
Abstract
Region growing, clustering, and thresholding are some of the segmentation techniques that are employed on images. K-means clustering is one of the proven efficient techniques in color segmentation. Finding the value of K that produces the most effective segmentation results is a crucial research issue. In this paper, we suggested an algorithm to determine the optimal K using the Gray Level Cooccurrence Matrix (GLCM). We retrieve the correlated features from the GLCM and calculate their aggregate probability of occurring given the pixel pairings. The number K is represented as spikes in this correlation. The results demonstrated our algorithm’s excellent efficiency, with 98% percent accuracy.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
Image segmentation is the process of breaking a picture into groups of pixel regions that are each represented by a mask or labeled image. By splitting an image into segments, you can process only the necessary regions rather than the complete image. Image segmentation aims to turn an image’s representation into something more insightful and understandable. It is typically used to identify objects and define boundaries; more precisely, it is the classification of an image into various categories. The process of image segmentation is to provide each pixel in an image a label such that pixels that have the same label have specific properties. If we wish to examine what is inside the image, image segmentation is a crucial phase in the image processing process that appears everywhere. For instance, if we want to determine whether a chair or a human is there in an indoor image, image segmentation may be required to separate the objects and then analyze each object separately to determine what it is. Image segmentation usually serves as the preprocessing before pattern recognition, feature extraction, and compression of the image.
Image segmentation has various applications, including, but not limited to, self-driving automobiles, healthcare, medical imaging, autonomous driving, and a variety of other fields.
A common technique is to look for abrupt discontinuities in the pixel values, which typically indicate edges that define a region. Another common approach is to detect similarities in the regions of an image. Some techniques that are used in region growing, clustering, and thresholding. In this article, we will discuss GLCM with K-means clustering. K-means is an unsupervised clustering algorithm which means that there is no labelled data available. It is used to identify different classes or clusters in the given data based on the similarity of the data. The data points in the same group are more similar to other data points in that same group than those in other groups. In image segmentation, the K-means algorithm is used to segment colors into related groups. It clusters, or partitions the given data into K-clusters or parts based on the K-centroids. The goal is to find certain groups based on some kind of similarity in the data with the number of groups represented by K. A co-occurrence matrix, also known as a co-occurrence distribution, is the allocation of co-occurring data at a particular offset across an image. Alternatively, it measures the length and angular spatial connection across a given picture sub-region. A grayscale image is used to build the GLCM, The GLCM estimates how frequently a pixel with gray-scale (gray-scale intensities or tone) value X appears vertically, diagonally, or horizontally to neighboring pixels with value Y.

GLCM matrix with the 4 major angles, each is represented in different color
As shown in Fig. 1, the formation of the GLCM matrix for various colors represent different directions for computing the frequency of varying combinations of components:
-
\(0^o\) is the Blue color
-
\(45^o\) is the Orange color,
-
\(90^o\) is the Green color,
-
\(135^o\) is the Gray color.
G1 (5, 4) = 2 is plainly visible in Fig. 1, indicating that elements ’5’ and ’4’ appear in pairs in the \(0^o\) direction twice in matrix M. (displayed as blue borders in the matrix in Fig. 1). Similarly, G2 (1, 2) = 3 denotes that entries ’1’ and ’2’ appear in pairs in the \(45^o\) direction three times in matrix M. (displayed like Orange color borders in matrix in Fig. 1). From GLCM we can calculate 3 important features as:
-
Construct: Local differences in the gray-level co-occurrence matrix are measured.
-
Energy: The sum of squared items in the GLCM is returned. Uniformity or the angular second moment are other terms for the same thing.
-
Homogeneity: The distance between the GLCM diagonal and the allocation of components in the GLCM.
-
Correlation: The combined likelihood of occurrence of the provided pixel pairings is calculated.
Image segmentation is an essential phase of image analysis and study. image segmentation can be defined as the method of dividing an image into different groups of pixels, each represents an object or a segment from the original image based on pixels properties. Segmentation plays an important role in many applications, such as object detection and classification, scene understanding, medical image analysis, robotic perception, video surveillance, and many others [1].
Different techniques were developed for segmenting images, several algorithms were proposed for each technique. Common image segmentation techniques can be classified as thresholding, clustering, edge, regional and other segmentation methods [2,3,4]. The author of [5] invented a novel approach in speading up image segmentation. Our proposed technique will be to use correlation in image segmentation.
2 Literature review
There are many papers discussed using GLCM in image segmentation and classification like [6]. Biometrics are a type of authentication that uses the subject’s physiological and behavioral traits. Of all the qualities, the iris is most suitable for biometric applications. A novel iris identification approach based on co-occurrence characteristics and neural network classification is provided in this research. The Correlation - based features are extracted using the gray level co-occurrence matrices, that are being used to build the neural network classifier. Various factors, such as the number of neurons in the hidden layer, the training functions, and the performance functions, are also examined. Experiments on the IITD iris database confirmed the effectiveness of the described technique. The suggested technique achieves the highest accuracy of 97.83 percent, which is comparable to state-of-the-art approaches.
The authors in [7] demonstrate that breastcancer is one the most prevalent diseases affecting women globally. Traditional methods for segmenting and classifying cancer cells are not always time-consuming, but are also repetitious. As a result, for automated segmentation and categorization of tumor tissue in breast cytology pictures, computer-aided analysis is required. In this study, a machine learning-based strategy is proposed for tumor cell classification and segmentation in breast cytology pictures. In the suggested method, cells are segmented using a level set technique, which is then utilized to obtain statistical information about cancer and normal cells. To utilize textural information, the gray-level co-occurrence matrix is calculated, and support vector machine-based classification and employed to classify cancerous and normal cells. Experiments revealed that the suggested method classified cancerous and normal cells with excellent precision (96.3%).
The picture is a crucial tool for humans to comprehend the world. The objective of image recognition research is to find out how to build a computer that can recognize images. Image segmentation technology has become an important direction for future research in image recognition. The gray-gradient maximum entropy approach is used to extract features from the picture. The K-means method is used to classify the images, and the results are evaluated using average precision (AP) and intersection over union (IU) assessment methods. The findings reveal that the K-means approach is quite effective at picture segmentation [8].
Another paper, [9] discussed numerous segmentation strategies used to medical photos in this study, emphasizing that neither of these problem spots has been satisfactorily resolved, and all of the techniques presented are open to significant improvement. We estimate that because LBM has the advantages of speed and adaptability of modeling to provide outstanding image processing quality with a reasonable number of computer resources, it’ll become a new study hot spot in image analysis.
Due to the spectrum resemblance of various crops, crop categorization in early phonological phases has proven problematic. Low-altitude platforms, such as drones, offer a lot of potential to provide high-resolution optical footage that may be used to identify different types of crops using MachineLearning (ML). Crop categorization is accomplished at various phonological phases using optical pictures taken from a drone in this study. Gray level co-occurrence matrix (GLCM)-based characteristics are derived from the vehicle’s base grayscale photos for this aim. ML methods such as support vector machine (SVM), naive Bayes (NB), random forest (RF) and neural network (NN) are used to categorize kinds of crops. The findings indicated that the machine learning algorithms performed much better on GLCM characteristics than the grayscale photos, with an accuracy rate margin of 13.65% [10].
The research in paper [11] also states that Covid-19 is a relatively emerging pandemic. The examination of the patient’s clinical signs and kit testing are used to diagnose associated disorders early. We suggest an effective classification approach to histogram equalization (HE), gray-level co-occurrence matrix (GLCM), and support vector machine (SVM) algorithms to diagnose this illness easily and automatically. As our first-hand data set, we collected 148 CT scans of healthy people and 148 CT images of patients, totaling \(512 \times 512 \times 3\). We center trimmed the photographs to \(400 \times 400 \times 3\) to emphasize the characteristics of the images. GLCM is an effective approach for extracting texture characteristics, and SVM may be used to effectively categorize them, the findings reveal that our system’s accuracy rate is higher than other commonly used approaches. The effectiveness of our suggested approach for the identification of Covid-19 is satisfactory. Another paper, [12], discusses the same. Gray-level co-occurrence matrix (GLCM) analysis is a cutting-edge computational tool for assessing textural patterns that may be used in nearly any microscopy application.
The goal of our study is to analyze nucleus in Saccharomyces cerevisiae yeast using GLCM after inducing sub-lethal cell damage with alcohol, and to compare the efficiency of different machine learning (ML) models in separating injured from undamaged cells. The second central moment, inverted difference moment, GLCM contrast, GLCM correlation, and textural variance were calculated for each cell nucleus. We used three machine learning algorithms to analyze the GLCM data: neural networks, random forests, and binomial logistic regression, comparing untreated and treated cells, statistically meaningful variations in GLCM characteristics were found. The classification accuracy of the perceptron neural network was the best. The model also had a high level of sensitivity and specificity, as well as great discriminating power when it came to distinguishing between treated and untreated cells. To the best of our knowledge, this is the first work to show that a GLCM-based ML model can be used to identify liquor damage in Saccharomyces cerevisiae cell nuclei with reasonable sensitivity.
Another paper [13] stated that image processing is a novel technique for transforming a real image into a clear digital image by applying numerous functions to it. However, it is a difficult assignment for medical professionals. The segmentation of images presents a considerable challenge due to reduced contrast and artefacts at the boundaries edges. As a result, an efficient and adaptable fuzzy GLCM-based segmentation approach was suggested in this study. The photos are the result of a bronchoscopy procedure. The ultimate purpose of the proposed methodology was to accurately recognize lung cancer, which is segmented. The adaptable F-GLCM segmentation method allows for the early and simple diagnosis of lung cancer, which benefits both physicians and patients by allowing adequate starting medication.
Although the paper [7] studied breast cancer and stated that it is among the most common diseases affecting women around the world. The traditional techniques for segmenting and classifying cancerous cells are not only repetitious, but also time-consuming. As a result, for automated segmentation and categorization of tumor tissue in breast cytology pictures, computer-aided analysis is required. In this study, a machine learning-based strategy is proposed for the detection and segmentation of malignant cells in breast histology pictures. A level set technique is employed to obtain statistical data about malignant from benign cells in the suggested approach for cell segmentation.To utilize textural data, the gray level co-occurrence matrix is produced, and support vector machine-based identification is applied for the categorization of cancerous and normal cells. Tests revealed that the proposed method obtained great precision (96.3%) in the identification of malignant and benign cells.
The purpose of the paper [14] is to see how far the cytoplasmic image segmentation technique that uses a single cell picture can provide texture and form analysis characteristics. This study used the RGB to HSV color conversion technique, which generates metric and irregularity values, to examine the shape of the cytoplasmic. The procedure of thresholding a picture and counting the broad area is then completed by converting the cutoff to a binary image. On the other hand, this study used the gray-level co-occurrence matrix (GLCM) and the K-means approach to generate contrasting, correlated, energy, and uniformity characteristics to examine the texture. The segmentation result for a normal single cell image sample of Pap smear was used to provide metric, contrasting, correlation, energy, and uniformity characteristics.
There are also many papers put huge effort in studying image classification and feature extrcation, such as: [15,16,17].
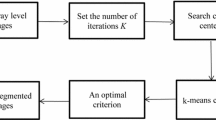
3 Methodology
One of the most important issues in K-means is to find the value of K, so that it gives optimal results. The correct choice of K is often ambiguous, with interpretations depending on the shape and scale of the distribution of points in a data set and the desired clustering resolution of the user. In addition, increasing K without penalty will always reduce the amount of error in the resulting clustering, to the extreme case of zero error, if each data point is considered its own cluster (i.e., when K equals the number of data points, n). Intuitively, then, the optimal choice of K will strike a balance between maximum compression of the data using a single cluster and maximum accuracy by assigning each data point to its own cluster.
Based on previous studies, our research is based on a combination of GLCM with K-means, so that we apply the GLCM features that come from GLCM. We can extract the chart from the features that produce spikes.
Thus, we will compute the number of spikes in the chart, from which we use this number as the number of clusters that used in K-means to segment the data.

Our Methodology
As shown in Fig. 2, our algorithm starts with taking the image and converting its RGB color system to the LAB system. L, a, and b are the three dimensions used to differentiate colors. The program calculates a value for this kind of color based on these three parameters. Every color has a unique identification value, and that is how the computer recognizes various hues. In the CIELab color space, the difference across black and grays in an image is represented by lightness. aandb are multicolored, showing every unit in contrast to its corresponding color.
After we convert the image to the LAB color space, we take each layer (dimension) separately and calculate the GLCM for each layer.

GLCM for the lightness layer in Lab

Detected spikes in Energy distribution
As shown in Fig. 3, which is a co-occurrence matrix, also known as a co-occurrence distribution, is the allocation of co-occurrence data at a particular offset across an image. Alternatively, it measures the length and angular spatial connection across a given picture sub-region, so the Matrix is created. Not only the matrix lightness layer (gray image) is created, but also the matrix for each layer of the image. Thus, the output is the matrix for L, the matrix for a, and the matrix for b are created, and the matrices are constructed. After that, normalization for the GLCM matrix is applied to allow calculating the features in the image. Then we calculated the features for the Matrix, from which the outputs will be Energy, Homogeneity, Correlation, and Construct; in this case, we relied on the first two, namely, Energy and Homogeneity, because they both focus on the uniformity of the data within the image. We calculate the energy using the equation
where \(P_{i,j}\) is an item of the normalized GLCM. The Homogeneity also is calculated using the equation:
Then we calculate these features for each layer of the CIE Lab separately and then take the average of these two features (Energy, Homogeneity) in the three layers.
The energy feature histogram in Fig. 4 shows the concentration and distribution of the elements in GLCM, which in turn shows the degree of uniformity (Energy) within the image.
After calculating the energy and homogeneity, the number of spikes in each feature is calculated.
Figure 4 shows the number of spikes in the Energy feature, which represents the extent of data concentration in positions and the extent of its decrease in other positions after calculating the number of spikes for the energy and homogeneity features.
If K is calculated from the average of the two values of energy and homogeneity as \(K = \frac{E + H}{2}\), the values of K are huge and don’t give suitable results. Therefore, we have applied the FreeDman-Diaconis rule that reduces the number of these values. FreeDman-Diaconis rule is very robust and works well.
FreeDman-Diaconis uses the equation \(K = 2 \times \frac{IQR}{\root 3 \of {n}}\) where IQR is the interquartile of the values, n is the number of values. To calculate the IQR, the equation \(IQR=Q3-Q1\) is used, where Q1 and Q3 are the first and third quartiles, respectively.
The Freedman-Diaconis rule Energy for homogeneity is calculated from the IQR.
We then calculate the average value for the result between the result of the Freedman-Diaconis rule for energy values and the result of the Freedman-Diaconis rule for homogeneity values.
where FE is the result of Freedman- Diaconis rule for Energy values and FH is the result of Freedman- Diaconis rule for homogeneity values.
The value of K is calculated from the last equation, which indicates the number of clusters that we want to apply in K-means.
K is a value that symbolizes the degree to which a difference is found between each focus of the data in one place and another, which in turn shows that the objects are located in the image.
The segmentation of the image is processed using K-means clustering algorithm and the value of K is that calculated previously.
After segmentation, we enter the results into a convolution neural network (CNN) to recognize the type of object inside the segmented image (Fig. 5).

Output of the CNN after applying it on segments come from our methodology
4 Result
We also used the deep learning algorithm in CNN for the classification process, especially vgg16, which is one of the most famous examples of CNN, and it is generally a deep-trained neural network on the famous dataset, which is imagenet. However, we re-trained it using another dataset called FMD (Flickr Material Database) [18].
The Flickr Material Database (FMD) is a growing collection of textural photos from the wild that have been tagged with a set of human-centric qualities based on texture perception. For the sake of study, these data can be made accessible to the field of computer vision. FMD is a texture collection of 5640 photos that are categorized using a set of 47 phrases (classes) based on human vision. Each class has 120 photos. The photos are among \(300 \times 300\) pixels and \(640\times 640\) pixels in size, and they comprise at least 90% of the total area reflecting the class property.
By using our suggested qualities and associated phrases as search queries, we were able to collect photographs from Google and Flicker. Amazon Mechanical Turk was used to annotate the photographs in numerous rounds. We give a key attribute (primary class) and a set of joint characteristics for each image. We implemented our work on IMAC I7 with 16GB RAM using Python and the openCV library, which is used for image processing in general, and we also used the tensorflow library provided by Google that provides algorithms for Neural Network and also deep learning such as vgg16.
After we trained VGG16 on the FMD dataset, we made a test for our model and the results were as follows in Figs. 6 and 7.

Output of VGG16 after applying it on segments come from our methodology for Group texture
As shown in Fig. 6, an algorithm was able to distinguish textures with high accuracy, as some results reached more than 98%.
Here is the strength of GLCM merging, which shows its strength in texture operations because it contains many features that distinguish each texture from the other with the K-means algorithm in image processing where we were able to extract the best value of K to get the best results in classification operations.
Figure 7 is another example that shows how efficient our algorithm is. The lowest result that could distinguish a texture was more than 91%.
We have applied our algorithm to more than one deep learning algorithm (CNN types), where we focused on 3 algorithms, VGG16, resnet50, and inception-v3. The results are shown in Table 2.
As shown in Table 1, our model achieved high results in FMD dataset, where the average of accuracy was 82.27%, and the average of precision was 81.45%, and the average of recall was 81.68%. If we look at the f1-score, its results are high with a value of 81.43%.
If we look closely at the Table 1, we find that the Foliage class obtained the highest results in terms of accuracy with a value of 87.48%, precision with a value of 86.4%, and recall with a value of 86.4%. It automatically obtains the highest result in the f1-score with a value of 86.4%.
The graph in Fig. 8 shows the strength of our model and shows the result for all the classes in the data set. The average was 82.27% in terms of accuracy, and shows that the best class was Foliage with the result of 87. 48% in terms of accuracy.

Output of VGG16 after applying it on segments come from our methodology for Group of textures
As shown in Table 2, VGG16 may be slightly better suited for texture classification due to its deeper network structure, and VGG16 is a deep network that can learn complex features.
As shown in Table 3, results using LAB get better accuracy than using RGB, and that is because LAB color space is perceptual.
4.1 Comparisons
As shown in Table 4, we have compared a group of popular models in this context with our own model. The results show that our model is clearly superior to the existing models. Our model in terms of vgg16 got 82.27% compared to vgg16 without using modification, where it got 65.43%, which is a large and clear difference.
It is also clear that when adding our modification to all models, it was greatly affected in terms of accuracy. For example, inceptionv3 improved from 62.74% to 79.12%.

Chart of result of Accuracy , Precision , Recall and f1-score for our model
As shown in Table 5, the proposed model is used with some general models. It is found that our proposed model clearly improved the results of general models. The proposed model improved the accuracy by around 16%, and these are great results and evidence of the strength of our model.

Loss vs. epoch between VGG16 without our modification and VGG16 with our modification
As shown in Fig. 9, where our model has reached the stability in a loss way and with a clear difference from the general model, and this indicates the strength of our model and also the acceleration of the descent of the model to stability is clear.
As shown in the graph of Fig. 10, here we compared our model with the general model, and we found that our model outperformed the general model with a clear result, as it outperformed it in the four criteria.

Chart comparing result from our model and others from normal CNN

Chart of result of Accuracy , Precision , Recall and f1-score for Our model Vs. Competitor models in Clustering

Chart of result of Accuracy , Precision , Recall and f1-score for Our model Vs. Competitor models in classification
The graph in Fig. 11 shows the strength of our model and shows the result for other models in clustering. The average was 82.27% in terms of accuracy and its the best result over all other models and shows the strength of merging the GLCM Features spikes model with FreeDman-Diaconis to get a value of K.
The graph in Fig. 12 shows the strength of our model and shows the result for other models in classification. The average was 82.27% in terms of accuracy and its best result over all other models and shows the strength of merging the GLCM principle with passion with deep rage to get the result.
4.2 Other segmentation results
The following figure (Fig. 13) shows the segmentation results for the images of the previous examples and using the calculated K for each image.

The segmentation results
As shown in Table 6, comparison between different technique in clustering as shown our model get the best result because is get specific number of centroid and make reduction on it.
As shown in Table 7,comparison between different technique in texture classification on feature extraction with VGG16 as shown our model get the best result because is get best accuracy , precision and recall because of our model extraction the feathers in many direction
5 Conclusion
In this article, we discussed an algorithm that uses GLCM (Gray Level Co-occurrence Matrix) to find the optimum K for K-means clustering algorithm, which is one of the crucial issues that makes the K-means either a success of a failure. In our paper, we extracted the correlation features of GLCM to get the combined likelihood of occurrence of the provided pixel pairings. This correlation gets spikes. These spikes are computed and given to the value of K. The image could be segmented using the K-means clustering and using the calculated K. To compare our results to others, 5640 images from the Flickr Material Database (FMD) are exposed to our technique. The results showed the efficiency of our algorithm and proved that the accuracy reached 82.27%.
Data Availability Statement
The data that support the findings of this study are available from Flickr Material Database (FMD), and well cited. These data were derived from the FMD and are available in the public domain: https://people.csail.mit.edu/celiu/CVPR2010/FMD/. No restrictions apply to the availability of these data, which were used under license for this study.
References
Sultana F, Sufian A, Dutta P (2020) Evolution of image segmentation using deep convolutional neural network: a survey. Knowl-Based Syst 201:106062
Yuheng S, Hao Y (2017) Image segmentation algorithms overview. arXiv preprint arXiv:1707.02051
Jeevitha K, Iyswariya A, RamKumar V, Basha SM, Kumar VP (2020) A review on various segmentation techniques in image processing. Eur J Mol Clin Med 7(4):1342–1348
Anjna E, Kaur ER (2017) Review of image segmentation techniques. Int J Adv Res Comput Sci 8(4):36–39
Sbaha M (2023) A novel approach for k-means optimization in image segmentation. In: INTIS 2023: \(11_{th}\) International conference on New Technologies, artificial Intelligence and Smart data, SPIE, Tangier, Morocco, vol 11, pp 51–58
Vyas R, Kanumuri T, Sheoran G, Dubey P (2017) Co-occurrence features and neural network classification approach for iris recognition. In: 2017 Fourth International Conference on Image Information Processing (ICIIP), pp 1–6. https://doi.org/10.1109/ICIIP.2017.8313730
Khan SU, Islam N, Jan Z, Haseeb K, Shah SIA, Hanif M (2022) A machine learning-based approach for the segmentation and classification of malignant cells in breast cytology images using gray level co-occurrence matrix (GLCM) and support vector machine (SVM). Neural Comput & Applic 34(11):8365–8372
Shan P (2018) Image segmentation method based on k-mean algorithm. EURASIP J Image Video Process 2018(1):1–9
Ramesh K, Kumar GK, Swapna K, Datta D, Rajest SS (2021) A review of medical image segmentation algorithms. EAI Endorsed Trans Pervasive Health Technol 7(27):e6
Iqbal N, Mumtaz R, Shafi U, Zaidi SMH (2021) Gray level co-occurrence matrix (GLCM) texture based crop classification using low altitude remote sensing platforms. PeerJ Comput Sci 7:536
Chen Y (2021) Covid-19 classification based on gray-level co-occurrence matrix and support vector machine. In: COVID-19: Prediction, Decision-Making, and its Impacts, Springer, pp 47–55
Davidovic LM, Cumic J, Dugalic S, Vicentic S, Sevarac Z, Petroianu G, Corridon P, Pantic I (2022) Gray-level co-occurrence matrix analysis for the detection of discrete, ethanol-induced, structural changes in cell nuclei: an artificial intelligence approach. Microsc Microanal 28(1):265–271
Yamunadevi M, Ranjani SS (2021) Efficient segmentation of the lung carcinoma by adaptive fuzzy-GLCM (AF-GLCM) with deep learning based classification. J Ambient Intell Humanized Comput 12(5):4715–4725
Merlina N, Noersasongko E, Nurtantio P, Soeleman M, Riana D, Hadianti S (2021) Detecting the width of pap smear cytoplasm image based on glcm feature. In: Smart Trends in Computing and Communications: Proceedings of SmartCom 2020, Springer, pp 231–239
Wu Y, Mu G, Qin C, Miao Q, Ma W, Zhang X (2020) Semi-supervised hyperspectral image classification via spatial-regulated self-training. Remote Sens 12(1):159
Ma X, Zhou Y, Wang H, Qin C, Sun B, Liu C, Fu Y (2023) Image as set of points. arXiv preprint arXiv:2303.01494
Qin C, Gong M, Wu Y, Tian D, Zhang P (2018) Efficient scene labeling via sparse annotations. In: Workshops at the Thirty-Second AAAI Conference on Artificial Intelligence
Liu C, Sharan L, Adelson EH, Rosenholtz R (2010) Exploring features in a bayesian framework for material recognition. In: CVPR, pp 239–246
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
The authors declare that they have no financial or personal relationships that could have inappropriately influenced this work.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Sabha, M., Saffarini, M. Selecting optimal k for K-means in image segmentation using GLCM. Multimed Tools Appl 83, 55587–55603 (2024). https://doi.org/10.1007/s11042-023-17615-9
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11042-023-17615-9