
Abstract
Hedonic regression and repeat sales are commonly used methods in real estate analysis. While the merits of combining these models when constructing house price indices are well documented, research on the utility of adopting the same approach for residential property valuation has not been conducted to date. Specifically, house value estimates were obtained by combining predictions from repeat sales and various hedonic regression specifications, which were enhanced to account for spatial effects. Three of these enhancements—regression kriging, mixed regressive-spatial autoregressive, and geographically weighted regression—are widely utilized spatial econometric models. However, a fourth augmentation, which addresses systematic residual patterns in regressions with district indicator variables and the presence of outliers in housing data, was also proposed. The resulting models were applied to a dataset containing 16,417 real estate transactions in Oslo, Norway, revealing that when the repeat sales approach is included, it reduces the median absolute percentage error of solely hedonic models by 6.8–9.5%, where greater improvements are associated with less accurate spatial enhancements. These improvements can be attributed to the inclusion of both spatial and non-spatial information inherent in previous sales prices. While the former has limited utility for well-specified spatial models, the non-spatial information that is implicit in previous sales prices likely captures otherwise difficult to observe phenomena, potentially making its contribution highly valuable in automated valuation models.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
Introduction
Accurate property valuation is essential for reducing the inherent uncertainty in housing transactions. Since home purchase represents the largest investment most individuals will make in their lifetime, uncertainty tolerance is low. This psychological component of what is essentially a financial transaction arguably underpins the real estate agent industry and its business of human appraisal of property market value (Levin 2001). Accurate property valuation is also critical for housing research. New, well-specified big datasets combined with more computer power have made it cost effective to construct more accurate valuation models. Corcoran and Liu (2014) point out that the growing demand for automatically generated housing value estimates, as an efficient and cost-effective alternative, may potentially contribute to a more transparent housing market.
In this article, the benefits derived by combining property price predictions yielded by two well-known valuation methods—repeat sales and hedonic regression—were investigated. The developed models were tested and applied to 16,417 residential property transactions in Oslo, Norway, between August 2016 and December 2017. Due to the spatial effects inherent in housing markets, the hedonic regression was enhanced with three widely-utilized spatial econometric models and one outlier-robust model. This was done to ensure that any change in model performance was caused by methodological effects from the model combination, rather than the correction of a spatially misspecified regression.
Historically, hedonic price regression models have been used when conducting house price analysis. First described by Rosen (1974) to value composite goods, this model assumes that the residential property value is merely the sum of the market value of its individual characteristics. Thus, accuracy of such hedonic house price predictions is determined by the data’s ability to identify important housing attributes and correctly estimate the structural characteristics, time, and location as the main determinants of the housing value. Although the first two factors require considerate specification, location modeling has proven particularly challenging in the classic hedonic regression framework. The issue primarily stems from the difficulty in capturing the spatial interactions in cross-sectional housing data, as these introduce simultaneity and feedback effects that necessitate use of spatial econometric models (Anselin 2010). This has been a long-neglected fact in the studies of economics, arguably because spatial analysis is commonly associated with disciplines like geography and geology (Dubin 1998).
The repeat sales model is another important real estate analysis methodology, and is based on the premise that the prices at which a specific property has been sold in the past are useful inputs for estimating future real estate market development (Bailey et al. 1963). When applying this model, it is common to multiply previous sale prices with the expected market growth to obtain current price estimates. While this method has been widely used, Case and Quigley (1991) demonstrated the merits of combining repeat sales with hedonic regression in the construction of house price indices. Their findings were subsequently confirmed and discussed by Case et al. (1991). However, extensive literature review has revealed that broader applicability of this combination has never been explored.Footnote 1
To get robust results against spatial misspecification of the hedonic model, repeat sales price predictions are combined with the predictions yielded by regression models, which are further enhanced by applying both traditional and state-of-the-art spatial models reported in pertinent literature, including an ad hoc spatial model proposed in this paper. Thus, in addition to the primary contribution to the house price valuation methods, we provide further empirical evidence on the utility of spatial econometric modeling of the housing market, linking the analyses and findings reported in this paper to one of the most prevalent research trends in real estate valuation (Krause and Bitter 2012).
Combining regression predictions with the estimates yielded by the repeat sales model improved the accuracy of all hedonic models with respect to all examined metrics. These improvements were attained even when novice combination techniques were adopted, which was primarily attributed to diversification effects (Bates and Granger 1969). The geographically weighted regression outperformed the other spatial specifications, indicating that spatial non-stationarity is more prominent than spatial dependence in the Oslo housing market. Furthermore, combining hedonic regression and repeat sales within a single model resulted in greater improvements to the outputs generated by regression models characterized by low accuracy. As the models differed in terms of location modeling only, it can be posited that repeat sales estimates contribute at least some spatial information to the overall model output. While the value of this contribution diminishes for well-specified spatial models, nonetheless, previous sales prices likely contain a certain amount of non-spatial information that is otherwise difficult to discern from the market trends. If this assumption holds, previous sales prices could be particularly valuable for developing automated property valuation tools, as few alternatives for detecting such information exist aside from human inspection.
The remainder of this article is organized as follows. First, the Norwegian housing market, specifically that of Oslo, is introduced in Section 2, while the data employed when testing the models is presented in Section 3. The real estate evaluation models are presented in Section 4, while their results are reported and discussed in Section 5. The main conclusions are presented in Section 6, along with some suggestions for future research directions in this field.
Background
The Norwegian Property Market
The Norwegian housing market has some noteworthy characteristics, making it highly suitable for studies on property pricing in general. First, the sales process can be characterized as an English auction, where the price is determined in a near-perfect bidding context (Olaussen et al. 2017). Second, most properties for sale in Norway are announced via standardized advertisements published on the FINN.no website.Footnote 2 Such a high degree of transparency and standardization facilitates a comparison between dwellings and provides high-quality data for market participants. Third, Norwegians have a strong preference for home ownership as opposed to renting, as indicated by the 82.7% ownership rate reported for 2016 by Eurostat (2016).
The Property Market of Oslo
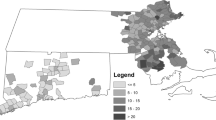
Oslo is the capital of Norway, and has a 2018 population of approximately 670,000. Historically, the city has been demographically divided between east and west, whereby industry workers were based around the Akerselva river in the central and eastern areas, while wealthier families mainly resided in the western parts (Amundsen 2015). Even though some former working-class districts like Grünerløkka and Gamle Oslo are becoming increasingly popular (Faksvåg 2015), the historical pattern with higher prices in western areas is still evident, as shown in Fig. 1.

Administrative districts of Oslo with the price/m2 ranking for 2017 given by Humberset (2018). Data for district Sentrum (denoted by grey color) were not available, while district Søndre Nordstrand is not represented in our dataset and is thus not shown on the map
Data
The real property transaction data are compiled from the property register of Oslo, and were provided by the firm Alva Technologies (Alva). The dataset comprises of all housing transactions that took place in Oslo between August 2016 and December 2017. This dataset provides accurate and comprehensive information on building characteristics for each transaction, including longitude and latitude of the relevant residential property. Alva also provided the previous transaction prices for the dwellings, if these were available. Prior to utilizing this data in the current investigation, some modifications were needed. For example, all entries related to the Marka district were discarded, all dwellings from district Sentrum were reassigned to St. Hanshaugen, and there were 36 dwellings labeled as Other unit type, which after manual checking, were labeled as Apartments. This data preprocessing resulted in 16,417 residential units within the dataset, which was further augmented by mapping administrative district information from Oslo Kommune (2018), as well as by obtaining additional data by reviewing the corresponding FINN advertisements. An overview of the variables included in the regression models is provided in Tables 1, 2, 3, 4, and 5, where all attributes are specified as indicator variables. Variables derived directly from FINN are described in Table 5.
Parts of the information sourced from FINN were obtained through word recognition, which was applied to the advertisement title. Thus, only the property characteristics highlighted by the seller/agent were examined, potentially disregarding the attributes that certain properties possess. However, the likelihood of missing potentially vital information was limited, as these titles are comprehensive, with the examined dwellings included in the dataset containing almost 17 words on average, which is sufficient for promoting multiple property characteristics. Furthermore, since data related to variables that typically enhance property value, such as Has a garden, were also retrieved, the effect of the problem on the models presented is negligible, as promoting such attributes is in the seller’s interest.
In the repeat sales method, Statistics Norway’s Price index for existing dwellings for Oslo and Bærum (Monsrud and Takle 2018) was used as a proxy for the expected price appreciation, as it provides sales information from 1993 to the present. The distribution of the numbers of previous sales for the dwellings used in the repeat sales method is provided in Table 6.
Methodology
In this section, an ordinary hedonic regression model is introduced, with an emphasis on the intercept area dummy variables constructed using the k-means and k-nearest neighbor algorithms. Next, the following four extensions to the basic regression model are described: regression kriging, mixed regressive, spatial autoregressive model, geographically weighted regression, and vicinity-based residual tuning.
Finally, the way in which the estimates yielded by the repeat sales model are combined with the hedonic regression estimates is delineated. The schematic representation of the proposed models is given in Fig. 2, where the geographically weighted regression is denoted by a dashed line, since variables related to districts are omitted in this model.

Overview of spatial models and extensions used in the present study. The dashed line indicates that district indicator variables cannot be specified in the GWR model
Basic Hedonic Regression Model
The hedonic regression model was first introduced by Rosen (1974), and has since been widely used in property valuation, due to the prevalent view that residential property value can be approximated by the sum of the market value of its constituents. In the model employed, the value of a given dwelling is represented by the sum of its common debtFootnote 3 at sales and the sales price, divided by the area in m2, as given below:
The natural logarithm of Pi given by Eq. (4.1) is estimated by evaluating contributions to the price by using multiple linear regression for each utility-bearing attribute. The general equation to be estimated is given by:
where P is the price variable as defined in Equation (4.1); Xk is a set of explanatory variables, describing a presence of the utility-bearing characteristic k (including both building characteristics and dummy variables pertaining to time); Dn is a set of n area indicator variables; ε is the error term, and β0, βk and δn are the parameters to be estimated, with their respective estimates denoted as \( {\hat{\beta}}_0 \), \( {\hat{\beta}}_k \) and \( {\hat{\delta}}_n \). As the data only span over 17 months and cover a single city, the common assumption that parameter vectors are invariant across space and time is deemed valid (de Haan and Diewert 2013). In line with the approach adopted by Koenker and Bassett Jr (1978), Equation (4.2) is estimated using least absolute deviation (LAD), since LAD is more robust towards outliers compared to ordinary least squares (OLS) and other estimators based on distributional assumptions (Yoo 2001). An overview of the structural explanatory variables used in Equation (4.2) is given in Tables 1, 2, 3, 4, and 5. To incorporate spatial and temporal variability in Equation (4.2), intercept indicator variables, which are further discussed in the following subsections, were introduced. Price predictions in nominal values are obtained by taking the exponential and multiplying it by a scale factor to minimize underestimation bias in the transformation. The scale factor is estimated by regressing unscaled price estimates from the training sample on their corresponding real prices through the origin, where the 1% most expensive dwellings are discarded to control for outliers in the data.
The prices of houses are volatile, as they are subject to seasonality and other effects, and are generally substantially influenced by time (Reichert 1990). However, since the aim was to model spatial effects, the temporal dimension is neglected. Specifically, to ensure that model output is unbiased by market price developments, this effect was isolated by including monthly dummies as explanatory variables into all regression models. Furthermore, the test sample was constructed by randomly drawing 20% of the observations from the full sample. Because of this approach, the two samples used for estimating and testing the models, respectively, span the same time horizon and thus eliminate the temporal dimension.
The k-means algorithm was applied to the training data sample to construct artificial market districts characterized by more homogeneous property pricing processes while retaining cohesiveness. For this purpose, the distance between dwellings was measured as a function of longitude, latitude and price, whereby the latter was calculated by applying Equation (4.1). After clustering the training set, k-nearest neighbors were used to classify dwellings in the test sample based on the newly constructed districts, measuring the distance in a classical, geographic sense using the haversine formula (Sinnott 1984). In empirical trials, the best results were obtained when the values of k in the k-means algorithm ranged from 14 to 20, and k = 18 was adopted in the final model. An illustrative plot comparing a k-means clustering with k = 14 and administrative borders is shown in Fig. 3. The k in the k-nearest neighbor algorithm was set to 3, based on empirical trials, as well as visual inspection of district shapes produced by the k-means.

Comparison of administrative districts (lines) and statistically generated districts delineated by using the k-means (colored markers) for the city of Oslo. The final k-means models are based on k = 18, whereas this map is obtained by using k = 14 for easier visual inspection of algorithm functioning. Color gradient indicates the average price/m2 for each k-means district, and is thus directly comparable to the map provided in Fig. 1. Number of observations is 13,133
Regression Kriging
As argued by Dubin (1988) and Basu and Thibodeau (1998), among others, spatial dependence in the housing price process can be modeled by assuming that the original functional relationship given by Equation (4.2) holds, while abandoning the assumption that the error term is independent and identically distributed (i.i.d.), which requires modeling of the error covariance structure. Adopting this approach for prediction builds on the statistical interpolation technique known as kriging. Following the previously outlined notation, Equation (4.2) can be rewritten as:
where C is the error correlation matrix. To estimate Equation (4.3), a functional form for the error term’s covariance structure must be assumed. The parameters of this function, along with the normal regression coefficients, are simultaneously estimated using the maximum likelihood method. However, it should be noted that estimation of Equation (4.3) can become very complex when the dataset includes nonlinear explanatory variables (Hengl et al. 2007). Moreover, parameter instability is another major concern commonly encountered in practice (Goovaerts 1999).
To mitigate these issues, the estimation process can be divided into two phases. First, the linear regression parameters β0, βk and δn are estimated using a less complex estimator—LAD, as previously noted. Next, the error covariance function parameters are estimated by simple krigingFootnote 4 with zero mean on the residuals from the first regression. The prediction process is finalized by adding the fitted residual from the simple kriging model to the fitted value from the linear regression. In mathematical terms, the predicted value for dwelling i in the test sample having structural characteristics X′ and D′ is given by
where \( \hat{\varepsilon} \) are the LAD residuals from the training sample, and wi j are the elements of the weight matrix W, determined by the a priori chosen covariance function. This two-step procedure was denoted as regression kriging by Odeh et al. (1995). Predictions yielded by Equation (4.4) and those resulting from directly estimating Equation (4.3) are mathematically equivalent. Indeed, Hengl et al. (2003) demonstrated that as long as the assumed covariance function is identical, the difference is restricted to the computational steps.
Several structural covariance functions are applicable in kriging, provided that correlation between observations decreases with increased physical distance. In the current analyses, it is assumed that the error covariance follows the negative exponential form given below, as proposed by Case et al. (2004).
where the parameters b1 and b2 are estimated in the second step of the regression kriging procedure outlined above; di j are Euclidean distances between dwelling i and dwelling j, and ci j are entries in the C-matrix derived from Equation (4.3). To calculate the weights based on the covariance matrix, the relationship W = C−1c was assumed, where c is a vector of the covariances between the training data points and the estimation point (Bohling 2005). To limit the computational cost, the number of neighbors for each dwelling was limited to 100.
At this juncture, it is important to note that generalized least squares (GLS) is typically recommended as the proper estimator in the first step of regression kriging, to account for spatial autocorrelation in the error term (Cressie 1990). However, Kitanidis (1993) demonstrated that the difference between several iterations of GLS and a single iteration (OLS) is too small to have any notable effect on the final output. To test this claim, both GLS and LAD were adopted, yielding marginal differences that were in line with the findings reported by Kitanidis (1993). Thus, LAD was chosen to ensure that a consistent choice of estimators is employed across all the models evaluated.
Mixed Regressive, Spatial Autoregressive Model
As argued by Can (1992), spatial dependence in the housing price determination process can be modeled by including a function of the dependent variable as an autoregressive term in the standard hedonic regression (Equation (4.2)). Using the specification put forth by Fotheringham (2009), the model can be expressed as:
where ρ is a measure of the overall level of spatial dependence among (ln(Pi), ln(Pj)) pairs for which wi j > 0 and wi j are spatial weights assigned to the sales price of dwelling j. Other variables are as described in Section 3. Including the dependent variable to the right-hand side of the equation induces simultaneity; hence, estimating Equation (4.5) with OLS or LAD produces biased estimates. However, this approach is commonly adopted, as appropriate estimation using maximum likelihood is extremely challenging (Farber and Yeates 2006). A different solution was proposed by Can and Megbolugbe (1997), who advocated for inclusion of an additional constraint, thus giving Equation (4.5) the following revised form:
The distinction between Equation (4.5) and (4.6) is that the dependent variables in the latter are determined at time t and are hence exogenous, rendering OLS and LAD unbiased estimators. The weighting function, again following Can and Megbolugbe (1997), is given by:
where di j are Euclidean distances between dwelling i and dwelling j, with j representing the 15 dwellings located closest to dwelling i, and having earlier sales dates than dwelling i. In the special case where two dwellings share the same location, di j is set to 10 m, to ensure that Equation (4.7) is defined for all observations.
It is also worth noting that some dwellings in the dataset are situated at remote locations and thus, no relevant neighbors are available for defining the autoregressive term. The same issue arises for the oldest transactions within the sample. Therefore, to retain the same number of observations for all models, the autoregressive term for the aforementioned dwellings was assumed to be equal to the average log (price) for the relevant district, with the price defined by Equation (4.1).
Geographically Weighted Regression
As argued by Wheeler and Calder (2007), the housing price process is non-stationary over space, and the coefficients in the traditional hedonic regression represent the global “average” only. Thus, accurate predictions necessitate application of an enhanced regression model that permits parameter variation across space (Yao and Fotheringham 2016). The geographically weighted regression method enables such a local parameter estimation. We adopt the notation given by Fotheringham et al. (2002), resulting in a revised traditional regression framework given by:
where ui and vi denote the coordinates of the ith point in space, and βk(ui, vi) is a realization of the continuous function βk(u, v) at point i. Note that the location area indicator variable D from Equation (4.2) is omitted in Equation (4.8), which contains a greater number of unknown variables. Consequently, at point i, Equation (4.8) is approximated by:
The parameters β0 and βk are independently estimated for all i locations with dwellings in the test sample. Estimation is conducted by weighting the observations in accordance with their proximity to location i, and the parameters are chosen to minimize the weighted sum of squared residuals. In line with the approach proposed by Fotheringham et al. (2002), Equation (4.9) is estimated with the weights calculated using a Gaussian kernel function:
where dij are the Euclidean distances between point i and j; b is denoted as bandwidth, and is chosen by applying the cross-validation optimization approach described by Cleveland (1979). The practical implication of this choice is that only a small subset of the observations in the training sample is used to estimate Equation (4.9) at the different points i. Thus, the estimate for a given dwelling is vulnerable to anomalies in the data related to the neighboring dwellings.
Vicinity-Based Residual Tuning
An automated variant—referred to as vicinity-based residual tuning, or VRT—of a valuation method commonly used by real estate agents is adopted. In the original approach, a limited number of recently sold properties in the immediate neighborhood (usually 3 to 6) is used to provide a house value estimate (Can and Megbolugbe 1997; Pace et al. 2000). The procedure outlined here is based on the premise that differences between properties are already controlled for in the residuals of a hedonic regression. Moreover, the issues that arise from including district intercept dummies in a regression, as outlined by Fik et al. (2003), are also addressed.
The fitted values for dwellings in the test set were obtained by using regression coefficients estimated on the training set. Next, for each dwelling in the test set, the sales date was denoted by τ. The κ closest neighbors from the training set sold before time τ, located within the same districtFootnote 5 and within a radius of maximum μ meters were identified. The residuals of the neighbors were extracted before calculating their median, which was multiplied by a deflation factor α (along with another deflation factor β if the number of neighbors is below λ). Finally, this residual was added to the fitted value to obtain the VRT estimate, as shown in Table 7.
Specifying area intercept dummies in a hedonic regression often results in low prediction accuracy close to district borders, where residuals with different magnitudes and signs are clustered on either side of the border. Figure 7 provides an example of such effects. To address this issue, the district constraint was included in the step (i) above. Further, an outlier with an extreme residual value included as a neighbor can have a severe impact on the model accuracy. In the present investigation, this effect was mitigated by using the median and including the (λ, β) clause in the step (ii) above, where λ = 3 corresponds to the lowest number of neighbors where the smallest and largest neighbor residual value is discarded in the calculation of the median. The remaining model parameters were determined by applying the following reasoning: μ was chosen intuitively, and α and β values were determined by empirical trials, while the selection of κ was based on the approach recommended by Can and Megbolugbe (1997).
Constructing and Combining Repeat Sales Predictions
A common drawback of all hedonic house price models stems from the high heterogeneity among dwellings, rendering the inclusion of all price-influencing attributes infeasible (Case et al. 1991). To overcome this issue, repeat sales analysis was conducted, as this allowed for some of the effects to be captured that would have been otherwise difficult to observe through the former sales prices of a given dwelling. The model is grounded in the assumption that residential property prices have developed in line with the overall market trends, as described by the house price index, implying that the quality of each dwelling is assumed comparable at the time of each sales transaction. As outlined in Section 3, Statistic Norway’s Price index for existing dwellings for Oslo and Bærum provides quarterly data dating back to 1993. In adopting this resource, a maximum of three previous transactions for each dwelling was considered, giving preference to the most recent transactions, excluding all sales that occurred prior to 1993, as this period precedes the development of the aforementioned price index.
The premise that a dwelling’s quality is similar at different transaction times is a questionable assumption. If previous sales conditions are unrepresentative for the dwelling’s condition at resale, the repeat sales estimate is likely to be erroneous. To remove such outliers, all repeat sales estimates deviating by more than 25% from the combined regression estimate were discarded, in line with the approach recommended by Anon (2013). To obtain one final prediction, the remaining estimates were combined following a step-by-step procedure. The weight given to the hedonic regression estimate was at least 60%,Footnote 6 and heavier weighting was given to predictions based on more recent sales than preceding transactions. In line with the approach utilized by Clemen (1989), only simple linear combination techniques were used.
Results and Discussion
The performanceFootnote 7 of an ordinary hedonic regression without any location attributes is displayed in the top row of Fig. 4. As this model includes no spatial information, it represents a benchmark for assessing the utility of all enhancements incorporated into subsequent models to address the spatial aspect of residential property pricing. A comparison of the results confirms the strong influence of location on housing value. Indeed, the sole addition of administrative district indicator variables (row 2) reduces the median error from 12.1% to 8.05%, an improvement of 33.5%. Interestingly, augmenting the benchmark model with either regression kriging (row 5) or the mixed regressive, spatial autoregressive model (row 9) yields similar improvements, from 12.1% to 8.18% and 7.70%, respectively. Thus, it can be argued that district intercept dummies incorporate the effect of location somewhat accurately, although several methods can be adopted to address this issue. The extensive use of indicator variables is likely driven by the intuitive interpretation of the parameters, as well as ease of implementation. However, reliance on such variables, particularly when based on administrative districts, disregards intra-district variation and tends to result in irregular residual patterns close to borders. The resulting residual pattern from using administrative borders is plotted in Fig. 7.

Model refers to the methods outlined in Section 4.1–4.5; Admin district and the K-means indicate if the boundaries for the area dummy variables are administrative districts or are generated by the k-means, respectively (irrelevant for the GWR model); Repeat sales indicates whether the results are obtained after combining the output with the repeat sales predictions; Q0.25, Q0.5 and Q0.75 denote the first, second, and third error quartile, respectively, where Q0.5 is boldfaced for emphasis; Within 10% specifies the fraction of errors below 10%; Row no. is row number provided for convenience when referring to this figure. The results shown are average values based on the outputs of 10 runs for each implementation. The number of observations used for model training is 13,133, while the number of out-of-sample observations is 3284
Statistically-generated districts can mitigate the aforementioned issues. A comparison of the administrative and a k-means based division of Oslo is depicted in Fig. 5. As the k-means operates independently of administrative districts, any area similarities are coincidental. An interesting case is found in the administrative district Alna, where k-means classifies the dwellings into four districts, indicating marked internal price differences. Further observations can be gleaned from comparing and Figs. 1 and 3, as well as Figs. 6, 7 and 8, which are provided in the Appendix. Improved performance from using k-means districts becomes evident when comparing row 2 and 3 in Fig. 4, as the median absolute percentage error improves from 8.05% to 7.67%. Moreover, the corresponding Moran’s I and Geary’s C values (Moran 1950; Geary 1954; Cliff and Ord 1970) indicate reduced spatial autocorrelation in the residuals. As stated in Subsection 4.1.2, the k-means is set to divide the city into a higher number of districts (18) than the administrative division (14), due to more stable performance. Results based on different values of k are shown in Appendix Table 8, supporting the algorithm’s conceptual advantages, as the improvement arising from implementing the k-means with 14 districts is relatively high compared to the improvement stemming from finer district fragmentation.

Visualization of improved performance achieved by combining repeat sales predictions with hedonic regression predictions. The bold number above the arrows indicates the reduction in median absolute percentage error in percentage terms. The row number at the bottom of each column indicates the corresponding row in Fig. 4
District indicators are insufficient to appropriately model refined spatial patterns. Thus, the performance of the global augmentations—the regression kriging, and mixed regressive, spatial autoregressive models—are examined here first. Without incorporating district variables, both models display improved prediction accuracy compared to the benchmark model, as already mentioned. When district variables are included in the model, accuracy increases further, although not substantially. A less intuitive result is that the two spatial models seem indifferent to the choice of district representation, as indicated by a comparison of results reported in row 6 with those in row 7, as well as row 10 with row 11 in Fig. 4, in contrast to the clear advantage of applying the k-means to the ordinary regression. Two possible explanations can be offered for this finding. First, the influence of district dummy variables declines when location is concurrently modelled by several methods. This assertion is supported by a comparison of the absolute values of the location dummy parameters from the hedonic regressions with the k-means districts and hedonic regressions, and the k-means districts and autoregressive term. Second, the two enhancements correct some spatial abnormalities caused by the administrative district, reducing the need for the k-means. Finally, the autoregressive model outperforms regression kriging. However, this finding cannot be compared to previously published results, as none are available. Moreover, in line with LeSage and Pace (2014), applying different weighting functions in the regression kriging model did not affect the results. However, while this might reduce the credibility of the kriging implementation presented here, the effect of combining these predictions with repeat sales estimates, which are discussed later in this section, coincides with the remaining spatial models.
The VRT model performs second-best among those aimed at spatial enhancements (as can be seen from the results reported in rows 14 and 15 in Fig. 5). These findings are supported by the arguments presented by Chan et al. (1999), who highlighted the severe impact of outliers on most models, which is avoided in VRT since it is constructed to be more outlier-robust. It is also noteworthy that the VRT model only performs well for specifications including district variables,Footnote 8 likely due to the inability to distinguish more district-wide trends when considering a very limited number of neighbors. However, rather than adjusting the model to capture such trends, it is intrinsically tailored to address spatial residual patterns emerging from the use of intercept dummy variables in a regression. Thus, the method probably has limited use in general forecasting. Nonetheless, it is highly effective in this specific context. VRT also seems indifferent to the choice of district representation, most likely for the reasons suggested earlier for regression kriging and the autoregressive model.
The geographically weighted regression emerges as the most precise spatial enhancement (as shown in row 17 of Fig. 4). Since this model assumes and addresses spatial non-stationarity, such significant improvement strongly suggests that this is the more prominent spatial effect in the Oslo housing market. The fact that GWR seems to outperform other spatial models for out-of-sample predictions corresponds with the findings reported by Farber and Yeates (2006) and Páez et al. (2008). However, it contrasts arguments put forth by Harris et al. (2010) and Harris et al. (2011), who recommended universal kriging. Although GWR tends to provide precise predictions, it has received criticism owing to its limited value for making inferences. Furthermore, the method is sensitive to outliers on a local level, which is particularly problematic in housing valuation, where outliers pose a permanent challenge.
The gain from combining repeat sales predictions with hedonic regression forecasts is evident in Fig. 4 and is further emphasized in Fig. 5, where the median absolute error achieved by the different regression models pre- and post-combination is plotted, which is equivalent to comparing rows 4, 8, 12, 16, and 18 with the corresponding values in Fig. 4. In fact, the tabulated results reveal that combining repeat sales predictions with hedonic regression forecasts improves model accuracy by every metric and for every variation of the hedonic regression. To support diversification as the main driver behind this improvement, as argued by Bates and Granger (1969), as opposed to a deterioration of highly accurate repeat sales predictions, independent repeat sales results are provided in Appendix Table 9. The data reported in this table confirm that, when used in isolation, repeat sales predictions are outperformed by all regression models incorporated into the combined models, supporting the diversification argument. It is also worth noting the considerable effect of outlier removal on the repeat sales estimates, which becomes evident when the two rows in Appendix Table 9 are compared. This is arguably a necessity to replicate the level of improvement from the repeat sales/hedonic regression combination.
Apart from the overall increase in model accuracy, Fig. 5 shows that improvements derived from combining repeat sales with other enhancements vary between the regression models, where a more substantial effect is observed when the initial regression error is large. Since the regression models only differ in terms of location modeling, it can be argued that repeat sales contribute at least some spatial information, the value of which diminishes for more sophisticated spatial models. Arguably, location is modeled well in the autoregressive, VRT, and GWR models, where the combination of the repeat sales method resulted in similar improvements of 0.51, 0.52, and 0.45 percentage points, respectively. Consequently, it is reasonable to conclude that the predominant part of these improvements stems from the incorporation of non-spatial information omitted from the hedonic regression. Although it is not verifiable, this argument is supported by the inherent heterogeneity of dwellings, making inclusion of all price-influencing attributes in a regression framework infeasible (de Haan and Diewert 2013).
Based on the preceding discussion, it can be posited that previous sales prices can provide specific value in two ways. Most importantly, they can incorporate information on difficult to observe attributes. This could have a pivotal value in automated property valuation, as there are few alternatives for detecting such information besides human inspection. Second, they enable the implementation of a scalable, parsimonious forecasting model, incorporating easily available attributes only, and relying on previous sales prices to incorporate information on the omitted, more market-specific attributes. As no universal hedonic specification presently exists (Bowen et al. 2001), local expertise remains necessary to identify relevant price-influencing attributes in each market (Gelfand et al. 1998).
While the conceptual advantages of combining the hedonic regression and repeat sales methods are demonstrated, some practical limitations of such approaches should also be noted. First, collecting previous sales price data reflecting current housing quality is generally hard, and can even be impossible in certain cases. Newly-built dwellings obviously lack such data, but very old sales prices are not informative either, as they rarely represent the current state of the property (Case and Shiller 1987). Thus, the combination might be less useful for markets where houses are traded less frequently, such as rural or suburban areas in which family homes predominate (Clapp et al. 1991). In addition, there will be an inevitable lack of data for some residential properties, preventing the method’s applicability to all dwellings. Finally, the scale of the model improvement should also be considered when deciding if combining the modeling approaches is useful in practice. For example, in the present analyses, the median error of GWR was reduced from 6.65% to 6.20% (a 6.8% improvement) when combining the regression predictions with estimates from repeat sales. This rather marginal improvement might imply that the combination has little practical implication. Arguably, both models are good enough for obtaining an approximate value estimate. Nonetheless, neither is good enough to make end users confident in the results.
Conclusion
A central aspect of uncertainty in housing transactions is inaccurate property valuation. In this article, the benefits derived by combining property price predictions yielded by two well-known valuation methods—repeat sales and hedonic regression—were investigated. The developed models were tested and applied to 16,417 historical residential property transactions in Oslo, Norway. Due to the spatial effects inherent in housing markets, the hedonic regression was enhanced with three widely-utilized spatial econometric models and one outlier-robust model. This was done to ensure that any change in model performance was caused by methodological effects from the model combination, rather than the correction of a spatially misspecified regression.
The studied combination resulted in improved accuracy for all hedonic regressions on all metrics, which was attributed to diversification, as proposed by Bates and Granger (1969). Models with lower pre-combination accuracy yielded greater improvements, where reduction in median absolute percentage error ranged from 9.5% for the ordinary regression to 6.8% for the geographically weighted regression. This difference in gains is argued to indicate that repeat sales predictions contribute at least some spatial information. While this contribution might have limited value for refined spatial models, the existence of some non-locational information in previous sales prices could nonetheless have pivotal value for automated property valuation, as there are few alternatives for detecting such information aside from human inspection.
When interpreting the findings reported in this paper, certain limitations of the model combination should be noted. Specifically, non-existent or inapplicable previous sales price data in certain markets is inevitable. Optimizing the simple combination scheme presented in this paper is also advantageous for future studies, e.g., through more considerate implementation of the temporal dimension of previous sales. Similarly, improving repeat sales accuracy by, for example, applying local price indices would be beneficial. With broader trends in automatic housing valuation, machine learning appears to be the focal point of research at the expense of hedonic regression (Park and Bae 2015). However, these tools remain highly dependent on the quality and quantity of observable, quantifiable data (Trawiński et al. 2017). Thus, given that previous sales prices seem to incorporate some otherwise difficult to capture information, a repeat sales/machine learning combination is an interesting direction for further research.
Notes
Extensive literature review has failed to uncover any publicly available research on this topic. However, some companies advertise automated valuation based on both models, e.g., Home Value Explorer® by FreddieMac (2017).
FINN covers approximately 70% of the Norwegian housing market (Norge et al. 2017). All properties in the dataset employed in the current investigation were announced on the site.
In Norway, cooperatives and apartment buildings can take on common debt, for example, to renovate the building. Especially for cooperatives, the common debt can be high compared with the transaction price of an apartment. The total price of a dwelling in Norway is the transaction price, plus the dwellings share of the total common debt.
The term simple kriging is used when the mean of the dependent variable is assumed to be known a priori (Cressie 1990).
Either administrative or generated by k-means, depending on the variable type required in the regression.
By testing different weighting and combinations we found no single optimal solution for multiple performance metrics, resulting in our choice of a “trail-and-error” based weight of 60% for the regression estimate that resulted on both high prediction and low volatility across multiple runs.
Generally, model performance is measured by median absolute percentage error (Q0.5).
Row 13 in Figure 4 shows unsatisfactory performance by VRT where district variables are omitted.
References
Amundsen, B. (2015). Rike og fattige flytter fra hverandre i Oslo [Rich and poor moving apart from each other in Oslo]. Forskning.no, Available at: https://forskning.no/samfunnsgeografi/2015/06/rike-og-fattige-flytter-fra-hverandre-i-oslo (accessed: 11 December 2017).
Anon. (2013). OECD, Eurostat, International Labour Organization, International Monetary Fund, The World Bank, and United Nations Economic Commission for Europe. Repeat sales methods. Handbook on Residential Property Prices Indices (RPPIs), OECD publishing, Paris, 67–72.
Anselin, L. (2010). Thirty years of spatial econometrics. Papers in Regional Science, 89(1), 3–25.
Bailey, M. J., Muth, R. F., & Nourse, H. O. (1963). A regression method for real estate price index construction. Journal of the American Statistical Association, 58(304), 933–942.
Basu, S., & Thibodeau, T. G. (1998). Analysis of spatial autocorrelation in house prices. The Journal of Real Estate Finance and Economics, 17(1), 61–85.
Bates, J. M., & Granger, C. W. (1969). The combination of forecasts. Journal of the Operational Research Society, 20(4), 451–468.
Bohling, G. (2005). Kriging. Data Analysis in Engineering and Natural Science, Kansas Geological Survey. Available at: http://people.ku.edu/~gbohling/cpe940/Kriging.pdf (accessed: 8 June 2018).
Bowen, W. M., Mikelbank, B. A., & Prestegaard, D. M. (2001). Theoretical and empirical considerations regarding space in hedonic housing price model applications. Growth and Change, 32(4), 466–490.
Can, A. (1992). Specification and estimation of hedonic housing price models. Regional Science and Urban Economics, 22(3), 453–474.
Can, A., & Megbolugbe, I. (1997). Spatial dependence and house price index construction. The Journal of Real Estate Finance and Economics, 14(1–2), 203–222.
Case, B., & Quigley, J. M. (1991). The dynamics of real estate prices. The Review of Economics and Statistics, 73(1), 50–58.
Case, K. E., & Shiller, R. J. (1987). Prices of single-family homes since 1970: New indexes for four cities. In NBER working paper series 2393. National Bureau of Economic: Research. https://doi.org/10.3386/w2393.
Case, B., Pollakowski, H. O., & Wachter, S. M. (1991). On choosing among house price index methodologies. Real Estate Economics, 19(3), 286–307.
Case, B., Clapp, J., Dubin, R., & Rodriguez, M. (2004). Modeling spatial and temporal house price patterns: A comparison of four models. The Journal of Real Estate Finance and Economics, 29(2), 167–191.
Chan, Y. L., Stock, J. H., & Watson, M. W. (1999). A dynamic factor model framework for forecast combination. Spanish Economic Review, 1(2), 91–121.
Clapp, J. M., Giaccotto, C., & Tirtiroglu, D. (1991). Housing price indices based on all transactions compared to repeat subsamples. Real Estate Economics, 19(3), 270–285.
Clemen, R. T. (1989). Combining forecasts: A review and annotated bibliography. International Journal of Forecasting, 5(4), 559–583.
Cleveland, W. S. (1979). Robust locally weighted regression and smoothing scatterplots. Journal of the American Statistical Association, 74(368), 829–836.
Cliff, A. D., & Ord, K. (1970). Spatial autocorrelation: A review of existing and new measures with applications. Economic Geography, 46, 269–292.
Corcoran, C., & Liu, F. (2014). Accuracy of Zillow’s home value estimates. Real Estate Issues, 39(1), 45–49.
Cressie, N. (1990). The origins of kriging. Mathematical Geology, 22(3), 239–252.
Dubin, R. A. (1988). Estimation of regression coefficients in the presence of spatially autocorrelated error terms. The Review of Economics and Statistics, 70(3), 466–474.
Dubin, R. A. (1998). Spatial autocorrelation: a primer. Journal of Housing Economics, 7(4), 304–327.
Eurostat. (2016). Distribution of population by tenure status, type of household and income group − EU-SILC survey. Available at: http://appsso.eurostat.ec.europa.eu/nui/show.do?datasetÆilc_lvho02&langÆen (accessed: 20 May 2018).
Farber, S., & Yeates, M. (2006). A comparison of localized regression models in a hedonic house price context. Canadian Journal of Regional Science, 29(3), 405–420.
Fik, T. J., Ling, D. C., & Mulligan, G. F. (2003). Modeling spatial variation in housing prices: A variable interaction approach. Real Estate Economics, 31(4), 623–646.
Fotheringham, A. S. (2009). Geographically weighted regression. In S. Fotheringham & P. Rogerson (Eds.), The SAGE handbook of spatial analysis, 243–254. London: SAGE Publications Ltd.
Fotheringham, A. S., Brunsdon, C., & Charlton, M. (2002). Geographically weighted regression: The analysis of spatially varying relationships. New York: Wiley.
FreddieMac. (2017). Home Value Explorer. Available at: http://www.freddiemac.com/hve/hve.html (accessed: 5 December 2017).
Geary, R. C. (1954). The contiguity ratio and statistical mapping. The Incorporated Statistician, 5(3), 115–146.
Gelfand, A. E., Ghosh, S. K., Knight, J. R., & Sirmans, C. F. (1998). Spatio-temporal modeling of residential sales data. Journal of Business & Economic Statistics, 16(3), 312–321.
Goovaerts, P. (1999). Using elevation to aid the geostatistical mapping of rainfall erosivity. Catena, 34(3–4), 227–242.
de Haan, J. & E. Diewert (2013), "Hedonic Regression Methods”. Handbook on Residential Property Price Indices, OECD Publishing, Paris, https://doi.org/10.1787/9789264197183-7-en.
Harris, P., Fotheringham, A., Crespo, R., & Charlton, M. (2010). The use of geographically weighted regression for spatial prediction: An evaluation of models using simulated data sets. Mathematical Geosciences, 42(6), 657–680.
Harris, P., Brunsdon, C., & Fotheringham, A. S. (2011). Links, comparisons and extensions of the geographically weighted regression model when used as a spatial predictor. Stochastic Environmental Research and Risk Assessment, 25(2), 123–138.
Helbich, M., Brunauer, W., Hagenauer, J., & Leitner, M. (2013). Data-driven regionalization of housing markets. Annals of the Association of American Geographers, 103(4), 871–889.
Hengl, T., Heuvelink, G. B. M., & Stein, A. (2003). Comparison of kriging with external drift and regression kriging. Technical note, ITC. Available at: https://webapps.itc.utwente.nl/librarywww/papers_2003/misca/hengl_comparison.pdf (accessed: 11 May 2018).
Hengl, T., Heuvelink, G. B. M., & Rossiter, D. G. (2007). About regression-kriging: From equations to case studies. Computers & Geosciences, 33(10), 1301–1315.
Humberset, K. (2018). Her må du punge ut 85.000 kroner for én kvadratmeter [Here you have to pay 85,000 NOK for one square meter]. aftenposten.no. Available at: https://www.aftenposten.no/bolig/Her-ma-du-punge-ut-85000-kroner-for-n-kvadratmeter-10982b.html (accessed: 4 June 2018).
Kitanidis, P. K. (1993). Generalized covariance functions in estimation. Mathematical Geology, 25(5), 525–540.
Koenker, R., & Bassett, G., Jr. (1978). Regression quantiles. Econometrica: Journal of the Econometric Society, 46(1), 33–50.
Krause, A. L., & Bitter, C. (2012). Spatial econometrics, land values and sustainability: Trends in real estate valuation research. Cities, 29, S19–S25.
LeSage, J. P., & Pace, R. K. (2014). The biggest myth in spatial econometrics. Econometrics, 2(4), 217–249.
Levin, J. (2001). Information and the market for lemons. RAND Journal of Economics, 32(4), 657–666.
Monsrud, I. J. & Takle, M. (2018). Price index for existing dwellings. Statistics Norway. Available at: https://www.ssb.no/en/priser-og-prisindekser/statistikker/bpi (accessed: 7 June 2018).
Moran, P. A. (1950). A test for the serial independence of residuals. Biometrika, 37(1/2), 178–181.
Eiendom Norge, Eiendomsverdi & FINN.no. (2017). Eiendom Norges boligprisstatistikk [Real Estate Norway housing price statistics]. Available at: http://eiendomnorge.no/wpcontent/uploads/2017/11/Boligstatistikk_oktober_01.pdf (accessed: 4 December 2017).
Odeh, I. O. A., McBratney, A. B., & Chittleborough, D. J. (1995). Further results on prediction of soil properties from terrain attributes: Heterotopic kriging and regression kriging. Geoderma, 67(3–4), 215–226.
Olaussen, J. O., Oust, A., & Solstad, J. T. (2017). Energy performance certificates–informing the informed or the indifferent? Energy Policy, 111, 246–254.
Oslo Kommune. (2018). Finn bydelen din her [Find your city district here]. Available at: https://www.oslo.kommune.no/politikk-og-administrasjon/bydeler/bydelsvelger/ (accessed: 13 May 2018).
Pace, R. K., Barry, R., Gilley, O. W., & Sirmans, C. F. (2000). A method for spatial–temporal forecasting with an application to real estate prices. International Journal of Forecasting, 16(2), 229–246.
Páez, A., Long, F., & Farber, S. (2008). Moving window approaches for hedonic price estimation: An empirical comparison of modelling techniques. Urban Studies, 45(8), 1565–1581.
Park, B., & Bae, J. K. (2015). Using machine learning algorithms for housing price prediction: The case of Fairfax County, Virginia housing data. Expert Systems with Applications, 42(6), 2928–2934.
Reichert, A. K. (1990). The impact of interest rates, income, and employment upon regional housing prices. The Journal of Real Estate Finance and Economics, 3(4), 373–391.
Rosen, S. (1974). Hedonic prices and implicit markets: Product differentiation in pure competition. Journal of Political Economy, 82(1), 34–55.
Sinnott, R. W. (1984). Virtues of the haversine. Sky and Telescope, 68(2), 159.
Trawiński, B., Lasota, T., Kempa, O., Telec, Z., & Kutrzyński, M. (2017). Comparison of ensemble learning models with expert algorithms designed for a property valuation system. In N. Nguyen, G. Papadopoulos, P. Jędrzejowicz, B. Trawiński, & G. Vossen (Eds.), Computational collective intelligence, ICCCI 2017, lecture notes in computer science, vol 10448. Cham: Springer.
Wheeler, D. C., & Calder, C. A. (2007). An assessment of coefficient accuracy in linear regression models with spatially varying coefficients. Journal of Geographical Systems, 9(2), 145–166.
Yao, J., & Fotheringham, A. S. (2016). Local spatiotemporal modeling of house prices: A mixed model approach. The Professional Geographer, 68(2), 189–201.
Yoo, S.-H. (2001). A robust estimation of hedonic price models: Least absolute deviations estimation. Applied Economics Letters, 8(1), 55–58.
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher’s Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Appendix
Appendix

Out-of-sample residuals from the hedonic regression without spatial enhancements or district indicators (referred to in Section 5 as the benchmark model) depicted on the map of Oslo. Lines represent administrative district boundaries, while marker color indicates residual value for each dwelling. Observations: 3284

Out-of-sample residuals from the hedonic regression with administrative district indicators depicted on the map of Oslo. Lines represent administrative district boundaries, whereas marker color indicates residual value for each dwelling. Observations: 3284

Out-of-sample residuals from the most accurate model that combines geographically weighted regression and repeat sales depicted on the map of Oslo. Lines represent administrative district boundaries, whereas marker color denotes residual value for each dwelling. Observations: 3284
Rights and permissions
About this article

Cite this article
Oust, A., Hansen, S.N. & Pettrem, T.R. Combining Property Price Predictions from Repeat Sales and Spatially Enhanced Hedonic Regressions. J Real Estate Finan Econ 61, 183–207 (2020). https://doi.org/10.1007/s11146-019-09723-x
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11146-019-09723-x