
Abstract
In data mining and machine learning communities, Neural Network (NN) is a popular classification method. On extremely unbalanced and complicated datasets, NN may achieve excellent classification accuracy. However, one disadvantage of NN is its inability to explain its reasoning process, which restricts its use in numerous sectors that need clear conclusions as well as high accuracy. To address this issue, rule-extraction mechanisms exist that extract intelligible classification-rules from NN and turn them into a white box. Attribute or network pruning, dealing with diverse attribute types, rule pruning, and dealing with class overlapping difficulties are all significant components or portions of many existing rule extraction methods, and present strategies to deal with these aspects are insufficiently successful. As a result, this study offers a rule extraction approach named “Comprehensible and Transparent Rule Extraction Using Neural Network”-CTRENN to address the aforementioned shortcomings and transform NN into a white box with high accuracy and better explain-ability. The suggested CTRENN is an expansion of the state-of-art Rule Extraction from Neural Network Using Classified and Misclassified Data technique (RxNCM). The CTRENN augments the RxNCM with a floating sequential search for feature and rule selection to improve feature and rule selection. CTRENN also distinguishes between continuous and discrete properties to improve the readability of the produced rules. Unlike RxNCM, the CTRENN employs a probabilistic technique to deal with the overlapping of attribute data ranges in various classes. Experiments are carried out using six real life datasets obtained from the UCI repository in order to illustrate the efficacy of the proposed CTRENN algorithm in comparison to the current methods.
Similar content being viewed by others

Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
In our digital era, massive volumes of data are acquired in various forms from many sources on a daily basis. This gathered data contains a wealth of important information that is challenging to extract appropriately. In response, data mining techniques [1] have developed supercomputing capabilities that can mine unseen patterns and information and apply them to various decision-making situations. Tasks related to data mining generally include regression, classification [2], clustering [3], association analysis [4], and so on. Among these tasks’ classification is the most common and popular[5]. Bayesian Classification [6], Decision Trees [7, 30, 31], Ensembles [8], Neural Networks [9], SVM [31], and other classification approaches are widely used and dominating. Among these approaches, the utilization of Neural Networks in Data Mining activity has increased in recent years due to their unparalleled capabilities of classifying data with mixed-mode properties, obtaining higher precision or accuracy, and keeping low computing complexity [10, 11]. The disadvantage of Neural Networks in decision-making is their black-box character, which is incapable of explaining the decision-making process in a comprehensible manner [12]. Because the black-box nature [13] of Neural Networks makes them incomprehensible in thinking and decision making, they suffer in sectors where an explanation for the conclusion is required [31, 32]. Medical diagnosis, financial decision-making, infrastructure management, and other professions sometimes demand a clear explanation of rationale and decision process. In medical diagnostics, for example, a clear explanation of the etiology of a disease is essential to raise awareness among the general public and to take preventative steps to prevent the sickness from spreading. As a result, several methods have been developed to extract intelligible rules from neural networks in order to turn the black-box nature of neural networks into white boxes [14].
Considering the approaches used to extract the rules, neural network rule extraction strategies can be classified as decompositional, pedagogical, or eclectic [15]. Analyzing the weights between units and activation functions is part of decompositional approaches. The association between the inputs and outcomes is examined in pedagogical approaches to derive rules. Eclectic methods include decompositional and pedagogical strategies together [16]. Because of lower processing in terms of computational requirement, ease of implementation, and superior accuracy than others, pedagogical approaches are commonly utilized [17]. RxREN [18], RxNCM [19], BRIANNE [20], and X-TREPAN [21] are some current and successful pedagogical techniques. Among them, the most recent is RxNCM, which extracts rules by reverse engineering a Neural Network by removing inconsequential input neurons and then generates rules using properly classified and misclassified patterns.
The RxNCM [19] algorithm has some inherent drawbacks in its workings. First, the RxNCM algorithm solely employs a sequential feature removal strategy in which a feature that is judged inconsequential is permanently eliminated; this is known as the nesting effect. This indicates that the significance of the feature will not be taken into account in subsequent iterations. As a result, the RxNCM technique does not evaluate the combinations of input neurons rather subsets in order to find the best one, and so its performance suffers. Second, regardless of whether the characteristics are continuous or discrete, the RxNCM computes data ranges for all of them. Because patterns with discrete properties cannot be adequately represented by data ranges, the resulting rules are erroneous in nature. Third, reclassification is used by the RxNCM to update the final ruleset. Though this improves accuracy, the new data range may still contain some overlapping.
Keeping all of these disadvantages in mind, the research objective was to present a new pedagogical rule extraction technique called Comprehensible and Transparent Rule Extraction using Neural Network (CTRENN) to enhance the RxNCM approach. Firstly, the CTRENN enhances the network-pruning phase by pruning the input neurons using backward floating approach. The backward floating approach considers characteristics that have been considered irrelevant for later iterations, eliminating nesting effect. Secondly, CTRENN has distinct approaches for handling discrete and continuous characteristics. For discrete characteristics, decision trees are used to produce IF-ELSE rules, while for continuous attributes, obligatory data ranges are used to generate rules. Finally, in the rule updating phase, CTRENN employs probabilistic techniques to address the class overlapping dilemma. The probabilistic technique eliminates overlap by changing the higher and lower data ranges based on the class likelihood of each characteristic. This enhances the performance of the extracted final set of rules.
CTRENN's performance is validated using six datasets from the UCI repository [33], and it is revealed that CTRENN provides more accurate and understandable rules than RxREN and RxNCM. The following is how the paper is structured: Sect. 2 discusses some of the significantly associated literatures, Sect. 3 goes over the suggested technique in-depth, Sect. 4 goes over the experimental findings for validating the algorithm, and Sect. 5 concludes the study.
2 Literature survey
Neural networks are effective tools for extracting patterns and detecting complex trends in data that may be utilized to generate meaning from difficult or inaccurate data. However, they have the disadvantage of being fundamentally black boxes in nature. There are, however, several techniques for converting neural networks into white boxes by extracting clear rules from them. Several rule-extraction strategies have been developed to uncover the information contained in neural networks. The rule extraction strategies may be classified into three approaches: decompositional, instructional, and eclectic. To take out rules from the network, decompositional algorithms evaluate the weights and activation functions of the hidden layer neurons.
Towell et al. [22] introduced the SUBSET method, which evaluates the incoming weights of hidden and output neurons, takes into account all potential subsets of incoming weights, and identifies all rule combinations bigger than a preset threshold. It was constrained by the ever-increasing number of propositional rules. Lu et al. [23] presented the NeuroRule method, a decompositional approach for extracting oblique classification rules from neural networks with one hidden layer. The RG component of NeuroRule creates rules that cover as many examples of a separate class as feasible with the fewest amounts of characteristics. NeuroLinear, a technique for obtaining oblique decision rules from neural networks, was proposed by [24]. It’s a rule extraction technique of decompositional approach with similar stages to NeuroRule [23]; the difference is in data pretreatment. It does not discriminate between discrete and continuous data as input. Gupta et al. [25] introduced an extended analytic rule extraction approach from feed-forward neural network that uses the strength of a Neural Network's connection weights to extract rules. This GLARE algorithm employs the typical network structure and training methods in rule extraction, as well as a direct mapping between input and output nodes to improve comprehensibility.
Odajima et al. [26] suggested a variant decompositional approach for discrete attribute datasets called Greedy Rule Generation (GRG). The discrete hidden layer activation values are subjected to this approach. Because this is a greedy technique, the number of rules created is significantly lower than that of NeuroRule. The instructional strategies attempt to map the relationship between input and output neurons as nearly as possible to how the Neural Network perceives the relationship. One such instructional approach is the BRIANNE technique introduced by [20], it has a significant benefit over the previously stated algorithms in that it does not require discretization and can function with continuous data. Craven and Shavlik [21] presented TREPAN, a method for extracting rules from Neural Networks in the form of decision trees. During the Neural Network's learning phase, this method queries the network to find the class patterns. Biswas et al. [19] introduced the RxNCM method, which is an enhancement on RxREN[18] algorithm. To produce the rules, the RxREN employs misclassified patterns after deleting inconsequential neurons. The RxNCM algorithm improves on this by generating rules utilizing both the misclassified and properly classified algorithms.
There are also eclectic techniques that combine elements of a decompositional approach with elements of a pedagogical approach. The FERNN algorithm was proposed by [27]. It is an eclectic rule extraction approach that discovers valuable hidden units by utilizing C4.5 to locate information gain. Final rules are created by recognizing and weighting relevant input connections to relevant hidden units. The Rex-CGA approach was proposed by [28]. This strategy works with several hidden layer layers. To produce rules, the Rex-CGA uses CGA to locate clusters of activation values in the hidden layers.
Iqbal [29] developed Hierarchical and Eclectic Rule Extraction through Tree Induction and Combination (HERETIC) which utilizes DT to produce rules from individual nodes in a network and then combines the rules generated by all nodes to construct final rules. To create rules, Fast Extraction of Rules from Neural Networks(FERNN) [27] detects the significant hidden neurons and significant input-hidden connections of a fully connected trained single hidden layer network. Jivani et al. [17] contrasted decompositional, pedagogical, and eclectic rule extraction methods. Using criteria such as network architecture, efficiency, extracted rules, and accuracy, they demonstrated that the pedagogical method is computationally quicker than both decompositional and eclectic strategies while retaining a relatively high level of accuracy.
3 Proposed CTRENN
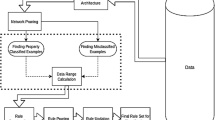
Figure 1 illustrates the algorithm's framework. The method distinguishes between discrete and continuous properties. It produces rules with discrete and contributing qualities one at a time, merging them if accuracy increases. If only discrete characteristics are provided, the algorithm creates rules using only those attributes, and if only continuous attributes are present, the method generates rules using only those attributes. Notations used in the following part has been described in Table 1.

Flowchart of CTRENN
The CTRENN method is divided into seven primary phases that includes- Optimal Network Architecture, Network Pruning, Attribute Separation, Data Range Calculation, Rule Construction, Rule Pruning, and Rule Updating. The ideal network architecture is determined in the first step. During the network pruning step, the trained neural network's unimportant input neurons are deleted. Following trimming, the qualities are classified as discrete or continuous. In the data range calculation step, the input data range of each relevant continuous attribute for classification is calculated. The rule creation step creates classification rules for discrete attributes (if present) and continuous attributes (if present) using the data ranges acquired in the previous phase, and combines both types of rules if both are available. During the rule trimming phase, these rules are trimmed to eliminate inconsequential ones. At last, the rule update process fine-tunes the rules by changing the data ranges. The following sections explain each phase of the proposed CTRENN algorithm:
3.1 Optimal network architecture
For rule extraction, a Back Propagation Neural Network (BPNN) with one hidden layer of \({\varvec{h}}\) neurons is utilized. The number \({\varvec{h}}\) is determined depending on the network's Mean Square Error(MSE). The network topology is modified from \({\varvec{l}}+1\) to \(2\boldsymbol{*}{\varvec{l}}\) hidden neurons, with \({\varvec{l}}\) being the number of input neurons, and the structure with the lowest MSE is selected for further processing.
3.2 Network pruning
Using the backward floating approach, the CTRENN eliminates irrelevant input neurons from the network. This backward floating approach increases the efficiency of the final set of rules extracted by making the feature/rule set more trustworthy by taking into account all possible combinations of features/rules. After eliminating the \({{\varvec{i}}}^{{\varvec{t}}{\varvec{h}}}\) input neurons, CTRENN calculates the number of misclassified cases \({\varvec{e}}{\varvec{r}}{{\varvec{r}}}_{{\varvec{i}}}\) for all input neurons \({{\varvec{l}}}_{{\varvec{i}}}\). Here ‘i’ ranges in between 1 to number of neurons. A temporary short-term pruned network is produced by removing the input neuron with the lowest \({\varvec{e}}{\varvec{r}}{{\varvec{r}}}_{{\varvec{i}}}\) value for the network. This temporary trimmed network's accuracy \({\varvec{A}}{\varvec{c}}{{\varvec{c}}}_{{\varvec{p}}}\) is determined. \({\varvec{A}}{\varvec{c}}{{\varvec{c}}}_{{\varvec{p}}}\) is compared to the starting network's current accuracy \({\varvec{A}}{\varvec{c}}{{\varvec{c}}}_{{\varvec{o}}}\). If \({\varvec{A}}{\varvec{c}}{{\varvec{c}}}_{{\varvec{p}}}>Ac{{\varvec{c}}}_{{\varvec{o}}}\), the program treats this temporarily trimmed network as the pruned network and sets \(\mathbf{A}\mathbf{c}{\mathbf{c}}_{\mathbf{o}}=\mathbf{A}\mathbf{c}{\mathbf{c}}_{\mathbf{p}}\). The pruned input neuron is removed from set A of the network and placed in set B for later consideration.
CTRENN successively adds the removed input neurons (in set B), to the pruned network (set A). If the new accuracy (\({\varvec{A}}{\varvec{c}}{{\varvec{c}}}_{{\varvec{p}}}\)) is strictly greater (\({\varvec{A}}{\varvec{c}}{{\varvec{c}}}_{{\varvec{p}}}>Ac{{\varvec{c}}}_{{\varvec{o}}}\)) than the current accuracy then that input neuron is added back into the network and the accuracy is updated (\({\varvec{A}}{\varvec{c}}{{\varvec{c}}}_{{\varvec{o}}}={\varvec{A}}{\varvec{c}}{{\varvec{c}}}_{{\varvec{p}}}\)). The similar procedure is executed for all the remaining input neurons.
3.3 Attribute separation
The significant attributes that remain after the network pruning is separated into two sets, continuous and discrete. Let C be the set of continuous attributes and D be the set of discrete attributes. The set C of continuous attributes are used in the data range computation phase.
3.4 Data range calculation
If any continuous attributes remain in the pruned network, this phase is executed. By evaluating the misclassified patterns \({{\varvec{E}}}_{{\varvec{i}}}\) in the absence of each \({{\varvec{l}}}_{{\varvec{i}}}\) and the properly classified patterns \({{\varvec{P}}}_{{\varvec{i}}}\) in the presence of each \({{\varvec{l}}}_{{\varvec{i}}}\), the CTRENN algorithm learns the functioning and relevance of each major continuous input neuron \({{\varvec{l}}}_{{\varvec{i}}}\). CTRENN organizes the examples in set \({{\varvec{U}}{\varvec{E}}{\varvec{P}}}_{{\varvec{i}}}\) with regard to each target class \({{\varvec{C}}}_{{\varvec{k}}}\) and then finds the number of examples \({{\varvec{c}}{\varvec{e}}{\varvec{p}}}_{{\varvec{i}}{\varvec{k}}}\) in each class to obtain the necessary data range of \({{\varvec{l}}}_{{\varvec{i}}}\) for each class \({{\varvec{C}}}_{{\varvec{k}}}\). The resulting matrix is known as a data length matrix. The number of examples in the set \({{\varvec{U}}{\varvec{E}}{\varvec{P}}}_{{\varvec{i}}}\) for the input neuron \({{\varvec{l}}}_{{\varvec{i}}}\) is \({{\varvec{e}}{\varvec{p}}}_{{\varvec{i}}}\). The value of \({\varvec{k}}\) is in the range \([1,{\varvec{n}}]\).
All of the characteristics may well not be required for categorizing patterns in all of the n classes, i.e., for classifying patterns in all of the n classes, a certain attribute may not be important. As a result, the algorithm chooses data ranges for those attributes which meet the following criteria(1)
The algorithm constructs a Data Range Matrix (DRM) by finding the lower range \({{\varvec{L}}}_{{\varvec{i}}{\varvec{k}}}\) and upper range \({{\varvec{U}}}_{{\varvec{i}}{\varvec{k}}}\) of data for each attribute \({{\varvec{l}}}_{{\varvec{i}}}\) in class \({{\varvec{C}}}_{{\varvec{k}}}\) if \({\varvec{c}}{\varvec{e}}{{\varvec{p}}}_{{\varvec{i}}{\varvec{k}}}>\alpha *e{{\varvec{p}}}_{{\varvec{i}}}\). The data range matrix is defined as \({\varvec{D}}{\varvec{R}}{\varvec{M}}\) with an order \({\varvec{m}}\boldsymbol{*}{\varvec{n}}\) as shown in Fig. 2. Each element of \({\varvec{D}}{\varvec{R}}{\varvec{M}}\) is represented by lower and upper data ranges of the corresponding attributes and classes i.e., \({{\varvec{L}}}_{{\varvec{i}}{\varvec{k}}}\) and \({{\varvec{U}}}_{{\varvec{i}}{\varvec{k}}}\). \({\varvec{D}}{\varvec{R}}{{\varvec{M}}}_{{\varvec{i}}{\varvec{k}}}\) is calculated using Eq. (2).

Data Range Matrix
3.5 Rule construction
The rule construction phase is composed of 2 parts if both discrete and continuous types of attributes are there in the network. The first part deals with discrete attributes and the second part deals with continuous attributes. In the first part, rules are constructed with the discrete attributes using C4.5 decision tree (DT). Next, for each rule in the rule-set, the rules with the continuous attribute (\({{\varvec{R}}}_{{\varvec{k}}}\)) are included and the accuracy is checked. If the accuracy increases then the rule with continuous attributes is kept in the final set. The working algorithm for rule construction phase if the pruned network contains both discrete and continuous attributes is given in Table 2.
If only discrete attribute is present, the algorithm only generates rules with discrete attributes using DT and goes rule pruning phase. Similarly, if only continuous attributes remains, the algorithm only generates rules with continuous attributes and goes to rule pruning phase.
3.6 Rule pruning
Redundant conditions from the rule-set are removed in this step. A condition \({\varvec{c}}{{\varvec{n}}}_{{\varvec{j}}}\) from initial rule \({{\varvec{R}}}_{{\varvec{k}}}\), is removed first and then the CTRENN algorithm calculates the current accuracy \({\varvec{A}}{\varvec{c}}{{\varvec{c}}}_{{\varvec{j}}}\). If \({\varvec{A}}{\varvec{c}}{{\varvec{c}}}_{{\varvec{j}}}>Ac{{\varvec{c}}}_{{\varvec{r}}}\) the removed condition is added to set D, considering \(Ac{{\varvec{c}}}_{{\varvec{r}}}\) as the initial accuracy. Next removed conditions in set D are sequentially added back one by one. If the accuracynew is strictly greater than the accuracycurrent then that condition is added back into the network permanently and the accuracy is updated.
3.7 Rule update
There may be overlap between various classes in the data range generated for the attribute. CTR-ENN's rule updating phase enhances accuracy by employing a probabilistic strategy to shift the upper and lower data range. For each and every rule, a condition \(-\mathrm{ c}{{\text{n}}}_{{\text{j}}}\) represents an attribute for which there is one lower limit value denotes by (\({\text{L}}\)) and one upper limit value denotes by (\({\text{U}}\)). The overlap happens if the data range of one category intersects with the data range of another. In the case of discrete attributes, the CTRENN considers each value and in the case of continuous attributes a defined range of values. CTRENN determines the probability (\({{\text{P}}}_{{\text{k}}}\), where \(\mathrm{k \epsilon }[1,\mathrm{ n}]\)) for each attribute value belonging to more than one class if the data spans for both classes. If \({{\varvec{P}}}_{{\varvec{k}}}>1/n\), where \({\varvec{n}}\) = number of classes, then it is allocated to the data range of that attribute for class \({\varvec{k}}\). Let the new minimum and maximum values of the attribute li for class Ck be \({{\varvec{m}}{\varvec{i}}{\varvec{n}}}_{{\varvec{i}}{\varvec{k}}}\) and \({{\varvec{m}}{\varvec{a}}{\varvec{x}}}_{{\varvec{i}}{\varvec{k}}}\). New \({{\varvec{D}}{\varvec{R}}{\varvec{M}}}_{{\varvec{i}}{\varvec{k}}}=\boldsymbol{ }{[{\varvec{m}}{\varvec{i}}{\varvec{n}}}_{{\varvec{i}}{\varvec{k}}},\boldsymbol{ }{{\varvec{m}}{\varvec{a}}{\varvec{x}}}_{{\varvec{i}}{\varvec{k}}}]\). The new rule set's classification accuracy is \({{\varvec{R}}}_{{\varvec{n}}{\varvec{e}}{\varvec{w}}{\varvec{a}}{\varvec{c}}{\varvec{c}}}\). Before updating rule-set R, the algorithm alters the \({{\varvec{c}}{\varvec{n}}}_{{\varvec{j}}}\) if \({{\varvec{R}}}_{{\varvec{n}}{\varvec{e}}{\varvec{w}}{\varvec{a}}{\varvec{c}}{\varvec{c}}}\ge {{\varvec{R}}}_{{\varvec{a}}{\varvec{c}}{\varvec{c}}}\), where \({{\varvec{R}}}_{{\varvec{a}}{\varvec{c}}{\varvec{c}}}\) is the classification accuracy. For each attribute, the rule change is repeated.
4 Experimental Results
Six authentic benchmark datasets from the UCI repository [33] were utilized to evaluate the proposed CTRENN method. Among the datasets, Breast Cancer was an example of continuous dataset, while the others were of mixed mode. Table 3 has a comprehensive overview of the six datasets.
Mean Square Error (MSE) of the network were utilized to find the optimal architecture with hidden nodes ranging from \(({\text{h}}={\text{l}}+1)\) to \(({\text{h}}=2*{\text{l}})\), where \({\text{h}}\) = number of hidden layer neurons and \({\text{l}}\) = number of input neurons plus one bias. Table 4 shows the optimal architectures for all datasets.
The following criteria’s were utilized to assess the performance of the model: tenfold Cross Validation (CV) accuracy, the average number of extracted rules (G.C.), the average number of antecedents (L.C.), the Recall, the Precision, the F-Measure and the FP-Rate. The tenfold CV method is widely regarded to minimize biases associated in validation. Two new pedagogical rule extraction models are used here to show the comparative performance of the CTRENN. Table 5 demonstrates the comprehensive comparison of CTRENN with RxREN and RxNCM using tenfold CV accuracy for each of the datasets. Figure 3 shows the graphical comparison of accuracy between the algorithms. The results show that CTRENN performs better than RxREN and RxNCM. Formulations have been stated in the following section.

Graphical Comparison of accuracy
The number of extracted rules gives a significance of the Global Comprehensibility (G.C.) of a rule set. This measure is useful in understanding the depth of the knowledge in the hidden layers of the neural networks. The number of antecedents gives a significance of the Local Comprehensibility (L.C.) of a rule set. This gives a measure of the significance of the attributes present in a rule. Table 6 shows the comparison between CTRENN, RxNCM and RxREN, with respect to L.C. and Table 7 shows comparison in terms of G.C. Comprehensibility is enhanced when the number of attributes is minimal. Figure 4a and 4b shows the graphical comparison of L.C. and G.C respectively among the algorithms. The results show that for all datasets CTRENN has both L.C. and G.C. higher than the other algorithms. Perhaps, the reason for this is that CTRENN uses separate rule generation procedures for discrete and continuous attributes/features. The higher number of rules results in a higher predictive accuracy but also results in lower comprehensibility.

a Graphical Comparison of L.C. b Graphical Comparison of G.C
Table 8, 9, 10, and 11 shows the comparison between CTRENN, RxNCM and RxREN in terms of Recall, Precision, F-Measure and FP-Rate. Fig. 5a and b shows the graphical comparison of Recall and Precision among the algorithms respectively. Fig. 6a and b shows the graphical comparison of F-Measure and FP-Rate among the algorithms respectively.

a Graphical Comparison of Recall. b Graphical Comparison of Precision

a Graphical Comparison of F-Measure Fig. 6b. Graphical Comparison of FP-Rate
The experimental results obtained above show that CTRENN is able to obtain better predictive accuracy than the other pedagogical algorithms – RxREN and RxNCM. It can be noted that RxREN and RxNCM do not distinguish between discrete and continuous attributes/features during rule generation. This leads to them always to have exactly 2 rules per rule set. In case of the CTRENN discrete and continuous attributes/features are separated for rule generation. This makes the classification rules produce higher predictive accuracy but suffers from having more rules per rule set. This leads to CTRENN to have worse comprehensibility than that of RxREN and RxNCM. Here, the compromise is between accuracy and comprehensibility.
All the results presented above show that the rules generated by the proposed algorithm are accurate and justifiable. And also, the rules generated are transparent enough to distinguish between different types of attributes making a decision.
5 Conclusion
The rule extraction algorithm CTRENN transforms a neural network from a black box to a white box structure by extracting the network's accumulated information as human-understandable rules. As the CTRENN algorithm follows the pedagogical approach to rule extraction, CTRENN extracts classification rules by utilizing the connection between the input and output layer neurons. The CTRENN improves upon the RxNCM algorithm by introducing three novelties. The novelties of the CTRENN algorithm lie in the network-pruning and rule-pruning phase, attribute separation into discrete and continuous sets, and the rule updating phase. To enhance the performance, the CTRENN algorithm utilizes the backward floating search strategy to prune the network and the rules. Moreover, Nesting effects which occur in the sequential feature selection approach are avoided using the backward floating technique. CTRENN uses separate methods for dealing with discrete and continuous attributes. For discrete attributes, IF-ELSE rules are generated using decision trees and for continuous attributes, the rules are generated using the corresponding attributes data range. To avoid the inherent overlap of classes, the CTRENN adopts a probabilistic method in rule updating phase. CTRENN eliminates overlap by changing upper and lower data-ranges based on the class likelihood of each attribute value.
Six real datasets from the UCI repository are utilized to validate the algorithm's performance. The results suggest that the proposed method is successful in terms of the accuracy and other performance metrics. When compared to the RxREN and RxNCM algorithms, the suggested CTRENN method generates more accurate but less comprehensible rules. Hence, the trade-off is between accuracy and comprehensibility. The presented rule extraction approach shows to be an effective tool for comprehending the decisions produced by a neural network in a human-understandable format. The algorithm has a wide range of applications, including medical diagnostics, financial issues, and more. To increase the comprehensibility of the ruleset, additional changes to the algorithm can be used to reduce the amount of produced rules. Data Range Calculation, Rule Construction, Rule Pruning, and Rule Updating process can be improvised to get better transparency with higher accuracy and comprehensibility. In this respect, further studies are required to make the model better in terms of comprehensibility with higher accuracy.
Data availability
The authors declare that the data supporting the findings of this study are available publicly, UCI repository [http://archive.ics.uci.edu/ml].
References
Han J, Pei J, Kamber M (2011) Data mining: concepts and techniques. Elsevier. https://doi.org/10.1016/C2009-0-61819-5
Midha N, Singh V (2015) A Survey on Classification Techniques in Data Mining. Int J of Comp Sci Management Stud 16(1):9–12
Mann AK, Kaur N (2013) Survey paper on clustering techniques. Int J Sci , Eng Technol Res 2(4):803–806
Shridhar M, Parmar M (2017) Survey on association rule mining and its approaches. Int J Comp Sci Eng (IJCSE) 5(3):129–135
Sharma AK, Sahni S (2011) A comparative study of classification algorithms for spam email data analysis. Int J Comp Sci Eng 3(5):1890–1895
Kaviani P, Dhotre S (2017) Short survey on naive bayes algorithm. Int J of Adv Eng Res Develop 4(11):607–611
Cohen S, Rokach L, Maimon O (2007) Decision-tree instance-space decomposition with grouped gain-ratio. Inf Sci 177(17):3592–3612. https://doi.org/10.1016/j.ins.2007.01.016
Mashayekhi M, Gras R (2015) Rule extraction from random forest: the RF+HC methods. In: Barbosa D, Milios E (eds) Advances in artificial intelligence. Canadian AI 2015. Lecture notes in computer science, vol 9091. Springer, Cham. https://doi.org/10.1007/978-3-319-18356-5_20
Kaikhah K, Doddameti S (2006) Discovering trends in large datasets using neural networks. Appl Intell 24(1):51–60. https://doi.org/10.1007/s10489-006-6929-9
Caruana R, Niculescu-Mizil A (2006) An empirical comparison of supervised learning algorithms. In: Proceedings of the 23rd International Conference on Machine Learning, pp 161–168. https://doi.org/10.1145/1143844.1143865
Dam HH, Abbass HA, Lokan C, Yao X (2007) Neural-based learning classifier systems. IEEE Trans Knowl Data Eng 20(1):26–39. https://doi.org/10.1109/TKDE.2007.190671
Mantas CJ, Puche JM, Mantas JM (2006) Extraction of similarity based fuzzy rules from artificial neural networks. Int J Approximate Reasoning 43(2):202–221. https://doi.org/10.1016/j.ijar.2006.04.003
Andrews R (1995) Inserting and extracting knowledge from constrained error back-propagation networks. In: Proceedings of the 6th Australian Conference on Neural Networks. NSW
Craven MW, Shavlik JW (2014) Understanding neural networks via rule extraction and pruning. In: Proceedings of the 1993 Connectionist Models Summer School. Psychology Press, pp 184–191
Botari T, Izbicki R, de Carvalho ACPLF (2020) Local interpretation methods to machine learning using the domain of the feature space. In: Cellier P, Driessens K (eds) Machine learning and knowledge discovery in databases. ECML PKDD 2019. Communications in computer and information science, vol 1167. Springer, Cham. https://doi.org/10.1007/978-3-030-43823-4_21
Bologna G, Hayashi Y (2018) A comparison study on rule extraction from neural network ensembles, boosted shallow trees, and SVMs. Appl Comput Intell Soft Comput 2018:1–20. https://doi.org/10.1155/2018/4084850.
Jivani K, Ambasana J, Kanani S (2014) A survey on rule extraction approaches based techniques for data classification using neural network. Int J Futuristic Trends Eng Technol 1(1):4–7
Augasta MG, Kathirvalavakumar T (2012) Reverse engineering the neural networks for rule extraction in classification problems. Neural Process Lett 35(2):131–150. https://doi.org/10.1007/s11063-011-9207-8
Biswas SK, Chakraborty M, Purkayastha B, Roy P, Thounaojam DM (2017) Rule extraction from training data using neural network. Int J Artif Intell Tools 26(03):1750006. https://doi.org/10.1142/S0218213017500063
Sestito S (1992) Automated knowledge acquisition of rules with continuously valued attributes. In: Proceedings of the 12th International Conference on Expert Systems and their Applications
Craven M, Shavlik J (1995) Extracting tree-structured representations of trained networks. Adv Neural Inf Process Syst 8
Towell GG, Shavlik JW (1993) Extracting refined rules from knowledge-based neural networks. Mach Learn 13(1):71–101. https://doi.org/10.1007/BF00993103
Lu H, Setiono R, Liu H (2017) Neurorule: a connectionist approach to data mining. arXiv preprint arXiv:1701.01358. https://doi.org/10.48550/arXiv.1701.01358
Setiono R, Liu H (1997) NeuroLinear: From neural networks to oblique decision rules. Neurocomputing 17(1):1–24. https://doi.org/10.1016/S0925-2312(97)00038-6
Gupta A, Park S, Lam SM (1999) Generalized analytic rule extraction for feedforward neural networks. IEEE Trans Knowl Data Eng 11(6):985–991. https://doi.org/10.1109/69.824621
Odajima K, Hayashi Y, Tianxia G, Setiono R (2008) Greedy rule generation from discrete data and its use in neural network rule extraction. Neural Netw 21(7):1020–1028. https://doi.org/10.1016/j.neunet.2008.01.003
Setiono R, Leow WK (2000) FERNN: An algorithm for fast extraction of rules from neural networks. Appl Intell 12(1–2):15–25. https://doi.org/10.1023/A:1008307919726
Hruschka ER, Ebecken NF (2006) Extracting rules from multilayer perceptrons in classification problems: A clustering-based approach. Neurocomputing 70(1–3):384–397. https://doi.org/10.1016/j.neucom.2005.12.127
Al Iqbal MR (2012) Eclectic rule extraction from neural networks using aggregated decision trees. In: 2012 7th International Conference on Electrical and Computer Engineering. IEEE, pp 129–132. https://doi.org/10.1109/ICECE.2012.6471502
Bhattacharya A, Parui, SK, Biswas SK, Mandal A (2023) An empirical study on credit risk assessment using ensemble classifiers. In: Chakraborty B, Biswas A, Chakrabarti A (eds) Advances in data science and computing technologies. ADSC 2022. Lecture notes in electrical engineering, vol. 1056. Springer, Singapore. https://doi.org/10.1007/978-981-99-3656-4_16
Bhattacharya A, Biswas SK, Mandal A (2023) Credit risk evaluation: a comprehensive study. Multimed Tools Appl 82:18217–18267. https://doi.org/10.1007/s11042-022-13952-3
Payrovnaziri SN, Chen Z, Rengifo-Moreno P, Miller T, Bian J, Chen JH, ... He Z (2020) Explainable artificial intelligence models using real-world electronic health record data: a systematic scoping review. J Am Med Inform Assoc 27(7):1173–1185. https://doi.org/10.1093/jamia/ocaa053
Dua D, Graff C (2019) UCI Machine Learning Repository [http://archive.ics.uci.edu/ml]. University of California, School of Information and Computer Science, Irvine
Acknowledgements
This research received no specific grant from any funding agency in the public, commercial, or not-for-profit sectors.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors declare no competing interests.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Biswas, S.K., Bhattacharya, A., Duttachoudhury, A. et al. Comprehensible and transparent rule extraction using neural network. Multimed Tools Appl 83, 71055–71070 (2024). https://doi.org/10.1007/s11042-024-18254-4
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11042-024-18254-4