
Abstract
Observing hand gestures during learning consistently benefits learners across a variety of tasks. How observation of gestures benefits learning, however, is yet unanswered, and cannot be answered without further understanding which types of gestures aid learning. Specifically, the effects of observing varying types of iconic gestures are yet to be established. Across two studies we examined the role that observing different types of iconic hand gestures has in assisting adult narrative comprehension. Some iconic hand gestures (typical gestures) were produced more frequently than others (atypical gestures). Crucially, observing these different types of gestures during a narrative comprehension task did not provide equal benefit for comprehension. Rather, observing typical gestures significantly enhanced narrative comprehension beyond observing atypical gestures or no gestures. We argue that iconic gestures may be split into separate categories of typical and atypical gestures, which in turn have differential effects on narrative comprehension.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
Introduction
Our ability to communicate is vital for our day-to-day interactions (Littlejohn and Foss 2010). While “communication” is often used to describe verbal messages, the nonverbal component of communication, including gestures, is similarly of great importance. When we interact, we do more than just exchange verbal messages: we might point to indicate direction or draw attention to an object, or we might make an action to accentuate a spoken message (Kelly et al. 1999). These nonverbal movements performed by the hands or arms, termed gestures, provide an external support to verbal communication (McNeil et al. 2000). While speech is primarily used to describe a situation, object, or action, gestures function to draw attention to, or visually depict a situation, object, or action (Kelly et al. 1999). Through accentuating a spoken message, gestures may benefit an observer’s learning. While the benefits of gesture are apparent for speech comprehension (Driskell and Radtke 2003) and problem-solving (Alibali and DiRusso 1999; Chu and Kita 2011), little research concerns narrative comprehension.
Narrative comprehension, the ability to interpret and make meaning of a story, is an important, if not the most important, cognitive tool for human development (Hough 1990; Lyle 2000; Schmithorst et al. 2006). We use narratives to produce meaning out of actions and events, indicating the crucial impact of narrative comprehension on communication (Lyle 2000). While the ability to comprehend narratives is important in children, allowing them to narrate their needs and feelings as well as understand those of others (Paris and Paris 2003), narrative comprehension is similarly crucial to adults. One’s understanding of moral and ethical concepts important in professional practice, such as in medicine, law, and education can be enhanced through one’s ability to comprehend narratives (Lyle 2000). Consequently, understanding the benefits of observing gesture on narrative comprehension could have valuable repercussions for learning.
It is theorized that speech and gesture combine to form a single underlying verbal-gestural communication system, whereby information that is presented by speech and gesture is processed simultaneously to form a single representation (McNeill 1992). Willems et al. (2006) supported this theory, showing through functional magnetic resonance imaging (fMRI) that speech and gesture recruit overlapping areas of the brain. In addition, Kelly et al. (2010) lent further support through their investigation of the automaticity of the integration of speech and gesture in a Stroop-like language comprehension task. They found that the reaction time of participants was significantly slower when presented with incongruent speech-gesture stimuli as compared to congruent speech-gesture stimuli. While this was modulated by context to an extent (i.e., reaction time was faster when the same person produced the gesture and the word compared to when different people produced the gesture and the word), the findings of Kelly et al. (2010) provide evidence that the integration of speech and gesture is to a degree automatic. It therefore appears that speech and gesture are integrated to form a single verbal-gestural communication system as argued by McNeill (1992).
Research has also suggested that listeners decode gesture and speech simultaneously when viewing a narrative (Cassell et al. 1999). This information is then used to form a unified representation of the story, suggesting that gesture together with speech influences narrative comprehension (Cassell et al. 1999). University students recalled more events from a story when the narrator gestured congruently with speech than when the story was narrated through speech only (Cutica and Bucciarelli 2008; Galati and Samuel 2011). Given that gesture has been shown to assist speech comprehension, observing gestures is expected to benefit narrative comprehension. However, not all gestures are created equal: if we are to learn from gestures then the types of gestures observed are likely to be important.
While gestures can be categorized as deictic, metaphoric, beat, or iconic in nature, iconic gestures are the focus of the current paper. Iconic gestures exhibit a concrete meaning, typically an object or action, which is semantically related to speech (Beattie and Shovelton 1999). For example, a person moving their hand upward while stating “a plane flew up into the sky”, representing the action of the plane rising. These concrete, meaningful gestures have been hypothesized to be important in the evolution of language (Arbib et al. 2008). Typically, however, iconic gestures are treated as homogeneous in the gesture literature, with no attention given to different types of iconic gestures. It may be that some iconic gestures are more beneficial for learning than others.
Past research that has investigated the effectiveness of observing iconic gestures in learning has found conflicting results. For example, Kelly and Church (1998) compared the effect of iconic gestures on speech recall compared to no gestures in university students and 10-year old children. No significant differences were found across conditions in children, or between the no gesture and iconic gesture condition. In comparison, iconic gestures were found to benefit the speech comprehension of preschool aged children compared to no gestures in a study by McNeil et al. (2000). A similar finding was also reported by Macoun and Sweller (2016), who found that observing iconic gestures significantly benefitted the narrative comprehension of preschool aged children compared to no gestures. Despite these studies all using iconic gestures, it is possible that the specific iconic gestures used by Kelly and Church (1998) were in some way less effective than the iconic gestures used by McNeil et al. (2000) and Macoun and Sweller (2016).
Different kinds of gestures, including deictic, beat, and iconic gestures, have been shown to be produced at different rates when relaying a spatial message (Austin and Sweller 2018, in press). Perhaps this extends within the category of iconic gestures, such that some iconic gestures are more commonly produced with certain words or phrases than others. That is, they are produced more frequently in the absence of specific instruction. It is possible that this could be the product of motor factors (i.e., they are easier or more efficient to produce), resemblance (i.e., they look more like the action that is being represented), or the fact that they are simply more common in usage (i.e., more automatic or ritualized). It is possible that gestures that are produced frequently (typical gestures) may benefit learning (including narrative comprehension) to a greater extent than gestures that are produced infrequently (atypical gestures).
One potential reason that typical gestures could be more beneficial to narrative comprehension is through focusing attention to the content of the accompanying speech. Through drawing attention to specific elements of a spoken message, the observation of gesture appears to support and expand upon verbally presented information, which in turn may facilitate comprehension (McNeill 1992). Such a theory is supported by findings that individuals have increased brain activity, particularly within the Superior Temporal Sulcus (STS) and Superior Temporal Gyrus (STG), when they observe gestures in combination with speech as compared to when they are presented with a spoken message only (Hubbard et al. 2009). Further research in this area has also found increased activation in the STS and the left inferior frontal cortex when iconic gestures specifically are observed in combination with speech (Holle et al. 2008; Willems et al. 2006). It is notable that increased activation in the left inferior frontal cortex in particular has been observed both when co-speech iconic gestures matched the semantic meaning of the given sentence and when the co-speech gestures matched the semantic meaning of the given sentence to a much lesser extent (Willems et al. 2006). Although the activation noted was greater when individuals observed gestures that matched the semantic meaning of a given sentence compared to individuals who observed gestures that matched the semantic meaning of a given sentence to a much lesser extent (Willems et al. 2006), both forms of gesture appeared to focus attention. Given the established role of the STS, STG, and left inferior frontal cortex in speech processing and comprehension, such findings suggest that the observation of iconic gestures regardless of their semantic relatedness to the co-occurring speech may indeed focus an individual’s attention on the content of speech, in turn potentially increasing comprehension (Hubbard et al. 2009). As a result, although semantically related typical gestures would be expected to capture attention and increase comprehension to the greatest extent, it may be that even atypical gestures could capture one’s attention, and improve comprehension in this way to a greater extent than when no co-speech gestures are presented.
Alternatively, it might be that atypical gestures are less semantically related to the content of accompanying speech. According to Woodall and Folger (1981), because iconic gestures offer semantically meaningful visual features to be encoded that represent the content of speech, the presented information should be processed more deeply and thus enhance recall. That is, observing iconic gestures while encoding spoken information should enhance recall to a greater extent than when no gestures or gestures that are not semantically related to speech are observed. Such an idea stems from research by Craik and Lockhart (1972) and Craik and Tulving (1975) which lead to the Depth of Processing Theory. This research suggests that semantically meaningful contextual cues are processed and thus encoded more deeply than cues that are not semantically meaningful (i.e., visual or phonetic information), resulting in enhanced encoding of the presented information (Craik and Lockhart 1972; Craik and Tulving 1975).
Our goal was to examine whether all iconic gestures are equal. Specifically, whether the observation of some iconic gestures (i.e., typical gestures) benefits narrative comprehension to a greater extent than others (i.e., atypical gestures). In Study 1, we established gestures that may be classed as typical for a given narrative, determined by their unprompted production by participants. Using these gestures, in Study 2, we addressed whether typical and atypical gestures have differential effects on learning.
Study 1
Research investigating iconic gestures with narrative comprehension is sparse (see Macoun and Sweller 2016), and what little research exists treats iconic gestures as homogenous. In Study 1 we examined the different iconic gestures that children and adults produce when re-telling a visual narrative. Participants were either instructed to gesture while re-telling the narrative, or were given no instructions regarding gesture. By examining the gestures performed when retelling the narrative, we identified distinct gestures for subsequent use in a narrative comprehension task.
Method
Participants
Thirty-two adults and 37 children participated in the study. Children were recruited from independent pre-schools in the Sydney area, and included 16 females and 21 males ranging from 3 years 2 months to 5 years 7 months (M = 4.96, SD = .51). Adults were recruited from a swim school associated with the experimenter, and from introductory psychology courses via advertisement on the Macquarie University Psychology Participant Pool. Adults included 16 females and 16 males ranging from 18 years 1 month to 52 years 3 months (M = 27.08, SD = 12.00). Participants were randomly allocated to one of two conditions: spontaneous gesture (18 adults, 21 children) or instructed gesture (14 adults, 16 children). Adult participants and parents of child participants signed written consent forms prior to participation in the study.
Materials and Procedure
Adult participants were seen within a room at Macquarie University or in a quiet corner of the swim school used to recruit participants. Children were seen in a quiet corner of their preschool, within view of preschool staff. All participants were presented with a short video cartoon on an iPad, of Donald Duck trying to refill a watering can to water his prized watermelons. After watching the cartoon, the participants completed a join-the-dots filler task. Different join-the-dots tasks were given to children and adults, and time allocated to complete the task was restricted to 120-s. The experimenter helped children with the join-the-dots task if they had difficulty.
After completing the filler task, the recording device (a video camera) was presented to the participant and the experimenter stated, “Now I am going to ask you some questions, is it okay if I turn the video camera on so that I can remember what you say later?” After verbal consent was obtained, the video camera was turned on. Participants were then asked four open-ended questions (See “Appendix A” section) about the content of the cartoon based on Stevanoni and Salmon (2005), including: “tell me everything that happened in the video you just saw”; “tell me everything that Donald Duck did in the video”; “tell me everything Donald Duck saw in the video”, and “is there anything else you can remember about the video?” If the participant appeared distracted or confused, the questions were repeated. Participants in the instructed gesture condition were encouraged to use their hands when answering the questions (e.g., “I’d like you to show me and tell me everything that happened in the video you just saw. Show me as you tell me using your hands”), while participants in the spontaneous gesture condition were not instructed to move their hands (e.g., “tell me everything that happened in the video you just saw”). Although participants in the spontaneous gesture condition were not explicitly asked to gesture while retelling the narrative, they were not discouraged from gesturing in any way.
Scoring
Verbal responses were transcribed, and all gestures produced by participants were coded and categorized by the experimenter. In the first instance, the gestures were coded according to their form and which event from the narrative they were depicting. For example, if a participant made a fist with their left hand and moved it in an up and down motion while saying, “Donald Duck pumped the lever” the gesture was categorized as a “pumping gesture with one hand”. Alternatively, if the participant made a fist with both hands and moved them up and down simultaneously while saying. “Donald Duck pumped the lever” the gesture was categorized as a “pumping gesture with two hands.” Once all gestures had been coded into categories, individual gesture types were summed together to form a higher-level category based on the event in the narrative that they represented. For example, all gestures that depicted a pumping motion were summed to form the category “pumping gesture”, whereas all gestures that represented the shape of a watering can were summed to make the category “watering can gesture.”
Reliability
A second coder independently coded 20% of adult videos and 20% of child videos to assess inter-rater reliability for the total number of gestures produced by participants. Intra-class correlations (ICC) were obtained to evaluate reliability using an absolute agreement model. As only the first coder’s scores were used in the final analyses, the single measure ICC is reported (ICC = .77, p < .0005).
Results and Discussion
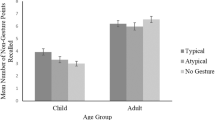
Study 1 investigated the type and frequency of iconic gestures that individuals performed while retelling a narrative. Through coding the gestures performed by participants, we were able to produce a definition of typical gestures and uncover gestures that may reflect a biologically primary skill. Typical gestures were determined to be any gesture naturally produced by participants in study 1. Of the gestures produced, 10 were selected for use in Study 2 (see Table 1).
The gestures used in Study 2 were produced by at least one participant in Study 1, were iconic, and reflected a major narrative event. Although some gestures produced in Study 1 were produced more frequently than some gestures selected for Study 2, they were excluded, as they reflected beat or deictic gestures. Overall, Study 1 identified iconic gestures that are frequently produced without prompting in response to a narrative.
Study 2
Study 1 identified iconic gestures that were produced frequently without prompting when recalling a narrative. However, we do not yet know the implications for the use of such gestures as instructional tools. Do more frequently produced gestures have a greater benefit for learning than gestures that are seldom produced? Using the typical gestures identified in Study 1, Study 2 clarified whether typical gestures aid learning to a greater extent than atypical gestures (i.e., gestures not produced by participants in Study 1, but that could be used to depict a narrative event). A further aim of Study 2 was to determine whether gestures are more beneficial to adults when a narrative is difficult to comprehend. McNeil et al. (2000) found gestures were more beneficial to children when accompanied by a spoken message that was difficult to understand. Similar findings are yet to be replicated in adults.
Participants viewed a video of a narrator telling a story about Donald Duck based on the cartoon presented in Study 1. The narrated story contained all the main plot points in the cartoon. Depending on experimental condition, the narrator either performed typical gestures, atypical gestures, or no gestures at certain points throughout the narrative. We predicted that participants in both gesture conditions would perform better at recall than participants in the no-gesture condition, and that participants in the typical gesture condition would perform better than those in the atypical gesture condition. Furthermore, we expected that gestures would aid narrative comprehension to a greater extent when the speech content of the narrative included infrequently used words than when it included words that are frequently used in conversation. As we have less exposure to low-frequency words, it is assumed they will be harder to comprehend than words we are frequently exposed to. Thus, gesture may be more helpful in improving narrative comprehension when the spoken narrative is harder to understand through inclusion of low-frequency words.
Method
Participants
One hundred and thirty students were recruited from introductory and cognitive psychology courses at Macquarie University via advertisement on the Macquarie University Psychology Participant Pool. The introductory psychology group consisted of 39 students (35 females and 4 males), ranging from 17 years 8 months to 42 years 10 months (M = 19.66, SD = 4.02). The cognitive psychology group consisted of 91 students (66 females and 25 males), ranging from 18 years 8 months to 52 years 5 months (M = 22.28, SD = 7.03).
Materials and Procedure
The PPVT-4 Form B (PPVT-4; Dunn and Dunn 2007) was used as a measure of participants’ receptive language vocabulary, an important component of comprehension (Joshi 2005). The primary stimulus was a 2-min visual narrative (See “Appendices B and C” section), based on the Donald Duck cartoon shown to participants in Study 1. The narrative was told by an adult female unknown to participants and was recorded using a video camera. The narrator was filmed wearing the same clothes with the same hairstyles in all conditions to prevent variability. In the typical gesture condition the narrator produced a series of typical iconic gestures at specific points throughout the narrative (only commonly used gestures, performed by participants in Study 1, such as using both hands in a pumping motion to signify Donald Duck pumping a lever). It is notable that there were multiple different kinds of gestures produced without prompting to depict a single event in the cartoon in Study 1 (e.g., some participants made a pumping motion with one hand while other participants made the movement with both hands). The gestures selected for use in Study 2 were of the form produced most frequently by participants in Study 1. For example, a pumping gesture was made more frequently with two hands in Study 1 than a pumping gesture made with one hand, and thus two hands were used in Study 2 to produce the pumping gesture.
In contrast, in the atypical gesture condition the narrator produced a series of atypical iconic gestures at specific points throughout the narrative (gestures, which are not commonly produced, such as making the shape of a circular rosette ribbon with both hands and holding it up to represent first prize). These gestures were never produced by participants in Study 1, but could have been produced in response to watching the narrative. In other words, these were gestures that accurately reflected the speech content of the narrative, but while they could have been produced in the absence of instruction, they were at no point produced by participants in Study 1. Furthermore, it was ensured the atypical gestures took the same amount of time as the typical gestures, and still semantically depicted the same point.
Gestures were presented by the narrator at the same point in the narrative for both the typical and atypical gesture conditions; the only difference between the two conditions was in the nature of the gestures produced. This was such that the atypical version of the typical gesture was still produced on the exact same phrase in the narrative as the typical gesture, for the same amount of time, and both shared the same semantic meaning. The only difference between typical and atypical gestures was that typical gestures were produced without prompting during Study 1 while atypical gestures could have been produced but were not during Study 1. In each condition, a total of 10 gestures were produced at specific items in the narrative: participants in the typical condition viewed 10 typical gestures, while participants in the atypical condition viewed 10 atypical gestures. Participants in the no-gesture condition saw no gestures, and the narrator kept a still body.
The narrative contained 10 phrases that were accompanied by gestures in the typical and atypical gesture conditions (termed gesture items), and six phrases that were not accompanied by gestures in any of the three conditions (termed non-gesture items). In the case of the no-gesture group, they only received the information about the narrative through speech, but the gesture items were still asked, as they were simply questions about the same points in the narrative where typical atypical groups saw gestures. That is, participants did not have to see the gestures to answer such questions, given that the information presented through gesture was the same as that given through speech. This allowed for the investigation of whether observing gestures benefits narrative comprehension when presented in addition to speech, as opposed to when the narrative is presented through speech alone. The phrases associated with the gesture items and non-gesture items were also manipulated for word frequency, as outlined below. The narrator gestured on the phrase “water began spurting out straight into Donald Duck’s eye” in the high-frequency condition and gestured on the phrase “water began spurting out straight into Donald Duck’s oculus” in the low-frequency condition. However, the narrator did not gesture on the phrase “the water only dribbled out” in the low-frequency condition or on the phrase “the water only percolated out” in the high-frequency condition. The gestures were therefore produced on the same phrase regardless of whether it was a low-frequency or high-frequency verbal item. In addition, the narrative contained 47 non-manipulated phrases that were not manipulated for gesture or word frequency. These phrases served as a filler to ensure that the narrative flowed smoothly. In total, the narrative contained 63 phrases.
Each gesture and non-gesture item contained either a high-frequency word used or a low-frequency word, manipulated within-subjects. High-frequency words were those that are frequently spoken in the English language (e.g., nostrils), while low-frequency words were those that are infrequently spoken in the English language (e.g., nares), as determined by the English Lexicon Project (http://elexicon.wustl.edu). Low-frequency words had frequency ratings that were at least half those of the paired frequent word. For example, the high-frequency word “broke” had an associated frequency rating of 14,085, while the low-frequency word “disunited,” while having the same meaning as the frequent word broke, had an associated frequency rating of 36.
The 16 manipulated points were split into eight high-frequency and eight low-frequency phrases (See “Appendix D” section). Of these 16 phrases, five high-frequency words and five low-frequency words related to the gesture items, while three high-frequency words and three low-frequency words related to the non-gesture items. The phrases that contained high-frequency versus low-frequency words presented in the narrative were counterbalanced within each gesture condition. This was such that the narrative viewed by the participant either followed a high-low frequency order (See “Appendix B” section) or a low–high frequency order (See “Appendix C” section). For the high-low frequency order, the first gesture and non-gesture item presented included a high-frequency word while the second included a low-frequency word, and this pattern continued throughout the narrative. For the low–high frequency order, the first gesture and non-gesture item presented included a low-frequency word while the second included a high-frequency word, and this pattern continued throughout the narrative. Gestures were performed on the same words in all gesture conditions, with gesture and non-gesture items consistent across conditions. After viewing the narrative, participants completed the same join-the-dots filler task given to participants in Study 1.
After completing the join-the-dots task, participants were asked to recall the narrative (See “Appendix E” section), and were both audio-and visual-recorded during recall. The experimenter stated, “First, tell me everything that you can remember about the story that you saw earlier.” Once the free recall question had been answered, the experimenter stated, “Now I am going to ask you a few more questions about the story that you saw earlier. The questions I am going to ask will not necessarily be in the same order as what you saw in the video.” The free recall question always preceded the specific recall questions, to ensure that the content of the specific recall questions did not prompt the participant to recall certain aspects of the narrative during free recall.
The specific recall questions were asked in a random order for each participant as determined by a random number generator (http://www.randomizer.org/form.htm). For each question if the participant indicated an incorrect response a forced-choice follow up question was asked. Questions were repeated if the participant appeared distracted or confused, and if they did not know the answer they were reminded that guessing was okay. Finally, participants completed the PPVT-4.
Scoring
Prior to scoring, all speech and gesture content of the interviews was transcribed. Participant responses that correctly represented the speech content of the narrative were coded as correct. Participant responses that did not correctly represent the speech content of the narrative, as well as non-responses to specific questions were coded as incorrect. Correct and incorrect responses were split into categories. For free recall, correct and incorrect responses were sorted into the following five categories: high-frequency gesture items, low-frequency gesture items, high-frequency non-gesture items, low-frequency non-gesture items, and non-manipulated items. A correct response during free recall was given a score of 1, with the maximum score being 63, based on the 63 phrases in the narrative. The categories for specific questions mirrored those for free recall, with the exception that there were no specific questions on non-manipulated items from the narrative.
The gestures produced by participants during recall were then coded for meaning (i.e., whether the gesture represented the correct answer to a specific question) and contributed to the total recall score, together with any verbal response. If a participant verbally answered the initial open-ended question correctly, they received a score of 2 and the follow-up forced-choice question was not asked. If the participant did not accurately answer the open-ended question verbally, but represented the correct response through the use of gesture (e.g., if the participant stated that Donald Duck used a lever to get more water but performed a pumping gesture with their hands), they also received a score of 2 and the follow-up question was not asked. Similarly, if the participant answered the open-ended question accurately both verbally and through gesture, they received a score of 2.
If a participant incorrectly answered the open-ended question, then the follow-up forced-choice question was asked. If the follow-up forced choice question was answered correctly verbally, through the use of gesture, or through a combination of speech and gesture, the participant received a score of 1. If both the open-ended and follow-up forced-choice question were answered incorrectly, the participant received a score of zero for that particular question. As each question was scored out of 2, participants could receive a maximum score of 10 for high-frequency gesture items, 10 for low-frequency gesture items, 6 for high-frequency non-gesture items, and 6 for low-frequency non-gesture items.
Reliability
A second coder independently coded 20% of the total transcripts in order to assess inter-rater reliability for all verbal and gestural responses. Intra-class correlations (ICC) were obtained to evaluate reliability using an absolute agreement model. The single measure ICC is reported, as only the first coder’s scores were used in the final analyses. For free recall, ICC = .92, p < .0005, and for the specific follow-up questions, ICC = .98, p < .0005.
Results and Discussion
The effect of gesture condition and word frequency on comprehension of the narrative was examined for free recall of the gesture items. A 3 (condition; between subjects) × (2) (word frequency; within subjects) mixed design ANOVA was carried out, with total score on free recall of gesture items as the dependent variable. As predicted, averaged across word frequency there was a main effect of gesture condition, F(2, 127) = 4.11, p = .019, partial η2 = .06 (see Table 2). Free recall of the gesture points was significantly higher for the typical gesture condition than for the control condition, F(1, 127) = 8.18, p = .005, partial η2 = .06.
Averaged across gesture condition, there was a main effect of word frequency, F(1, 127) = 4.55, p = .035, partial η2 = .04, such that participants performed significantly better when recalling high-frequency points from the narrative than when recalling low-frequency points from the narrative. The remaining main effect and interaction were non-significant.
The effect of gesture condition and word frequency on comprehension of gesture items was examined for the specific questions that related to gesture items in the narrative. A 3 (condition) × (2) (word frequency) mixed design ANOVA was carried out, with total score on questions relating to gesture items as the dependent variable. Averaged across word frequency, there was a main effect of gesture condition, F(2, 127) = 8.84, p < .0005, partial η2 = .12 (see Table 2). Recall on gesture items was significantly higher for the typical gesture condition than for both the control condition, F(1, 127) = 13.79, p < .0005, partial η2 = .18, and the atypical gesture condition, F(1, 127) = 12.67, p = .001, partial η2 = .17.
Averaged across condition, the results showed a main effect of word frequency, F(1, 127) = 5.55, p = .020, partial η2 = .04, such that participants performed significantly better when recalling high-frequency points from the narrative than when recalling low-frequency points from the narrative. The interaction was not significant.
Participants learned more from typical than atypical gestures, suggesting the two types of gestures differ qualitatively, with correspondingly different effects on learning. Study 2 provides evidence that typical, frequently produced iconic gestures are more beneficial to narrative comprehension than atypical, infrequently produced iconic gestures. In contrast, there was no significant difference in recall between the atypical gesture and control conditions, suggesting that observing atypical gestures is no better than observing no gestures at all.
While there is much discussion of the benefits of observing iconic gestures in the literature (e.g., Macoun and Sweller 2016; McNeil et al. 2000), this is the first study to examine whether certain iconic hand gestures are more beneficial to narrative comprehension than others. Study 2 thus suggests that if appropriate typical and atypical gestures can be defined, such gestures may have differential effects on other aspects of learning, such as problem solving.
General Discussion
Researchers frequently treat iconic gestures as a homogenous group. However, we now have good evidence suggesting that iconic gestures are not necessarily equivalent—there may be subtypes within iconic gestures that have differential impacts on learning. These results have important implications for gesture research: if participants are to observe gestures, simply stating that they viewed iconic gestures is insufficient.
Through observing the gestures that children and adults produced while retelling a narrative, Study 1 allowed us to identify frequently occurring iconic gestures that may be more beneficial to learning than iconic gestures that are seldom produced. In Study 2 the effects of these typical iconic gestures on narrative comprehension were compared with the effects of atypical gestures. Participants who observed typical gestures performed significantly better than participants who observed atypical gestures or no gestures. These results not only suggest that typical gestures benefit narrative comprehension to a greater extent than atypical gestures, but also that there are different subtypes of gestures that have differential impacts on learning within the category of iconic gestures.
It is likely, however, that atypical gestures represented a unique situation in Study 2. During an everyday conversation, for example, a speaker might use the occasional unexpected novel gesture, but would be unlikely to use them consistently in the one conversation. It could also be possible that the atypical gestures do not represent the actions as well as the typical ones do. If so, it could be that there is a difference in the semantic relatedness of the gestures in relation to the content of associated speech, and not just typicality. This is such that it is possible that typical gestures are more beneficial than atypical gestures as they are more semantically related to the accompanying speech and are therefore processed at a deeper level than atypical gestures leading to greater recall (Woodall and Folger 1981).
The difference found could also be related to cognitive load, with typical gestures placing a lower load on one’s working memory capacity than atypical gestures. Cognitive Load Theory (CLT) emphasises how information should be presented to learners in order to foster learning, noting that the number of elements that have to be simultaneously processed by a learner’s working memory reflects the complexity of the task at hand (Castro-Alonso et al. 2014; Marcus et al. 2013; Sweller et al. 1998). When a learner’s working memory capacity is surpassed by the cognitive load of a given task, the ability to learn decreases. It is possible that viewing atypical gestures was more demanding, subsequently increasing the load placed on working memory and consequently making it harder for participants to comprehend the given narrative. However, in the absence of any direct measures of cognitive load the above studies cannot determine whether this was indeed the case, providing an avenue for future research to explore.
It is notable that an interaction between word-frequency and condition was predicted, such that the difference between recall of low-frequency and high-frequency points in the narrative would be smaller for the gesture conditions compared to the control condition, and smaller again for the typical gesture condition compared to the atypical gesture condition. However, the interaction between word-frequency and condition was not significant either for free recall or for the specific follow-up questions. It is possible that this lack of an interaction effect was due to the nature of the word-frequency manipulation employed in Study 2. Given a low-frequency word is simply one that a learner is less familiar with it may not have been an adequate way of increasing the overall complexity of the narrative enough for the gestures to differentially take effect. In future, other methods of increasing task complexity could be explored such as through increasing the cognitive load placed on working memory while watching the narrative through having participants complete a secondary task. Such a manipulation could make the narrative complex enough that the gestures have the potential to be more beneficial than when a low-load is placed on working memory.
Regardless, it could be that the conflicting results of past research investigating the beneficial role of iconic gestures in learning stems from the kind of iconic gestures chosen for a given study. As a result, the results of the above studies have implications for future experimental designs. For example, when choosing gestures to accompany a comprehension task, care should be taken to articulate how the gestures were designed and whether they reflect typical gestures produced by speakers. Furthermore, the results of the abovementioned studies open the door for addressing questions about clinical populations, such as those with Autism Spectrum Disorder or other developmental disabilities, and whether their gesture production deviates from the norm or whether their ability to understand typical gestures better than atypical might also deviate.
Through the above studies, we investigated the effect of observing two forms of iconic hand gestures on narrative comprehension. While typical gestures were beneficial to narrative comprehension, atypical gestures were not beneficial on any measures of recall. These results suggest that not all gestures are equal: those we produce frequently are of the greatest benefit, while other, less frequently occurring gestures may be no better than viewing no gestures at all. While research has previously split gestures into categories such as iconic, deictic, metaphoric, and beat gestures and noted the benefits of each for learning, this study is the first to distinguish between iconic gestures that may be produced frequently without prompting by speakers, and gestures that are seldom produced in the absence of instruction.
References
Alibali, M. W., & DiRusso, A. (1999). The function of gesture in learning to count: More than keeping track. Cognitive Development, 14, 37–56. https://doi.org/10.1016/S0885-2014(99)80017-3.
Arbib, M. A., Liebal, K., & Pika, S. (2008). Primate vocalization, gesture, and the evolution of human language. Current Anthropology, 49, 1053–1076. https://doi.org/10.1086/593015.
Austin, E. E., & Sweller, N. (2018). Gesturing along the way: Adults’ and preschoolers’ communication of route direction information. Journal of Nonverbal Behavior, 42, 199–220. https://doi.org/10.1007/s10919-017-0271-2.
Beattie, G., & Shovelton, H. (1999). Mapping the range of information contained in the iconic hand gestures that accompany spontaneous speech. Journal of Language and Social Psychology, 18, 438–462. https://doi.org/10.1177/0261927X99018004005.
Cassell, J., McNeill, D., & Mccullough, K. (1999). Speech-gesture mismatches: Evidence for one underlying representation of linguistic and nonlinguistic information. Pragmatics and Cognition, 7, 1–34. https://doi.org/10.1075/pc.7.1.03cas.
Castro-Alonso, J. C., Ayres, P., & Paas, F. (2014). Learning from observing hands in static and animated versions of non-manipulative tasks. Learning and Instruction, 34, 11–21. https://doi.org/10.1016/j.learninstruc.2014.07.005.
Chu, M., & Kita, S. (2011). The nature of gestures’ beneficial role in spatial problem-solving. Journal of Experimental Psychology: General, 140, 102–116. https://doi.org/10.1037/a0021790.
Craik, F. I., & Lockhart, R. S. (1972). Levels of processing: A framework for memory research. Journal of Verbal Learning and Verbal Behavior, 11, 671–684. https://doi.org/10.1016/S0022-5371(72)80001-X.
Craik, F. I., & Tulving, E. (1975). Depth of processing and the retention of words in episodic memory. Journal of Experimental Psychology: General, 104, 268–294. https://doi.org/10.1037//0096-3445.104.3.268.
Cutica, I., & Bucciarelli, M. (2008). The deep versus the shallow: Effects of co-speech gestures in learning from discourse. Cognitive Science: A Multidisciplinary Journal, 32, 921–935. https://doi.org/10.1080/03640210802222039.
Driskell, J. E., & Radtke, P. H. (2003). The effect of gesture on speech production and comprehension. Human Factors, 45, 445–454. https://doi.org/10.1518/hfes.45.3.445.27258.
Dunn, L. M., & Dunn, D. M. (2007). Peabody picture vocabulary test (4th ed.). Minneapolis, MN: NCS Pearson, Inc.
Galati, A., & Samuel, A. G. (2011). The role of speech-gesture congruency and delay in remembering action events. Language and Cognitive Processes, 26, 406–436. https://doi.org/10.1080/01690965.2010.494846.
Holle, H., Gunter, T. C., Rüschemeyer, S., Hennenlotter, A., & Iacoboni, M. (2008). Neural correlates of the processing of co-speech gestures. NeuroImage, 39, 2010–2024. https://doi.org/10.1016/j.neuroimage.2007.10.055.
Hough, M. S. (1990). Narrative comprehension in adults with right and left hemisphere brain-damage: Theme organisation. Brain and Language, 38, 253–277. https://doi.org/10.1016/0093-934X(90)90114-V.
Hubbard, A. L., Wilson, S. M., Callan, D. E., & Dapretto, M. (2009). Giving speech a hand: Gesture modulates activity in auditory cortex during speech perception. Human Brain Mapping, 30, 1028–1037. https://doi.org/10.1002/hbm.20565.
Joshi, R. M. (2005). Vocabulary: A critical component of comprehension. Reading and Writing Quarterly, 21, 209–219. https://doi.org/10.1080/10573560590949278.
Kelly, S. D., Barr, D. J., Church, R. B., & Lynch, K. (1999). Offering a hand to pragmatic understanding: The role of speech and gesture in comprehension and memory. Journal of Memory and Language, 40, 577–592. https://doi.org/10.1006/jmla.1999.2634.
Kelly, S. D., & Church, R. B. (1998). A comparison between children’s and adults’ ability to detect conceptual information conveyed through representational gestures. Child Development, 69, 85–93. https://doi.org/10.1111/j.1467-8624.1998.tb06135.x.
Kelly, S. D., Creigh, P., & Bartolotti, J. (2010). Integrating speech and iconic gestures in a stroop-like task: Evidence for automatic processing. Journal of Cognitive Neuroscience, 22, 683–694. https://doi.org/10.1162/jocn.2009.21254.
Littlejohn, S. W., & Foss, K. A. (2010). Theories of human communication (10th ed.). Long Grove: Waveland Press Inc.
Lyle, S. (2000). Narrative understanding: Developing a theoretical context for understanding how children make meaning in classroom settings. Journal of Curriculum Studies, 32(1), 45–63. Retrieved from http://web.a.ebscohost.com/ehost/pdfviewer/pdfviewer?sid = 82648f15-d783-4bac-b0dc-1828b792a9d5%40sessionmgr4003&vid = 1&hid = 4214.
Macoun, A., & Sweller, N. (2016). Listening and watching: The effects of observing gesture on narrative comprehension. Cognitive Development, 40, 68–81. https://doi.org/10.1016/j.cogdev.2016.08.005.
Marcus, N., Cleary, B., Wong, A., & Ayres, P. (2013). Should hand actions be observed when learning hand motor skills from instructional animations? Computers in Human Behavior, 29, 2172–2178. https://doi.org/10.1016/j.chb.2013.04.035.
McNeill, D. (1992). Hand and mind: What gestures reveal about thought. Chicago: The University of Chicago Press.
McNeil, N. M., Alibali, A. W., & Evans, J. L. (2000). The role of gesture in children’s comprehension of spoken language: Now they need it, now they don’t. Journal of Nonverbal Behaviour, 24, 131–150. https://doi.org/10.1023/A:1006657929803.
Paris, A. H., & Paris, S. G. (2003). Assessing narrative comprehension in young children. International Reading Association, 38, 36–76. https://doi.org/10.1598/RRQ.38.1.3.
Schmithorst, V. J., Holland, S. K., & Plante, E. (2006). Cognitive modules utilized for narrative comprehension in children: A functional magnetic resonance imaging study. NeuroImage, 29, 254–266. https://doi.org/10.1016/j.neuroimage.2005,07.020.
Stevanoni, E., & Salmon, K. (2005). Giving memory a hand: Instructing children to gesture enhances their event recall. Journal of Nonverbal Behaviour, 29, 217–233. https://doi.org/10.1007/s10919-005-7721-y.
Sweller, J., van Merrienboer, J. J. G., & Paas, F. (1998). Cognitive architecture and instructional design. Educational Psychology Review, 10, 251–296. https://doi.org/10.1023/A:1022193728205.
Willems, R. M., Özyürek, A., & Hagoort, P. (2006). When language meets action: The neural integration of gesture and speech. Cerebral Cortex, 17, 2322–2333. https://doi.org/10.1093/cercor/bhl141.
Woodall, W. G., & Folger, J. P. (1981). Encoding specificity and nonverbal cue context: An expansion of episodic memory research. Communication Monographs, 48, 39–53. https://doi.org/10.1080/03637758109376046.
Acknowledgements
Warmest thanks to Laura Eason for narration of the task, and to Alessandra Teunisse and Elizabeth Austin for double-coding the data. This research did not receive any specific grant from funding agencies in the public, commercial, or not-for-profit sectors.
Author information
Authors and Affiliations
Contributions
Nicole Dargue and Naomi Sweller were jointly involved in conceptualising the design of the abovementioned studies. Nicole carried out all data collection and analysis. Both authors approve of the final manuscript.
Corresponding author
Ethics declarations
Conflict of interest
The authors declare that they have no conflict of interest.
Human and Animal Rights
All procedures performed in studies involving human participants were in accordance with the ethical standards of the institutional and/or national research committee and with the 1964 Helsinki declaration and its later amendments or comparable ethical standards. Furthermore, informed consent was obtained from all individual participants included in the study.
Appendices
Appendix A: Study 1 Interview Script
Now I’m going to ask you a few questions about the video you saw earlier. I want you to try to remember as much as you can about it.
Spontaneous Gesture Condition
-
1.
Tell me everything that happened in the video that you just saw.
-
2.
Tell me everything Donald duck did in the video.
-
3.
Tell me everything Donald duck saw in the video.
-
4.
Is there anything else you can remember about the video?
Instructed Gesture Condition
-
1.
Show me and tell me everything that happened in the video that you just saw. Show me as you tell me using your hands.
-
2.
Show me and tell me everything Donald duck did in the video. Show me as you tell me using your hands.
-
3.
Show me and tell me everything Donald duck saw in the video. Show me as you tell me using your hands.
-
4.
Is there anything else you can remember about the video?
Appendix B: Study 2 Narrative Gesture and Non-gesture Points (High-Low Version)
Gesture points are in bold; Non-gesture points are in italics.
Donald’s Garden
Donald Duck had a garden full of watermelons and one of them had won first prize at a local fair. While watering his garden, Donald Duck noticed that he had run out of water, so he skipped over to a water station to refill his bucket.
When Donald Duck first siphoned water out using the lever, the water did not fill up the bucket because the water only percolated out. When Donald Duck tried to use the lever again, the water came out too far. This frustrated Donald because he could not seem to fill up his bucket with water.
After using the lever again, the water finally went into the bucket. However, the water kept emanating out of the water station and pushed the bucket over to a ledge, where it began to tilt back and forth. Donald rushed over to the ledge to try and stop the bucket from falling, but it was too late. The bucket had fallen off the ledge, spilling all of the water onto the ground.
Donald Duck hoisted up the bucket and took it back to the water station. This time, Donald Duck moved the lever up and down so fast that the water station began to expand but only a drop of water came out. Donald duck looked into the tap to see why the water was not coming out, and all of a sudden, water began spurting out straight into Donald duck’s oculus.
Donald Duck then moved the lever up and down as fast as it could go. A stream of water spurted out, but it kept moving back and forth out of Donald Duck’s reach as he chased it with his bucket. He continued to chase the water all the way back to the water station, but he ran so fast that his nose got stuck in the nozzle and water burst out of his nares. Donald Duck slammed the bucket down in front of the water station and moved the lever up and down once more. The pressure in the water station built up so much that water came blasting out which caused Donald Duck to get pushed up.
When Donald Duck landed back on the ground he noticed that his bucket had been filled up with water. As he went to get it, the bucket disunited, leaving the water sitting there in the shape of a bucket. Donald Duck watched as the water burst. He looked down at the puddle quacking angrily, and watched as the water slowly evanesced into a hole in the ground.
Appendix C: Study 2 Narrative Gesture and Non-gesture Points (Low–High Version)
Gesture points are in bold; Non-gesture points are in italics.
Donald’s Garden
Donald Duck had a garden full of watermelons and one of them had won the highest laurel at a local fair. While watering his garden, Donald Duck noticed that he had run out of water, so he capered over to a water station to refill his bucket.
When Donald Duck first pumped water out using the lever, the water did not fill up the bucket because the water only dribbled out. When Donald Duck tried to use the lever again, the water came out too far. This embittered Donald because he could not seem to fill up his bucket with water.
After using the lever again, the water finally went into the bucket. However, the water kept spurting out of the water station and pushed the bucket over to a ledge, where it began to teeter back and forth. Donald rushed over to the ledge to try and stop the bucket from falling, but it was too late. The bucket had fallen off the ledge, spilling all of the water onto the ground.
Donald Duck picked up the bucket and took it back to the water station. This time, Donald Duck moved the lever up and down so fast that the water station began to distend but only a drop of water came out. Donald duck looked into the tap to see why the water was not coming out, and all of a sudden, water began spurting out straight into Donald duck’s eye.
Donald Duck then moved the lever up and down as fast as it could go. A stream of water spurted out, but it kept vacillating back and forth out of Donald Duck’s reach as he chased it with his bucket. He continued to chase the water all the way back to the water station, but he ran so fast that his snuffer got stuck in the nozzle and water burst out of his nostrils. Donald Duck slammed the bucket down in front of the water station and moved the lever up and down once more. The pressure in the water station built up so much that water came blasting out which caused Donald Duck to get levitated up.
When Donald Duck landed back on the ground he noticed that his bucket had been filled up with water. As he went to get it, the bucket broke, leaving the water sitting there in the shape of a bucket. Donald Duck watched as the water burst. He looked down at the puddle quacking angrily, and watched as the water slowly disappeared into a hole in the ground.
Appendix D: Study 2 High-Frequency and Low-Frequency Words
High-frequency words | Low-frequency words |
|---|---|
First | Highest laurel |
Pumped | Siphoned |
Tilt | Teeter |
Picked up | Hoisted up |
Expand | Distend |
Eye | Oculus |
Moving back and forth | Vacillating |
Nostrils | Nares |
Pushed up | Levitated |
Broke | Disunited |
Skipped | Capered |
Dribbled | Percolated |
Frustrated | Embittered |
Spurting | Emanating |
Nose | Snuffer |
Disappeared | Evanesced |
Appendix E: Study 2 Interview Script
Now I am going to ask you some questions about the video that you saw on the computer earlier. If you don’t know the answers you can just guess ok?
Free Recall Question: First, tell me everything you remember about the story you saw earlier.
Now I am going to ask you a few more questions about the video. The questions I am going to ask won’t necessarily be in the same order as what you saw in the video.
Specific Questions:
-
1.
What caused the bucket to move towards the ledge?
-
a.
Did the water spurt out and push the bucket towards the ledge or did Donald Duck place the bucket on the ledge?
-
a.
-
2.
What happened the first time Donald Duck tried to refill the bucket?
-
a.
Did the water dribble out or go too far the first time Donald Duck tried to refill the bucket?
-
a.
-
3.
How did Donald Duck feel when the water wasn’t going into the bucket?
-
a.
Did Donald Duck feel sad or frustrated?
-
a.
-
4.
What happened to Donald Duck’s beak?
-
a.
Did Donald Duck’s beak get stuck in the water station or did he get squirt by the water in his beak?
-
a.
-
5.
Where did the water go in the end?
-
a.
Did the water stay in the bucket or did it disappear into a hole in the ground?
-
a.
-
6.
How did Donald Duck initially make his way over to the water station?
-
a.
Did Donald Duck skip or run to the water station initially?
-
a.
-
7.
What place did Donald Duck win at the fair?
-
a.
Did Donald Duck win first prize or runner up?
-
a.
-
8.
What was Donald Duck doing to get the water into the bucket?
-
a.
Was Donald Duck pumping or turning on a tap to get the water into the bucket?
-
a.
-
9.
What happened to the bucket when it was on the ledge?
-
a.
Did the bucket wobble or fall straight off the side?
-
a.
-
10.
What did Donald duck do after the bucket fell over?
-
a.
Did Donald Duck pick up the bucket or leave it on the ground?
-
a.
-
11.
What happened to the water station when Donald Duck was moving the lever up and down really fast?
-
a.
Did the water station start to expand or explode when Donald Duck was moving the lever up and down really fast?
-
a.
-
12.
Where did the water squirt Donald Duck?
-
a.
Did the water squirt Donald Duck in the eye or in his mouth?
-
a.
-
13.
What did the water keep doing when Donald Duck kept trying to fill up his bucket?
-
a.
Did the water go into the bucket each time or did the water keep moving back and forth out of Donald Ducks reach?
-
a.
-
14.
Where did the water come out of Donald Duck?
-
a.
Did the water burst out of Donald Duck’s nostrils or ears?
-
a.
-
15.
Where did the water push Donald Duck?
-
a.
Did the water push Donald Duck up into the sky or down to the ground?
-
a.
-
16.
What happened to the bucket in the end?
-
a.
Did the bucket break or did Donald Duck use it to go and water his garden?
-
a.
Rights and permissions
About this article

Cite this article
Dargue, N., Sweller, N. Not All Gestures are Created Equal: The Effects of Typical and Atypical Iconic Gestures on Narrative Comprehension. J Nonverbal Behav 42, 327–345 (2018). https://doi.org/10.1007/s10919-018-0278-3
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10919-018-0278-3