
Abstract
Landslide susceptibility maps are key tools for land use planning, management and risk mitigation. The Landslide susceptibility map of Italy, scale 1:1,000,000 is being realized by using the Italian Landslide Inventory – Progetto IFFI and a set of contributing factors, such as surface parameters derived from 20 to20 m DEM, lithological map obtained from the geological map of Italy 1:500,000, and land use map (Corine Land Cover 2000). These databases have been subjected to a quality analysis with the aim of assessing the completeness, homogeneity and reliability of data, and identifying representative areas which may be used as training and test areas for the implementation of landslide susceptibility models. In order to implement the models, physiographic domains of homogeneous geology and geomorphology have been identified, and landslides have been divided into three main classes in order to take into account specific sets of conditioning factors: (a) rockfalls and rock-avalanches; (b) slow mass movements, (c) debris flows. The modelling tests performed with different techniques (Discriminant Anaysis, Logistic Regression, Bayesian Tree Random Forest) provided good results, once applied with the appropriate selection of training and validations sets and with a significant number of statistical units.
Access provided by Autonomous University of Puebla. Download chapter PDF
Similar content being viewed by others


Keywords
Introduction
Landslides are among the most problematic natural hazards in Italy, in terms of both casualties and economic losses. The management of landslide risk requires suitable actions at different levels, from national to municipal. In particular, at national level it is mandatory to correctly allocate the limited budget available for mitigation, thus recognizing the most critical areas where funds should be allocated. Moreover, it is important to know the fragility of the territory at trans-regional level in case of large disasters that require the intervention of National Civil Protection. For both needs, a map reporting the susceptibility of landslides at national scale is fundamental.
Some experiments of landslide susceptibility mapping at national scale have been already presented in the literature in Italy (Delmonaco et al. 2002; Günther et al. 2008) and in other countries (Malet et al. 2010). However, these maps have been produced using heuristic methods based on multi-criteria analysis of contributing factors and subjective judgement. None of these maps have been produced by systematically exploiting national-scale landslide inventories that are becoming available in many countries.
The aim of the work is to present the methodology adopted by ISPRA (Italian National Institute for Environmental Protection and Research) with the University of Florence, University of Milano-Bicocca and University of Rome “La Sapienza” for the development of a Landslide susceptibility map of Italy at 1:1,000,000 scale. This research is carried out in the framework of the European Thematic Strategy for Soil Protection and in particular in the activities of the JRC European Landslide Expert Group dealing with the definition of guidelines for delineating landslide prone areas in Europe and the development of preliminary models for landslide susceptibility assessment at European and national scale (Hervas 2007; Hervás et al. 2010; Van Den Eeckhaut et al. 2010).
The “Landslide susceptibility map of Italy” project activities include: (1) analysis and quality assessment of existing datasets for geology, land use, land surface and landslides; (2) identification of “homogeneous” physiographic settings, (3) test of different susceptibility models to assess advantages, disadvantages and the applicability at the scale of the analysis; (4) selection of an optimal model; (5) application of selected model to the entire area and production of Landslide Susceptibility Map of Italy. This paper presents the results of the first four activities.
Contributing Factors
Considering the expected significance in controlling landslides and the availability of complete datasets for the entire country, it has been decided to use as contributing factors the lithology, the land use and selected land surface parameters.
The lithological map was obtained from the 1:500,000 Geological Map of Italy (Compagnoni et al. 1976–1984) by reclassifying the 128 geological units in 16 classes, according with similar lithological and geomechanical characteristics. The geological classification is consistent and homogeneous for the entire area, even if not always optimized for landslide susceptibility (e.g., talus and alluvial deposits are not distinguished, pyroclastic soils around Vesuvius Volcano are not well classified). In some portions, the accuracy of the map is moderate, with errors in mapping limits higher than 50 mm, which correspond to acceptable graphicism error at 1:1,000,000 scale.
Land use was obtained by reclassified 1:100,000 Corine Land Cover Map (Büttner et al. 2002) in 11 classes based on landslide density and spatial significance of similar units in the area. The map is high homogeneous, and the resolution of boundaries is high for the scale of the analysis.
A 20 × 20 m DEM (IGM) was adopted for the description of land surface. This DEM derives from the interpolation of 25 m interval contour lines. Although the resolution is optimal for the scale of the analysis, the quality of the DEM is low in some sectors due to interpolation problems (e.g., terrace effect) and a strong smoothing effect. A number of DEM-derived variables have been created within GIS: slope gradient, aspect, curvatures, contributing area, topographic wetness index (Beven and Kirkby 1979), roughness (VRM, Sappington et al. 2007).
The Italian Landslide Inventory
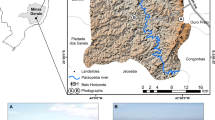
The Italian Landslide Inventory (Progetto IFFI – Inventario dei Fenomeni Franosi in Italia) has been used for the analysis (Fig. 1). This inventory includes 486,336 landslides which affect an area of about 20,800 km2 (6.9 % of Italy). The main types of movement are: rotational/translational slides (32.5 %), slow earth flows (15.3 %) and rapid debris flows (14.6 %).

Landslide density in Italy (From Trigila et al. 2010)
The inventory has been developed by ISPRA and 21 Regions and self-governing Provinces following a common protocol for both the geometric representation and the landslide attributes. Landslides have been identified using field surveys, historical documents, and aerial photo interpretation, and mapped within a GIS environment as polygon (78 %), line (11 %) or points (11 %), according to the shape, the typology and the dimension of the landslides.
The mapping scale is 1:10,000 in the most part of Italian territory. Less resolution scale (1:25,000) has been used in mountain and sparsely populated areas.
The attributes associated to each landslide are organised in three different levels of increasing detail. The 1st level contains the basic data on landslide location, type of movement and state of activity; the 2nd level provides data on geometry, lithology, geotechnical properties, land use, causes and activation date; the 3rd level gives detailed information on damages, investigations and remedial measures (Trigila and Iadanza 2008). For most of landslides, only the 1st level information is available.
The pre-existing degree of knowledge on landslides among the Regions was extremely different before the Project began. Despite the adoption of a common protocol for landslide identification and mapping, currently there is still a lack of homogeneity of the inventory, especially in terms of landslide density (ls/km2) (Trigila et al. 2010).
A further analysis allowed to recognize that this incompleteness is due to three main problems: (1) sources of information, (2) landslide size resolution, (3) interpretation of landslide typology.
Regions where landslide have been recognized mainly based on historical data report only events in urban areas and along the transportation network, thus neglecting all landslide bodies that can be recognized in sparsely populated areas by aerial photo-interpretation or field survey. Susceptibility models based on such limited information roughly describe the susceptibility of most active slopes, but generally underestimate the overall landslide potential (Carrara et al. 2003).
The size–frequency relationship allows to determine the resolution of the inventory and to estimate the completeness, under the assumption that a complete inventory should follow a power-law relationship for a wide range of orders of magnitude (Malamud et al. 2004). The analysis has been performed for all Regions and all landslide typologies (Fig. 2). In general, it is possible to observe a systematic difference in the modal size of landslides, and a strong deviation from power law below a certain threshold, which regionally varies.

Size-frequency curves for rotational and translational slides for Italian regions. Some regions present a censoring for landslides above 10,000 m2, which is due to an adoption of previous protocol for landslide mapping. For most regions, the size-frequency curve shows a deviation from power-law for landslides smaller than about 500,000 m2
Problems related to the interpretation of landslide typology has been observed in a few cases. In Apennine areas, slides, earthflows and complex landslides (mostly slide-earthflows) are not consistently classified among the Regions (Fig. 3a). However, this problem was overcome by grouping the three typologies together. The same occurs for rockfalls and complex landslide in the Alpine areas.

Example of problems related to the interpretation of landslide typology. (a) unclear distinction among earthflows, slides and complex landslides in the Apennine area; (b) cumulative probability as a function of size for DSGSD, showing different approaches to DSGSD mapping; (c) extract of DSGSD inventory in Regione Piemonte, with polygons reclassified according to planar area, showing the presence of extremely small DSGSD bodies
DSGSDs pose several problems of consistency. Some Regions considered DSGSDs as very large phenomena involving entire slopes and characterized by clear morpho-structural features (Agliardi et al. 2001). In other Regions, relatively small phenomena that are elsewhere considered as rock slides are classified as DSGSD. Although a susceptibility model for DSGSD will not be developed, this problem is important for the susceptibility model of slides, because an overestimation of DSGSD imply an underestimation of slides (cfr. Piemonte inventory in Figs. 2e and 3c).
Concluding, the non-homogeneity of the IFFI inventory requires a careful selection of training and validation sets for the susceptibility models, in order to avoid systematic errors in the analysis.
Moreover, to reduce problems related to the classification of landslides, the typologies have been reclassified into three classes: (1) slow-moving landslides (herein SML, including rotational and translational slides, earthflows and Apenninic complex landslides), (2) rockfalls and rock-avalanches (herein RRA, including rockfalls and Alpine complex landslides), and (3) debris flows (herein DF).
Susceptibility Modelling Tests
The strong geological and morphological heterogeneity of Italy required a subdivision of the area in 5 relatively homogeneous domains to be used for the training of the models: the Alps, the Northern Apennines, the foredeep-foreland (Apennine eastern slope until the Adriatic coast), the inner chain (Apennine western slope until the Tyrrhenian coast) and the Calabrian Arc (Calabria region and north-east Sicily). For each area and for each landslide typology class (SLM, RRA, DF), training and validation zones are identified according to the completeness and quality of database, and further refined based on the results of susceptibility modelling tests. Models developed for the training areas will then be applied to the entire domains and finally joined to develop the final Landslide Susceptibility Maps of Italy.
In order to be consistent over the entire areas, it was decided to adopt the same modelling techniques, for the choice of which a number of tests have been performed using Discriminant Analysis, Bayesian Tree Random Forest (BTRF) and Logistic Regression.
The modelling tests have been performed to analyse several issues that are relevant for susceptibility modelling:
-
The suitability of different terrain units (slope-units vs. grid cells)
-
The effect of different training and validation sets
-
The effect of different independent variable set
-
The effect of the size of the terrain units
-
The effect of different sampling techniques and density of points
The type and size of terrain units strongly affect the results and the quality of susceptibility models (Carrara et al. 2003). The optimal terrain units should be selected according to the typology and the mean size of landslides. For instance, grid-cells are suitable for debris flows and small landslides, whereas slope-units may be preferable for large slides. In some cases, however, the selection of a terrain unit is forced by data availability, or by the scale of the analysis.
For our modelling, it has been decided to adopt large grid cells as terrain units. Although geomorphologically not significant, these units can be used easily for extremely large areas. In order to assess the suitability of these terrain units, Discriminant Analysis was applied to 500 × 500 m grid-cells and to hydrologically significant slope units. As a results, the large grid-cells model performed as good as the slope-unit model, especially for SML (Fig. 4) and RRA.

Rotational and translational slide susceptibility maps developed by using Discriminant Analysis and different terrain units. (a) slope-units; (b) 500 × 500 m square cells. (c) ROC curves for the two models, showing a similar performance
The selection of appropriate training and validation sets is also fundamental.
Especially with small scale models, this issue can be extremely complex. Discriminant analysis was used for RRA susceptibility modelling of a large area that includes part of Lombardy and part of Piemonte. A first model was trained in Lombardy and validated in Piemonte, and the second vice versa (Fig. 5).

Rockfall and rock-avalanche susceptibility maps developed by using Discriminant Analysis and different training and validation sets. Model (b), developed by using Lombardia as training set, strongly overestimate susceptibility due to problems related to rockfall inventory mapping. A visual comparison of the two maps shows strong differences that are not appreciable with ROC curves (c)
The two models are very different, with the model trained in Lombardy strongly overestimating the landslide susceptibility. In spite of these differences, the ROC curves of the two models are very similar, thus demonstrating how difficult is the assessment of model quality when training and validation are performed with non-homogeneous datasets deriving from different sources.
The analyses performed in the Northern Apennine with the Bayesian Tree Random Forest (BTRF henceforth) focused on the estimation of the importance of the single input parameters and on the selection of the optimal configuration of a regression model. The results of these tests are displayed in Fig. 6. The model was initially applied using the complete set of input parameters at disposal (full version), automatically assigning them a rank by relevance and calculating the Receiver Operating Characteristic (ROC) curve (with relative Area Under Curve, AUC) using an independent testing dataset. Subsequently, reduced versions of the BRTF model were applied taking into account a progressively lower number of parameters. Step by step the least relevant parameters were discarded and the AUC values of every run was used to assess the effectiveness of the regression model.

Iterative procedure for the determination of the optimal configuration of the Bayesian Tree Random Forest model
This procedure, applied separately for each landslide typology in every homogeneous domain, allows to:
-
Sort the variables by relevance, determining the most important ones (an example is shown in Table 1);
Table 1 Ranking of the most important parameters involved in landslide susceptibility modelling in the Northern Apennine homogeneous domain -
Decide how many and which parameters need to be taken into account to best assess the landslide susceptibility (optimal configuration of the BTRF regression model) (Fig. 6).
Finally, the optimal configuration of the BTRF was applied to the whole study area (Fig. 7).

Application of the Bayesian Tree Random Forest model in a test area
The southern Italy represented a sort of test site for evaluating the performance of the Logistic Regression approach in the susceptibility assessment at the national scale. In particular, many tests have been performed in order to verify differences and analogies among the results which derive from different sampling strategies and/or different resolutions of the maps representing the contributing factors.
On one hand, a comparison was made of the models where the explanatory variables were sampled at different resolutions: the highest one (20 × 20 m) and the one resampled at 100 × 100 m. On the other hand, different approaches in terms of sampling strategy were carried out by varying the sampling pattern (random or systematic) (Figs. 8 and 9), the total number of sampled points (Fig. 10), the proportion between “landslide” and “no landslide” points.

Example of SML susceptibility maps obtained by applying the logit function with two different sampling strategies (sketch in the lower left corner), with related ROC curves: (a) randomly placed points; (b) “gridded” points

Results of the RRA susceptibility logit function with “gridded” points applied in the test area

Example of DF susceptibility maps obtained by applying the logit function with two different datasets (in terms of total number of sampled points), with related ROC curves and frequency tables: (a) one point is sampled in each scar area after applying a zonal statistic within the scar area itself; (b) all the landslide points are sampled. Despite the similar ROCs and AUCs, the results are markedly different as observable in the maps and frequency tables
Significant differences also come out by analyzing the results in the training areas as well as in the test ones. The ROC curves and the observation of true and false positive rates for specific cut-off values highlighted that the most reliable results are obtained with a systematic sampling on the 100 × 100 resolution grids, with a ratio of “landslide” points to “no landslide” points of at least 0.5. The ROC curves have been always coupled with the analysis of each single contingency table used to build them, in order to assess the actual efficiency and reliability of selected models, as the curves themselves do not always explicitly detect the real differences between different models.
Finally, it is possible to observe that logistic regression model is reliable even for large scale susceptibility assessment, where only a part of the territory is sampled and analyzed. Notwithstanding, it is important to emphasize that the coefficients of categorical variables (dummies) can assume negative values, thus estimating the inhibitory effect of a given land-use or lithology class on landslides, rather than the contributing effect.
Conclusion
The modelling tests performed for selected sub-areas of Italy provided good performance with all techniques, once applied with the appropriate selection of training and validations sets and with a significant number of statistical units.
These tests also demonstrated that large grid-cells (100 × 100 m, 500 × 500 m) are suitable terrain units for the scale of the analysis. Moreover, they showed that accuracy statistics or ROC curves are not sufficient to evaluate the models, since the same quality was assigned to extremely different models. A careful quality assessment needs an evaluation of geomorphologic significance of predicting variables and an appraisal of modeling results according to the sensibility of the operator.
Considering the results of the tests, the Bayesian Tree Random Forest model was selected to develop the national scale susceptibility map. The model will be applied to 100 × 100 m grid cells and then resampled up to 500 × 500 m. The models will be independently trained for the different physiographic settings and finally joined to produce the 1:1,000,000 susceptibility map of Italy.
References
Agliardi F, Crosta G, Zanchi A (2001) Structural constraints on deep-seated slope deformation kinematics. Eng Geol 59(1–2):83–102
Beven KJ, Kirkby MJ (1979) A physically-based variable contributing area model of basin hydrology. Hydrol Sci Bull 24(1):43–69
Büttner G, Feranec J, Jaffrain G (2002) Corine land cover update 2000 technical guidelines. European Environmental Agency technical report 89, 56 pp
Carrara A, Crosta G, Frattini P (2003) Geomorphological and historical data in assessing landslide hazard. Earth Surf Process Landf 28:1125–1142
Compagnoni B, Damiani AV, Valletta M, Finetti I, Cirese E, Pannuti S, Sorrentino F, Rigano C (1976–1984) Carta Geologica d’Italia alla scala 1:500,000 (5 fogli). Servizio Geologico d’Italia, Roma
Delmonaco G, Leoni G, Margottini C, Puglisi C (2002) La propensione del territorio italiano ai fenomeni franosi. Ital J Eng Geol Environ 1:111–116
Günther A, Reichenbach P, Hervás J (2008) Approaches for delineating areas susceptible to landslides in the framework of the European soil thematic strategy. In: Proceedings of the first world landslide forum, Tokyo, 18–21 Nov 2008, pp 235–238
Hervás J (ed) (2007) Guidelines for mapping areas at risk of landslides in Europe. In: Proceedings of the experts meeting held on 23–24 October 2007. Institute for Environment and Sustainability Joint Research Centre (JRC), Ispra, Italy EUR 23093 EN – 2007
Hervás J, Günther A, Reichenbach P, Malet JP, Van Den Eeckhaut M (2010) Harmonised approaches for landslide susceptibility mapping in Europe. In: Malet JP, Glade T, Casagli N (eds) Proceedings of international conference on mountain risks: bringing science to society, Florence, 24–26 Nov 2010. CERG Editions, Strasbourg, pp 501–505
Malamud BD, Turcotte DL, Guzzetti F, Reichenbach P (2004) Landslide inventories and their statistical properties. Earth Surf Process Landf 29(6):687–711
Malet JP, Thiery Y, Hervàs J, Günther A, Puissant A, Grandjean G (2010) Landslide susceptibility mapping at 1:1M scale over France: exploratory results with a heuristic model. In: Malet JP, Glade T, Casagli N (eds) Proceedings of the international conference mountain risks: bringing science to society, Florence, Italy, 24–26 Nov 2010. CERG Editions, Strasbourg, pp 315–320
Sappington JM, Longshore KM, Thompson DB (2007) Quantifying landscape ruggedness for animal habitat analysis: a case study using bighorn sheep in the Mojave Desert. J Wildl Manage 71(5):1419–1426
Trigila A, Iadanza C (2008) Landslide in Italy – special report 2008 (Rapporti 83/2008). ISPRA, Roma, 32 pp. URL: http://www.isprambiente.gov.it/site/it-IT/Pubblicazioni/Rapporti/Documenti/rapporto_83_08_landslides.html
Trigila A, Iadanza C, Spizzichino D (2010) Quality assessment of the Italian landslide inventory using GIS processing. Landslides 7(4):455–470
Van Den Eeckhaut M, Hervás J, Jaedicke C, Malet JP, Picarelli L (2010) Calibration of logistic regression coefficients from limited landslide inventory data for European-wide landslide susceptibility modelling. In: Malet J P, Glade T, Casagli N (eds) Proceedings of the international conference mountain risks: bringing science to society, Florence, Italy, 24–26 Nov 2010. CERG Editions, Strasbourg, pp 515–521
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2013 Springer-Verlag Berlin Heidelberg
About this chapter
Cite this chapter
Trigila, A. et al. (2013). Landslide Susceptibility Mapping at National Scale: The Italian Case Study. In: Margottini, C., Canuti, P., Sassa, K. (eds) Landslide Science and Practice. Springer, Berlin, Heidelberg. https://doi.org/10.1007/978-3-642-31325-7_38
Download citation
DOI: https://doi.org/10.1007/978-3-642-31325-7_38
Published:
Publisher Name: Springer, Berlin, Heidelberg
Print ISBN: 978-3-642-31324-0
Online ISBN: 978-3-642-31325-7
eBook Packages: Earth and Environmental ScienceEarth and Environmental Science (R0)