
Abstract
In recent decades, the role of gross domestic product (GDP) as an indicator of well-being has been sharply questioned by both researchers and institutions. This theoretical discussion leads to the international debate “Beyond GDP”, which aims to assess the progress of a country considering fundamental social and environmental dimensions of well-being, inequality, and sustainability. According to this perspective, well-being and quality of life, in general, deserve great attention at the institutional level; hence, this topic attracted the consideration of methodological researchers, and thus many statistical indicators have been proposed. Recently, most insiders have dealt with the problem of the multidimensionality of well-being, and many research has also stressed the importance of assessing trends and changes over time rather than observing indices in single instants. For this reason, this research proposes the use of functional data analysis to build new social indicators of well-being and to interpret them considering the original time observations as a continuous function. Indeed, repeated measures of social indicators of well-being can be considered as functions in the time domain. Moreover, this approach adds to the existing techniques interesting instruments of analysis, e.g. the derivatives and the functional principal components, and overcomes some strong assumptions of the time series analysis. To demonstrate the appropriateness of this approach, this study proposes an application to real data concerning “subjective well-being” within the Italian “BES project” The final aim of this research is to provide scholars and policy-makers with additional tools for assessing the “Equitable and Sustainable Well-being” over time.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
In recent decades, both scholars and institutions have stressed that macro-economic statistics (e.g. GDP) do not adequately represent the quality of people’s living conditions (OECD 2013). Moreover, the financial and economic crisis has strongly emphasised the importance of considering further indicators able to detect countries’ social progress effectively. Therefore, because “the dominant position of GDP as a measure of social progress is under fire” (Callens 2015), many attempts for developing indicators, which are as clear and appealing as GDP but more inclusive of environmental and social aspects of progress, have been made. The most important initiative in this regard is “Beyond GDP” (OECD 2014) that represents a strong institutional signal of the European Commission confirming the need of looking for adequate social indicators able to reflect the real condition of people’s well-being.
The study of social indicators of well-being has a long tradition (e.g. Andrews and Withey 1976; Andrews 1983; Diener et al. 1995; Biswas-Diener et al. 2004; Suter and Iglesias 2005; Betti et al. 2006; Veenhoven 2007; Michalos 2008), in recent decades, research on quality of life and its dimensions (e.g. subjective well-being) has proliferated attracting the attention of many worldwide scholars (e.g. Cutler 2009; Diener 2009; Maria 2009; Rosa et al. 2010; Mushongera et al. 2015; Lee and Kim 2016; Fattore et al. 2016; Di Spalatro et al. 2017; Rogge and Van Nijverseel 2018; Rojas 2018; Cummins 2018).
Traditionally, utility and related concepts form a compelling source of insights into well-being. Various forms of utilitarianism, including revealed preference and preference utilitarianism, which view well-being to be preference-fulfilment, have been analysed by Alkire (2015). However, according to Sen (1979), the doctrine for which well-being only depends on utility implies the rejection of any other values. Thus, after Sen’s paper (Sen 1980), it has been common to consider alternative informational bases to account for well-being issues. A strong motivation for considering well-being as a multidimensional issue has been provided by the publication of the report of the “Commission on the measurement of economic performance and social progress” (Stiglitz et al. 2009). The report identifies the limits of GDP as an indicator of economic performance and social progress and suggests to consider additional information for the production of more relevant indicators of social progress.
Consistent with the view of well-being as a multidimensional concept, novel approaches to build indicators or discuss the problems of the existing ones, have been proposed (e.g. Fattore and Arcagni 2014; Otoiu et al. 2014; Fattore 2015; Davino et al. 2016; Kuentz-Simonet et al. 2016; Fattore and Arcagni 2016; Betti 2016; Boccuzzo and Caperna 2017; Suter and Iglesias 2005; Betti et al. 2006; Maggino 2014; di Bella et al. 2016; Iglesias et al. 2016; Mauro et al. 2016; Fattore and Maggino 2017).
As highlighted in Boelhouwer and Bijl (2015) and ISTAT (2016), much of the power of well-being indicators is their availability as repeated measurements over time. In this regard, Maggino and Facioni (2015) stressed that analysing social phenomena such as well-being, one of the more interesting problem is the study of its dynamics expressed “in terms of stability and change”. In particular, in the context of subjective well-being (SWB) (more colloquially “happiness”), which can be defined as “a characteristic that reflects a person’s subjective evaluation of his or her life as a whole”, the theoretical problem of its (possible) change has been widely discussed in the literature (e.g. see Sheldon and Lucas 2014a). However, according to the perspective of Boelhouwer and Bijl (2015), policymakers could also be interested in comparing different groups of individuals through their subjective well-being measurement, e.g. older people vs young people or people living in large conurbations vs people living in rural localities.
From a theoretical perspective, many scholars believe that the happiness of a person is a personal fact that hardly changes over time. Indeed, some scholars argue that even people who have experienced serious positive or negative events do not change their happiness (e.g. see Sheldon and Lucas 2014a). In the last few decades, a more moderate theory has emerged with the idea that happiness can increase (“sustainable happiness theory”) but most scholars are suspicious that this improvement may last over time (“set-point theory”) (Headey and Wearing 1989; Lykken and Tellegen 1996; Easterlin and Switek 2014). In other words, there is a strong conviction of some scholars that happiness is a fact inherent in people and that, apart from fluctuations, happiness returns to the basic level in the long term (Lykken and Tellegen 1996). Indeed, a central hypothesis in the set-point theory is that subjective well-being fluctuates around a stable, genetically determined set point, and thus long-term levels of subjective well-being should be highly heritable and stable across time. Nonetheless, many empirical studies suggest that it is possible to become permanently happier or sadder due to important life events (Sheldon and Lucas 2014a).
The basic idea of this research is to propose a tool that can provide additional information for the study of the dynamics of well-being in the long term, i.e. the functional data analysis approach (FDA) (Ramsay and Dalzell 1991; Ramsay and Silverman 2002, 2005; Ramsay et al. 2009; Ferraty and Vieu 2003, 2006; Ferraty 2011; Febrero-Bande and de la Fuente 2012; Cuevas 2014). Consistent with the theoretical framework of multidimensional well-being, the input data is a set of time series each one recording well-being over time. Each time series can regard a different dimension of well-being or a diverse group of individuals (e.g. a different region of a geographic area). The novelty of the FDA approach is to assume that the measurements over time are temporally ordered samples of an underlying continuous function. That is, well-being evolves continuously over time, but we can get only some measurements (e.g. yearly measurements) of it. Usually, the estimation of the continuous function underlying the time series of measurements is performed by means of non-parametric fitting techniques (e.g. smoothing splines).
Differently from classic multivariate data, functional data embed the ordering on the time dimension. Moreover, the information in the slope and curvatures of functions, as reflected in their derivatives, can be used to study the dynamics of well-being indicators. By considering each continuous function as the unit of our analyses, we can also compare well-being measurements through metrics and semi-metrics on the entire functions rather than on single time instants, as in classic approaches.
After introducing FDA and some related concepts, the aim of this research is to propose the use of derivatives and functional principal components decomposition to interpret the dynamics of subjective well-being. Afterwards, the clustering of statistical units according to suitable metrics and semi-metrics for functional data is performed to discover homogeneous groups of subjective well-being measurements. Then, this study presents an application on subjective well-being measurements coming from the Italian report on the equitable and sustainable well-being (BES report) (ISTAT 2016). Clearly, this approach can be easily extended to other measures of well-being (in addition to the subjective well-being one).
The BES report is an annual publication of the Italian National Institute of Statistics (ISTAT) which, from 2013, provides an evaluation of the progress of the Italian society not only from an economic but also from a social and environmental point of view. It aims at becoming a reference point for citizens, civil society, the media, and politics for obtaining an overall picture of the primary social, economic and environmental phenomena that characterise Italy. From 2016, recent trends for selected indicators of BES report have become part of the Italian Economic and Financial Document (DEF) and every year a monitoring report has to be presented to the Italian Parliament.
During the last decades, in Italy, the institutions have shown significant interest in the topic of well-being, and one of the reasons is undoubtedly the economic situation of the country. Indeed, Italy is arguably “the only Western country where regional imbalances still play a major role nowadays: Italy’s North-South divide in terms of GDP has no parallels in any other advanced country of a similar size, and southern Italy is, after Eastern Europe, the biggest underdeveloped area inside the European Union” (Felice 2017). Specifically, Italy is composed of two areas: A Center-North much more homogeneous internally, and a more impoverished South. Moreover, the effectiveness of state intervention in the South was almost absent due to growing political clientelism, bad industrial choices, and organised crime (Felice 2017). Therefore, starting from 2010, ISTAT, initially in collaboration with CNEL (National Council for Economics and Labour), has developed a multidimensional approach to well-being which follows the theoretical framework of the OECD studies and projects (OECD 2011, 2013) as well as the “SSF Report” (Stiglitz et al. 2009). To this end, the traditional economic indicators, GDP first of all, have been integrated with measures of the quality of life and the environment.
Different commissions of experts detected the domains related to well-being and their proper statistical indicators. In total, 12 domains and 130 indicators were identified. Starting from the 2015 edition, the BES report also proposes synthetic measures of the overall performance of the various domains. These provide the aggregation of the individual indicators that make up a domain into a single value. However, these composite indicators have been elaborated only for the so-called “outcome domains”, i.e. health, education and training, work and life balance, economic well-being, social relationship, security, landscape and cultural heritage, environment, and subjective well-being. Furthermore, only those indicators that allowed a complete reconstruction of the historical series were considered. These criteria led to the elaboration of 9 composite indicators (BES 2016 Report) (ISTAT 2016): Health, Education and training, Employment, Quality of work, Income, Minimum economic conditions, Social relations, Life Satisfaction, and Environment. For the application, this study focuses on the subjective well-being domain; however, we remark that the FDA approach can easily be extended to the other outcome domains.
The remainder of this paper is structured as follows. Section 2 proposes a brief overview of the theory of FDA. Section 3 presents an application to a real data set concerning the BES project. Finally, Sect. 4 presents the discussion and conclusions.
2 Theory of FDA
The theory and practice of statistical methods in situations where available data are functions (instead of real numbers or vectors) is often referred to as FDA (Cuevas 2014). This topic has become very popular during the last decades and is now a major research field in statistics (e.g. Gattone and Di Battista 2009; Aguilera and Aguilera-Morillo 2013; Escabias et al. 2014; Maturo et al. 2018a). Dealing with functional data had a significant impact on statistical thinking and methods, changing the way in which we represent, model and predict data (Shang 2013).
The basic idea of FDA is to deal directly with the function generating the data instead of the sequence of observations, and thus to treat observed data functions as single entities. In real applications, functional data are often observed as a sequence of point data, and thus the function denoted by \(y=f(x)\) reduces to record of discrete observations that are denoted by the T pairs \((x_{j}; y_{j})\) where \(x\in \mathfrak {R}\) and \(y_{j}\) are the values of the function computed at the points \(x_{j}\), \(j=1,2,\ldots , T\) (Ramsay et al. 2009).
The first step in FDA is to convert the values \(y_{i1}, y_{i2},\ldots , y_{iT}\) for each unit \(i=1,2,\ldots ,N\) to a functional form computable at any desired point \(x\in \mathfrak {R}\). Thus, a functional variable X is a random variable taking values in a functional space \(\xi\). Thus, a functional data set is a sample \(x_1\),..., \(x_N\) (also denoted \(x_1(t)\) ,..., \(x_N(t)\)) drawn from a functional variable X (Ferraty and Vieu 2006). Supposing that the functional data y(t) is observed via the model \(y(t_i)=x(t_i)+\varepsilon (t_i)\) where the residuals \(\varepsilon (t)\) are independent with x(t), we can get back the original signal x(t) using a linear smoother (Ramsay et al. 2009):
where \(s_{i}(t_j)\) is the weight that the point \(t_j\) gives to the point \(t_i\).
Recently research has underlined the several advantages of the FDA approach. The first one is obviously to obtain a functional expression for representing the phenomenon under study. Then, Ferraty and Vieu (2006) highlighted that often crucial information is included in the first and second derivatives rather than in the data themselves. Ramsay and Dalzell (1991) stressed that sometimes the aim of a study can be functional in nature, and some modeling problems are more natural to consider functionally, e.g. monitoring ecological population dynamics (Maturo and Di Battista 2018; Maturo 2018), climatic variation forecasting (Ramsay and Silverman 2005), the analysis of growth curve, medical research, and diversity assessment (Maturo et al. 2018b); moreover, FDA allows us assessing important additional sources of pattern and variation among data. Cuevas (2014) notes that in this framework, in contrast to time series analysis, we do not need that data are sampled at equally spaced time points; in addition, FDA provides the theoretical possibility of observing the phenomenon in a much finer grid and, in the limit, to observe x(t) at any fixed instant t. Finally, one of the best advantages is that many essential notions and theorems of classical statistics can be extended to the infinite-dimensional context of FDA (Ramsay and Silverman 2005; Cuevas 2014).
To estimate the functional datum, many approaches have been proposed in the literature. The most common criteria are the functional principal component decomposition (Cardot et al. 1999; Ramsay and Silverman 2005), basis function approach (Ramsay and Silverman 2005), and the kernel smoothing (Ferraty and Vieu 2006).
The functional principal component decomposition is considered by many scholars (e.g. Cardot et al. 1999; Ramsay and Silverman 2005; Ferraty and Vieu 2006; Aguilera et al. 2011; Febrero-Bande and de la Fuente 2012; Escabias et al. 2014). It allows us to display the functions by a linear combination of a small number of functional principal components (FPC). The functional data can be rewritten as a decomposition in an orthonormal basis by maximizing the variance of x(t):
where \(\nu _{ik}\) is the score of the generic FPC \(\xi _{k}\) for the generic function \(x_i\) (\(i=1,2,\ldots ,N\)).
Generally, the advantage of this approach is that it finds a lower-dimensional representation preserving the maximum amount of information from the original data. Hence, in this context, in the point cloud space, functional principal components analysis finds the direction vector with greatest population variation maximizing the variance of the data projected onto the vector. This direction is found by either an eigenvalue analysis of the covariance matrix, or by a singular value decomposition of the data matrix (Zhao et al. 2004).
Another common method for representing the functional data is the basis approximation. Ramsay and Silverman (2005) suggested that functions can be obtained using a finite representation in a fixed basis. If \(x(t)\in \mathcal {L}_2\),Footnote 1 a basis function system is a set of K known functions \(\phi _j(t)\), that are linearly independent (see Ramsay and Silverman 2005) of each other and can be extended to include any number K in the system. Thus, a function x(t) can be expressed by a linear combination of these basis functions:
where \(c_j\) is the vector of coefficients defining the linear combination and \(\phi _j(t)\) is the vector of basis functions. Hence, \(x(t)=\widehat{x}(t)+\varepsilon (t)\) and the observed residual series is given by \(\varepsilon _i(t)=x_i(t)-\widehat{x_i}(t)\). Thus, a standard measure of the quality of fit for a series can be expressed by \(s_i^2=\frac{1}{n-K}\sum _{j=1}^n \varepsilon _i(t_j)^2\) (Ramsay and Silverman 2005). In the literature, different types of basis functions have been proposed, e.g. b-splines that are sets of polynomials (of order m) defined in subintervals constructed in such a way that in the border of the subintervals the polynomials coincide (up to \(m-2\) derivative), Fourier basis that are useful to represent periodic functions, wavelets, and polynomials.
Starting from the representation of functions, many classical statistical concepts can be adapted to the FDA frameworkFootnote 2 (e.g. see Ramsay and Silverman 2005; Ferraty and Vieu 2006; Aguilera et al. 2011; Febrero-Bande and de la Fuente 2012; Escabias et al. 2014). Furthermore, in the literature, some studies have also proposed to exploit FDA for parametric models known in advance (e.g. Maturo et al. 2017; Di Battista et al. 2017) or to approximate them with the classical FDA approach, e.g. item response models (e.g. Fortuna and Maturo 2018) and Hill’s numbers (e.g. Maturo and Di Battista 2018).
This research focuses on the classical FDA approach, i.e. it starts from a sequence of observations of a subjective well-being indicator over time for reconstructing the functional model. Furthermore, the additional information of derivatives and FPCs will be shown with a double aim: First, they are themselves meaningful in explaining functions behaviour; and second, they can be implemented for computing proximity measures among functional observations (e.g. composite indicators of well-being of different regions).
In the context of FDA, different proximity measures can be adopted for clustering purposes. The most used distance is certainly the \(L_2\)-distance. Limiting our attention to the case of the \(L_2\)-space, a commonly used distance between functional elements is given by
where w is the weight and the observed point on each curve are equally spaced (Febrero-Bande and de la Fuente 2012).
However, many scholars (e.g. Ferraty and Vieu 2006) believe that Eq. 4 does not necessarily provide the most informative proximity measures between functional elements, and therefore considering other distances between curves could give better information. For this reason, several metric and semi-metric distances have been proposed in the literature. Particularly, because of their high informative power, semi-metric proximity measures based on derivatives are widely adopted. The distance between the r-order derivatives of two curves \(x_1(t)\) and \(x_2(t)\) can be expressed as follows
where \(x_1^{(r)}(t)\) and \(x_2^{(r)}(t)\) are the r-derivatives of \(x_1(t)\) and \(x_2(t)\), respectively. In this context, the distance among first and second derivatives is particularly interesting because they represent the velocity and acceleration in increasing and decreasing of the original functions, respectively.
Another widely used semi-metric proximity measure between curves is that based on functional principal components (Ramsay and Silverman 2005; Ferraty and Vieu 2006; Febrero-Bande and de la Fuente 2012). The basic idea is to exploit the functional principal components decomposition (see Eq. 2) for computing the distance between functional elements as follows:
where \(\nu _{i,p}\) are the coefficients of the expansion, and \(\xi _p\) is the p-th orthonormal eigenvector.
3 Application and Results
Section 3 illustrates an application of the FDA approach in the context of subjective well-being indicators. Specifically, starting from sequences of observations, we show how to obtain smoothed functions representing the subjective well-being of different Italian regions over time. Then, the first and second functional derivatives, and the functional principal component decomposition will be illustrated. Finally, using four different proximity measures (those illustrated in Sect. 2), we propose the functional hierarchical clustering for grouping Italian regions according to their similarity in subjective well-being over time.
This study proposes an application to a real dataset concerning the “subjective well-being” within the Italian “BES project” (see Sect. 1). The international debate “Beyond GDP” has stimulated a national initiative by CNEL and ISTAT for measuring the “Equitable and Sustainable Well-Being”. In summary, the BES 2016 Report (ISTAT 2016) makes available 9 composite indicators (see Sect. 1); however, in this context, we focus only on the domain titled “subjective well-being” but, obviously, the proposed approach can be also extended to other domains. The subjective well-being domain considered within the BES (OECD 2013) concerns the evaluations and perceptions expressed directly by individuals on their life in general, but also those referring to specific areas. Specifically, the subjective well-being domain is represented by two dimensions, i.e. the cognitive and affective. The former is the process with which an individual evaluates one’s life, in terms of satisfaction and retrospectively, according to certain personal standards as expectations, desires, and experiences. Contrary, the latter indicates the emotions that subjects have during their daily life; this is linked to the present whereas the cognitive component implies a reflection a-posteriori (OECD 2013). In summary, subjective indicators can help explain individual and collective behaviors and also to identify areas of discomfort of particular portions of society. Particularly, the aggregate indicator “subjective well-being” (SWB), which is available from 2010 to 2016, consists of the average of three components (four items as shown in Table 1): Satisfaction for one’s life, leisure time satisfaction, and opinion on future perspectives.
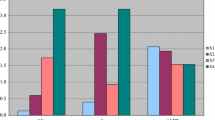
Respecting the original subdivision made by ISTAT, from here on this study presents generically Italian regions (keeping in mind that the autonomous provinces of Trento and Bolzano are considered as separate statistical units). Figures 1 and 2 illustrate the SWB of the Italian regions. Figure 1 is a simple interpolation of the seven observations over time whereas Fig. 2 displays the functional subjective well-being in its smoothed version computed using Eq. 3. The Campania region presents the lowest value over the whole time domain; instead, Trentino Alto-Adige, Bolzano, and Trento are characterized by better conditions.

Functional subjective well-being in the Italian regions

Smoothed functional subjective well-being in the Italian regions
Figure 3 displays the functional effect of being in specific regions, i.e. the centered smoothed functions. From 2011 to 2015, Campania, Basilicata, and Sicilia strongly decrease below the Italian average value. This trend seems to partially improve after the second half of 2014.

The functional effect of subjective well-being in the Italian regions
Figure 4 illustrates the first derivative of the functional subjective well-being of the Italian regions. This graph is particularly interesting for detecting the velocity in increasing or decreasing of the original functions, i.e. the velocity in changing conditions. From 2011 to 2012, all the first derivatives are negative, thus suggesting that all original functions are decreasing. Moreover, it is easy to observe that, from 2013 onwards, Trento is characterized by the fastest increase of subjective well-being whereas Basilicata is the most slow despite it is improving. The first derivatives emphasize that, after 2015, the subjective well-being improvement, in most regions, starts to considerably slow.

First derivatives of functional subjective well-being in the Italian regions
Figure 5 shows the second derivative of the functional subjective well-being of the Italian regions. This is an interesting instrument to capture the acceleration in improving or worsening the condition over time. In 2011, Trento has the strongest acceleration in increasing respect to the other Italian regions. However, this peak exhausts its effects in a couple of years. Regarding the recent period, most regions are decelerating, except Veneto.

Second derivatives of functional subjective well-being in the Italian regions
Figures 6 and 7 present the contour plot and the functional covariance surface, respectively. Note that Fig. 6 helps interpreting Fig. 7 (Ramsay et al. 2009). These graphs allows us detecting the association among functions over time. The pictures highlight that there is an increasing and progressive association from 2011 to 2016.

Contour plot of functional subjective well-being in the Italian regions

Functional covariance surface of subjective well-being in the Italian regions
Figure 8 illustrates the first three functional principal components (Eq. 2) and the bi-plot graphs. The first FPC explains 97.52% of the total variability; this is because the behaviour of the curves is quite similar. The first two FPCs mainly detect the last period whereas the third FPC better explains both first and last years. The bi-plots pictures allows us interpreting the association among regions and couples of FPCs, and looking for regions with different or similar patterns of subjective well-being according to the couples of FPCs.

Functional principal component decomposition of subjective well-being in the Italian regions. 1 = Piemonte, 2 = Valle d'Aosta, 3 = Liguria, 4 = Lombardia, 5 = Trentino-Alto Adige, 6 = Bolzano, 7 = Trento, 8 = Veneto, 9 = Friuli-Venezia Giulia, 10 = Emilia-Romagna, 11 = Toscana, 12 = Umbria, 13 = Marche, 14 = Lazio, 15 = Abruzzo, 16 = Molise, 17 = Campania, 18 = Puglia, 19 = Basilicata, 20 = Calabria, 21 = Sicilia, 22 = Sardegna
Figures 9, 10, 11, and 12 show the results of the functional hierarchical clustering for grouping Italian regions according the their subjective well-being evolution over time. The dendrograms are obtained using the average linkage method and adopting four different proximity measures (see Sect. 2). The optimal number of clusters has been selected using the R package “factoextra” and the “average silhouette method”. All the four different approaches led to the selection of two clusters.
Figure 9 is obtained using the \(L_2\)-distance among functions (Eq. 4) whereas Fig. 10 is computed using the semi-metric distance among FPCs (Eq. 6). We observe that these methods provide very similar results and the same clusters composition. The first cluster is composed of Valle d’Aosta, Trento, Trentino Alto Adige, and Bolzano. The second cluster is composed by the remaining regions; however, we underline that Campania is quite different from the other regions of the second grooup. This also confirms Figs. 2 and 3.

Hierarchical clustering of Italian regions according to the \(L_2\)-metric computed on their functional subjective well-being

Hierarchical clustering of Italian regions according to the FCPA semi-metric computed on their functional subjective well-being
Figure 11 is the result of the semi-metric distance among the first derivatives (Eq. 5 for \(r=1\)). We observe that the first group is composed of only Trento. The other regions are in the second group despite Molise appears to be very different within this group. Figure 12, which is obtained using the semi-metric distance among second derivatives (Eq. 5 for \(r=2\)), remarks this peculiar behaviour of Molise and Trento. However, in this case, group 1 is composed of Trento and Valle D’Aosta.

Hierarchical clustering of Italian regions according to the First derivative semi-metric computed on their functional subjective well-being

Hierarchical clustering of Italian regions according to the second derivative semi-metric computed on their functional subjective well-being
Figure 13 illustrates a comparison with the classical hierarchical clustering method. As we expected, the non-functional clustering results are similar to those obtained with the \(L_2\) distance and with the semi-metric of FPCA due to the low variability of the data. Nonetheless, it highlights some small differences within group 2, even if it does not lead to substantial changes in groups composition.

Classical non-functional hierarchical clustering of Italian regions (average linkage)
Figure 14 illustrates the results of the silhouette method to choose the optimal number of groups. This method has been implemented through the R factoextra package. In all cases, it can be stated that the optimal number of groups is two.

Silhouette method to select the optimal number of groups. a Distance \(L_2\); b semi-metric of FPC; c semi-metric of 1st derivative; d semi-metric of 2nd derivative; and e non-functional clustering approach
4 Discussion and Conclusions
In recent decades, subjective well-being and quality of life, in general, have attracted the attention of scholars and Institutions. The international debate “Beyond GDP” (OECD 2014) is a strong signal of the European Commission in this direction. The basic idea is that GDP is not an adequate social indicator able to reflect the real condition of a country, and thus, in recent decades, many studies have been carried out on this topic.
The theoretical debate on the possibility that happiness may or may not change is very lively, and interesting perspectives can be found in Headey and Wearing (1989); Lykken and Tellegen (1996); Sheldon and Lucas (2014a); Easterlin and Switek (2014). According to Sheldon and Lucas (2014a), it is possible to become permanently happier or sadder due to important life events; instead, following the set-point theory, happiness returns to the basic level in the long term (Lykken and Tellegen 1996). These controversial theoretical perspectives are accompanied by conflicting empirical results, and thus the research on well-being should pay attention both to theoretical and methodological aspects.
Indeed, from a quantitative perspective, two main issues regarding social indicators of quality of life are multidimensionality (e.g. see Fattore and Arcagni 2014; Fattore and Maggino 2017) and the need of proper tools for assessing trends and changes over time rather than observing indices in single instants (e.g. see Maggino and Facioni 2015). For this reason, also in the fields of mathematics and statistics, this topic has attracted the attention of many researchers and several indicators have been proposed for assessing people’s perceptions of subjective well-being.
This study focuses on the latter problem and thus proposes the use of functional data analysis for building new social indicators of subjective well-being and helping to interpret them. This proposal is strictly connected to the perspectives illustrated in the book of Sheldon and Lucas (2014b), because we consider that, if happiness may change, derivatives and functional tools, in general, could certainly be very useful and sensitive to detect changes in well-being. In the FDA framework, it is assumed that the measurements over time are temporally ordered samples of an underlying continuous function; thus, because repeated measures of a well-being indicator can be considered as functions in the time domain and FDA considers each continuous function as the atom of the analyses, this research suggests FDA as an additional tool to get interesting insights about the dynamic of subjective well-being.
Hence, this paper proposes to assess “subjective well-being” of Italian regions via some interesting tools of functional data analysis, e.g. derivatives, FPCA, and hierarchical clustering. Our analysis shows that the derivatives are useful additional instruments for highlighting specific behaviours of well-being indicators over time. Indeed, the plots of the velocity and acceleration of the amount of change in subjective well-being provide an immediate picture of what is happening at the local level because they are more sensitive to small changes than both the original time observations and the smoothed starting functions themselves. Furthermore, the derivatives provide an additional tool on which to calculate a semi-metric to identify groups of regions with similar behaviour based on a piece of specific information (different from that one limited to the starting time observations). Moreover, this approach allows us considering the phenomenon in a much finer grid and observing it at any fixed time instants.
Our clustering results detect the presence of two different groups according to the subjective well-being shapes over time. According to the \(L_2\)-distance and the semi-metric based on the FPCs, we found a clear separation between a group with high subjective well-being, which is composed of Valle d’Aosta, Trento, Trentino Alto Adige, and Bolzano, and a second group composed by the other regions with lower perceptions of subjective well-being. Particularly, very low values are present in Campania, Lazio, Basilicata, Puglia, and Sicilia. Those results are similar to those obtained with the classical hierarchical clustering (see Figs. 9, 10, 13), as we expected. In truth, in any functional study, when the variability of the data is quite low and the time domain is short, it happens that the classical clustering provides the same results of the functional clustering using the \(L_2\) distance. Hence, we observe that the composition of the groups is the same; nevertheless, we highlight that the classical clustering methods (Fig. 13) almost identifies the presence of a third group formed by Molise, Lazio, Basilicata, Puglia, and Sicily. On the contrary, the functional clustering results (Figs. 9 and 10) do not underline this slight difference because the smoothing approach tends to attenuate small intertemporal differences. In summary, the three approaches confirm that group 1 is made up of the happiest regions, i.e. Valle d’Aosta, Trento, Trentino Alto Adige, and Bolzano.
Therefore, the real additional value of this research can be mainly found in the decomposition into functional principal components and in the results of the derivative-based clustering of the subjective well-being over time. Regarding the decomposition into FPCs, it is very interesting to observe the biplot charts (see Fig. 8) because they reveal those regions that have similar/different trends of subjective well-being over time. This type of analysis has the strong advantage that, as it is based on the decomposition in FPCs, it takes little account of the small intertemporal variations of subjective well-being. For example, observing the biplot graph between the first two FPCs, we can observe that Bolzano (number 6) and Lazio (number 14) have very different trends (distant numbers), or conversely Valle D’Aosta (number 2) and Liguria (number 3) are very similar (close numbers). One advantage of the FDA approach is that the same kind of considerations are very difficult to do in the case of scalar values.
Concerning the derivative-based clustering, we observe very different results if compared with the classical clustering approach. The clustering based on the semi-metric of the first derivative leads to group those regions that have a similar behaviour of the rate of change of subjective well-being over time (velocity). On the contrary, the clustering based on the second derivative provides homogeneous groups with respect to the acceleration of the subjective well-being over time in the Italian regions. Therefore, the meaning is very different from what can be achieved with a classic approach, the \(L_2\) distance, and the semi-metric based on the FPCs. In fact, because the meaning is different, it makes little sense to compare the results as they simply bring additional information.
The clustering based on the first derivative shows that Trento has a behaviour that is totally atypical with respect to the other regions. This is due to the fact that Trento has observed a strong rate of growth of subjective well-being in the period between 2011–2015 (see Fig. 4) but has a deceleration in recent years. Instead, all the other regions have a much more homogeneous behaviour unlike Trento, and they continue to increase their subjective well-being at the same speed as in previous years. Moreover, most of the regions have started their rapid growth process since 2012. All these considerations make Trento to be a single group (Fig. 11).
With reference to the clustering based on the semi-metric of the second derivative, we can observe that Trento and Valle d’Aosta form a separate group (Fig. 12). This circumstance is due to the fact that both these regions have a peculiar behaviour of the acceleration and deceleration of the growth of the perceived subjective well-being over time (see Fig. 5). In fact, both regions have a very strong growth acceleration of subjective well-being in the period 2011–2012 and they suffer a reduction of this acceleration in the following years, unlike the other Italian regions. The findings regarding Trento, i.e. the increase and the decrease of the second derivative, are consistent and interesting in light of the theoretical perspectives that consider that even if happiness may increase, in the long-term it could return to the base level (e.g. see Sheldon and Lucas 2014a).
We highlight that FDA makes these considerations possible and adds interesting insights that may be interpreted by social scientists to understand the determinants of these trends. Hence, the main purpose of this study is to sensitize scholars to the use of additional tools based on functional data analysis for the study of social problems related to well-being. In truth, the attention for the quality of life today is not just for scientists but also for politicians and policymakers. The use of functional tools such as the derivatives and cluster can be a handy tool to verify and monitor perceived well-being at regional or national levels and thus to plan short-term or long-term economic and social policies. Furthermore, using the proposed approach, we can exemplify uneven local development and its evolution, that would not be captured by classical methods, e.g. dynamic regression models. Therefore, future studies could focus on the use of functional regression models to help policymakers identify the antecedents of different trends using the derivatives as possible outcomes.
We stress that this research proposes only a possible application of FDA for improving the study of subjective well-being but this approach can easily be extended to other well-being indicators; however, future developments of this line of research could focus on both multidimensionality and FDA, i.e. Multidimensional Functional Data Analysis. Moreover, we have shown how to build additional tools for evaluating subjective well-being in a functional framework, but this approach may be extended to each social indicator regarding the “Equitable and Sustainable Well-Being”.
Notes
Focusing on the case of an Hilbert space with a metric \(d(\cdot ,\cdot )\) associated with a norm so that \(d(x_1(t), x_2 (t)) = \Vert x_1(t) - x_2(t)\Vert\), and where the norm \(\Vert \cdot \Vert\) is associated with an inner product \(\langle \cdot ,\cdot \rangle\) so that \(\Vert x(t)\Vert =\langle x(t),x(t) \rangle ^{1/2}\), we can obtain as specific case the space \(L_2[a,b]\) of real square-integrable functions defined on [a, b] by \(\langle x_1(t),x_2(t) \rangle =\int _{a}^{b} x_1(t)x_2(t)dt\).
Some examples of classical statistical concepts adapted to the FDA framework are: the functional mean \(\overline{x}(t)=\frac{1}{N}\sum _{i=1}^N x_i(t)\), functional variance \(\sigma ^2_x(t)=\frac{1}{N}\sum _{i=1}^N\Bigl (\widehat{x}_i(t)-\overline{x}(t)\Bigr )^2\), functional covariance \(\sigma (s,t)=cov\Bigl (x(s),x(t)\Bigr )=\frac{1}{n}\sum _{i=1}^n \Bigl (x_i(s)-\overline{x}(s)\Bigr )\Bigl (x_i(t)-\overline{x}(t)\Bigr )\), and functional correlation \(\rho (s,t)=\frac{\sigma (s,t)}{\sqrt{\sigma (s,s)}\sqrt{(\sigma (t,t)}}\).
References
Aguilera, A., & Aguilera-Morillo, M. (2013). Penalized PCA approaches for b-spline expansions of smooth functional data. Applied Mathematics and Computation, 219, 7805–7819. https://doi.org/10.1016/j.amc.2013.02.009.
Aguilera, A., Aguilera-Morillo, M.C., Escabias, M., & Valderrama, M. (2011). Penalized spline approaches for functional principal component logit regression. In F. Ferraty (Ed.), Contributions to statistics (pp. 1–7). Heidelberg: Physica-Verlag. https://doi.org/10.1007/978-3-7908-2736-1_1.
Alkire, S. (2015). Capability approach and well-being measurement for public policy. OPHI working paper 94.
Andrews, F. M. (1983). Population issues and social indicators of well-being. Population and Environment, 6, 210–230. https://doi.org/10.1007/bf01363887.
Andrews, F. M., & Withey, S. B. (1976). Social indicators of well-being. New York: Springer. https://doi.org/10.1007/978-1-4684-2253-5.
Betti, G. (2016). Fuzzy measures of quality of life: A multidimensional and comparative approach. International Journal of Uncertainty, Fuzziness and Knowledge-Based Systems, 24, 25–37. https://doi.org/10.1142/s021848851640002x.
Betti, G., Cheli, B., Lemmi, A., & Verma, V. (2006). Multidimensional and longitudinal poverty: An integrated fuzzy approach. In A. Lemmi & G. Betti (Eds.), Fuzzy set approach to multidimensional poverty measurement (pp. 115–137). New York: Springer. https://doi.org/10.1007/978-0-387-34251-1_7.
Biswas-Diener, R., Diener, E., & Tamir, M. (2004). The psychology of subjective well-being. Daedalus, 133, 18–25. https://doi.org/10.1162/001152604323049352.
Boccuzzo, G., & Caperna, G. (2017). Evaluation of life satisfaction in Italy: Proposal of a synthetic measure based on poset theory. In F. Maggino (Ed.), Complexity in society: From indicators construction to their synthesis (pp. 291–321). Cham: Springer. https://doi.org/10.1007/978-3-319-60595-1_12.
Boelhouwer, J., & Bijl, R. (2015). Long-term trends in quality of life: An introduction. Social Indicators Research, 130, 1–8. https://doi.org/10.1007/s11205-015-1132-1.
Callens, M. (2015). Long term trends in life satisfaction, 1973–2012: Flanders in Europe. Social Indicators Research, 130, 107–127. https://doi.org/10.1007/s11205-015-1134-z.
Cardot, H., Ferraty, F., & Sarda, P. (1999). Functional linear model. Statistics & Probability Letters, 45, 11–22. https://doi.org/10.1016/s0167-7152(99)00036-x.
Cuevas, A. (2014). A partial overview of the theory of statistics with functional data. Journal of Statistical Planning and Inference, 147, 1–23. https://doi.org/10.1016/j.jspi.2013.04.002.
Cummins, R. A. (2018). Subjective wellbeing as a social indicator. Social Indicators Research,. https://doi.org/10.1007/s11205-016-1496-x.
Cutler, D. M. (2009). Measuring national well-being. In A. B. Krueger (Ed.), Measuring the subjective well-being of nations (pp. 107–112). Chicago: University of Chicago Press. https://doi.org/10.7208/chicago/9780226454573.003.0004.
Davino, C., Dolce, P., Taralli, S., & Vinzi, V. E. (2016). A quantile composite-indicator approach for the measurement of equitable and sustainable well-being: A case study of the italian provinces. Social Indicators Research,. https://doi.org/10.1007/s11205-016-1453-8.
Di Battista, T., Fortuna, F., & Maturo, F. (2017). BioFTF: An R package for biodiversity assessment with the functional data analysis approach. Ecological Indicators, 73, 726–732. https://doi.org/10.1016/j.ecolind.2016.10.032.
di Bella, E., Corsi, M., Leporatti, L., & Cavalletti, B. (2016). Wellbeing and sustainable development: A multi-indicator approach. Agriculture and Agricultural Science Procedia, 8, 784–791. https://doi.org/10.1016/j.aaspro.2016.02.068.
Di Spalatro, D., Maturo, F., & Sicuro, L. (2017). Inequalities in the provinces of Abruzzo: A comparative study through the indices of deprivation and principal component analysis (pp. 219–231). Cham: Springer. https://doi.org/10.1007/978-3-319-54819-7_15.
Diener, E. (Ed.) (2009). Conclusion: Future directions in measuring well-being. In Assessing well-being (pp. 267–274). Netherlands: Springer. https://doi.org/10.1007/978-90-481-2354-4_13.
Diener, E., Diener, M., & Diener, C. (1995). Factors predicting the subjective well-being of nations. Journal of Personality and Social Psychology, 69, 851–864. https://doi.org/10.1037/0022-3514.69.5.851.
Easterlin, R. A., & Switek, M. (2014). Set point theory and public policy. In K. Sheldon & R. E. Lucas (Ed.), Stability of happiness (pp. 201–217). Amsterdam: Elsevier.
Escabias, M., Aguilera, A. M., & Aguilera-Morillo, M. C. (2014). Functional PCA and base-line logit models. Journal of Classification, 31, 296–324. https://doi.org/10.1007/s00357-014-9162-y.
Fattore, M. (2015). Partially ordered sets and the measurement of multidimensional ordinal deprivation. Social Indicators Research, 128, 835–858. https://doi.org/10.1007/s11205-015-1059-6.
Fattore, M., & Arcagni, A. (2014). PARSEC: An R package for poset-based evaluation of multidimensional poverty. In R. Brüggemann, L. Carlsen & J. Wittmann (Eds.), Multi-indicator systems and modelling in partial order (pp. 317–330). New York: Springer. https://doi.org/10.1007/978-1-4614-8223-9_15.
Fattore, M., & Arcagni, A. (2016). A reduced posetic approach to the measurement of multidimensional ordinal deprivation. Social Indicators Research, 136, 1053–1070. https://doi.org/10.1007/s11205-016-1501-4.
Fattore, M., & Maggino, F. (2017). Some considerations on well-being evaluation procedures, taking the cue from “exploring multidimensional well-being in switzerland: Comparing three synthesizing approaches”. Social Indicators Research,. https://doi.org/10.1007/s11205-017-1634-0.
Fattore, M., Maggino, F., & Arcagni, A. (2016). Non-aggregative assessment of subjective well-being. In G. Alleva & A. Giommi (Eds.), Topics in theoretical and applied statistics (pp. 227–237). Cham: Springer. https://doi.org/10.1007/978-3-319-27274-0_20.
Febrero-Bande, M., & de la Fuente, M. (2012). Statistical computing in functional data analysis: The R package fda.usc. Journal of Statistical Software, 51, 1–28. https://doi.org/10.18637/jss.v051.i04.
Felice, E. (2017). The roots of a dual equilibrium: GDP, productivity and structural change in the italian regions in the long-run (1871–2011). SSRN Electronic Journal,. https://doi.org/10.2139/ssrn.3082184.
Ferraty, F. (2011). Recent advances in functional data analysis and related topics. Heidelberg: Physica-Verlag. https://doi.org/10.1007/978-3-7908-2736-1.
Ferraty, F., & Vieu, P. (2003). Curves discrimination: A nonparametric functional approach. Computational Statistics & Data Analysis, 44, 161–173. https://doi.org/10.1016/s0167-9473(03)00032-x.
Ferraty, F., & Vieu, P. (2006). Nonparametric functional data analysis. New York: Springer. https://doi.org/10.1007/0-387-36620-2.
Fortuna, F., & Maturo, F. (2018). K-means clustering item characteristic curves and item information curves via functional principal component analysis. Quality & Quantity,. https://doi.org/10.1007/s11135-018-0724-7.
Gattone, S., & Di Battista, T. (2009). A functional approach to diversity profiles. Journal of the Royal Statistical Society: Series C (Applied Statistics), 58, 267–284. https://doi.org/10.1111/j.1467-9876.2009.00646.x.
Headey, B., & Wearing, A. (1989). Personality, life events, and subjective well-being: Toward a dynamic equilibrium model. Journal of Personality and Social Psychology, 57, 731–739. https://doi.org/10.1037/0022-3514.57.4.731.
Iglesias, K., Suter, C., Beycan, T., & Vani, B. P. (2016). Exploring multidimensional well-being in switzerland: Comparing three synthesizing approaches. Social Indicators Research, 134, 847–875. https://doi.org/10.1007/s11205-016-1452-9.
ISTAT. (2016). Rapporto bes 2016: il benessere equo e sostenibile in italia. https://www.istat.it/it/files/2016/12/BES-2016.pdf.
Kuentz-Simonet, V., Labenne, A., & Rambonilaza, T. (2016). Using ClustOfVar to construct quality of life indicators for vulnerability assessment municipality trajectories in southwest france from 1999 to 2009. Social Indicators Research, 131, 973–997. https://doi.org/10.1007/s11205-016-1288-3.
Lee, S.J. & Kim, Y. (2016). Structure of well-being: An exploratory study of the distinction between individual well-being and community well-being and the importance of intersubjective community well-being. In Y. Kee, S. J. Lee & R. Phillips (Eds.), Social factors and community well-being (pp. 13–37). Cham: Springer. https://doi.org/10.1007/978-3-319-29942-6_2.
Lykken, D., & Tellegen, A. (1996). Happiness is a stochastic phenomenon. Psychological Science, 7, 186–189. https://doi.org/10.1111/j.1467-9280.1996.tb00355.x.
Maggino, F. (2014). Multi-indicator measures. In Encyclopedia of quality of life and well-being research (pp. 4193–4194). Netherlands: Springer. https://doi.org/10.1007/978-94-007-0753-5_1876.
Maggino, F., & Facioni, C. (2015). Measuring stability and change: Methodological issues in quality of life studies. Social Indicators Research, 130, 161–187. https://doi.org/10.1007/s11205-015-1129-9.
Maria, K. (2009). The effects of maternal deprivation on behavioural, neurochemical and neurobiological indices related to dopaminergic activity. Frontiers in Behavioral Neuroscience,. https://doi.org/10.3389/conf.neuro.08.2009.09.275.
Maturo, F. (2018). Unsupervised classification of ecological communities ranked according to their biodiversity patterns via a functional principal component decomposition of Hill’s numbers integral functions. Ecological Indicators, 90, 305–315. https://doi.org/10.1016/j.ecolind.2018.03.013.
Maturo, F., & Di Battista, T. (2018). A functional approach to hill’s numbers for assessing changes in species variety of ecological communities over time. Ecological Indicators, 84, 70–81. https://doi.org/10.1016/j.ecolind.2017.08.016.
Maturo, F., Fortuna, F., & Di Battista, T. (2018a). Testing equality of functions across multiple experimental conditions for different ability levels in the IRT context: The case of the IPRASE TLT 2016 survey. Social Indicators Research,. https://doi.org/10.1007/s11205-018-1893-4.
Maturo, F., Migliori, S., & Paolone, F. (2017). Do institutional or foreign shareholders influence national board diversity? Assessing board diversity through functional data analysis. In Š. Hošková-Mayerová, F. Maturo & J. Kacprzyk (Eds.), Mathematical-statistical models and qualitative theories for economic and social sciences, (pp. 199–217). Cham: Springer. https://doi.org/10.1007/978-3-319-54819-7_14.
Maturo, F., Migliori, S., & Paolone, F. (2018b). Measuring and monitoring diversity in organizations through functional instruments with an application to ethnic workforce diversity of the U.S. Federal agencies. Computational and Mathematical Organization Theory,. https://doi.org/10.1007/s10588-018-9267-7.
Mauro, V., Biggeri, M., & Maggino, F. (2016). Measuring and monitoring poverty and well-being: A new approach for the synthesis of multidimensionality. Social Indicators Research, 135, 75–89. https://doi.org/10.1007/s11205-016-1484-1.
Michalos, A. (2008). Education, happiness and wellbeing. Social Indicators Research: An International and Interdisciplinary Journal for Quality-of-Life Measurement, 87, 347–366.
Mushongera, D., Zikhali, P., & Ngwenya, P. (2015). A multidimensional poverty index for gauteng province, South Africa: Evidence from quality of life survey data. Social Indicators Research, 130, 277–303. https://doi.org/10.1007/s11205-015-1176-2.
OECD. (2011). How's Life?: Measuring Well-being. Paris: OECD Publishing. https://doi.org/10.1787/9789264121164-en.
OECD. (2013). OECD guidelines on measuring subjective well-being. Measuring subjective well-being (pp. 139–178). https://doi.org/10.1787/9789264191655-7-en.
OECD. (2014). GDP as a welfare metric: The beyond GDP agenda. https://doi.org/10.1787/9789264214637-16-en.
Otoiu, A., Titan, E., & Dumitrescu, R. (2014). Are the variables used in building composite indicators of well-being relevant? Validating composite indexes of well-being. Ecological Indicators, 46, 575–585. https://doi.org/10.1016/j.ecolind.2014.07.019.
Ramsay, J., & Dalzell, C. (1991). Some tools for functional data analysis. Journal of the Royal Statistical Society: Series B (Methodological), 53, 539–561.
Ramsay, J., Hooker, G., & Graves, S. (Eds.) (2009). Introduction to functional data analysis. In Functional data analysis with R and MATLAB (pp. 1–19). New York: Springer. https://doi.org/10.1007/978-0-387-98185-7_1.
Ramsay, J., & Silverman, B. (2005). Functional data analysis (2nd ed.). New York: Springer.
Ramsay, J. O., & Silverman, B. W. (Eds.). (2002). Applied functional data analysis: Methods and case studies. New York: Springer. https://doi.org/10.1007/b98886.
Rogge, N., & Van Nijverseel, I. (2018). Quality of life in the european union: A multidimensional analysis. Social Indicators Research,. https://doi.org/10.1007/s11205-018-1854-y.
Rojas, M. (2018). Indicators of people’s well-being. Social Indicators Research,. https://doi.org/10.1007/s11205-016-1507-y.
Rosa, P. D., Nicolau, B., Brodeur, J. M., Benigeri, M., Bedos, C., & Rousseau, M. C. (2010). Associations between school deprivation indices and oral health status. Community Dentistry and Oral Epidemiology, 39, 213–220. https://doi.org/10.1111/j.1600-0528.2010.00592.x.
Sen, A. (1979). Utilitarianism and welfarism. The Journal of Philosophy, 76, 463–489.
Sen, A. (1980). Equality of what?. Cambridge: Cambridge University Press. Reprinted in John Rawls et al., Liberty, equality and law (Cambridge: Cambridge University Press, 1987).
Shang, H. (2013). A survey of functional principal component analysis. AStA Advances in Statistical Analysis, 98, 121–142. https://doi.org/10.1007/s10182-013-0213-1.
Sheldon, K. M., & Lucas, R. E. (2014a). Is it possible to become a permanently happier person?. In K. Sheldon & R. E. Lucas (Eds.), Stability of happiness (pp. 1–7). Elsevier. https://doi.org/10.1016/b978-0-12-411478-4.00001-1.
Sheldon, K. M., & Lucas, R. E. (2014b). Preface. In K. Sheldon & R. E. Lucas (Eds.), Stability of happiness (pp. xv–xvi). Elsevier. https://doi.org/10.1016/b978-0-12-411478-4.00018-7.
Stiglitz, J. E., Sen, A. K., & Fitoussi, J. P. (2009). Report by the commission on the measurement of economic performance and social progress. Technical report.
Suter, C., & Iglesias, K. (2005). Relative deprivation and well-being: Switzerland in a comparative perspective. In H. Kriesi, P. Farago, M. Kohli & M. Zarin-Nejadan (Eds.), Contemporary Switzerland (pp. 9–37). UK: Palgrave Macmillan. https://doi.org/10.1057/9780230523586_2.
Veenhoven, R. (2007). Subjective measures of well-being. In M. McGillivray (Ed.), Human well-being (pp. 214–239). UK: Palgrave Macmillan. https://doi.org/10.1057/9780230625600_9.
Zhao, X., Marron, J., & Wells, M. (2004). The functional data analysis view of longitudinal data. Statistica Sinica, 14, 789–808.
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Maturo, F., Balzanella, A. & Di Battista, T. Building Statistical Indicators of Equitable and Sustainable Well-Being in a Functional Framework. Soc Indic Res 146, 449–471 (2019). https://doi.org/10.1007/s11205-019-02137-5
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11205-019-02137-5