
Abstract
Bearing fault diagnosis is a serious problem on which researchers have focused to ensure the reliability and availability of rotating machinery. Knowledge-based methods are capable of providing promising solution to bearing diagnosis problem with high accuracy performance thanks to effectively processing collected sensor and actuator data. Deep learning (DL) has the advantage of ignoring feature extraction and providing accurate diagnosis among the machine learning algorithms. In order to address this issue, in this paper, a novel DL based model is presented for fault detection and classification of motor bearing. In this work, first, time domain signals are converted to images by a proposed signal-to-image conversion approach. Then, the converted gray-scale images are fed into a novel deep residual learning (DRL) network structured to learn end-to-end mapping between images and health condition of the motor bearing. The performance of the proposed DRL network is evaluated on a commonly used real vibration dataset provided by Case Western Reserve University (CWRU). Experimental results obtained for 10 different health condition demonstrate encouraging and outperforming performance with an average accuracy of \(99.98\%\) compared to the state-of-art knowledge-based bearing fault diagnosis methods.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
Early detection of faults occurred in rolling bearings utilized in industrial systems is crucial to improve the reliability and availability of the systems [38]. Because an undetected fault may affect and damage other components of the system through chain reaction. As a result, it can jeopardize something invaluable, such as human health, and can lead to the collapse of the whole system and enormous economic losses [14].
Model-based, signal-based and knowledge-based fault diagnosis, and the combination of these methods named as hybrid fault diagnosis are the available approaches for general fault diagnosis [11]. In model-based fault diagnosis methods, the models of each industrial processes or components are determined either theoretically or utilizing system identification approaches in order to observe the consistency between predicted system output using system model and the real-time system output [11]. Signal-based fault diagnosis methods, which can be employed both in time and frequency domain, base on signal patterns of the regular systems instead of exact system models [28]. Unlike model-based and signal-based fault diagnosis methods, knowledge-based fault diagnosis approaches do not require neither an exact model nor signal patterns of the regular systems. However, a considerable data obtained from previous processes of the industrial system is necessary to construct a relation between raw data and its outcome [21]. Thanks to rapid development of the Internet, wireless sensors and actuators, and the smart industry, data collection has become easier and has lead researchers to use the power of big data for fault diagnosis [4].
The literature reports several research works focusing on dealing with the big data in knowledge-based fault diagnosis. K-nearest neighbor (kNN) [1], support vector machine (SVM) [22, 31], random forest (RF) [33], and artificial neural network (ANN) [7] are the available machine learning classifiers utilized for bearing fault diagnosis. Although the mentioned machine learning classifiers have been presented to be effective for bearing fault diagnosis, such conventional machine learning techniques are restricted in their ability to process the raw input data [24]. These approaches build classifiers based on handcrafted features computed from the raw inputs using feature extraction algorithms. Note that this feature extraction process requires domain expertise to design a feature extractor and therefore greatly affects the classification result [16].
Deep learning (DL) is a branch of representation learning which receives raw data as input and automatically explores the representations required for classification without human engineers [24]. DL has become more popular recently because of the increase in the amount of data, in Graphics Processing Unit (GPU) and the processing power and depth of the model. Therefore, several DL methods such as Convolutional Neural Network (CNN) [35], Stacked Auto-Encoder [34], Deep Belief Network (DBN) [30], Deep Boltzmann Machine [18], Recurrent Neural Network [6] have been approaching the area of bearing fault diagnosis as in computer vision, natural language processing and recommender systems etc.
CNN is the most popular algorithm of DL in bearing fault diagnosis. Since 1D data in time domain can be presented in space domain as 2D data, some researchers convert 1D signal to 2D data to utilize the great discriminating ability of CNN model. In this article, a deep residual learning (DRL) based network model dealing with raw 2D data directly is proposed for bearing fault diagnosis. The proposed model has the advantage of end-to-end mapping between raw 2D images converted from vibration signals and health conditions of the bearings. To the best of authors’ knowledge, this constitutes a novel study to solve the bearing fault diagnosis problem through DRL scheme. The experimental results indicate that the proposed DRL based network model has significant potential for bearing fault diagnosis since it outperforms several traditional machine learning methods and DL methods.
The motivation of this study is given as three folds:
-
1.
Researchers have been paying attention to bearing fault diagnosis to overcome or reduce safety hazards, unscheduled breakdown and performance reduction of rotating machinery. This issue has not been fully solved.
-
2.
Recently, DL based approaches have been started to be used in fault diagnosis area and reasonable results have been achieved. Furthermore, DL based approaches learn end-to-end mapping between input and output by ignoring feature extraction step.
-
3.
Changing domain of an input data may result in better classification accuracy. Therefore, time-domain signals acquired from bearing motor are converted into gray scale images and fed into the developed DL network.
The main contributions of this paper can be summarized as follows.
-
1.
Following the principle from deep residual networks [17] and new trends in bearing fault diagnosis, a novel deep residual learning based network model, referred as DRL, consisting of three sub-networks to classify the mechanical faults in a diagnosis system is proposed. In the feature representation sub-network, a convolutional layer followed by activation function and batch normalization (BN) layer is used to learn representative features from 2D images. Then, in the second sub-network, DRL fulfills the task of fault diagnosis. Finally, the health conditions are classified in classification sub-network. The proposed method achieves more accurate classification results without manually extracted input features. Nevertheless, the usage of residual network architecture further advances the classification performance without an evident increment on computational complexity.
-
2.
Two different scenarios based on the number of residual block and the usage of BN layer are thoroughly studied to determine the best DRL network model. In the first scheme, various network models are structured in order to analyze the effect of the number of residual block to the classification result. Then, the effect of the BN layer is studied by training a proposed network model only without the BN layer and comparing the results in detail.
-
3.
The proposed network model is compared with the several state-of-the-art machine learning based methods with hand-crafted features and DL based methods. The comparison results on a well-known benchmark dataset corroborates the superiority of the proposed model by outperforming the state-of-the-art methods.
The rest of this paper is organized as follows. Related works are presented in Sect. 2. The details of the proposed deep residual network architecture are given in Sect. 3. Section 4 presents a case study of bearing fault diagnosis to demonstrate the effectiveness of the proposed method. Conclusions are drawn in Sect. 5.
2 Related works
The related works reported in this section categorized into two section: 1) Knowledge-based fault diagnosis presenting recently proposed knowledge-based fault diagnosis studies for bearing fault diagnosis and 2) Residual learning and skip connection, and batch normalization presenting main sub-topics related to the proposed DRL network methodology.
2.1 Knowledge-based fault diagnosis
Although fault diagnosis approaches can be categorized into model-based, signal-based and knowledge-based fault diagnosis, and the combination of these methods [11], only knowledge-based fault diagnosis studies are presented in this sub-section because of the fact that they have the advantage of constructing the relationship between raw measured data and its outcome [21]. When complex industrial systems are considered, it is difficult to have exact system models or signal patterns of the regular systems [28].
Wen et al. [35] studied on a CNN-based method for fault diagnosis. The proposed CNN method inspired by LeNet-5 applied a commonly used motor bearing dataset which has 1D raw signals. The researchers converted these 1D raw signals into 2D gray-level images and obtained a dataset containing images. The obtained results indicate that the proposed CNN-based method has high potential for bearing fault diagnosis. Xia et al. [36] developed a CNN-based model utilizing 1D raw vibration signals of bearings for fault diagnosis. The authors demonstrated the effect of the using multiple sensors instead of utilizing a single one. Lei et al. [25] presented a two-stage learning method based on unsupervised feature learning for bearing fault diagnosis. The proposed approach uses 1D raw vibration signals to extract discriminative features by sparse filtering in the first stage. Then, softmax regression is employed to classify health conditions of the bearings. Guo et al. [13] proposed deep convolutional transfer learning network inspired by transfer learning for bearing fault diagnosis. The proposed approach is a two-stage approach, one of which use 1D CNN to learn the discriminative features from 1D raw signals and to classify the health conditions of the bearings. Wen et al. [34] studied on a deep transfer learning approach using 1D raw vibration signals of bearings for bearing fault diagnosis. A three-layer sparse auto-encoder is employed to extract the discriminative features from the raw data. The proposed approach tested on a commonly used motor bearing dataset and achieved better classification accuracy than traditional machine learning approaches. Liu et al. [26] proposed a solution for bearing fault diagnosis. The solution bases on deep adversarial domain adaptation model in which feature learning and a deep stack autoencoder are integrated to extract more effective fault features. That classification accuracy obtained by using the proposed model superior than other existing machine learning and deep learning methods is demonstrated in the study. Janssens et al. [20] developed a CNN model to learn features of 1D raw vibration signals of bearings and monitor the health condition of them. Guo et al. [15] studied on hierarchical deep CNN model for the fault diagnosis of rolling bearings. The researchers proposed an adaptive learning rate for the model and validated its superiority to traditional CNN. Ding and He [8] presented a deep convolutional network based bearing fault diagnosis method in which raw vibration signals were converted to 2D images. Eren [9] proposed a bearing fault detection system based on 1D CNN. The relation between raw vibration signals and health condition of bearings were learned by the network. Chen et al. [5] presented a DL based approach to improve the classification performance of bearing faults. Cyclic spectral analysis was utilized to acquire discriminative patterns for the type of bearing faults. Then, a CNN model was developed to classify faults thanks to high level feature learning ability. Xu et al. [37] proposed a hybrid DL model containing both a CNN model and deep forest model for bearing fault diagnosis. The CNN model was employed to extract features from time-frequency images obtained from vibration signals and extracted fault features fed into a deep forest classifier. Khorram et al. [23] studied an end-to-end DL method focusing on raw time-domain data for bearing fault diagnosis. The model was a combination of CNN and Long-Short-Term-Memory (LSTM) models and the model directly used raw vibration signals without any preprocessing or transformation method.
In this study, a novel DRL based network model is proposed for bearing fault diagnosis. Instead of using hand-crafted features suffering from limited representation capability for accurate classification, the proposed model learns the features with end-to-end mapping. In order to make the experimental results more robust, the effect of the number of residual block and the BN layer to the classification result are analyzed.
2.2 Residual learning and skip connection, and batch normalization
In the following, two methods related to the proposed study, i.e. residual learning and skip connection, and batch normalization are briefly reviewed.
-
1.
Residual learning and skip connection: Increasing the model complexity by stacking more layers in order to solve more complex task causes lower training accuracy. Besides, when the network goes deeper, it is hard to train it effectively. Another problem faced by deep CNN model is vanishing/exploding gradient during backpropagation which stops the network from converging. A residual learning scheme for CNN structure was originally proposed by He et al. [17] to address the aforementioned problems. Instead of desired original mapping, the residual mapping which is the difference between the layer output and ground truth is learned. Therefore, the optimization of deep CNN becomes easier and the accuracy is improved with such a DRL scheme. The residual mapping can be realized by skip connections skipping one or more layers. Therefore, skip connections act as an identity mapping and element-wise addition is performed between the outputs of the stacked layers and shortcut connections [2, 29, 32]. Using such connections makes the network easier to be optimized and gains classification performance in deeper networks unlike plain networks. The proposed model adopts the residual learning scheme with identity skip connection. The problem formulation of residual learning by explaining its relationship with identity skip connection is also explained to address the knowledge-based fault diagnosis problem which has not yet been solved using residual learning.
-
2.
Batch normalization: Optimizing an objective function with respect to its parameters is required for deep CNN models and mini-batch stochastic gradient descent (SGD) has been widely used as an optimization algorithm in order to minimize the objective function. Although mini-batch SGD is simple and effective, model parameters and learning rates need to be carefully set to initial values. Because each layer’s inputs change during the training of deep CNN and the layers need to comply with the changing. The usage of BN layer between convolutional layers and nonlinearities is suggested to address the above-mentioned problem referred as internal covariate shift [19]. It should be noted that any work has not been done on utilizing BN for knowledge-based fault diagnosis. However, this study experimentally proves that the usage of batch normalization improves classification accuracy as noted in studies [3, 19].
3 Proposed deep residual network architecture
3.1 Deep residual learning
The basic architecture of DL framework consists of combining basic layers in a cascade manner. The learning scheme corresponds to approximating a mapping with an underlying function H(x) directly, where x denotes the inputs of the first of stacked layers. In residual learning architecture, a skip connection or identity mapping is utilized to skip one or more layers by connecting the input and output of stacked layers, and the outputs of identity mapping are added to the outputs of the stacked layers along channel dimension. Therefore, the mapping function is turned into residual mapping \(\mathcal {F}(x):=H(x)-x\) and the original mapping function becomes \(\mathcal {F}(x)+x\).
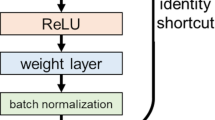
The residual learning scheme is adopted to every stacked layers in this work. The building block shown in Fig. 1a thus is defined as in Eq. 1.
where \(\mathcal {F}_l\) denotes the residual function. \(x_l\) represents the input feature to the l-th residual unit and \(x_{l+1}\) is the output feature from the unit. \(W_l\) gives a set of weights associated with the related residual unit. The mapping function for \(Block\_A\), which is shown in Fig. 1a, recasts into \(\mathcal {F}_l=\gamma (W_2\sigma (\gamma (W_1x_l)))\) in which \(\gamma\) and \(\sigma\) denote the BN layer and ReLU activation function, respectively. The element-wise addition performs \(\mathcal {F}_l+x_l\) operation along channel dimension and ReLU (i.e., \(\sigma (y)\)) follows the addition.
The shortcut connections used in \(Block\_A\) add neither extra parameter nor computational complexity. The convolutional shortcut connection applied in \(Block\_B\) causes only a small increase in computational cost. Therefore, the network can be easily trained end-to-end by an optimization algorithm as in cascade networks. Besides, the residual networks with extremely increased depth have not demonstrated the classification accuracy degradation.

Block structures utilized in the proposed architecture [17]

The architecture of the proposed DRL network
3.2 Network architecture
Figure 2 presents the architecture of DRL network which consists of three sub-networks: feature representation, DRL and classification networks. The feature representation net takes the input grayscale image in order to represent it as feature maps. Next, the DRL fulfills the task of fault diagnosis. Finally, the feature maps in the last layer of DRL net are fed into the classification net to determine the bearing condition.
The input of the feature representation net is a 64 \(\times\) 64 grayscale image which is convolved with 64 different filters, each of size \(7\times 7\), using a stride of 2 and padding of 3 in x and y dimension. The BN layer between convolutional layer and activation function is adopted as in Block_A and Block_B displayed in Fig. 1. The feature representation net ends with a maximum pooling layer which performs pooling within 3\(\times\)3 region using a stride of 2 and padding of 1. The resulting feature maps are then fed into DRL net which consists of between 1 and 4 blocks. The convolutional layers adopted in blocks have size of 3\(\times\)3 filters. The adopted strategy in order to design the filter number in a block is that the number of filters is doubled when the obtained feature map size is halved using a stride of 2. A skip connection is inserted to adopt the residual learning scheme by adding feature maps as illustrated in Fig. 1b. Block_A is directly used when the feature maps are of the same dimension whereas a projection scheme is applied to input feature map using 1\(\times\)1 convolutions in order to increase dimension. The classification net starts with an average pooling layer whose size is equal to output of the last convolution layer using a stride of same number. The resulting feature maps are passed through a 10-way fully-connected layer with softmax, 10 being the number of classes. The layer configurations for Model 1 to 4 are given in Table 1.
4 Experimental results
4.1 Experimental data description
In order to analyze the effectiveness of the proposed DRL method, a commonly used famous dataset containing vibration signals of motor bearing is utilized. The dataset provided by Case Western Reserve University (CWRU) [27] is publicly available and preferred in the studies focusing on bearing fault diagnosis [13, 15, 25, 34,35,36]. In addition to the regular healthy condition (RHC), the dataset contains three different faulty conditions: inner race fault (IRF), outer race fault (ORF), and roller fault (RF). Furthermore, each faulty condition has three different severity levels: 0.18 mm, 0.36 mm, and 0.54 mm. Therefore, there are totally ten different health conditions in the dataset. Vibration signals of these ten different conditions were gathered under four different load scenarios (0, 1, 2, and 3 hp) with 12 kHz sampling frequency. Table 2 summarizes the details of the bearing dataset.
4.2 Data preprocessing
1D raw vibration signals of bearing provided by the dataset [27] are first converted 2D images with the size of \(64\times 64\). Before the conversion process, the dataset containing 1D raw vibration signals are divided into training set, validation set and test set to train the proposed network architectures, to avoid overfitting problem and to estimate the performance of the proposed approach for new inputs, respectively. Each raw vibration signal is first divided into 20 pieces, then each piece is randomly placed in the training, validation and test sets to obtain 14 pieces in the training set, 3 pieces in the validation set and 3 pieces in the test set. Consequently, training, validation and test sets contain nonoverlapping \(70\%\), \(15\%\), and \(15\%\) of the raw vibration signal, respectively, and none of the sets is overlapping.
In the conversion process, first raw vibration signals are randomly segmented with the length of M. Then, M segments are used to obtain an image with the size of \(M \times M\). The first segment correspond the first row of the image, whereas the \(M^{th}\), i.e. the last, segment corresponds to the last row of the image. The created image is required to be normalized to obtain a gray level image. Therefore, pixel intensity values of the image are calculated using min-max normalization method in the range of (0, 255). Let I(i, j) and \(I_N(i,j), i=1,...,M\), and \(j=1,...,M\) represent pixel intensity value of the original and normalized images, respectively. Then, \(I_N(i,j)\) is calculated using Eq. 2.
where min(I) and max(I) denote the minimum and maximum values of I, and round(.) function rounds the final result to an integer value.
In this study, the length of each segment is set to 64 to obtain an image with the size of 64 \(\times\) 64. Some examples of the obtained images for each health condition are shown in Fig. 3.

Images converted from 1D vibration signals for ten different health conditions
4.3 Implementation details
The gray-level input images of size \(64\times 64\) from training dataset is used to train different models and no augmentation or preprocessing technique is applied to training images. Xavier initialization [12] is used to initialize the model weights and ReLU is employed as activation function as seen in Fig. 1. The models are trained with Stochastic Gradient Descent with Momentum (SGDM) optimizer by setting \(\gamma\) = 0.9. The minibatch size is set to 32 and the learning rate is initialized as \(10^{-4}\). All models are trained with about \(2 \times 10^5\) updates and trained from stratch rather than fine-tuned from a pre-trained model in the experiments.
4.4 Network architecture and parameter analysis
The proposed network are tested on the CWRU dataset. Starting from the simple model, various settings are gradually changed to make performance analysis. Table 3 presents the quantitative results.
First, the effects of the block size on classification accuracy are analyzed. Therefore, the number of blocks is changed from 1 to 4, and then the network architecture is designed as summarized in Table 1 and described in Sect. 3.2. Ten trials have been carried out to reduce the effects of the randomness. The average test accuracy is \(99.98\%\) by using 3 blocks, which is higher than \(99.94\%\), \(99.91\%\), \(99.97\%\) obtained using 1, 2 and 4 block, respectively. Therefore, from the average accuracy results depicted in Table 3, it is evident that Model-3, i.e. DRL with 3-block-deep wide, gives slightly better results than other network models.
Next, two different structures are tested to demonstrate the effectiveness of BN layer in DRL. The average training and test accuracies of Model-4 with or without BN layers are given in Table 4. The average test accuracy of \(99.97\%\) is achieved with using BN layer after each convolution layer, which is pretty higher than \(87.11\%\) obtained without using BN layer. The conducted experiments demonstrate the importance of BN layer in classification accuracy.
As a result, Model-3 with BN layer is selected as proposed DRL model to compare with state-of-the-art approaches.
4.5 Comparison with state-of-the-art methods
In order to show the effectiveness of the proposed method, other related works using the same motor bearing dataset are selected to compare the classification accuracy. The comparison results are displayed in Table 5 and DRL method denotes the proposed Model-3. As depicted in Table 5, the test accuracies of all comparative models are obtained under different number of load conditions. Result of the studies performed using all 4 load conditions are briefly summarized below.
Zhang et al. [39] proposed a bearing diagnosis model integrated permutation entropy, ensemble empirical mode decomposition and optimized SVM in order to classify 11 health conditions. The \(97.91\%\) test accuracy is obtained with their model. In [10], DBN based hierarchical diagnosis network is applied on the fault diagnosis and \(99.03\%\) classification accuracy is achieved. A two-stage learning method based on sparse filtering and softmax regression is proposed by Lei et al. [25] and the accuracy of \(99.66\%\) is obtained. Wen et al. [35] proposed a model based on CNN inspired by LeNet-5 for bearing fault diagnosis and the model is able to classify the health conditions with \(99.79\%\) accuracy. Xia et al. [36] developed a CNN-based model using multiple sensors and the accuracy of \(99.41\%\) is achieved. Xu et al. [37] proposed a hybrid DL model and classify 10 different health conditions with \(99.79\%\) accuracy.
The average test accuracy presented in Table 3 is severed as the term for comparison. From the results of Table 5, it can be clearly seen that the proposed DRL model achieves better classification result than comparative models and the proposed model obtains the best result of \(99.98\%\). The standard deviations of all DRL models are less than \(1\%\) and they have shown superior results.
Figure 4 presents the confusion matrix of Trial 10 for Model 3, which obtains the test accuracy of \(99.94\%\) as given in Table 3. The confusion matrix shows that all health condition except ORF\(\_\)54 have \(100\%\) test accuracy, meaning that the condition classes are definitely distinguished from each other. As can be seen, misclassification error only occurs on the ORF\(\_\)54 by misclassifying \(0.6\%\) of test images of the ORF\(\_\)54 as the IRF\(\_\)36. As the test accuracy on some other trials of Model 3 are \(100\%\), there is no need to show the confusion matrix.

Confusion matrix of the test accuracy on Trial 10 of Model 3
5 Conclusion
This paper introduces residual learning into the field of bearing fault diagnosis and proposes a novel DRL network architecture for bearing fault diagnosis. Firstly, the discriminative features are learned directly from images converted from raw time domain signals by learning end-to-end mapping between input images and health conditions without the need of hand-crafted features. Then, DRL scheme is adapted to mapping function to advance the classification accuracy by connecting input and output of stacked layers. In addition, batch normalization layer is utilized in the training process with increased accuracy in order to address internal covariate shift problem. By considering these three steps, four different DRL network models are designed to analyze the effect of the block size on fault diagnosis accuracy. In addition, to observe BN layer effect in DRL, two different structures are created. The performance of these various DRL network models is evaluated for bearing fault diagnosis using vibration datasets from CWRU. Ten trials are carried out to reduce the effect of randomness. The standard deviations of all DRL models are less than \(1\%\) and they shown promising results. However, the analysis results indicate that the proposed Model-3 network with BN layer produce higher diagnosis accuracy for the bearing faults. The Model-3 network achieves average classification accuracy of \(99.98 \%\) for the CWRU bearing dataset. Diagnosis rate of each health condition is visualized using the confusion matrix. Besides, comparative results confirm the superior classification performance of the proposed DRL model for fault diagnosis than state-of-the-art machine learning and DL approaches. In future works, transfer learning based approaches will be considered for bearing fault diagnosis.
References
Baraldi P, Cannarile F, Di Maio F, Zio E (2016) Hierarchical k-nearest neighbours classification and binary differential evolution for fault diagnostics of automotive bearings operating under variable conditions. Eng Appl Artif Intell 56:1–13
Bishop CM et al (1995) Neural networks for pattern recognition. Oxford University Press
Bjorck N, Gomes CP, Selman B, Weinberger KQ (2018) Understanding batch normalization. In: Adv Neural Inf Process Syst pp. 7694–7705
Chen XW, Lin X (2014) Big data deep learning: challenges and perspectives. IEEE Access 2:514–525
Chen Z, Mauricio A, Li W, Gryllias K (2020) A deep learning method for bearing fault diagnosis based on cyclic spectral coherence and convolutional neural networks. Mech Syst Signal Process 140:106683
Cho HC, Knowles J, Fadali MS, Lee KS (2009) Fault detection and isolation of induction motors using recurrent neural networks and dynamic bayesian modeling. IEEE Trans Control Syst Technol 18(2):430–437
Dhamande LS, Chaudhari MB (2016) Bearing fault diagnosis based on statistical feature extraction in time and frequency domain and neural network. Int J Veh Struct Syst 8(4):229
Ding X, He Q (2017) Energy-fluctuated multiscale feature learning with deep convnet for intelligent spindle bearing fault diagnosis. IEEE Trans Instrum Meas 66(8):1926–1935
Eren L (2017) Bearing fault detection by one-dimensional convolutional neural networks. Math Probl Eng
Gan M, Wang C et al (2016) Construction of hierarchical diagnosis network based on deep learning and its application in the fault pattern recognition of rolling element bearings. Mech Syst Signal Process 72:92–104
Gao Z, Cecati C, Ding SX (2015) A survey of fault diagnosis and fault-tolerant techniques-part i: Fault diagnosis with model-based and signal-based approaches. IEEE Trans Ind Electron 62(6):3757–3767
Glorot X, Bengio Y (2010) Understanding the difficulty of training deep feedforward neural networks. In: Proceedings of the Thirteenth International Conference on Artificial Intelligence and Statistics pp. 249–256
Guo L, Lei Y, Xing S, Yan T, Li N (2019) Deep convolutional transfer learning network: A new method for intelligent fault diagnosis of machines with unlabeled data. IEEE Trans Ind Electron 66(9):7316–7325
Guo L, Li N, Jia F, Lei Y, Lin J (2017) A recurrent neural network based health indicator for remaining useful life prediction of bearings. Neurocomputing 240:98–109
Guo X, Chen L, Shen C (2016) Hierarchical adaptive deep convolution neural network and its application to bearing fault diagnosis. Measurement 93:490–502
Han T, Jiang D, Wang N (2016) The fault feature extraction of rolling bearing based on emd and difference spectrum of singular value. Shock and vibration
He K, Zhang X, Ren S, Sun J (2016) Deep residual learning for image recognition. In: Proc IEEE Conf Comput Vis Pattern Recognit pp. 770–778
He XH, Wang D, Li YF, Zhou CH (2016) A novel bearing fault diagnosis method based on gaussian restricted boltzmann machine. Math Prob Eng
Ioffe S, Szegedy C (2015) Batch normalization: Accelerating deep network training by reducing internal covariate shift. arXiv preprint arXiv:1502.03167
Janssens O, Slavkovikj V, Vervisch B, Stockman K, Loccufier M, Verstockt S, Van de Walle R, Van Hoecke S (2016) Convolutional neural network based fault detection for rotating machinery. J Sound Vib 377:331–345
Jia F, Lei Y, Guo L, Lin J, Xing S (2018) A neural network constructed by deep learning technique and its application to intelligent fault diagnosis of machines. Neurocomputing 272:619–628
Kang M, Kim J, Kim JM (2015) Reliable fault diagnosis for incipient low-speed bearings using fault feature analysis based on a binary bat algorithm. Inf Sci 294:423–438
Khorram A, Khalooei M, Rezghi M (2021) End-to-end cnn+ lstm deep learning approach for bearing fault diagnosis. Appl Intell 51(2):736–751
LeCun Y, Bengio Y, Hinton G (2015) Deep learning. Nature 521(7553):436
Lei Y, Jia F, Lin J, Xing S, Ding SX (2016) An intelligent fault diagnosis method using unsupervised feature learning towards mechanical big data. IEEE Trans Ind Electron 63(5):3137–3147
Liu ZH, Lu BL, Wei HL, Chen L, Li XH, Rätsch M (2019) Deep adversarial domain adaptation model for bearing fault diagnosis. IEEE Trans Syst Man Cybern Syst
Loparo K (2012) Case western reserve university bearing data center
Pons-Llinares J, Antonino-Daviu JA, Riera-Guasp M, Lee SB, Kang TJ, Yang C (2014) Advanced induction motor rotor fault diagnosis via continuous and discrete time-frequency tools. IEEE Trans Ind Electron 62(3):1791–1802
Ripley BD, Hjort N (1996) Pattern recognition and neural networks. Cambridge University Press
Shao H, Jiang H, Zhang X, Niu M (2015) Rolling bearing fault diagnosis using an optimization deep belief network. Meas Sci Technol 26(11):115002
Soualhi A, Medjaher K, Zerhouni N (2014) Bearing health monitoring based on hilbert-huang transform, support vector machine, and regression. IEEE Trans Instrum Meas 64(1):52–62
Venables WN, Ripley BD (2013) Modern applied statistics with S-PLUS. Springer Science & Business Media
Wang Z, Zhang Q, Xiong J, Xiao M, Sun G, He J (2017) Fault diagnosis of a rolling bearing using wavelet packet denoising and random forests. IEEE Sensors J 17(17):5581–5588
Wen L, Gao L, Li X (2019) A new deep transfer learning based on sparse auto-encoder for fault diagnosis. IEEE Trans Syst Man Cybern Syst 49(1):136–144
Wen L, Li X, Gao L, Zhang Y (2018) A new convolutional neural network-based data-driven fault diagnosis method. IEEE Trans Ind Electron 65(7):5990–5998
Xia M, Li T, Xu L, Liu L, De Silva CW (2018) Fault diagnosis for rotating machinery using multiple sensors and convolutional neural networks. IEEE/ASME Trans Mechatron 23(1):101–110
Xu Y, Li Z, Wang S, Li W, Sarkodie-Gyan T, Feng S (2021) A hybrid deep-learning model for fault diagnosis of rolling bearings. Measurement 169:108502
Yan X, Jia M, Zhang W, Zhu L (2018) Fault diagnosis of rolling element bearing using a new optimal scale morphology analysis method. ISA Trans 73:165–180
Zhang X, Liang Y, Zhou J et al (2015) A novel bearing fault diagnosis model integrated permutation entropy, ensemble empirical mode decomposition and optimized svm. Measurement 69:164–179
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher’s Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Ayas, S., Ayas, M.S. A novel bearing fault diagnosis method using deep residual learning network. Multimed Tools Appl 81, 22407–22423 (2022). https://doi.org/10.1007/s11042-021-11617-1
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11042-021-11617-1