
Abstract
After the earthquake occurrence, collecting correct information about the extent of damage is essential for managing critical conditions and allocating limited resources. The prepared building damage maps sometimes bring about waste of time required for rescuing individuals under the rubble by wrongly conducting rescue teams toward regions with a lower rescue priority. In this research, an algorithm based on using a proposed standard at database level was developed to prioritize damaged buildings by considering five key elements of land use type, the degree of damage to buildings, the land use differentiation index, time of the highest population density in each land use, and time of disaster’s incidence. The steps of the proposed method which was implemented in the MATLAB environment include: detecting buildings on the pre- and post-event imagery, implementing texture features for each candidate building, choosing the optimal features by genetic algorithm, determining the degree of building damage in three classes of negligible damage, substantial damage, and heavy damage by using the difference between chosen features as inputs of the designed neurofuzzy inference system. Data collected from field observations were compared to the output obtained from the proposed algorithm. This comparison presented a general accuracy of 88% and Kappa coefficient of 79% in the classification of buildings into three damage classes. The proposed standard then was used for classifying damaged buildings into relief priorities of high, medium, and low. Findings revealed that the relief priority map could be a basis for correct guidance of relief and rescue teams during crucial times following earthquakes.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
Different forms of catastrophic events do have deadly effects when they occur in populated areas. Some of these catastrophic events include: floods, cyclones, hurricanes, heavy rains, landslides, avalanches, earthquake (Karimzadeh et al. 2014). Among these natural disasters, earthquakes with the largest number of fatalities, highest number of occurrences, and also posing serious threats to urban areas (Bartels and VanRooyen 2012; Berz et al. 2001; Ranjbar et al. 2014a) are regarded as the most devastating events (Ranjbar et al. 2016; Wei et al. 2017). After earthquake occurrence, detecting the level of damage for every individual building in the form of a building damage map is one of the extremely important operations required in the response and reconstruction phase of disaster management in affected areas (Aghamohammadi et al. 2013; Feng et al. 2013; Jin et al. 2011; Kakooei and Baleghi 2017; Rastiveis et al. 2013).
Collecting information about the affected areas by using field survey methods, although having high accuracy, still needs long time (Kakooei and Baleghi 2017) and more field work (Zhai et al. 2016). Remote sensing technology can be a very useful and powerful resource for post-earthquake damage assessment, due to continuous monitoring of the earth, rapid access of data and multitemporal coverage of areas (Jin et al. 2011; Li et al. 2008; Ranjbar et al. 2017a; Vu and Ban 2010; Zhai et al. 2016). Each remote sensing data has its own advantages which makes that source suitable for an appropriate purpose. For instance, information such as shape, texture, morphology, which could be easily extracted from optical images compared to other remote sensing data, is valuable property for damage assessment (Dong and Shan 2013; Ranjbar et al. 2017a; Rathje et al. 2005). Discriminating between buildings and other features also requires high spatial resolution data, which led to the use of high-resolution data, such as IKONOS, QuickBird, World View, GeoEye, and EROS in most recent researches (Hamedianfar and Shafri 2014; Li et al. 2010).
In addition to the properties of data and its resolution, there are three parameters affecting the process of building damage assessment; these include: accuracy, speed, and the operator role. Speeding up the process and reducing the role of operators can produce an instantaneous damage map and thus reduce the number of fatalities. On the contrary, the creation of damage map with low accuracy may increase the number of fatalities; hence, to avoid this scenario, it becomes necessary to properly optimize these three parameters. Researchers have tried to achieve this goal by using three different approaches, namely monotemporal, multitemporal, and a combination of imagery and vector maps. The main differences between these three approaches lie in optimizing the three mentioned parameters above.
The monotemporal approach for earthquake damage assessment, which involves using only the post-disaster imagery of damaged areas, is greatly used by researches after development in spatial resolution of satellite imagery (Li et al. 2010; Ranjbar et al. 2015; Vu and Ban 2010). Although the methods developed based on this approach have higher processing speed in comparison with the other methods, the results of these methods could not accurately discriminate between damaged and intact areas (Dong and Shan 2013). Various methods have been designed in this area using different properties, such as color, edge, texture, spectra, shape, and shadow. Liu et al. (2004) proposed a method to automatically identify damaged buildings by using structure and statistical information of texture. This method was developed based on the fact that the intact buildings generally showed even texture, while the damaged or semi-damaged buildings always exhibited uneven texture. The outputs of this method were in accordance with observations from field survey. Vu et al. (2005) proposed an automatic area independent methodology for damage identification of buildings after earthquake by using statistical textures, edge variance, and direction obtained from high-resolution satellite imagery. The algorithm showed a compromising result in classifying buildings with sustainable damage level. Rathje et al. (2005) implemented a semi-automatic method for extracting damage patterns due to earthquake in the city of Bam by using color and textural features. The results of this research approved that the selected optimum features and window sizes for discriminating damages significantly depend on the characteristics of the earthquake and the affected area. Guo et al. (2009) identified damaged buildings after earthquake by using a theory based on the combination of morphological features with reflection mechanism. The outputs of this research could be used for detecting damaged buildings due to other events. Vu and Ban (2010) developed an automatic approach for earthquake damage assessment by considering valuable information including spatial relations, shape, structure, spectra, and edge extracted from QuickBird images. The speed of this method was optimized 36 times by using parallel processing, and the accuracy of damage ratio was estimated about 80%. By considering the limitations of traditional approaches in extracting information and the speed required for damage assessment processing, Li et al. (2011) presented an object-based method for building damage identification by using post-event high-resolution satellite imagery which could achieve a higher accuracy in comparison with ordinary methods.
The multitemporal approach is another way of detecting damage grades after earthquake, which has more accurate results in comparison with the methods using the monotemporal approach (Dong and Shan 2013). The usefulness of this method was limited by differences between the environmental conditions, satellite sensor characteristics (Thonfeld et al. 2016), and the lack of pre-event reference data (Li et al. 2011). Deploying mathematical operations and independent classification are two different methods for detecting changed areas in this approach (Deng et al. 2008; Hussain et al. 2013; Ranjbar et al. 2014b; Singh 1989). The first method, which includes different techniques such as differencing, rationing, regression, principal component analysis, vegetation index differencing, and change vector analysis (CVA), regards each individual pixel as a separate object and labels it a different damage level comparing with its neighboring pixels (Rastiveis et al. 2013). In other words, these techniques are developed to identify the changes between temporal images based on using mathematical algebra and selecting threshold (Deng et al. 2008). Berberoglu and Akin (2009) analyzed and compared different techniques of traditional method for identifying changes and concluded that image rationing has the ability to reduce the effects of topographic such as shadow and illumination despite its unsatisfying results in comparison with image differencing and CVA. Coppin et al. (2004), Hussain et al. (2013), Lu et al. (2004), Singh (1989) also reviewed different pixel-based change detection techniques and summarized their pros and cons in more details. Selecting the optimum threshold value was considered as the most challenging task for discriminating class of change from class of no-change in the aforementioned method (Hussain et al. 2013; Lu et al. 2004; Xian and Homer 2010). Although this method is fairly simple and easy to use, complete information about changed areas could not be completely provided (Lu et al. 2004). By considering the limitations of traditional method such as the dependency of the output’s accuracy to the coregistration errors of images (Ban and Yousif 2016), the insufficiency of using solely spectral information for damage assessment (Rastiveis et al. 2013), and the necessity to high spatial resolution images for discriminating roof pixels from neighboring pixels (Dong and Shan 2013), most of the researchers (Chini et al. 2011; Gusella et al. 2005; Huyck et al. 2005; Ranjbar et al. 2016) used the second method for detecting different damage levels of buildings. Based on the results of a number of researches (Blaschke et al. 2011; Chen et al. 2012b; Hussain et al. 2013), the object-based method is considered more applicable for high spatial resolution images than the traditional method. In object-based method, pixels of image are initially segmented into image objects which are the basis for further analysis. So, defining suitable parameters for segmenting image into appropriate image objects is the main challenging task of the mentioned method (Rastiveis et al. 2013). Finally, each change detection technique has its own advantages which could make it appropriate for a particular application (Berberoglu and Akin 2009).
On the one hand, the other approach called the combination of imagery and vector maps could improve the accuracy and also decrease the time requiring for data processing of mono- and multitemporal damage detection approaches by identifying the building footprints more accurately in case of using updated vector maps (Dong and Shan 2013; Rastiveis et al. 2013), but on the other hand, the approach could have negative effects on the outputs in case of using outdated version of vector maps. Turker and San (2004) proposed a technique by using vector data of buildings for discriminating collapsed from intact buildings. The method was implemented based on the hypothesis that there would not be a shadow for a collapsed building. Although the overall accuracy of the developed technique was estimated about 96.15%, the technique failed to function normally in areas with complex building shapes. A procedure for rapid damage identification of buildings using ancillary data was developed by Gamba et al. (2007) and implemented in Bam city of Iran. The accuracy of the proposed damage detection method was improved notably due to extracting buildings and omitting other classes by using vector maps; the results indicated an acceptable accordance with data gathered from field survey. Based on using the combination of image features Trianni and Gamba (2008) carried out the idea of using satellite imagery and ancillary data at Algeria and Peru earthquakes occurred in 2003 and 2007, respectively. The results of this study proved the improvement of data interpretation, the robustness, and affordability of this procedure comparing with other methods. The information about the extent of the destructive earthquake which hit Tohoku of Japan in March 11, 2011, was captured by high-resolution satellite images. The difference between backscattering intensity of images was used in the research conducted by Liu et al. (2012) for detecting damaged buildings; moreover, in the proposed method each individual building was identified by its corresponding vector map. The results were reliable in comparison with the outputs of visual interpretation. Rastiveis et al. (2013) detected damaged buildings in four different grades by considering the shape of roofs in the post-earthquake imagery and comparing it with the shape of roofs in the pre-earthquake imagery. Identifying damaged buildings based on shapes besides other features like textures was the novelty of this research which had promising results. Ranjbar et al. (2016) presented a casualty estimation method based on object-based damage identification of buildings. In this research, the optimum texture features were extracted by visual interpretation from pre- and post-event high-resolution satellite imagery and the difference between selected features was used as inputs of a proposed fuzzy logic system for determining damage levels. The necessity to an expert operator for identifying optimum features and also preparing a set of rules for the fuzzy inference system was the main weakness of the mentioned algorithm. Although in this research a fuzzy-genetic approach was used for discriminating class of building from other classes, the accuracy of building detection was improved by using a vector map.
The damage map obtained from previous studies because of neglecting information related to the type of land use, the key parameters influencing the prioritization of regions requiring rescue and relief, and lack of a proposed standard for making relief processes at early moments following the incidence of earthquake could not be a reliable source for relief teams. In other words, these maps by only considering the damage level sometimes misdirect rescuers toward buildings that were devoid of inhabitants; this situation led to waste of time in the relief process (Ranjbar et al. 2017a). To support this issue, Hassanzadeh and Nedovic-Budic (2016) proposed a spatial index to prioritize building blocks by considering seven main criteria in the GIS environment. Thereafter Ranjbar et al. (2017a) developed a fuzzy hierarchical analysis for estimating the level of necessity to rescue actions for any building in the study area. Since proposing a comprehensive standard at database level for prioritizing buildings is indispensable, this research focused on developing an algorithm for detecting the degree of damage to buildings based on texture analysis on pre- and post-event high-resolution satellite images and converting the resultant to a relief priority map by integrating it with a proposed prioritization standard. The method was implemented in the Varzaghan district in Azarbaijan Province of Iran as a case study. This paper described the approach (Sect. 2) of the study and evaluated the performance on the case study (Sect. 3). In Sect. 4, the results were discussed and concluded.
2 Materials and methods
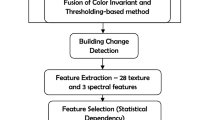
In this research by considering the necessity to a reliable standard for discriminating buildings with higher relief priority from buildings with lower relief priority in the early moments after the earthquake occurrence, an algorithm based on using a comprehensive standard at database level was presented. The developed algorithm consists of six main steps of pre-processing, building detection, texture analysis, optimum feature selection, damage assessment using an adaptive neurofuzzy inference system, and prioritization of damaged buildings based on using the proposed relief priority standard. The proposed algorithm is based on the flowchart shown in Fig. 1. In the proposed algorithm, damaged buildings initially were detected on pre-processed satellite images of the study area by using snakes and dynamic programming and vector map of the study area. Different texture features were extracted for every individual building to differentiate between damaged and undamaged buildings; the optimum features relevant to the problem were selected by the genetic algorithm (GA). Differences of the optimum features were then used as inputs of the proposed neurofuzzy inference system to estimate the rate of damage for the extracted buildings. Finally, a standard for prioritizing damaged buildings was prepared based on analysis of experiences of local crisis management teams, and the buildings requiring rescue and relief were identified.

Flowchart of the proposed algorithm
2.1 Pre-processing
This step involves pre-processing of satellite images and preparing GIS database of the study area requiring in the process of prioritizing damaged buildings after the earthquake occurrence in Varzaghan city, Iran. Initially, atmospheric and solar illumination effects of pre- and post-event satellite images were eliminated through using atmospheric correction, and the ground elevation of images was compensated by using a coarse digital terrain model (DTM). The satellite images were then pan-sharpened by fusing the multispectral and panchromatic channels of GeoEye-1 images, in order to utilize multispectral information at a higher spatial resolution. Afterward, the spectral similarity of pre- and post-event satellite images was increased by using histogram matching, and the two images were registered using 15 control points. Also, the GIS database of the study area was prepared in the way that could provide the necessary information of the proposed prioritization standard.
2.2 Building detection
Automatic extraction of buildings from satellite images is one of the most important steps in the proposed method which was achieved through the use of an algorithm presented by (Fazan and Dal Poz 2013). This algorithm was developed based on the assumption that buildings have straight lines with orthogonal angles. In this research, the buildings were initially formulated by using a snake model; then, the constructed formulation was solved as an optimization problem by a dynamic programming (DP) algorithm. The optimum solutions of the method would represent the candidate buildings of the study area. The snake model consists of an internal and an external energy term which are responsible for controlling the geometry of curve \(v\) and for moving the contour \(v\) along the candidate feature, respectively [Eq. (1)]. For additional details about this method, the reader is referred to (Fazan and Dal Poz 2013; Kass et al. 1988).
where the constants \(\alpha_{i}\) and \(\beta_{i}\) are weights of the first and second orders of internal energy term, and \(\gamma_{i}\) and \(\eta_{i}\) are negative and positive constants at \(v_{i}\) of the contour, respectively. \(\left| {\nabla G\left( {v_{i} } \right)} \right|\) is the gradient of image, \({\text{CS(}}v_{i} )\) is the result of an operator for corner detection, and \(\delta_{i}\) is the deflection angle.
Finally, the buildings were detected in the pre-event image of the study area by using the mentioned method and the outdated vector map. The extracted corners of buildings were mapped on the post-event image to find the boundary of buildings which were disappeared due to earthquake. Digital values of zero were assigned to the outer pixels of the boundary of buildings, in order to eliminate the effect of non-building classes in the class of building.
2.3 Texture analysis
Texture has been defined differently by a variety of researchers; the most commonly acceptable definition is that texture is a function of the spatial variation in pixel intensities to characterize the smoothness of a surface (Li et al. 2010). Damage detection methods using texture features were developed based on the hypothesis that the areas with high rate of damage had a more coarse texture than areas with lower level of damage (Dong and Shan 2013). Techniques using spectral information of the pixels for distinguishing damaged pixels from intact pixels in a building area yield unsatisfying results in comparison with the methods using complementary information such as textural information (Rastiveis et al. 2013). Also, the type of texture features plays an important role in the accuracy of damage detection methods (Ranjbar et al. 2016); thus, in this paper, features in six categories of first-order statistical, Haralick, geostatistics, wavelet, Gabor, and fractal features were implemented (Fig. 2). From this list, based on deploying genetic algorithm (GA) as an optimization method, ten features were selected as optimum features to be used with spectral features in the damage detection process (features in dashed line rectangles in Fig. 2). The selected features are described in greater detail in the forthcoming paragraphs.

Six categories of texture features implemented for damage detection (features in dashed line rectangles are those selected by GA)
First-order statistical features First-order statistical features were computed using the histogram of pixel intensities (Aggarwal and Agrawal 2012) for measuring the similarity of a gray value at a randomly chosen location in the image without considering pixel neighborhood relationships (Ranjbar et al. 2016; Rastiveis et al. 2013). The features were derived from the histogram of pixel intensities including moments, which are greatly used in statistics and mechanics. In this research, the first-order moment or mean (\(\mu_{1}\)) of gray values and weighted distance mean (\({\text{MW}}\)) of adjacent pixels in a region were considered as the first-order statistical features to be applied in the damage detection process. These features can be calculated using Eqs. (2) and (3):
where \(P(I)\) is defined as the probability of a digital number \(I\) existing within an image, \(N_{g}\) is the number of gray levels within an image, and \(d\) is the distance between the central pixel and pixel \((i,j)\).
Haralick features The first-order statistical features could not give any information about the relative positions of various gray levels within the image, to measure whether all low-value gray levels are positioned together or they are interchanged with high-value gray levels (Aggarwal and Agrawal 2012). As a result, the second-order statistical features were proposed based on a two-dimensional co-occurrence matrix to consider the neighboring pixel relationships. The co-occurrence matrix \(P[i,j]\) is an array which counts all pairs of pixels separated by \(d\) having gray levels \(i\) and \(j\) (Rastiveis et al. 2013). Among the features which could be derived from the co-occurrence matrix, homogeneity (\(H\)) and correlation (\(C\)) were selected in the damage detection process. These features can be calculated using Eqs. (4) and (5):
where \(N_{g}\) is the number of gray levels, and \(\mu_{i}\), \(\mu_{j}\) and \(\sigma_{i}\), \(\sigma_{j}\) are mean and standard deviation, respectively.
Geostatistics features The geostatistic features try to implement texture features based on two parameters, namely local changes and spatial correlation (Chica-Olmo and Abarca-Hernandez 2000). Local changes measure the separation of mean within an image, and spatial correlation assumes that the gray levels are distributed based on this assumption that closer pixels have more gray-level dependency (Ranjbar et al. 2016; Van der Meer 2012). Semi-variogram is the main tool to model these two parameters, which has a variety of applications in remote sensing techniques like damage assessment (Balaguer et al. 2010; Ranjbar et al. 2016; Rastiveis et al. 2013). Among the features which could be derived from semi-variogram the simple variogram and cross-variogram were selected as the optimum features in the damage detection process. These features can be calculated using Eqs. (6) and (7):
where \(\gamma_{k} (h)\) is defined as the variogram value in a number of variogram ranges \(h\), \({\text{DN}}_{k}\) is the digital number of \(x_{i}\) and \(x_{i} + h\) pixels, and in a region of image \(n(h)\) is the number of points in pair at a distance of \(h\).
Wavelet features The basic functions used in Fourier transform have an unlimited period; many signals are not continuous signals in nature. For instance, digital images are an example of discrete functions. In wavelet transform, a series of functions with a limited period is used as basic functions for composing a discrete signal with less coefficients and better accuracy. After defining a wavelet basis \(\psi (x)\), other functions are achieved by transferring and changing the function scale in the spatial domain. The Daubechies and Haar are a family of wavelets used in the feature extraction process of the current research. For additional details about these wavelets, the reader is referred to (Daubechies 1992; Haar 1910).
In two-dimensional imagery, basic wavelet functions will be according to Eq. (8).
where \(a\) represents the scale, and \(b_{x}\) and \(b_{y}\) represent the amount of filter transmission on the x-axis and y-axis, respectively.
Transformation is defined according to Eq. (9) as a function of inner multiplication in basic wavelet functions.
After applying the conversion stage, \(N \times N\) image is converted into four \(\frac{N}{2} \times \frac{N}{2}\)-point images without any loss of data (Myint et al. 2004). This makes it possible to move on to the next orders of conversion by considering the estimation image (LL) of the primary image as the input. The logarithm of energy (\(\log\)) and Shannon index (\({\text{SHAN}}\)), which could be derived from image approximation, were selected for damage detection process. These features can be calculated using Eqs. (10) and (11):
where \(P(i,j)\) is defined as the probability of a digital number \(I\) existing within an image; \(k\) is the gray levels within an image.
Gabor features Gabor filters reduce the complexity of texture analysis by decomposing an image into a number of scales (\(S\)) and orientations (\(k\)) (Khan et al. 2016). These filters can be designed according to the general form \(g(x,y)\) of a Gabor discrete transform which is defined by convolution of two functions including Gaussian and harmonic (Ranjbar et al. 2016; Wu et al. 2000). A set of Gabor filters can be calculated using Eq. (12).
where \(k\) is the total number of given directions and \(m\) and \(n\) are natural numbers.
After filtering the image with Gabor filters and forming sub-bands, standard deviation and mean of sub-bands are computed as obtained features. In many cases, only the real part of filter is used for calculating the features, while in some cases such as this study, both real and imaginary parts are used (sum of squares of real and imaginary images). For additional details about these Gabor filters, the reader is referred to (Manjunath et al. 1996; Wu et al. 2000).
2.4 Optimum feature selection
The optimum feature space is generated by removing repetitive and irrelevant descriptors to solving the problem. To form this space, the effective feature subset should be searched among existing features. This study used genetic algorithm, which is one of the most effective optimization algorithms, for selecting optimal descriptors. The algorithm is derived from the natural process of biological evolution and tries to solve problems using these principles (Tsai et al. 2013). In these algorithms, solutions are not developed, a set of solutions is kept in a generation, better solutions are provided with chance of producing child, while weaker solutions are removed (Ranjbar et al. 2017b).
The GA-based algorithm process starts with a random generation of one set of solutions required to evolve for a problem as the initial population in which candidate solutions were encoded on the genes of a variety of chromosomes. Here a chromosome is a string of bits that 1 and 0 represent the presence and absence of a feature in classification, respectively (Li et al. 2004). Genetic operators such as elitism, crossover, and mutation are then used to evolve the populations with an iteration process (Haddadi et al. 2011; Tsai et al. 2013). The reproductive success of each individual chromosome was evaluated based on using a fitness function (Pal 2013). Since classifying damaged buildings with the highest accuracy is the main aim of this research, the fitness value was defined in a way that could maximize the obtained overall accuracy of classification. In this way, sample buildings were initially classified by adaptive boosting method, and the computed overall accuracy was then assigned to corresponding chromosome as fitness value. Repeating this process, most times, leads to solutions that are better than the first generation. The overall process of optimal description space formation is shown in Fig. 3.

Optimal description space formation using genetic algorithm
2.4.1 Using adaptive boosting algorithm as a fitness function in the genetic algorithm
In this research, statistical adaptive boosting method was used for evaluating each chromosome in the process of optimum feature selection. Adaptive boosting is a meta-algorithm which has the ability to integrate with other learning algorithms in order to improve the performance of classification. In general, learning algorithms are grouped into weak or strong; strong classifier algorithms use techniques such as artificial neural network, while weak classifier algorithms use techniques such as Bayesian networks (Herfeh et al. 2013; Ibarra-Manzano and Almanza-Ojeda 2012). Boosting algorithm gives to each instance in S learning data equal weight of \(w_{j} (i)\). Learning algorithm makes a classifier \(h_{j}\) for the data, and then, a new weight value of \(w_{j + 1} (i)\) is assigned to each sample based on the output of the classifier. The weight of the samples that were properly classified is decreased, and the weight of the samples that were incorrectly classified is increased. This process resulted in a series of easy instances having low weight and a series of hard instances having high weight. In the next repetition, a classifier is created for reweighted data with a focus on the classification of hard instances. Again, samples’ weight based on new classifier is decreased or increased. After that, all weights were updated; the weights are normalized until the sum of the weights remains the same as the previous case. After all repetition, assumed value of \(h_{\text{final}} (x)\) is calculated (Herfeh et al. 2013). For additional details about the adaptive boosting method, the reader is referred to (Herfeh et al. 2013; Ibarra-Manzano and Almanza-Ojeda 2012). A sample code which was written for adaptive boosting algorithm is as follows:

After training this algorithm by using sample data in the selected description space, a confusion matrix was formed in order to evaluate the performance of each chromosome. This matrix compares the outputs of visual interpretation by an expert with the outputs of a supervised classification process. The overall accuracy can be calculated using Eq. (13).
where \(T_{c}\) is the total number of pixels classified properly and \(T_{tp}\) is the total number of sample pixels.
2.5 Damage assessment using an adaptive neurofuzzy inference system
After extracting optimal features from the pre- and post-event images, deploying methods for uncertainty modeling are inevitable due to the non-deterministic nature of damage identification techniques (Ranjbar et al. 2014a, 2016). By integrating fuzzy systems and neural networks, an intelligent system is achieved, which has both the learning capability of neural networks and the uncertainty modeling capability of fuzzy inference systems. Neurofuzzy system is a Takagi–Sugeno fuzzy model (\({\text{TS model}}\)) (Sugeno and Kang 1988) in which neural network weights are equivalent to the parameters of fuzzy system (Jang and Sun 1995; Jang et al. 1997). The general rule of \({\text{TS model}}\) is presented in Eq. (14).
where \(A\) and \(B\) are fuzzy sets, \(x\), \(y\), and \(z\) are input and output of the system, and \(z = f(x,y)\) is an explicit function which is usually a first-order or zero-order polynomial function. Figure 4 illustrates the \({\text{TS model}}\) architecture, and the rules related to the layers of this model are mentioned below (Jang et al. 1997).

The structure of neurofuzzy inference system equivalent to TS model (Jang et al. 1997)
Layer 1 In this layer, \(\mu_{{A_{i} }} (x)\) and \(\mu_{{B_{i} }} (y)\) are fuzzy membership functions (\({\text{MFs}}\)) of \(x\) and \(y\) in fuzzy sets \(A_{i}\) and \(B_{i}\), and \(O_{k,i}\) is the output of node \(i\) in layer \(k\) that are presented in Eq. (15).
In this study, input parameters are optimal features which were selected in the previous stage and the output of this layer is the membership degree of these variables to each fuzzy set.
Layer 2 This layer contains fixed nodes which multiply input signals based on the type of inference system; the output is presented in Eq. (16).
Layer 3 The output of this layer \(\bar{w}\) is the normalization of the previous layer \(w_{i}\); the output is presented in Eq. (17).
Layer 4 Each node of this layer is an adaptive node that its output is calculated by Eq. (18).
where \(\bar{w}_{i}\) is the normalized weight, \(x\) and \(y\) are the input parameters, and \(p_{i}\), \(q_{i}\), and \(r_{i}\) are the coefficients of the polynomial function.
Layer 5 In this layer, there is a fixed node named \(\varSigma\) that calculates the final output according to Eq. (19) by adding up the input signals.
Hybrid learning method which is a combination of the method of least square and backpropagation can be used for training the \({\text{TS model}}\) to modify the parameters of membership functions and polynomial coefficients during every individual iteration.
2.6 Prioritization of damaged buildings based on using the proposed relief priority standard
Lack of contextual information is considered to be the main reason for unsuccessful relief operations after the earthquake event (Chen et al. 2012a; Hassanzadeh and Nedovic-Budic 2016; Peña-Mora et al. 2010; Ranjbar et al. 2017a). Damage map in which only the buildings’ status and the extent of damage are detected (Rastiveis et al. 2013) cannot cover all the necessities of crisis management teams at the golden moments after the earthquake occurrence. This map by wrong conducting the relief teams toward places with lower relief priority leads to loss of time for saving people under the rubble (Ranjbar et al. 2017a). An updated GIS database which includes different levels of geospatial and attribute data of the study area could improve the performance of response actions of relief teams after the earthquake occurrence. This source of information has the capability for integrating with developed spatial support systems related to damage detection as a reliable and robust data infrastructure.
In this research, a prioritization standard was initially proposed based on using the contextual information derived from the GIS database of the study area (Table 1). To form this strategy, by the analysis of the operations of local relief teams, the main factors for prioritizing damaged buildings were identified which include type of land use (residential regions, schools, governmental, commercial, therapeutic, industrial centers, parks, and open space), the degree of building damage (negligible damage, substantial damage, and heavy damage), the differentiation index of each land use (an index was specifically considered for each individual land use), activity time of each land use (the time during which population density is considerable in that land use), and earthquake occurrence time. These factors were then investigated by local experts and scholars of the study area through a questionnaire method for assigning a prioritization degree: high, medium, and low. The standard was then implemented at database level in order to prioritize damaged buildings at the time of earthquake occurrence.
As mentioned previously, relief priority for each land use is considered at three levels: high, medium, and low by considering activity time, earthquake occurrence time, the amount of damage to each land use, type of land use, and the differentiation index. In other words, the land use in the study area was divided into seven main categories; for each category, a key element was considered by the point of disaster management experts as differentiation index of that land use which expertise the final decisions about the relief priority of that specific land use, namely type of school was pointed for the category of school or type of products was considered for the industrial land use. Activity time and earthquake incidence time were the other parameters which contributed in providing this priority catalog, as if an activity time of a land use like an elementary school with substantial damage is not within the time of earthquake occurrence, the relief priority for that land use is considered low. Some of the rules which were extracted from the standard could be found in Table 2. In the proposed standard, the considered activity time for each land use is the time when the specific land use has the highest population concentration, namely if the activity time of a land use is from 8 a.m. to 12 a.m. (midnight), but in which population concentration peak is from 17:00 p.m. to 20:00 p.m., the peak time is considered for the activity time of that land use. For instance, the low priority was considered for most of the schools because the activity time of schools in the study area was from 8:00 a.m. to 14:00 p.m., while the earthquake occurrence time was at 16:53 p.m. Finally, by preparing a relief priority map using the proposed standard at the early moments after the earthquake, it would be possible to properly organize a limited number of relief forces toward areas with higher relief priority.
3 Results and discussion
To evaluate the proposed damage detection method, two high-resolution images and 1:2000 vector map of the city of Varzaghan, Iran, were used. The pre- and post-Varzaghan earthquake satellite images with four spectral bands and size of \(3251 \times 2115\) pixels were acquired on the July 31, 2011, at 7:54:00 a.m. and August 15, 2012, at 7:36:00 a.m., respectively, by the GeoEye-1 satellite.
In the pre-processing phase, the atmospheric effects were corrected by using ERDAS IMAGINE 2015, and the relief effects were compensated on the pre- and post-event images by using a digital terrain model (SRTM). Then, in order to improve the spatial resolution in color mode and increase the spectral similarity between images, the pan-sharpening using Brovey method and the histogram matching were performed on the images. Finally, pre- and post-event images were registered to the vector map of the study area using 15 ground control points with root-mean-square errors (\({\text{RMSE}}\)) of 0.3861 and 0.4123, respectively. Figure 5 shows the pre-processed high-resolution satellite images of the study area. The GIS database of the study area with fields including type of land use, activity time period, population density of each land use, type of schools, type of governmental facility, type of parks, number of units in commercial centers, number of beds in therapeutic centers, and type of products in industrial centers was also prepared.

Pre-processed satellite images of the study area
After pre-processing, 1819 buildings were detected on the pre-event satellite image of the study area by using snake and dynamic programming technique and outdated vector map. To precede the building detection, as shown in Fig. 6, a number of seed points near buildings’ corners were defined by an expert operator; other points on buildings’ borders were predicted by the algorithm due to the hypothesis that buildings have straight sides. The results indicate that since the width of shadow border is wider than the border of building, the external energy of shadow border overcomes the total energy; thus, the DP algorithm selects shadow border instead of buildings’ border. To overcome this problem, the vector data of the study area were also used as a complementary source besides the snake building detection technique for buildings which the snake algorithm was unable to detect them. To assess the accuracy of the building detection technique used in this research, the amount of RMSE was estimated for 183 buildings extracted by an expert operator and those detected by the algorithm; the RMSE took the value of 0.98. Extracted corner points of buildings on the pre-event image were then located on the post-event image to detect buildings which their borders were disappeared due to the earthquake. In order to separate other classes from building class, a value of zero was assigned to all pixels that are located outside the building border.

Defining seed points near candidate buildings’ corners by expert operator
In order to detect the degree of damage for candidate buildings, 34 textural features were implemented in the MATLAB environment using a window with \(3 \times 3\) pixel size in four spectral bands; however, other windows with pixel size of \(5 \times 5\) or \(7 \times 7\) may be applied. During Haralick feature extraction, a co-occurrence matrix was generated along four major directions, that is: \(\theta = 0^{ \circ }\), \(\theta = 45^{ \circ }\), \(\theta = 90^{ \circ }\), and \(\theta = 135^{ \circ }\) with a distance of \(d = 1\); the four resulting matrices were averaged and the second-order statistical features were generated out of the averaged co-occurrence matrix. The geostatistics features were extracted by computing the mean of the calculated features along four main directions with a distance value of \(h = 1\). For extracting the four wavelet features of logarithm of energy, Shannon index, second angular moment, and entropy, the first and second orders of Daubechies, along with Haar wavelet, were used, in which the output of the first-order transform (LL) was used as the input of the second-order transform. Each type of wavelet feature was generated in the panchromatic bands and in both orders. Also, during extraction of Gabor features, a library of Gabor filters was developed with three different scales \(S = 3\) and four rotations \(K = 4\). Accordingly, mean and standard deviation of convolved Gabor filters with the image bands were extracted.
In the next step, the genetic algorithm was used to remove redundant and irrelevant textural features to damage detection. For this purpose, an initial generation was formed with chromosomes having 240 genes and a population of 20 chromosomes encoded using a random function with uniform distribution. The solutions were then evaluated by using the overall accuracy obtained from the adaptive boosting classification as a fitness value. The evaluation process was carried out using 183 buildings with pre-interpreted damage degree. The convergence of GA was obtained by considering the number of runs and the overall accuracy of classification which were set 80 and 99.95%, respectively. After computing the fitness value for each chromosome, among the 20 chromosomes of the initial generation, the strongest chromosome with a higher accuracy was transferred to the next generation (elitism). In total, 60% of the chromosomes were kept to produce two offspring by using crossover operator, and the rest of the chromosomes were then used to produce one offspring by using mutation operator. A random function with uniform distribution was deployed for selecting chromosomes in the evolution process. Finally, ten features were selected as optimal features that include: first-order features mean of red band (MeanR), weighted distance mean of near-infrared band (WDMeanNIR); second-order features homogeneity of near-infrared band (HomogeneityNIR), correlation of near-infrared band (CorrelationNIR); geostatistics features simple variogram of red band (SvariogramR), cross-variogram of near-infrared band (CvariogramNIR); wavelet features logarithm of energy of near-infrared band (first order of basic wavelet transform) (LOG1NIR), Shannon index of near-infrared band (second order of basic wavelet transform) (SHAN2NIR); Gabor features mean of red band (Gabor wavelet transform by using Gabor filters with scale of three and rotation of \(3^{ \circ }\)) (MeanGS3R0R), standard deviation of green band (Gabor wavelet transform by using Gabor filter with scale of two and rotation of \(0^{ \circ }\)) (StdGS2R0G).
Extracted optimum textural features were used as the inputs of the neurofuzzy inference system, and the damage degree of buildings was determined according to expert opinions. For each building, a number was assigned in the range of \([0,1]\), for which a degree closer to the value of 1 indicates a higher damage rate. The \({\text{TS model}}\) was implemented for 1819 buildings; 60% of the data, that is, 1091, were used to train the model, while 40% of the data, that is, 728, were used to evaluate the results of the proposed model. The parameters requiring for training the \({\text{TS model}}\) including the number and type of membership functions for each input (four \({\text{MFs}}\) and Gaussian membership function), the number of runs for training the model (1100 runs), training method (hybrid), and the order of polynomial function (first order) were defined by the user. The parameter of the \({\text{RMSE}}\) was also used in both evaluation and training phases of the \({\text{TS model}}\). The \({\text{TS model}}\) was implemented in the neurofuzzy toolbox of the MATLAB environment. Figure 7 shows the diagram for training the \({\text{TS model}}\). Finally, each building was classified into three categories of “negligible damage,” “substantial damage,” and “heavy damage” by considering linguistic variables for buildings’ damage degree on the output of the fuzzy system. Table 3 presents the computed confusion matrix for the proposed damage detection algorithm, in which the overall accuracy of 88% and Kappa coefficient of 79% were estimated. The damage map of the study area obtained by using the proposed neurofuzzy inference system is shown in Fig. 8.

Diagram for training phase of the TS model

Damage map of Varzaghan city, Iran
Based on the analysis of the experiences of local teams in the study area, a standard was then proposed for prioritizing damaged buildings. This standard by considering main factors such as the time of earthquake occurrence, activity time of each land use, type of land use, the damage degree of buildings, and a differentiation index tries to discriminate buildings with a higher relief priority from other buildings. The implemented standard at the database level could provide a relief priority map after earthquake occurrence. Figure 9 shows the relief priority map of the study area according to the proposed standard.

Relief priority map of Varzaghan city, Iran
4 Conclusion
Appropriate resource allocation after earthquake occurrence requires adequate and comprehensive information about the affected areas. Building damage maps sometimes leads to wrong guidance of relief teams toward regions with a low relief priority, due to inadequate contextual information; these maps only present degree of damage for each individual building. In other words, since the rate of success for rescue operations after earthquake occurrence severely depends on this issue that how geographically the rescue teams are distributed toward the areas with high degree of priority at the appropriate time, in this research, a method for prioritization of damaged buildings was proposed, which does not have the complexity of previous methods and could prepare a relief priority map solely based on the rules previously set at the database level. This algorithm could improve the efficiency of rescue operations in comparison with the field-based resource allocation techniques.
The building detection process which is the main pre-requisite of performing this algorithm was implemented by using the snake and dynamic programming technique. The inability of the used algorithm to differentiate between building borders and shadow borders and also the necessity of the algorithm to seed point definition along the sides of buildings by an expert operator make obstacles in the automatic process of building prioritization. So, modeling the local context of the study area for removing shadows and examining the capability of other automatic building detection algorithms is recommended for improving the efficiency of the building extraction. In this research, texture features were the main property of the pre- and post-event images which were used for damage degree identification. The results indicate texture features are not adequate for building damage detection in more than three grades; therefore, it is recommended that other properties such as building shadow, edge, spatial relationship, morphology, and shape are used in future works. The adaptive boosting method used as fitness function in the genetic algorithm, when compared with strong classifiers such as neural networks, was more complex, but in terms of execution speed, it is faster. Finally, the proposed algorithm could play an effective role for improving the efficiency of relief operations.
References
Aggarwal N, Agrawal RK (2012) First and second order statistics features for classification of magnetic resonance brain images. J Signal Inf Proc 3(2):146–153. https://doi.org/10.4236/jsip.2012.32019
Aghamohammadi H, Mesgari MS, Mansourian A, Molaei D (2013) Seismic human loss estimation for an earthquake disaster using neural network. Int J Environ Sci Technol 10(5):931–939. https://doi.org/10.1007/s13762-013-0281-5
Balaguer A, Ruiz LA, Hermosilla T, Recio JA (2010) Definition of a comprehensive set of texture semivariogram features and their evaluation for object-oriented image classification. Comput Geosci 36(2):231–240. https://doi.org/10.1016/j.cageo.2009.05.003
Ban Y, Yousif O (2016) Change detection techniques: a review. In: Ban Y (ed) Multitemporal remote sensing: methods and applications, 1st edn. Springer, Cham, pp 19–43. https://doi.org/10.1007/978-3-319-47037-5_2
Bartels SA, VanRooyen MJ (2012) Medical complications associated with earthquakes. Lancet 379(9817):748–757. https://doi.org/10.1016/S0140-6736(11)60887-8
Berberoglu S, Akin A (2009) Assessing different remote sensing techniques to detect land use/cover changes in the eastern Mediterranean. Int J Appl Earth Obs Geoinf 11(1):46–53. https://doi.org/10.1016/j.jag.2008.06.002
Berz G, Kron W, Loster T, Rauch E, Schimetschek J, Schmieder J, Siebert A, Smolka A, Wirtz A (2001) World map of natural hazards—a global view of the distribution and intensity of significant exposures. Nat Hazards 23(2–3):443–465. https://doi.org/10.1023/A:1011193724026
Blaschke T, Hay GJ, Weng Q, Resch B (2011) Collective sensing: integrating geospatial technologies to understand urban systems—an overview. Remote Sens 3(8):1743–1776. https://doi.org/10.3390/rs3081743
Chen AY, Peña-Mora F, Plans AP, Mehta SJ, Aziz Z (2012a) Supporting urban search and rescue with digital assessments of structures and requests of response resources. Adv Eng Inform 26(4):833–845. https://doi.org/10.1016/j.aei.2012.06.004
Chen G, Hay GJ, Carvalho LMT, Wulder MA (2012b) Object-based change detection. Int J Remote Sens 33(14):4434–4457. https://doi.org/10.1080/01431161.2011.648285
Chica-Olmo M, Abarca-Hernandez F (2000) Computing geostatistical image texture for remotely sensed data classification. Comput Geosci 26(4):373–383. https://doi.org/10.1016/S0098-3004(99)00118-1
Chini M, Cinti FR, Stramondo S (2011) Co-seismic surface effects from very high resolution panchromatic images: the case of the 2005 Kashmir (Pakistan) earthquake. Nat Hazards Earth Syst Sci 11(3):931–943. https://doi.org/10.5194/nhess-11-931-2011
Coppin P, Jonckheere I, Nackaerts K, Muys B, Lambin E (2004) Review article digital change detection methods in ecosystem monitoring: a review. Int J Remote Sens 25(9):1565–1596. https://doi.org/10.1080/0143116031000101675
Daubechies I (1992) Ten lectures on wavelets. Society for industrial and applied mathematics, Philadelphia. https://doi.org/10.1137/1.9781611970104
Deng JS, Wang K, Deng YH, Qi GJ (2008) PCA-based land-use change detection and analysis using multitemporal and multisensor satellite data. Int J Remote Sens 29(16):4823–4838. https://doi.org/10.1080/01431160801950162
Dong L, Shan J (2013) A comprehensive review of earthquake-induced building damage detection with remote sensing techniques. ISPRS J Photogramm Remote Sens 84:85–99. https://doi.org/10.1016/j.isprsjprs.2013.06.011
Fazan AJ, Dal Poz AP (2013) Rectilinear building roof contour extraction based on snakes and dynamic programming. Int J Appl Earth Obs Geoinf 25:1–10. https://doi.org/10.1016/j.jag.2013.03.003
Feng T, Hong Z, Wu H, Fu Q, Wang C, Jiang C, Tong X (2013) Estimation of earthquake casualties using high-resolution remote sensing: a case study of Dujiangyan city in the May 2008 Wenchuan earthquake. Nat Hazards 69(3):1577–1595. https://doi.org/10.1007/s11069-013-0764-1
Gamba P, Dell’Acqua F, Trianni G (2007) Rapid damage detection in the Bam area using multitemporal SAR and exploiting ancillary data. IEEE Trans Geosci Remote Sens 45(6):1582–1589. https://doi.org/10.1109/TGRS.2006.885392
Guo H, Lu L, Ma J, Pesaresi M, Yuan F (2009) An improved automatic detection method for earthquake-collapsed buildings from ADS40 image. Chin Sci Bull 54(18):3303–3307. https://doi.org/10.1007/s11434-009-0461-3
Gusella L, Adams BJ, Bitelli G, Huyck CK, Mognol A (2005) Object-oriented image understanding and post-earthquake damage assessment for the 2003 Bam, Iran, earthquake. Earthq Spectra 21(S1):225–238. https://doi.org/10.1193/1.2098629
Haar A (1910) Zur theorie der orthogonalen funktionensysteme. Math Ann 69(3):331–371. https://doi.org/10.1007/bf01456326
Haddadi GA, Sahebi MR, Mansourian A (2011) Polarimetric SAR feature selection using a genetic algorithm. Can J Remote Sens 37(1):27–36. https://doi.org/10.5589/m11-013
Hamedianfar A, Shafri HZM (2014) Development of fuzzy rule-based parameters for urban object-oriented classification using very high resolution imagery. Geocarto Int 29(3):268–292. https://doi.org/10.1080/10106049.2012.760006
Hassanzadeh R, Nedovic-Budic Z (2016) Where to go first: prioritization of damaged areas for allocation of urban search and rescue (USAR) operations (PI-USAR model). Geomat Nat Hazards Risk 7(4):1337–1366. https://doi.org/10.1080/19475705.2015.1058861
Herfeh MP, Shahbahrami A, Miandehi FP (2013) Detecting earthquake damage levels using adaptive boosting. In: 8th Iranian conference on machine vision and image processing (MVIP), Zanjan, Iran, pp 251–256. https://doi.org/10.1109/IranianMVIP.2013.6779989
Hussain M, Chen D, Cheng A, Wei H, Stanley D (2013) Change detection from remotely sensed images: from pixel-based to object-based approaches. ISPRS J Photogramm Remote Sens 80:91–106. https://doi.org/10.1016/j.isprsjprs.2013.03.006
Huyck CK, Adams BJ, Cho S, Chung H-C, Eguchi RT (2005) Toward rapid citywide damage mapping using neighborhood edge dissimilarities in very high-resolution optical satellite imagery—application to the 2003 Bam, Iran, earthquake. Earthq Spectra 21(S1):255–266. https://doi.org/10.1193/1.2101907
Ibarra-Manzano M-A, Almanza-Ojeda D-L (2012) An FPGA implementation for image interpretation based on adaptive boosting algorithm in the real-time systems. Procedia Technol 3:187–195. https://doi.org/10.1016/j.protcy.2012.03.020
Jang J-S, Sun C-T (1995) Neuro-fuzzy modeling and control. Proc IEEE 83(3):378–406. https://doi.org/10.1109/5.364486
Jang J-SR, Sun C-T, Mizutani E (1997) Neuro-fuzzy and soft computing-a computational approach to learning and machine intelligence [book review]. IEEE Trans Autom Control 42(10):1482–1484. https://doi.org/10.1109/TAC.1997.633847
Jin D, Wang X, Dou A, Dong Y (2011) Post-earthquake building damage assessment in Yushu using airborne SAR imagery. Earthq Sci 24(5):463–473. https://doi.org/10.1007/s11589-011-0808-0
Kakooei M, Baleghi Y (2017) Fusion of satellite, aircraft, and UAV data for automatic disaster damage assessment. Int J Remote Sens 38(8–10):2511–2534. https://doi.org/10.1080/01431161.2017.1294780
Karimzadeh S, Miyajima M, Hassanzadeh R, Amiraslanzadeh R, Kamel B (2014) A GIS-based seismic hazard, building vulnerability and human loss assessment for the earthquake scenario in Tabriz. Soil Dyn Earthq Eng 66:263–280. https://doi.org/10.1016/j.soildyn.2014.06.026
Kass M, Witkin A, Terzopoulos D (1988) Snakes: active contour models. Int J Comput Vis 1(4):321–331. https://doi.org/10.1007/bf00133570
Khan S, Hussain M, Aboalsamh H, Mathkour H, Bebis G, Zakariah M (2016) Optimized Gabor features for mass classification in mammography. Appl Soft Comput 44:267–280. https://doi.org/10.1016/j.asoc.2016.04.012
Li P, Hong Z, Zuxun Z, Jianqing Z (2004) Genetic feature selection for texture classification. Geo Spat Inf Sci 7(3):162–166. https://doi.org/10.1007/BF02826285
Li M, Cheng L, Gong J, Liu Y, Chen Z, Li F, Chen G, Chen D, Song X (2008) Post-earthquake assessment of building damage degree using LiDAR data and imagery. Sci China Ser E 51(Suppl 2):133–143. https://doi.org/10.1007/s11431-008-6014-1
Li P, Xu H, Guo J (2010) Urban building damage detection from very high resolution imagery using OCSVM and spatial features. Int J Remote Sens 31(13):3393–3409. https://doi.org/10.1080/01431161003727705
Li X, Yang W, Ao T, Li H, Chen W (2011) An improved approach of information extraction for earthquake-damaged buildings using high-resolution imagery. J Earthq Tsunami 5(4):389–399. https://doi.org/10.1142/s1793431111001157
Liu J, Shan X, Yin J (2004) Automatic recognition of damaged town buildings caused by earthquake using remote sensing information: taking the 2001 Bhuj, India, earthquake and the 1976 Tangshan, China, earthquake as examples. Acta Seismol Sin 17(6):686–696. https://doi.org/10.1007/s11589-004-0008-2
Liu W, Yamazaki F, Gokon H, Koshimura S (2012) Extraction of damaged buildings due to the 2011 Tohoku, Japan earthquake tsunami. In: 2012 IEEE international geoscience and remote sensing symposium, Munich, Germany, pp 4038–4041. https://doi.org/10.1109/IGARSS.2012.6350523
Lu D, Mausel P, Brondízio E, Moran E (2004) Change detection techniques. Int J Remote Sens 25(12):2365–2401. https://doi.org/10.1080/0143116031000139863
Manjunath B, Shekhar C, Chellappa R (1996) A new approach to image feature detection with applications. Pattern Recognit 29(4):627–640. https://doi.org/10.1016/0031-3203(95)00115-8
Myint SW, Lam NS-N, Tyler JM (2004) Wavelets for urban spatial feature discrimination. Photogramm Eng Remote Sens 70(7):803–812. https://doi.org/10.14358/PERS.70.7.803
Pal M (2013) Hybrid genetic algorithm for feature selection with hyperspectral data. Remote Sens Lett 4(7):619–628. https://doi.org/10.1080/2150704X.2013.777485
Peña-Mora F, Chen AY, Aziz Z, Soibelman L, Liu LY, El-Rayes K, Arboleda CA, Lantz TS Jr, Plans AP (2010) Mobile ad hoc network-enabled collaboration framework supporting civil engineering emergency response operations. J Comput Civ Eng 24(3):302–312. https://doi.org/10.1061/(asce)cp.1943-5487.0000033
Ranjbar HR, Ardalan AA, Dehghani H, Saradjian MR, Alidousti A (2014a) Evaluation of physical data extraction techniques of damaged buildings due to disasters, presentation and implementation the optimal pattern by using GIS and remote sensing layers (in Persian). Sepehr 23(91):21–42
Ranjbar HR, Ardalan AA, Dehghani H, Saradjian MR, Alidousti A (2014b) Facilitating response phase of disaster management by automatic extraction of building based on texture analysis using high resolution satellite images (in Persian). J Emerg Manag 3(1):5–19
Ranjbar HR, Ardalan AA, Dehghani H, Saradjian MR (2015) Rapid damage assessment by using SFAP mono temporal image acquired by UAVs in mobile disaster management bases (in Persian). In: 22th national conference on geomatics, Tehran, Iran, pp 1–12
Ranjbar HR, Dehghani H, Ardalan AA, Saradjian MR (2016) A GIS-based approach for earthquake loss estimation based on the immediate extraction of damaged buildings. Geomat Nat Hazards Risk. https://doi.org/10.1080/19475705.2016.1265013
Ranjbar HR, Ardalan AA, Dehghani H, Saradjian MR (2017a) A proposed spatial index to prioritize damaged buildings for allocating USAR operations. Geocarto Int. https://doi.org/10.1080/10106049.2017.1303088
Ranjbar HR, Dehghani H, Ardalan AA, Saradjian MR (2017b) Area based complementary approach for building detection by using high spatial resolution satellite imagery (in Persian). Iran Remote Sens GIS 8(4):45–64
Rastiveis H, Samadzadegan F, Reinartz P (2013) A fuzzy decision making system for building damage map creation using high resolution satellite imagery. Nat Hazards Earth Syst Sci 13(2):455–472. https://doi.org/10.5194/nhess-13-455-2013
Rathje EM, Crawford M, Woo K, Neuenschwander A (2005) Damage patterns from satellite images of the 2003 Bam, Iran, earthquake. Earthq Spectra 21(S1):295–307. https://doi.org/10.1193/1.2101047
Singh A (1989) Review article digital change detection techniques using remotely-sensed data. Int J Remote Sens 10(6):989–1003. https://doi.org/10.1080/01431168908903939
Sugeno M, Kang GT (1988) Structure identification of fuzzy model. Fuzzy Sets Syst 28(1):15–33. https://doi.org/10.1016/0165-0114(88)90113-3
Thonfeld F, Feilhauer H, Braun M, Menz G (2016) Robust change vector analysis (RCVA) for multi-sensor very high resolution optical satellite data. Int J Appl Earth Obs Geoinf 50:131–140. https://doi.org/10.1016/j.jag.2016.03.009
Trianni G, Gamba P (2008) Damage detection from SAR imagery: application to the 2003 Algeria and 2007 Peru earthquakes. Int J Navig Obs 2008:1–8. https://doi.org/10.1155/2008/762378
Tsai C-F, Eberle W, Chu C-Y (2013) Genetic algorithms in feature and instance selection. Knowl Based Syst 39:240–247. https://doi.org/10.1016/j.knosys.2012.11.005
Turker M, San BT (2004) Detection of collapsed buildings caused by the 1999 Izmit, Turkey earthquake through digital analysis of post-event aerial photographs. Int J Remote Sens 25(21):4701–4714. https://doi.org/10.1080/01431160410001709976
Van der Meer F (2012) Remote-sensing image analysis and geostatistics. Int J Remote Sens 33(18):5644–5676. https://doi.org/10.1080/01431161.2012.666363
Vu TT, Ban Y (2010) Context-based mapping of damaged buildings from high-resolution optical satellite images. Int J Remote Sens 31(13):3411–3425. https://doi.org/10.1080/01431161003727697
Vu TT, Matsuoka M, Yamazaki F (2005) Detection and animation of damage using very high-resolution satellite data following the 2003 Bam, Iran, earthquake. Earthq Spectra 21(S1):319–327. https://doi.org/10.1193/1.2101127
Wei B, Nie G, Su G, Sun L, Bai X, Qi W (2017) Risk assessment of people trapped in earthquake based on km grid: a case study of the 2014 Ludian earthquake, China. Geomat Nat Hazards Risk. https://doi.org/10.1080/19475705.2017.1318795
Wu P, Manjunath B, Newsam S, Shin H (2000) A texture descriptor for browsing and similarity retrieval. Signal Process Image Commun 16(1–2):33–43. https://doi.org/10.1016/S0923-5965(00)00016-3
Xian G, Homer C (2010) Updating the 2001 national land cover database impervious surface products to 2006 using Landsat imagery change detection methods. Remote Sens Environ 114(8):1676–1686. https://doi.org/10.1016/j.rse.2010.02.018
Zhai W, Shen H, Huang C, Pei W (2016) Building earthquake damage information extraction from a single post-earthquake PolSAR image. Remote Sens 8(3):171. https://doi.org/10.3390/rs8030171
Acknowledgements
The required data were prepared by the National Cartographic Center of Iran and Emergency Management Center of the Malek E Ashtar University of Technology. We would like to thank Prof. Alireza A. Ardalan and Mr. Ali Alidousti for their operational recommendations. The work described in this paper was completed as a doctoral thesis at the Malek E Ashtar University of Technology.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article

Cite this article
Ranjbar, H.R., Ardalan, A.A., Dehghani, H. et al. Using high-resolution satellite imagery to provide a relief priority map after earthquake. Nat Hazards 90, 1087–1113 (2018). https://doi.org/10.1007/s11069-017-3085-y
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11069-017-3085-y