
Abstract
In this work the development of a machine learning-based Reduced Order Model (ROM) for the investigation of hemodynamics in a patient-specific configuration of Coronary Artery Bypass Graft (CABG) is proposed. The computational domain is referred to left branches of coronary arteries when a stenosis of the Left Main Coronary Artery (LMCA) occurs. The method extracts a reduced basis space from a collection of high-fidelity solutions via a Proper Orthogonal Decomposition (POD) algorithm and employs Artificial Neural Networks (ANNs) for the computation of the modal coefficients. The Full Order Model (FOM) is represented by the incompressible Navier-Stokes equations discretized using a Finite Volume (FV) technique. Both physical and geometrical parametrization are taken into account, the former one related to the inlet flow rate and the latter one related to the stenosis severity. With respect to the previous works focused on the development of a ROM framework for the evaluation of coronary artery disease, the novelties of our study include the use of the FV method in a patient-specific configuration, the use of a data-driven ROM technique and the mesh deformation strategy based on a Free Form Deformation (FFD) technique. The performance of our ROM approach is analyzed in terms of the error between full order and reduced order solutions as well as the speed-up achieved at the online stage.
Similar content being viewed by others

Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction and Motivation
Coronary artery diseases is one of the main causes of death worldwide. When they occur, one or more coronary arteries are occluded causing a poor perfusion of oxygen-rich blood to the heart, leading to clinical complications such as heart attack and heart failure. Coronary Artery Bypass Grafts (CABGs) surgery is still one of the most used procedures worldwide, although after some years blood supply often fails again, causing the need for reintervention. Many papers [1,2,3,4,5,6] study different CABG configurations in order to establish a good clinical treatment, especially in term of mid-long survival. However an isolated stenosis of the main trunk is rare, and there is not a sample of consolidated studies which allow to establish the most appropriate procedure to perform in this case.
Computational Fluid Dynamics (CFD) applied to the cardiovascular system [7] represents a research area of significant importance and in recent times it had a strong impulse due to the increasing demand from the medical community for quantitative investigations of cardiovascular diseases. For the problem at hand, a better understanding of the blood flow behaviour in grafts and graft junctions could aid in surgical planning of grafting and improve the lifetime of grafts.
High-fidelity numerical methods, among which Finite Element (FE) and Finite Volume (FV) methods, often referred to as Full Order Models (FOMs), are commonly used for the solution of parameterized Navier-Stokes equations governing the blood flow dynamics, where the parameters are geometric features, boundary conditions and/or physical properties. However, for applications which require repeated model evaluations over a range of parameter values, FOMs are very expensive in terms of computational time and memory demand due to the large amount of degrees of freedom to be considered for a proper description of the flow system. In such a framework, Reduced Order Models (ROMs) [8,9,10,11,12,13,14,15] are applied to enable fast computations varying the parameters, as often required in the clinical context [16,17,18,19,20,21,22,23,24].
A further step forward in this scenario has been given by the development and diffusion of intelligent technologies. Many recent works use machine learning as an alternative to CFD simulations in order to reproduce hemodynamic parameters [25,26,27,28,29]. In all these works, CFD, that is used to compute the data set for training and testing, is seen as a black box whilst the machine learning algorithms are used to detect a nonlinear manifold that maps CFD inputs to their corresponding outputs of interest. Neural networks can in theory represent any functional relationship between inputs and outputs. However, many applications remain unexplored and this reinforces the need to carry out further studies in this area.
The main goal of this work is to propose a partnership between neural networks, ROM and CFD with the aim to lower the computational cost of the numerical simulations and at the same time to provide accurate predictions of the blood flow behaviour. In particular, the Proper Orthogonal Decomposition-Artificial Neural Network (POD-ANN) method [30, 31], where the POD is employed for the computation of the reduced basis and feedforward ANNs are adopted for the evaluation of the modal coefficients, is used to reconstruct in a fast and reliable way both primal variables (pressure and velocity) and derived quantities (the Wall Shear Stress (WSS)). The method is applied to the investigation of hemodynamics in a CABG patient-specific configuration when an isolated stenosis of the Left Main Coronary Artery (LMCA) occurs at varying of the inlet boundary conditions and of the severity of the stenosis. So we extend what has been done in [32] for the time reconstruction to a physical and geometrical parametric setting. The POD-ANN method has been successfully used in several application fields ranging between automotive [33], casting [34] and combustion [31].
With respect to the previous investigations focused on the development of a ROM framework for the evaluation of coronary artery disease, the novelties of our investigation include:
-
The use of the FV method in a patient-specific framework indeed, although the FV method is also adopted in [35], the geometric database used consists of idealized geometries, i.e. obtained from the deformation of a three-dimensional straight pipe by means of a discrete empirical interpolation method (DEIM). Other recent works, e.g. [36, 37], employ the FV method for the development of ROMs for hemodynamic applications but its adoption in this environment is still rather unexplored, so this work contributes to fill this gap. In addition many commercial codes widely used from bioengineering community are based on FV schemes, therefore the combination of ROM and FV methods is particularly appealing in this field.
-
The use of a data-driven ROM technique in all the previous works [16, 18, 23, 35], a standard POD-Galerkin method is adopted. Data-driven approaches are based only on data and do not require knowledge about the governing equations that describe the system. They are also non-intrusive, i.e. no modification of the simulation software is carried out. Typically data-driven methods are able to provide a computational speed-up larger than classic projection-based methods [36,37,38,39,40,41], so they are to be preferred by allowing real time simulations to be accessed in hospitals and operating rooms in a more efficient way.
-
The mesh deformation strategy in [16, 18], a centerlines-based parametrization is introduced to efficiently handle geometrical variations for a wide range of patient-specific configurations of CABGs in a FE environment. This method allows an efficient variation of geometrical quantities of interest, such as stenosis severity. However it is hardly compatible with the FV formulation of the governing equations that is not written in a reference domain setting. Conversely, the Free Form Deformation (FFD) allows to act directly on the mesh. Another mesh deformation strategy consistent with the FV approximation is introduced in [42]: while our approach uses a Non-Uniform Rational Basis Spline (NURBS) parameterization, [42] is based on a Radial Basis Function (RBF) approach. However, while RBF approach deforms the grid as a whole and therefore it does not preserve the original geometry, in the NURBS strategy all the vertices remains on the initial surface.
The rest of the paper is structured as follows. In Sect. 2, the computational domain as well as Navier-Stokes equations, representing our FOM, are introduced. Section 3 presents our ROM approach. Then the numerical results are reported in Sect. 4. Finally, in Sect. 5 we draw conclusions and discuss future perspectives of the current study.
2 The Full Order Model
2.1 The Computational Domain
The virtual geometry related to the CABG configuration at hand is shown in Fig. 1a. The model includes, beyond the LMCA, the Left Internal Thoracic Artery (LITA), the Left Anterior Descending Artery (LAD) and the Left Circumflex artery (LCx).

Three-dimensional reconstruction of the CABG (a) and view of the mesh on an internal section (b)
The patient-specific Computed Tomography (CT)–scan data, from which the virtual geometry has been obtained by using the procedure explained in [16], have been provided by Ospedale Luigi Sacco in Milan. The mesh, displayed in Fig. 1b, has been built by using the mesh generation utility snappyHexMesh available in OpenFOAM® (www.openfoam.org). Its features are shown in Table 1.
To introduce different severity of stenosis in the LMCA in a way that is compatible with the data-driven reduced order model which will be introduced next it is important to warp directly the mesh and not just the geometry, so that the same number of cells is present in all the deformed configurations. At this aim, FFD is performed by means of a NURBS volumetric parameterization [43]. The procedure consists of three main steps [44, 45]:
-
(i) A parametric lattice of control points is constructed by means of a structured mesh placed around the region of the LMCA to be deformed. Then the control points are used to define a NURBS volume which contains the LMCA portion to be warped.
-
(ii) The octree algorithm [44] can be used to find a matching between the control points of the lattice and the points of the computational domain:
-
1.
The parametric lattice is divided in eight subvolumes;
-
2.
The coordinates of the vertices of each subvolume are compared against the coordinates of the portion of LMCA under consideration. This allows to identify the subvolume in which the computational domain is embedded;
-
3.
The subvolumes are again divided and the procedure is repeated until a desirable accuracy is achieved.
-
1.
-
(iii) The coordinates of the control points are modified, so that the parametric volume and consequently the LMCA portion are deformed.

Introduction of the stenosis in the LMCA using FFD technique
In Fig. 2a the lattice and the LMCA region where the stenosis is introduced are illustrated in their initial configurations, whilst in Fig. 2b and c the deformed lattice and a \(50\%\) stenosis are displayed, respectively.
Finally we highlight that the introduction of the stenosis in the LMCA does not significantly affect the mesh quality.
2.2 The Navier–Stokes Equations
Let us consider the dynamics of the blood flow in a patient-specific domain
\(\Omega (\varvec{\mu }) \subset {\mathbb {R}}^3\) over a cardiac cycle (0, T], when the transient effects are passed:
in \(\Omega (\varvec{\mu }) \times (0,T]\), where \(\rho \) is the density, \({\textbf{u}}\) is the velocity, \(\partial _t\) denotes the time derivative and \({\mathbb {T}}\) is the Cauchy stress tensor. The vector \(\varvec{\mu } \in {\mathcal {P}} \subset {\mathbb {R}}^d\) represents a parameter vector in a d-dimensional parameter space \({\mathcal {P}}\) containing both physical and geometrical parameters of the problem. For the sake of simplicity, from now on the dependance of the variables on \(\varvec{x}\), t, and \(\varvec{\mu }\) will be omitted.
In this work, we model the blood as a Newtonian fluid, so the constitutive relation for \({\mathbb {T}}\) is given by
where p is the pressure, \(\mu \) is the dynamic viscosity and \(\mathbb {D({\textbf{u}})}=\frac{\nabla {\textbf{u}} + \nabla {\textbf{u}} ^T}{2}\) is the strain rate tensor. By using equation (2), the system (1) can be rewritten as
in \(\Omega \times (0,T]\), where \(P=\frac{p}{\rho }\) is the kinematic pressure, i.e. the pressure divided by the density, and \(\nu =\frac{\mu }{\rho }\) is the kinematic viscosity.
We also introduce the WSS defined as follows:
on \(\partial \Omega \), where \(\tau = \nu (\nabla {\textbf{u}} + \nabla {\textbf{u}}^T)\) is the stress tensor and \({\textbf{n}}_w\) is the unit normal outward vector to \(\partial \Omega \).
Finally, in order to characterize the flow regime under consideration, we define the Reynolds number as
where U and L are characteristic macroscopic velocity and length, respectively. For a blood flow in a cylindrical vessel, U is the mean sectional velocity and L is the diameter.
2.3 Boundary Conditions
The boundary \(\partial \Omega \) of our computational domain consists of:
-
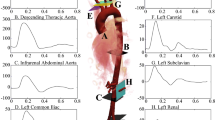
two inflow, the LMCA and the LITA sections. We consider a realistic flow rate waveform [46, 47]:
$$\begin{aligned} q_i(t)=f^i{\bar{q}}_i(t), \quad \quad i=\text {LMCA},\text {LITA}, \end{aligned}$$(6)where \(f^i \in \left[ \frac{2}{3}, \frac{4}{3} \right] \) (see [46,47,48]). The functions \({\bar{q}}_i(t)\) are represented in Fig. 3. Moreover, since the stenosis severity influences the inlet flow, in order to enforce more realistic inflow conditions, it is relevant to scale flow rates as follows:
$$\begin{aligned} {\bar{Q}}_{\text {LMCA}}^{\text {healthy}}={\bar{Q}}_{\text {LMCA}}^{\text {stenosis}} +{\bar{Q}}_{\text {LITA}}^{\text {stenosis}} =G{\bar{Q}}_{\text {LMCA}}^{\text {healthy}}+C{\bar{Q}}_{\text {LITA}}^{\text {healthy}}, \end{aligned}$$(7)where \({\bar{Q}}_i^{\text {healthy}}=\frac{1}{T}\int _0^T f^i{\bar{q}}_i(t)\, dt\), G scales as the square of the stenosis severity diameter, and C is consequently computed. Then, the inflow boundary conditions are given by:
$$\begin{aligned} q_{\text {LMCA}}(t)=G f^{\text {LMCA}}{\bar{q}}_{\text {LMCA}}(t), \quad q_{\text {LITA}}(t)=C f^{\text {LITA}}{\bar{q}}_{\text {LITA}}(t); \end{aligned}$$(8) -
the vessel wall, on which we enforce a no slip condition;
-
two outflow, the LAD and LCx sections, on which we enforce homogeneous Neumann boundary conditions. We highlight that it would be necessary to set outlet boundary conditions able to capture as much as possible the physiology of vascular networks outside of the domain of the model (see, e.g., [23, 24, 36, 37]. However such treatment is out of scope of this work and will be taken into account in a future contribution.

2.4 Time and Space Discretization
To discretize in time the problem (3), let us consider a time step \(\Delta t \in {\mathbb {R}}^+\) such that \(t^n=n \Delta t\), \(n=0,1,\ldots , N_t\) and \(T = N_t \Delta t\). Let \(({\textbf{u}}^n,P^n)\) be the approximations of the velocity and the pressure at time \(t^n\). We adopt a Backward Differentiation Formula of order 2 (BDF2):
where \({\textbf{b}}^{n+1}=\frac{4{\textbf{u}}^n-{\textbf{u}}^{n-1}}{2\Delta t}\).
Concerning the space discretization of the problem (9), we adopt a FV method within the C++ library OpenFOAM®. The computational domain \(\Omega \) is discretized into \(N_h\) non-overlapping control volumes \(\Omega _i\) with \(i = 1,\dots , N_h\). Let \({\textbf{A}}_j\) be the surface vector of each face j of the control volume \(\Omega _i\). Then the fully discretized form of problem (3) is given by
where \(\phi _j = {\textbf{u}}_j^{n} \cdot {\textbf{A}}_j\) is the convective flux associated to \({\textbf{u}}^{n}\) through face j of the control volume \(\Omega _i\), \({\textbf{u}}_{i,j}^{n+1}\) and \(P_{i,j}^{n+1}\) indicate the velocity and pressure associated to the centroid of face j normalized with respect to \(\Omega _i\), and \({\textbf{u}}_i^{n+1}\) and \({\textbf{b}}_i^{n+1}\) are the average velocity and the source term in the control volume \(\Omega _i\).
3 The Reduced Order Model
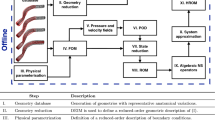
In this work we use the POD-ANN method consisting of the following stages:
-
Offline: a reduced basis space is built by applying POD to a database of high-fidelity solutions obtained by solving the FOM for different values of physical and/or geometrical parameters. Once the reduced basis space is computed, we project the original snapshots onto such a space by obtaining the corresponding parameter dependent modal coefficients. Then the training of the neural networks to approximate the map between parameters and modal coefficients is carried out. This stage is computationally expensive, however it only needs to be performed once.
-
Online: for any new parameter value, we approximate the new coefficients by using the trained neural network and the reduced solution is obtained as a linear combination of the POD basis functions multiplied by modal coefficients. During this stage, it is possible to explore the parameter space at a significantly reduced cost.
The following flowchart demonstrates the process of the proposed machine learning-based ROM.

3.1 The Proper Orthogonal Decomposition
The POD is one of the most widely-used techniques to compress data and extract an optimal set of orthonormal basis in the least-squares sense. There are two main strategies for the construction of the reduced basis: greedy algorithms [30, 52] and the POD method. The former allows to minimize the number of snapshots to be computed. However, a major drawback of greedy algorithms is that they are based on an a posteriori estimate of the projection error, which is often difficult to compute in practical applications. For this reason, in this paper, we opt for the POD method, which although often requires a larger number of snapshots, is in turn more general.
Let \({\mathcal {K}}= \{\varvec{\mu }_1, \dots , \varvec{\mu }_{N_k}\}\) be a finite dimensional training set of samples chosen inside the parameter space \({\mathcal {P}}\) and for each time instance \(t_r \in \{t_1, \dots , t_{N_t}\} \subset (0, T]\). We solve the FOM for each \(\varvec{\mu }_k \in {\mathcal {K}} \subset {\mathcal {P}}\). The total number of snapshots \(N_s\) is given by \(N_s = N_k \cdot N_t\). After computing the full order solutions, they are stored into a matrix \({\mathcal {S}}_{\Phi _h}\in {\mathbb {R}}^{N_{h} \times N_s}\) in a column-wise sense, i.e.:
for \(\Phi _h = \{{\textbf{u}}, P, \text {WSS} \}\). Commonly snapshot matrices are not square and denoting by \(R \le \text {min}(N_{h},N_s)\) the rank of \({\mathcal {S}}_{\Phi _h}\), the Singular Value Decomposition (SVD) allows to factorise \({\mathcal {S}}_{\Phi _h}\) as:
where \({\mathcal {W}}=\{ {\textbf{w}}_1| \dots |{\textbf{w}}_{N_{h}} \} \in {\mathbb {R}}^{N_{h} \times N_{h}}\) and \({\mathcal {Z}}=\{ {\textbf{z}}_1| \dots |{\textbf{z}}_{N_s} \} \in {\mathbb {R}}^{ N_s \times N_s}\) are two orthogonal matrices composed of left singular vectors and right singular vectors respectively in columns, and \({\mathcal {D}} \in {\mathbb {R}}^{ N_{h} \times N_s}\) is a diagonal matrix with R non-zero real singular values \(\sigma _1 \ge \sigma _2 \ge \dots \ge \sigma _R > 0\).
Our goal is to approximate the columns of \({\mathcal {S}}_{\Phi _h}\) by means of \(L<R\) orthonormal vectors. The Schmidt-Eckart-Young theorem states that the POD basis of rank L consists of the first L left singular vectors of \({\mathcal {S}}_{\Phi _h}\), also named modes [53]. So we can introduce the matrix with the extrapolated modes as columns:
It is well known [54] that the POD basis of size L is the solution to the minimization problem [55]:
where \(\Vert \bullet \Vert \) is the Frobenius norm. Therefore, the reduced basis is the set of vectors that minimize the distance between the snapshots and their projection onto the space spanned by the basis. In addition, the error committed by approximating the columns of \({\mathcal {S}}_{\Phi _h}\) via the vectors of \({\mathcal {V}}\) is equal to the sum of the squares of the neglected singular values [55]:
So by controlling the size L, we can approximate the snapshot matrix \({\mathcal {S}}_{\Phi _h}\) with arbitrary accuracy. Since the error is strictly related to the magnitude of the singular values, a common choice is to set L equal to the smallest integer L such that:
where \(\epsilon \) is a user-provided tolerance and the left hand side of (16) is the relative information content of the POD basis, namely the percentage of energy of the snapshots (or cumulative energy of the eigenvalues) retained by the first L modes.
Once the POD basis is available, the reduced solution \(\Phi _{\text {rb}} (t_r, \varvec{\mu }_k)\) that approximates the full order solution \(\Phi _h (t_r, \varvec{\mu }_k)\) is:
where \(({\mathcal {V}}^T \Phi _h (t_r, \varvec{\mu }_k))_j\) is the modal coefficient associated to the j-th mode.
3.2 Artificial Neural Network
An ANN is a computational model able to learn from observational data. It consists of neurons and a set of directed weighted synaptic connections among the neurons. It is an oriented graph, with the neurons as nodes and the synapses as oriented edges, whose weights are adjusted by means of a training process to configure the network for a specific application (see [56,57,58]).
Let us consider the neuron j. Three functions characterize completely the neuron j:
-
The propagation function \(u_j\). It is used to transport values through the neurons of the ANN. We use the weighted sum:
$$\begin{aligned} u_j=\sum _{k=1}^m w_{s_k,j}y_{s_k} + b_j, \end{aligned}$$where \(b_j\) is the bias, \(y_{s_k}\) is the output related to the sending neuron k, \(w_{s_k,j}\) are proper weights and m is the number of sending neurons linked with the neuron j. Other choices are possible for u [30].
-
The activation function \(a_j\). It quantifies to which degree neuron j is active. It is a function of the input \(u_j\) and the bias \(b_j\) chosen during the training process:
$$\begin{aligned} a_j=f_{\text {act}}\left( \sum _{k=1}^m w_{s_k,j}y_{s_k}+b_j\right) . \end{aligned}$$Commonly the activation functions are nonlinear. The activation function is an hyperparameter to be tuned in order to optimize the performance of the neural network. More details can be found in [59]. In this work we consider sigmoid function, hyperbolic tangent, RELU, SoftMax, SoftPlus and Gaussian function.
-
The output function \(y_j\). It is related to the activation function \(a_j\). Often it is the identity function, so that \(a_j\) and \(y_j\) coincide:
$$\begin{aligned} y_j=f_{\text {out}}(a_j)=a_j. \end{aligned}$$
In this work, we will use a specific type of ANNs, the feedforward neural networks.
3.2.1 The feedforward neural network
In a feedforward neural network (Fig. 4), neurons are arranged into layers, so input nodes define one input layer and the same holds for the output layer and for the hidden layers. Neurons in a layer can only be linked with neurons in the next layer, towards the output layer (see [60,61,62]). We use fully connected neural networks, so each node in layer l is connected to all nodes in layer \(l+1\) for all l. We highlight that the input layer of our network consists of the set of time/parameter instances \(\{ (t_1, \varvec{\mu }_1),\dots ,(t_{N_t},\varvec{\mu }_{N_k}) \}\), whilst the output one is given by the corresponding modal coefficients \(\{[{\mathcal {V}}^T \Phi _h (t_1, \varvec{\mu }_1)]_{j=1}^L, \dots , [{\mathcal {V}}^T \Phi _h (t_{N_t}, \varvec{\mu }_{N_k})]_{j=1}^L\}\). On the other hand, the number of hidden layers and of their neurons are hyperparameters of the network to be properly tuned to optimize the performance of the network.

Topology of the feedforward neural network
Layered feedforward networks have become very popular firstly because they have been found in practice to generalize well. Secondly, a training algorithm based on the so-called backpropagation can often find a good set of weights (and biases) in a reasonable amount of iterations (or, equivalently, epochs, that represent an hyperparameter of the network). During the training procedure the weights of the connections in the network are repeatedly changed in order to minimize the difference between the actual output vector of the net \(\tilde{\varvec{\pi }}(t_r, \varvec{\mu }_k)\) and the required output vector \(\varvec{\pi }(t_r, \varvec{\mu }_k)\). The key to backpropagation is a method for computing the gradient of the error with respect to the weights for a given input by propagating error backwards through the network [63, 64]. A loss function is introduced to optimize the parameter values in a neural network model. This class of functions maps a set of parameter values for the network onto a scalar value that shows how well those parameters achieve the purpose the network is intended to do.
The loss function \({\mathcal {L}} = {\mathcal {L}}(\tilde{\varvec{\pi }}(t_r, \varvec{\mu }_k),\varvec{\pi }(t_r, \varvec{\mu }_k))\) used in this work is the Mean Squared Error (MSE), that is the most common choice for regression problems:
To effectively compute the gradient of the loss function, the chain rule is used. Then the gradient of the loss function for a single weight \(w_{s_k,j}^l\) and for the biases \(b_j^l\) can be expressed as:
Operatively, in the forward pass the values of the output layers from the inputs data are computed and the loss function is calculated. After each forward pass, backpropagation performs a backward pass to compute the gradient of the loss function while adjusting the parameters of the model as follow:
where \(\varvec{w}\) and \(\varvec{b}\) are matrix representations of the weights and biases, \(\eta \) is an hyperparameter tuned to minimize the loss, named learning rate, the suffix \(\text {old}\) denotes the current values of weights and biases, while the suffix \(\text {new}\) is associated to the corresponding updated values.
The tuning of the hyperparamaters of the network reads as follows: given an activation function and a number of hidden layers, we increase the values of the learning rate and the hidden neurons until the overfitting phenomenon occurs [56]. It should be noted that, through such a process, we obtain several trained neural networks. We adopt the one providing the higher accuracy. The accuracy of the trained model is measured by the number of predictions within a certain tolerance \(\delta \) (i.e., the “correct" predictions) over the total number of predictions.
For the creation and training of the neural networks, we employed the Python library PyTorch.
3.2.2 Evaluation of the Modal Coefficients
As already reported in the previous subsection, the neural network employed provides a reliable approximation of the following input-output relationship:
Then during the online stage the solution for any new time instant \(t_{\text {new}}\) and new parameter \(\varvec{\mu }_{\text {new}}\) can be simply computed as follows [30, 32, 34, 38, 65]:
4 Numerical Results
In this section, we test the performance of our ROM approach. Two parametric cases are investigated:
-
Case 1 we verify the functionality of the ROM method in a physical parametric setting by considering \(f_i\) (see equation (6)) as parameters.
-
Case 2 we verify the functionality of the ROM method in a geometrical parametric setting by considering the stenosis severity as parameter.
Table 3 reports the hyperparameters of the neural networks. We highlight that the hyperparameters are tuned for Case 2, however they show a good functionality also for Case 1. The tolerance is set to \(\delta = 10^{-3}\) and the accuracy is \(93\%\) in all the cases.
First of all, a brief mesh convergence analysis for the primal variables, \({\textbf{u}}\) and P, is reported in order to ensure that the FOM solution converges. Beyond the mesh whose features are reported in Table 1 (here referred as Mesh 2), we consider other two meshes, respectively coarser, with 518.299 cells (Mesh 1), and finer than Mesh 2, with 1.829.291 cells (Mesh 3), having non-orthogonality and skewness features similar to the Mesh 2. We set \(f_{\text {LMCA}} = 1.12\) and \(f_{\text {LITA}} = 0.82\) adapted from [46,47,48].
In Fig. 5 the time evolution of the volume averaged pressure \({\overline{P}}/{\overline{P}}_{\text {max}}\) and of the volume averaged velocity \(\overline{{\textbf{u}}}\) are shown for the three meshes under consideration. We let the simulations run till transient effects have passed and we refer to three cardiac cycles. In addition, in Figs. 6 and 7 an illustrative comparison for pressure and velocity are shown in the region of the anastomosis for \(t/T=1.25\).

Time evolution over three cardiac cycles of the volume averaged pressure (left) and of the volume averaged velocity (right) for the three meshes under consideration

Spatial distribution of the pressure drop across the anastomosis for the three meshes under consideration at \(t/T=1.25\)

Spatial distribution of the velocity (m/s) on a slice downstream the anastomosis for the three meshes under consideration at \(t/T=1.25\)
From a qualitative viewpoint, it is clear that the results obtained are very close each to other but, in order to provide a more quantitative comparison, we compute the relative error of the Meshes 1 and 2 with respect to the Mesh 3:
where \(x = \{\mathbf {{\overline{u}}}, {\overline{P}}/{\overline{P}}_{\text {max}}\}\), the subscript 3 denotes the quantities related to the Mesh 3, j denotes the quantities related to the Meshes 1 and 2, and \({\hat{x}}_{3}\) is the time averaged quantity related to the Mesh 3. Table 2 reports the values of the relative errors (23). Based on these results, for all the simulations showed hereinafter, we will use the Mesh 2 that ensures a good compromise between accuracy and offline cost.
4.1 Case 1
We consider a 70% stenosis. The following finite-dimensional set is used to train the ROM:
whilst we set \(f_i = 1\) as test point. Note that when \(\varvec{\mu }= f_{\text {LITA}}\), \(f_{\text {LMCA}} = 1\) and viceversa.
The average Reynolds number characterizing the dynamics of the problem can be evaluated taking into account both the fluid properties and geometrical features as:
where \({\overline{U}}_i\) is the mean velocity at the inlet of the LMCA and of the LITA (with \(f_i=1\)), \(d_i\) is the diameter of the LMCA and of the LITA and \(\nu = 3.7\cdot 10^{-6}\) m\(^2\)/s. This result supports the employment of a laminar model.
100 full-order equally spaced time-dependent snapshots, one every 0.008 s, are collected for each \(f_i\) value, over a cardiac cycle \(T=0.8\) s. They are enough to generate a reliable reduced space as proved in [32]. Then we get 700 snapshots both for \(\varvec{\mu } = f_{\text {LITA}}\) and \(\varvec{\mu } = f_{\text {LMCA}}\).
Cumulative eigenvalues for pressure, velocity and WSS based on the first 50 most energetic POD modes are shown in Fig. 8a and b. In both cases, they exhibit a very similar trend for velocity and WSS whilst the pressure one grows faster. These results are expected because typically in hemodynamics applications the spatial variability in pressure is not that much compared to velocity (and WSS that is directly linked to the velocity): see, e.g., [32, 36, 37]. In addition, for each variable, one obtains similar trends for \(\varvec{\mu }= f_{\text {LITA}}\) and \(\varvec{\mu }= f_{\text {LMCA}}\). Even this result is not surprising by considering that \(f_{\text {LITA}}\) and \(f_{\text {LMCA}}\) play a very similar role and it is reasonable that they affect in the same way the dynamics of the system.

Cumulative eigenvalues for pressure, velocity and WSS
In Figs. 9 and 10 the temporal evolution of the modal coefficients shows that the neural network is able to provide a prediction consistent with the FOM simulation, also in presence of strong nonlinearities (see Figs. 9b, 10b and c).

Case 1: time evolution of some reduced coefficients including the prediction provided by ANN (red line) and the FOM simulation (blue points) for \(\varvec{\mu }= f_{\text {LITA}}\)

Case 1: time evolution of some reduced coefficients including the prediction provided by ANN (red line) and the FOM simulation (blue points) for \(\varvec{\mu }= f_{\text {LMCA}}\)
Next, we carry out a convergence test with respect to the number of the modes. In Figs. 11 and 12, all the variables show a monotonic convergence for the relative error \(\varepsilon _i\):
with \(i=P,{\textbf{u}},\text {WSS}\), as the number of the modes is increased. Both for \(\varvec{\mu }= f_{\text {LITA}}\) and \(\varvec{\mu }= f_{\text {LMCA}}\), \(L=3\) pressure modes (more than \(99\%\) of the cumulative energy) are enough to obtain a time-averaged error of about \(2\%\). On the other hand, for the velocity and WSS, we obtain an error of about \(3\%\) using \(L=10\) modes (more than \(96\%\) of the cumulative energy). It should be noted that for the pressure we show only two cases (\(L = 1,3\)) because with more than 3 modes we obtain that the error is on average the same. We highlight that the similarity of cumulative eigenvalues between velocity and WSS observed in Fig. 8 is also reflected on the trend of the corresponding relative errors (see Figs.11b, c, 12b and c).

Case 1 time evolution of the relative error for pressure, velocity and WSS at varying of the number of modes L for \(\varvec{\mu }= f_{\text {LITA}}\)

Case 1 time evolution of the relative error for pressure, velocity and wall shear stress at varying of the number of modes L for \(\varvec{\mu }= f_{\text {LMCA}}\)
Qualitative comparisons between FOM and ROM at \(t/T=0.8\) are displayed in Figs. 13, 15, 17 and 19. Moreover, in Figs. 14, 16, 18 and 20 we report some further full order solutions at the aim to provide some physical insights. We display the stenosis and the anastomosis region, which are those of major interest, because they are modifications with respect to the healthy configuration. In Fig. 13 a good ROM prediction for the pressure drop \(P^* = P/P_{\text {max}}\) is found across the anastomosis. It is an important quantity because is related to the intimal thickening of the blood vessels and therefore it represents a significant indicator for heart diseases [66]. As expected, if an higher flow is imposed on the LITA, the pressure increases across the anastomosis (Fig. 14).

Case 1 comparison between normalized pressure drop \(P^* = P/P_{\text {max}}\) in the anastomosis region computed by the FOM and by the ROM at \(t/T = 0.8\) for the test point \(f_{\text {LMCA}}=f_{\text {LITA}}=1\)

Case 1 comparison between normalized pressure drop \(P^* = P/P_{\text {max}}\) in the anastomosis region at \(t/T = 0.8\) related to two different values of \(f_{\text {LITA}}\). We set \(f_{\text {LMCA}} = 1\)
In Figs. 15 and 17, we can appreciate a good performance of our ROM in the reconstruction of WSS. We also observe that a region of locally high WSS is found across the stenosis and the anastomosis. It can represent a significant indication for the restenosis process. In addition, Fig. 16 shows that as the inlet flow rate of the LMCA is increased, also the WSS magnitude in the stenosis rises. In addition, as consequence of increased LITA inlet flow, in Fig. 18 a significant growth of the WSS magnitude in the region of the anastomosis can be observed.

Case 1 comparison between WSS (Pa) in the stenosis region computed by the FOM and by the ROM at \(t/T = 0.8\) for the test point \(f_{\text {LITA}} = f_{\text {LMCA}} = 1\)

Case 1 comparison between WSS (Pa) in the stenosis region at \(t/T = 0.8\) related to two different values of \(f_{\text {LMCA}}\). We set \(f_{\text {LITA}} = 1\)

Case 1 comparison between WSS (Pa) in the anastomosis region computed by the FOM and by the ROM at \(t/T = 0.8\) for the test point\(f_{\text {LMCA}}=f_{\text {LITA}}=1\)

Case 1 comparison between WSS (Pa) in the anastomosis region at \(t/T = 0.8\) related to two different values of \(f_{\text {LITA}}\). We set \(f_{\text {LMCA}}=1\)
Figure 19 shows the functionality of the ROM framework for the velocity. Furthermore, we can observe that the high velocity regions coincide with the high WSS ones. In addition, as LITA inlet flow is increased (Fig. 20), the velocity is higher both on the LITA and the LAD, which indicate on the whole a good functionality of the bypass.

Case 1 comparison between velocity (m/s) streamlines in the anastomosis region computed by the FOM and by the ROM at \(t/T = 0.8\) for the test point \(f_{\text {LMCA}}=f_{\text {LITA}}=1\)

Case 1 comparison between velocity (m/s) streamlines in the anastomosis region at \(t/T = 0.8\) for the test case \(f_{\text {LMCA}}=f_{\text {LITA}}=1\) related to two different values of \(f_{\text {LITA}}\). We set \(f_{\text {LMCA}}=1\)
4.2 Case 2
We set \(f_{\text {LMCA}} = 1.12 \) and \(f_{\text {LITA}}=0.82\) adapted from [46,47,48]. To train the ROM, we consider a uniform sample distribution of the stenosis severity ranging between \(50\%\) to \(75\%\) with step \(5\%\), except \(70\%\) which is considered as test point. This results in 500 snapshots.
Cumulative eigenvalues based on the first 120 most energetic POD modes are shown in Fig. 8c. It can be seen that, with respect to Case 1 (Fig. 8a and b), they increase slightly slower.
The time evolution of some reduced coefficients are displayed in Fig. 21. Even in this case, we can observe that there is consistency between the neural newtork prediction and the FOM solution.

Case 2 time evolution of some reduced coefficients including the prediction provided by ANN (red line) and the FOM simulation (blue points)
A convergence test at varying of the number of the modes is reported in Fig. 22. We use the same number of modes employed for Case 1. Even in this case all the variables show a monotonic convergence for the relative error \(\varepsilon _i\) (Eq. (24)) as the number of the modes is increased. A time-averaged error of about \(3.2\%\) is obtained for the pressure with \(L = 3\) modes (corresponding to the 99% of the cumulative energy) and of about \(3.8\%\) and \(4.9\%\) for the velocity and WSS, respectively, using \(L = 10\) modes (more than 96% of the cumulative energy).

Case 2 time evolution of the relative error for pressure, velocity and wall shear stress at varying of the number of modes L
We conclude by showing a qualitative comparison between FOM and ROM simulations at \(t/T = 0.8\) and giving some physical insights on the patterns showed by the variables at hand. As one can see from Fig. 23, our ROM is able to provide a good reconstruction of the normalized pressure drop across the stenosis. As expected, the pressure drop decreases with the stenosis severity (Fig. 24).

Case 2 comparison between normalized pressure drop \(P^* = P/P_{\text {max}}\) in the stenosis region computed by the FOM and by the ROM at \(t/T = 0.8\) for the test point (70% stenosis)

Case 2 comparison between normalized pressure drop \(P^* = P/P_{\text {max}}\) in the stenosis region at \(t/T = 0.8\) related to three different values of stenosis degree
From Figs. 25 and 27 we can observe that FOM and ROM solutions are very similar for WSS. Furthermore, we observe that the WSS magnitude rises as the severity of the stenosis increases both in the stenosis (Fig. 26) and the anastomosis (Fig. 28) regions. This could be due to the higher flow rate enforced on the LITA to compensate the lack of blood in the LMCA.

Case 2 comparison between WSS (Pa) distribution in the stenosis region computed by the FOM and by the ROM at \(t/T = 0.8\) for the test point (\(70\%\) stenosis)

Case 2 comparison between WSS (Pa) distribution in the stenosis region at \(t/T = 0.8\) related to three different values of stenosis degree

Case 2 comparison between WSS (Pa) distribution in the anastomosis region computed by the FOM and by the ROM at \(t/T = 0.8\) for the test point (\(70\%\) stenosis)

Case 2 comparison between WSS (Pa) distribution in the anastomosis region at \(t/T = 0.8\) related to three different values of stenosis degree
In Fig. 29 the FOM and ROM streamlines for the velocity field are depicted. We can appreciate a good matching between the two solutions. In Fig. 30 we observe that, as for the WSS, the velocity increases with the stenosis. The velocity is higher in the LITA because it supplies blood to the entire vessels network, oxygenating LAD and, going up this vessel, LCx too.
4.3 Computational Cost
We ran the FOM simulations in parallel using 20 processor cores. The simulations are run on the SISSA HPC cluster Ulysses (200 TFLOPS, 2TB RAM, 7000 cores). Each FOM simulation takes roughly 41 h in terms of wall time, or 820 h in terms of total CPU time (i.e., wall time multiplied by the number of cores). On the other hand, the ROM has been run on an Intel(R) Core(TM) i5-8265U CPU @ 1.60GHz 8GB RAM by using one processor core only. Our ROM approach takes less then 10 s for the computation of the reduced coefficients for each variable. So we obtain a speed-up of at least \(10^{5}\). In Table 4 we can find a more detailed description of the estimation of the time required for the online phase, for the SVD analysis and for the training of the ANNs for each variable. Notice that for the WSS we obtain the highest speed-up because it is related to only the boundary of the domain.

Case 2 comparison between velocity (m/s) streamlines in the anastomosis region computed by the FOM and by the ROM at \(t/T = 0.8\) for the test point (\(70\%\) stenosis)

Case 2 comparison between velocity (m/s) streamlines in the anastomosis region at \(t/T = 0.8\) related to three different values of stenosis degree
5 Conclusions and Perspectives
In this work a non-intrusive data-driven ROM is employed in order to investigate the hemodynamics in a CABG patient-specific configuration when an isolated stenosis of the LMCA occurs. The method extracts a reduced basis space from a collection of FOM solutions via a POD algorithm and employs ANNs for the computation of the reduced coefficients.
The use of artificial intelligence as a fast and accurate method for the development of ROM for CFD simulations in cardiovascular applications is a fast-growing research area, so we retain that this work can represent a further step forward in this direction. Furthermore, the choice of the FV method for the space discretization reveals a wide applicability and flexibility by considering that in the bioengineering community the use of FV-based commercial codes is pretty common.
After a computationally intensive offline stage, POD-ANN method has allowed to obtain accurate hemodynamic simulations of the problem at hand at a significantly reduced computational cost. This demonstrates that such technique would be able in perspective to allow real time simulations to be accessed in hospitals and operating rooms in a very efficient way.
However, several improvements are still feasible. It could be introduced a coupling with 0D models [36, 37] at the aim to enforce more realistic boundary conditions, which represents a crucial step to obtain meaningful outcomes. In addition, it could be interesting to investigate the performance of other frameworks based on different deep learning approaches with the aim to develop a more robust and versatile ROM, especially for what concerns the geometrical parametrization. In this context, one can act on a better prediction of the reduced coefficients by using, for example, physics-informed neural network [30, 65]. Another follow-up could be represented by the introduction of the autoencoders [67] providing a nonlinear alternative to POD: they may capture, more efficiently, features or patterns in the high-fidelity model results.
Data Availability
Enquiries about data availability should be directed to the authors.
References
Revault d’Allonnes, F., Corbineau, H., Le Breton, H., Leclercq, C., Leguerrier, A., Daubert, C.: Isolated left main coronary artery stenosis: long term follow up in 106 patients after surgery. Intervent. Cardiol. Surg. 87(6), 544–548 (2002)
Scott, R., Blackstone, E.H., McCarthy, P.M., Lytle, B.W., Loop, F.D., White, J.A., Cosgrove, D.M.: Isolated bypass grafting of the left internal thoracic artery to the left anterior descending coronary artery: late consequences of incomplete revascularization. Am. Assoc. Thoracic Surg. 120(1), 173–184 (2000)
Harling, L., Sepehripour, A.H., Ashrafian, H., Lane, T., Jarral, O., Chikwe, J., Dion, R.A.E., Athanasiou, T.: Surgical patch angioplasty of the left main coronary artery. Eur. J. Cardiothorac. Surg. 42(4), 719–727 (2012)
Gaudino, M., Massetti, M., Farina, P., Hanet, C., Etienne, P., Mazza, A., Glineur, D.: Chronic competitive flow from a patent arterial or venous graft to the circumflex system does not impair the long-term patency of internal thoracic artery to left anterior descending grafts in patients with isolated predivisional left main disease: Long-term angiographic results of 2 different revascularization strategies. J. Thorac. Cardiovasc. Surg. 148(5), 1856–1859 (2014)
Rosenblum, J.M., Binongo, J., Wei, J., Liu, Y., Leshnower, B.G., Chen, E.P., Miller, J.S., Macheers, S.K., Lattouf, O.M., Guyton, R.A., Thourani, V.H., Halkos, M.E., Keeling, W.B.: Priorities in coronary artery bypass grafting: is midterm survival more dependent on completeness of revascularization or multiple arterial grafts? J. Thorac. Cardiovasc. Surg. 161(6), 2070-2078.e6 (2020)
Rastan, A.J.: Treatment of coronary artery disease: randomized trials on myocardial revascularization and complete arterial bypass grafting. J. Thoracic Cardiovas. Surg 65(S03), S167–S173 (2017)
Formaggia, L., Quarteroni, A., Veneziani, A.: Cardiovascular Mathematics Modeling and Simulation of the Circulatory System. Springer, Milan (2009)
Hesthaven, J.S., Rozza, G., Stamm, B.: Certified Reduced Basis Methods for Parametrized Equations, p. 590. Springer, Berlin (2016)
Rozza, G., Huynh, D.B.P., Patera, A.T.: Reduced basis approximation and a posteriori error estimation for affinely parametrized elliptic coercive partial differential equations. Archives Comput. Methods Eng. 15, 229–275 (2008)
Huynh, D.B.P., Knezevic, D.J., Patera, A.T.: Certified reduced basis model validation: a frequentistic uncertainty framework. Comput. Methods Appl. Mech. Eng. 201, 13–24 (2012)
Benner, P., Schilders, W., Grivet-Talocia, S., Quarteroni, A., Rozza, G., Miguel Silveira, L.: Model order reduction: volume 3 applications, De Gruyter (2020)
Noor, A.K.: Recent advances in reduction methods for nonlinear problems, Comput. Methods Nonlinear Struct. Solid Mech., 31-44 (1981)
Quarteroni, A., Rozza, G.: Numerical solution of parametrized Navier-Stokes equations by reduced basis methods. Numer. Methods Partial Differ. Equ. An Int. J. 23(4), 923–948 (2007)
Manzoni, A., Quarteroni, A., Rozza, G.: Computational reduction for parametrized PDEs: strategies and applications. Milan J. Math. 80(2), 283–309 (2012)
Deparis, S., Rozza, G.: Reduced basis method for multi-parameter-dependent steady Navier-Stokes equations: applications to natural convection in a cavity. J. Comput. Phys. 228(12), 4359–4378 (2009)
Ballarin, F., Faggiano, E., Ippolito, S., Manzoni, A., Quarteroni, A., Rozza, G., Scrofani, R.: Fast simulations of patient-specific haemodynamics of coronary artery bypass grafts based on a POD-Galerkin method and a vascular shape parametrization. J. Comput. Phys. 315, 609–628 (2016)
Lassila, T., Manzoni, A., Quarteroni, A., Rozza, G.: A reduced computational and geometrical framework for inverse problems in hemodynamics. Int. J. Numer. Methods Biomed. Eng. 29(7), 741–776 (2013)
Ballarin, F., Faggiano, E., Manzoni, A., Quarteroni, A., Rozza, G., Ippolito, S., Antona, C., Scrofani, R.: Numerical modeling of hemodynamics scenarios of patient-specific coronary artery bypass grafts. Biomech. Model. Mechanobiol. 16(4), 1373–1399 (2017)
Manzoni, A., Quarteroni, A., Rozza, G.: Model reduction techniques for fast blood flow simulation in parametrized geometries. Int. J. Numer. Methods Biomed. Eng. 28(6–7), 604–625 (2012)
Manzoni, A., Quarteroni, A., Rozza, G.: Shape optimization for viscous flows by reduced basis methods and free-form deformation. Int. J. Numer. Meth. Fluids 70(5), 646–670 (2012)
Pitton, G., Quaini, A., Rozza, G.: Computational reduction strategies for the detection of steady bifurcations in incompressible fluid-dynamics: applications to coanda effect in cardiology. J. Comput. Phys. 344, 534–557 (2017)
Ballarin, F., Manzoni, A., Quarteroni, A., Rozza, G.: Supremizer stabilization of POD-Galerkin approximation of parametrized steady incompressible Navier-Stokes equations. Int. J. Numer. Meth. Eng. 102(5), 1136–1161 (2015)
Zainib, Z., Ballarin, F., Fremes, S., Triverio, P., Jiménez-Juan, L., Rozza, G.: Reduced order methods for parametric optimal flow control in coronary bypass grafts, toward patient-specific data assimilation. Int. J. Numer. Methods Biomed. Eng. 37(12), e3367 (2020)
Fevola, E., Ballarin, F., Jiménez-Juan, L., Fremes, S., Grivet-Talocia, S., Rozza, G., Triverio, P.: An optimal control approach to determine resistance-type boundary conditions from in-vivo data for cardiovascular simulations. Int. J. Numer. Methods Biomed. Eng. 37(10), e3516 (2021)
Mao, Z., Jagtap, A.D., Karniadakis, G.E.: Physics-informed neural networks for high-speed flows. Comput. Methods Appl. Mech. Eng. 360, 112789 (2020)
Kissas, G., Yang, Y., Hwuang, E., Witschey, W.R., Detre, J.A., Perdikaris, P.: Machine learning in cardiovascular flows modeling: predicting arterial blood pressure from non-invasive 4D flow MRI data using physics-informed neural networks. Comput. Methods Appl. Mech. Eng. 358, 112623 (2019)
Liang, L., Mao, W., Sun, W.: A feasibility study of deep learning for predicting hemodynamics of human thoracic aorta. J. Biomech. 99, 109544 (2020)
Gharleghi, R., Samarasinghe, G., Sowmya, A., Beier, S.: Deep learning for time averaged wall shear stress prediction in left main coronary bifurcations, In: International Symposium on Biomedical Imaging, pp. 1–4 (2020)
Su, B., Zhang, J., Zou, H., Ghista, D., Le Thao, T., Chin, C.: Generating wall shear stress for coronary artery in real-time using neural networks feasibility and initial results based on idealized models. Comput. Biol. Med. 126, 104038 (2020)
Hesthaven, J.S., Ubbiali, S.: Non-intrusive reduced order modeling of nonlinear problems using neural networks. J. Comput. Phys. 363, 55–78 (2018)
Wang, Q., Hesthaven, J.S., Ray, D.: Non-intrusive reduced order modeling of unsteady flows using artificial neural networks with application to a combustion problem. J. Comput. Phys. 384, 289–307 (2019)
Siena, P., Girfoglio, M., Rozza, G.: Fast and accurate numerical simulations for the study of coronary artery bypass grafts by artificial neural network. arXiv:2201.01804 (2021)
Zancanaro, M., Mrosek, M., Stabile, G., Othmer, C., Rozza, G.: Hybrid neural network reduced order modelling for turbulent flows with geometric parameters. Fluids 6(8), 296 (2021)
Shah, N.V., Girfoglio, M., Quintela, P., Rozza, G., Lengomin, A., Ballarin, F., Barral, P.: Finite element based model order reduction for parametrized one-way coupled steady state linear thermomechanical problems. Finite Elem. Anal. Des. 212, 103837 (2022)
Buoso, S., Manzoni, A., Alkadhi, H., Plass, A., Quarteroni, A., Kurtcuoglu, V.: Reduced-order modeling of blood flow for noninvasive functional evaluation of coronary artery disease. Biomech. Model. Mechanobiol. 18(6), 1867–1881 (2019)
Girfoglio, M., Ballarin, F., Infantino, G., Nicoló, F., Montalto, A., Rozza, G., Musumeci, F.: Non-intrusive PODI-ROM for patient-specific aortic blood flow in presence of a LVAD device. Med. Eng. Phys. 107, 103849 (2022)
Girfoglio, M., Scandurra, L., Ballarin, F., Infantino, G., Nicoló, F., Montalto, A., Musumeci, F.: Non-intrusive data-driven ROM framework for hemodynamics problems. Acta. Mech. Sin. 37(7), 1183–1191 (2021)
Pichi, F., Ballarin, F., Rozza, G., Hesthaven, J.S.: Artificial neural network for bifurcating phenomena modelled by nonlinear parametrized PDEs. Panam. Math. J. 20(S1), e202000350 (2021)
Papapicco, D., Demo, N., Girfoglio, M., Stabile, G., Rozza, G.: The neural network shifted-Proper orthogonal decomposition: a machine learning approach for non-linear reduction of hyperbolic equations. Comput. Methods Appl. Mech. Eng. 392, 114687 (2022)
Demo, N., Strazzullo, M., Rozza, G.: An extended physics informed neural network for preliminary analysis of parametric optimal control problems, arXiv:2110.13530 (2021)
Meneghetti, L., Demo, N., Rozza, G. A Dimensionality Reduction Approach for Convolutional Neural Networks. arXiv:2110.09163 (2021)
Stabile, G., Zancanaro, M., Rozza, G.: Efficient geometrical parametrization for finite-volume-based reduced order methods. Int. J. Numer. Meth. Eng. 121(12), 2655–2682 (2020)
Brujic, D., Ristic, M., Ainsworth, I.: Measurement-based modification of NURBS surfaces. Comput. Aided Des. 34(3), 173–183 (2002)
Amoiralis, E.I., Nikolos, I.K.: Freeform deformation versus B-spline representation in inverse airfoil design. J. Comput. Inf. Sci. Eng. 8(2), 024001 (2008)
Lamousin, H.J., Waggenspack, N.N.: NURBS-based free-form deformations. Comput. Graph. Appl. 14(6), 59–65 (1994)
Keegan, J., Gatehouse, P.D., Yang, G.Z., Firmin, D.N.: Spiral phase velocity mapping of left and right coronary artery blood flow: correction for through-plane motion using selective fat-only excitation. J. Magn. Reson. Imag. 20(6), 953–960 (2004)
Ishida, N., Sakuma, H., Cruz, B.P., Shimono, T., Tokui, T., Yada, I., Takeda, K., Higgins, C.B.: MR flow measurement in the internal mammary artery-to-coronary artery bypass graft: comparison with graft stenosis at radiographic angiography. Radiology 220(2), 441–447 (2001)
Verim, S., Öztürk, E., Küçük, U., Kara, K., Sağlam, M., Kardeşoğlu, E.: Cross-sectional area measurement of the coronary arteries using CT angiography at the level of the bifurcation: is there a relationship? Diag. Intervent. Radiol. J. 21(6), 454 (2015)
Girfoglio, M., Quaini, A., Rozza, G.: A Finite Volume approximation of the Navier–Stokes equations with nonlinear filtering stabilization. Comput. Fluids 187, 27–45 (2019)
Jasak, H.: Error Analysis and Estimation for the Finite Volume Method with Applications to Fluid Flows, Ph.D. Thesis, Imperial College, University of London (1996)
Issa, R.I.: Solution of the implicitly discretised fluid flow equations by operator splitting. J. Comput. Phys. 62(1), 40–65 (1985)
Bang-Jensen, J., Gutin, G., Yeo, A.: When the greedy algorithm fails. Discret. Optim. 1(2), 121–127 (2004)
Eckart, C., Young, G.: The approximation of one matrix by another of lower rank. Psychometrika 1(3), 211–218 (1936)
Kunisch, K., Volkwein, S.: Galerkin proper orthogonal decomposition methods for a general equation in fluid dynamics. J. Numer. Anal. 40(2), 492–515 (2002)
Quarteroni, A., Manzoni, A., Negri, F.: Reduced Basis Methods for Partial Differential Equations: An Introduction, vol. 92. Springer, Berlin (2015)
Goodfellow, I., Bengio, Y., Courville, A.: Deep Learning. MIT Press, Amsterdam (2016)
Kriesel, D.: A Brief Introduction on Neural Networks, Citeseer (2007)
Calin, O.: Deep Learning Architectures. Springer, Berlin (2020)
Sharma, S., Sharma, S., Athaiya, A.: Activation functions in neural networks. Towards Data Sci. 6(12), 310–316 (2017)
Rosenblatt, F.: The perceptron: a probabilistic model for information storage and organization in the brain. Psychol. Rev. 65(6), 386 (1958)
Minsky, M., Papert, S.: An Introduction to Computational Geometry. Cambridge Tiass, HIT 479, 480 (1969)
Fine, T.L.: Feedforward Neural Network Methodology. Springer, Berlin (2006)
Rojas, R.: The Backpropagation Algorithm in Neural networks. Springer, Berlin, Heidelberg (1996)
Rumelhart, D.E., Hinton, G.E., Williams, R.J.: Learning representations by backPropagating errors. Nature 323(6088), 533–536 (1986)
Chen, W., Wang, Q., Hesthaven, J.S., Zhang, C.: Physics-informed machine learning for reduced-order modeling of non linear problems. J. Comput. Phys. 446, 110666 (2021)
Loth, F., Fischer, P.F., Bassiouny, H.S.: Blood flow in end-to-side anastomoses. Annu. Rev. Fluid Mech. 40, 367–393 (2008)
Phillips, T.R., Heaney, C.E., Smith, P.N., Pain, C.C.: An autoencoder-based reduced-order model for eigenvalue problems with application to neutron diffusion. Int. J. Numer. Meth. Eng. 122(15), 3780–3811 (2021)
Acknowledgements
We acknowledge the support provided by the European Research Council Executive Agency by the Consolidator Grant project AROMA-CFD “Advanced Reduced Order Methods with Applications in Computational Fluid Dynamics”-GA 681447, H2020-ERC CoG 2015 AROMA-CFD, the European Union’s Horizon 2020 research and innovation program under the Marie Skłodowska-Curie Actions, grant agreement 872442 (ARIA), as well as developers and contributors of OpenFOAM®. FB also thanks the project “Reduced order modelling for numerical simulation of partial differential equations” funded by UniversitéCattolica del Sacro Cuore.
Funding
The authors have not disclosed any funding.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflicts of interest
The authors have not disclosed any competing interests.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Siena, P., Girfoglio, M., Ballarin, F. et al. Data-Driven Reduced Order Modelling for Patient-Specific Hemodynamics of Coronary Artery Bypass Grafts with Physical and Geometrical Parameters. J Sci Comput 94, 38 (2023). https://doi.org/10.1007/s10915-022-02082-5
Received:
Revised:
Accepted:
Published:
DOI: https://doi.org/10.1007/s10915-022-02082-5