
Abstract
Recently, the numerical solution of stiffly/highly oscillatory Hamiltonian problems has been attacked by using Hamiltonian boundary value methods (HBVMs) as spectral methods in time. While a theoretical analysis of this spectral approach has been only partially addressed, there is enough numerical evidence that it turns out to be very effective even when applied to a wider range of problems. Here, we fill this gap by providing a thorough convergence analysis of the methods and confirm the theoretical results with the aid of a few numerical tests.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
1 Introduction
In recent years, the efficient numerical solution of Hamiltonian problems has been tackled via the definition of the energy-conserving Runge-Kutta methods named Hamiltonian boundary value methods (HBVMs) [10,11,12,13]. Such methods have been developed along several directions (see, e.g., [4, 14, 19]), including Hamiltonian BVPs [1] and Hamiltonian PDEs (see, e.g., [6]): we also refer to the monograph [7] and to the recent review paper [8] for further details.
More recently, HBVMs have been used as spectral methods in time for solving highly oscillatory Hamiltonian problems [18], as well as stiffly oscillatory Hamiltonian problems [9] emerging from the space semi-discretization of Hamiltonian PDEs. Their spectral implementation is justified by the fact that this family of methods performs a projection of the vector field onto a finite dimensional subspace via a least squares approach based on the use of Legendre orthogonal polynomials [13]. This spectral approach, supported by a very efficient nonlinear iteration technique to handle the large nonlinear systems needed to advance the solution in time (see [12], [7, Chapter 4] and [8]), proved to be very effective. However, a thorough convergence analysis of HBVMs, used as spectral methods, was still lacking. In fact, when using large stepsizes, as is required by the spectral strategy, the notion of classical order of a method is not sufficient to explain the correct asymptotic behavior of the solutions, so that a different analysis is needed, which is the main goal of the present paper. Moreover, the theoretical achievements will be numerically confirmed by applying the methods to a number of ODE-IVPs.
It is worth mentioning that early references where numerical methods were derived by projecting the vector field onto a finite dimensional subspace are, e.g., [2, 3, 27, 28] (a related reference is [36]). A similar technique, popular for solving oscillatory problems, is that of exponential/trigonometrically fitted methods and, more in general, functionally fitted methods [22,23,24, 26, 29,30,31,32,33, 35, 37].
With these premises, the structure of the paper is as follows: in Section 2, we analyze the use of spectral methods in time; in Section 3, we discuss the efficient implementation of the fully discrete method; in Section 4, we provide numerical evidence of the effectiveness of such an approach, confirming the theoretical achievements. At last, a few conclusions are reported in Section 5.
2 Spectral approximation in time
This section contains the main theoretical results regarding the spectral methods that we shall use for the numerical solution of ODE-IVPs which, without loss of generality, will be assumed in the formFootnote 1
Hereafter, f is assumed to be suitably smooth (in particular, we shall assume f(z) to be analytic in a closed complex ball centered at y0). We consider the solution of problem (1) on the interval [0,h], where h stands for the time-step to be used by a one-step numerical method. The same arguments will be then repeated for the subsequent integration steps. According to [13], we consider the expansion of the right-hand side of (1) along the shifted and scaled Legendre polynomial orthonormal basis {Pj}j≥ 0,
with πj the set of polynomials of degree j and δij the Kronecker delta. One then obtains:
with the Fourier coefficients γj(y) given by
We recall that:
Let us now study the properties of the coefficients γj(y) defined at (3). To begin with, we report the following results.
Lemma 1
Let \(g:[0,h]\rightarrow V\) , with V a vector space, admit a Taylor expansion at 0. Then,
Proof
See [13, Lemma 1].
Corollary 1
The Fourier coefficients defined in (3) satisfy:γj(y) = O(hj).
We now want to derive an estimate which generalizes the result of Corollary 1 to the case where the stepsize h is not small. For this purpose, hereafter we assume that the solution y(t) of (1) admits a complex analytic extension in a neighbourhood of 0. Moreover, we shall denote by \(\mathcal {B}(0,r)\) the closed ball of center 0 and radius r in the complex plane, and \(\mathcal {C}(0,r)\) the corresponding circumference. The following results then hold true.
Lemma 2
LetPjbethejthshifted and scaled Legendre polynomial and, forρ > 1, letus define the function
Then,
Proof
One has, for |ξ| = ρ > 1, and taking into account (4):
Passing to norms, one has:
from which (6) follows.
Lemma 3
Letg(z) be analytic in theclosed ball\(\mathcal {B}(0,r^{*})\)of the complexplane, for a givenr∗ > 0.Then, for all 0 < h≤ h∗ < r∗,
is analytic in \(\mathcal {B}(0,\rho )\), with
We are now in the position of stating the following result.Footnote 2
Theorem 1
Assume that the function
and h in (2)–(3) satisfy the hypotheses of Lemma 3. Then, there exists κ = κ(h∗) > 0, such thatFootnote 3
Proof
By considering the function (7) corresponding to (9), and with reference to the function Qj(ξ) defined in (5), one has that the parameter ρ, as defined in (8), is greater than 1 and, moreover, (see (3))
Then, passing to norms (see (6)),
Moreover, observing that (see (9), (7), and (8)):
and using (6), one has, (see (8)):
from which (10) eventually follows.
Remark 1
It is worth mentioning that, in the bound (10), the dependence on h only concerns the parameter ρ > 1, via the expression (8), from which one infers that \(\rho \sim h^{-1}\), for all 0 < h ≤ h∗ < r∗. This, in turn, is consistent with the result of Corollary 1, when \(h\rightarrow 0\).
Let us now consider a polynomial approximation to (2),
where γj(σ) is defined according to (3) by formally replacing y by σ, i.e.,
Integrating term by term (11), and imposing the initial condition in (1), provide us with the polynomial approximation of degree s:
We now want to assess the extent to which σ(ch) approximates y(ch), for c ∈ [0,1]. When \(h\rightarrow 0\), it is known that y(h) − σ(h) = O(h2s+ 1) (see, e.g., [7, 8, 13]). Nevertheless, we here discuss the approximation of σ to y, in the interval [0,h], when h is finite and only assuming that the result of Theorem 1 is valid. The following result then holds true.Footnote 4
Theorem 2
Letybe thesolution of (1),σbedefined according to (13), and assume thatf(σ(z)) is analyticin\(\mathcal {B}(0,r^{*})\), for agivenr∗ > 0. Then,for all 0 < h≤ h∗ < r∗,there exist\(M,\bar {M}>0\),\(M=M(h^{*}), \bar {M}=\bar {M}(h^{*})\), andρ > 1,\(\rho \sim h^{-1}\),such that:
|σ(ch) − y(ch)|≤ chMρ−s,c ∈ [0,1];
\( |\sigma (h)-y(h)| \le {h \bar {M} \rho ^{-2s}} \).
Proof
Let y(t,ξ,η) denote the solution of the problem
and Φ(t,ξ) be the solution of the associated variational problem,
having set \(f^{\prime }\) the Jacobian of f. Without loss of generality, we shall assume that the function
is also analytic in \(\mathcal {B}(0,r^{*})\). We also recall the following well-known perturbation results:
Consequently, from (12) and (13), one has:
From the result of Theorem 1 applied to g(z) := f(σ(z)), we know that there exist κ = κ(h∗) and ρ > 1, \(\rho \sim h^{-1}\), such that, for the Fourier coefficients defined in (12),
Moreover, (see (4)) \(\|P_{j}\| = \sqrt {2j+1}\) and, considering that, for all h ∈ (0,h∗],
one has that
Consequently, the first statement follows from (15) by setting, with reference to the parameter ρ∗ defined in (8),
since, for all c ∈ [0,1]:
To prove the second statement (i.e., when c = 1), we observe that the result of Theorem 1 holds true also for the function (14) involved in the Fourier coefficients
Consequently, there exist κ1= κ1(h∗) > 0, such that
The second statement then follows again from (15) by setting
so that, by using same steps as above:
Let us now introduce the use of a finite precision arithmetic, with machine precision u, for approximating (2). Then, the best we can do is to consider the polynomial approximation (11)–(12)Footnote 5
such that
Integrating (18), and imposing that σ(0) = y0, then brings back to (13). We observe that because of (16), (19) may be approximately recast as
where \(\rho \sim h^{-1}\). Consequently, choosing s such that (19) (or (20)) is satisfied, we obtain that:
the polynomial σ(ch) defined by (18) and (13) provides a uniformly accurate approximation to y(ch), in the whole interval [0,h], within the possibility of the used finite precision arithmetic;
σ(h) is a spectrally accurate approximation to y(h). Moreover, in light of the second point of the result of Theorem 2, one has that the criterion (19) can be conveniently relaxed. In fact, making the ansatz (see (16) and (17)) κ = κ1, one has that
$$ |\sigma(h)-y(h)| \lesssim \frac{h\kappa^{2}}{1-\rho^{-2}}\rho^{-2s} \approx \frac{h(s+1)}{1-\rho^{-2}} |\gamma_{s}(\sigma)|^{2}. $$(21)Imposing the approximate upper bound to be smaller than the machine epsilon u, one then obtains:
$$ |\gamma_{s}(\sigma)| \lesssim {\sqrt{\frac{u(1-\rho^{-2})}{h(s+1)}}} \propto u^{1/2}, $$(22)which is generally much less restrictive than (19).Footnote 6 Alternatively, by considering that the use of relatively large time-steps h is sought, one can use \(\text {tol}\sim u^{1/2}\) in (19), that is,
$$ |\gamma_{s}(\sigma)| < \mathrm{tol} \cdot \max_{j<s} |\gamma_{j}(\sigma)|, \qquad \mathrm{tol}\sim u^{1/2}, $$(23)In other words, (21) means that the method maintains the property of super-convergence, which is known to hold when \(h\rightarrow 0\), also in the case where the time-step h is relatively large.
Remark 2
In particular, we observe that (19) (or (20) or (22)) can be fulfilled by varying the value of s, and/or that of the stepsize h, by considering that, by virtue of (8),
hold and hnew being the old and new stepsizes, respectively.
It is worth mentioning that the result of Theorem 2 can be also used to define a stepsize variation, within a generic error tolerance tol, thus defining a strategy for the simultaneous order/stepsize variation.
We conclude this section mentioning that, to gain efficiency, the criterion (19) for the choice of s in (18) can be more conveniently changed to
Similarly, the less restrictive criterion (22) can be approximately modified as:
or, alternatively, one uses \(\text {tol}\sim u^{1/2}\) in (24). As is clear, computing the norms of the coefficients γj(σ) permits to derive estimates for the parameters κ and ρ in (16), as we shall see later in the numerical tests.
3 SHBVMs
The approximation procedure studied in the previous section does not yet provide a numerical method, in that the integrals defining γj(σ), \(j=0,\dots ,s-1\), in (12)–(13) need to be computed. For this purpose, one can approximate them to within machine precision through a Gauss-Legendre quadrature formula of order 2k (i.e., the interpolatory quadrature rule defined at the zeros of Pk) with k large enough. In particular, following the criterion used in [9, 18], for the double precision IEEEFootnote 7, we choose
After that, we define the approximation to y(h) as
In so doing, one eventually obtains a HBVM(k,s), which we sketch below. Hereafter, we shall refer to such a method as to spectral HBVM (in short, SHBVM), since its parameters s and k, respectively defined in (19) (or (20) or (22)) and (25), are aimed at obtaining a numerical solution which is accurate within the round-off error level of the used finite precision arithmetic.
For sake of completeness, let us now briefly sketch what a HBVM(k,s) is. In general, to approximate the Fourier coefficient γj(σ), and assuming for sake of simplicity that full machine accuracy is gained, we use the quadrature
where the polynomial σ is that defined in (13) by formally replacing γj(σ) with \(\hat {\gamma }_{j}\), and (ci,bi) are the abscissae and weights of the Gauss-Legendre quadrature of order 2k on the interval [0,1].Footnote 8 Setting Yℓ = σ(cℓh), from (27), one then obtains the stage equations
with the new approximation given by (see (26))
Consequently, with reference to (28), setting
one easily realizes that (28) and (29) define the k-stage Runge-Kutta method with Butcher tableau:
From (28), one verifies that the Butcher matrix in (30) can be written as
with
and
In fact, setting \(\boldsymbol {e}_{i}\in \mathbb {R}^{k}\) the i th unit vector, and taking into account (31)–(33), one has
as defined in (28). From well-known properties of Legendre polynomials (see, e.g., [7, Appendix A]), one has that
from which one easily derives the following property relating the matrices (32)–(33) (see, e.g., [7, Lemma 3.6]):
Remark 3
From (32)–(34), one has that the Butcher matrix (31) can be rewritten as
Considering that, when k = s, (see (35)) \(\mathcal {P}_{s+1}\hat X_{s} = \mathcal {P}_{s}X_{s}\) and \(\mathcal {P}_{s}^{\top }{\Omega } = \mathcal {P}_{s}^{-1}\), so that A reduces to \(\mathcal {P}_{s} X_{s} \mathcal {P}_{s}^{-1}\), we observe that (36) can be also regarded as a generalization of the W-transformation in [25, Section IV.5].
At this point, we observe that the stage equation (28) can be cast in vector form, by taking into account (30)–(33), as
with an obvious meaning of f(Y ). On the other hand, the block vector of the coefficients in (27) turns out to be given by
Consequently, from (37), one obtains
and then, from (38), one eventually derives the equivalent discrete problem
which has (block) dimension s, independently of k (compare with (37)). Once it has been solved, the new approximation is obtained (see (29)) as \(y_{1}=y_{0}+h\hat {\gamma }_{0}\).
It is worth observing that the new discrete problem (39), having block dimension s independently of k, allows us to use arbitrarily high-order quadratures (see (25)), without affecting that much the computational cost.
In order to solve (39), one could in principle use a fixed-point iteration,Footnote 9
which, though straightforward, usually implies restrictions on the choice of the stepsize h. For this reason, this approach is generally not useful when using the methods as spectral methods, where the use of relatively large stepsizes is sought. On the other hand, the use of the simplified Newton iteration for solving (39) reads, by virtue of (35),
However, the coefficient matrix in (40) has a dimension s times larger than that of the continuous problem (i.e., m) and, therefore, this can be an issue when large values of s are to be used, as in the case of SHBVMs. Fortunately, this problem can be overcome by replacing the previous iteration (40) with a corresponding blended iteration [7, 8, 12] (see also [5]). In more details, once one has formally computed the m × m matrix
where σ(Xs) denotes, as is usual, the spectrum of matrix Xs, one iterates:
Consequently, one only needs to compute, at each time-step, the matrix \({\Sigma }\in \mathbb {R}^{m\times m}\) defined in (41),Footnote 10 having the same size as that of the continuous problem. Moreover, it is worth mentioning that for semi-linear problems with a leading linear part, the Jacobian of f can be approximated with the (constant) linear part, so that Σ is computed once for all [6, 9, 18].
Remark 4
It must be stressed that it is the availability of the very efficient blended iteration (41)–(42) which makes the practical use of HBVMs as spectral methods in time possible, since relatively large values of s can be easily and effectively handled.
A thorough analysis of the blended iteration can be found in [15]. Contexts where it has been successfully implemented include stiff ODE-IVPs [16], linearly implicit DAEs up to index 3 [17] (see also the code BiMD in TestSet for IVP Solvers “https://archimede.dm.uniba.it/~testset/testsetivpsolvers/”), and canonical Hamiltonian systems (see the Matlab code HBVM, available at “http://web.math.unifi.it/users/brugnano/LIMbook/”), while its implementation in the solution of RKN methods may be found in [38].
4 Numerical tests
The aim of this section is twofold: firstly, to assess the theoretical analysis of SHBVMs made in Section 2; secondly, to compare such methods w.r.t. some well-known ones. All numerical tests, which concern different kinds of ODE problems, have been computed on a laptop with a 2.8-GHz Intel-i7 quad-core processor and 16GB of memory, running Matlab 2017b. For the SHBVM, the criteria (23) and (25) have been respectively used to determine its parameters s and κ.
4.1 The Kepler problem
We start considering the well-known Kepler problem (see, e.g., [7, Chapter 2.5]), which is Hamiltonian, with Hamiltonian function
Consequently, we obtain the equations
which, when coupled with the initial conditions
provide a periodic orbit of period T = 2π that, in the q-plane, is given by an ellipse of eccentricity ε. In particular, we choose the value ε = 0.5. The solution of this problem has two additional (functionally independent) invariants besides the Hamiltonian (43), i.e., the angular momentum and one of the nonzero components of the Lenz vector [7, page 64] (in particular, we select the second one):
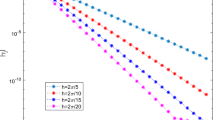
At first, we want to assess the result of Theorem 1. For this purpose, we apply the HBVM (20,16) for one step starting from the initial condition (45), and using time-steps hi = 2π/(5 ⋅ 2i− 1), \(i=1,\dots ,5\). Figure 1 is the plot (see (27)) of \(|\hat \gamma _{j}|\), for \(j=0,1,\dots ,15\), (solid line with circles), which, according to (16), should behave as \(\kappa \rho ^{-j}/\sqrt {j+1}\), due to the result of Theorem 1. A least squares approximation technique has been employed to estimate the two parameters (κ and ρ) appearing in the bound (16). These theoretical bounds are highlighted by the dashed line with asterisks in Fig. 1: evidently, they well fit the computed values, except those which are close to the round-off error level. Moreover, according to the arguments in the proof of Theorem 1, one also expects that the estimate of κ increases but is bounded, as \(h\rightarrow 0\), whereas ρ should be proportional to h− 1. This fact is confirmed by the results listed in Table 1.

Behavior of \(|\hat \gamma _{j}|\) for decreasing values of the time-step h for the Kepler problem (44)–(45) solved by the HBVM(20,16) with decreasing time-steps. The line with circles are the computed norms, whereas those with the asterisks are the estimated ones. Observe that for the smallest time-steps, the computed norms stagnate near the round-off error level
Next, we compare the following methods for solving (44)–(45):
the s-stage Gauss method (i.e., HBVM(s,s)), s = 1,2, which is symplectic and of order 2s. Consequently, it is expected to conserve the angular momentum M(q,p) in (46), which is a quadratic invariant [34];
the HBVM(6, s) methods, s = 1,2, which, for the considered stepsizes is energy-conserving and of order 2s;
the SHBVM method described above, where s and k are determined according to (23) and (25), respectively, with tol ≈ 10− 8. This tolerance, in turn, should provide us with full accuracy, according to the result of Theorem 2, because of the super-convergence of the method, which is valid for any used step-size.Footnote 11
It is worth mentioning that the execution times that we shall list for the Gauss, HBVM, and SHBVM methods are perfectly comparable, since the same Matlab code has been used for all of them. This code, in turn, is a slight variant of the hbvm function available at the url “http://web.math.unifi.it/users/brugnano/LIMbook/”.
In Tables 2, 3, and 4, we list the obtained results when using a time-step h = 2π/n over 100 periods. In more details, we list the maximum errors, measured at each period, in the invariants (43) and (46), eH,eM,eL, respectively, the solution error, ey, and the execution times (in sec). As it is expected, the symplectic methods conserve the angular momentum (since it is a quadratic invariant), whereas the energy-conserving HBVMs conserve the Hamiltonian function.Footnote 12 On the other hand, the SHBVM conserves all the invariants and has a uniformly small solution error, by using very large stepsizes. Further, its execution time is the lowest one (less than 0.5 sec, when using h = 2π/5), thus confirming the effectiveness of the method.
4.2 A Lotka-Volterra problem
We consider the following Poisson problem [20],
with \( y\in \mathbb {R}^{3}\) and, for arbitrary real constants a,b,c,ν,μ,
Moreover, assuming that abc = − 1, there is a further invariant besides the Hamiltonian H, i.e., the Casimir
The solution turns out to be periodic, with period T ≈ 2.878130103817, when choosing
For this problem, the HBVM(k,s) is no more energy-conserving, as well as the s-stage Gauss method. As matter of fact, both exhibit a drift in the invariants and a quadratic error growth in the numerical solution. The obtained results for the SHBVM, with tol ≈ 10− 8 in (23) for choosing s, κ given by (25), and using a stepsize h = T/n, are listed in Table 5, where it is reported the maximum Hamiltonian error, eH, the Casimir error, eC, and the solution error ey, measured at each period, over 100 periods. In such a case, all the invariants turn out to be numerically conserved, and the solution error is uniformly very small. Moreover, the SHBVM using the largest time-step (i.e., h = T/5 ≈ 0.57) turns out to be the most efficient one. For comparison, in the table, we also list the results obtained by using the Matlab solver ode45 used with the default parameters, requiring 5600 integration steps and stepsizes approximately in the range [2.2 ⋅ 10− 2,1.1 ⋅ 10− 1], and the same solver used with parameters AbsTol= 1e-15, RelTol= 1e-10, now requiring 121760 integration steps, with stepsizes approximately in the range [10− 3,4.2 ⋅ 10− 3].
4.3 A stiff ODE-IVP
At last, we consider a stiff ODE-IVP,
with g(t) a known function, having evidently solution y(t) = g(t). We choose
and consider the SHBVM with tol ≈ 10− 8 in (23) for choosing s (as before, κ is chosen according to (25)), so that full accuracy is expected in the numerical solution. The time-step used is h = 100/n for n steps. The measured errors in the last point (coinciding with the initial condition), are then reported in Table 6. For comparison, also the results obtained by the Matlab solver ode15s, using its default parameters, are listed in the table. This latter solver requires 6006 steps, with time-steps approximately in the range [1.9 ⋅ 10− 3,2 ⋅ 10− 2].
5 Conclusions
In this paper, we provide a thorough analysis of SHBVMs, namely HBVMs used as spectral methods in time, which further confirms their effectiveness. From the analysis, one obtains that the super-convergence of HBVMs is maintained also when using relatively large time-steps. SHBVMs become a practical method, due to the very efficient nonlinear blended iteration inherited from HBVMs. As a consequence, SHBVMs appear to be good candidates as general ODE solvers. This is indeed confirmed by a few numerical tests concerning a Hamiltonian problem, a Poisson (not Hamiltonian) problem, and a stiff ODE-IVP. The same tests show the numerical assessment of the theoretical achievements.
Notes
In fact, if problem (1) is non autonomous, t can be included in the state vector.
The used arguments are mainly adapted from [21].
Hereafter, for sake of clarity, we shall denote by |⋅| any convenient vector or matrix norm.
The proof uses arguments similar to those of [13, Theorem 4].
Hereafter, \(\doteq \) means “equal within the round-off error level of the used finite precision arithmetic”.
In such a case, the machine precision is u ≈ 10− 16.
i.e., \(0<c_{1}<\dots <c_{k}<1\) are the zeros of Pk.
Hereafter, the initial approximation \(\hat {\boldsymbol {\gamma }}^{0}=\bf 0\) is conveniently used.
i.e., factor Σ− 1.
As matter of fact, considering more stringent tolerances does not improve the accuracy of the computed numerical solution.
In this case, the Gauss methods exhibit a super-convergence in the conservation of the Hamiltonian (3 times the usual order) and HBVMs do the same with the angular momentum. This is due to the fact that the error is measured only at the end of each period.
References
Amodio, P., Brugnano, L., Iavernaro, F.: Energy-conserving methods for Hamiltonian Boundary Value Problems and applications in astrodynamics. Adv. Comput. Math. 41, 881–905 (2015)
Betsch, P., Steinmann, P.: Inherently energy conserving time finite elements for classical mechanics. J. Comp. Phys. 160, 88–116 (2000)
Bottasso, C.L.: A new look at finite elements in time: a variational interpretation of Runge–Kutta methods. Appl. Numer. Math. 25, 355–368 (1997)
Brugnano, L., Calvo, M., Montijano, J.I., Rández, L.: Energy preserving methods for Poisson systems. J. Comput. Appl. Math. 236, 3890–3904 (2012)
Brugnano, L., Frasca Caccia, G., Iavernaro, F.: Efficient implementation of Gauss collocation and Hamiltonian Boundary Value Methods. Numer. Algorithm. 65, 633–650 (2014)
Brugnano, L., Frasca-Caccia, G., Iavernaro, F.: Line Integral Solution of Hamiltonian PDEs. Mathematics 7(3), article n. 275. https://doi.org/10.3390/math7030275 (2019)
Brugnano, L., Iavernaro, F.: Line Integral Methods for Conservative Problems. Chapman and hall/CRC, Boca Raton (2016)
Brugnano, L., Iavernaro, F.: Line Integral Solution of Differential Problems. Axioms 7(2), article n. 36. https://doi.org/10.3390/axioms7020036 (2018)
Brugnano, L., Iavernaro, F., Montijano, J.I., Rández, L.: Spectrally accurate space-time solution of Hamiltonian PDEs. https://doi.org/10.1007/s11075-018-0586-z(2018)
Brugnano, L., Iavernaro, F., Trigiante, D.: Hamiltonian BVMs (HBVMs): A family of “drift-free” methods for integrating polynomial Hamiltonian systems. AIP Conf. Proc. 1168, 715–718 (2009)
Brugnano, L., Iavernaro, F., Trigiante, D.: Hamiltonian boundary value methods (energy preserving discrete line integral methods). JNAIAM J. Numer. Anal. Ind. Appl. Math. 5(1-2), 17–37 (2010)
Brugnano, L., Iavernaro, F., Trigiante, D.: A note on the efficient implementation of Hamiltonian BVMs. J. Comput. Appl. Math. 236, 375–383 (2011)
Brugnano, L., Iavernaro, F., Trigiante, D.: A simple framework for the derivation and analysis of effective one-step methods for ODEs. Appl. Math. Comput. 218, 8475–8485 (2012)
Brugnano, L., Iavernaro, F., Trigiante, D.: A two-step, fourth-order method with energy preserving properties. Comput. Phys. Commun. 183, 1860–1868 (2012)
Brugnano, L., Magherini, C.: Blended Implementation of Block Implicit Methods for ODEs. Appl. Numer. Math. 42, 29–45 (2002)
Brugnano, L., Magherini, C.: The BiM Code for the Numerical Solution of ODEs. J. Comput. Appl. Math. 164–165, 145–158 (2004)
Brugnano, L., Magherini, C., Mugnai, F.: Blended implicit methods for the numerical solution of DAE problems. J. Comput. Appl. Math. 189, 34–50 (2006)
Brugnano, L., Montijano, J.I., Rández, L.: On the effectiveness of spectral methods for the numerical solution of multi-frequency highly-oscillatory Hamiltonian problems. Numer. Algorithms. https://doi.org/10.1007/s11075-018-0552-9 (2018)
Brugnano, L., Sun, Y.: Multiple invariants conserving Runge-Kutta type methods for Hamiltonian problems. Numer. Algorithm. 65, 611–632 (2014)
Cohen, D., Hairer, E.: Linear energy-preserving integrators for Poisson systems. BIT 51, 91–101 (2011)
Davis, P.J.: Interpolation & Approximations. Dover, New York (1975)
Franco, J.M.: Exponentially fitted symplectic integrators of RKN type for solving oscillatory problems. Comput. Phys. Comm. 177(6), 479–492 (2007)
Franco, J.M.: Runge-kutta methods adapted to the numerical integration of oscillatory problems. Appl. Numer. Math. 50, 427–443 (2004)
Gautschi, W.: Numerical integration of ordinary differential equations based on trigonometric polynomials. Numer. Math. 3, 381–397 (1961)
Hairer, E., Wanner, G.: Solving Ordinary Differential Equations II, 2nd revised edition. Springer, Heidelberg (2002)
Hoang, N.S., Sidje, R.B., Cong, N.H.: On functionally-fitted Runge-Kutta methods. BIT 46, 861–874 (2006)
Hulme, B.L.: One-step piecewise polynomial Galerkin methods for initial value problems. Math. Comp. 26, 415–426 (1972)
Hulme, B.L.: Discrete Galerkin and related one-step methods for ordinary differential equations. Math. Discret. Comp. 26, 881–891 (1972)
Martin-Vaquero, J., Vigo-Aguiar, J.: Exponential fitted Gauss, Radau and Lobatto methods of low order. Numer. Algorithm. 48(4), 327–346 (2008)
Montijano, J.I., Van Daele, M., Calvo, M.: Functionally fitted explicit two step peer methods. J. Sci. Comput. 64(3), 938–958 (2015)
Kalogiratou, Z., Simos, T.E.: Construction of trigonometrically and exponentially fitted Runge-Kutta-Nyströ,m methods for the numerical solution of the Schrödinger equation and related problem -a method of 8th algebraic order. J. Math. Chem. 31 (2), 211–232 (2002)
Li, Y. -W., Wu, X.: Functionally fitted energy-preserving methods for solving oscillatory nonlinear Hamiltonian systems. SIAM J. Numer. Anal. 54(4), 2036–2059 (2016)
Paternoster, B.: Runge-kutta (-nyström) methods for ODEs with periodic solutions based on trigonometric polynomials. Appl. Numer. Math. 28, 401–412 (1998)
Sanz-Serna, J.M.: Runge-kutta schemes for Hamiltonian systems. BIT 28(4), 877–883 (1988)
Simos, T.E.: A trigonometrically-fitted method for long-time integration of orbital problems. Math. Comput. Modell. 40(11-12), 1263–1272 (2004)
Tang, W., Sun, Y.: Time finite element methods: a unified framework for numerical discretizations of ODEs. Appl. Math. Comp. 219, 2158–2179 (2012)
Vanden Berghe, G., De Meyer, H., Van Daele, M., Van Hecke, T.: Exponentially-fitted explicit Runge-Kutta methods. Comput. Phys. Commun. 123, 7–15 (1999)
Wang, B., Meng, F., Fang, Y.: Efficient implementation of RKN-type Fourier collocation methods for second-order differential equations. Appl. Numer. Math. 119, 164–178 (2017)
Acknowledgments
The authors are very grateful to two unknown referees, for the careful reading of the manuscript, and for their precious comments, which allowed to formulate in a cleaner and more precise way the results presented in the paper.
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Amodio, P., Brugnano, L. & Iavernaro, F. Analysis of spectral Hamiltonian boundary value methods (SHBVMs) for the numerical solution of ODE problems. Numer Algor 83, 1489–1508 (2020). https://doi.org/10.1007/s11075-019-00733-7
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11075-019-00733-7