
Abstract
H-Index is a widely used metric for measuring scientific output. In this paper we showcase the weakness of this index as regards co-authorship. By ignoring the number of co-authors, each author gets the full credit of a joint work, something that is not fair for evaluation purposes. For this purpose we report the results of simulation scenarios that demonstrate the impact that co-authorship can have. To tackle this weakness, and achieve a more fair evaluation, we propose a few simple variations of H-index that consider the number of co-authors, as well as the active time period of a researcher. In particular we propose using HI/co and HI/(coy), two metrics that are simple to understand and compute, and thus they are convenient for decision making. The simulation shows that they can tackle well co-authorship. Subsequently we report measurements over real data of researchers coming from five universities (Cambridge, Crete, Harvard, Oxford and Ziauddin), as well as other datasets, that reveal big variations in the average number of co-authors. In total, we analyzed 526 authors, having in total more than 127 thousands publications, and 16.7 million citations. These measurements revealed big variations of the number of co-authors. Consequently, by including the number of co-authors in the measures for scientific output (e.g. through the proposed HI/co) we get rankings that differ significantly from the rankings obtained by citations, or by the plain H-Index. The normalized Kendall’s tau distance of these rankings ranged from 0.28 to 0.46, which is quite high.
Similar content being viewed by others
Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
Introduction
H-Index (Hirsch, 2005) is a widely used bibliographic metric. It is a single positive integer that aims at considering both the quantity (number of publications), and quality (number of citations). It is heavily used in hiring, promotion, funding, and recognitions. However, a serious limitation of that metric is that it ignores the co-authors of the papers. By ignoring the number of co-authors, each author gets the full credit of a joint work, something that is unfair for evaluation purposes. Indeed, if F in number persons decide to jointly work and write a paper, then (a) they can create a better paper in the sense that more work can be dedicated to the paper (and thus it can have higher changes for acceptance), and (b) in case of acceptance this paper and its citations (and consequently its contribution to H-Index) will be added to the list of publications and citations of each of the F persons. In addition, quite likely this paper will get more citations not only through self-citations but also by citations from the network of the authors. Overall, and quite paradoxically, each of the F co-authors will get the full credit of that paper!
In this paper we showcase this weakness through simulations. Then we propose, and experimentally compare through simulation, a few simple variations of H-index that can tackle this weakness and lead to more fair evaluations. Apart from considering the number of co-authors, we include variations that include the time dimension (a quite overlooked one) since the active time period of a researcher does not only affect his cumulative scientific output (number of publications), but it also affects his citations. A rising question is how much co-authorship varies today. In order to answer this question we collect, extract and process the bibliographic data of the top-researchers (with respect to citations) of five universities (Cambridge, Crete, Harvard, Oxford and Ziauddin). In addition, and to avoid analyzing only top-researchers, we analyzed roughly all active researchers of two universities (University of Crete and University of Ziauddin), we analyzed the researchers of the schools of one university, all faculty members of a single department, as well as a list of famous scientists of the past. These measurements revealed big variations of the number of co-authors. Consequently, by including the number of co-authors in the measures for scientific output (e.g. through the proposed HI/co) we get rankings that differ significantly from the rankings obtained by citations, or by the plain H-Index. We quantify the differences in the obtained rankings using the normalized Kendall’s tau distance. The distance values that we get are in most cases bigger than 0.3, meaning that 30% of the relative rankings are different if we consider the number of co-authors, something that is quite high.
The rest of this paper is organized as follows. Section 2 describes the background, i.e. H-Index, for short HI, Sect. 3 describes simulation scenarios that showcase the problems of HI. Section 4 introduces alternative metrics for tackling the problems of HI. Section 5 evaluates the behaviour of these metrics over the simulation scenarios. Section 6 reports results over researchers coming from five universities, as well over a list of famous researchers of the past. Finally, Sect. 7 summarizes and concludes the paper.
Background
The H-index
H-Index was proposed by Hirsch in 2005 (Hirsch, 2005). Let A be the set of authors, P be the set of papers, and for an author \(a \in A\), let papers(a) be the set of papers, where a occurs as author. For a paper \(p \in P\), let cits(p) be the number of papers that cite p. The H-index of an author a, let’s denote it by HI(a), is the maximum integer value K such that there are K papers of a each having at least K citations, i.e. \(HI(a) = \max _K (| \{ p \in papers(a) ~|~ cits(p) \ge K \}| = K)\).
Related work
Several subsequent works are related to H-Index. Just indicatively, Malesios and Psarakis (2014) compares the H-index for different fields of research, Guns and Rousseau (2009) elaborates on the growth of the H-index, through simulations (however it does not focus on co-authorship), the robustness of H-Index to self-citations is described in Engqvist and Frommen (2008), while Bartneck and Kokkelmans (2011) focuses on H-index manipulation through self-citation.
As regards the importance of H-index in academy, Zaorsky et al. (2020) reported increasing H-index with consecutive academic rank throughout all medical fields. Analogously, Shanmugasundaram et al. (2023) evaluates the association of H-index with academic ranking in the interventional radiology community, and found that H-index correlates significantly with faculty position.
In general, the pros and cons of H-Index have been described extensively in the literature, e.g. in Bornmann and Daniel (2007). Several metrics have been proposed as alternatives of H-Index, e.g. Egghe et al. (2006) proposed the g-index (and various extensions of that index have been proposed, e.g. in Meštrović and Dragovic (2023)). The paper (Bi, 2022) also favors the ”fractional H-index”, proposed in Egghe (2008), that considers the number of authors, i.e. it gives to an author of an m-authored paper only a credit of c/m if the paper received c citations. The paper (Hirsch, 2010) proposes an alternative metric, \({\bar{h}}\), in order to quantify an individual’s scientific research output that takes into account the effect of multiple co-authorship, however that metric, as noted also in Bihari et al. (2023) is harder to calculate (it requires co-authors’ H-index), it penalises articles published with collaborative efforts, and may decrease after some time. Some interesting findings about the number and order of authors, as well as discipline-specific measurements over time, are given in Fire and Guestrin (2019). A recent, and quite detailed, review of H-index and its alternative indices is available at Bihari et al. (2023).
Of course, quantitative metrics is not a panacea, they do have weak points and limitations, e.g. as described in Fire and Guestrin (2019). That work analyzes the trends in current academic publishing and also mentions the issue of longer author lists, shorter papers, and surging publication numbers. However, as stated in Ioannidis and Maniadis (2023), the uncritical dismissal of quantitative metrics may aggravate injustices and inequities, especially in nonmeritocratic environments; quantitative metrics could help improve research practices if they are rigorous, field-adjusted, and centralized (Ioannidis & Maniadis, 2023).
Despite the aforementioned efforts and proposals, the number of citations and the H-index, remain to be the dominant methods which are used for the evaluation of research impact, and this is also evidenced by the default ranking that it is provided by the various bibliographic sources (e.g. Google Scholar). Indeed, two important merits of a metric, that affect its adoption, are simplicity and easy computation, in the sense that a community is hard to trust a metric that is not clear to all, or a metric that is difficult to compute.
In the current paper we focus on co-authorship. We demonstrate with simulations the importance of the problem, i.e. how co-authorship can affect the H-index, To investigate to what extend co-authorship varies in real data, we perform measurement over the researchers of five different universities. In comparison to Egghe (2008) and Bi (2022), Egghe (2008) elaborates on the mathematical lower and upper bounds of two versions of the fractional H-index and g-index. That work does not show the effect of co-authorship, and it does not report measurements. Also Bi (2022) favors fractional indexes, however it reports very few measurements (over 12 Nobel laureates).
Novelty To the best of our knowledge, this paper is the first that showcases the impact of co-authorship through simulations, and reports the ranges of co-authorship encountered today. In particular, the measurements (over more than 127 thousand publications) revealed big variations of the number of co-authors, and big variations of the rankings obtained if we consider the number of co-authors (The normalized Kendall’s tau distance of these rankings ranged from 0.28 to 0.46).
Simulation scenarios
Suppose that each researcher can dedicate a fixed amount of effort per year, corresponding to the effort required for writing E in number papers. Let assume a modest value for E, e.g. \(E=3\). Now consider the following publication “policies" that a researcher can follow:
-
\(R_{solo}\): Here our researcher writes papers alone (and probably with one or two students).
-
\(R_{fK}\): Here our researcher has K friends, and whenever he writes a paper he adds his K friend researchers to the list of authors. His friends behave the same, i.e. they also add our researcher in the papers that they write. For example, \(R_{f2}\) means that our researcher has two friends, \(R_{f3}\) means that our researcher has three friends, and so on.
Number of publications It follows that each year \(R_{solo}\) appears as author of E papers, while \(R_{fF}\) (i.e. if the number of friends is F) appears as author in \(E(1+F)\) papers. In Table 1, we can see the cumulative publications per year (\(Y=1,\ldots ,10\)), assuming \(E=3\), for \(R_{solo}\) and \(R_{fF}\) for \(F=\{1,3,5\}\). Recall that each of these 4 researchers has dedicated exactly the same amount of effort. The first, \(R_{solo}\), in 10 years appears in 30 papers, while \(R_{f5}\) appears in 180 papers! In an ideal evaluation system they should get the same score.
Citations Suppose that every year a paper p receives Cext external citations (not self citations), and Cself self-citations by each of the authors. Therefore we can assume that the total citations of a paper p of a researcher \(R_{fF}\), after Y years is given by \(citations(p,Y,R_{fF}) = (Y-1)*(Cext + (F+1)*Cself)\). In Table 2 we can see the citations of a paper assuming Cext = 2 and Cself = 1, for \(R_{solo}, R_{f1}, R_{f3}\) and \(R_{f5}\). Notice the difference between 27 and 72. The first is the number of citations of a paper written by \(R_{solo}\) after 10 years, while the second is the number of citations of a paper written by \(R_{f5}\) after 10 years.
Let us now compute the total citations of our researchers. We can compute them using the algorithm shown in Alg. 1. In that algorithm we use PpYear for the factor E.

Computation of citations
This gives the numbers shown in Table 3. Notice, that even if these researchers have dedicated the same effort the last 10 years, \(R_{solo}\) has in total 270 citations while \(R_{f5}\) has 5670 citations! The difference is tremendous. However, we should note that the simulation is not very precise in the sense that we have not considered any limit to the number of references than a paper can have. However, some conferences/journals do not impose any limit to the number of references.
H-index In order to compute the H-Index, for short HI, of our researchers, we first compute the citations of each of their papers (i.e. for each year we compute the citations to the publications published the previous years), and then we apply the formula given in §2.1. The results are shown in Table 3. Notice that \(R_{solo}\) has HI 12, while \(R_{f5}\) has HI 49. Again, the difference is tremendous.
Synopsis In brief, we have seen very big differences in the number of publications, number of citations and HI when F is greater than one.
Towards more fair measures
Here we introduce and comparatively evaluate measures that can tackle the aforementioned weakness of HI. In particular we will comparatively evaluate the following measures:
-
1.
HI as defined before, i.e. \(HI(a) = \max _K (| \{ p \in papers(a) ~|~ cits(p) \ge K \}| = K)\).
-
2.
HI/co: We compute the HI as before, and we divide it by the average number of co-authors, i.e. \(HI/co(a) = HI(a)/avgCoAuthors\), where \(avgCoAuthors = avg \{ ~authors(p) ~|~ p \in papers(a) \}\) This means that in the simulation scenarios of §3 we divide the HI by \(F+1\).
-
3.
HIdivCit: When computing HI we consider as number of citations of a paper its citations divided by the number of paper’s authors, i.e.: \(HIdivCit(a) = \max _K (| \{ p \in papers(a) ~|~ cits(p)/|authors(p)| \ge K \}| = K)\).
-
4.
HI/(coy): Since publications and citations increase over the years, to compare two researchers of different scientific age, i.e. with different periods of research production, we have to consider the time dimension too. For this reason it makes sense to divide publications, citations, and HI/co, by the number of years y. In particular, we propose dividing HI/co by the active research years, i.e.: \(HI/coy (a) = HI/co(a) / Y\) where Y is the active years of researcher a.
Comparative evaluation
Here we compare the four metrics of §4 over our simulated researchers. Table 4 and 5 show their values for various time periods, from 1 year to 10 years.
Observations
HI, HI/co and HIdivCit We can see that HI/co behaves well, almost all researchers get the same score (recall that they have worked equally hard). \(R_{solo}\) has a bit higher HI/co, something that is reasonable.
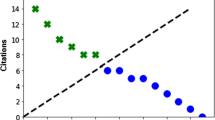
HIdivCit also behaves well, we observe small variations. These are evident also from Fig. 1 that shows these values for the case Y = 10.

The impact of F in 10 years at HI, HI/co and HdivCit
HI/(coy) As expected, we can see that according to this metric years do not matter, therefore it can be used to fairly compare researchers of different academic age. To see that Hi/(coy) manages to normalize over time, Fig. 2 shows the values of HI/co and HI/(coy) for various combinations of Years and F, in particular for the following cases: (Y = 3, F = 0), (Y = 3, F = 5), (Y = 8, F = 3), (Y = 8, F = 4), (Y = 10, F = 1), (Y = 10, F = 5). We can see that even if their HI/co varies a lot, HI/(coy) ranges 0.78 to 1.

HI/co and HI/(coy) for various (Y,F) combinations
Evaluation over real data
At first we describe our methodology (in §6.1) and how we implemented it (in §6.2). Then we analyze the top-10 profiles from five universities (in §6.3) where we also summarize our findings (at Sect. 6.3.6). Subsequently we report the results of a more thorough analysis that comprises roughly all researchers from two universities (in §6.4). Then we include an analysis of the faculty members of one department (in §6.5), as well as an analysis at school level (in §6.6). Subsequently, in §6.7, we analyze the bibliographic profiles of a few famous scientists of the past (and compare them with those of §6.3). Finally, in §6.8 we provide suggestions for the community and bibliographic sources, while in §6.9 we provide suggestions on how to compare researchers.
Methodology
To evaluate the impact of these metrics on real data, we analyzed various data. We have chosen 3 prestigious universities, one from US (Harvard) and two from Europe (Cambridge, Oxford), as well as, a relatively new one (University of Crete, founded less than 50 years ago), as well as a younger one, University of Ziauddin, and from these five universities we analyzed the profiles of the top-10 researchers, and the relative rankings as produced by various metrics. For not restricting our analysis to the top researchers only, for two universities (University of Crete and Ziauddin), we analyzed essentially all profiles. To test also the metrics on scientists of the same domain, we analyzed all profiles of one department (Computer Science Department, University of Crete). To test if co-authorship varies in all schools of a university, we analyzed all schools of the University of Crete. To test whether the metrics can reveal the different publishing policies of different eras, we also report results about a few famous scientists of the past. Finally, we should clarify that we focus on the fair evaluation of persons, not on the evaluation of departments nor of universities.
Implementation
Bibliographic Source We used Google ScholarFootnote 1 as the source of our data, which provides the ranking of researchers with respect to citations. In particular, if one searches using the name of one university and then from the top-left menu selects the option "Profiles”, he gets a list of all profiles associated with that university, ranked according to the number of citations. An example is shown in Fig. 3a. By clicking on a profile, the user can get the list of all publications of that author, sorted either by the number of citations or by date, as shown in Fig. 3b. In that list each publication is shown as an item of the list, however, in case of papers with many authors, only the first few authors are shown and a symbol "...". To overcome this inaccuracy, and thus get the complete list of authors of a paper, we have to click on the particular paper, as shown in Fig. 3c.

Getting information from Google Scholar
Method For each author that we examined we downloaded all of his/her papers and for each paper the number of its authors and the number of citations. This allowed us to compute the avgCoAuthors for each author, and thus to compute HI/co. In this way, we can compute the rank of each these profiles with respect to each metric, for investigating how co-authorship affects ranking.
Automating the extraction Obviously, the above process cannot be done manually. To automate the extraction process from Google Scholar, according to our methodology, we developed a playwrightFootnote 2 script (playwright is a tool for scraping the web, or testing a web application). It takes as input a domain name (e.g. "uoc.gr"), and the number of top author profiles to analyze. It can also take as input a text file containing the URLs of Google Scholar profiles. The script is about 700 lines of code, and uses the playwright tool. It took about 70 h to write and test the program. Note that Google Scholar, might temporary ban the IP address used if multiple calls happen in very short amount of time. To overcome this obstacle our script support custom delays. With the timeout used, to fetch all data of hundreds of profiles, requires a few days. The fetched data are then stored in an output file in JSON format. The size of the output file depends on the number of articles scraped from every user, it can be from 4MB to more than 50MB; it depends on how many articles the author has. Note that some profiles, especially those corresponding to the most cited researchers, can have 1000 or more articles. To fully scrape such a profile it takes around 35 minFootnote 3 Most of the time is spent waiting to avoid IP bans. All data that are presented below were downloaded on November and December of 2023.
Limitations The entire process is automatic, so the results of our analysis depend on the correctness of the data provided by Google Scholar. As mentioned earlier, the program that scrapes the data from each article checks the "Author" section in the Google Scholar page, in order to get the full list of authors. However, we have spotted a few cases where for some articles the number of authors listed is inaccurate, i.e. the author might be an "association" or some of the authors might be missing. Moreover we checked manually all 300 profiles of the University of Crete. We spotted only two cases where one researcher had two profiles (each corresponding to a different spelling of his/her name). This corresponds to around 1% inaccuracy in the analyzed profiles. Overall, these errors were too few, and we cannot say that they affect the main results of our analysis, i.e. that (as we shall see) the degree of co-authorship varies a lot. Moreover, to ensure transparency and enable reproducibility, the paper includes a link to a public folder where all data are placed.
Analyzing the top-10 researchers of universities
Below we analyze the researchers of five universities, in lexicographic order, specifically University of Cambridge (in §6.3.1), University of Crete (in §6.3.2), University of Harvard (in §6.3.3), a University of Oxford (in §6.3.4), and University of Ziauddin (in §6.3.5) For each university we downloaded the top-10 profiles according to citations. Then we analyzed all the papers of these authors, and then we computed the relative rankings of these top-10 persons with respect to the other criteria.
University of Cambridge
The top-10 researchers of University of Cambridge,Footnote 4 according to citations, plus the extra information that we scratched and computed for them, are shown in Table 6. We observe big variations in the average number of co-authors: from 7.44 to 41.98. Now the relative rankings of these top-10 researchers with respect to the other criteria and metrics, are shown in Table 7. We observe significant changes. For instance the 1st with respect to citations (Nicholas Wareham) is 5th according to HI/co. The 2nd with respect to HI/co (RH Friend) is 6th with respect to Pubs and HI. None of the top-3 with respect to HI/co, belongs to the top-3 with respect to HI.
To quantify the difference between the rankings obtained, we can use one distance function between rankings (Kumar & Vassilvitskii, 2010). We have selected the normalized Kendall tau distance. that counts the number of pairwise disagreements between two ranking lists. Let N be a universe of elements. Let \(S_N\) be the set of all permutations on N. The Kendall’s tau distance between two rankings s and t (where \(s,t \in S_N\)) measures the total number of pairwise inversions. In particular, the Kendall’s tau distance is given by \(K_d(s,t) = \sum _{\{i,j\} \in P, i<j} dist_{i,j}(s,t)\) where P is the set of unordered pairs N and \(dist_{i,j}(s,t) = 0\) if i and j are in the same order in s and t, while \(dist_{i,j}(s,t) = 1\) if they are in opposite order in s and t. It follows that \(K_d(s,t)\) is equal to 0 if s and t are identical, and is equal to \(\frac{1}{2} |N|(|N|-1)\) if one is the reverse of the other. The normalized Kendall tau distance, \(K_n\), is defined as \(K_n = \frac{K_d}{\frac{1}{2} |N| (|N|-1)}\) and therefore lies in the interval [0,1].
Hereafter we shall use \(R_X\) to denote the ranking obtained by a metric X, and \(dist(R_X, R_Y)\) to denote the the normalized Kendall tau distance between \(R_X\) and \(R_Y\), e.g. with \(dist(R_{cits}, R_{HI/co})\) we will denote the normalized Kendall tau distance between \(R_{cits}\) and \(R_{HI/co}\). Below we show the distance values obtained:
Notice that \(dist(R_{HI/co}, R_{HI}) = 0.28\) meaning that the relative rankings of 28% of the pairs of researchers, is different in HI and HI/co.
University of Crete
The top-10 researchers of UoC (University of Crete),Footnote 5 according to citations, plus the extra information that we scratched and computed, are shown in Table 8. We observe variations in the average number of co-authors: from 3.88 to 18.24. Now the rankings of these top-10 researchers of UoC, according to each criterion are shown in Table 9. We observe significant changes. For instance, the 1st with respect to HI/co (E. Economou), is 10th with respect to citations (!), and 7th with respect to HI.
Below we show the distances of these rankings:
Notice that \(dist(R_{HI/co}, R_{HI}) = 0.42\)
University of Harvard
The top-10 researchers of University of Harvard,Footnote 6 according to citations, plus the extra information that we scratched, are shown in Table 10. We observe variations in the average number of co-authors: from 1.94–48.22. The relative rankings are shown in Table 11. Here we observe that the 1st with respect to citations (Michael E. Porter) is also 1st with respect to HI/co, but 9th with respect to HI. In general we observe significant changes in the rankings, for instance the 2nd with respect to Hi/co (Andrei Shleifer) is 10th with respect to HI, and 8th with respect to citations.
Below we show the distances of these rankings:
Notice that \(dist(R_{HI/co}, R_{HI}) = 0.42\).
University of Oxford
The top-10 researchers of University of Oxford,Footnote 7 according to citations, plus the extra information that we scratched, are shown in Table 12. We observe big variations in the average number of co-authors: from 3.75–114.45. The relative rankings are shown in Table 13. We observe that the 1st according to HI/co (Robert M. May) is 10th with respect to citations, and 6th with respect to HI.
Below we show the distances of these rankings:
Notice that \(dist(R_{HI/co}, R_{HI}) = 0.46\), a very high value!
University of Ziauddin
Ziauddin University is a relative new university from Pakistan, founded in 1995, whose position in the ranking for 2024 produced by THE (Times Higher Education)Footnote 8 is very low.Footnote 9 It has seven academic faculties, i.e. health sciences, law, liberal arts and human sciences, eastern medicine and natural sciences, engineering science technology and management, pharmacy, and the nursing and midwifery, and some of these departments offer both undergraduate and postgraduate courses.
The top-10 researchers of University of Ziauddin,Footnote 10 according to citations, plus the extra information that we scratched, are shown in Table 14. Again we observe big variations in the average number of co-authors: from 2.33 to 24.39.
The relative rankings of these researchers are shown in Table 15. We observe that the 1st according to HI/co (Fauzia Shamim) is 9th according to H-Index. Below we show the distances of these rankings:
Again we can see very big differences in the rankings, mainly for those pairs that include HI/co.
Summary of findings by analyzing the top researchers of 5 universities
We have observed big variations of the number of co-authors. The ranges and the median encountered by analyzing only the top-10 profiles with respect to citations, are shown in Table 16. As regards co-authors, note that (Fire & Guestrin, 2019) that analyzed more than 120 million papers, from several domains, reports mean number of authors from 2.83 to 6.14. However, they also state that the maximal number of authors for a single paper in each year increased sharply over time, and have spotted some recent papers with more than 3,000 authors. In our case, we have seen much larger average number of co-authors. This provides evidence that the highly cited researchers, mainly have more co-authors in average.
Table 16 also shows shows the ranges and medians of HI and HI/co. These ranges are illustrated as interval plots in Fig. 4. Notice that UofCrete, has considerably lower range of HI, in comparison to Cambridge, Harvard and Oxford, but since it also has lower range of co-authors, its score in HI/co is considerably better.

Range and medians of HI, average co-authors, and HI/co of the top-10 profiles of 5 universities
We have observed that by considering the number of co-authors (through HI/co), the ranking of researchers changes significantly. The normalized Kendall’s tau distance between the rankings obtained by HI and HI/co, ranges from 0.28 to 0.46, meaning that more than one third of researcher pairs have different relative ranking in HI and HI/co.
Finally, we should clarify that we focus on the fair evaluation of individual researchers, not universities, so the role of the aforementioned data, is to provide information about the scale of co-authorship and to highlight that metrics that consider co-authorship affect the obtained rankings.
Analyzing all profiles of two universities
In the previous subsections we reported big variations in the rankings if co-authorship is considered. The real difference can be bigger in the sense that previously we have analyzed only the top-10 profiles. Since the scrapping process is slow, we decided to make a more complete analysis of two universities. We selected University of Crete, since it feasible for us to check the validity of the results, in addition the university of Zaudin (whose top researchers were analyzed in §6.3.5)
University of Crete For the university of Crete, we decided to analyze the top-300 profiles with respect to citations, and for these 300 profiles to provide the relative rankings. In brief, we noticed even bigger changes. Table 17 shows the top-15 researchers according to HI, HI/co, Pubs and Pubs/co. Note that we have also the column Pubs/co as indicator of the productivity of each researcher. Analyzing so many profiles enables us to inspect the difference in the rankings obtained by the metrics, not only over of the top researches, but also over the all members of the university (300 essentially contains all active members).
For reasons of space, in Table 18 we show only the top 55 with respect to citations At first we observe quite different researchers in top-10. The number of common elements between the top-10 with respect to Citations and the top-10 with respect to HI is 7 (i.e. 70%). The number common elements between the top-10 with respect to Citations and the top-10 with respect to HI/co is 2 (i.e. 20%). The number common elements between the top-10 with respect to Citations and the top-10 with respect to Pubs/co is 5 (i.e. 50%). In general we observe very big changes in the rankings. The 1st with respect to citations (Panos Vardas) is 49th with respect to HI/co. The 2nd with respect to citations (M K Tsilimbaris) is 207th with respect to HI/co. The 2nd with respect to HI/co (Eleftherios Zouros) was 27th with respect to to citations, and was not included in Table 9, as well as the 3rd with respect to HI/co (Stamatios Papadakis) who is 55th with respect to citations.
Below we show the distances of these rankings of 300 profiles:
Notice that \(dist(R_{HI/co}, R_{HI}) = 0.34\).
University of Ziauddin We downloaded all profiles of the University of Ziauddin, they are 169. Below we show the distances of induced rankings:
Here we observe smaller differences of the induced rankings i.e. from 0.14 to 0.22, in comparison to those of the University of Crete.
Analyzing all faculty members of one department
For checking how co-authorship varies if all compared researchers are of the same discipline, and how co-authorship affects the rankings at department level, we analyzed all faculty profiles associated with the Computer Science Department of the University of Crete. The data of these 25 profiles are shown in Table 19. For reasons of discretion, the last members of the list are written anonymously We observe the the avgCo-authors ranges from 2.96–8.44. The position of each faculty member with respect to various criteria is shown in Table 20. Again we observe significant changes, just indicatively, the 1st with respect to citations and HI is Nikos Komodakis, however the 1st with respect to HI/co is Ioannis G. Tollis, and the 1st with respect to Pubs/co is Constantine Stephanidis.
Since the members have different academic age, we can use Pubs/(co*y) and HI/(co*y) as a time-normalized version of Pubs/co and HI/co. As expected, the obtained ranking is different from the previous ones. The 1st with respect to HI/(coy) is Xenofontas Dimitropoulos. The range of HI/co is 1.88 to 12.53. Note that in the computation of Y we have considered the publication year of the first and the last paper. Alternatively, instead of considering the year of the first paper, one could consider the year of PhD graduation in order to avoid penalizing those researchers who have started publishing very early, e.g. when they were undergraduate students.
Below we show the distances of these rankings over the 25 faculty members:
Notice that \(dist(R_{HI/co}, R_{HI}) = 0.19\). This is the smallest value that we have observed, probably due to the fact that all scientists here come from the same domain (Computer Science), and because the range of average co-authors is smaller than the ranges measured at university level.
Analyzing faculty members by school
To check if there are variations at school level, we separated the 300 profiles of the University of Crete (those analyzed in Sect. 6.4) to three groups: (a) School of Sciences and Engineering (that comprises 6 departments) (b) Medical School (1 department) (c) Schools of Philosophy (3 departments), Education (2 departments), Social Sciences (4 departments), in total 9 departments. Hereafter, we shall use the term Humanities and Social Sciences, for the last group. For each of these three groups below we report measurements.
The first group (School of Sciences and Engineering) contains 135 profiles, the second (Medical School) contains 129, while the last (Humanities and Social Sciences) contains 36 profiles. Table 21 synopsizes the results. The first, and important, observation is that we can see big variations of the number of co-authors, in all schools! This is evident and in the left chart of Fig. 5. We can also see that the Medical School has the highest number of average co-authors, followed by the School of Sciences and Engineering. As regards HI/co, we observe that the Medical School has the lowest values. We should also note that the HI/co values of the researchers from Humanities and Social Sciences are relatively high, because only 36 profiles were included in the analysis (many researchers of that school do not have a Google Scholar profile). In any case, this analysis aims at understanding the degree of co-authorship, not to comparatively evaluate the schools of the University of Crete

Range and medians of the average co-authors and HI/co at the Schools of UoC
Also the ranking of the researchers in each of these schools is affected significantly if we consider the number of co-authors. This is evident if we look at the top-10 according to the different metrics: In particular, Table 22 shows the top rankings in Sciences and Engineering. Notice that only one person (Eleftherios N. Economou) appears to all the four rankings. Table 23 shows the top rankings in Medical School, here 4 persons appear in all rankings. Finally, Table 24 shows the top rankings in Humanities and Social sciences, here two persons appear in all rankings.
To conclude, we have seen big variations of the number co-authors in all schools of the University of Crete, which affects significantly the ranking of researchers.
Famous scientists of the past
Just for curiosity we also extracted and computed these metrics of some great scientists, that have a Google Scholar profile. The results are show in Table 25.
Of course, the eras (17th to 21st century) are not comparable in terms of the rate of production of scientific articles and the size of the scientific community. We should also consider that here we have scientists who are no longer alive, and their Google Scholar profile has many modern reprints of their old work. Consequently, the number of publications does not correspond to what they themselves wrote when they were alive. However, our data shows the low degree of co-authorship at that time, given the difficulty that existed then for remote collaboration. Although the eras are not comparable, while the HI of these famous scientists of the past is small (range 43–293) relative to the top university researchers we looked at (who have range 48–332, as shown in Sect. 6.3.6), their HI/co is higher: the range of HI/co of the famous scientists of the past is 20.02–159.06 while the range of the HI/co of the top researchers of the universities that we studied is 2.14\(-\)93.68. This is shown more evidently in Fig. 6.
Obviously, evaluating past scientists through bibliographic indices requires a different approach (therefore the ranking presented in Table 26 is just given for reasons of completeness), but we have seen that HI/co can distinguish them, from contemporaries, better than HI.

Range and medians of HI and HI/co of the top-10 profiles of 5 universities and the group of 13 famous scientists of the past
Suggestions for the community and the bibliographic services
Difficulties Currently, the task of fetching and obtaining complete and accurate information about publications, authors, and citations, is not an easy task. We had to develop a scrapper for performing the analysis that we presented. Below we list the main difficulties and how we could overcome them, for making sush analyses more easy.
Access Bibliographic sources do not enable in a straightforward manner to fetch all publications of a researcher in a structured manner. This is important for reasons of transparency.
Incompleteness Some bibliographic sources contain, or display, incomplete information, e.g. in the bibliographic entry of a paper sometimes dots are used in case of many authors, reducing in this way the effectiveness of web scraping techniques, i.e. it makes scrapping more difficult.
Suggestions It should be straightforward to fetch, in a structured manner, all publications of a researcher, and for each publication to get the complete set of authors, enabling in this way the computation of the average number of co-authors. Two suggestions follow:
Structured CVs Just like each researcher maintains a CV in pdf, it would be beneficial to maintain (and have published) a file that contains in a structured manner all publications and complete information about each publication. That would enable the computation of the number of publications, average authors and years, easily, without having to rely to bibliographic sources, and without having to perform web scrapping.
Bibliographic sources Based on our analysis in this paper, we believe that the systems that compute citations and provide related access services (like Google Scholar, ResearchGate, and others), should not provide ranking by citations and year. We suggest as default method for ranking the number of citations divided by the average co-authors, or HI/co. In general, such systems should offer various options for sorting (not just by citations and date).
Moreover, for transparency and for fostering the development of new metrics, it would be beneficial if such sources offer an API through which one can get all citations of one particular paper, without having to perform web scrapping. An even better service of such systems (like Google Scholar, ResearchGate, etc) would be to allow the user to define the formula (or code) to be used for computing the desired metric and get the induced ranking.
Suggestions for comparing researchers
In brief, one fair measure to measure the productivity of a researcher is Pubs/co-authors, while to measure the impact of her research is Citations/co-authors. If we want to use a single metric, then we suggest using HI/co. Finally, if we want to compare two or more researchers of different academic age, with a single metric, we suggest HI/(coY) and Pubs/(coY).
If we want to compare several researchers, using more than one metrics, one step is to compute the efficient set (else called Pareto front, maximal vector, or skyline) according to Pubs/co and HI/co, i.e. to exclude those candidates for which there is at least a candidate with higher values on both Pubs/co and HI/co. This can reduce a lot the number of candidates. For instance, the Pareto front of the 25 faculty members of Sect. 6.5, comprises the following three members: Ioannis G. Tollis, Constantine Stephanidis, and Yannis Stylianou. In Fig. 7 we can see the plot of the 25 members, the members in the Pareto front are in red.

Pareto front of the 25 faculty members of the UoC/CSD
In case the number of compared persons is low, it can be convenient to visualize the above metrics as a radar chart, for being able to show more than 2 metrics. An example, of a normalized radar chart, that shows the values of Pubs/co, HI/(coY) and HI/co for 3 professors from Sect. 6.5 is shown in Fig. 8.

Radar chart for comparing three researchers according to HI/co, HI/(coy) and Pubs/co
The above metrics usually are computed over all publications of an author. However, one one might decide to consider only the publications of an author in top-tier conferences and journals, and compute the H-index by considering only this restricted dataset. Again, the computation of the average number of co-authors (over that restricted dataset) will lead to more fair evaluation.
Other implications As we stated in the introductory section, collaboration is good, not only for the involved individuals, but for the research community in general for various reasons: complementarity of expertise, resource sharing, improved quality, more impact, etc. Papers with many authors are not necessarily written to hack bibliographic metrics. Our proposal is not for discouraging collaboration, but for avoiding cases of long lists of non contributing authors. However we should be try to avoid as much as possible unfair evaluation.
Concluding remarks
We need good measures not only to evaluate scientific output fairly, but also because they affect the goals and the activities of the scientific community. Obviously, the collaboration of researchers is not bad, quite the opposite, and papers with many authors are not necessarily written to hack bibliographic metrics. As we mentioned earlier, collaboration is beneficial, not only for the involved individuals, but for the research community in general: complementarity of expertise, resource sharing, improved quality, more impact, and others. However unfair evaluation is another thing, and we should try to use metrics that are as fair as possible, since they are used for hiring, promotion, funding, and recognitions. Therefore, it would be good for the community to discourage the misuse of the concept of author. Towards this objective, the key findings of our work, are the following:
-
Without dividing the number of publications and the number of citations by the number of paper authors, each author gets the full credit of a joint work, something that is not fair. Through simulation scenarios we have showcased the impact of the factor F, i.e. the number of "friend" co-authors. For instance, in 10 years time, with the same effort a "lonely" researcher can get HI equal to 12, while a group of 5 researchers will each get a HI equal to 49.
-
To tackle the weakness of HI, we proposed metrics, i.e HI/co, and HI/(coy). The results of simulations indicated that they can tackle these problems, i.e. equally strong researchers that have dedicated the same amount of effort, obtain the same values, independently of how many friend researchers they have.
-
The measurements performed over real data of researchers from five universities, top ones as well as weak ones, revealed big variations of the number of co-authors. In total, we analyzed 526 authors, having in total more than 127 thousands publications, and 16.7 million citations. The range of the average co-authors of the top-10 researchers (according to citations) from these 5 universities, is from 1.94 to 114.45. We have also seen big variations in the number of co-authors, both at department level, school level and university level. Consequently, the consideration of the number of co-authors (through Pubs/co and HI/co), affects significantly the ranking of researchers. Indeed, the normalized Kendall’s tau distance of these rankings ranged from 0.28 to 0.46, which is quite high.
-
We have also seen that the metrics that consider the number of co-authors, are capable to distinguish the famous scientists of the past, from the current ones.
-
One fair way to measure the productivity of a researcher is publications divided by the average co-authors, while to measure research impact we can use the number of citations divided by the average co-authors. If we want to use a single metric, then we suggest using HI/co. Finally, if we want to compare two or more researchers of different academic age, with a single metric, we suggest HI/(coy).
The are several directions for future research. One is to investigate diagrams and plots that facilitate the comparative evaluation of researchers. Another one, is to refine the notion of co-authorship and consider also the order of authors. Finally, another interesting direction is to elaborate on how additional criteria like open datasets, open source code, and others (e.g see Hicks et al. (2015) and the San Francisco Declaration on Research AssessmentFootnote 11), could be considered as well.
Data availability
The extracted datasets over which the metrics were computed are publicly accessible in JSON format at https://drive.google.com/drive/folders/1zB6zgJl4gP_vnMfl_9Oe9OyBuVejhy4n?usp=sharing.
Code availability
Upon request to the authors.
Notes
Based on our experiments, to download authorArticles in number articles, it takes about
2(authorArticles+1) seconds to scrape them, and around 7–8 min to scrap 100 profiles.
The profiles retrieved with the query "University of Cambridge".
The profiles retrieved with the query "uoc.gr".
The profiles retrieved with the query "Harvard".
The profiles retrieved with the query "University of Oxford".
In particular its position it resides at position 2651 of the 2671 universities that were evaluated.
The profiles were retrieved with the query "zu.edu.pk".
References
Bartneck, C., & Kokkelmans, S. (2011). Detecting H-index manipulation through self-citation analysis. Scientometrics, 87(1), 85–98.
Bi, H. H. (2022). Four problems of the H-index for assessing the research productivity and impact of individual authors. Scientometrics. https://doi.org/10.1007/s11192-022-04323-8
Bihari, A., Tripathi, S., & Deepak, A. (2023). A review on H-index and its alternative indices. Journal of Information Science, 49(3), 624–665.
Bornmann, L., & Daniel, H.-D. (2007). What do we know about the h index? Journal of the American Society for Information Science and technology, 58(9), 1381–1385.
Egghe, L. (2008). Mathematical theory of the H-and G-index in case of fractional counting of authorship. Journal of the American Society for Information Science and Technology, 59(10), 1608–1616.
Egghe, L., et al. (2006). An improvement of the H-index: The G-index. ISSI newsletter, 2(1), 8–9.
Engqvist, L., & Frommen, J. G. (2008). The H-index and self-citations. Trends in Ecology & evolution, 23(5), 250–252.
Fire, M., & Guestrin, C. (2019). Over-optimization of academic publishing metrics: Observing Goodhart’s law in action. GigaScience, 8(6), 053.
Guns, R., & Rousseau, R. (2009). Simulating growth of the D-index. Journal of the American Society for Information Science and Technology, 60(2), 410–417.
Hicks, D., Wouters, P., Waltman, L., De Rijcke, S., & Rafols, I. (2015). Bibliometrics: The Leiden manifesto for research metrics. Nature, 520(7548), 429–431.
Hirsch, J. E. (2005). An index to quantify an individual’s scientific research output. Proceedings of the National academy of Sciences, 102(46), 16569–16572.
Hirsch, J. E. (2010). An index to quantify an individual’s scientific research output that takes into account the effect of multiple coauthorship. Scientometrics, 85(3), 741–754.
Ioannidis, J. P., & Maniadis, Z. (2023). In defense of quantitative metrics in researcher assessments. Plos Biology, 21(12), 3002408.
Kumar, R., & Vassilvitskii, S. (2010). Generalized distances between rankings. In Proceedings of the 19th International Conference on World Wide Web (pp. 571–580)
Malesios, C., & Psarakis, S. (2014). Comparison of the H-index for different fields of research using bootstrap methodology. Quality & Quantity, 48, 521–545.
Meštrović, R., & Dragovic, B. (2023). Extensions of Egghe’s G-Index: Improvements of Hirsch H-Index. SSRN 4408038
Shanmugasundaram, S., Huy, B., Shihora, D., Lamparello, N., Kumar, A., & Shukla, P. (2023). Evaluation of H-index in academic interventional radiology. Academic Radiology, 30(7), 1426–1432.
Zaorsky, N. G., O’Brien, E., Mardini, J., Lehrer, E. J., Holliday, E., & Weisman, C. S. (2020). Publication productivity and academic rank in medicine: a systematic review and meta-analysis. Academic Medicine, 95(8), 1274–1282.
Acknowledgements
Many thanks to Evangelos Markatos, Xenofontas Dimitropoulos and Yannis Marketakis, for valuable comments and suggestions.
Funding
The authors have not disclosed any funding.
Author information
Authors and Affiliations
Contributions
All authors contributed to The study conception, design and writing of this work was done by Yannis Tzitzikas. The implementation of the system was done by Giorgos Dovas. All authors read and provided comments for improving the manuscript
Corresponding author
Ethics declarations
Conflict of interest
The authors have not disclosed any competing interests.
Ethical approval
Not applicable.
Consent for publication
Yes.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Tzitzikas, Y., Dovas, G. How co-authorship affects the H-index?. Scientometrics 129, 4437–4469 (2024). https://doi.org/10.1007/s11192-024-05088-y
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11192-024-05088-y