
Abstract
Visual saliency is an important research topic in the field of computer vision due to its numerous possible applications. It helps to focus on regions of interest instead of processing the whole image or video data. Detecting visual saliency in still images has been widely addressed in literature with several formulations. However, visual saliency detection in videos has attracted little attention, and is a more challenging task due to additional temporal information. A common approach for obtaining a spatio-temporal saliency map is to combine a static saliency map and a dynamic saliency map. In our work, we model the dynamic textures in a dynamic scene with local binary patterns to compute the dynamic saliency map, and we use color features to compute the static saliency map. Both saliency maps are computed using a bio-inspired mechanism of human visual system with a discriminant formulation known as center surround saliency, and are fused in a proper way. The proposed model has been extensively evaluated with diverse publicly available datasets which contain several videos of dynamic scenes, and comparison with state-of-the art methods shows that it achieves competitive results.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
Visual attention is one of the useful concepts for humans in their daily life and it holds an important place in computer vision applications such as object detection [4], image segmentation [1], robotic navigation and localization [21], video surveillance [27], object tracking [22], image re-targeting [14] and image/video compression [10]. For example, consider a visual scene which contains many objects with various visual characteristics such as shape, color, size and texture. Some of the objects might be moving while others are static. Despite the huge amount of available information, the visual information reaching our eyes is limited as we cannot acquire the whole scene at a time. Thus we perceive only a small part of the visual field and the remaining part looks blurry to us. This smaller part of the visual field is perceived clearly with maximum acuity. The mechanism in the brain that determines which part of the multitude of sensory data is currently of most interest is called selective attention. It is basically a process to detect a scene’s region which is different from the surroundings. Understanding this mechanism is an active research area in cognitive sciences.
Visual attention is generally processed in two approaches which are bottom-up approach and top-down approach. Bottom-up attention approach is stimulus driven and is derived solely from the conspicuousness of regions in a visual scene. Top-down attention approaches are goal driven and refer to voluntary allocation of attention to certain features, objects or regions in space [19]. Bottom-up approach is more thoroughly investigated than top-down attention approach because the data-driven stimuli are easier to control than cognitive factors such as knowledge and expectations [7].
While saliency detection is a widely studied problem, most of the existing techniques are limited to the analysis of static images. A recent survey of state-of-art methods can be found in [2, 3] and these approaches cannot be simply extended to the analysis of videos sequences. Indeed, a video contains strong spatial-temporal correlation between the regions of consecutive frames. Furthermore, the motion of foreground objects dramatically changes the importance of the objects in a scene which leads to a different saliency map of the frame representing the scene. In addition, we know that natural scenes are composed of several dynamic entities such as moving trees, waves in water, fog, rain, snow and different illumination variations. Additional camera motion along with dynamic entities further complicates the detection of foreground objects. All these characteristics make video processing for saliency evaluation a challenging task. However, detecting salient regions and salient objects in complex dynamic scenes would be helpful in applications such as tracking, robotic navigation and localization and many more. A majority of the existing spatio-temporal saliency models [17, 18, 27] uses optical flow methods to process the motion information. In these methods, motion intensity of each pixel is computed and the final saliency map represents the pixels which are moving against the background. Optical flow based methods can work when the scene studied has simple background and fail with complex background scenes.
To overcome the challenges of natural dynamic scenes, we propose a new spatio-temporal saliency detection method in this paper. Our method is based on local binary patterns (LBP) for representing the scene as dynamic textures. The dynamic textures are modeled using local binary patterns in orthogonal planes (LBPTOP) which is an extension of the LBP operator in temporal direction [30]. Our contributions are threefold. First, we apply a center-surround mechanism to the extracted dynamic textures in order to obtain a measure of saliency in different directions. Second, we propose to combine color and texture features. In our model, the spatial saliency map is computed using color features, and the temporal saliency map is computed using dynamic textures from LBP in two orthogonal planes. The different saliency maps are then fused to obtain a final spatio-temporal saliency map. Finally, we evaluate our spatio-temporal saliency detection method on two large and diverse datasets which, respectively contain salient objects and human eye fixations as a ground truth.
The rest of the paper is organized as follows. In Section 2, we review some of the spatio-temporal saliency detection methods presented in literature. In Section 3, we describe the proposed spatio-temporal saliency model based on LBPTOP and color features. Section 4, shows performance evaluation of our method and comparison with other approaches on two different datasets containing segmented salient objects and eye tracking data. Finally, Section 5 gives concluding remarks.
2 Related work
In this section, we provide a brief description of some of the saliency models described in literature, which all follow the bottom-up approach principles. In [4], authors proposed an information theoretic spatio-temporal saliency model which is computed from spatio-temporal volumes. In this method the spatial and temporal saliency are calculated separately and they are fused with a dynamic fusion method. Marat et al. [17] proposed a space-time saliency algorithm which is inspired by the human visual system. First, a static saliency map is computed using color features, and a dynamic saliency map is computed using motion information derived from optical flow. The two maps are then fused to generate space-time saliency map. In a similar way, Tong et al. [27] proposed a saliency model which is used for video surveillance. The spatial map is computed based on low level features and the dynamic map is computed based on motion intensity, motion orientation and phase.
A phase spectrum approach is proposed by Guo and Zhang [10]. In this method, motion is computed by taking the difference between two frames, and is combined with color and intensity. The features are put together using a quaternion representation and Quaternion Fourier Transform (QFT) is applied to get final saliency map. Kim et al. [12] presented a salient region detection method for both images and videos based on center-surround hypothesis. They used edge and color orientations to compute the spatial saliency. The dynamic saliency is computed by taking the absolute difference between the center and surround temporal gradients and is finally fused with the spatial map. Zhou et al. [31] proposed a dynamic saliency model to detect moving objects against dynamic backgrounds. This algorithm is based on the fact that the displacement of the foreground and the background can be represented by the phase change of the Fourier spectra, and the motion of background objects can be extracted by phase discrepancy in an efficient way.
In [23], Seo and Milanfar proposed a space-time saliency detection method which is based on a bottom-up framework and uses local regression kernels from a video as local features which differs from conventional filter responses. Local regression kernels capture the underlying local structure of the image very well even in the presence of significant distortions. In [23], authors use a non parametric kernel density estimation for such features, which results in a saliency map constructed from a local self-resemblance measure computed using cosine similarity which indicates likelihood of saliency. A similar method is developed in [15], where the video patches are modeled using dynamic textures and saliency is computed based on discriminant center-surround.
Mancas et al. [16] proposed a bottom-up saliency method based on global rarity quantification. The model is based on a multi-scale approach using features extracted from optical flow, the final saliency map gives the rarity of the statistics of a given video volume at several scales. The authors in [11] proposed a dynamic saliency visual attention model based on the rarity of features. They introduced the Incremental Coding Length (ICL) to measure the perspective entropy gain of each feature using sparse coding techniques to represent features. Zhang et al. [28] proposed a saliency detection method based on Bayesian framework. The authors suggest that the pre-attentive process must estimates the probability of a target given the visual features at every location in the visual field to achieve the goal for detecting potentially important targets. This methods is based on a Bayesian framework from which bottom-up saliency emerges naturally, using image statistics derived from a large collection of natural images. Fu et al. [8] extended graph based approaches for saliency detection in videos by combining static appearance and motion cues into the graph construction.
Most of these methods fail to address complex scenes. In particular, methods based on optical flow fail to compute accurate dynamic saliency maps for scenes with highly textured backgrounds as will be shown in the experimental results in Section 4.
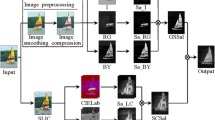
3 Spatio-temporal saliency detection using texture and color features
This section descibes the proposed spatio-temporal saliency detection method for dynamic scenes using LBP for describing the dynamic textures (DT) and color features for computing the static saliency. We first describe a method using only LBP feature computed in three orthogonal planes, and then show that using color features in combination with texture features produce better saliency maps.
3.1 Spatio-temporal saliency detection using LBPTOP descriptor
Dynamic or temporal textures are textures with motion that exhibit some stationary properties in time. The major difference between a DT and an ordinary texture is that the notion of self-similarity, central to conventional image texture, is extended to the spatio-temporal domain, thus a DT combines appearance and motion simultaneously [5]. Dynamic textures encompass the different difficulties of dynamic scenes such as moving trees, snow, rain, fog, crowd etc. Therefore, we use DT to model the varying appearance of dynamic scenes with time.
Several approaches have been developed to represent dynamic textures and a review of these methods can be found in [5]. In our work, we model DT using local binary patterns computed in orthogonal planes (LBPTOP) [30]. The LBPTOP operator extends LBP to temporal domain by computing the co-occurrences of local binary patterns on three orthogonal planes such as XY, XT and YT. The XT and YT planes provide information about the space-time transitions and the XY plane provides spatial information. These three orthogonal planes intersect at the center pixel. LBPTOP considers the feature distributions from each separate plane and then concatenates them into a single histogram.
In this work, we compute spatio-temporal saliency using a center-surround (CS) mechanism. CS is a discriminant formulation in which the features distribution of the center of visual stimuli is compared with the feature distribution of surrounding stimuli.
For each pixel location l=(x c ,y c ), we extract a center region r C and a surrounding region r S both centered at l. We then compute the feature distributions h c and h s of both regions as histograms and define the saliency of pixel l as the dissimilarity between these two distributions. More specifically, the saliency S(l) of pixel at location l is given by:
where h c and h s are the histograms distributions of r C and r S respectively, B is the number of bins of the histogram, and χ 2 is the Chi-square distance measure.
Note that we separately apply center-surround mechanism to each of the three planes XY, XT and YT. Hence, we compute three different saliency maps based on the three distributions derived from LBPTOP.
The final step of our method consists in fusing the previous three maps into a single spatio-temporal saliency map. This is done in two steps. First, the two maps containing temporal information, i.e. the saliency maps from XT and YT planes, are fused to get a dynamic saliency map. Then, this dynamic saliency map is fused with the static saliency map from the XY plane. As shown in [18], the fusion method affects the quality of the obtained final spatio-temporal saliency map.
It is worth mentioning that the fusion of both maps into a single spatio-temporal saliency map can be considered as a multiview information fusion problem for which several approaches have been proposed in literature [25, 26]. The main idea of those techniques is to treat each feature as a different view or a different projection of the data, and make use of the consistency and redundancy of different views to achieve better performance. In [25] it is shown that mutliview learning methods are based on the two main principles, which are consensus and complementary principles. The first principle aims to maximize the agreement on distinct multiple views, while the second one states that each view contains some information that other views do not have. Many multiview learning methods have been developed in recent years and the interested reader is referred to [24, 25] for an overview.
In this work, we adopt the simple Dynamic Weighted Fusion (DWF) method, which has shown best performance in a recent evaluation [18]. This fusion scheme produces a weighted combination of both maps and the weights are adapted to the characteristics of the dynamic scene. In DWF the weights are calculated by computing a ratio between the means of both the maps to combine, so they are updated from frame to frame. Let S X T and S Y T be the saliency maps obtained from the XT and YT planes respectively. They are fused into a dynamic saliency map M D as follows:
where \(\alpha _{D} = \frac {mean(S_{YT})}{mean(S_{XT})+mean(S_{YT})}\).
The obtained dynamic map M D and the static map M S = S X Y are fused in a similar manner.
3.2 Spatio-temporal saliency detection using color and texture feature
Since the final spatio-temporal saliency map is obtained as a fusion of the static and dynamic saliency maps, a proper static saliency map is needed in order to get an accurate spatio-temporal saliency map. In the previous approach, the spatial saliency map derived from the XY plane fails to highlight salient objects of some scenes because LBPTOP does not use color features. Threfore, we replace the LBP features computed in the XY plane by color features, since color is one of the salient feature in visual attention. In particular, we compute the spatial saliency map based on color features using the context-aware method of Goferman et al. [9] since this saliency detection method was shown to achieve best performance in a recent evaluation [3].
3.2.1 Spatial saliency
In our work, we used a saliency detection method based on context information [9]. Our choice is motivated by the fact that this method proves to be the best in a recent evaluation of saliency detection methods [3]. We only give a brief description of the method here, and we refer the interested reader to [9] for more details.
The saliency is computed in three steps. In the first step, local and global single scale saliency is computed for each pixel i in an image. A pixel i is considered salient if the appearance of the patch p i centered at pixel i is distinctive with respect to all other image patches. The dissimilarity measure between the patches p i and p j is defined by:
where d c o l o r represents the Euclidean distance between the vectorized patches p i and p j of sizes 7×7 in CIElab color space which are normalized to the range [0,1], and d p o s i t i o n is the Euclidean distance between the position of patches p i and p j . c is a constant scalar value set to c=3 in our experiments (changing the value of c does not significantly affect the final result).
To evaluate a patch’s uniqueness, there is no need to incorporate its dissimilarity to all the image patches. So for every patch p i , we search for the K most similar patches q k , k=1,…,K, in the image. The pixel i is considered salient when its dissimilarity d(p i ,q k ) is high ∀k∈[1,K].
In the second step, a multi-scale saliency is computed by considering different scales of the processed image. These multiple scales are utilized by representing each pixel i by the set of multi-scale image patches centered at it. The pixel i is considered as salient if it is consistently different from other pixels in multiple scales.
The final step includes the immediate context of the salient object. The immediate context suggests that areas that are close to the foci of attention should be explored significantly more than far-away regions. The visual context is simulated by extracting the most attended localized areas at each scale.
3.2.2 Spatio-temporal saliency map
The temporal saliency is computed as mentioned in Section 3.1. However, we consider here only two planes XT and YT which gives information only in the temporal direction. The LBP features are extracted in XT and YT planes and two saliency maps are computed in both planes separately. These two maps are fused into a single dynamic saliency maps using the DWT fusion scheme as in (2).
Finally, the obtained spatial and temporal saliency maps, respectively M S and M D , are fused into the final spatio-temporal saliency map as:
with \(\alpha = \frac {mean(M_{D})}{mean(M_{D})+mean(M_{S})}\), and S S T the final spatio-temporal saliency map.
The last step of our method consists in applying a post-processing scheme to suppress the isolated pixels or group of pixels with low saliency values. We start this post-processing by finding pixels whose saliency value is above a defined threshold (0.5 in our experiments, the final saliency map M S T is normalized to have values in [0,1]). Then, we compute the spatial distance D(x,y) from each pixel to the nearest non-zero pixel in the thresholded map. The spatio-temporal saliency map M S T is finally refined using the following equation:
where λ is a constant set to λ=0.5. We study the influence of this last parameter in the experimental results section.
4 Experimental evaluations
In this section we describe the experiments conducted to evaluate the efficiency of the proposed model. We performed two experiments to test the performance of the method in locating interesting foreground objects in complex scenes, and on the task of predicting human observers fixations. Firstly, we use a publicly available dataset of dynamic scenes [15] which contains ground truth segmentation of the salient objects for each frame of a sequence, thus allowing us to evaluate the ability of the method in detecting foreground objects in a complex scene. Secondly, we evaluate our model on another dataset in which the ground truth is given as eye tracking data, i.e. human observers fixations. This evaluates the performance of the model in predicting human fixation when viewing a video. The performances of the proposed method are also compared with various state-of-the-art methods.
4.1 Evaluation datasets and metrics
To evaluate the different spatio-temporal saliency models, we have selected two publicly available complex video scenes datasets: SVCL dataset [15] and ASCMN dataset [20]. The SVCL dataset, contains natural videos which are composed of dynamic entities such as waving trees, crowd, moving water, waves, snow and smoke filled environments. This dataset contains manually segmented objects for each frame which served as ground truth data.
The second dataset, ASCMN [20] is a collection of videos from various sources and provides data which cover a wider spectrum of video types. It contains totally 24 videos, together with eye tracking data collected from 13 human observers using eye tracking apparatus. The dataset is divided into 5 classes of sequences: abnormal, surveillance, crowd, moving and noise.
We use two evaluation metrics which are Area Under ROC Curve (AUC) [6] and Kullback-Leibler Divergence (KL-DIV) [13]. While only one of these measures is used in most of the previous works, in our experimental evaluation we use both measures to ensure that the discussion about the results is as independent as possible from the choice of the metrics.
AUC is used for assessing the degree of similarity of two saliency maps, and KL-DIV is used to estimate whether the saliency map produced by a saliency model matches human fixations. AUC varies from zero to one, with higher value indicating good performance, while KL-DIV varies from zero to infinity with zeros value indicating that two probability density functions are strictly equal.
4.2 Experiment 1: detection of salient objects in dynamic scenes
In this section, we evaluate the performance of the proposed spatio-temporal saliency detection algorithm in decting salient objects in complex dynamic scenes. We used the SVCL dataset for this experiment and compare our proposed methods with other state-of-the-art techniques. We compare two versions of our method which are LBPTOP (the method using only texture features from LBPTOP operator) and LBPTOP-COLOR (the method combining color features and LBPTOP features), and three existing methods: a method using optical flow to compute motion features (OF) [18], the self-resemblance method (SR) [23] and the phased discrepancy based saliency detection method (PD) [31]. For the last three methods, we use codes provided by the authors. For LBPTOP based saliency, we use center-surround mechanism described in Section 3.1 with a center region of size 17×17 and a surround region of size 97×97, and we extract LBP features from a temporal volume of six frames.
We evaluate the different spatio-temporal saliency detection methods by generating Receiver Operating Characteristic (ROC) curves and evaluating the Area Under ROC Curve (AUC). For each method, the obtained spatio-temporal saliency map is first normalized to the range [0,1], and binarized using a varying threshold t∈[0,1]. With the binarized maps, we compute the true positive rate and false positive rate with respect to the ground truth data.
The post-processing step described in Section 3.2.2 is important in order to obtain good final saliency maps. It basically lower the final saliency value of pixels far away from all pixels with saliency value above a defined threshold. The parameter λ in (5) controls the importance of the attenuation. In this experiment, we set the value λ=0.5 as it is, in average, the best value for all tested sequences.
The results obtained with all sequences by the different saliency detection methods are summarized in Table 1. As can be seen in Table 1, the proposed method combining color and texture features (LBPTOP-COLOR) achieves the best overall performance with an average AUC value of 0.914 for all twelve sequences. The optical flow based method (OF) achieves an average AUC value of 0.907, whereas as self-resemblance (SR), phase discrepancy (PD) and the method using texture features only(LBOTOP) achieve lower average AUC values, respectively 0.843, 0.837 and 0.745. These results confirm the observation that the combination of color features with LBP features produces better saliency map. In fact, the proposed method fusing color and LBP features gives an average AUC value which is 22 % higher that the value with LBPTOP features alone.
When we analize the individual sequences, we see that the best and least performances are obtained with the Boats and Freeway sequences, respectively, with average AUC values of 0.9394 and 0.7398 for all five saliency detection methods. The Boats sequence shows good color and motion contrasts, so both static and dynamic maps are estimated correctly, and all spatio-temporal saliency detection methods perform well. Note however that the texture only based method (LBPTOP) gives slightly lower accuracy than other techniques. On the other hand, the color contrast of the Freeway sequence is very limited. So getting a correct static saliency map is difficult with this sequence whereas the quality of the final spatio-temporal saliency map relies on the dynamic map. The best performing method with this sequence is the LBPTOP based technique with an average AUC value of 0.868, while optical-flow based technique achieves an average AUC value of only 0.545. This example illustrates that using LBP features to represent dynamic textures, and to compute the dynamic saliency map, gives very good results. The ROC curves comparing performances of the different methods on these two sequences are shown in Figs. 1 and 2.

Quantitative comparision with Freeway sequence from SVCL dataset and AUC metric

Quantitative comparision with Boats sequence from SVCL dataset and AUC metric
4.3 Experiment 2: prediction of human fixations
In this section we evaluate the performance of the proposed method in predicting human fixations using the ASCMN dataset [20] which contains 24 videos divided into five classes. We compare our proposed spatio-temporal saliency detection methods, LBPTOP and LBPTOP-COLOR, with four state-of-the-art methods which are the incremental coding length (ICL) method [11], the method based on natural images statistics (SUN) [29], the self-resemblance method (SR) [23], and the method of Mancas et al. [16].
For this second experiment, the parameter λ in (5) is set to λ=0.2 for the proposed LBPTOP-COLOR method as it is the best value for all tested sequences. We compare the different saliency detection methods both in terms of the evaluation metric used and the type of the video sequence used.
Table 2 summarizes the results obtained by the different saliency detection methods for all the twenty four video sequences of the dataset, using AUC and KL-DIV metrics respectively. First of all, we can see that the relative performances of the different methods depends on the evaluation metric used. This justify our idea of using more than one metric to ensure that the discussion about the results is as independent as possible from the choice of the metrics.
In terms on evaluation metrics, for AUC the higher the value the better is the performance of a method. On the contrary, for the KL-DIV measure, the lower the value the better the performance of a method. Table 2 shows that the proposed method combining color and texture features (LBPTOP-COLOR) achieves an average AUC value of 0.64, which is higher that the performance of ICL, LBPTOP and SUN methods which achieve average AUC values of 0.63, 0.53 and 0.61 respectively. However, LBPTOP-COLOR has a lower performance compared to MANCAS and SR methods which achieve average AUC value of 0.68 and 0.66 respectively. When using KL-DIV metric, the distributions given by the eye fixations points and the saliency maps produced by the model are first and the KL-divergence measure is computed between these two distributions to estimate whether the saliency map produced by a saliency model matches human fixations. From Table 2, we can see that LBPTOP-COLOR method achieves the second best result, being outperformed only by SR. However, we can also see that all saliency methods gives comparable results in terms of KL-DIV measure. A visual comparison of the results obtained with different methods is shown in Fig. 3.

5 Conclusion
This paper describes a spatio-temporal saliency detection method in dynamic scenes based on the combination of color and texture features. Color features are used to compute a static saliency map for each frame of a sequence, and local binary patterns describing dynamic textures are used to find a dynamic map. The obtained two saliency maps are then fused into a spatio-temporal saliency map which can be used for objects segmentation. Extensive experiments with two large and diverse datasets show that the proposed method combining color and texture features performs significantly better than a method using LBP feature only, and also better than method based on optical flow estimation for the dynamic saliency computation. The proposed method can, in particular, deal with dynamic scenes with difficult background textures, but achieves lower results when the contrast is poor.
A possible extension of this work could be the integration of depth cues into the spatio-temporal saliency model. The current availability of RGB-D sensor makes this possible and we will investigate this in the future. Also, we could consider the fusion of static and dynamic saliency maps as a multiview information fusion problem and adopt a multiview learning approach.
References
Achanta R, Estrada F, Susstrunk S, Hemami S Frequency-tuned salient region detection, Computer Vision and Pattern Recognition, 2009 pp 1597–1604
Borji A, Itti L (2013) State-of-the-art in visual attention modeling. IEEE Trans Pattern Anal Mach Intell 35(1):185–207
Borji A, Cheng MM, Jiang H, Li J (2015) Salient object detection: A benchmark. IEEE Trans Image Process 24(12):5706–5722
Chang L, Yuen PC, Qiu G (2009) Object motion detection using information theoretic spatio-temporal saliency. Pattern Recogn 42(11):2897–2906
Chetverikov D, Péteri R. (2005) A brief survey of dynamic texture description and recognition Computer Recognition Systems. Springer, , pp 17–26
Fawcett T (2006) An introduction to roc analysis. Pattern Recogn Lett 27 (8):861–874
Frintrop S (2011) Computational visual attention. Springer,
Fu K, Gu IYH, Yun Y, Gong C, Yang J Graph construction for salient object detection in videos, In: ICPR, 2014, pp 2371–2376
Goferman S, Zelnik-manor L, Tal A (2010) Context-aware saliency detection, In: IEEE CVPR
Guo CL, Zhang L (2010) A novel multiresolution spatiotemporal saliency detection model and its applications in image and video compression. IEEE TIP 19(1):185–198
Hou X, Zhang L Dynamic visual attention: searching for coding length increments, In: NIPS, Vol. 5, 2008, p 7
Kim W, Jung C, Kim C (2011) Spatiotemporal saliency detection and its applications in static and dynamic scenes. IEEE Trans Circuits Syst Video Techn 21 (4):446–456
Le Meur O, Baccino T (2013) Methods for comparing scanpaths and saliency maps: strengths and weaknesses. Behav Res Methods 45(1):251–266
Lu T, Yuan Z, Huang Y, Wu D, Yu H (2010) Video retargeting with nonlinear spatial-temporal saliency fusion, In: ICIP
Mahadevan V, Vasconcelos N (2010) Spatiotemporal saliency in dynamic scenes. IEEE Trans Pattern Anal Mach Intell 32(1):171–177
Mancas M, Riche N, Leroy J, Gosselin B Abnormal motion selection in crowds using bottom-up saliency. In: IEEE ICIP 2011, pp 229–232
Marat S, Phuoc TH, Granjon L, Guyader N, Pellerin D, Guérin-Dugué A (2009) Modelling spatio-temporal saliency to predict gaze direction for short videos. IJCV 82(3):231–243
Muddamsetty SM, Sidibé D, Trémeau A, Mériaudeau F (2013) A performance evaluation of fusion techniques for spatio-temporal saliency detection in dynamic scenes. In: ICIP
Pinto Y, Van der Leij AR, Sligte IG, Lamme VAF, Scholte HS (2013) Bottom-up and top-down attention are independent. J Vis 13(3):16
Riche N, Mancas M, Culibrk D, Crnojevic V, Gosselin B, Dutoit T (2013) Dynamic saliency models and human attention: A comparative study on videos Computer Vision–ACCV 2012. Springer, , pp 586–598
Siagian C, Itti L (2009) Biologically inspired mobile robot vision localization. IEEE Trans Robot 25(4):861–873
Sidibé D., Fofi D, Mériaudeau F. (2010) Using visual saliency for object tracking with particle filters. In: EUSIPCO
Seo HJJ, Milanfar P (2009) Static and space-time visual saliency detection by self-resemblance. J Vis 9(12):
Sun S (2013) A survey of multi-view machine learning. Neural Comput Appl 23 (7):2013–2038
Xu C, Tao D, Xu C A survey on multi-view learning, arXiv preprint (2013), pp 1304.5634
Xu C, Tao D, Xu C (2015) Multi-view intact space learning. IEEE Trans PAMI 37(12):2531–2544
Yubing T, Cheikh FA, Guraya FFE, Konik H, Trémeau A (2011) A spatiotemporal saliency model for video surveillance. Cogn Compuation 3(1):241–263
Zhang L, Tong MH, Marks TK, Shan H, Cottrell GW (2008) Sun: A bayesian framework for saliency using natural statistics. J. Vis 8(7):32
Zhang L, Tong MH, Cottrell GW Sunday: Saliency using natural statistics for dynamic analysis of scenes, In: Proceedings of the 31st Annual Cognitive Science Conference (2009) pp 2944–2949
Zhao G, Pietikäinen M (2007) Dynamic texture recognition using local binary patterns with an application to facial expressions. IEEE Trans Pattern Anal Mach Intell 29(6):915–928
Zhou B, Hou X, Zhang L A phase discrepancy analysis of object motion. In: Proceeding of the 10th Asian Confernce of Computer Vision, 2011, pp 225–238
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article

Cite this article
Muddamsetty, S.M., Sidibé, D., Trémeau, A. et al. Salient objects detection in dynamic scenes using color and texture features. Multimed Tools Appl 77, 5461–5474 (2018). https://doi.org/10.1007/s11042-017-4462-y
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11042-017-4462-y