
Abstract
In this paper we created and validated a predictive model for assessing the susceptibility of landslides along highway E-20 in Ecuador, by measuring the degree of spatial association of a landslide inventory with a set of spatial factors in an empirical way. The main aims of this paper are to: (1) determine what spatial factors are most associated with landslide occurrence, (2) determine whether the E-20 has any type of influence on landslide occurrence and, if so, up to what distance. For this, we created a landslide inventory based on multi-temporal images from different sources and used the Yule coefficient and the distance distribution analysis, which enabled us to determine which spatial factors are more closely related to the occurrence of landslides. The findings support the idea that landslides are not randomly distributed, but are associated (positively or negatively) to the different geo-environmental conditions of the study area; in this case, landslides have shown positive association with areas of active erosive processes, granitic rocks, volcanic sandstone and rainfall ranging from 1500 to 1750 mm. The statistical significance of the model was tested in two different ways; thus, it can be considered as valid, showing that each spatial factor has some influence on the occurrence of landslides.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
Landslide susceptibility analysis (LSA) attempts to establish a relationship between landslides and the factors associated with them, in order to determine the spatial probability of occurrence of new landslides in a given area (Marsh 2000; Remondo et al. 2003); this is done by identifying past landslides, their distribution and main characteristics and applying statistical and geographical information tools to establish which factors are more associated with landslides. The results from LSA are not predictions of landslide occurrence, but references of where they can generally be expected to occur in the future.
Ecuador, located in western South America, is frequently subject to natural disasters of different kinds and magnitudes (Cajas Alban and Fernandez 2012; Demoraes and D’ercole 2001; Tibaldi et al. 1995); landslides are mass movements containing soil, mud, rock and other materials that detach from a mountain or hill and move down a slope (Wang et al. 2005); they often affect the country’s road network and other critical infrastructure leaving entire communities destroyed or uncommunicated (Harden 2001; Hoy 2014a, b); furthermore, landslides have been found to be the deadliest disaster type in Ecuador, killing more people than flooding or epidemics (Zevallos 2004). By determining the geographical factors that are associated with landslides, the places that have the highest probabilities of landslides can be delineated, thereby raising awareness and enhancing community resilience and preparation.
Highway E-20 (from now on E-20) links Quito with Santo Domingo de los Tsáchilas (from now on Santo Domingo) and plays a major role in communicating communities in the high Andes with those in the coastal lowlands. The E-20 departs Alóag and climbs to the 3100 m.a.s.l. mark before beginning its steep descent to Santo Domingo, at 550 m.a.s.l. This section of the highway is often affected by landslides and frequently closed for days (Comercio 2014a, b), therefore being an important subject for LSA.
The main objectives of this paper are to: (a) determine what spatial factors are most associated with landslide occurrence, (b) determine whether the E-20 has any type of influence on landslide occurrence and, if so, up to what distance, and (c) create a landslide susceptibility map based on the findings.
This paper is firstly describes the location of the study area, followed by a section that describes the acquisition of the spatial data and the methods uses; here, the Yule coefficient (YC) and the distance distribution analysis (DDA) are presented as efficient tools for LSA, followed by the methodologies used to test the statistical significance of the model. Subsequently, the main results are outlined, then the discussion and finally a short conclusion.
2 Study area
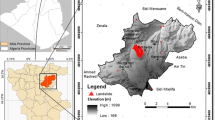
The study area is located in central Ecuador and comprises 12 municipalities (i.e. Parroquias) from the provinces of Pichincha and Santo Domingo de los Tsáchilas; it covers a total area of 5093 km2. The boundaries of the study area are: 10,010,636 m North to 9,913,845 m South and 773,147 m East to 674,910 m West. It was delineated by using the ‘Political Division—Parroquia’, and not using a geophysical characteristic (e.g. water sheds), because when the model is finished, it can be easily implemented by each administration in small scale, rather than the model having to pass a bureaucratic process in several Ministries before its approval and later use. There are three important topographic features of the study area: the Atacazo, Corazon and Guagua Pichincha volcanoes, all with elevations above 4000 m.a.s.l. and a high presence of outcrops and quarries of different sorts (Fig. 1).

Location of the study area. Source: Google Earth
The selected portion of the E-20 highway covers 98 km, and it is the central feature in the study area running from east to west; it connects the towns of Alóag, located in the east, at 2880 m.a.s.l., and Santo Domingo, located in the west, 530 m.a.s.l. The road crosses its highest section (3170 m.a.s.l.) approximately 12 km west of Alóag, crosses the western Ecuadorian Andes and descends to Santo Domingo, located in the coastal plains (see Fig. 2).

Elevation profile of highway E-20. Alóag is shown on the left hand, with the highest elevation and Santo doming on the right hand with the lowest elevation. Source: Google Earth
The topography of the area, as displayed in Fig. 3, is very rugged, with uneven terrain and high elevations in the east tending to more smooth hillsides and flat plains in the west. The highest and lowest elevation are 5218 and 240 m.a.s.l., respectively, this means that climate, rainfall, and vegetation types vary widely throughout the study area. On the one hand, the region surrounding Alóag is characterized by cool to mild temperatures averaging 12 °C, 79 % relative humidity and 1500 mm of rainfall each year; On the other hand, Santo Domingo has anywhere between 2000 and 3000 mm of rainfall and an average temperature of 22 °C (INAMHI 2013a, b). Once below 1300 m.a.s.l. the vegetation changes to evergreen forests of the coastal lowlands, which increases the amount of cloud cover and creates a semi-permanent blanket over the forest (Sierra 1999).

Elevation map of the study area highway E-20
The geology of the study area is characterized by marine volcano-sedimentary rocks of andesite and basalt composition with interbedded sediments of the Cretaceous era. The Macuchi formation is dominant in the area and is partially covered by volcaniclastic rocks, conglomerates, shales, tuffs (especially along the E-20) and marine sedimentary rocks such as limestone; to the east, continental Pleistocene–Holocene volcanic rocks of andesite composition are predominant. There are also ash and lahar deposits throughout the area. To the southeast, the lithology is characterized by pyroclastic fragments of volcanic eruptions such as ash and pumice lapilli, mostly form the Atacazo, Corazon and Guagua Pichincha volcanoes (GAD 2013).
3 Data and methods
3.1 Data collection
Data were collected from different sources and were used to generate the thematic layers (see Table 1). In spite of being in the Andes and close to three volcanoes, not enough spatial information is readily available regarding earthquakes to include them in this LSA.
The profile of the country was used as base to spatially align all other layers and to ensure the digital elevation model (DEM) was correctly located; the best available resolution for the DEM was 30 m, that is, each grid cell measured 30 m on each side; this was used for subsequent extraction of information (i.e. slope, aspect and curvature). The section of interest of the E-20 was obtained from the ‘National Road Network’ layer which was provided by the Ministry of Transport, while the outlines of the towns of Alóag and Santo Domingo where obtained from the ‘Cities and Towns’ shape file, provided by the Military Geographic Institute (IGM). The study area was selected from the ‘Political Division—Province’ on first stance, and ‘Political Division—Parroquia’ for the definite selection of municipalities. The ‘Geomorphology’ and ‘Land Use’ layers contain information on geology, lithology, land use and land cover for the study area. Lastly, the ‘Isohyets—Rainfall’ layer contains the rainfall ranges for all the study area, and it was generated by interpolation of the nation’s network of weather stations.
The processing of all layers was done using ArcGIS v10.2; this included the geo-referencing of layers, assigning coordinate systems and datums, visualization, extraction and geo-processing of the raster datasets. The selected datum and coordinate systems were: WSG 1984 and UTM Zone 17 South, respectively. In order to determine the spatial association of each spatial factor with the presence of landslides, Microsoft Excel was used.
3.2 Landslide inventory
In order to identify and map the locations of landslides, multi-temporal images from Google Earth and the IGM were geo-referenced and used; the former were comprised of several images of the whole study area and were dated: January/1970, June/2002, July/2003, June/2007, June/2012, Jul/2012 and September/2012, but only a small section of the study area had images from all the mentioned years. The latter were dated 2005 and scaled 1:5000, 1:20,000 and 1:30,000 and covered 1840 km2 (36 %) of the study area.
Out of 400 photos, 95 were selected on the basis of presence or absence of landslides; the chosen images were geo-referenced using between 6 and 10 ground control points, ensuring the root-mean-square error was below half of the pixel size (Hughes et al. 2006), which varied between photographs, hence making sure there was a good correlation between the locations the geo-objects in ground and their expected location in the map. Once geo-referenced, a new layer was created in ArcGIS and a polygon was created for every distinguishable landslide, hence creating the landslide inventory (see Fig. 4).

Landslide inventory
Google Earth Pro was also used to populate the inventory (Van Den Eeckhaut et al. 2012). In this case, digitalization of landslides was done directly in the program, by creating individual polygons and storing them in a database that would later be translated into ArcGIS. Having done this, the layer created in Google Earth Pro was added to the inventory created in ArcGIS, thereby having a total of 1328 polygons (i.e. landslides) for the study area in one single layer that could be superimposed to the other layers.
No Landsat images were used due to two main factors: (1) the resolution of the available images did not allow clear differentiation between landslides and other land uses, and (2) most images presented heavy could cover (over 40 %), which made landslide identification very difficult.
3.3 Spatial factors
Spatial factors are descriptions (i.e. characteristics) of spatial information; they can be presented in continuous (e.g. elevation) or categorical (e.g. land use) form. The spatial factors used for this project are shown in Figs. 5 and 6.

a Elevation, b slope, c curvature and d aspect

e Land use, f erosion, g lithology and h rainfall
Given that the elevation model represented the whole of Ecuador, the section corresponding to the study area was extracted by using the ‘Extract by Mask’ function in ArcGIS 10.2, resulting in a raster dataset with the exact extent (i.e. shape) of the study area; all subsequent raster operations were calculated for the study area only.
Regarding the continuous datasets: the DEM was used to derive the slope, aspect and curvature layers by using the appropriate function of the ‘Spatial Analyst’ toolbox with the following characteristics: (a) slope was calculated in per cent rise, (b) the aspect was expressed in degrees (i.e. 0–359.9) measured clockwise from the north and (c) the curvature, which varied between −8.5 and 9.1 showed if the cell represented an upwardly convex (i.e. positive value), a flat (i.e. value of zero) or an upwardly concave surface (i.e. negative value). All these layers had the same grid cell size of the DEM and were calculated as continuous data, meaning that each cell had a value composed of a number with a certain number of decimal places.
Because attribute tables in ArcGIS are only generated for categorical data, the slope, aspect, and curvature layers had to be reclassified. This was done with the ‘Slice’ function, which re-distributes the cell values into groups with roughly the same number of cells (see Fig. 5) (Chung and Fabbri 2003). By doing this, an attribute table for each layer was created, which allowed the usage of the ‘Zonal Statistics’ tool later on.
Now, for categorical datasets, the treatment was different, as all layers were initially in vector format (see Fig. 6). The ‘Land Use’ layer was generalized from 41 to 11 categories based on their representativeness in the study area and their similarities; land use is believed to play an important role in landslide occurrence according to CAN (2009) and Gonzales (2011). The main categories of land use in the study area are: Agriculture and Livestock with 33 %, followed by Conservation with 25 % and Agriculture and forestry with 18 % of the total area. Lithology has proven to be one of the main contributing factors for landslide occurrence Terrambiente (2006).
Regarding erosion, four categories have been identified in the study area: very active, active and potential, potential and null risk; about 22 % of the area has null risk of erosion, and 71 % (3643 km2) of the study falls under the ‘Active and Potential’ category; in other words, erosive processes are taking place in most of the study area, especially in the mountainous region which is characterized by higher altitudes and steeper slopes.
The lithology layer initially had 41 categories in the study area and was generalized to 22 based on their similarities In order to facilitate the interpretation of the results when using the YC.
The rainfall values for the study area are distributed in 13 categories, ranging from 500 to 5500 mm in the original layer, and were used that way; the layer was created by the National Institute for Meteorology and Hydrology of Ecuador (INAMHI), and covers years 1981–2010; it is believed that rainfall is an important contributing factor to landslides (CAN 2009; Zevallos 2004). All four layers (i.e. land use, erosion, lithology and rainfall) were transformed to raster format, using the same grid cell size as the DEM, in order to use the ‘Zonal Statistics’ tool.
3.4 Statistical analysis
The quantitative analysis used here was composed by two main statistical methodologies, the YC and the DDA. Both of these relate the occurrence of geo-objects, in this case landslides, with any given spatial factor (see Sect. 3.2) (Bijukchhen et al. 2013; Komac and Zorn 2009).
On the one hand, the YC (Yule 1900, 1912) is used to measure the association between two attributes; in this case, the attributes considered are (a) the presence of landslides and (b) slope, aspect, curvature, lithology, rainfall, land use and erosion. On the other hand, the DDA (Berman 1977, 1986) is used to determine the degree of association between geo-objects in terms of the how distant they are from each other; for this scenario the presence of landslides was weighed against their proximity to the E-20.
3.4.1 The Yule coefficient
The YC, also known as the Phi coefficient (Chedzoy 2004), has been used in the sciences as a reliable measure of association between variables, expressed as a dichotomy (e.g. presence–absence, true–false, yes–no) (Adeyemi 2011). This technique associates the presence of landslides to a given spatial actor and assigns a weight that represents the strength of the association between the two (Komac and Zorn 2009). When incorporated into a GIS, the relationship between landslides and categorical maps with multiple classes (e.g. lithology, rainfall ranges, aspect, etc.) can be established by addressing each combination of landslide and class, thereby treating it as a binary event (i.e. bivariate analysis). Among the advantages of using the YC, Adeyemi (2011) states the following: (a) it does not need corrections before/after, (b) it is quickly and easily computed, and (c) it is a measure of the proportional association of one variable to another.
To begin the process of obtaining the YC, the ‘Zonal Statistics as Table’ tool in ArcGIS was used to create a summary of how many landslide cells intersect the individual categories of each spatial factor; in other words, one can now how many landslides are present in each slope or rainfall range, as well as in each lithology category, etc. Having this information allowed to proceed with the calculation of the YC using the formula presented by Bonham-Carter (1994):
where T 11, area where both attributes are present; T 12, area where the first attribute is present but not the second; T 21, area where neither attribute is present; T 22, area where the second attribute is present but not the first one.
Now, Q varies between +1, when attributes have a positive correlation (i.e. complete association), and −1 when there is a negative correlation (i.e. complete disassociation). If Q = 0, then the attributes are independent from each other. It is important to know that the YC assumes that: (a) the attributes are only related to each other, that is, their relationship is not affected by external factors and (b) the attributes are shown in polygons and/or points (Bonham-Carter 1994; Ghosh et al. 2011).
The values for T 11, T 12, T 21 and T 22 were derived from the ‘Zonal Statistics as Table’ tool when combining the layer containing the landslides and the ones containing each spatial factor. This tool provides the following information for the YC: (a) the number of cells for each category in each spatial factor (Npix), and (b) the number of landslide cells that coincide with each layer (T 11). With this information, T 12, T 21 and T 22 can easily be derived in the following way as shown in Tables 2 and 3.
Firstly, the total number of pixels (NpixT) is obtained by adding all the pixels for each category (Npix AS). Afterwards, the total number of pixels of geo-objects of interest (Npixs) is calculated by adding all the values in column T11.
Then, T 12 (T12) is determined by subtracting the numbers in the T11 column from those in Npixs, hence showing the presence of landslides outside of the specified class. Then, T 21 (T21) is calculated by subtracting T11 from Npix AS, resulting in the number of cells that have each Aspect class, but no landslide.
Finally, T 22 (T22) is calculated by subtracting T11, T12 and T21 from the total number of pixels (NpixT). These is shown in Eqs. (2)–(6) and can be programed in ArcGIS or any spreadsheet, such as Excel. Having done this, the YC is calculated using Eq. (1). After this is done, the relationship between linear features and landslides can be determined, as the next section shows.
3.4.2 Distance distribution analysis
Given that the distance between geo-objects (i.e. proximity or adjacency) is used as a benchmark for describing their relationship, the DDA (Berman 1977, 1986) is a statistical tool that can be used when trying to establish de degree of association between linear features (e.g. roads, faults, power lines, etc.) and point or polygon features (e.g. landslides).
DDA compares the cumulative proportion of measured distances D(L), with the cumulative proportion of expected distances D(NL), of two sets of geo-objects; in this case landslides and the E-20 highway. This can be demonstrated as follows (Carranza 2009; Ghosh et al. 2011):
where N(C ij ∩ L), the cumulative number of pixels where landslides (L) and the ith class of the jth spatial factor coincide (i = 1, 2, …, n; and j = 1, 2, …, m); N(C ij ), the cumulative of the total number of pixels occupied by the ith class of the jth spatial factor (i = 1, 2, …, n; and j = 1, 2, …, m); N(L T ), the total number of landslide pixels in the area; and N(T), the total number of pixels of the map.
Having done this, the degree of association of landslide occurrences with a set of (linear) spatial factors is determined by comparing the graphs of D(L) and D(NL) following Berman (1977) and Carranza (2009):
If D ≅ 0, the geo-objects are said to be independent from each other; D > 0, there is a positive spatial association between the geo-objects; D < 0, there is a negative spatial association between the geo-objects.
Put more simply, D(L) represents a correlation between the linear feature (i.e. E-20) and the spatial location of geo-objects (i.e. landslides), while D(NL) represents a random correlation between the linear features and any location in the study area. Now, in order to assess the distribution of landslides along the E-20, the following steps have to be followed:
-
1.
Create a raster file by using the ‘Euclidean Distance’ tool in ArcGIS, using the highway as feature of origin. The resulting file has to be reclassified into ten percentile intervals by using Quantiles, and the break values exported to Excel. The latter ones will be in metres and have to be transformed into kilometres, that is, column ‘distance km’.
-
2.
The ‘npix’ column is filled in Excel, by using the attribute table for the recently created raster and counting the number of pixels on each class (i.e. distance).
-
3.
To calculate the distance distribution for non-landslide (D(NL)) locations with respect to the highway, the cumulative cell count (cnpix) and the total cell count are calculated. Equations (8), (9) and (10).
$${\text{cnpix}} = \sum {({\text{npix}})_{\text{cum}} }$$(8)$${\text{tnpix}} = \sum {({\text{cnpix}})}$$(9)$$D(NL) = \frac{\text{cnpix}}{\text{tnpix}}$$(10) -
4.
The ‘Zonal Statistics as Table’ tool in ArcGIS is applied to the landslide and the distance layers to find the number of landslides in a given class (i.e. distance from E-20); this is column ‘npix_d’.
-
5.
Columns ‘cnpix_d’ and ‘tnpix_d’ are now calculated by adding the number of landslides cells in each distance range, and counting the total number of landslide cells, respectively. This is shown in Eqs. (11) and (12).
$${\text{cnpix}}\_d = \sum {({\text{npix}}\_{\text{d}})_{\text{cum}} }$$(11)$${\text{tnpix}}\_d = \sum {({\text{cnpix}}\_{\text{d}})}$$(12) -
6.
Lastly, the cumulative proportion of measured distances is obtained by dividing ‘cnpix_d’ by ‘tnpix_d’, and the difference between D(L) and D(NL) can be calculated as per Eqs. (13) and (1), respectively:
$$D(L) = \frac{{{\text{cnpix}}\_d}}{{{\text{tnpix}}\_d}}$$(13)
The result of this procedure is shown in Table 4.
The importance of determining the degree of spatial association between the highway and the location of landslides is the possibility of the former being a controlling factor on the latter; by assessing this relationship one could map the landslide susceptibility of different locations, thereby allowing for actions to be taken ahead of time to prevent losses (Ghosh and Carranza 2010).
3.5 Model evaluation
As stated by Chung and Fabbri (2003), the evaluation of the model is an essential part of the process. In order to test the statistical significance of the model, the Chi-squared test was used due to its close relationship with the YC (Adeyemi 2011; Chedzoy 2004):
where ϕ 2 = phi coefficient or YC, squared; χ 2 = Chi-squared; N = number of pixels for each factor class
The next steps are to determine (a) the degrees of freedom (df), as shown in Eq. (15), and (b) the critical value for Chi-squared (Adeyemi 2011); in this case, the latter will be given by a confidence level of 0.999, that is, a 99.9 % assurance on the association, or lack of, between the variables:
where r and c are the number or rows and columns of the table respectively.
By determining the Chi-squared value, the hypotheses stated at the beginning of this paper can be accepted or rejected based on the comparison of these with the critical values of Chi-squared, based on a 0.999 upper confidence band. In addition to this test, Chedzoy (2004) states that one, rarely used, approximation to the standard error of ϕ can be done by dividing 1 by the square root of N (see Eq. 16). This estimation of the error will also be used here.
4 Results
The first results of the bivariate analysis were the calculation of the statistics for the YC. Coefficients are shown in Table 5, where values range from −1 (i.e. negative association) to +1 (i.e. positive association). The Aspect factor class presents low degree of association with landslides (see Fig. 7). Overall the values range from −0.065 to 0.084, which means that landslides are more or less evenly distributed among all slope aspects. As expected, flat areas are not associated with the occurrence of mass movements and present negative values for the YC (−0.508). In general, slopes that face north and northeast present the highest degree of association with landslide occurrence, despite the values being very small: 0.084 and 0.083, respectively. Slopes facing in all other directions have YC values that range from 0.039 to −0.065. This means that landslides occur regardless of the orientation of the slope with a slightly higher tendency to happen on slopes facing north and northeast.

Landslide distribution and aspect
The data suggests that landslide frequency increases gradually with slope (see Fig. 8); this is, the higher the slope, the higher the number of landslides present. Although no single slope range presents a complete association (i.e. YC = 1) with landslide occurrence, landslides are more associated with gradients over 34 % than to softer ones. Inclinations between 52 and 66 % present the highest degree of association with mass movements (YC = 0.138). Conversely, slopes below 7 % are not related to landslides, while slopes between 13 and 27 % are independent of landslides with YC values that range from −0.054 to 0.032.

Landslide distribution and slope
The curvature of a surface is related to its vertical plane, and it is related to the degree of change in the surface aspect and is related to certain types of landslides (Komac and Zorn 2009). The analysis shows that upwardly concave surfaces, represented by negative values in Fig. 9, have a YC = 0.134 and are more likely to be associated with mass movements than those upwardly convex, which are represented by positive values in Fig. 9, and have a YC = 0.085. Again, flat surfaces are not associated with landslides having the lowest value (−0.149) for the YC. Overall, landslides can occur in concave or convex surfaces with roughly the same frequency.

Landslide distribution and curvature
So far we have seen that the topographic characteristics of the area (i.e. slope, aspect and curvature) do not show high association with landslide occurrence, save for the slope which appears to have a positive association on four of its ten classes. Now, the results for spatial association of landslides and categorical factors (i.e. land use, lithology, rainfall and erosion), some of which are independent of the geological aspects (Tibaldi et al. 1995), are as follows.
Land use presents four classes with complete disassociation with mass movements (i.e. YC = −1); this means that no landslides were identified in the following areas: ‘Water’, ‘Cities and Towns’, ‘Unproductive land’ and ‘Forestry’ (see Fig. 10). This is because the first two are located low-lying flatlands with slopes up to 7 %, while ‘Unproductive lands’ refers to small areas (adding to 23 km2) located above 4000 m.a.s.l. Represented mainly by rock outcrops, quarries and glaciers and gravel. The ‘Forestry’ patch, on the other hand, is a privately managed parcel located close to Alóag; it presents a high land cover, has slopes below 13 % and does not record any landslides neither in the images from Google Earth nor in the ones from the IGM. Land uses ‘Agriculture and Livestock’, ‘Agriculture’ and ‘Livestock’ also have little association with landslide occurrence, with values for YC ranging from −0.328 to −0.118.

Landslide distribution and land use
Regarding the remaining land uses, the most associated with landslides are ‘Agriculture and Forestry’ with YC = 0.264, and ‘Livestock and Conservation’ with YC = 0.104. The former refers mainly to forests or planted forests mixed with fast rotation crops, while the latter refers to forests or shrubs mixed with different grass crops (for feeding livestock). In both cases, the land has to be cleared to make space for crops or cattle roaming. As for ‘Conservation’ and ‘Agriculture and Conservation’ is concerned, both have values close to zero (0.080 and −0.027) thereby showing a high degree of independence from the occurrence of landslides.
Now, almost 100 % of the landslides have been identified in the area for ‘Active and Potential’ erosion processes (see Fig. 11). Out of 1328 mapped landslides, only 2 lie out of named factor class and they are located in the null risk area (in other words, they are out of the official extent of the layer provided by the Ministry of Agriculture). This means that areas labelled as ‘Potential’ and ‘Very Active (past and present)’ have complete disassociation (YC = −1) and the ‘Active and Potential’ zone has complete association (YC = 1) with the presence of landslides.

Landslide distribution and erosion
Turning to precipitation, landslides are mostly associated with areas that have between 1250 and 2000 mm of rain annually, which are found in the south east section of the study area; this range is comprised of three categories with the following values for YC: 0.270, 0.186 and 0.134. The zones with the highest precipitation values (i.e. 3500–5500 mm), located mainly in the northwest, show disassociation with landslides (i.e. YC = −0.412 to −1) as shown in Fig. 12.

Landslide distribution and rainfall
By comparison, the association between landslides and different types of lithology is variable. Landslides present complete disassociation (YC = −1) with eight lithology classes: (1) Glacier deposits, (2) Alluvial terraces, (3) Undifferentiated terraces, (4) Intrusive rocks, (5) Andesite, basalt and shales, (6) Lava flows, (7) Tuff, sandstone, clay, agglomerates and (8) Tuff and alluvial sediments. These account for only 2 % of the study area, as shown in Fig. 13.

Landslide distribution and lithology
Furthermore, there are five classes that strong negative association with landslides: (1) Lava flows, tuff, andesite and pyroclastic agglomerates (YC = −0.491), (2) volcanic ashes, lapilli of pumice agglomerates (lahars) (YC = 0.447), (3) andesite (YC = −0.400), (4) agglomerates, tuff (YC = −0.291) and (5) clay agglomerate (YC = −0.189).
As far as positive association goes, there are four classes that could be linked to the presence of landslides: (1) granitic rocks, (2) volcanic sandstone, (3) andesite, and volcanic sandstone agglomerates and (4) agglomerates, which have the following YC values: 0.519, 0.299, 0.144, and 0.129, respectively.
Turning to the DDA, Fig. 14 shows that landslides are present both, north and south of the E-20 in roughly the same proportion; furthermore, 54 % of the landslides occur within approximately 10 km of the E-20, as seen on Table 6. This may be related to the land use of the area, where agriculture, forestry and livestock uses are closest to the main road, thereby contributing to land clearing and de-stabilization of the slopes.

Landslide distribution and distance from the E-20
In the DDA, the results show that, at the scale of this analysis, the E-20 does not influence the frequency of landslide occurrence. Figure 15 shows the cumulative relative frequency of distances of landslides to the E-20, represented as D(L), compared to the probability density distribution of landslides with respect to the highway (Ghosh and Carranza 2010).

Distance distribution analysis of landslides away from the E-20
As Fig. 15 and Table 3 illustrate, the difference between D(L) and D(NL) is close to zero, with the highest difference being 0.241 at 9.8 km, and the lowest being 0.000 at 44.4 km. This suggests that, at regional scale, landslides occur independently from the highway.
Now, the statistical significance of the study was tested by using Chi-squared and estimating the YC error by using Eq. (16); the results are summarized in Table 7, which shows that all factor classes, except for the distance from the road, have a higher Chi-squared value higher than the critical value.
Table 6 shows consistency with the results stated above, in the sense that it demonstrates that the occurrence of landslides in each factor class is not due to chance or randomness, but there is certain degree of influence (i.e. association) between both. In contrast, the distance from the highway shows a value lower than the critical value, meaning that there is 99.9 % of confidence that in this case, landslides are not associated with highway E-20. Furthermore, the values for the error approximation, following Chedzoy (2004), are very low, thereby supporting all the previous work.
Considering that: (a) the sample size (i.e. study area) is well over five million pixels, (b) landslides sum 11,163 pixels and (c) the results shown in Table 6, this model could be treated as valid. Knowing that the model is valid, the last step in the LSA is the creation of a landslide hazard map for the study area (see Fig. 16). This was done by reclassifying each of the previous maps into ten categories based the values of the YC. Since the distance from the road was not associated with the landslides, it was not included in this step. The maps were added with the ‘Raster Calculator’ tool in ArcGIS, and the results were classified into six categories.

Landslide susceptibility map for the study area
5 Discussion
5.1 Spatial factors
Results show that, there is a statistical relationship between the presence of landslides and different spatial factors in the study area. Factor classes that have shown the most relationship with landslides are: (a) active and potential for erosion (YC = 1), (b) granitic rocks and quartz diorite (YC = 0.519), (c) volcanic sandstones (YC = 0.299), (d) mean annual rainfall between 1500 and 1750 mm (YC = 0.270) and (e) land use devoted to agriculture and forestry (YC = 0.264). In contrast, there are 16 factor classes, 7 of them related to lithology and 4 to land use, which have positive disassociation with landslides. On the one hand, this may be due to their low proportion of the study area, which is (at best) 5.6 % of the total. On the other hand, the lack of mapped landslides in those areas, due to high cloud cover or low resolution of the images, may have led to a bias in the these results.
The data suggest that landslides occur independently of the slope aspect; this means that there is little influence of this factor on the distribution of mass movements, except for flat areas which have a strong negative association with them. Elsewhere, studies have evidence that this spatial factor, sometimes, but not always, influences the occurrence of landslides (Ghosh et al. 2011; Kamp et al. 2005; van Westen et al. 2013). In general, slope presents a weak positive association with landslides as the strongest association between the two is YC = 0.138, yet it has strong disassociation in areas with <7 % inclination. Nevertheless, this findings are consistent with those of Vivanco Quizhpe (2011), (Tibaldi et al. 1995) and Terrambiente (2006) in Ecuador, and by Brenning et al. (2014) and Das et al. (2010) elsewhere, which suggest that the landslides tend to be associated with high terrain inclinations.
Erosion is the only spatial factor that presents both, complete association and disassociation, to landslides; almost 100 % of mass movements occur in the region classified as very active, demonstrating consistency with the information provided by the Ministry of Agriculture and (Tambo 2011). Rainfall is another factor that is associated with landslides, especially in the 1250–1750 mm range. In this study, the annual mean rainfall was used, whereas others (Brenning et al. 2014; Komac and Zorn 2009) have shown that there is a big influence from both, the amount and the intensity of precipitation. Despite this, studies by INECO (2012) and Cajas Alban and Fernandez (2012) found that the combination of susceptibility to erosion and high rainfall plays a significant role in the cyclic occurrence of landslides close to Santo Domingo. Furthermore, in a national scale, water is the main controlling factor for landslides, especially during the wet seasons and during the El Nino events for landslide occurrence (Cajas Alban and Fernandez 2012).
The YC shows that mixed land uses tend to be more associated with landslides, such is the case of ‘Livestock and Conservation’ and ‘Agriculture and Forestry’, which are located in areas where erosive processes are very active. This is consistent with the findings for slope (see above) as these land uses taking place mostly in the western lowlands of the study area where there are soft inclinations (up to 7 %) and thus curvature values are close to flat.
Lithology and land use were found to be somewhat independent from landslide frequency, in accordance with Tibaldi et al. (1995) and Brenning et al. (2014). Despite some classes being disassociated, the results also suggest that the ones that are associated (i.e. granitic rocks, volcanic sandstone, and agglomerates) are similar to those found by Tambo (2011) and Brenning et al. (2014), who state that in the southern Andes; areas with metamorphic and granite bedrock have a higher tendency to initiate landslides. Furthermore, the study area is bordered by three volcanoes, which have been known to cause great rock fragmentation and increase landslide susceptibility (CAN 2009; Tibaldi et al. 1995). Brenning et al. (2014) also acknowledge that the results associated with this spatial factor may be subject to dilution given the variety of subunits that comprise the main geological units, which is also important for this study considering conditions of the study area.
The results of the DDA show no association between the location of landslides and their proximity to the E-20, whereas Brenning et al. (2014) state that there is a considerable increase in landslide susceptibility when in close proximity of paved highways in the southern Ecuadorian Andes; they also indicate that within 25 m of the edge of the road, there is up to one order of magnitude difference in the frequency of landslide occurrence from those further than 150 m. This disagreement between their findings and those from this study could be due to the differences in the scales and extent of the analysis, that is, local versus regional scale and 88 versus 5093 km2.
5.2 Statistical analysis
A statistical analysis (Wang et al. 2005) using the YC and DDA was performed to answer the res between landslides and their distance to the highway. On the other hand, the YC presents the following results: out of 77 factor classes,
-
16 (21 %) show complete disassociation (YC = −1),
-
9 (12 %) display negative association (−0.6 < YC < −0.3),
-
50 (65 %) are weakly associated or independent (−0.3 < YC > 0.3),
-
1 (1 %) is positively associates (0.3 > YC > 1), and
-
1 (1 %) shows complete association with landslides.
The statistical significance of the model was tested in two different ways: using Chi-square and the phi error. The former showed consistency with all other results, and the latter demonstrated that the phi error can be considered insignificant. In other words, the hypotheses presented in Sect. 1 of this study have been tested and are considered as valid, that is, each spatial factor has some sort of influence on the occurrence of landslides, and landslides do not occur in all factor classes.
5.3 Limitations
The main shortcoming of this study is related to the lack of information for the western part of the study area, where no landslides could be mapped due to several issues: (a) considerable cloud cover of the area in the images of Google Earth Pro, (b) no aerial photographs for that region, and (c) low resolution (i.e. 30 × 30 m pixel size) of the available information did not allow for identification and mapping of landslide where the first two limitations where overcome. This, in turn, may have led to bias in the distribution of landslides in the study area, potentially altering the results for the YC.
Another limitation on this study is related to the different scales of the thematic layers used. While in some areas, the aerial photographs provided by the IGM had large scales, which allow for better identification and mapping of landslides, other areas had information on a smaller scale, which might have led to smaller landslides not being identified and mapped. Considering that the eastern section of the study area has greater slopes, curvature values and land uses than the western section, the fact that the former had a better resolution of the Google Earth Pro images that the latter does impact on the ability to map landslides in each section, as stated before.
6 Conclusion
Under the assumption that future landslides will occur under similar conditions as those that caused them in the past (Guzzetti et al. 2006), an attempt of measuring the association between different spatial factors and landslide distribution has been presented and validated here. The findings support the idea that landslides are not randomly distributed, but are associated (positively or negatively) to the different conditions of the study area (Das et al. 2010); in this case, landslides have shown positive association with areas of active erosive processes, granitic rocks, volcanic sandstone and rainfall ranging from 1500 to 1750 mm. Future courses of action include: (a) field validation of the landslide inventory, (b) a low scale (i.e. 1:5000) study on the relationship of landslides with highway E-20 in order to test the findings by Brenning et al. (2014), (c) include the location, frequency and magnitude of earthquakes in the LSA for the study area, and (d) present Landslide Susceptibility Map to each local government in order to aid in the decision-making process for future infrastructure developments and land use planning.
References
Adeyemi O (2011) Measures of association for research in educational planning and administration. Res J Math Stat 3:82–90
Berman M (1977) Distance distributions associated with poisson processes of geometric figures. J Appl Probab 14:195–199
Berman M (1986) Testing for spatial association between a point process and another stochastic process. J R Stat Soc Ser C (Appl Stat) 35:54–62
Bijukchhen SM, Kayastha P, Dhital MR (2013) A comparative evaluation of heuristic and bivariate statistical modelling for landslide susceptibility mappings in Ghurmi-Dhad Khola, east Nepal. Arab J Geosci 6:2727–2743. doi:10.1007/s12517-012-0569-7
Bonham-Carter G (1994) Geographic information systems for geoscientists: modelling with GIS, vol 13. Pergamon, Oxford
Brenning A, Schwinn M, Ruiz-Páez A, Muenchow J (2014) Landslide susceptibility near highways is increased by one order of magnitude in the Andes of southern Ecuador, Loja province. Nat Hazards Earth Syst Sci Discuss 2:1945–1975
Cajas Alban L, Fernandez J (2012) Guia para la incorporacion de la variable riesgo en la gestion integral de nuevos proyectos de infraestructura. Secretaria Nacional de Gestion de Riesgos & Programa de las Naciones Unidas para el Desarrollo, Quito, Ecuador
CAN (2009) Atlas de las dinamicas del territorio andino: poblaciones y bienes expuestos a amenazas naturales. Secretaria General de la Comunidad Andina de Naciones, Cali, Colombia
Carranza EJM (2009) Geochemical anomaly and mineral prospectivity mapping in GIS. Elsevier, Amsterdam
Chedzoy OB (2004) Phi-coefficient. In: Encyclopedia of statistical sciences. Wiley, London. doi:10.1002/0471667196.ess1960.pub2
Chung C-J, Fabbri A (2003) Validation of spatial prediction models for landslide hazard mapping. Nat Hazards 30:451–472. doi:10.1023/B:NHAZ.0000007172.62651.2b
Comercio E (2014a) 5 Km de la panamerica norte estaran cerrados por 6 meses. www.elcomercio.com, Quito, Ecuador
Comercio E (2014b) La Alóag-Santo Domingo, cerrada este feriado. www.elcomercio.com, Quito, Ecuador
Das I, Sahoo S, van Westen C, Stein A, Hack R (2010) Landslide susceptibility assessment using logistic regression and its comparison with a rock mass classification system, along a road section in the northern Himalayas (India). Geomorphology 114:627–637
Demoraes F, D’ercole R (2001) Cartografia de riesgos y capacidades en el Ecuador, vol 1. Oxfam International, Quito
GAD (2013) Plan de desarrollo y ordenamiento territorial de Manuel Cornejo Astorga 2012–2025. Gobierno Autonomo Descentralizado Parroquial de Manuel Cornejo Astorga, Quito
Ghosh S, Carranza EJM (2010) Spatial analysis of mutual fault/fracture and slope controls on rocksliding in Darjeeling Himalaya, India. Geomorphology 122:1–24. doi:10.1016/j.geomorph.2010.05.008
Ghosh S, Carranza EJM, van Westen CJ, Jetten VG, Bhattacharya DN (2011) Selecting and weighting spatial predictors for empirical modeling of landslide susceptibility in the Darjeeling Himalayas (India). Geomorphology 131:35–56. doi:10.1016/j.geomorph.2011.04.019
Gonzales FA (2011) Analisis de peligro de deslizamientos. Edutio de cado: sur de la ciudad de Loja, provincia de Loja-Ecuador. Universidad de La Habana
Guzzetti F, Reichenbach P, Ardizzone F, Cardinali M, Galli M (2006) Estimating the quality of landslide susceptibility models. Geomorphology 81:166–184. doi:10.1016/j.geomorph.2006.04.007
Harden C (2001) Sediment movement and catastrophic events: the 1993 rockslide at La Josefina, Ecuador. Phys Geogr 22:305–320. doi:10.1080/02723646.2001.10642745
Hoy D (2014a) Tres rutas alternas para ingresar a Quito. www.hoy.com.ec, Quito, Ecuador
Hoy D (2014b) Un deslave colapso el trafico en la via Aloag-Sto. Domingo. www.hoy.com.ec, Quito, Ecuador
Hughes ML, McDowell PF, Marcus WA (2006) Accuracy assessment of georectified aerial photographs: Implications for measuring lateral channel movement in a GIS. Geomorphology 74:1–16. doi:10.1016/j.geomorph.2005.07.001
INAMHI (2013a) Mapa de Isotermas media anual serie 81—2010. Instituto Nacional de Meteorologia e Hidrologia, Quito
INAMHI (2013b) Mapa de Isoyetas media anual serie 81—2010. Instituto Nacional de Meteorología e Hidrología, Quito
INECO (2012) Anexo No 3. Geologia y geotecnia. Ministerio de Transporte y Obras Publicas
Kamp U, Growley BJ, Khattak GA, Owen LA (2005) GIS-based landslide susceptibility mapping for the Kashmir earthquake region. Geomorphology 101:631–642. doi:10.1016/j.geomorph.2008.03.003
Komac B, Zorn M (2009) Statistical landslide susceptibility modeling on a national scale: the example of Slovenia. Rev Roum Géogr 53:179–195
Marsh SH (2000) Landslide hazard mapping: summary report. British Geological Survey, Nottingham
Remondo J, González-Díez A, De Terán J, Cendrero A (2003) Landslide susceptibility models utilising spatial data analysis techniques. A case study from the lower Deba Valley, Guipuzcoa (Spain). Nat Hazards 30:267–279. doi:10.1023/B:NHAZ.0000007202.12543.3a
Sierra M (1999) Propuesta preliminar de un sistema de clasificación de vegetación para el Ecuador continental
Tambo W (2011) Estudio del peligro de deslizamiento del norte de la ciudad de Loja, provincia de Loja. Universidad de La Habana, Ecuador
Terrambiente (2006) EIAD Línea de Transmisión a 230 kV Santa Rosa—Pomasqui II y Ampliación de Subestación Pomasqui. Transelectric S.A., Quito
Tibaldi A, Ferrari L, Pasquarè G (1995) Landslides triggered by earthquakes and their relations with faults and mountain slope geometry: an example from Ecuador. Geomorphology 11:215–226. doi:10.1016/0169-555X(94)00060-5
Van Den Eeckhaut M, Hervás J, Jaedicke C, Malet JP, Montanarella L, Nadim F (2012) Statistical modelling of Europe-wide landslide susceptibility using limited landslide inventory data. Landslides 9:357–369. doi:10.1007/s10346-011-0299-z
van Westen C, Ghosh S, Jaiswal P, Martha T, Kuriakose S (2013) From landslide inventories to landslide risk assessment; an attempt to support methodological development in India. In: Margottini C, Canuti P, Sassa K (eds) Landslide science and practice. Springer, Berlin, pp 3–20. doi:10.1007/978-3-642-31325-7_1
Vivanco Quizhpe C (2011) Analisis comparativo de tecnicas estadisticas y de aprendizaje para evaluar la susceptibilidad del terreno a los deslizamientos superficiales. Universidad Tecnica Particular de Loja
Wang H, Liu G, Xu W, Wang G (2005) GIS-based landslide hazard assessment: an overview. Prog Phys Geogr 29:548–567. doi:10.1191/0309133305pp462ra
Yule GU (1900) On the association of attributes in statistics: with illustrations from the material of the childhood society, &c. Philos Trans R Soc Lond Ser A Contain Pap Math Phys Charact 194:257–319. doi:10.1098/rsta.1900.0019
Yule GU (1912) On the methods of measuring association between two attributes. J R Stat Soc 75:579–652. doi:10.2307/2340126
Zevallos O (2004) Informe tecnico final—Patrones y procesos de configuracion en Ecuador. EPN, La Red, IAI, Quito
Acknowledgments
We would like to acknowledge the National Secretary of Higher Education Science, Technology and Innovation—Ecuador (SENESCYT) for financing this project, and A/Prof. John Carranza for his guidance and insight. The authors would also like to thank the anonymous reviewers for many constructive comments.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article

Cite this article
Younes Cárdenas, N., Erazo Mera, E. Landslide susceptibility analysis using remote sensing and GIS in the western Ecuadorian Andes. Nat Hazards 81, 1829–1859 (2016). https://doi.org/10.1007/s11069-016-2157-8
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11069-016-2157-8