
Abstract
This paper proposes an image-based visual servoing control method for a moving target of a quadrotor UAV (QUAV). Firstly, the dynamic image model with moving target parameters is established based on the image moment features in the virtual camera plane. For the unpredictability of the moving target in space, we use a high-order differentiator to estimate the state parameters of the moving target. In order to solve the problem of image depth information caused by a monocular camera, we derive a nonlinear finite-time linear velocity observer from the virtual image plane, which can not only estimate the linear velocity information of QUAV but also avoid the measurement of image depth. Based on the above information, we design the global finite-time controller and use Lyapunov theory to prove the finite-time stability of the system. Finally, the numerical simulations verify the convergence of the proposed control scheme, and the ROS gazebo simulations demonstrate the improved performance of the proposed control scheme in tracking error.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
Quadrotor UAV (QUAV) has been widely used in autonomous detection [1, 2], payload transportation [3], target tracking [4], and other missions because of its vertical takeoff and landing characteristics. In these missions, the QUAV needs to have the ability of autonomous flight, and the primary task to achieve the autonomous flight of the QUAV is to obtain their spatial position information. The traditional QUAV combines low-cost GPS (Global Positioning System) and low-cost IMU (inertial measurement unit) to obtain its position information. However, this positioning method will not provide reliable position feedback when the QUAV is in an indoor, low latitude, and complex urban environment [5]. The most common way to solve this problem is to combine it with visual technology. Under this scheme, QUAV usually carries a low-cost monocular camera. The rich visual information provided by the camera can help us achieve QUAV target tracking [6, 7].
Using images to obtain the position and attitude information of the robot is called visual servoing [8]. Visual servoing technology has two branches: position-based visual servoing (PBVS) and image-based visual servoing (IBVS). PBVS requires complete spatial data for 3D reconstruction, which requires high computational power and is unsuitable for small QUAV. IBVS calculates the position and attitude information according to the selected image features. IBVS does not require the accuracy of the camera and has better robustness to calibration error and image noise [9], so it is suitable for small QUAV. It should be pointed out that due to the underactuated characteristics of QUAV, the dynamics and image of QUAV are coupled, so the IBVS of QUAV is more challenging than the full actuated system [10].
The earliest IBVS of QUAV was started by Nicolas [9], who realized image-based visual servoing of static targets using the optical flow feature. Due to optical flow features, the coupling degree of the QUAV visual servoing will be improved [11]. Researchers begin to try to use invariant features, such as image moments [12, 13]. Image moments contain many features, such as point features and line features. In addition, image moments are scale invariant. Taking advantage of this feature and introducing the concept of a virtual camera plane, Hamed and Giuseppe [14] eliminate the coupling of pitch angle and roll angle, reducing the complexity of controller design and designing an adaptive controller. Subsequently, image moment features in the virtual camera plane are widely used [15,16,17].
Because most QUAVs use low-cost monocular cameras for image-based visual servo, it will lead to the inability to obtain image depth information accurately. To solve this problem, Hamed Jabbari and Jungwon estimated the linear velocity of QUAV in the virtual camera plane [16]. This method uses an observer to compensate for the depth information of the image. After that, Zheng and Wang discussed the IBVS of QUAV under slope conditions [17]. They designed a nonlinear velocity observer to estimate the linear velocity information of QUAV. The linear velocity observer derived from the virtual plane can avoid acquiring depth information. Then they use the backstepping method to design the controller and prove the global asymptotic stability for the first time.
The above methods are designed for static targets. However, QUAV has an urgent need for tracking moving targets. Due to the lack of accurate prior parameters of moving targets, it is more challenging to track unpredictable targets. S. Masoud and A.Abdollah designed an indirect adaptive neural controller for QUAV using a radial basis function (RBF) neural network to enable QUAV to track moving targets [18]. After that, Masoud and Hamed Jabbari [19] used an artificial neural network to process the speed of moving targets and considered the influence of external interference. Ning [20] uses error symbol compensated robust integral (DCRISE) feedback control to design a visual servoing controller for moving targets, which improves the system’s robustness. Zhiqiang and Xuchao [21] use a higher-order differentiator to estimate the motion parameters of the moving target and transfer the parameters as feedforward to the design stage of the controller. This method eliminates the coupling of the controller to the motion parameters. Moreover, it should be noted that the QUAV often needs better system response capability when facing autonomous flight missions [22].
In the current research, the discussion on the convergence of the system controller is mainly asymptotic convergence. As time tends to infinity, the system state reaches the equilibrium point. Alexis [23] proposed a finite-time controller for position control, which realized the hover control of QUAV in a finite time . Tian et al. [24] applied a multivariable hyper twist algorithm to realize the attitude control of QUAV and proved the stability through theory and experiments. Harshavarthini [25] uses Lyapunov–Krasovskii functional to design a finite-time fault-tolerant controller for the attitude of the QUAV. Gajbhiye [26] considered the finite-time control of the slung payload transportation of QUAV and proposed a geometric finite-time inner–outer loop control strategy. Wenwu [27] uses the homogeneous theory to design the finite-time position controller and the finite-time attitude controller of QUAV so that QUAV can realize hovering control in a finite time. Guanglei and Guangbo [28] designed a finite-time controller using the nonsingular terminal sliding mode to realize the finite-time control of QUAV image-based visual servoing. We use a table to summarize the above research work, as shown in Table 1. We consider these methods through three dimensions: the convergence rate of the controller, whether to consider the depth information of targets, and whether to discuss external disturbances.
We can see that no control scheme can simultaneously satisfy the requirements of tracking a moving target, finite-time convergence, considering the target’s depth information, and verifying the disturbance. We propose a control scheme based on global finite-time stability to solve this problem. First, we use a nonlinear high-order tracking differentiator to estimate the parameters of moving objects. Using the backstepping method, we design a novel nonlinear global finite-time linear velocity observer for image depth information acquisition. Finally, we use the backstepping method to design the global finite-time controller of the system.
The main contributions of this paper are as follows:
-
(1)
We propose the global finite-time control scheme used for the image-based visual servoing of a moving target for the first time. In this scheme, we use a nonlinear tracking differentiator to estimate the parameters of the moving target. Then a global finite-time nonlinear linear velocity observer is designed using the backstepping method. Finally, we use the backstepping method to design the global finite-time controller of the QUAV.
-
(2)
To solve the problem of acquiring the image depth information of a monocular camera in the image-based visual servoing of a moving target, we propose a global finite-time nonlinear linear velocity observer. The depth information of the QUAV relative to the target is estimated by estimating the linear velocity of the altitude axis in the virtual camera plane.
-
(3)
The numerical simulation and ROS gazebo simulation results show high error convergence performance and better tracking control performance.
The rest of this paper is organized as follows. In Sect. 2, we introduce the QUAV and the image moment dynamics. In Sect. 3, we introduce the design of the controller. In Sect. 4, the simulation experiment of the proposed control scheme is carried out. Finally, our conclusions are given in Sect. 5.
2 Modeling of QUAV and image moment
In this section, we will introduce the dynamic modeling of QUAV and image moment feature dynamics.
2.1 Quadrotor model
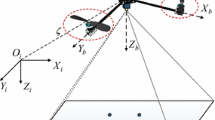
This section considers using two frames to describe the translation and rotation motion of the QUAV (see Fig. 1). The inertial frame \({I} = \left\{ {{O_i},{X_i},{Y_i},{Z_i}} \right\} \) is assumed to be fixed at a point on the earth. We assume that the mass center of the quadrotor UAV is the origin of the body-fixed frame \({B} = \left\{ {{O_b},{X_b},{Y_b},{Z_b}} \right\} \). Moreover, we assume that the quadrotor UAV is always a rigid body. The position of the origin of the body frame B in the inertial frame is expressed as \({\zeta } = {\left( {x,y,z} \right) ^T}\). We use three Euler angles \(\phi \), \(\theta \), and \(\psi \) to represent the rotation between two frames. \({\textbf{R}}:{B} \rightarrow {I}\) is the rotation matrix between two frames.

Inertial frame I and body frame B
Assumption 1
The roll and pitch angles belong to \(\left( -\frac{\pi }{2},\frac{\pi }{2} \right) \), and the yaw angle belongs to \(\left( -\pi ,\pi \right) \).
The mass of the QUAV is m and the inertia is \(\textbf{J} = diag\{[J_{xx}, J_{yy}, J_{zz}]\}\). The linear velocity and angular velocity in the body-fixed frame of the QUAV are expressed as \(\textbf{V} \in {{{\mathbb {R}}}^{3}}\) and \({\omega } = {\left( {{\omega _1},{\omega _2},{\omega _3}} \right) ^T} \in {{{\mathbb {R}}}^{3}}\). According to [29,30,31], the kinematics and dynamics equations used to describe QUAV with disturbance are expressed as follows:
where \(\textbf{sk}\left( {\omega } \right) \) is skew symmetric matrix, which means that \(\textbf{sk}\left( \textbf{a}\right) \textbf{b}=\textbf{a}\times \textbf{b}\), \(\textbf{a} \in {{{\mathbb {R}}}^{3}}\) and \(\textbf{b}\in {{{\mathbb {R}}}^{3}}\) are arbitrary vectors, and \(\times \) denotes the vector cross product. g is the gravity acceleration. \(\textbf{F} \in {{{\mathbb {R}}}^{3}}\) is the force. \({\tau } \in {{{\mathbb {R}}}^{3}}\) is the torque. \(U_1\) is the total thrust.
2.2 Image dynamics
This section also uses the image moment feature based on a virtual camera. First, we assume a camera frame \(C = \left\{ {{O_C},{X_C},{Y_C},{Z_C}} \right\} \), which coincides with the body-fixed frame of the QUAV. We assume that the camera is fixed at the mass center of the quadrotor and has a downward FOV. The virtual camera frame \(\nu \) is the same as the actual camera frame. However, the roll angle and pitch angle of the virtual camera frame are always zero, and the yaw angle is consistent with the actual orientation of the quadrotor (see Fig. 2).

Camera frame C and the virtual camera frame \(\nu \)
We assume that there is a fixed point \({}^I\textbf{P} = {\left[ {{}^Ix,{}^Iy,{}^Iz} \right] ^T}\) in the inertia frame, and it is represented as \({}^C\textbf{P} = {\left[ {{}^Cx,{}^Cy,{}^Cz} \right] ^T}\) in the camera frame and as \({}^\nu \textbf{P} = {\left[ {{}^\nu x,{}^\nu y,{}^\nu z} \right] ^T}\) in the virtual camera frame. Therefore, we get
where \({\textbf{R}}_\psi ^T\) is a rotation matrix used to describe rotation around the \(Z-\)axis, \(\psi \) denotes yaw angle. Then, we get
where \({\dot{O}_\nu }\) denotes the linear velocities of camera and virtual frameworks in the inertia frame. \(\textbf{v} = {\left[ {{}^{\nu }{v_x},{}^{\nu }{v_y},{}^{\nu }{v_z}} \right] ^T}\) is the linear velocity of camera framework in the virtual frame, and \(\textbf{d}\left( t \right) ={{\left[ v_{x}^{d},v_{y}^{d},v_{z}^{d} \right] }^{T}}\) is the velocity vector of a moving point in the virtual frame.
According to the perspective projection model, the projection of point \(\textbf{P}\) onto the virtual camera plane can be expressed as
where \(\lambda \) is focal length and \(\left( {{}^{\nu }u,{}^{\nu }n} \right) \) are the point coordinates in the virtual camera frame. From (7) and (8), one obtains
Suppose that there are N stationary points in a level plane in the inertial frame, which are subject to the following assumptions.
Assumption 2
The observed target is a planar object that locates at a level plane of inertial frame and its binary image is obtained by segmentation algorithm.
Assumption 3
Image points are always in the field of view(FOV) of the camera.
Assumption 4
The sensor can get an accurate measurement value in the controller design stage.
Remark 1
Assumptions 3 and 4 are difficult to guarantee in the natural environment. These two assumptions are added here only to ensure that in the simulation experiment, the image features will always remain in the camera FOV, and each sensor can also accurately give feedback.
Then according to [13], we can get that the image moment features are as follows:
where \({}^{\nu }{u_g} = \frac{1}{N}\sum \nolimits _{k = 1}^N {{}^{\nu }{u_k}} \) and \({}^{\nu }{n_g} = \frac{1}{N}\sum \nolimits _{k = 1}^N {{}^{\nu }{n_k}} \). \({}^{\nu }{u_k}\) and \({}^{\nu }{n_k}\) are the two components of the kth point. \(a = {}^{\nu }{\mu _{02}} + {}^{\nu }{\mu _{20}}\) and \({}^{\nu }{\mu _{ij}} = \sum \nolimits _{k = 1}^N {{\left( {{}^{\nu }{u_k} - {}^{\nu }{u_g}} \right) }^i}\left( {{}^{\nu }{n_k} - {}^{\nu }{n_g}} \right) ^j\). The desired value of a is \(a^*\).
Based on (9) and (10), the dynamics of the image features are defined as follows [14]:
where \(\textbf{q} = {\left[ {{q_x},{q_y},{q_z}} \right] ^T}\). \(z^*\) is the desired altitude.
In order to control the yaw motion of quadrotor UAV, we select the image feature \(q_\psi \) to describe the corresponding motion according to [12], which is defined as follows:
where the time derivative of \(q_\psi \) is \({\dot{q}_\psi } = - {\dot{\psi }} + \Delta _{\psi }\), and \(\Delta _{\psi }\) is the equivalent of an undefined term that indicates the velocity of the target in the yaw direction.
3 Controller design
This section first gives the closed-loop error equation of the system and then gives the design of the target trajectory observer and the design of the linear velocity finite-time observer in the plane of the virtual camera. Finally, we give the design process of the global finite-time controller. Figure 3 shows the block diagram of the whole system.
The following lemmas are useful to derive our main results.
Lemma 1
[32] Consider the nonlinear system \(\dot{x} = f\left( x\right) , f(0) = 0, x \in {{{\mathbb {R}}}^{n}}\), where \(f(\cdot ):{{{\mathbb {R}}}^{n}} \rightarrow {{{\mathbb {R}}}^{n}}\) is continuous function. Suppose that there exists a positive definite continuous function V(x) such that
where \(c > 0\) and \(\alpha \in (0,1)\). Then, the system is finite-time stable. In addition, the finite convergence time T(x) satisfies that
Lemma 2
[33] For any real numbers \(x_i,i=1,\ldots ,n\) and \(b \in \left( 0,1 \right] \) the following inequality holds:
When \(b = p/q \le 1\), where \(p>0,q>0\) are odd integers,
Lemma 3
[34] For real variables x, y, and any positive constants a, b, c, the following inequality is true.

Structure diagram of the system
3.1 Image feature error dynamics
We define the desired image features as follows:
Therefore, the image moment feature errors of translational motion are as follows:
Taking the derivative of the above formula and using (11), we can obtain the following dynamics
where \(\textbf{f}=-{{{\textbf{R}}}_{\phi \theta }}{{U}_{1}}{{\textbf{E}}_{3}}/m+g{{\textbf{e}}_{3}} = \left[ f_x,f_y,f_z \right] ^T,{{\textbf{R}}}_{\phi \theta } = {\textbf{R}}_{\theta } {\textbf{R}}_{\phi }\).
3.2 Trajectory observer
Before designing the controller, we need to estimate the trajectory parameters. The standard method uses a high-order differentiator, but the high-order differentiator is sensitive to noise. Therefore, we use the nonlinear tracking differentiator proposed by Han and Wang, proving its stability. The general form of the nonlinear tracking differentiator with the input v(t) is as follows [35]:
where \(x_1\) tracks the origin signal v(t) and \(x_{i+1} (i>0)\) is the estimation of ith-order derivative. R is a coefficient to determine the rate of convergence for (17). The function \(f\left( \cdot \right) \) is suggested by Han and Wang as follows [35]:
where
\(\alpha _i\) is a coefficient to reflect the degree of the nonlinearity, and \(\alpha _i = 1\) is corresponding to the linear case. \(\Delta \) is used to determine the linear interval, which can prevent vibration when the system is in the neighborhood of origin point.
For our system, the velocity of the target object is \(\textbf{d}\), its estimated value is \(\hat{\textbf{d}}\), and the estimation error is \(\tilde{\textbf{d}}\). Therefore, the following observer is designed as follows:
where \({{x}_{1}}=\hat{\textbf{d}},{{x}_{2}}=\dot{\hat{\textbf{d}}},{{x}_{3}}=\ddot{\hat{\textbf{d}}},{{x}_{4}}=\dddot{\hat{\textbf{d}}}\).
3.3 Finite-time velocity observer
In order to compensate for the depth information of the monocular camera, estimate the linear velocity in the virtual plane, and ensure the convergence performance of the observer, we design a finite-time linear velocity observer (FTO).
Theorem 1
The velocity observer and the corresponding update law are defined as follows:
where \({{{\dot{\hat{\textbf{q}}}}}_{1}}\) and \({\dot{\hat{\textbf{v}}}}\) are the estimated values of \(\textbf{q}_1\) and \(\textbf{v}\), respectively. \(k_1\) and \(k_2\) are positive constant. \(\tilde{\textbf{q}}_{1}^{\frac{5}{7}}={{\left[ \tilde{q}_{11}^{\frac{5}{7}},\tilde{q}_{12}^{\frac{5}{7}},\tilde{q}_{13}^{\frac{5}{7}} \right] }^{T}}\) and \({{{\tilde{\textbf{v}}}}^{\frac{5}{7}}}={{\left[ \tilde{v}_{1}^{\frac{5}{7}},\tilde{v}_{2}^{\frac{5}{7}},\tilde{v}_{3}^{\frac{5}{7}} \right] }^{T}}\). \({{{\tilde{\textbf{q}}}}_{1}}\) and \({{{{\tilde{\textbf{v}}}}}}\) are the corresponding estimation errors, which define as follows:
This linear velocity observer is globally finite-time stable.
Proof
We first take the time derivatives of (23) and (24) then substitute (13) and (14), respectively. We can get the following expression:
Now we choose a Lyapunov candidate function
Taking the derivative of time for (27). Then substitute (21) and (22) into to (27), we can get the following:
where r is a design parameter. (28) is definite negative. Inspired by [17] and [33], we can select a set of design parameters as follows:
where \(n=3\) represents the order of the system. Then, we use the parameter (29) in (28), and we can get
So far, we have been able to prove that the observer can be globally asymptotically stable (GAS). We continue to prove that it can be globally finite-time stable (GFTS). Scaling the (27), we can get
Combining (33) and (34) , and using Lemma 2, we can get
where \(r = 2\alpha \). And then, we select a function as follows:
The result means that \(\dot{L}\le -\frac{{{\beta }_{1}}}{4}{{L}^{\alpha }}\) holds. That is, we can find a Lyapunov function satisfying Lemma 1. So far, the proposed velocity observer is globally finite-time stable (GFTS). \(\square \)
3.4 Finite-time controller
We mainly use the backstepping scheme to design the IBVS controller of QUAV, and we need to use the proposed velocity observer.
We define the first Lyapunov function:
By substituting (13), we can get the time derivative of the Lyapunov function
We treat \({\hat{\textbf{v}}}\) as a virtual control input, and choose \({{{\hat{\textbf{v}}}}^{d}}={{c}_{1}}\textbf{q}_{1}^{\frac{5}{7}} + \textbf{d} , c_1>0, \textbf{q}_{1}^{\frac{5}{7}}={{\left[ q_{11}^{\frac{5}{7}},q_{12}^{\frac{5}{7}},q_{13}^{\frac{5}{7}} \right] }^{T}}\). According to the standard backstepping scheme, it is necessary to continue to define new error terms \(\textbf{q}_2\)
Update \(\dot{V}_1\) in (37) using (38)
Then we define the second Lyapunov function
Since we need to get the time derivative of (40), we need to get the time derivative of \(\textbf{q}_2\) first. Taking the time derivative of (38), then substituting (13) and (22) into it, we can get
where \(\textbf{q}_{1}^{-\frac{2}{7}}\text {=}{{\left[ q_{11}^{-\frac{2}{7}},q_{12}^{-\frac{2}{7}},q_{13}^{-\frac{2}{7}} \right] }^{T}}\). Now we can get the time derivative of the second Lyapunov function. Taking the time derivative of (40), then substituting (39), (41) and (33) into it, we can get
We can also prove that (42) is also GFTS.
Theorem 2
Considering \(\textbf{f}\) as a virtual control input and design \(\textbf{f}\) as follows:
\(\dot{V}_2\) is definite negative, and the system is GFTS.
Proof
Substituting (43) into (42), we can obtain
Using Lemma 3 to scale (44). The parameters are \(a=b=c=1\), then we can get
where \(-\textbf{q}_{\textbf{1}}^{\textbf{T}}\frac{1}{{{z}^{*}}}{\tilde{\textbf{v}}}\le -\frac{1}{2{{z}^{*}}}\left( \textbf{q}_{\textbf{1}}^{\textbf{T}}{{\textbf{q}}_{1}}+{{{{\tilde{\textbf{v}}}}}^{T}}{\tilde{\textbf{v}}} \right) ,{{z}^{*}}<0\).
Now use Lemma 2 for (45) and scale (40) simultaneously, then combine the results of the two equations, and we can get
The result means that \(\dot{V}_2 \le -\frac{\beta _2}{4}V^{\alpha }_{2}\) holds, where \({{\beta }_{2}}=2\min \left\{ \frac{{{c}_{1}}}{{{z}^{*}}},{{k}_{1}},\frac{{{k}_{2}}}{{{z}^{*}}},{{k}_{3}} \right\} \). So far, we have proved that \(V_2\) is GFTS. \(\square \)
Remark 2
If we use the small angle assumption, we can get the desired attitude of the QUAV through the following equation
However, this paper does not adopt this assumption, so it is necessary to continue the backstepping design to obtain the desired angular velocity.
Continue to define the third error term
Update \(\dot{V}_2\) in (42) using (43)
Then we define the third Lyapunov function
Using (50) and (49), we can get the time derivative of \(V_3\)
where \(\frac{1}{{{c}_{1}}}{{{\dot{\textbf{f}}}}_{d}}\) is expressed as follows:
Theorem 3
Considering \(\dot{\textbf{f}}\) as the control input and design \(\dot{\textbf{f}}\) as follows:
\(\dot{V}_3\) is definite negative, the system is GFTS.
Proof
Substituting (54) into (52), we can get
Using Lemma 3 to scale (55), we can get
Using Lemma 2 for (56) and scaling (51), we can obtain
The result means that \({{\dot{V}}_{3}}\le -\frac{{{\beta }_{3}}}{4}V_{3}^{\alpha }\) holds, where \({{\beta }_{3}}=2\min \left\{ \frac{{{c}_{1}}}{{{z}^{*}}},{{k}_{1}},\frac{{{k}_{2}}}{{{z}^{*}}},{{k}_{3}},{{k}_{4}} \right\} \). The \(V_3\) is GFTS. \(\square \)
So far, we have obtained the controller, but we also need to obtain the angular velocity and thrust that can be directly used to control the QUAV. Since in the virtual camera frame, the force \(\textbf{f}\) of the QUAV is expressed as
By taking the time derivative of (60) and substituting (15), we can get
Finally, we only need to combine (61) and (54) to obtain the desired thrust \(U_1\) and desired angular velocity \(\omega _1, \omega _2\) respectively.
Remark 3
This paper only studies the controller of translational motion obtained from the image moment features in the virtual camera plane. When we get the desired angular velocity, we can use a PD or PID controller to realize the translation control of the QUAV in the horizontal and altitude directions.
After the above process, we get the controller to control the translational motion, and we also need to get the controller to control the yaw motion. The image feature error is defined as
where \(q^d_{\psi }\) is the desired value. According to (12), we can get
Theorem 4
Design the control input as
with \(k_5 > 0\), the image feature error \(q_4\) while converge to zero in a finite-time.
Proof
The relationship between the time derivative of Euler angles and angular velocity is as follows:
From (64), we have
Now we choose a Lyapunov function
Then we take the time derivative of (66) and substitute (63) (65) into it, we get
By scaling (66) and combining the results with (67), we can get
The result means that \({{\dot{V}}_{\psi }}\le -\frac{{{k}_{5}}}{4}V_{\psi }^{\alpha }\) holds, and the \(V_{\psi }\) is GFTS. Finally, we can get that \(q_4\) will converge to zero in a finite time. \(\square \)
Remark 4
In the actual QUAV system, yaw motion control is usually regarded as an independent channel. Therefore, according to the characteristics of its dynamic model and image moment error model, the design parameters of the yaw motion controller are selected as follows:
Remark 5
After the above controller design process, we can use Lemma 1 to describe the convergence time of the system quantitatively. Recall that convergence time T(x) as follows:
Then the convergence time of the translation motion and the yaw motion can be expressed as follows:
where \(\textbf{q}_1\left( 0 \right) \) and \({{q}_{4}}\left( 0 \right) \) represent the corresponding initial state of the system, respectively.
Remark 6
In the controller design stage, the rotor of QUAV is assumed to be ideal. For the control allocation of the actuator, since the four rotors can produce a single thrust \(U_1\) and a full torque vector \({\tau }={{\left( {{\tau }_{1}},{{\tau }_{2}},{{\tau }_{3}} \right) }^{T}}\) for rotation, we can use the following equation to obtain the desired angular velocity of the four rotors.
where \(n_1, n_2,n_3\), and \(n_4\) denote the angular velocity of the front, right, rear, and left rotor, respectively. b and d are the thrust and drag factors. l is the distance between each rotor center and the center of mass of the QUAV.
4 Simulation
In order to verify the effectiveness of the proposed controller, we set up four groups of simulations. In the first group, we apply the proposed method to static targets to ensure that our method can be applied in static scenarios. We apply the proposed method to a moving target in the second group. We compare the proposed method with the previous methods in the third group. In the fourth group, we conduct a simulation comparison in Robot Operating System (ROS) gazebo environment. The model parameters of the QUAV and the camera are shown in Table 2.
The first three groups of simulation are numerical simulations conducted in MATLAB R2019b of Windows \(10\times 64\). The fourth group of ROS Gazebo moving target simulation was conducted under Ubuntu 18.04 amd64. The simulation calculation platform parameter is Intel i7-8700k with 64GB RAM.
4.1 Numerical simulation of the stationary target
The selection of control parameters of the controller is shown in Table 3. It should be noted that the current desired image moment can be obtained when the QUAV is at position \((0,0,-4)\text {m}\) in the inertial frame I with attitude \((0,0,0) \text {rad}\). Therefore, the desired height is \(z^* = -4 \text {m}\). The numerical simulation is divided into two groups: one without external disturbance and the other with external disturbance \(\textbf{dt}={{\left[ 0.2\sin \left( t \right) ,0.2\sin \left( t \right) ,0.2\sin \left( t \right) \right] }^{T}}\text {m}\cdot {{\text {s}}^{\text {-2}}}\).

Numerical simulation of the stationary target without external disturbance

Numerical simulation of the stationary target with external disturbance
Figure 4 shows the performance of the proposed control method on static targets without external disturbance. Figure 4a shows that QUAV finally hovers at the position of \((0,0,-4)\text {m}\), and Fig. 4b shows that the attitude of QUAV is \((0,0,0) \text {rad}\). Figure 4c shows the convergence of the image moment characteristic error in the plane of the virtual camera. It can be seen that the proposed control method can make the system reach the desired state, and it can be seen from the yaw feature that the system is stable in a finite time. Figure 4d shows the linear velocity in the virtual plane. We can see that the designed linear observer can accurately estimate the actual linear velocities of QUAV. Figure 4e, f shows the trajectories of feature points in the virtual camera plane and the actual camera plane, respectively. Through the axis of the trajectories, we can find that theoretically, using a low-cost 1080p resolution camera in practice is enough to deal with the current visual servoing task. Figure 4g, h shows the thrust input and torque input of the system, respectively. Figure 4i, j, k shows the observation state of the target motion observer in three axes, respectively. Figure 4l shows the space trajectory of the QUAV. We can see that the target observer can accurately estimate the motion state of the target.
Figure 5 shows the performance of the proposed control method on static targets with external disturbance. We can see that although we impose external disturbances on the system, the system is robust to external disturbances.
4.2 Numerical simulation of the moving target
Firstly, we give the motion constraint equation of the target, and its trajectory in space is a square in the xOy plane. The simulation results are shown in Fig. 6.
The motion constraint equation as follows:
The target is always kept in the xOy plane during movement, i.e., \(v_z = 0\,\text {m/s}\). At the same time, the target does not spin at any angle, that is, \(\omega _z = 0\,\text {rad/s}\). The numerical simulation is divided into two groups, one without external disturbance and the other with external disturbance \(\textbf{dt}={{\left[ 0.2\sin \left( t \right) ,0.2\sin \left( t \right) ,0.2\sin \left( t \right) \right] }^{T}}\text {m}\cdot {{\text {s}}^{\text {-2}}}\).

Numerical simulation of the moving target without external disturbance

Numerical simulation of the moving target with external disturbance
We focus on the following aspects for this simulation:
-
(1)
Image moment feature error.
-
(2)
Linear velocity observer.
-
(3)
Target trajectory observer.
Figure 6c shows the convergence of image moment characteristic error. We can see some weak fluctuations in the figure due to the QUAV tracking the target to the inflection point, but they can quickly converge to the desired value. Figure 6d shows the linear velocity in the plane of the virtual camera. We can see that the proposed finite-time linear velocity observer can also accurately estimate the linear velocity of QUAV in the scene of target motion. Figure 6i, j, k shows the situation of the target trajectory observer. We can see that in the scene of target motion, the target trajectory observer can also accurately estimate the motion parameters of the target. Figure 7 shows the performance of the proposed control method on moving targets with external disturbance. We can also see that the system is robust to external disturbances. Finally, Fig. 7l shows the spatial trajectory of QUAV. We can find that there is no time delay in the proposed control method for tracking the moving target.
To further illustrate the effectiveness of our proposed method, we also carried out a group of nonlinear target tracking simulations. The target trajectory parameters are as follows:

Numerical simulation of the nonlinear moving target
Figure 8 shows the numerical simulation results for nonlinear moving targets. Because we use a nonlinear tracking differentiator, we can get the motion trajectory estimation parameters of the target, so the system shows adaptability to nonlinear moving targets. Therefore, we can verify the effectiveness of the proposed control method for tracking nonlinear moving targets.

Image moment feature errors under three control methods. “VO” means “VE-backstepping” method

Control inputs under three control methods
4.3 Comparative simulation of moving targets
In order to better illustrate the performance of the proposed method, we conducted a set of comparative experiments. The methods involved in the comparison include the artificial neural network method proposed by Masoud [19], which is noted as RBFNN. The other method uses the target observer proposed by Zhiqiang [21], which is noted as VE-backstepping. The methods selected here all use the same dynamic model and image moment features in the virtual camera plane. At the same time, to quantitatively illustrate the performance of the proposed method, we use the four indicators proposed by Jing and Qiang [36, 37] to analyze the control method. Our method is noted as VE-FTO-FTC.
The four indices are as follows:
-
(1)
Integrated Absolute Error (IAE). It is used to measure the tracking performance of the control method.
$$\begin{aligned} {\textrm{IAE}}=\int {|e\left( t \right) |}{\textrm{d}}t. \end{aligned}$$ -
(2)
Integrated Square Error (ISDE). It shows the fluctuation degree of tracking error.
$$\begin{aligned} {\textrm{ISDE}}=\int {{{\left( e\left( t \right) -{\bar{e}}\left( t \right) \right) }^{2}}{\textrm{d}}t} \end{aligned}$$where \({\bar{e}}\) is the mean of the error.
-
(3)
Integrated Absolute Control (IAU). It shows the intervention of the controller.
$$\begin{aligned} {\textrm{IAU}}=\int {|u\left( t \right) |}{\textrm{d}}t. \end{aligned}$$ -
(4)
Integrated Square Control (ISDU). It is used to measure the fluctuation degree of control signal.
$$\begin{aligned} {\textrm{ISDU}}=\int {{{\left( u\left( t \right) -{\bar{u}}\left( t \right) \right) }^{2}}{\textrm{d}}t} \end{aligned}$$where \({\bar{u}}\) is the mean of the control input.
Remark 7
IAE represents the accumulation of absolute error, and the smaller this indicator is, the stronger the control effect is. ISDE represents the variance of error, which describes the fluctuation of error. When the control effect of the controller is more robust, the value is smaller. Similarly, IAU describes the accumulation of controllers. The higher the value, the stronger the control effect. ISDU is the variance of the controller. The more significant the value, the better the control intervention effect.
Figures 9 and 10 show the image moment feature errors and control inputs under three control methods, respectively. Figure 10 shows the control effect of our proposed method. However, the superiority of our proposed control method cannot be better demonstrated only by the data plots. Therefore, we use the above four indicators and obtain Tables 4 and 5.
As shown in Table 4, our control method has smaller IAE and ISDE, which means that our method can make the system reach the desired value as soon as possible. In addition, Table 5 shows that our proposed control method has large IAU and ISDE, which means that our method has a better control effect.
4.4 Simulation experiment in ROS gazebo

ROS gazebo simulation environment
The simulation parameters in ROS gazebo are shown in Table 6. And Table 7 shows the control parameters in ROS gazebo. Since the environment of the ROS gazebo is close to the actual environment, we suggest selecting relatively small control parameters. The simulation environment we use is Prometheus framework [38], which is developed based on MAVROS. We need to build our scenario to use this environment, as shown in Fig. 9a. For the requirements of the visual servoing task, we design the ground markers as shown in Fig. 9b.
In the ROS gazebo, the sensor parameters of QUAV are provided by the IMU module of the gazebo. It should be noted that the module can add Gaussian white noise to simulate the measurement noise. These parameters are ROS default, and we have not modified these parameters. Table 8 shows the parameters of the sensors.

Simulation in ROS gazebo

Time charts of image moment feature error under three control schemes
In the simulation process, we first make QUAV fly to the initial position and maintain the initial attitude. After that, the QUAV will hover in this position and wait for the command of the visual servoing. After receiving the start command, the QUAV starts to enter the IBVS task independently. At the same time, the system will record the current data of the QUAV for subsequent analysis. The motion constraint equation as follows:
The target is always kept in the xOy plane during movement, i.e., \(v_z = 0\,\text {m/s}\). At the same time, the target does not spin at any angle, that is, \(\omega _z = 0\,\text {rad/s}\).
As shown in Fig. 12c, the proposed control method can also converge the image feature error to the expected value in the ROS gazebo. Figure 12d shows that the designed finite-time observer can estimate the linear velocity of QUAV more accurately. Figure 12g shows the spatial trajectory of QUAV. It can be seen that the control effect is ideal. It should be noted that in Fig. 12b, the attitude angle in the figure has oscillated, but its range is within 2 degrees. Therefore, we think the QUAV can be in hovering mode.
We also conducted comparative experiments in ROS gazebo, and the comparative methods are still RBFNN and VE-backstepping. Figure 13 shows the variation of image moment feature error with time under three control schemes. We also use IAE and ISDE to analyze the performance of the controller. Table 9 shows the result.
The above simulation experiments show that the proposed control method has better control convergence, and the designed finite-time observer can also accurately estimate the linear velocity in the virtual image plane of the QUAV. However, parameters such as system quality, inertia, and camera focal length are not easy to obtain in practice. Therefore, we need to further discuss these problems in the future.
5 Conclusion
In this paper, we propose a novel image-based visual servoing control scheme combining target motion differentiator, finite-time observer, and finite-time controller, and we apply the scheme to the research of moving target tracking of QUAV. We use the differentiator to estimate the target motion parameters and transfer the parameters to the controller to ensure that the system can track the target in real time. Aiming to acquire camera depth information and the linear velocity of QUAV, we design a finite-time observer to compensate for this information. Finally, we design the global finite-time controller of the system using the simplified backstepping method. We have made assumptions about the visibility of the target, but in practice, the target is likely to be out of the field of view of the camera. At the same time, we do not conduct real machine experiments. Therefore, we plan to consider the target visibility constraint in future research and real machine verification.
Data availability
All data are available upon request at the authors’ email address.
References
Shao, X., Wang, L., Li, J., Liu, J.: High-order eso based output feedback dynamic surface control for quadrotors under position constraints and uncertainties. Aerosp. Sci. Technol. 89, 288–298 (2019)
Guerreiro, B.J., Silvestre, C., Cunha, R., Cabecinhas, D.: Lidar-based control of autonomous rotorcraft for the inspection of pierlike structures. IEEE Trans. Control Syst. Technol. 26(4), 1430–1438 (2017)
Guerrero-Sánchez, M.E., Mercado-Ravell, D.A., Lozano, R., García-Beltrán, C.D.: Swing-attenuation for a quadrotor transporting a cable-suspended payload. ISA Trans. 68, 433–449 (2017)
Tomic, T., Schmid, K., Lutz, P., Domel, A., Kassecker, M., Mair, E., Grixa, I.L., Ruess, F., Suppa, M., Burschka, D.: Toward a fully autonomous uav: research platform for indoor and outdoor urban search and rescue. IEEE Robot. Autom. Mag. 19(3), 46–56 (2012)
Sani, M.F., Shoaran, M., Karimian, G.: Automatic landing of a low-cost quadrotor using monocular vision and Kalman filter in gps-denied environments. Turk. J. Electr. Eng. Comput. Sci. 27(3), 1821–1838 (2019)
Chen, J., Liu, T., Shen, S.: Tracking a moving target in cluttered environments using a quadrotor. In: 2016 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pp. 446–453. IEEE (2016)
Beyeler, A., Zufferey, J.-C., Floreano, D.: Vision-based control of near-obstacle flight. Auton. Robot. 27(3), 201–219 (2009)
Chaumette, F., Hutchinson, S.: Visual servo control. i. Basic approaches. IEEE Roboti. Autom. Mag. 13(4), 82–90 (2006)
Guenard, N., Hamel, T., Mahony, R.: A practical visual servo control for an unmanned aerial vehicle. IEEE Trans. Rob. 24(2), 331–340 (2008)
Yesildirek, A., Imran, B.: Nonlinear control of quadrotor using multi lyapunov functions. In: 2014 American Control Conference, pp. 3844–3849. IEEE (2014)
Lee, D., Lim, H., Kim, H.J., Kim, Y., Seong, K.J.: Adaptive image-based visual servoing for an underactuated quadrotor system. J. Guid. Control. Dyn. 35(4), 1335–1353 (2012)
Chaumette, F.: Image moments: a general and useful set of features for visual servoing. IEEE Trans. Rob. 20(4), 713–723 (2004). https://doi.org/10.1109/TRO.2004.829463
Tahri, O., Chaumette, F.: Point-based and region-based image moments for visual servoing of planar objects. IEEE Trans. Robot. 21(6), 1116–1127 (2005). https://doi.org/10.1109/TRO.2005.853500
Jabbari, H., Oriolo, G., Bolandi, H.: An adaptive scheme for image-based visual servoing of an underactuated uav. Int. J. Robot. Autom. 29(1), 92–104 (2014)
Xie, H., Lynch, A.F.: State transformation-based dynamic visual servoing for an unmanned aerial vehicle. Int. J. Control 89(5), 892–908 (2016)
Asl, H.J., Yoon, J.: Adaptive vision-based control of an unmanned aerial vehicle without linear velocity measurements. ISA Trans. 65, 296–306 (2016)
Zheng, D., Wang, H., Wang, J., Chen, S., Chen, W., Liang, X.: Image-based visual servoing of a quadrotor using virtual camera approach. IEEE/ASME Trans. Mechatron. 22(2), 972–982 (2016)
Shirzadeh, M., Amirkhani, A., Jalali, A., Mosavi, M.R.: An indirect adaptive neural control of a visual-based quadrotor robot for pursuing a moving target. ISA Trans. 59, 290–302 (2015)
Shirzadeh, M., Asl, H.J., Amirkhani, A., Jalali, A.A.: Vision-based control of a quadrotor utilizing artificial neural networks for tracking of moving targets. Eng. Appl. Artif. Intell. 58, 34–48 (2017)
Liu, N., Shao, X.: Desired compensation rise-based ibvs control of quadrotors for tracking a moving target. Nonlinear Dyn. 95(4), 2605–2624 (2019)
Cao, Z., Chen, X., Yu, Y., Yu, J., Liu, X., Zhou, C., Tan, M.: Image dynamics-based visual servoing for quadrotors tracking a target with a nonlinear trajectory observer. IEEE Trans. Syst. Man Cybern. Syst. 50(1), 376–384 (2017)
Arif, A., Wang, H., Liu, Z., Castañeda, H., Wang, Y.: Adaptive visual servo control law for finite-time tracking to land quadrotor on moving platform using virtual reticle algorithm. Robot. Auton. Syst. 141, 103764 (2021)
Alexis, K., Nikolakopoulos, G., Tzes, A.: Experimental constrained optimal attitude control of a quadrotor subject to wind disturbances. Int. J. Control Autom. Syst. 12(6), 1289–1302 (2014)
Tian, B., Liu, L., Lu, H., Zuo, Z., Zong, Q., Zhang, Y.: Multivariable finite time attitude control for quadrotor uav: theory and experimentation. IEEE Trans. Industr. Electron. 65(3), 2567–2577 (2017)
Harshavarthini, S., Sakthivel, R., Ahn, C.K.: Finite-time reliable attitude tracking control design for nonlinear quadrotor model with actuator faults. Nonlinear Dyn. 96(4), 2681–2692 (2019)
Gajbhiye, S., Cabecinhas, D., Silvestre, C., Cunha, R.: Geometric finite-time inner-outer loop trajectory tracking control strategy for quadrotor slung-load transportation. Nonlinear Dyn. 107(3), 2291–2308 (2022)
Zhu, W., Du, H., Cheng, Y., Chu, Z.: Hovering control for quadrotor aircraft based on finite-time control algorithm. Nonlinear Dyn. 88(4), 2359–2369 (2017)
Zhao, G., Chen, G., Chen, J., Hua, C.: Finite-time control for image-based visual servoing of a quadrotor using nonsingular fast terminal sliding mode. Int. J. Control Autom. Syst. 18(9), 2337–2348 (2020)
Cabecinhas, D., Cunha, R., Silvestre, C.: A globally stabilizing path following controller for rotorcraft with wind disturbance rejection. IEEE Trans. Control Syst. Technol. 23(2), 708–714 (2014)
Islam, S., Liu, P.X., El Saddik, A.: Robust control of four-rotor unmanned aerial vehicle with disturbance uncertainty. IEEE Trans. Industr. Electron. 62(3), 1563–1571 (2014)
Amirkhani, A., Shirzadeh, M., Papageorgiou, E.I., Mosavi, M.R.: Visual-based quadrotor control by means of fuzzy cognitive maps. ISA Trans. 60, 128–142 (2016)
Bhat, S.P., Bernstein, D.S.: Finite-time stability of continuous autonomous systems. SIAM J. Control. Optim. 38(3), 751–766 (2000)
Huang, X., Lin, W., Yang, B.: Global finite-time stabilization of a class of uncertain nonlinear systems. Automatica 41(5), 881–888 (2005)
Qian, C., Lin, W.: Non-lipschitz continuous stabilizers for nonlinear systems with uncontrollable unstable linearization. Syst. Control Lett. 42(3), 185–200 (2001)
Han, J., Wang, W.: Nonlinear tracking-differentiator (in chinese). J. Syst. Sci. Math. Sci. 14(2), 177–183 (1994)
Na, J., Ren, X., Herrmann, G., Qiao, Z.: Adaptive neural dynamic surface control for servo systems with unknown dead-zone. Control. Eng. Pract. 19(11), 1328–1343 (2011)
Chen, Q., Ren, X., Na, J., Zheng, D.: Adaptive robust finite-time neural control of uncertain pmsm servo system with nonlinear dead zone. Neural Comput. Appl. 28(12), 3725–3736 (2017)
Amovlab: Prometheus autonomous UAV opensource project. https://github.com/amov-lab/Prometheus (2019)
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: The authors would like to thank the National Natural Science Foundation of China under Grant [52275003] and Grant [U1813220], in part by the Fundamental Research Funds for the Central Universities under Grant [buctrc202105] for their support in this research.
Author information
Authors and Affiliations
Contributions
WH involved in writing—original draft, validation and software. LY involved in writing—review and editing, and supervision.
Corresponding author
Ethics declarations
Conflict of interest
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Code availability
Custom code is available upon request at Liang Yuan email address.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
He, W., Yuan, L. Image-based finite-time visual servoing of a quadrotor for tracking a moving target. Nonlinear Dyn 111, 5307–5328 (2023). https://doi.org/10.1007/s11071-022-08107-w
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11071-022-08107-w