
Abstract
In this work, we derive the exact distribution of a random sum of the form \(S=U+X_1+\ldots +X_M\), where the \(X_j\)’s are independent and identically distributed positive integer-valued random variables, independent of the non-negative integer-valued random variables M and U (which are also independent). Efficient recurrence relations are established for the probability mass function, cumulative distribution function and survival function of S as well as for the respective factorial moments of it. These results are exploited for deriving new recursive schemes for the distribution of the waiting time for the rth appearance of run of length k, under the non-overlapping, at least and overlapping scheme, defined on a sequence of identically distributed binary trials which are either independent or exhibit a k-step dependence.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
1 Introduction
There is an extensive list of real-life problems where the stochastic nature of the phenomena under investigation can be modeled by the aid of a sum of a random number of random variables. In collective risk theory, for example, letting M denote the number of claims (or losses) in a specific time period and \(X_j\) the amount of the jth claim (or loss), for \(j=1,2,\ldots , M\), the sum \(X_1+X_2+\ldots +X_M\) corresponds to the aggregate amount of claims (or losses) of the insurance portfolio in that period (e.g., Klugman et al. 2019). In epidemiology, if M denotes the number of susceptibles at a specific time (e.g., Brauer 2008), then the number of infected individuals may be expressed as \(X_1+X_2+\ldots +X_M\), where \(X_j\) indicates whether the jth susceptible got infected (\(X_j=1\)) or not (\(X_j=0\)).
In general, let \(X_1,X_2,\ldots\) be a sequence of stochastically independent and identically distributed random variables (r.v.) and M a non-negative integer-valued r.v., independent of the \(X_j\)’s. The random variable
(convention: \(S_M=0\) if \(M=0\)) is usually referred to as random sum model. Note also that, in queueing theory, the equilibrium waiting time distribution in the G/G/1 model follows a distribution related to the random sum model (1); moreover, in ruin theory, several quantities (e.g., ruin probabilities, Laplace transform of ruin time, surplus before ruin and, density at ruin) of the celebrated Sparre Andersen risk model (e.g., Asmussen and Albrecher 2010) can be studied by the aid of the tail probability of the random sum model with M having a suitable geometric distribution.
When \(X_j\)’s follow a discrete distribution, (1) is usually referred to as discrete random sum model and its distribution as discrete compound distribution. In the collective risk theory, the discrete sum model can also be applied when the severity distribution, i.e., the distribution of \(X_j\), is defined on \(0,1,\ldots , x_{max}\) with its values representing multiples of some monetary unit. In this case, \(x_{max}\) will stand for the largest possible payment and could be finite or infinite. If M belongs to the well known Panjer class of counting distributions, Panjer (1981), Sundt (1982), and Waldmann (1996) derived very efficient recursive schemes for the probability mass function, cumulative distribution function and tail probabilities of \(S_M\).
However, considering, for example, an insurance company, it is reasonable to assume that besides the losses suffered due to the M claims, it also has an operational cost, say U; hence, its total expenses (operational costs and aggregate claims) will be given by
The main aim of the present article is the study of the extended random sum (2), when U and M belong to the Panjer class, \(X_j\)’s are i.i.d. positive integer-valued random variables and all random variables appearing in (2) are assumed to be independent. A sum of similar nature was discussed in Kalashnikov (1997) (Example 3.4), in terms of the time needed by a pedestrian to cross an one-way road.
Another motivation for looking at the aforementioned model stems from the fact that a number of waiting times distributions for runs defined on a sequence of binary trials can be expressed as extended random sums, and therefore, their exact distribution can be deduced as a special case of the distribution of (2). Note that the notion of run (also referred to as “spells” or “episodes” in social sciences; e.g., Cornwell 2015, Ch. 4) which can be defined as an interrupted sequence of identical events, plays a prominent role in many real-life applications (e.g., Fu and Lou 2003). For example, researchers are typically interested in studying the sequence of status (defective or not) of the inspected items from a production line, the number of consecutive days a worker spent in unemployment, and the number of consecutive insurance claims exceeding a predetermined limit, among others. Similar frameworks may be encountered in a plethora of different disciplines such as quality control, actuarial science, reliability theory, molecular biology, epidemiology, medicine, criminology, and experimental psychology, to mention a few (e.g., Lou 1996; Godbole et al. 1997; Glaz et al. 2001; Balakrishnan and Koutras 2002; Eryilmaz 2008; Glaz et al. 2009; Glaz and Balakrishnan 2012; Balakrishnan et al. 2021).
In the literature, several schemes of counting the number of runs in a (ordered) sequence of events have been employed; among them, the most popular are probably the non-overlapping, at least and overlapping scheme. According to these schemes, once a (pre-specified) number of consecutive identical events, say k, shows up, a run is counted and (a) the enumeration immediately starts from scratch, under the non-overlapping scheme, (b) the enumeration re-starts only after the current run is interrupted by a different type of event, under the at least scheme, whereas (c) we keep counting the occurrence of runs, as far as the same event is still occurring, under the overlapping scheme. For example, in the sequence of binary outcomes 0000111001000, we observe 4, 3 and 6 runs of zeros of length \(k=2\) under the non-overlapping, at least and overlapping scheme, respectively. The corresponding waiting time distributions for the rth appearance of a run of length k, which have been named as negative binomial distributions of order k, is then of special theoretical and applied interest; for example, in the previous binary sequence the waiting times for the appearance of \(r=3\) runs of zeros of length \(k=2\) equals 9, 12 and 4, under the non-overlapping, at least and overlapping scheme, respectively. Needless to say, for \(k=1\), the three waiting time distributions reduce to the well-known negative binomial distribution.
Probability mass functions, probability generating functions or recursive formulas of the three waiting time distributions mentioned above can be found in the literature, assuming, for example, that the sequence of binary trials consist of independent and identically distributed binary trials or Markov dependent trials (e.g., Koutras 1997; Balakrishnan and Koutras 2002, Ch. 4); however, for some of these methods the calculations needed to obtain the exact distribution turn out to be computationally intractable, especially, for large values of k and/or r. The present work also focuses to the derivation of computationally efficient recursive relations for the probability mass function, the cumulative distribution function and the tail probabilities of the negative binomial distributions of order k.
The rest of this paper is organized as follows. In Section 2, we study the relation between the negative binomial distributions of order k and the distribution of the extended discrete random sum. In Section 3, we derive efficient recurrence relations for the probability mass function, cumulative distribution function and survival function of S, along with recursive formulas for its factorial moments. The general results of Section 3 are subsequently used in Section 4 for studying the negative binomial distributions of order k, taking advantage of the relations established in Section 2. Some practical and numerical aspects of the new results are considered in Section 5, in terms of their application to the total expenses (operational costs and aggregate claims) of an insurance company.
2 Random sum representations for the negative binomial distributions of order k
In this section, we illustrate how the waiting times for multiple run occurrences can be represented as properly defined random sums. The approach taken here departs from the techniques used so far, which exploit representations as sums of fixed number of random variables; e.g., Hirano et al. (1991), Koutras (1997) or Balakrishnan and Koutras (2002).
To start with, consider a sequence \(Z_1, Z_2, \ldots\) of i.i.d. binary trials with \(Z_j\)=1 (success) or 0 (failure), for \(j=1,2,\ldots\) and \(P(Z_j=1)=p\in (0,1)\), \(P(Z_j=0)=q=1-p\). Let us also denote by \(T_{r,k}^{(N)}\), \(T_{r,k}^{(A)}\) and \(T_{r,k}^{(O)}\), the waiting time for the rth appearance of a success run of length k, under the the non-overlapping, at least and overlapping scheme, respectively; although the waiting times \(T_{r,k}^{(N)}\), \(T_{r,k}^{(A)}\), \(T_{r,k}^{(O)}\), are also denoted as \(T_{r,k}^{(I)}\), \(T_{r,k}^{(II)}\), \(T_{r,k}^{(III)}\), in the relevant literature (e.g., Balakrishnan and Koutras 2002), here we adopted the first notation as it may help the reader to more easily recall which scheme is being referred to.
Apparently, for \(r=1\), all three variables describe the waiting time for the first occurrence of a success run of length k; hence, \(T_{1,k}^{(N)}=T_{1,k}^{(A)}=T_{1,k}^{(O)}=T_k\) where \(T_k\) is a random variable following the geometric distribution of order k. The notations that will be used in the sequel are:
-
\(f_{r,k}^{(i)}(x)=P(T_{r,k}^{(i)}=x)\), i=N, A, O for the probability mass function of the negative binomial distributions of order k.
-
\(f_{k}(x)=P(T_k=x)\) for the probability mass function of the geometric distribution of order k; moreover, we shall write \(T_k\sim G_k(p)\).
The proof of the main result of this section, Theorem 1, makes use of some useful results, concerning the probability generating functions of the waiting times \(T_{r,k}^{(N)}\), \(T_{r,k}^{(A)}\) and \(T_{r,k}^{(O)}\). Using the formulas provided in Balakrishnan and Koutras (2002) (Ch. 4.2.2), one may easily conclude that the probability generating functions of \(T_{r,k}^{(N)}\), \(T_{r,k}^{(A)}\) and \(T_{r,k}^{(O)}\) take on the forms
where
Considering the special case \(r=1\), for any of (3)–(5), we readily obtain the probability generating function of \(T_k\sim G_k(p)\) as
From (3) and \(k=1\), we may deduce the next well known probability generating function of the negative binomial distribution with parameters r and p, symb. Nb(r, p),
Obviously, Nb(1, p) leads to the standard geometric distribution with support \(\{0,1,\ldots \}\), to be denoted hereafter by G(p), whereas the shifted geometric distribution with support \(\{1,2,\ldots \}\), will be denoted by \(G_{sh}(p)\).
Moreover, if B follows the typical binomial distribution with parameters r (number of trials) and p (success probability), symb. \(B\sim b(r,p)\), its probability generating function reads
Suppose now that Y follows the truncated geometric distribution with support \(1,2,\ldots ,k\), symb. \(Y\sim G_{tr}^{k}(p)\); then, the probability mass function of Y is given by
whereas its probability generating function by
One may easily verify that \(G_{tr}^{k}(p)\) is a conditional geometric distribution, namely, \(Y {\mathop {=}\limits ^{d}} T \vert T \le k\) where \(T\sim G_{sh}(p)\).
We are now ready to state the next theorem, expressing the distributions of the negative binomial distributions of order k, as the distributions of properly defined random sums.
Theorem 1
Suppose that the waiting times \(T_{r,k}^{(N)}\), \(T_{r,k}^{(A)}\) and \(T_{r,k}^{(O)}\) are defined on a sequence of independent and identically distributed binary trials, with success probability p. Then,
where
-
(a)
for i = N, we have
$$\begin{aligned} c=kr, U=0, M\sim Nb(r,p^k), \text { and } X_1,X_2,\ldots \sim G_{tr}^{k}(p), \end{aligned}$$ -
(b)
for i = A, we have
$$\begin{aligned} c=r(k+1)-1, U\sim Nb(r-1,q), M\sim Nb(r,p^k), \text { and } X_1,X_2,\ldots \sim G_{tr}^{k}(p), \end{aligned}$$ -
(c)
for i = O, we have
$$\begin{aligned} c=k+r-1, U+k\sim G_{k}(p), M\sim b(r-1,q), \text { and } X_1,X_2,\ldots \sim G_{k}(p), \end{aligned}$$
and all variables involved in the RHS of (11) (i.e., U, M and \(X_1,X_2,\ldots\) \()\) are independent.
Proof
(a) It is well known that, for the random sum \(S_M=X_1+X_2+\ldots +X_M\), we have
Since, \(M\sim Nb(r,p^k)\) we may write, by recalling (7), that
The probability generating function of \(P_X(u)\), when \(X_i\sim G_{tr}^k(p)\), is given by (10) and after simple algebraic calculations we get
which, in view of (3), yields
This completes the proof.
(b) Combining (4) and (12) we get
and upon observing that the first term in the RHS can be viewed as the probability generating function of \(U\sim Nb(r-1,q)\) (c.f. (7)) we may write
and therefore,
The result follows immediately by taking into account that U is independent of \(S_M\).
(c) By virtue of (5) we get
and if \(B\sim b(r-1,q)\) and \(T_k\sim G_k(p)\) we may write the RHS as follows (c.f. (6) and (8))
where \(S_{B}=X_1+X_2+\ldots +X_{B}\), with \(X_i\sim G_k(p)\). Making use of the independence of the random variables involved in the above expressions, we conclude that
and this completes the proof.
3 Recursive formulas for extended random sums
According to Theorem 1 a shifted version of the three negative binomial distributions of order k admits a random sum representation of the form \(U+\sum _{j=1}^{M}X_j\), where \(X_1, X_2, \ldots\), is a properly defined sequence of independent and identically distributed positive integer-valued random variables, independent of the non-negative integer-valued random variable M.
A common feature in the three representations provided in Theorem 1 is that the random variable M belongs to the Panjer class of counting distributions. Moreover, the random variable U is either degenerate (\(U=0\)) or it belongs to the same class (with different parameters). Before proceeding with the main results of this section, let us recall that a discrete random variable M belongs to the Panjer class of non-negative integer-valued random variables (symb., \(M\in {\mathcal {R}}(a,b,0)\)) if its probability mass function satisfies the recurrence relation
for some constants a and b; e.g., Panjer (1981). For this class of counting distributions, we always have \(a<1\), and the only non-degenerate members of this family are the Poisson, the binomial and the negative binomial distribution. It can be verified that b(r, p) and Nb(r, p) obey the recurrence scheme (13) with \(a=-p(1-p)\), \(b=(r+1)p/(1-p)\) and \(a=p\), \(b=(r-1)p\), respectively.
The next theorem provides efficient recursive schemes for the evaluation of the probability mass function and cumulative distribution function of \(U+S_M\); subsequently, an analogous recursion is given for its tail probabilities.
Theorem 2
Let \(X_1, X_2, \ldots\) be a sequence of independent and identically distributed positive integer-valued random variables, with probability mass function and cumulative distribution function f(x) and F(x), respectively. Let \(S=U+X_1+\ldots +X_M\), where \(M\in {\mathcal {R}}(a,b,0)\), \(U\in {\mathcal {R}}(a_1,b_1,0)\) are independent random variables which are independent of \(X_j\)’s as well. Then, the probability mass function \(f_S(x)=P(S=x)\) and cumulative distribution function \(F_S(x)=P(S\le x)\) of S obey the following recurrence relations:
with initial values \(f_S(0)=F_S(0)=P(U=0)P(M=0)\), and
where \(c_1=0\), \(c_i=a\sum _{m=1}^{i-1}f(m)a_1^{i-m-1}, i=2,3,\ldots ~.\)
Proof
(a) Let us denote by \(P_S(u)=E[u^S]\), \(P_{S_M}(u)=E[u^{S_M}]\), \(P(u)=E[u^X]\) the probability generating functions of \(S, S_M\) and \(X_j\)’s, respectively. The conditions set in Theorem 2 imply that U and \(S_M\) are independent random variables, and therefore, the probability generating function of S takes on the form
and differentiating with respect to u we get
Differentiating next the formula \(P_{S_M}(u)=P_M(P(u))\) with respect to u and taking into account that the probability generating function of M, \(P_{M}(u)=E[u^M]\), satisfies the differential equation,
we obtain
Substituting the last expression into the right-hand side of (17), and reusing (16), and (18), we may write
Let us next multiply both sides of (19) by \(u(1-a P(u))\), to obtain
and observe that
Replacing \(P_S(u)\) and P(u) by their series expansions and then picking up the coefficients of \(u^x\), \(x\ge 1\), we obtain that
and for \(x=2,3,\ldots\)
Since the last relation reproduces the previous one for \(x=1\), we may state that it holds true for all \(x=1,2,3,\ldots\). The proof is easily completed by extending the last summation in the range \(i=1,2,\ldots ,x\) (by convention \(c_1=0\)) and dividing both sides by x.
(b) Let \({\widehat{P}}_S(u)=\sum _{x=0}^{\infty }F_S(x)u^x\) be the generating function of \(F_S(x), x=0,1,\ldots\) and \(\widehat{P}_{1,S}(u)=\sum _{x=0}^{\infty }F_{1,S}(x)u^x\) the generating function of the auxiliary quantities \(F_{1,S}(x)=\sum _{i=0}^{x}F_S(i)\), for each \(x=0,1,\ldots\). Then, it can be easily verified that
Dividing both sides of (20) by \(1-u\) and taking into account (21), we get the following differential equation for \({\widehat{P}}_{S}(u)\),
which yields for \(x\ge 1\),
Observe next that, for \(x=1,2,\ldots\), we have
and since \(F_{1,S}(x-1)=\sum _{i=1}^{x}F_S(x-i)\) and \(F_Y(0)=0\), we may write
Substituting (23) into (22), recursion (15) follows.
Theorem 2 provides simple recurrences for the probability mass function and the cumulative distribution function of the random sum S which make use the parameters \(a,b,a_1,b_1\) of the Panjer families involved in the distributions of U and M, and the probability mass function f(x) of \(X_j\)’s. One can easily establish an analogous recurrence relation for the tail probabilities \(\overline{F}_S(x)=P(S>x)\) of S. This can be accomplished by following a procedure analogous to the one used for proving part (b) of Theorem 2 or by simply replacing \(\overline{F}_S(x)=1-F_S(x)\) in (15) and carrying our some simple algebraic calculations in the resulting equality. Hence, the deduced recurrence takes on the form
where
with initial condition \(\overline{F}_S(0)=1-P(U=0)P(M=0)\).
It is of interest to note that, the recurrences of Theorem 2 may be restated in the form
where \(A_i=af(i)\), \(B_i=bi f(i)+(a_1+b_1)(a_1^{i-1}-c_i)\) and \(B_i^{\prime }=B_i+(1-aF(i-1))\). The last expressions have an apparent resemblance to the Panjer recursions, as well as to the recurrences obeyed by the generalization of Panjer’s counting distributions class considered by Sundt (1982).
Manifestly, the recurrences developed in this section will reduce to the recurrences for the classical random sum \(S_M=\sum _{j=1}^{M}X_j\) (see Panjer 1981) if we set \(a_1=b_1=0\) in which case the random variable U becomes degenerate with its mass concentrated at 0.
Closing this section, we provide some hints for the calculation of the moments of \(S=U+S_M\). The mean and the variance of S can be easily obtained by noting that, by virtue of the independence of U and \(S_M\),
On the other hand, a well known result for the random sum \(S_M=\sum _{j=1}^{M}X_j\) states that
and taking into account that \(M\in {\mathcal {R}}(a,b,0)\), and \(U\in {\mathcal {R}}(a_1,b_1,0)\), we have (Panjer 1981)
Then, we easily arrive at the following expressions
We provide next a recurrence scheme for the evaluation of the factorial moments of S under the same conditions on M, U and \(X_j\), as in Theorem 2.
Theorem 3
Let
for \(n=1,2,\ldots\) be the factorial moments of order \(n \ge 1\) of S and X, respectively (convention: \(m_0=\mu _0=1\)). Then, the following recurrence holds true
where
Proof
Multiplying both sides of (19) by \(1-aP(u)\) we get
with \(R(u)=\frac{1}{1-a_1u}\). Application of Leibnitz’s formula for obtaining the derivative of order n in both sides of the above equation, gives
with \(M(u)=R(u)P(u)\). Now, since
relation (26) can equivalently be written as
or
The proof is completed by noting that
and
4 Recursions for the negative binomial distributions of order k
In this section, we are going to take advantage of the results of Sections 2 and 3 in order to derive recursive formulas for the distributions of \(T_{r,k}^{(N)}\), \(T_{r,k}^{(A)}\) and \(T_{r,k}^{(O)}\). We start with the simplest case where the waiting times \(T_{r,k}^{(N)}\), \(T_{r,k}^{(A)}\) and \(T_{r,k}^{(O)}\) are defined on a sequence \(Z_1, Z_2, \ldots\) of i.i.d. trials (Section 4.1) and apply Theorem 2 to establish recurrences for the probability mass function, cumulative distribution function, tail probabilities and moments in a unified way; it is worth stressing out that some of the results given in this section have also been obtained in the past by exploiting different techniques adjusted to the special nature of each waiting time variable.
Next, in Section 4.2, we derive new results under a more general set up for \(Z_1, Z_2, \ldots\). More specifically, we assume that \(Z_1, Z_2, \ldots\) is a sequence of binary random variables of order k (Aki 1985). This case is also treated in a uniform way by considering first a slight generalization of Theorem 2 and then deriving all the desired results by a direct application of that.
4.1 Independent and identically distributed binary variables
The next proposition provides recurrences for the probability mass function, the cumulative distribution function and the tail probabilities of \(T_{r,k}^{(N)}\), as well as for its factorial moments. In the statements and the proofs that follow we shall be using the next notations
and \(\epsilon _i=\epsilon _i(x,k,r)=1+(r-1)i\epsilon\), \(\eta _i=\epsilon _i(x+1,k+1,r)\), \(\alpha _i(p)=p^{i-1}-qp^{i-2}\min \{i-1,k\}\), \(i=1,2,\ldots\). We also set \(\xi _i(p)=1\) and \(\xi _i(p)=0\), for \(i=0\) and \(i\ge k+1\), respectively.
Proposition 4
For the probability mass function, the cumulative distribution function, the tail probabilities and the factorial moments \((m_n^{(N)})\) of \(T_{r,k}^{(N)}\), the following recursions hold true:
with initial conditions \(f_{r,k}^{(N)}(kr)=F_{r,k}^{(N)}(kr)=1-\overline{F}_{r,k}^{(N)}(kr)=p^{kr}\).
Proof
(i) According to Theorem 1a, \(T_{r,k}^{(N)}-kr\) has the same distribution with \(S=X_1+X_2+\ldots +X_{M}\), where \(M\in {\mathcal {R}}(a,b,0)\) with \(a=1-p^k\), \(b=(r-1)(1-p^k)\) and \(X_j\sim G_{tr}^{(k)}(p)\). Therefore, S satisfies the conditions of Theorem 2, with \(a_1=b_1=0\), and \(f(x)=\frac{q}{1-p^k}p^{x-1}\), \(x=1,2,\ldots ,k\). A direct application of Theorem 2i yields that the probability mass function of S satisfies the recursion
The proof of this part is easily completed on observing that \(f_S(x)=f_{r,k}^{(N)}(x+kr)\), for \(x=0,1,\ldots\).
(ii) The cumulative distribution function of \(X\sim G_{tr}^{(k)}(p)\) is given by (see (9))
and the sum \(\sum _{i=1}^{x}\delta _i(x)F_S(x-i)\) appearing in the RHS of (15) takes on the form
Hence, (15) reduces to
and the proof is completed by taking into account that \(F_S(x)=F_{r,k}^{(N)}(x+kr)\), for \(x=0,1,\ldots\).
(iii) Comparing (15) and (24), it is clear that \(F_S(x)\) and \(\overline{F}_S(x)\) obey the same recurrence scheme with the exception of the extra term \(\epsilon (x)\) appearing in \(\overline{F}_S(x)\). The proof is easily established by noting that in our case (\(a_1=b_1=0\)) we have \(x\epsilon (x)=(a+b)\sum _{i=1}^{x}if(i)=r\sum _{i=1}^{\min \{x,k\}}i p^{i-1}q\), for \(x=0,1,\ldots\) and use of \(F_S(x)=F_{r,k}^{(N)}(x+kr)\), for \(x=0,1,\ldots\).
(iv) Taking into account the form of \(\xi _i(p)\) and (9), we may write
where \(m_i^{(Y)}\) denotes the ith factorial moment of the random variable Y. Furthermore, from Theorem 1 we know that \(T_{r,k}^{(i)}-kr{\mathop {=}\limits ^{d}}\sum _{j=1}^{M}X_j\), \(M\sim Nb(r,p^k)\), and \(X_1,X_2,\ldots \sim G_{tr}^{k}(p)\). Then, using Theorem 3 with \(a=1-p^k, b=(r-1)(1-p^k), a_1=b_1=0\) and the above form of \(\xi _i(p)\), the proof is readily completed.
The recursive formula provided above for \(f_{r,k}^{(N)}(x)\) has also been given by Philippou and Georghiou (1989) while a similar recurrence is mentioned by Charalambides (1986). The techniques for deriving these results are entirely different from the one used here: the first authors exploited Fibonacci-type polynomials, the latter made use of truncated Bell polynomials. It is also noteworthy that, for \(f_{r,k}^{(N)}(x)\) there exists also closed formulae involving single and multiple summations with binomial or multinomial coefficients respectively; see Chapter 4 in Balakrishnan and Koutras (2002) for more details. The recursive schemes for \(F_{r,k}^{(N)}(x)\) and \(\overline{F}_{r,k}^{(N)}(x)\) given in part (ii) and (iii) of Proposition 4, to the best of our knowledge, have not appeared in the literature up to now.
The following result may be proved in much the same way as Proposition 4, and therefore, the proof is omitted.
Proposition 5
For the probability mass function, the cumulative distribution function, the tail probabilities and the factorial moments \((m_n^{(A)})\) of \(T_{r,k}^{(A)}\), the following recursions hold true:
with initial conditions
\(f_{r,k}^{(A)}\bigl ((k+1)r-1\bigr )=F_{r,k}^{(A)}\bigl ((k+1)r-1\bigr )=1-\overline{F}_{r,k}^{(A)}\bigl ((k+1)r-1\bigr )=q^{r-1}p^{kr}\).
As far as we know, no recurrence relations have appeared in the literature for the probability mass function, the cumulative distribution function, the tail probabilities and the factorial moments of \(T_{r,k}^{(A)}\). Muselli (1996) developed the following exact formula for the evaluation of \(f_{r,k}^{(A)}(x)\)
The results of this section are completed by providing formulae for computing the distribution of the waiting time corresponding to the overlapping scheme. More specifically, in the next Proposition the distribution of \(T_{r,k}^{(O)}\) is expressed in terms of the distribution of \(T_{r,k}^{(N)}\).
Proposition 6
For the probability mass function of \(T_{r,k}^{(O)}\), the following formula hold true, for \(x\ge k+r-1\):
The same formula remains valid if we replace the probability mass functions f by the cumulative distribution functions F and the tail probabilities \(\overline{F}\).
Proof
Following similar steps with those of proving Theorem 1c, we can see that \(T_{r,k}^{(O)}-(r-1)\) is distributed as \(S=X_1+X_2+\ldots +X_{B+1}\), with \(B\sim b(r-1,q)\) and \(X_i\sim G_k(p)\). Applying the total probability theorem we may write
where
and \(f_{i}^{*}(x)=P(X_1+\ldots +X_i=x)\). Note next that \(X_i\sim G_k(p)\) implies that \(f_{i}^{*}(x)=f_{i,k}^{(N)}(x)\), for \(x=0,1,\ldots\), and thus
Formula (i) is readily deduced by taking into account that \(f_S(x)=f_{r,k}^{(O)}(x+r-1)\), for \(x\ge r-1\), and thus \(f_{i,k}^{(N)}(x-r+1)>0\) for \(x\ge ki+r-1\). Arguing in a similar way, we may easily obtain (ii) and (iii).
Ling (1989) proved the formula given in Proposition 6, by carrying out mathematical induction on r. He also established the following recursive scheme which makes use of the probability mass function of \(G_k(p)\)
The computational efficiency of the above recursive schemes (Propositions 4-6), in terms of the time needed for computing the probability mass function (until its 90th percentile), is indicatively considered in Table 1. Specifically, the computational time of the recursive schemes of the negative binomial distributions of order k, as provided by Propositions 4-6 (i.e., the three different counting schemes), is demonstrated and further compared to the recursive schemes deduced by the Markov chain imbedding technique (e.g., Section 4.2.1, in Balakrishnan and Koutras 2002). For the overlapping scheme, we also provide the computational times of (29). As can be seen in Table 1, the suggested recursive schemes have the best computational times, in most of the cases. A notable exception to that is the case of the overlapping counting where for small values of k, the recursive scheme deduced by the Markov chain imbedding technique (MCI) exhibit the smallest computing times.
4.2 The case of binary sequence of order k
Let us recall that \(X_0, X_1, \ldots\), with \(X_j\in \{0,1\}\) for all \(j=1,2,\ldots ,\) is said to be a binary sequence of order k (Aki 1985), if there exist a positive integer k and real numbers \(0<p_1,\ldots ,p_k<1\) such that \(P(X_n=1\vert X_0=x_0, X_1=x_1, \ldots , X_{n-1}=x_{n-1})=p_j\), for any n with \(j=n_0-[(n_0-1)/k]k\), and \(n_0\) being the smallest positive integer with \(x_{n-n_0}=0\) ([a] stands for the largest integer not exceeding a; convention: \(P(X_0=0)=1\)). Note that if \(p_j=p\), for all j, then the sequence is i.i.d.
Under this type of dependence, it is known that the probability generating function of \(T_{r,k}^{(N)}\) is given by (Aki 1985)
where
with \(\pi _0=1\) and \(q_i=1-p_i\). Employing the Markov chain imbedding technique (e.g., Fu 1986; Fu and Koutras 1994; Koutras and Alexandrou 1997; Koutras 1997; Chadjiconstantinidis et al. 2000; Fu and Lou 2003), the next theorem can be proved.
Theorem 7
The probability generating functions of \(T_{r,k}^{(A)}\) and \(T_{r,k}^{(O)}\), defined on a binary sequence of order k, with probabilities \(p_1, p_2, \ldots , p_k\), are given by
Proof
In order to prove (30) and (31) we employ the Markov chain imbedding technique. Roughly speaking, consider a process \(Y_t\) which both keeps track of the current success run length and also of the number of success runs met until time t, under the at least scheme; i.e., \(Y_t=(i,r)\) if and only if the last i outcomes of the sequence are all successes (1) and the previous a failure (0), and r success runs with at least length k have already been met. Then, this process is a Markov chain embeddable variable of binomial type (e.g., Koutras 1997), wherein the only non-zero elements of the \((k+1)\times (k+1)\) transition matrices \(A=[a_{ij}]\) and \(B=[b_{ij}]\), are given by
Let \(\beta _i=\textbf{e}_iB\textbf{1}^{\prime }\), \(i=1,2,\ldots ,k+1\), where \(\textbf{1}^{\prime }\) represents the \((k+1)\times 1\) column vectors with all its entries being 1, and \(\textbf{e}_i\) is the \(1\times (k+1)\) row vector having 1 in the ith position and 0 elsewhere. Then \(\beta _i=0\) for \(i=1,2,\ldots ,k-1,k+1\) and \(\beta _k=p_k\). Thus, if
we get by Theorem 3.1 in Koutras (1997) that
where I is the identity matrix of order \(k+1\) and \(\textbf{e}_i^{\prime }\) is the transpose vector of \(\textbf{e}_i\); hence it is straightforward to see after some routine calculations that
Expanding the latter in a Taylor series around \(w=0\) and considering the coefficient of \(w^r\), we get
and so (30) follows.
In order to prove (31), a similar process is introduced with the \((k+1)\times (k+1)\) transition matrices \(A=[a_{ij}]\) and \(B=[b_{ij}]\) having non-zero elements given by
hence
Therefore, if \(H_2(u,w)=\sum _{r=0}^{\infty }E\left[ u^{Z_{r,k}^{(O)}}\right] w^r\), then again by Theorem 3.1 in Koutras (1997) we have that
and so expanding the latter into a Taylor series around \(w=0\) and considering the coefficient of \(w^r\), we get
which proves (31).
To state analogue results to Theorem 1, under the binary sequence of order k, we need the auxiliary i.i.d. positive integer-valued random variables \(Y_1, Y_2, \ldots\) with probability mass function
and the random variable W following \(Nb(r,\pi _k)\), \(r=1,2,\ldots\) independent of \(Y_j\)’s, having probability mass function
Moreover, let \(W_1, W_2, \ldots\) stand for a sequence of independent and identically distributed positive integer-valued random variables, with \(W_j\) following the extended geometric distribution of order k (Aki 1985), i.e., their probability generating function is given by \(E\left[ u^{T_{1,k}^{(N)}}\right]\). We are now ready to state the following theorem, through which the shifted distributions of \(T_{r,k}^{(N)}\), \(T_{r,k}^{(A)}\) and \(T_{r,k}^{(O)}\), defined on the binary sequence of order k, are expressed as properly defined random sums, similar to that of Theorem 1 (the proofs of the results of this section are omitted, because the steps are quite similar to the ones used for the i.i.d. case).
Theorem 8
Suppose that the waiting times \(T_{r,k}^{(N)}\), \(T_{r,k}^{(A)}\) and \(T_{r,k}^{(O)}\) are defined on a binary sequence of order k, with probabilities \(p_1, p_2, \ldots , p_k\). Assume also that all the random variables W, B, and U are independent random variables, being also independent of the previously defined \(Y_j\)’s and \(W_j\)’s. Then, each of the following results hold:
Based on the previous result and Theorem 2, the next corollary results.
Corollary 4.1
For the probability mass function, the cumulative distribution function and the tail probabilities of \(T_{r,k}^{(N)}\), defined on a binary sequence of order k, with probabilities \(p_1, p_2, \ldots , p_k\), the following recursions hold true:
with \(f_{r,k}^{(N)}(kr)=F_{r,k}^{(N)}(kr)=1-\overline{F}_{r,k}^{(N)}(kr)=\pi _{k}^r.\)
Note that the formulae of Corollary 4.1 are analogues to the ones provided in Proposition 4 (replace \(\eta +q\eta _i\) and \(p^{i-1}\) in Proposition 4, by \(\eta +q_i\eta _i\) and \(\pi _{i-1}\), respectively).
Similarly, due to Theorems 8 and 2, the next results for the distribution of \(T_{r,k}^{(A)}\) can be deduced.
Corollary 4.2
For the probability mass function, the cumulative distribution function and the tail probabilities of \(T_{r,k}^{(A)}\), defined on a binary sequence of order k, with probabilities \(p_1, p_2, \ldots , p_k\), the following recursions hold true:
with
and initial conditions \(f_{r,k}^{(A)}((k+1)r-1)=F_{r,k}^{(A)}((k+1)r-1)=1-\overline{F}_{r,k}^{(A)}((k+1)r-1)=1-q_k^{r-1}\pi _{k}^r\).
The next recursion refers to the waiting time corresponding to the overlapping scheme; please note that in the following relations the corresponding formulas for the waiting time of the non-overlapping scheme, as they provided by Corollary 4.1 are also used.
Corollary 4.3
For the probability mass function defined on a binary sequence of order k, with probabilities \(p_1, p_2, \ldots , p_k\), the following recursions hold true:
The same formula remains valid if we replace the probability mass functions f by the cumulative distribution functions F and the tail probabilities \(\overline{F}\).
5 Application
In this section, we discuss some details on the application of the extended random sum model \(S=S_M+U\), to the study of the total expenses of an insurance company. As already stated in Section 1, under this framework \(S_M=\sum _{j=1}^{M}X_j\) stands for the aggregate claims amount and U may encompass all company operational costs, with U and \(X_j\)’s taking positive integer values.
The questions to be faced by the practitioner when applying the model pertain to the selection of the appropriate distributions for U, M and \(X_j\)’s. In actuarial practice, the number of claims, M, is usually described by a member of the Panjer family R(a, b, 0) (e.g., Klugman et al. 2019), while for \(X_j\)’s it is necessary to engage distributions that can accommodate extreme observations, i.e., large claims that occur with low frequency.
The Pareto distribution is a very popular model for describing extreme phenomena. It was first introduced for the study of economic models dealing with income data. Due to its heavy tail, Pareto distribution has been extensively used as a severity distribution to describe extreme losses (e.g., Guillen et al. 2011), especially for the high-risk types of insurance, e.g., medical malpractice insurance. A more flexible model that contains the Pareto distribution as a special case is offered by the Burr (Type XII) distribution, symb. \(Br_{\theta }(\alpha ,\beta )\), with probability density function
where \(\alpha , \beta\) and \(\theta\) are positive parameters. Besides, the two parameter Pareto distribution (obtained for \(\beta =1\)), it also includes as special cases the log-logistic, exponential and Weibull distribution (as limiting cases). For more details, the interested reader is referred to Johnson et al. (2005).
In our framework, \(X_j\)’s may be seen as multiples of a monetary unit, while the underlying exact (continuous) severity distribution should posses the heavy-tail property. A reasonable approach to meet these requirements is offered by “discretizing” the \(Br_{\theta }(\alpha ,\beta )\) model. As stated by Klugman et al. (2019), a typical way for constructing a discrete severity distribution from a continuous one is to place the discrete probabilities on multiples of the desired unit of measurement h. If the exact losses Y (continuous random variable) follow (32), the implied discrete distribution of \(X_j\)’s (symb., \(DBr_{\theta }(\alpha ,\beta )\)) will be generated by the formulas
where
is the cumulative distribution function of \(Br_{\theta }(\alpha ,\beta )\).
According to the last formula, the probability placed at xh is obtained by accumulating all the probability of Y one-half span on either sides of xh, i.e., it rounds all amounts to the nearest monetary unit, h. For a detailed study of the Burr and Pareto distribution, including statistical inference and stochastic ordering properties, we refer to, e.g., Panjer (2006), Krishna and Pundir (2009), and Klugman et al. (2019).
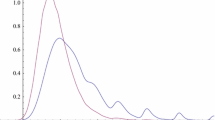
In Fig. 1, we present plots of the \(DBr_{\theta }(\alpha ,\beta )\) for several choices of \(\alpha ,\beta\), and \(\theta\) (using \(h=0.75\)). It is clear that the discretization of the Burr (Type XII) distribution still offers the opportunity to model (discrete) data with heavy tails, while most of the properties of \(Br_{\theta }(\alpha ,\beta )\) seem to carry over nicely to \(DBr_{\theta }(\alpha ,\beta )\) (e.g., unimodality for \(\beta >1\)), especially upon choosing the appropriate values for h.
Let us next move to the distribution of the third component of our model, i.e., the operating cost U. The heavy tail assumption made on \(X_j\)’s is typically not realistic for the operating costs r.v. U; on the contrary, a “smooth” discrete distribution seems to be a fair choice for that variable.
If the distribution of U has a shape similar to the normal distribution, a plausible discrete distribution that may be used for fitting our data is offered by b(m, p) with m sufficiently large to justify the convergence of \((U-mp)/(\sqrt{mp(1-p)})\) to the standard normal distribution. It should be stressed that, if we assume that \(U\sim b(m,p)\) we shall have \(V[U]/E[U]=1-p<1\), therefore this approach makes sense only for the case when the data justify the underdispersion (\(V[U]<E[U]\)) of the fitting distribution. Under this framework the exact distribution of the company total expenses, as expressed by the extended random sum model (2), can be easily calculated by the aid of recurrence (25), with \(B_1=bf(1)+mp/q\) and
The case of overdispersed data (\(V[U]>E[U]\)) can be treated by the use of the negative binomial distribution Nb(r, p) with \(p=E[U]/V[U]\). In this case, the resulting distribution for the total expenses obeys the recurrence (25) with \(B_1=bf(1)+rp\) and
Finally, if our data imply that \(V[U]\approx E[U]\) the most appropriate discrete distribution for U is the Poisson distribution with parameter \(\lambda =E[U]\approx V[U]\). Taking into account that the Poisson distribution with parameter \(\lambda\) can be viewed as a member of the Panjer family R(a, b, 0) with \(a=0\), \(b=\lambda\) we conclude that the distribution of the total expenses satisfies the recurrence scheme (25) with \(B_1=bf(1)+\lambda\) and
In Fig. 2, we provide plots for the probability mass function of the total expenses when \(X_j\sim DB_1(1,1)\) (with \(h=1\)), \(M\sim Nb(r,p)\), and U follows a binomial, negative binomial or Poisson distribution. At the left part of this figure, we can see how the distribution of the total expenses is affected, changing the distribution of the number of claims, M; note that U has a similar mean (close to 5), for every case (binomial, negative binomial and Poisson distribution). As it was expected, increasing the parameter value r of the distribution of M, the tails of the total expenses become heaviest. At the right part of Fig. 2, we consider the effect of changing the parameters of the distribution of U; generally, as the mean value of U is increasing, its role to the distribution of the total expenses becomes more significant, resulting also in heaviest tails. Fig. 3 includes the probability mass function of the total expenses when U and M follow a negative binomial distribution and \(X_j\sim DB_\theta (\alpha ,\beta )\) (with \(h=1\)), for several choices of \(\alpha ,\beta\), and \(\theta\); the heavy tail property is also met for appropriate choice of parameter values.

The probability mass function of \(DBr_{\theta }(\alpha ,\beta )\), for several choices of \(\alpha ,\beta\), \(\theta\) and \(h=0.75\)

The probability mass function of the extended sum, when \(X_j\)’s follow the \(DBr_{1}(1,1)\) (with \(h=1\)), M follows a negative binomial distribution and U follows a binomial, negative binomial or Poisson distribution

The probability mass function of the extended sum, when M, U follow a negative binomial distribution and \(X_j\)’s follow the \(DBr_{\theta }(\alpha ,\beta )\) (with \(h=1\)), for several choices of \(\alpha ,\beta\), and \(\theta\)
6 Conclusions
In this work, recursive relations for the probability mass function, cumulative distribution function, tail probabilities and the factorial moments, of an extension of the discrete random sum model was established. The new model and the suggested methodology was exploited for the study of the negative binomial distributions of order k (for the three most popular enumerating schemes, i.e., the non-overlapping, at least and overlapping), offering computationally efficient ways for obtaining their exact distribution functions. A roadmap is also highlighted for applying our results in the study of the total expenses (operational costs and aggregate claims) of an insurance company, providing a new direction to the study of this problem; for doing so, a discretization of the severity distribution is also suggested, which is a plausible way of keeping significant properties of well known heavy tailed continuous random variables.
Data Availibility Statement
The datasets/materials used and/or analysed during the current study are available from the authors on reasonable request.
References
Aki S (1985) Discrete distributions of order \(k\) on a binary sequence. Ann Inst Stat Math 37(2):205–224
Asmussen S, Albrecher H (2010) Ruin Probabilities. World Scientific, Singapore, 2nd edition
Balakrishnan N, Koutras MV (2002) Runs and Scans with Applications. John Wiley & Sons, New York
Balakrishnan N, Koutras MV, Milienos FS (2021) Reliability Analysis and Plans for Successive Testing: Start-up Demonstration Tests and Applications. Academic Press
Brauer F (2008) Compartmental models in epidemiology. Mathematical Epidemiology. Springer, Berlin, pp 19–79
Chadjiconstantinidis S, Antzoulakos DL, Koutras MV (2000) Joint distributions of successes, failures and patterns in enumeration problems. Adv Appl Probab 32(3):866–884
Charalambides CA (1986) On discrete distributions of order \(k\). Ann Inst Stat Math 38(3):557
Cornwell B (2015) Social Sequence Analysis: Methods and Applications. Cambridge University Press
Eryilmaz S (2008) Run statistics defined on the multicolor urn model. J Appl Probab 45(4):1007–1023
Fu JC (1986) Reliability of consecutive-\(k\)-out-of-\(n\): F systems with \((k-1)\)-step Markov dependence. IEEE Trans Reliab 35(5):602–606
Fu JC, Koutras MV (1994) Distribution theory of runs: a Markov chain approach. J Am Stat Assoc 89(427):1050–1058
Fu JC, Lou WW (2003) Distribution theory of runs and patterns and its applications: a finite Markov chain imbedding approach. World Scientific, Singapore
Glaz J, Balakrishnan N (2012) Scan Statistics and Applications. Springer Science & Business Media
Glaz J, Naus JI, Wallenstein S (2001) Scan Statistics. Springer, New York
Glaz J, Pozdnyakov V, Wallenstein S (2009) Scan Statistics: Methods and Applications. Springer Science & Business Media
Godbole AP, Papastavridis SG, Weishaar RS (1997) Formulae and recursions for the joint distribution of success runs of several lengths. Ann Inst Stat Math 49(1):141–153
Guillen M, Prieto F, Sarabia JM (2011) Modelling losses and locating the tail with the Pareto positive stable distribution. Insurance Math Econom 49(3):454–461
Hirano K, Aki S, Kashiwagi N, Kuboki H (1991) On Ling’s binomial and negative binomial distributions of order \(k\). Statist Probab Lett 11(6):503–509
Johnson NL, Kemp AW, Kotz S (2005) Univariate Discrete Distributions. John Wiley & Sons
Kalashnikov VV (1997) Geometric Sums: Bounds for Rare Events with Applications: Risk Analysis, Reliability. Queueing. Springer Science & Business Media, Dordrecht
Klugman SA, Panjer HH, Willmot GE (2019) Loss Models: from Data to Decisions. John Wiley & Sons, Hoboken, NJ, 5th edition
Koutras MV (1997) Waiting time distributions associated with runs of fixed length in two-state Markov chains. Ann Inst Stat Math 49(1):123–139
Koutras MV, Alexandrou VA (1997) Sooner waiting time problems in a sequence of trinary trials. J Appl Probab 34(3):593–609
Krishna H, Pundir PS (2009) Discrete Burr and discrete Pareto distributions. Statistical Methodology 6(2):177–188
Ling K (1989) A new class of negative binomial distributions of order \(k\). Statist Probab Lett 7(5):371–376
Lou WW (1996) On runs and longest run tests: a method of finite Markov chain imbedding. J Am Stat Assoc 91(436):1595–1601
Muselli M (1996) Simple expressions for success run distributions in Bernoulli trials. Statist Probab Lett 31(2):121–128
Panjer HH (1981) Recursive evaluation of a family of compound distributions. ASTIN Bulletin: The Journal of the IAA 12(1):22–26
Panjer HH (2006) Operational Risk: Modeling Analytics. John Wiley & Sons
Philippou AN, Georghiou C (1989) Convolutions of Fibonacci-type polynomials of order \(k\) and the negative binomial distributions of the same order. Fibonacci Quart 27:209–216
Sundt B (1982) Asymptotic behaviour of compound distributions and stop-loss premiums. ASTIN Bulletin: The Journal of the IAA 13(2):89–98
Waldmann K-H (1996) Modified recursions for a class of compound distributions. ASTIN Bulletin: The Journal of the IAA 26(2):213–224
Funding
No funding was obtained for this study.
Author information
Authors and Affiliations
Contributions
All authors contributed to the study conception and design. Material preparation and analysis were performed by S. Chadjiconstantinidis, M.V. Koutras and F.S. Milienos. The first draft of the manuscript was written by S. Chadjiconstantinidis. All authors read and approved the final manuscript.
Corresponding author
Ethics declarations
Conflicts of Interest
The authors have no competing interests as defined by Springer, or other interests that might be perceived to influence the results and/or discussion reported in this paper.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Chadjiconstantinidis, S., Koutras, M.V. & Milienos, F.S. The distribution of extended discrete random sums and its application to waiting time distributions. Methodol Comput Appl Probab 25, 49 (2023). https://doi.org/10.1007/s11009-023-10027-0
Received:
Revised:
Accepted:
Published:
DOI: https://doi.org/10.1007/s11009-023-10027-0
Keywords
- Runs
- Multiple run occurrences
- Probability generating functions
- Recursive schemes
- Markov chain imbedding technique
- Collective risk model
- Claims distribution