
Abstract
We develop a fast variational approximation scheme for Gaussian process (GP) regression, where the spectrum of the covariance function is subjected to a sparse approximation. Our approach enables uncertainty in covariance function hyperparameters to be treated without using Monte Carlo methods and is robust to overfitting. Our article makes three contributions. First, we present a variational Bayes algorithm for fitting sparse spectrum GP regression models that uses nonconjugate variational message passing to derive fast and efficient updates. Second, we propose a novel adaptive neighbourhood technique for obtaining predictive inference that is effective in dealing with nonstationarity. Regression is performed locally at each point to be predicted and the neighbourhood is determined using a measure defined based on lengthscales estimated from an initial fit. Weighting dimensions according to lengthscales, this downweights variables of little relevance, leading to automatic variable selection and improved prediction. Third, we introduce a technique for accelerating convergence in nonconjugate variational message passing by adapting step sizes in the direction of the natural gradient of the lower bound. Our adaptive strategy can be easily implemented and empirical results indicate significant speedups.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
Gaussian process (GP) models provide a flexible, probabilistic approach to regression and are widely used. However, application of GP models to large data sets is challenging as the memory and computational requirements scale as \(O(n^2)\) and \(O(n^3)\) respectively, where n is the number of training data points. Various sparse GP approximations have been proposed to overcome this limitation. A unifying framework of existing sparse methods is given in Quiñonero-Candela and Rasmussen (2005). We consider the stationary sparse spectrum GP regression model introduced by Lázaro-Gredilla et al. (2010), where the spectrum of the covariance function is sparsified instead of the usual spatial domain. The SSGP algorithm developed by Lázaro-Gredilla et al. (2010) for fitting this model uses conjugate gradients to optimize the marginal likelihoood with respect to the hyperparameters and spectral points. Comparisons with other state-of-the-art sparse GP approximations such as the fully independent training conditional model (first introduced as sparse pseudo-input GP in Snelson and Ghahramani 2006) and the sparse multiscale GP (Walder et al. 2008), showed that SSGP yielded significant improvements. However, optimization with respect to spectral frequencies increases the tendency to underestimate predictive uncertainty and poses a risk of overfitting in the SSGP algorithm.
In this paper, we develop a fast variational approximation scheme for the sparse spectrum GP regression model, which enables uncertainty in covariance function hyperparameters to be treated. In addition, we propose an adaptive local neighbourhood approach for dealing with nonstationary data. Although accounting for hyperparameter uncertainty may be of little importance when fitting globally to a large data set, local fitting within neighbourhoods results in fitting to small data sets even if the full data set is large, and here it is important to account for hyperparameter uncertainty to avoid overfitting. Our examples show that our methodology is particularly beneficial when combined with the local fitting approach for this reason. Our approach also allows hierarchical models involving covariance function parameters to be constructed. This idea is implemented in the context of functional longitudinal models by Mensah et al. (2014) so that smoothness properties of trajectories can be related to individual specific covariates.
GPs have diverse applications and various methods have been developed to overcome their computational limitations for handling large data sets. A good summary of approximations used in modelling large spatial data sets is given in Ren et al. (2011). Computational costs can also be reduced through local GP regression as a much smaller number of training data is utilized in each partition. This approach has been considered in machine learning (e.g. Snelson and Ghahramani 2007; Nguyen-Tuong et al. 2009; Park and Choi 2010) and in spatial statistics (e.g. Vecchia 1988; Haas 1995; Stein et al. 2004; Kim et al. 2005). Urtasun and Darrell (2008) propose fitting GP models in local neighbourhoods which are defined online for each test point. However, covariance hyperparameters are estimated only for a subset of all possible local neighbourhoods. Different local experts are then combined using a mixture model capable of handling multimodality. Our idea of using adaptive nearest neighbours in GP regression is inspired by techniques in classification designed to mitigate the curse of dimensionality (Hastie and Tibshirani 1996). For each test point, we fit two models. In the first instance, the neighbourhood is determined using the Euclidean metric. Lengthscales estimated from the first fitting are then used to redefine the distance measure determining the neighbourhood for fitting the second model. Experiments suggest that this approach improves prediction significantly in data with nonstationarities, as hyperparameters are allowed to vary across neighbourhoods adapted to each query point. Weighting dimensions according to lengthscales downweights variables of little relevance and also leads to automatic variable selection. Our approach differs from methods where local neighbourhoods are built sequentially to optimize the choice of the neighbourhood. Examples include Vecchia (1988) and Stein et al. (2004), where the Gaussian likelihood is approximated by the use of an ordering and conditioning on a subset of past observations. In Gramacy and Apley (2014), an empirical Bayes mean-square prediction error criterion is optimized. While greedy searches usually rely on fast updating formulae available only in the Gaussian case, our approach works in non-Gaussian settings as well. Stein et al. (2004) suggest making neighbourhoods non-local to improve learning of covariance parameters, but local neighbourhoods may work better when the motivation is to handle nonstationarity. Lindgren et al. (2011) make a connection between discrete spatial Markov random fields and continuous Gaussian random fields with covariance functions in the Matérn class.
For fitting the sparse spectrum GP regression model, we derive a variational Bayes (VB, Attias 1999) algorithm that uses nonconjugate variational message passing (Knowles and Minka 2011) to derive fast and efficient updates. VB methods approximate the intractable posterior in Bayesian inference by a factorized distribution. This product density assumption is often unrealistic and can lead to underestimation of posterior variance (Wang and Titterington 2005). However, optimization of a factorized variational posterior can be decomposed into local computations that only involve neighbouring nodes in the factor graph and this often gives rise to fast computational algorithms. VB has also been shown to be able to give reasonably good estimates of the marginal posterior distributions and excellent predictive inferences (e.g. Blei and Jordan 2006; Braun and McAuliffe 2010). Variational message passing (Winn and Bishop 2005) is a general-purpose algorithm that allows VB to be applied to conjugate–exponential models (Attias 2000). Nonconjugate variational message passing extends variational message passing to nonconjugate models by assuming that the factors in VB are members of the exponential family. We use nonconjugate variational message passing to derive efficient updates for the variational posteriors of the lengthscales, which are assumed to be Gaussian. Ren et al. (2011) use VB for spatial modelling via GP, where they also treat uncertainty in the covariance function hyperparameters. However, they propose using importance sampling within each VB iteration to handle the intractable expectations associated with the covariance function hyperparameters. Variational inference has also been considered in machine learning for sparse GPs that select the inducing inputs and hyperparameters by maximizing a lower bound to the exact marginal likelihood (Titsias 2009), and heteroscedastic GP regression models where the noise is input dependent (Lázaro-Gredilla and Titsias 2011).
VB is known to suffer from slow convergence when there is strong dependence between variables in the factors. To speed up convergence, Qi and Jaakkola (2006) propose parameter expanded VB to reduce coupling in updates, while Tan and Nott (2013) considered partially noncentered parametrizations. Here, we introduce an adaptive strategy to accelerate convergence in nonconjugate variational message passing, which is inspired by adaptive overrelaxed bound optimization methods (Salakhutdinov and Roweis 2003). Previously, Tan and Nott (2014) showed that nonconjugate variational message passing is a natural gradient ascent algorithm with step size one and step sizes smaller than one correspond to damping. Here, we propose using step sizes larger than one which can help to accelerate convergence in fixed point iterations algorithms (see Huang et al. 2005). Instead of searching for the optimal step size, we use an adaptive strategy which ensures that the lower bound increases after each cycle of updates. Empirical results indicate significant speedups. Honkela et al. (2003) considered combining parameter-wise updates to form a diagonal direction for a line search. A general iterative algorithm for computing VB estimators (defined as means of variational posteriors) has also been proposed by Wang and Titterington (2006) and its convergence properties investigated for normal mixture models.
Section 2 describes the sparse spectrum GP regression model and Sect. 3 develops the nonconjugate variational message passing algorithm for fitting it. Section 4 presents an adaptive strategy for accelerating convergence in nonconjugate variational message passing. Section 5 discusses how the predictive distribution can be estimated and the measures used for performance evaluation. Section 6 describes the adaptive neighbourhood approach for local regression. Section 7 considers examples including real and simulated data and Sect. 8 concludes.
2 Sparse spectrum Gaussian process regression
Given a data set \(\{(x_i,y_i)|i=1,\dots ,n\}\), we assume each output \(y_i\in \mathfrak {R}\) is generated by an unknown latent function f evaluated at the input, \(x_i \in \mathfrak {R}^d\), and independently corrupted by additive Gaussian noise such that
A GP prior is assumed over f(x) for \(x \in \mathfrak {R}^d\). For any set of inputs \(\{x_i|i=1,\dots ,n\}\), \([f(x_1),\dots ,f(x_n)]^T\) has a joint Gaussian distribution, N(0, K), where K is a covariance matrix. We assume that the mean of the process is zero. It is straightforward to allow for a nonzero mean, but a zero mean is sufficient for the examples in this paper. The entries of K are given by \(K_{ij}=E\{f(x_i)f(x_j)\}=k(x_i,x_j)=k(h)\), where \(h=(x_i-x_j) \in \mathfrak {R}^d\) and k is some stationary covariance function. For example, we consider the stationary squared exponential covariance function,
where \(\sigma ^2>0\), \({\varLambda } = \text {diag} ([\lambda _1^2, \dots , \lambda _d^2]^T)\) and \(\lambda _l\ge 0\) for \(l=1,\dots ,d\).
Lázaro-Gredilla et al. (2010) introduced a novel perspective on GP approximation by sparsifying the spectrum of the covariance function. They considered the linear regression model,
where \(a_r\), \(b_r\) are independent and identically distributed as \(N(0,\frac{\sigma ^2}{m})\) and \(s_r\) is a d-dimensional vector of spectral frequencies. The power spectral density of a stationary covariance function k is
and \(S_k(s)\) is proportional to a probability density \(p_k(s)\) such that \(S_k(s)=k(0)p_k(s)\). When \(\{s_1,\dots ,s_m\}\) are drawn randomly from \(p_k(s)\), Lázaro-Gredilla et al. (2010) showed that (2) can be viewed as a sparse GP that approximates the full stationary GP by replacing the spectrum with a discrete set of spectral points.
From (3), the probability density \(p_k(s)\) associated with the squared exponential covariance function in (1) is \(N(0,\frac{1}{4\pi ^2}{\varLambda }^{-1})\). If \(\{s_1,\dots ,s_m\}\) is generated randomly from \(N(0,I_d)\), then \(\{\tfrac{1}{2\pi }{\varLambda }^{\frac{1}{2}}s_1,\dots ,\tfrac{1}{2\pi }{\varLambda }^{\frac{1}{2}}s_m\}\) is a random sample from \(p_k(s)\). From (2), a sparse GP approximation to f(x) is
where \({\varLambda }^{\frac{1}{2}}=\text {diag}(\lambda )\), \(\lambda = [\lambda _1, \dots , \lambda _d]^T\) is a vector of lengthscales and \(\odot \) denotes element by element multiplication of two vectors. Within the sparse GP approximation, we can allow the components of \(\lambda \) to be negative. Let \(s=[s^1, \dots , s^d]^T\) and \(x=[x^1, \dots , x^d]^T\). Note that in (1) \(\lambda _j\) appears as its square in \({\varLambda }\) so that k(h) remains positive semidefinite. Ignoring the non-negativity constraint allows us to use a Gaussian variational posterior for \(\lambda \). The associated expectations in the variational lower bound can then be derived in closed form (see Sect. 3). This is a highly novel aspect of our algorithm allowing a fast method that still handles covariance function hyperparameter uncertainty. This is especially important when fitting locally as described in Sect. 6 where training datasets may be small. The squared exponential covariance function also implements automatic relevance determination since the magnitude of \(\lambda _j\) is a measure of how relevant the jth variable is. When \(\lambda _j\) goes to zero, the covariance function becomes almost independent of the jth variable, essentially removing it from inference. See Rasmussen and Williams (2006) for more discussion.
Using the stationary sparse GP approximation in (4), we consider variational inference for
Let \(\alpha =[a_1,\dots ,a_m,b_1,\dots ,b_m]^T\), \(y=[y_1,\dots ,y_n]^T\), \(\epsilon =[\epsilon _1,\dots ,\epsilon _n ]^T\) and \(Z=[ Z_1,\dots ,Z_n]^T\), where
Then this model can be written as
where \(\alpha \sim N(0,\frac{\sigma ^2}{m}I_{2m})\). For Bayesian inference, we assume the priors: \(\lambda \sim N(\mu _\lambda ^0, {\varSigma }_\lambda ^0)\), \(\sigma \sim \text {half-Cauchy}(A_\sigma )\) and \(\gamma \sim \text {half-Cauchy}(A_\gamma )\), where the hyperparameters \(\mu _\lambda ^0\), \({\varSigma }_\lambda ^0\), \(A_\sigma \) and \(A_\gamma \) are assumed to be known. The density function of a random variable x distributed as \(\text {half-Cauchy}(A)\) is \(\tfrac{2A}{\pi (A^2+x^2)}\), where \(x>0\) and \(A>0\). While inverse-Gamma priors are more commonly used for variance parameters in hierarchical models due to the conditional conjugacy relationship with Gaussian families, Gelman (2006) recommends use of the half-Cauchy family as priors because resulting inferences can be sensitive to inverse-Gamma hyperparameters when variance estimates are close to zero. We made the same observation in our experiments with inverse-Gamma priors for \(\sigma ^2\) and \(\gamma ^2\). In particular, predictive inferences are sensitive to inverse-Gamma priors in local regressions (see Section 6), where only a small neighbourhood is used for fitting at each test point.
3 Variational inference
We consider variational inference for the sparse spectrum GP regression model in (5). Let \(\theta =\{\alpha ,\lambda ,\sigma ,\gamma \}\) be the set of unknown parameters and \(p(\theta |y)\) be the true posterior of \(\theta \). In variational approximation, \(p(\theta |y)\) is approximated by a \(q(\theta )\) for which inference is more tractable, and the Kullback–Leibler divergence between \(q(\theta )\) and \(p(\theta |y)\) is minimized. This is equivalent to maximizing a lower bound \(\mathcal {L}\) on the log marginal likelihood \(\log p(y)\), where \(p(y) = \int p(y,\theta )\,d\theta \),
and \(E_q\) denotes expectation with respect to \(q(\theta )\).
Next, we review some important results in VB and nonconjugate variational message passing, which will be used to construct the variational algorithm. In VB, \(q(\theta )\) is assumed to factorize into \(\prod _{i=1}^M q_i(\theta _i)\) for some partition \(\{\theta _1,\dots ,\theta _M\}\) of \(\theta \). The optimal densities may be obtained from
where \(E_{-\theta _i}\) denotes expectation with respect to \(\prod _{j\ne i}q_j({\theta _j})\) (see, e.g. Ormerod and Wand 2010). For conjugate–exponential models, the optimal densities have the same form as the priors and it suffices to update the parameters of \(q_i\), such as in variational message passing (Winn and Bishop 2005). However, for nonconjugate models, the optimal densities will not belong to recognizable density families. Apart from the product assumption, nonconjugate variational message passing (Knowles and Minka 2011) further assumes each \(q_i(\theta _i)\) is a member of some exponential family, that is,
where \(\eta _i\) is the vector of natural parameters and \(t_i(\cdot )\) are the sufficient statistics. Hence, we only have to find each \(\eta _i\) that maximizes the lower bound \(\mathcal {L}\). Nonconjugate variational message passing can be interpreted as a fixed point iterations algorithm where updates are obtained from the condition that the gradient or natural gradient (see Amari 1998; Hoffman et al. 2013) of \(\mathcal {L}\) with respect to each \(\eta _i\) is zero when \(\mathcal {L}\) is maximized. Suppose \(p(y,\theta )=\prod _a f_a(y,\theta )\), \(S_a = E_q\{\log f_a(y,\theta )\}\) and let \(\mathcal {V}_i(\eta _i)=\frac{\partial ^2 h_i(\eta _i)}{\partial \eta _i \partial \eta _i^T}\) denote the variance–covariance matrix of \(t_i(\theta _i)\). Provided \(\mathcal {V}_i(\eta _i)\) is invertible, Tan and Nott (2014) showed that the natural gradient of \(\mathcal {L}\) with respect to \(\eta _i\) is
Therefore, the update for each \(\eta _i\) is
where the summation is over all factors in \(N(\theta _i)\), the neighbourhood of \(\theta _i\) in the factor graph of \(p(y,\theta )\). Updates in nonconjugate variational message passing reduce to those in variational message passing when the factors \(f_a\) are conjugate (see Knowles and Minka 2011; Tan and Nott 2013). However, unlike variational message passing, the lower bound \(\mathcal {L}\) is not guaranteed to increase at each step and convergence problems may be encountered sometimes. Knowles and Minka (2011) suggest using damping to fix convergence problems.
When \(q_i(\theta _i)=N(\mu _{\theta _i}^q,{\varSigma }_{\theta _i}^q)\), Wand (2014) showed that the update in (9) can be simplified to
Here \(\text {vec}(A)\) denotes the vector obtained by stacking the columns of a matrix A under each other, from left to right in order.

3.1 Algorithm 1
We consider a variational approximation of the form
From (7), the optimal densities \(q(\alpha )\) and \(q(\sigma ,\gamma )\) are \(q(\alpha ) = N(\mu _{\alpha }^q, {\varSigma }_{\alpha }^q)\) and \(q(\sigma ,\gamma )=q(\sigma )q(\gamma )\), where
and \(\mathcal {H}(p,q,r)=\int _0^\infty x^p\exp \{-qx^2-\log (r+x^{-2})\}\;dx\), \(p\ge 0\), \(r>0\). The variational parameter updates of \(\mu _{\alpha }^q\), \({\varSigma }_{\alpha }^q\), \(C_\sigma ^q\) and \(C_\gamma ^q\) can also be derived from (7). As \(\mathcal {H}(p,q,r)\) can be arbitrarily large or small, Wand et al. (2011) suggest evaluating \(\log \mathcal {H}(p,q,r)\) efficiently using quadrature. A discussion can be found in Appendix B of Wand et al. (2011) and we follow their methods. For \(q(\lambda )\), \(p(y|\alpha ,\lambda ,\gamma )\) is not a conjugate factor and we use nonconjugate variational message passing. Assuming \(q(\lambda )=N(\mu _\lambda ^q,{\varSigma }_\lambda ^q)\), updates for \(\mu _\lambda ^q\) and \({\varSigma }_\lambda ^q\) can be derived using (10) and matrix differential calculus (see Magnus and Neudecker 1988). The expectations with respect to q in (10) are given in Appendices 1 and 2. Let \(\vartheta =\{ \mu _{\alpha }^q, {\varSigma }_{\alpha }^q, \mu _\lambda ^q, {\varSigma }_\lambda ^q, C_\sigma ^q, C_\gamma ^q\}\) denote the set of variational parameters. An iterative scheme for finding \(\vartheta \) is given in Algorithm 1.
A unique aspect of our variational scheme is the way covariance function uncertainty is handled, with the expectations involving \(\lambda \) in the lower bound computable in closed form. In particular, \(E_q(Z)\) and \(E_q(Z^TZ)\) can be evaluated in closed form (see Appendix 1). Let \(\mu _\alpha ^q{\mu _\alpha ^q}^T +{\varSigma }_\alpha ^q\) be partitioned as \(\left[ {\begin{matrix} A &{} B^T \\ B &{} D \end{matrix}}\right] \) where A, B and D are all \(m \times m\) matrices. In algorithm 1, we define \(t_{ir}=s_r \odot x_i\),
for \(i=1,\dots ,n\), \(r=1,\dots ,m\), \(l=1,\dots ,m\).
The lower bound \(\mathcal {L}\) defined in (6) is commonly used for monitoring convergence. It can be evaluated in closed form (see Appendix 2) and is given by
The above expression applies only after the updates in steps 5 and 6 of Algorithm 1 have been made.
4 Adaptive nonconjugate variational message passing
In the sparse spectrum GP regression model (5), Z and \(\alpha \) are intimately linked. Each time the lengthscales \((\lambda )\) are changed by a small amount, the amplitudes (\(\alpha \)) will have to respond to this change in order to match the observed y. In (11), we have assumed that the variational posteriors of \(\lambda \) and \(\alpha \) are independent so that expectations with respect to q are tractable and closed form updates can be derived for a fast algorithm. However, strong dependence between \(\lambda \) and \(\alpha \) implies that only small steps can be taken in each cycle of updates and a large number of iterations will likely be required for Algorithm 1 to converge.
To accelerate convergence, we propose modifying the updates in steps 1 and 2. Let \(\eta _\lambda \) be the natural parameter of \(q(\lambda )\) and \(\hat{\eta }_\lambda \) be the update of \(\eta _\lambda \) in nonconjugate variational message passing. Tan and Nott (2014) showed that nonconjugate variational message passing is a natural gradient ascent method with step size one. At iteration t, we consider
where \(\hat{\eta }_\lambda ^{(t)} = \mathcal {V}_\lambda (\eta _\lambda ^{(t-1)})^{-1}\sum _{a \in N(\lambda )} \frac{\partial S_a}{\partial \eta _\lambda } \big |_{\eta _\lambda ^{(t-1)}}\). When \(a_t=1\), (13) reduces to the update in nonconjugate variational message passing. Taking \(a_t<1\) may be helpful when updates in nonconjugate variational message passing fail to increase \(\mathcal {L}\). From our experiments, instability in Algorithm 1 usually occur within the first few iterations. Beyond that, the algorithm is usually quite stable and taking larger steps with \(a_t>1\) can result in significant speed-ups.
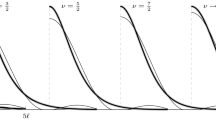
Recall that nonconjugate variational message passing is a fixed point iterations algorithm. Figure 1 illustrates in a single variable case (where we are solving \(x=f(x)\)) how taking steps larger than one can accelerate convergence. Instead of taking \(x^{(t)}=f( x^{(t-1)})\), consider \(x^{(t)}=x^{(t-1)}+a_t(\hat{x}^{(t)}-x^{(t-1)})\), where \(\hat{x}^{(t)}=f( x^{(t-1)})\) and \(a_t>1\). The solid line starting from \(x^{(0)}\) indicates the conventional path in fixed point iterations while the dot dash line indicates the path with a step size greater than 1. The dot dash line moves towards the point of convergence faster than the solid line. However, it may overshoot if \(a_t\) is too large. In Algorithm 2, we borrow ideas from Salakhutdinov and Roweis (2003) to construct an adaptive algorithm where \(a_t\) is allowed to increase by a factor \(\rho >1\) after each cycle of updates whilst \(\mathcal {L}\) is on an increasing trend and we revert to \(a_t=1\) when \(\mathcal {L}\) decreases.


Solid line starting from \(x^{(0)}\) indicates conventional path in fixed point iterations while the dot dash line indicates path to convergence with a step size greater than 1
The adaptive nonconjugate variational message passing algorithm is given in Algorithm 2. In Appendix 3, we show that (13) reduces to the updates:
Step 3(b) has been added as a safeguard as the updated \({\varSigma }_\lambda ^q\) may not be symmetric positive definite due to rounding errors or when \(a_t\) is large. In this case, we propose reducing the step size by a factor \(\rho \) until all eigenvalues of \({\varSigma }_\lambda ^q\) are positive. It is useful to insert step 3(b) in Algorithm 1 after \({\varSigma }_\lambda ^q\) has been updated as well as it can serve as damping. For both Algorithms 1 and 2, we initialize \(\mu _\lambda ^q\) as \([0.5,\dots ,0.5]^T\) (which is one half of the amplitudes of the inputs after any rescaling), \({\varSigma }_\lambda ^q\) as \(\text {diag}[0.5,\dots ,0.5]^T\), \(C_\gamma ^q\) as \((\frac{n}{2}-1) \cdot \text {var}(y)/4\), \(C_\sigma ^q\) as \((m-1) \cdot \text {var}(y)\), and \(\mu _\alpha ^q\) and \({\varSigma }_\alpha ^q\) are initialized using the updates in steps 3–4 of Algorithm 1. We set the maximum number of iterations as 500 and the algorithms are deemed to have converged if the relative increase in \(\mathcal {L}\) is less than \(10^{-6}\). Salakhutdinov and Roweis (2003) recommend taking the factor \(\rho \) to be close to but more than 1. Using this as a guide, we have experimented with \(\rho \) taking values 1.1, 1.5 and 2. While all these values lead to improvement in efficiency, we find \(\rho =1.5\) to be more favourable, as the step sizes increase rather slowly when \(\rho =1.1\) and too fast when \(\rho =2\), leading to many failed attempts to improve \(\mathcal {L}\). While Algorithm 2 does not necessarily converge to the same local mode as Algorithm 1, results from the two algorithms are usually very close. Algorithm 2 sometimes demonstrates the ability to avoid local modes with the larger steps that it takes. We compare and quantify the performance of the two algorithms in Sect. 7.1. Note that in Algorithm 2, each failed attempt to improve \(\mathcal {L}\) is also counted as an additional iteration in step 5(b) even though step 1 does not have to be reevaluated.
We note that Algorithms 1 and 2 are not guaranteed to converge due to the fixed point updates in nonconjugate variational message passing. However, convergence issues can usually be mitigated by rescaling variables and varying the initialization values. As the fixed point updates may not result in an increase in \(\mathcal {L}\), it is possible to compute \(\mathcal {L}\) after performing the updates and reduce \(a_t\) if necessary. However, this requires computing a lower bound of a more complex form than (12) at each iteration. Our experiments indicate that a decline in \(\mathcal {L}\) is often due to \({\varSigma }_\lambda ^q\) not being symmetric positive definite, and hence installing step 3(b) suffices in most cases. We also find that checking the simplified form of \(\mathcal {L}\) in (12) at the end of each cycle and simply reverting \(a_t\) to 1 if necessary is more economical. If premature stopping occurs in Algorithms 1 or 2 due to a decrease in the lower bound at some iteration, this can be detected by examination of the lower bound values and remedied if needed by damping where values \(a_t<1\) are considered.
5 Predictive distribution and performance evaluation
Let \(D =\{(x_i,y_i)|i=1,\dots ,n\}\) and \(T =\{(x_j^*,y_j^*)|j=1,\dots ,n^*\}\) be the training and testing data sets respectively. Let \(S=\{s_1,\dots ,s_m\}\) be the set of spectral frequencies randomly generated from \(N(0,I_d)\). Bayesian predictive inference is based on the predictive distribution,
assuming \(y_j^*\) is conditionally independent of D given \(\alpha \), \(\lambda \) and \(\gamma \). We replace \(p(\alpha ,\lambda ,\gamma |D)\) with our variational approximation \(q(\alpha ,\lambda ,\gamma )=q(\alpha )q(\lambda )q(\gamma )\) so that

From (15), the posterior predictive mean of \(y_j^*\) is
where
and \(E_q(Z_j^*)\) can be computed using results in Appendix 1. The posterior predictive variance is
In the examples, we follow Lázaro-Gredilla et al. (2010) and evaluate performance using two quantitative measures: normalized mean square error (NMSE) and mean negative log probability (MNLP). These are defined as
The MNLP is implicitly based on a normal predictive distribution for \(y_j^*\) with mean \(\mu _j^*\) and variance \({\sigma _j^*}^2\), \(j=1,\dots ,n^*\).
6 Adaptive neighbourhoods approach for predictive inference
We propose a new technique of obtaining predictive inference by fitting models locally using adaptive neighbourhoods. Our proposed approach consists of two stages: For each test point \(x_j^*\), \(j=1,\dots ,n^*\),
-
1.
we first find the k nearest neighbours of \(x_j^*\) in D (that are closest to \(x_j^*\) in terms of Euclidean distance) and denote the index set of these k neighbours by \({N}_1\). We use Algorithm 2 to fit a sparse spectrum GP regression model, \(M_1\), to \(\{(x_i,y_i)|i \in {N}_1\}\).
-
2.
Next, we use the variational posterior mean of the lengthscales, \(\mu _\lambda ^q\), from \(M_1\) to define a new distance measure:
$$\begin{aligned} d(x_j^*,x_i)= \sqrt{(x_j^*-x_i)^T \text {diag}({\mu _\lambda ^q}^2) (x_j^*-x_i)}, \end{aligned}$$(16)where the dimensions are weighted according to \({\mu _\lambda ^q}^2\). This will effectively downweight or remove variables of little or no relevance. Using this new distance measure, we find the k nearest neighbours of \(x_j^*\) in D and denote the index set of these k neighbours by \({N}_2\). We use Algorithm 2 to fit a sparse spectrum GP regression model, \(M_2\), to \(\{(x_i,y_i)|i \in {N}_2\}\) and use the variational posterior from \(M_2\) for predictive inference.
In summary, the first fitting \((M_1)\) is used to find out which variables are more relevant in determining the output. From (1), a large value of \(\lambda _l\) indicates that the covariance drops rapidly along the dimension of l and hence the neighbourhood should be shrunk along the lth dimension. Using \(\mu _\lambda ^q\) from the first fit as an estimate of the lengthscales, the neighbourhood is then adapted before performing a second fitting \((M_2)\) to improve prediction. We do not recommend iterating the fitting process further since this may result in cyclical behaviour with the neighbourhood successively expanding and contracting along a certain dimension as the iterations proceed. In the examples, when the SSGP algorithm is implemented using this adaptive neighbourhood approach, we replace the variational posterior mean value \(\mu _\lambda ^q\) (which does not exist for the SSGP method since it does not estimate a variational posterior distribution for \(\lambda \)) by the point estimates of the lengthscales \(\hat{\lambda }\) obtained by the SSGP approach.
The adaptive neighbourhood approach is well-placed to handle data with nonstationarities as stationarity is only assumed locally and local fitting can adapt the noise and the degree of smoothing to the nonstationarities. Adapting the neighbourhood can also be very helpful in improving prediction when there are many irrelevant variables due to automatic relevance determination implemented via the lengthscales. A major advantage of the variational approach is that it allows uncertainty in the covariance hyperparameters to be modelled within a fast computational scheme. This is especially important when fitting using local neighbourhoods as plug-in approaches to estimating hyperparameters will tend to underestimate predictive uncertainty when the data set is small. This approach is advantageous for dealing with large data sets as well. As we only consider fitting models to a small subset k of data points at each test point, a smaller number of basis functions (m) might suffice. While the computational requirements grow linearly with the number of prediction locations, this approach is trivially parallelizable to get a linear speed-up with the number of processors.
7 Examples
We compare the performance of the variational approach with the SSGP algorithm using three real data sets: the pendulum data set, the rainfall-runoff data set and the Auto-MPG data set. The implementation of SSGP in Matlab is obtained from http://www.tsc.uc3m.es/~miguel/simpletutorialssgp.php. There are two versions of the SSGP algorithm: SSGP (fixed) uses fixed spectral points while SSGP (optimized) optimizes the marginal likelihood with respect to the spectral points. We will only consider SSGP (fixed). We observe some sensitivity in predictive performance to the basis functions and adopt the following strategy for better results: for each implementation of Algorithm 1 (or 2), we randomly generate ten sets of spectral points from \(N(0,I_d)\), perform 2 iterations of the algorithm, and select the set with the highest attained lower bound to continue to full convergence. A similar strategy was used by Lázaro-Gredilla et al. (2010) to initialize the SSGP algorithm. Due to the zero mean assumption, we center all target vectors, y by subtracting the mean \(\bar{y}\) from y. In the examples, “VA” refers to the variational approximation approach implemented via Algorithm 2, “global” refers to using the entire training set for fitting while “local” refers to the adaptive neighbourhood approach described in Sect. 6.
7.1 Pendulum data set
The pendulum data set (available at http://www.tsc.uc3m.es/~miguel/simpletutorialssgp.php) has \(d=9\) covariates and contains 315 training points and 315 test points. The target variable is the change in angular velocity of a simulated mechanical pendulum over 50 ms and the covariates consist of different parameters of the system. Lázaro-Gredilla et al. (2010) used this example to show that SSGP (optimized) can sometimes fail due to overfitting. We rescale the input variables in the training set to lie in \([-1,1]\) and consider the number of basis functions, \(m \in \{10,25,50,100,200\}\). We compare the performance of Algorithm 2 with SSGP (fixed) using NMSE and MNLP values averaged over ten repetitions. We set \(\rho =1.5\), \(A_\sigma =A_\gamma =25\) for the half-Cauchy priors, following Gelman (2006) and Wand et al. (2011) and \(\mu _\lambda ^0=0\), \({\varSigma }_\lambda ^0=10I_d\) for the lengthscales in Algorithm 2.
For this data set which is quite small, we note that the adaptive neighbourhood approach did not yield significant improvements as all inputs are relevant and there is no strong nonstationarity. Hence we report only results for global fits, which are shown in Figure 2. The NMSE and MNLP values produced by Algorithm 2 are comparable with that of SSGP (fixed) for small m and are better for large m. On the whole, Algorithm 2 produces reasonably good NMSE performance and is less prone to overfitting than the SSGP algorithm. The ability of the variational approach to treat uncertainty in the covariance function hyperparameters reduces underestimation of predictive uncertainty, resulting in better MNLP performance.

Pendulum data set. NMSE (left) and MNLP (right) values produced by Algorithm 2 (global VA) and global SSGP (fixed) and averaged over ten repetitions plotted against number of basis functions (m)
Next, we compare the performance of Algorithm 1 with Algorithm 2 both in terms of efficiency and the lower bound attained at convergence. We use Algorithm 1 to re-perform the runs for \(m \in \{10,25,50,100\}\), using the same sets of spectral points that were used in Algorithm 2. These runs are indexed from 1 to 40 (there are ten repetitions for each m). Figure 3 shows a plot of the lower bound attained at convergence on the left and a plot of the number of iterations required for convergence on the right for each of the 40 runs. Figure 3 indicates that, except for runs 3 and 40, the lower bound attained by Algorithms 1 and 2 are almost indistinguishable. However, Algorithm 2 required a much smaller number of iterations to converge than Algorithm 1. Excluding runs 3 and 40 where the lower bound attained by Algorithms 1 and 2 differs significantly, using Algorithm 2 instead of Algorithm 1 leads on average to a reduction of 49 % in the number of iterations required for convergence. The highest reduction observed is 84 % at run 9. At run 3, Algorithm 2 was able to escape a local mode and attained a higher lower bound at convergence. However, at run 40, it was caught in a local mode. We re-performed run 40 using \(\rho =1.1\) and Algorithm 2 was then able to attain the same lower bound as Algorithm 1 but in around half the number of iterations.

Pendulum data set. Left Plot of lower bound attained at convergence against index of runs. Right Plot of number of iterations required for convergence against index of runs. Solid circles correspond to Algorithm 2 with \(\rho =1.5\) while empty circles correspond to Algorithm 1
The typical behaviour of Algorithm 2 is illustrated in Fig. 4. On the left is a plot of the lower bound against iteration number and on the right is a plot of the adaptive step size \((a_t)\) used in Algorithm 2 against iteration number (t) for run 33. The step size typically increases by a factor of 1.5 at each iteration but falls back to 1 when the lower bound fails to increase. The step size may also be reduced by factors of 1.5 due to the requirement that the covariance matrix be symmetric positive definite in step 2(b) of Algorithm 2. The reduction in the number of iterations that Algorithm 2 takes to converge as compared to Algorithm 1 is 74 % for run 33.

Pendulum data set. Run 33. Left Plot of lower bound against iteration number (solid line corresponds to Algorithm 2 with \(\rho =1.5\) while dashed line corresponds to Algorithm 1). Right Plot of the adaptive step size \((a_t)\) used in Algorithm 2 against iteration number (t)
7.2 Performance of SSGP and VA with adaptive neighbourhood approach
For the next four subsections, our discussion concerns performance of the adaptive neighbourhood approach. We compare the performance using two real datasets: the rainfall-runoff data set and the Auto-MPG data set. We fit these data globally using SSGP (fixed), VA and MCMC, and compare results with the adaptive neighbourhood approach, implemented using both SSGP (fixed) and Algorithm 2 with factor \(\rho =1.5\). For the priors, we set \(A_\sigma =A_\gamma =25\), \(\mu _\lambda ^0=0\). For \({\varSigma }_\lambda ^0\), we set \({\varSigma }_\lambda ^0 = 100I_d\) for the rainfall-runoff data where a less smooth mean function is expected and \({\varSigma }_\lambda ^0 = I_d\) for the Auto-MPG data. The prior variance for the lengthscales can be chosen empirically by predictive performance on a test set or using prior knowledge. Prior knowledge about the hyperparameters in the covariance function can be elicited by thinking about the prior degree of expected correlation of the mean function for covariates separated by lag one in each dimension when the covariates are standardized. For both the global SSGP (fixed) and VA approach, we consider the number of basis functions \(m \in \{20,40,60,80,100\}\). In addition, we generate ten artificial covariates on top of the existing covariates in both the rainfall-runoff and Auto-MPG data set to test the capability of Algorithm 2 in automatic relevance determination.
7.3 Rainfall-runoff data
In this example, we consider data from a deterministic rainfall-runoff model, which is a simplification of the Australian Water Balance Model (AWBM, Boughton 2004). The AWBM estimates catchment streamflow using time series of rainfall and evapotranspiration data and is widely used in Australia for estimating catchment water yield or design flood estimation. The model has three parameters—the maximum storage capacity S, the base flow index BFI and the baseflow recession factor K. We have model simulations for around eleven years of average monthly potential evapotranspiration and daily rainfall data for the Barrington River catchment, located in New South Wales, Australia. The model was run for 500 different values of the parameters (S, K, BFI) generated using a maximin Latin hypercube design. This data contains 500 data points for each of 3700 days, with a total of 1.85 million data points. For each day, the total rainfall is also recorded. A subset of this data has been studied in Nott et al. (2012).
Even though the size of the data is large, the computational demands of the adaptive neighbourhood approach will depend mostly on the number of query points and the neighbourhood size. This makes our approach highly suitable for this data set. This is especially true since emulation of the model will be most interesting near values of peak rainfall input and generally for events of hydrological significance, where there might be a flood risk for example. So the proportion of interesting query points in this example is a small fraction of the total data set size and furthermore we expect the model output to vary rapidly in some parts of the parameter space but very little in other parts so the ability of the local method to smooth adaptively is very attractive for this problem. We will consider prediction for the two days with the highest rainfall inputs. We take AWBM streamflow response as the target y, and S and K as covariates, omitting BFI. A small amount of independent normal random noise with standard deviation 0.01 was added to y to avoid degeneracies in regions of the space where the response tends to be identically zero. For each day, we randomly selected 100 data points as the test set and use the remaining 400 data points as the training set. These data are highly nonstationary with large flat regions, a few rapidly varying regions and the noise level changes a lot over the space.
Figure 5 shows the NMSE and MNLP values averaged over ten repetitions for the rainfall-runoff data with peak rainfall. For global SSGP (fixed), we observe a slight improvement in NMSE values as m increases, while MNLP values remain largely constant at around 3.75 even for large m. Due to the nonstationary nature of this data, a global stationary fit does very poorly in MNLP. For the adaptive neighbourhood approach, we consider neighbourhoods of size \(k=20, 40, 60, 80, 100\), fixing the number of basis functions, \(m=20\). For the local methods, the dotted lines correspond to results from the initial fitting where the k nearest neighbours are determined based on Euclidean distance. The solid lines correspond to results from the final fit where the k nearest neighbours are determined using the new distance measure with dimensions weighted according to the lengthscales. The improvement brought about by adapting the neighbourhood is more apparent in VA than in SSGP (fixed).

Rainfall-runoff data on day with peak rainfall. NMSE and MNLP values averaged over ten repetitions plotted against the number of basis functions (first column) and against the number of neighbours (second and third columns). Number of basis functions used in the local methods was 20. Lower MNLP is better
Figure 6 shows the NMSE and MNLP values averaged over ten repetitions for the rainfall-runoff data with the second highest rainfall. In this example we also observe that a global stationary fit does very poorly in MNLP, again due to the nonstationary nature of the data. Similarly, when adapting the neighbourhood approach, there are greater improvements in VA than in SSGP (fixed). It is clear that the adaptive neighbourhood approach is critical for this data set where the mean function varies rapidly over some parts of the space but very little over other parts. The variational approach performs very well when using just a small neighbourhood about each test point both in terms of NMSE and MNLP.

Rainfall-runoff data on day with second highest rainfall. NMSE and MNLP values averaged over ten repetitions plotted against the number of basis functions (first column) and against the number of neighbours (second and third columns). Number of basis functions used in the local methods was 20. Lower MNLP is better
Figure 7 illustrates how the neighbourhood of a test point changes from the initial to the final fit for the case \(k=60\), when Algorithm 2 was being used. The plot on the left shows the neighbours (denoted by circles) of a test point (denoted by solid circle) determined using Euclidean distance. The plot on the right shows the neighbours of the same test point determined using the new distance measure. In this case, the component of \(\mu _\lambda ^q\) corresponding to the covariate S is much larger than that corresponding to the covariate K, resulting in the neighbourhood being shrunk along the S axis. The adapted neighbourhood leads to an improvement in the estimation of the predictive mean and especially the predictive variance of the test point.

Rainfall-runoff data on day with peak rainfall. Plot of neighbourhood of test point determined using Euclidean distance (left) and new weighted distance measure (right). Circles denote neighbours and solid circle denotes test point
Table 1 shows the computation times of the VA, SSGP (fixed) and MCMC algorithms on the rainfall-runoff data with peak rainfall input. We ran the MCMC using Rstan (Stan Development Team 2014) on a dual processor Windows PC 3.30 GHz workstation and both SSGP (fixed) and VA in Matlab using a 3.2 GHz Intel Core I5 Quad Core iMac. For the global approach, computation times for SSGP (fixed) and VA are averaged over 10 repetitions, while MCMC is based on a single run with 2000 iterations. For the adaptive neighbourhood approach, Table 1 shows the total time it takes to run all 100 test points. Note that the timing for the local approaches can be significantly reduced by parallelizing. In terms of computation speed, SSGP (fixed) is the fastest followed by VA. We observe that MCMC is substantially slower than the other methods and the computation time increases significantly when the size of neighbourhood increases. We do not observe such significant increase in computation times for VA and SSGP (fixed).
7.4 Rainfall-runoff with simulated data
We consider rainfall-runoff data on the day with peak rainfall and generate ten additional covariates artificially. As both covariates S and K lie in the interval [0, 1], we simulate each of the ten additional covariates randomly from the uniform distribution on the interval [0, 1]. We compare the performance of SSGP (fixed) and Algorithm 2 using a global fit with the adaptive neighbourhood approach. We set \(\rho =1.5\) in Algorithm 2 and use the same priors as in Sect. 7.3. For the global approach, we consider the number of basis functions, \(m \in \{20,40,60,80,100\}\) while for the adaptive local neighbourhood approach, we consider neighbourhoods of size \(k=20, 40, 60, 80, 100\), fixing the number of basis functions, \(m=20\). The results are shown in Fig. 8.

Rainfall-runoff simulated data. NMSE and MNLP values averaged over ten repetitions plotted against the number of basis functions (first column) and against the number of neighbours (second, third and fourth columns). Number of basis functions used in the local methods was 20
For the global approach, the results of SSGP (fixed) are quite similar to those in the 2 covariates case. For the local approach, a small neighbourhood with \(k=20\) does not work well for both SSGP (fixed) and VA, indicating that a larger neighbourhood is likely required for high dimensional problems. There is a clear improvement in the MNLP values from adapting the neighbourhood according to the lengthscales and Algorithm 2 achieved the lowest MNLP values among the methods that were studied, using a smaller neighbourhood. The MNLP values achieved by Algorithm 2 are close to those attained in Sect. 7.3, indicating that the adaptive neighbourhood approach is effective in eliminating covariates of little relevance. The variational approach is able to provide significant improvement in this aspect and is much more robust to overfitting for small neighbourhoods. However, the NMSE values obtained in the adaptive neighbourhood approach are higher than those obtained in the global approach. Finally, we note that a good neighbourhood size is dependent on the number of covariance function parameters to be estimated and on the degree of nonstationarity, which is very much problem specific. Some experimentation with different neighbourhood sizes is probably necessary.
7.5 Auto-MPG data
In this example, we consider the Automobile city-cycle fuel consumption in miles per gallon (Auto-MPG) data taken from the CMU Statistics library. This dataset was used in the 1983 American Statistical Association Exposition and is available at http://archive.ics.uci.edu/ml/datasets.html. The dataset contains 398 instances and nine attributes. Quinlan (1933) used this data to predict the attribute “MPG”, which is the city-cycle fuel consumption in miles per gallon. The other eight attributes include two multi-valued discrete, four continuous attributes and two categorical variables. We drop the two categorical variables, car name and origin, and keep the four continuous attributes and two multi-valued discrete variables. Six of the data points are removed as they have missing entries in some of the input variables. We randomly select 80 data points as the test set, and use the remaining 312 data points as the training set.

Auto-MPG data. NMSE and MNLP values averaged over ten repetitions plotted against the number of basis functions (first column) and against the number of neighbours (second and third columns). Number of basis functions used in the local methods was 20
Figure 9 shows the NMSE and MNLP values averaged over ten repetitions. For the global SSGP (fixed) and VA methods, we observe slight improvements in both the NMSE and MNLP values as m increases. The MNLP and NMSE values for MCMC and global VA are also better than for global SSGP (fixed). For the adaptive neighbourhood approach, we consider neighbourhoods of size \(k = 20, 40, 60, 80, 100\), while fixing the number of basis function \(m=20\). For local VA, the final fit is slightly better than the initial fit. There is an improvement brought about by adapting the neighbourhood as Figure 9 shows that the MNLP values of both the initial and final fits are lower than the MCMC method for neighbourhood size of 40, 60, 80 and 100.
For local SSGP (fixed), we observe that their performance is worse than MCMC. Moreover, it seems that the initial fit is better than the final fit, for neighbourhood size of 80 and 100. This may be because the lengthscales are not accurate enough to be used for the final fit. We also examined the local SSGP approach with larger neighbourhood sizes of 150, 200 and 250. We found that, at a neighbourhood size of 150, the performance of the final fit of local SSGP (fixed) (MNLP and NMSE of 2.38 and 0.129 respectively) is slightly better than MCMC. Adapting the neighbourhood approach is still more apparent in the variational approach as it is able to achieve MNLP and NMSE value of 2.26 and 0.117 respectively at neighbourhood size of 60.
7.6 Auto-MPG with simulated data
We now consider the Auto-MPG data and look at the influence of irrelevant covariates on the model. This is again done by generating ten additional covariates artificially and randomly from the uniform distribution on the interval [0,1]. Once again, like the rainfall-runoff data, it seems that a larger neighbourhood is required to attain the best performance for the variational approach when irrelevant covariates are added. In this example, for the variational approach, we found that neighbourhood size of 100 produces the best peformance with MNLP and NMSE values of 2.30 and 0.127 respectively (see Fig. 10). Again, after examining the local SSGP (fixed) approach with larger neighbourhood sizes, we found that it attains the best performance (MNLP and NMSE of 2.43 and 0.141 respectively) at a neighbourhood size of 150.

Auto-MPG data with 10 simulated covariates. NMSE and MNLP values averaged over ten repetitions plotted against the number of basis functions (first column) and against the number of neighbours (second and third columns). Number of basis functions used in the local methods was 20

Auto-MPG data with 10 simulated covariates. Histogram of estimated posterior predictive means and variances over 100 repetitions. Number of basis functions used in the local methods was 20
In order to explain why there is a difference in the stability of the adaptive neighbourhood approach between VA and SSGP (fixed), we examined the estimated predictive mean and variance for one test point from the Auto-MPG test set with 10 simulated irrelevant covariates. We implement the adaptive neighbourhoods approach based on just the initial fitting, which uses the shortest Euclidean distance. Figure 11 shows 100 posterior predictive means and variances from SSGP (fixed) and VA with the adaptive neighbourhood approach. In the 100 replications, only the spectral points change. Since VA accounts for hyperparameter uncertainty, it is more robust towards the choice of spectral points. We observe that the posterior predictive means and variances are concentrated around a smaller range of values even when the size of neighbourhood is small. On the other hand, for local SSGP (fixed), the posterior predictive means vary more for different choices of the spectral points with the values ranging from 0 to 20 and with many of the posterior predictive variances small when the size of the neighbourhood is small.
8 Conclusion
In this paper, we have presented a nonconjugate variational message passing algorithm for fitting sparse spectrum GP regression models where closed form updates are possible for all variational parameters, except for the evaluation of \(\mathcal {H}(p,q,r)\). We note that \(\mathcal {H}(p,q,r)\) can be evaluated very efficiently using quadrature and there is almost no computational overhead when compared to updates based on conditionally conjugate Inverse-Gamma priors for the variance parameters. However, half-Cauchy priors lead to much better predictive inference especially in the adaptive neighbourhood approach where the amount of training data is small. A Bayesian approach has been adopted for parameter estimation which allows covariance function hyperparameter uncertainty to be treated and empirical results suggest that this improves prediction (especially in the MNLP values) and prevents overfitting. We also propose a novel adaptive neighbourhood technique for obtaining predictive inference which is adept at handling data with nonstationarities and this approach can be extended to large data sets as well. The simulated data sets showed that weighting the dimensions according to the lengthscales estimated from an initial fit is very effective at downweighting variables of little relevance, leading to automatic variable selection and improved prediction. In addition, we introduce a technique for accelerating convergence in nonconjugate variational message passing by taking step sizes larger than one in the direction of the natural gradient of the lower bound. We do not attempt to search for the optimal step size but adopt an adaptive strategy that can be easily implemented, and empirical results indicate significant speed-ups. Algorithm 2 is thus an attractive alternative for fitting sparse spectrum GP regression models, which is stable, robust to overfitting for small data sets and capable of dealing with highly nonstationary data as well when used in combination with the adaptive neighbourhood approach.
References
Amari, S.: Natural gradient works efficiently in learning. Neural Comput. 10, 251–276 (1998)
Attias, H.: Inferring parameters and structure of latent variable models by variational Bayes. In: Laskey, K., Prade, H. (eds.) Proceedings of the 15th Conference on Uncertainty in Artificial Intelligence, pp. 21–30. Morgan Kaufmann, San Francisco, CA (1999)
Attias, H.: A variational Bayesian framework for graphical models. In: Solla, S.A., Leen, T.K., Müller, K.-R. (eds.) Advances in Neural Information Processing Systems 12, pp. 209–215. MIT Press, Cambridge, MA (2000)
Blei, D.M., Jordan, M.I.: Variational inference for Dirichlet process mixtures. Bayesian Anal. 1, 121–144 (2006)
Boughton, W.: The Australian water balance model. Environ. Model. Softw. 19, 943–956 (2004)
Braun, M., McAuliffe, J.: Variational inference for large-scale models of discrete choice. J. Am. Stat. Assoc. 105, 324–335 (2010)
Gelman, A.: Prior distributions for variance parameters in hierarchical models. Bayesian Anal. 1, 515–533 (2006)
Gramacy, R.B., Apley, D.W.: Local Gaussian process approximation for large computer experiments. J. Comput. Gr. Stat. To appear (2014)
Haas, T.C.: Local prediction of a spatio-temporal process with an application to wet sulfate deposition. J. Am. Stat. Assoc. 90, 1189–1199 (1995)
Hastie, T., Tibshirani, R.: Discriminant adaptive nearest neighbor classification. IEEE Trans. Pattern Anal. Mach. Intell. 18, 607–616 (1996)
Hoffman, M.D., Blei, D.M., Wang, C., Paisley, J.: Stochastic variational inference. J. Mach. Learn. Res. 14, 1303–1347 (2013)
Honkela, A., Valpola, H., Karhunen, J.: Accelerating cyclic update algorithms for parameter estimation by pattern searches. Neural Process. Lett. 17, 191–203 (2003)
Huang, H., Yang, B., Hsu, C.: Triple jump acceleration for the EM algorithm. In: Han, J., Wah, B. W., Raghavan, V., Wu, X., rastogi, R. (eds.) Proceedings of the 5th IEEE International Conference on Data Mining, pp. 649–652. IEEE Computer Society, Washington, DC, USA (2005)
Kim, H.-M., Mallicka, B.K., Holmesa, C.C.: Analyzing nonstationary spatial data using piecewise Gaussian processes. J. Am. Stat. Assoc. 100, 653–668 (2005)
Knowles, D.A., Minka, T.P.: Non-conjugate variational message passing for multinomial and binary regression. In: Shawe-Taylor, J., Zemel, R.S., Bartlett, P., Pereira, F., Weinberger, K.Q. (eds.) Advances in Neural Information Processing Systems 24, pp. 1701–1709. Curran Associates, Inc., Red Hook, NY (2011)
Lázaro-Gredilla, M., Quiñonero-Candela, J., Rasmussen, C.E., Figueiras-Vidal, A.R.: Sparse spectrum Gaussian process regression. J. Mach. Learn. Res. 11, 1865–1881 (2010)
Lázaro-Gredilla, M., Titsias, M.K.: Variational heteroscedastic Gaussian process regression. In: Getoor, L., Scheffer, T. (eds.) Proceedings of the 28th International Conference on Machine Learning, pp. 841–848. Omnipress, Madison, MI, USA (2011)
Lindgren, F., Rue, H., Lindström, J.: An explicit link between Gaussian fields and Gaussian Markov random fields: the stochastic partial differential equation approach. J. R. Stat. Soc. Ser. B 73, 423–498 (2011)
Magnus, J.R., Neudecker, H.: Matrix Differential Calculus with Applications in Statistics and Econometrics. Wiley, Chichester, UK (1988)
Nguyen-Tuong, D., Seeger, M., Peters, J.: Model learning with local Gaussian process regression. Adv. Robot. 23, 2015–2034 (2009)
Nott, D.J., Tan, S.L., Villani, M., Kohn, R.: Regression density estimation with variational methods and stochastic approximation. J. Comput. Gr. Stat. 21, 797–820 (2012)
Ormerod, J.T., Wand, M.P.: Explaining variational approximations. Am. Stat. 64, 140–153 (2010)
Park, S., Choi, S.: Hierarchical Gaussian process regression. In Sugiyama, M. and Yang, Q. (eds.) Proceedings of 2nd Asian Conference on Machine Learning, pp. 95–110 (2010)
Qi, Y., Jaakkola, T.S.: Parameter expanded variational Bayesian methods. In: Schölkopf, B., Platt, J., Hofmann, T. (eds.) Advances in Neural Information Processing Systems 19, pp. 1097–1104. MIT Press, Cambridge (2006)
Quinlan, R.: Combining Instance-Based and Model-Based Learning. In Proceedings on the Tenth International Conference of Machine Learning, 236-243. University of Massachusetts, Morgan Kaufmann, Amherst (1993)
Quiñonero-Candela, T., Rasmussen, C.E.: A unifying view of sparse approximate Gaussian process regression. J. Mach. Learn. Res. 6, 1939–1959 (2005)
Rasmussen, C.E., Williams, C.K.I.: Gaussian Processes for Machine Learning. MIT Press, Cambridge, MA (2006)
Ren, Q., Banerjee, S., Finley, A.O., Hodges, J.S.: Variational Bayesian methods for spatial data analysis. Comput. Stat. Data Anal. 55, 3197–3217 (2011)
Salakhutdinov, R., Roweis, S.: Adaptive overrelaxed bound optimization methods. In: Fawcett, T., Mishra, N. (eds.) Proceedings of the 20th International Conference on Machine Learning, pp. 664–671. AAAI Press, Menlo Park, CA (2003)
Snelson, E., Ghahramani, Z.: Sparse Gaussian processes using pseudo-inputs. In: Weiss, Y., Schölkopf, B., Platt, J. (eds.) Advances in Neural Information Processing Systems 18, pp. 1257–1264. MIT Press, Cambridge, MA (2006)
Snelson, E., Ghahramani, Z.: Local and global sparse Gaussian process approximations. In: Meila, M., Shen, X. (eds) JMLR Workshop and Conference Proceedings, vol. 2: AISTATS 2007, pp. 524–531 (2007)
Stan Development Team: RStan: the R interface to Stan, Version 2.5.0. http://mc-stan.org/rstan.html (2014)
Stein, M.L., Chi, Z., Welty, L.J.: Approximating likelihoods for large spatial data sets. J. R. Stat. Soc. Ser. B 66, 275–296 (2004)
Tan, L.S.L., Nott, D.J.: Variational inference for generalized linear mixed models using partially non-centered parametrizations. Stat. Sci. 28, 168–188 (2013)
Tan, L.S.L., Nott, D.J.: A stochastic variational framework for fitting and diagnosing generalized linear mixed models. Bayesian Anal. 9, 963–1004 (2014). doi:10.1214/14-BA885
Titsias, M.K.: Variational learning of inducing variables in sparse Gaussian processes. In: van Dyk, D., Welling, M. (eds.) Proceedings of the 12th International Conference on Artificial Intelligence and Statistics, pp. 567–574 (2009)
Urtasun, R., Darrell, T.: Sparse probabilistic regression for activity-independent human pose inference. IEEE Conf Comput. Vis. Pattern Recognit. 2008, 1–8 (2008)
Vecchia, A.V.: Estimation and model identication for continuous spatial processes. J. R. Stat. Soc. Ser. B 50, 297–312 (1988)
Walder, C., Kim, K.I., Schölkopf, B.: Sparse multiscale Gaussian process regression. In McCallum, A. and Roweis, S. (eds.) Proceedings of the 25th International Conference on Machine Learning, pp. 1112–1119. ACM Press, New York (2008)
Wand, M.P., Ormerod, J.T., Padoan, S.A., Frührwirth, R.: Mean field variational Bayes for elaborate distributions. Bayesian Anal. 6, 847–900 (2011)
Wand, M.P.: Fully simplified multivariate normal updates in non-conjugate variational message passing. J. Mach. Learn. Res. 15, 1351–1369 (2014)
Wang, B., Titterington, D.M.: Inadequacy of interval estimates corresponding to variational Bayesian approximations. In: Cowell, R. G., Ghahramani, Z. (eds.) Proceedings of the 10th International Workshop on Artificial Intelligence and Statistics, pp. 373–380. Society for Artificial Intelligence and Statistics (2005)
Wang, B., Titterington, D.M.: Convergence properties of a general algorithm for calculating variational Bayesian estimates for a normal mixture model. Bayesian Anal. 3, 625–650 (2006)
Winn, J., Bishop, C.M.: Variational message passing. J. Mach. Learn. Res. 6, 661–694 (2005)
Acknowledgments
We thank Lucy Marshall for supplying the rainfall-runoff data set. Linda Tan was partially supported as part of the Singapore Delft Water Alliance’s tropical reservoir research programme. David Nott, Ajay Jasra and Victor Ong’s research was supported by a Singapore Ministry of Education Academic Research Fund Tier 2 grant (R-155-000-143-112). We also thank the referees and associate editor for their comments which have helped improved the manuscript.
Author information
Authors and Affiliations
Corresponding author
Appendices
Appendix 1: Derivation of \(E_q(Z)\) and \(E_q(Z^TZ)\)
Lemma 1
Suppose \(\lambda \sim N(\mu ,{\varSigma })\) and \(t_1\), \(t_2\) are fixed vectors the same length as \(\lambda \). Let \(t_{12}^-=t_1-t_2\) and \(t_{12}^+=t_1+t_2\), then
By setting \(t_2=0\) in the first and third expressions, we get
Proof
\(E[\exp \{i\lambda ^T(t_1-t_2)\}]=\exp \{i \mu ^T (t_1-t_2)- \tfrac{1}{2}(t_1-t_2)^T {\varSigma } (t_1-t_2)\}\) implies
and
Replacing \(t_2\) by \(-t_2\), we get
and
(17) + (19) gives the first equation of the lemma, (17) – (19) gives the second and (18) + (20) gives the third. \(\square \)
Using Lemma 1, we have
where

and \(t_{ir}=s_r \odot x_i\) for \(i=1,\dots ,n\), \(r=1,\dots ,m\). We also have \(E_q(Z^TZ)=\sum _{i=1}^n E_q(Z_iZ_i^T)\) where \(E_q(Z_iZ_i^T)=\left[ {\begin{matrix} P_i &{} Q_i^T \\ Q_i &{} R_i \end{matrix}}\right] \), where \(P_i\), \(Q_i\), \(R_i\) are all \(m\times m\) matrices and
\(t_{irl}^-=t_{ir}-t_{il}\), \(t_{irl}^+=t_{ir}+t_{il}\) for \(r=1,\dots ,m\), \(l=1,\dots ,m\).
Appendix 2: Derivation of lower bound
From (6), the lower bound is given by
where
The terms in the lower bound can be evaluated as follows:
Putting these terms together and making use of the updates in steps 5 and 6 of Algorithm 1 gives the lower bound in (12).
Appendix 3: Derivation of simplified updates in Algorithm 2
It can be shown (see Wand 2014; Tan and Nott 2013) that the natural parameter of \(q(\lambda )=N(\mu _\lambda ^q,{\varSigma }_\lambda ^q)\) is
where \(D_d\) is a unique \(d^2 \times \tfrac{d}{2}(d+1)\) matrix that transforms \(\text {vech}(A)\) into \(\text {vec}(A)\) for any \(d \times d\) symmetric square matrix A, that is, \(D_d\text {vech}(A)=\text {vec}(A)\). We use \(\text {vech}(A)\) to denote the \(\tfrac{1}{2}d(d+1) \times 1\) vector obtained from \(\text {vec}(A)\) by eliminating all supradiagonal elements of A. Magnus and Neudecker (1988) is a good reference for the matrix differential calculus involved in the derivation below. From (13) and (Tan and Nott 2013, pg. 7), we have
where \(\dfrac{\partial S_a}{\partial \text {vec}({\varSigma }_\lambda ^q)}\) and \(\dfrac{\partial S_a}{\partial \mu _\lambda ^q}\) are evaluated at
Let
The first line of (21) simplifies to
The second line of (21) gives
Rights and permissions
About this article

Cite this article
Tan, L.S.L., Ong, V.M.H., Nott, D.J. et al. Variational inference for sparse spectrum Gaussian process regression. Stat Comput 26, 1243–1261 (2016). https://doi.org/10.1007/s11222-015-9600-7
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11222-015-9600-7