
Abstract
In this paper, we introduce a novel iterative method for finding the minimum-norm solution to a pseudomonotone variational inequality problem in Hilbert spaces. We establish strong convergence of the proposed method and its linear convergence under some suitable assumptions. Some numerical experiments are given to illustrate the performance of our method. Our result improves and extends some existing results in the literature.
Similar content being viewed by others


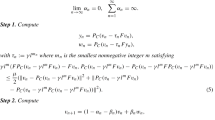
Avoid common mistakes on your manuscript.
1 Introduction
Throughout this paper, assume that C is a nonempty, convex and closed subset of the real Hilbert space H with the inner product \(\langle , \rangle\) and the norm \(\Vert . \Vert\). Let \(F: {H} \rightarrow {H}\) be a Lipschitz continuous operator. The object of our investigation is the following variational inequality problem (shortly, VI(C, F)):
Find \({{x}^{*}}\in C\) such that
We denote the solution set of VI(C, F) by Sol(C, F).
Many problems in various fields such as physic, economics, engineering, optimization theory can be led to variational inequalities. Iterative methods for solving these problems have been proposed and analyzed (see, for example, Facchinei and Pang (2003), Gibali et al. (2017), Kassay et al. (2011), Kinderlehrer and Stampacchia (1980), Konnov (2001) and references therein). One of the most famous methods for solving VI(C, F) is the extragradient method introduced by Korpelevich (1976). In this method, one needs to calculate two projections onto C at each iteration. This may affect the efficiency of the method when finding a projection onto a closed and convex set C is not an easy problem.
In recent years, many authors are interested in the extragradient method and improved it in various ways, see, e.g. Anh et al. (2020), Censor et al. (2011a, b, 2012b), Reich, Thong and Dong et al. (2021), Reich, Thong and Cholamjiak et al. (2021), Thong and Hieu (2018), Thong and Vuong (2021), Yang et al. (2018), Yang (2021) and references therein. The subgradient extragradient method, proposed by Censor et al. (2012a) for solving VI(C, F) in real Hilbert spaces is one of these modifications.
where \(\lambda \in (0,\dfrac{1}{L}),\) and L is a Lipschitz constant of F. This method replaces two projections onto C by one projection onto C and one onto a half-space. The sequence \(\{x_n\}\) generated by (2) converges weakly to an element of Sol(C, F) provided that Sol(C, F) is nonempty.
Kraikaew and Seajung (2014) used the subgradient extragradient method and Halpern method to introduce an algorithm for solving VI(C, F) as follows:
where \(\lambda \in (0,\dfrac{1}{L}), \{\alpha _n\}\subset (0,1), \alpha _n\rightarrow 0, \sum _{n=1}^\infty \alpha _n =+\infty .\) They proved that the sequence \(\{x_n\}\) generated by (3) converges strongly to \(P_{Sol(C,F)}x_0\) if F is monotone and L-Lipschitz continuous. The main disadvantage of Algorithms (2), (3) is a requirement to know the Lipschitz constant of F or at least to know some its estimation.
Very recently, Yang (2021) proposed a modification of subgradient extragradient method with step size rule using the inertial-type method as follows: Given \(\lambda _0>0, \mu <\mu _0\in (0,1)\). Let \(x_0, x_1\in H\) be arbitrary
Under the pseudomonotonicity and sequential weak continuity of the mapping, the convergence of the algorithm was established without the knowledge of the Lipschitz constant of the mapping.
Motivated and inspired by the above mentioned works, and by the ongoing research in these directions, in this paper, we suggest a new iterative scheme for finding the minimum-norm solution to VI(C, F) (1). It is worth pointing out that the proposed algorithm does not require the prior knowledge of the Lipschitz-type constant of the variational inequality mapping and only requires to compute one projection onto a feasible set per iteration as well as without the assumption on the weakly sequential continuity of the mapping. Moreover, the convergence rate is obtained under strong pseudomonotonicity and Lipschitz continuity assumptions of the variational inequality mapping.
The paper is organized as follows. In Sect. 2, we recall some basic definitions and results. In Sect. 3, we present and analyze the convergence of the proposed algorithms. Finally in Sect. 4, we present some numerical experiments to illustrate the performance of the proposed method.
2 Preliminaries
Lemma 2.1
([Cottle and Yao (1992), Lemma 2.1]) Consider the problem VI(C, F) with C being a nonempty, closed, convex subset of a real Hilbert space H and \(F : C \rightarrow H\) being pseudo-monotone and continuous. Then, \(x^*\) is a solution of VI(C, F) if and only if
Lemma 2.2
Let H be a real Hilbert space. Then the following results hold:
-
(i)
\(\Vert x+y\Vert ^2=\Vert x\Vert ^2+2\langle x,y\rangle +\Vert y\Vert ^2 \ \forall x,y\in H;\)
-
(ii)
\(\Vert x+y\Vert ^2\le \Vert x\Vert ^2+2\langle y,x+y\rangle \ \forall x,y\in H.\)
Definition 2.1
Let \(T:C\rightarrow H\) be an operator, where C is a closed and convex subset of a real Hilbert space H. Then
-
T is called L-Lipschitz continuous with \(L>0\) if
$$\begin{aligned} \Vert Tx-Ty\Vert \le L \Vert x-y\Vert \ \ \ \forall x,y \in C. \end{aligned}$$ -
T is called monotone if
$$\begin{aligned} \langle Tx-Ty,x-y \rangle \ge 0 \ \ \ \forall x,y \in C. \end{aligned}$$ -
T is said to be pseudo-monotone if
$$\begin{aligned} \langle Tx,y-x \rangle \ge 0 \Longrightarrow \langle Ty,y-x \rangle \ge 0. \end{aligned}$$It is called \(\delta\)-strongly pseudo-monotone if there is \(\delta > 0\) such that
$$\begin{aligned} \langle Tx,y-x \rangle \ge 0 \Longrightarrow \langle Ty,y-x \rangle \ge \delta \Vert y - x\Vert ^2. \end{aligned}$$ -
T is said to be weakly sequentially continuous if, for each sequence \(\{x_n\}\) in C, \(\{x_n\}\) converges weakly to a point \(x\in C\), then \(\{Tx_n\}\) converges weakly to Tx.
-
T is called weakly closed on C if for any \(\{x_n\} \subset C,\) \(x_n \rightharpoonup x,\) and \(T(x_n) \rightharpoonup y,\) then \(T(x) = y.\)
-
T is said to have \(*\)-property on C, if the function \(\Vert T(x)\Vert\) is weakly lower-semicontinuous (w.l.s.c.) on C, i.e., for any \(\{x_n\} \subset C,\) \(x_n \rightharpoonup x,\)
$$\begin{aligned} \Vert T(x)\Vert \le \liminf _{n\rightarrow \infty }\Vert T(x_n)\Vert . \end{aligned}$$
A relation between the weakly sequential continuity, weak closedness and \(*\)-property are revealed in the following simple statement.
Lemma 2.3
-
(i)
Any weakly sequentially continuous operator is weakly closed and have the \(*\)-property.
-
(ii)
A weakly closed operator, mapping bounded subsets into bounded subsets, is weakly sequentially continuous.
-
(iii)
An operator having the \(*\)-property and mapping bounded subsets into bounded subsets is not necessarily weakly sequentially continuous, and hence is not necessarily weakly closed.
Proof
i. Suppose T is weakly sequentially continuous on C. Then it is weakly closed by definition. Further, let \(C \ni x_n \rightharpoonup x,\) then \(T(x_n) \rightharpoonup T(x),\) and due to the weak lower continuity of the norm, one gets \(\Vert T(x)\Vert \le \liminf _{n\rightarrow \infty }\Vert T(x_n)\Vert ,\) which means the \(*\)-property of T.
ii. Assume that T is weakly closed and maps bounded subsets into bounded subsets. Let \(x_n \rightharpoonup x,\) than the sequence \(\{x_n\}\) is bounded, hence, the set \(\{T(x_n)\}\) is also bounded. Let \(\zeta\) be a weak cluster point of \(\{T(x_n)\}.\) There exists a weakly convergent subsequence \(T(x_{n_k}) \rightharpoonup \zeta .\) Since \(x_{n_k} \rightharpoonup x,\) by the weak closedness of T, one gets \(\zeta = T(x).\) Thus, \(T(x_n) \rightharpoonup T(x).\)
iii. Let H be a real Hilbert space with an orthonormal basis \(\{e_n\}\) and C be a closed ball centered at 0 with radius \(r:= \sqrt{2}.\) Define the operator \(T: C \rightarrow H\) by \(T(x) := \Vert x\Vert x.\) Obviously, T maps bounded subsets into bounded subsets. Further, T has the \(*\)-property. Indeed, let \(x_n \rightharpoonup x,\) then \(\Vert T(x)\Vert = \Vert x\Vert ^2 \le \left( \liminf _{n\rightarrow \infty }\Vert x_n\Vert \right) ^2 \le \liminf _{n\rightarrow \infty }\Vert x_n\Vert ^2 = \liminf _{n\rightarrow \infty }\Vert T(x_n)\Vert\). On the other hand, T is not weakly sequentially continuous. Indeed, let \(x_n = e_n + e_1.\) Then \(x_n \rightharpoonup e_1,\) and for \(n \ge 2\), \(T(x_n) = \sqrt{2}(e_n + e_1) \rightharpoonup \sqrt{2}e_1 \ne T(e_1) = 2 e_1\).
Lemma 2.4
(Saejung and Yotkaew (2012)) Let \(\{a_n\}\) be a sequence of nonnegative real numbers, \(\{\alpha _n\}\) be a sequence of real numbers in (0, 1) with \(\sum _{n=1}^\infty \alpha _n=\infty\) and \(\{b_n\}\) be a sequence of real numbers. Assume that
If \(\limsup _{k\rightarrow \infty } b_{n_k} \le 0\) for every subsequence \(\{a_{n_k}\}\) of \(\{a_n\}\) satisfying \(\liminf _{k\rightarrow \infty }(a_{n_k+1}-a_{n_k})\ge 0\) then \(\lim _{n\rightarrow \infty }{a_n} = 0\).
Definition 2.2
(Ortega and Rheinboldt (1970)) Let \(\{x_n\}\) be a sequence in H.
-
(i)
\(\{x_n\}\) is said to converge R-linearly to \(x^*\) with rate \(\rho \in [0, 1)\) if there is a constant \(c>0\) such that
$$\begin{aligned} \Vert x_n-x^*\Vert \le c\rho ^n \ \ \forall n\in \mathbb {N}. \end{aligned}$$ -
(ii)
\(\{x_n\}\) is said to converge Q-linearly to \(x^*\) with rate \(\rho \in [0, 1)\) if
$$\begin{aligned} \Vert x_{n+1}-x^*\Vert \le \rho \Vert x_n-x^*\Vert \ \ \forall n\in \mathbb {N}. \end{aligned}$$
3 Main results
In this work, we assume the following conditions:
Condition 1
The feasible set C is nonempty, closed, and convex.
Condition 2
The mapping \(F:H\rightarrow H\) is L-Lipschitz continuous, pseudomonotone on H. However, the information of L is not necessary to be known.
Condition 3
The solution set Sol(C, F) is nonempty.
The proposed algorithm is of the form:
Algorithm 3.1
-
Initialization: Let \(\{\alpha _n\}\) be a sequence of nonnegative real numbers satisfying \(\sum _{n=1}^\infty \alpha _n <+\infty\). Let \(\theta >0\), \(\tau _1>0\), \(\mu \in (0,1)\) and \(x_0,x_1\in H\) be arbitrary. We assume that \(\{\theta _n\}\), \(\{\epsilon _n\}\) and \(\{\gamma _n\}\) are three positive sequences such that \(\{\theta _n\}\subset [0,\theta )\) and \(\epsilon _n=o(\gamma _n)\), i.e., \(\lim _{n\rightarrow \infty }\dfrac{\epsilon _{n}}{\gamma _n}=0\), where \(\{\gamma _n\}\subset (0,1)\) satisfies the following conditions:
$$\begin{aligned} \lim _{n\rightarrow \infty }\gamma _n=0, \quad \sum _{n=1}^\infty \gamma _n=\infty . \end{aligned}$$Iterative Steps: Calculate \(x_{n+1}\) as follows:
-
-
Step 1. Given the iterates \(x_{n-1}\) and \(x_n\) \((n\ge 1)\), choose \(\theta _n\) such that \(0\le \theta _n\le \bar{\theta }_n\), where
$$\begin{aligned} \begin{aligned} \bar{\theta }_n= {\left\{ \begin{array}{ll} \min \bigg \{\theta , \frac{\epsilon _n}{\Vert x_n-x_{n-1}\Vert }\bigg \}&{}\text {if} \ x_n \ne x_{n-1}, \\ \theta &{}\text { otherwise}. \end{array}\right. } \end{aligned} \end{aligned}$$(4)Step 2. Set \(u_n=(1-\gamma _n)(x_n+\theta _n(x_n-x_{n-1}))\) and compute
$$\begin{aligned} q_n=P_C(u_n-\tau _n Fu_n). \end{aligned}$$Step 3. Compute
$$\begin{aligned} x_{n+1}=P_{T_n}(u_n-\tau _nFq_n), \end{aligned}$$where \(T_n:=\{x\in H| \langle u_n-\tau _nFu_n-q_n,x-q_n\rangle \le 0 \}.\)
-
-
-
Update
$$\begin{aligned} \begin{aligned} \tau _{n+1}:= {\left\{ \begin{array}{ll}\min \{\mu \frac{\Vert u_n-q_n\Vert ^2+\Vert x_{n+1}-q_n\Vert ^2}{2\langle Fu_n-Fq_n,x_{n+1}-q_n\rangle },\tau _n+\alpha _n\}\ \text { if } \langle Fu_n-Fq_n,x_{n+1}-q_n\rangle > 0,\\ \tau _n+\alpha _n \text { otherwise. } \end{array}\right. } \end{aligned} \end{aligned}$$(5)Set \(n:=n+1\) and go to Step 1.
-
Remark 3.1
As noted in Liu and Yang (2020), the sequence generated by (5) is allowed to increase from iteration to iteration. Hence, our results in this work are different from those in Yang et al. (2018), Yang (2021).
Lemma 3.5
(Liu and Yang (2020)) Assume that Condition 2 holds. Let \(\{\tau _n\}\) be the sequence generated by (5). Then
where \(\alpha =\sum _{n=1}^\infty \alpha _n\). Moreover
Theorem 3.1
Assume that Conditions 1–3 hold. If the mapping \(F:H\rightarrow H\) satisfies the \(*\)-property then the sequence \(\{x_n\},\) generated by Algorithm 3.1, converges strongly to an element \(z\in Sol(C,F)\), where \(z=P_{Sol(C,F)}(0)\).
Proof
To improve readability, we split the proof of our main theorem into some parts.
Claim 1.
Since \(z\in C\subset T_n\) and \(P_{T_n}\) is firmly nonexpansive, see, for example Reich and Shafrir (1987), we have
This implies that
Since z is the solution of VI, we have \(\langle Fz,x-z\rangle \ge 0\) for all \(x\in C\). By the pseudomontonicity of F on C we have \(\langle Fx,x-z\rangle \ge 0\) for all \(x\in C\). Taking \(x:=q_n\in C\) we get
Thus,
Since \(q_n=P_{T_n}(u_n-\tau _n Fu_n)\) and \(x_{n+1}\in T_n\) we have
It follows from (6) that
Combining (10) and (11), we obtain
Substituting (12) into (9) we obtain
Claim 2. The sequence \(\{x_n\}\) is bounded. Indeed, we have
On the other hand, since (4) we have
which implies that \(\lim _{n\rightarrow \infty }\bigg [ (1-\gamma _n)\dfrac{\theta _n}{\gamma _n}\Vert x_n-x_{n-1}\Vert +\Vert z\Vert \bigg ]=\Vert z\Vert\), hence there exists \(M>0\) such that
Combining (13) and (14) we obtain
Moreover, we have \(\lim _{n\rightarrow \infty }(1-\mu \dfrac{\tau _n}{\tau _{n+1}})=1-\mu >\dfrac{1-\mu }{2}\), hence there exists \(n_0\in \mathbb {N}\) such that \(1-\mu \dfrac{\tau _n}{\tau _{n+1}}>0 \ \ \forall n\ge n_0.\) By Claim 1 we obtain
Thus
Therefore, the sequence \(\{x_n\}\) is bounded.
Claim 3.
Indeed, we have \(\Vert u_n-z\Vert \le (1-\gamma _n)\Vert x_n-z\Vert +\gamma _n M\), this implies that
where \(M_1:=\max \{2(1-\gamma _n)M \Vert x_n-z\Vert +\gamma _n M^2:\ \ n\in \mathbb {N}\}\). Substituting (16) into Claim 1 we get
Or equivalently
Claim 4.
\(\forall n\ge n_0.\) Indeed, using Lemma 2.2 ii) and (15) we get
Claim 5. \(\{\Vert x_n-z\Vert ^2\}\) converges to zero.
Indeed, by Lemma 2.4 it suffices to show that \(\limsup _{k\rightarrow \infty }\langle -z, x_{n_k+1}-z\rangle \le 0\) and \(\limsup _{k\rightarrow \infty }\Vert u_{n_k}-x_{n_k+1}\Vert \le 0\) for every subsequence \(\{\Vert x_{n_k}-z\Vert \}\) of \(\{\Vert x_n-z\Vert \}\) satisfying
For this purpose, suppose that \(\{\Vert x_{n_k}-z\Vert \}\) is a subsequence of \(\{\Vert x_n-z\Vert \}\) such that \(\liminf _{k\rightarrow \infty }(\Vert x_{n_k+1}-z\Vert -\Vert x_{n_k}-z\Vert )\ge 0.\) Then
By Claim 3 we obtain
This implies that
Thus
Now, we show that
Indeed, using \(\lim _{n\rightarrow \infty }\gamma _n=0\) we have
Since the sequence \(\{x_{n_k}\}\) is bounded, it follows that there exists a subsequence \(\{x_{n_{k_j}}\}\) of \(\{x_{n_k}\}\), which converges weakly to some \(z^*\in H\), such that
Using (19), we get
Using (17), we obtain
Now, we show that \(z^*\in Sol(C,F)\). Indeed, since \(q_{n_k}=P_C(u_{n_k}-\tau _{n_k}Fu_{n_k})\), we have
or equivalently
Consequently
Being weakly convergent, \(\{u_{n_k}\}\) is bounded. Then, by the Lipschitz continuity of F, \(\{Fu_{n_k}\}\) is bounded. As \(\Vert u_{n_k}-q_{n_k}\Vert \rightarrow 0\), \(\{q_{n_k}\}\) is also bounded and \(\tau _{n_k} \ge \min \{\tau _1,\dfrac{\mu }{L}\}\). Passing (21) to limit as \(k\rightarrow \infty\), we get
Moreover, we have
Since \(\lim _{k\rightarrow \infty }\Vert u_{n_k}-q_{n_k}\Vert =0\) and F is L-Lipschitz continuous on H, we get
which, together with (22) and (23) implies that
Next, we choose a sequence \(\{\epsilon _k\}\) of positive numbers decreasing and tending to 0. For each k, we denote by \(N_k\) the smallest positive integer such that
Since \(\{ \epsilon _k\}\) is decreasing, it is easy to see that the sequence \(\{N_k\}\) is increasing. Furthermore, for each k, since \(\{q_{N_k}\}\subset C\) we can suppose \(Fq_{N_k}\ne 0\) (otherwise, \(q_{N_k}\) is a solution) and, setting
we have \(\langle Fq_{N_k}, v_{N_k}\rangle = 1\) for each k. Now, we can deduce from (24) that for each k
From F is pseudomonotone on H, we get
This implies that
Now, we show that \(\lim _{k\rightarrow \infty }\epsilon _k v_{N_k}=0\). Indeed, since \(u_{n_k}\rightharpoonup z^{*}\) and \(\lim _{k\rightarrow \infty }\Vert u_{n_k}-q_{n_k}\Vert =0,\) we obtain \(q_{N_k}\rightharpoonup z^{*} \text { as } k \rightarrow \infty\). By \(\{q_n\}\subset C\), we obtain \(z^*\in C\). Since F has \(*\)-property, we have
Since \(\{q_{N_k}\}\subset \{q_{n_k}\}\) and \(\epsilon _k \rightarrow 0\) as \(k \rightarrow \infty\), we obtain
which implies that \(\lim _{k\rightarrow \infty } \epsilon _k v_{N_k} = 0.\)
Now, letting \(k\rightarrow \infty\), then the right-hand side of (25) tends to zero by F is uniformly continuous, \(\{u_{N_k}\}, \{v_{N_k}\}\) are bounded and \(\lim _{k\rightarrow \infty }\epsilon _k v_{N_k}=0\). Thus, we get
Hence, for all \(x\in C\) we have
By Lemma 2.1, we get
Since (20) and the definition of \(z=P_{Sol(C,F)}(0)\), we have
Combining (18) and (26), we have
Hence, by (27), \(\lim _{n\rightarrow \infty }\dfrac{\theta _n}{\gamma _n}\Vert x_n-x_{n-1}\Vert =0\), \(\lim _{k\rightarrow \infty }\Vert x_{n_k+1}-u_{n_k}\Vert =0\), Claim 5 and Lemma 2.4, we have \(\lim _{n\rightarrow \infty }\Vert x_n-z\Vert =0,\) which was to be proved.
Remark 3.2
It should be noted that if the operator F is monotone, the \(*\) property is redundant, see Denisov et al. (2015), Vuong (2018).
4 Convergence Rate
In this section we establish a convergence rate for the so-called relaxed inertial subgradient extragradient method. Actually, we consider the following modification of Algorithm 3.1:
Algorithm 4.2
Let \(\{\alpha _n\}\) be a sequence of nonnegative real numbers which satisfies \(\sum _{n=1}^\infty \alpha _n <+\infty\). Given \(\theta \in [0,1), \gamma \in (0,\dfrac{1}{2}), \ \mu \in (0,1)\) and \(\tau _1>0\), Let \(x_0,x_1\in H\) be arbitrary. Let
where \(T_n:=\{x\in H| \langle u_n-\tau _nFu_n-q_n,x-q_n\rangle \le 0 \}\),
Update
Throughout this section, the operator F is assumed to be L-Lipschitz continuous on H and \(\delta\)-strongly pseudo-monotone on C. We now prove that the iterative sequence generated by Algorithm 4.2 converges strongly to the unique solution of problem (VI) with an R-linear rate.
Theorem 4.2
Assume that \(F: H\rightarrow H\) is L-Lipschitz continuous on H and \(\delta\)-strongly pseudo-monotone on C. Let \(\theta \in \bigg [0,\dfrac{\delta }{L+\delta }\bigg )\), \(\mu \in \bigg (\dfrac{\theta }{1+\theta }\dfrac{L}{\delta },\dfrac{1-\theta }{1+\theta }\bigg )\) and \(\tau _1 >\dfrac{\mu }{L}\). Then the sequence \(\{x_n\}\) generated by Algorithm 4.2 converges in norm with an R-linear convergence rate to the unique element z in Sol(C,F).
Proof
Since \(\langle Fz,q_n-z\rangle \ge 0\), the \(\delta\)-strong pseudo-monotonicity of F on C yields the inequality
This implies that
Now, using (28) and a similar argument as in Claim 1 of Theorem 3.1, we get
Since \(\theta <\dfrac{\delta }{L+\delta }\), it follows that
therefore there always exists
From \(\mu <\dfrac{1-\theta }{1+\theta },\) one finds \(\dfrac{1-\mu }{2}>\dfrac{\theta }{1+\theta }\) and \(\mu >\dfrac{ \theta }{1+\theta }\dfrac{L}{\delta }\) implies that \(\delta \dfrac{\mu }{L}>\dfrac{\theta }{1+\theta }\). Fix \(\epsilon \in \bigg (\dfrac{\theta }{1+\theta }, \min \bigg \{\dfrac{1-\mu }{2},\delta \dfrac{\mu }{L}\bigg \}\bigg )\). We have
and
Therefore, there exists \(N\in \mathbb {N}\) such that for all \(n\ge N\), we get
On the other hand, we have
We also have
Therefore, we get
Since \(\gamma \in (0,\dfrac{1}{2}),\) it implies \(\dfrac{1-\gamma }{\gamma }>1\). Hence, we obtain
This follows that
We now show that
and
Indeed, since \(\epsilon \in (\dfrac{\theta }{1+\theta }, \min \bigg \{\dfrac{1-\mu }{2},\delta \dfrac{\mu }{L}\bigg \})\), this implies that \(\epsilon >\dfrac{\theta }{1+\theta }\), or, \(1-\epsilon <\dfrac{1}{1+\theta }\) that is \((1-\epsilon )(1+\theta )<1\), hence \(1-\gamma (1-(1-\epsilon )(1+\theta ))\in (0,1)\). It is easy to see that
Therefore, we deduce
Letting \(a_n:=\Vert x_n-z\Vert ^2+\Vert x_n-x_{n-1}\Vert ^2\) and \(\xi :=(1-\gamma (1-(1-\epsilon )(1+\theta )))\), we get
Thus, the sequence \(\left\{ x_n \right\}\) converges R-linearly to z, as desired.
Remark 4.3
It should be emphasized that we obtain the linear convergence rate of Algorithm 4.2 instead of the strong convergence as in Shehu et al. (2021).
Remark 4.4
In Theorem 4.2, the \(*\)- property of F is not assumed.
5 Numerical Illustrations
In this section, we present some numerical experiments in solving variational inequality problems. In the first example, we compare the proposed algorithm with three well-known algorithms including Algorithm 1 of Yang et al. (2018), Algorithm 3.1 of Yang (2021), and the subgradient extragradient algorithm (SEGM) of Censor et al. (2012a) and illustrate the convergence of the proposed algorithm. In the second example, we compare the proposed algorithm with Algorithm 1 of Yang et al. (2018), Algorithm 3.1 of Yang (2021) and [Shehu et al. (2021), Algorithm 1]. In the last example, we compare the proposed algorithm with Algorithm 3.1 of Yang (2021) and [Shehu et al. (2021), Algorithm 1]. All the numerical experiments are performed on an HP laptop with Intel(R) Core(TM)i5-6200U CPU 2.3GHz with 4 GB RAM. The programs are written in Matlab 2015a.
Remark 5.5
We usually choose \(\alpha _n=\theta _0\) for Algorithm 3.1 of Yang (2021) because \(\alpha _n\) and \(\theta _n\) have similar roles in their algorithm as well as in our proposed algorithm. Similarly, we take \(\lambda =\tau _0\) for the subgradient extragradient algorithm of Censor et al. (2012a).
In the numerical experiments, we choose parameters as follows:
Example 1
Assume that \(F:\mathbb {R}^m \rightarrow \mathbb {R}^m\) is defined by \(F(x) = Mx + q\) with \(M = NN^T + S + D\), N is an \(m\times m\) matrix, S is an \(m\times m\) skew-symmetric matrix, D is an \(m\times m\) diagonal matrix, whose diagonal entries are positive (so M is positive definite), q is a vector in \(\mathbb {R}^m\), and
It is clear that F is monotone and Lipschitz continuous with the Lipschitz constant \(L =\Vert M\Vert\). For \(q = 0\), the unique solution of the corresponding variational inequality is \(x^*=0\).
For the experiment, all entries of B, S and D are generated randomly from a normal distribution with mean zero and unit variance. The process is started with the initial \(x_0=(1,..., 1)^T \in \mathbb {R}^m\) and \(x_1 =0.9x_0\). To terminate algorithms, we use the condition \(D_n =\Vert x_n-x^*\Vert ^2 \le \epsilon\) with \(\epsilon =10^{-6}\) or the number of iterations \(\ge\) 2000 for all algorithms. We choose \(\mu =0.5\) for the proposed algorithm, Algorithms 1 of Yang et al. (2018), Algorithm 3.1 of Yang (2021) and \(\gamma _n=\frac{1}{n+1}\) for the proposed algorithm. Case 1: We take \(\lambda =\frac{0.7}{\Vert M\Vert }\) for the subgradient extragradient algorithm of Censor et al. (2012a) and \(\tau _0=\frac{0.7}{\Vert M\Vert }\) for Algorithm 1 of Yang et al. (2018), Algorithm 3.1 of Yang (2021) and the proposed algorithm. The numerical results are described in Table 1 and Figs. 1 and 2.

Comparison of all algorithms with \(m=50\)

Comparison of all algorithms with \(m=100\)
Case 2: We take \(\lambda =\frac{0.9}{\Vert M\Vert }\) for the subgradient extragradient algorithm of Censor et al. (2012a) and \(\tau _0=\frac{0.9}{\Vert M\Vert }\) for Algorithm 1 of Yang et al. (2018), Algorithm 3.1 of Yang (2021) and the proposed algorithm. The numerical results are described in Table 2 and Figs. 3 and 4.

Comparison of all algorithms with \(m=50\)

Comparison of all algorithms with \(m=100\)
Tables 1 and 2 and Figs. 1–4 give the errors of the proposed algorithm, algorithm of Censor et al. (2012a), Algorithm 1 of Yang et al. (2018), Algorithm 3.1 of Yang (2021) as well as their execution times. They show that the proposed algorithm is less time consuming and more accurate than those of Yang et al. (2018), Yang (2021), Censor et al. (2012a).
In Fig. 5 we illustrate the convergence rate of the proposed algorithm for different choices of the \(\theta\) with \(\lambda =\frac{0.7}{\Vert M\Vert }, \mu =0.5, m=50\) and \(\gamma _n=\frac{1}{n+1}\).

Convergence rate of the proposed algorithms for different choice of the \(\theta\)
In Fig. 6 we illustrate the convergence rate of the proposed algorithm for different choices of the \(\gamma _n\) with \(\lambda =\frac{0.7}{\Vert M\Vert }, \mu =0.5, m=50\) and \(\theta =0.5\).

Convergence rate of the proposed algorithm for different choice of the \(\gamma _n\)
Figures 5 and 6 show that the rate of convergence of the proposed algorithm in general depends strictly on the convergent rate of sequence of \(\gamma _n\) and \(\theta\).
Example 2
In the second example, we study an important Nash–Cournot oligopolistic market equilibrium model, which was proposed originally by Murphy et al. (1982) as a convex optimization problem. Later, Harker reformulated it as a monotone variational inequality in Harker (1984). We provide only a short description of the problem, for more details we refer to Facchinei and Pang (2003), Harker (1984), Murphy et al. (1982). There are N firms, each of them supplies a homogeneous product in a non-cooperative fashion. Let \(q_i \ge 0\) be the ith firm’s supply at cost \(f_i(q_i)\) and p(Q) be the inverse demand curve, where \(Q \ge 0\) is the total supply in the market, i.e., \(Q =\sum _{i=1}^{N} q_i\). A Nash equilibrium solution for the market defined above is a set of nonnegative output levels \((q_1^*,q_2^*,...q_N^*)\) such that \(q_i^*\) is an optimal solution to the following problem for all \(i= 1,2 ..... N\):
where
A variational inequality equivalent to (29) is (see Harker (1984))
where \(F(q^*) = (F_1(q^*), F_2 (q^*), ... F_N(q^*))\) and
As in the classical example of the Nash-Cournot equilibrium Harker (1984), Murphy et al. (1982), we consider an oligopoly with N firms, each with the inverse demand function p and the cost function \(f_i\) take the form
Each entry of \(c_i, L_i\) and \(\beta _i\) are drawn independently from the uniform distributions with the following parameters
We choose \(\mu =0.5, \tau =\tau _0=0.01\) for the proposed algorithm, Algorithm 1 of Yang et al. (2018), Algorithm 3.1 of Yang (2021), \(\gamma _n=\frac{1}{n+1}\) for the proposed algorithm and \(\theta = 0.9, \rho _n = \rho = 0.4\) for Shehu et al. [Shehu et al. (2021), Algorithm 1]. The process is started with the initial \(x_0=10*(1,..., 1)^T \in \mathbb {R}^N\) and \(x_1 =0.9*x_0\) and stopping conditions is \(\text {Residual} := \Vert u_n - q_n\Vert \le 10^{-10}\) or the number of iterations \(\ge\) 200 for all algorithms. The numerical results are described in Table 3 and Figs. 7 and 8.

Comparison of all algorithms with \(N=500\)

Comparison of all algorithms with \(N=1000\)
Example 3
Consider the following fractional programming problem:
subject to \(x \in X:=\{x \in \mathbb {R}^m: b^Tx+b_0>0\}\), where Q is an \(m \times m\) symmetric matrix, \(a, b \in \mathbb {R}^m\), and \(a_0, b_0 \in \mathbb {R}\). It is well known that f is pseudoconvex on X when Q is positive-semidefinite. We consider the following cases:
Case 1:
We minimize f over \(C := \{x \in \mathbb {R}^4 : 1 \le x_i \le 10, i = 1,\cdots , 4\} \subset X\). It is easy to verify that Q is symmetric and positive definite in \(\mathbb {R}^4\) and consequently, f is pseudo-convex on X.
We choose \(\mu =0.5, \tau =\tau _0=0.5\) for the proposed algorithm and Algorithm 3.1 of Yang (2021), \(\theta = 0.9, \rho _n = \rho = 0.4, \alpha _n = \frac{1}{n\sqrt{n}}\) for [Shehu et al. (2021), Algorithm 1] and \(\alpha _n = \frac{1}{n\sqrt{n}}, \gamma _n=\frac{1}{\gamma '(n+\gamma '')},\) where \(\gamma ' = 10^6, \; \gamma '' = 10^5\) for the proposed algorithm.
The process is started with the initial \(x_0=(20,-20, 20,-20)^T\) and \(x_1 =0.9*x_0\) and stopping conditions is \(\text {Residual} := \Vert u_n - q_n\Vert \le 10^{-10}\) or the number of iterations \(\ge\) 1000 for all algorithms. The numerical results are described in Fig. 9 and Table 4.

Comparison of all algorithms
Case 2: In the second experiment, we make the problem even more challenging. Let matrix \(A:\mathbb {R}^{m \times m} \rightarrow \mathbb {R}^{m \times m}\), vectors \(c, d,y_0 \in \mathbb {R}^m\) and \(c_0,d_0\) be generated from a normal distribution with mean zero and unit variance. We put \(e=(1,1,\cdots ,1)^T \in \mathbb {R}^m, Q=A^TA+I, a:=e+c, b:=e+d, a_0=1+c_0, b_0=1+d_0\). We minimize f over \(C := \{x \in \mathbb {R}^m : 1 \le x_i \le 10, i = 1,\cdots , m\} \subset X\). Because Matrix Q is symmetric and positive definite in \(\mathbb {R}^m\), f is pseudo-convex on X.
The process is started with the initial \(x_0:=m*y_0\) and \(x_1 =0.9*x_0\), stopping conditions and parameters as in Case 1. The numerical results are described in Figs. 10 and 11 and Table 5.

Comparison of all algorithms with \(m=30\)

Comparison of all algorithms with \(m=50\)
Data Availability
The datasets generated during and/or analysed during the current study are available from the corresponding author on reasonable request.
References
Anh PK, Thong DV, Vinh NT (2020) Improved inertial extragradient methods for solving pseudo-monotone variational inequalities. Optimization. https://doi.org/10.1080/02331934.2020.1808644
Censor Y, Gibali A, Reich S (2011a) The subgradient extragradient method for solving variational inequalities in Hilbert space. J Optim Theory Appl 148:318–335
Censor Y, Gibali A, Reich S (2011b) Strong convergence of subgradient extragradient methods for the variational inequality problem in Hilbert space. Optim Meth Softw 26:827–845
Censor Y, Gibali A, Reich S (2012a) Algorithms for the split variational inequality problem. Numer Algor 59:301–323
Censor Y, Gibali A, Reich S (2012b) Extensions of Korpelevich’s extragradient method for the variational inequality problem in Euclidean space. Optimization 61:1119–1132
Cottle RW, Yao JC (1992) Pseudo-monotone complementarity problems in Hilbert space. J Optim Theory Appl 75:281–295
Denisov SV, Semenov VV, Chabak LM (2015) Convergence of the modified extragradient method for variational inequalities with non-Lipschitz operators. Cybern Syst Anal 51:757–765
Facchinei F, Pang JS (2003) Finite-dimensional variational inequalities and complementarity problems. Springer Series in Operations Research, vol I. Springer, New York
Gibali A, Reich S, Zalas R (2017) Outer approximation methods for solving variational inequalities in Hilbert space. Optimization 66:417–437
Harker PT (1984) A variational inequality approach for the determination of oligopolistic market equilibrium. Math Program 30:105–111
Kassay G, Reich S, Sabach S (2011) Iterative methods for solving systems of variational inequalities in reflexive Banach spaces. SIAM J Optim 21:1319–1344
Kinderlehrer D, Stampacchia G (1980) An introduction to variational inequalities and their applications. Academic Press, New York
Konnov IV (2001) Combined relaxation methods for variational inequalities. Springer-Verlag, Berlin
Korpelevich GM (1976) The extragradient method for finding saddle points and other problems. Ekonomikai Matematicheskie Metody 12:747–756
Kraikaew R, Saejung S (2014) Strong convergence of the Halpern subgradient extragradient method for solving variational inequalities in Hilbert spaces. J Optim Theory Appl 163:399–412
Liu H, Yang J (2020) Weak convergence of iterative methods for solving quasimonotone variational inequalities. Comput Optim Appl 77:491–508
Murphy FH, Sherali HD, Soyster AL (1982) A mathematical programming approach for determining oligopolistic market equilibrium. Math Program 24:92–106
Ortega JM, Rheinboldt WC (1970) Iterative solution of nonlinear equations in several variables. Academic Press, New York
Reich S, Thong DV, Dong QL et al (2021) New algorithms and convergence theorems for solving variational inequalities with non-Lipschitz mappings. Numer Algor 87:527–549
Reich S, Thong DV, Cholamjiak P et al (2021) Inertial projection-type methods for solving pseudomonotone variational inequality problems in Hilbert space. Numer Algor 88:813–835
Reich S, Shafrir I (1987) The asymptotic behavior of firmly nonexpansive mappings. Proc Amer Math Soc 101:246–250
Saejung S, Yotkaew P (2012) Approximation of zeros of inverse strongly monotone operators in Banach spaces. Nonlinear Anal 75:742–750
Shehu S, Iyiola OS, Yao JC (2021) New projection methods with inertial steps for variational inequalities. Optimization. https://doi.org/10.1080/02331934.2021.1964079
Shehu Y, Iyiola OS, Reich S (2021) A modified inertial subgradient extragradient method for solving variational inequalities. Optim Eng. https://doi.org/10.1007/s11081-020-09593-w
Thong DV, Hieu DV (2018) Weak and strong convergence theorems for variational inequality problems. Numer Algor 78:1045–1060
Thong DV, Vuong PT (2021) Improved subgradient extragradient methods for solving pseudomonotone variational inequalities in Hilbert spaces. Appl Numer Math 163:221–238
Vuong PT (2018) On the weak convergence of the extragradient method for solving pseudomonotone variational inequalities. J Optim Theory Appl 176:399–409
Yang J, Liu H, Liu Z (2018) Modified subgradient extragradient algorithms for solving monotone variational inequalities. Optimization 67:2247–2258
Yang J (2021) Self-adaptive inertial subgradient extragradient algorithm for solving pseudomonotone variational inequalities. Appl Anal 100:1067–1078
Acknowledgements
The authors are thankful to the handling editor and two anonymous reviewers for comments and remarks which substantially improved the quality of the paper. We also would like to express our gratitude to Professor Terry Friesz, Editor-in-Chief, for giving us the opportunity to revise and resubmit this manuscript.
Funding
The second and the third authors were partially supported by Vietnam Institute for Advanced Study in Mathematics (VIASM).
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflicts of Interest
The authors declare that they have no conflict of interest.
Additional information
Publisher’s Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Thong, D.V., Anh, P.K., Dung, V.T. et al. A Novel Method for Finding Minimum-norm Solutions to Pseudomonotone Variational Inequalities. Netw Spat Econ 23, 39–64 (2023). https://doi.org/10.1007/s11067-022-09569-6
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11067-022-09569-6
Keywords
- Subgradient extragradient method
- Variational inequality problem
- Pseudomonotone operator
- Strong convergence
- Convergence rate