
Abstract
The focus of this paper is on developing and evaluating a practical methodology for determining if and when different types of traffic can be safely managed within different class of services and satisfying reliability criteria. Our approach relies on an analytical model developed under a number of simplifying assumptions, which we test using several real traffic traces under fault condition corresponding to different types of services for clients and satisfying reliability degree for the connection request of link failure and searching of backup path dynamically that can give rise to substantial performance deviations with different class of service that is high, medium and low class. The results show that a hop-by-hop, link-state routing protocol, like Open shortest path first, can be extended to efficiently support class-based Quality of Service traffic differentiation. We have used auxiliary graph based open shortest path heuristic (AGBOSPH) technique to select back up path as a restoration strategy. It is found that average bandwidth utilization for large scale network is 12.62% less than previous studies. At the time of starting both have similar performance but under restoration AGBOSPH is more satisfactory and give excellent performance for higher scale of network. The proposed algorithm shows improvements at all traffic loads. At heavy loads the improvement is more pronounced and average improved performance for high degree of traffic load is of the order of 28.56%.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
1 Introduction
Failures of link causes variation in traffic performance depending on the type of protection switching mechanism adopted (Tacca et al. 2003; Pandi et al. 2004; Wosinska et al. 2003; Zhou et al. 2004; Zhang et al. 2003; Wu et al. 2003; Gerstel and Sasaki 2002). Automatic protection switching mechanism is adopted with randomly searching of shortest path. In Differentiated Services (DS) model Open Shortest path algorithm is adopted for distinct degree of services and reliability. Commercial available differentiated services are generally designated as Platinum, Gold, Silver, Bronze and Iron.In the latest literature various optical networking techniques primarily focused on cost effective broadband user access has been compared on several factors such as network constructions, technical characteristics and status of standardization (Saradhi and Murthy (2002); Sridharan et al. 2002; Fumagalli and Tacca 2006; Fumagalli and Tacca 2001a; Fumagalli and Tacca 2001b; Chlamtac et al. 2001; http www.infonetics.com, resources, whitepaper. xxxx). The significant application of Differentiated Services (DS) is to divide traffic into distinct degree of multiple classes, and manage them differently, especially for optimum utilization of resources and to reduce network, operational and capital cost. DS is characterized by 2 properties: one is not depending on resource reservation or admission control; and second relying on prioritization for resource arbitration. The importance of DS model is good scalability, incremental deployment and relatively simple network operations.DS structure is defined by Reference for Communication (RFC 2474) which is renamed by Type of Service (ToS) by Differentiated Services Code points (DSCP). DSCP denotes the forward treatment the packet should receive and signifies Packet per Hop Behavior (PHB). DS standardized Assured Forwarding (AF) group and Expediting Forwarding (EF) group the Per Hop Behavior (PHB) group by (RFC 2597) and (RFC 2598).This groups are used for real time applications and virtual private Network respectively. The DS at present extended to Multi-Protocol Level Switching (MPLS) support for DS [RFC3270] and DS-aware Traffic Engineering (DSTE) [RFC3564].The most promising solutions have been analyzed to narrow down to the techniques for more economical network technologies and virtual network topology implementation. Presently compared to voice, data and video services are expanding at faster rate yielding more revenues. Technologies should also address to vital factors such as future expansion and effectiveness for management. All these factors should be looked with the broadband access methods that would enable the user to know the performance and partially control the broadband (Doshi et al. 1999; Kant et al. 1999; Iannone et al. 2000a,OPTIWAVE 2000b; Wosinska 2001, 1983; Wosinska and Thylen 1998). All these important characteristics are available in optical fiber broadband networks (www.optiwave.com; Marson et al. 1999; Fumagalli et al. 2001; Saxena and Goel 2012, 2011, 2011, 2011, 2009). Now the additional focus is being given to delivering differentiated services up to the customer’s premises and the reliability issues. High reliability means smaller failure rate but that comes at the higher cost of WDM system. Because of this sometimes it becomes necessity to match the reliability requirement of the client irrespective of increase of failure rate. This necessitates that we have a method to analyze different degree of reliability in given optical Wavelength Division Multiplexing (WDM) network (Ho and Mouftah 2003; Ho 2003, 2004; Wu et al. 2009; Ho and Mauftah 2000; Ho et al. 2006). Basics of differentiated reliability in WDM network have been introduced. Here a graphical technique to analyze and interpret differentiated reliability in topology of a WDM optical network has been proposed for reliability based route selection which is one of the key parameters in optical WDM network design. The main objectives are to reduce network resources thus reducing network cost and at the same time satisfy the client requirement as per reliability requirements. Proposed methodology is extendable to any WDM optical network. Using this methodology dynamic routing of connection requests with Differentiated Reliability (DiR) requirements can be investigated. There are three Reliability and availability criteria as per International Telecommunication Standard (ITU) (www.opnet.com; Ho and Mouftah 2004; Bin et al. 2010; Tapolcai 2008; Hongbin luo et al 2012; Kong et al. 2016). As the bandwidth demand is increasing exponentially dynamic network services based on the latest technology like cloud computing in which availability of data centers is of prime importance, big data and virtualization of services for optimum utilization of resources and services are the predominant area of research studies (Kong et al. 2016; Tang 2019). Various cloud computing data centers are spatially dispersed in the network. This greatly increases the traffic demand pattern with geographically asymmetrical scenario increases the complexity for managing traffic efficiently.The high capacity optical transport networks currently in use have been mostly designed assuming bidirectional symmetric traffic. This leads to poor utilization of network capacity when the traffic is asymmetric (Sheng et al. 2018; Tang et al. 2018; Chen 2015). Availability aware algorithm with protection or restoration schemes will provide optimum utilization of network resources and restoration strategy will focus on high availability criteria that is of six nine (Castro et al. 2014; Savi 2017). Both terms Reliability and availability are used for assessment of network operation for continuity of service in terms of five nine, four nine and three nine availability criteria. Lena Wosinska et.al in (Wu et al. 2009; Ho and Mauftah 2000; Ho et al. 2006) have explained mean downtime in depth with all availability criteria. First is five nine availability criteria (99.999%), second is four nine availability criteria (99.99%) and the third is three nine availability (99.9%) criteria (Zhang et al. 2015; Pavon-Marino 2015; Pandey and Goel 2013). Six minutes in a year refer to down time of five nine availability criteria. Sixty minutes down time in a year refer to four nine availability criteria and 600 min in a year to three nine availability criteria. Networks are subject to a wide variety of unintentional failures caused by natural disasters (earthquakes, fires, and floods), wear out, overload, software bugs, human errors, and so on, as well as calculated outage caused by maintenance accomplishment or sabotage. Any of these failures cause disruption in the normal transmission over the network which eventually affects the services to both and individual customers.
Telephone and other type of communication services has become lifeline of social and economic activities. Any disruption in communication will result in unpredictable problems. Planned commercial functions also explain a rising dependence on communication services. For business customers, interruption of communication can delay critical operations. This may cause a significant loss of revenue which customer may decide to recover from service provider and customer. It is important to remember that service provider is the first customer of its own services for managing and maintaining its own communication path and services. For all customers support, it is thus vital to provide a high level of service availability of order of six nine or five nine. This depends on the permanence of those network functions required to make the differentiated communication services run and to maintain high quality of service with quality of transmission in access network (Pandey and Goel 2014, 2016, 2014; Ibrahimov et al. 2020). Before discussing the type of failures that can happen in a communications network and their impact on differentiated services, we define some terms commonly used in the context of network reliability. Considering the drastic nature of some failures and the unacceptable impact on crucial communication services, we take a broad variety of actions to overcome the burden caused by frequently occurring outage. The emerging technologies with the implementation of 5G technology will be new innovative research technologies and WDM optical network as a backend support for large scale network [Zhang et al. 2015; Zhang et al.2003; Zhou et al. 2004].
2 Methodology
Each link can accommodate one fiber that carries W wavelengths. Each link is bidirectional so if any fault occurs than propagation in light paths is interrupted in both directions. Each link (i, j) is represented by two parameters one is cost c(i, j) and the other is the link failure probability represented by Pf(i, j). The link failure probability is expressed as the conditional probability that the identified link is faulted giving the occurrence of single outage. We have assumed single outage at a time and probability of more than one fault is negligible. The probability of link failure is numerically equal to Pf(i, j) = τ. length(i, j)/SFP, τ is the link downtime ratio, length(i, j) is the length of fiber link and SFP is the overall single fault probability (Fumagalli and Tacca 2001a).The cost of path expressed as C(P) is the sum of link cost of the links that is given by \(C(P) = \sum\nolimits_{(i,j) \in P} {c(i,j)}\).
The connection request is given by four parameter (s, d, b, r) where s is source, d is the destination, b is the bandwidth and r is the maximum allowed down time ratio. The maximum allowed downtime ratio is the fraction of time during which the connection is not available due to optical network failure (Fumagalli and Tacca 2001a). An analytical technique has been proposed for reliability based route selection that has been one of the key parameters in optical WDM network design. High reliability means smaller failure rate but that comes at the higher cost of WDM mesh or ring based system. It becomes important to match the reliability requirement of the client irrespective of increase of failure rate. This necessitates that we have a method to analyze different degree of reliability in given optical WDM network. Here a graphical method has been proposed with main objectives to reduce network resources thus reducing network cost and at the same time satisfying the client requirement of degree of reliability. Evidence of this trend over the last decade has been to incorporate the concept such as Quality of Service (QoS) (Fumagalli and Tacca 2001a; Ho 2003; Wu et al. 2009; Ho and Mauftah 2000; Ho et al. 2006) and differentiated services where multiple level of service performance can be provided in the same network.
In this concept each connection in the network layer under consideration is guaranteed a minimum absolute reliability allowed for the connection. Each connection is individually analyzed to choose the reliability matching the client’s requirements. Sometimes the client’s requirement of QoS may be different for voice and data services. For such multiple degree of service requirements reliability is chosen for the application whose reliability requirement is more stringent. Auxiliary graph technique is used for resource allocation and service request for optimum utilization of bandwidth and to satisfy availability and reliability criteria to satisfy client requirements.
Here we propose a graphical methodology to analyze and interpret differentiated reliability in topology of a WDM optical network. A simple WDM network with nodes A, B, C, D, and E is shown in Fig. 1 where AS1, AS2, AS3 and AS4 are active paths and illustration with respect to Differentiated reliability is given in Fig. 2. Proposed methodology is extendable to any WDM optical network. Basics of differentiated reliability in WDM network have been introduced. Using this methodology dynamic routing of connection requests with Differentiated Reliability (DiR) requirements can be investigated.

WDM network for reliability definition

An illustration of reliability calculation in six nodes WDM ring network

Representative graph of WDM Network Topology, Connection request (A, E, 1, 0.1)
Our objective is to satisfy the reliability degree for that feasible active path (AP). A feasible active path (AP) is that path in which the reliability degree is satisfied.
Definition–“Feasible active segment (AS) of an active path (AP).Given an active segment (AS) an active path (AP) is said to be feasible if the sum of the failure probability of those links that are in active path (AP) but not in the active segment (AS) is less than the required reliability (r)” (Fumagalli and Tacca 2001a).
The key findings of our work.
Network delay of 150 ms would meet the requirements of even the highly video interactive applications like Video On demand. Network delay up to 150–400 ms is acceptable for video interactive applications. Therefore, this requirement is largely applicable to all video and voice interactive applications. Network delay is defined as the time the first bit of the packet is put on the wire near the source reference point to the time the last bit of the packet is received at the receiver reference point [RFC2679].This is referred to by ITU-T as IP Packet Transfer Delay (IPTD), and sometimes explicitly as one-way delay. Delay variation can be caused by the following factors:
-
(1)
Different packets can have different queuing delays at the same networking device.
-
(2)
Different packets can have different processing delays at the same networking device. The difference will usually be small for modern networking devices that use hardware-based packet forwarding but can be big for legacy networking devices that use software-based packet forwarding with caching.
-
(3)
Different packets may travel via different network paths and accumulate different queuing delays and propagation delay.
-
(4)
Network delay variation below 50 ms would meet the need of even the applications with stringent delay variation requirements. Many applications don’t even have an explicit requirement on delay variation. Packet loss ratio below 0.1 percent would meet the need of most interactive video applications.
The motivation and key findings of research work are Auxiliary Graph Based Open Shortest Path Heuristic (AGBOSPH) with restoration technique is used to satisfy reliability and availability criteria with minimum down time. It can be applied for medium and large scale network. By using AGBOSPH network performance is improved with optimum utilization of resources. To manage busty traffic like video on demand services minimum extra bandwidth cost is incurred to maintain Quality of services and to satisfy client requirements.
3 A simple graph based heuristic algorithm (SGBH)
Consider the network topologies of Fig. 1. The number next to each link is its failure probability.
Let AS is the Active segment, AP is the Active Path, r is the required reliability, ra is the actual reliability, Pf is the Probability of failure of optical link. For feasible active segment ra≤r, suppose required reliability r = 0.2 and our objective is to find the actual reliability for active segment AS1, AS2, AS3 and AS4, ra for AS2 = ΣPf(C,D) + Pf(D,A) = 0.01 + 0.02 = 0.03. Since ra ≤ r, ra for AS1 is said to feasible. ra for AS3 = giving ra = 0., so AS3 is also feasible. ra for AS3 covers all the nodes, so actual reliability is zero. Source node is itself a destination node. Here according to definition there is no active segment. Therefore, ra = 0 ≤ 0.2, so ra for AS3 is feasible. ra for AS4 ra = Pf(A,B) giving ra = 0.1 ≤ 2, so AS4 is also feasible.
Now consider a typical WDM optical mesh network topology as shown in Fig. 2 above. Suppose a request is generated for connection A-B-C-D and r = 0.6. This will offer two solutions as following:
-
(1)
Active path A-F-E-D with ra = 0.5(< r), but with no backup active segment.
-
(2)
Active path A-B-C-D with ra = 0.4(< r), and backup active segment C-E-D, (total ra = 0.5 (= r). Meet the reliability requirement for a failure of single link C-D. Links A-B and B-C shall remain unprotected.
Always with the connection request, bandwidth requirement is also sent. Considering that the bandwidth requirement of each link is 1, than for the backup path we have to spare 5 units of bandwidth in Fig. 2. If required reliability is 0 than we have to consider two disjoint path pair (A-B-C-D) and (A-F-E-D) and we have to spare 6 units of bandwidth. We conclude that by improving the reliability degree the network cost has been increased.
Now if r = 0.5, both the solutions above cannot meet the reliability requirement even under single link failure. Such situations can be handled by suitably providing auxiliary paths as explained in the next algorithm.
4 Auxiliary Graph Based Open Shortest Path Heuristic Algorithm (AGBOSPH)
In some cases, especially for dynamic arrival of connection requests, Simple Graph Based Heuristic (SGBH) is not able to provide solutions. In such cases connection requests are dropped, even though the solution might exist. First a simple example of failure of SGBH will be shown. Then, the possible solution will be discussed which will be AGBOSPH. At the end algorithmic step shall be given. Consider Fig. 3 with connection request as (s, d, b, r) where s is the source, d is destination, b is the bandwidth and r is the required reliability (A, E, 1, 0.1). For simplification bandwidth 1 is assumed for all links.
Figure 4 illustration for the active path A-B-C-D-E, ra = 0.16 > 0.1, hence request will be dropped, because no BS is available to protect the active path such that ra ≤ r.

Active path A-B-C-D-E for the request (A, E, 1, 0.1)
In actual scenarios, the topology is much more complex Fig. 4 and spare capacity is shared. It can be safely assumed that from such complex topology, certain links can selected (links have sufficient spare capacity) as shown in Fig. 5. (Selection can be different, very simple or more complex; the present selection is only to explain the working of AGBOSPH).

Auxiliary graph (Backup Segment) for A-B-C-D-E
Now by selecting the backup segments A-F-B, B-G-C and D-H-E, the links A-B,B-C and D-E of the selected active path A-B-C-D-E are fully protected giving ra = 0.1 = r. Hence the request can be admitted. Thus AGBOSPH looks for the possible active segments in the complex topology to achieve the required reliability, which is not done by SGBH. At times different links have different cost. In this situation if more than one option is available, it is desirable to have the lower cost active segment. Such search may take longer time than admissible. A method is then to choose first alternate path whose total cost is ≤ present cost of the active path + v. Otherwise search continues. If no such alternate path is found, alternate path with minimum value is chosen.
4.1 AGBOSPH Algorithm

In this paper basics of differentiated reliability in WDM network have been introduced. Using this methodology dynamic routing of connection requests with (DiR) requirements can be investigated. It has also been observed that in order to meet DiR requirement of different application of customer, in some cases a protection topology may be necessary. Since a complex restoration process is required for shared protection, the restoration time cannot be guaranteed on failure (Saxena and Goel 2011; Ho and Mouftah 2003).
5 Result and Discussion
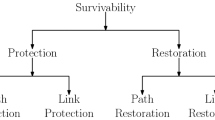
In our simulation case study with Network Simulator 2.28, we have randomly chosen a network with 26 nodes with 39 links and different designated optical routers as shown in Fig. 6. Node 0 as shown in simulation environment is a source node and node 18 is considered as destination node. A connection request is set up between source node 0 and destination node 18. Our investigation study is carried under failure scenario that is failure of a link to maintain continuity of service with minimum congestion, delay and with reduction of actual bandwidth required. There are two concepts for maintaining continuity of service. One is protection and the other is restoration. In protection environment the network cost is increased because we have to install back up links with optical component. The advantage is that the switching time is less as compared to restoration. Restoration with less usage of network resources works under dynamic environment with selection of back up path using different routing technique. In our simulation study we have not considered backup protection of any link. We have used AGBOSPH technique to select back up path dynamically. In dynamic environment the switching time is more but network resources used in Failure scenario are less. Thus network cost is reduced.
Three types of differentiated services one is fully devoted to data oriented services whose priority is designated to be the lowest. The other services called as convergent services (data and voice known as convergent services) work under medium priority level. The third level of services is data, voice and video which is a designated level of differentiated service to be assigned with highest priority i.e. high level of reliability and availability. All the three types of services have been considered. In our research investigation differentiated reliability concept is implemented in network. This is simply a set of techniques that allows telecom operators to match the level of reliability to different services and application requirements. In our simulation study single failure occurs in dynamic fashion and probability of failing two links at a time is assumed to be negligible. Single failure occurs at non uniform time interval. The link failures and time of failures have been as following:
Link between node N1 and N2 down after 3 s.
Link between node N5 and N10 down at 4.20 s.
Link between node N1 and N5 down at 5.20 s.
Link between node N2 and N10 down at 5.50 s.
Link between node N2 and N13, down at 6.10 s.
The link failures are shown practically in Fig. 6. Failures of link causes variation in traffic performance depending on the type of protection switching mechanism adopted. Automatic protection switching mechanism is adopted with randomly searching of shortest path. In Differentiated services model Open Shortest path algorithm (OSPF) is adopted for distinct degree of services and reliability. Commercial available differentiated services are generally designated as Platinum, Gold, Silver, Bronze and Iron. It has been assumed that nodes are fully reliable, only links fail and also that all the wavelength channels of a link have same reliability. It is further assumed that all links have equal length and link cost is 1. Each link carries 16 wavelengths. Connection requests arrive according to Poisson process with an average arrival rate λ, mean waiting time 1/λ. Each request is (1, 18, 16, and 0.95). Two algorithms AGBOSPH and previous work (Kong et al. 2016) AGUHT have been discussed for performance assessment. Performance assessment is done between the proposed heuristic algorithm AGBOSPH techniques under faulty conditions. The objective is to meet customer requested reliability at relatively lowest cost under network link failure scenario. If one of the link fails than alternative back up path is set up with shortest path. This proposed technique improves the overall network performance without increasing the network cost. Mainly extra computational overhead is causing delays. But the failures of different links have been too frequent. If failures are not often but occur once in a while, the extra computational overhead will be absorbed in due course of time.

Failure outage of link between Router 1 and 4 of node 1 and 2 after 3 s

source to destination connection request
Failure outage of a link between node 5 and node 10 from

Failure of link between node N1 and N5 and N2 and N10 in small interval of time
Recent trends have large volume of multimedia applications with distinct degree of Quality of service requirement and the degree of reliability. Protection or restoration is not required at all levels or for all applications. Critical applications like video conferencing cannot be delayed even for millisecond whereas email services can be delayed for some time. The main research criterion is that delay in services should be unnoticeable or it should be within QoS limits. As shown in Fig. 7 after some random time link between nodes N5, N10 (randomly chosen) fails and therefore without any break in availability traffic is rerouted by dynamically selection of backup path. Figure 8 shows two link failure in a small interval of time between node N1 and N5 and N2 and N10, respectively. Like this backup paths come in to picture with remaining link failures as well. Links are down at random discrete time interval and the traffic of failed links are reestablished with rerouted back up path within switching time of Optical Cross Connect. In our simulation study we have taken maximum fragmented size 1024 byte, UDP header of 8 byte and IP header of 20 byte and packet size of 1052.Traffic scenario is taken as Pareto type with burst time of 500 ms. UDP presents the worst scenarios because unlike TCP, it does not provide acknowledgement and retransmission so the protection totally depends on the mechanism offered by the network. After failure of the links shortest path is selected with proposed AGBOSPH algorithm. The proposed Heuristic algorithm is developed with new approach to develop a communication layer between transport and service layer, thus providing service differentiation and to maintain QoS according to customer need and service level agreements. In case of failures dynamic shortest path is selected by AGBOSPH. By this technique restoration of the failed link is done between 100 and 200 ms with burst time set to be at 500 ms.
The nature of data traffic and video traffic is shown in the results as shown in Fig. 9. X axis in data traffic is dividing in time slot and on Y axis traffic in bytes/msec. With respect to data traffic it is shown to vary uniformly with respect to time whereas video traffic is more dynamic in nature so high reliability and availability is expected with highest priority. The network of video traffic is busty that works under critical dynamic environment as shown in Fig. 10. Media services are generally differentiated into three classes one is for data services. Data services accumulate large volume of bandwidth and assigned with lowest priority of traffic that is known as best effort (BE) services. Expedited forwarding class (EF) is assigned for high priority of service with stringent QoS (data + voice + video). Assured forwarding class (AF) is assigned for medium priority classes (data + voice). It is obvious that handling video traffic with busty environment in which delays beyond ITU standard are not permissible, which makes management of video data much more complex than normal data traffic.

Graph between data traffic and time slot

Graph between video traffic and time slot
It can be seen that the overall bandwidth used by the proposed algorithm is less. Bandwidth utilization for the proposed scheme is sufficiently managed and there is no bottle neck and reserve capacity is always there under faulty condition. After repeated iterations of run time simulations it is found bandwidth shared for complete request is 8.89% less than previous studies for small and medium scale network and for large scale network it is profound to be more significant of 12.64% (Kong et al. 2016). Both performance for higher scale of network as shown in Fig. 11. Both algorithm AGBOSPH and AGUHT work with similar performance linearly for lower number of nodes and confidence level limit of 5% whereas for large scale network the non linearity behavior dynamics persist with significant confidence level difference from 8 to 12%.At the time of starting both have similar performance but under restoration AGBOSPH is more satisfactory and give excellent performance for higher scale of network as shown in Fig. 11. Figure 12 display results for lower loads very significant difference around 8–10% is observed in blocking probability and it significantly increases for higher number of loads.The performance of proposed algorithm is linear for higher number of loads and previous work shows non linear dynamics for blocking probability results. The proposed algorithm shows improvements at all traffic loads. At heavy loads the improvement is more pronounced, and the average improved performance at heavy loads is found to be 28.56%. In proposed scheme availability of backup path is always there of the order of 99.99–99.999 and with negligible amount of variation with similar performance linearly for lower number of nodes and confidence level limit algorithm AGBOSPH and AGUHT have similar performance, but under restoration AGBOSPH is more satisfactory and give excellent performance of 5% confidence level,for large scale network the non linearity behavior dynamics persist with significant confidence level difference from 8 to 12%. For higher loads the difference in blocking probability is nonlinear and it is significant from the results.

Comparison of the bandwidth used in for maintaining the normal traffic under fault conditions using proposed algorithm and the conventional schemes

Comparison of results of blocking probability AGBOSPH proposed with AGUHT
The three techniques for restoration and protection is Differentiated services with restoration, Differentiated services with protection and Differentiated service aware restoration technique. Figure 13 below display the cost for achieving three different level of reliability. For high reliability level cost is almost double of the cost for low level of reliability. The increase in cost is almost linear. Cost for medium level of reliability is in between. This difference in cost was very much expected. As the bandwidth increases the relative difference in the cost will also increase. The cost of providing the same level of reliability (0.95) to highest level of service (data + voice + video) is almost twice of the cost for same level of reliability to only data service.Low priority services that involve large volume of data services in which network delay of 100 ms would meet the need of even the highly interactive applications. Network delay up to 350–400 ms is acceptable for interactive applications. Roughly speaking, network delay of 75–100 ms is equivalent to end-to-end delay of 130–150 ms, which is recommended by ITU [G.114], and is commonly referred. Therefore, this requirement is largely applicable to all interactive applications involving humans. Network delay variation below 50 ms would meet the need of even the applications with stringent delay variation requirements. Packet loss ratio below 1 percent would meet the need of most applications.

Comparison of network cost and Bandwidth with three distinct level of reliability
Medium priority services which involves QoS requirements for voice and data involve cost more than low priority applications and based on real-world testing, Cisco recommends end-to-end performance objectives for voice-over IP [Szigeti] with delay of 150 ms for high quality and 200 ms for acceptable quality Packet loss ratio is 1 percent which are the key findings in our studies, for voice video and data applications respectively.
An example of interactive video is video teleconferencing which comes under High level of services. The QoS requirements of interactive video can vary significantly depending on quality requirement of the picture, degree of interactivity, amount of motion, and size of the picture. International Telecommunication Union [ITU] did not recommend any explicit delay, delay variation, and packet loss ratio, but to manage high quality services a high value cost is invested in provisioning of 18–20 percent more bandwidth over the average rate to account for burst and headers which are the key findings in our studies in Fig. 13.
Figure 14 shows some marginally extra computation is required by AGBOSPH. On other performance parameters, like blocking probability, packet delivery ratio, bandwidth utilisation the proposed algorithm gives better performance. Relative network costs for three different types of services have been compared.

Comparison of overhead between Extended AGBOSPH and DiR overhead
5.1 Conclusion
This paper is concerned with the problem of satisfying quality of service when it is possible to managed different class of services when both resource allocation like bandwidth management and performance monitoring is done at the class level. Our goal is to develop a reasonably simple methodology of satisfying reliability degree for specific connection request that can generate significant performance deviations. The methodology we propose is based on a set of Auxiliary graph and open shortest path first algorithm and was simulated in network tool. The effectiveness of the methodology is evaluated through simulations by exploring its prediction ability across a number of scenarios involving real traffic environment. The paper establishes that the methodology, though simple, is quite successful and robust in identifying different class of services that can result in performance deviations for distinct degree of services. The amount of additional bandwidth needed to provide for high class users and the cost involved increases as compared to low and medium class users. AGBOSPH is used for distinct degree of reliability services with high class of clients have the privilege to avail highest availability of services designated as Platinum. Gold, silver, and bronze comes under lower priority with less network infrastructure as compared to platinum. Types of service are also differentiated on the basis of Quality of service and type of services provided to client. By our result discussion it has been proved that the cost incurred to have same level of reliability for (voice + video + data) is twice as compared with data services.
References
Andrew Fumagalli et al.: Photonic slot routing: a cost effective approach to designing all optical access and metro networks, IEEE Communications Magazines, Nov (2001)
Bin Wu et al.: Optional allocation of monitoring trails for fast SRLG failure localization in all optical networks, IEEE GLOBECOM proceedings (2010)
Castro, A., Martinez, R., Casellas, R., Velasco, L., Munoz, R., Vilalta, R., Comellas, J.: Experimental assessment of bulk path restoration in multi-layer networks using PCE-based global concurrent optimization. J. Lightw. Technol. 32(1), 81–90 (Jan. 2014)
Chen, X., et al.: Flexible availability-aware differentiated protection in software-defined elastic optical networks. J. Lightwave Technol. 33(18), 3872–3882 (2015)
Chlamtac, I., Fumagalli, A., Valcarenghi, L.: Use of computational intelligence techniques for designing optical networks. In: Pedrycz, W., Vasilakos, A. (eds.) Computational Intelligence Telecommunications Network, pp. 1–528. CRC Press. ISBN 9780849310751 (2001)
Doshi, B.T., Dravida, S., Harshavardhana, P., Hauser, O., Wang, Y.: Optical network design and restoration. Bell Lab. Tech. J. 4(1), 58–84 (1999)
Fengxian Tang: Crosstalk-aware counter-propagating core assignment to reduce inter-core crosstalk and capacity wastage in multi-core fiber optical networks. J. Lightwave Technol. Vol. 37, No. 19 (2019)
Fumagalli, A., Tacca, M.: Optimal design of differentiated reliability (DiR) optical ring networks, in International Workshop on QoS in Multiservice IP Networks (QoS-IP) (2001)
Fumagalli, A., Tacca, M.: Differentiated reliability (DiR) in WDM Rings. IEEE/ACM Transactions Netw. (TON) 14(1), 159–168 (2006)
Fumagalli, A., M. Tacca, M.: Differentiated reliability (DiR) in WDM rings without wavelength converters, in ICC 2001, IEEE International Conference on Communication, vol. 9, pp. 2887–2891 (2001)
Gerstel, O., Sasaki, G.: Quality of protection (QoP): A quantitative unifying paradigm to protection service grades. Opt. Netw. Mag. 3(3), 40–49 (2002)
Ho, P.-H., et al.: Segment shared protection in mesh communications networks with bandwidth guaranteed tunnels. IEEE/ACM Trans. Netw. 12(6), 1105–1118 (Dec. 2004)
Hongbin luo et al.: Routing reliability guaranteed connections in WDM Mesh network, Photonic Network Communication, Accepted (2012)
http://www.infonetics.com/resources/whitepaper.
Ibrahimov, B.G., Hasanov, M.H., Mardanov, N.T.: Research and analysis efficiency optical telecommunication networks on the basis optical WDM and DWDM technologies systems of signals generating and processing in the field of on board communications, pp. 1–4. IEEE, Moscow, Russia (2020)
Janos Tapolcai et al.: A new shared segment protection method for survival networks with guaranteed recovery time, IEEE proceedings on reliability, vol. 57, No.2, June (2008)
Jitendra Saxena and Aditya Goel: Graphical methodology to analyze and interpret differentiated reliability in WDM optical network, ICOP 2009-International conference on optics and photonics, CSIO Chandigarh, India, 30 Oct–1 Nov (2009)
Jitendra Saxena and Aditya Goel: Reliability based bandwidth design model in WDM ring network advances in wireless and mobile communications, Research India Publications, Vol.4, No. 2, pp 191- 200, Sep (2011)
Jitendra Saxena and Aditya Goel: Reliability and maintainability of passive optical component, Int J Computer Trends Technol, ISSN: 2231–2803, pp. 20–23, Sep.-Oct (2011)
Kant, L., Hsing, D., Wu,T.: Modeling and simulation study of the survivability performance of ATM-based restoration strategies for the next generation high-speed networks, in Proc. 8th Int. Conf. Computer Communications and Networks, pp. 469–473, Oct. (1999)
Kong, J., et.al :Availability-Guaranteed Virtual Optical Network Mapping with Shared Backup Path Protection IEEE conference and Exhibition on Global communication (2016)
Kong, J., et al.: “Availability-Guaranteed Virtual Optical Network Mapping with Selective Path Protection.” In OFC, pp. W1B-4 (2016)
Iannone, P.P., et al.: A flexible metro WDM Ring using wavelength independent subscriber equipment to share bandwidth, pp. 281–283. AT and T Laboratories, Netherlands (2000)
Iannone, P.P., et al.: A transparent WDM network featuring shared virtual rings. J Lightw. Technol. 18(12), 1995 (2000)
Manso, C., Munoz, R., Yoshikane, N., Casellas, R., Vilalta, R., Martinez, R., Tsuritani, T., Morita, I.: J. Opt. Commun. Netw. 13(1), 21–33 (2021)
Marson et al.: All–optical WDM multi–rings with differentiated QoS, IEEE Communication Magazines, pp.58–66, Feb (1999)
Marco Savi: An application-aware multi-layer service provisioning algorithm based on auxiliary graphs, OFC conference (2017)
Pandey, G., Goel, A.: Enhanced colorless and broadcast capable symmetrical 10-Gbps bidirectional transmission in WDM-PON using RSOA and EAM. Optik-Int J Light Electron Optics 124(23), 6245–6249 (Dec. 2013)
Pandey, G., Goel, A.: Long reach colorless WDM OFDM-PON using direct detection OFDM transmission for downstream and OOK for upstream. Optic Quantum Electron 46(12), 1509–1518 (Dec. 2014)
Pandey, G., Goel, A.: Performance analysis of symmetrical 10Gbps colorless WDM-PON using subcarrier modulated downstream and wavelength converted upstream through RSOA. Optik-Int J Light Electron Optics 125(17), 4951–4954 (Sept. 2014)
Pandey, G., Goel, A.: Performance analysis of long reach colorless WDM-OFDM-PON using broadcast capability, Optical Engineering, SPIE, vol. 55, no. 7, pp. 076101–1–076101–8 (2016)
Pandi, Z., Fumagalli, A., Tacca, M., Wosinska, L. :Impact of OXC failures on network reliability, in Proc. SPIE Photonics Europe’04, Strasbourg, France, April (2004)
Pavon-Marino, P., et al.: Net2Plan: an open source network planning tool for bridging the gap between academia and industry, IEEE Network (2015)
Pin-Han, H., et al.: Diverse routing for shared protection in survivable optical networks, IEEE GLOBECOM 2003, pp. 2520-2523 (2003)
Pin-Han Ho et al.: A novel dynamic availability aware survivable routing architecture with partial restorability, 23rd Biennal symposium on communications, pp. 360–363 (2006)
Pin-Han, H., Mauftah, HT.: SLSP: a new path protection scheme for the optical internet, optical Society of America (2000)
Pin-Han, H., and Mauftah, HT.: Shared protection in mesh WDM Networks, IEEE communications magazine, January, pp. 70–76 (2004)
Qi-Guo et al.: Availability constrained shared backup path protection (SBPP) for GMPLS based spare capacity re-provisioning, IEEE communications society proceedings (2007)
Pin-Han, H., Mouftah, H.T.: A Frame work of space capacity reallocation for wavelength routed dynamic WDM network. Opt. Netw. Mag. 4(6), 45–58 (2003)
Saradhi, C.V., Murthy, C.S.R.: Routing differentiated reliable connections in WDM optical networks. Opt. Netw. Mag. 3(3), 50–67 (2002)
Sheng, Y., Zhang, Y., Guo, H., Bose, S.K., Shen, G.: Benefits of unidirectional design based on decoupled transmitters and receivers intackling traffic asymmetry for elastic optical networks. IEEE/OSA J. Opt. Commun. Netw. 10(8), C1–C14 (Jun. 2018)
Sridharan, M., Salapaka, M.V., Somani, A.K.: A practical approach to operating survivable WDM networks. IEEE J. Sel. Areas Commun. 20(1), 34–46 (Jan. 2002)
Saxena, J., Goel, A.: Quality of service and reliability with weighted fair queuing and custom queuing in optical communication. Int J Eng Sci. Technol. 3(9), 6889–6893 (2011)
Saxena, J., Goel, A.: Quality of service and reliability in optical network. Int. J. Distrib. Parallel Syst. 3(1), 181–184 (2012)
Tacca, M., Fumagalli, A., Paradisi, A., Ungbvary, F., Gadhiuaju, K., Lakshmanan, S., Rossi, S.M., de Campos Sachs, A., Shah, D.S.: Differentiated reliability in optical networks: theoretical and practical results. J. Lightwave Technol. 21(11), 2576–2586 (2003)
Tang, F., Li, L., Bose, S.K., Shen, G.: Assigning counter-propagating cores in multi-core fiber optical networks to suppress inter-core crosstalk and inefficiency due to bi-directional traffic asymmetry. In: Optical Fiber Communications Conference and Exposition (OFC), San Diego, CA, USA, pp. 1–3 (2018)
Vittorio Curri: Software-defined WDM optical transport in disaggregated open optical networks 22nd International conference on transparent optical networks (ICTON), IEEE, Bari, Italy, pp. 1–4, (2020)
Wosinska, L.: Reliability study of fault-tolerant multi-wavelength non-blocking optical connect based on InGaAsP/InP laser-amplifier gate switch arrays. J. Lightw. Techn. 5(10), 1206–1209 (1993)
Wosinska, L., et al.: Large capacity strictly non-blocking optical cross connects based on microelectro-opto-mechanical (MEOMS) switch matrices: reliability performance analysis. J Lightw. Technol. 19(8), 1065–1075 (Aug. 2001)
Wosinska, L., Pedersen, L., Svensson, T.: improving connection availability in optical networks in Proc. NFOEC’03, September, Orlando. USA, (2003)
Wosinska, L., Thylen, L.: Reliability performance of optical cross connects switches-requirements and practice, in OFC’98, San Jose, USA, Feb (1998)
Wu, K., Valcarenghi,L., Fumagalli, A.: Restoration schemes with differentiated reliability, in Proc. IEEE Int. Conf. Communications (ICC 03), Anchorage, Ak, May (2003)
Wu, B., Yeung, K.L., Ho, P., Jiang, X.: Minimum delay scheduling for performance guaranteed switches with optical fabrics. J. Lightwave Technol. 27(16), 3453–3465 (2009)
WWW.OPNET.COM
WWW.OPTIWAVE.COM
J. Zhang et al.: Dynamic virtual network embedding over multilayer optical networks, IEEE/OSA JOCN, (2015)
Zhang, J., Zhu, K., Zang, H., Mukherjee, B., :A new provisioning framework to provide availability-guaranteed service in WDM mesh networks, in Proc. IEEE Int. Conf. Communications (ICC’03), Anchorage, AK, vol. 2, pp. 1484–1488, (2003)
Zhou, L., Held, M., Wosinska, L.: Analysis and optimization of connection availabilities in optical networks with different protection strategies in Proc. SPIE Photonics Europe’04, Strasbourg, France April (2004)
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Saxena, J., Goel, A. Differentiated services and its importance in fault tolerant WDM optical network. Opt Quant Electron 53, 162 (2021). https://doi.org/10.1007/s11082-021-02757-7
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s11082-021-02757-7