} , \ldots \ldots , w_{j \textrm{t}}\right\}\) by knowledge representation. Knowledge representation includes three stages: knowledge graph construction, knowledge querying, and knowledge injection.
Knowledge graph construction Due to the limited content of news pieces, especially short ones, the full information cannot be represented by the text alone. We believe that embedding knowledge can provide additional information and enrich the context. We take into account the following factors when constructing the KG: (1) For multi-domain fake news datasets, the news entities cover multiple domains, and thus a large-scale knowledge base is needed in knowledge injection. (2) There is specific knowledge in some specific domains, so it is a need to add some domain-specific knowledge.
Considering the above, we first choose an open CN-Dbpedia [47] as an external knowledge base and select only entity triplets to construct the KG. CN-Dbpedia extracts knowledge from Chinese encyclopedia websites, including basically common-sense entity knowledge. Background knowledge in domain specific can better assist in the detection of fake news in their domain. Therefore, we develop two domain-specific KGs, EducationKG and MedicineKG. MedicineKG is from Baidu and includes a total of 17890 triples about symptoms, diseases, sites, and treatments. EducationKG gets information about the famous universities in China released by the Alumni Association in 2020 and contains a total of 7368 triples, including the abbreviation of the university, the type of university it belongs to, and the time when it was founded. Figure 3 shows parts of triples in MedicineKG.

Parts of triples in MedicineKG. The orange circles represent the entities in the news content, the yellow indicates the related entity knowledge found in the knowledge graph, and the relationship between the two is indicated by the blue arrows
Knowledge querying Knowledge querying is performed before injecting knowledge and refers to extracting the entities contained in the news text and then querying the triples corresponding to KG. The process can be expressed as Eq. 1.
where \(\mathrm {\textit{E}}\) is the set of triples matched from the news text \(P_i\) and KG .
Knowledge injection To reduce the impact of KN, an effective strategy is to allow entities to have different representations when different relationships are involved. In this paper, a sentence tree structure T is used to add the entity triples in E to the corresponding positions. Equation 2 represents the knowledge injection process, and the sentence tree structure T is shown in Fig. 4. After that, the problem is solved by the soft position and visible matrix, which will be discussed in the next section.
3.3 Knowledge embedding
Knowledge embedding aims to convert the sentence tree into an embedded representation and feed it into the mask-transformer to obtain the embedding features, which is the key of KG-MFEND. Knowledge embedding consists of three modules, i.e., embedding layer, seeing layer, and mask-transformer.
Embedding layer Similar to the BERT model, the embedding layer performs three segments of processing: token embedding, location embedding, and segment embedding. KG-MFEND optimizes the two parts of token embedding and location embedding, and the segment embedding process is the same as BERT. The final embedding vector of each news piece is the result of directly summing the above three parts.
Token embedding aims to learn locations for specific tokens from the token vocabulary. In this study, we use the sentence tree structure as a tag sequence for sequential input. Like BERT, KG-MFEND also adopts [CLS] as a classification tag and uses [MASK] to mask tokens. Then, we use the vocabulary provided by Google BERT to convert the sentence tree into an embedding vector using a trainable lookup table. The tokens in the sentence tree require re-arrangement into a single sequence. As shown in Fig. 4, a selected fragment of real news content, we can see that the original sentence “Demi Lovato surprises musicians with hours of free studio time” becomes “Demi Lovato is from America Person Artist surprises musicians good at music with hours of free studio time” after knowledge injection, and the sentence tree tokens are also reordered. However, the sentence may lose its correct semantic structure after the reordering, making it impossible to be recognized correctly. KG-MFEND introduces the soft position and the visible matrix to solve this problem. The soft position is described in the position embedding, and the visible matrix is implemented through the visible layer.
Position embedding describes the position of words in the sentence tree. As shown in Fig. 4, the background knowledge [person] and [artist] related to Demi Lovato are introduced between [Lovato] and [surprises], and if marked directly, it appears that [artist] is the subject of [surprises], causing the sentence to be unreadable. To solve this problem, we mark [person] and [surprises] together as 3, so that these two words have equivalent positions. And yet the [good at] and [with] group structures impose a connection with the rest of the content. Similarly, [music] only has an effect on [musicians], not on [America]. The visible matrix is used to control the relationships between content and entity triples.

Structure of the sentence tree. Red numbers are soft position indexes and black numbers are hard position indexes
Seeing layer The visible matrix is the key to improving model classification performance because it controls the visible area of each token. We refer to the visible matrix as \(X_{m}\). The relationship between each token can be expressed as follows:
where \(\in\) represents the same branch and \(\ne\) indicates the different branch. If \(p_{i}\) and \(p_{j}\) are both interacting in the same branch, they are represented as 0 in the visible matrix. \(\mathrm {\textit{i}}\) and \(\mathrm {\textit{j}}\) represent the hard position index.
We use the hard-position index for each token of the visible matrix, shown in Fig. 5a. The visible matrix achieves two goals by limiting the visible area of each token: (1) effectively injects background knowledge while preserving the original sentence’s meaning. (2) reduces the risk of semantic changes due to the injection of too much or irrelevant information.

a Depicts the visible matrix for token representation of the above news by hard position, and b depicts multiple mask-self-attentive blocks in the mask-transformer
Mask-transformer The above work has obtained the embedding vector and visible matrix, which need to be input to the encoder in this section. However, the transformer encoder in BERT cannot directly identify the visible matrix X. KG-MFEND improves it into the mask-transformer, which is a stack of multiple mask-self-attention blocks. Mask-self-attention blocks are similar to self-attention and can effectively learn X while maintaining the original semantics. The structure is shown in Fig. 5b. And the formulas for mask-self-attention blocks are shown as:
where \(W_q\), \(W_k\) and \(W_v\) are three trainable model parameters. \(h^i\) represents the i-th mask-self-attention block of the hidden state. We add the visible matrix \(\textit{X}\) to Eq. 5, where \(d_k\) is the scaling factor. When \(p_k\) is not visible to \(p_j\) meaning that \(w_k\) does not work on \(w_j\), the score \(G_{j k}^{i+1}\) will be 0 by the representation of \(X_{d k}\).
3.4 Prediction
In this section, we input the learned feature representation \(h^{i+1}\) into a multilayer perception (MLP) network and a Softmax layer to make a prediction. The news predictor is defined as:
The model generates a binary prediction vector \(\hat{y}\), and \(y^{i}\) denotes the actual news label. For binary classification tasks, scholars tend to encode the labels with one-hot encoding, where the hard label vector has a target category probability of 1 and a non-target category probability of 0.
The cross-entropy loss function is applied to minimize the loss between the prediction \(\hat{y}\) and the label \(y^i\).
However, there are unavoidable noise labels (incorrect labels) because the datasets are manually labeled, which greatly affect the generalization ability of the model [20, 48]. Considering the problem, we use a new loss function to supervise the model for the binary classification task in the training process. We first add label smoothing to train a soft label loss based on the cross-entropy loss. Label smoothing is a regularization strategy that generates soft labels by applying a weighted average between evenly distributed and hard labels. The soft labels are constantly updated during the training phase to monitor the model, which can suppress the overfitting of the training model and further improve the classification performance.
The probability distribution after adding label smoothing becomes:
where \(\epsilon\) denotes the smoothing factor. The soft loss function can be described as:
Finally, we balance the hard and soft labels with \(\theta\). The total training loss can be expressed as:
4 Experiments
In the following section, we conduct extensive experiments to evaluate the validity of the proposed KG-MFEND model. Specifically, we aim to answer the following four research questions:
RQ1: Can our model outperform state-of-the-art baselines in different domain datasets?
RQ2: What is the effect of each component of the proposed KG-MFEND for fake news detection?
RQ3: Can the modeling framework be applied to real-world scenarios and make predictions on future data?
RQ4: How sensitive are the hyperparameters in KG-MFEND?
4.1 Datasets and evaluation settings
4.1.1 Datasets
Fake news detection models are generally data-dependent. In other words, most methods perform well on trained datasets but are difficult to apply to other domains due to domain shift. In this paper, we evaluate the efficacy of our model on two real-world Chinese datasets, covering mixed-domain and multi-domains. The details of datasets are listed below:
Weibo 21 The dataset was developed by [4]. This is a multi-domain Chinese dataset covering nine domains (science, military, education, disaster, politics, health, finance, entertainment, and society), collected from Sina Weibo for the period from 2014 to 2021. The dataset totally consists of 4488 fake and 4640 real news pieces, which we name Data-single. In addition, we randomly mixed the datasets of the nine domains into an overall dataset, which we named Data-total. The specific statistics are shown in Table 2.
Chinese dataset In the real world, we can only rely on historical data to classify recent news as true or fake. We adopted the Chinese dataset to simulate the real-world scenario. This mix-domain dataset was presented by [49] and includes selected news pieces from 2010 to 2018. We use time-separated measurement to divide it into training, validation, and testing sets. The data between 2010 and 2017 are used as a training set to verify and test the 2018 sample data. News pieces with length of less than 2 contain too little information to judge their authenticity, and irrelevant features are often injected by knowledge graph embedding if the news is an entity. Therefore, we remove news pieces with length of less than 2. We called the dataset Data-mix. Table 3 shows the detailed dataset actually used in the experiments.
4.1.2 Comparison methods
In this section, we use state-of-the-art baselines for comparative analysis. All baselines can be divided into three groups. The first group is the single-domain baselines, which include BiGRU, TextCNN, and BERT. In the first group, a model can only be tested on one domain at a time. The second group adopts BiGRU, TextCNN, BERT, CompareNet, and KAHAN as the mix-domain baselines. The difference compared with the first group is that the mixed-domain methods conduct experiments and obtain results in multiple domains at a time. The last group is the multi-domain baselines, including EANN, MMoE, MoSE, EDDFN, MDFEND, FuD-FEND, and \(M^{3}\)FEND. We introduce the above models in detail.
-
BiGRU [29] is a widely used baseline in fake news detection. We implement a single-layer BiGRU with a hidden size of 300 and model each news piece as sequential input to BiGRU to preserve sequential information.
-
TextCNN [50] is a popular text encoder. We implement TextCNN with 5 kernels and adopt the same 64 channels for the 5 kernels. The embedding input of TextCNN is obtained by word2vec.
-
BERT [51] is used to encode the tokens of news pieces. We freeze all the layers in BERT and embed the average of the words in the last layer as sentence representations into the multi-layer perception for prediction.
-
CompareNet [18] aims to establish news and external knowledge connections through knowledge entities. The network learns news content, entity, and topic relations through graph attention networks to obtain semantic feature representations, which are compared with entity features for fake news detection. For a fair comparison, we do not consider topic features.
-
KAHAN [52] is a knowledge-aware hierarchical attention network (KAHAN) that integrates external knowledge into text and comments separately and then uses attention mechanisms to learn their relationship for fake news classification. For a fair comparison, we do not consider topic features.
-
EANN [53] is a multimodal fake news detection method composed of three components: a feature extractor, an event discriminator, and a fake news detector. To be fair, we only use the branch of text extraction.
-
MMoE [15] is a multi-task learning model designed to be suitable for multi-domain learning using a hybrid expert structure. Each domain consists of a shared expert (MoE) and a specific leader. In this paper, we consider MLP an expert and special leader.
-
MoSE [54] is also a multi-task learning model that uses Long Short-Term Memory (LSTM) to mix multiple experts for multi-task learning.
-
EDDFN [46] is a multi-domain fake news detection model that feeds centralized domain-specific and domain-shared representations to a classifier to identify fake news in different domains.
-
MDFEND [4] is also a multi-domain fake news detection model, which uses multiple experts (networks) to extract news features, and then assigns weights to different experts through domain gates to obtain the final news feature vectors.
-
FuD-FEND[55] is a recent multi-domain fake news detection technology that uses the fuzzy inference mechanism to generate fuzzy domain labels to distinguish the specific features of specific domains. This model can be trained in datasets without domain labels to identify multi-domain fake news.
-
\(M^{3}\)FEND [56] is the latest multi-domain fake news detection model, which detects fake news from three perspectives: semantics, style, and sentiment. The model realizes cross-view feature interaction through a domain adapter.
4.1.3 Experimental setting
We randomly divide all datasets into training, validation, and test sets at a ratio of 4:1:1. To make a fair comparison, the final results are obtained by averaging over ten experiments. We do not perform any dataset-specific tuning except for early stopping on validation sets. We conduct all experiments on an Intel i7 2.60GHz processor and RTX A5000 GPU with 45 GB memory. All codes are implemented in Python 3.8. All baselines follow the parameter settings in the original papers. KG-MFEND is improved according to Google BERT; we set the same parameters as it. We adopt the Adam optimizer for optimization and \(\theta\) for balancing soft and hard labels. The detailed parameters of the model are listed in Table 4. Following most existing work [36, 49, 57], we report accuracy (ACC), precision, area under ROC (AUC), recall, and F1-score metrics to measure model performance.
4.2 Performance comparison(RQ1)
To answer RQ1, we conduct experiments on Data-single and Data-total datasets and compare our model against related baselines introduced in Sect. 4.1.2. The experimental results of F1 scores on the Data-single dataset are shown in Table 5. And we visualize the results of F1, ACC, and AUC metrics on the Data-total dataset in Fig. 6. We can draw the following conclusions:
-
(1)
The experimental results show that our model outperforms the baselines in most domains. Compared with the best baseline on the Data-single dataset, the domains of science and technology, military, education, disease, politics, entertainment, and society are increased by 3.80\(\%\), 2.19\(\%\), 1.27\(\%\), 0.44\(\%\), 0.67\(\%\), 0.50\(\%\), and 0.41\(\%\). Additionally, the F1, ACC, and AUC have increased on the Data-total dataset by 0.39\(\%\), 0.46\(\%\), and 0.38\(\%\), respectively. The results indicate that KG-MFEND is an effective method to detect fake news in multiple domains.
Table 5 Experimental results on Data-mix dataset. The best model performance values and the best baseline model values are highlighted in bold and italics, respectively Fig. 6 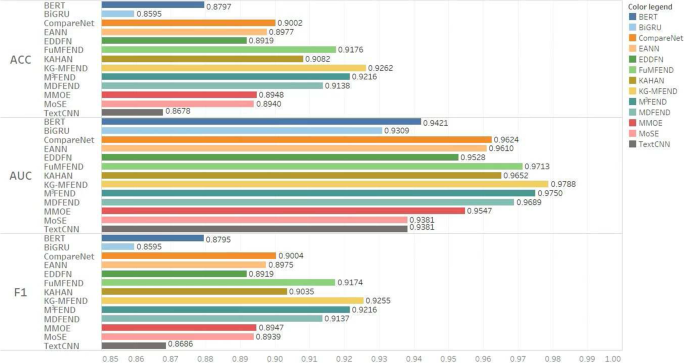
Experimental results on Data-total dataset
-
(2)
We find that the mixed-domain methods are superior to the single-domain methods in general, which indicates that the multi-domain joint training method can improve performance in the specific domain. The reason is that the domain features of single-domain news are not independent and may involve other domain features. In particular, the hybrid features are more prominent when the number of datasets is small. Noticeably, BERT in the mixed domain performs worse than BERT in the single-domain group, which suggests that simply combining data from different domains may result in negative effects.
-
(3)
It can be observed that CompareNet and KAHAN achieve better results than BiGRU, TextCNN, and BERT, proving that knowledge embedding is beneficial and can provide more rich clues. In particular, they are more effective than many multi-domain methods (EANN, MMoE, MoSE). KAHANT shows better performance than CompareNet. The reason is that CompareNet learns more noisy information by comparing entity features directly to text embedding features, while KAHANT assigns weights to entities in sentences through the attention mechanism. KG-MFEND performs best which shows that it is valuable for knowledge embedding to consider knowledge noise and heterogeneous embedding space problems.
-
(4)
Our model shows better performance than EANN, MMoE, MoSE, and EDDFN in the multi-domain approaches. In EANN, the shared network is directly learned through adversarial training. MMoE and MoSE are both based on a shared bottom and multiple independent heads to learn different domains’ features. Domain-specific subnetworks and domain-sharing subnetworks in EDDFN are learned. All of them employ sharing mechanisms to acquire shared knowledge across domains. However, it is difficult to learn common knowledge with a common structure from direct learning in multiple domains [8, 29]. In contrast, our model integrates useful entity knowledge through knowledge embedding, which is a soft sharing mechanism. And we use the soft position and visible matrix to control excessive knowledge embedding when sharing entity knowledge.
-
(5)
(5) Soft-sharing mechanisms are also adopted in MDFEND, FuDFEND, and \(M^{3}\)FEND. Their contributions to multi-domains are undeniable, which inspired the design of KG-MFEND. FuDFEND works better than MDFEND because the model uses a fuzzy inference label learning method that effectively learns some unlabeled or incorrectly labeled features. However, MDFEND and FuDFEND ignore the unclear domain problem, especially for short news texts. \(M^{3}\)FEND presents a domain memory repository to enrich domain information. But our proposed model is a more simple and effective approach by treating knowledge with multi-domain information as a mixed-domain expert to enrich domain knowledge. In addition, KG-MFEND can effectively conduct experiments on specific domains separately.

4.3 Ablation Study (RQ2)
In this section, we analyze the effectiveness of different components of our proposed KG-MFEND and perform ablation experiments by discarding the related variables. We define the KG-MFEND variants as follows:
-
“w/o soft position” is a variant of KG-MFEND and refers to the experiment where hard positions are used to replace soft positions.
-
“w/o visible matrix” means that no visible matrix is adopted in KG-MFEND, that is, all markers are visible to each other.
-
“w/o KG” is also a variant of KG-MFEND and refers to the model without KG. Without KG, we do not also consider soft positions and the visible matrix.
-
“K-bert” is similar to K-BERT [19] and a variant of KG-MFEND. ”K-bert” only uses the CN-Dbpedia as an external knowledge without two domain-specific KGs (EducationKG and MedicineKG). ”K-bert” also doesn’t add label smoothing to the training.
Tables 6, 7, and 8 represent those variants’ performance on Data-total and Data-mix datasets. Due to space limitations, we only exhibit the experimental results in two specific domains (society and disaster) on the Data-single dataset shown in Fig. 7. We have the following observations:

A part of experimental results on Data-sing dataset
-
(1)
As we can see from the results, our proposed model outperforms the four variants, which indicates that it is indispensable to consider both knowledge location and encoding in knowledge injection.
-
(2)
The KG-MFEND variant without the visible matrix performs less well than without KG, indicating that improper injection of knowledge can produce knowledge noise and lead to degraded model performance. KG-MFEND achieves better results than k-bert, which demonstrates that domain-special KGs and label smoothing are effective in multi-domain fake news detection.
-
(3)
According to the trend in Fig. 7, KG-MFEND tends to be stable in the second epoch, while BERT converges in the fourth epoch, which proves that KG-MFEND converges faster than BERT. We can infer that the combined action of soft position and visible matrix makes KG-MFEND more robust to KN interference when knowledge is injected.
4.4 Real-world testing(RQ3)
To verify whether KG-MFEND can be applied in real-world scenarios and make predictions on future data, we conduct experiments on the Data-mix dataset and select four models from the above as baselines to evaluate the performance of our method, including BiGRU, EANN, BERT, and MDFEND. Those baselines follow the parameter settings in [46]. Specifically, the batch size is set to 64. BiGRU has one layer with a hidden size of 768. The window sizes of TextCNN are set to \(\left\{ 1, 2, 3, 5, 10\right\}\). The best learning rates of those baselines are different: BiGRU (0.0009), EANN (0.0001), BERT (7\(e\) \(-\)05), and MDFEND (7\(e\) \(-\)5). We report the experiment’s results of accuracy, precision, recall, and F1 score in Table 8. The results of F1 and accuracy for all baselines over ten epochs are shown in Fig. 8. We come up with the following conclusions:

Accuracy and F1 score visualization
-
(1)
We observe that the proposed KG-MFEND performs better than all comparison models and detects fake news with high accuracy, indicating the effectiveness of our framework for future data. The reason is that the knowledge triples injected into the model are objective background knowledge, which generally does not change over time.
-
(2)
From the results, we see that both EANN and MDFEND as multi-domain detection methods, do not perform as well as BERT and BiGRU. The main reason is that domain differences in the mixed-domain dataset are not well distinguished. So, it is challenging for EANN to capture common features in the mixed-domain dataset. The domain experts of the MDFEND model play a less effective role in the mixed-domain dataset.
-
(3)
We visualize the experimental results of accuracy and F1 values and compare the F1 standard deviation of the baselines and KG-MFEND, as shown in Fig. 8 and Table 9, respectively. We can observe that the results of our model are relatively stable.
4.5 Analysis of hyperparameter sensitivity (RQ4)
In this section, we test the sensitivity of multiple hyperparameters based on the Data-mix dataset, including dropout value, maximum sequence length, \(\theta\) value, and leaning rate. The results are shown in Fig. 9. We also test the running time of KG-MFEND and compare it with the baselines in Sect. 4.4. For a fair comparison, we set the maximum sequence length of all baselines to 256. Tables 10 and 11, respectively, show the results of the average running time of each epoch and different max lengths.
We observe that KG-MFEND can achieve the best result with dropout (0.4), max length (256), \(\theta\) value (0.6), and learning rate (2e−05). In particular, our model performs better than the best baseline (ACC: 0.8412) even at the worst setting (ACC: 0.8602) on the Data-mix dataset, which proves that KG-MFEND is insensitive to the above hyperparameters [56].
From Fig. 9b and Table 11, we find that longer input lengths of the model do not necessarily improve performance but can increase model complexity and add running time. Figure 9c shows the accuracy of KG-MFEND as \(\theta\) varies. It can be seen that the accuracy of KG-MFEND with \(\theta\) set to 0.6 is higher than the accuracy with \(\theta\) set to 1, showing that model performance can be improved by adding the label smoothing. The reason is that label smoothing focuses the predicted value on the categories with higher probabilities and assigns some probabilities to other categories, which alleviates the problem of overfitting and label noise [48].
As shown in Table 10, KG-MFEND shows a slightly longer running time compared to all baselines. We can see that when the max length is 128 or 170, the running time of KG-MFEND is similar and even lower than some baselines, but it is much less accurate than the performance of the max length of 256, so we choose to sacrifice some running time to improve the model’s performance.

Performance (ACC) of KG-MFEND with various hyperparameters
5 Conclusions
In this paper, we present a novel knowledge graph-based model, namely KG-MFEND, to detect multi-model fake news. In KG-MFEND, we construct a new multi-domain knowledge graph consisting of a public knowledge graph and two domain-specific knowledge graphs. Next, we inject knowledge triples and construct a knowledge tree structure in the embedding layer. To achieve the embedding of the sentence tree structure without over-injecting entity knowledge, KG-MFEND uses soft position and visible matrices. The soft position is used to retag the word order and visible matric controls the relationships between content and entity triples. In addition, we add label smoothing to the loss function during model training to prevent overfitting of the model. We conduct extensive experiments on real datasets and compare three baseline models, including single-domain, mixed-domain, and multi-domain models. The results on Data-single and Data-total datasets show that KG-MFEND significantly outperforms state-of-the-art baselines. Additionally, our proposed KG-MFEND on the Data-mix dataset improves the F1 score by 2.36\(\%\) over the optimal baseline. Those experiments demonstrate the applicability and superiority of the KG-MFEND.
However, there are several limitations to our model. First, we only extract special knowledge from two related professional domains. Second, we share knowledge in different domains only considering the word level. It can be found that the model doesn’t perform better than the optimal baseline in the health and finance domains, which indicates that only considering domain-sharing information from knowledge is still not enough and that more domain shifts need to be learned.
In future work, we will further explore the domain differences across domains for multi-domain fake news detection and also study more effective knowledge embedding methods to improve model performance while reducing runtime .
Data availability
The data that support the findings of this study are available from the publicly accessible website (https://github.com/ICTMCG/M3FEND.git and https://github.com/ICTMCG/ENDEF-SIGIR2022.git). Those data are also available from the corresponding author; please contact s210701005@neau.edu.cn.
References
Song C, Ning N, Zhang Y, Wu B (2021) A multimodal fake news detection model based on crossmodal attention residual and multichannel convolutional neural networks. Inf Process Manag 58(1):102437
Vishwakarma D-K, Varshney D, Yadav A (2019) Detection and veracity analysis of fake news via scrapping and authenticating the web search. Cogn Syst Res 58:217–229
Bai N, Meng F, Rui X, Wang Z (2021) Rumour detection based on graph convolutional neural net. IEEE Access 9:21686–21693
Nan Q, Cao J, Zhu Y, Wang Y, Li J (2021) MDFEND: multi-domain fake news detection. In: Proceedings of the 30th ACM International Conference on Information & Knowledge Management, pp 3343–3347
Cohen J, Normile D (2020) New SARS-like virus in China triggers alarm
Ashraf N, Nayel H, Taha M (2022) A comparative study of machine learning approaches for rumors detection in Covid-19 tweets. In: 2022 2nd International Mobile, Intelligent, and Ubiquitous Computing Conference (MIUCC). IEEE, pp 384–387
Jin Z, Cao J, Guo H, Zhang Y, Wang Y, Luo J (2017) Detection and analysis of 2016 us presidential election related rumors on twitter. In: International Conference on Social Computing, Behavioral-Cultural Modeling and Prediction and Behavior Representation in Modeling and Simulation, pp 14–24
Weiss K, Khoshgoftaar T-M, Wang D (2016) A survey of transfer learning. J Big data 3(1):1–40
Zhu Y, Zhuang F, Wang D (2019) Aligning domain-specific distribution and classifier for cross-domain classification from multiple sources. In: Proceedings of the AAAI Conference on Artificial Intelligence, pp 5989–5996
Potthast M, Kiesel J, Reinartz K, Bevendorff J, Stein B (2018) A stylometric inquiry into hyperpartisan and fake news. In: Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics, pp 231–240
Wang W-Y (2017) ”Liar, liar pants on fire”: a new benchmark dataset for fake news detection. In: Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics, pp 422–426
Horne B-D, Adali S (2017) This just in: fake news packs a lot in title, uses simpler, repetitive content in text body, more similar to satire than real news. In: Eleventh International AAAI Conference on Web and Social Media, pp 759–766
Thorne J, Vlachos A, Christodoulopoulos C, Mittal A (2018) FEVER: a large-scale dataset for fact extraction and VERification. In: Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pp 809–819
Boididou C, Andreadou K, Papadopoulos S, Dang-Nguyen D-T, Boato G, Riegler M, Kompatsiaris Y (2015) Verifying multimedia use at mediaeval 2015. MediaEval 3(3):7
Ma J, Zhao Z, Yi X, Chen J, Hong L, Chi E-H (2018) Modeling task relationships in multi-task learning with multi-gate mixture-of-experts. In: Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, pp 1930–1939
Chen X, Jia S, Xiang Y (2020) A review: knowledge reasoning over knowledge graph. Expert Syst Appl 141:112948
Pan J-Z, Pavlova S, Li C, Li N, Li Y, Liu J (2018) Content based fake news detection using knowledge graphs. In: International Semantic Web Conference, pp 669–683
Hu L, Yang T, Zhang L, Zhong W, Tang D, Shi C, Zhou M (2021) Compare to the knowledge: graph neural fake news detection with external knowledge. In: Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (vol 1. Long Papers), pp 754–763
Liu W, Zhou P, Zhao Z, Wang Z, Ju Q, Deng H, Wang P (2020). K-bert: Enabling language representation with knowledge graph. In Proceedings of the AAAI Conference on Artificial Intelligence, pp 2901–2908
Wang Y, Ma X, Chen Z, Luo Y, Yi J, Bailey J (2019) Symmetric cross entropy for robust learning with noisy labels. In: Proceedings of the IEEE/CVF International Conference on Computer Vision, pp 322–330
Pennycook G, Rand D-G (2021) The psychology of fake news. Trends Cogn Sci 25(5):388–402
Bondielli A, Marcelloni F (2019) A survey on fake news and rumour detection techniques. Inf Sci 497:38–55
Ratkiewicz J, Conover M, Meiss M, Gonçalves B, Patil S, Flammini A, Menczer F (2011) Truthy: mapping the spread of astroturf in microblog streams. In: Proceedings of the 20th International Conference Companion on World Wide Web, pp 249–252
Nguyen V-H, Sugiyama K, Nakov P, Kan M-Y (2020) Fang: leveraging social context for fake news detection using graph representation. In: Proceedings of the 29th ACM International Conference on Information & Knowledge Management, pp 1165–1174
Shu K, Mahudeswaran D, Wang S, Liu H (2020) Hierarchical propagation networks for fake news detection: investigation and exploitation. In: Proceedings of the International AAAI Conference on Web and Social Media, pp 626–637
Shu K, Zhou X, Wang S, Zafarani R, Liu H (2019) The role of user profiles for fake news detection. In: Proceedings of the 2019 IEEE/ACM International Conference on Advances in Social Networks Analysis and Mining, pp 436–439
Wang Y, Wang L, Yang Y, Lian T (2021) SemSeq4FD: integrating global semantic relationship and local sequential order to enhance text representation for fake news detection. Expert Syst Appl 166:114090
Ma J, Gao W, Mitra P, Kwon S, Jansen B-J, Wong K F, Cha M (2016) Detecting rumors from microblogs with recurrent neural networks
Xing F, Guo C (2019) Mining semantic information in rumor detection via a deep visual perception based recurrent neural networks. In: 2019 IEEE International Congress on Big Data (BigDataCongress). IEEE, pp 17–23
Vo N, Lee K (2019) Learning from fact-checkers: analysis and generation of fact-checking language. In: Proceedings of the 42nd International ACM SIGIR Conference on Research and Development in Information Retrieval, pp 335–344
Zhou K, Shu C, Li B, Lau J-H (2019) Early rumour detection. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pp 1614–1623
Li Q, Zhang Q, Si L (2019) Rumor detection by exploiting user credibility information, attention and multi-task learning. In: Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, pp 1173–1179
Shelke S, Attar V (2022) Rumor detection in social network based on user, content and lexical features. Multimedia Tools Appl 81(12):17347–17368
Chen X, Zhou F, Zhang F, Bonsangue M (2021) Catch me if you can: a participant-level rumor detection framework via fine-grained user representation learning. Inf Process Manag 58(5):102678
Ma J, Gao W, Wong K-F (2017) Detect rumors in microblog posts using propagation structure via kernel learning. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics, pp 708–717
Bian T, Xiao X, Xu T, Zhao P, Huang W, Rong Y, Huang, J (2020) Rumor detection on social media with bi-directional graph convolutional networks. In: Proceedings of the AAAI Conference on Artificial Intelligence, pp 549–556
Yuan C, Ma Q, Zhou W, Han J, Hu S (2019) Jointly embedding the local and global relations of heterogeneous graph for rumor detection. In: 2019 IEEE International Conference on Data Mining. IEEE, pp 796–805
Tan L, Wang G, Jia F, Lian X (2022) Research status of deep learning methods for rumor detection. Multimedia Tools Appl. https://doi.org/10.1007/s11042-022-12800-8
Wang W, Lv Y, Wen Y, Sun X (2022) Rumor detection based on knowledge enhancement and graph attention network. Discrete Dyn Nat Soci. https://doi.org/10.1155/2022/6257658
Li Q, Zhang Q, Si L, Liu Y (2019) Rumor detection on social media: datasets, methods and opportunities. arXiv preprint arXiv:1911.07199
Sicilia R, Francini L, Soda P (2021) Representation and knowledge transfer for health-related rumour detection. In: 2021 IEEE 34th international symposium on computer-based medical systems (CBMS). IEEE, pp 591–596
Wang Q, Mao Z, Wang B, Guo L (2017) Knowledge graph embedding: a survey of approaches and applications. IEEE Trans Knowl Data Eng 29(12):2724–2743
He S, Luo H, Chen W, Zhang M, Zhang Y, Wang F, et al. (2020) Multi-domain learning and identity mining for vehicle re-identification. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, pp 582–583
Zhou X, Zheng W, Li Y, Pearce R, Zhang C, Bell E-W et al (2022) I-TASSER-MTD: a deep-learning-based platform for multi-domain protein structure and function prediction. Nat Protoc 17(10):2326–2353
Zhang J, Zhao Q, Adeli E, Pfefferbaum A, Sullivan E-V, Paul R et al (2022) Multi-label, multi-domain learning identifies compounding effects of HIV and cognitive impairment. Med Image Anal 75:102246
Silva A, Luo L, Karunasekera S, Leckie C (2021) Embracing domain differences in fake news: Cross-domain fake news detection using multi-modal data. In: Proceedings of the AAAI Conference on Artificial Intelligence, pp 557–565
CN-DBpedia, X B. X Y A Never-ending Chinese knowledge extraction system. In: International Conference on Industrial, Engineering and Other Applications of Applied Intelligent Systems, pp 428–438
Zhang C-B, Jiang P-T, Hou Q, Wei Y, Han Q, LiZ Cheng M-M (2021) Delving deep into label smoothing. IEEE Trans Image Process 30:5984–5996
Zhu Y, Sheng Q, Cao J, Li S, Wang D, Zhuang F (2022) Generalizing to the future: mitigating entity bias in fake news detection. arXiv preprint arXiv:2204.09484
Yoon K (2014) Convolutional neural networks for sentence classification. In: Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing. Association for Computational Linguistics, pp 1746–1751
Kenton J-D-M-W-C, Toutanova L-K (2019) Bert: pre-training of deep bidirectional transformers for language understanding. In: Proceedings of NAACL-HLT, pp 4171-4186
Tseng Y-W, Yang H-K, Wang W-Y, Peng W-C (2022) KAHAN: knowledge-aware hierarchical attention network for fake news detection on social media. In: Companion Proceedings of the Web Conference, pp 868–875
Wang Y, Ma F, Jin Z, Yuan Y, Xun G, Jha K, et al. (2018) Eann: event adversarial neural networks for multi-modal fake news detection. In: Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, pp 849–857
Qin Z, Cheng Y, Zhao Z, Chen Z, Metzler D, Qin J (2020) Multitask mixture of sequential experts for user activity streams. In: Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, pp 3083–3091
Liang C, Zhang Y, Li X, Zhang J, Yu Y (2022) FuDFEND: fuzzy-domain for multi-domain fake news detection. In: Natural Language Processing and Chinese Computing: 11th CCF International Conference, pp 45–57
Zhu Y, Sheng Q, Cao J, Nan Q, Shu K, Wu M et al (2022) Memory-guided multi-view multi-domain fake news detection. IEEE Trans Knowl Data Eng. https://doi.org/10.1109/TKDE.2022.3185151
Yang Y, Wang Y, Wang L, Meng J (2022) PostCom2DR: utilizing information from post and comments to detect rumors. Expert Syst Appl 189:116071
Funding
This research was funded by General Project of Philosophy and Social Science of Heilongjiang Province, grant number: 20SHB080.
Author information
Authors and Affiliations
Contributions
Lifang Fu provided guidance on the paper and suggested changes to it. Huanxin Peng wrote the manuscript, performed the formal analysis, and performed the data analysis. Shuai Liu performed the validation. All authors have checked the manuscript and have agreed to the submission.
Corresponding author
Ethics declarations
Ethical a pproval
Not applicable.
Conflict of interest
The authors declare that they have no known conflicts of interest or personal relationships that might affect the work reported in this article.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
fu, L., Peng, H. & Liu, S. KG-MFEND: an efficient knowledge graph-based model for multi-domain fake news detection. J Supercomput 79, 18417–18444 (2023). https://doi.org/10.1007/s11227-023-05381-2
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11227-023-05381-2