
Abstract
In recent years, personalized dialogue systems have drawn growing attention as they can serve as a personalized assistant for a specific user. A key feature of personalized dialogue systems is the ability to maintain the consistent personality and contextual expression that matches the user’s individual style and needs. Numerous approaches have been developed for creating personalized dialogue systems. However, most existing approaches depend heavily on explicit persona information, such as predefined persona-defining sentences or key-value persona data. When using predefined explicit user persona knowledge in real-world situations, users need to spend more time crafting clear and descriptive persona information. To address this issue, we introduce IMPACT, a generative-based personalized dialogue model that leverages dialogue history to discover implicit persona knowledge. Both implicit and explicit persona knowledge are equally valuable. IMPACT is designed to discover the user’s personalized expression style within dialogues and generate responses that reflect the consistent style. Achieving dialogue consistency requires modeling the complex relationships between the user’s message, persona, and dialogue history. In addition, we use an unlikelihood training objective to optimize the model and further improve dialogue consistency. We conduct comprehensive experiments on two large datasets, and the results show that our method outperforms all baseline models.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
Developing a personalized open-domain dialogue system is a fascinating yet challenging area of study that has garnered significant attention from both academic and industrial communities. While there are numerous dialogue methods, certain challenges still exist and have yet to be effectively addressed [1]. One of the major challenges in this field are dialogue consistency [2, 3]. Ensuring dialogue consistency in open-domain dialogue systems is an ongoing challenge. Two widely adopted strategies to improve response consistency are persona consistency and contextual consistency. The responses must be coherent and consistent with persona knowledge and dialogue history. In the open-domain dialogue systems, explicit persona knowledge refers to a set of descriptive sentences and the features that determine the expression, personality and behaviors. Recent theoretical advancements have emphasized the importance of dialogue systems exhibiting consistent persona characteristics to establish and maintain long-term user trust. A well-designed dialogue system should avoid generating responses that contradict its predefined persona knowledge and previous responses in terms of logic and reasoning. Therefore, equipping dialogue systems with consistent persona and generating responses that maintain a consistent expression are critical research tasks.
A few attempts have been made for personalized dialogue generation. Zhang et al. [4] create the PersonaChat dataset and utilize a memory network to store and retrieve persona knowledge. This research represents a relatively novel area of study. Song et al. [5] exploit persona knowledge from context and incorporate a conditional variational autoencoder(CVAE) model to generate diverse conversations. Previous research has focused on manually constructing explicit persona knowledge, which can take the form of personalized descriptions [6] or key-value formatted persona knowledge [7]. The studies mentioned above primarily aim at incorporating explicit persona knowledge into the responses but may need to look into the implicit persona knowledge derived from the dialogue history. Implicit persona reflects the hidden character of interlocutors. It is always hidden in dialogue history. Therefore, there is a need for research that can effectively integrate both explicit and implicit persona knowledge. A significant amount of implicit persona knowledge can be derived from the dialogue history, making it a promising approach for discovering such information [8,9,10,11]. Incorporating implicit persona knowledge into dialogue systems can also significantly enhance dialogue consistency. In the following section, we will discuss the advantages of leveraging implicit persona knowledge.

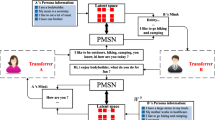
Different users reply differently to the same question. The implicit persona knowledge is hidden in the dialogue history
Based on the above discussion, we propose integrating implicit and explicit persona knowledge to generate more consistent and contextually appropriate responses. The advantage of implicit persona knowledge can be summarized in two parts. Firstly, when it comes to convenience and extensibility, implicit persona knowledge is often more favorable than explicit persona knowledge. Acquiring a significant amount of explicit persona knowledge requires extensive manual labeling, which can be a labor-intensive and time-consuming process. In a practical setting, users may also be unwilling to provide labels for personalized sentences, making it difficult to gather such data at scale. Furthermore, implicit persona knowledge is more easily updated as the dialogue history accumulates, since it is naturally learned over time. Implicit persona knowledge is more flexible and adaptable compared with explicit persona knowledge. Secondly, various personalized expressing characteristics regularly hide in the dialogue history. Here, the personalized expressing characteristics mean the personalized attributes(e.g., dialogue habit, prerequisite knowledge, and preferences). These personalized attributes are valuable to enhance the dialogue system’s ability to generate coherent responses. As illustrated in Fig. 1, implicit persona knowledge can be derived from the dialogue history, as users with different persona knowledge may respond differently to the same question. This demonstrates personalized expression characteristics can be concealed within the dialogue history. Personalized expression characteristics become a valuable source of information for dialogue systems. Taking the question Where do you live and what did you do today? as an example shown in Fig. 1, the user with personas I live in New York. and I love sandwich. replies I live in New York and I will be making some sandwiches today., the user with persona I live in Midwest America. replies I live in Midwest America.. As shown in Fig. 1, the dialogue history shows user B thinks listening to music is a good way to release stress when user B receives the question What do you do when you’re unhappy?, user B replies I love to read or listen to music. Most existing personalized dialogue generation methods use explicit persona information for dialogue generation. Persona information is expensive to label. It is necessary to model the user’s persona information from dialogue history.
Motivated by the positive impact of leveraging implicit persona knowledge, we have developed a new dialogue model named IMPACT which focuses on integrating implicit persona knowledge from dialogue history. Our proposed approach involves generating a consistent response from two perspectives: discovering implicit personalized characteristics and modeling a consistent expressive style through contextual and persona consistency. The former aims at discovering implicit personalized characteristics from the dialogue history and explicit persona knowledge. The latter considers the interdependent relationship between the current query, the user’s persona and the dialogue history to ensure consistency. However, existing approaches often lack clear and consistent modeling objective. To address this, we utilize unlikelihood training objective [12] to improve dialogue consistency.
To be more specific, we first develop a personalized characteristics discovering module that utilizes multi-layer attentive modules to capture multi-grained personalized characteristics. We simultaneously execute self-attention and cross-attention with historical responses, related posts, explicit persona knowledge and current query at each layer. By doing so, we can obtain personalized attributes and better understand the contextual relationships between responses and historical posts. Secondly, we build a dialogue consistency matching module to model dialogue consistency. We model the relationship between the current query and the dialogue history from two perspectives: contextual-level relevance and word-level relevance. Additionally, we model the relationship between the current query and persona knowledge similarly. Finally, we integrate three matching features in the fusion process to generate the most appropriate response. Moreover, since these methods lack a consistency modeling objective, we employ the unlikelihood training objective to mitigate inconsistent responses. To validate the effectiveness of our proposed model, we conduct comprehensive experiments on two publicly available datasets. We evaluate the model using automatic and human evaluation metrics for personalized response generation. Furthermore, we test our method in a persona-sparse setting since not all dialogues require the integration of persona knowledge. Experimental results show that our model outperforms all baseline models. Our contributions are threefold:
-
To generate consistent responses, we propose IMPACT to model the personalized expression characteristics and construct the implicit persona knowledge from dialogue history.
-
We model the inner relations between the query, persona and dialogue history from multi-views, including contextual consistency and persona consistency. Moreover, we employ the unlikelihood training objective to alleviate the inconsistency expressed.
-
We carry out comparative experiments in various environments to prove the effectiveness of our method. Extensive experiments show that our model outperforms all the baseline models.
2 Related work
As a challenging task in natural language processing, dialogue systems have attracted significant attention from researchers due to their broad application. Previous dialogue systems, such as Parry [13] and Eliza [14], aim to imitate human dialogue behavior to pass various Turing tests. Generally speaking, there are two kinds of dialogue systems: task-oriented and non-task-oriented dialogue systems. Task-oriented dialogue systems [15,16,17,18,19] are designed for specific purposes, such as flight reservations, hotel bookings, customer service, technical support, and other particular fields. They have been successfully employed in some real-world applications. Generally speaking, there are two types of dialogue systems: task-oriented and non-task-oriented. Task-oriented dialogue systems, such as those used for flight reservations, hotel booking, customer service, technical support, and other specific fields, have been successfully employed in real-world applications. On the other hand, non-task-oriented dialogue systems are more challenging to develop as they aim to generate open-ended conversations. Personalized dialogue generation is one of the most active research topics in non-task-oriented dialogue systems, which aims to generate persona-aware responses in multi-turn conversations [20,21,22].
Recently, personalized dialogue generation has attracted interest from various fields, and a significant amount of influential work is aimed to construct personalized dialogue systems [23]. Li et al. [24] and Zhang et al. [25] incorporate persona knowledge by encoding it into a vector and then decoding it in the utterance prediction process to capture individual characteristics. Such approaches require conversational data tagged with user persona, which can be costly to obtain for large amounts of data. Therefore, Wang et al. [26] introduce personalized models with only categorical attributes (e.g., gender, hobbies, and location). The categorical attributes are converted into vectors and fed into the decoder for response generation. However, user identities are often unavailable, which makes external supervision difficult. Therefore, Zhang et al. [27] design a neural dialogue model that generates consistent responses by preserving specific features that are correlated to personas and topics. Cheng et al. [28] introduce a novel approach for studying dynamically updated speaker embeddings in conversational contexts. Unlike other methods that require external supervision-specific data, this approach leverages dialogue data to train persona feature extractors and self-supervised topics. The resulting neural model captures the nuances of speakers’ personalities and conversational topics, which can be used for content ranking in dialogue action estimation. This approach has the potential to improve the effectiveness of conversational agents and other dialogue-based systems by enabling them to better understand and respond to users’ needs and preferences.
Although Ouchi et al. [29] and Zhang et al. [30] prove that user embedding is an efficacious arrangement to restrict the characters of speakers, penalization in these models is handled implicitly and, therefore, not easy to interpret and control in producing desired replies. So the researchers begin modeling the user embedding with explicit persona knowledge. Qian et al. [31] propose an explicit persona model to produce well-organized replies considering a specified user profile. The personality chatbot is defined by a key-value form composed of gender, hobbies, names, or other relative factors. Over a generation, the model first picks the key-value pairs from the profile and then decodes a reply from backward and onward. XiaoIce also applies an explicit persona model [32]. Many personalized dialogue datasets have been proposed to develop models. The explicit personal information is human-annotated. Persona-Chat [4] is such a dataset that has extensively promoted the development of this field. Along with the Persona-Chat, Zhang et al. [5] introduce a structure based on memory mechanism to exploit persona knowledge from context and apply a conditional variational autoencoder(CVAE) to produce sustainable and various conversations. Owning to the one-stage decoding model can relieve inconsistent persona words generation barely. Thus, Song et al. [33] introduce a three-stage framework employing a generate-delete-rewrite mechanism to remove inconsistent words from a produced reply prototype and re-write it to a personality-consistent one. However, most daily conversations do not aim to show their personality within narrow turns of interactions. Namely, the dialogues from the real world are not generally related to the speaker’s personality. Based on this fact, Zheng et al. [34] release a Chinese persona-sparse dataset PersonalDialog which guides the model to imitate the conversation between people in the real world. The above methods to increase dialogue consistency are used to explicitly define a set of agents and learn to generate a personalized response. However, such methods need a more consistent modeling process, these personalized dialogue models still have the inconsistency challenge [35]. So Welleck et al. [35] frame the consistency of the dialogue generation task as a natural language inference(NLI) task. They make a novel natural language inference dataset called Dialogue NLI (DNLI). To discover the consistent relations between attribute information and reply, Song et al. [7] create a large-scale human-annotated dataset called KvPI, which labels the relation between profile and response. To use the persona knowledge correctly and generate consistent responses, Xu et al. [36] propose the Persona Exploration and Exploitation(PEE) framework, extending the persona description with semantically correlated content before exploiting them to produce dialogue responses.
In the above, we have discussed the methods of building personalized dialogue systems, which control conversation generation using explicitly defined user persona knowledge. The existing challenges of modeling personalized dialogue methods can be concluded in three points: (1)The most existent approaches need to be more sufficient in modeling the psychological personality of speakers from dialogue history. (2)Ignore the inner relations between the user’s message, persona and dialogue history. (3)Lack of modeling consistency training objective. Next, we will introduce our model in detail from the above three challenges.
3 Methodlogy
3.1 Task formulation
Personalized dialogue generation consists in predicting an utterance R, given a context \(x=\{q, K, H\}\) that includes dialogue query q, persona sentences K and dialogue history utterances H from interlocutors who take continuous turns. Response requires to reflect the personality defined by persona knowledge K. More importantly, the response requires consistency with persona K and previous responses in the dialogue history H.
3.2 Preliminary
The general goal of Personalized dialogue systems is to generate the most proper response which reflects explicit and implicit persona. The generative dialogue model is to predict the output distribution \(p_{\gamma }\left( r^{*} \mid q, K, H\right) \) for a given message q under the dialogue history H and given persona knowledge K. For a single-turn dialogue system, \(H=\varnothing \) and responses are generated from the above distribution for input message q and persona knowledge K. For a multi-turn dialogue system, H is the context of the previous conversation turns. This work investigates generating an inconsistent response in a multi-turns dialogue system. We divide the problem of consistency into context consistency and persona consistency. The consistent issue can be formally defined as: given the dialogue history H, and a set of persona knowledge \(K=\{k_{1},k_{2},...,k_{n}\}\), to generate a response \(r^{*}\) based on H and K. Moreover, \(r^{*}\) should be consistent with the persona knowledge set K and dialogue history H, which means NLI category between \(r^{*}\), \(\forall K, H, \text {NLI}(r^{*},K) \in \{E,N\}, \text {NLI}(r^{*},H) \in \{E,N\}\), where E and N mean entailment and neutral, respectively. The notations used in this paper defined in Table 1.
3.3 IMPACT overview

Main framework of our method
Two significant aspects impact the consistency of the dialogue agent’s expression. First, the dialogue agent should be consistent with previous personalized expression regarding the dialogue history. The preferred expression usually determines such a personalized expression manner. Second, how a dialogue agent generates a personalized response is also conditioned on the internal relations between the current query, personalized preference and dialogue history. Given the same dialogue query, different users may provide different reactions, and we attempt to gain personalized preference from dialogue history. Based on this, we presume the personalized description consists of two aspects: (1) personalized expression manner S and (2) consistency matching style \(C_{H}\), \(C_{P}\) and \(C_{K}\) which measure the context consistency and persona consistency, respectively.
Figure 2 shows the structure of IMPACT. Specifically, we first build a Personalized expression Cognition module(in Sect. 3.5), which intends to cache the personalized expression representation \(g^S\) utilizing dialogue historical reactions. Next, we design dialogue consistent matching module(in Sect. 3.6) which measures the consistency degree between persona knowledge \(g^{C_{K}}\) and dialogue history \(g^{C_{H}}\), \(g^{C_{P}}\). Then, three matching modules match separately, and in the model fusion module(in Sect. 3.7), we merge three types of features to figure out the final matching grade. In the remaining parts of this section, we will introduce each component’s details.
3.4 Foundation: attentive module
In this part, we demonstrate the fundamental module in our method, the attentive module, which is a necessary part of our approach. Inspired by previous works [37, 38], we employ the attentive module to transform the semantics under the dialogue context into embedding representation. Attentive Module is a variant of Transformer structure [39]. Compared with the multi-head attention layer employed in Transformer, the attentive module only adopts one head for attention. Specifically, attentive module \(\text {Attn}(Q, K, V)\) takes \(Q \in {\mathbb {R}}^{l \times d}\), \(K \in {\mathbb {R}}^{l \times d}\), and \(V \in {\mathbb {R}}^{l \times d}\) as input, where l and d denotes the sequence length and the number of hidden dimensions, respectively. The attentive module maps Q, K, V to a weighted output. Weights are calculated by making each token focus the tokens in critical sentences by scaled dot production:
Then we employ the residual connection with layer normalization to obtain a better representation and keep the gradient from vanishing. The final result is computed from a feed-forward network(FFN) with ReLU activation:
where x has same shape with query Q, b and \({\textbf{W}}\) are trainable parameters. We denote the above process as \(f_{\text {Attn}}(\cdot , \cdot , \cdot )\).
3.5 Personalized characteristics discovering module
It is important to incorporate personalized expression into the conversation to ensure that a personalized dialogue system can generate coherent and consistent responses that accurately reflect a user’s persona. This can be achieved by developing a Personalized Characteristics Discovering Module to analyze a user’s historical responses and identify patterns in their preferred speaking style. User personas and dialogue history are modeled in an interactive style. Then, we obtain persona-related representations from the dialogue history, that is implicit persona information. Finally, we integrate the captured multi-views persona features and use them for downstream personalized response generation.
Formally, given dialogue history \(H=\{(p_{1},r_{1}),(p_{2},r_{2}),...,(p_{t-1},r_{t-1})\}\), persona knowledge K and dialogue query at t time step \(q^{t}\). The personalized Characteristics Discovering Module aims to get a matching vector \(g^S(q^{t},K,H)\), which mines the personalized feature from persona K and historical context. The personalized matching module achieves the goal via three layers, Semantic Extraction Layer, Interaction Layer and Fusion Layer. Semantic Extraction Layer models multi-grained semantic representations for historical response and persona knowledge. Knowledge Interaction Layer executes matching operation at each semantic scale. Fusion Layer fuses matching signals between historical response and persona knowledge to obtain \(g^S(q^{t},K,H)\). We will introduce these layers in detail as follows:
Semantic Extraction Layer aims to gain multi-grained semantic representation \(R_{c}^j=\{r^j_{0}, r^j_{1},...,r^j_{n}\}\) for personalized style, and it also get the cross-attention representations \(P_{c}^j=\{c^p_{0}, c^p_{1},...,c^p_{n}\}\), \(K_{c}^j=\{c^k_{0}, c^k_{1},...,c^k_{n}\}\) for historical response \(r_j, j\in [1, t-1]\), dialogue query q and persona knowledge K by n attentive modules.
Taking \(j-th\) response \(r_j\) as example, we employ \(R_{c}^j=\{r^j_{0}, r^j_{1},...,r^j_{n}\}\) to represent the contextual semantic feature of \(r_j\). Specifically, firstly, we initialize word representation \(r^j_{0}\) by Word2Vec [40]. Next, we feed the word embedding into n attentive modules to obtain deep contextual response representations.
where \(r_{l}^{j}\) is the contextual representation output by \(l-th\) attentive module.
Furthermore, the personalized is also conditioned on dialogue posts. In view of this, we let the representation \(r_j \in R^j\) attend to corresponding post representation \(p_j\) to obtain cross-attention representation \(P^j=\{c^p_{0}, c^p_{1},...,c^p_{n}\}\):
where \(p_{l}^j\) is obtained in same way as \(r_{l}^j\). \(K^j\) is calculated between \(q_t\) and persona knowledge K.
In the conversation process, we believe that dialogue posts and current dialogue queries are essential for persona understanding; redundant persona knowledge will negatively impact dialogue generation. In view of this, we also make cross-attention between dialogue posts P, current query q and persona knowledge K to obtain \(K_{c}^{j}=\{c_1^K, c_2^K,...,c_n^K\}\) and \(R^{j}=\{c_1^q, c_2^q,...,c_n^q\}\):
Knowledge Interaction Layer aims to generate a personalized style state \(M_s\) which measures the personalized matching degree at the multi-grained level. Specifically, given \(j-th\) dialogue post \(p^j_{l}\) and its corresponding response \(r_{l}^{j}\), we calculate \({m1}_{l}^{j}\) which measure the relations between dialogue post and response. Then, we compute \({m2}_{l}^{j}\) and \({m3}_{l}^{j}\) to obtain the relations between dialogue posts, persona knowledge and dialogue query:
where d is dimension of embeddings and l denotes the representation output by \(l-th\) attentive module. Therefore, for t historical context \(H=\left\{ (p_{1},r_{1}),...,(p_{t-1},r_{t-1})\right\} \), we have \(M1_{l}=\{{m1}_{l}^{1},...,{m1}_{l}^{t-1}\}\), \({{M2}}_{l}=\{{{m2}}_{l}^{1},...,{{m2}}_{l}^{t-1}\}\) and \({{M3}}_{l}=\{{{m3}}_{l}^{1},...,{{m3}}_{l}^{t-1}\}\) to mine the personalized feature from dialogue history and persona knowledge.
To share the above matching matrices, we transforme these matrices into a shared feature space:
where \(f_{\text {stack}}(\cdot )\) refers to concatenation operation on a new dimension. \(M_{s} \in {\mathbb {R}}^{3(n+1) \times (t-1) \times L \times L}\) and L is maximum sequence length.
Inspired by [41, 42], we extract matching features from personalized style state \(M_s\) via Convolutional Neural Network(CNN) in Fusion Layer. CNN can simply and effectively aggregate the character characteristics of multiple perspectives, including the explicit persona features, implicit persona features and dialogue history features. High dimension feature is then linear mapped into a lower-dimensional feature space via multi-layer perceptron(MLP):
Especially, the personalized matching matrix \(V_{s}\) contains the matching feature between dialogue history and dialogue query. Due to the dialogues being sorted by time in conversation, the impact of long-distance dialogue will disappear. Though dialogues are sorted by time in conversation, temporal patterns disappear for the historical response. We thus employ self-attention to sum the personalized matching state up \(V_{s}\) dynamically. Finally, we obtain the personalized matching feature \(g^S(q^{t},K,H)\):
where \(s_{\text {Attn}} \in {\mathbb {R}}^{(t-1) \times d}\) means the attention weights and \(\odot \) denotes element-wise multiplication.
3.6 Dialogue consistency matching module
Generative persona-grounded dialogue systems should output coherent responses consistent with the context. These contexts are essential for generating a consistent response. For example, the chatbot once said he likes to drink tea, and regarding what he hated drinking, the chatbot reply was also tea. The above context inconsistent phenomenon will make it difficult for users to gain trust in the chatbot and lose its application value. Under the above observation, we design a Dialogue Context Consistency Matching module to model the consistency feature from the dialogue.
The consistency matching module aims to obtain consistency matching state vector \(g^C(q,H)\) and \(g^C(q,K)\), which measures the relevance between dialogue query q, dialogue history H and persona knowledge K. Unrelated dialogue history and persona knowledge can have a negative effect on response generation. Therefore, we need to filter out unrelated dialogue history and personal knowledge. Intuitively, we can compute the relevance vector \(s_H \in {\mathbb {R}}^{t-1}\), \(s_P \in {\mathbb {R}}^{t-1}\) and \(s_K \in {\mathbb {R}}^{t-1}\) that measure the topic relatedness between current query q, historical posts \(p=\{p_1,p_2,...,p_{t-1}\}\) and persona knowledge K. Then, we re-weight the dialogue history H, dialogue posts P and persona knowledge K:
We assume the topic relatedness can be divided into contextual-level relevance and word-level relevance. The relevance state s consists of contextual-level relevance state \(s_1\) and word-level relevance state \(s_2\).
For contextual-level relevance state:
where \(u^q = \mathop {\mathrm{{mean}}}\limits _{\dim = 1} {q}\) and \(U^{P} = \mathop {\mathrm{{mean}}}\limits _{\dim = 2} {P}\) are sentence representation obtained by mean pooling over the word dimension.
For word-level relevance state, we compute the word-level matching state matrix \(M_w \in {\mathbb {R}}^{(t+1) \times L \times L}\) by:
where \({\textbf{W}}_{1} \in {\mathbb {R}}^{d \times d \times (t+1)}\), \({\textbf{W}}_{2} \in {\mathbb {R}}^{d \times d \times (t+1)}\) and \({\textbf{W}}_{3} \in {\mathbb {R}}^{(t+1) \times 1}\). \(K=\{k_{1},k_{2},...,k_{t-1}\}\) is the contextual representation for historical posts. To obtain the most important matching features, we employ the max-pooling on the word-level matching state matrix and then use the softmax function linear into the word-level relevance vector \(s_2\):
where[; ] is concatenation operation. We combine context-level and word-level relevance vector by:
Relevance vector s is obtained using current query q as a key to attend to persona knowledge and related historical posts. Then we design a multi-hop perception method to track the multi-hop conversation dynamically. Specifically, we store historical posts in the dialogue buffer and persona buffer. At each hop, the most related historical dialogue \(s^{H_j}\) and persona knowledge \(s^{K_j}\) will be selected and then make up \(S=\{(s^{H_1}, s^{k_1}),(s^{H_2}, s^{k_2}),...,(s^{H_{t-1}}, s^{k_{t-1}})\}\). At hop-1, \(S=\varnothing \) and the relevance score is computed by Eq. (15) with current query q. Then, we update the current query q by:
We then obtain a new relevance score s via Eq. (15) using the updated representation q. \(s^i\) means the relevance score of hop-i. We then linearly map these cores into the final re-weighting scores:\({\bar{s}}_{H} = S \cdot \varvec{\beta _{H}}\), where \(\varvec{\beta _{H}} \in {\mathbb {R}}^{k \times 1}\) and \({\bar{s}}_{H} \in {\mathbb {R}}^{t+1}\). Thus, we can rewrite the Eq. (11) to:
To thoroughly measure the relevance between dialogue history, current query and persona knowledge, we construct three matching matrices:
where \(B_* \in {\mathbb {R}}^{d \times d}\) and d is embedding size.
As with the personalized matching process, we use 2D CNN with max-pooling to extract advanced match features. Since dialogue history is chronological, we utilize a single GRU layer to capture the response pairs’ time signals in a dialogue history. We employ the GRU’s final state as the consistency matching feature \(g^{C_{H}}(q,H)\), \(g^{C_{P}}(q,P)\), and \(g^{C_{K}}(q,K)\) is is calculated in the same way.
3.7 Module fusion module
In Sects. 3.5 and 3.6, we obtain three matching features:(1) personalized matching features \(g^S(q_t, K, H)\), which mine the personalized feature from persona K and historical context; (2) context-aware consistent matching feature \(g^{C_{H}}(q,H)\), \(g^{C_{P}}(q,P)\) and (3) persona-aware consistent matching feature \(g^{C_{K}}(q,K)\), which measure the various consistency of generated responses. We concatenate three matching features jointly to get the final match vector. Next, we use an MLP with a sigmoid activation function to calculate the final matching score:
3.8 Unlikelihood training
We train our model in an Unlikelihood method [12, 35, 43] to learn the ability to understand coherence from large-scale dialogue inference data. We employ negative log-likelihood loss (NLL) and unlikelihood loss for dialogue generation and consistency understanding. Details will be provided in this section.
We collect positive samples \({\mathcal {D}}^\text {p}\) from entailed category and collect negative samples \({\mathcal {D}}^\text {n}\) from contradicted category in DNLI:
where \({\bar{P}}\) and \({\bar{R}}\) are premise and hypothesis. For data from \({\mathcal {D}}^+\), we employ NLL loss:
For data from \({\mathcal {D}}^\text {n}\), we apply the unlikelihood objective to minimize the likelihood of contradictions:
which reduces the probability of inconsistent tokens in the generation process. Training steps can be summarized as follows:
-
(1)
Response prediction Given dialogue query q, persona knowledge K and dialogue historyH from personalized dialogue data, our model calculates the dialogue loss following Eq. (20);
-
(2)
Consistency Enhancing Given \({\mathcal {D}}^\text {p}\) and \({\mathcal {D}}^\text {n}\) in DNLI, our model calculate the unlikelihood loss \({\mathcal {L}}=\varvec{\beta } {\mathcal {L}}_\mathrm{{UL}}^{p} + (1-\varvec{\beta }){\mathcal {L}}_\mathrm{{UL}}^{n}\).
4 Experiments
In this section, we will illustrate and discuss some of the experimental results to validate the effectiveness of our approach and explore its limitations. Our code will be released on https://github.com/fuyongxu0908/IMPACT.
4.1 Datasets
To assess the performance of our model, we performed persona-based dialogue generation experiments in a persona-dense and a persona-sparse scenario with two publicly available datasets:
-
PersonaChat [4] is a crowdsourced dataset that covers wealth persona features. The dialogue in this dataset is based on specific personal facts. Here we use ConvAI2 [44], so the results are comparable to existing methods.
-
PersonalDialog [45] is a persona-sparse dataset which is collected from Weibo. This dataset provides persona profiles and conversations, but most conversations are not about the character. Random and biased test sets are available. Random test sets are distributed similarly to train sets, and biased test sets are hand-selected to cover personality-related characteristics.
The key statistics of two personalized dialogue datasets are summarized in Table 2. As aforementioned, we leverage two dialogue inference datasets, DNLI [35] and KvPI [7] for unlikelihood training. The statistics of these inference datasets are summarized in Table 3.
4.2 Baselines
-
Seq2Seq [46] is the standard Seq2Seq Model with attention. We string together persona descriptions and historical discourse as sequence inputs and generate responses.
-
HRED(Hierarchical Recurrent Encoder-Decoder) [47] model with attention.
-
Generative Profile Memory network(GPMN) [4] is a generative model that encodes each persona description as an individual memory representation within a memory network.
-
Persona-CVAE(Per-CVAE) [5] is a memory enhancement structure based on chatbots persona that focuses on diverse types of conversation responses.
-
Transformer [39] is employed as a baseline for both PersonaChat and PersonalDialog experiments. Personas linked to dialogue queries.
-
CMAML [48] is a meta-learning-based approach that learns from rarely filmed characters through custom model structures.
-
GDR [33] is a three-stage framework that employs a generation-deletion-rewrite mechanism to remove inconsistent words from a generated response prototype and rewrite them into a personality-consistent prototype.
-
Generative Split Memory Network(GSMN) [49] is a memory network that utilizes the splitting memories, one for persona knowledge and the other for dialogue history.
4.3 Evaluation metrics
We evaluate our approach primarily in three areas: response quality, diversity, and consistency. For comparison of different models, we employ automatic metrics and human evaluations.
4.3.1 Automatic metrics
We employ perplexity (PPL.) and distinct 1/2 (Dist.1/2) following by common practice [4, 34] to evaluate our method. Lower perplexity means our approach has a better performance for language modeling. Distinct 1/2 [50] is the proportion of different uni-grams/bi-grams, and higher distinct means generated responses are more diverse. Distinct 1/2 is formulated as:
where \(f({\hat{Y}}, s)\) is the number of s in \({\hat{Y}}\), k=1,2.
We employ Consistency Score (C.Score) [51] and Delta Perplexity (\(\Delta P\)) [12] to test our method for response consistency. Consistency Score(C.Score) leverages a referee model to predict consistency and can be defined as:
Here the NLI function is a pre-trained Roberta model finetuned with the dialogue inference datasets, i.e., DNLI and KvPI, as described in Table 2. Delta Perplexity(\(\Delta P\)) evaluates consistency from the model’s internal distributions. Li et al. [12] first estimate the perplexity of entailed (p.Ent) and contradicted (p.Ctd) dialogues in the inference dataset. A well-understood dialogue model should reduce perplexity about inevitable dialogue and increase perplexity about contradictions. Based on this, \(\Delta P\) can be defined as:
where a larger \(\Delta P\) means model has a better ability to distinguish entailment from contradiction.
4.3.2 Human evaluations
We recruit five volunteers who are skilful in language tasks while knowing nothing about the models. We sample 100 samples for each volunteer to evaluate our model. These volunteers are requested to measure dialogue quality from three aspects. fluency(Flue.), informativeness(Info.), and relevance(Relv.). Each aspect is rated on a five scale, where 1, 3, and 5 indicate inappropriate, intermediate, and ideal performance. Volunteers are likewise instructed to label the consistency between context, persona and response(Con.C. and Per.C.). 1 means consistent, 0 means neutral, and -1 means contradicted.
4.4 Results and analysis
Not all conversations need to integrate persona knowledge in the real world; the persona in dialogue is sparse. To verify the effectiveness of our method, we experiment in two dialogue environments Persona-Dense dialogue and Persona-Sparse dialogue. The results are shown below (Figs. 3 and 4).
4.4.1 Persona-dense results

Results on full PersonaChat
We first inform the results with PersonaChat in Table 4. Our approach reaches better performance overall human and automatic evaluation metrics, which indicates our model’s effectiveness. Our model obtains significant advancements on all metrics on \(\Delta P\) and C.Score. From these results, it is clear that our model could differentiate entailment from contradiction more effectively than other baseline approaches, which shows our model better understands persona consistency. Besides, our method also has a specific improvement on PPL and diversity. Lower PPL demonstrates that our model gets an excellent language modeling ability. Higher diversity represents our model can generate diverse responses more effectively. Furthermore, dialogue quality is better than other baseline models from human evaluation metrics, including consistency evaluation metrics.
For Ablation Study, we respectively remove (1)the unlikelihood training objective(UL), (2)the Personalized Characteristics Discovering Module(PCD), and (3)the Dialogue Consistency Matching Module(DCM) of IMPACT to investigate their effectiveness. Results are shown in Table 4. Diversity metrics D.AVG has an inevitable descent when removing PCD. Without PCD, IMPACT only employs explicit persona knowledge to generate the personalized response. So implicit persona knowledge from Personalized Characteristics Discovering Module(PCD) can improve the diversity of generated responses. From Per.C, we also conclude that PCD can improve persona knowledge consistency. Then, when we remove DCM, \(\Delta P\) and Con.C also decline. Besides, when we add PCD and DCM, the final response becomes less fluent from PPL and Fluc. While mining implicit semantics, PCD and DCM may introduce some noise to affect response fluency. Moreover, when removing UL, the consistency metrics Con.C and Per.C are also reduced.
4.4.2 Persona-sparse results
In the real world, persona knowledge is sparse in conversation, and not all responses need to be integrated with a specific persona. We further validate our model in a persona-sparse setting and test our model’s performance in different contexts. Random test datasets are persona-sparse, sampled from the real-world conversation process. Biased test dataset was purposely selected to provide different contexts under which speakers tend to show their personas. We report the evaluation results on both random and biased test datasets in Tables 5 and 6.
In persona-sparse settings, the performance of our model in persona consistency can not exceed the GDR model with a rewriting mechanism. One possible reason is that the task of dialogue using persona-sparse data degenerates into conventional dialogue generation tasks, so the advantages of our model can only partially be demonstrated. At the same time, we also found that our model improves contextual consistency in a persona-sparse environment. From the results, it is clear that when we remove DCM and only use PCD for feature extraction and fusion, our model is better than our final result in diversity. Although DCM plays a positive role in enhancing consistency understanding, it is reverse optimized in the perceptual fusion of persona knowledge and improves the diversity of generated response. This phenomenon is because our model tends to generate the words in persona and context after adding DCM, resulting in the decline of diversity. On the contrary, on the biased dataset with richer persona knowledge, our method obtains the best results on consistency metrics \(\Delta P\), C.Score, Con.C., and Per.C., demonstrating our approach’s effectiveness in improving consistency. When we remove the unlikelihood training objective(UL), the consistency metrics inevitably decline, and the results now provide evidence to prove the effectiveness of the consistency modeling objective. We observed the diversity of generated response slightly improved when we removed DCM. While focusing on consistency modeling, DCM tends to generate tokens in the above dialogue and given persona text, so there is a certain degree of repetition. The degree of dialogue consistency reduction proves the effectiveness of DCM in dialogue consistency modeling. From the descent of the auto-evaluating metrics, it is apparent that implicit persona knowledge and dialogue consistency modeling is necessary.

PPL and F1 results in PersonalDialog
Results in PersonalDialog are similar to PersonaChat as shown in Table 7. Our method beats all the baseline models in consistent automatic evaluation metrics \(\Delta P\) and C.Score. The results of the experiment found clear support for consistent improvement. When we removed the unlikelihood training objective(UL) and used regular training objective cross-entropy in the Chinese dataset, the dialogue quality was slightly reduced, especially the consistency of context and persona. The possible reasons are that the unlikelihood training objective may not be sensitive to Chinese, and it is challenging to understand Chinese semantics.
4.5 Experimental settings
In our model, we adopt Word2Vec [40] to initialize the word embedding. In our experiments, all baseline models apply word embedding. The max length of the input is 128, and the reference of sequence is 64. We set the number of attentive modules for the personalized characteristics discovering module as 5. The hidden states in our model are 256 (Fig. 5c and d). We optimize the model employing the Adam method with a learning rate set as 0.00001 (Fig. 5a and b) and the dropout set as 0.3. In the predicting process, we use beam search with a beam size of 10. We tune IMPACT and all baseline models on the validation set and evaluate them on the test set. For different datasets, we employ the different batch-size as shown in Fig. 5e and f and train the model for 20 epochs on one GeForce RTX 3090 24 G GPU. \(\alpha \), \(\beta _{H}\), \(\beta _{P}\), \(\beta _{K}\) are 0.5, 0.3, 0.3, and 0.5, respectively.

Performance with different parameters
4.6 Case study
In this section, we show the dialogue examples generated from IMPACT, conversation as shown in Table 7. Our method can effectively mine implicit role information from dialogue history and promote understanding of role and context in the generation model, consistent with the given persona and context.
5 Conclusion and future work
This paper proposes a personalized dialogue system(IMPACT) that discovers the implicit persona knowledge to generate consistent responses. IMPACT generates consistent responses to achieve such a target from two aspects. Firstly, our method discovers the implicit persona knowledge, including personalized expression manner style. Secondly, the dialogue consistency matching module could enhance dialogue consistency from multi-views, including contextual consistency and persona consistency. IMPACT could be optimized through unlikelihood training objective to improve dialogue consistency. Extensive experimental results on two large datasets show that our method outperforms all previous baseline models and verify IMPACT is effective. Moreover, the external implicit persona knowledge may be noise data to a certain extent, which affects the model’s understanding of the persona. Therefore, we will consider screening persona knowledge and select knowledge valuable for interaction in future work. Our method is to mine some hidden knowledge from predefined knowledge. With the development of large model and text generation technology, large models, such as ChatGPT have been produced. How to migrate knowledge from the large model is also a good direction.
Availability of data and materials
The training data of our work are now made public as follows: https://github.com/facebookresearch/ParlAIhttps://github.com/ghosthamlet/persona.
References
Ma L, Li M, Zhang W, Li J, Liu T (2022) Unstructured text enhanced open-domain dialogue system: a systematic survey. ACM Trans Inf Syst 40(1):1–44
Huang M, Zhu X, Gao J (2020) Challenges in building intelligent open-domain dialog systems. ACM Trans Inf Syst 38(3):1–32
Nie Y, Williamson M, Bansal M, Kiela D, Weston J (2021) I like fish, especially dolphins: addressing contradictions in dialogue modeling. In: Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing, ACL/IJCNLP, pp 1699–1713
Zhang S, Dinan E, Urbanek J, Szlam A, Kiela D, Weston J (2018) Personalizing dialogue agents: I have a dog, do you have pets too? In: Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics, ACL, pp 2204–2213
Song H, Zhang W, Cui Y, Wang D, Liu T (2019) Exploiting persona information for diverse generation of conversational responses. In: Proceedings of the Twenty-Eighth International Joint Conference on Artificial Intelligence, IJCAI, pp 5190–5196
Gu J, Ling Z, Wu Y, Liu Q, Chen Z, Zhu X (2021) Detecting speaker personas from conversational texts. In: Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, EMNLP, pp 1126–1136
Song H, Wang Y, Zhang W, Zhao Z, Liu T, Liu X (2020) Profile consistency identification for open-domain dialogue agents. In: Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing, EMNLP, pp 6651–6662
Li J, Liu C, Tao C, Chan Z, Zhao D, Zhang M, Yan R (2021) Dialogue history matters! personalized response selection in multi-turn retrieval-based chatbots. ACM Trans Inf Syst 39(4):1–25
Qian H, Dou Z, Zhu Y, Ma Y, Wen J (2021) Learning implicit user profiles for personalized retrieval-based chatbot. CoRR abs/2108.07935
Li Z, Zhang J, Fei Z, Feng Y, Zhou J (2021) Conversations are not flat: modeling the dynamic information flow across dialogue utterances. In: Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing, ACL/IJCNLP, pp 128–138
Zhou W, Li Q, Li C (2021) Learning from perturbations: diverse and informative dialogue generation with inverse adversarial training. In: Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing, ACL/IJCNLP, pp 694–703
Li M, Roller S, Kulikov I, Welleck S, Boureau Y, Cho K, Weston J (2020) Don’t say that! making inconsistent dialogue unlikely with unlikelihood training. In: Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, ACL, pp 4715–4728
Colby KM, Weber S, Hilf FD (1971) Artificial paranoia. Artif Intell 2(1):1–25
Weizenbaum J (1983) ELIZA—a computer program for the study of natural language communication between man and machine (reprint). Commun ACM 26(1):23–28
Guo J, Shuang K, Li J, Wang Z (2021) Dual slot selector via local reliability verification for dialogue state tracking. In: Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing, ACL/IJCNLP, pp 139–151
Yang R, Chen J, Narasimhan K (2021) Improving dialog systems for negotiation with personality modeling. In: Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing, ACL/IJCNLP, pp 681–693
Feng Y, Wang Y, Li H (2021) A sequence-to-sequence approach to dialogue state tracking. In: Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing, ACL/IJCNLP, pp 1714–1725
Hudecek V, Dusek O, Yu Z (2021) Discovering dialogue slots with weak supervision. In: Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing, ACL/IJCNLP, pp 2430–2442
Wu Y, Zeng Z, He K, Xu H, Yan Y, Jiang H, Xu W (2021) Novel slot detection: a benchmark for discovering unknown slot types in the task-oriented dialogue system. In: Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing, ACL/IJCNLP, pp 3484–3494
Liu S, Zheng C, Demasi O, Sabour S, Li Y, Yu Z, Jiang Y, Huang M (2021) Towards emotional support dialog systems. In: Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing, ACL/IJCNLP, pp 3469–3483
Wang Y, Zheng Y, Jiang Y, Huang M (2021) Diversifying dialog generation via adaptive label smoothing. In: Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing, ACL/IJCNLP, pp 3507–3520
Gu J, Tao C, Ling Z, Xu C, Geng X, Jiang D (2021) MPC-BERT: a pre-trained language model for multi-party conversation understanding. In: Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing, ACL/IJCNLP, pp 3682–3692
Xu F, Xu G, Wang Y, Wang R, Ding Q, Liu P, Zhu Z (2022) Diverse dialogue generation by fusing mutual persona-aware and self-transferrer. Appl Intell 52(5):4744–4757
Li J, Galley M, Brockett C, Spithourakis GP, Gao J, Dolan WB (2016) A persona-based neural conversation model. In: Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics, ACL, pp 994–1003
Zhang W, Zhu Q, Wang Y, Zhao Y, Liu T (2019) Neural personalized response generation as domain adaptation. World Wide Web 22(4):1427–1446
Wang J, Wang X, Li F, Xu Z, Wang Z, Wang B (2017) Group linguistic bias aware neural response generation. In: Proceedings of the 9th SIGHAN Workshop on Chinese Language Processing, SIGHAN@IJCNLP, pp 1–10
Zhang Y, Gao X, Lee S, Brockett C, Galley M, Gao J, Dolan B (2019) Consistent dialogue generation with self-supervised feature learning. CoRR abs/1903.05759. arXiv:1903.05759
Cheng H, Fang H, Ostendorf M (2019) A dynamic speaker model for conversational interactions. In: Proceedings of the Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, NAACL-HLT, pp 2772–2785
Ouchi H, Tsuboi Y (2016) Addressee and response selection for multi-party conversation. In: Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing, EMNLP, pp 2133–2143
Zhang R, Lee H, Polymenakos L, Radev DR (2018) Addressee and response selection in multi-party conversations with speaker interaction rnns. In: Proceedings of the Thirty-Second Conference on Artificial Intelligence, AAAI, pp 5690–5697
Qian Q, Huang M, Zhao H, Xu J, Zhu X (2018) Assigning personality/profile to a chatting machine for coherent conversation generation. In: Proceedings of the Twenty-Seventh International Joint Conference on Artificial Intelligence, IJCAI, pp 4279–4285
Zhou L, Gao J, Li D, Shum H (2020) The design and implementation of xiaoice, an empathetic social chatbot. Comput Linguist 46(1):53–93
Song H, Wang Y, Zhang W, Liu X, Liu T (2020) Generate, delete and rewrite: a three-stage framework for improving persona consistency of dialogue generation. In: Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, ACL, pp 5821–5831
Zheng Y, Zhang R, Huang M, Mao X (2020) A pre-training based personalized dialogue generation model with persona-sparse data. In: The Thirty-Fourth Conference on Artificial Intelligence, AAAI, pp 9693–9700
Welleck S, Weston J, Szlam A, Cho K (2019) Dialogue natural language inference. In: Proceedings of the 57th Conference of the Association for Computational Linguistics, ACL, pp 3731–3741
Xu M, Li P, Yang H, Ren P, Ren Z, Chen Z, Ma J (2020) A neural topical expansion framework for unstructured persona-oriented dialogue generation. In: 24th European Conference on Artificial Intelligence,ECAI, pp 2244–2251
Yuan C, Zhou W, Li M, Lv S, Zhu F, Han J, Hu S (2019) Multi-hop selector network for multi-turn response selection in retrieval-based chatbots. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing, EMNLP-IJCNLP, pp 111–120
Zhou X, Li L, Dong D, Liu Y, Chen Y, Zhao WX, Yu D, Wu H (2018) Multi-turn response selection for chatbots with deep attention matching network. In: Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics, ACL, pp 1118–1127
Vaswani A, Shazeer N, Parmar N, Uszkoreit J, Jones L, Gomez AN, Kaiser L, Polosukhin I (2017) Attention is all you need. In: Advances in Neural Information Processing Systems 30: Annual Conference on Neural Information Processing Systems, NIPS, pp 5998–6008
Mikolov T, Sutskever I, Chen K, Corrado GS, Dean J (2013) Distributed representations of words and phrases and their compositionality. In: NIPS, pp 3111–3119
Qian H, Dou Z, Zhu Y, Ma Y, Wen J (2021) Learning implicit user profile for personalized retrieval-based chatbot. In: The 30th ACM International Conference on Information and Knowledge Management, CIKM, pp 1467–1477
Zhu Y, Nie J, Zhou K, Du P, Dou Z (2021) Content selection network for document-grounded retrieval-based chatbots. In: ECIR. Lecture notes in computer science, vol 12656. Springer, pp 755–769
Song H, Zhang W, Hu J, Liu T (2020) Generating persona consistent dialogues by exploiting natural language inference. In: AAAI, pp 8878–8885
Dinan E, Logacheva V, Malykh V, Miller AH, Shuster K, Urbanek J, Kiela D, Szlam A, Serban I, Lowe R, Prabhumoye S, Black AW, Rudnicky AI, Williams J, Pineau J, Burtsev MS, Weston J (2019) The second conversational intelligence challenge (convai2). CoRR abs/1902.00098. arXiv:1902.00098
Zheng Y, Chen G, Huang M, Liu S, Zhu X (2019) Personalized dialogue generation with diversified traits. CoRR abs/1901.09672. arXiv:1901.09672
Bahdanau D, Cho K, Bengio Y (2015) Neural machine translation by jointly learning to align and translate. In: Proceedings of 3rd International Conference on Learning Representations, ICLR
Serban IV, Sordoni A, Bengio Y, Courville AC, Pineau J (2015) Hierarchical neural network generative models for movie dialogues. CoRR abs/1507.04808. arXiv:1507.04808
Song Y, Liu Z, Bi W, Yan R, Zhang M (2020) Learning to customize model structures for few-shot dialogue generation tasks. In: Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, ACL, pp 5832–5841
Wu Y, Ma X, Yang D (2021) Personalized response generation via generative split memory network. In: Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, NAACL-HLT, pp 1956–1970
Li J, Galley M, Brockett C, Gao J, Dolan B (2016) A diversity-promoting objective function for neural conversation models. In: Proceedings of the Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, NAACL-HLT, pp 110–119
Madotto A, Lin Z, Wu C, Fung P (2019) Personalizing dialogue agents via meta-learning. In: Proceedings of the 57th Conference of the Association for Computational Linguistics, ACL, pp 5454–5459
Funding
This work was supported in part by the National Social Science Foundation under Award 19BYY076, in part Key R & D project of Shandong Province 2019JZZY010129 and in part by the Shandong Provincial Social Science Planning Project under Award 18CXWJ01, Award 19BJCJ51 and Award 18BJYJ04.
Author information
Authors and Affiliations
Contributions
FX wrote the main manuscript text and prepare the experiment data. ZD, ZZ and PL correct the expression style of this article. All authors reviewed the manuscript.
Corresponding authors
Ethics declarations
Conflict of interest
The authors state that they have no known competing financial interests or personal relationships that could affect the work reported in this article.
Ethical approval
Not applicable.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Xu, F., Ding, Z., Zhu, Z. et al. Exploring implicit persona knowledge for personalized dialogue generation. J Supercomput 79, 14545–14570 (2023). https://doi.org/10.1007/s11227-023-05209-z
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11227-023-05209-z