
Abstract
A subset of Mayan languages feature “prosodic allomorphy,” a phenomenon involving morphological alternations at certain prosodic boundaries. In previous work, Henderson (2012) proposes that prosodic allomorphs in K’iche’ provide evidence for non-isomorphisms in the correspondence between syntax and prosody. In this paper, I argue against this view by building on a related extraposition analysis in Aissen 1992. I contribute novel data from prosodic allomorphy from two Mayan languages, Chuj and K’iche’, and show that upon further inspection, there is strong evidence for a syntactic analysis different from the one assumed in Henderson 2012. The new syntax leads to several predictions that are borne out, and crucially, does not force us to posit mismatches, allowing for a one-to-one correspondence between syntax and prosody. By taking apparent instances of mismatches as suggestive that the syntactic analysis must be revisited, the proposal aligns with work such as Steedman (1991), Wagner (2005, 2010), and Hirsch and Wagner (2015). Finally, I discuss how the proposal could be restated within phase theoretic approaches to the interface between syntax and phonology, concluding that Mayan prosodic allomorphy poses an interesting challenge for such accounts.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
Many approaches to the interface between syntax and prosody adopt the underlying assumption that prosodic phrasing and surface syntax show systematic non-isomorphisms (or mismatches) (e.g. Selkirk 1984, 1986, 2011; Beckman and Pierrehumbert 1986; Nespor and Vogel 1986; Truckenbrodt 1995, Henderson 2012; Ito and Mester 2013; Elfner 2012; Bennett et al. 2016; Clemens 2014, 2021). Mismatches can arise due to a confluence of factors, including universal eurythmic constraints on prosodic structuring (e.g. Nespor and Vogel 1986; Gussenhoven 1991; Tilsen 2011; Bennett et al. 2016), assumed universal properties specific to the way prosodic structure is built (e.g. the sense unit condition and the strict layer hypothesis, Selkirk 1984, 1986), or a pressure for prosodic domains to match the edges of syntactic phrases (e.g. edge-based accounts as in Selkirk 1986, 1995, Chen 1987; or match theory as in Selkirk 2011; Elfner 2012). Allowing mismatches in the correspondence between syntax and prosody is not without consequence, however; it implies that prosody is not necessarily a reliable tool for syntactic evidence.
Another family of accounts argues that there are no mismatches in the correspondence between syntax and prosody (e.g. Steedman 1991; Wagner 2005, 2010). Instead, apparent instances of mismatches are taken as evidence that something is wrong with the syntactic analysis, and that it should be revisited to accommodate the prosodic observations. Under such accounts, prosody can be viewed as a reliable tool to gain insight into the syntax.
The goal of this paper is to zoom in on a particular phenomenon, extant across a handful of Mayan languages, which has been previously argued to involve mismatches between syntax and prosody (Henderson 2012). I show, in the spirit of accounts that take prosody as a reliable tool for syntactic evidence, that a different account of the same phenomenon without mismatches is not only possible, but guides us to several correct predictions about the syntax of these languages. The main claim I put forward is that the alleged mismatches in Henderson 2012 arise because of an issue with the assumed syntax; upon further inspection, it becomes clear that the constituents which are at the source of the apparent mismatch have a different syntax, and that this new syntax no longer leads us to mismatches. The phenomenon at hand is “prosodic allomorphy” (also known as “phrase-final morphology”), well-documented across different Mayan languages (see e.g. Day 1973; Craig 1977; Maxwell 1982; Dayley 1985; Aissen 1992; Barrett 2007; Henderson 2012; Can Pixabaj 2015; Bennett 2016; Mateo Toledo 2017; Mateo Toledo and Mateo Pedro 2017). In languages which feature prosodic allomorphy, a set of morphemes are realized differently depending on their position in the sentence. The two languages of study are Chuj, a Q’anjob’alan Mayan language spoken in Huehuetenango, Guatemala and Chiapas, Mexico by roughly 70,000 speakers (Piedrasanta 2009, Buenrostro 2013); and K’iche’, a K’ich’ean language spoken in nine departments of Guatemala by approximately 900,000 speakers (Richards 2003, Can Pixabaj 2015).Footnote 1 K’iche’ is also the language of study in Henderson 2012.
The paper is structured as follows. In Sect. 2, I present the puzzle of prosodic allomorphy in K’iche’, and summarize Henderson’s (2012) solution to this puzzle. In Sect. 3, I provide a detailed description of prosodic allomorphy in Chuj. In Sect. 4, I develop an alternative proposal of prosodic allomorphy that builds on previous work by Aissen (1992), and which does not make use of mismatches between syntax and prosody. In Sect. 5, I provide several pieces of evidence from both Chuj and K’iche’ that support this alternative. Finally, in Sect. 6, I conclude by providing a discussion of how the proposal could be restated in terms of phases, concluding that Mayan prosodic allomorphy brings to light an interesting challenge for phasal accounts of prosody.
2 Henderson (2012): An account with mismatches
In this section, I provide the puzzle of prosodic allomorphy in K’iche’, as presented in Henderson 2012 (Sect. 2.1). I then summarize the analysis he proposes as a solution to this puzzle (Sect. 2.2).
2.1 The puzzle of prosodic allomorphy in K’iche’
Following observations in Mondloch 1978 and Larsen 1988, Henderson (2012) describes two sets of morphemes in K’iche’ that undergo morphological alternations at certain phrasal boundaries. One set of such morphemes include a class of CVC clitics, which only appear in their full CVC form in certain positions. This is the case, for example, with the question particle k’u(t) in (1) (note that there are many more reported cases of prosodic allomorphs in K’iche’, see e.g. Can Pixabaj 2015, Table 4.2):Footnote 2
-
(1)


As shown above, the question particle k’u(t) exhibits morphological alternations depending on its position in the clause. When it appears in sentence-final position (1a), it must be realized as k’ut; when it appears immediately before a direct object (1b), it must be realized in its shorter form as k’u.
In addition to the CVC clitics, Henderson (2012) describes a second class of morphemes subject to morphological alternations at the edge of certain phrases, “status suffixes,” which across Mayan are used to encode information about transitivity, aspect, and mood (Coon 2016; Aissen et al. 2017). These include the transitive status suffix (a harmonic vowel -V, glossed “tv”), and the intransitive status suffix (-ik, glossed “iv”). Examples of relevant alternations are provided below.
-
(2)


-
(3)


As shown above, both the transitive status suffix and the intransitive status suffix alternate with a null morpheme, represented as “-Ø” above. Following Henderson (2012), I assume that -Ø is an allomorph of both status suffixes.
Crucially, Henderson (2012) shows that CVC clitics and status suffixes are sensitive to the exact same boundaries, and thus form a natural class. In the rest of this paper, I refer to this class of morphemes as “prosodic allomorphs,” and refer to longer (or overt) forms of prosodic allomorphs as “long allomorphs,” and to the shorter (or covert) forms as “short allomorphs.”
Given the data from (1) to (3), one might wonder whether long allomorphs only appear in sentence-final position. However, as Henderson (2012) demonstrates with examples like the ones in (4), long allomorphs sometimes arise in other positions:
-
(4)


In the examples in (4), status suffixes are found in positions other than at the end of the sentence. In (4a), the transitive status suffix is found immediately before a complement clause. In (4b), the clause that forms the antecedent of the conditional ends with an intransitive status suffix. In (4c), the intransitive status suffix is found immediately before a because-clause (Henderson refers to these as “reason adjuncts”).
Given these facts, the following research question emerges: What conditions the presence of long allomorphs? In the next subsection, I summarize one possible answer to this question, put forth in Henderson 2012.
2.2 Henderson (2012): An account with mismatches
Henderson (2012) offers an edge-based account of the distribution of long allomorphs in K’iche’. Assuming prosodic hierarchy theory (see Selkirk 1984, 1986, 1995), a widely-assumed approach to prosody that posits that prosodic constituents are universally organized in domains of increasing sizes, he proposes that the following generalization accounts for the distribution of long allomorphs:
-
(5)


In other words, long allomorphs are governed by phonology: they are required to appear last within a certain prosodic domain, the intonational phrase (henceforth “ι-phrase”). Following Selkirk (1995), Henderson assumes four layers of hierarchically-ordered prosodic constituents (from largest to smallest):
-
(6)


As standard in prosodic hierarchy theory, the distribution of ι-phrases is itself determined via a syntax-prosody mapping algorithm, implemented as a set of Optimality Theory (OT) constraints (Prince and Smolensky 1993). The mapping algorithm provided in Henderson 2012 can be summarized as follows:Footnote 3
-
(7)


As Henderson notes, ι-phrases in K’iche’ are associated with independent phonetic cues, such as the presence of a high boundary tone at their right edge, a pattern that is replicated across several Mayan languages (DiCanio and Bennett 2018). For instance, Aissen (1992) notes the presence of a noticeable rise in intonation at the end of ι-phrases in the related Mayan languages Tsotsil and Popti’, except at the end of discourse segments (or “paragraphs”), where a fall in pitch is perceived. As Aissen further notes, ι-phrases are characterized by their ability to be immediately followed by a significant pause.
As Henderson shows, the proposal in (5), coupled with the syntax-prosody mapping algorithm in (7), can derive the vast majority of occurrences of long allomorphs in K’iche’ without mismatches. Assuming that full sentences are CPs, long allomorphs are predicted to arise in sentence-final position. That is, the end of a sentence will always correspond to the right edge of a CP, which will in turn always coincide with the right edge of an ι-phrase:
-
(8)


One of the fundamental hypotheses underlying prosodic hierarchy theory is the strict layer hypothesis, which maintains that prosodic phrasing is non-recursive (e.g. an ι-phrase cannot be dominated by another ι-phrase) (Selkirk 1984, 1986, 1995). With this assumption, the proposal in Henderson 2012 also derives the presence of long allomorphs before complement clauses.Footnote 4 Assuming that complement clauses surface as sisters to verbs, as schematized in (9b), the left edge of the complement clause triggers the presence of an ι-phrase boundary, as illustrated in (9c) (ι-phrase boundaries are represented with “∥”). Note that assuming the strict layer hypothesis is instrumental in deriving this pattern. Without it, the right edges of the ι-phrases corresponding to the matrix and embedded CPs would coincide at the end of the sentence. This is illustrated with the bracketing in (9a), where the right edges of the embedded CP and matrix CP coincide in the syntax. Since the placement of long allomorphs is determined by ι-phrase finality (see (5)), the strict layer hypothesis predicts two environments for long allomorphs in sentences with complement clauses—one immediately before the complement clause, and another at the end of the sentence:
-
(9)
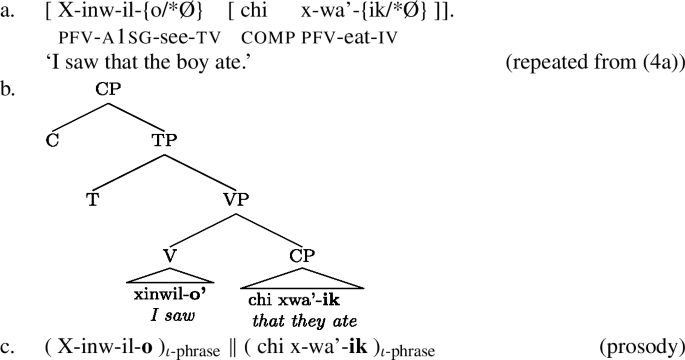

The result in (9c) is that there are two (non-recursive) ι-phrases, and so two environments for long allomorphs to arise. The presence of both status suffixes in (9) is therefore accounted for.
Though most of K’iche’ prosodic allomorphy is derived without appealing to mismatches, Henderson (2012) argues that an imperfect correspondence sometimes arises. Specifically, he argues that mismatches arise with structures like (10a), which according to the syntax-prosody mapping algorithm in (7) should lead to the prosody in (10b). However, in order to derive the appearance of the phrase-final -ik in (10a), we require the prosody in (10c).
-
(10)


This type of mismatch is argued to arise with because-clauses, which Henderson assumes involve a PP that selects for a clause and adjoins to VP:
-
(11)


In (11b), the word rumal ‘because’ heads a PP and takes a CP as complement. Given the mapping algorithm in (7), we expect there to be an ι-phrase boundary after the word rumal. However, based on the presence of the overt status suffix, we are required to posit an ι-phrase boundary before it:
-
(12)


There are two issues in (12). First, the algorithm in (7) underpredicts the ι-phrase boundary attested at the left edge of the PP, immediately before rumal. Second, the algorithm overpredicts an ι-phrase boundary to the left of the CP complement, immediately after rumal (Henderson 2012).
Henderson proposes to account for this apparent mismatch by appealing to a high-ranking markedness constraint in OT, seen in (13), which incurs a violation whenever a functional head is not parsed in the same prosodic constituent as its complement (see Werle’s 2004complement-ω, Clemens’s (2014, 2019) and Clemens and Coon’s (2018) argument-ϕ, and Richards’ (2016) selectional contiguity for similar constraints):
-
(13)


This constraint, based on the sense unit condition (Selkirk 1984, 1986), forces the functional item rumal to appear in the same phonological phrase as its complement, xinchakunik in (11) above. Since its complement is a CP, this means that rumal will have to be included as part of the ι-phrase of that CP, accounting for the observed mismatch.
Having reviewed the background empirical facts on K’iche’ prosodic allomorphs and an account of their distribution, I turn next in Sect. 3 to Chuj, another Mayan language, which possesses a set of morphemes that exhibit morphological alternations at the same clausal boundaries as the ones described for K’iche’ in Henderson 2012. The discussion of Chuj is important, since its inventory of prosodic allomorphs allows us to test predictions that would not be testable by only looking at K’iche’. In Sect. 4, I turn to an alternative account of prosodic allomorphy in both languages, and show that a different account that maintains an isomorphic relationship between syntax and phonology is not only possible, but leads to correct predictions about the syntax of these languages. In particular, we will see that there is independent evidence that the clauses that create the apparent mismatches in both Chuj and K’iche’ are located structurally much higher than previously assumed. Though my goal is not to show that mismatches are never possible, the overall conclusion will be that keeping with the underlying hypothesis that there are none can lead to important findings regarding the syntax.
3 Prosodic allomorphy in Chuj
Chuj, a Mayan language of the Q’anjob’alan branch, is distantly related to K’iche’. It closely patterns with K’iche’, however, in possessing a class of morphemes that are subject to prosodic allomorphy.Footnote 5 For instance, the Chuj cognates of the K’iche transitive and intransitive status suffixes, -V’ and -i, exhibit a strikingly similar distribution. Consider the two examples in (14), which are comparable to the examples given for K’iche’ in (3).
-
(14)


As shown above, the intransitive status suffix is overtly realized sentence finally in (14a), but is absent when immediately followed by the subject (14b) or an adverb (14c). As is common in Mayan languages (England 1991; Aissen 1992; Clemens and Coon 2018), Chuj verbs appear initially in discourse-neutral contexts, as in (14b), and the basic order of constituents is VOS (see (17c)).
Moreover, as seen for K’iche’ status suffixes in (4), Chuj transitive and intransitive status suffixes appear before complement clauses (15a), at the end of embedded clauses (15b), and before because-clauses (15c).
-
(15)


In the rest of this section, I provide a description of prosodic allomorphy in Chuj. I then provide empirical evidence that long allomorphs pattern with high-rising pitch contours. Finally, I show that Chuj’s large inventory of prosodic allomorphs allows us to observe another environment where long allomorphs are required: when last in a topicalized constituent.
3.1 The range of prosodic allomorphy in Chuj
To date, there has been no detailed description of prosodic allomorphy in Chuj (though clause-final allomorphy is reported since Hopkins 1967 and Maxwell 1982). Table 1 provides a list, likely not exhaustive, of prosodic allomorphs.
As seen in Table 1, Chuj prosodic allomorphy spans over a wide range of functional morphemes from different categories, including status suffixes, relational nouns, noun classifiers, a wh-word, and a dubitative mood marker. As in K’iche’, while some morphemes alternate with a null allomorph, others alternate with a “shorter” form. For reasons of exposition, and given Chuj’s large inventory of prosodic allomorphs, I only focus on two types of long allomorphs in the rest of this paper: status suffixes and so-called “noun classifiers,” described further below. However, data relevant to each category of morpheme affected by prosodic allomorphy is provided in the Appendix.
Though we have already seen Chuj examples with status suffixes in (14) and (15), we have not yet seen any examples with noun classifiers. Noun classifiers are used in Chuj to mark distinctions of definiteness (see Buenrostro et al. 1989, Royer 2019), and the choice of classifier depends on properties of the nominal referent (e.g. male human, female human, animal, wood, stone/metal, etc.) (see Craig 1986; Zavala 2000; Hopkins 2012; Royer 2017, 2019 on noun classifiers in Q’anjob’alan languages). Importantly, they can also appear without a noun, in which case they function as third person pronouns (henceforth “classifier pronouns”). Examples showing the pre-nominal and pronominal uses of the noun classifier ni(’o’), used with young male individuals, are provided below:Footnote 6
-
(16)


As shown above, the classifier can either appear pre-nominally as a determiner, or alone, as a classifier pronoun. Since the presence of an overt noun when the classifier functions as a determiner always blocks the long form from appearing, as in (16a), long allomorphs are only ever perceived when the classifier functions as a pronoun, as in (16b).
Additional examples of the pronominal usage of the classifier ni(’o’) are provided below in (17). As can be seen, the distribution of the long forms of classifier pronouns is dictated by the same factors as the ones observed for other prosodic allomorphs in Chuj and K’iche’.
-
(17)


As shown above, the long allomorph ni’o’ does not only appear sentence finally (see (16b)), but also when immediately followed by a complement clause, as illustrated in (17a), or by a because-clause, as in (17b). On the other hand, the presence of a nominal argument after the classifier pronoun, as in (17c), enforces the use of the short allomorph. These are exactly the same environments as the ones observed for alternations in status suffixes in Chuj in (14) and (15), and for prosodic allomorphs in K’iche’ in the previous section.
3.2 Prosodic correlates of long allomorphs
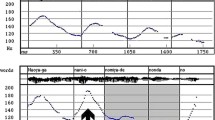
We now turn to the phonetic correlates of the boundaries associated with long allomorphs. In both Chuj and K’iche’, long allomorphs correlate with a peak of prominence, generally realized as a high-rising pitch contour. Similar high-rising pitch contours are reported at the end of clauses for various Mayan languages from different branches, independently of whether these languages feature prosodic allomorphy (see e.g. Hopkins 1967; Berinstein 1991; Bennett 2016, and DiCanio and Bennett 2018). This is illustrated in the pitch track in Fig. 1, which corresponds to the example in (18). As shown, the long form of ni(’o’) coincides with the realization of a high boundary tone at the end of the sentence.
-
(18)



Pitch track for (18)
Rising intonation is also observed immediately before complement clauses, as seen in Fig. 2, corresponding to example (19). Again, this correlates with the long form of ni(’o’) immediately before the complement clause.
-
(19)



Pitch track for (19)
Following Henderson (2012), I assume that the correlation between high boundary tones and long allomorphs is not an accident. That is, high prominence is an environment that triggers the presence of long allomorphs. Though I do not provide a full-fledged account here, readers are referred to Henderson 2012 for a specific proposal on how this allomorphy could be derived.
3.3 Topics and prosodic allomorphy
A subset of Chuj prosodic allomorphs (noun classifiers and relational nouns) provide evidence that long allomorphs are required in one additional environment: at the end of topicalized constituents. This environment is not identified in Henderson 2012.Footnote 7 Before providing the relevant data, it is important to mention that though basic constituent order in discourse-neutral contexts in Chuj is VOS, nominal arguments are routinely realized pre-verbally to mark topic and focus, allowing for a range of possible constituent order configurations (see e.g. England 1991 and Aissen 1992 on topic and focus in Mayan, and Bielig 2015 specifically on Chuj). Although both topics and foci appear pre-verbally (though see Sect. 5.1.3 for right-side topics), they exhibit two morphosyntactic differences. To illustrate, consider the following two examples:
-
(20)


In both of the examples in (20), the subject DP ix chichim ‘the elder’ appears pre-verbally. Both topics and foci are preceded by the marker ha, which I will gloss as “ha”. In the topic construction in (20a), the topicalized DP is obligatorily co-referential with a resumptive classifier pronoun in the main clause. Following Aissen (1992) and Bielig (2015), I assume that such topics are “external,” meaning that they are base generated in a high peripheral position, above the domain of the main clause.Footnote 8 In the focus construction in (20b), no resumptive classifier is found (nor allowed), and the extraction of transitive subjects forces the presence of Agent Focus morphology, -an, on the verb stem (see e.g. Stiebels 2006; Coon et al. 2014; Aissen 2017a and Coon et al. 2020 for more on Agent Focus). Following Aissen (1992) and Bielig (2015), I assume that, contrary to external topics, focused constituents arrive at their pre-verbal position via A’-movement to a position within the main clause. These different options are schematized below:
-
(21)


Now consider the example in (22), where a prosodic allomorph, ni(’o’), is found at the end of a topicalized constituent:
-
(22)


In (22), the long form of the classifier pronoun ni(’o’) is required as the last element in a DP that has been topicalized. Since this is a topic construction, the topic is obligatorily co-referential with a resumptive classifier pronoun in the main clause (Bielig 2015).
Focused classifier pronouns differ from topicalized ones in that they must appear as short allomorphs:
-
(23)


The fact that long allomorphs are required with topics, and short allomorphs are required with foci, fits particularly well with Aissen’s (1992, 2000) observations in other Mayan languages (Tsotsil, Popti’, Tz’utujil) that (external) topics must form their own ι-phrase, whereas foci must appear as part of the ι-phrase of the matrix clause (see also Bennett 2016 and England and Baird 2017 on “external” topics). This is schematized below in (24).
-
(24)


As (24) predicts, a high-rising pitch contour is generally found on the last syllable of topicalized constituents. This can be observed in the pitch track in Fig. 3, which corresponds to the example in (25).
-
(25)



Pitch track for (25)
3.4 Summary
This section described the range of prosodic allomorphy in Chuj. I showed that prosodic allomorphs affect a wide range of morphemes from different functional categories, and that they coincide with prominent high-rising pitch contours. I also showed that an additional environment, not present in K’iche’, licenses the presence of long allomorphs: topics. In the next section, we turn to an alternative account of prosodic allomorphy, which does away with the mismatch proposed in Henderson 2012. As we will see, topic constructions play an important role in motivating the proposal.
4 An account of prosodic allomorphy without mismatches
We now return to the principle research question addressed in this paper: What conditions the presence of long allomorphs? In Sect. 2.2, I summarized one possible answer to this question, put forth in Henderson 2012. Under this account, most instances of long allomorphs were straightforwardly derived via a one-to-one mapping from syntax to prosody. However, the proposal relied on the compromise that non-isomorphisms in the correspondence between syntax and prosody be sometimes tolerated. Specifically, there were times where the mapping algorithm predicted that a syntax like (26a) should output a prosody like (26b), but what actually obtained was the prosody in (26c).
-
(26)


To resolve this issue, Henderson proposed a constraint, complement-ϕ, which allowed the circumvention of mismatches like the one in (26) by forcing functional heads to appear in the same prosodic domain as their complement.
-
(27)


The upshot of tolerating mismatches, however, is that prosody cannot necessarily be viewed as a reliable tool for diagnosing syntactic structure.Footnote 9
In this section, I explore the possibility that prosody is, in fact, a reliable source of syntactic evidence, and show how an account of prosodic allomorphy that keeps to this premise could be formalized. In Sect. 5, I then show that there is strong evidence that this revised account is on the right track, since it leads to a number of syntactic predictions which are borne out. Important to mention at this juncture, however, is the fact that the alternative proposal put forth below remains compatible with one of the central insights in Henderson 2012 regarding the implications of prosodic allomorphy on the architecture of the syntax-phonology interface (see Henderson’s Sect. 4.3.2). Specifically, Henderson argues that prosodic allomorphy provides strong evidence for late-insertion theories of morphology (see e.g. Ackema and Neeleman 2003), since morphological insertion is sometimes sensitive to prosodic information (see also Hayes 1990 and Chung 2003). That is, prosodically-governed allomorphy, of the type found in Chuj and K’iche’, is not compatible with models of morphology such as Embick and Noyer (2001), which posit that morphological insertion takes place before prosodic structure is built. Since the alternative proposed here ultimately maintains, like Henderson (2012), a phonological account of prosodic allomorphy, it remains necessary for at least some prosodic information to be made available prior to morphological insertion. Though I will not discuss the determining factors behind the choice of allomorphic variants here, readers are referred to Henderson 2012, Sect. 4.2 and 4.3, where short and long forms of prosodic allomorphs are argued to be in a suppletive relationship.
My proposal follows that of Henderson (2012) in one crucial respect: I argue that prosodic allomorphy is a morphophonological phenomenon. As discussed in Henderson 2012, Sect. 3.1, one could try to formalize the distribution of long allomorphs syntactically, by making reference to CP edges. For example, long allomorphs could be argued to arise at the end of every CP.Footnote 10 However, there are good reasons to favour a phonological account. For one, in Chuj, long allomorphs can sometimes arise in positions other than ι-phrase boundaries (or apparent CP edges), in order to resolve illicit coda consonant clusters:
-
(28)


In both (28a) and (28b), the long forms of the status suffixes -i and -ok are forced to appear immediately before a noun and a manner adverb, where long allomorphs are usually forbidden (see e.g. (14c)). However, note that without the presence of the status suffix in each example, the verb would end with a coda containing a consonant cluster, which are categorically banned in Chuj (see Hopkins 1967, Coon 2019, and also Mateo Pedro 2011 and Mateo Toledo 2017 on Q’anjob’al). In this case, based on the syntactic structure, we expect the short form, but the phonology forces the appearance of the long form. This supports the premise that prosodic allomorphs are phonologically conditioned.
A purely syntactic account would face another issue: there are times where a syntactically present but phonetically null element is (arguably) found after prosodic allomorphs, but this does not block the long form from appearing. To illustrate, consider the Chuj example in (29b), where the internal argument cannot be overtly pronominalized, as opposed to (29a), where it can.
-
(29)


As seen above, the expression te’ onh ‘the avocado’ in the first conjunct of the sentence in (29a) can be referenced with the use of the classifier pronoun te’ in the second conjunct of the sentence. This is the case since, as discussed in Sect. 3, noun classifiers can be used to refer back to full DPs. However, in Chuj, a subset of nouns never appear with noun classifiers (Buenrostro et al. 1989; Royer 2019). This means that certain expressions, such as chocolate ‘chocolate’ in (29b), cannot be referenced with an overt pronoun. Assuming that null pronouns are nevertheless realized in the syntax, an account of prosodic allomorphs formalized solely on syntactic grounds would not predict the presence of a long allomorph in (29b). That is, the status suffix in (29b) does not occupy the last position in the CP, since the null pronoun follows it, and so a purely syntactic account would undergenerate instances of long allomorphs.
Given these data, I conclude that, as already argued in Henderson 2012, prosodic allomorphs must be conditioned by morphophonological factors. To capture the distribution of long allomorphs in Chuj and K’iche’, I therefore posit the following generalization:
-
(30)


While the second condition on the placement of long allomorphs accounts for data like the one in (28), where a long allomorph appears to resolve a consonant cluster, more needs to be said about the first condition in (30). Following the tradition in prosodic hierarchy theory (PHT) (Selkirk 1984, 1986, 2011), I adopt the term “intonational phrase boundary” to identify the prosodic boundary that tends to coincide with full (illocutionary) clauses (see Sect. 3.2). However, the account does not rely on the assumption made in PHT, and in Henderson 2012, that there exists an intermediate level of structure on which phonological processes apply (Selkirk 1984, 1986, 2011). That is, in PHT, phonological processes must apply to hierarchically-organized prosodic categories, themselves derived from designated syntactic constituents of different sizes (see Hale and Selkirk 1987 and Dresher 1994 on so-called “designated categories”). For instance, an ι-phrase would likely correspond to the level of the clause (Selkirk 1984), and would thus align with both the right and left edges of CPs. Under the current account, referring to both edges of constituents in the syntax is not needed—ι-phrase boundaries can be solely determined based on one position in the syntax, as proposed in (31).Footnote 11
-
(31)


The proposals in (30) and (31) permit the derivation of basic instances of long allomorphs. For instance, as illustrated below, long allomorphs are predicted to appear sentence finally, since the sentence-final position will always correspond to the end of a CP (ι-phrase boundaries are represented with “∥”).
-
(32)


These proposals, however, do not suffice to derive the occurrence of long allomorphs before complement clauses and clausal adjuncts, including because-clauses. In order to account for such occurrences, I propose that the assumed syntax in Henderson 2012 must be revisited. In particular, I propose, building on previous work by Aissen (1992), that complement clauses and clausal adjuncts (including because-clauses) appear in a position structurally much higher than assumed in Henderson 2012:
-
(33)


This syntactic generalization simply describes the proposal, which we will see strong evidence for in Sect. 5, that complement clauses and because-clauses appear extraposed above the matrix CP.Footnote 12 As schematized in (34), their high attachment ultimately forces the presence of an ι-phrase boundary between them and the last element in the matrix CP, as per (31).
-
(34)


The generalization in (33) straightforwardly accounts for the presence of long allomorphs immediately before complement clauses and clausal adjuncts. Since both types of constituents are guaranteed to fall outside the domain of the matrix CP, an ι-phrase boundary will always be found immediately before right-branching complement clauses and clausal adjuncts.
Crucially, this new syntax allows us to maintain a one-to-one correspondence between syntax and prosody. To illustrate this, recall that Henderson (2012) assumes that because-clauses like (35) adjoin to VP (for tree, see (11b)). Given Henderson’s syntax-prosody mapping algorithm, a mismatch of the type schematized in (12), repeated in (36), arises:
-
(35)


-
(36)


As previewed in Sect. 2.2, two issues arise. First, the algorithm (7) in Henderson 2012underpredicts the ι-phrase boundary to the left of rumal in (36a), since no boundary is expected in the absence of a CP boundary. Second, the algorithm overpredicts an ι-phrase boundary to the right of rumal, because the CP following rumal should induce an ι-phrase boundary. Henderson proposes to resolve the mismatch by resorting to a high-ranking constraint, complement-ϕ (13), which requires functional heads to be parsed in the same prosodic constituent as their complements.
The present proposal, on the other hand, derives the relevant prosodic boundaries without mismatches. That is, clausal adjuncts attach outside the domain of the matrix clause, and so an ι-phrase boundary is predicted to be found immediately before the because-clause. Furthermore, unlike the account proposed in Henderson 2012, the current account does not overpredict an ι-phrase boundary at the left edges of CPs, since ι-phrase boundaries are only proposed to appear at the right edges of CPs. The predicted structure for the K’iche’ utterance in (35) is thus (37):
-
(37)


The fact that clausal adjuncts may be derived without mismatches is a welcome consequence of the current account, since it allows us to maintain the hypothesis that prosody is a reliable diagnostic for syntactic constituency.
Finally, to account for the presence of long allomorphs after topicalized constituents (see (22) above) and other constituents that can surface in a position above the matrix CP, I argue that the generalization in (38), based on work by Wagner (2010, 2015), must universally hold:Footnote 13
-
(38)


The above generalization builds on previous work, which assumes that prosody reflects the relative attachment height of constituents in the syntax (see e.g. Chomsky and Halle 1968; Lehiste 1973; Cooper and Paccia-Cooper 1980, and Wagner 2005, 2010). That is, it has commonly been assumed that projections adjoined higher in the syntax must end with prosodic boundaries of greater or equal strength than the prosodic boundaries separating projections lower in the syntax (see e.g. Wagner 2015). The generalization in (38) thus derives the distribution of ι-phrase boundaries after constituents that adjoin above matrix CP, including topics, which as discussed in Sect. 3.3, have been independently argued to adjoin above this position (Aissen 1992; Bielig 2015).
In sum, the placement of the relevant prosodic boundaries under the current account is considerably simplified. ι-phrase boundaries are entirely derived by referring only to one position in the syntax, the right edge of CPs, and by an independently motivated feature of prosodic phrasing: monotonicity (Chomsky and Halle 1968; Lehiste 1973; Wagner 2010, a.o.). In Henderson 2012, on the other hand, it is crucial that ι-phrases map to both the right and left edges of CPs (see (7) above). Moreover, contrary to the current account, which remains neutral with respect to the recursive nature of prosody, the account in Henderson 2012 relies on the assumption that prosody is non-recursive (see example (9) above), an assumption that has been contested in recent work (see e.g. Truckenbrodt 1999; Wagner 2005, 2010; and Selkirk 2011; Elfner 2012).
Finally, before moving on, it is important to note that the components of the proposal in (30), (31) and (33) are very similar to those involved in Aissen’s (1992) analysis of a similar phenomenon in the related Mayan languages Popti’ and Tsotsil. In these languages, Aissen demonstrates that certain clitics can only appear in a certain set of environments in the sentence, identified as the edges of ι-phrases (like Chuj and K’iche’ prosodic allomorphs). The placement of ι-phrase boundaries is in turn derived via a syntax-prosody mapping algorithm, which based on work by Hale and Selkirk (1987) makes use of ungoverned maximal projections (Chomsky 1986):
-
(39)


The mapping proposed in this paper (31) is very similar to the one proposed in Aissen 1992 (39), in that ι-phrase boundaries are derived by making reference to the right edges of designated constituents in the syntax. For instance, in Aissen’s system, ι-phrase boundaries are predicted to appear sentence finally, since matrix clauses are always ungoverned. This is quite similar to the claim in this paper that ι-phrase boundaries appear sentence-finally, since that position corresponds to the end (or right edge) of a CP.
Furthermore, as in the current proposal, the proposal in Aissen (1992) relies on the extraposition of complement clauses and clausal adjuncts to derive the correct placement of ι-phrase boundaries (see Sect. 3.2.2. of Aissen 1992 for details of the account). The only point of divergence between the extraposition in Aissen 1992 and the one proposed here is the attachment height. Aissen (1992) proposes that complement clauses and clausal adjuncts extrapose to the specifier of the projection within which they originated (i.e. to the specifier of VP) (see Chomsky 1986, based on Ross 1967 and Baltin 1978 on the “right roof constraint”). In the current account, on the other hand, complement clauses and clausal adjuncts extrapose above the matrix CP. As we will see in the next section, there is evidence favouring the current account.
5 Evidence for an extraposition account
Having introduced the core components of the proposal, we turn to the empirical evidence in favour of an extraposition account. In particular, I show that the components of the proposal in (30), (31), (33), and (38), repeated together in (40), successfully derive the distribution of prosodic allomorphy in both Chuj and K’iche’ without the need for mismatches.
-
(40)


In Sects. 5.1 and 5.2, I provide evidence from both Chuj and K’iche’ that shows that the proposal in (40) makes a number of correct predictions about the syntax of complement clauses (Sect. 5.1) and clausal adjuncts (Sect. 5.2) in both languages—predictions which do not necessarily follow from the account in Henderson 2012. In Sect. 5.3, I provide additional empirical data in support of the extraposition account.
5.1 Evidence for the high attachment of complement clauses
5.1.1 Word order
One straightforward piece of evidence supporting the high attachment of complement clauses comes from word order. Both K’iche’ and the variants of Chuj under study exhibit basic VOS word order (Maxwell 1982; Kaufman 1990; Buenrostro 2013; Clemens and Coon 2018). Relevant examples are provided in (41), for Chuj, and (42) for K’iche’.
-
(41)


-
(42)


For both languages, however, there is a crucial exception to VOS: postverbal complement clauses must follow the subject, as shown in (43) and (44). Importantly, apart from their relative position in the sentence, complement clauses behave like regular (DP) objects of transitive verbs insofar as the subject is marked ergative (Set A marking), the verb appears with the transitive status suffix -V’, and no overt Set B (absolutive) marking is expected, since third person singular absolutive is always null in both languages.
-
(43)


-
(44)


This difference in word order between DP and CP objects is well documented across Mayan languages that exhibit VOS word order (see e.g. Craig 1977; Aissen 1992, 2000, 2017b), and Henderson (2012) also acknowledges the fact that complement clauses must surface after the subject (see p. 762-763). However, Henderson dismisses a right extraposition account on the basis of examples with maximal free relatives, such as (45):
-
(45)


Such examples would indeed be a challenge for an account that relies on extraposition. In the examples in (45), there is no evidence (from word order at least) that free relatives in K’iche’ can extrapose—since Henderson claims that they must appear before the subject—yet the presence of the status suffix immediately before the free relative is still required. That being said, my attempts at corroborating these judgments have failed, and the K’iche’ speakers I have consulted have all judged the example in (45a) as ungrammatical. Moreover, Can Pixabaj (2020), in recent work on free relatives in K’iche’, excludes this type of construction as a possible free relative. According to Can Pixabaj (2020, p. 274) “all wh-expressions in [maximal free relatives] need to be immediately followed by one of the definite determiners,” which is not the case in (45a).Footnote 14 Future work should therefore establish whether example pairs like (45) truly challenge the analysis proposed here.Footnote 15
The crucial point, however, is that obligatory VSO order with object complement clauses is a welcome syntactic prediction of the current proposal. If complement clauses occupy a position outside the domain of the matrix CP, as per (33), then they are predicted to appear after the subject, as schematized in (46). As made salient in this structure, I assume, based on observations to be discussed in Sect. 5.1.3, that complement clauses are base-generated in their surface position, and are co-referential with a null resumptive pronoun (Mayan languages do not have overt CP proforms).
-
(46)


5.1.2 The relative position of adverbs
A second piece of evidence favouring an extraposition account comes from the relative ordering of complement clauses and adverbs. If complement clauses occupy a high peripheral position, as proposed here, then we predict that they should obligatorily appear after VP-level adjuncts, such as junelxo ‘again’. This prediction is borne out, as shown by the Chuj examples in (47).
-
(47)


As seen above, complement clauses must follow VP-level adverbs such as junelxo ‘again’. The presence of the adverb after the complement clause, as in (47b), would force a reading in which it is interpreted as modifying the verb inside the complement clause, which in this case leads to infelicity (as this utterance would be describing the improbable rebirth of a baby).
Note that higher adverbs, such as temporal adverbs, must also be positioned before complement clauses, as seen in the examples in (48).
-
(48)
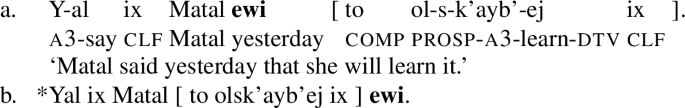
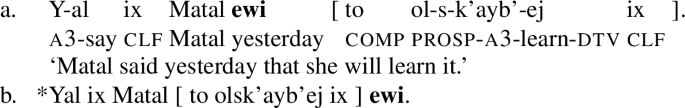
Though the data in (48) remain compatible with the claim that complement clauses are base-generated high, it does not immediately follow that temporal adverbs such as ewi ‘yesterday’ should be banned from appearing after complement clauses. Temporal adverbs across languages can often be topicalized (e.g. English (as for) yesterday, I bought a book). Future work should establish whether other factors could influence the relative position of adverbs and complement clauses in Chuj and K’iche’, such as language-specific properties of the relevant adverbs, or independent conditions on prosodic heaviness.Footnote 16
5.1.3 Parallels with topics
Another strong piece of evidence in favour of the syntax proposed in (33) comes from certain parallelisms observed between right-side topics and complement clauses. Though all of the evidence I present here come from Chuj, the parallelisms might also apply to K’iche’, which features similar topic constructions (England 1997; Can Pixabaj 2004; Can Pixabaj and England 2011).
With a few exceptions (Can Pixabaj 2004; Curiel 2007; Polian 2013), most of the literature on topicalization in Mayan has focused on left-side topics. However, under certain circumstances, Chuj also allows the presence of right-side topics. Examples are provided below:
-
(49)


-
(50)


These two examples show all of the basic properties of topics discussed in Sect. 3.3.Footnote 17 Both must appear with the marker ha, and both are co-referential with a resumptive classifier pronoun in the matrix clause. Building on Aissen 1992 and Bielig 2015, I assume that right-side topics, like left-side topics (see Sect. 3.3 above), are “external topics.” According to the criteria established in Aissen 1992, this means that they must (i) be base-generated above the matrix CP, (ii) be co-referential with a resumptive pronoun, and, crucially, (iii) form their own ι-phrase. There is overt evidence supporting all of these facts. For instance, as shown in (50), resumptive classifier pronouns are also obligatory with right-side topics. Moreover, as also seen in this example, long allomorphs are forced to appear immediately before right-side topics: only the long form of ni(’o’) is possible. This suggests that right-side topics are excluded from the domain of the ι-phrase of the matrix CP, as schematized below:
-
(51)


Consider now a different example, (52), where the verb lies immediately to the left of a right-side topic. This forces the presence of another kind of long allomorph—the transitive status suffix—immediately before the DP topic:
-
(52)


In (52a), the topicalized DP appears with the marker ha, but contrary to (51), it is not co-referential with an overt classifier pronoun in the matrix clause. As previously mentioned in Sect. 4, such examples can arise because not all Chuj nouns have a corresponding noun classifier. This the case with ib’ ‘strength’, which cannot be overtly pronominalized.
It is with examples like (52a) that a parallel between complement clauses and DP topics reveals itself. Recall from example (15a), repeated below, that status suffixes are also required before complement clauses:
-
(53)


Under the current proposal, the parallel between DP topics and complement clauses is expected: both are positioned above the matrix CP, represented here as adjuncts to CP. As schematized in (54), complement clauses (when immediately following verbs) pattern like topicalized DPs, and unlike in situ DPs, in triggering the obligatory presence of a status suffix (ss) on the verb.
-
(54)


Given (54), I assume that complement clauses are base-generated high, and like DP topics, co-refer with a null resumptive pronoun in the main clause:Footnote 18
-
(55)


Finally, if right-side topics and complement clauses are parallel in adjoining as adjuncts above the main CP, it is interesting to consider utterances containing both a complement clause and DP topic. Though such utterances are uncommon in narratives, speakers have no problem allowing them in elicitation, as demonstrated by the acceptability of both utterances in (56).
-
(56)


The examples in (56) offer crucial information. First, notice that in both examples, there is a total of three environments in which long allomorphs are licensed: (i) immediately to the left of the right-side topic; (ii) between the topic and the complement clause, and (iii) at the end of the sentence. This is exactly what the current account predicts. As per (38), ι-phrase boundaries should appear on each of the projections that adjoin above the matrix CP:
-
(57)


The examples in (56) provide a second important piece of information: that complement clauses and DP topics can be freely ordered with respect to each other. This is compatible with an analysis in which complement clauses are adjoined above the CP (like the current account), but it is not compatible with accounts that place complement clauses in structurally lower positions. This not only includes Henderson 2012, where complement clauses surface as sisters to the verb, but also Aissen 1992, where extraposed complement clauses adjoin to a lower position in the structure.
5.1.4 Summary
The alternative account of prosodic allomorphs proposed in (40) involved changes regarding our assumptions about the syntax of complement clauses, namely that they occupy a much higher position in the syntax than previously assumed. The new syntax, which does not force us to posit mismatches between syntax and prosody, led us to a number of predictions regarding the behaviour of complement clauses, which were all shown to be borne out. These syntactic observations, none of which immediately follow from the syntax assumed in Henderson 2012, are summarized in Table 2.
5.2 Evidence for the high attachment of clausal adjuncts
We now turn to a central point of divergence between Henderson 2012 and the current proposal: whether because-clauses in Chuj and K’iche’ serve as evidence for a syntax-prosody mismatch. Recall that long allomorphs appear immediately before because-clauses. The relevant examples are repeated below.
-
(58)


As already noted for K’iche’ in Sect. 2.2, because-clauses in both languages are headed by “relational nouns,” which agree in person and number with their complement. Agreement is realized by the same Set A morphology found with ergative and possessor DPs, always formally third person singular with clausal adjuncts. Following Henderson (2012), I assume that in their use as subordinating conjunctions, the relational nouns -umal in K’iche’ and -oj in Chuj appear in a functional projection and select for a CP. In Chuj, as seen in (58b), the morphosyntactic composition is transparent: both the relational noun yoj ‘for’ and the complementizer to get realized.Footnote 19 Though I follow Henderson in labelling the projection containing the relational noun as a PP, the exact categorical status is not important for the arguments that follow.
Recall that Henderson (2012) assumes a syntax where because-clauses adjoin to VP (see structure in (11b) above). This leads to a mismatch, since the ι-phrase boundary before the subordinating conjunction rumal ‘because’ is not expected. In contrast, the present proposal posits that clausal adjuncts in Chuj and K’iche’ always exhibit the syntax in (59). Since clausal adjuncts (including because-clauses) attach outside the matrix clause, an ι-phrase boundary is predicted to be found immediately before the because-clause:
-
(59)


In what follows, I discuss the predictions of the proposal in (59), and show evidence from both Chuj and K’iche’ that these predictions are borne out. Before moving on, however, note that the syntax in (59) and the predictions that follow from it do not only apply to because-clauses, but to all clausal adjuncts in Chuj and K’iche’. To my knowledge, all clausal adjuncts (e.g. while-clauses, if-clauses, and other clauses headed by subordinating conjunctions) pattern syntactically with because-clauses, as corroborated by the fact that long allomorphs are required before them. An example with a clausal adjunct introduced with wach’xom ‘although’ is provided below.
-
(60)


5.2.1 Position of clausal adjuncts relative to DP topics and CP complements
A first piece of evidence supporting the structure in (59) comes from the position of clausal adjuncts with respect to topicalized constituents and complement clauses. In Chuj, clausal adjuncts are judged more natural when they appear after topics, rather than before them:
-
(61)


The same facts are observed with complement clauses. As shown in (62), speakers prefer placing clausal adjuncts after complement clauses (62a), and dislike the opposite configuration (62b):
-
(62)


In Sect. 5.1.3, we saw that DP topics and complement clauses occupy peripheral positions outside the matrix CP. Therefore, the judgments reported above suggest that clausal adjuncts occupy a very high position in the syntax, attaching above complement clauses and topicalized constituents. This is schematized in the structure in (63) for the Chuj sentence in (61).Footnote 20
-
(63)


The current proposal, which posits that clausal adjuncts adjoin outside the matrix CP, is completely compatible with the facts detailed above.
5.2.2 K’iche’ adjunct extraction
A second piece of evidence is specific to K’iche’. The evidence comes from the appearance of a special particle, wi(h), which appears in a subset of K’ichean languages when certain adjuncts are extracted (see e.g. Velleman 2014; Can Pixabaj 2015; Mendes and Ranero 2021). An example is provided in (64), where an instrument adjunct is extracted in order to form a wh-question:
-
(64)


In (64), the extraction of the instrument adjunct jas ruuk’ ‘with what’ triggers the obligatory presence of the particle wi(h) in its base position. This is also the case with other (low) adjuncts in K’iche’, including locatives, comitatives, and prepositional datives (for similar facts in Kaqchikel, see Henderson 2008).
But as discussed in Mendes and Ranero (2021) and previous work, not all cases of adjunct extraction trigger wi(h). In particular, a set of high adjuncts, which in K’iche’ include temporal and clausal adjuncts, never trigger wi(h). This is illustrated below in (65), with the extraction of the wh-word jacha’ ‘why’, which I assume is the interrogative equivalent of a because-clause.
-
(65)


Under the current account, the absence of wi(h) above can receive a rather straightforward explanation. Clausal adjuncts never trigger this particle, since they are base-generated high and thus never undergo extraction.
5.2.3 Ordering with respect to other adjuncts
A final piece of evidence supporting the proposal comes from the relative ordering of clausal adjuncts with respect to other adjuncts. That is, if clausal adjuncts attach high, then it follows that they should obligatorily appear after VP-level adjuncts, or any other higher non-clausal adjuncts for that matter. As shown in (66), this prediction is borne out.
-
(66)


The context in (66) forces an interpretation in which the PP adjunct must modify the matrix verb—one in which the buying happened in Nentón, but the asking in Mexico. As shown by the infelicity of (66b), the only way for this interpretation to arise is if the PP adjunct appears before the because-clause. These facts follow from the current proposal: by being base-generated high, clausal adjuncts should appear after other non-clausal adjuncts.
5.2.4 Summary
In order to maintain an isomorphic relationship between syntax and prosody, I proposed that clausal adjuncts exhibit a different syntax than the one assumed in Henderson 2012, one in which they adjoin above the matrix CP. In this section, I provided empirical evidence, summarized in Table 3, supporting this proposal. The account in Henderson 2012, on the other hand, is not immediately compatible with any of these empirical observations.
5.3 Additional arguments from Chuj
Having provided evidence that complement clauses and clausal adjuncts appear in a high peripheral position in Chuj and K’iche’, I now provide four additional arguments, specific to Chuj, that independently support the proposal in this paper. In Sects. 5.3.1 and 5.3.2, I show that Chuj long allomorphs are optional before certain types of constituents, and that this optionality receives a straightforward explanation under the current proposal. I then show in Sect. 5.3.3, that the different proposals diverge on one prediction related to relative clauses, and that the current proposal makes the right prediction. Finally, in Sect. 5.3.4, I argue that complement-ϕ, instrumental in deriving long allomorphs in Henderson 2012, cannot be high-ranked in Chuj.
5.3.1 Optionality in the attachment height of PPs
In Chuj, long allomorphs are optional immediately before regular PP adjuncts:
-
(67)


As seen above, consultants judge the presence of both short and long allomorphs acceptable immediately before PP adjuncts, an optionality that can also be observed in Chuj texts. Importantly, PP complements do not exhibit this optionality; long allomorphs do not appear before PP complements:
-
(68)


An analysis that resorts to different syntactic configurations as the determining factor in the realization of ι-phrase boundaries can explain this optionality. We must simply allow Chuj PP adjuncts to adjoin either to the VP, in which case no long allomorph is predicted, or above the CP, in which case a long allomorph is predicted (for similar extraposition facts in English, see e.g. Stowell 1981 and Neeleman and Payne 2020). Optionality in attachment height correctly predicts that there should be two possible prosodic parses of the utterance in (67), depending on the attachment height of the PP adjunct. If the PP attaches low (69a), we predict only one ι-phrase boundary; if it attaches high, we predict two ι-phrase boundaries (69b). While the former option blocks the long allomorph from appearing, the latter option will enforce it.
-
(69)
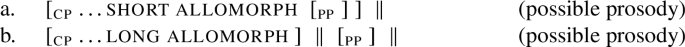
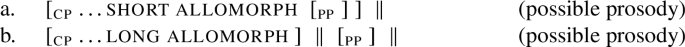
K’iche’ does not appear to exhibit variability in the attachment height of PP adjuncts, and neither Henderson (2012) nor Can Pixabaj (2015) describe the position preceding PP adjuncts as a position in which long allomorphs may appear. But the current argument is not dependent on this datapoint. A reasonable possibility could be that Chuj and K’iche’ are different, in that the former allows optional PP extraposition, whereas the latter does not.
A question that remains is why extraposition of PP adjuncts in Chuj is optional, whereas extraposition of CP adjuncts is obligatory. Though a detailed discussion of this question falls outside the scope of this paper, note that variability in extraposition possibilities seems highly language-dependent, even across different Mayan languages. For instance, Aissen (1992) describes the optional extraposition of CP adjuncts in another Mayan language, Tsotsil. The relevant examples are provided below:
-
(70)


In (70a), the Tsotsil clausal adjunct k’alal lilok’otkotik ‘when we left’ appears extraposed in a position following the subject, enabling the appearance of the prosodically-conditioned clitic un immediately before it. Importantly, un has the same distribution as the prosodic allomorphs discussed in this paper, and Aissen (1992) argues that it can only appear at the right edge of ι-phrases. In (70b), on the other hand, the clausal adjunct appears before the subject, which Aissen (1992) argues indicates it has not extraposed. In this case, the prosodically-governed enclitic un cannot appear before the clausal adjunct.
This is not a possibility in Chuj, where similar clausal adjuncts must appear extraposed in a position following the subject:
-
(71)


In sum, these data suggest that extraposition of different constituent types can be variable across languages, even fairly closely-related languages like Chuj, K’iche’, and Tsotsil. Future work should establish whether this variability can be explained given independent properties related to these languages.
5.3.2 Maximal free relatives
A second type of optionality is observed with maximal (or definite) free relatives in Chuj, which can be optionally preceded by short or long allomorphs:
-
(72)


In previous work on Chuj, Kotek and Erlewine (2016, 2019) and Royer (2020) follow Caponigro (2003, 2004) in analyzing maximal free relatives as CPs with a covert DP layer. Maximal free relatives contrast with existential (or indefinite) free relatives, which lack this covert DP layer.
The optionality of long allomorphs before free relatives is compatible with the account put forth here. In fact, recall from Sect. 5.1.3 that Chuj DPs can be optionally generated as right-side topics. If maximal free relatives have a covert DP layer, as proposed in previous work, then their ability to optionally extrapose follows from the fact that, like other DPs, they can be generated in right-side topics.Footnote 21 Interestingly, existential free relatives, which have been argued to lack a covert DP layer, cannot be preceded by a long allomorph:
-
(73)
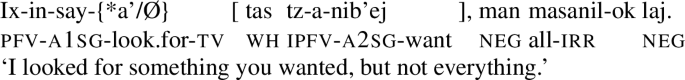
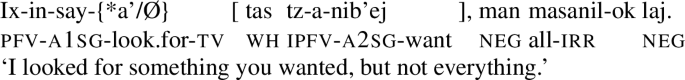
The above data suggest that existential free relatives cannot extrapose. Though I leave the details of this contrast for future work, one possibility is that existential free relatives are required to stay low for compositional reasons: to receive an existential interpretation, they must denote predicates that combine directly with the verb through Predicate Modification (Caponigro 2003, 2004), thereby preventing extraposition to a higher syntactic position.
5.3.3 Relative clauses and an overprediction in Henderson (2012)
The account in Henderson 2012 and the current account make a diverging prediction regarding relative clauses. Recall that Henderson derives the distribution of ι-phrase boundaries by making reference to alignment constraints that target both the left and the right edges of CPs. Targeting the left edge of CPs was especially important to derive the presence of long allomorphs before complement clauses, which would otherwise not be predicted. Assuming relative clauses are CPs, this account predicts that an ι-phrase boundary should be found between the head and the rest of a relative clause, as in (74b).
-
(74)


In contrast, the current proposal does not make this prediction: ι-phrase boundaries are solely derived by making reference to the end of CPs. Therefore, no ι-phrase boundary is predicted after the head of a relative clause:
-
(75)


Though these different predictions are difficult to test in K’iche’, since K’iche’ does not have prosodic allomorphs that can instantiate the head of a relative clause, a subset of prosodic allomorphs in Chuj can: classifier pronouns. As shown in (76), only the short allomorph ni can appear as the head of a relative clause, and not its long allomorph counterpart ni’o’:
-
(76)


These Chuj data thus support the prediction made here that long allomorphs should be illicit after the head of a relative clause. Also note that the lack of ι-phrase boundaries before relative clauses, as opposed to complement clauses, was also noted in Aissen 1992 for the related Mayan languages Popti’ and Tsotsil, which I take as further evidence in favour of the current account.
5.3.4 Complement- ϕ cannot be a high-ranking constraint in Chuj
Recall that the proposal in Henderson 2012 relies on the existence of a high-ranking constraint, complement-ϕ, which requires functional heads to be parsed together with their complements. This constraint is responsible for the absence of an ι-phrase boundary between the subordinating conjunction rumal ‘because’ and the CP that it takes as a complement, which is otherwise expected (see example (12) above). Ranking this constraint high in Chuj, however, would lead to clear undergeneration issues. Though functional heads, such as prepositions and complementizers, are often parsed together with their complements, it is not hard to find examples in which they are not (assuming, as standard, that prosodic breaks are a diagnostic for prosodic boundaries). Consider, for instance, the naturally-occurring example in (77), where a prosodic boundary (represented with “∣”) is found between the preposition t’a and its nominal complement frontera chi’ ‘the border’.
-
(77)


A pitch track for (77) is provided in Fig. 4. As seen, the preposition t’a (realized with a voiced stop as [da]) and its complement are separated by a considerable prosodic break, in apparent violation of complement-ϕ.Footnote 22 Note that the prosodic break in (77) is likely caused by a prosodic boundary other than an ι-phrase boundary, since high-rising pitch contour, the characterizing trait of ι-phrase boundaries, is not found on the preposition.

Pitch track for (77)
Importantly, the prosodic break in (77) is not obligatory. As is common with prosodic breaks, there is variation in whether speakers produce them, a fact which is compatible with the current account. It is not clear, however, how such variation can be captured by accounts that rely on the high-ranking of constraints like complement-ϕ, which without further stipulation, predict that configurations like (77) should be altogether banned.
Another example is provided in (78). This time, a prosodic break is found between the complementizer to and the rest of the CP. As shown in the pitch track corresponding to this example in Fig. 5, speakers can produce a considerable prosodic break between a complementizer and the rest of the CP.
-
(78)



Pitch track for (78)
In sum, these examples show that, at least in Chuj, complement-ϕ is likely not a high-ranking constraint. In this language, speakers routinely produce prosodic breaks between functional heads and their complements. Assuming that the distribution of Chuj and K’iche’ prosodic allomorphs is governed by similar factors, the above data cast doubt on the pivotal role of this constraint in Henderson 2012, offering additional support for an alternative account.
Note that my proposal does not immediately account for data like (78), where the complementizer is parsed in the same prosodic domain as the elements in the matrix clause. If complement clauses always extrapose to a position above the matrix CP, then why can the complementizer sometimes be parsed as in (78)? Though I leave this question for future work, there are several possible avenues to explore. One possibility could be that complement clauses are base generated low, and TPs can sometimes extrapose alone, stranding the complementizer in its base position. Another possibility could be that complementizers are prosodic clitics, which are optionally prosodified with a preceding or following prosodic domain. Evidence for the latter possibility comes from the observation that complementizers do not block the presence of long allomorphs, as in (79). Moreover, Fig. 6 shows that when the complementizer prosodifies with the preceding clause, the high-rising pitch contour is exceptionally produced on the penultimate morpheme of that clause.
-
(79)



Pitch track for (79)
Since, as shown above, the complementizer is ignored in determining the placement of ι-phrase boundaries and its conditioning effects on prosodic allomorphy, I conclude that an account that treats the complementizer as a prosodic clitic independent of the prosodic domain of the matrix clause should be favoured over one that recourses to TP extraposition. I leave a formal implementation of the above observations for future work.
6 Discussion
6.1 Summary and future work
In this paper, I provided an alternative account of prosodic allomorphy in two Mayan languages: Chuj and K’iche’. The alternative proposal assumed a one-to-one correspondence between syntax and phonology, and derived the distribution of prosodic allomorphy without resorting to mismatches. Throughout the paper, the strategy was to take prosody as a reliable tool for syntactic evidence. By doing so, we were guided to interesting predictions about the syntax of Chuj and K’iche’, which were all shown to be borne out. In other words, by taking prosody seriously as syntactic evidence, certain syntactic aspects of Chuj and K’iche’—that may have otherwise gone unnoticed—were revealed. This is expected if certain types of mismatches are in fact impossible, and apparent instances of mismatches serve as evidence that the syntactic analysis must be revisited (Steedman 1991; Wagner 2010; and Hirsch and Wagner 2015). Though I have by no means presented evidence that non-isomorphisms are never possible, I believe that the most interesting hypothesis should always be that there are none. Doing so can lead to important findings relevant to the way syntax works and allows us to consider prosody as a reliable tool for syntactic evidence.
Going back to the larger syntax-phonology question, I have argued for a generalization of the distribution of long allomorphs that is much closer to syntax than the one proposed in Henderson 2012, and more similar to the line of argument taken in Aissen 1992 on similar phenomena in other Mayan languages. This raises the possibility that the distribution of long allomorphs is purely syntactic, contrary to Henderson 2012. At the very beginning of Sect. 4, however, we saw an argument in favour of a prosodic analysis. That is, phonotactic factors can also result in the placement of long allomorphs, in particular when their absence would result in a consonant cluster in coda position (see (28) above). Moreover, a positive consequence of maintaining a prosodic analysis is that it leaves intact Henderson’s (2012) arguments in favour of late-insertion theories of morphology.
There remains a lot of potential for future work. For one, the proposal reveals many interesting properties of complement clauses and clausal adjuncts in these two Mayan languages (and potentially across other Mayan languages): that they occupy a very high position in the syntax. I have remained silent about why these facts hold, but future work should explore this question further. For instance, it is conceivable that complement clauses extrapose for semantic reasons, as argued in Moulton (2009, 2015). In fact, Coon (2019) and Coon and Royer (2020) recently argued that verbal roots in Chuj require semantic saturation with an argument of type e. But CPs are usually analyzed as propositions (sets of possible worlds) or as predicates with propositional content, of type 〈e, 〈s,t〉〉 (see e.g. Hintikka 1969, Kratzer 2006, and Moulton 2015). Under the current proposal, I argue that CPs show a number of parallels with DP topics, which are obligatorily coindexed with a resumptive pronoun in their base position. If CPs, like DP topics, are coindexed with a null pronoun of type e, then this would provide the verb with an argument of the right type to compose. This could be one possible explanation for the obligatory extraposition of complement clauses.
Another area of future work concerns the adaptability of the current proposal to independent proposals on the syntax-phonology interface. I provided an account of prosodic allomorphs that derives their distribution entirely from surface syntax: long allomorphs appear at ι-phrase boundaries, which in turn arise at the end of every CP. In other words, the current account derives the placement of the relevant prosodic boundaries by making direct reference to the edges of certain syntactic constituents. At the same time, many recent approaches to the interface between syntax and prosody assume that syntactic structure—and transfer from syntax to the interfaces—proceeds in cycles (Uriagereka 1999; Chomsky 2001, 2008; Seidl 2001; Dobashi 2003, 2013; Kahnemuyipour 2005; Wagner 2005, 2010; Adger 2007, Kratzer and Selkirk 2007; Pak 2008; Newell 2008; Selkirk 2009, a.o.).Footnote 23 It is interesting to consider, then, how the account could be reformulated to derive ι-phrase boundaries, and by extension the distribution of long allomorphs, in terms of cyclic spell-out domains. In the remaining subsection, I provide a short discussion of how the current account could be reformulated in such terms. As we will see, prosodically-conditioned allomorphy sensitive to large prosodic domains, such as Mayan prosodic allomorphy, cannot be straightforwardly accounted for with standard phase theoretic assumptions, bringing to light an interesting challenge to standard phasal accounts of the transfer from syntax to phonology.
6.2 A cyclic account?
Recall that one of the factors triggering the presence of long allomorphs described above is the end (or right-edges) of CPs, which correspond to ι-phrase boundaries in phonology. To derive this generalization with a cyclic account, we could simply assume that prosodic boundaries arise at the end of every cyclic spell out domain, as in (80). Notice that this kind of account would enable us to avoid having to refer to CPs in deriving the generalization about the placement of prosodic boundaries, since there is no reference to any syntactic phrase in (80).
-
(80)


If (80) is a strict phonological rule that always takes place in both languages, it is possible to derive the distribution of long allomorphs with the two phonological conditions in the rule in (81):
-
(81)


Condition (i) guarantees the placement of a long allomorph at ι-phrase boundaries. Condition (ii) is meant to capture the fact that, as already seen in the examples in (28) of Sect. 4, long allomorphs also arise if their absence otherwise results in a consonant cluster in coda position.
With (80) and (81), we predict the presence of long allomorphs at the edge of every spell-out domain, which given common assumptions on phases (see e.g. Citko 2015 for an overview), potentially overgenerates ι-phrase boundaries (and by extension long allomorphs). That is, the literature on phases generally recognizes the existence of more than one phase for every CP, minimally vP and CP (Chomsky 2001; Legate 2003; Kahnemuyipour 2005; Kratzer and Selkirk 2007; Newell 2008; Citko 2015 a.o.). Without further stipulation, the proposal therefore predicts at least two ι-phrase boundaries in the same clause—one after the vP spell-out domain, and another after the CP spell-out domain. To illustrate, consider the following structure, which following Aissen (1992) and Little (2020) assumes that VOS word order in Mayan is derived with right-specifier subjects (phase heads are underlined and what they spell out is in bold).Footnote 24
-
(82)


Notice that the object in (82) is the last item in the spell out domain of vP.Footnote 25 Thus, the generalizations in (80) and (81) predict that the object should coincide with an ι-phrase boundary. This means that if the object is a prosodic allomorph, it will have to be realized as a long allomorph. This prediction is not borne out. As shown in (83), objects in VOS clauses must be realized as short allomorphs. Moreover, previous literature on Mayan languages all converge on the observation that sentential-level stress tends to only occur once per clause (Hopkins 1967, Berinstein 1991, DiCanio and Bennett 2018).
-
(83)


Without further stipulation, then, it is probable that a basic phasal account of long allomorphs will run into an overprediction issue: phases below CP should not end with an ι-phrase boundary. There are at least two conceivable solutions to this issue. First, since the issue arises because vP is assumed to be a phase, one possibility could be to deny the phasal status of vP altogether, or the existence of any other phase below CP for that matter—at least in Chuj and K’iche’. This type of proposal is already put forth in Mendes and Ranero 2021, where it is argued that vP cannot be a phase in K’iche’ and its close relative Kaqchikel (see also Keine 2017 for evidence that vP is not a phase in Hindi). I do not discuss this possibility here, but see Sect. 5.2 of Mendes and Ranero 2021 for detailed arguments. One potential problem with denying the existence of phases below CP, however, is that we can no longer make use of lower phases to determine the placement of prosodic boundaries associated with smaller prosodic domains, which likely exist in Chuj and K’iche’ (see e.g. Dobashi 2003 and Kratzer and Selkirk 2007 for phasal accounts of prosodic domains associated to the vP phase, and also Henderson 2012, Sect. 3.2.1., for evidence of the presence of Phonological Phrase boundaries in K’iche’). Another potential issue is that this proposal clashes with evidence within the framework of Distributed Morphology for the existence of several phases below CP (see e.g. Marantz 2001; 2007; Newell 2008; and Embick 2010).
To maintain the existence of phases below the CP phase, another possible solution to the overprediction issue is to assume that phonology is able to distinguish between different types of phases, and allow for ι-phrase boundaries to be specifically associated with CP phases. This type of solution is independently assumed in many accounts of the syntax-prosody interface, which require prosodic domains to map to “designated categories” in the syntax (e.g. Hale and Selkirk 1987 or any account adopting prosodic hierarchy theory or match theory; also see Dresher 1994 and Wagner 2005 for arguments against designated categories), including phasal accounts that assume prosodic hierarchy theory (see e.g. Kratzer and Selkirk 2007). For instance, assuming prosodic hierarchy theory, the mapping algorithm could be formalized such that the vP spell-out domain aligns with Phonological Phrases, and the CP spell-out domain with ι-phrases. If this is so, one can simply formalize the distribution of long allomorphs with respect to the right edge of ι-phrases. Theories that do not assume prosodic hierarchy theory, on the other hand, could similarly posit that ι-phrase boundaries arise at the end of every CP spell-out domain, as in (84).
-
(84)


However, in order to maintain the existence of phases below CP all while accounting for prosodically-conditioned allomorphy conditioned by ι-phrase boundaries—such as Chuj and K’iche’ prosodic allomorphy—an additional stipulation is in order. Regardless of what theory one assumes, it is crucial that the spell out of earlier cycles be delayed at least until the CP phase head is merged. To illustrate, first consider the following utterance, where the object of a transitive clause appears at the end of a sentence:
-
(85)


Assuming a syntax like (82) and, the existence of more than one phase per CP, the direct object in (85) will have to be spelled out as part of the vP phase. However, as shown above, the realization of the direct object pronoun is morphologically conditioned by the ι-phrase boundary (see pitch track in Fig. 1). Therefore, if the CP phase is what determines the placement of the ι-phrase boundary, and the ι-phrase boundary is what conditions prosodic allomorphy, then it follows that the spell out of the complement of vP (which contains the direct object) must be delayed until the CP head is merged. That is, if the complement of vP were to undergo Vocabulary Insertion before the CP head were merged, then the phonologically-conditioned allomorphy in (81) could not apply, since the specification of an ι-phrase boundary would be absent from the derivation at the moment the morpheme corresponding to the prosodic allomorph is inserted.
This issue is closely related to Henderson’s (2012) discussion of the implications of prosodic allomorphy on the timing of morphological insertion (see Henderson’s Sect. 4.3.2). As discussed at the beginning of Sect. 4, Henderson argues that prosodically-conditioned allomorphy provides strong evidence that prosodic information must be present early in the derivation, prior to Vocabulary Insertion, thereby supporting late-insertion theories of morphology (e.g. Ackema and Neeleman 2003). Since ι-phrase boundaries are associated with CPs, any account of Mayan prosodic allomorphy that embraces phase theory will therefore be forced to assume that spell out can only proceed once a CP head is merged. While at first glance this restriction seems potentially compatible with previous work on phases, which has standardly assumed that the spell out of a phase is delayed until the next phase head is merged (e.g. Chomsky 2001), no theory requires spell out to be delayed to the moment a phase head of a certain type is merged. Moreover, the moment one assumes there is more than one phase below CP, a possibility that is very likely (e.g. it is widely assumed that DPs and even other syntactic projections, such as nP and aP can be phases; see e.g. Marantz 2001, 2007; Adger 2003; Svenonius 2004; Bošković 2008; Newell 2008; Embick 2010; Citko 2015), the view that spell out is delayed until the next phase head is merged can no longer be used to account for prosodic allomorphy.
In sum, prosodically-conditioned allomorphy sensitive to large prosodic domains, such as Mayan prosodic allomorphy, brings to light an interesting challenge to standard phase theoretic approaches to the transfer from syntax to phonology. Specifically, to account for Mayan prosodic allomorphy by embracing phase theory, we must either assume (i) that there are no phases below CP (contra standard assumptions), or (ii) that spell out of any phase below CP must be delayed until the CP phase head is merged (also contra standard assumptions). It therefore remains to be seen how phasal accounts can be adjusted to account for prosodically-conditioned allomorphy and other prosodic phenomena, both in Chuj and K’iche’, and across languages.
Notes
All Chuj data come from speakers of the Nentón and San Mateo Ixtatán variants. Data were collected through original elicitation in Guatemala, Mexico, and Canada and in texts available on the Archive of Indigenous Languages of Latin America (Mateo Pedro and Coon 2017). For Chuj grammars, see Hopkins 1967, Maxwell 1982, and García Pablo and Domingo Pascual 2007. The K’iche’ data come from previous work by other authors and from questionnaires with two speakers of Santa Lucía Utatlán (one of the two dialects under study in Henderson 2012). For recent overviews on K’iche’, see Can Pixabaj 2015, 2017.
Abbreviations: a: “Set A” (ergative/possessive); af: agent focus; b: “Set B” (absolutive); clf: noun classifier; comp: complementizer; dep: dependent clause marker; dir: directional; ha: topic/focus marker; indf: indefinite; ipfv: imperfective; iv: intransitive status suffix; m: masculine; neg: negation; pl: plural; pron: pronoun; prosp: prospective; q: question; pfv: perfective; rn: relational noun; sg: singular; top: topic; tv: transitive status suffix. Glosses in examples from other sources have been modified in some cases for consistency, and translations from Spanish to English are my own.
(7) is formalized in OT with two alignment constraints (see Henderson for more details).
The strict layer hypothesis has been contested in much recent work, including Truckenbrodt (1999), Wagner (2005, 2010), and Selkirk (2011) (see Elfner 2018 for overview). The analysis proposed in this paper will remain neutral with respect to this debate. However, note that the strict layer hypothesis falls under the category of syntax-prosody mismatches, and is therefore another type of mismatch required in Henderson 2012.
Note that, in addition to prosodic allomorphy in Chuj and K’iche’, similar paradigms are found in other Mayan languages from distinct branches, such as Tsotsil (Cholan-Tseltalan); Popti’ and Q’anjob’al (Q’anjob’alan); and Tz’utujil (K’ichean) (Day 1973; Craig 1977, 1986; Aissen 1992; Mateo Toledo 2017). Although the affected morphemes vary, the allomorphy appears to be governed by similar clausal boundaries across all of these languages.
The classifier ni(’o’) is only used in the Nentón variant of Chuj.
This could potentially be tested for K’iche’ with a DP topic ending with a verb-final relative clause. I have not been able to check this environment in K’iche’, but future work should establish whether this environment triggers the presence of a status suffix.
In the Mayanist literature, “external” topics are contrasted with “internal” topics, the latter of which appear inside the domain of the matrix clause and do so via movement (Aissen 1992). As argued in Bielig 2015, Chuj only seems to have “external” topics. Popti’, a close relative of Chuj, is also argued in Aissen 1992 to only feature external topics. On similar external topics across languages and their effects on prosody, see e.g. Nespor and Vogel 1986 (on English), Bresnan and Mchombo 1987 and Kanerva 1990 (on Chichewa), and Frascarelli 2000 (on Italian).
This issue becomes especially relevant when considering language acquisition. As hinted by a reviewer, one reason to favour a “no mismatch” account is that a matching syntax-prosody relationship could help explain the well-known effects of phonological bootstrapping on the acquisition of syntax (see e.g. Morgan 1986, the work cited in Morgan and Demuth 1996, and Christophe et al. 2008). That is, if syntax and prosody always match, learners can trust that prosody will inform them on syntactic constituency, but if they do not match, then learners might not trust that phonology will accurately inform them about syntax, in which case we might expect them to disregard it entirely (unless syntax-prosody mismatches are universally systematic, which to my knowledge is not the usual assumption). Since we know from the aforementioned work that prosodic cues play an important role in the acquisition of syntax, then an isomorphic relationship is to be preferred.
As pointed out to me by Scott AnderBois and an anonymous reviewer, it is rather unusual in syntactic theory to reference the right edges of CPs, unless discussing the syntax-prosody interface. I take this to be an additional argument in favour of a phonological account of prosodic allomorphy.
As an anonymous reviewer signals, a commonly held assumption in current syntactic theory is that the syntactic component is to some extent “order free.” Indeed, many accounts assume that at least part of the order of constituents is determined post-syntactically (see e.g. Bennett et al. 2016 and references therein). If this is true, then, one wonders how the phonological component can identify “the end” or the “right edges” of syntactic constituents, as proposed here. But it is not entirely clear to me to what extent syntax should be considered order free; and reference to the edges of syntactic constituents remains standard in the literature that assume post-syntactic ordering (for instance, Bennett et al. (2016) use match theory, which references XP edges). For now, I make the assumption that the phonological component can identify the edges of syntactic constituents, and I leave the exact implementation of how this works open.
I use the term “extraposition” in its most general sense to describe the placement of constituents in structurally higher positions than what is considered canonical or expected (Büring and Hartmann 1997). There are various reasons why constituents could appear extraposed, including A’-movement (Ross 1967; Reinhart 1980; Baltin 1982 a.o.), high base-generation (Koster 1978; Culicover and Rochemont 1990, a.o.), or leftward movement of other constituents (e.g. Kayne 1994). For an overview of extraposition, see Baltin 2006.
To derive the presence of ι-phrase boundaries at the end of topicalized constituents, one could alternatively recourse to the idea that topicalized constituents involve full CPs with elided material, following Ott 2014. This would eliminate the need to posit (38).
When co-occurring with a determiner, wh-det relatives must extrapose. For instance, such relatives must follow matrix clause subjects (Telma Can Pixabaj p.c.).
One reviewer raises the possibility that (45a) could be grammatical in another dialect of K’iche’, which is indeed very possible. If (45a) were to be grammatical, then one might be led to conclude that in this dialect (i) status suffixes do not drop and (ii) free relatives do not extrapose. Such facts are actually independently attested in other Mayan languages. For example, status suffixes are never dropped in several other Mayan languages (see e.g. Coon 2016 for relevant data on Ch’ol), and Chuj free relatives do not necessarily extrapose (see Sect. 5.3.2 below).
Though more work is required, there are reasons to believe that Chuj temporal adverbs like ewi ‘yesterday’ are unlike similar temporal adverbs in English in that they cannot surface as topics. For instance, though ewi can appear preverbally, a consultant seemed to dislike prosodic boundaries between it and the verb. This is unlike topics, which are generally followed by a clear prosodic boundary (see e.g. Sect. 3.3).
Though right-side topics are possible, there is no evidence that right-side foci are possible in Chuj. For instance, right-dislocated DPs cannot trigger Agent Focus morphology.
Note, however, that nothing hinges on this assumption: complement clauses could equally well appear in their surface position via movement.
Notice that the result in Chuj is a morpheme combining the prepositional element yoj with the complementizer to, which together form the subordinating conjunction. This is a common configuration for subordinating conjunctions across languages (e.g. Spanish porque (lit. ‘for-that’)). There is no consensus on the syntactic status of subordinating conjunctions (see e.g. Haumann 1997). While some have argued that they are headed by PPs (e.g. Emonds 1976), others have argued that they realize the head of CP (e.g. Hendrick 1976).
Without further stipulation about the syntax of negation, the structure proposed in (63) makes the prediction that negation should not be able to take scope over the because-clause (see e.g. Lasnik 1972; Torrego 2018). At least in Chuj, this prediction is not borne out. There are different ways this fact could be explained. One possibility is that because-clauses are generated in a lower position and reconstruction allows them to scope under negation (though see Sect. 5.2.2 for potential reasons not to opt for this route). A second possibility is that negation can be interpreted very high, allowing it to sometimes scope over CP adjuncts. Since there is little work on the syntax and semantics of negation in Mayan, this issue falls outside the scope of the paper, and I leave it to future work.
Note that right-side topics usually appear with the marker ha, absent in (72). I hypothesize that the absence of ha is due to the absence of an overt nominal.
An anonymous reviewer asks how we can be sure that examples like (77) are not due to instances of speakers searching for vocabulary items, rather than to a grammatical property of the language. This question should be further investigated in future work (e.g. by establishing the frequency of breaks after prepositions and complementizers), however, I note for the moment that prosodic breaks between prepositions, complementizers, and their respective complements are not hard to find, and my intuition is that speakers who produce such breaks do not sound like they are searching for their words, as is the case for example with “tip-of-the-tongue” pauses.
Phasal accounts of the syntax-phonology interface have been proposed within both “direct-reference” and “indirect-reference” approaches. See Elfner 2018 for an overview.
Following Chomsky (2001), I assume that phase heads spell out their complements.
References
Ackema, Peter, and Ad Neeleman. 2003. Context-sensitive spell-out. Natural Language and Linguistic Theory 21: 681–735.
Adger, David. 2003. Core syntax: A minimalist approach. Oxford: Oxford University Press.
Adger, David. 2007. Stress and phasal syntax. Linguistic Analysis 33: 238–266.
Aissen, Judith. 1992. Topic and focus in Mayan. Language 68: 43–80.
Aissen, Judith. 2000. Prosodic conditions on anaphora and clitics in Jakaltek. In The syntax of verb initial languages, eds. Andrew Carnie and Eithne Guilfoyle, 185–200. Oxford: Oxford University Press.
Aissen, Judith. 2017a. Correlates of ergativity in Mayan. In Oxford handbook of ergativity, eds. Jessica Coon, Diane Massam, and Lisa Travis. Oxford: Oxford University Press.
Aissen, Judith. 2017b. Special clitics and the right periphery in Tsotsil. In Looking into words (and beyond), eds. Claire Bowern, Laurence Horn, and Raffaella Zanuttini, 235–261. Berlin: Language Science Press.
Aissen, Judith, Nora C. England, and Roberto Zavala. 2017. Introduction. In The Mayan languages, eds. Judith Aissen, Nora C. England, and Roberto Zavala, 1–12. London: Routledge.
Baltin, Mark. 1978. Toward a theory of movement rules. Doctoral dissertation, MIT.
Baltin, Mark. 1982. A landing site theory of movement rules. Linguistic Inquiry 13: 1–38.
Baltin, Mark. 2006. Extraposition. In The Blackwell companion to syntax, eds. Martin Everaert and Henk van Riemsdijk, 237–271. Oxford: Blackwell Publishers.
Barrett, Rusty. 2007. The evolutionary alignment of glottal stops in K’ichean. In Berkeley Linguistics Society (BLS) 33, Berkeley: University of California Press.
Beckman, Mary E., and Janet B. Pierrehumbert. 1986. Intonational structure in Japanese. Phonology Yearbook 3: 225–309.
Bennett, Ryan. 2016. Mayan phonology. Language and Linguistics Compass 10: 469–514.
Bennett, Ryan, Emily Elfner, and James McCloskey. 2016. Lightest to the right: An apparently anomalous displacement in Irish. Linguistic Inquiry 2: 169–234.
Berinstein, Ava E. 1991. The role of intonation in K’ekchi Mayan discourse. In Texas linguistic forum, ed. Cynthia McLemore, 1–19. University of Texas Austin.
Bielig, Louisa. 2015. Resumptive classifiers in Chuj high topic constructions. BA Thesis, McGill University.
Bošković, Željko. 2008. What will you have, DP or NP? In North East Linguistics Society (NELS) 37. Amherst: GLSA.
Bresnan, Joan, and Sam A. Mchombo. 1987. Topic, pronoun, and agreement in Chichewa. Language 63: 741–782.
Buenrostro, Cristina. 2009. Chuj de San Mateo Ixtatán. Mexico City: El Colegio de México.
Buenrostro, Cristina. 2013. La voz en Chuj de San Mateo Ixtatán. Doctoral dissertation, El Colegio de México, Mexico City.
Buenrostro, Cristina, José Carmen Díaz, and Roberto Zavala. 1989. Sistema de clasificación nominal del Chuj. In Memorias del segundo coloquio internacional de Mayistas, Vol. II, Mexico City: UNAM.
Büring, Daniel, and Katharina Hartmann. 1997. Doing the right thing. The Linguistic Review 14: 1–42.
Can Pixabaj, Telma. 2004. La topicalización en K’ichee’: una perspectiva discursiva. Licenciatura thesis, Universidad Rafael Landívar, Guatemala.
Can Pixabaj, Telma. 2009. Morphosyntactic features and behaviors of verbal nouns in K’ichee’. Master’s thesis, University of Texas Austin.
Can Pixabaj, Telma Angelina 2015. Complement and purpose clauses in K’iche’. Doctoral dissertation, University of Texas Austin.
Can Pixabaj, Telma A. 2017. K’iche’. In The Mayan languages, eds. Judith Aissen, Nora C. England, and Roberto Zavala Maldonado, 461–499. London: Routledge.
Can Pixabaj, Telma Angelina 2020. Headless relative clauses in K’iche’. In Headless relative clauses in Mesoamerica languages, eds. Ivano Caponigro, Harrold Torrence, and Roberto Zavala. 260–289. Oxford: Oxford University Press.
Can Pixabaj, Telma, and Nora C. England. 2011. Nominal topic and focus in K’ichee’. In Representing language: Essays in honor of Judith Aissen, eds. Rodrigo Gutiérrez-Bravo, Line Mikkelsen, and Eric Potsdam, 15–30. University of Texas: Linguistics Research Center.
Caponigro, Ivano. 2003. Free not to ask: On the semantics of free relatives and wh-words cross-linguistically. Doctoral dissertation, University of California at Los Angeles.
Caponigro, Ivano. 2004. The semantic contributions of wh-words and type shifts: Evidence from free relatives crosslinguistically. Semantics and Linguistic Theory 14: 38–55.
Chen, Matthew. 1987. The syntax of Xiamen tone sandhi. Phonology 4: 109–150.
Chomsky, Noam. 1986. Barriers. Cambridge: MIT Press.
Chomsky, Noam. 2001. Derivation by phase. In Ken Hale: A life in language, ed. Michael Kenstowicz, 1–52. Cambridge: MIT Press.
Chomsky, Noam. 2008. On phases. In Foundational issues in linguistic theory, eds. Robert Freidin, Carlos Otero, and Maria-Luisa Zubizaretta, 133–166. Cambridge: MIT Press.
Chomsky, Noam, and Morris Halle. 1968. The sound pattern of English. New York: Harper and Row.
Christophe, Anne, Séverine Millotte, Savita Bernal, and Jeffrey Lidz. 2008. Bootstrapping lexical and syntactic acquisition. Language and Speech 51: 61–75.
Chung, Sandra. 2003. The syntax and prosody of weak pronouns in Chamorro. Linguistic Inquiry 34: 547–599.
Citko, Barbara. 2015. Phase theory: An introduction. Cambridge: Cambridge University Press.
Clemens Lauren Eby. 2014. Prosodic noun incorporation and verb-initial syntax. Doctoral dissertation, Harvard University.
Clemens Lauren Eby. 2019. Prosodic noun incorporation: The relationship between prosody and argument structure in Niuean. Syntax 22: 337–377.
Clemens, Lauren. 2021. The use of prosody as a diagnostic for syntactic structure: The case of verb-initial order. In Vp-fronting, eds. Vera Lee-Schoenfeld and Dennis Ott. Oxford: Oxford University Press. To appear.
Clemens Lauren Eby, and Jessica Coon. 2018. Deriving verb initial order in Mayan. Language 94: 237–280.
Coon, Jessica. 2010. VOS as predicate fronting in Chol. Lingua 120: 354–378.
Coon, Jessica. 2016. Mayan morphosyntax. Language and Linguistics Compass 10: 515–550.
Coon, Jessica. 2019. Building verbs in Chuj: Consequences for the nature of roots. Journal of Linguistics 55: 35–81.
Coon, Jessica, and Justin Royer. 2020. Nominalization and selection in two Mayan languages. In Nominalization: 50 years on from Chomsky’s Remarks, eds. Artemis Alexiadou and Hagit Borer. 139–169. Oxford: Oxford University Press.
Coon, Jessica, Pedro Mateo Pedro, and Omer Preminger. 2014. The role of case in A-bar extraction asymmetries: Evidence from Mayan. Linguistic Variation 14: 179–242.
Coon, Jessica, Nico Baier, and Theodore Levin. 2021. Mayan agent focus and the ergative extraction constraint: Facts and fictions revisited.
Cooper, William, and Jeanne Paccia-Cooper. 1980. Syntax and speech. Cambridge: Harvard University Press.
Craig, Colette Grinevald. 1977. The structure of Jacaltec. Austin: University of Texas Press.
Craig, Colette Grinevald. 1986. Jacaltec noun classifiers. Lingua 70: 241–284.
Culicover, Peter, and Michael Rochemont. 1990. Extraposition and the complement principle. Linguistic Inquiry 21: 23–47.
Curiel, Alejandro. 2007. Estructura de la información, enclíticos y configuración sintáctica en tojol ’ab’al. Master’s thesis, CIESAS, México.
Day, Christopher. 1973. The Jacaltec language. Vol. 12 of Language science monographs. Indiana University.
Dayley, Jon. 1985. Tzutujil grammar. Berkeley: University of California Press.
DiCanio, Christian, and Ryan Bennett. 2018. Prosody in Mesoamerican languages. In The Oxford prosody handbook, eds. Carlos Gussenhoven and Aoju Chen. Oxford: Oxford University Press.
Dobashi, Yoshihito. 2003. Phonological phrasing and syntactic derivation. Doctoral dissertation, Cornell University.
Dobashi, Yoshihito. 2013. Autonomy of prosody and prosodic domain formation: A derivational approach. Linguistic Analysis 38: 331–355.
Dresher, Bezalel Elan. 1994. The prosodic basis of the Tiberian Hebrew system of accents. Language 70: 1–52.
Elfner, Emily. 2012. Syntax-prosody interactions in Irish. Doctoral dissertation, University of Massachusetts Amherst.
Elfner, Emily. 2018. The syntax-prosody interface: Current theoretical approaches and outstanding questions. Linguistics Vanguard 4: 1–14.
Embick, David. 2010. Localism versus globalism in morphology and phonology. Cambridge: MIT Press.
Embick, David, and Rolf Noyer. 2001. Movement operations after syntax. Linguistic Inquiry 32: 555–595.
Emonds, Joseph. 1976. A transformational approach to English syntax. New York: Academic Press.
England, Nora. 1991. Changes in basic word order in Mayan languages. International Journal of American Linguistics 57: 446–486.
England, Nora C. 1997. Topicalización, enfoque y énfasis. In Cultura de Guatemala, año XVIII, Vol. 2, 273–288. Universidad Rafael Landívar.
England, Nora, and Brandon Baird. 2017. Phonology and phonetics. In The Mayan languages, eds. Judith Aissen, Nora England, and Roberto Zavala Maldonado, 175–200. New York: Routledge.
Frascarelli, Mara. 2000. The syntax-phonology interface in focus and topic constructions in Italian. Dordrecht: Kluwer.
García Pablo, Gaspar, and Pascual Martín Domingo Pascual. 2007. Stzolalil sloloni-spaxtini heb’ chuj: Gramática descriptiva chuj. Academia de Lenguas Mayas de Guatemala.
Gussenhoven, Carlos. 1991. The English Rhythm Rule is an accent deletion rule. Phonology 8: 1–35.
Hale, Kenneth, and Elisabeth O. Selkirk. 1987. Government and tonal phrasing in Papago. Phonology Yearbook 4: 185–194.
Haumann, Dagmar. 1997. The syntax of subordination. Tübingen: Niemeyer.
Hayes, Bruce. 1990. Precompiled phasal phonology. In The phonology-syntax connection, eds. Sharon Inkelas and Draga Zec, 85–108. Chicago: University of Chicago Press.
Henderson, Robert. 2008. Observaciones sobre la sintaxis de la extracción de adjuntos en kaqchikel (maya). In Memorias del congreso de idiomas indígenas de latinoamérica 3, ed. B’alam Mateo-Toledo. Austin.
Henderson, Robert. 2012. Morphological alternations at the intonational phrase edge: The case of K’ichee’. Natural Language and Linguistic Theory 30: 741–787.
Hendrick, Randall. 1976. Prepositions and the X-bar theory. In Proposals for semantic and syntactic theory, ed. Joe Emonds, 95–122. UCLA Papers in Syntax.
Hintikka, Jaakko. 1969. Semantics for propositional attitudes. In Models for modalities, ed. Jaakko Hintikka, 87–111. Dordrecht: Springer.
Hirsch, Aron, and Michael Wagner. 2015. Rightward movement affects prosodic phrasing. In North East Linguistics Society (NELS) 45, eds. Deniz Ozyildiz and Thuy Bui.
Hopkins, Nicholas. 1967. The Chuj language. Doctoral dissertation, University of Chicago.
Hopkins, Nicholas. 2012. Noun classifiers of the Chuchumatán Mayan languages: A case of diffusion from Otomanguean. International Journal of American Linguistics 78: 411–427.
Ito, Junko, and Armin Mester. 2013. Prosodic subcategories in Japanese. Lingua 124: 20–40.
Kahnemuyipour, Arsalan. 2005. Towards a phase-based theory of sentential stress. In Perspectives on phases, eds. Martha McGinnis and Norvin Richards, 125–146. Cambridge: MIT Working Papers in Linguistics.
Kanerva, Jonni M. 1990. Focusing on phonological phrases in Chichewa. In The phonology-syntax connection, eds. Sharon Inkelas and Draga Zec, 145–161. Chicago: University of Chicago Press.
Kaufman, Terrence. 1990. Algunos rasgos estructurales de los idiomas mayances con referencia especial al K’iche’. In Lecturas sobre la lingüística maya, eds. Nora England and Stephen R. Elliot, 59–114. Antigua: CIRMA.
Kayne, Richard S. 1994. The antisymmetry of syntax. Cambridge: MIT Press.
Keine, Stefan. 2017. Agreement and vp phases. In A schrift to fest Kyle Johnson, eds. Nicholas LaCara, Keir Moulton, and Anne-Michelle Tessier, 177–185. University of Massachusetts Amherst: Linguistics Open Access Publications.
Koster, Jan. 1978. Locality principles in syntax. Dordrecht: Foris.
Kotek, Hadas, and Michael Yoshitaka Erlewine. 2016. Unifying definite and indefinite free relatives: Evidence from Mayan. In North East Linguistics Society (NELS) 46, 241–254.
Kotek, Hadas, and Michael Yoshitaka Erlewine. 2019. Wh-indeterminates in Chuj (Mayan). Canadian Journal of Linguistics 64: 62–101.
Kratzer, Angelika. 2006. Decomposing attitude verbs. Handout from talk given at The Hebrew University of Jerusalem.
Kratzer, Angelika, and Elisabeth Selkirk. 2007. Phase theory and prosodic spellout: The case of verbs. The Linguistic Review 24: 93–135.
Larsen, Thomas W. 1988. Manifestations of ergativity in Quiché grammar. Doctoral dissertation, University of California Berkeley.
Lasnik, Howard. 1972. Analyses of negation in English. Doctoral dissertation, Massachusetts Institute of Technology.
Legate, Julie Ann. 2003. Some interface properties of the phase. Linguistic Inquiry 34: 506–516.
Lehiste, Ilse. 1973. Phonetic disambiguation of syntactic ambiguity. Glossa 7: 107–122.
Little, Carol-Rose. 2020. Mutual dependencies of nominal and clausal syntax in Ch’ol. Doctoral dissertation, Cornell University.
Marantz, Alec. 2001. Words. Ms., Cambridge: MIT.
Marantz, Alec. 2007. Phases and words. In Phases in the theory of grammar, eds. S. H. Choe, D. W. Yang, S. H. Kim, and Alec Marantz. Seoul: Dong In Publisher.
Mateo Pedro, Pedro. 2011. The acquisition of unaccusativity in Q’anjob’al Maya. Ms. Harvard University.
Mateo Pedro, Pedro, and Jessica Coon. 2017. Chuj oral tradition collection of Pedro Mateo Pedro and Jessica Coon. Archive of Indigenous Languages of Latin America: University of Texas Austin.
Mateo Toledo, Eladio. 2017. Q’anjob’al. In The Mayan languages, eds. Judith Aissen, Nora C. England, and Roberto Zavala Maldonado, 533–569. London: Routledge.
Mateo Toledo, Eladio, and Pedro Mateo Pedro. 2017. La prominencia prosódica en la adquisición de la morfosintaxis del q’anjob’al (maya). Signos Lingüísticos 8: 8–53.
Maxwell, Judith. 1982. How to talk to people who talk chekel ‘different’: The Chuj (Mayan) solution. Doctoral dissertation, University of Chicago.
Mendes, Gesoel, and Rodrigo Ranero. 2021. Chain reduction via substitution: Evidence from Mayan. Glossa: A journal of general linguistics 6(1): 10. 1–31. https://www.glossa-journal.org/articles/10.5334/gjgl.1087/.
Mondloch, James. 1978. Disambiguating subjects and objects in Quiché. Journal of Mayan Linguistics 1: 3–19.
Morgan, James L. 1986. From simple input to complex grammar. Cambridge: MIT Press.
Morgan, James L., and Katherine Demuth. 1996. Signal to syntax: An overview. In Signal to syntax: Bootstrapping from speech to grammar in early acquisition, eds. James L. Morgan and Katherine Demuth, 1–22. Mahwah: Lawrence Erlbaum Associates Publishers.
Moulton, Keir. 2009. Natural selection and the syntax of clausal complementation. Doctoral dissertation, University of Massachusetts at Amherst.
Moulton, Keir. 2015. CPs: Copies and compositionality. Linguistic Inquiry 46: 305–342.
Neeleman, Ad, and Amanda Payne. 2020. PP-Extraposition and the order of adverbials in English. Linguistic Inquiry 51: 1–50.
Nespor, Marina, and Irene Vogel. 1986. Prosodic phonology. Dordrecht: Foris.
Newell, Heather. 2008. Aspects of the morphology and phonology of phases. Doctoral dissertation, McGill University, Montreal, QC.
Ott, Dennis. 2014. An ellipsis approach to contrastive left-dislocation. Linguistic Inquiry 45: 269–303.
Pak, Marjorie. 2008. The postsyntactic derivation and its phonological reflexes. Doctoral dissertation, University of Pennsylvania.
Piedrasanta, Ruth. 2009. Los chuj, unidad y rupturas en su espacio. Guatemala City, Guatemala: Amrar Editores.
Polian, Gilles. 2013. Gramática del tseltal de Oxchuc. Publicaciones de la Casa Chata. México: Centro de Investigaciones y Estudios Superiores en Antropología Social.
Prince, Alan, and Paul Smolensky. 1993. Optimality Theory: Constraint interaction in generative grammar. In Ruccs technical report no. 2, Piscataway: Rutgers University Center for Cognitive Science.
Reinhart, Tanya. 1980. On the position of extraposed clauses. Linguistic Inquiry 24: 461–507.
Richards, Michael. 2003. Atlas lingüístico de Guatemala. Guatemala City: Editorial Serviprensa.
Richards, Norvin. 2016. Contiguity theory. Cambridge: MIT Press.
Ross, John R. 1967. Constraints on variables in syntax. Doctoral dissertation, MIT.
Royer, Justin. 2017. Noun and numeral classifiers in Chuj (Mayan). In Proceedings of the Berkeley Linguistics Society, eds. Julia Nee, Margaret Cychosz, Dmetri Hayes, Tyler Lau, and Emily Remierez, 29–38. Berkeley: Berkeley Linguistics Society.
Royer, Justin. 2019. Domain restriction and noun classifiers in Chuj. In North East Linguistics Society (NELS) 49, eds. Maggie Baird and Jonathan Pestesky. Vol. 3, 87–97.
Royer, Justin. 2020. Headless relative clauses in Chuj. In Headless relative clauses in Mesoamerican languages, eds. Ivano Caponigro, Harrold Torrence, and Roberto Zavala Maldonado. 327–361. London: Oxford University Press.
Seidl, Amanda. 2001. Minimal indirect reference: A theory of the syntax-phonology interface. London: Routledge.
Selkirk, Elisabeth. 1984. Phonology and syntax: The relation between sound and structure. Cambridge: Cambridge University Press.
Selkirk, Elisabeth O. 1986. On derived domains in sentence phonology. In Phonology yearbook, Vol. 3, 371–405.
Selkirk, Elisabeth. 1995. Sentence prosody: Intonation, stress and phrasing. In The handbook of phonological theory, ed. John Goldsmith, 550–569. London: Blackwell.
Selkirk, Elisabeth. 2009. On clause and intonational phrase in Japanese: The syntactic grounding of prosodic constituent structure. Gengo Kenkyu 136: 35–73.
Selkirk, Elisabeth. 2011. The syntax-phonology interface. In The handbook of phonological theory, eds. John A. Goldsmith, Jason Riggle, and C. L. Alan. Blackwell.
Steedman, Mark. 1991. Structure and intonation. Language 67: 260–296.
Stiebels, Barbara. 2006. Agent focus in Mayan languages. Natural Language and Linguistic Theory 24: 501–570.
Stowell, Tim. 1981. Origins of phrase structure. Doctoral dissertation, MIT.
Svenonius, Peter. 2004. On the edge. In Peripheries: Syntactic edges and their effects, eds. David Adger, Cecile de Cat, and George Tsoulas, 259–287. Dordrecht: Kluwer Academic Publishers.
Tilsen, Sam. 2011. Metrical regularity facilitates speech planning and production. Laboratory Phonology 2: 185–218.
Torrego, Esther. 2018. Phasehood and Romance adverbial because-clauses. In Language, syntax, and the natural sciences, eds. Ángel Gallego and Roger Martin, 99–113. Cambridge: Cambridge University Press.
Truckenbrodt, Hubert. 1995. Phonological phrases: Their relation to syntax, focus and prominence. Doctoral dissertation, MIT.
Truckenbrodt, Hubert. 1999. On the relation between syntactic phrases and phonological phrases. Linguistic Inquiry 30: 219–255.
Uriagereka, Juan. 1999. Multiple spell-out. In Working minimalism, eds. Samuel Epstein and Norbert Hornstein, 251–282. Cambridge: MIT Press.
Velleman, Leah. 2014. Focus and Movement in a variety of K’ichee’. Doctoral dissertation, University of Texas at Austin.
Wagner, Michael. 2005. Prosody and Recursion. Doctoral dissertation, MIT.
Wagner, Michael. 2010. Prosody and recursion in coordinate structures and beyond. Natural Language and Linguistic Theory 28: 183–237.
Wagner, Michael. 2015. Phonological evidence in syntax. In Syntax—theory and analysis: An international handbook, eds. T. Kiss and Artemis Alexiadou. Vol. 2, 1154–1198. Mouton de Gruyter.
Werle, Adam. 2004. Enclisis and proclisis in Bosnian/Serbian/Croatian. In West Coast Conference on Formal Linguistics (WCCFL), eds. Benjamin Schmeiser, Ann Kelleher, Angelo Rodríguez, and Vineeta Chand, 801–814.
Zavala, Roberto. 2000. Multiple classifier systems in Akatek (Mayan). In Systems of nominal classification, ed. Gunter Senft, 114–146. Cambridge: Cambridge University Press.
Acknowledgements
¡Yuj wal yos t’ayex Matal Torres, Agenor Torres País, Tigo Torres País, Yun Torres, Elsa Torres Velasco, Xun Torres Velasquez, Ana Velasco and Heb’in Velasco, ixexkolwaj yib’an jun munlajel tik! Many thanks to Jessica Coon and Michael Wagner for their guidance on this project. For their comments and valuable feedback, I also would like to thank Telma Can Pixabaj, Meghan Clayards, Lauren Clemens, Aurore Gonzalez, Robert Henderson, Aron Hirsch, Carol-Rose Little, Martina Martinović, Clifton Pye, Rodrigo Ranero, Junko Shimoyama, the NLLT editor Daniel Harbour, three anonymous reviewers, members of the McGill syntax-semantics and prosody reading groups and participants of CILLA IX, NELS 50, and the LSA (94). A special thanks to Telma and Silvia Can Pixabaj for help with K’iche’. For funding, I thank the Social Sciences and Humanities Research Council and McGill University’s Faculty of Arts.
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher’s Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Appendix: Data: Prosodic allomorphs in Chuj
Appendix: Data: Prosodic allomorphs in Chuj
1. Relational nouns: Across Mayan languages, relational nouns, which are formally possessed nominals, function more or less like prepositions in introducing oblique arguments (Coon 2016; Aissen et al. 2017):
-
(86)


2. The interrogative word tas(i): The long form of tas(i) is only observed in its use as a wh-indefinite, since only in such cases is it possible for it to appear at a clausal boundary:
-
(87)


3. The dubitative marker: The morpheme (h)am(a’) is described as a dubitative mood marker in previous work on Chuj (see e.g. Maxwell 1982):
-
(88)


Rights and permissions
About this article

Cite this article
Royer, J. Prosody as syntactic evidence. Nat Lang Linguist Theory 40, 239–284 (2022). https://doi.org/10.1007/s11049-021-09506-1
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11049-021-09506-1