
Abstract
A novel concept is presented to capture route choice behaviours and to account for the correlation of routes in the logit model. The issue that route choice models are easily affected when irrelevant alternatives are included in the choice set is tackled. The concept of equivalent impedance is presented to simplify and aggregate a set of links based on the idea that people tend to remember and process road network information at an abstract level. Then, the equivalent impedance is utilized to derive a correction term for the utility of a multinomial logit model in which the advantages of a closed-form structure and easy computation remain unchanged. The results from the numerical examples suggest that the proposed model obtains reasonable results and provides more stable predictions than comparable models when the composition of the choice set changes. An application in a real urban network with GPS data is presented, and estimation results suggest that the new model is practical due to its robustness.
Similar content being viewed by others
Avoid common mistakes on your manuscript.
Introduction
A route choice model captures travellers’ behavioural choices when facing different alternative routes between an origin–destination (OD) pair. The stochastic route choice model provides the probability of each route being chosen; thus, future traffic demand can be forecasted for transportation planning and management. Due to the closed-form expression and high computational efficiency, the logit model is one of the most commonly used models in route choice analysis.
The multinomial logit (MNL) model is derived based on the assumption that the errors of alternatives are independently and identically extreme value distributed, which leads to a primary drawback: the model cannot interpret the correlation degree of routes due to the independence of the irrelevant alternatives property (IIA), referred to as the overlapping problem, and thus it leads to enlarged probabilities for correlated routes. Several solutions have been proposed to overcome the overlapping problem. The nested logit (NL), cross nested logit (CNL), and paired combinatorial logit (PCL) models interpret the correlation relation explicitly (Chu 1989; Bekhor and Prashker 2001; Bierlaire 2006) in which the correlated routes are classified into the same nest. However, the large set of nesting parameters to be estimated creates a burden for large transportation networks. The mixed logit model incorporates the normal distribution and employs the covariance matrix to interpret the correlation (Bekhor et al. 2007; McFadden and Train 2000; Walker et al. 2001) but the non-closed form requires simulation-based estimation and computation, which are even more time-consuming than the nested logit models. Therefore, the approximation method that adds one correction term to the utility of the MNL model appears to be the most popular in application because of the favourable trade-off between rapid computation and accuracy in prediction. The correlation of routes is considered a disutility to decrease the attraction of overlapped routes and the merits of the MNL model, such as closed-form and efficiency, remain unchanged. We introduce some popular models of this type. The C-logit model (Cascetta et al. 1996) introduced a commonality factor (CF) that is proportional to the correlated parts. The path size logit (PSL) model was proposed with a similar concept (Ben-Akiva and Bierlaire 1999; Frejinger and Bierlaire 2007). The correction term, called the path size (PS), is derived from a property of the Gumbel distribution to aggregate alternatives. Bovy et al. (2008) proposed an alternative method to derive the PS term and named it the path size correction (PSC). These models have been integrated into transportation software, such as ParamicsFootnote 1 and MITSIM.Footnote 2
The MNL models with utility correction are widely used due to their simple form and efficient computation; however, these models appear to be sensitive to the composition of the route choice set. In most cases, researchers and practitioners can only obtain the chosen route of each trip and must generate the non-chosen alternatives to form the choice set of the model; the choice set that actually considered by each traveller is not always available. Moreover, calculating route choice probabilities also requires the definition of a choice set. Algorithms have been proposed to generate and approximate the choice set considered by travellers but results suggest that it is difficult to include all of the actually chosen routes in the generated set (Ramming 2002; Frejinger and Bierlaire 2007), which means that it is difficult to construct a “perfect” choice set in application. This raises the concern of whether the composition of the choice set affects the performance of route choice models. Moreover, if irrelevant, unreasonably long, or time-consuming routes are included in the choice set, how are the choice probabilities of the most attractive routes affected? Prato and Bekhor analysed this issue (2007) and revealed that the most common route choice models are affected by the composition of choice set and that non-nested logit models yield more robust parameter estimates. Bovy et al. (2008) proposed the PSC-logit model and analysed this choice set issue in non-nested models in which the problem existed. Bliemer and Bovy (2008) tested the same experiment on nested models and found that most route choice models do not appear to have sufficient robustness of choice prediction at the level of individual routes. This is an issue that has been overlooked for years and it appears that few studies have provided solutions. In application, the generation of large choice sets is usually required (Bekhor et al. 2008) and irrelevant routes might be inevitable, indicating the need for a more robust and flexible model to account for this issue. In fact, we mostly focus on the most attractive routes and thus the probabilities of choosing the most attractive routes should ideally be unaffected when unattractive routes are unexpectedly included in the choice set.
We propose a model that is more robust to the composition of choice set and we introduce a novel idea to capture the correlation of routes to better model route choice behaviours. We notice that in route choice analysis there is a trend to simplify the road network to explore travel behaviours. Prato (2009) noted that the degree of complication in transportation analysis increases exponentially with the complexity of the road network and additional study of network simplification approaches might provide more efficiency and accuracy in engineering applications and research. Because travellers do not remember and process the road network in their brain in a link-by-link style and instead tend to process the information in a more abstract style, e.g., using landmarks or major roads, the transportation models should be adjusted accordingly. The concept of a subnetwork was first used in traffic assignment to reduce the computational burden (Xie et al. 2010; Boyles 2012; Barton and Hearn 1979). Frejinger and Bierlaire (2007) used the subnetwork concept in route choice behaviour analysis to simplify the modelling process. The analyst can define a sub-network by choosing major roads from the network hierarchy or by interviewing travellers to identify the most frequently used trips. The same idea is adopted by Lai et al. (2016), named the subpath, and employed in a CNL model rather than a mixed logit model to decrease the computational burden. The subpath idea can significantly decrease the number of nests so that the CNL model can be more flexible. Kazagli et al. (2016) propose the mental representation items to interpret these behaviours and describe usages in CNL and recursive logit (Fosgerau et al. 2013). Li et al. (2015) uses the equivalent impedance for traffic assignment. It is practical and rational to build route choice models considering the fact that people may consider utility or impedance of links as a whole or an aggregation. In discrete choice analysis, the Expected Maximum Perceived Utility (EMPU), or the inclusive utility, measures individual’s expected utility associated with a choice situation (Cascetta et al. 2009). It would be a suitable method to represent travellers’ perceived impedance of routes, and intuitively would be a possible means for road network simplification; however, it seems that few attempts succeeded due to the high correlation of routes in the road network. In this regard, we investigate whether a route choice model could be derived based on the concept of network simplification, even though not every network or not the whole network could be simplified. We focus on the MNL model with utility correction because it is the most favourable in application due to its simple form. Therefore, we concentrate on derivation of the correction term. The main contributions to the literature are as follows: (1) we present the concept of the equivalent impedance of a set of links under the logit assumption by which an MNL-based route choice model and the correction term are derived. (2) The proposed model exhibits robustness to the composition of choice set, which has been an issue that has been overlooked for years.
The rest of this paper is organized as follows: “Methodology” section describes the methodology, in which two calculation rules are proposed to merge links in series or in parallel for simplification, based on which the correction term is derived for a route pair. The routes in the choice set are treated in pairs and the overall correction is determined. Additionally, the variance heterogeneity of the perception error is also discussed. “Numerical example: when a relevant route becomes irrelevant” section provides a three-alternative case, a modified “red/blue bus” network where one relevant route gradually becomes irrelevant, to test the robustness of the new model and compare it with others. “Investigating the choice set composition effect: synthetic data” section presents a grid network and the experiment from Bliemer and Bovy (2008) is used to further investigate the effect of choice set, where estimation and forecasting with synthetic observations are provided. “Application in a real road network” section presents an application in an actual network with GPS data, where estimation and cross-validation are performed to test the practicality of the new model. Conclusions are presented in “Conclusions” section.
Methodology
Consider \( C_{rs} \) as the route choice set that includes all the routes from origin r to destination s; a correction term \( \Delta_{i} \) is added to the utility function to decrease the attractiveness of the correlated route, which is described by Eq. (1)
where \( U_{i} \) is the utility of route i, \( x_{i} \) is a vector of attributes, \( \beta \) is the corresponding parameter vector to be estimated, \( \beta x_{i} + \Delta_{i} \) can be considered as the impedance of route i, namely \( I_{i} \), \( - (\beta x_{i} + \Delta_{i} ) \) is the deterministic utility, namely \( V_{i} \), \( \varepsilon_{i} \) is the error term of the utility, and all the error terms of the alternative routes in the choice set \( C_{rs} \) are Gumbel distributed and independently identically distributed (IID). According to the properties of the EV distribution, the probability that travellers choose route i from choice set \( C_{rs} \) can be described by Eq. (2), which is similar to the MNL model with an extra correction term \( \Delta_{i} \),
where \( \theta_{rs} \) is the scale parameter of the OD pair rs with a non-negative value and the variance \( \sigma_{i}^{2} \) of \( \varepsilon_{i} ,\forall i \in C_{rs} \) is \( \sigma_{i}^{2} = {{\pi^{2} } \mathord{\left/ {\vphantom {{\pi^{2} } {6\theta_{rs}^{2} }}} \right. \kern-0pt} {6\theta_{rs}^{2} }} \).
The derivation of \( \Delta_{i} \) in this paper is based on the concept of network simplification. It would be desirable in network analysis if a portion of the road network can be replaced by a link, and then the network could be simplified to some extent. In particular, from the perspective of travellers, the replaced road network and the link should have equal perceived impedances, we term it as the equivalent impedance, therefore the travellers would then consider them as equal. If the equivalent impedance of a network can be explicitly calculated, then the difference in the impedances between the network and routes can be compared and the impact of the correlated portion of routes can be determined. We would elaborate the concept of the equivalent impedance in the next section.
Equivalent impedance
The concept of equivalent impedance for a set of links is used in the proposed model to derive the correction term in Eq. (2). Two calculation rules are proposed to consider links in series or in parallel.
Links in series
Consider a network in which the links are all in series, as shown in Fig. 1. The deterministic utility of link a is \( V_{a} = - \beta x_{a} \). It is assumed that the attributes are all link-additive, so that the deterministic utility of the network from r to s is
where \( \varGamma \) is the set of links. We define \( I_{rs} = - V_{rs} = \beta \sum\limits_{a \in \varGamma } {x_{a} } \) as the equivalent impedance of the network, which is the impedance of the only route in the network.

Network with links in series
Links in parallel
Consider a network that consists of only parallel links connecting r and s (solid lines in Fig. 2). We would like to measure travellers’ assessment of the links in this network, and we consider the Expected Maximum Perceived Utility (EMPU), also known as the inclusive utility (Cascetta et al. 2009), is suitable to describe the concept of the equivalent impedance in this case. Therefore, when the underlying assumption on the perception errors of travellers are IID Gumbel, we have

Network with links in parallel
Notice that the formulation of equivalent impedance is not standalone, therefore, we utilize an alternative way to derive the equivalent impedance. An interesting result is discovered that the proposed derivation leads to the same expression as Eq. (4). Besides, the idea of the proposed method is straightforward, and could be easily extended to other cases where the underlying distribution for the error terms is not Gumbel, e.g. it could be Weibull or normal. We elaborate the derivation as follows. Consider a virtual link v connecting r and s with utility \( U_{v} = - \beta x_{v} + \varepsilon_{v} \) (dashed line in Fig. 2), such that the probability that travellers choose the virtual link is identical to the probability that travellers choose the original network.
According to this assumption, the error terms \( \varepsilon_{v} \) and \( \varepsilon_{a} ,\forall a \in \varGamma \), are IID Gumbel distributed; thus, the following holds:
By solving Eq. (5), the deterministic part of the utility of link v is
Because the probability that travellers choose link v is the same as the probability that travellers choose the original network, it is reasonable to use its deterministic utility to represent the equivalent impedance of the network, namely
Two properties naturally result:
-
(1)
Monotonicity with respect to link set size This property implies that any additional parallel link to the network leaves the traveller no worse than before the addition. For example,
$$ I_{rs} (a,b) \ge I_{rs} (a,b,c) , $$(8)where \( I_{rs} (a,b) \) is the equivalent impedance of the network with links a and b in parallel and \( I_{rs} (a,b,c) \) has links a, b and c in parallel.
-
(2)
Monotonicity with respect to impedance This property implies that the equivalent impedance of the road network does not decrease if the impedance of any of parallel link increases. For example,
$$ \frac{{\partial I_{rs} (a,b,c)}}{{\partial I_{k} }} \ge 0,\forall k \in \left\{ {a,b,c} \right\} . $$(9)
These two properties are in accordance with travellers’ perceptions and behaviours. Regarding the first property, increasing the number of alternatives in a road network implies more flexibility. Thus, travellers would perceive the road network as less negative and the equivalent impedance will be lower. Regarding the second property, if one route becomes congested, travellers would perceive the road network as being worse, increasing its equivalent impedance.
Note that not all networks can be simplified using the proposed rules but most can be simplified to some degree, which is desirable for derivation of the correction term.
Different distribution assumptions
The sections above present the equivalent impedance in which the underlying model is logit and the error terms are assumed to have a Gumbel distribution. Other models with different distribution assumptions, such as probit with normal distribution, weibit with Weibull distribution (Yao and Chen 2014), and other distributions (Li 2011; Kitthamkesorn and Chen 2014; del Castillo 2016), can also incorporate this approach when network simplification is needed, especially when the links are in parallel. In particular, some models are inevitably under the assumption of independent distribution, in which the IIA property holds (Kitthamkesorn and Chen 2013), so a customized correction term for overlapping can be derived using the following proposed approach with their own distributions to obtain consistency in model distribution assumptions. If the underlying model changes, e.g., the weibit model with the Weibull distribution, then Eq. (6) would change accordingly.
Even though the derived Eq. (7) has the same expression as the EMPU, however, there are differences between the EMPU and the equivalent impedance. As for the EMPU, it is proposed to measure a perceived maximum value of a set of routes, and thus the motivation is to assess a choice context. On the other hand, as for the equivalent impedance, the motivation is to measure the impedance of a set of links, and thus the goal is to simplify a network. Therefore it could involve a choice context (where the links are in parallel), but it could also not involve a choice context (where the links are in series). In the latter case, the EMPU is not applicable. As for the case in “Links in parallel” section, where we employed a choice assumption for the derivation of Eqs. (5)–(7), we consider the EMPU and Eq. (7) are conceptually the same.Footnote 3 The concepts of the equivalent impedance and the EMPU are not equivalent, and other formulations that could well explain the concept of the equivalent impedance should be considered and thus would be desirable.
Utility correction term
Correction of a route
The more routes that route i is correlated with, the larger \( \Delta_{i} \) should be, which means that every route that route i correlates with should contribute to the total correlation degree of route i. If route i is completely independent, there is no overlapping issue for i and \( \Delta_{i} = 0 \). Inspired by the paired combinatorial logit model (Chu 1989), the corrections are treated in route pairs. Any route j that i correlates contributes a disutility \( \Delta_{i}^{ij} \) to route i, where \( \Delta_{i}^{ij} \) is the correction to route i from route pair ij. All \( \Delta_{i}^{ij} \) terms (\( \forall j \in C_{rs} ,j \ne i \)) should account for the overall correlation degree of route i. Moreover, \( \Delta_{i}^{ij} \) is only dependent on route i, j and their correlation. The overall correction can be determined as the summation of all paired corrections. Consider route choice set Crs that consists of N routes; thus, there are \( {{N(N - 1)} \mathord{\left/ {\vphantom {{N(N - 1)} 2}} \right. \kern-0pt} 2} \) distinct route pairs. It is natural to assume that the pair corrections are additive. There are several reasons to make the additive assumption: firstly, the more routes that route i correlates, the larger \( \Delta_{i} \) should be; secondly, every route that route i correlates should be added for the total correlation degree of route i, it is very difficult to explicitly consider the correlation degree of a large network but it would be more tractable if routes are treated in pairs. Therefore, we define the total correction of route i is the summation of all corrections in which i exists, which is
This summation has the same protocol as the PSL and C-logit models to account for the overall correction. Using the PSL model for an example: all the link size factors of PSL are summed as the overall correction for one route, where the corrections from other routes are actually pre-divided and assigned to each link and the overall correction is computed using a link-by-link addition style (Bovy et al. 2008). The additive assumption is employed in a route-based style in this study: the link corrections are considered by the correlated route j, \( \forall j \in C,j \ne i \) and the more routes that use link a, the larger the overall correction is. In particular, for the different pairs, the overlapping parts are different so that the correction terms are due to different parts. Therefore, Eq. (10) can be seen as a systematic “counter” to record how many times link a is used by other routes that does not miss or re-count instances.
After the correction, the utility of route i becomes
Derivation of the correction from route pairs
We analyse routes by pair and without loss of generality, two routes i and j from choice set Crs, as shown in Fig. 3, are studied. Routes i and j share a common link a and the independent parts are denoted as b and c, respectively. For illustrative purpose we define in Fig. 3: (1) the overall network of a route pair: the area that composed by the physical links of route pair i and j, \( \forall i,j \in C_{rs} \). (2) The sub-network of a route pair: the non-overlapping part of routes i and j.

Two correlated routes. Route i: \( b \to a \), route j: \( c \to a \)
We assume that the probability that travellers choose route i between rs is equal to the probability that they choose link b between rg, which is
where the notation \( b \to a \) represents the route that uses link a and then link b, which is based on the hypothesis that the impedance of a route is link-additive. Because the goal is to derive a term to represent the overlapping degree of the routes, it is reasonable to assume that travellers only consider the link-additive attributes when they perceive the degree of overlap in the network. Moreover, the scale parameter \( \theta_{rs} \) for the overall network of a route pair is different from the scale parameter \( \theta_{rg} \) of the sub-network.
Note that the assumption of Eq. (11) does not mean that the model ignores the “overlapping” issue of logit models. We emphasize here that only the different portions of the routes are used in the travellers’ decision making, which is important for building the new model.
Now consider the sub-network in which the error terms of links b and c are \( \varepsilon_{b} \) and \( \varepsilon_{c} \), assumed to be IID Gumbel distributed with the variance \( \sigma_{rg}^{2} = {{\pi^{2} } \mathord{\left/ {\vphantom {{\pi^{2} } {6\theta_{rg}^{2} }}} \right. \kern-0pt} {6\theta_{rg}^{2} }} \). The utility of links b and c are \( U_{b} = - \beta x_{b} + \varepsilon_{b} = - \beta (x_{i} - x_{a} ) + \varepsilon_{b} \) and \( U_{c} = - \beta x_{c} + \varepsilon_{c} = - \beta (x_{j} - x_{a} ) + \varepsilon_{c} \), respectively, thus the right-hand side of Eq. (12) is
Denoting the equivalent impedance of the overall network between rs by \( I_{rs} \), then the equivalent impedance of the sub-network between rg is \( I_{rg} = I_{rs} - \beta x_{a} \). According to the calculation rule in “Links in parallel” section, \( I_{rg} \) can be calculated using the following equation
and Eq. (14) can be rewritten as
Substituting Eq. (15) into the right-hand side of Eq. (13), we have
The utilities of routes i and j of the overall network are \( U_{i} = - \beta x_{i} + \varepsilon_{i} \) and \( U_{j} = - \beta x_{j} + \varepsilon_{j} \), respectively. Correction terms are added to modify the utility of each route because routes i and j overlap; therefore, the left-hand side of Eq. (11) becomes
where \( \Delta_{i}^{ij} \) is the utility correction term to decrease the attraction of route i because of the overlap between routes i and j. Because the equivalent impedance of the overall network between rs is \( I_{rs} \), we have \( \exp \left[ { - \theta_{rs} I_{rs} } \right] = \exp \left[ { - \theta_{rs} \left( {\beta x_{i} + \Delta_{i}^{ij} } \right)} \right] + \exp \left[ { - \theta_{rs} \left( {\beta x_{j} + \Delta_{j}^{ij} } \right)} \right] \) and therefore Eq. (17) can be rewritten as
Combining Eqs. (12), (16) and (18), we have
Equation (19) can be further simplified as
Solving Eq. (20), the correction to route i from route pair ij is given by
Similarly, the correction to route j from correlated link a is
where \( I_{rs} = I_{rg} + \beta x_{a} = - \frac{{\ln \left[ {\exp \left( { - \theta_{rg} \beta x_{b} } \right) + \exp \left( { - \theta_{rg} \beta x_{c} } \right)} \right]}}{{\theta_{rg} }} + \beta x_{a} \).
Calculation of scale parameters of sub-networks
The calculation of the correction term requires the scale parameter \( \theta_{rg} \) from the non-overlapping part of the route pairs; however, this raises a calculation problem: if there are N routes in the choice set, there would be \( {{N(N - 1)} \mathord{\left/ {\vphantom {{N(N - 1)} 2}} \right. \kern-0pt} 2} \) pairs of routes, which means there are \( {{N(N - 1)} \mathord{\left/ {\vphantom {{N(N - 1)} 2}} \right. \kern-0pt} 2} \) of \( \theta_{rg} \) to be estimated. An efficient method is to assume that all \( \theta_{rg} \) are linked to the network topology (Sheffi 1985; Chen et al. 2012), i.e., assuming that the variance of the perception error is proportional to the route length, which means that a shorter route would correspond to a smaller variance. Because the algorithm to find the shortest route is mature and widely used, it would be reasonable to adopt it to interpret the choice context. Therefore, the variance of the non-correlated portion of the shorter route is
where \( \sigma^{2} = {{\pi^{2} } \mathord{\left/ {\vphantom {{\pi^{2} } {6\theta_{rs}^{2} }}} \right. \kern-0pt} {6\theta_{rs}^{2} }} \) is the variance of the perception error between OD, \( L_{ij}^{\hbox{min} } \) is the length of the shorter route in route pair \( (i,j) \), and \( l_{ij} \) is the length of the overlap between routes i and j. Therefore, the scale parameter \( \theta_{rg} \) is given by
Setting the scale parameters linked to their impedances decreases the estimation difficulty. If one parameter is fixed, then the others can then be determined, which is desirable in application.
Properties of the route-pair correction term
The proposed route-paired correction term has several properties:
Property 1
If the length of the shortest link in the sub-network, e.g., \( l_{ij} \), goes to zero, the correction term for its corresponding route goes to zero.
Property 2
The correction terms for two correlated routes in a pair are different and depend on their own impedances.
Property 3
If routes i and j are not correlated, then \( \theta_{rg} = \theta_{rs} \) and the correction term \( \Delta_{i}^{{}} \) is zero, resulting in Eq. (2) collapsing into an MNL model.
Property one shows that if unattractive routes are added into the choice set and they have little/no correlation with the relevant routes, the corrections for the attractive routes are small/zero and the probabilities of attractive routes would not be highly affected by the addition of unattractive routes. This property is discussed with an illustrative example in the next section. Property two is useful because the corrections rely not only on their correlation but also on their own impedances (Eqs. (21), (22)), therefore a shorter route with lower impedance has a smaller correction to maintain its attractiveness and vice versa. This is different from the C-Logit, PSL and PSCL models in which the corrections are similar for two routes if they correlate. This property is discussed below with case studies. Property three provides the extreme case of the correction term.
Numerical example: when a relevant route becomes irrelevant
Figure 4 is a revised version of the “red/blue bus” network (Ben-Akiva and Bierlaire 1999), where \( l_{a} \) varies from 0 to 10, the impedance of route k (the lower route) varies from 10 to 20, and route i (the upper route) and route j (the middle route) are always 10. When \( l_{a} = 0 \), the three routes have equal lengths and are completely independent; thus, the probability of each route choice should be 1/3 for each alternative. When \( l_{a} = 10 \), routes i and j are two separate routes and have the same length of 10 but route k has a length of 20 and is an unattractive route compared with the other two routes. The majority of travellers would choose routes i and j and the probability of choosing each route should be approximately 1/2; few travellers would choose route k.

Experimental network containing three routes. Route i: b, route j: \( c \to a \), route k: \( d \to a \)
Five logit-based models and the probit model were selected for comparison with the new model; their formulas and specifications are presented in "Appendix 2". The probit model was set as the reference. The probabilities of choosing route j with varying la values are shown in Fig. 5. The curves of the PCL model and the new model almost overlap with each other (the triangle-labelled and hollow-circle labelled lines, respectively). In Table 1, we provide the root-mean-square error (RMSE) of each route to compare with the results of the probit models and the summation of the RMSE of all routes. The results in Fig. 5 show that the nested models and the new model can provide reasonable results as \( l_{a} \) varies. The three utility-correction models, C-logit, PSL and the PSCL, show their defects as the length of \( l_{a} \) increases when the third route becomes an unattractive choice. The models underestimate the probabilities of choosing route j because it correlates with irrelevant route k. Consequently, the C-logit, PSL and PSCL models overestimate the probabilities of the independent route i. The results in Table 1 show that the model generally has the smallest RMSE compared with the probit, followed by the PCL and the two CNL models. The C-logit, PSL and PSCL models have the largest RMSE. The results suggest that these three utility-correction models have the issue that if the relevant route is “unfortunately” correlated with the irrelevant route, then the choosing probability is affected. In our case, the nested models, the two CNLs and the PCL, have more stable and robust performance than the C-logit, PSL and PSCL models. The new model has very satisfying results regarding the robustness with irrelevant routes, moreover, it retains the simple form of the MNL model with less parameters requiring estimation.

Probabilities of choosing route j calculated using different models
Similar results were discovered by Bovy et al. (2008) that the PSL and PSCL models were sensitive to the composition of the choice set. Following is an explanation for the differences between the traditional utility-correction models, the C-logit, PSL and PSCL models, and the proposed model. If two routes are correlated, the traditional models allocate the same correction values for both. Therefore, if an unattractive route is added to the choice set and correlates with other routes, the probabilities of the attractive routes will be significantly affected. However, the new model calculates the corrections not only based on the correlations but also on their own impedances according to the \( \beta x_{i} \) term in Eq. (21). Therefore, in the new model, an alternative with a smaller impedance has a smaller correction and vice versa.
As the PCL model and the new model had very similar results in this test, we further compared models in the original “red/blue bus” network, where \( l_{d} = 10 - l_{a} \) and all routes have the same length. The results are shown in Fig. 6. All models reproduced the trend that when \( l_{a} = 0 \), all routes are independent, so the choosing probabilities are all 1/3; when \( l_{a} = 10 \), routes j and k are 100% correlated so both have a choosing probability of 1/4. The new model has the most similar curve to the probit and the PCL model shows less satisfying results. This suggests that the new model performs better than the PCL model in terms of resolving the overlapping problem in this network. Therefore, the PCL and the new model perform well when a route in the choice set is irrelevant but the new model outperforms the PCL in modelling correlation of routes.

Comparison of models in the original “red/blue bus” network
Investigating the choice set composition effect: synthetic data
We investigate the choice set issue in a grid network and estimate and apply the models using synthetic data generated by the probit model. The experiment is the same as that conducted by Bliemer and Bovy (2008) to study how the composition of choice set affects model performance. The motivation of the experiment is that, in application, we estimate a model with choice set \( C_{e} \) and then apply the model for forecasting with choice set \( C_{f} \), where irrelevant routes are inevitably included in \( C_{e} \) and \( C_{f} \). Therefore, we analyse how models perform if: (1) \( C_{e} \) only includes relevant routes and \( C_{f} \) includes irrelevant routes and (2) \( C_{e} \) includes irrelevant routes and \( C_{f} \) only includes relevant routes. The simulated results from the probit model serve as the observations for estimation and for comparison with the prediction results. We refer readers to Bliemer and Bovy (2008) for more information on the design of the experiment.
The grid network shown in Fig. 7 is a single OD pair from origin 1 to destination 16. The length of each link is marked by a double arrow. Four types of models are compared in this case: the probit model (as the “true value”), the traditional MNL models with/without utility modification: the logit, PSL, PSCL and C-logit models, the PCL and CNL models (because they exhibited good performance in “Numerical example: when a relevant route becomes irrelevant” section), and the new model.

Study network with a single origin–destination pair from 1 to 16
Choice set generation
Alternative routes are generated by enumeration and sorted by length. We consider routes 1–5 to be the most relevant routes, routes 6–11 are relevant routes, and routes 12–25 are the irrelevant routes. Three choice sets of different sizes are considered, named \( C_{1} \), \( C_{2} \) and \( C_{3} \), as shown in Table 8 in "Appendix 1.1".
Experiment specification
The experiment was carried out by: (1) Generating synthetic observations with the probit model and \( C_{1} \) and estimating the parameters of models using these postulated data. (2) Using the estimated models to compute route choice probabilities with choice sets \( C_{1} \), \( C_{2} \) and \( C_{3} \). (3) Comparing the computation results with the probit model. The probabilities computed using the probit model are calculated with a Monte Carlo simulation with 10,000 repetitions. The simulation results from the probit model are assumed to be the synthetic data (postulated observations), which are used for estimation of the models compared. The variance of the probit model is assumed to be the same as that of the logit model to define the scale parameter. The postulated probabilities are shown in Fig. 12 in "Appendix 1.2".
We first estimate the models with choice set \( C_{1} \) and the corresponding probit data, then compute the probabilities of \( C_{1} \), \( C_{2} \) and \( C_{3} \). The results are shown in Fig. 13 in "Appendix 1.2", where the x-axis is the identification number of the routes in the choice set (the first, second and third columns show \( C_{1} \), \( C_{2} \) and \( C_{3} \)) and the y-axis shows the probit probabilities. We then estimate the models with choice set \( C_{3} \) and compute the probabilities of \( C_{3} \), \( C_{2} \) and \( C_{1} \). The results are shown in Fig. 14 in "Appendix 1.2". Thus, the estimation–computation exercises were performed twice. Although the data set for estimation and prediction is the same, it does not contradict with the motivation of this experiment. A formal cross-validation with different datasets from actual observations is presented in “Cross-validation” section.
We compare the RMSE of the models against that of the probit, the “true” model, and a lower RMSE indicates better performance. Apart from the purely statistical considerations, correlation among routes has behavioural impacts, therefore, we also estimate the correlation parameters: for the PSL, PSCL, C-Logit and the new models, this parameter is for the correction term; for the PCL, it is for the similarity index; for the CNL, it is the nest scale parameter in which all are assumed to be the same.
Analysis of robustness
The RMSE of models are reported in Table 2: the second and last rows can be interpreted as the “goodness-of-fit” in estimation and the other rows can be interpreted as the computation precision.
Regarding “C1 (estimated)”, the results suggest that the CNL model obtains the best goodness-of-fit, followed by the PSL and C-logit models, the new model, and the PSCL and the PCL models perform the worst. For \( C_{2} \) and \( C_{3} \), the new model has average performance among the compared models: the 4th smallest RMSE in \( C_{2} \) and the 2nd smallest RMSE in \( C_{3} \).
Regarding “C3 (estimated)”, the proposed model has the 3rd smallest RMSE in goodness-of-fit and appealing prediction results: the second best in \( C_{2} \) and the best in \( C_{1} \), indicating its robustness when irrelevant routes are included in the choice set. In both cases, except for the new model, the MNL-structure models show unstable performances as the choice set changes, as the probabilities of the most irrelevant routes are affected by removal or inclusion of irrelevant routes. The PCL model, which has good performance in the three-alternative case, does not perform well in this test. The CNL model with the estimated parameters has satisfying results in this case for both estimation and prediction, which suggests satisfying robustness.
We compare the probabilities of the five shortest routes computed by the CNL and new models and the results are shown in Fig. 8. As the choice set diminishes (Fig. 8a), the probabilities of the shortest routes generally increased and vice versa (Fig. 8b). It appears that the results of the proposed model are more stable when the choice set changes, we provide absolute differences in probabilities. Figures 13 and 14 in "Appendix 1.2" show more detail in the variations as the choice set changes.

Variations in probabilities of the five shortest routes when the choice set changes. aC1 is estimated, bC3 is estimated
These findings are similar to those of previous studies (Bovy et al. 2008; Bliemer and Bovy 2008) in which the models with a utility correction were found to be sensitive to the composition of the choice set. We test these models with a new grid network and re-validate their findings. The results also show that the proposed model exhibits robust performance in this test and satisfying results in both estimation and prediction, suggesting that it is suitable for application.
Application in a real road network
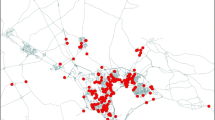
The city studied, Guangzhou, is in southern China and contains approximately 10 million inhabitants and 20,000 taxis. Only the central business district, the screenshot shown in Fig. 9, is studied. Observations were collected using GPS devices from urban taxis when they were transporting passengers. The GPS devices were installed by a management company for monitoring purposes, not for navigation; thus, the route choice behaviours were based on the drivers’ own judgments and not from navigation suggestions. Information on the network and the data collected are shown in Tables 3 and 4.

Map of the region of Guangzhou city studied
Model specification
Four attributes, shown in Table 5, are chosen for the utility functions. Length and time are two highly similar and correlated attributes, so one is sufficient for the utility function. However, a precise travel time is difficult to obtain before departure. When drivers decide which route to choose, they generally process the information that they consider to be more stable and distance is relatively more stable than the travel time in the example, so the distance is employed in the utility function rather than the time. The Artery Road Ratio is the ratio of artery road in the trip. It is used to test the assumption that travellers prefer to drive on an artery road and a higher ratio is expected to have larger utility. The Nb. of Signal- and Non-signal-controlled intersections are expected to have significant effects on urban route choice.
The MNL, PSL, PCL, logit kernel (LK) and new models are compared in this case. The LK model is selected because it is difficult to use the probit model for a large road network but the LK model has an error term that consists of two parts: an IID Gumbel distributed part and normally distributed one. It can be interpreted as a mixture of the logit and probit models. The formula and specification of the LK model are in "Appendix 2"; it requires a simulation-based method for estimation because of the non-closed form expression.
The utility is specified with a linear-in-parameters formulation. Apart from the purely statistical considerations, correlation among routes may have behavioural impacts, so the impact of the \( \Delta \) and lnPS factors on the choice behaviour should be described by the parameters \( \beta_{D} \) (for \( \Delta \)) and \( \beta_{PS} \) (for \( \ln PS \)) that are estimated from observations (Frejinger and Bierlaire 2007). We only consider length as the impedance to compute \( \Delta \). The deterministic utility Vi for the alternative i in the new model is shown in Eq. (26), which is different from Eq. (27) because the to-be-estimated parameter \( \beta \) “absorbs” the negative sign.
Model estimation
Estimations of parameters are provided in Table 6. The choice sets are generated by link elimination (Azevedo et al. 1993) and the chosen route is added to the choice set if it is not included in the generated choice set. Two choice sets were used for the analysis, one with 30 routes and one with 50 routes, based on the fact that 30 is large enough for a traveller to process and 50 is even larger. The large route choice sets enable investigation of whether the model is too sensitive to those irrelevant routes because the larger the choice set is, the more likely that the choice set includes unrealistic and irrelevant routes.
Most of the estimates have the expected signs, except for the parameter of Nb. of non-signal intersections: the models all have positive signs except for the logit and LK models with larger choice sets that have the expected negative sign. A possible explanation is that the larger Nb. of non-signal intersections suggests more flexibility in the alternative route and is therefore positive for travellers’ utility. Moreover, the Nb. of signal intersections has a more negative and dominant impact on travellers’ utility than the Nb. of non-signal intersections, so the former should be negative but not necessarily the latter.
The new model, the MNL and PSL models share an MNL-like structure, and they have same magnitudes for different estimates. Regarding the new model, the estimates are significantly different from 0 as the t test results are greater than 1.96. Moreover, the estimate for the correction term has the expected negative sign, suggesting a disutility to decrease the attraction of a correlated route. The estimation times of the MNL, PSL and new models were only 1 or 2 sec but the PCL model took approximately 10 min and the LK model took 1–2 h. The new model has the advantage of fast computation due to the MNL structure; this feature is useful when applied to traffic assignment in a large-scale network.
The goodness-of-fit of models is compared using the adjusted likelihood ratio index \( \bar{\rho }^{2} \). A higher \( \bar{\rho }^{2} \) indicates a better model fit. In both cases, the CNL model has the highest \( \bar{\rho }^{2} \), followed by the new model, then the PSL and MNL. The PCL and LK models have the worst goodness-of-fit, even worse than the MNL model. The weak performance of the LK model may be due to the small number of draws for simulation. The results from two choice set sizes suggest that a larger choice set has a better goodness-of-fit as the \( \bar{\rho }^{2} \) is higher.
The CNL and the new model have the best goodness-of-fit in estimation. Note that only the log-likelihood function of the new model can obtain the global maximum because of the linear assumption in the utility function, therefore the estimation process is fast. Conversely, only a local maximum can be achieved with the CNL model because of its complicated structure, moreover, the estimates are very sensitive to the initial value settings and upper and lower bounds. In our case, in which all the nesting scales are assumed to be the same, the estimation of this single scale requires repeated adjustment of the settings. Estimation of additional scale parameters, e.g., the individual scale for each nest, would not be easy and would likely fail. In this sense, the MNL-structure of the new model has an obvious advantage in application.
Cross-validation
We perform a cross-validation test to further investigate the forecasting abilities of the models. The MNL, PSL, CNL and new models are compared because of their goodness-of-fit and shorter computation times. The observations are divided into two parts: 80% of the OD pairs are randomly selected for estimation and the remaining 20% are for forecasting validation. This was carried out 100 times and the results are presented in two boxplots in Figs. 10 and 11. “CC = 30” and “CC = 50” represent the choice set sizes of 30 and 50. The averages of the log-likelihoods of 100 repetitions are reported in Table 7.

Boxplot of estimation log-likelihoods (100 repetitions)

Boxplot of forecasting-validation log-likelihoods (100 repetitions)
The new model performs the best in this test, as its median and average of log-likelihoods in estimation and forecasting-validation are the largest among the compared models for both choice set sizes. The PSL, CNL and the new model exhibit better performances than the MNL model, suggesting that considering the correlations of routes interprets the route choice behaviours better. Although the CNL model has the best goodness-of-fit in estimation with the full data set, it does not outperform the PSL and new models in this test. Summarizing the estimation and cross-validation results in this case study, we conclude that the new model provides reasonable and practical results: it has an obvious advantage in computational efficiency due to its MNL structure, and it exhibits robustness to the composition of choice set and estimation and forecasting results suggest that it is a suitable model for application.
Conclusions
In this paper, the concept of equivalent impedance is proposed to simplify a set of links in a road network, with the motivation that travellers remember, perceive, and process road network information at an abstract and conceptual level. According to this idea, we propose a novel route choice model that aims for greater robustness and practicality in capturing the route choice behaviours of travellers. A correction term is derived based on the proposed concept of equivalent impedance to account for the correlation of routes in an MNL route choice model. A major contribution of this paper is the proposal of a new model that tackles a persistent issue in the route choice literature: models should be robust for the composition of the choice set.
Three tests are presented in this paper: a revised version of the “red/blue bus” network, a grid network with postulated observations, and an actual network with GPS data. Among the models compared, the new model exhibits reasonable and satisfying outcomes. The results from “toy” networks exemplify the model’s robustness in providing stable results when adding irrelevant routes to the choice set, and it appears to be less sensitive to the choice set composition than other models. The results from the actual case suggest that the new model is suitable in application and generally outperforms other models in tests.
The new method explores additional possibilities for simplifying networks: it explicitly calculates the utility for a set of links and may provide some perspective for future research on complex urban networks. An advantage of this model is that it is also useful for a wider range of other domains in discrete choice analysis, e.g., residential choice and online product choice, in which the actual choice set is difficult to obtain and the choice set could be inevitably large, and thus, the robustness of the proposed model would be desirable.
A possible future direction of the proposed method is to relax the assumption in Eq. (23), in which the scales are assumed to be linked rather than estimated from observations to reduce the complexity of large network analysis. This is a common problem encountered by many route choice models, such as the CNL and mixed logit models. A possible solution is to model the route correlation using a more abstract rather than a link-specific manner, such as the sub-path method with the CNL model (Lai et al. 2016) and the subnetwork approach with mixed logit models (Frejinger and Bierlaire 2007). Another possible direction would be to explore the correction terms for other models, such as weibit, in which the independently Weibull distributed assumption is made for its error terms, and thus, the model cannot account for the correlation degree in route choice (Kitthamkesorn and Chen 2013). The proposed method provides a possible solution to derive a correction term that is based on the Weibull distribution. Besides, we consider the formulations for the equivalent impedance are not standalone, and more explorations on this concept would be desirable. In particular, a systematic method to compute the equivalent impedance of a complicated network, where routes are highly correlated, would be valuable.
Notes
As pointed out by one anonymous reviewer, while the links are in parallel, the inclusive utility and equivalent impedance, as same concept, both allow network simplification.
References
Azevedo, J., Costa, M.S., Madeira, J.S., Martins, E.V.: An algorithm for the ranking of shortest paths. Eur. J. Oper. Res. 69(1), 97–106 (1993). doi:10.1016/0377-2217(93)90095-5
Barton, R.R., Hearn, D.W.: Network aggregation in transportation planning models. Report DOT-TSC-RSPA-79-18. United States Department of Transportation (1979). https://trid.trb.org/view/89025
Bekhor, S., Ben-Akiva, M.E., Ramming, M.S.: Adaptation of logit kernel to route choice situation. Transp. Res. Rec. J. Transp. Res. Board 1850, 78–85 (2007). doi:10.3141/1805-10
Bekhor, S., Prashker, J.N.: Stochastic user equilibrium formulation for generalized nested logit model. Transp. Res. Rec. 1752, 84–90 (2001). doi:10.3141/1752-12
Bekhor, S., Toledo, T., Prashker, J.N.: Effects of choice set size and route choice models on path-based traffic assignment. Transportmetrica 4(2), 117–133 (2008)
Ben-Akiva, M.E., Bierlaire, M.: Discrete choice methods and their applications to short term travel decisions. In: Hall, R.W. (ed.) Handbook of Transportation Science, pp. 5–33. Kluwer, Dordrecht, Netherlands (1999)
Bierlaire, M.: A theoretical analysis of the cross-nested logit model. Ann. Oper. Res. 144(1), 287–300 (2006)
Bliemer, M.C.J., Bovy, P.H.L.: Impact of route choice set on route choice probabilities. Transp. Res. Rec. 2076, 10–19 (2008). doi:10.3141/2076-02
Bovy, P.H.L., Bekhor, S., Prato, C.G.: The path size factor revisited: an alternative derivation. In: Proceedings of the 87th Transportation Research, Washington DC, USA (2008)
Boyles, S.D.: Bushed-based sensitivity analysis for approximating subnetwork diversion. Transp. Res. Part B Methodol. 46(1), 139–155 (2012). doi:10.1016/j.trb.2011.09.004
Cascetta, E.: Transportation Systems Analysis: Models and Applications. Springer, New York (2009)
Cascetta, E., Nuzzolo, A., Russo, F., Vitetta, A.: A modified logit route choice model overcoming route overlapping problems: specification and some calibration results for interurban networks. In: Transportation and traffic theory. Proceedings of the 13th international symposium on transportation and traffic theory, Lyon, France, 24–26 July 1996, pp 697–711. Elsevier, Oxford (1996)
Chen, A., Pravinvongvuth, S., Xu, X., Ryu, S., Chootinan, P.: Examining the scaling effect and overlapping problem in logit-based stochastic user equilibrium models. Transp. Res. Part A 46, 1343–1358 (2012). doi:10.1016/j.tra.2012.04.003
Chu, C.: A paired combinatorial logit model for travel demand analysis. In: Proceedings of the Fifth World Conference on Transportation Research, pp 295–309. Ventura, CA, 1989
del Castillo, J.M.: A class of rum choice models that includes the model in which the utility has logistic distributed errors. Transp. Res. Part B Methodol. 91, 1–20 (2016). doi:10.1016/j.trb.2016.04.022
Fosgerau, M., Frejinger, E., Karlstrom, A.: A link based network route choice model with unrestricted choice set. Transp. Res. Part B Methodol. 56, 70–80 (2013). doi:10.1016/j.trb.2013.07.012
Frejinger, E., Bierlaire, M.: Capturing correlation with subnetworks in route choice models. Transp. Res. Part B Methodol. 41, 363–378 (2007). doi:10.1016/j.trb.2006.06.003
Kazagli, E., Bierlaire, M., Flötteröd, G.: Revisiting the route choice problem: a modeling framework based on mental representations. In, vol. Technical report. Transport and Mobility Laboratory, Ecole Polytechnique Fédérale de Lausanne (2016)
Kitthamkesorn, S., Chen, A.: A path-size weibit stochastic user equilibrium model. Transp. Res. Part B Methodol. 57, 378–397 (2013). doi:10.1016/j.trb.2013.06.001
Kitthamkesorn, S., Chen, A.: Unconstrained weibit stochastic user equilibrium model with extensions. Transp. Res. Part B Methodol. 59, 1–21 (2014). doi:10.1016/j.trb.2013.10.010
Lai, X., Li, J., Li, Z.: A subpath-based logit model to capture the correlation of routes. Promet Traffic Transp. 28(3), 235–245 (2016)
Li, B.: The multinomial logit model revisited: a semi-parametric approach in discrete choice analysis. Transp. Res. Part B Methodol. 45(2), 461–473 (2011)
Li, J., Huang, Y., Lai, X.: Modeling stochastic route choice behaviors with equivalent impedance. Math. Probl. Eng. 2015, 10 (2000)
McFadden, D., Train, K.: Mixed MNL models for discrete response. J. Appl. Econom. 15(5), 447–470 (2000)
Prashker, J., Bekhor, S.: Investigation of stochastic network loading procedures. Transp. Res. Rec. J. Transp. Res. Board 1645, 94–102 (1998). doi:10.3141/1645-12
Prato, C.G.: Route choice modeling: past, present and future research directions. J. Choice Model. 2(1), 65–100 (2009). doi:10.1016/S1755-5345(13)70005-8
Prato, C.G., Bekhor, S.: Modeling route choice behavior: how relevant is the composition of choice set? Transp. Res. Rec. 2003, 64–73 (2007). doi:10.3141/2003-09
Ramming, M.S.: Network knowledge and route choice. Massachusetts Institute of Technology (2002)
Sheffi, Y.: Urban Transportation Networks: Equilibrium Analysis with Mathematical Programming Methods. Prentice Hall, London (1985)
Vovsha, P., Bekhor, S.: Link-nested logit model of route choice: overcoming route overlapping problem. Transp. Res. Rec. 1645, 133–142 (1998). doi:10.3141/1645-17
Walker, J.: Extended discrete choice models: integrated framework, flexible error structures, and latent variables. MIT (2001)
Xie, C., Kockelman, K., Waller, S.T.: Maximum entropy method for subnetwork origin–destination trip matrix estimation. Transp. Res. Rec. J. Transp. Res. Board 2196, 111–119 (2010). doi:10.3141/2196-12
Yao, J., Chen, A.: An analysis of logit and weibit route choices in stochastic assignment paradox. Transp. Res. Part B Methodol. 69, 31–49 (2014). doi:10.1016/j.trb.2014.07.006
Acknowledgements
We appreciate Professor Michel Bierlaire and Dr. Jingmin Chen for their valuable suggestions on the earlier version of this paper. We are grateful to three anonymous reviewers for their constructed comments to improve the quality of the paper. We acknowledge that this work was supported by the National Natural Science Foundation of China (No. 51178475 and No. 71601052).
Author information
Authors and Affiliations
Corresponding author
Appendices
Appendix 1
Appendix 1.1
See Table 8.
Appendix 1.2

Simulated probit probabilities of 25 routes in the grid network

Probabilities of routes compared with the probit model (the bar label) as the choice set changes (x-axis); C1 is estimated

Probabilities of routes compared with the probit model (the bar label) as the choice set changes (x-axis); C3 is estimated
Appendix 2
(1) The models compared in "Numerical example: when a relevant route becomes irrelevant" section are:
-
Multinomial logit models with utility correction, including path size logit (PSL), C-logit and path size correction logit (PSCL) models. The probability of choosing route i from choice set Crs is formulated as follows:
$$ \Pr (i\left| {C_{rs} } \right.) = \frac{{\exp \left[ { - \theta_{rs} \left( {\beta x_{i} + \beta_{corr} corr_{i} } \right)} \right]}}{{\sum\nolimits_{{j \in C_{rs} }} {\exp \left[ { - \theta_{rs} \left( {\beta x_{j} + \beta_{corr} corr_{j} } \right)} \right]} }} , $$(27)where \( corr_{i} \) is the utility-based correction term for route i, \( \beta_{corr} \) is to be estimated, and \( corr_{i} \) from the C-logit model is called the commonality factor and can be expressed as (Cascetta et al. 1996)
$$ corr_{i} = CF_{i} = \ln \sum\nolimits_{{i \in C_{rs} }} {\left( {{{l_{ij} } \mathord{\left/ {\vphantom {{l_{ij} } {\sqrt {L_{i} L_{j} } }}} \right. \kern-0pt} {\sqrt {L_{i} L_{j} } }}} \right)} , $$(28)where \( l_{ij} \) is the length of the overlap between routes i and j and \( L_{i} \) and \( L_{j} \) are the lengths of routes i and j, respectively. The correction terms in the PSL (Ben-Akiva and Bierlaire 1999) and PSCL (Bovy et al. 2008) models, denoted as PS and PSC, respectively, can be expressed as
$$ corr_{i} = \ln (PS_{i} ) = \ln \left( {\sum\limits_{{a \in \varGamma_{i} }} {\frac{{l_{a} }}{{L_{i} }}\frac{1}{{\sum\nolimits_{{j \in C_{rs} }} {\delta_{aj} } }}} } \right) $$(29)$$ {\text{and}}\;corr_{i} = PSC_{i} = - \sum\limits_{{a \in \varGamma_{i} }} {\left( {\frac{{l_{a} }}{{L_{i} }}\ln \frac{1}{{\sum\nolimits_{{j \in C_{rs} }} {\delta_{aj} } }}} \right)} $$(30)where \( PS_{i} \) is the path size for route i, \( PSC_{i} \) is the path size correction term for route i, \( \varGamma_{i} \) is the set of links belonging to route i, \( \delta_{aj} \) is a route-link incidence dummy which is equal to one if route j uses link a and zero otherwise. The estimated \( corr_{i} \) parameters for the PSL and PSCL models are expected to be negative whereas the value for the C-logit model is expected to be positive.
-
The paired combinatorial logit model (Chu 1989) in which the routes are compared in pairs. The probability of choosing route i is formulated as
$$ \Pr (i\left| {C_{rs} } \right.) = \sum\limits_{{j \in C_{rs} ,j \ne i}} {\Pr \left( {ij} \right)\Pr \left( {\left. i \right|ij} \right)} , $$(31)where \( \Pr \left( {\left. i \right|ij} \right) \) is the conditional probability of choosing route i given a chosen pair ij:
$$ \Pr (\left. i \right|ij) = \frac{{\exp \left( { - \frac{{\theta_{rs} \beta x_{i} }}{{1 - \sigma_{ij} }}} \right)}}{{\exp \left( { - \frac{{\theta_{rs} \beta x_{i} }}{{1 - \sigma_{ij} }}} \right) + \exp \left( { - \frac{{\theta_{rs} \beta x_{j} }}{{1 - \sigma_{ij} }}} \right)}} . $$(32)\( \Pr \left( {ij} \right) \) is the marginal probability of choosing pair ij:
$$ \Pr (ij) = \frac{{\left[ {\exp \left( { - \frac{{\theta_{rs} \beta x_{i} }}{{1 - \sigma_{ij} }}} \right) + \exp \left( { - \frac{{\theta_{rs} \beta x_{j} }}{{1 - \sigma_{ij} }}} \right)} \right]^{{1 - \sigma_{ij} }} }}{{\sum\limits_{k = 1}^{N - 1} {\sum\limits_{l = k + 1}^{N} {\left[ {\exp \left( { - \frac{{\theta_{rs} \beta x_{k} }}{{1 - \sigma_{kl} }}} \right) + \exp \left( { - \frac{{\theta_{rs} \beta x_{l} }}{{1 - \sigma_{kl} }}} \right)} \right]^{{1 - \sigma_{kl} }} } } }} , $$(33)where N is the number of routes in Crs. The similarity index \( \sigma_{ij} \) is defined as \( \sigma_{ij} = \left( {{{l_{ij} } \mathord{\left/ {\vphantom {{l_{ij} } {\sqrt {L_{i} L_{j} } }}} \right. \kern-0pt} {\sqrt {L_{i} L_{j} } }}} \right)^{\gamma } \) based on the topology of the network (Prashker and Bekhor 1998).
-
A link-based CNL model (Prashker and Bekhor 1998; Vovsha and Bekhor 1998) in which each link can be considered a nest and a route that uses a link belongs to the nest, which can be expressed as:
$$ \Pr (i\left| {C_{rs} } \right.) = \sum\limits_{m \in \varGamma }^{{}} {\Pr \left( {\left. i \right|m} \right)\Pr \left( m \right)} , $$(34)where \( \varGamma \) is the link set, \( \Pr \left( {\left. i \right|m} \right) \) is the conditional probability of choosing route i given the nest m is chosen, i.e., route i uses link m, and \( \Pr \left( m \right) \) is the marginal probability of choosing nest (link) m. The following are the formulations for the conditional and marginal probabilities:
$$ \Pr (\left. i \right|m) = \frac{{\alpha_{im} \exp \left( {{{ - \theta_{m} \beta x_{i} } \mathord{\left/ {\vphantom {{ - \theta_{m} \beta x_{i} } {\theta_{rs} }}} \right. \kern-0pt} {\theta_{rs} }}} \right)}}{{\sum\nolimits_{{j \in C_{m} }} {\alpha_{jm} \exp \left( {{{ - \theta_{m} \beta x_{j} } \mathord{\left/ {\vphantom {{ - \theta_{m} \beta x_{j} } {\theta_{rs} }}} \right. \kern-0pt} {\theta_{rs} }}} \right)} }} $$(35)$$ {\text{and}}\;\Pr (m) = \frac{{\left( {\sum\nolimits_{j \in C} {\alpha_{jm}^{{{{\theta_{m} } \mathord{\left/ {\vphantom {{\theta_{m} } {\theta_{rs} }}} \right. \kern-0pt} {\theta_{rs} }}}} e^{{ - \theta_{m} \beta x_{j} }} } } \right)^{{\frac{{\theta_{rs} }}{{\theta_{m} }}}} }}{{\sum\nolimits_{p = 1}^{M} {\left( {\sum\nolimits_{j \in C} {\alpha_{jp}^{{{{\theta_{p} } \mathord{\left/ {\vphantom {{\theta_{p} } {\theta_{rs} }}} \right. \kern-0pt} {\theta_{rs} }}}} e^{{ - \theta_{p} \beta x_{j} }} } } \right)^{{\frac{{\theta_{rs} }}{{\theta_{p} }}}} } }} $$(36)where \( C_{m} \) is the choice set that includes all the routes that use link m, M is the number of links in \( \varGamma \), the inclusive parameters are \( \alpha_{im} = l_{m} /L_{i} \), and \( \theta_{m} \) is the scale parameter of nest m, which is to be estimated.
-
A probit model, which is taken as the “true” model that represents the true route choice behaviour. In this case, it is solved using a Monte Carlo simulation in which each link has a random utility \( U_{a} = - l_{a} + \varsigma_{a} \), where \( \varsigma_{a} \sim N(0,\lambda l_{a} ) \). The probability of the route choice is calculated as the average from one million simulation cycles.
The scale parameters \( \theta_{rs} \) for the logit-based models are assumed to be one. The route length is the only attribute in \( x_{i} \) and the corresponding parameter \( \beta \) is assumed to be 1 (notice we have a negative sign in front of \( \beta \) and therefore length is a disutility). The correction parameter \( corr_{i} \) is assumed to be 1 for the C-logit model and −1 for the PSL and PSCL models. The paired scale parameter of the non-overlapping part is \( \theta_{rg} = \sqrt {{{10} \mathord{\left/ {\vphantom {{10} {\left( {10 - l_{a} } \right)}}} \right. \kern-0pt} {\left( {10 - l_{a} } \right)}}} \) for the new model. All the nesting scale parameters in the CNL model are set at \( \theta_{m} = 1.5 \) or \( \theta_{m} = 2 \), identified as CNL-1.5 and CNL-2 in Fig. 4. The probit model uses the scale parameter \( \lambda \) whereas the MNL, PCL, CNL, PSL and C-logit models use the parameter \( \theta_{rs} \). To ensure consistency among different models, we assume that the variance of the logit perception errors is the same as that of the shortest route in the probit model, which is \( {{\pi^{2} } \mathord{\left/ {\vphantom {{\pi^{2} } {6\theta_{rs}^{2} }}} \right. \kern-0pt} {6\theta_{rs}^{2} }} = \lambda L_{\hbox{min} } \), where \( L_{\hbox{min} } \) is the length of the shortest route in choice set \( C_{rs} \).
(2) The formula and specification of the LK model used in “Application in a real road network” section: The utility of route i in the LK model is
where \( {\mathbf{F}}_{(N \times N)} \) is the factor loadings matrix (N is the number of routes) and an element \( f_{ij} \) of \( {\mathbf{F}}_{(N \times N)} \) is the length which path i overlaps with path j\( (i,j \in C) \) and \( {\mathbf{T}}_{(N \times N)} = diag(\lambda_{1} ,\lambda_{2} , \ldots ,\lambda_{N} ) \) (\( \lambda_{N} \) is the covariance parameter, which is to be estimated). We assume that all parameters are the same \( \lambda_{LK} = \lambda_{1} = \lambda_{2} = \cdots = \lambda_{N} \), \( \xi_{(N \times 1)} \) is a vector of the IID N(0, 1) variate, and \( \varepsilon_{i} \) is a vector of the IID Gumbel distributed variate.
Rights and permissions
About this article

Cite this article
Li, J., Lai, X. Modelling travellers’ route choice behaviours with the concept of equivalent impedance. Transportation 46, 233–262 (2019). https://doi.org/10.1007/s11116-017-9799-6
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11116-017-9799-6