
Abstract
Performance metrics are usually evaluated only after the neural network learning process using an error cost function. This procedure can result in suboptimal model selection, particularly for imbalanced classification problems. This work proposes the direct use of these metrics as cost functions, which are often derived from the confusion matrix. Commonly used metrics are covered, namely AUC, G-mean, F1-score and AG-mean. The only implementation change for model training occurs in the backpropagation error term. The results were compared to the standard MLP using the Rprop learning algorithm, SMOTE, SMTTL, WWE and RAMOBoost. Sixteen classical benchmark datasets were used in the experiments. Based on average ranks, the proposed formulation outperformed Rprop and all sampling strategies, namely SMOTE, SMTTL and WWE, for all metrics. These results were statistically confirmed for AUC and G-mean in relation to Rprop. For F1-score and AG-mean, all algorithms were considered statistically equivalent. The proposal was also superior to RAMOBoost for G-mean given average ranks. However, it was statistically faster than RAMOBoost for all metrics. It was also faster than SMTTL and statistically equivalent to Rprop, SMOTE and WWE. More, the solutions obtained are generally non-dominated ones compared to all other techniques, for all metrics. The results showed that the direct use of performance metrics as cost functions for neural network training favors generalization capacity and also computation time in imbalanced classification problems. Its extension to other performance metrics derived directly from the confusion matrix is straightforward.
Similar content being viewed by others

Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
Imbalanced classification problems have been a major challenge for neural network learning in recent decades. Since most learning methods are based on global error objective functions, induced models tend to inherit imbalance that is contained in the data. There are many methods for dealing with this problem, which can be grouped into three categories, namely sampling procedures, ensemble learning and cost-sensitive functions. Reviews on them can be found in [1,2,3,4,5,6,7,8,9,10], to mention a few. Sampling methods refer mainly to the under-/over-sampling of the imbalanced data set, having Synthetic Minority Over-sampling Technique (SMOTE) [9], Weighted Wilson’s Editing (WWE) [11] and Adaptive Synthetic Sampling (ADASYN) [12] as their most popular representatives. Ensemble learning consists of a combination of learning algorithms [13, 14], which also appear in other contexts, but in this case aim to compensate performance on individual classes by aggregating classifiers. The work presented in this paper refer to a cost-sensitive method [1, 2, 5, 15, 16], since it is based on new cost functions that aim to compensate for the imbalance in the data.
Classifier evaluation, after learning with error functions, is given by additional performance metrics that estimate the response among all classes [17, 18]. Perhaps the greatest difficulty with the class imbalance problem is that such metrics are only evaluated after training, despite being the ultimate learning goal. Learned models that do not satisfy the performance metric for the imbalanced class are often retrained. This situation is due to the fact that most learning algorithms are based on the inductive principle of global error minimization, which are easier to implement and manipulate analytically. This situation prints an empirical component in the entire learning process, since the learned models can not be changed by the performance metric after obtaining its parameters. It seems reasonable, therefore, that metrics should also be considered to induce the set of parameters in the learning phase, aiming for models closer to the final performance goal without the need for retraining.
The following are examples of works related to strategies for dealing with the imbalanced classification problem. Durden et al. [19] investigated the impact of the sizes of the training and validation datasets on the performance of a convolutional neural network classifier given the imbalance problem. This application refereed to the classification of marine fauna images. Using a residual neural network, Langenkämper et al. [20] showed that the problem of concept drift in seafloor fauna images was less important than the amount of training data in the context of imbalance. Slightly shifted visual characteristics in images of the same class occur, for example, due to the use of different imaging systems. In another work, Langenkämper et al. [21] investigated the use of over-/under-sampling methods combined with data augmentation for the class imbalance problem in marine image data using convolutional neural networks. Mellor et al. [22] analyzed the effect of data imbalance on classification accuracy for land cover classification. The authors employed an ensemble learning classifier based on random forests using a margin criteria in the confusion matrix.
The main contribution of this work is to shed light on how performance metrics can be used not only in the evaluation of already trained classifiers, but also as loss functions for training [2]. In other words, instead of considering the metric just as a post-training validation criterion, it is considered as the objective function and is effectively used in the training phase. As performance metrics are often drawn from the confusion matrix, we show how to consider them as loss functions and also how to implement them with gradient descent learning. Instead of using accuracy as a performance metric, which may favor the majority class, other metrics, also often used as post-learning metrics, were adopted in this work [23,24,25,26]. Namely, AUC (area under the ROC curve) [27], Kubat’s G-mean (Geometric mean) [28], F1-score [29] and AG-mean (Adjusted Geometric-mean) [30]. This approach is capable of compensating for performance and computation time when compared to classical algorithms. The following algorithms, which are representative of the most common strategies to deal with the imbalanced classification problem, were considered for comparison purposes: SMOTE (Synthetic Minority Oversampling Technique) [9], an oversampling method; SMTTL (SMOTE + Tomek Links) [31], an oversampling method with pruning; WWE (Weighted Wilson’s Editing) [11], an undersampling method; RAMOBoost (Rated Minority Oversampling in Boosting) [32], an ensemble method; and the Rprop [33], an error minimization learning algorithm for training MLPs, with the cross-entropy loss function.
Section 2 describes the formulation of objective functions based on performance metrics, which are derived from the confusion matrix. Section 3 shows the corresponding derivation of the backpropagation error term to be used during network training. Section 4 presents the results obtained for a series of classical benchmark datasets, which are compared to commonly used methods for imbalanced data. Final considerations are given in Sect. 5.
2 Approximate Performance Metrics
This section presents a general formulation for directly using performance metrics as cost-sensitive objective functions. The starting point for this is the confusion matrix, shown in Table 1, from which most metrics are obtained. The formulation is shown for AUC, G-mean, F1-score and AG-mean, which are widely used to evaluate imbalanced classification problems [23,24,25,26]. This formulation can readily be extended to any performance metric based on the confusion matrix.
Considering a binary classification problem, for which targets \(y \in {\mathcal {Y}} = \{0,1\}\) and model estimates \({\hat{y}} \in {\mathcal {R}} = [0,1]\), the confusion matrix can be approximated in terms of y and \({\hat{y}}\) according to Table , where n is the number of samples.
In sequence, each performance metric is rewritten using the elements from the previous approximate confusion matrix. Table 3 shows the resulting representation for them. Next section shows how to obtain the corresponding backpropagation error terms.
3 Backpropagation Error Term for the Approximate Performance Metrics
Backpropagation equations can be obtained directly from the cost functions presented in Table 3. In fact, the change in the objective function only affects the backpropagation error term (\(\delta ^n\)), since the other weight update terms remain unaltered. The update equation can be obtained by applying the gradient descent algorithm to \(\partial J(\theta )/\partial \theta ^{n-1})\) and \(\partial J(\theta )/\partial z^{n-1}\) as shown in Eqs. 1 and 2, respectively. The resulting backpropagation error term is given in Eq. 3. Rprop [33] was used for implementing gradient descent.
where:
-
\(\theta :\) Network weights
-
\(J(\theta )\): Loss function
-
n: Layer number
-
a: Neuron ouput
-
\(g(\cdot )\): Activation function
-
z: Neuron input
The metrics considered in this work (AUC, G-mean, F1-score and AG-mean) are in the range [0, 1], where 1 represents the best performance, therefore, the derived functions (Table 3) should all be maximized. Also, although they are differentiable, there can be gradient convergence problems, hence, the negative logarithm should be used instead (Eq. 4).
Equations 5, 6, 7 and 8 show how to obtain the error term for the loss functions proposed in Table 3. Sigmoid functions were used as activation of output neurons, that is, \({\hat{y}}_i = g(z^{(n)}_i) = 1/(1+exp^{-z^{(n)}_i})\). The formulation is general and other activation functions can also be used.
Next step refers to obtaining the derivative of the negative logarithm of the loss functions. The resulting backpropagation error terms associated with AUC, G-mean, F1-score and AG-mean are shown in the following sections.
3.1 AUC
One of the most important goals in imbalanced classification problems concerns the correct classification of the minority class without compromising the performance of the majority class. This is the case, for example, with the medical diagnosis of rare events. The AUC (area under the ROC curve) metric is extremely useful for this purpose, as it equates to the probability of labeling a positive instance (rare event) with greater confidence than a negative one [27]. Due to its importance, this metric has been widely used to evaluate classifiers mainly in case of unbalanced data. Differentiable approximations of the Wilcoxon-Mann-Whitney statistic, which is equivalent to AUC, were developed in previous works [35,36,37]. In this work, the objective function associated with this metric is based on the confusion matrix as shown in Table 3. Equation 9 presents the corresponding backpropagation error term.
3.2 G-mean
Obtaining satisfactory scores for minority and majority classes simultaneously is a challenge in binary classification. The geometric mean metric (G-mean) appeared in this context taking into account the accuracy of both classes [28, 38]. This metric has been widely applied to imbalanced classification problems with the main objective of finding a good balance between TP and TN rates [34, 39,40,41,42,43]. The resulting backpropagation error term for the loss function associated with G-mean (Table 3) is given in Eq. 10.
3.3 F-score
When negative cases are not in the center of a classifier’s performance, precision and recall are often used measures. The F1-score metric combines the two [39] (Eq. 11). This metric appeared in the context of information retrieval, where samples are positive if they contain attributes of interest [38], in order to compensate for precision and recall [44, 45]. The \(\beta \) parameter controls the balance between them, with \(\beta >1\) favoring recall, and otherwise, precision [46].
A commonly used value for \(\beta \) is 1, which results in the harmonic mean between precision and recal [45] (Eq. 12). In this particular case, it is called F1-score or F1-measure. This metric has been applied to many imbalanced classification problems with different classifiers like SVM [47] and logistic regression [48]. The Empirical Utility Maximization (EUM) [49] and the General F-measure Maximize (GFM) [50] algorithms were used in previous works to approximate and maximize F-score. The corresponding backpropagation error term for the loss function associated with F1-score (Table 3) is given in Eq. 13.
3.4 AG-mean
Many practical situations require maximizing the classification of positive samples as much as possible while keeping the majority class rating to a minimum. This is the case with medical diagnosis, where false positives can be very undesirable. However, increasing the scores of both classes simultaneously are conflicting goals [51]. The adjusted G-mean metric (AG mean) was proposed in this context, focusing on the positive class, through the balance between sensitivity (SE) and specificity (SP) [30]. Given its importance for class imbalanced problems, this work proposes its direct use as a loss function for MLP training (Table 3). Equation 14 shows the corresponding backpropagation error term.
4 Results and Discussions
This section presents the results of directly considering AUC, G-gmean, F1-score and AG-mean as cost functions for training MLPs. These metrics were considered given the focus of this work on imbalanced classification problems. To make this analysis broader, sixteen classical datasets presenting different imbalance ratios were used [52]. They are summarized in Table 4. All were preprocessed according to [1]. For example, the first dataset, called Ionosphere, has two classes, one with 126 (n1) and one with 225 (n2) samples, which results in an imbalance ratio (\(n_1/(n_1 +n_2)\)) of 0.359.
Since MLPs are not based on explicit class density estimation for learning, margin information is more relevant than sample size. Considering that network training in this work is based on metrics that are less sensitive to imbalance, the neural network is able to learn even with small sample sizes. This is also due to the properties of the cost functions used (AUC, G-mean, F1-score and AG-mean), that are capable to balance majority and minority classes, regardless of their sizes.
About neural network topology, activation functions for all network units were sigmoidal [1]. Given the binary classification approach using the OvA (one-versus-all) procedure, the cutoff value between classes was equal to 0.5. Rprop was used to implement gradient descent as the learning algorithm in all cases [33]. The number of hidden units was defined by means of a cross validation procedure as follows. Each dataset was initially divided into ten subsets, which were subdivided into ten training (70%) and test (30%) sets. These sets were used for model selection, that is, to define the number of hidden units, through a \(5-\)fold cross-validation procedure. Next, they were then combined for model re-identification, given the selected number of hidden units. Model performance was evaluated with the previous ten test sets.
Our proposal was then compared with commonly used methods for handling imbalanced classes: Rprop [33], SMOTE [9], SMTTL (SMOTE + Tomek Links) [31], WWE (Weighted Wilson’s Editing) [11], RAMOBoost (Ranked Minority Oversampling in Boosting) [32]. Cross-entropy was used as the loss function in all cases. The comparative analysis employed the classical non-parametric Nemenyi and Bonferroni-Dunn tests, which allows a comparison considering all datasets at once, given a performance metric [53,54,55].
Tables 5, 7, 9 and 11 show the average performance for AUC, G-mean, F1-score and AG-mean, respectively. The average computation time (in seconds) involving training and testing is presented respectively in Tables 6, 8, 10 and 12. The results for MLP, SMOTE, SMTTL, WWE and RAMOBoost, are also shown for comparison purposes. The results related to the proposed objective functions are referred to as AUC-MLP, G-MLP, F-MLP and AG-MLP, respectively. The best performance in each experiment is highlighted in bold.
4.1 Non-parametric Tests
The Wilcoxon statistical test is applied to compare pairs of classifiers [55, 56], while the Nemenyi post-hoc test (Eq. 15), based on Friedman statistic (Eq. 16) [57], is used in case there are multiple classifiers. The Friedman statistic considers applying L classifiers to M datasets. Its is based on average ranks (\(R_j\)), where \(R_j=\frac{1}{M}\sum _{i=1}^{M}r_i^j\), \(1\le j \le L\), is the average rank of the \(j^{th}\) classifier given all datasets. The null hypothesis (\(H_{0}\)) of the Nemenyi test states that all classifiers perform similarly, that is, their average ranks are close. Such values are shown in the last row of Tables 5, 7, 9 and 11, which are relative to the performance metric, and of Tables 6, 8, 10 and 12, for the computation time. When the null hypothesis is rejected, another statistical test should be performed to quantify the difference between the classifiers [55]. The most used test in this case is the Bonferroni-Dunn post-hoc test [58]. Two classifiers are not considered similar if the difference between their average ranks is greater than a critical difference CD (Eq. 17), where \(q_\alpha \) is the critical value at the significance level given the Student statistic.
Given the average rank values, \(M = 16\) (number of datasets) and \(L = 6\) (number of classifiers), the Friedman statistic (\(F_F\)) is equal to 4.1235, 2.7496, 1.9697 and 1.3823, for Tables 5, 7, 9 and 11 (for performance metric), respectively, and to 22.7953, 26.0758, 22.7104 and 35.3748, for Tables 6, 8, 10 and 12 (for computation time), respectively. The critical value for the Nemenyi statistic is given by \(F_F((L-1)=5;(L-1)(M-1)=75;\alpha =0.01) = 1.9256\) [59]. Thus, the null hypothesis was rejected for all metrics except for AG-meanFootnote 1, and for all computation times. Next, the Bonferroni-Dunn post-hoc test was applied to verify the performance of the proposed approaches in relation to all other classifiers (strategy one-versus-all). Tables 13, 14, 15 and 16 show the differences between the average rank values for AUC, G-mean, F1-score and AG-mean, respectively. They also show the results for computation time. The critical difference (CD) is equal to 1.7125. Differences beyond this critical value, which point out to different performances, are highlighted in bold.
4.2 Discussions
The results for AUC-MLP are summarized in Tables 5 (metric performance) and 6 (computation time), with average rank values equal to 2.75 and 2.37, respectively. It can be seen that its performance is very close to that of RAMOBoost, which had the best average rank value (2.63), and mainly surpass the standard Rprop (5.06). Regarding computation time, AUC-MLP is comparable to Rprop, which presented the best average rank value (2.06), and much higher than RAMOBoost (6.00). According to the Bonferroni-Dunn post-hoc test (Table 13), its performance is statistically comparable to RAMOBoost and sampling strategies, namely SMOTE, SMTTL and WWE, and superior to Rprop. Furthermore, its computation time is competitive with Rprop, SMOTE and WWE, and statistically better than RAMOBoost and SMTTL. In summary, AUC-MLP is statistically equivalent to SMOTE and WWE, but has higher average ranks for performance and computation time.
The results for G-MLP are presented in Tables 7 and 8. They show that it is best for performance and second best for computation time, with average rank values of 2.75 and 2.44, respectively. The best computation times were obtained by Rprop and SMOTE, with average ranks of 2.19 and 2.44, respectively. The Bonferroni-Dunn post-hoc test (Table 14) indicates that G-MLP outperforms Rprop and is similar to SMOTE, SMTTL, WWE and RAMOBoost. In terms of computation time, it is faster than STMTTL and RAMOBoost, and equivalent to Rprop, SMOTE and WWE. G-MLP is statistically similar to SMOTE and WWE, however when ranks are considered, it performs slightly better than both. Also, its computation time is equivalent to that of SMOTE, and slightly better than that of WWE, despite being statistically equivalent.
It can be observed that the performance of the F-MLP is competitive with the other classifiers (Table 9), as it presents the second best average rank, equal to 3.00. The best value, for RAMOBoost, is 2.44. Regarding the computation time (Table 10), it proved to be advantageous, as it presented the best average rank value, equal to 2.19. From the Bonferroni-Dunn post hoc test (Table 15), it can be seen that the proposal is statistically equivalent to all other classifiers in terms of model performance. This may be due to the fact that F1-score is a difficult convergence function [48,49,50, 60]. The number of iterations during model training may also have influence. Regarding computation time, it was similar to Rprop, SMOTE and WWE, and faster than SMTTL and RAMOBoost.
AG-MLP resulted in the second best performance, after RAMOBoost, with average rank values of 3.06 and 2.63, respectively (Table 11). RAMOBoost, however, had the highest computation time than all other classifiers (Table 12), in contrast with AG-MLP which resulted in the shortest computation time with an average rank equal to 2.00. Rprop comes next with 2.13, while RAMOBoost comes with 6.00. According to the Nemenyi post-hoc test, all classifiers performed similarly, as the null hypothesis was not rejected. This result can also be seen in Table 16. Despite the statistically equivalent performance of AG-MLP to Rprop, it can be observed that the proposed approach performs better in 10 out of the 16 datasets (Table 11) and presents a better average rank, 2.63 against 4.00. Regarding computation time, AG-MLP has similar to Rprop, SMOTE and WWE, and is faster than SMTTL and RAMOBoost (Table 12).

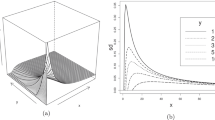
Average rank plots considering computation time (x-axis) versus performance metric (y-axis) simultaneously. (\(\Diamond \): Rprop, \(\Box \): SMOTE, \(\triangle \): SMTTL, \(\times \): WWE, \(+\): RAMOBoost, : This work)
To summarize the results previously discussed, Figure 1 presents plots of the average ranks of the computation time against the performance metric, according to Tables 5 to 12. Each refers to a specific metric. For instance, Figure 1(a) shows the average ranks obtained for the computation time (x axis; Table 12) and performance metric (y axis; Table 5) for AUC metric. Since both time and performance rank values should be minimized, the resulting problem actually involves a trade-off between them, since one objective affects the other. For example, to reduce computation time, performance can be degraded. The optimality of the corresponding bi-objective problem is evaluated according to the non-dominated solutions given the Pareto frontier. The objective in this case, given the formulated optimization problem, is to obtain a good compromise between them. It can be observed that the results of the methods presented in this work are not dominated by the others, as they generally provided lower average rank values in both objectives. For example, considering AUC-MLP (Figure 1a), Rprop has less computation time, however, at the cost of a lower performance (that is, a higher average rank value), and RAMOBoost has slightly higher performance with much higher computation time. This is also the case for G-mean. That is, Rprop had the smallest computation time (lower rank value), but with the worst performance (higher rank value). In contrast, RAMOBoost showed a satisfactory performance, however, at the expense of more computation time. The proposal of this work for G-mean presented a relatively small computation time, with the best performance. For F1-score and AG-mean, RAMOBoost had the best performance, but with the worst computation time. Rprop presented a satisfactory computation time, however, with a worse performance in relation to the best results. The proposals of this work for F1-score and AG-mean presented the best computation time, and the second best performance, only behind RAMOBoost, which, however, presented the highest computation time. These results show that the direct use of performance metrics as loss functions results in well-balanced classifiers between performance and computation time.
5 Conclusions
This work proposes the direct use of performance metrics as cost functions for training MLP neural networks in imbalanced classification problems. Usual performance metrics, namely AUC, G-mean, F1-score and AG-mean, were addressed. The formulation is derived directly from the commonly used confusion matrix and implemented with standard backpropagation, for which the only change is to the error term.
A general experiment, employing average rank values, showed that the use of cost functions based on performance metrics outperformed both the standard RProp and all sampling strategies, namely SMOTE, SMTTL and WWE, for all metrics. These results were statistically corroborated for the AUC and the G-mean in relation to the Rprop. For F1-score and AG-mean, all algorithms were considered statistically equivalent. Also, it was superior to RAMOBoost for G-mean, given the average rank values. However, it was statistically faster than this oversampling procedure for all metrics. The proposal also showed faster computation than SMTTL and was equivalent to Rprop, SMOTE and WWE. Furthermore, it presented non-dominated solutions for the bi-objective problem when performance and computation time are evaluated simultaneously, even considering the standard Rprop. In short, the proposal generally showed higher performance for all metrics under relatively high imbalance ratios. Other methods, such as DEBOHID [61], as well as other performance metrics considering the confusion matrix, can be used. Implementations of more efficient gradient descent learning algorithms are also possible.
In conclusion, this work presented a new perspective for the imbalanced learning problem, which is usually treated as a two-step problem, as it is first trained with an objective function, such as a global error, and then evaluated with a different metric. Direct use of performance metrics as objective functions allows to approach the problem from a single-step perspective, avoiding retraining. Lastly, the methodology proposed in this work can be extended to multiclass classification problems.
Availability of data and material (data transparency):
All datasets used in this work are available in the public UCI Machine Learning Repository (http://archive.ics.uci.edu/ml).
Notes
Still, the post-hoc test was also computed for AG-mean.
References
Castro CL, Braga AP (2013) Novel cost-sensitive approach to improve the multilayer perceptron performance on imbalanced data. IEEE Trans Neural Netw Learn Syst 24(6):888
Aurelio YS, Almeida GM, Castro CL, Braga AP (2019) Learning from imbalanced data sets with weighted cross-entropy function. Neural Process Lett 50:1937
Haixiang G, Yijing L, Shang J, Mingyun G, Yuanyue H, Bing G (2017) Learning from class-imbalanced data: review of methods and applications. Expert Syst Appl 73(1):220
Lan J, Hu MY, Patuwo E, Zhang GP (2010) An investigation of neural network classifiers with unequal misclassification costs and group sizes. Decis Support Syst 48(4):582
Thai-Nghe N, Gantner Z, Schmidt-Thieme L (2010) Cost-sensitive learning methods for imbalanced data, in Proc. International Joint Conference on Neural Networks (IEEE, 2010), pp. 1–8
He H, Garcia EA (2009) Learning from imbalanced data. IEEE Trans Know Data Eng 21(9):1263
Chawla NV, Japkowicz N, Kotcz A (2004) Editorial: special issue on learning from imbalanced data sets. ACM SIGKDD Explor Newsl 6(1):1
Batista GEAPA, Prati RC, Monard MC (2004) A study of the behavior of several methods for balancing machine learning training data. ACM SIGKDD Explor Newslett 6(1):20
Chawla NV, Bowyer KW, Hall LO, Kegelmeyer WP (2002) SMOTE: synthetic minority over-sampling technique. J Artif Intell Res 16:321
Michie D, Spiegelhalter DJ, Taylor CC (1994) Machine learning, neural and statistical classification. Machine learning neural and statistical classification. Prentice Hall, USA
Barandela R, Valdovinos RM, Sánchez JS, Ferri FJ (2004) The imbalanced training sample problem: Under or over sampling?, in Structural, Syntactic, and Statistical Pattern Recognition, LNCS, vol. 3138, ed. by A. Fred, T.M. Caelli, R.P.W. Duin, A.C. Campilho, D. de Ridder (Springer, 2004), pp. 806–814
He H, Bai Y, Garcia EA, Li S (2008) ADASYN: Adaptive synthetic sampling approach for imbalanced learning, in Proc IEEE International Joint Conference on Neural Networks (IEEE World Congress on Computational Intelligence) (IEEE, 2008), pp. 1322–1328
Chen S, He H, Garcia EA (2010) RAMOBoost: ranked minority oversampling in boosting. IEEE Trans Neural Netw 21(10):1624
Sun Y, Kamel MS, Wong AKC, Wang Y (2007) Cost-sensitive boosting for classification of imbalanced data. Pattern Recognit 40(12):3358
Tao X, Li Q, Guo W, Ren C, Li C, Liu R, Zou J (2019) Self-adaptive cost weights-based support vector machine cost-sensitive ensemble for imbalanced data classification. Inform Sci 487:31
Zhang C, Tan KC, Li H, Hong GS (2018) A cost-sensitive deep belief network for imbalanced classification. IEEE Trans Neural Netw Learn Syst 30(1):109
Weiss GM (2004) Mining with rarity: a unifying framework. ACM SIGKDD Explor Newsl 6(1):7
Caruana R, Niculescu-Mizil A (2004) Data mining in metric space: an empirical analysis of supervised learning performance criteria, in Proc. 10th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (ACM, 2004), pp. 69–78
Durden JM, Hosking B, Bett BJ, Cline D, Ruhl HA (2021) Automated classification of fauna in seabed photographs: the impact of training and validation dataset size, with considerations for the class imbalance. Prog Oceanogr 196:102612
Langenkämper D, van Kevelaer R, Purser A, Nattkemper TW (2020) Gear-induced concept drift in marine images and its effect on deep learning classification, Frontiers in Marine Science (2020)
Langenkämper D, van Kevelaer R, Nattkemper TW (2019) Strategies for Tackling the Class Imbalance Problem in Marine Image Classification, in Pattern Recognition and Information Forensics (ICPR 2018), vol. 11188, ed. by Z. Zhang, D. Suter, Y. Tian, A.A. Branzan, N. Sidère, E.H. Jair (Springer, 2019), vol. 11188
Mellor A, Boukir S, Haywood A, Jones S (2015) Exploring issues of training data imbalance and mislabelling on random forest performance for large area land cover classification using the ensemble margin. ISPRS J Photogramm Rem Sens 105:155
Boughorbel S, Jarray F, El-Anbari M (2017) Optimal classifier for imbalanced data using Matthews Correlation Coefficient metric. PloS one 12(6):e0177678
Chawla NV (2009) Data mining for imbalanced datasets: an overview, Data mining and knowledge discovery handbook pp. 875–886
Gu Q, Zhu L, Cai Z (2009) Evaluation measures of the classification performance of imbalanced data sets, in International symposium on intelligence computation and applications (Springer, 2009), pp. 461–471
Kuncheva LI, Arnaiz-González Á, Díez-Pastor JF, Gunn IA (2019) Instance selection improves geometric mean accuracy: a study on imbalanced data classification. Prog Artif Intell 8(2):215
Fawcett T (2006) An introduction to ROC analysis. Pattern Recognit Lett 27(8):861
Kubat M, Matwin S (1997) Addressing the curse of imbalanced training sets: One-sided selection, in Proc 14th International Conference on Machine Learning, vol. 97, pp. 179–186
Pazzani M, Billsus D (1997) Learning and revising user profiles: the identification of interesting web sites. Mach Learn 27:313
Batuwita R, Palade V (2012) Adjusted geometric-mean: a novel performance measure for imbalanced bioinformatics datasets learning. J Bioinform Comput Biol 10(4):1250003
Tomek I (1976) Two modifications of CNN IEEE transactions on systems man and cybernetics. SMC 6(11):769
Provost F, Fawcett T (2001) Robust classification for imprecise environments. Mach Learn 42:203
Riedmiller M, Braun H (1992) RPROP: A fast adaptive learning algorithm, in Proc. ISCIS VII (1992)
Hong X, Chen S, Harris CJ (2007) A kernel-based two-class classifier for imbalanced data sets. IEEE Trans Neural Netw 18(1):28
Castro CL, Braga AP (2008) Optimization of the Area under the ROC Curve, in Proc. 10th Brazilian Symposium on Neural Networks (IEEE, 2008), pp. 141–146
Rakotomamonjy A (2004) Optimizing area under ROC curves with SVMs, in Proc. 1st International Workshop on ROC Analysis in Artificial Intelligence (2004), pp. 71–80
Yan L, Dodier RH, Mozer MC, Wolniewicz RH (2003) Optimizing classifier performance via an approximation to the Wilcoxon-Mann-Whitney statistic, in Proc. 20th International Conference on Machine Learning (2003), pp. 848–855
Kubat M, Holte RC, Matwin S (1998) Machine learning for the detection of oil spills in satellite radar images. Mach Learn 30:195
Antanasijević J, Antanasijević D, Pocajt V, Trišović N, Fodor-Csorba K (2016) A QSPR study on the liquid crystallinity of five-ring bent-core molecules using decision trees. MARS Artif Neural Netw, RSC Adv 6(22):18452
Kim HJ, Jo NO, Shin KS (2016) Optimization of cluster-based evolutionary undersampling for the artificial neural networks in corporate bankruptcy prediction. Expert Syst Appl 59:226
Nguyen GH, Bouzerdoum A, Phung SL (2009) Learning pattern classification tasks with imbalanced data sets, Learning pattern classification tasks with imbalanced data sets (2009)
Xu L, Chow M, Timmis J, Taylor LS (2007) Power distribution outage cause identification with imbalanced data using artificial immune recognition system (AIRS) algorithm. IEEE Trans Power Syst 22(1):198
Xu L, Chow MY (2006) A classification approach for power distribution systems fault cause identification. IEEE Trans Power Syst 21(1):53
van Rijsbergen CJ (1979) Information retrieval, Information retrieval. Butterworths, USA
Hripcsak G, Rothschild AS (2005) Agreement, the F-measure, and reliability in information retrieval. J Am Med Inform Assoc 12(3):296
Sasaki Y (2007) The truth of the F-measure, Teach Tutor Mater (2007)
Joachims T (2005) A support vector method for multivariate performance measures, in Proc. 22nd International Conference on Machine Learning (ACM, 2005), pp. 377–384
Jansche M (2005) Maximum expected F-measure training of logistic regression models, in Proc. Conference on Human Language Technology and Empirical Methods in Natural Language Processing (ACL, 2005), pp. 692–699
Nan Y, Chai KMA, Lee WS, Chieu HL (2012) Optimizing F-measure: a tale of two approaches, in Proc. 29th International Conference on Machine Learning, ed. by J. Langford, J. Pineau (2012), pp. 1555–1562
Dembczynski K, Waegeman W, Cheng W, Hüllermeier E (2011) An exact algorithm for F-measure maximization, in Proc. 24th International Conference on Advances on Neural Information Processing Systems, ed. by J. Shawe-Taylor, R.S. Zemel, P.L. Bartlett, F. Pereira, K.Q. Weinberger (2011), pp. 1404–1412
Batuwita R, Palade V (2009) A new performance measure for class imbalance learning. Application to bioinformatics problems, in Proc. International Conference on Machine Learning and Applications (IEEE, 2009), pp. 545–550
Dua D, Graff C (2019) UCI Machine Learning Repository Uci machine learning repository (2019). http://archive.ics.uci.edu/ml
Trawiński B, Smketek M, Telec Z, Lasota T (2012) Nonparametric statistical analysis for multiple comparison of machine learning regression algorithms. Int J Appl Mathe Comput Sci 22:867
Adnan MN, Ip RH, Bewong M, Islam MZ (2021) BDF: a new decision forest algorithm. Inform Sci 569:687
Demšar J (2006) Statistical comparisons of classifiers over multiple data sets. J Mach Learn Res 7:1–30
Gibbons JD, Chakraborti S (2011) Nonparametric statistical inference, in International Encyclopedia of Statistical Science, ed. by M. Lovric (Springer, 2011), pp. 977–979
Friedman M (1937) The use of ranks to avoid the assumption of normality implicit in the analysis of variance. J Am Statist Assoc 32(200):675
Dunn OJ (1961) Multiple comparisons among means. J Am Statist Assoc 56(293):52
Sheskin DJ (2007) Handbook of parametric and nonparametric statistical procedures, Handbook of parametric and nonparametric statistical procedures
Parambath SP, Usunier N, Grandvalet Y (2014) Optimizing F-measures by cost-sensitive classification, in Proc. 27th International Conference on Neural Information Processing Systems, vol. 2, ed. by Z. Ghahramani, M. Welling, C. Cortes, N.D. Lawrence, K.Q. Weinberger (2014), vol. 2, pp. 2123–2131
Kaya E, Korkmaz S, Sahman MA, Cinar AC (2021) DEBOHID: a differential evolution based oversampling approach for highly imbalanced datasets. Expert Syst Appl 169:114482
Acknowledgements
The authors would like to thank the following Brazilian research funding agencies for their nancial support, CNPq (The National Council for Scientic and Technological Development), FAPEMIG (The Minas Gerais Research Foundation) and CAPES (The Coordination for the Improvement of Higher Education Personnel).
Funding
This work was financially supported by the following Brazilian research funding agencies, CNPq (The National Council for Scientific and Technological Development), FAPEMIG (The Minas Gerais Research Foundation) and CAPES (The Coordination for the Improvement of Higher Education Personnel).
Author information
Authors and Affiliations
Contributions
(optional: please review the submission guidelines from the journal whether statements are mandatory): The study conception and design were performed by Antonio Padua Braga and Cristiano Leite de Castro. Material preparation, data collection and results generation were carried out by Yuri Sousa Aurelio. Gustavo Matheus de Almeida contributed to the analysis of the results together with the other authors. All contributed and approved the final version of the manuscript.
Corresponding author
Ethics declarations
Conflicts of interest/Competing interests (include appropriate disclosures):
There are no conflicts of interest in this work.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Aurelio, Y.S., de Almeida, G.M., de Castro, C.L. et al. Cost-Sensitive Learning based on Performance Metric for Imbalanced Data. Neural Process Lett 54, 3097–3114 (2022). https://doi.org/10.1007/s11063-022-10756-2
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11063-022-10756-2