
Abstract
In recent years, there has been an increasing interest in spatial modeling, and flood hazard prediction is a major area of interest within the field of hydrology. It is necessary to consider return periods for identifying the flood hazard zones. In hydraulic modeling such as HEC-RAS, this is usually done, but in spatial modeling by machine learning (ML) models, this has not been taken into account so far. This study seeks to obtain data that will help to address this research gap. The Sentinel-1 Radar images have been used for identifying the flooded locations in different return periods. An embedded feature selection algorithm (i.e., recursive feature elimination random forest; RFE-RF) was used in the current research for key feature selection. Then, three ML models of neural networks using model averaging, classification and regression tree, and support vector machine were employed. The flood hazard prediction demonstrated a great performance for all the applied models (i.e., accuracy and precision > 90%, Kappa > 88%). Sensitivity analysis disclosed that the variables of elevation and distance from stream are in the first importance order, the variables of precipitation, slope, and land use are in the second importance order, and other variables are in the third importance order in all return periods. The modeling results indicated that among man-made land uses the irrigated area between 17.7 and 31.4%, dry farming from 0.5 to 2.4%, and residential areas between 8.3 and 25.1% are exposed to high and very high flood hazard areas. The current findings add to a growing body of literature on the spatial modeling of floods.
Similar content being viewed by others

Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
Among natural disasters, floods cause the most damage to agriculture, fisheries, housing, and infrastructure and strongly affect economic and social activities (Madadi et al. 2015; Heidarpour et al. 2017; Mosavi et al. 2018). Improper human intervention in ecosystems, uncontrolled exploitation of forests, and excessive grazing of livestock are the most important factors exacerbating this natural hazard, which reduces soil holding capacity, wastes fertile soils, and increases surface runoff (Olorunfemi et al. 2020; Minea et al. 2022; Sarkar et al. 2022). Over the past several decades, floods have led to many economic losses and human losses in different parts of the world (Guo et al. 2014; Mehta and Yadav 2020; Rahim et al. 2022). In 2010 alone, more than 178 million people worldwide were affected by floods; also, from 1960 to 2017, 34% of natural disasters were related to floods, which resulted in on average 1254 deaths and $ 2.5 billion economic damages per year (Petit-Boix et al. 2017). The world population has reached more than 7 billion in 2018 (UNFPA 2018; Gutierrez et al. 2014); this increase in population leads to the development of urbanization and consequently to the impact on the environment (Djalante 2012; Udomchai et al. 2018).
One of the basic steps to reduce the harmful effects of floods is to identify flood-prone areas and to grade and classify these areas in terms of flood hazard (Patial et al. 2008). Hence, in recent years, there has been an increasing interest in spatial modeling, and flood hazard prediction has been a major area of interest within the field of hydrology. For identifying the flood hazard zones, it is necessary to consider return periods; which is usually done in hydraulic modeling such as HEC-RAS (e.g., Khattak et al. 2016; Khalfallah and Saidi 2018; Romali et al. 2018), but in the spatial modeling with machine learning models this has not been taken into account so far.
Considering that in the spatial modeling and identification of flood hazard zones in watersheds using machine learning models, the dependent variable is flooded locations during previous events; the lack of selection of these locations based on the return periods is one of the main research gaps (as recommended for future studies by Hosseini et al. 2020). In this regard, many studies around the world have used machine learning models for flood hazard modeling, but the flood locations have not been selected based on the return period for hazard map extraction. For instance, in the study of Nandi et al. (2016), the location of flood events from 1904 to 2012 was used to extract a hazard map without considering the return period of floods, while each flood has a different return period and the area affected by each of them will be different. Likewise, other studies such as Mojaddadi et al. (2017) by collecting 110 flood events from 2010 to 2015, Gigović et al. (2017) using the analytic hierarchy process (AHP), Popa et al. (2019) by providing the historical flood locations from 1970 to 2012, Khosravi et al. (2020) by collecting 2769 historical flood records, Eini et al. (2020) and Norallahi and Seyed Kaboli (2021) using 117 flooding points in 2016–2019 in the same study area, Janizadeh et al. (2021b) using 118 historic flood locations, Pourghasemi et al. (2020) by obtaining the location of 365 floods, Janizadeh et al. (2021a) by 256 flood locations, and Luu et al. (2021) using flood events during 2007, 2010, and 2016, have not considered return periods in flood hazard assessment.
In reviewing the literature as mentioned above, the hazard maps have been presented without considering return periods in spatial modeling of the flood, because the selection of training and validation points has not been based on the return periods. However, a major problem with spatial modeling of floods in previous studies is the lack of hazard maps for each return period. Therefore, this study seeks to obtain data that will help to address this research gap. Since this type of data is not recorded by any organization, so the radar images have been used for identifying the flooded locations in different return periods to fill this research gap. Therefore, the foremost objective of the present research was to predict the hazard maps for different return periods by machine learning models.
2 Material and methods
2.1 Study area
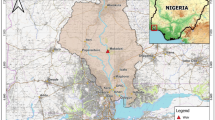
The present study was conducted to determine the hazardous zones of floods in the Simineh River Basin located in the West Azerbaijan Province, Iran. The area of the watershed is about 3841 square kilometers, which lies between the eastern longitudes of 45 degrees and 31 min to 46 degrees and 24 min, and the northern latitudes of 36 degrees and 40 min to 37 degrees and 5 min (Fig. 1). The length of the Simineh River is about 180 km which originates from the mountains of Mahabad, Saqez, and Baneh toward Lake Urmia, after joining several tributaries of small rivers on its way and passing through the city of Bukan and around the city of Miandoab (Ahmadaali et al., 2017). The average discharge in the outlet of the watershed is about 15.5 cubic meters per second according to the Pole Miandoab hydrometric station from the year of 1964 to 2019.

Location of the Simineh River Basin
The Simineh River is among the most water-rich rivers in the country that have high flooding intensity (Kazemi et al., 2016; Ahmadaali et al., 2017). For example, in the flood that occurred in Murch 2019, about 4000 hectares of agricultural lands in Miandoab city were inundated and more than 320 billion rials damages were estimated (Miandoab Press, 2019). Therefore, to manage such areas due to their extent and susceptibility, researchers and managers must make more efforts to know about them as much as possible.
2.2 Prediction of flood hazard zones
Hazard is anything that can cause harm. It is attributed to natural, physical and environmental elements (Pelling, 2003). In this study, the following measures have been taken to determine high-hazard areas in the Simineh River Basin: (i) extracting the location of flood areas for each return period, (ii) collection and preparation of effective factors on flood occurrence, (iii) feature selection, (iv) flood hazard modeling, and (v) validation. Each of the above steps is described below:
2.2.1 Radar images and flood location extraction
Since the location of flooded points in the study area is not recorded by any organization, Sentinel 1 radar images were used to identify the flood pixels. The steps are as follows:
-
(i)
Collection of the occurred flood statistics: date of flood events, mean daily discharge, and instantaneous maximum discharge from 1965 to 2019 for the outlet of the watershed were received from the West Azerbaijan Regional Water Company. The location of the hydrometric station (i.e., Miandoab station) on the Simineh River is shown in Fig. 1.
-
(ii)
Selection of the best statistical distribution: Miandoab station (located at the basin outlet) which had long-term data (55 years, 1965–2019) was used to calculate flood return periods. The instantaneous maximum flow for this station was used to select the best statistical distribution. Then, using two goodness-of-fit tests including the Kolmogorov–Smirnov (KS) and Anderson–Darling (AD), the best statistical distribution among the distributions of Gamma, Log-Gamma, Gamble, Pearson 3P, Log-Pearson 3P, Normal, Log-Normal 3P were selected using the EasyFit software. The KS and AD tests are based on the comparison of experimental cumulative distribution function (CDF) with fitting distributions. The KS test statistics show the largest difference between CDF of experimental and fitted distributions, while the AD test gives more value to tails of CDF than the KS test (Kolmogorov 1933; Smirnov 1948; Anderson and Darling 1954).
-
(iii)
Calculation of flood return period: After selecting the best statistical distribution, flood discharge values for return periods of 2, 5, 10, 25, 50, 100, and 200 years were calculated using the EasyFit software.
-
(iv)
Determining the return period of the occurred floods: By comparing the values of the instantaneous maximum discharge that occurred in the watershed outlet with the estimated flood values by the best statistical distribution, the return period of the occurred floods in the watershed was determined. Since Sentinel 1 radar images have been available since 2014, floods from this year onwards were assessed.
-
(v)
Selection of pair images from flood and non-flood date: After determining the return period of floods, the presence of Sentinel 1 radar images on the date of flood events was investigated. In such a way that for each return period, radar images were investigated by the Google Earth Engine system in flood dates, and the image capture and coverage of the basin were checked. After determining the presence of the image in the flood dates, the image for non-flood days was selected, too. The post-flood and pre-flood images were selected in the same month to avoid variations in baseline river flow due to the seasonal conditions.
-
(vi)
Attributes of radar images and required processing: The Sentinel-1 satellite has two sensors, Sentinel-1 A and Sentinel-1 B, which are located at a distance of 180 degrees from each other. The Sentinel-1 A was launched on 3 April 2014 and the Sentinel-1 B on 25 April 2016 by the European Space Agency. These sensors operate in the C-band range and are called synthetic aperture radar (SAR). The spatial resolution of these sensors is 10 m, and the temporal resolution is 6 days (Kussul et al. 2011; Bayik et al. 2018).
The above-mentioned features cause this satellite to capture images from the ground during the day and night and in all atmospheric conditions. Sentinel-1 radar images are sensitive to soil moisture and, contrary to optical data, are not affected by cloudy and rainy weather; therefore, it is possible to extract water areas during floods (Tholey et al. 1997; Kussul et al. 2011; Kuenzer et al. 2013).
The attributes of the images used in this research are presented in Table 1. Images downloaded from Google Earth Engine (GEE) (COPERNICUS/S1_GRD). All required pre-processing on Sentinel-1 images in the GEE system is done by the Sentinel-1 Toolbox, which includes applying orbit file, GRD border noise removal, thermal noise removal, radiometric calibration, and terrain correction. However, to reduce speckle noise, which causes fine and coarse grains and interferes with reflected signals, a 3 × 3 filter was used (Clement et al. 2018; Cao et al. 2019).
-
(vii)
Extraction of flooded pixels:
After receiving the flood and non-flood images, flood pixels were identified based on the change detection and thresholding (CDAT) method provided by Long et al. (2014). Based on this, the difference between flood (F) and non-flood/reference (R) images is first calculated using Eq. 1:
$$D = {\text{float}}\left( F \right) - {\text{float}}\left( R \right)$$(1)In the difference (D) image, the flooded pixels are in dark color. Since permanent water bodies (such as lakes, wetlands, and river base flow) are dark in both flood and non-flood images, they take a gray color in the D image, meaning no change occurred in the pixels. Therefore, only water levels caused by floods are shown in the D image as dark.
Then, filtering was performed to remove the detected false points. Errors such as shadowing and changes in brightness due to different signal return angles from hills and slopes cause false flood pixels (Long et al., 2014; Clement et al. 2018; Cao et al. 2019). To eliminate such errors, combined filtration was used by two layers of slope and height above nearest drainage (HAND). In this sense, surfaces that are not topographically likely to be flooded but radar images have mistakenly detected flooding were filtered. Therefore, areas with a slope above 15° and a HAND above 10 m were excluded from the difference image (calculated by Eq. 1) (Clement et al. 2018; Cao et al. 2019).
After filtering, thresholding was performed. Long et al. (2014) determined the best threshold for identifying flood levels as follows:
$$P_{F} {\text{ < }}\mu (D) - k_{f} \times \left[ {\sigma (D)} \right]$$(2)\({\text{P}}_{F}\) represents the flooded pixels, μ and σ represent the mean and standard deviation of the remaining pixels from the D after filtration, respectively. Also, \({\text{k}}_{\text{f}}\) is a coefficient with an optimal value of 1.5 (Long et al. 2014).
After extracting the flood pixels by the above-mentioned steps, non-flood pixels are also required. Therefore, equal to the number of flood pixels, non-flood pixels were randomly considered at non-flood areas for each return period. Non-flooded pixels were extracted using the Create Random Points tool in ArcGIS software. Finally, the values of zero and one were considered for non-flood and flood pixels, respectively, as the dependent variable.
2.2.2 Flood influencing factors
The influencing factors include topographic, hydro-climatic, geology, land use, soil, and vegetation (Fig. 2), which were collected and prepared as follows:

Flood influencing factors
Elevation: Elevation changes at the watershed level, directly and indirectly, affect floods. The hydrological behavior of the basins, such as runoff speed, runoff volume, and losses, is directly affected by floods. Indirectly, elevation changes cause changes in other effective factors of flood such as soil order, land use, climate, geology, and vegetation. In this study, the ALOS PALSAR digital elevation model (DEM) with a pixel size of 12.5 × 12.5 m was received from the Alaska satellite facilities (https://vertex.daac.asf.alaska.edu) (Fig. 2a).
Slope: The amount of slope affects flow velocity, volume, and accumulation. The slope is an effective factor both in flood generation and in flood inundation. Areas with high slopes increase the velocity and movement of runoff and flood generation, while low-slope areas are effective in catching and flood inundation. In this study, the slope of the watershed was extracted using the DEM digital layer in ArcGIS software (Fig. 2b).
Aspect: Different weather conditions (rainfall, temperature, and sunlight) in different aspects affect soil conditions, vegetation, etc., which all affect hydrological conditions and floods. Therefore, it is expected that the hydrological reaction of different aspects be different. In this study, the aspect layer was extracted using the DEM in ArcGIS (Fig. 2c).
Curvature: The curvature of the earth shows the shape of the earth, which includes convex, flat, and concave shapes that are effective in the production and accumulation of runoff. In this study, the earth curvature map was extracted using the DEM in ArcGIS software (Fig. 2d).
Topographic position index (TPI): This index indicates the elevation of each cell in a digital elevation model relative to the average elevation of the surrounding cells (Fig. 2e). In other words, this index is calculated from the difference in elevation between each pixel relative to the average of the neighborhoods of that pixel (Eq. 3):
where Z0 is the elevation of the desired pixel, \(\stackrel{\mathrm{-}}{\text{Z}}\) is the average elevation of the neighboring pixels with the desired pixel, n is the number of pixels around Z0, Zi is the elevation of each adjacent pixel, and R is the radius to consider the neighboring points.
Topographic roughness index (TRI): This index is presented by Riley et al. (1999) and provides a quantitatively objective measure of topographic heterogeneity. In other words, the difference in elevation of a pixel with 8 adjacent pixels shows:
where Zn is the elevation of the desired pixel, Zi is the neighboring pixel elevation, N is the number of surrounding pixels, which is usually considered eight. SAGA GIS software was used to calculate this index (Fig. 2f).
Topographic wetness index (TWI): This index shows the spatial variation of soil moisture, which was first introduced in the TOPMODEL rainfall–runoff model by Beven and Kirkby in 1979. Using this index, the effect of topography on runoff production is quantified and the areas of surface saturation and spatial distribution of soil moisture are approximated:
where As is the upstream area per special catchment area, tan(β) is the slope angle of the site for estimating the hydraulic angle (Beven and Kirkby 1979). This index is extracted by SAGA GIS software (Fig. 2g).
Drainage density: In a watershed, the higher density of the canal network, the greater and certainly the greater the role in collecting rainwater. The higher density of the canals, the shorter the time it takes for the flow to reach its peak. For this reason, in high-density basins, severe floods appear shortly after rainfall. In this study, drainage density was extracted using the Line Density tool in ArcGIS using the streams map (Fig. 2h).
Flow accumulation: It shows the cumulative number of cells upstream of a cell and how many cells flow from the upstream areas to that cell. The amount of flow accumulation increases from the upstream of the basin to the downstream, and the higher the value of this criterion, the greater the potential for flooding and accumulation of water. To calculate this index, the flow direction map was used in the ArcGIS environment (Fig. 2i).
Distance from stream (DFS): It is an important factor in identifying hazardous areas. Naturally, areas closer to waterways and rivers are more prone to flooding. In this study, the distance map of the streams was extracted using the Euclidean distance tool in ArcGIS using the streams map (Fig. 2j).
Precipitation: Precipitation is the main factor for the onset of runoff and floods. In this study, the total precipitation of the previous seven days of each flood event for meteorological stations inside and outside the basin (20 stations) was considered for flood modeling (Fig. 2k, l). The reason for considering seven-day precipitation is its effect on river flow and flood discharge on pre-event hydrological conditions. In other words, previous precipitations affect hydrological factors such as soil moisture, infiltration, and basal flow, which all affect the volume of floods. Using the kriging method, interpolation and preparation of precipitation maps were performed for each flood event. The location of the meteorological stations is shown in Fig. 1.
Normalized difference vegetation index (NDVI): This index shows the amount of vegetation in the area. The value of this index is between + 1 and − 1, that it for dense vegetation tends to be one, and the clouds, snow, and water are characterized by negative values. Barren lands are found in values close to zero. This index is calculated by the reflectance in the near-infrared (NIR) and red (RED) bands by Eq. 5:
In this study, the NDVI index for the month of occurred floods was prepared by Sentinel 2 images in the Google Earth Engine system (Fig. 2m, n).
Soil order: Different soil conditions affect the permeability and runoff. In this study, other soil data were not available, so the soil order prepared by the Institute of Soil and Water (with a scale of 1: 250,000) was used (Fig. 2o).
Landuse: Different land uses create different amounts of runoff and different hydrological conditions depending on the type of soil, vegetation cover, permeability, etc. Therefore, the type of land use affects the occurrence of floods. Rangelands, irrigated areas, dry farming, residential, forest, barren land, and water are the main land uses of the watershed (Fig. 2p) that is extracted by Sentinel-2 images in May 2018.
Lithology: Different units of lithology have different effects on runoff due to different conditions such as permeability. In this study, the geological map was obtained from the Geological Survey and Mineral Exploration of Iran (with a scale of 1:250,000) (Fig. 2q).
2.2.3 Feature selection
After preparing the flood influencing factors mentioned in the previous step, the selection of key features was done in two steps: (i) multicollinearity of factors was investigated using the variance inflation factor (VIF), and the nonlinear factors were selected, (ii) using the recursive feature elimination (RFE) method, redundant features were removed and key features for modeling were identified. In the RFE method, first, the classification is done based on all the attributes and for each attribute a value of importance (rank) is determined. Then, the classification is done using the most important features and the accuracy of the classification is calculated. This is repeated for different quantities of the most important features, and finally, the number of the most important features with the highest classification accuracy is selected (Guyon et al., 2002).
To perform the RFE, the k-fold cross-validation method was used and the data were classified into K = 10 sections. Then, during the different stages of K, each time one part of K is considered as a test set, and K − 1 of parts is considered as training data. Finally, the average evaluation results are reported. The RFE is a wrapper and model-based approach in which the random forest (RF) as an estimator was used in this study (Feng et al., 2017). Therefore, the embedded feature selection algorithm (i.e., recursive feature elimination random forest; RFE-RF) was used in the current research. The selection of key features is done in the R software environment.
2.2.4 Modeling approach
According to the dependent variable (location of flood and non-flood points) and independent variables obtained from the feature selection approach, flood hazard modeling was performed for those return periods that the flood locations were identified by the radar image processing. Data (including independent and dependent variables) are randomly divided into two groups calibration (70%) and validation (30%). The ‘createDataPartition’ function in the CARET library of R software was used for random sampling and balanced distribution of data. Balanced means that if the variable y is a class (such as zeros and ones), random sampling is performed in each class and the overall distribution of the classes in each group is maintained. The models were trained based on the training group, and the relationships between independent and dependent variables were identified. For this purpose, the capabilities of machine learning (ML) models such as support vector machine (SVM), classification and regression tree (CART), and averaged neural networks (avNNet) were used in R software:
-
Support vector machine (SVM)
In its simplest form, SVM is a super plan that separates a set of positive and negative samples with a maximum distance. The use of SVM, which is proposed by Vapnik (1963), has expanded as one of the solutions in machine learning and pattern recognition. SVM makes its predictions using a linear combination of the kernel function that operates on a set of training data called backup vectors. The method provided by SVM is different from comparable methods such as neural networks; SVM training always finds the global minimum. The characteristics of an SVM are largely related to its kernel selection. SVM training leads to a quadratic programming problem that can be very difficult to solve for large volumes of samples with numerical methods. Therefore, to simplify the solution to this optimization problem, several methods have been proposed that can be used and implemented according to the needs. In the learning process, the system needs to be trained first and then tested for new input values. Mathematically, the machine learning problem can be thought of as a mapping in which xi → yi. A machine is defined by a set of possible mappings as x → f (x, α) in which the functions f (x, α) can be adjusted by the α. It is assumed that the system is definite and always gives a specific output equal to f (x, α) for a particular input x and the choice of α. Choosing the right α is the same thing that the trained machine does. The prediction y (x, w) is expressed by the linear combination of the basic function Φm (x) (Eq. 8):
$$y\left(x,w\right)=\sum_{m=0}^{M}{W}_{m}{\Phi }_{m}\left(x\right)={W}^{T}\Phi$$(8)where Wm are model parameters called weights. In SVM, basic functions are used as kernel functions, for each Xm in the training set we have Φm (X) = K (X, Xm), where k (0,0) is the kernel function. Weight estimation in the SVM is achieved by optimizing criteria that simultaneously try to minimize the y (x, w) function. As a result, some weights are zeroed, resulting in a sparse model whose prediction management is based on Eq. 8 and depends only on a subset of the kernel function (Bishop and Tipping 2013).
-
Classification and regression tree (CART)
Decision trees are widely used in computer science and software engineering. These trees also have a special place in data mining and classification, and many classification algorithms are based on these trees. This is why they are called decision trees because they can make a specific decision based on a set of actual information. Meanwhile, one of the most popular decision tree algorithms is the CART decision tree, which is developed by Breiman et al. (1984), that has many applications in classification and regression studies. CART is based on binary trees, so to build a decision tree it divides the data into binary parts and builds a binary tree based on them. The CART procedure consists of three phases: i) creation of maximum tree; ii) selection of the optimum tree size; and iii) construction or classification of new data using the constructed tree (Timofeev 2004).
-
Averaged neural networks (avNNet)
The avNNet is a type of feedforward neural network with a hidden layer. In NNET, the connection between the constituent units does not form a cycle. Unlike recursive neural networks, in these types of networks, information travels in only one direction which is the forward direction (Ripley and Venables 2016). In this model, modeling is done using different random numbers, and the results of all models are used for prediction. For regression modeling, the output of each network is averaged. For classification, the performance of the models is averaged and then translated to the predicted classes (Ripley 2007). The avNNet has two parameters: hidden units (number of neurons in the hidden layers of the network) and weight decay (penalty parameter for the error function to avoid over-modeling). The optimal values of parameters were obtained through the tuneLength function in the CARET library in R software (Ripley and Venables 2016).
2.2.5 Validation
In each of the ML models, after constructing and ensuring the training of the models, validation was performed. The validity of the trained models was assessed using the excluded data (30% of the total data) through evaluation criteria. The models were evaluated by Hit and Miss analysis using a contingency table (Johnson and Olsen 1998). The contingency matrix contains true and false (so-called binary) classifications of modeling data versus observations. The criteria used to evaluate the models in the training and validation stages include accuracy (Eq. 9), precision (Eq. 10), and kappa coefficient (Eq. 11), which were calculated from the contingency table information:
where H, FA, M, and CN are the number of hits, false alarms, misses, and correct negatives, respectively, in the contingency table (Sokolova et al., 2006). The values of the accuracy and precision statistics are between zero and one, the closer to one the better the prediction of the model. The kappa coefficient is a numerical measure between − 1 and + 1, and the values closer to + 1 indicate a proportional and direct agreement. Values close to − 1 indicate the existence of an inverse agreement and values close to zero indicate disagreement.
In addition to the above statistics, the visual method of receiver operating characteristic (ROC) graph was used to evaluate the models. In this diagram, the area under curve (AUC) is the performance criterion of the model. The higher AUC, the better the performance of the model.
3 Results and discussion
3.1 Extraction of flooded points from radar images
To extract the flooded points, first, the flood return period was calculated for the Watershed. The results of fitting different statistical distributions to the 54-year data of instantaneous maximum flood at the watershed outlet (in the Pole Miandoab hydrometric station) showed that the Log-Pearson 3P was the best distribution, according to Kolmogorov–Smirnov (KS) and Anderson–Darling (AD) statistics (Table 2).
So, using the Log-Pearson 3P, discharge values of 591, 544, 487, 436, 342, 272, and 183 m3/s are estimated for return periods of 200, 100, 50, 25, 10, 5, and 2, respectively. After estimating the flood return period with the best statistical distribution, the return period of occurred floods was determined for the existence date of Sentinel 1 radar images (from 2014 onwards). Table 3 shows the date of occurred floods in the Simineh River basin along with the amount of their return period. As can be seen, from April 2014, a total of 42 floods have been recorded at the outlet of the watershed. Among these floods, three floods with a return period of 10 years, two floods with a return period of five years, one flood with a return period of two years, and 36 floods with a return period of lower than two years occurred (Table 3).
From 2014 to 2020, six floods with a return period of 2 years and above occurred (Table 3), which only two flood dates (i.e., 2017-04-16 and 2019-01-30) correspond to the radar image-taking period (each six-day). Therefore, from the floods with the return period of 2, 5, and 10 years from 2014 to 2020, the radar has taken images for the return periods of 5 and 10 years. However, for occurred flood in 2016-01-09 with a return period of 2 years the Sentinel 1 data is not available means that the flood date did not correspond to the six-day radar imaging period of the Sentinel 1 (Table 4). Table 4 presents the Radar status at the date of the flood events and selected reference images. For each of the flood events, the first reference (non-flood) image taken before the flood event (i.e., six days before) was considered. In the sense that non-flood images show the normal flow of the river and somehow show the pre-flood discharge conditions (in the same month).
Figure 3 shows an example of Sentinel-1 images for the non-flood and flood dates (with return periods of 5 and 10 years) located in the outlet of watershed, which was received by the Google Earth Engine (GEE) system. As it turns out, these images display the flood zones well. The dark surfaces in Fig. 3c and d show well the extent of the flood area compared to the normal flow mode (non-flood image) (Fig. 3).

Example of Sentinel-1 images for non-flood and flood dates at the outlet of Simineh River Basin. Darker areas show flooding
After receiving the flood and non-flood images from the GEE, the first step was to calculate the difference image between flood and non-flood images. By differentiating, permanent water levels that are not caused by floods (such as normal river flow, lake, or wetland) were removed. For example, in Fig. 5, it is clear that in the difference image, the surface of the Qarah Gol wetland is removed and it is ensured that the water surfaces that are not due to flooding will not be present in the extracted flood pixels. Also, some parts of the riverbed that are involved in the flood are well visible (Fig. 4).

Comparison of the status of Qarah Gol wetland in non-flood (2019-01-24), flood (2019-01-30), and difference images
Finally, flooded pixels were extracted using combined filtration by slope and HAND layers and also by using the thresholding method presented in the methodology. Figure 5 shows the flood pixels for the 5- and 10-year return periods.

Flood pixels extracted by Sentinel-1 radar images for 5-year a and 10-year b return periods
3.2 Feature selection results
First, the multicollinearity analysis between independent variables was investigated using the variance inflation factor (VIF). Table 5 shows the VIF values for the 5- and 10-year return periods. As it turns out, the variables of slope and topographic roughness index (TRI) for both return periods have a VIF higher than 10, which are collinear variables. When there is collinearity, the model coefficients are not valid, because the effect of each descriptive variable on the "response variable" includes the effect of other variables in the model, too. Therefore, the variance of regression coefficient estimators is increased and, in practice, the prediction by the model will be associated with a large error. The reason for the relationship between the TRI and slope is due to the nature of the calculation of these two variables from the elevation map. In calculating both variables, the elevation values of adjacent pixels are used, and based on this, a high correlation is obtained between the two variables. The existence of collinearity between TRI and slope in previous studies in different regions has also been confirmed (Lee et al. 2018; Kalantar et al. 2019; Lee et al. 2020; Amare et al. 2021).
In the next step, to eliminate collinearity, the TRI variable was removed from the list of input variables, and VIF was checked again. The results showed that only by removing the TRI variable, the problem of collinearity between the input variables is solved (i.e., the VIF values are lower than 5, Table 5).
After excluding the TRI variable and ensuring that the remaining variables have no collinearity, the selection of key variables was performed using the recursive feature elimination (RFE) method through R software separately for each return period. According to this method, the data were divided into k = 10 folds, and in each run, 9 folds were used to train the model, and one of the folds was set aside for validation. In the RFE method, first, the classification is done based on all the features and a value of importance (rank) is determined for each feature. Then, the classification is performed using the most important variables from one variable to n variables (in this study, 14 variables), and the performance in each execution is reported. In this study, based on the number of variables and folds, the model run was repeated 140 times:
Number of folds (10) × Number of variables (14) = Number of runs (140).
The priority of the features based on the total frequency of presence in 140 runs is presented in Table 6. The variables of distance to stream, elevation, NDVI, and rainfall more than other variables were present, respectively, in 100, 93, 86, and 79% of runs as the most important variables (in both return periods). While the variables of flow cumulation, lithology, curvature, and soil order were present less than other variables, respectively, in 30% (25%), 24% (7%), 14% (29%), and 7% (14%) of the model implementations for the return period of 5 years (10 years) (Table 6).
The average performance of the RFE method in different iterations for different numbers of features is presented in Fig. 6. As can be seen, when the number of features is equal to 10, the average accuracy of the RFE method for both 5- and 10-year return periods is higher than the other number of features (accuracy is equal to 0.9889 and 0.9886, respectively). Therefore, based on the results of the RFE method (taking into account the results of Fig. 6 and Table 6), 10 variables of distance to stream, elevation, NDVI, precipitation, TPI, aspect, drainage density, TWI, land use, and slope were selected as key features to model flood hazard.

Mean performance of the RFE method in different iterations for different number of features. Solid signs show better performance
Therefore, variables of flow accumulation, lithology, curvature, and soil order were among the least important variables and were excluded from the modeling process. The reason for low importance of these variables can be attributed to (i) the lack of spatial relationship between occurrence and non-occurrence of floods with these variables and (2) uniform spatial distribution or non-variability of these variables in flooded areas (Bui et al. 2019). For example, large areas around the river and near the outlet of the basin are affected by floods with low flow accumulation. The uniformity of the pixel values in the flooded areas reduces the effect of the curvature variable. In this regard, in the case of variables lithology and soil order, the reason for the low importance can be attributed to the lack of a large-scale map in more detail. Using 1: 250,000 maps with large polygons may not be sufficient information for modeling. Therefore, the use of more detailed maps and other soil information can be more effective in the modeling. In previous studies, some of these variables have been removed in the process of selecting key variables. For example, in the study of Hosseini et al. (2020) and Bui et al. (2019), the variables of lithology and soil order are recognized as low-importance variables and are excluded from the modeling process.
3.3 Flood hazard modeling results
The optimal values of the modeling parameters are presented in Table 7. For the SVM model, the optimal value of the sigma parameter was 0.2 and 0.4, and the optimal value of the Cost parameter was 50 and 20, respectively, in the return periods of 5 and 10 years. For the CART model, the optimal values of the cp parameter were calculated to be 0.0011 and 0.0020, respectively, for the return periods of 5 and 10 years (Table 7). For the avNNet model, the optimal value of the weight decay parameter is 0.0075 and 0.0001, and the optimal value of the hidden units is 13 and 13, respectively, in the return period of 5 and 10 years (Table 7).
After ensuring adequate training of the models, the models were validated based on 30% of data excluded from the training process. Table 8 shows the performance results of the models for the validation phase. As can be seen, the modeling accuracy and precision values for all models are more than 90%, which indicates the very good performance of the models for predicting flood zones. Kappa values also show a high performance of 88% by all models, which according to Monserud and Leemans (1992) is a great agreement between modeled and observational data. Also, the AUC values for all models are higher than 98% in the five-year return period and higher than 96% in the ten-year return period (Table 8).
In general, comparing the performance of the models shows that although the SVM model offers higher performance, the CART and avNNet models also have a very close performance to it. In this regard, Tehrany et al. (2015) found that the SVM model has a good performance in predicting flood hazards in the Kuala Terengganu watershed of Malaysia. In another study, Shafizadeh-Moghadam et al. (2018) showed that the performance of the ANN model is higher than the CART model in flood hazard modeling in the Haraz watershed. Also, Davoudi Moghaddam et al. (2019) highlighted that the CART model has a good performance for the extraction of flood zones in southwestern Iran.
Finally, after ensuring the performance of the models, the information of all the pixels in the area was provided to the trained models and the flood hazard maps were predicted for 5- and 10-year return periods. Modeled maps show flood hazards varying from 0 to 1. Using the equal-interval method in ArcGIS, the maps are divided into five classes: very low hazard (values 0 to 0.2), low (values 0.2 to 0.4), medium (values 0.4 to 0.6), high (values 0.6 to 0.8), and very high (values 0.8 to 1) (Figs. 7, 8, 9).

Predicted flood hazard map using the SVM model in the return periods of five (top) and ten years (bottom)

Predicted flood hazard map using the CART model in the return periods of five (top) and ten years (bottom)

Predicted flood hazard map using the avNNet model in the return periods of five (top) and ten years (bottom)
As can be seen from the hazard maps (Figs. 7, 8, 9), the very low zone has the highest area. 92, 85, and 80% of the watershed area, respectively, in the SVM, avNNet, and CART models are related to the very low hazard zone in the return period of 5 years, while, in the 10-year return period are about 90, 81, and 82%, respectively. The area of the low hazard zone is equal to 1.98% (1.95%), 16% (11%), and 7% (6%) in SVM, avNNet, and CART models with a return period of 5 years (10 years), respectively. The area of average hazard zone is about 1.44, 0.42, and 2.54% of the watershed area for SVM, avNNet, and CART models with a return period of 5 years, respectively, while in the return period of 10 years is equal to 1.71, 1.57, and 4.42%, respectively. The high hazard zone for SVM, avNNet, and CART models in the 5-year return period comprises 1.48, 0.88, and 2.38% of the watershed area, respectively; these values for the 10-year return period are equal to 2.61, 1.83, and 3.55%. Area of very high class is equal to 2.85, 3.01, and 2.83% for 5-year return period and 4.12, 5.03, and 3.51% for 10-year return period in SVM, avNNet, and CART, respectively (Figs. 7, 8, 9).
3.4 Sensitivity analysis and variables’ contribution
To evaluate the importance of the variables, the sensitivity analysis method of the Jackknife test (Miller 1974) was used. Each time one of the variables was removed from the modeling process and the modeling performance was calculated in the absence of that variable relative to the total performance (i.e., when all variables are present in the modeling). In this method, after removing the variable, the more the modeling performance decreases, the more important the variable is. The criterion for measuring the importance of variables in this test was the rate of decrease in area under curve of the ROC, which is presented as percentage in Fig. 10.

Relative importance of the predictive variables in the return period (RP) of five (top) and ten (bottom) years
Based on the results of the SVM model, the variables of elevation and distance from stream (DTS) were the most important in modeling flood hazard zones. Thus, the contribution rate is 49 and 28% in the return period of 5 years and 54% and 21% in the return period of 10 years, respectively. The importance degree for each of the other variables was less than 8%, with a total contribution of 23 and 25% in the return period of 5 and 10 years, respectively (Fig. 10). The results of the CART model showed that the variables of elevation, DTS, and rainfall had the highest contribution in the modeling, which, respectively, are equal to 27, 26, and 21% in the return period of 5 years and 28, 23, and 20% in the return period of 10 years. Slope and land use with the importance of 11 and 10% in the return period of 5 years and 13% and 11% in the return period of 10 years are in the next degree of importance. The total significance of the other variables is about 5% for both 5- and 10-year return periods (Fig. 10). Unlike the SVM and CART models, the importance of variables does not differ much from each other by the avNNet model and the degree of importance varies between 7 and 14%. However, the variables of elevation (14%), DTS (13%), precipitation (12%), slope (12%), and TWI (11%) in the return period of 5 years were more important than other variables. In the return period of 10 years, the variables of elevation (14%), DTS (13%), precipitation (12%), slope (12%), and land use (11%) had the most contribution in the modeling process. Each contribution of other variables was less than 10%, but they are more important than the SVM and CART models (Fig. 10).
3.5 Flood hazard status of man-made land uses
The flood hazard status of man-made land uses (including agricultural and orchard lands, dry farming, and residential areas) was assessed. By overlaying the land-use map and flood hazard zones, it was found that about 21.4% (14,649 ha) of irrigated areas (including agriculture and orchards) in the return period of 5 years and about 29.8% (20,437 ha) in the return period of 10 years are exposed to high and very high flood hazard areas for the SVM model. These values are equal to 17.7% (12,159 ha) and 22.3% (14,830 ha) for 5-year return period and 31.4% (21,522 ha) and 30.5% (20,703 ha) for 10-year return period, respectively for the CART and avNNet models (Table 9). From dry farming, about 0.5% (839 ha), 1% (1647 ha), and 2.1% (3360 ha), respectively, for the SVM, CART, and avNNet models are exposed to high and very high flood hazard areas in 5-year return period, while for 10-year return period these values are increased, respectively, equal to 0.7% (1093 ha), 1.3% (2130 ha), and 2.4% (3877 ha). Also, 11.5% (841 ha), 8.3% (604 ha), and 14.3% (1048 ha) of residential areas are located at high and very high flood hazard zones for the SVM, CART, and avNNet models, respectively, during the return period of 5 years, while their areas, respectively, are about 22.1% (1608 ha), 17.1% (1252 ha), and 25.1% (1833 ha) in 10-year return period (Table 9).
4 Conclusion and future outlooks
Unlike previous studies conducted by machine learning models, this study set out to produce hazard maps based on the return period. The aim of this study was not to compare the hazard maps with and without considering return periods, but it is necessary to identify flood hazard areas based on return periods and must be done. The modeling results of this study demonstrated a great performance for all the applied models (i.e., accuracy and precision > 90%, kappa > 88%). The findings in this report are subject to at least three limitations: (i) the Sentinel-1 radar images were the main source to extract the flooded pixels. Due to the 6-day capturing of images, many flood dates are not monitored. Given that no organ collects such information, this problem is one of the inevitable limitations of the research. (ii) Lack of soil map can be mentioned as another limitation of this research. Using soil maps, valuable information (such as infiltration, soil texture, soil hydrological groups, and Curve Number) can be considered that are very important in the generation of floods. Although in this study, considered soil order could indirectly indicate the soil information, it is recognized as a low importance variable due to the uniformity of the map and its large polygons. (iii) For the sake of computer limitation, the high time of processing during modeling can be considered as another problem and limitation of this research. Regarding the pixel size (12.5 m) and the adopted method for modeling with 10 folds with frequent repetition (cross-validation method), the modeling process to prepare a hazard map for a model took up to a week. Respectively, for addressing the above-mentioned limitations, considering other sources of data for flood location extraction, providing a detailed soil map or studying a watershed that has it, and applying a strong processor are recommended. It should be noted that the flood hazard maps are affected by climate change, environmental changes (deforestation, etc.), and human intervention, thus it would be interesting to assess their effects to update the maps over time. The findings of this study have some important implications for future practice such as flood risk management plans and provide a clear picture of flood risk and flood damage in the watershed to decide on urban, rural, agricultural, and industrial areas development plans.
Data availability
The data that support the findings of this study are available from the corresponding author, B.C., upon reasonable request.
References
Ahmadaali J, Barani GA, Qaderi K, Hessari B (2017) Calibration and validation of model WEAP21 for Zarrineh rud and Simineh rud basins. Iran J Soil Water Res 48(4):823–839
Amare S, Langendoen E, Keesstra S, Ploeg MVD, Gelagay H, Lemma H, van der Zee SE (2021) Susceptibility to gully erosion: applying random forest (RF) and frequency ratio (FR) approaches to a small catchment in Ethiopia. Water 13(2):216
Anderson TW, Darling DA (1954) A test of goodness of fit. J Am Stat Assoc 49(268):765–769
Bayik C, Abdikan S, Ozbulak G, Alasag T, Aydemir S, Sanli FB (2018) Exploiting multi-temporal Sentinel-1 SAR data for flood extend mapping. Int Arch Photogramm Remote Sens Spatial Inf Sci 42(3):109
Beven KJ, Kirkby MJ (1979) A physically based, variable contributing area model of basin hydrology/Un modèle à base physique de zone d’appel variable de l’hydrologie du bassin versant. Hydrol Sci J 24(1):43–69
Bishop CM, Tipping M (2013) Variational relevance vector machines. arXiv preprint arXiv:1301.3838
Breiman L, Friedman JH, Olshen RA, Stone CJ (1984) Classification and regression trees. Wadsworth and Brooks/Cole, Monterey
Bui DT, Tsangaratos P, Ngo PTT, Pham TD, Pham BT (2019) Flash flood susceptibility modeling using an optimized fuzzy rule based feature selection technique and tree based ensemble methods. Sci Total Environ 668:1038–1054
Cao H, Zhang H, Wang C, Zhang B (2019) Operational flood detection using Sentinel-1 SAR data over large areas. Water 11(4):786
Clement MA, Kilsby CG, Moore P (2018) Multi-temporal synthetic aperture radar flood mapping using change detection. J Flood Risk Manag 11(2):152–168
Davoudi Moghaddam D, Pourghasemi HR, Rahmati O (2019) Assessment of the contribution of geo-environmental factors to flood inundation in a semi-arid region of SW Iran: comparison of different advanced modeling approaches. Natural hazards GIS-based spatial modeling using data mining techniques. Springer, Cham, pp 59–78
Djalante R (2012) Adaptive governance and resilience: the role of multi-stakeholder platforms in disaster risk reduction. Nat Hazards Earth Syst Sci 12:2923–2942
Eini M, Kaboli HS, Rashidian M, Hedayat H (2020) Hazard and vulnerability in urban flood risk mapping: machine learning techniques and considering the role of urban districts. Int J Disaster Risk Reduct 50:101687
Feng C, Cui M, Hodge BM, Zhang J (2017) A data-driven multi-model methodology with deep feature selection for short-term wind forecasting. Appl Energy 190:1245–1257
Gigović L, Pamučar D, Bajić Z, Drobnjak S (2017) Application of GIS-interval rough AHP methodology for flood hazard mapping in urban areas. Water 9(6):360
Guo EL, Zhang ZQ, Ren XH et al (2014) Integrated risk assessment of flood disaster based on improved set pair analysis and the variable fuzzy set theory in central Liaoning Province. China Nat Hazards J 74:947–965
Gutierrez F, Parise M, De Waele J, Jourde H (2014) A review on natural and humaninduced geohazards and impacts in karst. Earth Sci Rev 138:61–88
Guyon I, Weston J, Barnhill S, Vapnik V (2002) Gene selection for cancer classification using support vector machines. Mach Learn 46(1):389–422
Heidarpour B, Saghafian B, Yazdi J, Azamathulla HM (2017) Effect of extraordinary large floods on at-site flood frequency. Water Resour Manage 31(13):4187–4205
Hosseini FS, Choubin B, Mosavi A, Nabipour N, Shamshirband S, Darabi H, Haghighi AT (2020) Flash-flood hazard assessment using ensembles and Bayesian-based machine learning models: application of the simulated annealing feature selection method. Sci Total Environ 711:135161
Janizadeh S, Pal SC, Saha A, Chowdhuri I, Ahmadi K, Mirzaei S, Tiefenbacher JP (2021) Mapping the spatial and temporal variability of flood hazard affected by climate and land-use changes in the future. J Environ Manage 298:113551
Janizadeh S, Vafakhah M, Kapelan Z, Mobarghaee Dinan N (2021) Hybrid XGboost model with various Bayesian hyperparameter optimization algorithms for flood hazard susceptibility modeling. Geocarto Int. https://doi.org/10.1080/10106049.2021.1996641
Johnson LE, Olsen BG (1998) Assessment of quantitative precipitation forecasts. Weather Forecast 13(1):75–83
Kalantar B, Ueda N, Lay US, Al-Najjar HAH, Halin AA (2019) Conditioning factors determination for landslide susceptibility mapping using support vector machine learning. In: IGARSS 2019–2019 IEEE International Geoscience and Remote Sensing Symposium, IEEE, pp 9626–9629
Kazemi A, Rezaei Moghaddam MH, Nikjoo MR, Hejazi MA, Khezri S (2016) Zoning and management of the hazards of floodwater in the Siminehrood river using the HEC–RAS hydraulic model. Environ Manag Hazards 3(4):379–393
Khalfallah CB, Saidi S (2018) Spatiotemporal floodplain mapping and prediction using HEC-RAS-GIS tools: case of the Mejerda river, Tunisia. J Afr Earth Sc 142:44–51
Khattak MS, Anwar F, Saeed TU, Sharif M, Sheraz K, Ahmed A (2016) Floodplain mapping using HEC-RAS and ArcGIS: a case study of Kabul River. Arab J Sci Eng 41(4):1375–1390
Khosravi K, Panahi M, Golkarian A, Keesstra SD, Saco PM, Bui DT, Lee S (2020) Convolutional neural network approach for spatial prediction of flood hazard at national scale of Iran. J Hydrol 591:125552
Kolmogorov A (1933) Sulla determinazione empirica di una lgge di distribuzione. Inst Ital Attuari Giorn 4:83–91
Kuenzer C, Guo H, Huth J, Leinenkugel P, Li X, Dech S (2013) Flood mapping and flood dynamics of the Mekong Delta: ENVISAT-ASAR-WSM based time series analyses. Remote Sens 5(2):687–715
Kussul N, Shelestov A, Skakun S (2011) Flood monitoring from SAR data. Use of satellite and in-situ data to improve sustainability. Springer, Dordrecht, pp 19–29
Lee DH, Kim YT, Lee SR (2020) Shallow landslide susceptibility models based on artificial neural networks considering the factor selection method and various non-linear activation functions. Remote Sens 12(7):1194
Lee JH, Sameen MI, Pradhan B, Park HJ (2018) Modeling landslide susceptibility in data-scarce environments using optimized data mining and statistical methods. Geomorphology 303:284–298
Long S, Fatoyinbo TE, Policelli F (2014) Flood extent mapping for Namibia using change detection and thresholding with SAR. Environ Res Lett 9(3):035002
Luu C, Bui QD, Costache R, Nguyen LT, Nguyen TT, Van Phong T, Pham BT (2021) Flood-prone area mapping using machine learning techniques: a case study of Quang Binh province. Vietnam Nat Hazards 108(3):3229–3251
Madadi MR, Azamathulla HM, Yakhkeshi M (2015) Application of Google earth to investigate the change of flood inundation area due to flood detention dam. Earth Sci Inf 8(3):627–638
Mehta DJ, Yadav SM (2020) Hydrodynamic simulation of river Ambica for riverbed assessment: a case study of Navsari Region. Advances in water resources engineering and management. Springer, Singapore, pp 127–140
Miandoab Press (2019) Retrieved from http://miandoabpress.ir/index.php?newsid=377. Accessed 28 Jan 2021
Miller RG (1974) The jackknife-a review. Biometrika 61(1):1–15
Minea G, Mititelu-Ionuș O, Gyasi-Agyei Y, Ciobotaru N, Comino JR (2022) Impacts of grazing by small ruminants on Hillslope hydrological processes: a review of European current understanding. Water Resour Res. https://doi.org/10.1029/2021WR030716
Mojaddadi H, Pradhan B, Nampak H, Ahmad N, Ghazali AHB (2017) Ensemble machine-learning-based geospatial approach for flood risk assessment using multi-sensor remote-sensing data and GIS. Geomat Nat Haz Risk 8(2):1080–1102
Monserud RA, Leemans R (1992) Comparing global vegetation maps with the Kappa statistic. Ecol Model 62(4):275–293
Mosavi A, Ozturk P, Chau KW (2018) Flood prediction using machine learning models: literature review. Water 10(11):1536
Nandi A, Mandal A, Wilson M, Smith D (2016) Flood hazard mapping in Jamaica using principal component analysis and logistic regression. Environ Earth Sci 75(6):1–16
Norallahi M, Seyed Kaboli H (2021) Urban flood hazard mapping using machine learning models: GARP, RF MaxEnt and NB. Nat Hazards 106(1):119–137
Olorunfemi IE, Komolafe AA, Fasinmirin JT, Olufayo AA, Akande SO (2020) A GIS-based assessment of the potential soil erosion and flood hazard zones in Ekiti State, Southwestern Nigeria using integrated RUSLE and HAND models. CATENA 194:104725
Patial JP, Savangi A, Singh OP, Singh AK, Ahmad T (2008) Development of a GIS interface for estimation of runoff from watersheds. Water Res Manag 22:1221–1239
Pelling M (2003) The vulnerability of cities: natural disasters and social resilience. Earthscan
Petit-Boix A, Sevigne-Itoiz E, Rojas-Gutierrez LA, Barbassa AP, Josa A, Rieradevall J, Gabarrell X (2017) Floods and consequential life cycle assessment: integrating flood damage into the environmental assessment of stormwater Best Management Practices. J Cleaner Prod 162:601–608
Popa MC, Peptenatu D, Drăghici CC, Diaconu DC (2019) Flood hazard mapping using the flood and flash-flood potential index in the Buzău river catchment. Romania Water 11(10):2116
Pourghasemi HR, Kariminejad N, Amiri M, Edalat M, Zarafshar M, Blaschke T, Cerda A (2020) Assessing and mapping multi-hazard risk susceptibility using a machine learning technique. Sci Rep 10(1):1–11
Rahim AS, Yonesi HA, Shahinejad B, Podeh HT, Azamattulla HM (2022) Flow structures in asymmetric compound channels with emergent vegetation on divergent floodplain. Acta Geophys. https://doi.org/10.1007/s11600-022-00764-0
Riley SJ, DeGloria SD, Elliot R (1999) Index that quantifies topographic heterogeneity. intermountain J Sci 5(1–4):23–27
Ripley BD (2007) Pattern recognition and neural networks. Cambridge University Press
Ripley B, Venables W (2016) nnet: Feed-Forward Neural Networks and Multinomial Log-Linear Models (Version 7.3–12). Retrieved from https://CRAN.R-project.org/package=nnet
Romali NS, Yusop Z, Ismail AZ (2018) Application of HEC-RAS and Arc GIS for floodplain mapping in Segamat town, Malaysia. GEOMATE J 15(47):7–13
Sarkar SK, Ansar SB, Ekram KMM, Khan MH, Talukdar S, Naikoo MW, Mosavi A (2022) Developing robust flood susceptibility model with small numbers of parameters in highly fertile regions of Northwest Bangladesh for sustainable flood and agriculture management. Sustainability 14(7):3982
Shafizadeh-Moghadam H, Valavi R, Shahabi H, Chapi K, Shirzadi A (2018) Novel forecasting approaches using combination of machine learning and statistical models for flood susceptibility mapping. J Environ Manage 217:1–11
Smirnov N (1948) Table for estimating the goodness of fit of empirical distributions. Ann Math Stat 19(2):279–281
Sokolova M, Japkowicz N, Szpakowicz S (2006) Beyond accuracy, F-score and ROC: a family of discriminant measures for performance evaluation. AI 2006: advances in artificial intelligence. Springer, Berlin, pp 1015–1021
Tehrany MS, Pradhan B, Mansor S, Ahmad N (2015) Flood susceptibility assessment using GIS-based support vector machine model with different kernel types. CATENA 125:91–101
Tholey N, Clandillon S, De Fraipont P (1997) The contribution of spaceborne SAR and optical data in monitoring flood events: Examples in northern and southern France. Hydrol Process 11(10):1409–1413
Timofeev R (2004) Classifcation and regression trees (CART) theory and applications. In: Master Thesis. Center of Applied Statistics and Economics, Humboldt University, Berlin
Udomchai A, Hoy M, Horpibulsuk S, Chinkulkijniwat A, Arulrajah A (2018) Failure of riverbank protection structure and remedial approach: a case study in Suraburi Province, Thailand. Eng. Failure Anal. 91
UNFPA (2018) United Nations population fund. https:// www.unfpa.org/. Accessed on 29 Aug 2018
Vapnik VN, Lerner A (1963) Pattern recognition using generalized portrait method. Autom Remote Control 24:774–780
Acknowledgements
This research is the output of a research project (No. 24-36-29-017-000336) in the Agricultural Research, Education, and Extension Organization (AREEO) using financial support from the Iran National Science Foundation (INSF) (Grant No. 99017414).
Funding
This work was supported by Iran National Science Foundation (INSF) (Grant No. 99017414).
Author information
Authors and Affiliations
Contributions
BC was involved in conceptualization, formal analysis, project administration, supervision, writing-original draft; FSH contributed to data curation, validation; OR investigated the study; BC and FSH done methodology; BC and OR did software; MMY made visualization; All were involved in writing—review and editing.
Corresponding author
Ethics declarations
Conflict of interest
The authors have no relevant financial or non-financial interests to disclose.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Springer Nature or its licensor holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Choubin, B., Hosseini, F.S., Rahmati, O. et al. A step toward considering the return period in flood spatial modeling. Nat Hazards 115, 431–460 (2023). https://doi.org/10.1007/s11069-022-05561-y
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11069-022-05561-y