
Abstract
Governing protein–protein interaction networks are the cynosure of cell signaling and oncogenic networks. Multifarious processes when aligned with one another can result in a dysregulated output which can result in cancer progression. In the current research, one such network of proteins comprising VANG1/SCRIB/NOS1AP, which is responsible for cell migration, is targeted. The proteins are modeled using in-silico approaches, and the interaction is visualized utilizing protein–protein docking. Designing drugs for the convoluted protein network can serve as a challenging task that can be overcome by fragment-based drug designing, a recent game-changer in the computational drug discovery strategy for protein interaction networks. The model is exposed to the extraction of hotspots, also known as the restrained regions for small molecular hits. The hotspot regions are subjected to a library of generated fragments, which are then recombined and rejoined to develop small molecular disruptors of the macromolecular assemblage. Rapid screening methods using pharmacokinetic tools and 2D interaction studies resulted in four molecules that could serve the purpose of a disruptor. The final validation is executed by long-range simulations of 100 ns and exploring the stability of the complex using several parameters leading to the emergence of two novel molecules VNS003 and VNS005 that could be used as the disruptors of the protein assembly VANG1/SCRIB/NOS1AP. Also, the molecules were explored as single protein targets approbated via molecular docking and 100 ns molecular dynamics simulation. This concluded VNS003 as the most suitable inhibitor module capable of acting as a disruptor of a macromolecular assembly as well as acting on individual protein chains, thus leading to the primary hindrance in the formation of the protein interaction complex.
Graphic abstract

Similar content being viewed by others

Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
Introduction
Protein–protein interactions bolster crucial physiological phenomena like signal transduction [1], gene expression [2], normal cell growth and maintenance, and tumorigenesis [3]. The rapid evolution and conglomeration of cancer genomics, gene ontology analysis, and proteomics studies have led to the visualization of these complex macromolecular assemblies that ease the process of untangling these networks responsible for uncontrolled cell cycles, thereby resulting in cancer progression [4]. Protein–protein interactions serve as a multifaceted forum that plays a part once the oncogenic signaling has been established. It does so via relaying of signals that give a concrete biological output, thereby evading the normal cell cycle and activating the process of carcinogenesis [4]. The ability to sustain the abnormal, chronic proliferation is maintained by these interactions, which serve as a new generation hallmark of carcinogenesis [5]. Recent advances in the domain of proteomics led to the establishment of these interaction networks in several species including Homo Sapiens [6]. Certain PPI networks that serve as a fundamental core for triggering cell proliferation cascades include Akt/FOXO-3a/14–3-3 and Akt/Bad/14–3-3, which mediate resistance to cell death by transcription-dependent and transcription-independent mechanisms, respectively [7]. Additionally, it also comprises the complexes like MDMB/p53 and CDK4/pRB that circumvents the obstacles provided by the growth suppressors, [8] hence enhancing tumorigenesis. Protein–protein interactions of TWIST/Mi2/NuRD, composites of an EMT regulating pathway, harnesses metastasis, cell invasion, and migration by squelching of the epithelial marker, E-cadherin [9]. It is evident that proteins rarely function in isolation; rather, it requires a milieu of other interactors to function sustainably. With the progression of resources and adequate studies, the importance of these interactomes serves as more profound targets than single receptors. Thus, directing the focus toward these biomolecular assemblies could provide a reasonable module that could inhibit oncogenic signaling.
The cynosure of the current research is on the protein complex VANGL1/SCRIB/ NOS1AP of the Wnt signaling and Hippo signaling network, which is primarily involved in breast cancer metastasis. [10] Research evidence suggests that the Wnt and Hippo signaling network induces metastasis via dendritic development and induction of apical–basal polarity, which ultimately results in the loss of cell–cell adhesion [11, 12] (Fig. 1a). Moreover, the aberrant expression of planar cell polarity protein Scribble denoted as SCRIB in Drosophila melanogaster causes dysregulation and delocalization of EMT markers, E-cadherin, and β-catenin [13], thereby resulting in the loss of apical–basal polarity [14]. In humans, recent studies along the lines of ovarian cancer proclaim the role of SCRIB in metastasis. SCRIB overexpression facilitates the epithelial to mesenchymal transition by upregulating N-cadherin, Snail, TGF-β1, and SMAD 2/3, with a simultaneous decrease in the expression of E-cadherin [15]. VANGL1 (Vang-like protein-1) maintains the developmental process via stem cell maintenance, and alteration of this gene results in the enhancement of cell motility [10]. Studies of the correlation of this overexpressed gene with survival data of patients concluded that this oncogenic target is associated with those individuals who belong to the estrogen receptor (ER)-positive subset [14]. VANGL1 expression could also predict the progression of metastasis in colorectal cancers as is evident from the gene expression signature experiment in CRC patients [16]. Furthermore, NOS1AP or nitric oxide synthase 1 adaptor protein unlike VANGL1 and SCRIB is not a relevant marker in breast carcinomas, as it hardly shows any overexpression. However, it binds to Scribble protein with a good affinity to channel out dendritic protrusions [12]. Despite failing to showcase a high level of individualistic relevance in breast cancer prognosis, the intertwining of these three proteins can act as tumor drivers in metastasis. Recent research has derived a connection between SCRIB, VANGL1, and NOS1AP to form a distinct complex that results in the cell invasion and migration in breast tumorigenesis [10]. The PPI network of these genes supersedes their individual expression in breast cancer metastasis, hence leading to migration and development of leading-trailing polarity [10]. Herein, the protein–protein interactions of these biomarkers are ascertained via the String Database (Fig. 1b). It is also evident from the studies conducted by Anastas et al. that shRNA knockout of the distinguished genes caused a reduction in the migration of the breast cancer cell lines MDA-MB-231, thereby leading to the hypothesis that VANGL1/SCRIB/NOS1AP interaction network colocalizes at the cellular protuberance in invasive breast cancer metastasis [10]. There is however limited research executed on this network profile that could lead to an establishment of the signaling cascade it influences or the pathways that it triggers.

a VANG1/SCRIB/NOS1AP genes in EMT cell signaling pathways. b String interaction network elucidating the interactions between the proteins VANG1-SCRIB-NOS1AP
Targeting a protein interaction network as such consummates as a daunting process because of the unavailability of “druggable pockets,” lack of binding regions, and excessive presence of flat and wide interfaces [17]. This reduced “druggability” of the protein interaction complexes results in decreased hits on the unapproachable surfaces for a given library. Designing PPI modulators also faces the internal conflict between maximizing the contact area and optimizing the pharmacokinetic properties [18]. Classical computational approaches cannot be utilized where the surfaces of the protein associations are flat and the majority of the binding capacity is restricted in regions popularly known as the “hotspots” of the interaction vinculum [19]. Thus, there is a requirement for a suitable computational tool to maintain the amenability of designing novel entities that could bind and modulate the terrain regions of a protein network. Fragment-Based Drug Discovery serves as an influential mechanism to target these undruggable sites. The process involves the breaking down of compounds to a smaller size that serves as an optimized probe to target the arduous domains of a protein–protein interaction interface. The moieties generated are rebuilt to form a drug molecule that shows inhibitory properties. These techniques are deliberately advantageous as a primary screening process due to the lower cost and their efficiency in binding to a single receptor target or congregation of a protein nexus [20]. The relatively smaller weight of the molecules hence results in more probable hits [21]. Also, the accessibility of an immense library of such small molecular fragments makes it viable to substantiate diverse targets [22].
The present work involves the modeling of these proteins into macromolecular assemblies, which can be targeted by designing novel disruptors resulting in the inhibition of the interaction network, thus serving as a therapeutic module for breast carcinogenesis. The protein models are built and docked to simulate the interacting assemblage. The hotspot regions are determined and fragments are generated using molecules extracted from the reference inhibitor AF-6, a known molecular target for the given interaction domains [23]. These molecules are recombined to result in a newly designed chemical entity, which is docked on the protein surface for screening using binding energy scores and pharmacokinetic properties. Ultimately, the selected molecules are subjected to a lengthy simulation to evaluate and validate the dynamics of the molecules in the network pockets to result in novel disruptors for the signaling network. Further validations are carried out by docking and exploring the dynamics of the molecules over a single protein target.
Materials and methods
The basic methodologies used in this research are shown in Fig. 2.

Workflow of the in-silico studies carried out in this project
Retrieval of the amino acid sequences
The amino acid sequences of the three proteins VANGL1, SCRIB, and NOS1AP (accession numbers: Q8TAA9, Q14160, O75052, respectively) were extracted from the UniProt Database (https://www.uniprot.org/). PDB Database had an absence of validated protein structures for these interacting proteins. Since the proteins were lengthy, the protein–protein interaction sites were figured out by extensive literature review. The FASTA sequences of the interacting domains were extracted for ab initio modeling purposes.
Modeling and structural minimization of protein 3D structures
The interacting regions scraped using a literature review of the three proteins (C-terminal region of VANGL1, PTB region of NOS1AP, and PDZ 3–4 domain of SCRIB) were used as input sequences in the I-TASER server (https://zhanggroup.org/I-TASSER/), which uses multiple threading approach for identification of structural templates from PDB, and establishes full-length atomic model by iterative template-based fragment assembly simulations [12]. The models were downloaded and verification of the 3-dimensional structure of the protein was performed using various servers like ERRAT [24], PROCHECK (https://saves.mbi.ucla.edu/) [25], ProSA (https://prosa.services.came.sbg.ac.at/prosa.php) [26], and MolProbity [27] (http://molprobity.biochem.duke.edu/). The computationally modeled proteins were led to structural minimization via the server, YASARA (http://www.yasara.org/minimizationserver.htm), following which they were subjected to further validation [28].
Docking of the proteins to model the protein–protein interactions
HADDOCK server version 2.4, a free web interface (https://wenmr.science.uu.nl/haddock2.4/) [29, 30] was used for modeling the protein–protein interactions by docking. Three protein PDB structures of VANGL1, SCRIB, and NOS1AP were uploaded to the server. The number of sampling structures was increased to 10,000 for rigid-body docking, and 400 each for semi-flexible and final refinement to reduce false positives. It is performed via three steps 1) it0; the rigid-body minimization, 2) it1; introduction of flexibility in the backbone, chain, and interface and 3) refinement with explicit solvent. Water refinement simulation was carried out for minimizing the 3 chains subjected to docking using default parameters. Structural validation of the docked protein was again carried out by the PROCHECK and ERRAT servers to see whether any undesirable stereochemical bonds or angles were present after docking and energy minimization.
Detection of protein–protein interaction Hotspots
To predict the hotspots in the protein–protein interaction interfaces, two kinds of approaches are taken into account. Firstly, the KFC-2 server, a well-recognized and accepted server (KFC2 Server—Protein Interface Hot Spot Prediction (ornl.gov)), uses a machine learning approach to calculate the target hotspots [31]. Secondly, the FTMap server (https://ftmap.bu.edu/serverhelp.php), a computational analog of physical techniques like NMR-based screening or X-ray crystallography [32], is utilized that calculates the hydrogen-bonded as well as the other non-bonded interactions of all the three chains of the complex together reproducing scores of probes and macromolecules, using a detailed energy expression. Moreover, the common regions of the KFC-2 server, the FTMap server (non-bonded and h-bonded) are further mapped using the PyMOL visualizer.
Fragment-based ligand discovery approach
From the literature, a reference compound was selected to produce the structures and fragments for the novel molecules. AF-6, a trifluorinated compound, which is a known disruptor for the protein–protein interaction complexes was chosen. It mainly binds to the PDZ domains of the target protein molecule, thereby disrupting their activity [33]. Furthermore, the flavonoid compounds also showed high affinity to these binding sites [34]. Similar molecules extracted from these two structures were then filtered from the PubChem site (https://pubchem.ncbi.nlm.nih.gov/), following which a library of 130 ligands was generated. Maestro Schrodinger software (Schrödinger Release 2021–4: Maestro, Schrödinger, LLC, New York, NY, 2021) was used for the further steps. From this set of compounds, fragments were generated by a command run using the Schrodinger PowerShell.
Run fragment_molecule.py -h
The protein was prepared for docking with the help of the protein preparation wizard using the default settings in Schrodinger. The fragments generated were docked by using Glide on to the hotspot sites of the protein molecules detected previously. A receptor grid was generated using the amino acids identified as hotspots, and Glide docking of the fragments was done. The grid was of the dimension 30A° × 30A° × 30A° with − 4.93 as the x-center, 0.44 as the y-center, and 1.38 as the z-center.
After the fragments were docked on the receptor surface, the Breed program of Schrodinger was run to associate the fragments to generate a complete molecule. The resulting molecules were subjected to another round of docking, along with the reference molecule prepared using LigPrep to project the binding affinity using standard precision protocol. Before proceeding to the screening of the compounds, the aforementioned docking protocol Glide SP was compared with the other available protocols Glide HTVS via redocking and the implementation of the receiver operating characteristic analysis (ROC). This was performed with the help of enrichment analysis tools incorporated in Schrodinger Maestro. A set of 1010 ligands were used (1000 decoys from the Schrodinger library and 10 actives which were the top 10 ligands with the best docking score) for this validation protocol.
After the confirmation of the reliability of our docking protocol, the docking energy was used as the first step toward the screening of ligands. Secondly, the descriptor properties of the ligands using the RDkit program incorporated within the Schrodinger software were evaluated to filter out the best possible ligands. 2D interactions of the compounds were studied using the Discovery studio visualizer. Additionally, to identify the reactants that facilitate the synthesis of the molecules Pathfinder module was utilized.
Molecular dynamics simulation
To elucidate the behavior of the disruptor molecules binding to the protein–protein interaction network and monitor the conformational changes the complex undergoes over a stipulated time interval, the macromolecular assembly along with the designed disruptor is subjected to molecular dynamics simulation for a 100-ns time frame using GROMACS 2019.6 package [35] and following the standard protocols [36]. The complexes were enforced with CHARMM 27 all-atom forcefield to undergo the process of simulation. The protein interaction complex comprising VANGL1, SCRIB, and NOS1AP along with the selected disruptor entities was solvated in a dodecahedron box separated by a distance of 1.0 nm from its edges. Na+ and Cl− ions were used for neutralizing the setup, supervened by the energy minimization of the system utilizing the Lincs constraint algorithm and the steepest descent algorithm. To enforce the normal experimental conditions the temperature and pressure of the system were adjusted to 300 K and 1 atm, respectively. To necessitate the bond interactions such as hydrogen bonds, Van der Waals interactions, and electrostatic interactions, the LINCS algorithm, Verlet algorithm, and particle-mesh Ewald (PME) were implemented for the respective interactions [37]. Van der Waals interaction limit was set to 1.2 nm. The NVT equilibration (canonical ensemble) of the system uses a velocity-scale thermostat, distinct from GROMACS keeping a reference temperature of 300 K. This was successively followed by an NPT equilibration (isobaric–isothermal ensemble), known as the Brendson pressure coupling adapted to the ongoing temperature coupling with a reference pressure of 1 atm. Both the coupling processes are carried on for 100 ps [37]. On the completion of the pressure and temperature equilibration of the system, the final molecular dynamic simulation run is performed using the above-mentioned molecular dynamics procedure. After the completion of the 100 ns MD simulation run, the RMSD (root-mean-square deviations), RMSF (root-mean-square fluctuations), number of hydrogen bonds, and paired distance values are compiled using GROMACS functions. To visualize the ligand stability within the hotspots of the interaction networks, graphs and images produced with the help of QtGrace version 0.2.6 (Grace Home (Weizmann.ac.il) are incorporated. The trajectories of the ligands for the entire simulation are formulated using a PyMOL visualizer. MM-PBSA (Molecular Mechanics Poisson-Boltzmann Surface Area) methods are incorporated to calculate the overall binding energy of the dynamic complex utilizing the g_mmpbsa GROMACS function (Kumari et al., 2014).
Validation of binding of the designed molecules using single protein chains
After analyzing the binding modes of the inhibitors into the protein assembly, these small molecules are further validated using single protein chain studies. The selected inhibitors are exposed to another round of docking and MD simulation studies using the protein chains separately to elucidate that they bind to the targets at unique and specific binding sites. The protein molecules are also docked separately to explore whether the interaction interfaces coincide with the inhibitor binding residues. Docking is performed using AutoDock Vina, and 100 ns molecular dynamic simulations on separate chains are performed using GROMACS 2019.6 following the above-mentioned algorithms [36].
Results and discussion
Protein model preparation, structural minimization, and validation
There exist two protein–protein interaction domains in VANGL1, which are located in the C-terminal region [14]. The amino acids of the C-terminal region, 294 residues in length, were selected to build up the model for VANGL1. For NOS1AP, the phosphotyrosine-binding (PTB) domain in the N-terminal region (154 amino acids) was the main interaction site with SCRIB and VANGL proteins [12]. The PDZ binding region of the SCRIB protein, specifically the PDZ3 and PDZ4 regions (212 amino acids), was exclusively the active protein interaction sites [11]. These interacting domains are used to build up the proteins using I-TASSER to assess the ongoing interactions.
I-TASSER matches the query sequence against the non-redundant sequence database using PSI-BLAST techniques. The top template hits based on structure-based and sequence-based scores are selected, and the quality is judged by a z-score [38], which was found to be greater than 1 in case of the VANGL1, SCRIB, and NOS1AP complex, thereby signifying good alignment. The quality of the model is estimated by the C-score, which typically ranges between [− 5, 2], and the scores ranging in the upper limit are an indication of refined models. Hence, models with a C-score of 0.91, − 0.23, and 0.57 were used for carrying out further experiments.
The verification of the modeled 3D structures was carried out using open servers ERRAT, PROCHECK, ProSA, and MolProbity (Table 1). The results indicated that the proteins must be subjected to structural minimization to obtain better scores. Therefore, protein structural minimization was carried out using YASARA server using YASARA force field that combines AMBER all-atom force field equation along with multi-dimensional knowledge-based torsion potential maximizing accuracy with a consistent set of force field parameters [28]. The results returned by the YASARA server showed considerable improvement, which was further validated by Ramachandran plots and Z-scores using the above-mentioned servers.
ERRAT considers non-covalently bonded atom–atom interactions predominantly CC, CN, CO, NN, NO, OO, and by observing the statistics of these pairwise atomic interactions, and monitoring any error, if present in the model [24]. The overall quality factor of more than 90 indicates a good-quality model. In the present study, the overall quality factor of the models was 89.5105, 97.8799, and 93 for VANGL1, SCRIB, and NOS1AP, respectively, as returned by the ERRAT server (Table 1). Following energy minimization, the server returned values were observed to be 97.8799 for VANGL1, 94.818 for SCRIB, and 97.917 for NOS1AP, indicating the finesse in the quality of the models (Table 1). PROCHECK results of the modeled protein advocated an overall G-factor score of − 0.51 for VANGL1, − 0.5 for both SCRIB and NOS1AP before minimization, which is mainly a measure of how normal or unusual a stereochemical property is (Table 1). The G-factor considers torsion angles as well as covalent geometry of the model and is a log-odds score of the observed distributions of the stereochemical parameters. The lower negative G-factor indicates more disallowed regions, which are − 0.5 for SCRIB and NOS1AP and − 0.51 for VANGL1 (Table 1). The disallowed regions were also > 2% in the Ramachandran plot for SCRIB and NOS1AP, indicating that the structure is not of an excellent quality (Table 1). However, following energy minimization, the assessment of the increment in G-scores as returned by the server was found to be 0.02, − 0.01, and − 0.02 for VANGL1, SCRIB, and NOS1AP, respectively, that in turn concluded an increment in the quality of the protein structures (Table 1). The percentage of disallowed regions for the three proteins VANGL1, SCRIB, and NOS1AP (1.8%, 1.8%, and 1.4%, respectively) decreased due to structural minimization (Table 1). The Ramachandran plots of the three proteins before and after the minimization process are shown in Fig.S1. ProSA measures the Z-score, which is a measure of the energy distribution of random configurations. Usually, the range lies between − 10 and 10 and the Z-scores within this domain are considered to be of good-quality, acceptable models. Herein, all the models show Z-score (− 5.56 for VANGL1, − 6.31 for SCRIB, and − 4.87 for NOS1AP before minimization and − 5.97, − 6.73, and − 5.52 for VANGL1, SCRIB, and NOS1AP, respectively, after minimization) within the acceptable range (Table 1), (Fig.S2). MolProbity server indicates favored rotamers of VANGL1, SCRIB, and NOS1AP as 71.09%, 76.22%, and 71.22%. After minimization, there is a decent increase to values > 90%, for all three structures (Table 1). The percent of bad bonds and bad angles are also decreased, rectifying the model to a greater degree (Table 1). The percentage of Ramachandran outliers also decreases from 9.59% to 2.74% for VANGL1 after minimization substantially indicating 97.26% of regions that are allowed; similarly, for SCRIB, the value changes from 4.76% to 2.38% after it is minimized resulting in the allowed regions as high as 97.62%, similarly for NOS1AP the percentage of favored regions returned was 97.33%, indicating that energy minimization was necessary for all the protein structures.
Protein–protein docking
Protein–protein docking provides tools and techniques for fundamental studies of protein interactions and a suitable base for structure-based drug designing [39]. The HADDOCK scoring function comprises linear combinations of various energies like Van der Waals intermolecular energy (Evdw), electrostatic intermolecular energy (Eelec), distance restraints energy (Eair) radius of gyration restraints energy, direct RDC restraint energy, intervector projection angle restraints energy, pseudocontact shift restraint energy, diffusion anisotropy energy, dihedral angle restraints energy, symmetry restraints energy (NCS and C2/C3/C5 terms), buried surface area (BSA), binding energy (Etotal complex—Sum[Etotal components]), desolvation energy (Edesol) [30], computed at all three stages:
At it0, HADDOCK Score = 0.01 Evdv + 1.0 Eelec + 1.0 Edesol + 0.01 Eair − 0.01 BSA
At it1, HADDOCK Score = 1.0 Evdv + 1.0 Eelec + 1.0 Edesol + 0.1 Eair − 0.01 BSA
At water, HADDOCK Score = 1.0 Evdv + 0.2 Eelec + 1.0 Edesol + 0.1 Eair − 0.01 BSA
The overall HADDOCK score as well as the different energy scores of the clusters is given in Table 2. In this study, twelve clusters were generated with cluster sizes varying from 2 to 3. RMSD values are not considered while selecting the perfect cluster, on account of the absence of predictive values and reference structures. The HADDOCK scores were utilized as the leading value. The top 10 best clusters of the docked proteins are available in Fig. 3. The clusters are superimposed on one another (Fig.S3) to show that they occupy more or less the same spatial domain and the clustering is successful. The default clustering algorithm followed by HADDOCK clustering is Quality Threshold in which for the retrieved clusters none of the pair of frames exhibits a similarity value greater than that of the specified threshold [29]. The fraction of common contacts vs the HADDOCK score is shown in Fig.S4. Analysis of the bokeh plots of different energies to their i-RMSD values is shown in Fig.S5. The different energy values of the clusters are also compared through a bokeh plot as shown in Fig.S6. We select Cluster 11 as the best cluster, considering the second-best HADDOCK score (− 100.9), since cluster 12 did not show combined interaction between all the three proteins. This model is used further for the advanced water refinement stage which improved the HADDOCK score to − 335.2 (Table S1). Moreover, there was an improvement in the scores of the protein interaction model as validated by PROCHECK and ERRAT servers (Table S2).

Top 10 best clusters after HADDOCK run
Hotspot areas of the complex protein
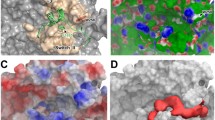
Hotspot areas of a protein–protein interface are a requirement when a fragment-based method is approached to design inhibitors to figure out the ligand-binding sites. Hotspots are preferred over ordinary binding sites since they show less sensitivity to the conformational changes of the protein [40] and are predicted by two different servers using a different approach in the calculation. The first server KFC-2 also known as knowledge-based FADE uses a machine learning approach. It uses classifiers to recognize the local environments that are indicative of a hotspot [31]. Chain A-B interactors showed residues 14, 15, 19, 23, 24, 28, 33 for chain A (VANGL1) and 18, 19, 22, 84, 88, 90 for chain B (SCRIB) (Table 3). Chain A-C interactors showed residues 11, 12, 238, 239, 240, 242, 243, 246, 282 for chain A and 21, 91, 92, 139, 143, 144, 147, 148 for Chain C (NOS1AP) (Table 3). Chain B-C interactors showed residues 71 and 95 for SCRIB and 113 for NOS1AP (Table 3). Figure 4b shows the pictorial representation interacting residues as extracted from the KFC- 2 server. KFC-2 server can provide excellent results if only 2 proteins interfaces are involved. However, since the interactions are among 3 proteins, further validations are required. FTMap sever provides interactive areas for the entire complex combined. It uses organic probe molecules of different sizes and shapes, calculating the most favorable position for each probe after which it clusters the probes and ranks the cluster of probes according to their energy (Fig. 4a). The interacting and H-bonded residues can be seen in Table 3 for all the three chains. There were not many common residues involved with KFC-2 server because the predictors use completely different approaches and parameters for identification. However, those common residues detected were taken as an ideal hotspot for binding of our ligands. They were mapped into the protein surface for markers of ligand target (Fig. 4c). The residues include 14, 28, 34, 238, 239 of Chain A, 20 and 88 for Chain B, and 89 for Chain C.

a Results of the FTP server. (i) Marks the interactive regions with the help of probes in the protein complex. (ii) Shows the energy distribution of various non-bonded and H-bonded interactions. b Results of the KFC-2 server. Interaction between the chains is shown by the spherical points (i) Shows the interaction of A-B chain (VANGL1-SCRIB), (ii) interaction of A-C chain (Vang-NOS1AP), (iii) interaction of the interface of the B-C chain (SCRIB-NOS1AP). c The hotspots that are targeted for fragment-based drug designing
Fragment-based ligand screening and docking
Fragmentation and docking
Molecular docking is incorporated in structure-based drug designing methods to screen a vast library of chemicals to predict their viable binding poses to a known macromolecular target. To design disruptors for unexplored protein–protein interaction, fragmentation followed by docking can be regarded as one of the best approaches. The reference molecule identified as AF-6 contains mainly a trifluoromethyl group attached to benzene along with a thiazole ring. More than 7000 fragments were formed from the reference library of 130 molecules out of which some attached themselves to the docking site, on executing the GLIDE algorithm. These fragments were several groups that could bind to the particular hotspots selected. Once bound, these pieces were joined using the BREED algorithm. It generated de novo inhibitors using hybridization and combinations of the fragments generated from the known ligands by the superimposition of two ligands, which on overlapping get split and recombined simultaneously [41]. Only one generation of novel ligands is generated by executing the breed algorithm for once. The novel disruptors bind to the exact location of the protein region (Fig. S7). The enumerate file generated after exposing the ligands to the BREED algorithm contained purely the ligands (around 10,000), diverse from each other formed by recombination.
Once full-fledged chemical inhibitors are formed, another round of docking was performed to calculate the best docking pose along with its docking energy, for the Enumerate file by incorporating the Glide algorithm. While docking ligands with Glide, the ligands were flexible, but the receptor remained rigid. More than 6000 viable poses were formed. The accuracy of the docking methods was validated and compared to other protocols, using Enrichment Calculator. Standard precision methods and high-throughput virtual screening modes for Glide were set against each other. After redocking using the top 10 ligands binding to the protein along with 1000 decoy ligands available in the Schrodinger interface, the receiving output characteristics (ROC) curve and its AUC together with the % screen curve elucidated the efficiency of our docking method (Figure S8). Glide SP showed better precision than Glide HTVS, with more ranking actives and fewer outranking decoys (Table S4). The docking scores of the first 10 compounds are given in Table S3. The ligands with a better docking score than the reference compound − 5.416 kJ/mol were screened out.
Screening of compounds using pharmacokinetic properties
The analysis of the pharmacokinetic properties like absorption, distribution, metabolism, and excretion enables to maximization of the screening of potential compounds [42]. The analysis of the pharmacokinetic properties was performed using the RDkit tool incorporated within the Schrodinger software. Since compounds are mainly designed to inhibit protein–protein interactions, the molecules chosen must have a size enough to disrupt the major interactions within the protein. Also, they must possess the lead-likeness, a newer term for de novo molecules, where the rule of Lipinski is scaled down [43]. Since they are designed to cause an interruption in the protein interactions, their size must be optimized to not result in any adverse effects [43]. Mainly protein interactions are probed using fragment-based generated molecules, which must follow the rule of three to generate a better lead compound. The rule of three includes the molecular weight to be lesser than equal to 300, and the number of hydrogen receptors and donors should not be greater than 3. Recent studies by Veber and his co-workers suggested that the number of rotatable bonds is important in determining the pharmacokinetic property of a molecule that governs its bioavailability. For small disruptors in PPI, the value for NROT should not be more than 3, logP, which gives us an idea about the lipophilicity of a molecule should be within 3. The molecule needs to remain soluble within the body along with possessing the capability of crossing the cell membranes and other lipophilic membranes as such. Total polar surface area, which determines the distribution of the functional groups over the surface of the molecule, establishes an idea about our active conformer. It should be within 60 (angstrom)2 [43]. Out of the 473 ligands which had a better docking score than the reference, 8 compounds were retained (VNS001, VNS004, VNS005, VNS006, VNS007, and VNS008), whose ADME values were according to the rule of three (Table S5).
Binding site analysis
The 2D interactions and the 3D binding site of the selected compounds were analyzed using the Discovery Studio Visualizer site of the ligand molecules (Fig. 5a), and the residues are provided in Table 4. The 2D interactions of the molecules included Van der Waals interactions, conventional, and carbon-hydrogen bonds mainly. The pi cloud of the aromatic ring was involved in pi-alkyl where it showed interactions with an alkyl group of the amino acids mainly leucine, alanine, and tryptophan. There was also an interesting interaction observed, t-shaped pi-pi interactions where the aromatic ring of the amino acid interacted with the pi-electron cloud of the inhibitor perpendicularly to give a t-shaped stacking of the electron clouds. TYR 60 of VANGL1 was the amino acid involved. ALA 19 and PRO 90 were the amino acid groups from the SCRIB protein unit that was observed in the interactions with the inhibitor molecule. The fluorine atoms of VNS005 were directly involved in the halogenic interactions with VAL 236 of VANGL1 and ALA 19 of SCRIB protein. It can be observed that almost all of the ligands in Fig. 5a contain fluorine atoms, similar to the reference molecule AF-6, which is a probable interactor. To become a good disruptor of the protein–protein interaction, the given molecule should show interactions with more than one protein chain that is docked together. Four out of the eight compounds showed atomic, molecular, or electronic interactions with only one chain. The rest of the compounds showed chain A and chain B in the binding site and were filtered out for further simulation studies (Fig. 6). The interacting chains Chain A and Chain B were further docked using the HADDOCK server to validate the interacting regions of the chains as the binding site for the ligands (Fig. 5b). The properties of the four compounds selected for simulation studies are available in Table S6.

a 2D and 3D interactions of the inhibitor compounds with the protein network. b Docked chains A and B with binding site residues highlighted

a (i) Root-mean-square deviation values of all the complexes along with the protein chain interactions. (ii) Number of hydrogen bond values of all the inhibitor complexes. (iii) Paired distance of all the ligand molecules with the protein network. b Root-mean-square fluctuations of individual protein chains—(i) VANGL1, (ii) SCRIB, (iii) NOS1AP. c 100 ns trajectories of the complex showing the movement of the ligand around the hotspot region
Reaction pathways and synthesis
The pathfinder module traces the reagents backward to provide us with the reactants that are used for the synthesis of these de novo drugs. Reaction-based enumeration determines the practicality of the novel compounds and gives an idea about the chemical synthesis of the same. Suzuki-2 synthesis is used for the synthesis of all four compounds. A trifluoro-boron anion is used as a Suzuki coupling reagent. The functional group to be incorporated into the structure is used as a derivative of this reagent. The main reagent used should be brominated to facilitate this coupling. The brominated part of the ring structure exerts a -I effect on the ring making it positive. This helps in a smoother attack of the anion seeking a positive domain (Fig.S9).
MD simulation Phase 1
Molecular dynamics simulation serves as a reliable method for studying the dynamics of the disruptors binding to the protein–protein network target. The protein structural–functional dynamics can be exploited by the incorporation of time-dependent simulation trajectories. The four selected disruptor molecules, along with the reference compound, were exposed to a long-range 100 ns molecular dynamics simulation with the protein interaction network. The use of MD simulation strategies to expose the macromolecular assembly in an explicit dynamic visualization platform suggests valuable validation of the stability of the inhibitor-macromolecular complex. Through parameters like root-mean-square deviations (RMSD), root-mean-square fluctuations (RMSF), hydrogen bond count, and pairwise distance analysis, explicit insights can be extracted about the stability of the designed disruptor molecule in the network pockets.
Root-mean-square deviation is the quantitative measurement of the similarity between two protein structures. The RMSD values of the protein backbone without the inhibitor compound served as the absolute control for the root-mean-square deviation analysis of the complexes. The overall high RMSD values, which is a conglomeration of deviations of the docked protein and the inhibitor complex, are because the protein chains are docked together making it an overall huge macromolecular entity [44]. The average RMSD value of the protein interaction network was around 1.078205 nm (Table 5), due to the extremely high fluctuation of the assembly after 35 ns (Fig. 6a(i)). However, the association of disruptor moieties VNS003 and VNS005 drastically brings down the deviation scores resulting in a stable ensemble. The mean RMSD value of the network–disruptor complex for VNS003 and VNS005 was found to be 0.467142 nm and 0.517843 nm (Table 5), respectively, along with a high constant nature of the RMSD trajectory (Fig. 6a(i)) suggesting the ligand-binding stability of the unstable protein conformation. VNS001 and VNS007 nevertheless show huge disruptions in the values resulting in the intimation of the idea that they could be hardly stable in the network pockets (Fig. 6a(i)). These large fluctuations in the RMSD scores after 30 ns of the protein network backbone, reference molecule complex, and complexes VNS001 and VNS007 indicate a change in the binding posture or alteration in the structural conformation of the macromolecular association (Fig. 6a(i)).
To confer on the residual fluctuations of each protein chain comprising the interaction network, the residual mean fluctuation of the separate proteins was assessed. The proteins without the inhibitor molecules exhibited high RMSF scores around 1.523171 nm, 1.433732 nm, and 1.247259 nm for Chain A (VANGL1), Chain B (SCRIB), and Chain C (NOS1AP), respectively (Table 5). Overall values for all the complexes indicated that protein SCRIB undergoes maximum fluctuation as concluded by the mean RMSF values compared to its associated proteins except for VNS007, where NOS1AP showed the highest average score. Also, the complexes VNS007 and VNS001 showed higher RMSF values than the protein backbone and the reference molecule over the entire trajectory (Fig. 6b). VNS003 and VNS005 had overall RMSF values within 0.35 nm for all the protein chains, lesser than the reference compound (< 0.56 nm), which ultimately leads to the conclusion that the disruptor binding dynamics of the ensemble is highly stable and also leads to the validation of these modules as suitable interrupters of the protein interaction network (Table 5).
To assess the binding of the ligands in the pockets of the protein interaction surface or hotspots, parameters like hydrogen bond count and paired distance are taken into consideration (Fig. 6a(ii), (iii)). Hydrogen bond count is extricated using the gmx_hbond GROMACS function. The average hydrogen bond count is maximum for VNS001 (1.357464) and minimum for VNS003 (0.218978) (Table 5). VNS005 possessed the mean range of hydrogen bond count of 1.09949 which was also higher than the reference molecule (0.560244) (Table 5). Over 100 ns of the trajectory, the number of bonds was calculated for every 10-picosecond interval. The strength of hydrogen bonds varies inversely according to the distance between the protein and the ligand molecule, whereby 0.22–0.24 nm depicts the strongest hydrogen bonds, moderately strong bonds fall in the range 0.25–0.32 nm, and the weaker bonds range within 0.32–0.4 nm [45]. Here, the paired distance of the ligand molecule concerning the interaction assembly did not aberrate greatly (> 0.21 nm), indicating the molecules were in a steady pose with the protein complex entity.
For visualizing the movement of the ligand over the protein–protein interface, the molecular dynamics trajectory was extracted for each complex at every 20 ns of simulation time. The reference ligand, VNS003, and VNS005 showed hardly any alterations in the binding pocket of the proteins, except for slight changes in the binding pose of the disruptor entities (Fig. 6c). However, VNS001 demonstrates a significant movement from the hotspot regions at around 40 ns timestep, along with VNS007, which reveals explicit instability of the module starting from 20 ns misappropriating them as therapeutic moieties to bind within the intertwined protein networks and causing its dysregulation (Fig. 6c).
Calculation of free binding energy
MMPBSA (Molecular Mechanics Poisson-Boltzmann Surface Area) method was an appropriate and rigorous strategy despite its large exhaustion in the computational resources for deriving the binding affinity or the ΔG of the complexes solvated in implicit solvents calculated based on the formula:
ΔG = average free binding energy, ΔEMM = molecular mechanics energy, ΔGPBSA = solvation free energy, TΔSMM = solution configuration entropy.
The ligands with weaker affinity (VNS001 & VNS007) to the complex show positive values for their binding energy, where the polar solvation energy fails to compensate for the repulsive/weak Van der Waals forces and electrostatic energies. Since our compound is charged, deviations were observed, which occur in presence of polarized solvents surrounding the solute molecule during computation of free binding energies, hence resulting in weaker values [46]. When compared to the binding energy of the reference molecule (− 26.533 kJ/mol), compounds VNS003 (− 56.525 kJ/mol) and VNS005 (− 33.014 kJ/mol) showed more negative values indicating greater binding affinities of the molecules approbating them as suitable novel entities for disruption of the targeted protein–protein interaction network (Table 6).
Molecular docking and MD simulations (Phase 2)
Molecular docking and 2D interaction studies Phase 2
The ligands designed are supposed to disrupt the complex formed as per the first approach. Validation using single-chain ligands enables the inhibition of the protein chains which derails the formation of the interaction complex. Also, it provides significant insights into the binding of the ligands to the specific amino acid residues resulting in the confirmation of the active site. Though the ligand molecule does not bind to the NOS1AP chain during the procedure of disruption, it can attach itself to the unattached chain, thus preventing the formation of the complex. Chain A (VANGL1) and Chain B (SCRIB) amino acid residues which show active participation in the formation of hotspot residues of the complex can be now validated when the ligand binds to each of them separately as well. Table S7 shows the docking scores along with the binding site amino acid residues of the single chains. The 2D interaction of the binding site residues can be seen in Fig. 7. As from Fig. 7a, the interacting residues for VANGL1 coincide with the interacting residues, namely ARG14, TYR60, ARG104, LEU65, TRP233, ARG234, LEU235, VAL236, and SER237 in the interactome complex (Fig. 5a) serving as a secondary validation for the binding of the ligands. However, the ligands binding to SCRIB (Fig. 7b) bind to different residues that it does in the complex. However, this does not nullify the binding affinity of the ligands, as the proteins are now not present in the interactome, and binding sites may be different. Similar binding sites validate those residues as active sites. For the NOS1AP chain (Fig. 7c), similar amino acids residues form the binding site for the ligand molecules. The greater binding affinity of the ligand molecules from the reference moiety (Table S7), for all the three chains, confirms them as suitable modules to target the proteins of this macromolecular complex, individually. The binding of these ligands and the dynamics of the binding are further validated by molecular dynamics simulation studies.

a Selected ligands binding to VANGL1 chain. b Selected ligands binding to SCRIB protein. c Selected ligands binding to NOS1AP residue
MD simulation studies Phase 2
The simulation studies with separate chains allow us to decipher the dynamics of the ligands with the individual protein chains. For VANGL1 protein, the RMSD values (Fig. 8a(i)) of all the molecules except VNS007 (0.727063 nm) were lesser than the protein backbone (0.713406 nm) indicating the stable binding dynamics of the designed ligands (Table 7). Also, VNS003 (0.570544) and VNS005 (0.580893) showed better values than the reference moiety (0.608826) (Table 7). For SCRIB (Fig. 8a(ii)), the RMSD value of the protein backbone is the lowest (0.3155 nm). However the reference molecule AF-6 (0.337606 nm), VNS003 (0.406125 nm), and VNS005 (0.421146 nm) (Table 7) have comparable RMSD. For NOS1AP (Fig. 8a(iii)), the protein molecule was the most stable (0.313951 nm), followed by the reference (0.403518 nm), VNS007 (0.423935 nm), and VNS003 (0.486113 nm). This disparity is because the ligands were generated based on hotspot regions, which correlated with VANGL1 when individually docked but bound at different zones in SCRIB and NOS1AP, thus distorting the stability.

a RMSD of the ligands (VNS001, VNS003, VNS005, VNS007, and reference with proteins VANGL1 (i), SCRIB (ii), and NOS1AP (iii). b RMSF of the ligands (VNS001, VNS003, VNS005, VNS007, and reference with proteins VANGL1 (i), SCRIB (ii), and NOS1AP (iii). c No of hydrogen bonds of the ligands (VNS001, VNS003, VNS005, VNS007, and reference with proteins VANGL1 (i), SCRIB (ii), and NOS1AP (iii). d Paired distance of the ligands (VNS001, VNS003, VNS005, VNS007, and reference with proteins VANGL1 (i), SCRIB (ii), and NOS1AP (iii)
The residual fluctuations of each amino acid residue were recorded as their RMSF values (Fig. 8b). For VANGL1, VNS001(0.255735 nm) and VNS003 (0.286183) portrayed acceptable RMSF values along with all the designed ligands, showing lesser RMSF values than the protein backbone (Table 7). SCRIB (0.163079 nm) and NOS1AP (0.171147 nm) proteins showed the best RMSF values without the ligand molecules. However, VNS003 showed comparable values of 0.220882 nm for SCRIB and 0.198507 nm for NOS1AP, the best among all the designed ligands (Table 7).
The hydrogen bond count (Fig. 8c) and the paired distance (Fig. 8d) were calculated at 10 picosecond intervals over a 100 ns trajectory time. The number of hydrogen bond counts accounts for the strength in the binding capacity over the MD simulation. VNS001 (0.725027), for protein VANGL1, VNS005 (0.355464) for protein SCRIB, and VNS001 (0.495451) showed the maximum count in the average number of H-bonds, which also exceeds the bond count of the reference molecule AF-6 (Table 7). The paired distance of the ligand molecules to that of the protein backbone, an inverse complement of the hydrogen bond count as stated previously in MD simulation phase 1 was the least for Reference AF-6 for all three molecules VANGL-1 (0.1741 nm), SCRIB (0.175801 nm), and NOS1AP (0.182262 nm) followed by VNS003 (0.189607 nm) with VANGL1 protein, VNS001 (0.486113 nm) with SCRIB, and VNS003 (0.350641 nm) with NOS1AP (Table 7).
The trajectory of the molecules bound to individual protein chains is shown in Fig. 9. Except for VNS005, all the other molecules show stable binding around the binding pocket for protein VANGL1 (Fig. 9a). For SCRIB, the Reference molecule shows stable binding over 100 ns, and VNS003 shows stability in the binding dynamics up to 80 ns (Fig. 9b), and all other ligands got dissociated from the protein backbone at the early phases of MD simulation. For NOS1AP (Fig. 9c), only VNS003 and Reference molecule remain bound to the protein even though at different binding sites over time. Therefore, besides the Reference molecule, VNS003 shows good binding dynamics as extracted by MD simulation studies.

a 100 ns trajectory of ligands (VNS001, VNS003, VNS005, VNS007, and Reference) with VANGL1. b 100 ns trajectory of ligands (VNS001, VNS003, VNS005, VNS007, and Reference) with SCRIB. c 100 ns trajectory of ligands (VNS001, VNS003, VNS005, VNS007, and Reference) with NOS1AP
MMPBSA free binding energy calculation
As recognized in MD simulation, phase 1, MMPBSA (Molecular Mechanics Poisson-Boltzmann Surface Area) method, can be approbated as an extensive method to derive the free binding energy of the molecule with its protein complement. VNS003 showed the most binding affinities with the least binding energies of − 80.608 kJ/mol and − 32.693 kJ/mol with the proteins VANGL1 and SCRIB, respectively (Table 8). For NOS1AP, the Reference molecule had the least binding energy of − 66.237 kJ/mol which was parallelly close to VNS003 (− 54.749 kJ/mol), indicating its efficiency as an inhibitory ligand for not only a macromolecular complex of VANGL/SCRIB/NOS1AP but also the individual protein counterparts of the assembly (Table 8).
Conclusion
Fragment-based drug discovery exhibits a consortium with protein–protein interaction networks in recent ages of exhaustive computational drug discovery. Due to the highly intertwined networking of the protein in cell signaling cascades, targeting these oncogenic nexuses has become vital in the development of anti-cancer therapeutics. The protein interaction networks play the central role in cellular processes, serving as the major attraction for biomedical and pharmaceutical researchers to target it as a remedial interposition for many incurable forms of cancer [19].
The current research involves developing entities that target a major PPI network VANG1/SCRIB/NOS1AP using fragmentation and recombination of a library of chemicals to result in novel inhibitors. The interaction is modeled using a comprehensive in-silico approach, and the regions for the target are derived. Molecules are developed via algorithms that break a molecule into fragments and rejoin them on the targeted surface. Such molecules are screened using pharmacokinetic screening programs and monitoring the association of the ligands using 2-dimensional and 3-dimensional interaction studies. Four such molecules were exposed to MD simulation studies, which served as the final validation where the screened molecules are subjected to a dynamic time frame that could govern the changes in the conformation and behavior of the molecules within the protein pocket. VNS003 and VNS005 exhibited excellent stability within the protein complex when governed by parameters like RMSD, RMSF, and trajectory analysis. The molecules also showed more negative binding energies than the reference molecule derived using the MMPBSA approach.
The four ligands VNS001, VNS003, VNS005, and VNS007 were also subjected to single protein molecules VANGL1, SCRIB, and NOS1AP via molecular docking to designate the binding site of the protein chains, as well as to explore the behavior of these ligands as single receptor inhibitors. VNS003 showed the best properties when enforced to a 100 MD simulation with good RMSD and RMSF values. The MMPBSA free binding energy methods also confirmed its efficacy as an inhibitor module.
Thus, VNS003, a cinnoline derivative, can be explored further as disruptor modules that could interrupt the signaling cascade VANG1/SCRIB/NOS1AP, which are responsible for cell migration and metastasis. However, the availability of the desired chemicals to expose them in in vitro treatment is the only gap in the present research. Nevertheless, the synthesis and treatment of cells could further promote the molecules to clinical trials, making them discernable as novel anti-cancer modules.
References
Boriack-Sjodin PA, Margarit SM, Bar-Sagi D, Kuriyan J (1998) The structural basis of the activation of Ras by Sos. Nature 394(6691):337–343. https://doi.org/10.1038/28548
Iii FA, Ladurner AG, Inouye C, Tjian R, Nogales E (1999) Three-dimensional structure of the human TFIID-IIA-IIB complex. Science (80-). 286:2153–2157
Lu H et al (2020) Recent advances in the development of protein–protein interactions modulators: mechanisms and clinical trials. Signal Transduct Target Ther. https://doi.org/10.1038/s41392-020-00315-3
Cruz DL et al (2014) Condição bucal e estado nutricional de pacientes de clínicas oral. Rev Univap São José dos Campos-SP-Brasil 21(37):21–30. https://doi.org/10.1016/j.tips.2013.04.007.Targeting
Wells JA, McClendon CL (2007) Reaching for high-hanging fruit in drug discovery at protein-protein interfaces. Nature 450(7172):1001–1009. https://doi.org/10.1038/nature06526
Goll J, Uetz P (2008) Analyzing protein interaction networks. Bioinform From Genom Ther 3:1121–1177. https://doi.org/10.1002/9783527619368.ch31
Hennessy BT, Smith DL, Ram PT, Lu Y, Mills GB (2005) Exploiting the PI3K/AKT pathway for cancer drug discovery. Nat Rev Drug Discov 4(12):988–1004. https://doi.org/10.1038/nrd1902
Hanahan D, Weinberg RA (2011) Hallmarks of cancer: the next generation. Cell 144(5):646–674. https://doi.org/10.1016/j.cell.2011.02.013
Fu J et al (2011) The TWIST/Mi2/NuRD protein complex and its essential role in cancer metastasis. Cell Res 21(2):275–289. https://doi.org/10.1038/cr.2010.118
Anastas JN et al (2012) A protein complex of SCRIB, NOS1AP and VANGL1 regulates cell polarity and migration, and is associated with breast cancer progression. Oncogene 31(32):3696–3708. https://doi.org/10.1038/onc.2011.528
Bonello TT, Peifer M (2019) Scribble: a master scaffold in polarity, adhesion, synaptogenesis, and proliferation. J Cell Biol 218(3):742–756. https://doi.org/10.1083/jcb.201810103
Wang J, Jin L, Zhu Y, Zhou X, Yu R, Gao S (2016) Research progress in NOS1AP in neurological and psychiatric diseases. Brain Res Bull 125:99–105. https://doi.org/10.1016/j.brainresbull.2016.05.014
Bilder D, Li M, Perrimon N (2000) Cooperative regulation of cell polarity and growth by Drosophila tumor suppressors. Science (80-). 289(5476):113–116. https://doi.org/10.1126/science.289.5476.113
Hatakeyama J, Wald JH, Printsev I, Ho HYH, Carraway KL (2014) Vangl1 and Vangl2: Planar cell polarity components with a developing role in cancer. Endocr Relat Cancer 21(5):345–356. https://doi.org/10.1530/ERC-14-0141
Hussein UK et al (2021) Scrib is involved in the progression of ovarian carcinomas in association with the factors linked to epithelial-to-mesenchymal transition and predicts shorter survival of diagnosed patients. Biomolecules 11(3):1–18. https://doi.org/10.3390/biom11030405
Peyravian N et al (2021) Increased expression of vangl1 is predictive of lymph node metastasis in colorectal cancer: Results from a 20-gene expression signature. J Pers Med 11(2):1–22. https://doi.org/10.3390/jpm11020126
Wang X, Ni D, Liu Y, Lu S (2021) Rational Design of Peptide-Based Inhibitors Disrupting Protein-Protein Interactions. Front Chem 9(May):1–15. https://doi.org/10.3389/fchem.2021.682675
Laraia L, McKenzie G, Spring DR, Venkitaraman AR, Huggins DJ (2015) Overcoming Chemical, Biological, and Computational Challenges in the Development of Inhibitors Targeting Protein-Protein Interactions. Chem Biol 22(6):689–703. https://doi.org/10.1016/j.chembiol.2015.04.019
Turnbull AP, Boyd SM, Walse B (2014) Fragment-based drug discovery and protein – protein interactions. Dovepress. https://doi.org/10.2147/RRBC.S28428
Doak BC, Norton RS, Scanlon MJ (2016) The ways and means of fragment-based drug design. Pharmacol Ther 167:28–37. https://doi.org/10.1016/j.pharmthera.2016.07.003
Li Q (2020) Application of fragment-based drug discovery to versatile targets. Front Mol Biosci 7(August):1–13. https://doi.org/10.3389/fmolb.2020.00180
Kidd SL, Osberger TJ, Mateu N, Sore HF, Spring DR (2018) Recent applications of diversity-oriented synthesis Toward novel, 3-dimensional fragment collections. Front Chem. https://doi.org/10.3389/fchem.2018.00460
Vargas C et al (2014) Small-molecule inhibitors of AF6 PDZ-mediated protein-protein interactions. ChemMedChem 9(7):1458–1462. https://doi.org/10.1002/cmdc.201300553
Colovos C, Yeates TO (1993) Verification of protein structures: Patterns of nonbonded atomic interactions. Protein Sci 2(9):1511–1519. https://doi.org/10.1002/pro.5560020916
Laskowski RA, Rullmann JAC, MacArthur MW, Kaptein R, Thornton JM (1996) AQUA and PROCHECK-NMR: Programs for checking the quality of protein structures solved by NMR. J Biomol NMR 8(4):477–486. https://doi.org/10.1007/BF00228148
Wiederstein M, Sippl MJ (2007) ProSA-web: interactive web service for the recognition of errors in three-dimensional structures of proteins. Nucleic Acids Res 35:407–410. https://doi.org/10.1093/nar/gkm290
Chen VB et al (2010) MolProbity: all-atom structure validation for macromolecular crystallography. Acta Crystallogr Sect D Biol Crystallogr 66(1):12–21. https://doi.org/10.1107/S0907444909042073
Krieger E et al (2009) Improving physical realism, stereochemistry, and side-chain accuracy in homology modeling: Four approaches that performed well in CASP8. Proteins Struct Funct Bioinforma 77(SUPPL. 9):114–122. https://doi.org/10.1002/prot.22570
González-Alemán R, Hernández-Castillo D, Caballero J, Montero-Cabrera LA (2020) Quality threshold clustering of molecular dynamics: a word of caution. J Chem Inf Model 60(2):467–472. https://doi.org/10.1021/acs.jcim.9b00558
De Vries SJ, Van Dijk M, Bonvin AMJJ (2010) The HADDOCK web server for data-driven biomolecular docking. Nat Protoc 5(5):883–897. https://doi.org/10.1038/nprot.2010.32
Darnell SJ, LeGault L, Mitchell JC (2008) KFC server: interactive forecasting of protein interaction hot spots. Nucleic Acids Res. 36:265–269. https://doi.org/10.1093/nar/gkn346
Kozakov D et al (2015) The FTMap family of web servers for determining and characterizing ligand-binding hot spots of proteins. Nat Protoc 10(5):733–755. https://doi.org/10.1038/nprot.2015.043
Chi CN, Bach A, Strømgaard K, Gianni S, Jemth P (2012) Ligand binding by PDZ domains. BioFactors 38(5):338–348. https://doi.org/10.1002/biof.1031
Wang NX, Lee HJ, Zheng JJ (2008) Therapeutic use of PDZ protein-protein interaction antagonism. Drug News Perspect 21(3):137–141. https://doi.org/10.1358/dnp.2008.21.3.1203409
Abraham MJ et al (2015) Gromacs: High performance molecular simulations through multi-level parallelism from laptops to supercomputers. SoftwareX 1–2:19–25. https://doi.org/10.1016/j.softx.2015.06.001
Gajula M, Kumar A, Ijaq J (2016) Protocol for molecular dynamics simulations of proteins. Bio-Protoc 6(23):1–11. https://doi.org/10.21769/bioprotoc.2051
Lemkul J (2019) From proteins to perturbed hamiltonians: a suite of tutorials for the GROMACS-2018 molecular simulation package [Article v1.0]. Living J Comput Mol Sci 1(1):1–53. https://doi.org/10.33011/livecoms.1.1.5068
Roy A, Kucukural A, Zhang Y (2010) I-TASSER: a unified platform for automated protein structure and function prediction. Nat Protoc 5(4):725–738. https://doi.org/10.1038/nprot.2010.5
Vakser IA (2014) Protein-protein docking: from interaction to interactome. Biophys J 107(8):1785–1793. https://doi.org/10.1016/j.bpj.2014.08.033
Dennis S, Kortvelyesi T, Vajda S (2002) Computational mapping identifies the binding sites of organic solvents on proteins. Proc Natl Acad Sci U S A 99(7):4290–4295. https://doi.org/10.1073/pnas.062398499
Pierce AC, Rao G, Bemis GW (2004) BREED: generating novel inhibitors through hybridization of known ligands. Application to CDK2, P38, and HIV protease. J Med Chem 47(11):2768–2775. https://doi.org/10.1021/jm030543u
Vuppala PK (2013) Importance of ADME and bioanalysis in the drug discovery. J Bioequiv Availab 05(04):4–5. https://doi.org/10.4172/jbb.10000e31
Någren K (2003) PET and knockout mice in drug discovery. Drug Discov Today 8(19):876. https://doi.org/10.1016/S1359-6446(03)02765-X
Kufareva I, Abagyan R (2012) Methods of protein structure comparison. Methods Mol Biol 857:231–257. https://doi.org/10.1007/978-1-61779-588-6_10
Dannenberg JJ (1998) Book reviews. 123(39), 1009–1011
Reif MM, Oostenbrink C (2014) Net charge changes in the calculation of relative ligand-binding free energies via classical atomistic molecular dynamics simulation. J Comput Chem 35(3):227–243. https://doi.org/10.1002/jcc.23490
Acknowledgements
We would like to dedicate our acknowledgment to the Department of Biosciences and Bioengineering, along with the Centre for Nanotechnology at IIT Guwahati. We would like to thank the School of Health Science and Technology, Param-Ishan, and BSL facilities of IIT Guwahati. Also, a sincere acknowledgment is directed toward Schrodinger and Senior Scientist Dr. Prajwal Nandekar, for licensing the use of the software.
Author information
Authors and Affiliations
Contributions
All the author(s) listed mentioned have made a direct, significant, and conceptual contribution to the work, approving it for publication.
Corresponding author
Ethics declarations
Conflict of interest
The author(s) declare that there was no potential conflict of interest that could influence the work reported in this paper.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary Information
Below is the link to the electronic supplementary material.
Rights and permissions
About this article

Cite this article
Acharyya, S.R., Sen, P., Kandasamy, T. et al. Designing of disruptor molecules to restrain the protein–protein interaction network of VANG1/SCRIB/NOS1AP using fragment-based drug discovery techniques. Mol Divers 27, 989–1010 (2023). https://doi.org/10.1007/s11030-022-10462-0
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11030-022-10462-0