
Abstract
In this work we propose a novel method to extract illumination insensitive features for face recognition called local centre of mass face (LCMF). In this LCMF approach the gradient angle between the centre of mass and centre pixel of a selected neighborhood is extracted. Theoretically it is shown that this feature is illumination invariant using the Illumination Reflectance Model (IRM) and is robust to different illumination variations. It is also shown that this method does not involve any explicit computation of Luminance (L) component and as centre of mass is an inherent feature of a mass distribution, its slope with the centre pixel of the neighborhood has local edge preserving capabilities. The angle of the slope obtained using Centre of Mass with the centre pixel of the neighborhood is used as a feature vector. This feature vector is directed from the darkest section of the neighborhood to the brightest section of the neighborhood as Centre of Mass is always positioned towards the brighter side of a mass distribution and hence encrypts the edge orientation. Using the L1 norm distance measure, these feature vectors are used to classify the images. The method does not involve any preprocessing and training of images. The proposed method has been successfully tested under different illumination variant databases like AR, CMU-PIE, and extended Yale B using standard protocols, and performance is compared with recently published methods in terms of rank-1 recognition accuracy. The method is also applied on Sketch-Photo pair database like CUHK. For unbiased or fair performance evaluation, the Sensitivity and Specificity are also being measured for the proposed method on all the databases. The proposed method gives better accuracy performance and outperforms other recent face recognition methods.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
The field of biometric pattern recognition have increasingly become important in the nvestigation of crimes, security, personal identification and authentication [60]. With the increase in societal fraud, it has become natural that the one can no longer rely on empirical evidence. However, reliable personal identification data has become more and more challenging to obtain [37]. There are various aspects of personal identification that one can explore such as voice recognition, face recognition, behavior recognition, etc. All of these are based on a person’s biometric characteristics [16]. Human Face Recognition (HFR) is a fast developing technology in the domain of biometrics [35].
Humans are experts when it comes to recognizing faces of individuals and associate such faces with the correct person. In fact, they are more likely to recognize a face correctly than the name of the person. Our brains have highly specialized regions when it comes to process visual information. However, identify hundreds of images within a limited time is manually impossible. Therefore, an automatic system needs to be developed that can correctly match an image to it’s appropriate class. This creates an enormous potential for research in this field. Depending on applicabilities, various recognition algorithms have been introduced. These include eigenfaces [77], fisherfaces [6], neural networks [48], Laplacian faces [32], elastic bunch graph matching [85] and others [31, 57, 65]. Although these HFR algorithms are efficient and standardized, they have all considered databases which consist of facial images captured within a controlled lighting environment. Therefore they face difficulty when natural images are taken into consideration: images that are captured with pose variations, varying illumination conditions, aging, expressions, partial occlusions, etc. For accurate face recognition, it is mandatory that the variations within the images of a certain class (Intra-class variations) is minimal and the variations within the classes having different images (Inter-class variations) is maximal. However, when the images are taken under varying illumination conditions, it poses an enormous hindrance to this. As same image lit under different illumination conditions gives different feature representations and when these representations are matched with each other they prove to be incorrect [22]. Therefore changes in illumination is an enormously challenging problem as it brings down the accuracy of recognition dramatically [1]. The main features of the proposed LCMF approach are as follows:
-
i.
The extracted features are illumination invariant.
-
ii.
Luminance Component (L) is automatically rejected so no need to estimate illumination.
-
iii.
Preserves important local characteristic of individual neighborhoods as centre of mass is reflective of the neighborhood mass distribution or intensity distribution.
-
iv.
It is a local method, as it is based on the gradient angle between the centre of mass and centre pixel of the neighborhood.
-
v.
The relative positions of key facial features are not modified. As around the centre of mass the entire mass sums to zero.
-
vi.
LCMF does not require any training set and is therefore computationally inexpensive. The method is also computationally very efficient with time complexity of the order O(n 2).
-
vii.
No smoothing preprocessing of the images is performed so, there is no loss of texture, i.e., the reflection components (R) is preserved. It also preserves all edges as a intrinsic property of the centre of mass.
2 Literature study
There has been a vast amount of work done to mitigate the illumination variation problem in HFR. There are pre-processing techniques in which face images are usually transformed using some normalization process at a pre-processing stage. The traditional methods used are Histogram Equalization (HE) [29], gamma correction [30] and logarithmic transformation [67]. Others include equalization methods like Adaptive Histogram Equalization (AHE) [78], block-based histogram equalization [87] and region based histogram equalization [68]. Amongst the other popular methods, Jobson et al. [38] proposed the Multi-Scale Retinex (MSR) method to remove halo artefacts. The Local Histogram Equalization (LHE) was proposed by Lee et al. [50] to preserve the edges by obtaining the oriented LHE features. The machine learning concept of using line edge maps, for face recognition tasks, was first introduced by Takeo Kanade [39] and is later used by Gao & Leung for face recognition [23]. The approach was to generate edge maps and to use them in conjunction with the Hausdorff distance to recognize faces. Chen et al. [13] introduced a local edge preserving method using image factorization. Lian et al. [52] proposed an algorithm for estimation of illumination in local areas by using low-frequency Discrete Cosine Transform (DCT) coefficients. The Quotient Image (QI) method introduced by Shashua et al. [70] is illumination invariant at different levels and is dependent only on albedo information. Wang et al. [80] extended this concept in the method of Self Quotient Image (SQI) [81, 82] in which the test image is divided by a smoothened version of itself. Wavelet transform solutions have been provided in [11, 17, 28]. Bhoumik et al. [8] introduced a multi resolution image fusion method by fusing thermal and visual image using their wavelet coefficients. Another pre-processing for illumination normalization method is given in [75]. However, some of these methods are not satisfactory because in some cases they require smoothening of information at the pre-processing stage which causes elimination of some useful information and hence reduces the recognition rate and accuracy of the algorithm [24].
Another school of approach to tackle the problem of illumination variation is the model-based approach. Illumination variation depends on three factors: the direction of the incident source light, the levels of degree of the source light and the structure of a human face in a 3D space. Batur and Hayes [4] proposed a segmented linear subspace model to generalize the 3D linear subspace model such that it is unaffected by shadows. Blanz et al. [9] established a statistical model which learns from textures of 3D scanned head faces and provides an estimate by fitting this model to the images. Belhumeur et al. [5] presented the 3D linear subspace method where a large number of training images are required under varying lighting conditions to form a 3D basis for the linear subspace. The recognition proceeds by comparing the distance between the test image and linear subspace of the each image belonging to every class, using the Fisher Discriminant analysis. Belhumeur and Kriegman [6] established that an illumination cone could be obtained by forming a linear subspace of training images illuminated by a finite number of distant point sources, at a fixed pose. Basri and Jacobs [3] proposed a spherical harmonics representation method in which intensity of object surface can be approximated by a 9-dimensional linear subspace. All the model based approaches require multiple images under different lighting conditions and make the shape information a necessity during the training process. A non-model based approach was also introduced by Lee et al. [49] in which it showed that a subspace is resulting from nine images lit under the nine-point direction of incident source light, of an individual, could be used for better recognition.
There is another school type of approach where the illumination invariant features are extracted for a face recognition system. Chen et al. [12] showed that the image gradient is a function of face characteristics is an illumination invariant feature. Although these methods are established, they fail to yield satisfactory results especially when the lighting conditions vary in large amount. To combat this problem, there have been various methods which obtain illumination invariant features based on local pixel differences. These methods include Local Binary Patterns (LBP) [2], Local Ternary Patterns (LTP) [74], Local Directional Number Patterns (LDN) [64] and enhanced Local Directional Patterns (ELDP) [91]. The LBP and LTP methods use binary strings to encode edge information through the use of a certain thresholding technique from the centre of the pixel whereas the ELDP and LDN use Kirch compass masks to generate Edge maps [40, 41]. Zhang et al. [89] showed that ‘Gradient Face’ (G-face), in which images obtained in the gradient domain, is a strong illumination invariant feature. Wang et al. [83] proposed that the ratio between the local intensity variation and the background is a good illumination invariant feature. This method is called ‘Weber Face’ (W-face) and is based on Weber’s Law. Roy et al. [66], in his Local Gravity Face algorithm (LG-Face), showed that the direction of the force exerted by the neighboring pixels at its centre, is an illumination invariant feature. The Logarithmic Fractal Analysis (LFA) [19] proposed by Faraji used a combination of Logarithmic transformation and fractal analysis as an edge enhancer. Lai et al. [46] proposed a method of multiscale logarithmic difference edge maps (MSLDE) to eliminate the light intensity factor. Of late, work on compounding challenges of heterogeneity have evolved. New algorithms has come up to deal with challenges like sketch-pair matching, infrared matching, thermal matching, etc. Works on heterogeneous databases are discussed in [7, 25, 26, 42–44, 53, 76, 84, 90].
Inspired from local characteristic features in G-Face [89] and physics based properties in LG-face [66], we propose a method which exploits the properties of centre of mass in a 3 × 3 neighborhood and it’s gradient angle with the centre pixel for that eight neighborhood as a local characteristic descriptor. This descriptor reveals the surface characteristics of that neighborhood. When this is conducted over all neighborhoods of the image, a Local Centre of Mass Face (LCMF) is obtained. In the proposed LCMF method:
-
We find a novel local characteristic descriptor, Local Centre of Mass, for each and every neighborhood of an image.
-
We find the gradient angle between the centre of masss and the centre pixel of the neighborhood.
-
We prove that this gradient angle is an illumination invariant feature.
-
This feature is highly discriminative and it gives high rank-1 recognition accuracy on the CMU-PIE [27], Extended Yale-B [27], AR [55] and CUFS [79] databases.
The paper is divided into the following Sections. Section 3.1 introduces the concept of Centre of Mass and the properties of the centre of mass. Section 3.2 states the Illumination Reflectance Model, and its’ relevance to the proposed method. Section 3.3 proposes the extraction of illumination invariant feature from the image using the model of IRM and the properties of Centre of Mass theory. Section 3.4 posits the advantages of using Centre of Mass Face over other methods. Section 4 discusses the experiments conducted and the results obtained. Section 5 discusses the future scope of the method and concludes the paper.
3 Proposed method
In the proposed method, we show the effective extraction of an illumination invariant feature from an image and introduce how the feature obtained reduces the effect of illumination in the image. At first, we introduce the theoretical analysis of centre of mass and its gradient with the centre of the neighborhood. Further on, we provide a detailed description on how to obtain the gradient angle as an illumination invariant feature by using the Illumination Reflectance Model. We also examine the effectiveness of using Centre of Mass as a local characteristic feature.
3.1 Theory of Centre of Mass
A rigid body means a body in which the distance between each pair of particles remains invariant. If it undergoes some displacement, every particle in it suffers the same displacement. If the body turns through a certain angle about an axis, every particle in it rotates through the same angle, about that axis, at the same time. Furthermore, a rigid body is such an agglomeration of particles held together by cohesive forces that action and reaction between any two particles are equal and opposite.
In a rigid body system of particles, the centre of mass is the point at which all of the system’s mass are concentrated. It is the unique point where the weighted relative positions of a mass distribution sum up to zero. Also, any external force applied at this point will cause rigid body movement in the direction of force without any rotational movement.
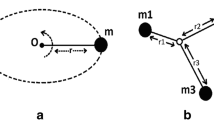
In Fig. 1, two particles of mass m1 and m2 are given. At rest, position vectors are given by \( \overrightarrow{v_1} \) and \( \overrightarrow{v_2} \) respectively with reference of origin O. The total force acting on mass m1 is the vector sum of two forces: \( \left(\overrightarrow{F_1}\right) \) ext., which is an external force acting on the system and \( \overrightarrow{F_{12}} \), which is an internal force acting within the system due to mass m 2 . The above phenomenon is represented by the following Equation.

A system with two particles
Similarly the total force acting of the mass m2 is given by:
Adding Eqs. (1) and (2) the total force acting on the system is given by:
According to Newton’s third law of motion, in a system of two particles, \( \overrightarrow{\Big({F}_{12}}\left)=-\overrightarrow{\Big({F}_{21}}\right) \)
So, using Newton’s second law of motion will give:
Here, \( \overrightarrow{s_1} \) and \( \overrightarrow{s_2} \) are the velocities of the two mass particles m1 and m2 respectively. Now \( \overrightarrow{s_1}=\frac{d}{ d t}\left(\overrightarrow{v_1}\right) \) and \( \overrightarrow{s_2}=\frac{d}{ d t}\left(\overrightarrow{v_2}\right) \). Thus, the total force acting on the system is:
Here, M = m 1 + m 2; M, represents the total mass of the system. If the same system consists of multiple particles m1,m2,...,mn then the above Equation will represent the motion of a hypothetical body of mass M of n particles. The position vector of such a force is given by:
The point which has the position vector \( \overrightarrow{C} \) is called the centre of mass and it is the point around which the whole distribution of mass is balanced. If the system is at rest and considered isolated from other systems, then the external force acting on the system will be zero. If the system of particles is at rest, the only force acting on the centre of mass with position vector \( \overrightarrow{C} \) will be internal. The resultant force in such a system will be directed towards the centre of mass.
We can consider individual pixels as bodies in space or charged particles in space. If such is the case, then the pixels would exhibit similar physical properties as bodies in space does. A similar proposition is discussed in [73]. Everything that has any mass has an innate reflecting capability. This is an inherent characteristic of the body just like the force of gravity [59]. We view the world through the medium of light and we comprehend objects as the light that is reflected by them. Therefore the incident light falling on the object gets reflected at certain angles due to the surface characteristic and nature of the object. This property of reflectance enables us to view the shape of an object, its size, its color and other properties. The reflecting light is called luminance or the luminous density. It informs us how much luminous energy will be detected by the eye when viewed from a certain position. It can also be considered as the degree of brightness of the body. So this amount of luminance coming off the object’s surface is recorded and stored by a camera in the form of pixels through various image acquisition processes [10, 61].Therefore, pixels are the smallest units of an image array with each of them having an intrinsic property of intensity and spatial position quite similar to a planetary body or atom [15, 21]. The luminosity of a star is essentially the total amount of energy emitted from the object. Knowing its mass one can obtain its luminosity [18]. In a similar way, knowing the mass of a pixel or the intensity of a pixel one can obtain the luminance information of the pixel. These pixels will exhibit similar properties like planetary bodies and since pixels are the basic units of a digital image, establishing relationships amongst the pixel intensities is essential to obtain the luminance information of an image.
Using this pixel-mass analogy, various algorithms have been established for several applications [34, 45, 54, 58, 62, 86]. In our proposed method, we have used the fundamental property of Centre of Mass as unique feature of a pixel neighborhood and it’s gradient direction with the centre pixel of the neighborhood as an illumination invariant feature. Being a fundamental property of mass distribution, Centre of Mass gradient holds important local characteristics of an image and is used on challenging illumination variant databases and sketch databases with high rates of accuracy.
In Fig. 2, we get the upper rightmost neighborhood 3, (i . e., I(x + 1, y + 1)),exerts an internal force F 3 on the centre of mass C at an angle of (α + β). Note that the centre pixel of the neighborhood, 5 (i . e., I(x, y)), does not necessarily coincide with the Centre of Mass. Thus, the Centre of mass is towards south east of the centre pixel of the neighborhood. For other mass distribution C can be anywhere within the neighborhood depending on the mass of the body, i.e., intensity of the pixel. This shows that position of the centre of mass is reflective of the neighborhood mass distribution or intensity distribution, thereby preserving an important local characteristic of individual neighborhoods.

Centre of Mass on Its Neighborhood
3.2 Illumination reflectance model (IRM)
The Illumination Reflectance Model as introduced by Horn [33] considers a face as an object. It states that the intensity I of a pixel position (x,y) is the product of its reflectance R(x,y) and luminance L(x,y). The basis of retinex Theory in [47, 72] explains the above theory. The theory is presented in Eq. (7).
Here (x,y) are the spatial coordinates and L(x,y) is it’s luminance component whereas R(x,y) is it’s reflectance component. According to the basis of Retinex Theory [47], L(x,y) is dependent on the source of incident light whereas R(x,y) depends on the surface characteristics of a body which, in this case, is the face. Since (x,y) is a homogeneous body, reflectivity will be same as reflectance. Therefore in a face image, R(x,y) will express the key facial component information like edges and structures. L(x,y) on the other hand is not dependent on the surface characteristics of the image. As seen in [20, 47, 72, 89], L hardly varies across spatial variations and is assumed to be constant in a small neighborhood. R, on the other hand, varies greatly when it comes to edges and other discontinuities. So even in a small neighborhood, R can vary. Therefore the elimination of L from these regions keeping R intact can preserve critical facial information. In the frequency domain, L would occupy the low-frequency bands while R will occupy the high-frequency bands. So removal of L will result in a feature image with sharper image characteristics and enhanced contrast. Since R is clearly considered as an illumination invariant feature of an image I, it must be separated from L to get the illumination invariant resultant. Two ways to do this are:
1) Subtraction in Logarithmic Domain: Using this method, intensity can be represented as an addition of Reflectance and Luminance rather than a multiplication of the two.
Taking logarithm gives:
In the logarithmic domain, the illumination invariant component (R) is simply obtained by subtracting the luminance (L) component from the logarithm of the image component (I) as given in Eq. (8). However, in this approach, L has to be explicitly calculated or approximated, which can be a tough challenge. In [23, 39] appropriate number of DCT coefficients are taken to exclude L. In other approaches [11, 28, 82], a number of wavelet bands are removed in the wavelet transform to eliminate L. In [19], the fractal analysis is done in the logarithmic domain to remove L.
2) Division Method applied to pairs of adjacent pixels of an image to eliminate the illumination component: If two adjacent pixels (x,y) and (x + 1,y) are considered, then the ratio of their intensities is given by:
As we know since the pixels are adjacent to each other and L varies very slowly from (x + 1,y) to (x,y). Therefore L(x + 1,y) and L(x,y) are approximately equal. Taking this approximation the above Equation can be written as.
Division mechanisms are used in G-Face [89] and W-Face [83] directly. Other methods like the Local Binary Pattern (LBP) [2] and the Local Ternary Pattern (LTP) [75] use thresholds to obtain their binary strings. Even though they do not implement division method directly, they do implement them indirectly. It generates a string based on the following relation
Where I c is the centre pixel of a neighborhood, I i is the ith neighbor. Aplying the Horn’s Law the above relation can be written as:
If we use the relation from the IRM where the intensity is a product of the reflectance and luminance, the above relation turns out to be
As L i and L c are luminance obtained for the adjacent pixels over a 3 × 3 neighborhood the above relation can be written as
ELDP [64] and LDP [91], both involve in obtaining ratio values and therefore both indirectly uses the division method. The division method is much more superior and computationally efficient than subtraction in logarithmic domain as the former does not involve any computation of the L component whereas subtraction methods have to deal with the calculation of L component. Finding the L component is quite difficult. Even the results obtained by division methods employed in [2, 33, 64, 75, 83, 89, 91] are far superior compared to the ones obtained by the logarithmic domain subtraction methods used in [11, 23, 28, 39].The proposed method involves in establishing a ratio between the position of Centre of Mass and the Centre of Neighborhood and uses the division method. To avoid division by zero error, ε (a very small quantity) is added to the whole image before the features are obtained.
3.3 Obtaining the illumination invariant Centre of Mass feature
As seen in Section 3.1, Centre of the mass (of a particular mass distribution) is a position vector in the space around which the mass is evenly distributed. It may be present within the distribution space or outside the distribution space. In either case, Centre of Mass is a unique feature of a particular mass distribution and utilization of such a feature in the context of facial images help in preserving discriminative features of the human face. The position vector \( \overrightarrow{C} \) will have components in the x and y directions. This is shown in Fig. 3.

Vector representation of Centre of Mass
Similarly, the centre pixel can also be considered as a position vector having x and y components. Local Centre of Mass Face (LCMF) is essentially the arctangent of the difference between the centre of mass and the centre pixel of the neighborhood, in y and x directions. It is proven that this feature is an illumination invariant feature.
Consider a local neighborhood window of size 3 × 3 where the pixel intensities represent the mass distribution within the window. According to the theory of centre of mass, the mass distribution is balanced around the Centre of Mass position vector \( \overrightarrow{C} \). The position vector can be represented as:
Here, \( M=\sum_{i=1}^9\left({m}_i\right) \) represents the sum of all the 9 pixels in the neighborhood and \( \overrightarrow{v_i}\forall i \) are the corresponding position vectors. From the analogy of individual pixel intensity as masses in the neighborhood distribution, Eq. (15) can be written as:
Here, I = (I 1 + I 2 + … + I 9 ) is the total intensity value of the neighborhood window.
Theorem : The arctangent of the difference between the Centre of Mass and the Centre Pixel of a neighborhood is an illumination invariant feature in a 3 × 3 neighborhood of an image I(x,y).
Proof: Let us consider the Centre pixel of a neighborhood to be\( \overrightarrow{P} \) having x and y components as P X and P Y respectively. Both\( \overrightarrow{C} \) and be\( \overrightarrow{P} \) are obtained with reference to the origin of the image O. As the computation of the CM-Face is a local facial feature, the origin must be subtracted from both these vectors. The obtained Centre of Mass gradient would be given by:
Here, O is the origin of the image space. The magnitude of the gradient will be given by:
Moreover, the angle of gradient is given by the Equation:
Putting the corresponding values of G X and G Y , Eq. (18) can be written as
Using the representation of \( \overrightarrow{C} \) given in Eq. (16), Eq. (19) can be stated as
Using the relation given in Eq. (6), where I = R ∙ L, R being the reflectance component and L being the luminance component of the pixel I(x,y), the above equaiton (20) can be rewritten as.
Now due to the widely held assumption that luminance L varies very slowly within a 3 × 3 neighborhood, we can say L 1 ≈ L 2 ≈ L. Using this Eq. ((21)) can be stated as
As it is already established that R component of any pixel is an illumination invariant feature. Hence, θ, is an illumination invariant feature (proved).
Implemention, of Local Centre of Mass face requires the following two steps on every pixel other than the boundary pixels.
1.To obtain the Coordinates of the Centre of Mass of every neighborhood by using Eq. (16).
4 2. To obtain the direction angle of Centre of Mass gradient using the Eq. (22).
When an image of size M × N is taken and the corresponding CM-Face (LCMF) is computed by taking 3 × 3 filter over the pixels we obtain a feature face of size ((M − 1) × (N − 2). The feature face comprises of gradient angles θ i where θ ∈ [0, 2π ] and 1 ≤ i ≤ (M − 2) X (N − 2). Figure 4 represents a typical CM-Face feature.

Centre of Mass Gradient Angle
4.1 Advantages of local Centre of Mass Face Approach over other methods
As discussed in Section 3.1, Centre of Mass is a fundamental property of a mass distribution around which the entire mass is distributed uniformly and around which the relative positions of such mass sums to zero. The theorem in Section 3.3 states that the gradient of Centre of Mass with the centre of the neighborhood preserves local edge characteristics as in [51]. Therefore it makes it superior to the other methods. Both the logarithmic total variations (LTV) [14] and the Log-DCT [13], methods require a sort of estimation: whether it be the estimation of L component or the number of cosine coefficients to be eliminated. Such a case can never suffice fully as an optimization is required. Also, as mentioned in Section 3.2 , is computationally inefficient. OLHE [50] involves removal of luminance component but it also involves in forming (n-1) sub-images for n neighborhoods and is, therefore, inefficient. The ELDP and LDN methods also extend the use of Kirsch mask operators. The MSLDE algorithm involves in taking a sub-region which is large enough to have slight illumination variations. This affects the accuracy. Also, along with the Weber face algorithm, it involves the use of parameterized functions for estimation. Gradient Face uses Gaussian smoothing to remove noise however it has some shortcomings because it produces artifacts and use of smoothing requires some loss of edge details. This affects the recognition rate. LG-Face employs gradient features based on the direction of gravitational force, but it assumes the centre of the neighborhood as the balancing point around which directional feature is obtained. It also employs fixed point on every neighborhood which is not an accurate description of the intensity distribution.
In the Centre of Mass Face (LCMF) method, the centre of mass is used for determining the balancing point around which the mass of the whole system is balanced. Therefore it is gradient direction with the centre of that distribution is essentially the one which points from the brightest section in the neighborhood to the darkest section in the neighborhood and it is also quite efficient in determining the edge characteristics. It is an accurate physical description of a an intensity distribution as it is a physical property. Furthermore, it has more discriminative property as it rightfully leans towards the brighter parts of the mass distribution. The distance of the centre of mass from the higher intensity section of the neighborhood is less than the centre pixel of the neighborhood. This is due to Equation (6) where \( \overrightarrow{C} \) is obtained as a weighted result.
According to the law of conservation of energy, the total energy within a particularly isolated system has to remain same. So essentially Fig. 5b and c should conserve the potential energy of the system. We also know that \( \overrightarrow{C} \) is closer to the brighter section of the neighborhood intensity distribution and it’s distance r c to the brighter section,(Fig. 5c), is less than distance r between the centre of the neighborhood and the brighter section of the distribution Fig. 5b.

(From Left to Right) a A 3 × 3 neighborhood, b a fixed point characteristic, c centre of mass characteristic
A neighborhood of 3 × 3 is chosen because neighborhoods of higher dimensions will violate the Retinex Theory [20, 72] and will not follow the Illumination Reflectance Model (IRM) as proposed by Horn [51]. This is due to the fact, that for larger neighborhood IRM Equation may not hold true. Also for large neighborhood it also loses out various subtle edge details, which is counterproductive. Even though other neighborhood sizes were considered initially, it was found out that a size 3 × 3 gives the most detailed feature and produce the best results.
So according to the conservation of potential energy,
Here, \( {\overrightarrow{F}}_{int} \) is the total internal force acting on centre of mass, \( \overrightarrow{C} \), as given in Fig. 5(c). \( \overrightarrow{F} \) is the force acting on neighborhood centre as given in Fig. 5(b). Now as the energy is same and \( \left|{\overrightarrow{r}}_c\right|<\left|\overrightarrow{r}\right| \), therefore \( {\overrightarrow{F}}_{int}>\overrightarrow{F} \). The internal force \( {\overrightarrow{F}}_{int} \) is greater because the position vector \( \overrightarrow{C} \) is closer to the brighter section of the neighborhood and the force exerted by the brighter pixels are more. As a result of this, the force on \( \overrightarrow{C} \) from the brightest section of the neighborhood would be more and will point to the direction towards the darkest section of the neighborhood thereby creating more contrast and better gradient. Therefore, it preserves the local characteristics of a neighborhood. Finally the neighborhood can be scaled higher and for each scale new characteristics would be preserved unlike LG-face. Also, the algorithm can be modified into a multi-scale algorithm in an extremely quick time by the use of integral images [51]. As discussed in the results section, this nature holds true when it comes to determining features.
For an image of size M × N, and Z be the number of pixels in the neighborhood, the computational complexity for obtaining the Centre of Mass Face (LCMF), is O(M × N × Z). Thus number of basic operations is {(M × N × Z) + (M − 2)(N − 2)}. Considering Z as a constant as in the case of LCMF, the time complexity of the proposed LCMF method is O(M × N). The computational complexity of deriving a LG-face [66] with image size of m × n and window size w × h is O(mnwh). The computational complexity of deriving a G-face [89] with dimensions of m × n and neighborhood of size h is O(mnh), which is higher than CM Face (LCMF). Now, considering the neighbourhood size, h, as a constant in G-Face, the computational complexities of both G-Face and LCMF will be of the same order, i.e. O(mn). However, the actual number of operations required by G-Face is more as it has an additional initial smoothening function (Gaussian Kernel function). So for a huge dataset LCMF will be more beneficial than G-Face even though they are of the same order.
5 Experimental results
The proposed LCMF Method was applied on various sets of data from a range of databases. Challenging scenarios were created for the databases on which the performance of the proposed method sustained itself. The results of the experiments have been compared with other competitive methods in same scenarios. In all cases, it has been shown that the proposed method performs the best. The minimum system requirements needed for the present work are. CPU 1.5 GHz Dual Core, Ram 2GB, OS Windows 7, Programming Language MatLab 2010. This section also discusses the similarity measure used and the standard metrics used to test and compare the performance of our method to other competitive methods.
5.1 Similarity measure
Centre Mass face uses the θ obtained from the directional invariant process in order to find out the similarity between two images. The input is taken as a m x n matrix and local centre of mass face is obtained by the proposed method. The LCMF obtained is a (m-2) x (n-2) matrix which contains the θ values for all the 3 × 3 neighborhoods of the given image. A LCMF typically takes the following form.
Where θ ij is the centre of mass feature obtained for the [i-1…i + 1, j-1…j + 1] neighborhood of a given image I. For the purpose of similarity, we convert this matrix to a CF feature vector of then length x, where x = (m − 2)∗(n − 2). For any two images we obtain CF1 and CF2 vectors. The L1 norm is obtained for the two vectors. Here, L1 norm is essentially the minimum angle distance difference between the corresponding angles of the two feature vectors. It is given by the following Equation:
Where CF 1 = [cf 11 , cf 12 , …, cf 1x ] and CF 2 = [cf 21 , cf 22, …, cf 2x ] are the corresponding LCMF feature vectors. This is in accordance to Zhang et al. [89] where the smaller the distance (CF 1 , CF 2 ) is the better the similarity between the two vectors.
5.2 Results on illumination variant databases
All the methods are tuned according to our experiment. The proposed LCMF method is applied on various illumination invariant databases namely the CMU-PIE database [71], Extended Yale B database [27] and the AR Face Database [55]. All the competing state of the art methods are implemented and tuned according to our parameters and specifications. The rank-1 recognition rate [36] is obtained. The results are further compared with other competing and cutting edge algorithms and we show that the proposed method outmatches the other latest algorithms.
5.2.1 Results on CMU-PIE database
The CMU-PIE database [71] is a collective database of 41,368 images obtained from 68 different subjects of size 640 × 486 pixels. It is a database consisting of 13 pose variations, 43 illumination variation and four facial expression changes. The images are captured by 13 different cameras and 21 different flashes. For our experiment, the camera position C27 is considered which gets the images having a frontal pose with neutral expression. The 21 different flashes produce 21 images for the frontal pose. In our experiment, we used two sets of images, PA and PB. Set PA consists of 68 subjects and each subjecting comprises 21 images. All these images are captured using background lights on. Set PB consists of 68 subjects and each subject comprises 21 images. Each of these images is captured using background lights off. All the images are first converted to grayscale and cropped to extract only the facial part and resized to 150 × 150 resolution. We use one image per subject as a reference image and the rest of the images as test images for each class.
Figure 6(a) shows an example of Set PA in the CMU-PIE database with their respective centre of mass features. Figure 6(b) shows an example of Set PB in the CMU-PIE database with their respective centre of mass features. Note how LCMF method retains the salient features when it comes to illumination variation. Even though conditions in (a) and (b) are quite different, all the salient features are retained.

a Images from CMU-PIE database from Set PA and their corresponding CM-Faces. b Images from CMU-PIE Database from Set PB and their corresponding CM-Faces
The total number of test images are 2856 with 1428 images for each set. The average rank 1 recognition accuracy results are shown in Table 1. As can be seen, the experiment is compared with other competitive methods like histogram equilization (HE) [29], Multi-Scale Retinex (MSR) [38], Self Quotient Image (SQI) [81, 82], logarithmic total variation (LTV) [75], Log-DCT [39], G-Face [89], W-Face [83], local gravity face LG-Face [66], multiscale logarithmic difference edge maps (MSLDE) [46], Oriented Local Histogram Equilization (OLHE) [50], Local Binary Pattern (LBP) [2], Local Directional Number Patterns (LDN) [64], enhanced Local Directional Patterns (ELDP) [91] and Local Fractal Analysis (LFA) [19] and it outperforms all of them. Also, when the method is applied on Set PA, it gives a higher recognition rate than when applied on Set PB. This is because images of Set PB has larger variations in lighting conditions as the background light is off. It can also be seen that the results of LCMF on both Sets PA and PB are superior to that of other competitive methods.
Another experiment is conducted where each image of 68 subjects are taken as a reference image, in turns, and their corresponding Rank-1 recognition accuracy rates are obtained. The graph in Fig. 7 shows the results of the experiment. It can be seen from Fig. 7 that LCMF yields the best accuracy results for most of the reference images.

Average Recognition accuracy of various methods on the CMU-PIE Database.by considering each image (one at a time) as a Reference image
5.2.2 Results on extended Yale B database
The Extended Yale B Face Database [27] comprises 38 subjects with nine different poses and each pose is subjected to 64 different illumination angles of size 192 × 168 pixels. All the images are first converted to grayscale and cropped to extract only the face part and resized to 150 × 150 resolution. For our experiment, five different sets are formed based on the illumination angle. They are divided into five subsets based on the angle of the light source directions using standard protocols [27]. Set I consists of images with source angle of 0° to 12°, Set II consists of images with source angle of 13° to 25°, Set III consists of images with source angle of 26° to 50°, Set IV consists of images with source angle of 51° to 77° and Set V consists of images with source angle above 78°. Set-I consists of 266 images (7 image per subject) while Set II and Set III consists of 456 images each (12 images per subject), Set IV consists of 532 images (14 images per subject) and Set V consists of 722 images (19 images per subject). All the images considered here are having frontal pose.
In general, the images from extended Yale B are much challenging in nature compared to the CMU-PIE images, especially those from Set III, Set IV, and Set V. Whenever the angle of lights increase and long shadows are formed, the challenge of the problem rises. Figure 8 shows a set of images from the Extended Yale B database and its corresponding Local CM-Face (LCMF) features.

Some sample images from Extended Yale B database and their corresponding LCMF Feature Images
In the Extended Yale B database, one image from every Set is taken as reference image while the rest of the images are included in the test set for each class. The proposed method is tested on the five sets and the results are shown in Fig. 9. From Fig. 9, we can see that our proposed LCMF method has an average Rank-1 accuracy that is superior to other competitive recognition methods.

Recognition Accuracy on five Sets of Extended Yale B Database
Also, methods like Linear Subspace [49], Cones-Attached [27], Cones Cast [27] and Harmonic Images [88] have been outperformed by LCMF. It has also been shown the LCMF is superior to cutting-edge methods like the Gradient Face, Weber Face, LG-Face and MSLDE. It also outperforms every one of them on individual sets of data. Not only does the average accuracy remains high because of impressive results on Set I and Set II, but the method also yields terrific results on Set III, Set IV, and Set V. The difference between the accuracies amongst the various sets is minimum in the LCMF method. This also shows the robustness of the method as far as the change in illumination angles is concerned. The method is consistent and sustains itself on various challenges caused by drastic changes in the direction of illumination.
5.2.3 Results on the AR face database
The AR database [55], comprises more than 4000 color images of 126 subjects, of size 768 × 576 pixels, characterizes divergence from ideal. It comprises 14 images per subject conducted in a session and 14 images per subject conducted in another session. This database is a challenging one as it not only consists of images with varying lighting conditions but also images comprising expression changes. It also consists of two occlusion images: one with a scarf and another with sunglasses. Illumination changes occur when the images are lit using the left light on, right light on or both lights on. For our experiment, we had to cropped only the facial portion of the image. Then we converted all the images to grayscale and resized them to a resolution of 100 × 100. The reference image was taken as the one having a neutral expression with equal lighting conditions. The rest of the images were taken as the test images for each class. Figure 10 shows a typical subject in varying conditions as presented in the AR Database.

Images of a subject from AR Database (Top) and their corresponding LCMF Feature Images (bottom)

(Top) AR Database Image with variations in Gaussian Noise and (Bottom) The corresponding CM-Face Feature Images to noise variations. From (left to right), Gaussian Noise with standard deviation σ=0, σ=0.01, σ=0.02, σ=0.03, σ=0.04

Recognition accuracy of different methods of noisy samples of variable deviation in AR Database

(Above) AR Database photo and their corresponding LCM-Face Feature images and (Below) AR Sketch images and their corresponding LCM-Face Feature Images

(Above) CUHK Student Face Database photos with Corresponding LCM-Face Features and (below) CUHK Face Sketch Images with their corresponding LCM-Face Features
The proposed method was applied to the dataset and the accuracy results are shown in Table 2. From Table 2, we can see that recognition accuracy obtained by the proposed method is better than the ones of cutting edge algorithms like noise-resistant LBP NRLBP [63] (which is a version of LBP that is adequately robust to noise), LG-Face, and G-Face. The significance of the method further increases when Gaussian Noise is added to reference images (Fig. 11). When noise is added with varying standard deviation, σ, many methods show tremendous variability in the accuracy rates. However out method sustains itself despite high noise variations upto σ=0.04. Both NRLBP and LGFA are highly robust methods when it comes to noise but LCMF shows more resistance (Fig. 12).
From Fig. 12, we can see that the CM-Face (LCMF) method, compared to other methods, demonstrates better results when it comes to resisting noise. The method has an accuracy rate of above 90% (σ=0.02) and 89.5% (σ=0.03) which is higher than G-face, LGFA and NRLBP methods. This shows the ability of the method to deter noise. It extends the logic of centre of mass being an accurate representation of the pixel distribution in a neighborhood. As it preserves the local characteristics and the edge features of the face, the basic structural element remains intact despite the overlay of noise on it.
5.2.4 Results on sketch-photo databases
Three sketch-Photo Pair databases are used: The CUHK Student Face Database [79], AR Sketch Database [55] sketch pairs and the XM2VTS [56] Database. Together they make the CUHK Face Sketch Database (CUFS) [79] of size. It is a data set of 606 sketch and photo pairs that comprises 188 pairs from the CUHK Student Database, 123 pairs from AR Database and 295 pairs from the XM2VTS database. Each pair consists of one photo image and their respective sketch image.
Some examples of the sketch-photo pairs from the AR-Data Set are shown in Fig. 13. The CUHK Student Database sketch-photo pair and their corresponding LCMF features are shown in Fig. 14. In our experiment, the photo image is taken as the reference image, while it’s corresponding sketch image is taken as the test image. There were a total of 606 pairs of images. All images were converted to their grayscale correspondence and only their face part is cropped. Then resized to the resolution of 100 × 100. The LCMF method was applied to the dataset, and the recognition accuracy was obtained. The results are shown in Table 3. For this experiment, all the competitive methods such as embedded hidden markov model (E-HMM) [25], sparse neighbor selection-sparse-representation-based enhancement (SNS-SRE) [26], Transductive Face Sketch-Photo Synthesis (TSFP) [84], Enhanced Uniform Circular Local Binary Pattern (EUCLBP) + GA [7], Coupled Information-Theoretic encoding (CITP) [90], for face photo-sketch recognition [90], Scale Invariant Feature Transform-multiscale local binary patterns (SIFT + MLBP) [44], partial least squares (PLS) [69] and kernel prototype recognition similarities (KP-RS) [43] were compared with the LCMF method.
From Table 3, we can observe all are cutting edge methods. However, both sparse neighbor selection-sparse-representation-based enhancement SNS-SRE and Enhanced Uniform Circular Local Binary Pattern (EUCLBP) + GA have a high standard deviation. The top methods are CITP, SIFT + MLBP and LGFA with high rank-1 accuracy and moderate standard deviation. The proposed method LCMF performed better than the top methods with almost perfect accuracy and having minimum deviation. Despite CUFS possessing a different set of challenges, LCMF sustained itself and performed the best when it came to sketch-photo pairs. The fact that it achieves almost a perfect accuracy proves that the local centre of mass features give a better local direction for recognition purposes.
5.2.5 Unbaısed recognition performance
However, Recognition rate is not always sufficient for performance evaluation as it can provide results biased to a particular class. For unbiased performance evaluation other performance metrics such as Sensitivity and Specificity have also been defined which are based on quantitative terms defined below. When an input image is tested, it may or it may not belong to a class. For a class, say A, the test generates one of the following results:
True Positive (TP) means that the input test image is assigned to class A and it actually belongs to class A.
False Positive (FP) means that the input test image is assigned to class A and it does not belong to class A.
True Negative (TN) means that the input test image is not assigned to class A and it actually does not belong to class A.
False Negative (FN) means that the input test image is not assigned to class A but it belongs to class A.
Sensitivity is measured as the proportion of test images of an individual that are correctly identified. It can be calculated as given in Eq. (25).
Specificity is measured as the ratio of correctly identified test images of an individual to all the test images that are identified as that individual and calculated by using Eq. (26).
To calculate the sensitivity and specificity, all methods are implemented according to our experimental setup and test parameters. For all databases, LCMF demonstrates superior sensitivity and specificity measures.
CMU-PIE database
For unbaised face recognition on the CMU-PIE database having a dataset of 68 individuals each having 21 images, the test dataset is prepared in the following manner:
-
i.
CMU-PIE for Lights on (E1): A dataset of 68 classes is formed with each class containing a total of 26 images, of which 21 images are of a particular individual and the remaining 5 images are of different individuals taken randomly using permutation. For testing only the one image of each class is considered as reference image and the remaining 25 images are used as testing samples. In the experiments for simplicity the first image of each class is taken as the reference image.
CMU- PIE for Lights Off (E2): Similarly a dataset of 68 classes is formed with each class containing a total of 26 images, of which 21 images are of a particular individual and the remaining 5 images are of different individuals taken randomly. For testing only the first image of each class is considered as reference image.
The unbaised performance measure in percentage (%) of the proposed LCMF and its comparision with other well known methods are shown below in Table 4.
As it can be see from Table 4, the proposed method outperforms the other mehods when it comes to sensitivity and specificity measures.
Extended Yale B database
Similarly the unbiased performance on the extended Yale B is described in the next two Tables i.e. Tables 5 and 6. For establishing the specificity and sensitivity of LCMF on the extended Yale B database, the five different datasets created on the basis of illumination change are prepared according to the standard protocols [27] in the following manner:
-
1.
Set I: The test data set is formed such that, each class of Set I consists of 11 images. Of this, 6 images are of the same class and 5 images are from other classes. The 5 images are taken randomly.
-
2.
Set II: Each class of Set II consists of 16 images. Of this 16 images, 11 images are of the same class and 5 images are from other classes taken randomly.
-
3.
Set III: Similarly each class of Set III consists of 16 images. Of this 16 images, 11 images are of the same class and 5 images are from other classes. The 5 images are taken randomly.
-
4.
Set IV: The test data set is formed in such a way, that each class of Set IV consists of 18 images. Of this 18 images, 13 images are of the same class and 5 images are from other classes. These 5 images are taken randomly.
-
5.
Set V: The test data set is formed in such a way, that each class of Set V consists of 23 images. Of this 23 images, 18 images are of the same class and 5 images are from other classes. These 5 images are taken randomly.
The reference data set for each of sets are formed by taking one image from each class of that Set. For example, the reference data set of Set I contains 38 images such that every image belongs to a distinct class of Set I. All the reference data sets are taken according to such specificitaions. The sensitivity and speficity measures are compared below in Tables 5 and 6 respectively for (Set I to Set V of extended Yale B database).
As it can be seen, LCMF not only outperforms the other methods in it’s sensitivity and specifcity measures but also maintains a consistent rate across the various sets of data. As the original data sets are formed according to the direction of incidence light falling on the faces, the consistency of LCMF across multiple sets demonstrates the robustness of the algorithm when it is subjected to varying lighting conditions.
AR database
The AR Database consists of 126 classes with each class having 14 images. Of this, the reference data set is formed by taking the first image of every class. The first image is the one with neutral expression, frontal pose and illuminated unifromly. The test data set is formed by taking the remaining 13 images from the same class and 5 images from other classes taken randomly. For example, a test class I of AR database will comprise 13 images from class I and 5 images from other classes. The sensitivity and specificty measure are compared and shown in Table 7. From this Table, it is clear that LCMF outperforms the other methods, because of it’s distinct discriminative local features.
6 Conclusion
The paper presents a novel approach, on Face Recognition, called Local Centre of Mass Face (LCMF). It calculates the gradient angle between the centre of mass and centre pixel of neighborhood for every neighborhood in an image, thereby retaining the structural properties of the image. It also retains the pixel distribution information as the centre of mass reveals the distribution of pixels in a neighborhood. This is an illumination invariant feature and is successful in separating the Reflectance component from the Luminance component without the need for any explicit computation. Not only is the gradient angle illumination invariant but also the position of Centre of Mass. The proposed method can cope with changes in illumination, changes in noise as well as heterogeneous sketch-photo pair matching. It shows remarkable performance accuracy when it compares to the other competitive methods on Extended Yale B, CMU-PIE and AR Databases. The method also proves that it is competent when it comes to changes in Gaussian Noise in the AR Database and outperforms all other cutting edge methods. It also had a near perfect accuracy when it came to the CUFS sketch-photo pair dataset. In future, the method would be combined with other dimension reduction algorithms to compress the number of features despite retaining maximum information. Further, LCMF has low computational cost, does not require any preprocessing and training of images such that it can be applied to practical applications.
References
Adini Y, Moses Y, Ullman S (1997) Face recognition: the problem of compensating for changes in illumination direction. IEEE Trans Pattern Anal Mach Intell 19(7):721–732
Ahonen T, Hadid A, Pietikainen M (2006) Face description with local binary patterns: application to face recognition. IEEE Trans Pattern Anal Mach Intell 28(12):2037–2041
Basri R, Jacobs DW (2003) Lambertian reflectance and linear subspaces. IEEE Trans Pattern Anal Mach Intell 25(2):218–233
Batur AU, Hayes MHIII (2001) Linear subspaces for illumination robust face recognition. In Computer Vision and Pattern Recognition, 2001. CVPR 2001. Proceedings of the 2001 I.E. Computer Society Conference on 2, II-296, IEEE
Belhumeur PN, Kriegman DJ (1998) What is the set of images of an object under all possible illumination conditions? Int J Comput Vis 28(3):245–260
Belhumeur PN, Hespanha JP, Kriegman DJ (1997) Eigenfaces vs. fisherfaces: recognition using class specific linear projection. IEEE Trans Pattern Anal Mach Intell 19(7):711–720
Bhatt H S, Bharadwaj S, Singh R, Vatsa M (2010) September. On matching sketches with digital face images. In Biometrics: Theory Applications and Systems (BTAS), 2010 Fourth IEEE International Conference on (pp. 1–6), IEEE
Bhowmik MK, Bhattacharjee D, Nasipuri M, Basu DK, Kundu M (2010) Quotient based multiresolution image fusion of thermal and visual images using daubechies wavelet transform for human face recognition, international journal of computer science issues (IJCSI). Mauritius 7(3):18–27
Blanz V, Vetter T (2003) Face recognition based on fitting a 3D morphable model. IEEE Trans Pattern Anal Mach Intell 25(9):1063–1074
Brown LG (1992) A survey of image registration techniques. ACM computing surveys (CSUR) 24(4):325–376
Cao X, Shen W, Yu LG, Wang YL, Yang JY, Zhang ZW (2012) Illumination invariant extraction for face recognition using neighboring wavelet coefficients. Pattern Recogn 45(4):1299–1305
Chen HF, Belhumeur PN, Jacobs DW (2000) In search of illumination invariants. In Computer Vision and Pattern Recognition, 2000. Proceedings. IEEE Conference on 1, 254–261. IEEE
Chen W, Er MJ, Wu S (2006a) Illumination compensation and normalization for robust face recognition using discrete cosine transform in logarithm domain. IEEE Trans Syst Man Cyber Part B (Cybernetics) 36(2):458–466
Chen T, Yin W, Zhou XS, Comaniciu D, Huang TS (2006b) Total variation models for variable lighting face recognition. IEEE Trans Pattern Anal Mach Intell 28(9):1519–1524
Crewe AV, Wall J, Langmore J (1970) Visibility of single atoms. Science 168(3937):1338–1340
Delac K, Grgic M (2004) June. A survey of biometric recognition methods. In Electronics in Marine, 2004. Proceedings Elmar 2004. 46th International Symposium, 184–193, IEEE
Du S, Ward RK (2010) Adaptive region-based image enhancement method for robust face recognition under variable illumination conditions. IEEE Trans Cir Syst Vid Technol 20(9):1165–1175
Duric N (2004) Advanced astrophysics, Cambridge University Press, Cambridge, UK
Faraji MR, Qi X (2014) Face recognition under varying illumination with logarithmic fractal analysis. IEEE Signal Process Lett 21(12):1457–1461
Fattal R, Lischinski D, Werman M (2002) July. Gradient domain high dynamic range compression. In ACM Transactions on Graphics (TOG) (Vol. 21, No. 3, pp. 249–256), ACM
Flynn C, Holmberg J, Portinari L, Fuchs B, Jahreiß H (2006) On the mass-to-light ratio of the local galactic disc and the optical luminosity of the galaxy. Mon Not R Astron Soc 372(3):1149–1160
Ganguly S, Bhattacharjee D, Nasipuri M (2015) Illumination, pose and occlusion invariant face recognition from range images using ERFI model. Intern J Syst Dynamics Appl (IJSDA) 4(2):1–20
Gao Y, Leung MK (2002) Face recognition using line edge map. IEEE Transactions on Pattern Analysis and Machine Intelligence 24(6):764–779
Gao W, Cao B, Shan S, Chen X, Zhou D, Zhang X, Zhao D (2008a) The CAS-PEAL large-scale Chinese face database and baseline evaluations. IEEE Trans Syst Man Cybern-Part A: Syst Humans 38(1):149–161
Gao X, Zhong J, Li J, Tian C (2008b) Face sketch synthesis algorithm based on E-HMM and selective ensemble. IEEE Trans Circuit Syst Video Technol 18(4):487–496
Gao X, Wang N, Tao D, Li X (2012) Face sketch–photo synthesis and retrieval using sparse representation. IEEE Trans. Circuits Syst Video Technol 22(8):1213–1226
Georghiades AS, Belhumeur PN, Kriegman DJ (2001) From few to many: illumination cone models for face recognition under variable lighting and pose. IEEE Trans Pattern Anal Mach Intell 23(6):643–660
Goh YZ, Teoh ABJ, Goh MKO (2011) Wavelet local binary patterns fusion as illuminated facial image preprocessing for face verification. Expert Syst Appl 38(4):3959–3972
Gonzalez RC, Woods RE (2008) Digital image processing, Prentice Hall, Upper Saddle River, N.J.
Gross R, Brajovic V (2003) June. An image preprocessing algorithm for illumination invariant face recognition. In International Conference on Audio-and Video-Based Biometric Person Authentication, Vol. 2688 of the series Lecture Notes in Computer Science, pp.10–18, Springer Berlin Heidelberg
Guo G, Li S Z, Chan K (2000) Face recognition by support vector machines. In Automatic Face and Gesture Recognition, 2000. Proceedings. Fourth IEEE International Conference on 196–201. IEEE
He X, Yan S, Hu Y, Niyogi P, Zhang HJ (2005) Face recognition using Laplacianfaces. IEEE Trans Pattern Anal Mach Intell 27(3):328–340
Horn B (1986) Robot vision. MIT press, Cambridge
Hurley DJ, Nixon MS, Carter JN (2000) A new force field transform for ear and face recognition. In Image Processing, 2000, Proceedings. 2000 International Conference on 1, 25–28, IEEE
Jain AK, Li SZ (2011) Handbook of face recognition. Springer, New York
Jain AK, Duin RPW, Mao J (2000) Statistical pattern recognition: a review. IEEE Trans Pattern Anal Mach Intell 22(1):4–37
Jain AK, Pankanti S, Prabhakar S, Hong L, Ross A (2004) August. Biometrics: A grand challenge. In Pattern Recognition, 2004. ICPR 2004. Proceedings of the 17th International Conference on 2, 935–942, IEEE
Jobson DJ, Rahman ZU, Woodell GA (1997) A multiscale retinex for bridging the gap between color images and the human observation of scenes. IEEE Trans Image Process 6(7):965–976
Kanade T (1977) Computer recognition of human faces. Interdiscipl Syst Res 47:1–106 Birkhäuser
Kar A, Bhattacharjee D, Basu D K, Nasipuri M, Kundu M (2013a) An adaptive block based integrated LDP, GLCM, and Morphological features for Face Recognition. arXiv preprint arXiv:1312.1512.
Kar A, Bhattacharjee D, Basu D K, Nasipuri M, Kundu M (2013b) Face Recognition using Hough Peaks extracted from the significant blocks of the Gradient Image. arXiv preprint arXiv:1312.1683
Klare B, Jain AK (2010) August. Heterogeneous face recognition: Matching nir to visible light images. In Pattern Recognition (ICPR), 2010 20th International Conference on IEEE, pp. 1513–1516
Klare BF, Jain AK (2013) Heterogeneous face recognition using kernel prototype similarities. IEEE Trans Pattern Anal Mach Intell 35(6):1410–1422
Klare B, Li Z, Jain AK (2011) Matching forensic sketches to mug shot photos. IEEE Trans Pattern Anal Mach Intell 33(3):639–646
Kundu S (1999) Gravitational clustering: a new approach based on the spatial distribution of the points. Pattern Recogn 32(7):1149–1160
Lai ZR, Dai DQ, Ren CX, Huang KK (2015) Multiscale logarithm difference edgemaps for face recognition against varying lighting conditions.IEEE. Trans Image Process 24(6):1735–1747
Land EH, McCann JJ (1971) Lightness and retinex theory. JOSA 61(1):1–11
Lawrence S, Giles CL, Tsoi AC, Back AD (1997) Face recognition: a convolutional neural-network approach. IEEE Trans Neural Netw 8(1):98–113
Lee KC, Ho J, Kriegman D (2001) Nine points of light: Acquiring subspaces for face recognition under variable lighting. In Computer Vision and Pattern Recognition, 2001. CVPR 2001. Proceedings of the 2001 I.E. Computer Society Conference on 1, I-519, IEEE
Lee PH, Wu SW, Hung YP (2012) Illumination compensation using oriented local histogram equalization and its application to face recognition. IEEE Trans Image Process 21(9):4280–4289
Li B, Jevtic A, Söderström U, Ur Réhman S, Li H (2013) Fast edge detection by center of mass. In The 1st IEEE/IIAE International Conference on Intelligent Systems and Image Processing 2013 (ICISIP2013), (pp. 103–110).
Lian Z, Er MJ, Liang Y (2012) A novel efficient local illumination compensation method based on DCT in logarithm domain. Pattern Recogn Lett 33(13):1725–1733
Lin D, Tang X (2006) May. Inter-modality face recognition. In European Conference on Computer Vision (pp. 13–26), Springer Berlin Heidelberg
Lopez-Molina C, Bustince H, Fernández J, Couto P, De Baets B (2010) A gravitational approach to edge detection based on triangular norms. Pattern Recogn 43(11):3730–3741
Martinez A M, Benavent, R (1998) “The AR Face Database,” CVC Technical Report #24, June
Messer K, Matas J, Kittler J, Luettin J, Maitre G (1999) March. XM2VTSDB: The extended M2VTS database. In Second international conference on audio and video-based biometric person authentication (Vol. 964, pp. 965–966).
Moghaddam B, Jebara T, Pentland A (2000) Bayesian face recognition. Pattern Recogn 33(11):1771–1782
Ni J, Matsakis P (2010) An equivalent definition of the histogram of forces: theoretical and algorithmic implications. Pattern Recogn 43(4):1607–1617
Olenick RP, Apostol TM, Goodstein DL (2008) The Mechanical Universe: Introduction to Mechanics and Heat, Cambridge University Press
Pankanti S, Bolle RM, Jain A (2000) Biometrics: the future of identification [guest editors introduction]. Computer 33(2):46–49
Pernkopf F, O'Leary P (2003) Image acquisition techniques for automatic visual inspection of metallic surfaces. NDT & E International 36(8):609–617
Rashedi E, Nezamabadi-Pour H, Saryazdi S (2009) GSA: a gravitational search algorithm. Inf Sci 179(13):2232–2248
Ren J, Jiang X, Yuan J (2013) Noise-resistant local binary pattern with an embedded error-correction mechanism. IEEE Trans Image Process 22(10):4049–4060
Rivera AR, Castillo JR, Chae OO (2013) Local directional number pattern for face analysis: face and expression recognition. IEEE Trans Image Process 22(5):1740–1752
Roy H, Bhattacharjee D (2015) Heterogeneous face matching using geometric edge-texture feature (GETF) and multiple fuzzy-classifier system. Appl Soft Comput 46:967–979
Roy H, Bhattacharjee D (2016) Local-gravity-face (LG-face) for illumination-invariant and heterogeneous face recognition. IEEE Trans. Inf. Forensics Security 11(7):1412–1424
Savvides M, Kumar BV (2003) Illumination normalization using logarithm transforms for face authentication. In International Conference on Audio-and Video-Based Biometric Person Authentication, pp. 549–556, June,Springer Berlin Heidelberg
Shan S, Gao W, Cao B, Zhao D (2003) October. Illumination normalization for robust face recognition against varying lighting conditions, In Analysis and Modeling of Faces and Gestures, 2003( AMFG 2003),IEEE International Workshop on 157–164. IEEE
Sharma A, Jacobs DW (2011) June. Bypassing synthesis: PLS for face recognition with pose, low-resolution and sketch. In Computer Vision and Pattern Recognition (CVPR), 2011 I.E. Conference on (pp. 593–600), IEEE
Shashua A, Riklin-Raviv T (2001) The quotient image: class-based re-rendering and recognition with varying illuminations. IEEE Trans Pattern Anal Mach Intell 23(2):129–139
Sim T, Baker S, Bsat M (2002) May. The CMU pose, illumination, and expression (PIE) database. In Automatic Face and Gesture Recognition, 2002. Proceedings. Fifth IEEE International Conference on (pp. 46–51), IEEE
Štruc V, Pavešić N (2009) September. Illumination invariant face recognition by non-local smoothing, In European Workshop on Biometrics and Identity Management (pp. 1–8), Springer Berlin Heidelberg
Sun G, Liu Q, Liu Q, Ji C, Li X (2007) A novel approach for edge detection based on the theory of universal gravity. Pattern Recogn 40(10):2766–2775
Tan X, Triggs B (2007) October. Enhanced local texture feature sets for face recognition under difficult lighting conditions. In International Workshop on Analysis and Modeling of Faces and Gestures (pp. 168–182), Springer Berlin Heidelberg
Tan X, Triggs B (2010) Enhanced local texture feature sets for face recognition under difficult lighting conditions. IEEE Trans Image Process 19(6):1635–1650
Tang X, Wang X (2004) Face sketch recognition. IEEE Trans Circuits Syst Video Technol 14(1):50–57
Turk M, Pentland A (1991) Eigenfaces for recognition. J Cogn Neurosci 3(1):71–86
Vishwakarma VP, Pandey S, Gupta MN (2009) Adaptive histogram equalization and logarithm transform with rescaled low frequency DCT coefficients for illumination normalization. Intern J Recent Trends Eng 1(1):318–322
Wang X, Tang X (2009) Face photo-sketch synthesis and recognition. IEEE Trans Pattern Anal Mach Intell 31(11):1955–1967
Wang H, Li S Z, Wang Y (2004a) May. Face recognition under varying lighting conditions using self-quotient image. In Automatic Face and Gesture Recognition, 2004. Proceedings. Sixth IEEE International Conference on. 819–824, IEEE
Wang H, Li SZ, Wang, Y (2004b) July. Generalized quotient image. In Computer Vision and Pattern Recognition, 2004. CVPR 2004. Proceedings of the 2004 I.E. Computer Society Conference on 2, 491–498. IEEE
Wang H, Li S Z, Wang Y, Zhang J (2004c) October. Self-quotient image for face recognition. In Image Processing, 2004. ICIP'04. 2004 International Conference on 2, 1397–1400. IEEE
Wang B, Li W, Yang W, Liao Q (2011) Illumination normalization based on Weber's law with application to face recognition. IEEE Signal Process Lett 18(8):462–465
Wang N, Tao D, Gao X, Li X, Li J (2013) Transductive face sketch-photo synthesis. IEEE Trans Neural Netw Learn Syst 24(9):1364–1376
Wiskott L, Fellous JM, Kuiger N, Von Der Malsburg C (1997) Face recognition by elastic bunch graph matching. IEEE Trans Pattern Anal Mach Intell 19(7):775–779
Wright WE (1977) Gravitational clustering. Pattern Recogn 9(3):151–166
Xie X, Lam KM (2005) Face recognition under varying illumination based on a 2D face shape model. Pattern Recogn 38(2):221–230
Zhang L, Samaras D (2003) June. Face recognition under variable lighting using harmonic image exemplars. In Computer Vision andnnnnn, 2003. Proceedings. 2003 I.E. Computer Society Conference on 1, 1–19, IEEE
Zhang T, Tang YY, Fang B, Shang Z, Liu X (2009) Face recognition under varying illumination using gradientfaces. IEEE Trans Image Process 18(11):2599–2606
Zhang W, Wang X, Tang X (2011) June. Coupled information-theoretic encoding for face photo-sketch recognition. In Computer Vision and Pattern Recognition (CVPR), 2011 I.E. Conference on (pp. 513–520), IEEE
Zhong F, Zhang J (2013) Face recognition with enhanced local directional patterns. Neurocomputing 119:375–384
Author information
Authors and Affiliations
Corresponding author
Additional information
Arindam Kar and Sanchayan Sarkar are both first authors
Rights and permissions
About this article

Cite this article
Kar, A., Sarkar, S. & Bhattacharjee, D. Local Centre of Mass Face for face recognition under varying illumination. Multimed Tools Appl 76, 19211–19240 (2017). https://doi.org/10.1007/s11042-017-4579-z
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11042-017-4579-z