
Abstract
The present study examines that a research and development (R&D) performance creation process conforms to the stepwise chain structure of a typical R&D logic model regarding a national technology innovation R&D program. Based on a series of successive binary logistic regression models newly proposed in the present study, a sample of n = 929 completed government-sponsored R&D projects was analyzed empirically. Sensitivity analyses are summarized where the performance creation success probability is predicted for some key R&D performance factors.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
Introduction
Researchers have emphasized a systematic data investigation, analysis, and evaluation framework related to national research and development (R&D) programs. In addition to the quantitative efficiency perspective, the qualitative effectiveness viewpoint is underscored in the field of R&D performance evaluation. Proponents for this view suggest that it is implemented by identifying a clear relationship between R&D inputs and crucial performance created by government-sponsored R&D projects (i.e., GSPs) (McLaughlin and Jordan 1999; Ruegg and Feller 2003; WKKF 2004; Ruegg 2006; KISTEP 2011; MKE KIAT 2012; STAR METRICS 2014).
Generally, public sector R&D performance is evaluated based on a typical R&D logic model, and the performance efficiency, effectiveness, and relevance of GSPs is analyzed quantitatively using various methods (Wholey 1983; Bickman 1987; Wholey 1987; McLaughlin and Jordan 1999; Ruegg and Feller 2003; WKKF 2004). Ruegg and Feller (2003) and WKKF (2004) classified the following performance factors according to three different time periods (1) short-term, technical (1–3 years) outputs; (2) mid-term, economic (4–6 years) outcomes; and (3) long-term, socioeconomic (7–10 years) impacts, most of which occur after a project is completed.
Typical flow-chart type R&D logic models in the literature include the Advanced Technology Program (ATP) of U.S. Department of Commerce (DOC) (Ruegg and Feller 2003), the Research and Technology Development and Deployment Program (RTDDP) of U.S. Department of Energy (DOE) (McLaughlin and Jordan 1999), and so forth. Representative national technology innovation R&D programs can be found, such as the ATP under the DOC, the Industrial Technology Development Program (ITDP) administered by the Ministry of Economic Affairs (MEA) with the Taiwanese government and the Knowledge Economy Technology Innovation Program (KETIP) conducted by the Ministry of Knowledge Economy (MKE) with the Korean government (Ruegg and Feller 2003; Shipp et al. 2005; Ruegg 2006; Hsu and Hsueh 2009; KEIT 2010, 2011, 2013). As discussed in detail in Sect. 2, in the national R&D program planning and deployment stage, effective government subsidy allocations are required with the consideration of performance differences between institution types and between R&D collaboration types (KEIT 2010, 2011, 2013; OMB OSTP 2012; OSTP 2012). For example, among the initial ATP’s 50 completed GSPs, 42 GSPs (84 %) were conducted through R&D collaboration.
As for the national technology innovation R&D programs mentioned above, previous studies are very limited regarding whether statistically significant differences exist in R&D performance between institution types and between R&D collaboration types. In particular, it is not easy to find empirical cases using a large dataset. In the empirical analyses of related studies, a common research limitation is the incomplete panel samples that do not fully consider the time lag between R&D inputs and performance (Wu et al. 2006; Guan and Chen 2010; Chen et al. 2011). The inherent scarcity of GSPs achieving R&D performance may be another reason why researchers have not collected a proper datasets. A research need has been raised regarding the extent to which R&D inputs exert substantial influence to achieve R&D performance (Shipp et al. 2005; Ruegg 2006; KEIT 2013). In terms of methodology, various nonparametric statistical models have been used in the literature and have primarily discussed ways to enhance technology innovation productivity (Fritsch and Lukas 2001; Belderbos et al. 2004; Laursen and Salter 2006; Berchicci 2013; Robin and Schubert 2013).
As we can see, most of aforementioned studies and related literature reviewed in Sect. 2 showed various R&D performance analyses based on typical R&D logic models. Still, only a limited number of studies have been conducted relating to verifying the applicability of typical R&D logic models for technology innovation R&D performance evaluation. Therefore, the present study is motivated to fill this gap, which aims to investigate whether the fundamental framework of typical R&D logic models can be applied to a national technology innovation R&D program’s performance especially. From the ex-post evaluation perspective, various types of R&D performance factors can be evaluated more systematically within technology innovation R&D programs based on typical R&D logic models. On the other hand, some useful policy implications can be derived for restructuring subsequent R&D programs as well as R&D budget allocations more effectively from the ex-ante evaluation point of view.
The present study conducted an empirical analysis to verify whether a national technology innovation R&D program’s performance was created in accordance with the stepwise chain structure of typical R&D logic models, which is taken for granted in public sector R&D performance evaluations. Specifically, the present study aimed to answer the following three major questions. First, to what extent do R&D inputs exert their influence on R&D performance? Second, is there an apparent chain relationship between previous and subsequent performance factors? Third, do significant differences exist in R&D performance between institution types and between R&D collaboration types?
A sample of n = 929 completed GSPs during the last five performance follow-up survey years (2009–2013) was analyzed. Data were collected from representative national technology innovation R&D programs administered by the Ministry of Science, ICT and Future Planning (MSIP) with the Korean government. The present study proposes a new analysis framework, successive binary logistic regression models, in which the inherent characteristics of observations (i.e., completed GSPs) can be reflected appropriately. In particular, this new methodology shows how to deal with the R&D performance creation success-failure binary characteristic. The present study is organized as follows. Section 2 states the background and literature review of the present study, Sect. 3 explains the research model and hypotheses, Sect. 4 presents the empirical analysis associated with the design of the successive binary logistic regression models, and Sect. 5 explains the sensitivity analyses that display the predicted probability of R&D performance creation success. Finally, conclusions are summarized in Sect. 6.
Background and literature review
Berchicci (2013) analyzed a survey sample of 2537 Italian firms for the 13 years from 1992 to 2004 using a Tobit regression model. He argued that an inverted U-shape relationship existed between the share of external R&D activities and the firm’s innovative performance (i.e., the share of turnover from new or significantly improved products). He concluded that firms with low R&D capacity could enhance their innovative performance by increasing external R&D activity share compared to those firms with high R&D capacity. Esteve-Pérez and Rodríguez (2013) analyzed a sample of small and medium-sized enterprises (SMEs) in Spanish manufacturing industry drawn from a Business Strategy Survey from 1990 to 2006. They argued that some types of R&D collaboration with suppliers, clients, universities and technological centers could be more relevant for SMEs to improve sales and technology innovation activities. Robin and Schubert (2013) carried out a survey associated with French and German companies between 2004 and 2008. They analyzed the sample using a Tobit regression model and found that R&D collaboration with public sector institutions increased only product innovation (i.e., the percentage of total sales of new products). Based on 1435 SMEs in Australia from 2004 to 2007, Gronum et al. (2012) examined the role of networks in SMEs and showed that strong and heterogeneous ties engaged with different actors improved innovation and long-term performance in SMEs. Chen et al. (2011) compared the productivity change of 73 information technology companies in China using a data envelopment analysis-based Malmquist index model. They argued that R&D collaboration was necessary between large companies and SMEs. Ortega-Argilés et al. (2009) mentioned that innovative SMEs tend to rely heavily on external knowledge, which is a crucial complement to in-house R&D and innovation management practices. Laursen and Salter (2006) investigated a survey sample of 2707 UK firms in 2001 using a Tobit regression model. They identified that a dependent variable for innovative performance (i.e., the fraction of the firm’s turnover relating to products new to the world market) was curvilinearly related to the breadth and depth of an external knowledge and it took an inverted U-shape. Belderbos et al. (2004) analyzed the influence of R&D collaboration on labor productivity and technology innovation productivity of 2056 companies in the Netherlands for the 3 years (1996–1998) based on a regression model. The analysis revealed that productivity pursued by each R&D collaboration type was different from one another. Fritsch and Lukas (2001) examined a survey sample of 1800 German companies based on a two-stage decision-making model (i.e., 1st stage: a Logit model, 2nd stage: a Poisson regression model). They verified a statistically significant positive (+) correlation between the R&D collaboration frequency and firm size (i.e., the number of employees) as well as the R&D intensity (i.e., the percentage of R&D employees).
Most of the literature has used nonparametric statistical models. Because of the inherent scarcity of GSPs achieving R&D performance and the extremely skewed to the right distribution, the literature seems to adopt nonparametric techniques, such as Tobit regression models, to cope with censored characteristics, logistic regression models dealing with R&D performance creation of success-failure binary characteristic, and so on. Meanwhile, related to measuring efficiency and productivity change in R&D programs, some prior literature has provided excellent classification on R&D inputs and performance factors to be considered in R&D performance evaluation (Meng et al. 2006; Wu et al. 2006; Sharma and Thomas 2008; Hsu and Hsueh 2009; Guan and Chen 2010; Chen et al. 2011; Park 2014).
Recently, the U.S. government emphasized the need for R&D collaboration associated with its R&D budget compilation and execution. The Office of Management and Budget (OMB) and the Office of Science and Technology Policy (OSTP) discussed the 2014 federal R&D budget priorities, and announced the top nine science and technology areas needing R&D collaboration as including information technology, nanotechnology and biological innovation, etc. (OMB OSTP 2012). The ATP accepted applications from single companies and joint ventures. For-profit companies could apply as single applicants to receive an award up to $2 million USD over 3 years to cover project costs (Ruegg and Feller 2003). The Korean government established a database management system (DBMS) called the National Science and Technology Information Service (NTIS) in which GSP R&D inputs and performance information is updated yearly and data are opened to the public. In particular, six key performance factors of the NTIS are as follows: (1) research article publications, (2) patent applications and registrations, (3) technology transfer, (4) commercialization sales, (5) technology manpower cultivation and (6) academic-technology training (KISTI 2008; MKE 2009; MST OSTI 2008). Practitioners in charge of R&D performance evaluation pay attention to specific topics, including identifying the relationship between R&D inputs and performance factors, verifying performance differences among institutions and R&D collaboration types, and so on (Åström et al. 2010; KEIT 2010, 2011, 2013; Elg and Håkansson 2012).
In particular, regarding project-level’s R&D performance evaluation, Linton et al. (2002) reported a Data Envelopment Analysis (DEA)-based methodological framework for the analysis, ranking and selection of R&D projects in a portfolio. Farris et al. (2006) presented a case study of how DEA was applied to compare engineering design projects of the Belgian Armed Forces, and they explained a variable-reduction process where the initial 23 input–output variables were reduced to the final five input–output variables. Hsu and Hsueh (2009) evaluated DEA efficiency of 110 GSPs; consequently, they emphasized the need for an appropriate upper limit on the ratio of the amount of government support in the R&D budget. In addition, Lee et al. (2009) evaluated the efficiency of multiple R&D programs supported by the Korean government. They utilized a DEA/AR (Assurance Region) model in order to consider the importance of input–output variables associated with six heterogeneous R&D programs. At the firm-level’s R&D performance evaluation, for pharmaceutical and semiconductor companies, Kim et al. (2009) argued that the number of patents per R&D expenditure declined with the firm size (i.e., the firm sales) for both industries based on regression analyses. Chen et al. (2004) assessed the R&D efficiency of 31 computer-related companies in Taiwan based on DEA. They examined the total efficiency, technical efficiency and scale efficiency respectively, and revealed the correlations between inputs and outputs.
Meanwhile, the fundamental concept of the research model explained in Sect. 3 accords with the basic mechanism of network DEA models. Färe and Grosskopf (2000) proposed the framework of a network DEA. This DEA modeling approach was designed to measure and improve disaggregated process performance within the network structure. In the fundamental concept behind this approach, intermediate outputs of one stage may be used as inputs in another stage. Löthgren and Tambour (1999) conducted a multi-stage performance evaluation. They point out that the analyst can evaluate the performance of a customer node that is interrelated with a production node. Similarly, Cooper et al. (2004) discussed various network DEA models. They argue that a DEA research should focus more on performance management decision-making that coordinates activities among different levels in a system concerned. Recently, Liang et al. (2011) developed an advanced form of network DEA model for examining performance in the feedback setting, and they illustrated an application involving the measurement of performance of a set of Chinese universities. Chen and Guan (2012) applied a relational network DEA to the systematic evaluation of the innovation efficiency of regional innovation systems by decomposing the innovation process into the two connecting sub-processes, technological development and subsequent technological commercialization. Guan and Chen (2012) proposed a relational network DEA model for measuring the innovation efficiency of the national innovation systems by decomposing the innovation process into a network with a two-stage innovation production framework, an upstream knowledge production process and a downstream knowledge commercialization process respectively.
For technology innovation, technology management and R&D management, some research papers were reported using citation analyses (Narin and Noma 1985; Albert et al. 1991; Jaffe and Trajtenberg 2002; Hu and Jaffe 2003; Branstetter and Ogura 2005; Bacchiocchi and Montobbio 2009; Hu 2009; Lee 2015; Tan et al. 2015).
Lee (2015) investigated the multidisciplinary characteristics of technology management through a journal citation network analysis. He showed that technology management had a high degree of interaction with the six disciplines of science and technology: business and management, marketing, economics, planning and development, information science, and industrial engineering and operations research. Tan et al. (2015) presented a comparative impact analysis on collaborative research in Malaysia using journal articles published in the 10-year period spanning, the years 2000–2009. Bacchiocchi and Montobbio (2009) estimated the process of diffusion and decay of knowledge from university, public laboratories and corporate patents in six countries, and tested the differences across countries and across technological fields using data from the European Patent Office. The distribution of the citation lags showed that knowledge embedded in university and public research patents tended to diffuse more rapidly relative to corporate ones in particular in the U.S., Germany, France and Japan. Hu (2009) investigated the extent to which East Asia had become a source of international knowledge diffusion and whether such diffusion was localized to the region. Branstetter and Ogura (2005) supported the notion that the nature of the U.S. inventive activity had changed with an increased emphasis on the use of the knowledge generated by university-based scientists. Hu and Jaffe (2003) examined patterns of knowledge diffusion from the U.S. and Japan to Korea and Taiwan using patent citations as an indicator of knowledge flow. They found that Korean patents cited Japanese patents than the U.S. patents, whereas Taiwanese inventors tended to learn evenly from both the U.S. and Japanese inventors. Jaffe and Trajtenberg (2002) reported that patents registered by universities were comparable to patents of companies in terms of the patent citations in the U.S. Albert et al. (1991) presented a new and direct validation study of the use of patent citation analysis, in which a strong association was found between citation counts for highly cited the U.S. patents and knowledgeable peer opinion as to the technical importance of the patents. Narin and Noma (1985) showed that there was a substantial amount of citation from biotechnology patents to the modern bioscience literature.
Regarding the performance evaluation perspectives, Roper et al. (2004) discussed the ex-ante and ex-post R&D performance evaluation framework that comprised two main elements: (1) an inventory of the global private and social benefits which might be resulted from any R&D projects and (2) an assessment of the share of these global benefits which might accrue to a host region. Lenihan (2011) demonstrated that traditional enterprise evaluation metrics focused almost exclusively on private firm impacts rather than broader societal impacts caused by the pervasive nature of new enterprise policies and illustrated how R&D logic models could be expanded to account for these broader impacts.
Research model and hypotheses
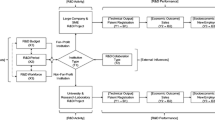
Figure 1 shows the research model of the present study in which important measures of R&D inputs and performance are organized based on typical R&D logic models in the literature (McLaughlin and Jordan 1999; Ruegg and Feller 2003; WKKF 2004; Meng et al. 2006; Wu et al. 2006; Bitman and Sharif 2008; Sharma and Thomas 2008; Hsu and Hsueh 2009; Guan and Chen 2010; Chen et al. 2011; Park 2014). In Fig. 1, drawn with squares, multiple R&D inputs and performance factors comprises the stepwise chain structure of the research model. Ruegg and Feller (2003) and Hsu and Hsueh (2009) presented representative R&D inputs and performance factors for a GSP-level performance analysis. The important R&D inputs were a government subsidy to the GSP, GSP budget from the government subsidy recipient, staff members and the post-project period. The four key performance factors suggested included published articles, patent applications and registrations, patents used, and profited commercialization sales. Additionally, some external influence factors were pointed out, such as the institution type, R&D collaboration, the internal R&D capability, accumulated knowledge, and experience of the institution (Geuna et al. 2003; Stephan 2010). As described in Sect. 4, Fig. 1 is designed as a parsimonious model composed of verifiable quantitative characteristics of GSPs analyzed in the present study.

An R&D logic model with inputs, performance and external influences
In particular, regarding national technology innovation R&D programs, representative R&D logic models are the ATP’s R&D logic model (Ruegg and Feller 2003; Shipp et al. 2005; Ruegg 2006) and the RTDDP’ R&D logic model (McLaughlin and Jordan 1999). These two typical R&D logic models contain the stepwise chain structure of creating performance, and they provide a general framework for evaluating public-sector R&D performance especially. Hence, this methodological framework is adopted for the present study. Furthermore, the R&D logic models classify some important measures of R&D performance. Also, Hsu and Hsueh (2009) provided a summary of representative factors of R&D inputs and performance of GSPs. In particular, they divided the four performance factors into the two sequential time ordered categories: (1) the intermediate outputs (publication articles, patent stocks) and (2) the final outputs (patents used in commercialization, profited commercialization).
The total of ten variables describe the overall characteristics of each observation (i.e., GSP), which included R&D inputs, performance and external influence factors as shown in Fig. 1. For the input variables, three characteristics are considered: R&D Budget (X1), R&D Period (X2), and R&D Workforce (X3). The five performance variables analyzed are SCI Publications (Y1), Patent Registration (Y2), Technology Transfer (Y3), Sales (Y4) and New Employment (Y5). The present study also considers two additional external influence variables such as Institution Type (T1) and R&D Collaboration Type (T2).
As explained in Sect. 4, the five performance variables (Y1, Y2, Y3, Y4, and Y5) are converted into five corresponding binary variables defined as Eq. (1) to Eq. (5) to deal with the sample characteristics. For example, for the ith observation, if the condition of Y1 i > 0 (i.e., the case of SCI Publications performance creation success), then the corresponding SCI Publications performance creation success-failure binary variable B1 i is defined as 1. However, the potential information loss can occur to some extent when the five continuous variables are converted into the corresponding five binary variables. Therefore, if it is possible, it is better to use the original continuous variables rather than to use the corresponding binary variables. But, as seen in the related literature, typical samples regarding technology innovation R&D projects tend to be sparse matrices in which most of the elements are zero. Mainly, for this reason, to cope with this nonnormal and censored characteristic of the sample, the present study attempts the binary variable conversions in spite of the information loss. Therefore, there is a trade-off between the benefits and the disadvantages of the variable conversions (Fritsch and Lukas 2001; Laursen and Salter 2004, 2006; Berchicci 2013; Robin and Schubert 2013).
Specifically, many studies reported data transformation before applying nonparametric regression models to the samples (e.g., (1) Logarithmic data transformation: Mairesse and Mohnen 2002; Greene 2003; Laursen and Salter 2006; Berchicci 2013; Robin and Schubert 2013; (2) Binary-Logit data transformation: Fritsch and Lukas 2001; Laursen and Salter 2004). After these data transformations, the literature aforementioned applied nonparametric models (e.g., Logit, Poisson and Tobit regression models) to the transformed samples (Mullahy 1986; Gujarati 1995; Winkelmann and Zimmermann 1995; Fritsch and Lukas 2001; Mairesse and Mohnen 2002; Greene 2003; Laursen and Salter 2004; Laursen and Salter 2006; Berchicci 2013; Robin and Schubert 2013).
In evaluating the performance of technology innovation R&D programs, the number of publication articles is regarded as one of the key short-term, technical output performance factors accompanied with patent stocks. For this reason, SCI Publications (Y1 → B1) is included as one of the short-term, technical output variables of the present study. In particular, the studies listed below used the number of academic articles published in journals as one of the short-term, technical output variables for evaluating R&D performance: Georghiou (1999), Osawa and Murakami (2002), Ruegg and Feller (2003), Lee and Park (2005), Meng et al. (2006), Wang and Huang (2007), Eilat et al. (2008), Hsu and Hsueh (2009), Thomas et al. (2011). In addition, the following studies analyzed the number of patents registered in patents offices as one of the output variables for evaluating R&D performance: Osawa and Murakami (2002), Revilla et al. (2003), Ruegg and Feller (2003), Chen et al. (2004), Lee and Park (2005), Wang and Huang (2007), Eilat et al. (2008), Hashimoto and Haneda (2008), Hsu and Hsueh (2009), Kim et al. (2009), Thomas et al. (2011), Cullmann et al. (2012).
Meanwhile, in the variables selection stage, NTIS data availability was checked beforehand and the core dataset closely related to GSP-level performance evaluation was extracted for the sample preparation. Because data uploaded into the NTIS are examined thoroughly, the reliability of the sample is regarded as fully verified.
Two external influence variables T1 and T2 are defined as Eq. (6) and Eq. (7), respectively. First, T1 is a 4-level categorical variable. According to the institution type of the ith observation, T1 has four distinct values, T1 i = L (Large Company), T1 i = U (University), T1 i = R (Research Laboratory) and T1 i = S (SME). Next, the binary variable T2 is defined as Eq. (7) in which T2 is classified into two separate values based on the R&D collaboration type of the ith observation, T2 i = 1 (R&D Collaboration) and T2 i = 0 (Single Institution R&D).
Specifically, X1 is the pure amount of government R&D subsidy, and institution type, denoted by T1 i = R, referred to government-funded research laboratory only. Meanwhile, the four institution types can be categorized into two broader institution types a for-profit (i.e., Large Company and SME) and not-for-profit (i.e., University and Research Laboratory). If only the ith observation reported R&D collaboration activities between the two heterogeneous institution types conducted within itself, then T2 i is equal to one.
Model (1) is a binary logistic regression model defined as Eq. (8), which explains the binary response variable B1 with the three predictor variables X1, T1, and T2. Therefore, Model (1) analyzes SCI Publications performance creation success-failure probability response to changes in the R&D budget, types of institution, and R&D collaboration. As verified in Sect. 4, statistically significant positive (+) correlations existed among the three input variables X1, X2, and X3. Assuming that the multicollinearity problem could be caused by including the three input variables together in the regression model, Model (1) is established as a reduced model that contains only one representative input variable X1. In the same manner of Model (1) in Eq. (8), Model (2) in Eq. (9) is defined to analyze the relationship between the response variable B2 and the three predictor variables. For interpretation purpose, Eq. (10) is derived from the Logit transformation formula in which the logistic distribution link function is applied to the probability of B1 i = 1 (i.e., SCI Publications performance creation success probability π1 i ). Therefore, Eq. (10) becomes a general linear regression model, and its response variable is the natural log-transformation of the odds ratio of π1 i .
Because T1 is a 4-level categorical variable, Model (1) in Eq. (8) is converted to Eq. (11) in practice based on the reference case and reference levels specified in Sect. 4. In Eq. (11), T1 is replaced by three binary variables, \(T1^{U}\), \(T1^{R}\), and \(T1^{S}\) where \(T1^{U}\), \(T1^{R}\), and \(T1^{S}\) correspond to the three institution types, University, Research Laboratory and SME, respectively. In the same context, Eq. (10) is converted to Eq. (12). The T1 variable applied conversion is commonly to from Model (2) to Model (5) explained afterwards.
According to the chain structure of the research model as depicted in Fig. 1, a series of three additional successive binary logistic regression models are developed from Model (3) in Eq. (13) to Model (5) in Eq. (15). As seen, Model (3) in Eq. (13) analyzes the relationship between the response variable B3 (i.e., Technology Transfer performance creation success-failure binary variable) and two predictor variables, B1 and B2. Likewise, Model (4) in Eq. (14) carries out further investigation on the relationship between the response variable B4 and another predictor variable B3. Finally, Model (5) in Eq. (15) is regarded as a fully extended model that relates the New Employment performance creation success-failure binary variable B5 located at the end of the research model to the remaining four binary performance predictor variables positioned ahead (i.e., B1, B2, B3 and B4).
Based on the theoretical background found in the literature, the following four hypotheses are proposed to answer the three aforementioned research questions.
Hypothesis 1
A positive (+) correlation exists between the input variables.
Hypothesis 2
A positive (+) correlation exists between the input and performance variables, but the correlation strength reduces gradually as the position of each performance variable moves forward along with the research model chain path from the short-term, technical outputs, to the long-term, socioeconomic impacts, via the mid-term, economic outcomes.
Hypothesis 3
A positive (+) correlation exists between the previous and subsequent performance variables.
Hypothesis 4
A performance difference exists between institution types and between R&D collaboration types.
Hypothesis 4.1
For-profit institutions obtain higher performance creation success probability in the mid-term, economic outcomes. Not-for-profit institutions obtain higher performance creation success probability in the short-term, technical outputs.
Hypothesis 4.2
Compared to single institution R&D, R&D collaboration induces a higher performance creation success probability.
Empirical analysis
Description of the sample
As mentioned, the sample analyzed in the present study is a set of completed GSPs within two representative national technology innovation R&D programs administered by the MSIP (i.e., formerly the MKE) with the Korean government, the Industry Convergence Technology Development Program (ICTDP) and Global Expertise Technology Development Program (GETDP), over the last five performance follow-up survey years (2009–2013). Initially, the sample consisted of 2036 completed GSPs, which was divided into two groups, such as 1627 ICTDP’s and 409 GETDP’s completed GSPs.
It is noted that some papers cope with the time lag very simply. For example, Berchicci (2013) and Wang and Huang (2007) used the samples of R&D inputs and performance with the 3-year time lag. Meanwhile, the present study used the sample with the time lag statistics as follows: the mean = 57.29 months and the median = 54.00 months. Furthermore, the sample of the present study was composed of completed GSPs so that the performance data were gleaned for the duration from GSPs’ completion to the performance follow-up survey year of 2013. Even though the completion years of each GSP were slightly different, this sample can be regarded as properly considering the time lag between R&D inputs and performance.
For the initial sample, the first data collection was conducted through the NTIS DBMS provided by Korea Institute of S&T Evaluation and Planning (KISTEP). For the second data investigation stage, the data obtained from the NTIS DBMS were verified and missing data from the first data collection stage were gleaned using the eR&D DBMS operated by the Korea Evaluation Institute of Industrial Technology (KEIT). After the two stages, 1314 completed GSPs of ICTDP and 226 completed GSPs of GETDP, for a total of 1540 completed GSPs were prepared, which was 75.6 % of the initial sample. The third online survey was carried out to verify the data reliability associated with the technology transfer royalty and sales. Consequently, the sample of n = 929 completed GSPs (i.e., 45.6 % of the initial sample) was prepared and consisted of 841 completed GSPs from ICTDP and 88 completed GSPs from GETDP.
Table 1 shows the descriptive statistics of the sample. As seen, the five continuous performance variables, Y1, Y2, Y3, Y4, and Y5, are severely skewed to the right, respectively. For example, even if Y2 has the smallest coefficient of variation (CoefVar), its CoefVar is equal to 2.48. With respect to the five continuous performance variables, the number of observations with a value greater than zero (i.e., the number of observations achieving performance) are as follows: (1) the two short-term, technical output variables, Y1, 456 (456/929 × 100 = 49 %) and Y2, 428 (46 %), (2) the two mid-term, economic outcome variables, Y3, 259 (28 %) and Y4, 182 (20 %) and (3) the socioeconomic impact variable, Y5 143 (15 %). Here, an interesting phenomenon is found that the number of observations achieving performance decreases monotonically when the position of each performance variable moves forward along with the research model chain path from the starting to ending points. These proportions exactly coincide with the means of the five binary variables, B1, B2, B3, B4 and B5 (mean = 0.49, 0.46, 0.28, 0.20, and 0.15, respectively). Again, the inherent scarcity of observations achieving performance can be confirmed because the medians of these five continuous performance variables are zero. In preparing the sample, the exchange rate of 1000 Won/$1 USD was applied to the raw data to convert monetary units, and Y3 was defined as the number of completed GSPs generated with a technology transfer royalty greater than zero.
Regarding the external influence variable T1, the sample composition proportions are as follows: (1) T1 = L, 81 (81/929 × 100 = 8.72 %); (2) T1 = U, 179 (19.27 %); (3) T1 = R, 314 (33.80 %); and (4) T1 = S, 355 (38.21 %). Hence, 436 observations (46.93 %) were conducted among for-profit institutions (i.e., Large Company and SME), and 493 observations (53.07 %) were carried out among not-for-profit institutions (i.e., University and Research Laboratory). The two types of institutions are proportionate to each other. The external influence variable T2 has Mean = 441/929 = 0.47. Hence, among the sample of n = 929 observations, R&D collaboration is observed within 441 GSPs while the other 488 GSPs are conducted using single institution R&D (i.e., T2 = 0).
Frequency analysis
Prior to analyzing the series of successive binary logistic regression models discussed later, a preliminary frequency analysis on the sample is necessary. A relevant frequency analysis can provide insight and guidance to build an organized and systematic regression analysis framework. Table 2 summarizes the sample frequencies classified by the two performance creation success-failure binary variables B1 and B2, respectively. Table 2 reveals that the reduction patterns of observations achieving the performance are quite different in each case. For example, among 428 observations satisfying the condition of B2 = 1, 151 (151/428 × 100 = 35 %) observations obtain B3 = 1, and 277 (65 %) observations obtain B3 = 0. Among 501 observations that satisfied the condition of B2 = 0, 108 (108/501 × 100 = 22 %) observations obtain B3 = 1 but 393 (78 %) observations obtain B3 = 0. It is expected that an observation with Patent Registration performance creation success is more likely to achieve Technology Transfer performance that is placed immediately after Patent Registration in the research model (i.e., 35 > 22 %).
By stepping down one layer, among 151 observations satisfying the condition of (B2 = 1 and B3 = 1), 50 (50/151 × 100 = 33 %) observations obtain B4 = 1, and 101 (67 %) observations obtain B4 = 0. Further, among 277 observations satisfying the condition of (B2 = 1 and B3 = 0), 46 (46/277 × 100 = 17 %) observations obtain B4 = 1, and 231 (83 %) observations obtain B4 = 0. Similarly, compared to observations that achieves Patent Registration performance only, those that achieves both Patent Registration and Technology Transfer performance show a higher probability for Sales performance creation success that is located immediately after the two previous performance factors (i.e., 33 > 17 %).
The following case may be the most notable illustration showing the relationship between the two directly connected performance factors. Fifty observations satisfy the conditions of B2 = 1, B3 = 1, and B4 = 1. Among them, 35 (35/50 × 100 = 70 %) observations obtain B5 = 1, which outnumbers the opposite group of 15 observations that obtain B5 = 0. On the contrary, among 101 observations that satisfy the conditions of B2 = 1, B3 = 1, and B4 = 0, 3 (3/101 × 100 = 3 %) observations obtain B5 = 1, and 98 (97 %) observations obtain with B5 = 0. It is noted that the key prerequisite for New Employment performance creation success could be generating Sales (i.e., 70 > 3 %). From the frequency analysis, it can be anticipated that two directly connected performance factors in the research model would have a strong positive (+) relationship with each other. In other words, the successor performance creation can be dependent on whether the predecessor performance is created.
(r × c) Contingency table
Table 3 supplements the interpretation on the frequency analysis above by providing accompanying statistical significance. In particular, Table 3 is a contingency table in which each value of B2 is arranged for the stratum, and two values of B3 and B4 are decomposed into the row levels (r = 2) and column levels (c = 2), respectively. Referring to the case of Table 3b with the stratum of B2 = 1, two test statistics, Pearson Chi-Sq (\(\chi^{ 2}\)) = 15.303 and Likelihood Ratio χ 2 = 14.809 have P values of 0.000***; the χ 2 independence test for null hypothesis can be rejected. A strong interaction exists between B3 and B4; therefore, it can be concluded that the B4 column frequencies significantly depend on the two values of B3. In Table 3, *, ** and *** indicate statistical significance at the significance level α = 10, 5 and 1 %, respectively.
Additionally, compared to the stratum of B2 = 0 in Table 3a, that of B2 = 1 in Table 3b shows the larger proportion for B3 = 1. Furthermore, confined within Table 3b, the proportion of B4 = 1 in the case of (B2 = 1, B3 = 1) is larger than the corresponding value in the case of (B2 = 1, B3 = 0). It is difficult to confirm the statistical significance on this proportion difference. In this context, it is necessary to analyze the sample systematically using a series of successive binary logistic regression models discussed below to understand the overall structural relationship among R&D inputs, performance, and external influence variables simultaneously associated with statistical significance.
R&D input and performance variables’ correlation analysis
When a correlation exists among the R&D input variables X1, X2 and X3, the multicollinearity impairs the precision of the estimated regression coefficients as a whole. When a full model including all these input variables together is estimated, the standard errors of the estimated regression coefficients usually tend to be inflated drastically. Therefore, the stability of the estimated regression models cannot be ensured. In a general linear regression analysis, the degree of multicollinearity can be measured by Variance Inflation Factor (VIF). Because of the nonparametric characteristics in the present study, three kinds of correlation coefficients among the input variables are scrutinized, including the parametric Pearson’s r and the nonparametric Kendall’s τ B and Spearman’s ρ s (Table 4). As seen in Table 4, strong correlations exist among these input variables, as expected. In particular, the largest correlation coefficients are found between X1 and X3, and all nine correlation coefficients in Table 4 have their own P values at 0.000***. Therefore, Hypothesis 1 is accepted. Hereafter, assuming that X1 is a representative input variable, a reduced model is analyzed associated with the input variable X1 only.
On the whole, most of correlation coefficients are positive (+) with statistical significance between R&D input variables and between performance variables. Additionally, between R&D input variables and performance variables, the majority of correlation coefficients are positive (+) accompanied with statistical significance. For a few instances only, negative (−) correlations are found between Y1 and Y4, Y5 and between X2 and Y4, Y5. In Sect. 4.5.5, it is confirmed again that the binary variable of SCI Publications is not significant to the three response variables B3, B4 and B5.
Logistic regression analysis
Model structure
Table 5 shows the primary results obtained from analyzing Model (1). In Table 5, the case of the response variable B1 = 1 is defined as the reference case. As for the two external influence variables, the levels of T1 = L and T2 = 0 are defined as the reference levels. The main results from Model (2) to Model (5) are summarized in Tables 6, 7, 8 and 9, respectively. Hereafter, a more detailed explanation is provided on the results of Model (1) in Table 5, and then only the unique and complementary contents listed in the remaining tables are discussed additionally.
Model diagnosis
Regarding Model (1) with a total of five predictor variables, the null hypothesis Eq. (16) and the alternative hypothesis Eq. (17) are established to test the model significance. In contrast to Model (1), the null hypothesis model including only the intercept term could be estimated. In the likelihood ratio test, the deviance difference between Model (1) and the null hypothesis model is calculated as \(\chi^{2} = D_{{{\text{Fitted}}\;(1)}} - D_{\text{Null}} = 213.253\), and P = 0.000*** where \(D_{{{\text{Fitted}}\; ( 1 )}}\) and \(D_{\text{Null}}\) denote the deviance of Model (1) and the null hypothesis model, respectively. Hence, Eq. (17) is accepted, and Model (1) is significance as a whole.
In addition to the basic likelihood ratio test, three χ 2 goodness of fit test statistics are provided based on Pearson, Deviance, and Hosmer–Lemeshow. Among them, two χ 2 goodness of fit test statistics, calculated using the Pearson and Deviance methods, have P values of less than 0.01, which implies that Model (1) is a sufficient fit for the sample.
Figure 2a illustrates the diagnostic plot showing of the Delta χ 2 (\(\Delta \chi^{2}\)) versus the predicted probability to pinpoint ill-fitted observations in Model (1). For example, the observation with the worst (i.e., the largest) \(\Delta \chi^{2}\) = 27.321 has the highest predicted probability = 0.964. By scrutinizing the sample, this worst observation includes raw data, such as X1 = 20.90 and T1 = R. Considering the X1 mean = 2.69 and median = 1.50, this observation consumes a comparably large amount of X1. However, it fails to achieve SCI Publications performance. Consequently, even though some observations of the sample spend a relatively large amount of R&D inputs, they fails to achieve any performance at all, which can be one reason for the ill-fit.

Delta χ 2 versus predicted probability diagnostic plots
In the range greater than the predicted probability of 0.5 in Fig. 2a, a group of observations is noticed as existing in the top-right upward trajectory, which shows exponential increases in \(\Delta \chi^{2}\). These observations can be interpreted as SCI Publications performance creation failures having their own B1 = 0, in spite of relatively higher predicted probabilities likely derived from relatively larger R&D inputs. On the other hand, in the range of less than or equal to the predicted probability of 0.5, as seen in Fig. 2a, a group of observations also forms a top-left upward trajectory with an exponentially increasing \(\Delta \chi^{2}\). These observations can be regarded as SCI Publications performance creation successes having their own B1 = 1 in spite of relatively lower predicted probabilities affected by smaller R&D inputs. For example, the observation with the minimum predicted probability = 0.182 and \(\Delta \chi^{2}\) = 4.515 includes raw data such as X1 = 0.34 and T1 = S. Considering the two central measures of X1, this observation consumes a relatively small amount of X1; however, in practice, it achieves SCI Publications performance.
Scanning down the diagnostic plots from Fig. 2a–e, an interesting movement of the \(\Delta \chi^{2}\) trajectory is detected. As illustrated, the top-right upward trajectory diminishes, and the top-left upward trajectory becomes clearly notable. In summary, despite the high predicted probability, some observations fail to create the short-term, technical output performance. On the contrary, overcoming the low predicted probability, multiple observations succeed in creating not only the economic outcomes, but also the socioeconomic impact performance.
Three measures of association of Model (1) are calculated to examine the prediction capability: (1) Somer’s D = 0.55, (2) Goodman–Kruskal γ = 0.55, and (3) Kendall’s τ A = 0.28. Practically, these measures of association can be referred to in the comparisons with the remaining four models [Model (2) to Model (5)]. In Model (1), all three measures of association are greater than the corresponding values of the other three models from Model (2) to Model (4); therefore, the prediction capability of Model (1) is excellent. As comprehensively explained in Table 10, the predictor variable X1 in Model (1) has the largest absolute value of the estimated coefficient and the strongest statistical significance compared to the X1 s from Model (2) to Model (5). This may contribute to the superior prediction capability of Model (1). It also meets the expectation that SCI Publications performance creation success probability could be explained better by the predictor variable X1 because SCI Publications, a short-term, technical output performance, is placed closest to the R&D inputs in the research model. Besides Model (1), Model (5) also has relatively larger measures of association, including Somer’s D = 0.85 and Goodman–Kruskal γ = 0.86. In the comparisons of measures of association, Model (1) and Model (5) are superior to the other three models from the prediction perspective.
Among the 215,688 (=456 × 473) pairs of (success, failure) observations, the number of concordant pairs (166,882; 77.4 %) is larger than the number of discordant pairs (48,084, 22.3 %). In this binary logistic regression analysis, the concordant pair indicates the pair with the predicted probability of the success observation is larger than the predicted probability of the failure observation. Inversely, the discordant pair is defined as the pair whose predicted probability of the failure observation is higher than that of the success observation. In terms of the concordant and discordant pair counts, Model (1) gains good predictive power on the probability for B1. Among the five models, Model (5) has the largest proportion of concordant pairs (99.2 %) and Model (1) has the second largest proportion (77.4 %). The other three models retain similar quantities, 69.4, 68.1, 75.0 %, respectively. Therefore, Model (5) and Model (1) show better prediction capabilities, which also agrees with the interpretation of the measures of association.
Model estimation (1): input versus performance
As shown in Table 5, X1 is a statistically significant predictor variable in Model (1) with a positive (+) estimated coefficient \(\hat{\beta }_{1} = 0.179\) and P = 0.000***. Based on the odds ratio exp(\(\hat{\beta }_{1}\)) = 1.20, we interpret that SCI Publications performance creation success probability odds ratio increases 1.20-fold with 1 unit increment in X1. Meanwhile, it is known that changes in the odds ratio increase when the probability of success is closer to 0.5 (Hosmer and Lemeshow 2000; Montgomery et al. 2001; Minitab 2005; IBM SPSS 2009).
Table 7 details the results from the binary logistic regression analysis on Model (3). As seen, compared to Model (1), Model (3) has an extended structure that includes a total of seven predictor variables in which the two response variables of Model (1) and Model (2) (i.e., B1 and B2) are inserted as additional predictor variables to verify the relationship between the successor performance B3 and the two directly connected predecessor performance B1 and B2. The case of the response variable B3 = 1 is defined as the reference case (Table 7). Likewise, Table 7 shows that the levels of T1 = L and T2 = 0 are the reference levels. Furthermore, for the two newly added predictor variables, reference levels are defined as B1 = 0 and B2 = 0. In Table 7, X1 is also a statistically significant predictor variable in Model (3), which has a positive (+) estimated coefficient \(\hat{\beta }_{ 1} = 0.095\) and P = 0.000***. The odds ratio is exp(\(\hat{\beta }_{ 1}\)) = 1.10. An interesting point is that changes of the estimated coefficients of X1 are (+) 0.179*** → (+) 0.153*** → (+) 0.095*** → (+) 0.092*** → (+) 0.010 through the successive model extension from Model (1) to Model (5). As seen, all five estimated coefficients of X1 have positive signs (+) consistently, and the absolute values decrease monotonically along with the successive model extension. Finally, in Model (5), the estimated coefficient of X1 becomes statistically insignificant. Therefore, a phenomenon is found that R&D inputs can exert their influence more on the chronologically adjacent short-term, technical output performance factors such as B1 and B2. Afterwards, against the mid-term, economic outcome performance factors such as B3 and B4, the influence decreases. Moreover, it is expected that it would not be easy for the R&D inputs to demonstrate their influence in the long-term, socioeconomic impact performance factor B5 located farthest. Therefore, Hypothesis 2 is accepted.
Model estimation (2): external influences
Table 5 presents three distinct estimated coefficients associated with T1 in Model (1), except for the reference level T1 = L. The level T1 = U has a positive (+) estimated coefficient, \(\hat{\beta }_{{T1^{U} }} = 1.489\) and P = 0.000***, which is statistically significant to the response variable B1. Because the level of T1 = U yields a positive (+) estimated coefficient, the odds ratio exp(\(\hat{\beta }_{{T1^{U} }}\)) = 4.43 is larger than one. Thus, SCI Publications performance creation success probability odds ratio increases 4.43-fold when the level of T1 changes from the reference level T1 = L to T1 = U. Next, the level of T1 = S has a negative (−) estimated coefficient, \(\hat{\beta }_{{T1^{S} }} = - 0.894\) and P = 0.001***, which is statistically significant to the response variable B1. Because the level of T1 = S has a negative (−) estimated coefficient, the odds ratio, exp(\(\hat{\beta }_{{T1^{S} }}\)) = 0.41 is less than one. Therefore, SCI Publications performance creation success probability odds ratio decreases 0.41-fold by changing the level of T1 from the reference level T1 = L to T1 = S. The decreasing sequence of exp(\(\hat{\beta }_{{T1^{U} }}\)) = 4.43*** → exp(\(\hat{\beta }_{{T1^{R} }}\)) = 1.25 → exp(\(\hat{\beta }_{{T1^{S} }}\)) = 0.41*** implies that SCI Publications performance creation success probability odds ratio decreases when institution type changes from the not-for-profit to for-profit as follows: University (1st) → Research Laboratory (2nd) → Large Company (3rd) → SME (4th). Therefore, SCI Publications performance creation success probability is sensitive to institution types. Specifically, University shows the best, and SME the worst in SCI Publications performance. The two other institution types (i.e., Research Laboratory and Large Company) are located in between and are not statistically significantly different.
The results regarding T1, listed in Tables 5, 6, 7, 8 and 9 are also summarized in Table 11. As for Model (2) in Table 6, three odds ratios are arranged as exp(\(\hat{\beta }_{{T1^{U} }}\)) = 2.28*** → exp(\(\hat{\beta }_{{T1^{R} }}\)) = 1.42 → exp(\(\hat{\beta }_{{T1^{S} }}\)) = 0.73, which shows exactly the same sequence as Model (1) in Table 5. Similarly, Patent Registration performance creation success probability odds ratio declines when institution type changes from the not-for-profit to for-profit. Regarding the two response variables, B4 and B5 in Tables 8 and 9, a completely opposite sequence is found. Because the odds ratios of T1 in Table 8 yield an increasing sequence, exp(\(\hat{\beta }_{{T1^{U} }}\)) = 0.54 → exp(\(\hat{\beta }_{{T1^{R} }}\)) = 0.62 → exp(\(\hat{\beta }_{{T1^{S} }}\)) = 4.13***, Sales performance creation success probability odds ratio also increases when institution type changes from the not-for-profit to for-profit as follows: University (4th) → Research Laboratory (3rd) → Large Company (2nd) → SME (1st). Even though statistical significances are not accompanied, the odds ratios of T1 in Table 9 can also be arranged as exp(\(\hat{\beta }_{{T1^{R} }}\)) = 0.44 → exp(\(\hat{\beta }_{{T1^{U} }}\)) = 0.48 → exp(\(\hat{\beta }_{{T1^{S} }}\)) = 1.51 (i.e., Research Laboratory (4th) → University (3rd) → Large Company (2nd) → SME (1st)). Sales and New Employment performance creation success probability odds ratio increases when institution type changes from research-oriented not-for-profit to commercialization-oriented for-profit institutions. Therefore, Hypothesis 4.1 is partially accepted. Specifically, SME performs best in the aspect of Sales. Meanwhile, University is excellent in the two performance factors of SCI Publications and Patent Registration.
Second, T2 has a positive (+) estimated coefficient, \(\hat{\beta }_{T2}\) = 0.314 and P = 0.036** (Table 5), which is statistically significant to the response variable B1. Based on the odds ratio exp(\(\hat{\beta }_{T2}\)) = 1.37, SCI Publications performance creation success probability odds ratio increases 1.37-fold with the change from the reference level T2 = 0 to T1 = 1. As seen in Tables 5, 6, 7, 8 and 9, the coefficients of T2 are estimated with a positive (+) sign consistently as (+) 0.314** → (+) 0.202 → (+) 0.278* → (+) 0.097 → (+) 0.227; however, only two models yield statistical significance (i.e., Model (1) and (3)). For this reason, external influences of R&D collaboration may be restricted within the boundary up to the mid-term, economic outcome performance. Hence, Hypothesis 4.2 is also partially accepted.
Model estimation (3): performance chain
This section presents a comprehensive investigation on how closely the time-ordered previous and subsequent performance factors relate to one another. First, between the response variable B3 and the two predictor variables B1 and B2 of Model (3) in Table 7, only B2 has a positive (+) estimated coefficient, \(\hat{\beta }_{B2}\) = 0.658 and P = 0.000***, and is statistically significant to the response variable B3. Based on the odds ratio, exp(\(\hat{\beta }_{B2}\)) = 1.93, Technology Transfer performance creation success probability odds ratio increases 1.93-fold when an observation achieves Patent Registration performance in advance. In particular, among a total of seven predictor variables in Model (3), B2 has the largest odds ratio.
Second, Table 8 explains the relationship between the response variable B4 and three predictor variables B1, B2 and B3 of Model (4). Among them, only two, B2 and B3, have positive (+) estimated coefficients, \(\hat{\beta }_{B2}\) = 0.699 and \(\hat{\beta }_{B3}\) = 0.968 accompanied with P = 0.000***. We can interpret this result that Sales performance creation success probability odds ratio increases 2.01-fold and 2.63-fold, respectively when an observation achieves Patent Registration and Technology Transfer performance based on the two odds ratios, exp(\(\hat{\beta }_{B2}\)) = 2.01 and exp(\(\hat{\beta }_{B3}\)) = 2.63. As a result, not only Patent Registration but also Technology Transfer performance creation success can be crucial to enhancing Sales performance creation success probability. In the comparison of the two odds ratios, it is confirmed that B3 closer to B4 has a stronger relationship than does B2 indirectly connected to B4.
Third, referring to Model (5) in Table 9, we identify that the two predictor variables of B2 and B4 are statistically significant to the response variable of B5. Most notably, B4 has the largest positive (+) estimated coefficient, \(\hat{\beta }_{B4}\) = 4.123 with P = 0.000***. Based on the odds ratio, exp(\(\hat{\beta }_{B4}\)) = 61.71, it can be anticipated that New Employment performance creation success probability odds ratio increases as much as 61.71-fold when an observation achieves Sales performance. This finding implies that New Employment performance creation success probability odds ratio increases drastically by achieving Sales performance in advance. In the comparison with B4, B2 still survives as a significant predictor variable against the response variable B5 even though both the absolute size of the estimated coefficient and the statistical significance are weakened slightly. Specifically, B2 has a positive (+) estimated coefficient, \(\hat{\beta }_{B2}\) = 0.541 with P = 0.072*, and its odds ratio is exp(\(\hat{\beta }_{B2}\)) = 1.72.
Table 10 provides a summary of significant predictor variables in the series of five successive binary logistic regression models analyzed from Tables 5, 6, 7, 8 and 9. When we navigate backward along with the research model shown in Fig. 1, the path of B5 ← B4 ← B3 ← B2 ← X1 is clearly identified and statistically significant. Therefore, Hypothesis 3 is accepted. Meantime, the binary variable of SCI Publications (B1) does not show any statistical significance in the three models from Model (3) to Model (5). It implies that the influence of SCI Publications is relatively weaker compared with Patent Registration against the three subsequent performance factors B3, B4 and B5. Therefore, the factor of scientific publications is more an indicator of scientific exploration than of commercialization, and the influence of scientific publications on the economic growth can be indirect.
Sensitivity analyses: prediction models
Figure 3 presents a sensitivity analysis of the predicted probability for B2 = 1 based on Model (2) in Table 6. The range of X1 is 0–20 (US$ 106), and the predicted probability is calculated for the four distinct levels of T1. The key features displayed in Fig. 3 are as follows. First, the predicted probability for Patent Registration performance creation success shows a smooth S-shape nonlinear growth curve. Below the inflection point of X1, around 10, the predicted probability increases sharply, and it changes rather slowly after the inflection point. Second, as mentioned in the interpretation of the estimated coefficients of T1, the level of T1 = U has the highest predicted probability for Patent Registration performance creation success. On the other hand, the two for-profit institutions, denoted by T1 = L and T1 = S, show relative lower predicted probabilities.

Sensitivity analysis on the predicted probability of patent registration (B2) with the common condition of T2 = 1
Two panels in Fig. 4 present another illustration in which the predicted probability for B4 = 1 is displayed based on Model (4) in Table 8. Figure 4 reveals obviously contrasted features against Fig. 3. First, in Fig. 4a, the predicted probability for Sales performance creation success seems insensitive to changes in X1, which forms a slightly low slope linear trend. Second, the curves in Fig. 4b shift upward compared with the corresponding curves in Fig. 4a, which means that Sales performance creation success probability increases by changing the institution type from T1 = U to T1 = S. Third, Sales performance creation success probability is very sensitive to the performance of its two predecessors. In particular, an observation achieving Technology Transfer performance can expedite Sales performance creation.

Sensitivity analysis on the predicted probability of sales (B4) with the common conditions of T2 = 1 and B1 = 1: a T1 = U, b T1 = S
Conclusions
A systematic framework has been emphasized to enhance the reliability of a national R&D program performance evaluation. By using an appropriately designed framework, the accountability of a R&D performance evaluation can be enhanced to plan subsequent R&D programs and budget allocation in practice. Meanwhile, the applicability of a typical R&D logic model that is taken for granted in public sector R&D performance evaluations and should be verified by examining the relationship among various R&D inputs, performance, and external influence factors. It is also necessary to develop a well-organized model and application procedure based on a typical R&D model.
The present study analyzed a sample of n = 929 completed GSPs during the last five performance follow-up survey years (2009–2013) in representative national technology innovation R&D programs administered by the Korean government. The main feature of the present study was the series of five successive binary logistic regression models that considered both the stepwise chain structure of the research model and the nonparametric sample characteristics simultaneously. The two additional categorical and binary variables were incorporated into the model and were associated with the external influences.
Major results of the present study are summarized as follows. First, strong positive (+) correlations were found among the three R&D input variables from the parametric and nonparametric perspectives. In particular, the correlation coefficients between X1 and X3 are larger than the other correlation coefficients as a whole. Second, the R&D input variable X1 (i.e., R&D Budget) had the positive (+) estimated coefficients consistently against all five response variables concerned in the present study. The absolute values of these coefficients decreased monotonically along with the successive model extension. Therefore, it can be pointed out that R&D inputs could exert their influence more on the chronologically adjacent short-term, technical output performance factors. Afterwards, against the mid-term, economic outcome performance factors, the R&D inputs’ influence is diminishing gradually. Moreover, in the sensitivity analysis, we found that the predicted probability for Patent Registration performance creation success showed a smooth S-shape nonlinear growth curve as X1 increased. Third, a statistically significant relationship was identified among the performance factors. This finding implies that the successor performance creation can be very dependent on whether predecessor performance is achieved. Specifically, the path of B5 ← B4 ← B3 ← B2 ← X1 was more clearly detected in the research model shown in Fig. 1. Among the two short-term, technical output performance factors, Patent Registration retained more connections with subsequent performance factors compared to SCI Publications. Fourth, as for the external influence variable T1, the institution type of SME performed the best with respect to Sales performance. On the contrary, University was excellent in both SCI Publications and Patent Registration. Further, the external influence of R&D collaboration can be restricted within the boundary up to the mid-term, economic outcome performance.
Based on the results summarized above, some policy implications can be proposed with respect to R&D performance management. First, because of the strong relationship between the two directly connected performance factors, we need to encourage a sequential performance creation as much as possible to extend a GSP R&D performance creation life cycle. Second, practitioners should carefully apply measures of efficiency that can quantify the size of ratio of outputs over inputs to performance factors beyond the mid-term, economic outcomes boundary, because the influence of R&D inputs is effective only within that boundary. Third, considering the significant performance differences between institution types and between R&D collaboration types, it is required to select performance-oriented GSPs in building subsequent R&D programs. Specifically, it is required to expedite R&D collaboration. An SME-friendly planning and deployment is also recommended for national technology innovation R&D programs focusing on Sales performance especially. The probability prediction models can also be used to pinpoint some benchmark of GSPs that actually create performance in spite of a low predicted probability.
The present study did not consider other key R&D inputs, such as R&D capability and accumulated R&D knowledge and experience owned by the institutions; therefore, these intangible R&D inputs should be reflected in a future modification of the research model. Furthermore, ordinal logistic regression models can be incorporated into the successive regression analysis procedure to reflect more finely categorized values of the five R&D performance variables.
Appendix
In Sect. 4.5.5, the binary variable of SCI Publications (i.e., B1) does not obtain any statistical significance in the three subsequent models from Model (3) to Model (5). It implies that the influence of SCI Publications is relatively weaker compared with Patent Registration to the three subsequent performance factors B3, B4 and B5.
Now, it is necessary to see if there is an indirect influence of scientific publications. For this, the original research model in Fig. 1 is modified as Fig. 5 shown below. In Fig. 5, the arc linking between SCI Publications (B1) and Technology Transfer (B3) is disconnected, and a new arc is added to connect between SCI Publications (B1) and Patent Registration (B2) in order to verify the relationship between scientific publications and patent stocks. To verify the relationship between scientific publications and patent stocks, it is needed to modify Model (2). Equation (18) is the modified model, Model (2)-Modified, where a new predictor variable B1 is newly added.

A modified research model for verifying an indirect influence of SCI publications (Y1 → B1)
Table 12 shows the results from the binary logistic regression analysis with Model (2)-Modified. Between the response variable B2 and the predictor variables B1 in Model (2)-Modified, B1 has a positive (+) estimated coefficient, \(\hat{\beta }_{B1} = 0.778\) and P = 0.000***, and is statistically significant to the response variable B2. Also, based on the odds ratio, exp(\(\hat{\beta }_{B1}\)) = 2.18, Patent Registration performance creation success probability odds ratio increases 2.18-fold when an observation achieves SCI Publications performance in advance. Therefore, there is a strong relationship between the two technical output factors, which implies that scientific publications can exert their influences indirectly on the mid-term, economic outcomes via patent stocks beforehand.
References
Albert, M., Avery, D., Narin, F., & McAllister, P. (1991). Direct validation of citation counts as indicators of industrially import patents. Research Policy, 20(3), 251–259.
Åström, T., Jansson, T., Mattsson, P., Faugert, S., Hellman, J. & Arnold, E. (2010). Summary impact analysis of support for strategic development areas in the Swedish manufacturing industry. VINNOVA Analysis VA 2010:07, Sweden: VINNOVA.
Bacchiocchi, E., & Montobbio, F. (2009). Knowledge diffusion from university and public research. A comparison between US, Japan and Europe using patent citations. Journal of Technology Transfer, 34(2), 1169–1181.
Belderbos, R., Carree, M., & Lokshin, B. (2004). Cooperative R&D and firm performance. Research Policy, 33(10), 1477–1492.
Berchicci, L. (2013). Towards an open R&D system: Internal R&D investment, external knowledge acquisition and innovative performance. Research Policy, 42(1), 117–127.
Bickman, L. (1987). The functions of program theory. Special Issue: Using Program Theory in Evaluation, New Directions for Program Evaluation, 1987(33), 5–18.
Bitman, W. R., & Sharif, N. (2008). A conceptual framework for ranking R&D projects. IEEE Transactions on Engineering Management, 55(2), 267–278.
Branstetter, L. & Ogura, Y. (2005). Is academic science driving a surge in industrial innovation? Evidence from patent citations. NBER working paper, no. 11561.
Chen, C.-T., Chien, C.-F., Lin, M.-H., & Wang, J.-T. (2004). Using DEA to evaluate R&D performance of the computers and peripherals firms in Taiwan. International Journal of Business, 9(4), 347–359.
Chen, K. H., & Guan, J. C. (2012). Measuring the efficiency of China’s regional innovation systems: An application of network DEA. Regional Studies, 46(3), 355–377.
Chen, X., Wang, X., & Wu, D. D. (2011). Analysing firm performance in Chinese IT industry: DEA Malmquist productivity measure. International Journal of Information Technology and Management, 10(1), 3–23.
Cooper, W. W., Seiford, L. M., & Zhu, J. (2004). Handbook on data envelopment analysis. Boston MA: Springer.
Cullmann, A., Schmidt-Ehmcke, J., & Zloczysti, P. (2012). R&D efficiency and barriers to entry: A two stage semi-parametric DEA approach. Oxford Economic Papers, 64(1), 176–196.
Eilat, H., Golany, B., & Shtub, A. (2008). R&D project evaluation: An integrated DEA and balanced scorecard approach. Omega, 36(5), 895–912.
Elg, L. & Håkansson, S. (2012). Impacts of innovation policy—Lessons from VINNOVA’s impact studies. VINNOVA Analysis VA 2012:01, Sweden: VINNOVA.
Esteve-Pérez, S., & Rodríguez, D. (2013). The dynamics of exports and R&D in SMEs. Small Business Economics, 41(1), 219–240.
Färe, R., & Grosskopf, S. (2000). Network DEA. Socio-Economic Planning Sciences, 34(1), 35–49.
Farris, J. A., Groesbeck, R. L., Aken, E. M. V., & Letens, G. (2006). Evaluating the relative performance of engineering design projects: A case study using data envelopment analysis. IEEE Transactions on Engineering Management, 55(3), 471–482.
Fritsch, M., & Lukas, R. (2001). Who cooperates on R&D? Research Policy, 30(2), 297–312.
Georghiou, L. (1999). Socio-economic effects of collaborative R&D-European experiences. Journal of Technology Transfer, 24(1), 69–79.
Geuna, A., Salter, A. J., & Steinmueller, W. E. (2003). Science and innovation: Rethinking the rationales for funding and governance, new horizons in the economics of innovation. Northampton MA: Edward Elgar.
Greene, W. H. (2003). Econometric analysis (5th ed.). Upper Saddle River, NJ: Prentice Hall.
Gronum, S., Verreynne, M.-L., & Kastelle, T. (2012). The role of networks in small and medium-sized enterprise innovation and firm performance. Journal of Small Business Management, 50(2), 257–282.
Guan, J., & Chen, K. (2010). Modeling macro-R&D production frontier performance: An application to Chinese province-level R&D. Scientometrics, 82(1), 165–173.
Guan, J. C., & Chen, K. H. (2012). Modeling the relative efficiency of national innovation systems. Research Policy, 41(1), 102–115.
Gujarati, D. N. (1995). Basic econometrics (3rd ed.). New York, NY: McGraw-Hill.
Hashimoto, A., & Haneda, S. (2008). Measuring the change in R&D efficiency of the Japanese pharmaceutical industry. Research Policy, 37(10), 1829–1836.
Hosmer, D. W., & Lemeshow, S. G. (2000). Applied logistic regression (2nd ed.). New York, NY: Wiley.
Hsu, F. M., & Hsueh, C. C. (2009). Measuring relative efficiency of government-sponsored R&D projects: A three-stage approach. Evaluation and Program Planning, 32(2), 178–186.
Hu, A. G. (2009). The regionalization of knowledge flows in East Asia: Evidence from patent citations data. World Development, 37(9), 1465–1477.
Hu, A. G., & Jaffe, A. (2003). Patent citations and international knowledge flow: The cases of Korea and Taiwan. International Journal of Industrial Organization, 21(6), 849–880.
IBM SPSS (2009). PASW Statistics Release 18. Armonk, NY: IBM Corp.
Jaffe, A., & Trajtenberg, M. (2002). Patents, citations and innovations: A window on the knowledge economy. Cambridge, MA: The MIT Press.
Kim, J., Lee, S. J., & Marschke, G. (2009). Relation of firm size to R&D productivity. International Journal of Business and Economics, 8(1), 7–19.
Korea Evaluation Institute of Industrial Technology (KEIT). (2010). 2010 Performance investigation and analysis of knowledge economy technology innovation program. Korea: KEIT.
Korea Evaluation Institute of Industrial Technology (KEIT). (2011). 2011 Performance investigation and analysis of knowledge economy technology innovation program. Korea: KEIT.
Korea Evaluation Institute of Industrial Technology (KEIT). (2013). 2012 Performance investigation and analysis of knowledge economy technology innovation program. Korea: KEIT.
Korea Institute of S&T Evaluation and Planning (KISTEP). (2011). International case studies on major issues for performance evaluation system improvement. Korea: KISTEP.
Korea Institute of Science and Technology Information (KISTI). (2008). Law-enforcement ordinance-enforcement regulations. http://www.ntis.go.kr/ThMain.do. Accessed August 1, 2014.
Laursen, K., & Salter, A. (2004). Searching high and low: What types of firms use universities as a source of innovation? Research Policy, 33(8), 1201–1215.
Laursen, K., & Salter, A. (2006). Open for innovation: The role of openness in explaining innovation performance among U.K. manufacturing firms. Strategic Management Journal, 27(2), 131–150.
Lee, H. (2015). Uncovering the multidisciplinary nature of technology management: Journal citation network analysis. Scientometrics, 102(1), 51–75.
Lee, H. Y., & Park, Y. T. (2005). An international comparison of R&D efficiency: DEA approach. Asian Journal of Technology Innovation, 13(2), 207–222.
Lee, H., Park, Y., & Choi, H. (2009). Comparative evaluation of performance of national R&D programs with heterogeneous objectives: A DEA approach. European Journal of Operational Research, 196(3), 847–855.
Lenihan, H. (2011). Enterprise policy evaluation: Is there a ‘new’ way of doing it? Evaluation and Program Planning, 34(4), 323–332.
Liang, L., Li, Z.-Q., Cook, W. D., & Zhu, J. (2011). Data envelopment analysis efficiency in two-stage networks with feedback. IIE Transactions, 43(5), 309–322.
Linton, J. D., Walsh, S. T., & Morabito, J. (2002). Analysis, ranking and selection of R&D projects in a portfolio. R&D Management, 32(2), 139–148.
Löthgren, M., & Tambour, M. (1999). Productivity and customer satisfaction in Swedish Pharmacies: A DEA Network model. European Journal of Operational Research, 115(3), 449–458.
Mairesse, J., & Mohnen, P. (2002). Accounting for innovation and measuring innovativeness: An illustrative framework and application. American Economic Review, 92(2), 226–230.
McLaughlin, J. A., & Jordan, G. B. (1999). Logic models: A tool for telling your program’s performance story. Evaluation and Program Planning, 22(1), 65–72.
Meng, W., Hu, Z. H., & Liu, W. B. (2006). Efficiency evaluation of basic research in China. Scientometrics, 69(1), 85–101.
Ministry of Knowledge Economy (MKE). (2008). 2007 Electric power industry R&D programs. Korea: MKE.
Ministry of Knowledge Economy and Korea Institute for Advancement of Technology (MKE KIAT). (2012). 2012 Guideline of knowledge economy R&D performance index design. Korea: MKE KIAT.
Ministry of Science and Technology and Office of Science and Technology Innovation (MST OSTI). (2008). 2008 Internal evaluation manual of national R&D programs. Korea: MST OSTI.
Minitab. (2005). Minitab Release 14.20 StatGuide. State College PA: Minitab Inc.
Montgomery, D. C., Peck, E. A., & Vining, G. G. (2001). Introduction to linear regression analysis (3rd ed.). New York, NY: Wiley.
Mullahy, J. (1986). Specification and testing in some modified count data models. Journal of Econometrics, 33(3), 341–365.
Narin, F., & Noma, E. (1985). Is technology becoming science? Scientometrics, 7(3–6), 369–381.
Office of Management and Budget and Office of Science and Technology Policy (OMB OSTP). (2012). Memorandum for the heads of executive departments and agencies, subject: Science and technology priorities for the FY 2014 budget. http://www.whitehouse.gov/omb/. Accessed August 1, 2014.
Office of Science and Technology Policy (OSTP). (2012). Innovation for America’s economy, America’s energy, and american skills: Science, technology, innovation, and STEM education in the 2013 budget. http://www.ostp.gov/. Accessed August 1, 2014.
Ortega-Argilés, R., Vivarelli, M., & Voigt, P. (2009). R&D in SMEs: A paradox? Small Business Economics, 33(1), 3–11.
Osawa, Y., & Murakami, M. (2002). Development and application of a new methodology of evaluating industrial R&D projects. R&D Management, 32(1), 79–85.
Park, S. (2014). Analyzing the efficiency of small and medium-sized enterprises of a national technology innovation research and development program. SpringerPlus, 3(1), 1–12.
Revilla, E., Sarkis, J., & Modrego, A. (2003). Evaluating performance of public-private research collaborations: A DEA analysis. Journal of the Operational Research Society, 54(2), 165–174.
Robin, S., & Schubert, T. (2013). Cooperation with public research institutions and success in innovation: Evidence from France and Germany. Research Policy, 42(1), 149–166.
Roper, S., Hewitt-Dundas, N., & Love, J. H. (2004). An ex ante evaluation framework for the regional benefits of publicly supported R&D projects. Research Policy, 33(3), 487–509.
Ruegg, R. (2006). Bridging from project case study to portfolio analysis in a public R&D program: A framework for evaluation and introduction to a composite performance rating system. Gaithersburg, MD: Economic Assessment Office, Advanced Technology Program, National Institute of Standards and Technology, U.S. Department of Commerce.
Ruegg, R. & Feller, I. (2003). A toolkit for evaluating public R&D investment: Models, methods and findings from ATP’s first decade. Gaithersburg, MD: Economic Assessment Office, Advanced Technology Program, National Institute of Standards and Technology, U.S. Department of Commerce.
Sharma, S., & Thomas, V. J. (2008). Inter-country R&D efficiency analysis: An application of data envelopment analysis. Scientometrics, 76(3), 483–501.
Shipp, S., Chang, C. & Wisniewski, L. (2005). Evaluation best practices and results: The advanced technology program. Gaithersburg, MD: Economic Assessment Office, Advanced Technology Program, National Institute of Standards and Technology, U.S. Department of Commerce.
STAR METRICS. (2014). https://www.starmetrics.nih.gov/. Accessed August 1, 2014.
Stephan, P. E. (2010). Chapter 5. The economics of science. In B. H. Hall & N. Rosenberg (Eds.), Handbook of the economics of innovation (Vol. 1, pp. 217–273). Boston, MA: North Holland.
Tan, H. X., Ujum, E. A., Choong, K. F., & Ratnavelu, K. (2015). Impact analysis of domestic and international research collaborations: A Malaysian case study. Scientometrics, 102(1), 885–904.
Thomas, V., Sharma, S., & Jain, S. K. (2011). Using patents and publications to assess R&D efficiency in the states of the USA. World Patent Information, 33(1), 4–10.
W. K. Kellogg Foundation (WKKF). (2004). W. K. Kellogg Foundation Logic Development Guide. Battle Creek MI.
Wang, E. C., & Huang, W. (2007). Relative efficiency of R&D activities: A cross-country study accounting for environmental factors in the DEA approach. Research Policy, 36(2), 260–273.
Wholey, J. S. (1983). Evaluation and effective public management. Boston, MA: Little Brown.
Wholey, J. S. (1987). Evaluability assessment: Developing program theory. Special Issue: Using Program Theory in Evaluation, New Directions for Program Evaluation, 1987(33), 77–92.
Winkelmann, R., & Zimmermann, K. F. (1995). Recent developments in count data modelling: Theory and application. Journal of Economic Surveys, 9(1), 1–24.
Wu, W., Tsai, H., Cheng, K., & Lai, M. (2006). Assessment of intellectual capital management in Taiwanese IC design companies: Using DEA and the Malmquist productivity index. R&D Management, 36(5), 531–545.
Acknowledgments
The author acknowledges the contribution of the following institutions who permit data available in the present study such as the Korea Evaluation Institute of Industrial Technology (KEIT), the Korea National IT Industry Promotion Agency (NIPA) and the Ilshin Accounting Corporation. This study was partially supported by Baekseok University Research Grant.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article

Cite this article
Park, S. The R&D logic model: Does it really work? An empirical verification using successive binary logistic regression models. Scientometrics 105, 1399–1439 (2015). https://doi.org/10.1007/s11192-015-1764-6
Received:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11192-015-1764-6
Keywords
- Binary logistic regression
- Performance evaluation
- Probability prediction
- R&D logic model
- Sensitivity analysis
- Sequential estimation