
Abstract
The risk of floods from tropical storms is increasing due to climate change and human development. Maps of past flood extents can aid in planning and mitigation efforts to decrease flood risk. In 2021, Hurricane Ida slowed over the Mid-Atlantic and Northeast United States and released unprecedented rainfall. Satellite imagery and the Random Forest algorithm are a reliable combination to map flood extents. However, this combination is not usually applied to urban areas. We used Sentinel-2 imagery (10 m), along with derived indices, elevation, and land cover data, as inputs to a Random Forest model to make a new flood extent for southeastern Pennsylvania. The model was trained and validated with a dataset created with input from PlanetScope imagery (3 m) and social media posts related to the flood event. The overall accuracy of the model is 99%, and the flood class had a user’s and producer’s accuracy each over 97%. We then compared the flood extent to the Federal Emergency Management Agency flood zones at the county and tract level and found that more flooding occurred in the Minimal Hazard zone than in the 500-year flood zone. Our Random Forest model relies on publicly available data and software to efficiently and accurately make a flood extent map that can be deployed to other urban areas. Flood extent maps like the one developed here can help decision-makers focus efforts on recovery and resilience.
Graphical abstract

Similar content being viewed by others

Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
1.1 Harms of floods and hurricanes
Flooding has become a devastating and destructive hazard due to human development in high-risk areas (CRED 2015) and climate change. The World Bank estimated in 2022 that 1.81 billion people, or 23% of the world’s population, are at risk of intense floods (Rentschler et al. 2022). Floods cause many types of harm (de Bruijn et al. 2019; Rosser et al. 2017), including economic losses (Pinos and Quesada-Román, 2022), damages to private homes/assets, damages to public infrastructure (Goffi et al. 2020), involuntary displacement, impacts on mental health (Markhvida et al. 2020), and disruptions to daily life and traffic flow (Hosseiny et al. 2020). In the most dangerous circumstances, floods can lead to loss of life (Goffi et al. 2020), taking 146 lives in 2021 in the U.S. (US Department of Commerce, 2021). The economic losses of floods in the U.S. has an average yearly cost of $4.5B (Smith 2023). Tropical storms, including hurricanes, cause economic losses through flood and wind damages, with an average yearly cost of $22.2B (Smith 2023). The economic and social costs of floods are high, and the amount of precipitation, and by extension risk of floods, from hurricanes is expected to increase due in part to trends in climate change (Kossin 2018; Trenberth et al. 2018) and human development.
Climate change is heating the atmosphere, allowing it to hold more moisture and increasing precipitation frequency and intensity (Van Oldenborgh et al. 2017), leading to higher flood risk (Ireland et al. 2015; Van Oldenborgh et al. 2017). In addition to more extreme precipitation, the U.S. faces higher-intensity hurricanes forming in the Atlantic (Kossin et al. 2007). On the global scale, the speed of tropical cyclones is decreasing, and their precipitation rates are increasing (Kossin 2018). In the U.S., this same trend applies to North Atlantic tropical cyclones, which are stalling more often along the coast and have increasing precipitation rates (Hall and Kossin 2019). Some research has linked the increasing hurricane intensity (Holland and Bruyère 2014) precipitation, and stalling (Kossin 2018) to climate change, while other research has not found the same link (Bender et al. 2010; Zhang et al. 2020). As more research is conducted, the global and local hurricane trends and their links to climate change may shift.
Hurricane Ida was a category 4 hurricane that landed in the U.S. on August 29, 2021, bringing catastrophic damage (Beven II et al. 2022). In the first days of September, Hurricane Ida stalled, becoming an extratropical cyclone and bringing heavy rains with rates around 3 inches per hour to states in the Mid-Atlantic and Northeast (Beven II et al., 2022). The storm caused dozens of fatalities and damaged homes, businesses, vehicles and infrastructure (Smith 2023). The National Oceanic and Atmospheric Association (NOAA) National Centers for Environmental Information (NCEI) estimates that the cost of Hurricane Ida was $80.2 Billion (Consumer Price Index-Adjusted) (Smith 2023), the costliest hazard of 2021.
In Pennsylvania, Hurricane Ida brought precipitation and floods that caused damage (Beven II et al., 2022). In the aftermath of Hurricane Ida, individuals and households in Pennsylvania received $124 M in funding from the Federal Emergency Management Agency (FEMA) to cover damages (Cooper et al. 2022). Even with this influx in funding, many counties in the state are still recovering from the damages of Hurricane Ida, including Philadelphia, Montgomery, Delaware and Bucks counties (Cooper et al. 2022). Given the trends in intensifying hurricanes, it is imperative to plan for future events using insights from past flood events (Brandt et al. 2021).
1.2 Unequal distribution of risk
People in poverty are disproportionately at risk of floods around the globe (Garbutt et al. 2015; Kawasaki et al. 2020; Mtapuri et al. 2018; Winsemius et al. 2018). This trend signifies that flood risk is not equally distributed (Wing et al. 2022). This imbalance occurs globally because people in poverty are more likely to live in a floodplain due to the concentration of jobs and transportation (Mtapuri et al. 2018). In the U.S., the same trend of inequitable flood risk applies, where flood risk disproportionately impacts poorer communities (Wing et al. 2022). At the city level, one case study of Los Angeles found that poorer communities have disproportionately higher flood risk, but this trend varied by flood type (Sanders et al. 2022). These findings at the national and local scale show that it is important to investigate the distribution of flood impacts to help inform emergency response and recovery.
1.3 Flood extent from satellite imagery
Satellite imagery is a reliable data source (Hermas et al. 2021) that is regularly used to map surface water and flood dynamics across various scales (Ayanu et al. 2012; Jones 2019; Pekel et al. 2016; Tulbure et al. 2016). Machine learning is an effective method for classifying floods in satellite imagery (Tulbure et al. 2022). It has higher classification accuracy than parametric strategies (Maxwell et al. 2018), such as using a single water index (Goffi et al. 2020).
Supervised machine learning classification of satellite imagery relies on accurate training and validation data (Olofsson et al. 2014). A known flood extent from a reliable dataset (Hondula et al. 2021) or created from aerial photography (Rosser et al. 2017; Schnebele et al. 2014) is ideal training data. However, it is not available for every flood event. In the case of Hurricane Ida, aerial imagery was not collected in the study area of southeastern Pennsylvania (US Department of Commerce 2022). Since an accurate flood extent was unavailable as training and validation data, we created one from satellite imagery and social media (Ireland et al. 2015; Perin et al. 2022).
Urban environments have complex waterways, shallow and ephemeral flooding, and ponding, meaning the flood extent is discontinuous (Tanim et al. 2022; Woznicki et al. 2019). Flood maps can be generated by flood models in urban areas (Knighton et al. 2021; Liu et al. 2015), however, flood maps generated from satellite imagery are considered closer to ground conditions. Synthetic aperture radar (SAR) data can collect data through clouds, but is limited in urban areas due to its side-looking nature (Mason et al. 2014) and can have gaps due to tall buildings causing radar shadowing or layover (Clement et al. 2018). Optical imagery cannot permeate through clouds, but does not face the same challenges with tall buildings. For our study area after Hurricane Ida, there was optical imagery, Sentinel-2, collected, but no freely available SAR data collected. In this study we used optical data and combined it with several datasets in our machine learning model to address the complexity of urban environments.
1.4 Gaps and objectives
There is currently no Hurricane Ida flood extent in Pennsylvania, including the city of Philadelphia and surrounding counties. The floods resulting from Hurricane Ida dissipated slowly and coincidentally overlapped with Sentinel-2 imagery collection, providing a unique opportunity for testing flood detection methods in an urban environment. Previous research has predominantly used satellite imagery and machine learning to detect floods using a vetted flood extent (from satellite imagery or a flood model) and rarely applies these methods to an urban area. Therefore we focused on the urban area of Philadelphia and surrounding counties after Hurricane Ida, an event without a vetted flood extent available, to fill these gaps.
The objectives of this research were to: (1) combine Sentinel-2 imagery and other data in a Random Forest (RF) machine learning algorithm to create a novel flood extent in southeastern Pennsylvania after Hurricane Ida; (2) compare the flood extent to FEMA’s flood zones; (3) use the flood extent to calculate flood exposure and determine the equality of its distribution. Since hurricanes and floods are expected to increase, methods for accurate and timely flood extent maps in urban areas are fundamental for improving recovery and mitigation efforts.
2 Methodology
2.1 Study site
Philadelphia, located in southeastern Pennsylvania, is the sixth largest city by population in the U.S., with over 1.5 million people (U.S. Census Bureau 2021). Over the past hundreds of years, the city has grown and developed, building over the existing streams. Floods occur in Philadelphia 12 days per year, and this frequency is expected to increase (Sweet et al. 2019). While the city is regularly flooded, it has made considerable efforts to reduce floods through multiple avenues, including its stormwater management program and strict design requirements (Hosseiny et al. 2020).
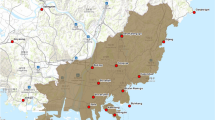
On September 1, 2021, Philadelphia was directly in the path of Hurricane Ida (Fig. 1) and received 2.37 inches of precipitation, significantly more than its annual monthly mean precipitation of 0.12 inches (NOAA 2021). The impacts of Hurricane Ida in Philadelphia and the resulting floods were wide-ranging from disrupting daily life to damaging personal assets (Pulcinella et al. 2021). In addition to Philadelphia, surrounding less urban counties, including Delaware, Bucks, and Montgomery counties, were impacted by Hurricane Ida flooding and incorporated into our study area (Cooper et al. 2022). According to the U.S. 2020 Census, Philadelphia (both the name of the city and county) is the most urban at 100%, then Delaware and Montgomery counties at 88% and 76%, respectively, and lastly, Bucks County at 44% (U.S. Census Bureau 2020).

From left to right: the Hurricane Ida track in 2021 in the U.S. from NOAA’s National Hurricane Center and Central Pacific Hurricane Center, the study area of four counties (Delaware, Montgomery, Bucks, Philadelphia) in southeastern Pennsylvania all impacted by flooding with permanent water from the USGS National Hydrography Dataset, and Sentinel-2 false color imagery (SWIR2, NIR, Red as RGB) on August 13, 2021 (pre-flood) and September 2, 2021 (post-flood)
2.2 Inputs for random forest model
2.2.1 Satellite imagery
We selected Sentinel-2 imagery because it was collected on the same day as peak Hurricane Ida flooding (Stuckey et al. 2023) in our study area and was the highest spatial resolution of publicly available imagery. Sentinel-2 is a mission run by the European Space Agency and produces publicly available satellite imagery of the globe at a 10–60 m spatial resolution and a temporal resolution of ~ 5 days. We used Sentinel-2 imagery that was collected less than a day after Hurricane Ida passed through the study area (September 2, 2021) with little (< 1%) cloud cover, making it an optimal data source. The Sentinel-2 imagery was collected in the afternoon, while the peak flooding occurred in the morning (Stuckey et al. 2023). Therefore, the imagery may underestimate the full flood extent of Hurricane Ida flooding. In Google Earth Engine (GEE), we obtained the imagery, filtered it temporally and spatially, and removed dense and cirrus cloud pixels using the quality assessment band (QA60) (Tiwari et al. 2024).
Other imagery that was considered included synthetic aperture radar (SAR) data, PlanetScope imagery and aerial imagery. The Sentinel-1 imagery dates did not align with the peak flooding in the study area. We considered PlanetScope imagery as the basis for the flood extent but instead used it to create the training and validation data for the RF model since it is best practice to use a higher resolution image for training and validation data than the model input (Olofsson et al. 2014). We did not consider aerial imagery because it was not collected by the National Geodetic Survey after Hurricane Ida in the study area (US Department of Commerce 2022).
The RF inputs included all Sentinel-2 surface reflectance bands, two vegetation indices and six water indices, all previously shown to be important when mapping floods with satellite data (Goffi et al. 2020; Tulbure et al. 2016, 2022) (Table 1). We produced all the indices in GEE. The vegetation indices are used to help classify NotWater pixels by identifying areas of vegetation. We used several water indices, each with different strengths, to help categorize Water (permanent) and Flood pixels in the model.
The normalized difference water index (NDWI) is the standard for classifying water using green and near-infrared (NIR) bands (McFeeters 1996). The Modified Normalized Difference Water Index (MNDWI) is a variation of NDWI that uses shortwave infrared (SWIR) instead of NIR and is more suitable in built-up areas than NDWI (Xu 2006). The Automated Water Extraction Index (AWEI) uses five spectral bands to improve water classification by decreasing the environmental noise of shadows and dark surfaces (Feyisa et al. 2014). Two variations of the AWEI formulas (AWEInsh and AWEIsh) have different effectiveness in urban areas. The AWEInsh formula is more equipped for urban areas because it effectively eliminates built surfaces. The AWEIsh formula is more equipped for filtering out shadows, but is less equipped for urban areas because it tends to misclassify reflective roofs as water.
We also used linear spectral unmixing (LSU) to produce three inputs, each with the percent of three different “endmembers” (water, urban and vegetation) or classes for each pixel. Pixels have mixed spectral signatures because the underlying land cover is mixed and highly variable (C. Yang et al. 2007). LSU addresses this heterogeneity by using all bands to estimate each pixel’s “endmember” percent (C. Yang et al. 2007). LSU is helpful in the context of floods because it can be used to determine the fraction of water in each pixel and produce flood maps (Bangira et al. 2017; Gómez-Palacios et al. 2017).
2.2.2 Additional inputs
In addition to Sentinel-2 surface reflectance bands and derived indices, several other datasets readily available in GEE were incorporated into the RF model (Table 2). A digital elevation model (DEM) can be used to derive data (e.g., slope) that influences where floods occur (Tulbure et al. 2016). In our model, we used the United States Geological Survey (USGS) 3DEP 10 m National Map (U.S. Geological Survey 2023) in GEE to calculate slope, aspect, and hillshade. We also used the USGS National Land Cover Database at 30 m resolution in the model resampled to 10 m, because land cover and impervious surface contribute to flood extent (Apel et al. 2016; Blum et al. 2020).
In GEE we also incorporated datasets of 30 m resolution from the European Commission’s Joint Research Centre (JRC), including surface water occurrence and surface water classification (water, seasonal, permanent) (Pekel et al. 2016). We downscaled the JRC datasets and the USGS national land cover database in GEE using the resample function and bilinear method to match the other RF inputs at 10 m resolution. In GEE, we combined the non-Sentinel-2 inputs and reprojected them to match the Sentinel-2 inputs. Next, all the inputs were combined, and a 3 × 3 window was created for each band.
2.2.3 Training and validation data
In QGIS, we created the training and validation dataset by hand using several datasets (Fig. 2) (Perin et al. 2022). We used PlanetScope (3 m) imagery, which is higher resolution than our model inputs (Maxwell et al. 2018; Olofsson et al. 2014), and the National Hydrography Dataset (NHD), as reference to create Flood and Water polygons at the resolution of Sentinel-2 (10 m) imagery (Ireland et al. 2015). We also used social media posts from Global Flood Monitor, a publicly available database of flood-related tweets (de Bruijn et al. 2019). We used ~ 3,000 tweets, including text and photos, and ~ 140 unique points to guide the creation of Flood polygons (Akhtar et al. 2021; Schnebele et al. 2014).

The training and validation polygons were drawn by hand in QGIS for the RF model using several layers to corroborate the class (NotWater, Water, Flood). These layers included Google roads and satellite basemaps, PlanetScope (3 m) false color imagery (Blue, NIR, Red as RGB) from September 2, 2021, Sentinel-2 (10 m) false color imagery (SWIR2, NIR, Red as RGB) from September 2, 2021, and the USGS National Hydrography Dataset (NHD) and flood-related tweets curated by Global Flood Monitor
The Google basemaps in QGIS provided high-resolution imagery for drawing NotWater polygons (Perin et al. 2022). Random points in each county were used to guide the location of NotWater polygons. Before drawing the NotWater polygons, we ensured that the polygon was outside the NHD and that the basemap imagery was clear of pools and other surface water. For all three classes (NotWater, Water, Flood), every layer of data was checked to verify the accuracy of the polygon class. The training and validation dataset was 420 polygons consisting of 160 NotWater, 130 Water and 130 Flood polygons.
Next, we uploaded the training and validation dataset into GEE and we split the polygons into two separate stratified random samples, with 70% for training and 30% for validation (Table 3). Then, we converted the polygons into 10 m pixels. The rarer classes of Water and Flood are both randomly oversampled (Maxwell et al. 2018; Olofsson et al. 2014).
2.3 Random forest model
The RF machine learning algorithm is an effective strategy for classifying imagery (Phan et al. 2020; Tiwari et al. 2024; Tulbure and Broich 2013) and floods in particular (Tulbure et al. 2016, 2022). The RF algorithm has several advantages and is more accurate than parametric classifiers (Maxwell et al. 2018; Phan et al. 2020). RF performs well with multi-source datasets and noisy data (Phan et al. 2020), and it is resilient to mislabeled data (Maxwell et al. 2018). The drawbacks are it is a ‘black box’, meaning you cannot visualize all trees, and it requires a large training sample that can be labor-intensive to build (Maxwell et al. 2018). There are more ML methods than RF, such as deep learning methods, including neural networks (Portalés-Julià et al. 2023), but these are more complex and require more computational power (Thomas et al. 2023). In a study comparing ML algorithms’ accuracies in mapping floods with satellite imagery, the RF algorithm outperformed an artificial neural network (Feng et al. 2015).
The RF machine learning algorithm is an ensemble classifier that uses a large number of decision trees that each use different random samples and a subset of features to assign a class, then the majority vote of all the trees classifies the data (Breiman 2001; Maxwell et al. 2018). The GEE platform runs the RF algorithm in under 10 minutes, and using the platform allows the method to be shared easily with the public and applied to other areas. While there are many ML algorithms to choose from, the accuracy (Maxwell et al. 2018), low computational cost, simplicity, and shareability of the RF algorithm executed in GEE makes it a practical method for classifying floods (Phan et al. 2020).
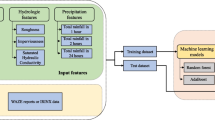
We executed the RF algorithm in GEE with the steps outlined in Fig. 3. We used the ee.Classifier.smileRandomForest function in GEE to train the model on the training data, then classify the entire study area and determine feature importance. The number of pixels used to train and validate are outlined in Table 3. We used the validation data to create a confusion matrix. After the first run of the algorithm, we ran the model with the Sentinel-2 features and indices and different combinations of additional features and parameters in order to select the features and parameters (number of trees, number of features at each split) that produce the highest overall accuracy. The final parameters chosen for the algorithm were the default numbers, 100 trees and eight features per split. These parameters align with those chosen in other research using RF classification in GEE (Phan et al. 2020). After these parameters were selected, the algorithm was run again with the optimal parameters and all the features.

Flow chart of methodology
2.4 Datasets for assessment of floods
The National Flood Hazard Layer (NFHL) is a database of flood zones and flood insurance requirements maintained by FEMA in support of the National Flood Insurance Program (NFIP) (FEMA 2023). The NFHL is available for the entire study area, therefore, every flooded pixel will occur in a FEMA flood zone. The flood zones we focus on in this study are the 100-year, 500-year, and Minimal Hazard zones because they are the primary risk classifications. The 100-year and 500-year flood zones have a 1% and 0.2% likelihood of flooding yearly (FEMA 2020). We combined all other FEMA flood zones (floodway, 1% annual chance flood hazard contained in channel, area with reduced flood risk due to levee, and 1% depth less than 1 foot) into an “Other” category that encapsulates areas that are less common. The Minimal Hazard zone is outside the 500-year flood zone and at higher elevations. Once we created the Hurricane Ida flood extent, we used the FEMA flood zones to determine the area and percent area of the Hurricane Ida flood that occurred in the different zones at the county and tract level.
The Centers for Disease Control and Prevention (CDC) and Agency for Toxic Substances and Disease Registry (ATSDR) Social Vulnerability Index (SVI, hereafter) is a vulnerability index at the tract and county level in the United States. Vulnerability is a community’s ability to prevent suffering and financial loss due to a disaster (Fielding 2018). The CDC’s SVI dataset estimates an overall vulnerability score using four themes (socioeconomic status, household characteristics, racial & ethnic minority status, and housing type & transportation) (Centers for Disease Control and Prevention 2020). From the CDC’s SVI 2020 dataset, we used the sum of the four themes as the SVI index and the number of people below the 150% federal poverty level. The poverty data in the CDC’s SVI dataset came from the 2016–2020 American community survey (ACS). These two attributes were used to determine if Hurricane Ida floods disproportionately impacted people in poverty and vulnerable populations.
After we created a flood extent with our RF model, we exported it from GEE and converted it from a raster to a vector file to compare to the vector file of FEMA flood zones. Then, the flood polygons were clipped to different FEMA flood zones. In this study, we calculated the area and percent flood in four different FEMA flood zones: 100-year, 500-year, Minimal Hazards, and Other. The Other category consists of areas, including floodways, that are likely to be flooded; therefore, we expected most flooding to occur in the 100-year and Other zone. After the flood extent was clipped to the different zones, the area (km2) and the percent of the flood that occurred in each FEMA flood zone were calculated at the county and census tract level. Since the flood extent used in these calculations reflects flooding from the peak day but not the peak time, the extent may underestimate the flood extent.
We assessed the flood exposure equality by plotting Lorenz Curves and calculating the Gini coefficient. The Gini coefficient is typically used to study income inequality (Lorenz 1905), but can also be applied to studying flood exposure inequalities (Sanders et al. 2022). The Gini coefficient ranges from − 1 to 1, 0 representing perfect equality. To determine the equality of flooding, we first merged the CDC’s SVI data and flood data by tract, then calculated flood exposure per tract. In this instance, the flood exposure is the tract population multiplied by the percent of the tract flooded. To measure equality in the different FEMA flood zones, flood exposure is the tract population multiplied by the percent of a given FEMA zone in the tract, then multiplied by the percent of the zone flooded. Then, we sorted the table by desired variables (population below the poverty line, SVI score) and plotted the Lorenz Curve with the cumulative percent of flood exposure on the y axis and the cumulative percent of population on the x axis. Then, we calculated the Gini coefficient to determine if there was a disproportionate impact on people in poverty and vulnerable populations, and if this impact varied by flood zone.
3 Results
We quantified the flood extent after Hurricane Ida in southeastern Pennsylvania using Sentinel-2 satellite imagery, derived indices, linear unmixing, land cover and surface water data in a RF model trained with polygons of three classes: NotWater, Water and Flood. The training data used PlanetScope imagery and incorporated crowdsourced social media and permanent water data. When creating a flood extent, this approach proved highly accurate (> 99% overall accuracy). The resulting flood extent compared to the FEMA flood zones also reveals that, in this event, there was more than double the area of floods in the Minimal Hazard zones than in the 500-year flood zone.
3.1 Flood extent generated with random forest model
Our methods produced a new flood extent map after Hurricane Ida of three classes: Notwater, Water and Flood for the study area of four counties in southeastern Pennsylvania, including the urban area of Philadelphia County, where no prior flood extent existed. The result is a map of flood extent for September 2, 2021, a day after Hurricane Ida passed through the study area and the day the Sentinel-2 mission captured data (Fig. 4). When zooming into different land uses in the study area, the RF model Flood classification is visually well matched with the dark blue areas (Water/Flood) of the Sentinel-2 false color imagery (Fig. 5).

Flood extent map after Hurricane Ida on September 2, 2021, created using our RF model

Examples of flood extent in different land uses (Farm, Neighborhood, Highway/urban) created using our RF model after Hurricane Ida on September 2, 2021. From left to right, Sentinel-2 false color imagery (SWIR2, NIR, Red as RGB) on August 13, 2023 (pre-flood), on September 2, 2021 (post-flood), and RF classification of flood extent overlaid on September 2, 2021 imagery
We created a confusion matrix for our RF Model using the validation dataset. The overall accuracy was 99.68%, and for the Flood class, the producer’s and the user’s accuracy were over 97% (Table 4).
We found the relative feature importance using the explain function in GEE (Table 5). The most important feature for classification came from the Sentinel-2 Band 1, aerosols and aerosols 3 × 3 window; the next important feature was water vapor, then slope. The most important water index was MNDWI 3 × 3 window. Consistently, the least important features were JRC Water and JRC Water 3 × 3 window.
3.2 Comparison to FEMA flood zones
After we created a flood extent for Hurricane Ida using our RF model, we calculated the area and percent of floods that occurred in the different FEMA flood zones (Table 6). The FEMA flood zones we investigated were the 100-year, 500-year, Minimal Hazard zones and Other (a combination of rarer zones). All counties experienced less than half a percent of the total county area being flooded. Bucks County had the most flooding by area, while Philadelphia and Bucks counties had the highest percentage of the area flooded, with 0.50% and 0.42%, respectively.
Most flooding occurred in the 100-year and Other FEMA flood zones. All counties received some amount of flooding in Minimal Hazard zones and more flooding by area and percent in the Minimal Hazard zone than the 500-year zone. In Bucks County, ~ 15.9% ± 1.6% of total floods occurred in the Minimal Hazard zone. The percentage of FEMA zones flooded told a slightly different story with the Other zone receiving the highest proportion of flooding, then the 100-year, then 500-year, then the Minimal Hazard zone (Table 7).
Tract-level flood information can reveal more local patterns in flooding. Figure 6 shows the percentage of floods that occurred in a subset of FEMA flood zones (100-year, 500-year, Minimal Hazard). The tract-level shows a similar pattern to the county information, showing that the highest percent of floods occurs in the 100-year and Minimal Hazard zones and the smallest percent of floods occurs in the 500-year zone.

Flood percent and area (km2) per tract that occurred in a subset of FEMA flood zones
3.3 Vulnerability and poverty distribution
In addition to investigating the distribution of Hurricane Ida floods across FEMA flood zones, we also investigated the distribution of floods across tract poverty and SVI scores. We found that flood exposure did not disproportionately impact people below the poverty line or vulnerable populations (higher SVI scores) (Fig. 7). People below the poverty line were underexposed to floods in the Minimal Hazard zone (G = − 0.331) and slightly underexposed to floods overall, and in FEMA’s Other, 100-year and 500-year zones (− 0.2 < G < − 0.1). Vulnerable populations (i.e. higher SVI scores) were underexposed to floods overall (G = − 0.265), as well as in FEMA’s Other (G = − 0.257), 100-year (G = − 0.259) and Minimal Hazard zones (G = − 0.371). For both variables studied, there was a weak underexposure to floods for people below the poverty line and vulnerable populations in FEMA’s 500-year zones (− 0.2 < G < − 0.1).

Lorenz Curves of flood exposure for people in poverty (top row) and vulnerable populations (bottom row), with Gini coefficients (G) for total flood exposure and flood exposure within FEMA flood zones (Other, 100-year, 500-year, Minimal Hazard)
4 Discussion
We developed reproducible methods for creating a flood extent after a major flood event in an urban area using the RF algorithm and mostly freely available data and software. While the RF algorithm and satellite imagery has been previously used to detect floods (Schaffer-Smith et al. 2020; Tulbure et al. 2018, 2022), these methods are rarely applied in an urban environment. We successfully applied these methods to the dense urban county of Philadelphia and three surrounding, less urban counties. We then used this novel flood extent of Hurricane Ida to investigate its distribution in FEMA flood zones and across the population.
4.1 Flood extent
The flood extent for the study area had an overall accuracy of 99% and the Flood class had a user's and producer’s accuracy both over 97%. These metrics demonstrate that our methods are accurate when producing a flood extent in urban and suburban areas. A visual inspection also showed that in Philadelphia our RF model accurately classified floods in the frequently flooded neighborhood of Manayunk, the highway Interstate-676, and along a popular path, the Schuylkill Banks.
Our RF model accuracy is relatively high, compared to the accuracies of other studies that used remotely sensed imagery to classify water. Feng et al. (2015) and Rosser et al. (2017) focused on urban flooding in China (87.3% accuracy) and the United Kingdom (95% accuracy), respectively. Studies in non-urban areas also had relatively high accuracies. A study mapping hurricane flooding in North Carolina, USA had an accuracy of 91% (Schaffer-Smith et al. 2020) and a study mapping surface water in a semi-arid river basin in Australia had an overall accuracy of 99% with 80% as the user’s accuracy of the water class (Tulbure et al. 2022). Some of these variations in accuracy likely come from the classification method and type of remote sensing imagery used. Most of the studies used RF methods, similar to our study (Feng et al. 2015; Schaffer-Smith et al. 2020; Tulbure et al. 2022), but others used the Otsu method (Rosser et al. 2017). Additionally, each of these studies used a different type of remote sensing imagery, including Unmanned Aerial Vehicle (Feng et al. 2015), Landsat-8 (Rosser et al. 2017), SAR (Schaffer-Smith et al. 2020), and Harmonized Landsat Sentinel-2 (Tulbure et al. 2022). One possibility of the higher accuracy of this RF model is the relatively small study area and use of several datasets in addition to the satellite imagery.
While the overall accuracies of the flood extent and the Flood class were high, there were undetected Water and Flood areas. Since optical imagery cannot permeate obstructions (e.g., bridges, trees), the RF model did not detect water or floods under these areas. Optical imagery also cannot permeate clouds, therefore to create a flood map for an event with heavy cloud cover, these methods can be applied with SAR imagery. The RF model can be adapted for a cloudy flood event and use SAR imagery, which can permeate clouds, as the main input along with supporting DEM and land cover data, to create a flood extent map.
The RF model had difficulty detecting narrow rivers or creeks. When this occurred, the creek was usually categorized as NotWater or if the river’s banks flooded, then it was categorized as Flood. This was the case for most creeks, for example, Pennypack Creek and Wissahickon Creek, both ~ 20 miles long crossing multiple counties. This study used Sentinel-2 imagery in part because it is publicly accessible, but applying this RF model with higher-resolution imagery from the private sector (e.g. PlanetScope data) may improve classification, especially for smaller water bodies (Cooley et al. 2017).
Our RF model’s feature importance varied from other models detecting surface water. For instance, in our RF model the highest-ranked feature was aerosols (Band 1 of Sentinel-2, central wavelength 443 nm, 60 m resolution), and we have not found other models with a similar pattern. Slope was also a highly ranked feature, likely because it is a good predictor of floods since it influences water pooling. The AWEI indices (AWEIsh and AWEInsh) are useful for mapping surface water, along with MNDWI and NDWI (Feyisa et al. 2014; Pickens et al. 2020; Tulbure et al. 2016). In our RF model, the highest-ranked water index was MNDWI. While AWEIsh is usually helpful for mapping surface water, it may have been less important in this model because it tends to misclassify highly reflective surfaces (such as skyscrapers) as floods (Feyisa et al. 2014).
The JRC Water input, which is a dataset created using Landsat imagery and classifying pixels into permanent, seasonal or not water, (Pekel et al. 2016) was consistently the least important feature. It is likely the least important because the JRC Yearly Water Classification History dataset does not include bodies of water smaller than 30 m by 30 m (Pekel et al. 2016) and the spatial resolution of our study is 10 m. Despite this drawback, when experimenting with different feature combinations, this dataset still slightly increased accuracy and was included in the final RF model.
Overall, it is difficult to compare our RF model and other RF models detecting floods and surface water because each uses different satellite imagery and input features. Our study area also tends to be smaller and more urban than other studies, which is potentially the reason our feature importance differs from other research. While the indices and datasets for this RF model were carefully selected, there is room for model simplification and decreasing the number of features. In addition to decreasing the number of features, experimentation can be done to determine which features are more effective in urban areas versus suburban areas to tailor the RF model to each county.
These methods created an accurate flood extent for an urban area with GEE and free imagery as inputs. While the training data took time to compile, the methods are accessible. They can be quickly deployed to find the flood extent in another urban area when satellite imagery is available. One limitation in making the training and validation dataset is that the curated flood-related tweets obtained from Global Flood Monitor are unavailable after February 2023 due to a change in Twitter’s web scraping policies (Calma 2023).
These accurate flood extents can be used to improve and validate flood models and calculate flood depth (Bangira et al. 2017; Woznicki et al. 2019). Outside of modeling, accurate flood maps created with satellite imagery can help governments at the local and state level with preparedness and mitigation efforts (Akhtar et al. 2021). It can also help governments address the impacts of floods through adaptation projects and fixing zoning regulations (Wing et al. 2022).
4.2 FEMA flood zones
In our study area, Hurricane Ida’s flood extent, by area and percent, predominantly occurred in the 100-year and Other FEMA flood zones. These flood zones also had the highest proportion of floods compared to the other zones. This result aligns with FEMA’s flood zone descriptions because 100-year flood zones have a 1% chance of flooding every year and the Other category includes zones that are designed to flood. Since our study compared a singular event to the FEMA flood zones, which represent the probability of yearly flooding, no conclusions can be drawn about the effectiveness of the FEMA zones.
In every county twice the amount of floods, by area and percent, occurred in the Minimal Hazard zone than the 500-year zone. Since we did not quantify the flood depth or damages, this is not necessarily cause for concern, more a reflection of where water pooled. One county that stood out with a high proportion of flooding in the Minimal Hazard zone was Bucks County. There may be more floods in the Minimal Hazard zone because the 100-year and 500-year zones are substantially smaller. When investigating the percentage of the FEMA zones flooded, a higher percentage of the 500-year flood zone was flooded (0.05–0.58%) than the Minimal Hazard zone (0.02–0.07%) in all counties. There are two patterns occurring: by county, more floods occurred in the Minimal Hazard zone than the 500-year zone, whereas by zones, the 500-year flood zone had more flooding than the Minimal Hazard zone.
Our research shows that flooding can and does occur in the Minimal Hazard zone, which is important given the misconception that living outside the FEMA flood zone means there is no flood risk (Billings et al. 2022; Wing et al. 2022). FEMA flood zones underestimate flood exposure (Wing et al. 2018) and do not account for pluvial floods (U.S. Government Accountability Office 2021). Floods and resulting damages regularly occur outside the FEMA 100-year flood zone (Collins et al. 2022). Our Hurricane Ida flood map can reveal areas with a high proportion of floods in minimal-risk areas that may benefit from recovery assistance and future mitigation. Future research could expand the time scale and determine the rate of floods and the overall effectiveness of different FEMA flood zones in this study area.
4.3 Flood distribution
We used the flood extent of Hurricane Ida to investigate if flood exposure was equally distributed in the study area. We found that total flood exposure did not disproportionately impact people in poverty and vulnerable populations. While this finding does not align with previous research showing that vulnerable populations are more exposed to floods (Tate et al. 2021), there are a few caveats. Firstly, we looked at a subset of counties impacted by Hurricane Ida. Secondly, we used flood exposure at the Census tract level, when block group level or land parcel level can capture more detailed spatial heterogeneity (Brelsford et al. 2017). Thirdly, for the flood exposure calculation, we used flood area and not flood depth or damages. Still, this result demonstrates an efficient method to get a snapshot of flood distribution and can be deployed again in conjunction with flood depth for a more accurate flood exposure calculation. Too often, flooding disproportionately affects vulnerable populations with the fewest resources to recover (Schaffer-Smith et al. 2020; Tate et al. 2021). Therefore, it is important to research this trend and highlight vulnerable areas that received high amounts of flooding and could benefit from additional support and resources to recover after flooding.
5 Conclusion
Accurate methods for quantifying flood extent can provide insights into the affected area and damages (Rosser et al. 2017), and inform response (Akhtar et al. 2021). Satellite imagery and the RF algorithm are a reliable combination to create a flood extent but are not often applied in urban areas. Our methods combine GEE, satellite imagery and other freely available data to create a RF model. This model created a new flood extent of Hurricane Ida in southeastern Pennsylvania with 99% accuracy and can be applied to other urban areas. This flood extent can be used to validate flood models and view patterns of flooding at the tract level. We investigated the distribution of this event in FEMA flood zones and found that most flooding occurred in the 100-year and Other zones. In our study area, more floods occurred in the Minimal Hazard zone than the 500-year zone, affirming previous research that consistently found flooding outside FEMA’s flood zones. This research refined methods for creating an accurate flood extent in urban areas and created a new one for our study area. Flood extent maps can serve stakeholders such as land use managers (Sofia et al. 2017), emergency planners (Goffi et al. 2020), city planners and residents (Hosseiny et al. 2020). The maps can help inform recovery efforts, prioritize mitigation efforts (Hosseiny et al. 2020) and plan for future development (Sofia et al. 2017), making our cities more resilient to the increasing risk of floods.
References
Akhtar Z, Ofli F, Imran M (2021) Towards using remote sensing and social media data for flood mapping. In: ISCRAM 2021 Conference Proceedings–18th International Conference on Information Systems for Crisis Response and Management, pp 536–551
Apel H, Martínez Trepat O, Hung NN, Chinh DT, Merz B, Dung NV (2016) Combined fluvial and pluvial urban flood hazard analysis: Concept development and application to can tho city, Mekong Delta. Vietnam Nat Hazard Earth Syst Sci 16(4):941–961. https://doi.org/10.5194/nhess-16-941-2016
Ayanu YZ, Conrad C, Nauss T, Wegmann M, Koellner T (2012) Quantifying and mapping ecosystem services supplies and demands: a review of remote sensing applications. Environ Sci Technol 46(16):8529–8541. https://doi.org/10.1021/es300157u
Bangira T, Alfieri SM, Menenti M, Van Niekerk A, Vekerdy Z (2017) A spectral unmixing method with ensemble estimation of endmembers: application to flood mapping in the caprivi floodplain. Remote Sens 9(10):1013. https://doi.org/10.3390/rs9101013
Bender MA, Knutson TR, Tuleya RE, Sirutis JJ, Vecchi GA, Garner ST, Held IM (2010) modeled impact of anthropogenic warming on the frequency of intense Atlantic Hurricanes. Science 327(5964):454–458. https://doi.org/10.1126/science.1180568
Beven II J, Hagen A, Berg R (2022) National hurricane center tropical cyclone report: Hurric Ida. NOAA. https://www.nhc.noaa.gov/data/tcr/AL092021_Ida.pdf
Billings SB, Gallagher EA, Ricketts L (2022) Let the rich be flooded: the distribution of financial aid and distress after hurricane harvey. J Financ Econ 146(2):797–819. https://doi.org/10.1016/j.jfineco.2021.11.006
Blum AG, Ferraro PJ, Archfield SA, Ryberg KR (2020) Causal effect of impervious cover on annual flood magnitude for the United States. Geophys Res Lett 47(5):e2019GL086480. https://doi.org/10.1029/2019GL086480
Boschetti M, Nutini F, Manfron G, Brivio PA, Nelson A (2014) comparative analysis of normalised difference spectral indices derived from modis for detecting surface water in flooded rice cropping systems. PLoS ONE 9(2):e88741. https://doi.org/10.1371/journal.pone.0088741
Brandt SA, Lim NJ, Colding J, Barthel S (2021) mapping flood risk uncertainty zones in support of urban resilience planning. Urban Plan 6(3):258–271. https://doi.org/10.17645/up.v6i3.4073
Breiman L (2001) Random forests. Mach Learn 45(1):5–32. https://doi.org/10.1023/A:1010933404324
Brelsford C, Lobo J, Hand J, Bettencourt LMA (2017) Heterogeneity and scale of sustainable development in cities. Proc Natl Acad Sci 114(34):8963–8968. https://doi.org/10.1073/pnas.1606033114
Calma J (2023) Scientists say they can’t rely on Twitter anymore. The Verge. https://www.theverge.com/2023/5/31/23739084/twitter-elon-musk-api-policy-chilling-academic-research
Centers for disease control and prevention (2020) CDC/ATSDR Social Vulnerability Index [Database State]. https://www.atsdr.cdc.gov/placeandhealth/svi/data_documentation_download.html
Clement MA, Kilsby CG, Moore P (2018) Multi-temporal synthetic aperture radar flood mapping using change detection. J Flood Risk Manag 11(2):152–168. https://doi.org/10.1111/jfr3.12303
Collins EL, Sanchez GM, Terando A, Stillwell CC, Mitasova H, Sebastian A, Meentemeyer RK (2022) Predicting flood damage probability across the conterminous United States. Environ Res Lett 17(3):034006. https://doi.org/10.1088/1748-9326/ac4f0f
Cooley SW, Smith LC, Stepan L, Mascaro J (2017) Tracking dynamic northern surface water changes with high-frequency planet cubesat imagery. Remote Sensing 9(12):1306. https://doi.org/10.3390/rs9121306
Cooper K, Rizzo E, Schmidt S (2022, September 1). One year after Hurricane Ida, Pa. Residents are still paying the price. WHYY. https://whyy.org/articles/pensylvannia-hurricane-ida-one-year-anniversary/
CRED (2015) The human cost of natural disasters: a global perspective. centre for research on the epidemiology of disasters (CRED). http://repo.floodalliance.net/jspui/44111/1165
de Bruijn JA, de Moel H, Jongman B, de Ruiter MC, Wagemaker J, Aerts JCJH (2019) A global database of historic and real-time flood events based on social media. Scientific Data 6(1):311. https://doi.org/10.1038/s41597-019-0326-9
FEMA. (2020, July 8). Flood zones. https://www.fema.gov/glossary/flood-zones
FEMA. (2023, October 23). Laws and regulations. https://www.fema.gov/flood-insurance/rules-legislation/laws
Feng Q, Liu J, Gong J (2015) Urban flood mapping based on unmanned aerial vehicle remote sensing and random forest classifier—a case of Yuyao China. Water 7(4):1437–1455. https://doi.org/10.3390/w7041437
Feyisa GL, Meilby H, Fensholt R, Proud SR (2014) Automated water extraction index: a new technique for surface water mapping using Landsat imagery. Remote Sens Environ 140:23–35. https://doi.org/10.1016/j.rse.2013.08.029
Fielding JL (2018) Flood risk and inequalities between ethnic groups in the floodplains of England and Wales. Disasters 42(1):101–123. https://doi.org/10.1111/disa.12230
Gao B (1996) NDWI—A normalized difference water index for remote sensing of vegetation liquid water from space. Remote Sens Environ 58(3):257–266. https://doi.org/10.1016/S0034-4257(96)00067-3
Garbutt K, Ellul C, Fujiyama T (2015) Mapping social vulnerability to flood hazard in Norfolk. England Environ Hazards 14(2):156–186. https://doi.org/10.1080/17477891.2015.1028018
U.S. Geological Survey (2023) 3D Elevation Program 10-Meter Resolution Digital Elevation Model. https://www.usgs.gov/the-national-map-data-delivery
Goffi A, Stroppiana D, Brivio PA, Bordogna G, Boschetti M (2020) Towards an automated approach to map flooded areas from Sentinel-2 MSI data and soft integration of water spectral features. Int J Appl Earth Obs Geoinf 84:101951. https://doi.org/10.1016/j.jag.2019.101951
Gómez-Palacios D, Torres MA, Reinoso E (2017) Flood mapping through principal component analysis of multitemporal satellite imagery considering the alteration of water spectral properties due to turbidity conditions. Geomat Nat Haz Risk 8(2):607–623. https://doi.org/10.1080/19475705.2016.1250115
Hall TM, Kossin JP (2019) Hurricane stalling along the North American coast and implications for rainfall. Npj Climate Atmos Sci 2(1):17. https://doi.org/10.1038/s41612-019-0074-8
Hermas E, Gaber A, El Bastawesy M (2021) Application of remote sensing and GIS for assessing and proposing mitigation measures in flood-affected urban areas Egypt. Egyptian J Remote Sens Space Sci 24(1):119–130. https://doi.org/10.1016/j.ejrs.2020.03.002
Holland G, Bruyère CL (2014) Recent intense hurricane response to global climate change. Clim Dyn 42(3):617–627. https://doi.org/10.1007/s00382-013-1713-0
Hondula KL, DeVries B, Jones NC, Palmer MA (2021) Effects of using high resolution satellite‐based inundation time series to estimate methane fluxes from forested wetlands. Geophys Res Lett 48(6):e2021GL092556. https://doi.org/10.1029/2021GL092556
Hosseiny H, Crimmins M, Smith VB, Kremer P (2020) A generalized automated framework for urban runoff modeling and its application at a citywide landscape. Water 12(2):357. https://doi.org/10.3390/w12020357
Huete A (1997) A comparison of vegetation indices over a global set of TM images for EOS-MODIS. Remote Sens Environ 59(3):440–451. https://doi.org/10.1016/S0034-4257(96)00112-5
Ireland G, Volpi M, Petropoulos GP (2015) Examining the capability of supervised machine learning classifiers in extracting flooded areas from landsat TM imagery: a case study from a mediterranean flood. Remote Sens 7(3):3372–3399. https://doi.org/10.3390/rs70303372
Jones JW (2019) Improved automated detection of subpixel-scale inundation—revised dynamic surface water extent (DSWE) partial surface water tests. Remote Sens 11(4):374. https://doi.org/10.3390/rs11040374
Kawasaki A, Kawamura G, Zin WW (2020) A local level relationship between floods and poverty: a case in Myanmar. Int J Disaster Risk Reduct 42:101348. https://doi.org/10.1016/j.ijdrr.2019.101348
Knighton J, Hondula K, Sharkus C, Guzman C, Elliott R (2021) Flood risk behaviors of United States riverine metropolitan areas are driven by local hydrology and shaped by race. Proc Natl Acad Sci 118(13):e2016839118. https://doi.org/10.1073/pnas.2016839118
Knutson TR, Sirutis JJ, Zhao M, Tuleya RE, Bender M, Vecchi GA, Villarini G, Chavas D (2015) Global Projections of Intense Tropical Cyclone Activity for the Late Twenty-First Century from Dynamical Downscaling of CMIP5/RCP4.5 Scenarios. J Climate 28(18):7203–7224. https://doi.org/10.1175/JCLI-D-15-0129.1
Kossin JP (2018) A global slowdown of tropical-cyclone translation speed. Nature 558(7708):104–107. https://doi.org/10.1038/s41586-018-0158-3
Kossin JP, Knapp KR, Vimont DJ, Murnane RJ, Harper BA (2007) A globally consistent reanalysis of hurricane variability and trends. Geophys Res Letters 34 (4). https://doi.org/10.1029/2006GL028836
Kriegler FJ, Malila WA, Nalepka RF Richardson W (1969) Preprocessing transformations and their effects on multispectral recognition, p 97. https://ui.adsabs.harvard.edu/abs/1969rse..conf...97K
Lin N, Emanuel K, Oppenheimer M, Vanmarcke E (2012) Physically based assessment of hurricane surge threat under climate change. Nature Climate Change 2(6):462–467. https://doi.org/10.1038/nclimate1389
Liu L, Liu Y, Wang X, Yu D, Liu K, Huang H, Hu G (2015) Developing an effective 2-D urban flood inundation model for city emergency management based on cellular automata. Nat Hazard 15(3):381–391. https://doi.org/10.5194/nhess-15-381-2015
Lorenz MO (1905) Methods of measuring the concentration of wealth. Publ Am Stat Assoc 9(70):209. https://doi.org/10.2307/2276207
Markhvida M, Walsh B, Hallegatte S, Baker J (2020) Quantification of disaster impacts through household well-being losses. Nature Sustain 3(7):538–547. https://doi.org/10.1038/s41893-020-0508-7
Mason DC, Giustarini L, Garcia-Pintado J, Cloke HL (2014) Detection of flooded urban areas in high resolution synthetic aperture radar images using double scattering. Int J Appl Earth Obs Geoinf 28:150–159. https://doi.org/10.1016/j.jag.2013.12.002
Maxwell AE, Warner TA, Fang F (2018) Implementation of machine-learning classification in remote sensing: an applied review. Int J Remote Sens 39(9):2784–2817. https://doi.org/10.1080/01431161.2018.1433343
McFeeters SK (1996) The use of the normalized difference water index (NDWI) in the delineation of open water features. Int J Remote Sens 17(7):1425–1432. https://doi.org/10.1080/01431169608948714
Mtapuri O, Dube E, Matunhu J (2018) Flooding and poverty: two interrelated social problems impacting rural development in Tsholotsho district of Matabeleland North province in Zimbabwe. Jamba: J Disaster Risk Stud 10(1):1–7. https://doi.org/10.4102/jamba.v10i1.455
US Department of Commerce N. (2021). NWS preliminary US flood fatality statistics. NOAA’s National Weather Service. https://www.weather.gov/arx/usflood
NOAA (2021, September) National weather service forecast office. https://www.weather.gov/wrh/climate?wfo=phi
Olofsson P, Foody GM, Herold M, Stehman SV, Woodcock CE, Wulder MA (2014) Good practices for estimating area and assessing accuracy of land change. Remote Sens Environ 148:42–57. https://doi.org/10.1016/j.rse.2014.02.015
Pekel J-F, Cottam A, Gorelick N, Belward AS (2016) High-resolution mapping of global surface water and its long-term changes. Nature 540(7633):418–422. https://doi.org/10.1038/nature20584
Perin V, Tulbure MG, Gaines MD, Reba ML, Yaeger MA (2022) A multi-sensor satellite imagery approach to monitor on-farm reservoirs. Remote Sens Environ 270:112796. https://doi.org/10.1016/j.rse.2021.112796
Phan TN, Kuch V, Lehnert LW (2020) Land cover classification using google earth engine and random forest classifier—the role of image composition. Remote Sens 12(15):2411. https://doi.org/10.3390/rs12152411
Pickens AH, Hansen MC, Hancher M, Stehman SV, Tyukavina A, Potapov P, Marroquin B, Sherani Z (2020) Mapping and sampling to characterize global inland water dynamics from 1999 to 2018 with full Landsat time-series. Remote Sens Environ 243:111792. https://doi.org/10.1016/j.rse.2020.111792
Pinos J, Quesada-Román A (2022) Flood risk-related research trends in Latin America and the Caribbean. Water 14(1):10. https://doi.org/10.3390/w14010010
Portalés-Julià E, Mateo-García G, Purcell C, Gómez-Chova L (2023) Global flood extent segmentation in optical satellite images. Scien Reports 13(1):20316. https://doi.org/10.1038/s41598-023-47595-7
Pulcinella M, Meyer K, Cooper K (2021, September 1). Long recovery ahead as Ida’s remnants lead to historic flooding, tornadoes in Philly region. WHYY. https://whyy.org/articles/philly-says-to-shelter-in-place-as-schuylkill-river-expected-to-rise-to-major-flood-stage/
Rentschler J, Salhab M, Jafino BA (2022) Flood exposure and poverty in 188 countries. Nature Commun 13(1):3527. https://doi.org/10.1038/s41467-022-30727-4
Rosser JF, Leibovici DG, Jackson MJ (2017) Rapid flood inundation mapping using social media, remote sensing and topographic data. Nat Hazards 87(1):103–120. https://doi.org/10.1007/s11069-017-2755-0
Sanders BF, Schubert JE, Kahl DT, Mach KJ, Brady D, AghaKouchak A, Forman F, Matthew RA, Ulibarri N, Davis SJ (2022) Large and inequitable flood risks in Los Angeles, California. Nat Sustain 6:1–11. https://doi.org/10.1038/s41893-022-00977-7
Schaffer-Smith D, Myint SW, Muenich RL, Tong D, DeMeester JE (2020) Repeated hurricanes reveal risks and opportunities for social-ecological resilience to flooding and water quality problems. Environ Sci Technol 54(12):7194–7204. https://doi.org/10.1021/acs.est.9b07815
Schnebele E, Cervone G, Waters N (2014) Road assessment after flood events using non-authoritative data. Nat Hazard 14(4):1007–1015. https://doi.org/10.5194/nhess-14-1007-2014
Settle JJ, Drake NA (1993) Linear mixing and the estimation of ground cover proportions. Int J Remote Sens 14(6):1159–1177. https://doi.org/10.1080/01431169308904402
Shen L, Li C (2010) Water body extraction from Landsat ETM+ imagery using adaboost algorithm. 2010 18th International In: Conference on Geoinformatics, pp 1–4. https://doi.org/10.1109/GEOINFORMATICS.2010.5567762
Smith AB (2023). U.S. billion-dollar weather and climate disasters, 1980—present (NCEI Accession 0209268). NOAA national centers for environmental information. https://doi.org/10.25921/STKW-7W73
Sofia G, Roder G, Dalla Fontana G, Tarolli P (2017) Flood dynamics in urbanised landscapes: 100 years of climate and humans’ interaction. Scin Reports 7(1):40527. https://doi.org/10.1038/srep40527
Stuckey MH, Conlon MD, Weaver MR (2023) Characterization of peak streamflows and flooding in select areas of Pennsylvania from the remnants of Hurricane Ida, September 1–2, 2021. In: Scientific investigations report (2023–5086). U.S. Geological Survey. https://doi.org/10.3133/sir20235086
Sweet W, Dusek G, (Gregory P ) Marcy DC, Greg (Gregory W) C Marra J (2019) 2018 State of U.S. high tide flooding with a 2019 outlook. https://doi.org/10.25923/RBV9-TH19
Tanim AH, McRae CB, Tavakol-Davani H, Goharian E (2022) Flood detection in urban areas using satellite imagery and machine learning. Water 14(7):1140. https://doi.org/10.3390/w14071140
Tate E, Rahman MA, Emrich CT, Sampson CC (2021) Flood exposure and social vulnerability in the United States. Nat Hazards 106(1):435–457. https://doi.org/10.1007/s11069-020-04470-2
Thomas M, Tellman E, Osgood DE, DeVries B, Islam AS, Steckler MS, Goodman M, Billah M (2023) A framework to assess remote sensing algorithms for satellite-based flood index insurance. IEEE J Sel Topics Appl Earth Obser Remote Sens 16:2589–2604. https://doi.org/10.1109/JSTARS.2023.3244098
Tiwari V, Tulbure MG, Caineta J, Gaines MD, Perin V, Kamal M, Krupnik TJ, Aziz MA, Islam AT (2024) Automated in-season rice crop mapping using sentinel time-series data and google earth engine: a case study in climate-risk prone Bangladesh. J Environ Manage 351:119615. https://doi.org/10.1016/j.jenvman.2023.119615
Trenberth KE, Cheng L, Jacobs P, Zhang Y, Fasullo J (2018) Hurricane harvey links to ocean heat content and climate change adaptation. Earth’s Future 6(5):730–744. https://doi.org/10.1029/2018EF000825
Tulbure MG, Broich M (2013) Spatiotemporal dynamic of surface water bodies using Landsat time-series data from 1999–2011. ISPRS J Photogramm Remote Sens 79:44–52. https://doi.org/10.1016/j.isprsjprs.2013.01.010
Tulbure MG, Broich M, Stehman SV, Kommareddy A (2016) Surface water extent dynamics from three decades of seasonally continuous Landsat time series at subcontinental scale in a semi-arid region. Remote Sens Environ 178:142–157. https://doi.org/10.1016/j.rse.2016.02.034
Tulbure MG, Broich M, Perin V, Gaines M, Ju J, Stehman SV, Pavelsky T, Masek JG, Yin S, Mai J, Betbeder-Matibet L (2022) Can we detect more ephemeral floods with higher density harmonized Landsat Sentinel 2 data compared to Landsat 8 alone? ISPRS J Photogramm Remote Sens 185:232–246. https://doi.org/10.1016/j.isprsjprs.2022.01.021
Tulbure MG, Broich M, Ju J, Masek JG, Wearne J (2018) Quantifying surface water extent and flooding in a dynamic dryland river system using the harmonized landsat/sentinel-2 reflectance product. 2018 H21E-08.
U.S. Census Bureau (2020). County-level Urban and Rural information for the 2020 Census. https://www.census.gov/programs-surveys/geography/guidance/geo-areas/urban-rural.html
U.S. Census Bureau (2021). City and Town Population Totals: 2020-2021. https://www.census.gov/data/tables/time-series/demo/popest/2020s-total-cities-and-towns.html
U.S. Government accountability office. (2021). FEMA Flood Maps: Better Planning and Analysis Needed to Address Current and Future Flood Hazards. https://www.gao.gov/assets/gao-22-104079.pdf
US Department of Commerce. (2022, October 26). Hurricane Ida Emergency Response Imagery. https://oceanservice.noaa.gov/news/aug21/ngs-storm-imagery-ida.html
Van Oldenborgh GJ, Van Der Wiel K, Sebastian A, Singh R, Arrighi J, Otto F, Haustein K, Li S, Vecchi G, Cullen H (2017) Attribution of extreme rainfall from hurricane harvey, August 2017. Environ Res Lett 12(12):124009. https://doi.org/10.1088/1748-9326/aa9ef2
Wing OEJ, Bates PD, Smith AM, Sampson CC, Johnson KA, Fargione J, Morefield P (2018) Estimates of present and future flood risk in the conterminous United States. Environ Res Lett 13(3):034023. https://doi.org/10.1088/1748-9326/aaac65
Wing OEJ, Lehman W, Bates PD, Sampson CC, Quinn N, Smith AM, Neal JC, Porter JR, Kousky C (2022) Inequitable patterns of US flood risk in the Anthropocene. Nat Climate Change 12(2):156–162. https://doi.org/10.1038/s41558-021-01265-6
Winsemius HC, Jongman B, Veldkamp TIE, Hallegatte S, Bangalore M, Ward PJ (2018) Disaster risk, climate change, and poverty: Assessing the global exposure of poor people to floods and droughts. Environ Dev Econ 23(3):328–348. https://doi.org/10.1017/S1355770X17000444
Woznicki SA, Baynes J, Panlasigui S, Mehaffey M, Neale A (2019) Development of a spatially complete floodplain map of the conterminous United States using random forest. Sci Total Environ 647:942–953. https://doi.org/10.1016/j.scitotenv.2018.07.353
Xu H (2006) Modification of normalised difference water index (NDWI) to enhance open water features in remotely sensed imagery. Int J Remote Sens 27(14):3025–3033. https://doi.org/10.1080/01431160600589179
Yang C, Everitt JH, Bradford JM (2007) Using multispectral imagery and linear spectral unmixing techniques for estimating crop yield variability. Trans ASABE 50(2):6676–674. https://doi.org/10.13031/2013.22658
Zhang G, Murakami H, Knutson TR, Mizuta R, Yoshida K (2020) Tropical cyclone motion in a changing climate. Sci Adv 6(17):eaaz7610. https://doi.org/10.1126/sciadv.aaz7610
Acknowledgements
We appreciate the thorough comments and suggestions from the anonymous reviewers and editor. We also appreciate the European Space Agency for Sentinel-2 data, Planet Labs for PlanetScope data, Google for the Google Earth Engine (GEE) platform, and Global Flood Monitor for flood-related social media posts.
Funding
The authors declare that no funds, grants, or other support were received during the preparation of this manuscript.
Author information
Authors and Affiliations
Contributions
Rebecca Composto: Conceptualization, investigation, methodology, formal analysis, visualization, writing—original draft, writing—review and editing. Mirela Tulbure: Supervision, conceptualization, methodology, writing—review and editing. Varun Tiwari: Methodology (supporting), formal analysis (supporting GEE code), writing—review and editing. Mollie D. Gaines: Methodology (supporting), formal analysis (supporting python code), writing—review and editing. Júlio Caineta: Methodology (supporting), writing—review and editing.
Corresponding author
Ethics declarations
Competing interest
The authors have no relevant financial or non-financial interests to disclose.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Composto, R.W., Tulbure, M.G., Tiwari, V. et al. Quantifying urban flood extent using satellite imagery and machine learning. Nat Hazards (2024). https://doi.org/10.1007/s11069-024-06817-5
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s11069-024-06817-5