
Abstract
To weaken and control effectively the harm of flyrock in open-pit mines, this study aimed to develop a novel Harris hawks optimization with multi-strategies-based support vector regression (MSHHO–SVR) model for predicting the flyrock distance (FD). Several parameters such as hole diameter (H), hole depth, burden-to-spacing ratio, stemming, maximum charge per delay, and powder factor were recorded from 262 blasting operations to establish a FD database. The MSHHO–SVR model compared the predictive performance with several other models, including Harris hawks optimization-based support vector regression (HHO–SVR), back-propagation neural network, extreme learning machine, kernel extreme learning machine, and empirical methods. The root mean square error (RMSE), the mean absolute error (MAE), the determination coefficient (R2), and the variance accounted for (VAF) were employed to evaluate model performance. The results indicated that the MSHHO–SVR model not only performed better in the training phase but also obtained the most satisfactory performance indices in the testing phase, with RMSEs of 12.2822 and 9.6685, R2 values of 0.9662 and 0.9691, MAEs of 8.5034 and 7.4618, and VAF values of 96.6161% and 96.9178%, respectively. Furthermore, the calculation results of the SHAP values revealed that H was the most critical parameter for predicting FD. Based on these findings, the MSHHO–SVR model can be considered as a novel hybrid model that effectively addresses flyrock-like problems caused by blasting.
Similar content being viewed by others
Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
Introduction
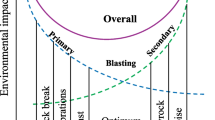
Blasting has been a widely used rock-breaking technique in various fields, particularly in open-pit and underground mining (Monjezi et al., 2013; Wang et al., 2018a, b; Li et al., 2022a; Chen and Zhou, 2023; Hosseini et al., 2023). However, studies revealed that a significant portion of the energy (over 70%) produced by blasting is wasted, while the remaining energy is utilized to break and displace hard rocks (Khandelwal and Singh, 2005; Singh and Singh, 2005; Hosseini et al., 2022a, b). Moreover, blasting also raises environmental concerns, particularly in surface mining (Fig. 1). Among various environmental issues, flyrock stands out as the most hazardous and destructive (Bakhtavar et al., 2017; Hasanipanah et al., 2017; Mahdiyar et al., 2017; Koopialipoor et al., 2019; Nguyen et al., 2019; Murlidhar et al., 2021). Bajpayee et al. (2004) reported that flyrock was the direct cause of at least 40% of fatal accidents and 20% of serious accidents in blasting accidents. Accordingly, it is extremely important to calculate the flyrock distance (FD) to prevent deaths, damage to equipment, and other serious accidents.

Negative impacts of blasting in open-pit mines
In previous studies (Lundborg et al., 1975; Roth, 1979; Gupta, 1980; Olofsson, 1990; Richards and Moore, 2004; McKenzie, 2009), a variety of empirical formulas were proposed to predict and control FD. Bagchi and Gupta (1990) established an empirical formula between stemming (ST), burden (B) and FD. Little (2007) developed an empirical formula based on the drill hole angle, B, ST, and explosive charge per meter (CPM) to predict FD. Trivedi et al. (2014) also used the ratio of ST to B to establish an empirical equation for estimating FD. Nevertheless, the prediction performance of the empirical formula is not ideal. The most obvious reason is the absence of valid parameters and the simple consideration of the linear and nonlinear relationship between the parameters and the predicted target (Zhou et al., 2020a, b). In addition to empirical formulas, various researchers have attempted to estimate FD using statistical analyses, such as Monte Carlo simulation methods, and simple and multiple regression equations (Rezaei et al., 2011; Ghasemi et al., 2012; Raina et al., 2014; Armaghani et al., 2016; Faradonbeh et al., 2016; Ye et al., 2021). However, the regression and simulation models have obvious shortcomings, namely (a) new data other than the original data can reduce the reliability of the regression model (Marto et al., 2014); and (b) a historical database cannot be used to control/determine input distribution of a simulation model (Little and Blair, 2010). Generally, there are two types of parameters that contribute to estimating FD: controllable and uncontrollable. Controllable parameters, commonly referred to as blast design parameters, include hole diameter (H), B, ST, CPM, powder factor (PF), spacing (S), total charge, hole depth (HD), and delay timing (Rezaei et al., 2011; Trivedi et al., 2015; Rad et al., 2018; Han et al., 2020; Zhou et al., 2020a). These parameters can be adjusted manually and have a direct impact on the generation of flyrock. Figure 2 illustrates several potential conditions and corresponding mechanisms that induce face bursting. Furthermore, if the ratio of ST to H is small and the stemming quality is poor, it may lead to cratering and rifling (Lundborg and Persson, 1975; Ghasemi et al., 2012; Saghatforoush et al., 2016; Hasanipanah et al., 2018a). In contrast, uncontrollable parameters refer to characteristic indices related to the physical properties of a rock mass, such as rock density (RD), blastability index (BI), and block size (BS) (Monjezi et al., 2010, 2012; Hudaverdi & Akyildiz, 2019), geological properties of a rock mass including geological strength index (GSI), rock mass rating (RMR), rock quality designation (RQD), and uniaxial compressive strength (UCS) (Trivedi et al., 2015; Asl et al., 2018), as well as environmental factors like weathering index (WI) (Murlidhar et al., 2021).

Three important flyrock generation mechanisms
Over the past few years, a broad spectrum of artificial intelligence (AI) algorithms represented by machine learning (ML) models has been developed and employed to forecast FD based on both controllable and uncontrollable parameters (Table 1). In general, a single ML method was usually employed to predict FD, e.g., artificial neural network (ANN) (Monjezi et al., 2010, 2011; Hosseini et al., 2022a, b, c; Wang et al., 2023), least squares–support vector machine (LS–SVM) (Rad et al., 2018), extreme learning machine (ELM) (Lu et al., 2020), support vector regression (SVR) (Armaghani et al., 2020; Guo et al., 2021b), back-propagation neural network (BPNN) (Yari et al., 2016), adaptive neuro-fuzzy inference system (ANFIS) (Armaghani et al., 2016), random forest (RF) (Han et al., 2020; Ye et al., 2021), and deep neural network (DNN) (Guo et al., 2021a). Nonetheless, most single ML models, particularly ANN, SVR, RF, and ANFIS, have low learning rates and easily fall into local optimum (Wang et al., 2004; Moayedi and Armaghani, 2018; Wang et al., 2021b; Li et al., 2022a, b). However, it is extremely time-consuming and difficult to select hyperparameter parameters of a single ML model by manual methods for solving complex problems (Li et al., 2022d). In other words, the hyperparameter selection problem can also be considered as an optimization problem. Recently, the use of metaheuristic algorithms is effective for solving optimization problems (Monjezi et al., 2012; Armaghani et al., 2014; Kumar et al., 2018). Besides, metaheuristic algorithms have been noticed and used to improve the predictive ability of traditional ML models in solving engineering problems, including evolution-based (Majdi and Beiki, 2010; Yagiz et al., 2018; Zhang et al., 2022a), physics-based (Khatibinia and Khosravi, 2014; Liu et al., 2020; Momeni et al., 2021), and swarm-based (Zhou et al., 2021c; Li et al., 2022a, b, 2023; Adnan et al., 2023a, b; Ikram et al., 2023a; Zhou et al., 2023a, b, c, d) methods. Swarm-based optimization methods, such as the grey wolf optimization algorithm (GWO), sparrow search algorithm (SSA), and Harris hawks optimization (HHO), offer the advantage of requiring only a few parameters, namely population and iteration, to be adjusted in order to enhance the optimized performance (Kardani et al., 2021; Li et al., 2021d; Zhou et al., 2021b, c, 2022b, c, 2023c, d). To improve the accuracy of single ML model for predicting FD, researchers have applied various metaheuristic algorithms-based swarm to the hyperparameter optimization of ML models (Hasanipanah et al., 2016, 2018b; Kalaivaani et al., 2020; Murlidhar et al., 2020, 2021; Guo et al., 2021b; Nguyen et al., 2021; Fattahi and Hasanipanah, 2022). However, the performance of metaheuristic algorithms-based swarm is limited by the lack of initial population diversity (Zhou et al., 2021d, 2022d). Meanwhile, the low precision convergence and convergence time of metaheuristic algorithms in the optimization of multi-dimensional complex problems have already become traditional weaknesses (Li et al., 2021c).
Therefore, the objective of this study was to develop a novel and comprehensive optimization model, which combines multi-strategies (MS) and HHO algorithm to optimize SVR model for predicting FD. The proposed model is named the MSHHO–SVR model. A database was created based on the monitoring of 262 blasting operations from various open-pit mines, where a series of influence parameters related to FD were collected. Three other ML models and an empirical equation were also developed to predict FD and were compared with the HHO–SVR and MSHHO–SVR models. The prediction performance of all models was evaluated using root mean square error (RMSE), mean absolute error (MAE), determination coefficient (R2), and variance accounted for (VAF) in both training and testing phases. Additionally, the Shapley additive explanations (SHAP) method, an emerging additive explanatory method, was employed to calculate the influence of input parameters on FD in the sensitivity analysis.
Methodologies
Support Vector Regression
SVR is a specialized algorithm within the family of support vector machines (SVM) developed by Vapnik (1995) for resolving regression problems. For the SVR algorithm, the structural risk minimization (SRM) is the core of the optimizer algorithm used to obtain the minimum training error (Li et al., 2021b; Zhou et al., 2021c; Zhang et al., 2022b). In other words, the nonlinear regression prediction is also a function fitting problem by using SVR model, which can be described as:
where w represents a weight vector, \(\Psi (z)\) describes a nonlinear mapping between input space and high-dimensional space, b represents a model error also called threshold value. Then, the minimization of w and b can be calculated according to the SRM as:
Finally, Eq. 1 is rewritten as:
where C represents a penalty factor for balancing the model smoothness, \(\zeta_{i}\) and \(\zeta_{i}^{*}\) represent the slack parameters, M denotes number of pattern records, \(\left\| W \right\|^{2} /2\) represents the smoothness, \(\vartheta\) is set to default value of 0.1, and \(\kappa \left( {z_{i} ,z_{j} } \right) = \Psi (z_{i} )\Psi (z_{j} )\) indicates the kernel function. In this study, the radial basis function (RBF) was employed as a widely used kernel function to solve the prediction problem. Therefore, C and the kernel parameter (\(\gamma\)) were the main hyperparameters of SVR model in this study.
Harris Hawks Optimization
The HHO algorithm, developed by Heidari et al. (2019), is an emerging metaheuristic optimization algorithm, which is inspired by the unique cooperative hunting activities of Harris’s hawk in nature called “surprise pounce.” For solving the optimization problems, each Harris’s hawk can be considered as a candidate solution, and the best solution is faulty when considered as the prey. The standard HHO is split into two parts named the exploration and the exploitation, as well as different perching and attacking strategies (Fig. 3a).

A standard HHO algorithm: (a) all phases; (b) soft besiege with progressive rapid dives; (c) hard besiege with progressive rapid dives
Exploration is the beginning of a successful foraging campaign. Harris’s hawks use their dominant eyes to search for and track prey. Especially when prey is highly alert, they wait, observe, and monitor for about 2 h. There are two different perching strategies that can be executed with the same probability or chance, which are expressed mathematically as (Zhou et al., 2021b):
where \(X\left( n \right)\) and \(X\left( {n + 1} \right)\) denote the positions of hawks in the nth and n + 1th iterations, respectively; \(X_{{{\text{rand}}}} (n)\) and \(X_{{{\text{prey}}}} (n)\) illustrate the positions of the randomly selected hawk and prey in nth iteration, respectively. The parameters q, r1, r2, r3, and r4 represent random numbers varying from 0 to 1 in each iteration. LB and UB delegate the lower and upper boundaries of the internal parameters, respectively. Notably, the mean position of the hawks (\(X_{{\text{m}}} \left( n \right)\)) is expressed as:
where I is the number of Harris’s hawks and \(X_{i} (n)\) illustrates the position of the ith individual hawk in the nth iteration.
After identifying the prey and its location, the hawks can select from a range of attacking strategies based on the available energy. The energy consumption during the attack is mathematically expressed as:
where E and E0 represent the escaping energy and initial energy of the prey, respectively; n indicates the current iteration, and the maximum number of iterations is illustrated by T in the HHO algorithm. When E is less than 1, hawks continue to stay in exploration phase to obtain a better prey. In contrast, hawks start to execute different attack strategies to hunt prey in exploitation phase.
In the exploitation phase, hawks can choose the appropriate attacking strategy according to the different escape behaviors and energy surplus of prey. Assuming the prey has an escape chance of prey is Ec, then the chances of successful escape and capture are expressed as \(E_{{\text{c}}} \ge 0.5\) or \(E_{{\text{c}}} < 0.5\). Combining the escaping energy of prey, there are four possible attacking strategies selected by hawks to hunt prey, as written in Eqs. 7, 8, 9, and 10.
No. 1. Soft besiege: this attack strategy is triggered once the prey (e.g., rabbit) has enough escape energy (\(\left| E \right| \ge 0.5\)) but still did not escape out of hawk’s territory (\(E_{c} \ge 0.5\)).
No. 2. Hard besiege: once the escape energy of prey is exhausted (\(\left| E \right| < 0.5\)) but it still does not escape the hawk’s territory (\(E_{{\text{c}}} \ge 0.5\)), hawks initiate the hard besiege strategy to capture the prey.
No. 3. Soft besiege with progressive rapid dives (see Fig. 3b): When the prey has enough escape energy (\(\left| E \right| \ge 0.5\)) and can use different deceptive behaviors to escape the hawk’s territory (\(E_{{\text{c}}} < 0.5\)).
No. 4. Hard besiege with progressive rapid dives (see Fig. 3c): if the prey has less escape energy (\(\left| E \right| < 0.5\)) while can take different deceptive behaviors to escape the hawk's territory (\(E_{{\text{c}}} < 0.5\)), hawks try to save more moving distance for hunting the prey. This trigger condition of No. 4 strategy is similar to No. 3.
where \(\Delta X(n)\) represents the difference of position between prey and hawk in the nth iteration, J represents the intensity of escape movement, which is changed randomly between 0 and 2; D and S express the dimension of searching space and a random vector, respectively; Fitness () represents the fitness evaluation function in iteration; and LF describes the levy flight function, which can be written as:
where \(\mu\) and \(\upsilon\) represent random values in the range of [0, 1], and \(\beta\) represents a constant, which is set to 0.5 by default in the HHO algorithm.
Harris Hawks Optimization with Multi-Strategies
Despite the extensive use of the HHO algorithm in solving various engineering problems by many researchers (Moayedi et al., 2020; Murlidhar et al., 2021; Zhang et al., 2021; Zhou et al., 2021d; Kaveh et al., 2022), it still faces the challenge of low convergence accuracy and premature convergence while dealing with high-dimensional and complex optimization problems. To address these issues, several methods have been proposed to enhance the performance of the HHO algorithm, including chaotic local search (Elgamal et al., 2020), self-adaptive technique (Wang et al., 2021a; Zou and Wang, 2022), hybridizing supplementary algorithms (Fan et al., 2020; Hussain et al., 2021). In any case, the goal of improving HHO is to optimize the initial HHO algorithm’s exploration and exploitation. In this study, three strategies named chaotic mapping, Cauchy mutation, and adaptive weight were used to enhance the performance of the initial HHO algorithm.
Chaotic Mapping
Several studies have shown that chaotic mapping can be used to create a more diverse population by using chaotic sequences (Kohli and Arora, 2018). Among the chaotic mapping functions, logistic mapping is used widely to enrich the diversity of population for improving the performance of metaheuristic algorithms (Hussien and Amin, 2022). Therefore, the initial population of the HHO was generated by using a logistic mapping written as:
and the novel candidate solution generated can be obtained as:
where \({\text{Log}}^{s + 1}\) and \({\text{Log}}^{s}\) represent the s + 1 and s order chaotic sequence, respectively; \(\kappa\) represents a constant between 0 and 4; Cs delegates the candidate solution; TP illustrates the target position; \(C^{\prime}\) represents the maps; and \(\varepsilon\) represents a factor related to the iteration, which is calculated as:
where \({\text{Max}}_{{{\text{iteration}}}}\) represents the maximum number of iterations, and \({\text{Cur}}_{{{\text{iteration}}}}\) indicates the current iteration.
Cauchy Mutation
The Cauchy distribution function is a simple yet effective method for addressing the problem of metaheuristic algorithms being susceptible to local optima (Yang et al., 2018). The Cauchy variation can augment the diversity of a population in the search space of hawks, thereby improving the global search capability of the original HHO algorithm. The mathematical representation of Cauchy mutation is written as:
After applying the Cauchy mutation, the search algorithm can explore more global optima, thus:
Adaptive Weight
An adaptive weight method was employed in this study to update the position of prey during the exploitation phase in the HHO algorithm. The adaptive weight factor (wf) has different functions in improving the performance of local optimization, such as a smaller wf can increase the exploitation time and result in a better solution. This process is represented as:
The framework of using the MSHHO-based SVR model to predict FD is shown in Figure 4. Besides, four comparison models were established to compare the predictive performance with the HHO- and MSHHO-based SVR models, including ELM, KELM, BPNN, and empirical models. The principles of these models above were described in detail in literature (Roth, 1979; Huang et al., 2006; McKenzie, 2009; Chen et al., 2016; Yari et al., 2016; Zhang and Goh, 2016; Wang et al., 2017; Elkatatny et al., 2018; Luo et al., 2019; Shariati et al., 2020; Jamei et al., 2021). To learn relationships between the input parameters and FD accurately, the database was divided into two subsets, i.e., training set and test set (70% and 30% of the total data, respectively). Note that all data should be normalized into the range of 0 to 1 or − 1 to 1. The latter was considered in this study. Furthermore, the fitness function built by RMSE was set as the only criterion for evaluating the performance of each hybrid model. The better model with the suitable hyperparameters has lower value of fitness than other models. Finally, all developed models should be evaluated using performance indices or other evaluation approaches like as regression analysis and Taylor diagrams (Zhou et al., 2021c, 2023a, b).

Framework of FD prediction
Study Site and Dataset
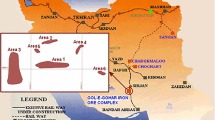
In order to forecast the flyrock phenomenon, six open-pit mines (i.e., Taman Bestari, Putri Wangsa, Trans Crete, Ulu Tiram, Masai, and Ulu Choh) were investigated in Malaysia. Their locations are shown in Figure 5. A big data survey showed that the total amount of blasting in these mines reached 240,000 tons a year, with average of 15 large-scale blasting operations carried out every month (Han et al., 2020). The blasting operation with high charge and high frequency is bound to cause a serious flyrock phenomenon (see Fig. 5). According to Table 1, different controllable and uncontrollable parameters were used as predictors in previous flyrock studies. In this study, we monitored 262 blasts and recorded six individual influence parameters, namely H, HD, BTS, ST, MC, and PF, as input parameters to predict FD. Although uncontrollable parameters of RQD and Rn were also measured, only the range values were recorded and could not be adopted in this study. Figure 6 shows the distribution of the input parameters.

Locations of six open-pit mines in Malaysia used for predicting FD

Distribution pattern of input parameters
Figure 7 displays the correlation coefficients and data distributions of the input parameters and output parameters. The purpose of the correlation analysis was to select the appropriate parameters to build the prediction model. Two parameters that are highly correlated with each other are a burden in building a model because their contributions to the target prediction are approximate. However, if the direct correlation coefficient (R) between an input parameter and the predicted target is large, it indicates that the input parameter has a key influence on whether the target can be accurately predicted. As shown in this picture, the values of R between input parameters are low, and each input parameter has a good linear relationship with FD. Therefore, the six parameters selected can be used to build the prediction model.

Correlations between input and output parameters
Model Evaluation
To evaluate the reliability and accuracy of the proposed model, as well as three other ML models and an empirical formula for predicting FD, it was necessary to apply statistical indices to quantify their predictive performance. RMSE, R2, MAE, and VAF are widely utilized as performance indices in model evaluation, as reported in several published studies (Hasanipanah et al., 2015; Armaghani et al., 2021; Jamei et al. 2021; Murlidhar et al. 2021; Zhou et al. 2021a; Dai et al., 2022; Du et al., 2022; Ikram et al., 2022a, b; Li et al. 2022c; Mikaeil et al. 2022; Chen et al., 2023; Ikram et al., 2023b; Zhou et al. 2023d). These aforementioned indices are defined as follows.
where U represents the number of used samples in the training or testing phase; \({\text{FD}}_{o,u}\) and \(\overline{{{\text{FD}}_{o} }}\) indicate observed FD value of the uth sample and mean of observed FD values, respectively; and \({\text{FD}}_{p,u}\) indicates the predicted FD value of the uth sample.
Developing the Models for Predicting FD
In this study, an enhanced HHO algorithm with multi-strategies was employed to select the hyperparameters of SVR model for predicting FD. The other five different models, i.e., HHO–SVR, ELM, KELM, BPNN, and empirical formula, were also considered for comparison with the predictive performance of the proposed MSHHO–SVR model. The procedures for model development and assessment are described in the following sections.
Evaluation Performance of MSHHO Model
As previously mentioned, the logistic mapping of chaotic sequences was used to initialize the population of HHO for increasing swarm diversity, the Cauchy mutation was utilized to expand the search space and improve the global search capability (i.e., exploration) of HHO, and the local optimization capability (i.e., exploitation) was improved by assigning the adaptive weight strategy. Three MSHHO algorithms were generated by using the aforementioned strategies, namely HHO–Logistic mapping (HHO–Log), HHO–Cauchy mutation and adaptive weight (MHHO), and MHHO–Log. To compare the performance of MSHHO algorithms with the initial HHO, six benchmark functions consisting of three unimodal functions and three multimodal functions (Zhou et al., 2022a) were used to obtain the objective function values as shown in Table 2. The performance of different algorithms can be demonstrated by the average (Aver.) and standard deviation (S.D.) values of their objective functions. To balance out the interference of other conditions, the dimension and iteration time were set as 30 and 200 in each algorithm. Besides, the initial population was given three values (25, 50 and 75) to increase the complexity and reliability of the verification. The results of performance evaluation for all algorithms are shown in Table 3. As can be seen in this table, all enhanced HHO algorithms obtained better performance than the unchanged HHO algorithm by resulting in lower values of Aver. and S.D. of objective functions, especially for the MHHO–Log algorithm. It can be noted that each algorithm had the best performance with a population of 50 in different functions. Figures 8 and 9 reflect the dynamic convergence performance of all algorithms based on the unimodal and multimodal benchmark functions during 200 iterations. It is obvious that the MHHO–Log had the lowest values of objective function in F6 when the population was 50. Furthermore, the performance of all MSHHO algorithms was improved to be superior to HHO by adjusting the population, the capability of global search and local optimization.

Comparisons between HHO and MSHHO by using the unimodal benchmark functions

Comparisons between HHO and MSHHO by using the multimodal benchmark functions
Development of MSHHO–SVR Model
After verifying the performance of all MSHHO algorithms, a series of hybrid models that combine MSHHO algorithms and SVR was developed to search the optimized hyperparameters for predicting FD. To confirm the optimization performance of MSHHO, the populations were also set equal to 25, 50 and 75 in 200 iterations. Figure 10 displays the iteration curves of all hybrid models with different populations. The lowest fitness value of each hybrid SVR model was obtained in the population of 50. In particular, the MHHO–Log–SVR model with 50 populations had the best performance by means of the lowest value of fitness among all models. The rest of the results of the minimum values of fitness are given in Table 4. Therefore, the MHHO–Log–SVR model was considered the optimal MSHHO model for forecasting FD, namely the MSHHO–SVR model.

Development results of HHO–SVR and MSHHO–SVR models
Development of ELM Model
The ELM model's development solely depends on the number of neurons present in a single hidden layer (Li et al. 2022a, b). In order to obtain the most accurate ELM model for estimating FD, seven models were constructed using different number of neurons ranging from 20 to 200. The R2 was utilized to evaluate the predictive ability of these models. The results of the seven models during both the training and testing phases are reported in Table 5. The results indicate that increasing the number of neurons in the training phase results in an increased value of R2. However, the third ELM model achieved the highest R2 value (0.8173) using the test data with 80 neurons in a hidden layer. Accordingly, the final ELM model with 80 neurons in a hidden layer was employed to predict FD in this study.
Development of KELM Model
The KELM model eliminates the need for selecting and determining the number of neurons in the hidden layer, instead it relies on kernel function (such as the RBF) parameters to optimize the performance of the ELM model (Huang et al., 2011). Similar to the SVR model, the range of regularization coefficient (K) and \(\gamma\) of KELM model must be defined manually. Zhu et al. (2018) used a range of 2−20–220 for K and \(\gamma\). Baliarsingh et al. (2019) considered the K and \(\gamma\) in the range of 2−8–28 to solve their problem. Therefore, the variation range of hyperparameters of KELM model was considered as 2-2, 2-1, …, 27, 28 to predict FD. The development results of KELM models in the training and testing phases are shown in Figure 11. As can be shown in Figure 11a, K had a positive relationship with any value of \(\gamma\). However, if K was smaller than 21, the R2 increases first and then decreases as \(\gamma\) increases, and the turning point was when \(\gamma\) = 21. However, the highest value of R2 was obtained in the testing phase when K was 24 and \(\gamma\) was 2−1. As can be realized, the best hyperparameters of KELM model were 24 (K) and 2−1 (\(\gamma\)) for predicting FD.

Development of KELM model: (a) training phase; (b) testing phase
Development of BPNN Model
The BPNN model was devised with the purpose of minimizing predictive errors through the application of back-propagation to regulate the weights and biases of the neural network. This technique has gained widespread usage in addressing a range of engineering problems (Li et al., 2021a). The BPNN is also a typical multilayer neural network with input, hidden, and output layers. To develop a BPNN model, the numbers of hidden and neurons are the major concerns. Although a better performing BPNN model has more hidden layers and neurons, it may result in overfitting and it may increase unnecessary computation time (Yari et al., 2016). Several formulas can be used to calculate the neurons of hidden layers (Han et al., 2018). The values of R2 were used here to describe the BPNN performance in the training and testing phases (Fig. 12). Ultimately, the neural network model with a configuration of 6–5–4–1 (i.e., 6 neurons in the input layer, 5 neurons in the first hidden layer, 4 neurons in the second hidden layer, and 1 neuron in the output layer) achieved the highest R2 value in the testing phase. This model was determined to be the most optimal BPNN model for predicting FD in this study.

Performance of the BPNN model: (a) training phase; (b) testing phase
Development of Empirical Equation
There are many empirical formulas for predicting FD by using blast design parameters (Lundborg et al., 1975; Roth, 1979; Gupta, 1980; Olofsson, 1990). Nevertheless, the accuracy of empirical models is extremely dependent on input parameters (Richards and Moore, 2004; Little, 2007; Ghasemi et al., 2012; Trivedi et al., 2014; Zhou et al., 2021c). Therefore, a multiple linear regression formula was established, which describes the relationship between the considered six controllable parameters and FD; thus,
where Dflyrock represents FD.
Results and Discussion
After obtaining the ideal hyperparameters for all models, each model was run based on the same database and their prediction performances were evaluated using RMSE, R2, MAE, and VAF. Table 6 presents the results of performance comparison of the proposed model and other five models in the training phase. It can be seen intuitively that the performance indices of SVR models optimized by HHO and MSHHO were significantly superior to other models. The best and worst models were the MSHHO–SVR and ELM models, respectively, with RMSEs of 12.2822 and 28.3539, R2 values of 0.9662 and 0.8197, MAEs of 8.5034 and 21.6415, and VAF values of 96.6161 % and 81.965 %, respectively. Following the MSHHO–SVR model, other models, including the HHO–SVR model, KELM model, BPNN model, and empirical equation, exhibited favorable performance based on the aforementioned evaluation metrics for predicting FD.
The regression diagrams were used to evaluate the performance of the six models in the training phase as shown in Figure 13. The horizontal axis represents the observed FD values, while the predicted values are listed on the vertical axis. Each diagram includes a line at 45°, which is colored differently per model. The points along these lines indicate that the error between the predicted and the observed values is zero. A greater number of points on or close to the 45° line indicate that a model has better predictive accuracy. Meanwhile, the dotted lines with the equation of y = 1.1x and y = 0.9x were set as the prediction boundaries, and those points outside these boundaries indicate poor performance. As can be seen in this picture, the predicted values by MSHHO–SVR model were more concentrated on the 45° line, followed by HHO–SVR model, KELM model, BPNN model, empirical and ELM model. Meanwhile, the MSHHO–SVR model had better performance indices compared to the other models.

Regression diagrams of all models using the training set: (a) HHO–SVR; (b) MSHHO–SVR; (c) ELM; (d) KELM; (e) BPNN; (f) Empirical
It is worth noting that a model that performed well in the training phase cannot be directly applied to predict FD. In order to verify their efficacy, the proposed model, along with five others, should undergo validation using the test set. It is important to note that the models may not necessarily reproduced the same luminous results in the testing phase. Table 7 displays the results of the four performance indices generated by all the models. The MSHHO–SVR model emerged as the most effective among them, yielding the highest R2 (0.9691) and VAF (96.9178%), as well as the lowest RMSE (9.6685) and MAE (7.4618). Conversely, the empirical model displayed poor prediction accuracy with RMSE of 26.4389, R2 of 0.7689, MAE of 20.4681, and VAF of 76.9583%. Furthermore, the empirical equation also generated predictive values that deviated significantly from the 45° line. Conversely, the MSHHO–SVR model's prediction performance was the most superior (Fig. 14), whereby all its predicted values fell within the prediction boundary and were positioned closer to the 45° line. The HHO–SVR model, followed by the BPNN model and the KELM model, performed less effectively than the MSHHO–SVR model in FD prediction.

Regression diagrams of all models using the test set: (a) HHO–SVR; (b) MSHHO–SVR; (c) ELM; (d) KELM; (e) BPNN; (f) Empirical
Figure 15 presents graphical Taylor diagrams that comprehensively compare the predictive performances of all models in both the training and testing phases. In the Taylor diagrams, the RMSE and R of observed value were set by default to 0 and 1, respectively. Then, the positions of all models can be determined according to the values of S.D., RMSE, and R of the respective prediction results. Accordingly, the best model has less deviations from the observed values compared to the other models. As can be seen in these diagrams, the MSHHO–SVR model was certainly closer to the observed values in both the training and testing phases, indicating that it is the best model for predicting FD.

Graphical Taylor diagrams for comparison of all models. The horizontal and vertical axes represent S.D. of predicted values per model, which are drawn by blue circular lines. The green circles represent the RMSEs of different models, and the black lines from the origin (0, 0) to the outermost circle shows the R in the range of 0 to 1
Figure 16 illustrates the curves of observed and predicted FDs using the test set, enabling a detailed assessment of the predictive performance of each of the six models. Overall, there is little difference between the predicted and observed curves for all models. However, local observation shows that the values predicted by the empirical models had large errors from the observed values of samples Nos. 33–35, and the errors obtained by ELM, KELM, and BPNN models were almost the same but significantly larger than that obtained by the HHO–SVR model. Compared to the HHO–SVR model, there was little error between the predicted and observed values of samples Nos. 20–30 based on the MSHHO–SVR model, which means that the MSHHO–SVR model was more suitable for predicting FD than of the other models based on prediction accuracy.

Curves for predicting FD in the testing phase by all models
In order to further compare prediction performance between the HHO–SVR and MSHHO–SVR models, the relative deviation was defined to measure the difference in prediction performance of the proposed models in the training and testing phases. If the relative deviation is greater than 10% or less than − 10%, the prediction is considered wrong. According to the obtained results (Fig. 17), the relative deviation of the MSHHO–SVR model was more concentrated in the range [− 10%, 10%] compared to that of the HHO–SVR model in both of the training and testing phases. This is strong evidence that MSHHO can help SVR do a much better job of predicting FD.

Variation in relative deviation for evaluating the performance of HHO–SVR and MSHHO–SVR mode
Although six controllable parameters related to the blasting design were considered as input parameters in this study, the importance of each of them still needs to be checked in the MSHHO–SVR model. The SHAP method inspired by cooperative game theories is used widely to calculate parameter importance (Lundberg and Lee, 2017; Chelgani et al., 2021; Zhou et al., 2022b; Qiu & Zhou, 2023). The result of the importance scores obtained using SHAP values is shown in Figure 18. As can be seen in this figure, the order of parameter importance is H > PF > MC > HD > ST > BTS with mean SHAP values of 40.25, 19.98, 10, 3.81, 3.76, and 2.81, respectively. The biggest advantage of the SHAP method is that the influence of features can be reflected per sample, which also shows the positive and negative influence of a parameter. Figure 19 displays the influence of each parameter on FD prediction. In this figure, the overlap points depict the SHAP value distribution per parameter. The higher the positive or negative SHAP values, the greater the impact on FD prediction. The results illustrate that FD significantly increases with H and PF. Meanwhile, all input parameters are positively correlated with FD.

Importance scores of input parameters

Influence results of each parameter on FD prediction
In this study, the MSHHO–SVR model has confirmed as the effective model to predict FD with an excellent performance, which is similar with most of published hybrid models for the years 2012–2022 as shown in Table 8. The best model was HHO–MLP proposed by Murlidhar et al. (2021) by means of the highest value of R2 (0.998). However, the difference in the used number of samples in database and considered input parameters is the root cause of the difference in model performance. Based on the same data set considered in this study, Ye et al. (2021) developed genetic programming (GP) and RF models to predict FD with good prediction accuracy of R2 are 0.908 and 0.9046, respectively; Armaghani et al. (2020) proposed a SVR model to estimate FD with high accuracy (R2 = 0.9373); Murlidhar et al. (2020) used biogeography-based optimization (BBO) to optimize the ELM model for predicting FD, with R2 = 0.94. The current study has yielded superior results for predicting FD, as determined by the use of the most effective model, the MSHHO–SVR, which yielded higher R2 values (0.9662 for the training set and 0.9691 for the test set). Therefore, the authors are confident that the proposed MSHHO–SVR model exhibits superior performance compared to the existing models on the same dataset.
Conclusion
Flyrock has long been a significant safety concern in open-pit mines. This study examined a rich database from six open-pit mines in Malaysia, comprising 262 blasting operations. A novel optimization model that combines HHO and MS was developed to fine-tune the SVR model, named the MSHHO–SVR model. This model was compared for predictive performance with other models, including the HHO–SVR, ELM, KELM, BPNN, and empirical models for predicting FD. The main conclusions of this study are listed as follows.
-
(1)
The evaluation results indicated that the MSHHO–SVR model had the highest predictive accuracy among all models, as reflected by its RMSEs of 12.2822 and 9.6685, R2 values of 0.9662 and 0.9691, MAEs of 8.5034 and 7.4618, and VAF values of 96.6161% and 96.9178% in the training and testing phases, respectively.
-
(2)
It was verified that multi-strategies can significantly improve the performance of the HHO algorithm for tunning the hyperparameters of the SVR model. In addition, the combination of MSHHO and SVR model had superior prediction accuracy compared to the other models using the same FD database.
-
(3)
The result of sensitivity analysis showed that H was the most sensitive parameter and BTS was the least sensitive parameter to FD. The importance rankings of the other input parameters were PF, MC, HD, and ST. Note that all input parameters, especially H and PF, were positively correlated with FD.
Although the proposed novel hybrid model was able to predict FD with satisfactory predictive accuracy, if the range of input parameter values extends beyond those employed in this study, the findings may be subject to bias. Therefore, it is necessary to obtain more data from field investigation and inspection to enrich the database and improve the model generalization. Furthermore, some physics rules between input parameters and the model output can be included in future flyrock studies. In this regard, predicted FD by using previous empirical formulas can be considered as model inputs. This idea might be more interesting for mining and civil engineers because they can learn more about how data are prepared and how input and output parameters are related.
References
Adnan, R. M., Meshram, S. G., Mostafa, R. R., Islam, A. R. M. T., Abba, S. I., Andorful, F., & Chen, Z. (2023a). Application of advanced optimized soft computing models for atmospheric variable forecasting. Mathematics, 11(5), 1213.
Adnan, R. M., Mostafa, R. R., Dai, H. L., Heddam, S., Kuriqi, A., & Kisi, O. (2023b). Pan evaporation estimation by relevance vector machine tuned with new metaheuristic algorithms using limited climatic data. Engineering Applications of Computational Fluid Mechanics, 17(1), 2192258.
Armaghani, D. J., Hajihassani, M., Mohamad, E. T., Marto, A., & Noorani, S. A. (2014). Blasting-induced flyrock and ground vibration prediction through an expert artificial neural network based on particle swarm optimization. Arabian Journal of Geosciences, 7(12), 5383–5396.
Armaghani, D. J., Harandizadeh, H., Momeni, E., Maizir, H., & Zhou, J. (2021). An optimized system of GMDH-ANFIS predictive model by ICA for estimating pile bearing capacity. Artificial Intelligence Review, 55, 1–38.
Armaghani, D. J., Koopialipoor, M., Bahri, M., Hasanipanah, M., & Tahir, M. M. (2020). A SVR-GWO technique to minimize flyrock distance resulting from blasting. Bulletin of Engineering Geology and the Environment, 79(8), 4369–4385.
Armaghani, D. J., Mohamad, E. T., Hajihassani, M., Abad, S. A. N. K., Marto, A., & Moghaddam, M. R. (2016). Evaluation and prediction of flyrock resulting from blasting operations using empirical and computational methods. Engineering with Computers, 32(1), 109–121.
Asl, P. F., Monjezi, M., Hamidi, J. K., & Armaghani, D. J. (2018). Optimization of flyrock and rock fragmentation in the Tajareh limestone mine using metaheuristics method of firefly algorithm. Engineering with Computers, 34(2), 241–251.
Bagchi, A., & Gupta, R.N. (1990). Surface blasting and its impact on environmental. In Workshop on Environmental Management of Mining Operations, Varanasi (pp 262–279).
Bajpayee, T. S., Rehak, T. R., Mowrey, G. L., & Ingram, D. K. (2004). Blasting injuries in surface mining with emphasis on flyrock and blast area security. Journal of Safety Research, 35(1), 47–57.
Bakhtavar, E., Nourizadeh, H., & Sahebi, A. A. (2017). Toward predicting blast-induced flyrock: a hybrid dimensional analysis fuzzy inference system. International journal of environmental science and technology, 14, 717–728.
Baliarsingh, S. K., Vipsita, S., Muhammad, K., Dash, B., & Bakshi, S. (2019). Analysis of high-dimensional genomic data employing a novel bio-inspired algorithm. Applied Soft Computing, 77, 520–532.
Chelgani, S. C., Nasiri, H., & Alidokht, M. (2021). Interpretable modeling of metallurgical responses for an industrial coal column flotation circuit by XGBoost and SHAP-A “conscious-lab” development. International Journal of Mining Science and Technology, 31(6), 1135–1144.
Chen, C., & Zhou, J. (2023). A new empirical chart for coal burst liability classification using Kriging method. Journal of Central South University, 30(4), 1205–1216.
Chen, D. F., Feng, X. T., Xu, D. P., Jiang, Q., Yang, C. X., & Yao, P. P. (2016). Use of an improved ANN model to predict collapse depth of thin and extremely thin layered rock strata during tunnelling. Tunnelling and Underground Space Technology, 51, 372–386.
Chen, Y., Yong, W., Li, C., & Zhou, J. (2023). Predicting the thickness of an excavation damaged zone around the roadway using the DA-RF hybrid model. CMES-Computer Modeling in Engineering & Sciences, 136(3), 2507–2526.
Dai, Y., Khandelwal, M., Qiu, Y., Zhou, J., Monjezi, M., & Yang, P. (2022). A hybrid metaheuristic approach using random forest and particle swarm optimization to study and evaluate backbreak in open-pit blasting. Neural Computing and Applications, 34, 6273–6288.
Du, K., Liu, M., Zhou, J., & Khandelwal, M. (2022). Investigating the slurry fluidity and strength characteristics of cemented backfill and strength prediction models by developing hybrid GA-SVR and PSO-SVR. Mining, Metallurgy & Exploration, 39(2), 433–452.
Elgamal, Z. M., Yasin, N. B. M., Tubishat, M., Alswaitti, M., & Mirjalili, S. (2020). An improved harris hawks optimization algorithm with simulated annealing for feature selection in the medical field. IEEE Access, 8, 186638–186652.
Elkatatny, S., Mahmoud, M., Tariq, Z., & Abdulraheem, A. (2018). New insights into the prediction of heterogeneous carbonate reservoir permeability from well logs using artificial intelligence network. Neural Computing and Applications, 30(9), 2673–2683.
Fan, Q., Chen, Z., & Xia, Z. (2020). A novel quasi-reflected Harris hawks optimization algorithm for global optimization problems. Soft Computing, 24(19), 14825–14843.
Faradonbeh, R. S., Jahed Armaghani, D., & Monjezi, M. (2016). Development of a new model for predicting flyrock distance in quarry blasting: a genetic programming technique. Bulletin of Engineering Geology and the Environment, 75(3), 993–1006.
Fattahi, H., & Hasanipanah, M. (2022). An integrated approach of ANFIS-grasshopper optimization algorithm to approximate flyrock distance in mine blasting. Engineering with Computers, 38, 1–13.
Ghaleini, E. N., Koopialipoor, M., Momenzadeh, M., Sarafraz, M. E., Mohamad, E. T., & Gordan, B. (2019). A combination of artificial bee colony and neural network for approximating the safety factor of retaining walls. Engineering with Computers, 35(2), 647–658.
Ghasemi, E., Sari, M., & Ataei, M. (2012). Development of an empirical model for predicting the effects of controllable blasting parameters on flyrock distance in surface mines. International Journal of Rock Mechanics and Mining Sciences, 52, 163–170.
Guo, H., Nguyen, H., Bui, X. N., & Armaghani, D. J. (2021a). A new technique to predict fly-rock in bench blasting based on an ensemble of support vector regression and GLMNET. Engineering with Computers, 37(1), 421–435.
Guo, H., Zhou, J., Koopialipoor, M., Jahed Armaghani, D., & Tahir, M. M. (2021b). Deep neural network and whale optimization algorithm to assess flyrock induced by blasting. Engineering with Computers, 37(1), 173–186.
Gupta, R. N. (1980). Surface blasting and its impact on environment. In: N. J. Trivedy, B. P. Singh (Eds.), Impact of mining on environment, (pp 23–24). Ashish Publishing House, New Delhi.
Han, H., Jahed Armaghani, D., Tarinejad, R., Zhou, J., & Tahir, M. M. (2020). Random forest and bayesian network techniques for probabilistic prediction of flyrock induced by blasting in quarry sites. Natural Resources Research, 29(2), 655–667.
Han, L., Fuqiang, L., Zheng, D., & Weixu, X. (2018). A lithology identification method for continental shale oil reservoir based on BP neural network. Journal of Geophysics and Engineering, 15(3), 895–908.
Hasanipanah, M., Amnieh, H. B., Arab, H., & Zamzam, M. S. (2018a). Feasibility of PSO–ANFIS model to estimate rock fragmentation produced by mine blasting. Neural Computing and Applications, 30, 1015–1024.
Hasanipanah, M., Jahed Armaghani, D., Bakhshandeh Amnieh, H., Koopialipoor, M., & Arab, H. (2018b). A risk-based technique to analyze flyrock results through rock engineering system. Geotechnical and Geological Engineering, 36(4), 2247–2260.
Hasanipanah, M., Jahed Armaghani, D., Bakhshandeh Amnieh, H., Majid, M. Z. A., & Tahir, M. (2017). Application of PSO to develop a powerful equation for prediction of flyrock due to blasting. Neural Computing and Applications, 28(1), 1043–1050.
Hasanipanah, M., Keshtegar, B., Thai, D. K., & Troung, N. T. (2020). An ANN-adaptive dynamical harmony search algorithm to approximate the flyrock resulting from blasting. Engineering with Computers, 38, 1–13.
Hasanipanah, M., Monjezi, M., Shahnazar, A., Armaghani, D. J., & Farazmand, A. (2015). Feasibility of indirect determination of blast induced ground vibration based on support vector machine. Measurement, 75, 289–297.
Hasanipanah, M., Noorian-Bidgoli, M., Jahed Armaghani, D., & Khamesi, H. (2016). Feasibility of PSO-ANN model for predicting surface settlement caused by tunneling. Engineering with Computers, 32, 705–715.
Heidari, A. A., Mirjalili, S., Faris, H., Aljarah, I., Mafarja, M., & Chen, H. (2019). Harris hawks optimization: Algorithm and applications. Future generation computer systems, 97, 849–872.
Hosseini, S., Lawal, A. I., & Kwon, S. (2023). A causality-weighted approach for prioritizing mining 4.0 strategies integrating reliability-based fuzzy cognitive map and hybrid decision-making methods: A case study of Nigerian mining sector. Resources Policy, 82, 103426.
Hosseini, S., Poormirzaee, R., & Hajihassani, M. (2022a). An uncertainty hybrid model for risk assessment and prediction of blast-induced rock mass fragmentation. International Journal of Rock Mechanics and Mining Sciences, 160, 105250.
Hosseini, S., Poormirzaee, R., & Hajihassani, M. (2022b). Application of reliability-based back-propagation causality-weighted neural networks to estimate air-overpressure due to mine blasting. Engineering Applications of Artificial Intelligence, 115, 105281.
Hosseini, S., Poormirzaee, R., Hajihassani, M., & Kalatehjari, R. (2022c). An ANN-fuzzy cognitive map-based Z-number theory to predict flyrock induced by blasting in open-pit mines. Rock Mechanics and Rock Engineering, 55(7), 4373–4390.
Huang, G. B., Zhou, H., Ding, X., & Zhang, R. (2011). Extreme learning machine for regression and multiclass classification. IEEE Transactions on Systems, Man, and Cybernetics, Part B (Cybernetics), 42(2), 513–529.
Huang, G. B., Zhu, Q. Y., & Siew, C. K. (2006). Extreme learning machine: Theory and applications. Neurocomputing, 70(1–3), 489–501.
Hudaverdi, T., & Akyildiz, O. (2019). A new classification approach for prediction of flyrock throw in surface mines. Bulletin of Engineering Geology and the Environment, 78(1), 177–187.
Hussain, K., Neggaz, N., Zhu, W., & Houssein, E. H. (2021). An efficient hybrid sine-cosine Harris hawks optimization for low and high-dimensional feature selection. Expert Systems with Applications, 176, 114778.
Hussien, A. G., & Amin, M. (2022). A self-adaptive Harris Hawks optimization algorithm with opposition-based learning and chaotic local search strategy for global optimization and feature selection. International Journal of Machine Learning and Cybernetics, 13(2), 309–336.
Ikram, R. M. A., Dai, H. L., Al-Bahrani, M., & Mamlooki, M. (2022a). Prediction of the FRP reinforced concrete beam shear capacity by using ELM-CRFOA. Measurement, 205, 112230.
Ikram, R. M. A., Hazarika, B. B., Gupta, D., Heddam, S., & Kisi, O. (2023a). Streamflow prediction in mountainous region using new machine learning and data preprocessing methods: A case study. Neural Computing and Applications, 35(12), 9053–9070.
Ikram, R. M. A., Mostafa, R. R., Chen, Z., Islam, A. R. M. T., Kisi, O., Kuriqi, A., & Zounemat-Kermani, M. (2022b). Advanced hybrid metaheuristic machine learning models application for reference crop evapotranspiration prediction. Agronomy, 13(1), 98.
Ikram, R. M. A., Mostafa, R. R., Chen, Z., Parmar, K. S., Kisi, O., & Zounemat-Kermani, M. (2023b). Water temperature prediction using improved deep learning methods through reptile search algorithm and weighted mean of vectors optimizer. Journal of Marine Science and Engineering, 11(2), 259.
Jamei, M., Hasanipanah, M., Karbasi, M., Ahmadianfar, I., & Taherifar, S. (2021). Prediction of flyrock induced by mine blasting using a novel kernel-based extreme learning machine. Journal of Rock Mechanics and Geotechnical Engineering, 13(6), 1438–1451.
Kalaivaani, P. T., Akila, T., Tahir, M. M., Ahmed, M., & Surendar, A. (2020). A novel intelligent approach to simulate the blast-induced flyrock based on RFNN combined with PSO. Engineering with Computers, 36(2), 435–442.
Kardani, N., Bardhan, A., Roy, B., Samui, P., Nazem, M., Armaghani, D. J., & Zhou, A. (2021). A novel improved Harris Hawks optimization algorithm coupled with ELM for predicting permeability of tight carbonates. Engineering with Computers, 38, 1–24.
Kaveh, A., Rahmani, P., & Eslamlou, A. D. (2022). An efficient hybrid approach based on Harris Hawks optimization and imperialist competitive algorithm for structural optimization. Engineering with Computers, 38(2), 1555–1583.
Khandelwal, M., & Singh, T. N. (2005). Prediction of blast induced air overpressure in opencast mine. Noise & Vibration Worldwide, 36(2), 7–16.
Khatibinia, M., & Khosravi, S. (2014). A hybrid approach based on an improved gravitational search algorithm and orthogonal crossover for optimal shape design of concrete gravity dams. Applied Soft Computing, 16, 223–233.
Kohli, M., & Arora, S. (2018). Chaotic grey wolf optimization algorithm for constrained optimization problems. Journal of computational design and engineering, 5(4), 458–472.
Koopialipoor, M., Fallah, A., Armaghani, D. J., Azizi, A., & Mohamad, E. T. (2019). Three hybrid intelligent models in estimating flyrock distance resulting from blasting. Engineering with Computers, 35(1), 243–256.
Kumar, N., Mishra, B., & Bali, V. (2018). A novel approach for blast-induced fly rock prediction based on particle swarm optimization and artificial neural network. In Proceedings of International Conference on Recent Advancement on Computer and Communication (pp. 19–27). Springer.
Li, C., Li, J., Chen, H., Jin, M., & Ren, H. (2021a). Enhanced Harris hawks optimization with multi-strategy for global optimization tasks. Expert Systems with Applications, 185, 115499.
Li, C., Zhou, J., Armaghani, D. J., & Li, X. (2021b). Stability analysis of underground mine hard rock pillars via combination of finite difference methods, neural networks, and Monte Carlo simulation techniques. Underground Space, 6(4), 379–395.
Li, C., Zhou, J., Armaghani, D. J., Cao, W., & Yagiz, S. (2021c). Stochastic assessment of hard rock pillar stability based on the geological strength index system. Geomechanics and Geophysics for Geo-Energy and Geo-Resources, 7(2), 1–24.
Li, C., Zhou, J., Dias, D., & Gui, Y. (2022a). A kernel extreme learning machine-grey wolf optimizer (KELM-GWO) model to predict uniaxial compressive strength of rock. Applied Sciences, 12(17), 8468.
Li, C., Zhou, J., Khandelwal, M., Zhang, X., Monjezi, M., & Qiu, Y. (2022). Six novel hybrid extreme learning machine-swarm intelligence optimization (ELM–SIO) models for predicting backbreak in open-pit blasting. Natural Resources Research, 31, 1–23.
Li, C., Zhou, J., Tao, M., Du, K., Wang, S., Armaghani, D. J., & Mohamad, E. T. (2022). Developing hybrid ELM-ALO, ELM-LSO and ELM-SOA models for predicting advance rate of TBM. Transportation Geotechnics, 36, 100819.
Li, C., Zhou, J., Du, K., & Dias, D. (2023). Stability prediction of hard rock pillar using support vector machine optimized by three metaheuristic algorithms. International Journal of Mining Science and Technology. https://doi.org/10.1016/j.ijmst.2023.06.001
Li, D., Koopialipoor, M., & Armaghani, D. J. (2021d). A combination of fuzzy Delphi method and ANN-based models to investigate factors of flyrock induced by mine blasting. Natural Resources Research, 30(2), 1905–1924.
Li, E., Yang, F., Ren, M., Zhang, X., Zhou, J., & Khandelwal, M. (2021e). Prediction of blasting mean fragment size using support vector regression combined with five optimization algorithms. Journal of Rock Mechanics and Geotechnical Engineering, 13(6), 1380–1397.
Li, E., Zhou, J., Shi, X., Jahed Armaghani, D., Yu, Z., Chen, X., & Huang, P. (2021f). Developing a hybrid model of salp swarm algorithm-based support vector machine to predict the strength of fiber-reinforced cemented paste backfill. Engineering with Computers, 37(4), 3519–3540.
Li, J., Li, C., & Zhang, S. (2022d). Application of six metaheuristic optimization algorithms and random forest in the uniaxial compressive strength of rock prediction. Applied Soft Computing, 131, 109729.
Little, T.N. (2007) Flyrock risk. In Proceedings EXPLO (pp. 3–4).
Little, T. N., & Blair, D. P. (2010). Mechanistic Monte Carlo models for analysis of flyrock risk. Rock Fragmentation by Blasting, 9, 641–647.
Liu, B., Wang, R., Zhao, G., Guo, X., Wang, Y., Li, J., & Wang, S. (2020). Prediction of rock mass parameters in the TBM tunnel based on BP neural network integrated simulated annealing algorithm. Tunnelling and Underground Space Technology, 95, 103103.
Lu, X., Hasanipanah, M., Brindhadevi, K., Bakhshandeh Amnieh, H., & Khalafi, S. (2020). ORELM: A novel machine learning approach for prediction of flyrock in mine blasting. Natural Resources Research, 29(2), 641–654.
Lundberg, S. M., & Lee, S. I. (2017). A unified approach to interpreting model predictions. In: Advances in neural information processing systems, 30.
Lundborg, N., Persson, A., Ladegaard-Pedersen, A., & Holmberg, R. (1975). Keeping the lid on flyrock in open-pit blasting. Engineering and Mining Journal, 176, 95–100.
Luo, J., Chen, H., Hu, Z., Huang, H., Wang, P., Wang, X., & Wen, C. (2019). A new kernel extreme learning machine framework for somatization disorder diagnosis. IEEE Access, 7, 45512–45525.
Mahdiyar, A., Hasanipanah, M., Armaghani, D. J., Gordan, B., Abdullah, A., Arab, H., & Majid, M. Z. A. (2017). A Monte Carlo technique in safety assessment of slope under seismic condition. Engineering with Computers, 33(4), 807–817.
Majdi, A., & Beiki, M. (2010). Evolving neural network using a genetic algorithm for predicting the deformation modulus of rock masses. International Journal of Rock Mechanics and Mining Sciences, 47(2), 246–253.
Marto, A., Hajihassani, M., Jahed Armaghani, D., Tonnizam Mohamad, E., & Makhtar, A. M. (2014). A novel approach for blast-induced flyrock prediction based on imperialist competitive algorithm and artificial neural network. The Scientific World Journal. https://doi.org/10.1155/2014/643715
McKenzie, C. K. (2009). Flyrock range and fragment size prediction. In Proceedings of the 35th annual conference on explosives and blasting technique (Vol. 2). International Society of Explosives Engineers.
Mikaeil, R., Bakhtavar, E., Hosseini, S., & Jafarpour, A. (2022). Fuzzy classification of rock engineering indices using rock texture characteristics. Bulletin of Engineering Geology and the Environment, 81(8), 312.
Moayedi, H., & Armaghani, J. D. (2018). Optimizing an ANN model with ICA for estimating bearing capacity of driven pile in cohesionless soil. Engineering with Computers, 34(2), 347–356.
Moayedi, H., Gör, M., Lyu, Z., & Bui, D. T. (2020). Herding Behaviors of grasshopper and Harris hawk for hybridizing the neural network in predicting the soil compression coefficient. Measurement, 152, 107389.
Momeni, E., Yarivand, A., Dowlatshahi, M. B., & Armaghani, D. J. (2021). An efficient optimal neural network based on gravitational search algorithm in predicting the deformation of geogrid-reinforced soil structures. Transportation Geotechnics, 26, 100446.
Monjezi, M., Amini Khoshalan, H., & Yazdian Varjani, A. (2012). Prediction of flyrock and backbreak in open pit blasting operation: a neuro-genetic approach. Arabian Journal of Geosciences, 5(3), 441–448.
Monjezi, M., Bahrami, A., & Varjani, A. Y. (2010). Simultaneous prediction of fragmentation and flyrock in blasting operation using artificial neural networks. International Journal of Rock Mechanics and Mining Sciences, 3(47), 476–480.
Monjezi, M., Bahrami, A., Varjani, A. Y., & Sayadi, A. R. (2011). Prediction and controlling of flyrock in blasting operation using artificial neural network. Arabian Journal of Geosciences, 4(3), 421–425.
Monjezi, M., Hasanipanah, M., & Khandelwal, M. (2013). Evaluation and prediction of blast-induced ground vibration at Shur River Dam, Iran, by artificial neural network. Neural Computing and Applications, 22(7), 1637–1643.
Murlidhar, B. R., Kumar, D., Jahed Armaghani, D., Mohamad, E. T., Roy, B., & Pham, B. T. (2020). A novel intelligent ELM-BBO technique for predicting distance of mine blasting-induced flyrock. Natural Resources Research, 29(6), 4103–4120.
Murlidhar, B. R., Nguyen, H., Rostami, J., Bui, X., Armaghani, D. J., Ragam, P., & Mohamad, E. T. (2021). Prediction of flyrock distance induced by mine blasting using a novel Harris Hawks optimization-based multi-layer perceptron neural network. Journal of Rock Mechanics and Geotechnical Engineering, 13(6), 1413–1427.
Nguyen, H., Bui, X. N., Choi, Y., Lee, C. W., & Armaghani, D. J. (2021). A novel combination of whale optimization algorithm and support vector machine with different kernel functions for prediction of blasting-induced fly-rock in quarry mines. Natural Resources Research, 30(1), 191–207.
Nguyen, H., Bui, X. N., Nguyen-Thoi, T., Ragam, P., & Moayedi, H. (2019). Toward a state-of-the-art of fly-rock prediction technology in open-pit mines using EANNs model. Applied Sciences, 9(21), 4554.
Nikafshan Rad, H., Bakhshayeshi, I., Wan Jusoh, W. A., Tahir, M. M., & Foong, L. K. (2020). Prediction of flyrock in mine blasting: A new computational intelligence approach. Natural Resources Research, 29(2), 609–623.
Olofsson, S. O. (1990). Applied explosives technology for construction and mining. Applex Publisher.
Qiu, Y., & Zhou, J. (2023). Short-term rockburst prediction in underground project: Insights from an explainable and interpretable ensemble learning model. Acta Geotechnica. https://doi.org/10.1007/s11440-023-01988-0
Rad, H. N., Hasanipanah, M., Rezaei, M., & Eghlim, A. L. (2018). Developing a least squares support vector machine for estimating the blast-induced flyrock. Engineering with Computers, 34(4), 709–717.
Raina, A. K., Murthy, V. M. S. R., & Soni, A. K. (2014). Flyrock in bench blasting: A comprehensive review. Bulletin of Engineering Geology and the Environment, 73(4), 1199–1209.
Rezaei, M., Monjezi, M., & Varjani, A. Y. (2011). Development of a fuzzy model to predict flyrock in surface mining. Safety Science, 49(2), 298–305.
Richards, A., & Moore, A., (2004). Flyrock controle by chance or design. In The Proceedings of the 30th Annual Conference on Explosives and Blasting Technique (p. 335e348). The International Society of Explosives Engineers
Roth, J. (1979). A model for the determination of flyrock range as a function of shot conditions. NTIS.
Saghatforoush, A., Monjezi, M., Shirani Faradonbeh, R., & Jahed Armaghani, D. (2016). Combination of neural network and ant colony optimization algorithms for prediction and optimization of flyrock and back-break induced by blasting. Engineering with Computers, 32(2), 255–266.
Shariati, M., Mafipour, M. S., Ghahremani, B., Azarhomayun, F., Ahmadi, M., Trung, N. T., & Shariati, A. (2020). A novel hybrid extreme learning machine–grey wolf optimizer (ELM-GWO) model to predict compressive strength of concrete with partial replacements for cement. Engineering with Computers, 38, 1–23.
Singh, T. N., & Singh, V. (2005). An intelligent approach to prediction and control ground vibration in mines. Geotechnical & Geological Engineering, 23(3), 249–262.
Trivedi, R., Singh, T. N., & Gupta, N. (2015). Prediction of blast-induced flyrock in opencast mines using ANN and ANFIS. Geotechnical and Geological Engineering, 33(4), 875–891.
Trivedi, R., Singh, T. N., & Raina, A. K. (2014). Prediction of blast-induced flyrock in Indian limestone mines using neural networks. Journal of Rock Mechanics and Geotechnical Engineering, 6(5), 447–454.
Trivedi, R., Singh, T. N., & Raina, A. K. (2016). Simultaneous prediction of blast-induced flyrock and fragmentation in opencast limestone mines using back propagation neural network. International Journal of Mining and Mineral Engineering, 7(3), 237–252.
Vapnik, V. N. (1995). The nature of statistical learning. Theory.
Wang, M., Chen, H., Li, H., Cai, Z., Zhao, X., Tong, C., & Xu, X. (2017). Grey wolf optimization evolving kernel extreme learning machine: Application to bankruptcy prediction. Engineering Applications of Artificial Intelligence, 63, 54–68.
Wang, M., Shi, X., & Zhou, J. (2018a). Charge design scheme optimization for ring blasting based on the developed scaled Heelan model. International Journal of Rock Mechanics and Mining Sciences, 110, 199–209.
Wang, M., Shi, X., Zhou, J., & Qiu, X. (2018b). Multi-planar detection optimization algorithm for the interval charging structure of large-diameter longhole blasting design based on rock fragmentation aspects. Engineering Optimization, 50(12), 2177–2191.
Wang, S. M., Zhou, J., Li, C. Q., Armaghani, D. J., Li, X. B., & Mitri, H. S. (2021a). Rockburst prediction in hard rock mines developing bagging and boosting tree-based ensemble techniques. Journal of Central South University, 28(2), 527–542.
Wang, S., Jia, H., Abualigah, L., Liu, Q., & Zheng, R. (2021b). An improved hybrid aquila optimizer and harris hawks algorithm for solving industrial engineering optimization problems. Processes, 9(9), 1551.
Wang, X., Hosseini, S., Jahed Armaghani, D., & Tonnizam Mohamad, E. (2023). Data-driven optimized artificial neural network technique for prediction of flyrock induced by boulder blasting. Mathematics, 11(10), 2358.
Wang, X., Tang, Z., Tamura, H., Ishii, M., & Sun, W. D. (2004). An improved backpropagation algorithm to avoid the local minima problem. Neurocomputing, 56, 455–460.
Yagiz, S., Ghasemi, E., & Adoko, A. C. (2018). Prediction of rock brittleness using genetic algorithm and particle swarm optimization techniques. Geotechnical and Geological Engineering, 36(6), 3767–3777.
Yang, Z., Duan, H., Fan, Y., & Deng, Y. (2018). Automatic carrier landing system multilayer parameter design based on Cauchy mutation pigeon-inspired optimization. Aerospace Science and Technology, 79, 518–530.
Yari, M., Bagherpour, R., Jamali, S., & Shamsi, R. (2016). Development of a novel flyrock distance prediction model using BPNN for providing blasting operation safety. Neural Computing and Applications, 27(3), 699–706.
Ye, J., Koopialipoor, M., Zhou, J., Armaghani, D. J., & He, X. (2021). A novel combination of tree-based modeling and Monte Carlo simulation for assessing risk levels of flyrock induced by mine blasting. Natural Resources Research, 30(1), 225–243.
Zhang, H., Nguyen, H., Bui, X. N., Pradhan, B., Asteris, P. G., Costache, R., & Aryal, J. (2021). A generalized artificial intelligence model for estimating the friction angle of clays in evaluating slope stability using a deep neural network and Harris Hawks optimization algorithm. Engineering with Computers, 38, 1–14.
Zhang, H., Wu, S., & Zhang, Z. (2022a). Prediction of uniaxial compressive strength of rock via genetic algorithm—Selective ensemble learning. Natural Resources Research, 31(3), 1721–1737.
Zhang, W., & Goh, A. T. (2016). Multivariate adaptive regression splines and neural network models for prediction of pile drivability. Geoscience Frontiers, 7(1), 45–52.
Zhang, Y., Tang, J., Cheng, Y., Huang, L., Guo, F., Yin, X., & Li, N. (2022b). Prediction of landslide displacement with dynamic features using intelligent approaches. International Journal of Mining Science and Technology, 32(3), 539–549.
Zhou, J., Aghili, N., Ghaleini, E. N., Bui, D. T., Tahir, M. M., & Koopialipoor, M. (2020a). A Monte Carlo simulation approach for effective assessment of flyrock based on intelligent system of neural network. Engineering with Computers, 36(2), 713–723.
Zhou, J., Zhang, R., Qiu, Y., & Khandelwal, M. (2023a). A true triaxial strength criterion for rocks by gene expression programming. Journal of Rock Mechanics and Geotechnical Engineering. https://doi.org/10.1016/j.jrmge.2023.03.004
Zhou, J., Chen, C., Wang, M., & Khandelwal, M. (2021a). Proposing a novel comprehensive evaluation model for the coal burst liability in underground coal mines considering uncertainty factors. International Journal of Mining Science and Technology, 31(5), 799–812.
Zhou, J., Dai, Y., Du, K., Khandelwal, M., Li, C., & Qiu, Y. (2022a). COSMA-RF: New intelligent model based on chaos optimized slime mould algorithm and random forest for estimating the peak cutting force of conical picks. Transportation Geotechnics, 36, 100806.
Zhou, J., Dai, Y., Khandelwal, M., Monjezi, M., Yu, Z., & Qiu, Y. (2021b). Performance of hybrid SCA-RF and HHO-RF models for predicting backbreak in open-pit mine blasting operations. Natural Resources Research, 30(6), 4753–4771.
Zhou, J., Huang, S., & Qiu, Y. (2022b). Optimization of random forest through the use of MVO, GWO and MFO in evaluating the stability of underground entry-type excavations. Tunnelling and Underground Space Technology, 124, 104494.
Zhou, J., Koopialipoor, M., Murlidhar, B. R., Fatemi, S. A., Tahir, M. M., Jahed Armaghani, D., & Li, C. (2020b). Use of intelligent methods to design effective pattern parameters of mine blasting to minimize flyrock distance. Natural Resources Research, 29(2), 625–639.
Zhou, J., Dai, Y., Huang, S., Armaghani, D. J., & Qiu, Y. (2023b). Proposing several hybrid SSA—Machine learning techniques for estimating rock cuttability by conical pick with relieved cutting modes. Acta Geotechnica, 18(3), 1431–1446.
Zhou, J., Huang, S., Zhou, T., Armaghani, D. J., & Qiu, Y. (2022c). Employing a genetic algorithm and grey wolf optimizer for optimizing RF models to evaluate soil liquefaction potential. Artificial Intelligence Review, 55(7), 5673–5705.
Zhou, J., Huang, S., Tao, M., Khandelwal, M., Dai, Y., & Zhao, M. (2023c). Stability prediction of underground entry-type excavations based on particle swarm optimization and gradient boosting decision tree. Underground Space, 9, 234–249.
Zhou, J., Qiu, Y., Armaghani, D. J., Zhang, W., Li, C., Zhu, S., & Tarinejad, R. (2021c). Predicting TBM penetration rate in hard rock condition: A comparative study among six XGB-based metaheuristic techniques. Geoscience Frontiers, 12(3), 101091.
Zhou, J., Qiu, Y., Zhu, S., Armaghani, D. J., Li, C., Nguyen, H., & Yagiz, S. (2021d). Optimization of support vector machine through the use of metaheuristic algorithms in forecasting TBM advance rate. Engineering Applications of Artificial Intelligence, 97, 104015.
Zhou, J., Shen, X., Qiu, Y., Shi, X., & Khandelwal, M. (2022d). Cross-correlation stacking-based microseismic source location using three metaheuristic optimization algorithms. Tunnelling and Underground Space Technology, 126, 104570.
Zhou, J., Shen, X., Qiu, Y., Shi, X., & Du, K. (2023d). Microseismic location in hardrock metal mines by machine learning models based on hyperparameter optimization using Bayesian optimizer. Rock Mechanics and Rock Engineering. https://doi.org/10.1007/s00603-023-03483-0
Zhu, L., Zhang, C., Zhang, C., Zhou, X., Wang, J., & Wang, X. (2018). Application of Multiboost-KELM algorithm to alleviate the collinearity of log curves for evaluating the abundance of organic matter in marine mud shale reservoirs: A case study in Sichuan Basin, China. Acta Geophysica, 66(5), 983–1000.
Zou, T., & Wang, C. (2022). Adaptive relative reflection Harris Hawks optimization for global optimization. Mathematics, 10(7), 1145.
Acknowledgment
This research is partially supported by the National Natural Science Foundation Project of China (42177164) and the Distinguished Youth Science Foundation of Hunan Province of China (2022JJ10073). The first author was funded by China Scholarship Council (Grant No. 202106370038).
Author information
Authors and Affiliations
Corresponding authors
Ethics declarations
Conflict of Interest
The authors declare that they have no known competing financial interests or personal relationships that could have appeared to influence the work reported in this paper.
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Li, C., Zhou, J., Du, K. et al. Prediction of Flyrock Distance in Surface Mining Using a Novel Hybrid Model of Harris Hawks Optimization with Multi-strategies-based Support Vector Regression. Nat Resour Res 32, 2995–3023 (2023). https://doi.org/10.1007/s11053-023-10259-4
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11053-023-10259-4