
Abstract
With enormous development in diverse kinds of images through electronic communication networks, it becomes a demanding chore to retrieve the efficient result from a wide collection of images. CBIR i.e. content based image retrieval answers the problem as it selects visual image contents or features to deal with images. Since images are represented by certain features to facilitate accurate retrieval of the required images here this article proposed a method to extract certain features from the image based on color, texture, and shape. This paper has proposed an approach named as weighted edge matching information retrieval (WEMIR) to perform content based image retrieval. It is a fusion approach to extract the color, texture and shape features from images. With the single feature extraction, acceptable outcomes are not formed. Hence multi-feature extraction is developed to perform retrieval of images. To extract the color feature, the higher order of confined mean is used to improve the lower contrast to gain high contrast. To extract the texture features multi optimization techniques are used and for shape feature extraction weighted edge matching technique is used. Pixel content is extracted from each image present in the database as well as for the test image provided. Based on the proposed method WEMIR the optimal features are obtained for query and image database. By using image distance measure corresponding images are retrieved from the database. The competence of the proposed WEMIR is measured using precision and recall. The proposed method shows better retrieval results while compared with the traditional methods.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
In recent years, as the digital image technology has been improved there is a rapid development of digital content like images and videos are accessible by the user. The wide collection of images has created rising challenges to computer systems to find and retrieve identical images competently. Algorithmic explanation of this task for accomplishment on computer is extremely complicated. CBIR (Content based image retrieval) is a powerful tool. It deals with the visual content to search images from a wide collection and retrieves the required images. Various methods and techniques have been adopted for this retrieval system. The feature extractions of images are based on color, texture and shape [15, 18, 26, 28] representation of the image contents. Techniques [29, 41, 42] are employed for extracting the image content and are applied directly for measuring the similarity for the test as well as image collection using statistical methods.
Manoj Kumar [43] in his work showed the features extracted by discrete wavelet transform (DWT) and local binary pattern algorithm are used. These features are pooled to a unique feature vector for the image using fusion technique. He carried out his work for medical images but focused on grey scale images. Swati Agarwal [27] in her work she focused on approximation of shapes but not on comparison of objects present in the image and also limitation of this work includes only on transformed images using line segment preprocessing algorithm. Ibrahim [6] in his research proposed an efficient image retrieval system which is used in texture feature by using grey level co-occurrence matrix and color co-occurrence matrix to form a single feature vector. His work is having the limitation of only color and texture features.
Joshi [49] found an image equivalent criterion and system which uses spatial information and visual features represented by dominant wavelet coefficients. This system allows the user to provide the outline of the test image based on the image supplied his work provides the improved matching over the image based on distance measure. His work provides spatial information and approximation of an image. Numerous works has been carried out and techniques have been found for content based image retrieval algorithm [16, 33, 40, 48]. As CBIR plays a major role in developing web based visual search engine. This paper proposed an algorithm which undergoes the separation of features and then identifying the minimum edge for feature comparison.
According to [34, 44] to confine the subjectivity, image retrieval tools might provide Relevance feedback (RF) techniques involove the users in the process of clarifying the exploration. The relevance feedback is applied in CBIR, where the user submits to the system a query image which is an example of the interested image [35,39,40,38]. The system will assigns to each image in the database a rank will be given according to the similarity measurement between each image and the query image. Based on the users choice the top 10/20/30 images reteived to the user that shows them relevant or irrelevant so that the system will consider relevant images in the order displayed. This will help the users to identify the relevant images as well as the availability of this additional information the system can improve the qualioty of the search results [45,46,47].
The paper has been organized as follows, Section 2 explains the preprocessing to reduce the features as well as time taken in retrieval system, Section 3 explains about the working principle of the proposed method. Section 4 discusses the results obtained from the method proposed in terms of precision and recall and also about the comparative study with traditional methods and finally conclusion gives the analysis as well as the future work to be continued.
2 Preprocessing
Before the image information is extracted from the query image supplied, it has to be pre processed by using certain methods to reduce the features as well as time taken in retrievel system. Prepocessing in CBIR system involves the process of preparing the template and query images into a form that enhance the procedure for feature detection and image retrieval. The proposed retrieval system in this research work consists of three different tasks. The first task involves grouping of data points using multi optimization technique, and the second task applies image enhancement and the third task done by using DWT technique. Before the formal processing of the image, the system will first perform some necessary preprocessing mentioned above on the image to meet the requirements of the subsequent steps to achieve faster and better. Classification is one of the major probing data analysis method used to get an perception about the structure of the data [32]. It will detect the data points by identifying the subgroups having near values as one group. The variation between the data points are identified using Euclidean distance.
2.1 The process involved in grouping the data points is as follows
-
1.
Initialize the number of groups. (Say G1, G2, G3…Gk).
-
2.
Based on the initialization of groups pick the RGB pixel values which are in a random position.
-
3.
Compute the distance between all the data points and the group initiated by using the Euclidean distance formula. (If R = {R1, R2, R3, …,Rn} and S ={S1, S2,S3,…,Sn} are two points, then the distance from R to S, or from S to R is given by:\( \sqrt{\sum_{i=1}^n{\left({R}_i-{S}_i\right)}^2} \)
-
4.
The above steps are repeated for all the pixel values in the image
-
5.
The single iteration process is not sufficient, so new groups are to be identified.
-
6.
To obtain the new group, compute the mean of the pixel values concerning each group new
-
7.
After obtaining the mean value for R, G, B channels separately, calculate the difference between the old group values and the new group values
-
8.
For the completion of the single iteration, The process will be repeated until there is no further change in the group values
-
9.
If the difference is more than the threshold value then assign the new values to the current values and continue from step 3.
2.2 The process involved in adjusting image intensities to enhance contrast
Histogram equalization is used to enhance contrast [17, 30].The first one needs to calculate the PMF (probability mass function) of all the pixels in the image. The next step involves a calculation of CDF (cumulative distributive function). For normalization, divide the frequency of each pixel intensity value by the total number of pixels present in the image. This is equal to the resolution of the image. i.e. (Nrows x Ncols).
-
1.
Represent the resultant group image in the form of the matrix I
-
2.
Let I be a given image represented as an Rr by Rc matrix of integer pixel intensities ranging from 0 to N. N is the number of possible intensity values, often 255. Let H denote the normalized approximate of the distribution of numerical data I with a bin for each possible intensity. So
$$ \mathrm{Hm}=\frac{No. of\ pixel\ swith\ intensity\ m}{Total\ no. of\ pixel s}\mathrm{m}=0,1,\dots, \mathrm{N} $$
The resultant equalized image E will be defined as
where floor() rounds down to the nearest integer. This is equivalent to transforming the pixel intensities, t, of I by the function
-
3.
The impetus for this transformation comes from view of the intensities of I and E as continuous random variables U,V on [0,N] with Z defined by
$$ \mathrm{Z}=\mathrm{P}\left(\mathrm{t}\right)=\left(\mathrm{N}\right){\int}_0^U Hu(u) du $$Where Hu is the probability density function of I.
-
4.
P is the cumulative distribution function of U multiplied by N. Assume for simplicity that P is differentiable and invertible. It can then be shown that Z defined by P(U) is uniformly distributed on (0,N),namely that Hv(v)=\( \frac{1}{N} \)
$$ {\displaystyle \begin{array}{c}{\int}_0^v Hv(v) dv=\mathrm{probability}\ \mathrm{that}\ 0\le V\le v\\ {}\begin{array}{c}=\mathrm{probability}\ \mathrm{that}\ 0\le U\le {p}^{-1}(v)\\ {}={\int}_0^{p^{-{1}_{(v)}}} Hu(k) dk\\ {}\frac{d}{dv}\left({\int}_0^v Hv(v) dz= Hv(v)= Hu\Big({P}^{-1}(v)\frac{d}{dv}\left({P}^{-1}(v)\right)\right)\end{array}\\ {}\begin{array}{c}\mathrm{Note}\ \mathrm{that}\ \frac{d}{dv}P\left({P}^{-1}(v)\right)=\frac{d}{dv}v=1, so\\ {}\frac{dP}{du}\mid u={P}^{-1}(v)\frac{d}{dv}\left({P}^{-1}(v)\right)=(N) Hu\left({P}^{-1}(v)\right)\frac{d}{dv}\left({P}^{-1}(v)\right)=1\\ {} which\kern0.5em means\kern0.5em Hv(v)=\frac{1}{N}\end{array}\end{array}} $$
Finally, the new image contrast has been enhanced for the resultant images generated from the groups.
2.3 Process involved in Discrete Wavelet Transform
The DWT (Discrete Wavelet Transform) performs on the principle of sub-band coding. Because of its various features and characteristics, it acts as a good technique for image processing. One such method called wavelets,which are used to decompose images and other signals, into multi-level signal resolution [1,2,3]. The more number of resolution levels provides higher image details. The wavelet used in DWT is appropriate for computerized processing [17, 30].The complication and computational precision on the processor is extensively low, due to the use of primary statistical operations, such as multiplication and addition. Wavelets are functions generated from one single function called the prototype or mother wavelet scaling and translations in the time domain. The interpretation for the discrete wavelet is shown in equation (3)
-
1.
For wavelet Ψ(w), the other wavelet Ψx,y(w) can be represented as
Where x and y are two arbitrary real numbers. The variables x and y represent the parameters for scaling and translations in the time axis. The parameter x causes contraction of Ψ(w) in the time axis when x<1 and expansion or stretching when x>1. The normalizing factor of \( \frac{1}{\sqrt{\left|x\right|}} \) ensures that energy stays the same for all x and y.
-
2.
For discrete wavelet transform, the dilation and translation parameters are discretized using
$$ x={x_0}^{-1},y=1{y}_0{x_0}^{-1} $$
where i and l are integers, substituting x and y in (4) the discrete wavelet can be represented by
So, the wavelet coefficients for function z(w) are given by
-
3.
The most common choice here is x0 =2 and y0=1, hence x=2 and b=l2i. this way of sampling is known as dyadic sampling and the corresponding decomposition of the
-
4.
The signal z(w) can be reconstructed from the discrete wavelet coefficients as,
$$ w(z)=\sum \limits_{i=-\infty}^{\infty}\sum \limits_{j=-\infty}^{\infty }{D}_{i,j}(z)\Psi \mathrm{i},\mathrm{j}\left(\mathrm{w}\right) $$
The wavelet shown in Eq. (4) is also called a discrete-time wavelet transform.
3 Proposed method
In MPEG-7, the edge description in an image is standardized in terms of edge histogram descriptor (EHD) [31, 39, 50, 51]. The EHD describes five edge types in the image, namely horizontal, vertical, two diagonal, and non-directional edge types [7,8,9,10]. Population for these five types of edges in a local image region of a sub-image is represented by a histogram with five bins. Specifically, the image space is divided into 16 (4 × 4) non-overlapping sub-images and for each subimage a histogram with five edge bins is generated, yielding a combined edge histogram with 80 (16×5) bins for the entire image. The histogram with 80 bins is the standardized edge descriptor for MPEG-7. The apparent role of the EHD is to provide primitive information on the edge distribution in the image. Since the EHD is basically a collection of local edge histograms, it is quite primitive and flexible, allowing us to extract various image features from the 80-bin histogram. In addition, according to the definition of the EHD in MPEG7, one can always generate the sixth feature from the 5 types of edge bins for each 4 × 4 sub-image. This sixth feature represents the relative population of the non-edge types in the sub-image. Forming a feature vector with 6 edge/nonedge bins, we can extract 33 different feature vectors (or 33 × 6 = 198 feature elements) including 16 vectors from 4 × 4 sub-images, 1 vector from a global histogram, 13 vectors from semi-global histograms, 1 vector from entropy, and 2 vectors from centers of gravity [11,12,13,14]. A statistical hypothesis testing is employed to see which feature elements (or feature vectors), among all 198 feature elements (or 33 feature vectors), are most informative to differentiate different image classes. But the proposed method described here extracts only 65 features [5].
The proposed system (WEMIR) identifies the discontinuities in an image having isolated points so that these points would not occur frequently in most images. This method aims to identify and locate the sharp discontinuities in an image and to extract the minimum feature which gives the optimal solution for retrieval. The proposed method (WEMIR) works based on extracting the LL image from the DWT technique which is obtained after completing the pre-processing phase which is further fed into a single value decomposition technique for size reduction to carry out further process of image intensity extraction.
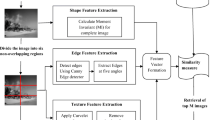
The proposed method is depicted in Fig. 1 which shows the entire process taking place when a query image is provided for finding relevant images. In the initial stage, the user will provide the test image for the extraction of its pixel content using preprocessing followed by WEMIR. Once the features are extracted, the feature vectors are stored in a feature database. The same process is repeated for the images present in database. The feature database is compared by using Euclidean and Manhattan similarity measures between the test image and the database image. The image feature which gets matched is retrieved and displayed as ascending order based on the image distance measure value.

System architecture of proposed method WEMIR
The working principle of the proposed method WEMIR as follows
-
Step:1
Consider the LL image for further extraction which has been attained after preprocessing
-
Step:2
Reduce the image size by using single value decomposition (SVD) for the LL image obtained. The process involved in finding SVD is as follows
-
1.
The image matrix I can be factorized as I = U S VT where U and V are orthogonal matrices with eigenvectors chosen from AAT and ATA respectively.
-
2.
S is a diagonal matrix with r elements equal to the root of the positive eigenvalues of AAT or ATA. The diagonal elements are composed of singular values.
i.e mxn matrix can be factorized as Amxn = UmxmSmxnVnxnT
-
3.
Once SVD has been computed proceed to step 3 for Identifying the minimum edge intensity values
-
Step:3
Check whether the number of rows is equal to the number of columns. If yes, problem is balanced one; if not, then add a dummy row or column to make the image matrix a balanced one by padding zero value to each cell of the dummy row or column.
-
Step:4
Row Subtraction: Subtract the minimum pixel intensity value of each row from all values of that row. Note: If there is zero in each row, there is no need for row subtraction.
-
Step:5
Column Subtraction: Subtract the minimum pixel intensity value of each column from all values of that column. Note: If there is zero in each column, there is no need for column subtraction.
-
Step:6
Draw minimum number of horizontal and vertical lines to cover all zeros. To draw the minimum number of lines the following procedure may be followed:
-
1.
Select a row containing exactly one uncovered zero and draw a vertical line through the column containing this zero and repeat the process till no such row is left.
-
2.
Select a column containing exactly one uncovered zero and draw a horizontal line through the row containing the zero and repeat the process till no such column is left.
-
Step:7
If the total lines covering all zeros are equal to the size of the matrix, pick the minimum weighted pixel value and store in a dataset; if not, subtract the minimum uncovered element from all uncovered elements and add this element to all elements at the intersection point of the lines covering zeros.
-
Step:8
Repeat Steps 4 and 5 till the minimum number of lines covering all zeros is equal to the size of the matrix.
-
Step:9
Select a row containing exactly one unmarked zero and surround it by, and draw a vertical line through the column containing this zero. Repeat this process till no such row is left; then select a column containing exactly one unmarked zero and surround it by,and draw a horizontal line through the row containing this zero and repeat this process till nosuch column is left. Note: If there is more than one unmarked zero in any row or column,it indicates that an alternative solution exists. In this case, select anyone arbitrarily and pass two lines horizontally and vertically.
-
Step:10
Store the intensity value of the identified minimum edge which shall be stored in feature dataset.
-
Step:11
Similarly the feature vectors for all other images in the database are computed and stored
-
Step:12
Compute similarity measures for the stored value of query and Database images using an image distance measure, corresponding matching images will be displayed
4 Experimental results
To test the performance of the proposed system, real-world images from standard dataset called Corel databases are used. The database consists of a total of 1500 images with 15 different categories. Each category in the dataset consists of exactly 100 images. The categories represent different semantic meanings such as buses, buildings, flowers, elephants, dinosaur, food, vegetables, pyramids, horses, Mountains, Lions, Bears, etc. Figure 2 shows the sample images from the database taken for testing the efficiency of the system designed. The images considered in this work are of variable size [19,20,21,22,23,24,25]. James S. Wang et al. [27] has provided a database which is known as WANG database.

Sample images of the corel database
The values after computation of row minima and column minima are shown as the screenshots 1, 2, 3.These values gives the features extracted from the image after applying the weighted minima edge detection to identify the optimal features for retrieval.

Shows the pixel intensity value of the query image (elephant)

Shows the row and column minima operation performed on the pixel intensity values of the query image (Elephant)

Shows the minimum edge identified pixel intensity values for the query image (Elephant)
Screenshot 1 shows the pixel values of the query image elephant and Screenshot 2 shows the row and column minima operation to identify the minimum weighted edge and Screenshot 3 shows the implementation of the query image extraction using python and the corresponding minimum edge intensity values obtained for the sample image from elephant category is shown. The central pixel value is extracted from the minimum edge identified by the porposed algorithm WMIR and are stored in the feature database for similarity matching. Figure 6 shows the intensity values obtianed from elephant image of size 387x256.The total features extracted from the elephant image is 65. Figure 3 shows the test image taken for corresponding image retreival from wide collection.

Test image
The screenshot 1 shows the sample pixel values of the query image taken for retreival. Considering these values for the next step to identify the unique features of the query image.
Screenshot 2 shows the values obtained after applying the row and column minima.once the row and cloumn operations are done for the image, then the next step is to identify the minimum pixel value for each 5x5 matrix by satisfying the condition specified in proposed method with step1 to step12. Then the final output value obatined is shown in screen shot 3 (Fig. 4).

Represent the snapshot of the resultant image obtained after applying multi optimization technique for a specific query image and DWT first level approximation output after applying confined mean.
The experimentation has been carried out with all categories of images such as pyramids, vegetables, foods, bulidings, buses,etc. While performing the analysis the results will be displayed as 10 images in a screen, 20 images as outputs and 30 images as output.when the images are selected with less quantity in display the output will be of exact match, but when the retrieval increase from 10 to 20 or 30 then there will be increase in irrelavant images (Figs. 5 and 6).

Represent the snapshot of resultant images retrieved after providing a sample query image for retrieval using Euclidean distance measure

Represent the snapshot of resultant images retrieved after providing a sample query image for retrieval using Manhattan distance.
In Figs. 7 and 8 the retrieval results for 10 images are displayed for relevant images and but Figs. 5 and 6 shows the retrieval results for 30 images displayed. Observations are made that if first 10 images are selected for relevant images then there will be more accuracy is obtained but if more number of images are selected for retrieval then there will be varaition in the retreival obtained which clearly shows the retreival results will be good if less number of retrieval and the accuracy of retrieval will decrease as the image size increases for retreival.

Represent the snapshot of resultant images retrieved after providing a sample query image for 10 images retrieval using Euclidean distance

Represent the snapshot of resultant images retrieved after providing a sample query image for 10 images retrieval using Manhattan distance
In Fig. 9, the 10 retrieval results for bus is shown where 9 images are exactly retrieved where as one image is irrrelevant to the query image.

Represent the snapshot of resultant images retrieved after providing a sample query image for 10 images retrieval using Euclidean distance
5 Performance Evaluation of Results
Evaluation is more important to validate the performance of the system. The evaluation of image retrieval is a difficult yet essential topic for the successful operation of systems in practical applications. The main tools that image retrieval research borrowed from information retrieval are precision and recall measures. In this work, performance is evaluated to measure the efficiency of the proposed method in comparison with the existing method. The proposed method returns the desired set of similar images from the database based on the score computed by the user selection of similarity distance metric. The performance of this system measured by recall and precision. This proposed work developed an efficient algorithm for retrieving similar images from a database of digital images using visual contents based on the minimum edge detection. These features are extracted using the technique Hungarian algorithm and the CorelDB is used for the creation of data set with 10 categories of images. This algorithm has better performance against others in retrieving some category of images such as Dinosaurs, Birds ,Elephants, and Beaches but failed to get good results in case of Food images.
The proposed method WEMIR is examined with the corel database having 1500 images. The images are taken as random for the purpose of testing 15 categories of images are considered. From which ten category of images are taken for experimentation to evaluate the precision values of the method proposed. The similarity measure is used for the calculation of image distance measure between the query and the database image. For performance analysis the average precision of all the queries are computed. To judge the efficiency of the system precision and recall are the two metrics used in information retrieval.
The precision of the retrieval is defined as the fraction of the retrieved images that are indeed relevant for the query:
The recall is the fraction of relevant images that are returned by the query
Some of the sample images are shown in Fig. 2 from the Corel database. The retrieval result from the Corel database has been shown in Figs. 8 and 9 using two similarity measures. Euclidean distance shows good retrieval results when compared with Manhattan. The effectiveness of the proposed WMIR has been validated by different query images using precision and recall.
In order to assess the retrieval performance of WEMIR system, used average normalized modified retrieval rank (ANMRR) [53]. It takes into consideration the order of the retrieved images. ANMRR values are within the range[0, 1]. Low ANMRR value means highly accurate retrieval.
The performance evaluation was carried out in terms of ANMRR criteria and query running time. The reason for selecting the ANMRR evaluation metric is that ANMRR is defined in MPEG-7 standard to measure retrieval performance based on both, the number of suitably retrieved images and how highly these images are ranked which distinct ANMRR from other evaluation metrics such as precision and recall [4, 32, 34, 52]. Moreover, the ANMRR measure approximately coincides with the results of subjective retrieval accuracy evaluation of search engines [54].
Table 2 provides average precision and recall obtained for the random categories of images tested with the Corel database. The proposed WEMIR used four different similarity measures and their corresponding images retrieved are already shown in experimental results. The performance of this method is shown as precision 86 % and recall as 29%. Detailed performance evaluation has been discussed in chapter 6 with existing systems as well as proposed methods. The graphical representation of the precision and recall are as shown in Fig. 10

Graphical representation of precision and recall of WEMIR
To judge the efficiency of the prposed method,various criteria are correlated with the traditional method and preferred as a standard for this works as minimum edge detection, WANG dataset, number of image retrieved and the performance measure (precision-recall) (Figs. 11, 12 and 13).

Graphical representation of WEMIR precision and recall with existing methods

Graphical representation of precision and recall with existing methods

Graphical representation of accuracy
Table 1 shows that the performance of the proposed method WEMIR works better than the existing method in seven categories: Buidings,Flowers,Dinosaurs,Elephants,Mountains,Beaches and Horses. For African people ,Food the difference between existing methods is not that much variation slightly difference. But for Bus the variation is quite more,so it has to look for other features to ensure the relevant features. The pixel content pulling is difficult for each category of images based on the images contain features that despair from the other categories. Based on the validation results, the WEMIR shows improved results in terms of precision and recall for seven categories and slight variation for two categories and quite variation for single category.
As per Table 2, the results shown while comparing with the traditional methods proved that the average precision for WEMIR is 0.8571 while that of the existing methods. The difference is 0.02 in favor to the proposed method yields a higher precision result in CBIR and it is enhanced to the exisitng methods in terms of accuracy (Table 3).
The information present in Table 4 consists of the accuracy rate of the proposed method WEMIR. Irrespective of the algorithm used, the accuracy of retrieval will decrease as the images are increased under the circumstances of the similar image number and also the accurateness will decrease with the images under more in the image category. From this one can understand that the increase in image number along with image category the retrieval process will leads to turn down of retrieval accuracy. Yet, the increase in image categories has less influence on retrieval accuracy than image count. Moreover, as per the traditional systems the retrieval accuracy will go down dramatically. Accuracy is defined as the ratio of proper images to the total retrieved images from record and recall is defined as the percentage of proper images to all relevant images.
From Table 5 it is clear that the proposed method WMIR is superior when compared with other methods average precision values. In order to measure the running time of an algorithm in multitasking operating system environment precisely, first we measured the running time of algorithm applied to three subsets with 100, 200, and 400 images of corel database. Then the measured running time of each subset was divided by the number of its images in order to compute the running time for an image. Finally, an average over the three running times obtained by three subsets was computed as the running time of the algorithm. Table 6 shows the running time of the proposed algorithm with other methods running time. The computational cost required for executing this application reqiures 3.02s (Table 7).
6 Conclusion
This paper has presented a novel technique WEMIR based on hybrid combination of features for content based image retrieval. The features are of the form color, texture and shape are quite robust results in better retrieval of similarity images. From the feature extraction technique, it shows that the performance of WEMIR is good in retrieval of images. The projected method is examined with the average image retrieval precision value of the previous findings of researchers which gives the precision value of WEMIR is 85.71%.In future the work may be expanded by considering other unique features of the images to enhance the retrieval process.
References
Agarwal S, Verma AK (2013) Preetvanti singh content based image retrieval using discrete wavelet transform and edge histogram descriptor, 978-1-4673-5986-3/13/$31.00 ©2013 IEEE
A.Anandh, K.Mala, S.Suganya (2016) Content based image retrieval system based on semantic information using color, texture and shape features, 978-1-4673-8437-7/16/$31.00 ©2016 IEEE
Ashraf, Rehan, et al. "Content based image retrieval by using color descriptor and discrete wavelet transform." J Med Syst 42.3 (2018): 44.
Balasubramani R, DVK (2009) Efficient use of MPEG7 color layout and edge histogram descriptors in CBIR systems. Global Journal of Computer Science and Technology:157–163
Choudhary R, Raina N, Chaudhary N, Chauhan R, Goudar RH (2014) An integrated approach to content based image retrieval , 978-1-4799-3080-7114/$31.00 ©2014 IEEE
Datta R, Joshi D, Li J, Wang JZ (2008, 5:1–5:60) Image retrieval: ideas, influences, and trends of the new age. ACM Comput Surv 40(2). https://doi.org/10.1145/1348246.1348248
Deniziak RS (2017) Content based image retrieval using approximation by shape. International Journal of Computer Science and Applications, Techno mathematics Research Foundation 14(1):47–64
Deniziak, Stanislaw, and Tomasz Michno (2016) Content based image retrieval using query by approximate shape. 2016 Federated Conference on Computer Science and Information Systems (FedCSIS). IEEE
Deniziak S, Michno T (2016) Content based image retrieval using query by approximate shape. In: 2016 Federated Conference on Computer Science and Information Systems (FedCSIS). IEEE
Deniziak, Stanislaw, and Tomasz Michno. (2016) Content based image retrieval using query by approximate shape. 2016 Federated Conference on Computer Science and Information Systems (FedCSIS). IEEE
Deniziak S, Michno T (2016) Content based image retrieval using query by approximate shape. In: 2016 Federated Conference on Computer Science and Information Systems (FedCSIS). IEEE
Doulamis N, Doulamis A (2002) Optimal recursive similarity measure estimation for interactive content-based image retrieval. Proc Int Conf Image Process 1. IEEE
Doulamis A, Katsaros G (2016) 3D modelling of cultural heritage objects from photos posted over the Twitter. 2016 IEEE International Conference on Imaging Systems and Techniques (IST). IEEE
Doulamis AD, Doulamis ND, Kollias SD (2000) A fuzzy video content representation for video summarization and content-based retrieval. Signal Process 80(6):1049–1067
Gonzalez A-WRC, Woods RE (1992) Digital image processing. MA, Reading
Grosky W (2010) Image retrieval-existing techniques, content-based (cbir) systems. Department of Computer and Information Science, University of Michigan-Dearborn, Dearborn, MI, USA vol. 14
Gudivada V, Raghavan V (September 1995) Content-based image retrieval systems. IEEE Computer 28(9):18–22
Han K-KMJ (2007) Rotation-invariant and scale-invariant gabor features for texture image retrieval. Image Vis Comput 25:14741481
Hegde SP, Ramachandran S (2015) Implementation of wavelet based video encoder. International journal of advanced research in science enigneerig and technology 2(6):680–684
Hernandez W, Mendez A (March 16th 2018). Application of principal component analysis to image compression, statistics - growing data sets and growing demand for statistics. Türkmen Göksel, IntechOpen: https://doi.org/10.5772/intechopen.75007. Available from: https://www.intechopen.com/books/statistics-growing-data-sets-and-growing-demand-for-statistics/application-of-principal-component-analysis-to-image-compression
Huu QN, Thu HNT, Quoc TN (2012) ’An efficient content based image retrieval method for retrieving images. International journal of innovative computing, Information and control ICIC international 8(4)
Ibraheem CM, Reddy GU (October 2015) Content based Image retrival system using HSV color ,Shape and GLCM Texture. International Journal of Advanced Research in Computer and Communication Engineering 4(10)
Jain M, Singh SK (2019) An efficinet content based image retrieval algorithm using clustering techniques for large dataset. IEEE,29 July ,10.1109/CCAA 2018.8777591
Manpreet Kaur, Neelofar Sohi (2017) A novel technique for content based image retrieval using color, texture and edge features. IEEE, https://doi.org/10.1109/CESYS.2016.7889955
Kavitha N, Jeyanthi P (2015) Exemplary content based image retrieval using visual contents & genetic approach, 978-1-4799-8081-9/15/$31.00 © 2015 IEEE
Kokare BCM, Biswas PK (2007) Texture image retrieval using rotated wavelet filters. Pattern Recogn Lett 28:1240–1249
Kumar M, Singh KM (2016) Content based medical image retrieval system using DWT and LBP for ear images. J C T A 9(40):353–358 © International Science Press
Lin YCCH, Chen RT (2009) A smart content-based image retrieval system based on color and texture feature. Image Vis Comput 27(6):658–665
Liu Y et al (2007) A survey of content-based image retrieval with high-level semantics. Pattern Recogn 40(1):262–282
Mandal MK, Aboulnasr T, Panchanathan S (August 1996) Image indexing using moments and wavelets. IEEE Trans Consum Electron 42(3)
Manjunath BS, Salembier P, Sikora T (2002) Introduction to MPEG-7. Wiley, Chichester
Manjunath BS, Ohm JR, Vasudevan VV, Yamada A (2011) Color and texture descriptors. IEEE Transactions on Circuits and Systems for Video Technology 11:703–715
Nascimento XLMA, Sridhar V (2003) Effective and efficient region-based image retrieval. J Vis Lang Comput 14:151–179
Ndjiki-Nya P, Meiers T, Ohm J-R, Seyferth A, Sniehotta R (2000) Subjective evaluation of the MPEG-7 retrieval accuracy measure (ANMRR)
Phadikar BS, Phadikar A, Maity GK (2018) Content-based image retrieval in DCT compressed domain with MPEG-7 edge descriptor and genetic algorithm. Pattern Anal Applic 21(2):469–489
Piras L, Giacinto G (2017) Information fusion in content based image retrieval: A comprehensive overview. Information Fusion 37:50–60
Quellec G et al (2009) Adaptive nonseparable wavelet transform via lifting and its application to content-based image retrieval. IEEE Trans Image Process 19(1):25–35
Rashno A, Sadri S Content-based image retrieval with color and texture features in neutrosophic domain , 978-1-5090-6454-0/17/$31.00c IEEE
Rayar F (2017) ImageNet MPEG-7 visual descriptors technical report, arXiv:1702.00187v1 [cs.CV] 1 Feb 2017
Royal XQM, Chang R (2007) Learning from relevance feedback sessions using a k-nearest-neighbor-based semantic epository. IEEE International Conference on Multimedia and Expo (ICME07), Beijing, China:1994–1997
Rui Y, Huang TS (2001) Relevance feedback techniques in image retrieval. In: Lew MS (ed) Principles of Visual Information Retrieval. Springer-Verlag, London, pp 219–258
Shirazi SH, Khan N u A, Umar AI, Razzak MI (2016) Content-based image retrieval using texture color shape and region. (IJACSA) International Journal of Advanced Computer Science and Applications 7(1) www.ijacsa.thesai.org
Shkurko XQK (2007) A radial basis function and semantic learning space based composite learning approach to image retrieval. IEEE Interna-tional Conference on Acoustics, Speech, and Signal Processing (ICASSP07) (1):945–948
Smeulders AWM et al (2000) Content-based image retrieval at the end of the early years. IEEE Trans Pattern Anal Mach Intell 22(12):1349–1380
Srivastava P, Khare A (2017) Integration of wavelet transform, local binary patterns and moments for content-based image retrieval. J Vis Commun Image Represent 42:78–103
Srivastava P, Khare A (2017) Integration of wavelet transform, local binary patterns and moments for content-based image retrieval. J Vis Commun Image Represent 42:78–103
Tamilkodi R, Kumari GRN (2017) A new approach anticipated for CBIR by means of local and global mean. J Adv Res Dynamical & Control Systems 9(1)
Nehal M. Varma , Arshi Riyazi (2018) Content retrieval using hybrid feature extraction from query image, 978-1-5386-5510-8,2018,IEEE
Wang HH, Mohamad D, Ismail NA (2010) Approaches, challenges and future direction of image retrieval. J Comput 2(6):193–199
Won CS (2004) Feature extraction and evaluation using edge histogram descriptor in MPEG-7. In: Aizawa K., Nakamura Y., Satoh S. (eds) Advances in Multimedia Information Processing - PCM 2004. PCM 2004. Lecture Notes in Computer Science, vol 3333. Springer, Berlin, Heidelberg. https://doi.org/10.1007/978-3-540-30543-9_73\
Chee Sun Won, Dong Kwon Park, Soo-Jun Park (2002) Efficient use of MPEG-7 edge histogram descriptor, 01 February 2002, Volume 24, Issue 1, https://doi.org/10.4218/etrij.02.0102.0103
Wong KM (2004) Content based image retrieval using MPEG-7 dominant descriptor’. University of Hong Kong
Wong, Ka-Man, Kwok-Wai Cheung, and Lai-Man Po. (2005) MIRROR: an interactive content based image retrieval system. 2005 IEEE International Symposium on Circuits and Systems. IEEE
Zhang D et al (2000) Content-based image retrieval using Gabor texture features. IEEE Transactions Pami 13
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Tamilkodi, R., Nesakumari, G.R. A novel framework for retrieval of image using weighted edge matching algorithm. Multimed Tools Appl 80, 19625–19648 (2021). https://doi.org/10.1007/s11042-020-10452-0
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11042-020-10452-0