
Abstract
Context
Obtaining accurate and precise maps of landscape features often requires intensive spatial sampling and interpolation. The data required to generate reliable interpolated maps varies with sampling density and landscape heterogeneity. However, there has been no rigorous examination of sampling density relative to landscape characteristics and interpolation methods.
Objectives
Our objective was to characterize the 3-way relationship among sampling density, interpolation method, and landscape heterogeneity on interpolation accuracy and precision in simulated and in situ landscapes.
Methods
We simulated landscapes of variable heterogeneity and sampled at increasing densities using gridded and random strategies. We applied three local interpolation methods (i.e., Inverse Distance Weighting, Universal Kriging, and Nearest Neighbor) to the sampled data and estimated accuracy (slope and intercept) and precision (R2) between interpolated surfaces and the original surface. Finally, we applied these analyses to in situ data using a normalized difference vegetation index raster collected from pasture with various resolutions.
Results
In our simulations, all interpolation methods and sampling strategies yielded similar accuracy and precision except in the case of Universal Kriging with random sampling. Additionally, low heterogeneity and increasing sample density improved both accuracy and precision, with cross-validation slopes and R2 values approaching optimal values. In situ analysis demonstrated that heterogeneity decreased with resolution. Nearest Neighbor under both sampling strategies and Universal Kriging using the gridded sampling strategy had the highest accuracy and precision. Decreased heterogeneity and increased sampling density improved accuracy and precision for all combinations of interpolation method and sampling strategies.
Conclusions
Heterogeneity of the landscape is a major influence on the accuracy and precision of interpolated maps. There is a need to create structured tools to aid in determining sampling design most appropriate for interpolation methods across landscapes of various heterogeneity.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
Introduction
Measurement of ecological processes at a landscape level requires a thorough understanding of spatial relationships of the target resource across landscape gradients. Originally focused within landscape ecology or biogeography (Turner and Gardner 2015), measuring landscape heterogeneity has emerged as an important research front in movement ecology, agroecology, disturbance ecology, precision agriculture, and other landscape-level sciences focused on ecological processes and the spatial configuration of resources (Carlile et al. 1989). For example, spatial configuration of forage mass and quality influence landscape utilization and grazing pressure by cattle (Bos taurus) and bison (Bison; Kohl et al. 2013) and browse selection by moose (Alces; Balluffi-Fry et al. 2020; Leroux et al. 2017). Further, spatial sampling is commonly used in agricultural fields to identify areas which may need alternative management strategies, such as increased nutrient inputs (Franzen 1995), or designate wildlife habitat and conservation areas (Burger 2019), which can result in economic and environmental improvements (Sun and Brus 2021). As such, a common objective of landscape-level studies is the creation of data layers or maps that accurately portray the distribution forage biomass, nutrient density, species distribution, habitat, soil quality or landscape condition (Turner and Gardner 2015).
Given that complete measurement of resources across the landscape is virtually impossible, the full landscape of resource availability is often approximated by sampling predetermined locations and performing spatial interpolation to estimate resource values at unobserved locations (Li and Heap 2008). Accuracy and precision of estimated resource values generally depend upon: (1) the sampling strategy employed (Cobby et al. 1985); (2) number of samples collected (Tsutsumi et al. 2007); (3) the degree of variability among samples across the landscape (Sun and Brus 2021); (4) the interpolation method used (Li and Heap 2008); and (5) the spatial scale under investigation (Wu 2004; Turner and Gardner 2015). These effects have been individually examined, often in detail. For example, ecologists have utilized gridded, random, stratified random, and cyclic sampling strategies in hopes of identifying some optimum strategy that efficiently and accurately describes a landscape variable (Burrows et al. 2002; Turner and Gardner 2015). Additionally, the minimum number of samples required to accurately model the landscape must be considered given that sample collection is often labor and cost intensive (Burrows et al. 2002; Tsutsumi et al. 2007; Turner and Gardner 2015). Spatial heterogeneity is driven by underlying biotic and abiotic processes and their interactions. For instance, the heterogeneity of available forage can be driven by interactions between grazing patterns of herbivorous animals, soil type, moisture availability and infiltration, slope gradient, plant species distribution, and soil microbe populations (Barthram et al. 2005; Hirata et al. 2012). Interpolation methods provide a means of creating a continuous surface from point processes; however, selection of the best method for a specific process and sample strategy is difficult (Li and Heap 2008). Finally, defining the appropriate spatial scale matched with the correct sampling strategy and sample number is required to accurately and precisely model landscape resources (Wiens 1989; Fryxell et al. 2008; Turner and Gardner 2015; Sun and Brus 2021).
Clearly there has been substantial attention to each of these components regarding spatial sampling; however, there is not yet a comprehensive demonstration of how these factors interact to determine the accuracy and precision of common interpolation strategies. In keeping with recent calls for critical utilization of currently existing metrics of landscape structure and scale (Turner and Gardner 2015), herein we use well-defined metrics with clear application to examine the relationship among sampling strategy, sampling density, and landscape heterogeneity within the context of scale (Wu 2004). Particularly, we focus on systematic and random sampling strategies because these are commonly used techniques for landscape sampling in agriculture and forestry (e.g., Burrows et al. 2002; Jordan et al. 2003; Clark et al. 2008; Sun and Brus 2021). We generate multiple simulated landscapes representing a gradient of landscape heterogeneity and perform interpolation using 3 common geostatistical techniques (i.e., Nearest Neighbor, Universal Kriging, Inverse Distance Weighting) to estimate continuous surfaces from derived samples (Li and Heap 2008). We then explicitly consider how landscape heterogeneity interacts with sample size and the interpolation method itself to determine the accuracy (i.e., a 1-to-1 relationship) and precision (i.e., goodness-of-fit; R2) between predicted and observed surfaces (Fig. 1). Finally, we repeat these procedures using in situ data to validate our findings from simulation with empirical data, and to evaluate interpolation accuracy as spatial resolution decreases.

Conceptual representation of the expected precision (R2) due to sampling density (left) and an increase in landscape heterogeneity (right)
Methods
Simulated landscapes
We simulated a series of landscapes, similar to, Matthiopoulos et al. (2015), using the bkde2D kernel density function in the kernsmooth package in program R (Wand, 2021). Landscape dimensions and average resource availability were held at 600 × 600 pixels and 50 units, respectively. Resources were distributed across the landscape around one resource epicenter and smoothed outward according to unique bandwidths (analogous to the extent to which resources were spread) ranging from 30 to 740. This created a landscape dataset of 300 unique landscape simulations with a broad representation of heterogeneity. Then, we measured landscape heterogeneity for each simulated landscape using rho (Tsutsumi et al. 2007), with higher rho values indicating greater landscape similarity and autocorrelation structure. Rho was calculated as the squared mean divided by the squared standard deviation of the landscape resource (\({\upmu }^{2}/{\upsigma }^{2}\); Tsutsumi et al. 2007).
We created sampling densities ranging from 0.28 to 2.8 samples per 10,000 pixels, which equate to 10 to 100 locations increased in 1-step increments (range = 10 – 100 samples), resulting in 91 unique sampling densities. Sampling points were created via regular gridded and uniform spatial random sampling using the spsample function from R package sp (Hijmans et al. 2021). Gridded sampling points were set a specified distance apart at the intersection of evenly spaced gridlines laid across the landscape. For both gridded and random sampling strategies, and for each simulated landscape × sample number combination, we extracted resource values from simulated landscape surfaces at each sampling location and used extracted values to create predicted landscape surfaces using each of 3 interpolation methods. First, we used Universal Kriging by implementing the autokrige function within the automap R package (Hiemstra 2013; Gräler et al. 2016) to create a kriged surface. Next, we created an Inverse Distance Weighting interpolated surface with the idw function available within the gstat R package (Gräler et al. 2016). Finally, we created a Nearest Neighbor interpolated surface using Thiessen polygons and identifying the closest observed point from which to interpolate using the whichmin function (Brunson 2019; R Core Team 2021). Interpolated landscape surfaces created from each combination of interpolation method, sampling strategy, and sampling density were then compared to their original simulated landscape using simple linear regression between the interpolated and true landscape surface with the lm function (R Core Team 2021). This is a common cross-validation technique whereby performance of a defined model (here, an interpolation method and sampling density) is evaluated based on 1-to-1 agreement between the predicted (interpolated) and observed (true) surface (Harrell, 2001; Tedeschi 2006). Accuracy of the interpolation model is indicated when the intercept of the regression equals 0 and the slope equals 1, and precision when the R2 value approaches 1 (Harrell 2001; Tedeschi 2006). This provided a robust framework from which to make comparisons among interpolation method, sampling strategy, and sampling density given decreasing levels of landscape heterogeneity.
To see whether methods performed similarly, we compared R2 values for each sampling strategy and interpolation method using Pearson Correlation Coefficients calculated via the cor function and pairwise comparisons via the t.test function, in the base R package (R Core Team 2021). For Pearson Correlation Coefficients we determine high correlation with a coefficient > 0.70 (Nettleton, 2014) and for t-tests, we adjusted significance for multiple comparisons using the Bonferroni correction given the number of comparisons (Ott & Longnecker 2016). We then examined the effect of landscape surface heterogeneity (rho), interpolation method (Inverse Distance Weighting, Nearest Neighbor, or Universal Kriging), sampling strategy (gridded or random), and sampling density (n) on accuracy and precision of interpolated landscape surfaces using generalized linear regression with the glm function (R Core Team 2021). We tested post-hoc mean differences using the emmeans function in the emmeans R package (Lenth et al. 2018). Effect comparisons were demonstrated using density and line plots with the geom_density and geom_line functions in the ggplot2 package (Wickham et al. 2019). Finally, we ran a series of beta regression models using the betareg R package (Cribari-Neto and Zeileis 2010) to evaluate the effect of landscape heterogeneity (rho), sampling strategy and density, and interpolation method on the precision (R2) value obtained from interpolated versus true surface cross validations (values fell between 0 and 1, range = 0.001–0.98). Given the large variation in raw values (Figure S1), we used beta regression model to create 3-dimensional plot using wireframe within the lattice R package (Sarkar 2008).
Application to in situ data from pastoral landscape
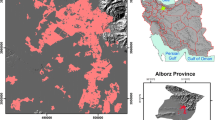
Following our simulation exercise, we applied the same approach to remotely sensed data collected from an experimental grazing facility in Starkville, Mississippi, USA (33 26′07 N 88 48′03 W; Fig. 2) in June 2019. The pasture was ~ 9.35 ha and consisted of a mixture of tall fescue (Festuca arundinacea), bermudagrass (Cynodont dactylon), and annual ryegrass (Lolium multiflorum), which was inter-seeded across one-half of the pasture in fall 2018. Remotely sensed imagery was collected using a Red Edge MX hyperspectral camera (MicaSense®, Seattle, WA, USA) mounted on a Matrice 100 unmanned aerial system (DJI, Shenzhen, Guangdong, China). The camera collected reflectance in the green, blue, red, near-infrared, and red-edge spectral bands at 8.5 cm resolution from a flight altitude of 122 m above ground level with 80% overlap. After imagery was collected, individual pictures were mosaiced utilizing Pix 4D software (Pix 4D Inc. Prilly, Switzerland). Last, we calculated the normalized difference vegetation index (NDVI) at each pixel following standard procedure (Huete et al. 2002).

The 307 forage sampling locations (equating to a sampling density of 32 samples/ha) used to collect forage samples during an 11-month grazing study in 2019 in a pasture in Starkville Mississippi, USA (inset)
We conducted an identical analysis to that used in the simulated landscapes, increasing resolution from 0.085 to 100 m at 1 m increments and measured accuracy and precision metrics (cross-validation model intercepts, slope, and R2) to observe the consequences of decreasing heterogeneity on the landscape (Wu 2004). At each resolution, resampling was conducted at increasing rates of sample density, ranging from 1 to 185 samples per hectare (equating to 0.003 to 0.49 samples/10,000 pixels at a 0.085 m resolution and 26 to 261,515 samples/10,000 pixels at 100 m resolution) with a minimum of 9 and maximum 1726 actual samples collected at each resolution. Sampling points were identified using gridded and random sampling designs identical to the simulated procedures outlined above. Interpolation techniques, identical to those used for simulated landscapes, were applied to each combination of landscape resolution (i.e., heterogeneity measured with rho), interpolation method, sampling strategy, and sampling density, and then compared to the original landscape to measure interpolation accuracy and precision, resulting in 111,000 interpolation attempts. All simulations and applications of simulation methods to in situ data were performed in R version 3.6.3 (R Core Team 2021).
Results
Simulated landscapes
We depict the expected relationship of the predictive accuracy and precision for each interpolation method (Fig. 1) as landscape complexity decreases across simulated landscapes (Fig. 3). Across simulated landscapes, average values of rho were 98 and ranged from 0 (most heterogeneous) to 333 (least heterogenous; Figure S2). In total, 163,800 interpolations were attempted but 163,292 were successful because 508 simulation attempts using original kriging failed to fit a variogram when using the grid sampling strategy. This provided a robust dataset from which to make inference for each combination of interpolation method, sampling strategy, sampling density, and landscape heterogeneity.

Examples of simulated landscapes, each containing the same volume of resources, but with varying gradients around the resource epicenter, resulting in heterogeneities ranging from 0 (most heterogeneous) to 300 (least heterogeneous)
To evaluate the effect of interpolation method, sampling strategy, sampling density, and landscape heterogeneity on precision and accuracy of interpolated surfaces, we conducted both Pearson correlations, a generalized linear model, and paired t-tests. Pearson correlation tests between interpolated and true surfaces demonstrated substantial differences among combination of interpolation method and sampling strategy for metrics of accuracy and precision (Table S1 –S6). For accuracy, correlation coefficients indicated that only Inverse Distance Weighting and Nearest Neighbor gridded sampling intercepts were similar (i.e., r ≥ 0.70, Table S1), while there were no slopes across interpolation method and sampling strategies that were similar (Table S3). However, pairwise t-test demonstrated varying and significant differences between both cross-validation intercepts and slopes across both interpolation method and sampling strategy (Table S2 and S4), with Universal Kriging paired with random points showing the greatest divergence in accuracy from all other methods. For precision (i.e., R2 values), 5 interpolation methods and sampling strategies performed similarly according to both correlation coefficients and paired differences (Table 1. Pearson correlations between linear model intercept values for 3 interpolation methods (Inverse Distance Weighting, Nearest Neighbor, or Universal Kriging) and 2 sampling strategies (gridded or random points).S5 and S6).
Generalized linear regressions for accuracy (cross-validation intercept and slope) and precision (cross-validation R2) revealed that interpolation method combined with sampling strategy provided the largest effect on both the accuracy and precision of the interpolated landscape surface, (Fig. 4) compared to landscape heterogeneity (Fig. 5 and 7). Universal Kriging paired with random sampling strategy over-predicted resource availability and provided the least accurate and precise interpolation sampling strategy as demonstrated by a positive intercept greater than 0, slope less than 1 (Fig. 4 a, c), and the lowest R2 values (Fig. 4e). At greater sampling densities, Universal Kriging with random sampling intercepts were closer to 0, slopes were closer to 1, and precision increased, though values were always well below idealized values (Fig. 4b, d, f). Conversely, for both sampling strategies, Inverse Distance Weighting under-predicted resource availability, with cross-validation model intercepts and slopes ranging from -10 to -40, and slopes 1.0 to 1.8, respectively (Fig. 4 a, c). Intercepts and slopes for Inverse Distance Weighting did get closer to 0 and 1, respectively, as sampling density increased although these changes were marginal (Fig. 4b, d). However, Inverse Distance Weighting predicted with similar precision as other interpolation methods and sampling strategies across sampling densities other than random sampling with Universal Kriging (Fig. 4e, f). Both sampling strategies with Nearest Neighbor produced the most accurate predictions across all sampling densities (Fig. 4). All pairs of interpolation methods and sampling strategies interacted in a positive manner with increasing sampling density and lower landscape heterogeneity demonstrated in Fig. 4 (panels b, d, and f). The positive interaction is most pronounced in Universal Kriging paired with random sampling, and Inverse Distance Weighting where both gridded and random sampling strategies demonstrated increased accuracy and precision (approached 0 and 1 for cross-validation model intercept and slope, respectively) as sample density increased. In all instances, we see cross-validation model intercept, slope, and R2 approach theoretical perfect agreement between interpolated and original landscape surfaces (0, 1, and 1 for cross-validation model intercept, slope, and R2, respectively).

Effects of interpolation method (Inverse Distance Weighting, Nearest Neighbor, or Universal Kriging), sampling strategy (Gridded or Random) and sampling density (n) on the accuracy (cross-validation model intercepts and slopes) and precision (R2 values) for simulated landscapes. Perfect accuracy of 0 and 1 for intercepts and slopes, respectively, and perfect precision of 1 for R2 values are indicated by solid horizontal black lines. Density distributions of model a) intercepts, c) slopes, and e) R2 values, along with the change in b) intercepts, d) slopes and f) R2 as sampling density increases is provided

Precision (R2) of Inverse Distance Weighting, Nearest Neighbor, and Universal Kriging interpolation applied to simulated landscapes at increasing sample densities and landscape heterogeneities (with 0 being more heterogeneous) using a systematic or random sampling strategy. Raw values are provided in Supplementary Fig. 3 and values for some heterogeneities < 10 (given the rates of change at these values of rho) are provided in Supplementary Tables 4–9
Finally, we focused on the effect of landscape heterogeneity and its interaction with interpolation method, sampling strategy, and sample density on interpolation precision (R2) using beta-regression model. Results from simulated landscapes indicated that all combinations of interpolation methods and sampling strategies had similar levels of precision (values between 0.8 and 1.0) except for Universal Kriging combined with random sampling strategy (Fig. 4 and 5). The greatest precision for these interpolation-sampling combinations occurred at low levels of landscape heterogeneity regardless of sampling density and values beyond 10 approached a 1:1 relationship (Fig. 5). In contrast, Universal Kriging under a random sampling strategy yielded a convex relationship with consistently low precision before increasing markedly as sampling density increased; landscape heterogeneity had no effect on precision (Fig. 5).
Application to in situ pastoral landscape
We decreased the resolution of the pasture (Figure S3) in 1-m increments from 0.085 to 100 m, which resulted in moderate levels of heterogeneity (rho = 34 – 111) compared to simulated landscapes. Again, there were large deviations for intercepts, slopes, and R2 values for most interpolation methods and sampling techniques, although Nearest Neighbor under both sampling strategies and gridded Universal Kriging had distributions of values closest to idealized values (Fig. 6). Increased sampling density allowed the intercepts and slopes of these interpolation-sampling combinations to get closer to 0 and 1, respectively, although Universal Kriging with gridded sampling obtained the best precision (Fig. 6). Decreased landscape heterogeneity and increasing sample density were associated with increased precision from all interpolation techniques, although the level of precision was again highest for Universal Kriging with gridded sampling (Fig. 6 and 7). In this case, there was a greater effect of landscape heterogeneity on precision compared to sampling density (Fig. 7). Gridded sampling resulted in the highest accuracy values for Universal Kriging, and this performance was matched in random sampling for Nearest Neighbor and Inverse Distance Weighting (Fig. 6 and 7). Decreasing landscape heterogeneity increased the accuracy and precision of both Inverse Distance Weighting and Nearest Neighbor interpolation (Fig. 7). We observed qualitative agreement between our simulation analysis and our application to in situ pastoral landscapes except in the case of Universal Kriging with random sampling.

Effects of interpolation method (Inverse Distance Weighting, Nearest Neighbor, or Universal Kriging), sampling strategy (Gridded or Random) and sampling density (n) on the accuracy (cross-validation model intercepts and slopes) and precision (R2) values of interpolated landscapes applied to NDVI values collected via remote sensing, controlling for the effect of landscape heterogeneity (rho). Perfect accuracy of 0 and 1 for intercepts and slopes, respectively, and perfect precision of 1 for R2 values are indicated by solid horizontal black lines

Precision (R2) of Inverse Distance Weighting, Nearest Neighbor, and Universal Kriging interpolation applied to NDVI values collected via remote sensing at increasing sample densities and decreasing landscape resolution to reduce heterogeneity (with 0 being more heterogeneous) using a gridded or random sampling strategy
Discussion
Our objective was to evaluate the ability of different interpolation methods to produce accurate and precise representations of a known landscape under variable landscape heterogeneity, sampling strategies, sample densities, and spatial scales. Our simulations and use of in situ pastoral NDVI data showed that both accuracy and precision are strongly affected by the interpolation method and sampling density (Fig. 4 and 6), and that the choice of interpolation method, sampling strategy and sampling density interact with landscape heterogeneity to have substantial influence on the precision and accuracy of interpolated landscapes (Tsutsumi et al. 2007). Accuracy and precision are affected negatively by increased landscape heterogeneity, with decreased heterogeneity substantially improving the accuracy and precision of interpolated landscape surfaces. However, in the case of simulated data, the effect of landscape heterogeneity could be overcome by employing gridded sampling strategies, increasing sample density, and carefully selecting the interpolation method (Fig. 5). In contrast, while careful consideration of the interpolation method and sampling strategy also applied to NDVI data, there was a strong effect of landscape heterogeneity, which would likely not be overcome by sampling density across interpolation methods (Fig. 7). For both datasets, trends in sampling density and heterogeneity indicate there are threshold levels of sampling given the heterogeneity encountered (Fig. 5 and 7).
We demonstrated that random sampling strategies, especially when paired with the Universal Kriging method for interpolation, provides the least accurate and precise interpolated surface. This is surprising given it has been shown in other landscape simulations that random sampling is superior for estimating forage biomass on the landscape (Tsutsumi et al. 2007) and better captures the necessary lag distance within a pine wood stands (Burrows et al. 2002). As such, it is suggested that a systematic approach to landscape sampling better captures landscape structure than does a random sampling strategy. While there has been use of other sampling strategies including transect sampling, stratified random sampling, and cyclic sampling (Sun and Brus 2021), transect and stratified random sampling combine methods inherent to both grid and completely random strategies, and likely would have similar results to the ones obtained in this study. In contrast, cyclic sampling strategies attempts to match the sampling distance to the expected spatial autocorrelation pattern across the landscape and reduce the number of redundant points sampled; however, implementation requires prior knowledge of the landscape to inform the expected autocorrelation of landscape structure (Sun and Brus 2021), which cannot be easily obtained. Further strategies should be explored if they are believed to be of value in improving interpolations.
In addition to demonstrating the importance of selecting the appropriate sampling strategy, we also showed variation in accuracy, but not necessarily precision, across interpolation methods (Fig. 4 and 6, Tables S1 – S6). We note that while pairwise differences between accuracy and precision varied between combinations of interpolation methods and sampling strategy were statistically significant, we would expect these results given the high n used in comparisons and thus caution should be used when interpreting those results. This is consistent with other studies where it has been shown that Nearest Neighbor and Universal Kriging can have a greater ability to capture landscape heterogeneity, particularly at lower sampling densities within more heterogenous landscapes compared to other interpolation methods (Coelho et al. 2008). Our use of random sampling with no prior attention given to matching sampling point distance to an expected variogram inhibited Universal Kriging as we failed to capture the appropriate lag distance. Under these conditions, we would recommend a systematic sampling strategy, such as gridded, paired with Universal Kriging if the sample point distance captured the appropriate lag as demonstrated by the variogram.
There were increases in accuracy and precision with increasing sample density, but this effect was dependent on the interpolation method (Fig. 4 and 6). While it is known that sampling density can increase precision (Tsutsumi et al. 2000; Jordan et al. 2003), this relationship is often described as asymptotic, which assumes that ever increasing numbers of samples will continue to push accuracy and precision ever closer to a 1:1 match at some diminishing rate. In our case, sampling never achieved a perfect asymptote, which is most likely due to the low sampling densities explored within our simulations given the size of the simulated landscape. A moderate sampling strategy is typically sufficient to accurately create interpolated maps of forage quality (Jordan et al. 2003), and simulation exercises within grasslands of varying levels of heterogeneity demonstrated a similar phenomenon (Tsutsumi et al. 2007).
Like sample density, we observed a positive relationship between precision and landscape heterogeneity for most sampling strategies and interpolation methods. This is in line with our predictions, given that as the landscapes became more heterogenous, the distance over which self-similarity occurs increases; therefore, decreasing the total variability within the landscape while increasing the number of samples required to detect small or spatially isolated differences. These relationships were further emphasized when we applied the same techniques to in situ pastoral data where we observed a decrease in the rate of return as heterogeneity diminished (Fig. 7). While adequately measuring heterogeneity can be a complex endeavor in both cases, it is worthy of increased attention given its influence on precision.
We demonstrated the influence of sampling strategy on accuracy and precision estimates across sampling densities and heterogeneities in our simulations (Fig. 4 and 5). As the resolution decreased, the measured heterogeneity of the NDVI landscape also decreased, which indicates a loss of information (Supplementary Figure S3). Indeed, decreased resolution caused dominant values on the landscape to become more predominant with continued aggregation (Turner et al. 1989), effectively causing a reduction in the total observed plant productivity. This effect is driven by how dispersed the variation is across the landscape (Turner et al. 1989). Clearly, changing the resolution has dramatic impacts on the information available at that scale (Turner et al. 1989), and should be carefully considered with respect to meeting the needs and objectives of the analysis (Reynolds et al. 2016).
Our results indicate that it is important to carefully consider interpolation method, sampling density, sampling strategy, and landscape heterogeneity and understand how heterogeneity is influenced by landscape-level processes to construct a useful sampling design. While we showed that capturing landscape-level heterogeneity can occur irrespective of most sampling regimes and interpolation methods, exploring how sampling density and heterogeneity perform under other sampling regimes may be useful. Further, it is also expected that relationships between sampling density and heterogeneity may change with different landscape metrics. This was demonstrated in the wide variation of samples required to predict within crop variation in nitrogen, phosphorous, potassium, and sulfur (Jordan et al. 2003). Thus, spatial sampling should be structured to capture the most heterogenous variable of interest to ensure adequate sampling of all variables. Finally, while we look at the spatial relationships among interpolation method, sampling density and strategy, and landscape heterogeneity, it is likely that these relationships also change temporally. Indeed, we examined these relationships at the height of the growing season, a time when factors affecting landscape heterogeneity, such as resource restriction and grazing pressure, are likely less influential (Cid and Brizuela 1998). We would also expect sampling requirements to vary based on plant phenology and abiotic factors such as rainfall. For example, the sample number required to precisely measure silage production and plant nutrient values varies between cuttings over the summer and by metric of nutrient density (Jordan et al. 2003). As a result, more work on temporal changes in resource distribution is needed to precisely and accurately predict the level of heterogeneity expected within a given landscape; such an investigation is likely critical to target areas of rapid change.
Conclusion
Landscape ecology requires mapping resource distribution across the landscape. Thus, a thorough understanding of spatial relationships allows for selection of the appropriate sampling structure and interpolation method to arrive at accurate and meaningful results (Reynolds et al. 2016), though landscape heterogeneity may be an underlying driver of mapping accuracy for in situ pastoral data. The current body of knowledge offers less than desired guidance for selection between methods. This and future work should lay foundations for a structured decision-making process which will allow researchers and managers to clearly identify sampling strategies and interpolation prediction methods to meet their specific objectives in a resource efficient manner.
References
Balluffi-Fry J, Leroux SJ, Wiersma YF, Heckford TR, Rizzuto M, Richmond IC, Vander Wal E (2020) Quantity–quality trade-offs revealed using a multiscale test of herbivore resource selection on elemental landscapes. Ecol Evol 10(24):13847–13859
Barthram GT, Duff EI, Elston DA, Griffiths JH, Common TG, Marriott CA (2005) Frequency distributions of sward height under sheep grazing. Grass Forage Sci 60(1):4–16
Brunson C (2019) An introduction to R for Spatial Analysis and Mapping, 2nd edn. SAGE Publications Ltd, Singapore
Burger LW, Evans KO, McConnell MD, Burger LM (2019) Private lands conservation: a vision for the future. Wildl Soc Bull 43:398–407
Burrows SN, Gower ST, Clayton ST, Mackay DS, Ahl DE, Norman JM, Diak G (2002) Application of geostatistics to characterize leaf area index (LAI) from flux tower to landscape scales using a cyclic sampling design. Ecosystems 5:667–679
Carlile DW, Skalski JR, Batker JE, Thomas JM, Cullinan VI (1989) Determination of ecological scale. Landsc Ecol 2(4):203–213
Cid MS, Brizuela MA (1998) Heterogeneity in tall fescue pastures created and sustained by cattle grazing. J Range Manag 51(6):644–649
Clark PE, Hardegree SP, Moffet CA, Pierson FB (2008) Point sampling to stratify biomass variability in sagebrush steppe vegetation. Rangel Ecol Manage 61(6):614–622
Cobby JM, Ridout MS, Bassett PJ, Large RV (1985) An investigation into the use of ranked set sampling on grass and grass-clover swards. Grass Forage Sci 40(3):257–263
Coelho EC, de Souza EG, Uribe-Opazo MA, Neto RP (2008) The influence of sample density and interpolation type on the elaboration of thematic maps. Int Conf Agric Eng. https://doi.org/10.4025/actasciagron.v31i1.6645
Cribari-Neto F, Zeileis A (2010) Beta regression in R. J Stat Softw 34(2):1–24
Franzen DW, Peck TR (1995) Field soil sampling density for variable rate fertilization. J Prod Agric 8(4):568–574
Fryxell JM, Hazell M, Borger L, Dalziel BD, Haydon DT, Morales JM, Rosatte RC (2008) Multiple movement modes by large herbivores at multiple spatiotemporal scales. Proc Natl Acad Sci 105(49):19114–19119
Gräler B, Pebesma E, Heuvelink G (2016) Spatio-temporal interpolation using gstat. R Journal 8(1):204–218
Harrell F (2001) Chapter 5: resampling, validating, describing, and simplifying the model. In Regression modeling strategies with applications to linear models, logisitic regression, and survival analysis (1st ed., pp. 87–101). Springer. https://doi.org/10.1007/978-1-4757-3462-1
Hiemstra, P. (2013). Automatic interpolation package. R CRAN Project, 15. Retrieved from https://cran.r-project.org/web/packages/automap/automap.pdf
Hijmans R, Sumner M, Macqueen D, Lindgren F, Brien JO, Rourke JO (2021) Package ‘ sp ’ R topics documented. https://cran.r-project.org/doc/Rnews/
Hirata M, Murakami K, Ikeda K, Oka K, Tobisa M (2012) Cattle use protein as a currency in patch choice on tropical grass swards. Livest Sci 150(1–3):209–219
Huete A, Didan K, Miura T, Rodriguez EP, Gao X, Ferreira LG (2002) Overview of the radiometric and biophysical performance of the MODIS vegetation indices. Remote Sens 83(83):195–213
James G, Witten D, Hastie T, Tibshirani R (2017) Chapter 5: Resampling Methods. An Introduction to Statistical Learning with Applications in R. Springer, New York
Jordan C, Shi Z, Bailey JS, Higgins AJ (2003) Sampling strategies for mapping “Within-field” variability in the dry matter yield and mineral nutrient status of forage grass crops in cool temperate climes. Precision Agric 4(1):69–86
Kohl MT, Krausman PR, Kunkel K, Williams DM (2013) Bison versus cattle: are they ecologically synonymous. Rangel Ecol Manag 66(6):721–731
Lenth R, Singmann H, Love J, Buerkner P, Herve M (2018) Package ‘emmeans.’ R Package Version 1.15-15 34(1):216–221. https://doi.org/10.1080/00031305.1980.104830311
Leroux SJ, Wal EV, Wiersma YF, Charron L, Ebel JD, Ellis NM, Yalcin S (2017) Stoichiometric distribution models: ecological stoichiometry at the landscape extent. Ecol Lett 20(12):1495–1506
Li J, Heap AD (2008) A review of spatial interpolation methods for environmental scientists. Geoscience Australia Canberra
Matthiopoulos J, Fieberg J, Aarts G, Beyer HL, Morales JM, Haydon DT (2015) Establishing the link between habitat selection and animal population dynamics. Ecol Monogr 85(3):413–436
Nettleton D (2014) Chapter 6—Selection of Variables and Factor Derivation. In: Nettleton D (ed) Commercial Data Mining Morgan Kaufmann. Elsevier, Cham
Ott RL, Longnecker M (2016) An Introduction to Statistical Methods and Data Analysis, 7th edn. Cengage Learning, College Station
R Core Team. (2021). R: A languange and environment for statistical computing. Vienna, Austria: R Foundation for Statistical Computing. Retrieved from https://www.r-project.org/
Reynolds JH, Knutson MG, Newman KB, Silverman ED, Thompson WL (2016) A road map for designing and implementing a biological monitoring program. Environ Monit Assess. https://doi.org/10.1007/s10661-016-5397-x
Sarkar D (2008) Lattice: multivariate data visualization with R. Springer. http://lmdvr.r-forge.r-project.org/
Sun XL, Brus DJ (2021) Transferability of a soil variogram for sampling design: a case study of three grasslands in Ireland. Eur J Soil Sci 72(1):69–79
Tedeschi LO (2006) Assessment of the adequacy of mathematical models. Agric Syst 89(2–3):225–247. https://doi.org/10.1016/j.agsy.2005.11.004
Tsutsumi M, Itano S, Shiyomi M (2007) Number of samples required for estimating herbaceous biomass. Rangeland Ecol Manage 60(4):447–452
Tsutsumi M, Shiyomi M, Hayashi H, Takahashi S, Sugawara K (2000) Small-scale spatial heterogeneity of live-shoot biomass of plant species composing sown grassland communities. J Japanese Soc Grassl Sci 46(3):209–216
Turner MG, Gardner RH (2015) Landscape Ecology in Theory and Practice (2nd Editio). Springer. https://doi.org/10.1007/978-1-4939-2794-4
Turner MG, O’Neill RV, Gardner RH, Milne BT (1989) Effects of changing spatial scale on the analysis of landscape pattern. Landsc Ecol 3(3–4):153–162
Wand M (2021) KernSmooth: functions for kernel smoothing supporting Wand & Jones (1995). https://cran.r-project.org/package=KernSmooth
Wickham H, Averick M, Bryan J, Chang W, McGowan LD, Franois R, Grolemund G, Hayes A, Henry L, Hester J, Kuhn M, Pedersen TL, Miller E, Bache SM, Miller K, Ooms J, Robinson D, Seidel DP, Spinu V, Takahashi K, Vaughan D, Wilke C, Kara Woo, Yutani H (2019). Welcome to the Tidyverse. J Open Sour Softw 4(43):1686. https://doi.org/10.21105/joss.01686
Wiens JA (1989) Spatial scaling in ecology. Funct Ecol 3(4):385
Wu J (2004) Effects of changing scale on landscape pattern analysis: scaling relations. Landsc Ecol 19(2):125–138
Acknowledgements
We thank Jane Dentinger, Natasha Ellison, and members of the QuEST lab for valuable feedback and discussion. We also thank the farm crew of the H.H. Leveck Animal Research Center for their professional support.
Funding
This work was supported by Thinking Like a Mountain to Improve Animal Production Systems Ecology, Energy Budgets, and Mechanistic Models, grant no. 2018–67016-27481/project accession no.1014926 from the USDA National Institute of Food and Agriculture, Mississippi Agriculture and Forestry Experiment Station (MAFES), and Noble Research Institute, LLC.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors declare no conflict or competing interests.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary Information
Below is the link to the electronic supplementary material.
Rights and permissions
Springer Nature or its licensor holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Parsons, I.L., Boudreau, M.R., Karisch, B.B. et al. Aiming for the optimum: examining complex relationships among sampling regime, sampling density and landscape complexity to accurately model resource availability. Landsc Ecol 37, 2743–2756 (2022). https://doi.org/10.1007/s10980-022-01523-8
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10980-022-01523-8