
Abstract
This paper extends the fixed effect panel stochastic frontier models to allow group heterogeneity in the slope coefficients. We propose the first-difference penalized maximum likelihood (FDPML) and control function penalized maximum likelihood (CFPML) methods for classification and estimation of latent group structures in the frontier as well as inefficiency. Monte Carlo simulations show that the proposed approach performs well in finite samples. An empirical application is presented to show the advantages of data-determined identification of the heterogeneous group structures in practice.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
1 Introduction
Unobserved heterogeneity plays an important role in the estimation of panel stochastic frontier models, and since heterogeneity is a latent feature of the data, its extent is unknown a priori in empirical practices. Therefore, neglecting unobserved heterogeneity in the data can lead to inconsistent estimation of frontier parameters, and misleading inferences and predictions of the inefficiency indices. Greene (2005a; 2005b) pointed out that if individual-specific heterogeneity is not adequately controlled for, the predicted inefficiency may be picking up some, if not all, of the individual-specific heterogeneity. Thus, recent work on panel stochastic frontier models have focused on how to control for unobserved heterogeneity (see, for example, Guan et al. (2009), Wang and Ho (2010), Colombi et al. (2014), Chen et al. (2014), Kumbhakar et al. (2014), Tsionas and Kumbhakar (2014), Kutlu et al. (2019), and Kutlu and Tran (2019) for reference therein).
However, all the papers mentioned above, except Kutlu et al. (2019), typically assumed complete slope homogeneity (i.e., the frontier parameters are the same across individuals), and unobserved heterogeneity is modeled through individual-specific effects. Kutlu et al. (2019) allow only a subset of variables to have different slopes for individuals. Tsionas (2002) considered a pooled panel stochastic frontier model that allowed for slope heterogeneity where the frontier parameters are random so that they are completely different for different individuals; however, he assumed that the intercept term is common for all individuals over time, and hence he did not control for individual-specific effects. Whilst allowing for cross-section slope heterogeneity may help to improve on the specification bias of the frontier, its main disadvantage is the loss of power due to cross-section averaging in the estimation of the response patterns that may be common across individuals (i.e., certain groups of individuals in the panel). Moreover, since the parameters are random, this model is subject to standard problems of random effects models, e.g., inconsistent parameter estimates when the slopes are correlated with the error term. Thus, for the panel stochastic frontier model, it is essential to control for unobserved heterogeneity in the data as well as for the potential heterogeneity in the response mechanisms that characterizes within the model.
In this paper, we extend previous work on panel stochastic frontier models, and specifically the Wang and Ho (2010) model, to allow for both unobserved heterogeneity via individual-specific effects and for group heterogeneity in the slope parameters. In the standard panel regression models with individual-specific effects, Su et al. (2016) develop a new estimation and inference procedure when the regression parameters are heterogeneous across groups. They treat individual group membership as unknown and the group classification is determined empirically. We follow their lead in this paper and extend their approach to panel stochastic frontier models. Specifically, we use first-differencing transformation to remove the fixed effect, and then propose a penalized maximum likelihood estimation procedure to consistently estimate the frontier parameters, classification of groups and their memberships as well as technical inefficiency scores. Moreover, we also extend the model to allow for some or all regressors to be endogenous and propose a different estimation approach for which we term as penalized control function maximum likelihood.
Our proposed model is related to the class of the metafrontier model developed by Battese et al. (2004) and among others, in the sense that both models consider the group-wise heterogeneity in response coefficients. However, our proposed model differs from the metafrontier literature in the following ways. First, the number of groups is specified a priori in the metafrontier model whilst they are determined endogenously based on the data in our model. Second, unobserved individual-specific effects can be different even among the firms within each group, but the metafrontier model does not allow for such effects and our model certainly allows for it. Finally, the metafrontier model assumes there exists a deterministic frontier which envelopes the groups’ frontiers. However, we do not make such an assumption in our model due to the presence of the general (unobserved) individual-specific effects. Nevertheless, we believe that it can be readily extended to allow for a such deterministic frontier. Thus, our proposed model is more general and flexible.
The remainder of the paper is organized as follows. Section 2 outlines the model and estimation procedure. Specifically, we consider first-differencing transformations in the estimation procedures to remove the individual-specific effects and show how to determine the number of groups, classification of group membership, and prediction of technical inefficiency scores. Section 3 extends the model to accommodate for endogenous regressors. A detailed computational algorithm of the proposed approach is given in Section 4. Section 5 provides some Monte Carlo simulations to examine the finite sample performance of the proposed estimators. An empirical application is presented in Section 6, and finally, Section 7 concludes the paper.
2 The model with exogenous regressors
In order to fix the ideas, we will describe the estimation of a production function. However, with standard minor modifications in the model, a cost function can be estimated as well. Suppose we observed a panel data {(xit, yit): i = 1, ..., N; t = 1, ..., T} where yit is a scalar representing (log) output of firm i at time t and xit is k × 1 vector of (log) inputs of firm i at time t. The fixed effects stochastic frontier model with group-specific pattern heterogeneity can be written as:
where αi are scalar individual effects, βi is a kx × 1 vector of parameters of interest, vit is a random symmetric error term representing factors that are beyond the firm’s control, uit ≥ 0 is a one-sided stochastic variable representing a technical inefficiency component, hit is a positive function of a kq × 1 vector of non-stochastic inefficiency determinants (qit), and δ is a kq × 1 vector of unknown parameters. We assume that the random variable \(u_i^ \ast\) is independent of all T observations on vit, and both \(u_i^ \ast\) and vit are independent of all T observations on {xit, qit}. For identification purposes, we further assume that neither xit nor qit contains a constant term, and at least one variable in qit is not time-invariant. Following Su et al. (2016) (hereafter SSP), we allow for βi to follow a group-specific pattern of the general form:
where in (2), for any j ≠ l, γj ≠ γl, Gj ∩ Gl = ∅, and \(\cup _{j = 1}^{J_0}G_j = \{ 1,2,...,N\}\). Let Nj = #Gj, j = 1, ..., J0, denote the cardinality of the set Gj. To simplify the discussion, for now we assume that the number of groups, J0 is known and fixed but each individual’s group membership is unknown. In addition, we implicitly assume that individual group membership does not vary over time. The above model can be thought of as an extension of the models of Wang and Ho (2010) and Chen et al. (2014), which allows for the slopes to vary according to a specific group. Note that in (1d) we assume that δ is the same for all i. Allowing for δ to vary with i would complicate the analysis further since the group classification is now needed to be done simultaneously. It is beyond the scope of this paper and we will leave it for future research.
2.1 First-difference penalized likelihood (FDPL) estimation
Following Wang and Ho (2010), we first introduce the following notations. For any random variable rit, let Δrit = rit − rit−1, and \(\Delta \tilde r_i = (\Delta r_{i2},...,\Delta r_{iT})\prime\) for i = 1, ..., N. In general, with a slight abuse of notation, \(\Delta \tilde r_i\) represents a matrix with relevant columns obtained from each variable. For example, \(\Delta \tilde x_i\) is a (T − 1) × kx matrix. Then, taking the first difference of Eqs. (1a)–(1c), the model becomes:
where in Eq. (3b), the first-difference of vit introduces correlations of Δvit within the ith panel and the (T − 1) × (T − 1) matrix Σ is given by:
Note that, after the transformation, Eq. (3d) is the same as Eq. (1e) implying that the half-normality of \(u_i^ \ast\) is unaffected by the transformation, and this is the key aspect of the model that leads to a tractable derivation of the likelihood function. Under the above assumptions, the marginal log-likelihood function of panel i in the model is given by:
where \(\mu _{i \ast } = - \frac{{\Delta \widetilde e_i^\prime {\mathrm{\Sigma }}^{ - 1}\Delta \tilde h_i}}{{\Delta \tilde h_i^\prime {\mathrm{\Sigma }}^{ - 1}\Delta \tilde h_i + \sigma _v^2{\mathrm{/}}\sigma _u^2}}\), \(\sigma _{i \ast }^2 = \frac{{\sigma _v^2}}{{\Delta \widetilde h_i^\prime {\mathrm{\Sigma }}^{ - 1}\Delta \widetilde h_i + \sigma _v^2{\mathrm{/}}\sigma _u^2}}\), \(\Delta \widetilde e_i = \Delta \widetilde y_i - \Delta \widetilde x_i\beta _i\), and Φ(.) is the standard normal CDF. Let \({\mathbf{\gamma }} = (\gamma _1^\prime ,...,\gamma _J^\prime )^\prime\), \({\mathbf{\beta }} = (\beta _1^\prime ,...,\beta _N^\prime )^\prime\), and \(\theta = (\delta ^\prime ,\sigma _v^2,\sigma _u^2)^\prime\). We estimate β, γ, and θ by maximizing the following FDPL criterion:
where η1 = η1,NT is a tuning parameter, \(\left\| A \right\|\) denotes the Frobenius norm, and the second term on the right-hand side of Eq. (6) represents a penalty term. As in SSP, the penalty term takes a mixed additive-multiplicative form, which is different from the traditional penalized estimation (where the additive penalty term is normally used). The additive component is needed for the identification of {βi} and {γj} jointly; and the main reason for the inclusion of the multiplicative term is that, for each i, βi can take any one of the J0 unknown values, γ1, ..., γJ, and it is not known a priori to which point βi should shrink. Maximizing Eq. (6) produces FDPL or Classifier-Lasso (C-Lasso) estimates \(\widehat {\mathbf{\beta }}\) = \((\hat \beta _1^\prime ,...,\hat \beta _N^\prime )^\prime\), \(\widehat {\mathbf{\gamma }}\) = \((\hat \gamma _1^\prime ,...,\hat \gamma _J^\prime )^\prime\), and \(\hat \theta = (\hat \delta ^\prime ,\hat \sigma _v^2,\hat \sigma _u^2)^\prime\) of γ = \((\gamma _1^\prime ,...,\gamma _J^\prime )^\prime\), β = \((\beta _1^\prime ,...,\beta _N^\prime )^\prime\), and \(\theta = (\delta ^\prime ,\sigma _v^2,\sigma _u^2)^\prime\), respectivelyFootnote 1.
2.2 Determination of the number of groups
The discussion in the previous sub-section assumes that the number of groups J0 is known a priori. However, in practice, the exact number of groups is rarely known and must be estimated. In this sub-section, we show how to determine the number of groups using an information criterion (IC) procedure. Our approach follows along the argument given in SSP. First, we assume that J0 is bounded from above by a finite integer Jmax. For a given \(J \in \{ 1,...,J_{\max }\}\), let \(\{ \hat \beta _i(J,\eta _1),\hat \gamma _j(J,\eta _1)\}\) and \(\hat \theta\) denote the FDPL (or C-Lasso) estimators of {βi, γj} and θ discussed above; and individual i is classified into group \(\hat G_j(J,\eta _1)\) according to \(\hat G_j(J,\eta _1) = \{ i \in \{ 1,2,...,N\} :\hat \beta _i(J,\eta _1) = \hat \gamma _j(J,\eta _1)\}\) for j = 1, ..., J. Finally, let \(\hat G(J,\eta _1) = \{ \hat G_1(J,\eta _1),...,\hat G_J(J,\eta _1)\}\) and \(\hat \gamma _{\hat G_j(J,\eta _1)}\) denote the post-FDPL (or post-Lasso) estimator. Then, we select J so that it minimizes the following IC:
where λ1,NT is a tuning parameter, and K1 = kx + kq + 2. That is, the number of groups, J is chosen such that \(\hat J(\eta _1) = \mathop {{{\mathrm{arg}}\,{\mathrm{min}}}}\limits_{1 \le J \le J_{{\mathrm{max}}}} IC_1(J,\eta _1)\).
Remark 1: As noted by SSP, the choice of the tuning parameter λ1,NT and η1,NT respectively, can play an important role in determining the correct number of groups and post-FDPL estimates in practice. Following SSP, we impose the following conditions on the tuning parameters λ1,NT and η1,NT.
A.1: As (N, T) → ∞, λ1,NT→ 0 and λ1,NTNT → ∞.
A.2: As (N, T) → ∞, (i) \(T\eta _1^2{\mathrm{/}}(\ln T)^{6 + 2\upsilon } \to \infty\) and \(\eta _1(\ln T)^\upsilon \to 0\) for some υ > 0; (ii) \(N^{1/2}T^{ - 1}(\ln T)^9 \to 0\) and N2T1−q/2 → c ∈ [0, ∞) for some q ≥ 6.
The condition A.1 reflects the conditions for consistency of model selection, i.e., λ1,NT cannot shrink to zero too quickly or too slowly. Condition A.2 holds if η1,NT ∝ T−a for any a ∈ (0, 1/2).
In practice, under A.1, we can fine-tune λ1,NT over a finite set Λ1 = {λ1 = κl(NT)−1/2, l = 1, ..., L} for some κl > 0. Similarly, under A.2, we also suggest to fine-tune η1,NT over a finite set ℵ1 = {η1 = clT−1/3, cl = c0ζl, l = 1, ..., L} for some c0 > 0 and ζ > 1. In essence, these tuning parameters are analogous to the bandwidth selections in the kernel smoothing.
Remark 2: Under certain regularity conditions, SSP derive the asymptotic properties of the post-Lasso estimators including the oracle property for the non-stochastic frontier models. It can be shown that our proposed estimator satisfies the regularity conditions set out in SSP, and hence it is consistent, asymptotically normal, and achieves the oracle property as wellFootnote 2. For inference purposes, it is important to recognize that our post-FDPL estimator belongs to the class of M-estimators, and hence the asymptotic variance has the form: \(a{\mathrm{var}}(\hat \psi _j) = A_{0j}^{ - 1}B_{0j}A_{0j}^{ - 1}\) where \(\hat \psi _j = (\hat \theta _j,\widehat {\mathbf{\beta }}_j,\widehat {\mathbf{\gamma }}_j)\), \(A_{0j} = - E[\nabla _{\psi _j\psi _j}\log L_{NT,\eta _1}^{(J_0)}(\psi _{0j})]\) and \(B_{0j} = E[\nabla _{\psi _j}\log L_{NT,\eta _1}^{(J_0)}(\psi _{0j})\nabla _{\psi _j}\log L_{NT,\eta _1}^{(J_0)}(\psi _{0j})^\prime ]\), with \(\nabla _{\psi _j}\) and \(\nabla _{\psi _j\psi _j}\) denoting the vector of first and second derivatives of the log-likelihood function, respectively, \(\psi _{0j}\) is the true parameter vector and j = 1, ..., J0. The estimated asymptotic variance can be obtained by replacing the true parameters with their estimates discussed above, and the expectation is replaced by the sample average over NT observations.
2.3 Prediction of the inefficiency index
The primary interest in estimating model (1) is to obtain the prediction for technical inefficiency, uit. The conditional expectation estimator E(uit | eit) proposed by Jondrow et al. (1982) is often used for this purpose. For our proposed model, a similar conditional expectation estimator can also be used but with one simple modification. As Wang and Ho (2010) pointed out, instead of conditioning on the level of eit, it is more convenient to compute the expectation of uit condition on \(\Delta \tilde e_i\) since \(\Delta \tilde e_i = \Delta \tilde y_i - \Delta \tilde x_i\beta _i\) does not depend on the estimates of individual-specific effect, \(\hat \alpha _i\). In addition, the vector \(\Delta \tilde e_i\) contains all the information of individuals i within each group in the sample. Thus, given the estimates of \(\hat \beta _i\) and \(\hat \theta\) discussed previously, the conditional expectation estimator \(E(u_{it}|\Delta \tilde e_i)\) and efficiency estimate Effit can be written as:
where \(\mu _{i \ast }\) and \(\sigma _{i \ast }\) are defined previously, and the expression in Eq. (6) is evaluated at \(\Delta \tilde e_i = \Delta \widehat {\tilde e}_i\), \(h_{it} = h(q_{it}^\prime \hat \delta )\), \(\mu _{i \ast } = \hat \mu _{i \ast }\), and \(\sigma _{i \ast } = \hat \sigma _{i \ast }\). The group-wise efficiency prediction can be computed as \(Eff_{it}^{(\hat J)} = \exp ( - \hat u_{it}^{(\hat J)})\) where \(\hat u_{it}^{(\hat J)} = E(u_{it}^{(\hat J)}|\Delta \tilde e_i^{(\hat J)})\).
3 Model with endogenous regressors
3.1 Control function penalized likelihood (CFPL) estimation
In this section, we relax the independence assumption between {xit, qit} and vit (See for example, Kutlu 2010; Tran and Tsionas 2013; Amsler et al. 2016, 2017; Karakaplan and Kutlu 2017; Kutlu et al. 2019). In particular, we assume that a kp × 1 sub-vector, pit of {xit, qit} is correlated with vit. However, we assume that {xit, qit} and \(u_i^ \ast\) are independent. In addition, we assume that there is a kz × 1 vector of (strictly) exogenous instruments zit, where kz ≥ kp in the sense that E(vit | zis) = 0 for all t and s. Under these assumptions, we use a single-stage control function approach to deal with the endogeneity issue. That is, we use the following system of equations for the stochastic frontier model:
where Π is a kp × kz matrix of unknown coefficients, εit is a kp × 1 vector of reduced form errors, and βi follows a group-specific pattern as in Eq. (2).
Under the specification of the above model, the endogeneity problem is introduced by allowing the reduced form error term εit to be correlated with vit. More explicitly, we assume that conditional on zit,
where Ω is a kp × kp variance-covariance matrix of εit, and ρ is a kp × 1 vector representing the correlation between \(\varepsilon _{it}^ \ast\) and vit. To simplify the discussion, we assume for now that the number of groups, J0 is known and fixed but each individual’s group membership is unknown. Taking the first difference of Eq. (9) to eliminate the fixed effects and stacking all T − 1 observations, we have:
Recall that \(\Delta \tilde x_i\) and \(\Delta \tilde \varepsilon _i\) are (T − 1) × kp matrices and \(\Delta \tilde z_i\) is a (T − 1) × kz matrix. By a Cholesky decomposition of the variance-covariance matrix of \((\varepsilon _{it}^{ \ast \prime },v_i)^\prime\), we obtain:
where \(\varepsilon _{it}^ \ast\) and \(w_{it}^ \ast \sim N(0,1)\) are independent. Therefore, we have:
where \(\varphi = \frac{{\sigma _w{\mathrm{\Omega }}^{ - 1/2}\rho }}{{\sqrt {1 - \rho \prime \rho } }}\), \(\sigma _w = \sigma _v\sqrt {1 - \rho \prime \rho }\), and \(w_{it} = \sigma _ww_{it}^ \ast\). After first differencing, we get: \(\Delta \tilde v_i = \Delta \tilde \varepsilon _i\varphi + \Delta \tilde w_i\). Then, the frontier Eq. (11a) can be written as:
where \(\Delta \tilde \xi _i = \Delta \tilde w_i - \Delta \tilde u_i\) and \(\Delta \tilde \varepsilon _i\varphi\) is the endogeneity bias correction term. The density function of \(\Delta \tilde w_i\) is given byFootnote 3:
Similarly, the joint density function of \(\Delta \tilde \varepsilon _i\) is given by:
Since \(\Delta \tilde \varepsilon _i\) and \(\Delta \tilde \xi _i\) are independent, after tedious but straightforward derivation, the marginal log-likelihood function of the panel i is given by:
where
and
where
\(\mu _{i \ast \ast } = - \frac{{\Delta \tilde \xi _i^\prime {\mathrm{\Sigma }}^{ - 1}\Delta \tilde h_i}}{{\Delta \tilde h_i^\prime {\mathrm{\Sigma }}^{ - 1}\Delta \tilde h_i + \sigma _w^2{\mathrm{/}}\sigma _u^2}}\), \(\sigma _{i \ast \ast }^2 = \frac{{\sigma _w^2}}{{\Delta \tilde h_i^\prime {\mathrm{\Sigma }}^{ - 1}\Delta \tilde h_i + \sigma _w^2{\mathrm{/}}\sigma _u^2}}\), \(\Delta \tilde \xi _i = \Delta \tilde y_i - \Delta \tilde x_i\beta _i - \Delta \tilde \varepsilon _i\varphi\), and \(\Delta \tilde \varepsilon _i = \Delta \tilde x_i - {\Pi}\Delta \tilde z_i\). As before, let β = (β1, ..., βN)′, γ = (γ1, ..., γJ)′, and \(\theta ^ \ast = (vec({\Pi})^\prime ,\delta ^\prime ,\rho ^\prime ,\sigma _v^2,\sigma _u^2)^\prime\), then we propose to estimate β, γ, and θ* by maximizing the following CFPL criterion:
where η2 = η2,NT is a tuning parameter. Maximizing Eq. (18) produces the CFPL estimates \(\overline {\mathbf{\beta }}\) = \((\bar \beta _1,...,\bar \beta _N)^\prime\), \(\overline {\mathbf{\gamma }}\) = \((\bar \gamma _1,...,\bar \gamma _J)^\prime\), and \(\bar \theta ^ \ast = (vec(\bar {\Pi})^\prime ,\bar \delta ^\prime ,\bar \rho ^\prime ,\bar \sigma _v^2,\bar \sigma _u^2)^\prime\).
3.2 Determination of the number of groups
Similar to the case of exogenous regressors, when the number of groups J is unknown, we replace J0 by \(J \in (1,...,J_{\max })\) to obtain the CFPL (or C-Lasso) estimates \(\{ \bar \beta _i(J,\eta _2),\bar \gamma _j(J,\eta _2)\}\) and \(\bar \theta ^ \ast\) of {βi, γj} and θ* discussed above. We then classify individual i into group \(\bar G_j(J,\eta _2)\) according to \(\bar G_j(J,\eta _2) = \{ i \in \{ 1,2,...,N\} :\bar \beta _i(J,\eta _2) = \bar \gamma _j(J,\eta _2)\}\). Let \(\bar G(J,\eta _2)\) = \(\{ \bar G_1(J,\eta _2),...,\bar G_J(J,\eta _2)\}\) and \(\bar \gamma _{\bar G_j(J,\eta _2)}\) denote the post-CFPL (or post-Lasso) estimator. Then, we suggest selecting J that minimizes the following IC:
where λ2,NT is a tuning parameter, and K2 = kx + kq + kz + 2. That is, the number of groups J is chosen such that \(\bar J(\eta _2) = \mathop {{{\mathrm{arg}}\,{\mathrm{min}}}}\nolimits_{1\, \le \,J\, \le \,J_{{\mathrm{max}}}} IC_2(J,\eta _2)\). For the choice of the tuning parameters η2,NT and λ2,NT in practice as well as discussion on the asymptotic properties of the proposed estimator, see Remark 1 and Remark 2 above.
3.3 Prediction of inefficiency score
As earlier, given the CFPL estimates of \(\bar \beta _i\) and \(\bar \theta ^ \ast\), the conditional expectation estimator \(E(u_{it}|\Delta \tilde \xi _i)\) can be written as:
where \(\mu _{i \ast \ast }\) and \(\sigma _{i \ast \ast }\) are defined previously, and the expression in Eq. (20) is evaluated at \(\Delta \tilde \xi _i = \Delta \overline {\tilde \xi } _i\) where \(\Delta \overline {\tilde \xi } _i = \Delta \tilde y_i - \Delta \tilde x_i\bar \beta _i - \Delta \tilde \varepsilon _i\bar \varphi\), and \(\Delta \overline {\tilde \varepsilon } _i = \Delta \tilde x_i - \bar {\Pi}\Delta \tilde z_i\); \(h_{it} = h(q_{it}^\prime \bar \delta )\), \(\mu _{i \ast \ast } = \bar \mu _{i \ast \ast }\); and \(\sigma _{i \ast \ast } = \bar \sigma _{i \ast \ast }\). As in the exogenous regressors case, the group-wise efficiency prediction can be computed as \(Eff_{it}^{(\bar J)} = \exp ( - \hat u_{it}^{(\bar J)})\) where \(\hat u_{it}^{(\bar J)} = E(u_{it}^{(\bar J)}|\Delta \tilde \xi _i^{(\bar J)})\).
4 Computational algorithm
In this section, we briefly outline an iterative numerical algorithm to obtain the FDPL estimates \(\widehat {\mathbf{\gamma }}\), \(\widehat {\mathbf{\beta }}\), and \(\hat \theta\) discussed in Section 2.1. For the CFPL estimation, a similar algorithm can be applied. Let s be the iteration index.
Step 1: Set s = 1 and start with the initial value \(\hat \gamma ^{(0)} = (\hat \gamma _1^{(0)},...,\hat \gamma _J^{(0)})\), \(\hat \beta ^{(0)} = (\hat \beta _1^{(0)},...,\hat \beta _N^{(0)})\), and \(\hat \theta ^{(0)} = (\hat \delta ^{(0)},\hat \sigma _v^{2(0)},\hat \sigma _u^{2(0)})\) such that \(\mathop {\sum}\nolimits_{i = 1}^N {\left\| {\hat \beta _i^{(0)} - \hat \gamma _j^{(0)}} \right\|\, \ne \,0}\) for j = 2, ..., J.
Step 2: Given \(\hat \gamma ^{(r - 1)}\), \(\hat \beta ^{(r - 1)}\), and \(\hat \theta ^{(r - 1)}\), choose (γ1, β, θ) to maximize:
and obtain the updated ((\(\widehat {\mathbf{\beta }}^{(r)},\)\(\hat \theta ^{(r)},\hat \gamma _1^{(r)}\))). Repeat this procedure until we obtain the updated of \((\widehat {\mathbf{\beta }}^{(r)},\hat \theta ^{(r)},\hat \gamma _J^{(r)})\).
Step 3: Update s to s + 1 and repeat Step 2 until convergence.
Define the final estimate of γ as \(\widehat {\mathbf{\gamma }}\) = \((\hat \gamma _1^{(S)},...,\hat \gamma _J^{(S)})\) where S denotes the final iteration such that the convergence is achieved. Then, individual i is classified as a member of group \(\hat G_j\) if \(\hat \beta _i^{(S,j)} = \hat \gamma _j\); otherwise, \(\hat \beta _i\) is allocated to the \(\gamma _j^{(S)}\) that is nearest to some \(\hat \beta _i^{(S,k)}\), for k = 1, ..., J. The initial value in Step 1 is chosen based on random initial conditions to find the best starting value (10,000 searches). If a failure occurs, a new random search is used. We use this choice of initial value throughout our simulations as well as the empirical application below.
5 Monte Carlo simulations
5.1 Data generating process (DGP)
To examine the finite sample performance of the estimation and classification procedure, we consider two DGP that cover both exogenous and endogenous regressors. We consider sample sizes N = {250,500} and time periods T = {10, 20, 40}. For each sample, the observations in each DGP are drawn from three groups with the proportion{N1:N2:N3} = {0.4:0.4:0.3}. Throughout the experiments, the fixed effect αi is standard normal, independent across i. The one-sided error \(u_i^ \ast\) is generated as i.i.d. from a half-normal with σu = {1, 2}, and \(u_i^ \ast\) is independent of αi and all regressors.
DGP 1(Exogenous Regressors): The observations (yit, xit, qit) are generated from the model (1a)–(1e). The exogenous regressors xit = (x1it, x2it)′ = (0.5αi + ω1it, 0.5αi + ω2it)′ where ω1it, ω2it ~ i.i.d.N(0, 1) are mutually independent, and independent of αi. The two-sided error vit is standard normal, independent across i and t, and independent of αi, \(u_i^ \ast\) and all the regressors. The environmental variable qit is generated as i.i.d. from a Uniform distribution on [−1, 1] and \(h_{it} = \exp (0.2q_{it})\). Finally, the true coefficients for the three groups (β11, β12), (β21, β22), and (β31, β32) are (0.5, 1.5), (1, 1), and (1.5, 0.5), respectively. FDPL will be used for this DGP.
DGP 2(Endogenous Regressors): For this DGP, the observations are generated from the model (9a)–(9e). We assume that x2,it is exogenous and is generated as in DGP 1, whilst x1,it is endogenous and is generated as x1it = 0.4αi + 0.8zit + εit where zit ~ i.i.d.N(0, 1) and
In each experiment, we set ρ = {0.2, 0.4, 0.8} which corresponds to a weak, moderate and strong correlation between vit and εit, respectively. The environmental variable qit and the true coefficients for the three groups are the same as in DGP 1. Finally, the Monte Carlo replications for each DGP is 500.
Our first simulation exercise is to assess how well the proposed IC selects the number of groups for each DGP. As discussed earlier, the choice of the fine-tune parameters ηjNT and λjNT for j = 1, 2, can be important in selecting the correct number of groups. For the tuning parameter ηjNT, we choose \(\eta _j = c_js_{\Delta y}^2T^{ - 1/3}\) for j = 1, 2, where \(s_{\Delta y}^2\) is the sample variance of Δyit and cj ∈ {0.125, 0.25, 0.5, 1, 2}. As for the tuning parameter λjNT we use the following λj = κ(NT)−1/2 for j = 1, 2, where \(\kappa \in \left\{ {\frac{1}{4},\frac{1}{3},\frac{1}{2},\frac{2}{3},\frac{3}{4}} \right\}\). We experimented with many alternatives, and found that cj = 0.25 and κj = 2/3 for j = 1, 2, work fairly well and they are used throughout the simulations and the empirical application. For DGP 1, we pick up from the set candidate values of η1 that maximizes \(IC_1(\hat J(\eta _1),\eta _1)\), and similarly for GDP 2, we pick up from the set candidate values of η2 that maximizes \(IC_2(\tilde J(\eta _2),\eta _2)\). In all experiments, we use the initial starting value described in Section 4 and the BFGS numerical algorithm procedure from NETLIB in Fortran77, GNU compiler to maximize the log-likelihood function with the convergence criterion is set at 10−5. In almost all cases the convergence was quick and stable.
5.2 Results
Tables 1 and 2 report the empirical probability that a particular group size from 1 to 5 is selected according to the proposed IC when the true number of groups is 3. In particular, Table 1 shows the results for DGP 1 (exogenous case), whilst Table 2 display the results for DGP 2 (endogenous case). In line with our prior expectation, the correct classification percentage approaches 100% as T increases for both DGPs.
Next, we focus our attention on the classification of individual units and the point estimation of post-Lasso, given the true number of groups (J0 = 3). Due to the space limitation, all tabulated results are produced using cj = 0.25, j = 1, 2, albeit the outcomes are found to be robust over the specified range of constants. For comparison purposes, we also include the oracle estimator \(\hat \gamma _{G_j}\) or \(\bar \gamma _{G_j}\) which defines as the infeasible estimator that utilizes the true group identity Gj. For conservation of space, we only report the results for the first coefficient \(\gamma _1 = (\gamma _{11},...,\gamma _{1J_0})\prime\), and since γ1 is a J0 × 1 vector, we use the average statistics over their weight Nj/N, j = 1, ..., J0. The results are depicted in Tables 3 and 4. We report the bias, root-mean-squared errors (RMSE), and the percentage of correct classification of the N units, computed as \(N^{ - 1}\mathop {\sum}\nolimits_{j = 1}^3 {\mathop {\sum}\nolimits_{i \in \hat G_j} {1\{ \beta _i = \gamma _k\} } }\) averaged over 500 replications. The results indicate that the estimated bias and RMSE of the oracle and post-Lasso estimators are decreasing as either N or T decreases. Moreover, the bias and RMSE of the oracle’s estimator are slightly smaller than those of post-Lasso. The main reason for these (mild) discrepancies of the RMSE is that the estimated bias and standard deviation of the post-Lasso estimator are inflated by some misclassification units, which mask as outliners against most of the group members. Nevertheless, our results seem to confirm the oracle properties of the proposed estimators.
6 An empirical application
In this section we present an empirical application of US banks to illustrate the usefulness of our proposed models and estimation methods discussed earlier.
6.1 The data
The data we use in this paper is the annual year-end bank-level which include all FDIC-insured commercial banks from 1976–2007. The data was taken from Koetter et al. (2012) and the detailed description of the data is given in their paper.
For the input prices, we truncated these variables at the 1st and 99th percentiles of their respective empirical distributions to mitigate the influence of outliers. In addition, we use the 2005 Consumer Price Index for all urban consumption (published by the U.S. Bureau of Labor Statistics) to deflate all nominal quantities. Since our proposed approach requires large N and T, we use an unbalanced panel data and first include all banks with time dimension Ti ≥ 10. There are N = 14,168 banks included in our data set for the analysis. The average length of time periods for all banks is about \(N^{ - 1}\mathop {\sum}\nolimits_{i = 1}^N {T_i \approx 21.9}\). Figure 1 plots the frequency distribution of Ti.

Frequency distribution of the data
Following Sealey and Lindley (1997), the bank’s production technology is modeled using the “intermediation approach”. Labour, physical capital as well as liabilities are used as inputs to the bank’s production process, whilst assets (other than physical) are considered as outputs. The following variables are used as outputs (y) and inputs (x) in the production technology: Securities (y1) and loans (y2); fixed assets (x1), labor (x2), borrowed funds (x3) as well as equity capital (x4). The inclusion of equity capital as an additional input can be argued that banks may use it to guard against losses, and hence it can be considered as a source of loanable funds.
In order to contextualize the economic environment in which banks operate, we include the following variables, both internally and externally, to capture bank’s characteristics in our instrumental variables (zit) and environmental variables (qit). The instrumental variables zit include: (1) the bank’s total assets as a proxy for its size and scale of operation; (2) the bank’s asset market share in a given state to capture its dominance in the market (see, for example, Stiroh and Strahan 2003; Boyd and DeNicolo 2005); (3) the bank’s ratio of equity to total assets; (4) the bank’s ratio of securities to total assets; (5) the share of non-interest income (Koetter et al. 2012); (6) the share of loan-loss provisions and loan-loss reserves in the bank’s total loans to proxy for credit risk; and (7) macroeconomic variables such as the disposable personal income and the state’s unemployment rate. The environmental variables (qit) include: (1) the number of bank mergers in the state in a given year; (2) the bank’s z-score to proxy for the overall risk of bank failure (see Laeven and Levin 2009); (3) the Hirschman-Herfindahl index across the banks’ different types of loans; (4) an indicator for the top-hundred banks in a given year; and (5) three indicators to capture the institutional changes in states that correspond to deregulation in the intrastate branching, the interstate expansion and the post-IBBEA interstate banking.
The above chosen variables have important implications for bank efficiency and market power since they are more than likely to influence bank’s business strategies in their quest to maximize its franchise value (Demsetz and Strahan 1997; DeYoung and Rice 2004). For more details on the construction and rationale behind these variables, see Koetter et al. (2012).
Production technology is described by an output distance function (ODF). Suppose the inputs are X1, ..., XK, and the outputs are Y1, ..., YM. Define \(x_k = \ln X_k,k = 1,...,K\), \(y_1 = \ln Y_1\) and \(y_m = \ln \left( {Y_m{\mathrm{/}}Y_1} \right),m = 2,...,M\). This transformation is used to ensure that the IDF is homogeneous of degree one in outputs. Then, the output distance function (ODF) takes the following form:
Let \(\tilde y_{it} = (y_{2,it},...,y_{M,it})^\prime\) and \(x_{it} = (x_{1,it},...,x_{K,it})^\prime\). If we adopt a translog specification, we have:
where \(B_{x_i}\), \(B_{y_i}\), and \(B_{xyi}\) are parameter matrices, βxi and βyi are parameter vectors. We can write the ODF as follows:
where \(x_{ \ast ,it} = [1,x_{it}^\prime ,vech(x_{it} \otimes x_{it})^\prime ,\tilde y_{it}^\prime ,vech(\tilde y_{it} \otimes \tilde y_{it})^\prime ]^\prime\). We treat both log inputs and log output ratios as endogenous. Under certain economic assumptions, log output ratios can be treated as predetermined. However, econometrically, there is no compelling reason to adopt this as conclusive evidence that they can be treated as exogenous. In fact, profit maximization would imply that both inputs and outputs are economically (and, in all likelihood, econometrically, as well) endogenous. In addition to the instruments listed above, we also include interactions among the variables in zit, interactions of time dummies with all other time-invariant variables in zit as well as the lagged values of time-varying instruments along with their interactions with all other variables as additional instruments.
6.2 Results
We first determine the appropriate number of groups using Eqs. (7) and (19) for the case of exogenous and endogenous regressors, respectively, and the results are depicted in Fig. 2. For the exogenous regressor case, the optimal number of groups is seven, whilst for the endogenous regressors’ case, the optimal group is four implying that endogeneity may be an issue for our model. To check for the endogeneity problem, we plot the density of the ratio of the root mean squares forecast errors (RMSFE) and our results show that the regressors are indeed endogenous (see Fig. 3). As a further evidence for the endogeneity of these variables, we conduct a simple test for φ = 0 in (14) using F-statistics (see, for example, Amsler et al. (2016) and Karakaplan and Kutlu (2017)). The value of the F-statistics is 64.78 with a p-value of 0.000 indicating that the null hypothesis of φ = 0 is rejected at a one percent significant level. Thus, in what follows we only report the results for the endogenous case. For comparison purposes, we also estimate the homogenous coefficient stochastic model with endogenous regressors using the approach developed in Kutlu et al. (2019).

Identification of number of groups

Density plot of the ratio of RMSFE
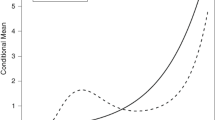
For the sake of convenience and simplicity, Table 5 and Fig. 5 report only the summary of estimated groups’ productivity measures, which include returns to scale (RTS), efficiency change, technical change, and productivity growthFootnote 4. For comparison purposes, the estimated productivity measures for the homogenous-coefficients model are given in the second row of Table 5 and Fig. 4a, b, respectively. Our results indicate that RTS for the homogenous-coefficient model is close to one (i.e., constant RTS) and statistically significant at the 1% level, whilst other measures such as efficiency change (EC), technical change (TC), and productivity growth are not statistically significant. In contrast, the results based on our proposed approach, the CFPL classifies the banks into four groups based on the variables that are related to the banks’ size and scale operation, market shares, as well as the ratio of equity and securities to total assets. The results in Table 5 and Fig. 5 show that (RTS) vary over the four groups, and they average 0.627, 0.888, 0.835, and 0.656 indicating that different groups have different properties in terms of RTS, albeit in all groups, we have decreasing returns to scale. Efficiency change is mostly positive for all groups. The densities of efficiency change exhibit bimodal for groups one and four with a dominant mode at near-zero value for group two, and a positive value of approximately 0.0065 for group four. The average efficiency scores for the four groups are 0.821, 0.924, 0.935, and 0.845, respectively. For the most part, technical change is positive and consequently, productivity growth is positive except for group 4, which has significantly less technical change and productivity growth compared to the other groups. As the groups are different in terms of RTS, technical change, efficiency change, and productivity growth, any policy measures will have heterogeneous effects on specific banks according to the group to which they belong. Consequently, ignoring the group-wise heterogeneity when it is present, can provide misleading estimates of productivity and efficiency measures which may have negative consequences on policy and banking supervisions.

a Density plot of returns to scale: homogenous case. b Density plot of TC, EC and PG: homogenous case

Density plots of productivity and efficiency change measurements
Finally, as a robustness check, we also consider the case where Ti ≥ 9 and Ti ≥ 8. In these cases, the number of banks (N) increased to 14,974 and 15,729, respectively. Using our approach for both cases, the optimal number of groups obtained is still 4 and the productivity measures are similar to those in Table 5. For the conservation of space, we do not report these results here but available from the authors upon request.
7 Concluding remarks
This paper extends the fixed effects panel stochastic frontier model of Wang and Ho (2010) to allow group heterogeneity in the slope coefficients. We propose the first-difference penalized maximum likelihood (FDPML) and control function penalized maximum likelihood (CFPML) methods for classification and estimation of latent group structures in the frontier as well as inefficiency. Monte Carlo simulations show that the proposed approach performs well in finite samples. An empirical application indicates the advantages of data-determined identification of the heterogeneous group structures in practice.
The approach in this paper can also be adapted to the Chen et al. (2014) model where they leave the inefficiency term uit unspecified. In this case, the density of the transformation errors (using either first-difference or within transformation) can be obtained with a similar approach as in Chen et al. (2014) using the closed skew normal results. Also, it would be interesting to extend our approach to the four-component stochastic frontier models of Colombi et al. (2014), Kumbhakar et al. (2014), and Tsionas and Kumbhakar (2014). Finally, under the endogenous regressors case, it is possible to extend the current method to allow for some or all inputs to be correlated with both uit and vit. Using Amsler et al. (2017) approach, one can construct the joint density of all the errors in the model via copula function. Alternatively, the correlation between some or all inputs and inefficiency can be modeled using the correlated effects as it has been done in Griffiths and Hajargasht (2016). We will leave these topics for future research.
Notes
C-Lasso is termed by SSP.
Even if we do not formally establish the asymptotic properties of the FDPL estimator, it is worth pointing out that the results of our Monte Carlo simulations are consistent with the belief that these asymptotic properties hold. See Section 5 for more details.
Note that \(\left| {\mathrm{\Sigma }} \right| = T\).
Detailed results for the estimated frontier parameters are available from the authors up request.
References
Amsler C, Prokhorov A, Schmidt P (2016) Endogeneity in stochastic frontier models. J Econ 190:280–288
Amsler C, Prokhorov A, Schmidt P (2017) Endogenous environmental variables in stochastic frontier models. J Econ 199:131–140
Battese GE, Rao DSP, O’Donnell CJ (2004) A metafrontier production function for estimation of technical efficiencies and technology gap for firms operating under different technologies. J Prod Anal 21:91–103
Boyd JH, De Nicolo G (2005) The theory of bank risk taking and competition revisited. J Financ 60:1329–1343
Chen Y-Y, Schmidt P, Wang H-J (2014) Consistent estimation of the fixed effects stochastic frontier model. J Econ 181:65–76
Colombi R, Kumbhakar S, Martini G, Vittandini G (2014) Closed-skew normality in stochastic frontiers with individual effects and long/short-run efficiency. J Prod Anal 42:123–136
Demsetz RS, Strahan PE (1997) Diversification, size, and risk at bank holding companies. J Money Credit Bank 29:300–313
DeYoung R, Rice T (2004) Non-interest income and financial performance at U.S. commercial banks. Financ Rev 39:101–127
Greene WH (2005a) Fixed and random effects in stochastic frontier models. J Prod Anal 23:7–32
Greene WH (2005b) Reconsidering heterogeneity in panel data estimators of the stochastic frontier model. J Econ 126:269–303
Griffiths WE, Hajargasht G (2016) Some models for stochastic frontiers with endogeneity. J Econ 190:341–348
Guan Z, Kumbhakar SC, Myers RJ, Lansink AO (2009) Measuring excess capital capacity in agricultural production. Am J Agric Econ 91:765–776
Jondrow J, Lovell CAK, Materov IS, Schmidt P (1982) On the estimation of technical inefficiency in the stochastic frontier production function model. J Econ 19:233–238
Karakaplan MU, Kutlu L (2017) Handling endogeneity in stochastic frontier analysis. Econ Bull 37:889–901
Koetter M, Kolari JW, Spierdijk L (2012) Enjoying the quiet life under deregulation? Evidence from adjusted lerner indices for U.S. banks. Rev Econ Stat 94:462–480
Kumbhakar SC, Lien G, Hardaker JB (2014) Technical efficiency in competing panel data models: a study of Norwegian grain farming. J Prod Anal 41:321–337
Kutlu L (2010) Battese-Coelli estimator with endogenous regressors. Econ Lett 109:79–81
Kutlu L, Tran KC, Tsionas MG (2019) A time-varying true individual effects model with endogenous regressors. J Econ 211:539–559
Kutlu L, Tran KC (2019) Heterogeneity and endogeneity in panel stochastic frontier models. In: Tsionas EG (ed) Panel data econometrics, Volume I: Theory, Chapter 5. Elsevier Publisher, Amsterdam, The Netherland
Laeven L, Levin R (2009) Bank governance, regulation and risk taking. J Financial Econ 93:259–275
Sealey Jr. CW, Lindley JT (1997) Inputs, outputs, and theory of production cost at depository financial institutions. J Financ 32:1251–1266
Stiroh KJ, Strahan PE (2003) Competitive dynamics of competition: evidence from U.S. banking. J Money Credit Bank 35:801–828
Su L, Shi Z, Phillips PCB (2016) Identifying latent structures in panel data. Econometrica 84:2215–2264
Tran KC, Tsionas EG (2013) GMM estimation of stochastic frontier model with endogenous regressors. Econ Lett 118:233–236
Tsionas EG (2002) Stochastic frontier models with random coefficients. J Appl Econ 17:121–47
Tsionas EG, Kumbhakar SC (2014) Firm heterogeneity, persistent and transient technical inefficiency: a generalized true random effects model. J Appl Econ 29:110–132
Wang HJ, Ho CW (2010) Estimating fixed-effect panel stochastic frontier models by model transformation. J Econ 157:286–296
Acknowledgements
We would like to thank the Editor, the Associate Editor and two anonymous referees for constructive comments and suggestions that helped improve this paper. An earlier draft of this paper was presented at The EcoSta Conference in Hong Kong, June 2017. We would like to thank Artem Prokhorov, Dan Henderson, and the participants in our invited session for their comments and suggestions.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors declare that they have no conflict of interest.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Kutlu, L., Tran, K.C. & Tsionas, M.G. Unknown latent structure and inefficiency in panel stochastic frontier models. J Prod Anal 54, 75–86 (2020). https://doi.org/10.1007/s11123-020-00584-8
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11123-020-00584-8
Keywords
- Classification
- Fixed effect
- Group heterogeneity
- Panel stochastic frontier
- Penalized control function maximum likelihood
- Penalized first-difference maximum likelihood.