
Abstract
The aim of low-light image enhancement algorithms is to improve the luminance of images. However, existing low-light image enhancement algorithms inevitably cause an enhanced image to be over- or underenhanced and cause color distortion, both of which prevent the enhanced images from obtaining satisfactory visual effects. In this paper, we proposed a simple but effective low-light image enhancement algorithm based on a membership function and gamma correction (MFGC). First, we convert the image from the RGB (red, green, blue) color space to the HSV (hue, saturation, value) color space and design a method to achieve the self-adaptation computation of traditional membership function parameters. Then, we use the results of the membership function as the γ value and adjust coefficient c of the gamma function based on the characteristics of different images with different gray levels. Finally, we design a linear function to avoid underenhancement. The experimental results show that our method not only has lower computational complexity but also greatly improves the brightness of low-light areas and addresses uneven brightness. The images enhanced using the proposed method have better objective and subjective image quality evaluation results than other state-of-the-art methods.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
1 Introduction
High dynamic range images are widely used in computer vision, target recognition, traffic supervision, and other fields [38]. However, the actual captured images are usually affected by the low brightness around the target scene, which can produce images with some problems, such as dark color, low overall brightness and uneven brightness. These problems may cause images to be unsuitable for this type of application. Therefore, the low-light image enhancement field has received an increasing amount of attention. We can generally divide existing low-light image enhancement algorithms into three types [34].
The first type of algorithm is the histogram equalization (HE)-based method [30], the main idea of which is to redistribute the dynamic range of image gray levels and make the dynamic range fall within the range [0,1]. Based on this idea, many extended HE algorithms have been proposed. For example, contrast-limited adaptive histogram equalization (CLAHE) [25] divides the input image into several equally sized subimages and then uses the HE method in each subimage; however, the enhanced images easily exhibit color distortion, and HE-based methods do not consider the noise hidden in the dark regions of the image.
The second type of algorithm is the retinex-based algorithm. This type of method considers that an image is composed of an illumination component and a reflectance component [14, 17, 18]. The illumination component represents the dynamic range of pixels of the image, and the reflectance component represents the details and outlines of the object surface [40]. Classical algorithms of this type include the single-scale retinex (SSR), multiscale retinex (MSR) and multiscale retinex with color restoration (MSRCR) [37]. Some improved algorithms introduce a bright-pass filter to replace the traditional Gaussian filter [10, 33]. This type of method uses different filters to decompose the input image into illumination and reflectance and then enhances these two components using different algorithms to achieve low-light enhancement; however, the enhanced results often exhibit halo effects and over- or underenhancement.
The last type of algorithm is based on nonlinear transformation. This type of algorithm uses nonlinear transform functions (NTFs) to directly operate on each pixel of the image. Commonly used nonlinear functions include gamma functions and improved gamma corrections [15, 27]. The shortcoming of NTF-based method is that if the parameter γ is too small, it will amplify the noise of the target image. However, in contrast, if the parameter γ is near 1, satisfactorily enhanced results will not be obtained. Therefore, choosing a suitable γ value is the key to obtaining satisfactory results when using gamma correction [16]. To alleviate the noise of the enhanced image, the sigmoid function result is introduced as the γ value [31] because this method limits the minimum value of γ to 0.5. In addition, some other improved gamma correction algorithms use the probability density function (PDF) or cumulative distribution function (CDF) to adaptively adjust the γ value [4, 13].
In this paper, we utilize an improved fuzzy set membership function to adaptively estimate the γ value and redesign the coefficient c of the gamma function for global low-light images. The final experimental results show that compared with other state-of-the-art methods, the enhanced images obtained with our algorithm achieve better qualitative and quantitative evaluations. Examples of natural images and enhanced images with the proposed method are shown in Fig. 1.

Top row: natural low-light images, bottom row: enhanced images with the proposed MFGC method
Contribution
First, we successfully overcome the defect of the traditional fuzzy set membership function in that parameters must be manually set. Second, we creatively combine the gamma function and fuzzy set membership function and avoid over- or underenhancement. Third, according to the different types of images, we redesign the objective exposure measure method (OEM) for the HSV color space.
The remainder of this paper is organized as follows: In Sect. 2, related work on the proposed method is introduced. Details of the proposed algorithm are expressed in Sect. 3. Section 4 presents the experimental results with other state-of-the-art methods and describes the enhanced image quality evaluation results. All work is concluded in Sect. 5.
2 Related work
In this section, we introduce the HSV color space, gamma correction and membership function, which construct the basis of our method.
2.1 HSV color space
The HSV color space is a cylindrical color space widely used in computer vision and image processing. It can be decomposed into the H (hue) component, S (saturation) component and V (value) component [19, 35]. The advantages of the HSV color space are that any component can be adjusted without affecting the others [9, 21]. More specifically, the input image is transferred from the RGB color space to the HSV color space, which can eliminate the strong color correlation of the image in the RGB space; thus, this work is based on the HSV color space. To present the original hue and saturation, only the V component is processed.
2.2 Gamma correction
Gamma correction has been widely used for low-light image enhancement and image contrast enhancement [5]. The proposed algorithm is based on the gamma function, which is simple and efficient. In the field of computer vision and digital image processing, the gamma function can be expressed as follows [1, 20]:
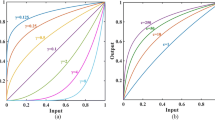
where \(g\left(x,y\right)\) denotes the enhanced pixels of the image, and \(n\left(x,y\right)\) is the pixel of the original image. The shape of the gamma function can be affected by parameter γ and coefficient c, and the influences of different values of γ and c are shown in Fig. 2. Figure 2 shows that when \(\gamma >1\), as γ increases and a large number of low grayscale levels are compressed to a smaller range, the image darkens. When \(\gamma =1\), the gamma function is a linear function, and the mapping result is equal to the input value. When \(0<\gamma <1\), as the γ value decreases, a large number of low grayscale levels are transformed to a larger range, and the image brightens. From Fig. 2, we can also learn that the coefficient c determines the maximum value of the enhanced pixel. Thus, to brighten the image, we must let the size of γ be within the range of [0,1].

Shape of the gamma function with different γ and c values. (a) With coefficient c = 1, (b) With parameter γ = 1
2.3 Membership function
A fuzzy set (A) with a finite number of supports \({x}_{1}\),\({x}_{2}\),…,\({x}_{n}\) in the inverse of discourse U is defined as [8, 26]
where \(\frac{{u}_{i}}{{x}_{i}}\) denotes the membership degree at \({x}_{i}\) in \(A\), \({u}_{i}\) is a membership function, and \({x}_{i}\) is a member of \(A\). With this concept of a fuzzy set, the image \(X\) of size \(M\times N\) with \(L\) gray levels can be considered the collection of fuzzy singletons [7, 11] and can be expressed as
where \(\frac{{u}_{i,j}}{{x}_{i,j}}\) denotes the membership degree of the pixel located at \(\left(i,j\right)\), and \({x}_{i,j}\) is the pixel gray-level value. \({u}_{i,j}\) is a membership function and can be expressed as follows, where the smaller the value of \({u}_{i,j}\), the lower the pixel value [36, 39].
where \({X}_{max}\) represents the maximum value of the gray level of an image, and \(Fe\) and \(Fd\) are conversion coefficients. The shape of the membership function can be affected by conversion coefficients \(Fe\) and \(Fd\), and the influences of different values of \(Fe\) and \(Fd\) are shown in Fig. 3. As shown in Fig. 3, when gray-level values fall within the range (0,1), the value of the membership function falls within the range (0,1), and the membership function is a smooth curve, which satisfies the variation characteristics of the gamma function; thus, we use this membership function to estimate the γ parameter value in this paper. Figure 3a shows that as the \(Fd\) value increases, the value of \({u}_{i,j}\) increases. In other words, when \(Fd>0\), the smaller the \(Fd\) is, the smaller \({u}_{i,j}\), and we can obtain a larger value of the enhanced gray level via gamma correction. As shown in Fig. 3b, when \(Fe>0\), the value of \({u}_{i,j}\) falls within the range (0,1); thus, if we want to increase the gray-level value via gamma correction, we must ensure \(Fe>0\). Therefore, the values of \(Fe\) and \(Fd\) should be greater than 0 to ensure that \({u}_{i,j}\) falls within the range of [0,1].

Shape of the membership function with Fd and Fe. (a) With parameter \(Fe=1\), (b) With parameter \(Fd=0.5\)
3 Proposed algorithm
In this work, we focus on estimating parameter γ and adjusting coefficient c. According to the previous description, the key to enhancing the image brightness is how to estimate the parameter γ. To address this problem, we apply the improved fuzzy set membership function to obtain a suitable γ in the proposed method for the following reasons: Fig. 1 shows that the smaller the value of the gamma parameter, the larger the value of the enhanced pixel. In addition, according to the previous description, we know that the smaller the value of \({u}_{i,j}\), the lower the brightness. Thus, we proposed the MFGC method by combining the membership function and gamma function.
3.1 Details of gamma correction
The traditional fuzzy set membership function is mainly used for image contrast enhancement [24, 26]. In the proposed algorithm, we modify the traditional membership function. An improved membership function is adopted to compute γ value of the gamma function in our method. Based on the description in Sect. 2, we can further infer the membership function in V channel, which can be expressed as follows.
where \({u}_{x,y}\) denotes the membership degree of the pixel gray level, \({V}_{max}\) is the maximum value of the gray level of channel V, \({V}_{x,y}\) is the pixel gray level, and \(Ve\) and \(Vd\) are conversion coefficients. From the descriptions in Sect. 2.2, we can see that if we want to brighten the low-light image, we must ensure that the γ value lies in the range (0,1); therefore, we must ensure that the \({u}_{x,y}\) value lies in the range (0,1). In other words, we must ensure that the values of \(Fe\) and \(Fd\) are greater than 0.
However, the traditional membership function must manually set the values of \(Ve\) and \(Vd\) according to the different properties of images [26]. To address this shortcoming, we proposed an adaptive method based on the low-light image property to adjust the values of \(Ve\) and \(Vd\). Different scenes have different intensities of light and different light sources, which generate different images with different properties, such as different maximum pixel values, minimum pixel values and average pixel values. Based on these attributes, we propose an adaptive method to calculate the parameters and coefficients as follows. First, by using the improved OEM to estimate the exposure value of the V channel component, the normal OEM can be defined as Eq. (6) [30], which describes an objective measurement method for the intensity exposure of the image.
where \(h\left(k\right)\) denotes the histogram of the gray level k, k is the gray level, L is the total number of gray levels, and the dynamic value range of the image exposure falls within the range (0, 1). Due to the properties of low-light images, the maximum value of the pixel gray level of different images differs considerably, but the exposure value of low-light images is very similar. Thus, to enlarge the gap between the exposure value of low-light images, we introduce the maximum value of the V channel to redefine the OEM function and render it suitable for low-light images, and it can be expressed as Eq. (7).
Considering the different properties of different images when estimating the parameter γ, the maximum and average values are introduced to estimate the value of \(Vd\) and parameter \(Ve\). Different low-light images have different mean values of global gray levels; therefore, the mean value is another important property. The mean value of the V channel can be expressed as Eq. (8).
where \(p \left(i\right)\) represents the histogram of gray level \(i\), and m and n denote the width of the image and the height of the image, respectively. Based on previous descriptions, we design a linear function to adaptively compute the value of parameter \(Vd\) according to the properties of different low-light images. The expression of \(Vd\) is shown as Eq. (9).
It is known that the gray-level value is not less than 0, which indicates that \(i>0\), and we can infer that
Then, we obtain
The pixel value falls in the range (0,1). In addition, we have
According to the above descriptions, we also know that the \(Exposure\) value falls within the range (0,1). We can obtain the following expression:
and we have
Then, we can prove that
According to Eq. (1), if we want to brighten the image, we must ensure that γ falls within the range (0,1). In other words, we also must guarantee that the value of parameter \(Ve\) is greater than 0 to let \({u}_{x,y}\) lie in the range (0,1). Therefore, we design an equation to automatically compute \(Ve\). The equation can be expressed as
where \({V}_{max}\) is the maximum value of the V channel, and \(Q\) denotes a constant value for adjusting the size of \({u}_{x,y}\). In this paper, we set \(Q\) equal to 0.15. Based on the above descriptions, we must guarantee that the value of \(Ve\) is greater than 0. It is known that the maximum pixel value of an image falls in the range (0,1), and we will obtain
Then, we also know that \(Q=0.15\). Finally, we obtain
Substituting Eq. (9) and Eq. (16) into Eq. (5), we can further infer the adaptive membership function of the V channel, which can be expressed as Eq. (19).
After this step, we obtain a new membership function \({u}_{x,y}\) and adopt it to compute the value of γ. In this expression, we can see that the value of term \(\frac{2.35\cdot \left({V}_{max}-{V}_{x,y}\right)}{{V}_{mean}+{V}_{max}+V^\prime}\) is not less than zero because \({V}_{max}-{V}_{x,y}\ge 0\); thus, we can obtain the next term \(1+\frac{2.35\cdot \left({V}_{max}-{V}_{x,y}\right)}{{V}_{mean}+{V}_{max}+V^\prime}\ge 1\). From Eq. (16), we know that \(Ve={V}_{max}+Q>0\); therefore, we can infer that \({u}_{x,y}\) of Eq. (19) falls within the range [0,1].
To illustrate the effect of different parameters, we display the shape of the membership function with different parameters, as shown in Fig. 4. Figure 4a shows that the smaller the value of \({V}_{mean}\) is, the smaller the \({u}_{x,y}\) value we obtain. Similarly, Fig. 4b shows that with the decrease in the \(V^\prime\) value, the \({u}_{x,y}\) value decreases. Based on the above descriptions, we know that the smaller the mean value, the lower the brightness of the image; the smaller the \(Exposure\) value, the smaller the \(V^\prime\) value, which also indicates the lower the brightness of the image. The lower the brightness of the image, the smaller the γ value we need to adjust the brightness. Thus, we can use parameters \({V}_{mean}\) and \(V^\prime\) to estimate the γ value. We can also see that a smaller \({V}_{mean}\) value and \(V^\prime\) value may lead to an \({u}_{x,y}\) value that is too small and cause overenhancement. To avoid overenhancement, we use the parameter \({V}_{max}\) to optimize the \({u}_{x,y}\) value, and the effect of the \({V}_{max}\) parameter is shown in Fig. 4c. As shown in Fig. 4c, as the \({V}_{max}\) value decreases, the \({u}_{x,y}\) value increases. Therefore, we can use the image features to estimate the value for the gamma function parameter.

Shape of the membership function with different parameters. (a) With parameters \({V}_{max}=1\) and \(V=0.4\), (b) With parameters \({V}_{max}=1\) and \({V}_{mean}=0.4\), (c) With parameters \({V}_{mean}=0.4\) and \({V}_{max}=1\)
According to the concept of the membership function of an image, we can see that if an image has global low-light sources or no light sources, the value of membership will be near 0. However, a gamma parameter that is too small will increase the brightness too much and decrease the contrast of the enhanced image. To address this problem, we consider the value of coefficient c to adjust the enhanced pixel values. Figure 1b shows that the value of coefficient c determines the enhancement amplitude of the gamma function. We utilize the maximum value of the V channel to compute coefficient c because the darker the image, the smaller the maximum value of the gray-level intensity, which can efficiently decrease the brightness enhancement amplitude. The function of coefficient c is expressed as follows.
Substituting Eq. (19) and Eq. (20) into Eq. (4), we can obtain the improved gamma function, which is shown as Eq. (21).
3.2 Linear enhancement
Utilizing Eq. (21), we can obtain the enhanced V channel, which is referred to as V1. To avoid underenhancement, we designed the expansion coefficient e to linearly enlarge the gray-level dynamic range according to channel V1. While further adjusting the brightness, we should ensure that the maximum does not exceed 1 to avoid overenhancement. The maximum value of the V1 channel must be measured, and we design a simple but effective expansion coefficient e based on the maximum value of the V1 channel to enhance the global brightness, which can be expressed as Eq. (22).
where \({V1}_{max}\) denotes the maximum pixel value of the V1 channel. Because the value of the V1 channel ranges between 0 and 1, if the original image’s maximum value is less than 1, we know that the value of e is greater than 1, which means that \(e=\frac{1}{{V1}_{\mathit{ma}x}}>1\). Combining Eq. (21) and Eq. (22), we obtain the final enhancement function to enlarge the gray-level range, which can be expressed as follows.
Based on the proposed adaptive gamma function for the V channel, we can obtain the final enhanced edition of the enhanced V channel called V2 via Eq. (23). The complete flowchart of the proposed algorithm is shown in Fig. 5.

Flowchart of the proposed algorithm
We choose an image named “bicycles” to illustrate the enhancement process of the proposed method. The original V channel, V1 channel and new V2 channel are shown in Fig. 6, and the corresponding gray-level histograms are shown in Fig. 7.

Original V channel and enhanced results. (a) V channel, (b) Enhanced channel V1, (c) Enhanced channel V2

Gray-level histogram. (a) Histogram of the V channel, (b) Histogram of enhanced channel V1, (c) Histogram of enhanced channel V2
The H channel, S channel and V2 channel are merged in HSV color space, and we obtain an enhanced image after color space conversion from HSV to RGB. The input image, output image and corresponding gray-level histograms are shown in Fig. 8.

Images and corresponding gray-level histograms. (a) Input image, (b) Gray-level histogram of input image, (c) Enhanced image, (d) Gray-level histogram of enhanced image

Comparison of the enhanced results of School with different methods. (a) Input image, (b) Enhanced with LECARM, (c) Enhanced with FFM, (d) Enhanced with RRM, (e) Enhanced with JIEP, (f) Enhanced with SDD, (g) Enhanced with JED, (h) Enhanced with proposed MFGC method

Comparing enhanced results of Painting with different methods. (a) Input image, (b) Enhanced with LECARM, (c) Enhanced with FFM, (d) Enhanced with RRM, (e) Enhanced with JIEP, (f) Enhanced with SDD, (g) Enhanced with JED, (h) Enhanced with proposed MFGC method

Comparing enhanced results of Vehicle with different methods. (a) Input image, (b) Enhanced with LECARM, (c) Enhanced with FFM, (d) Enhanced with RRM, (e) Enhanced with JIEP, (f) Enhanced with SDD, (g) Enhanced with JED, (h) Enhanced with proposed MFGC method

Comparing enhanced results of Bulldozer with different methods. (a) Input image, (b) Enhanced with LECARM, (c) Enhanced with FFM, (d) Enhanced with RRM, (e) Enhanced with JIEP, (f) Enhanced with SDD, (g) Enhanced with JED, (h) Enhanced with proposed MFGC method

Comparing enhanced results of Cars with different methods. (a) Input image, (b) Enhanced with LECARM, (c) Enhanced with FFM, (d) Enhanced with RRM, (e) Enhanced with JIEP, (f) Enhanced with SDD, (g) Enhanced with JED, (h) Enhanced with proposed method MFGC method
4 Experimental results and discussion
This section describes the comparative experiment with other existing state-of-the-art methods and experimental results. The selected comparison algorithms include low-light image enhancement using the camera response model (LECARM) method [29], the fractional-order fusion model (FFM) method [6], the robust retinex model (RRM) method [18], a joint intrinsic-extrinsic prior model (JIEP) method [2], the semi-decoupled decomposition (SDD) method [12] and the joint enhancement and denoising method (JED) method [28]. All experiments are performed in MATLAB R2020b on a personal computer running Windows 10 with an Intel Core i7-10875H CPU @ 2.30 GHz and 16 GB of RAM. In this paper, all displayed images are obtained from our dataset; all displayed images are captured by a Sony digital camera; and the camera model is ILCE-6400. Due to the length limitations of this paper, the total number of images used is fourteen. The original images and enhanced images are shown as follows.
4.1 Subjective assessment
For image quality assessment (IQA), the mean opinion score (MOS) is a widely used method for describing the subjective quality assessment of images [3]. The equation for calculating the MOS value can be expressed as follows [41]:
where \({S}_{i,j}\) denotes the score of image j graded by subject i, and n is the number of subjects. To calculate the MOS value, we completed a questionnaire and invited 15 people to anonymously rate the enhanced images. The scoring rules are expressed as follows: The score range is 1 to 5, and when the score is 5, the image visual effect is excellent. A score of 4 indicates that the image visual effect is good and the details of the image are clear. When the score is 3, the image details are disturbed but can be distinguished. A score of 2 indicates that the image is difficult to distinguish. When the score is 1, the image cannot be recognized. We calculated the MOS values of all enhanced images, and the results are shown in Table 1.
Table 1 shows that the LECARM method and proposed MFGC method perform well due to the higher brightness and restore more information from dark areas. Generally, both results are better than those of the other five comparison methods, and the average value difference between LECARM and our method is only 0.033. In this case, the proposed method obtains the highest MOS value four times and the second-best MOS value three times. We can also determine that the MOS value of Painting is the highest of all values that are enhanced with the proposed method, which is 60.8 percent higher than the score of JIEP. Although the results of SSD obtain a reasonable visual effect and three highest values, the backgrounds of some images are blurry, which yields an MOS below that of the proposed method, such as the Figs. 9, 10 and 11, and the average value is 4.7 percent lower than that of the proposed method. We learn that the RRM method and JED method have similar visual perception effects for human eyes, and from the Figs. 12 and 13 we can see that they have lower brightness than other methods. The average score of JED is 9.1 percent lower than that of our method, and the average score of RRM is 4.6 percent lower than that of JED. In addition, we know that the MOS values of the FFM method and JIEP method are similar and smaller than those of the other algorithms, which indicates that the enhanced images of both cannot adequately restore the detailed information of dark areas with a lower visual effect. The average value of FFM is only 0.127 higher than the score of JIEP, and the score of JIEP is 19.6 percent lower than that of the proposed method.
4.2 Objective assessment
To confirm the quality of the image enhanced with the proposed method, we choose two no-reference IQA metrics (Perception-based Image Quality Evaluator (PIQE) and Blind/Referenceless Image Spatial Quality Evaluator (BRISQUE)) to measure the enhanced image quality. To further illustrate the efficiency of the proposed method, we perform a comparative analysis of the computational complexity of the methods and give the time consumption of image processing.
4.2.1 Image quality assessment
First, the mathematical expressions for the image quality measure metrics PIQE and BRISQUE are described below. The expression for BRISQUE can be expressed as Eq. (25) [23].
where \(\tau\) is a gamma function and is shown as Eq. (26), \(v\) is a parameter, and \({\sigma }_{l}\) and \({\sigma }_{r}\) are scale parameters that control the spread on each side of the general asymmetric generalized Gaussian distribution model.
The mathematical expression for PIQE is shown in Eq. (27) [32].
where \({N}_{SA}\) is the number of spatially active blocks in the image, \({D}_{sk}\) is the distortion assignment procedure for each image block, and \(CT\) is a positive constant (\(CT=1\) in this quality evaluator).
The results of different quality measure metrics are shown in Tables 2 and 3. The smaller the measurement metric results, the better the image quality. The best scores are highlighted in bold, and the second-best scores are underlined. To show the changes in the data more intuitively, we have made the average values of Tables 2 and 3 into a line statistical chart, as shown in Fig. 14a.


Comparing enhanced results of Bicycles with different methods. (a) Input image, (b) Enhanced with LECARM, (c) Enhanced with FFM, (d) Enhanced with RRM, (e) Enhanced with JIEP, (f) Enhanced with SDD, (g) Enhanced with JED, (h) Enhanced with proposed MFGC method

Comparing enhanced results of College with different methods. (a) Input image, (b) Enhanced with LECARM, (c) Enhanced with FFM, (d) Enhanced with RRM, (e) Enhanced with JIEP, (f) Enhanced with SDD, (g) Enhanced with JED, (h) Enhanced with proposed MFGC method

Comparing enhanced results of Laboratory with different methods. (a) Input image, (b) Enhanced with LECARM, (c) Enhanced with FFM, (d) Enhanced with RRM, (e) Enhanced with JIEP, (f) Enhanced with SDD, (g) Enhanced with JED, (h) Enhanced with proposed MFGC method
Table 2 and Fig. 14a show that the PIQE results for the different methods are quite different; thus, the values have reasonable distinguishability. It is shown that the proposed MFGC method performs well, the enhanced images obtain the best score four times and obtain the second-best score four times, and the average score is nearly 31 percent lower than the average score of the RRM method. In comparison, the second-best values are obtained by the JIEP algorithm, which obtains the best score three times and a lower score than the proposed method one time. The average value of JIEP is 0.76 lower than that of the proposed method. The quality of the enhanced images obtained via LECARM and FFM is similar to and lower than that of the proposed method. The difference between LECARM and FFM is only 0.368, which represents the enhanced image quality with similar image quality. The largest PIQE is obtained by the RRM algorithm, and the PIQE of RRM is 15.604 higher and 44.7 percent higher than those of the proposed method, which indicates that the enhanced results have lower image quality than the other methods, and the enhanced images lose some detailed information. The results of both the SDD method and the JED method are not satisfactory. The average value of the JED method is 23.2 percent higher than that of the proposed method, and the value of the SDD method is 7 percent higher than that of JED. Combined with the enhanced images, this finding is attributed to the blurriness of some areas of the enhanced images, such as the middle area of Figs. 15 and 16.
Table 3 clearly shows that the statistics of the diagram are irregularly scattered, and the average value falls within the range from 18.5 to 31.4. In this case, the proposed method obtains the three best scores and two second-best scores because the object information is restored well and the average value is the smallest. The average value of the proposed method is 40.9 percent lower than that of RRM. The second-best average value is obtained by the LECARM method, which obtains the two best scores, and the enhanced images have satisfactory brightness. The average score of LECARM is 0.419 higher than that of the proposed method. Table 3 and Fig. 14a also show that the statistics of FFM and JIEP are higher than those of the other methods, and the difference between FFM and JIEP is only 0.512, indicating lower image quality. From the Figs. 17, 19 and 20 we can see that the enhanced image brightness of both methods is lower than that of other methods. The results of SDD and JED are similar to the PIQE results because some areas of the enhanced image become blurry, which causes a loss of detailed information. We can see that the average score of SDD is 33 percent higher than that of the proposed method. In this case, the score of JED is 3.014 higher than that of SDD. Due to the poor recovery of object information in dark areas, the results of the RRM method are lower than those of the other comparison algorithms, and the average score is 12.866 higher than that of the proposed method.
4.2.2 Image quality assessment with different datasets
We choose a multi-exposure image fusion (MEF) dataset [22] and a fusion-based enhancing (AFE) dataset [10] to test the enhanced image quality with different methods to further improve the effectiveness of the proposed method. The results are shown in Table 4, and the line statistical chart is shown in Fig. 14b (these values represent the average value).
Table 4 and Fig. 14b show that the proposed method obtains the best score three times, and the PIQE value of the MEF dataset processed by our proposed method is the best, which is 0.232 lower than the second-best score of the JED method. Similarly, the BRISQUE value of the MEF dataset processed by our proposed method is also 0.166 lower than the second-best score of the JED method. In contrast, the proposed method obtains the best value and the second-best value in the NIQE and BRISQUE measurement metrics of the AFE dataset; the PIQE value of the proposed method is 23 percent lower than the second-best result of the FFM method, and the BRISQUE score is only 2 percent higher than the best score of the RRM method. Figure 14 also show that for the image enhancement of different datasets, the performance of the proposed algorithm is the most stable, while the performances of other algorithms are not stable enough, and the image quality after enhancement changes greatly. In general, the enhanced image quality of the proposed method is outperformed by the other methods.
4.2.3 Computational complexity comparison
In addition to the no-reference image quality measure metrics, the computational complexity is important for algorithms. We use ten images with increasing sizes from 100 × 100 to 1000 × 1000 to test the computational complexity of all comparison methods, and the length and width difference between adjacent images is 100 pixels. We run all the algorithms three times, record the results each time, and take the average of the three results. The final results are shown in Fig. 18.

Results of computational complexity with different methods

Comparing enhanced results of Flower with different methods. (a) Input image, (b) Enhanced with LECARM, (c) Enhanced with FFM, (d) Enhanced with RRM, (e) Enhanced with JIEP, (f) Enhanced with SDD, (g) Enhanced with JED, (h) Enhanced with proposed MFGC method

Comparing enhanced results of Library with different methods. (a) Input image, (b) Enhanced with LECARM, (c) Enhanced with FFM, (d) Enhanced with RRM, (e) Enhanced with JIEP, (f) Enhanced with SDD, (g) Enhanced with JED, (h) Enhanced with proposed MFGC method
Figure 18 shows that the computational complexity of the proposed method is the lowest; conversely, the RRM method has the highest computational complexity of nearly O(N2). The SDD method has the second-highest computational complexity, and its computational complexity is below that of RRM. The computational complexities of FFM, JED, and JIEP are O(NlogN) and below O(N2). In addition, we know that the computational complexities of both LECARM and the proposed MFGC method are O(N). In this case, as shown in Fig. 18, as the amount of calculation data increases linearly, the time increase of the proposed MFGC algorithm is the smallest, followed by the LECARM method, and the largest increase occur with the RRM method. Therefore, we can infer that the image processing time of the proposed MFGC method is the shortest. In addition, according to Fig. 18, we can infer that the image processing speed of the RRM method is the slowest.
To verify the computational complexity of the comparison methods, we measured the image processing time of different methods. The time consumed for different algorithms to process images is shown in Table 5, where the shortest times are highlighted in bold, and the second-shortest times are underlined. As shown in Table 5, due to the high computational complexity of the RRM method, this method takes the longest time on each image, and the average computational time of RMM is more than 378 times that of the proposed method. In this case, the proposed MFGC method takes the shortest time on all test images. We also note that the average time consumption of the proposed method is less than one-fifth the calculation time of the LECARM method. The time consumptions of FFM, JIEP and JED are similar because of the similar computational complexity, and the average computational time of the three methods is more than 67 times that of the proposed method. The image processing time of the SDD algorithm is between that of the RRM and FFM methods, and it is more than 150 times that of our method. The statistics of Table 5 also prove that the computational complexity of the proposed MFGC method is the lowest.
5 Conclusions
We proposed a simple and efficient algorithm based on a membership function and gamma correction to achieve low-light image enhancement in this paper. The images enhanced with the proposed method do not exhibit over- or underenhancement, balance the global brightness, and have higher brightness and higher image quality than those of the comparison methods. In addition, our method has lower computational complexity than other methods, which means that our method has faster processing speed. The performance of the proposed method is sufficiently stable, and the method proposed in this paper was shown via comparative experimental and image quality assessment results to perform better than other state-of-the-art methods.
References
Ashiba MI, Tolba MS, El-Fishawy AS, El-Samie FEA (2019) Gamma correction enhancement of infrared night vision images using histogram processing. Multimed Tools Appl 78(19):27771–27783
Cai B, Xu X, Guo K, Jia K, Hu B, Tao D (2017) A joint intrinsic-extrinsic prior model for retinex. IEEE International Conference on Computer Vision (ICCV) 4020–4029
Cao J, Wang S, Wang R, Zhang X, Kwong S (2019) Content-oriented image quality assessment with multi-label SVM classifier. Signal Processing: Image Communication 78:388–397
Chang Y, Jung C, Ke P, Song H, Hwang J (2018) Automatic contrast-limited adaptive histogram equalization with dual gamma correction. Ieee Access 6:11782–11792
Cheng H, Long W, Li Y, Liu H (2020) Two low illuminance image enhancement algorithms based on grey level mapping. Multimed Tools Appl 1–24
Dai Q, Pu YF, Rahman Z, Aamir M (2019) Fractional-order fusion model for low-light image enhancement. Symmetry-Basel 11(4):574–561
Deng H, Sun X, Liu M, Ye C, Zhou X (2016) Image enhancement based on intuitionistic fuzzy sets theory. Iet Image Process 10(10):701–709
Deng H, Deng W, Sun X, Liu M, Ye C, Zhou X (2017) Mammogram enhancement using intuitionistic fuzzy sets. IEEE Trans Biomed Eng 64(8):1803–1814
Dhal KG, Ray S, Das S, Biswas A, Ghosh S (2019) Hue-preserving and gamut problem-free histopathology image enhancement. Iran J Sci Technol-Trans Electr Eng 43(3):645–672
Fu X, Zeng D, Huang Y, Liao Y, Ding X, Paisley J (2016) A fusion-based enhancing method for weakly illuminated images. Signal Process 129:82–96
Hanmandlu M, Verma OP, Kumar NK, Kulkarni M (2009) A novel optimal fuzzy system for color image enhancement using bacterial foraging. Ieee T Instrum Meas 58(8):2867–2879
Hao S, Han X, Guo Y, Xu X, Wang M (2020) Low-light image enhancement with semi-decoupled decomposition. Ieee T Multimedia 22(12):3025–3038
Huang SC, Cheng FC, Chiu YS (2013) Efficient contrast enhancement using adaptive gamma correction with weighting distribution. Ieee T Image Process 22(3):1032–1041
Jobson DJ, Rahman ZU, Woodell GA (1997) Properties and performance of a center/surround retinex. Ieee T Image Process 6(3):451–462
Kallel F, Hamida AB (2017) A new adaptive gamma correction based algorithm using DWT-SVD for non-contrast CT image enhancement. IEEE Trans Nanobioscience 16(8):666–675
Kansal S, Tripathi RK (2019) Adaptive gamma correction for contrast enhancement of remote sensing images. Multimed Tools Appl 78(18):25241–25258
Land EH, Mccann JJ (1971) Lightness and retinex theory. J Opt Soc Am 61(1):1–11
Li MD, Liu JY, Yang WH, Sun XY, Guo ZM (2018) Structure-revealing low-light image enhancement via robust retinex model. Ieee T Image Process 27(6):2828–2841
Li Z, Jia Z, Yang J, Kasabov N (2020) Low illumination video image enhancement. IEEE Photonics J 12(4):1–13
Li C, Tang S, Yan J, Zhou T (2020) Low-light image enhancement via pair of complementary gamma functions by fusion. Ieee Access 8:169887–169896
Lyu WJ, Lu W, Ma M (2020) No-reference quality metric for contrast-distorted image based on gradient domain and HSV space. J Vis Commun Image Represent 69:102797–102806
Ma K, Duanmu Z, Yeganeh H, Wang Z (2018) Multi-exposure image fusion by optimizing a structural similarity index. IEEE Transactions on Computational Imaging 4(1):60–72
Mittal A, Moorthy AK, Bovik AC (2012) No-reference image quality assessment in the spatial domain. Ieee T Image Process 21(12):4695–4708
Mouzai M, Tarabet C, Mustapha A (2020) Low-contrast X-ray enhancement using a fuzzy gamma reasoning model. Med Biol Eng Comput 58:1177–1197
Ooi CH, Kong NSP, Ibrahim H (2009) Bi-histogram equalization with a plateau limit for digital image enhancement. Ieee T Consum Electr 55(4):2072–2080
Pal SK, King RA (1981) Image enhancement using smoothing with fuzzy sets. IEEE Trans Syst Man Cybern 11(7):495–501
Rahman S, Rahman MM, Abdullah-Al-Wadud M, Al-Quaderi GD (2016) Shoyaib M (2016) An adaptive gamma correction for image enhancement. Eurasip J Image Vide 1:35–48
Ren X, Li M, Cheng W, Liu J (2018) Joint enhancement and denoising method via sequential decomposition. In: 2018 IEEE International Symposium on Circuits and Systems (ISCAS) 1–5
Ren Y, Ying Z, Li TH, Li G (2019) LECARM: Low-light image enhancement using the camera response model. Ieee T Circ Syst Vid 29(4):968–981
Singh K, Kapoor R (2014) Image enhancement using exposure based sub image histogram equalization. Pattern Recogn Lett 36:10–14
Srinivas K, Bhandari AK (2020) Low light image enhancement with adaptive sigmoid transfer function. Iet Image Process 14(4):668–678
Venkatanath N, Praneeth D, Maruthi Chandrasekhar Bh, Channappayya SS, Medasani SS (2015) Blind image quality evaluation using perception based features. 2015 Twenty First National Conference on Communications (NCC), 1–6
Wang S, Zheng J, Hai-Miao Hu, Li B (2013) Naturalness preserved enhancement algorithm for non-uniform illumination images. IEEE Trans Image Process 22:3538–3548
Wang W, Wu X, Yuan X, Gao Z (2020) An experiment-based review of low-light image enhancement methods. Ieee Access 8:87884–87917
Wang WC, Chen ZX, Yuan XH, Wu XJ (2019) Adaptive image enhancement method for correcting low-illumination images. Inf Sci 496:25–41
Wang Z, Wang K, Liu Z, Zeng Z (2019) Study on denoising and enhancement method in SAR image based on wavelet packet and fuzzy set. IEEE 4th Advanced Information Technology, Electronic and Automation Control Conference (IAEAC) 1541–1544
Wu YH, Zheng JY, Song WR, Liu F (2019) Low light image enhancement based on non-uniform illumination prior model. Iet Image Process 13(13):2448–2456
Ying Z, Li G, Ren Y, Wang R, Wang W (2017) A new low-light image enhancement algorithm using camera response model. IEEE International Conference on Computer Vision Workshop(ICCVW) Venice, Italy, 3015–3022
Yun HJ, Wu ZY, Wang GJ, Tong G, Yang H (2016) A novel enhancement algorithm combined with improved fuzzy set theory for low illumination images. Math Probl Eng 2016:1–9
Zhou ZY, Feng Z, Liu JL, Hao SJ (2020) Single-image low-light enhancement via generating and fusing multiple sources. Neural Comput Appl 32(11):6455–6465
Zhu W, Zhai G, Hu M, Liu J, Yang X (2018) Arrow’s impossibility theorem inspired subjective image quality assessment approach. Signal Process 145:193–201
Acknowledgements
This work was supported by Science and Technology Department of Sichuan Province, People’s Republic of China (No. 2020JDRC0026).
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
We declare that we do not have any commercial or associative interest that represents a conflict of interest in connection with the manuscript entitled “Low-Light Image Enhancement Based on Membership Function and Gamma Correction”.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Liu, S., Long, W., Li, Y. et al. Low-light image enhancement based on membership function and gamma correction. Multimed Tools Appl 81, 22087–22109 (2022). https://doi.org/10.1007/s11042-021-11505-8
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11042-021-11505-8