
Abstract
With the prevalence of deep learning and convolutional neural network (CNN), data augmentation is widely used for enriching training samples to gain model training improvement. Data augmentation is important when training samples are scarce. This work focuses on improving data augmentation for training an industrial steel surface defect classification network, where the performance is largely depending on the availability of high-quality training samples. It is very difficult to find a sufficiently large dataset for this application in real-world settings. When it comes to synthetic data augmentation, the performance is often degraded by incorrect class labels, and a large effort is required to generate high-quality samples. This paper introduces a novel off-line pre-augmentation network (PreAugNet) which acts as a class boundary classifier that can effectively screen the quality of the augmented samples and improve image augmentation. This PreAugNet can generate augmented samples and update decision boundaries via an independent support vector machine (SVM) classifier. New samples are automatically distributed and combined with the original data for training the target network. The experiments show that these new augmentation samples can improve classification without changing the target network architecture. The proposed method for steel surface defect inspection is evaluated on three real-world datasets: AOI steel defect dataset, MT, and NEU datasets. PreAugNet significantly increases the accuracy by 3.3% (AOI dataset), 6.25% (MT dataset) and 2.1% (NEU dataset), respectively.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
Introduction
Artificial neural networks have led to significant achievements in the field of supervised learning algorithms to solve data classification problems (Abiodun et al., 2018; Meireles et al., 2003; Saritas & Yasar, 2019). A variety of probability-based algorithms such as learning vector quantization and probabilistic neural networks (Burrascano, 1991; Mao et al., 2000) have been widely used for supervised statistical pattern classification-based models. The models aim to learn feature representations of a class region related to competitive learning algorithms. However, using this straightforward approach for high-dimensional features comes with a huge computational complexity and time. Nowadays, in the era of deep learning, convolutional neural networks (CNN) as typical feed-forward neural networks have performed remarkably in the various computer vision systems including image classification (He et al., 2016; Krizhevsky et al., 2017; Simonyan & Zisserman, 2014; Tan & Le, 2019) object detection (Liu et al., 2016; Redmon et al., 2016; Ren et al., 2015) semantic segmentation (He et al., 2017; Ronneberger et al., 2015), etc. One of the most challenging supervised learning applications of CNN in the manufacturing industry is product defect recognition which has been extensively studied. In order to train a deep neural network model for real-world industrial use, probably the first immediate task is to collect sufficient labeled data. Without high-quality training data, overfitting will mostly occur, which causes the learned model to be highly biased to the seen samples but not be able to generalize against unseen data. It is well-known that regularization techniques can alleviate model overfitting, including the extended techniques of (Choe et al., 2020; Ghiasi et al., 2018; Singh & Lee, 2017) and batch normalization (Krizhevsky et al., 2017). Various heuristic techniques such as weight decay and early training stopping can reduce overfitting by penalizing parameter norms. Despite the practical values of these heuristics, the training of large network models for complex real-world industrial applications still demands a large amount of high-quality data.
Data augmentation is an effective approach to battle model overfitting (Shorten & Khoshgoftaar, 2019). Data augmentation is the process of supplementing and enriching available data for better generalization during training. For most computer vision problems, image transformations such as rotating, cropping, scaling, noise perturbation, or color adjusting are popular means to substantially improve data amount (Hernández-García & König, 2018). When dealing with natural images, rotating, flipping, and scaling transformations are de facto approaches used during training. Unfortunately, not all transformations are useful for every dataset or problem. For example, all categories in CIFAR10, CIFAR100 and ImageNet datasets should be invariant to horizontal flips, since the mirror of an object is typically visually valid (e.g., a mirrored car is still a good training sample). However, not all image transformations are valid for problems such as character recognition (LeCun et al., 1998), where non-existing symbols or symbol label change after transformation (e.g., a flipped ‘6’ becomes ‘9’) can harm model training.
In the process of augmentation paradigm, there are mainly three ways in which augmentation techniques can be applied, namely off-line augmentation, on-line augmentation, and hybrid methods. Off-line augmentation user has access to screening the augmented results but needs to concern about the quality of new samples. On other hand, on-line augmentation provides virtually infinite samples during training, however without ground truth for validation. Numerous image recognition works apply off-line augmentation by producing synthetic images (Bowles et al., 2018; Frid-Adar et al., 2018) to effectively improve model training and alleviate over-fitting. However, the new synthetic samples are still generated from the modeling of existing samples, thus they are typically not sufficiently diverse. It is common that incorrectly augmented transformations can induce features far away from the original sample, which harms model training. Since there is no easy way to find out but to check model effectiveness at the end of training, the evaluation of data augmentation can be very time-consuming in the real-world setting. In this work, our major goal is to develop an efficient method that can provide insight on the selection process of off-line data augmentation sample generation, such that more diverse and representative samples can be generated to improve target model training.
Specifically, we develop an off-line data augmentation optimization approach that can effectively improve the screening of augmented samples to boost model training. We choose the industrial surface defect classification as the targeted application for evaluation. We construct an independent, lightweight data augmentation network named pre-augmentation network (PreAugNet) that consists of a data augmentation generator, a feature extractor, and a data management module. Motivated by the idea of effective classification of support vector machine (SVM) in determining decision boundary (Vapnik, 1999), We design an SVM classifier that predicts the label of a generated sample based on its extracted features. This process iterates in updating the new samples regarding the SVM decision boundary being modeled that are related to the data augmentation transformation process.
-
We propose a lightweight PreAugNet that improves the off-line data augmentation for training a defect classification model. The pre- augmentation network learns to extract features from input sample images and produce proper transformations to generate new sample images for data augmentation.
-
We design an SVM decision boundary analysis to screen and iteratively update the samples produced from the PreAugNet to ensure the suitability of the transformed samples for target network training. We show how the iterative estimation and updating of class decision boundaries can be very effective in screening and producing diverse augmentation samples that generalize better.
-
Extensive experiments are performed to evaluate the performance of the PreAugNet against other state-of-the-art online and offline data augmentation methods. Specifically, we use ResNet (He et al., 2016) as the target network that is trained on three real-world datasets, namely AOI, MT, and NEU datasets for steel surface defect inspection. PreAugNet significantly increases the classification accuracy by 3.3% (AOI), 6.25% (MT) and 2.1% (NEU), respectively.
The rest of this paper is organized as follows: "Related work" section discusses related works. "Methodology" section introduces the principle of pre-augmentation network, augmentation generator, and the SVM decision boundary update process. "Experimental results" section describes experimental results and performance analysis. "Conclusion" section provides discussions and the conclusion.
Related work
Data augmentation
As a highly effective method to tackle data limitations, data augmentation has been successfully designed in many cases. Extensive works on real-time image augmentation offer massive efforts in image classification (Shorten & Khoshgoftaar, 2019). Augmentation with Cutout (DeVries & Taylor, 2017) shows the simple regularization technique of randomly masking out square regions of input during training that can be used to improve the robustness and overall performance of CNN. In order to enhance the regularization strategy of the network, augmentation with Cutmix (Yun et al., 2019; Zhang et al., 2017) uses cut and paste operation on the patch area from the source image to the training image. Another popular data augmentation method for training CNN is random erasing (Zhong et al., 2020a, 2020b), where it randomly selects a rectangle region in an image and erases its pixels with random values. With this simple learning principle, these augmentation methods regularize CNN better. In the case of surface defect, evaluating traditional augmentation methods shown in (Farady et al., 2021) where the various data augmentation methods including pixel-level and spatial-level used to evaluate the accuracy results. For creating additional training samples from existing data, (Farady et al., 2022; Wong et al., 2016) shows the benefit of creating synthetic samples via combining the two approaches of data warping and synthetic over-sampling. Data warping methods generate samples through transformations that are applied in the data-space, while synthetic over-sampling creates samples according to the feature-space. The generative adversarial networks (GAN) (Goodfellow et al., 2020) are widely used in producing new realistic samples of certain data or class. By training using adversarial examples monitored by the discriminator, the generator of GAN can synthesize realistic-looking images that are sufficiently different from the original images (Liu & Tuzel, 2016; Zhu et al., 2017).
Industrial defect inspection
Steel surface defect inspection has received increased attention for ensuring quality control of industrial products (Czimmermann et al., 2020; Kumar, 2008; Luo et al., 2020; Ngan et al., 2011). Currently, most deep learning models for image recognition use transfer learning concepts to train the model on new dataset. It then becomes a popular solution to reduce training time in modern deep learning models and defect datasets (Abu et al., 2021; Pan et al., 2020; Zhang et al., 2021a). With transfer learning, instead of starting the learning process of CNN model from scratch on small training data. In the following works (Marino et al., 2020; Zhang et al., 2022, 2021a, 2021b, 2021c), the networks exploit the transfer learning knowledge of a model that has learned from the training on a sufficiently large dataset. Additionally, domain adaptation (Saito et al., 2020; Yang et al., 2021) approaches have been implemented in many industrial cases such as machinery fault diagnosis. Surface defect detection is usually performed against complex industrial scenarios, which ends up as a challenging problem with hard usage constraints. Surface defects are the main cause of low-quality steel products. Steel surface defect recognition and classification approaches have improved significantly since the debut of deep learning with many advantages in the past decades (Chen et al., 2020; Cheon et al., 2019; Huang et al., 2020a, 2020b; Park et al., 2016). In recent years, exploring the benefit of machine learning algorithms emerged when CNN features have been successfully integrated with a basic superior classifier such as the support vector machine (SVM) (Vapnik, 1999). The works (Elleuch et al., 2016; Kang et al., 2017; Niu & Suen, 2012) can classify both linear and nonlinear problems with SVM kernel functions. In (Chen et al., 2020; Li et al., 2017), image data are successfully enhanced using CNN to produce better classification results. Many developments from these hybrid methods emerge in cases when the amount of available data is limited, which is particularly true for industrial defect inspection. As shown in (Joshi et al., 2020; Sun et al., 2019; Xue et al., 2016), the CNN structure has been well-suited to deal with non-natural images with quality and scalability issue.
Data augmentation for defect inspection
Many applications regarding industrial image processing face barriers of severe data scarcity. The works of (He et al., 2019a, 2019b; Jain et al., 2022) overcome the shortage of defective samples by adopting GAN for effective data augmentation. In addition to generating images with an autoencoder, (Yun et al., 2020) proposed a combination convolutional variational autoencoder (CVAE) algorithm to address the insufficient imbalance data. In the discriminative training of GAN (Zhong et al., 2020a, 2020b), the computational cost of the generator increases, which tends to overfit to real data where data augmentation should be avoided. Regarding applying GAN data augmentation for industrial defect datasets, the GAN generator can learn a complex distribution from the limited available dataset. However, how useful the synthetic samples in regarding model training is questionable. GANs might not be able to cover the entire diversity of defect types, as the available defect samples in the first place can be already very scarce.
In contrast to the previous approaches, in this work, we designed an effective data augmentation approach based on feature enhancement that goes hand-in-hand with their class decision boundary that are crucial for training the target network. Our approach leverages CNN features that will be refined in an SVM decision boundary representation, such that new data augmentation samples can be created via data-driven learning and iteratively update. This way, our approach can create diverse but representative samples, that the target network has mostly not seen before to boost training its performance.
Methodology
We start with the main idea of introducing a Pre-Augmentation Network (PreAugNet) to perform off-line data augmentation that can improve the training of the target network model for industrial defect recognition. We first describe the PreAugNet with a detailed module design and then explain the data flow regarding the splitting, sampling, and collecting of the augmented samples inside the PreAugNet in "Off-line pre-augmentation network" section. We describe how the PreAugNet updates the sample decision boundary during the sample search process in "The decision boundary update process for augmentation sample screening" section. Finally, we discuss the target network settings and how the augmented samples are added to improve its training in "Target network" section.
Off-line pre-augmentation network
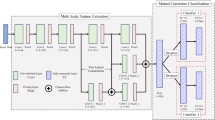
Figure 1 shows the architecture of the proposed PreAugNet, which is attached to a target network for training with data augmentation. PreAugNet produces new transformed samples via an augmentation generator, where the samples are screened to ensure that they gain representative and diverse features that are sufficiently different from the original samples. The generated samples are merged with the original samples for target network training.

Overview of the proposed off-line PreAugNet to improve data augmentation for the training of an industrial defect classification network
The PreAugNet consists of four parts: (1) a data management module, (2) the augmentation generator, (3) the feature extractor, and (4) the augmentation sample classifier. The data management module manages data distribution including data splitting, collection, sample dropping, and merging for target network training. The data management module controls the data flow inside the PreAugNet and data pre-processing of the target network. It also plays an important role in maintaining a balance between the synthetic samples vs. the desired amount of total training samples. The augmentation generator produces a diverse set of new transformed images/samples, which will be screened and picked in the next step. The feature extractor consists of a standard CNN that extracts high-dimensional features from the original images. The augmentation sample classifier is an SVM that performs classification based on the extracted features and estimates the decision boundary to gauge the quality and suitability of the generated samples. Figure 2 illustrates the proposed PreAugNet data augmentation pipeline jointly with the training of the target model.

The PreAugNet data augmentation as an integrated pipeline for target network training
The augmentation generator \({\mathbb{G}}\) in Fig. 2 performs image transformations to the original samples to generate images in different sizes and shapes. Both affine transformations in the spatial domain and color intensity adjustments in the pixel domain are incorporated for data augmentation selection. Those image transformations are effective means for data augmentation as they align with variations in the physical world. In reality, the same defect can occur at various sizes and locations on the steel surface with different illumination and viewing conditions. This way, the augmentation generator can effectively generate realistic new samples that are suitable for model training. Surface defect images often exhibit very few amounts of information as features. Thus, a robust feature extractor is essential for acquiring representative feature vectors from defective samples. We use Inception-v3 (Szegedy et al., 2016) to extract features, with the same configuration for both the original and augmented images. The deep structure of Inception-v3 at the last fully connected layer retrieves 2048-dimensional features, which are fed into the classifier for boundary classification.
Figure 3 describes the augmented sample update process within the PreAugNet. Consider a dataset \(X={\left\{{x}_{i},{y}_{i}\right\}}_{i=1}^{N}\), where \({x}_{i}\) is an input image, \({y}_{i}\) the associated class label, \(N\) the number of samples. Denote \({X}^{^{\prime}}\) for the set of newly generated images, and \(\alpha \) for the percentile of new samples w.r.t. the number of original samples. In this setup, the augmentation generator \({\mathbb{G}}\) takes input dataset \(X\) and produces augmented samples \({X}^{^{\prime}}\), namely, \({\mathbb{G}} = X \to X^{\prime}\). The augmentation process typically consists of multiple operations such as hue saturation adjustments, adding various noise types (random, multiplicative, and additive Gaussian), removing high-frequency components via jpeg compression, randomly drop channel of the input image and image blurring, i.e., \({\mathbb{G}}= \left\{{a}_{1},{a}_{2},..{a}_{n}\right\}\). These image transformations are important as they provide the source of variability for image augmentation.

The boundary update process in the pre-augmentation network. The original image x is transformed to \({x}^{^{\prime}}\) via augmentation generator \({\mathbb{G}}\) which contains several augmentation methods \(\left\{{a}_{1},{a}_{2},{a}_{3},\dots {a}_{n}\right\}\) In the next iteration, classifier \({\mathbb{C}}\) updates the sample decision boundary according to new augmented images and performs the class prediction of the new input samples. The output of the \({\mathbb{C}}\) specifies a new sample \({x}^{^{\prime}}\) to be collected into the sample pool or discarded for all classes. The red x’ represents the correct class and black \({x}^{^{\prime}}\) is the discarded sample. The update process inside PreAugNet continues until the predetermined \(\alpha \) ratio of the target network matches
As shown in Fig. 3, the augmentation generator \({\mathbb{G}}\) is able to produce a large amount of images. However, not all the outputs of \({\mathbb{G}}\) are useful for training the target network. In order to control the distribution and variation of new generated samples, we apply a selection process to collect only “good” samples with the concept of the decision boundary of an SVM classifier \({\mathbb{C}}\). In the first iteration of the pre-augmentation network, data management module performs a “drop-select” function based on a ratio \(\alpha \). The ratio \(\alpha \) controls the targeted number of new samples selected as correct results from the classifier \({\mathbb{C}}\). While the rest of misclassified samples will be dropped, the data management module starts to recalculate the minimum number of new samples \({x}^{^{\prime}}\) to fulfill the needs of the target network. In this phase, the next iteration starts and will automatically repeat the process until the specified condition is reached.
The decision boundary update process for augmentation sample screening
We construct a feature similarity measure by a classifier \({\mathbb{C}}\), where, in the case of given a high dimensional feature from \(X\) and X′ samples. We aim to obtain an optimal boundary separation between \(X\) and X′ for each class by learning the similarity degree and relationship among the features. We formulate the problem of searching the samples on the predicted result of the classifier \({\mathbb{C}}={\left\{{x}^{^{\prime}},{y}_{i}^{^{\prime}}\right\}}_{i=1}^{N}\) with SVM. The basic idea is mapping the input feature vector into a high-dimensional space and generating a maximal distance of the separation boundary.
As shown in Fig. 4, in the process of searching the boundaries, the SVM classifier learns the n-dimensional features \(\left(x,y\right)\) from both the training set and new samples in feature-space and calculates the maximum boundary margin between the new observation samples of the class label in one iteration. When the pre-augmentation network updates this process for n-iteration times, at the same time classifier automatically produces another correct sample with their respective labels. As illustrated in Fig. 4, the boundary line of SVM will adjust to new generated samples and find the optimum with the input samples. In this condition, the classifier simply marks the output sample \({x}^{^{\prime}}\) as 1 (red) and 0 (black) for the correct samples and misclassified samples respectively (as illustrated in Fig. 3). In other words, the classifier \({\mathbb{C}}\) not only provides the class label of \({x}^{^{\prime}}\) but also the misclassified position of \({x}^{^{\prime}}\) for the new sample in \({y}_{i}^{^{\prime}}\) classes. Thus, our data management module performs the “drop-select” function on the classifier results \({\mathbb{C}}\) for next iteration where all the 1’s (red) output will only be selected and stored into sample pool.

Illustration of the boundary update of two class data observations for new generated samples \({x}^{^{\prime}}\) (red and black) under 2-dimensional and linear conditions. The dashed line represents the boundary of the classifier \({\mathbb{C}}\) where the boundary line dynamically moves according to new samples input for each iteration update (Color figure online)
Target network
The target network as shown in Figs. 5 is the network model that demands data augmentation. Experiments are designed to evaluate how the various ways of data augmentations affect the training of this target network. For industrial defect recognition, we use the ResNet (He et al., 2016) model as our target network. Specifically, we use the same configuration as the original ResNet18 structure, including the loss function, batch normalization, and optimizer.

Structure of the ResNet18 as target network for defect classification. During the training process, the input images for training consist of a combination of the original images and the collected samples from the screened augmented samples. The training process is the same as the original ResNet-18 training pipeline, except for the data augmentation introduced in this paper
In the baseline method, the target network is trained without using any augmentations at pre-processing and testing stage. The only change is in the adjustment of the input image size which is adjusted to the original model implementation. In order to control the number of augmentation samples, we define the \(\alpha \) ratio where the ratio is cumulative augmented images in a single training process. We set the \(\alpha \) ratio in percent of the original image and limit the ratio to no more than the original data. This ratio concept is applied for both online and off-line pre-augmentations.
Experimental results
Dataset and training details
We perform the experiments on three challenging real-world industrial steel surface defect datasets to evaluate the proposed method: (1) the Automatic Optical Inspection (AOI) steel defect dataset,Footnote 1 (2) the Magnetic Tile (MT) surface defect dataset (Huang et al., 2020a, 2020b), and (3) the NEU defect dataset (He et al., 2019a, 2019b). The AOI dataset is a private dataset that contains five types of steel surface defect: void defect, horizontal defect, vertical defect, edge defect, and particle defect. The MT and NEU datasets are well-known public datasets and are widely used for defect classification and detection. The MT dataset contains five types of defect: blowhole, break, crack, fray and uneven. The NEU dataset contains six defect classes: crazing, inclusion, patches, pitted surface, rolled-in scale and scratches. The red boxes of Fig. 6 highlight steel defects in these datasets, which is visually quite similar to the steel background. Images are grayscale and the information provided by the defect samples is typically scarce.

Sample images of each class from the AOI industrial inspection dataset. Red boxes highlight steel defects (Color figure online)
Table 1 summarizes the number of defect images of the three datasets. Note that the number of defect samples is extremely low when compared with other image classification datasets such as ImageNet or COCO for different applications. The three datasets show two challenging conditions in the industrial use case. First, all datasets contain small-scale training data and lack of surface defect image representations. For instance, AOI defect dataset consists of five classes of defects with a total image for the whole raw data is 1854 images and similarly in NEU dataset also consists of 1800 images. The MT dataset consists of 1344 images where only 392 defect images available. Secondly, the imbalance data of the three datasets cause additional challenging. Collecting a specific type of industrial defect sample is not an easy task, since the same type of defect does not frequently appear in a production line. It reflects in AOI and MT datasets where distribution data among the classes is not in the same average amount of images. In the case of AOI and MT datasets, imbalanced data distribution has obviously become a problem for defect recognition and detection. However, the NEU dataset shows another real problem that all classes have the same low number of images (300 defect images/class) and equally distributed.
We implement the proposed methods in PyTorch. Experiments are performed on a workstation with Linux and NVIDIA RTX 2080i GPU. Baseline experiments are performed with the original settings, where the AOI, MT, and NEU datasets are directly processed by the baseline model without augmentation. In the next round, online augmentations take part for training based on α ratio to transform images in one single online augmentation method. The online augmentation performs random operations of transformation to original images during the training process. On the other hand, the off-line pre-augmentation network runs augmentation operation from the Albumentation (Buslaev et al., 2020) library to produce all samples inside the augmentation generator G that runs separately from the target network.
Evaluation Metrics The effectiveness of our proposed method on target network is examined in terms of final prediction accuracy for unseen test images. Compared with other classification methods, accuracy (%) is used to perform the evaluation of the prediction result. The accuracy is defined as the ratio of the number of test images correctly classified to the number of all test images in the target network.
Evaluation results
We next present experimental results of the PreAugNet with ResNet-18 target network on the AOI, MT, and NEU defect inspection datasets. Since the pre-augmentation network and target network are independent, we can separately train the baseline and pre-augmentation network. We prepare the pre-augmentation network to perform searching samples in parallel, where the data management automatically collects the samples. The number of the correct samples from the classifier will be added to target network before performing the off-line augmentation.
Results on AOI dataset
The AOI dataset consists of 1854 images from five types of defects. As shown in Table 1, horizontal defect class-2 (100 images) and edge effect class-4 (240 images) have significant differences in terms of image distributions. In the case of AOI defect dataset, we conduct two scenarios to prove our off-line pre- augmentation network. The first scenario, we tackle the imbalance problem by adding more samples for the lowest class. At the initial stage of experiments, we adjust images from class-2 as the main source for generating new samples. Data management in the pre-augmentation network distributes only images from class-2 to the augmentation generator. The augmentation generator specifically generates new samples from class-2 with ratio \(\alpha \le N\) of original images. Since class-2 consists of 100 images, pre-augmentation network updates the searching process 7 times before reaching the maximum number of new samples. In the next phase, we try to generate another sample from another lower class. For class-4 our pre-augmentation network needs 5 iterations update to produce a similar number of samples. We present the result of pre-augmentation from the two classes in Table 2. We assume that the number of updates process heavily depends on the amount of original images. The more resources we have the faster searching process will be. As we can see in Table 2 adding new samples for imbalance class data improves the accuracy of the target network.
The goal of the second scenario for AOI dataset is aiming to balance all the classes. This is the typical pre-augmentation scenario where the goal of this approach is to generalize data distribution among the classes. In this case, we primarily generate more samples with more augmentation methods to the lower class and randomly set less transformation methods in higher class images. As the result, all classes share the same number of samples in the target network. The effect of this approach is the dataset will share the same average number of images. In practice, we carefully train pre-augmentation network for all classes and set the limit of \(\alpha \) in the data management module to match with the target sample distributions. With this scenario, the new samples from our pre-augmentation network successfully achieved better accuracy about 3.1% of AOI dataset compared to the baseline.
Results on the MT dataset
MT dataset is a typical steel dataset with 5 defect classes and the defect types (foreground) are very close to the background. Since MT dataset has a small number of defect images for all classes, then pre-augmentation network will be directed to produce more samples from all class distributions. The augmentation generator \({\mathbb{G}}\) produces more samples of the color transformation methods from class with a lower number to class with a higher number of images. We train the pre-augmentation network according to α ratio for all class distributions where we set α from 0.1 to 0.9 of the original image distributions (Figs. 7, 8).

Sample images of each class from the MT industrial inspection dataset. Red boxes highlight steel defects (Color figure online)

Sample images of each class from the NEU industrial inspection dataset. Red boxes highlight steel defects (Color figure online)
In the target model prediction results as presented in Table 3, after adding samples from pre-augmentation network the final accuracy increased about 5% at the maximum \(\alpha \) ratio (0.7). Despite that on-line augmentation yielded the highest accuracy about 3.7% of the baseline, Pre-augmentation consistently matches or outperforms the baseline with alteration to all lists of \(\alpha \) ratios employed. In the scenario with same \(\alpha \) ratio for all classes in Fig. 9, we also found that the new samples from pre-augmentation network surpassed the baseline after \(\alpha \)= 0.2 and achieve better accuracy at higher ratios. It seems that relatively small number of samples in the MT training dataset are not generalized well but with larger ratio and more samples added, pre-augmentation is become more robust across general on-line augmentation.

Test accuracy (%) on AOI, MT and NEU defect datasets. Comparisons across baseline, default on-line augmentation, Pre-augmentation and combination method with different \(\alpha \) ratios
Results on the NEU dataset
Because NEU dataset is composed of equally distributed images for all classes, the off-line Pre-augmentation strategy for NEU dataset may differ substantially from AOI and MT datasets. In NEU dataset, our pre-augmentation network is focused on generating new samples by increasing the number of samples for all classes equally where we set the same initial \(\alpha \) ratio for all classes during the pre-augmentation training. The pre-augmentation network simply generates new samples for all classes in the same manner for all \(\alpha \) ratios. In details, the augmentation generator produces new samples in several stages by determining the types and number of transformations accordingly that it requires several updates in the process of collecting new samples in sample pool. That means, even though during the process of updating the new samples in classifier the number of iterations required is not the same for each class, but at the end of searching process all classes will get the same number of new samples.
Our testing results are shown in Table 4. As can be seen from the results, PreAugNet improves the overall accuracy over the general augmentation and synthetic GAN method (Jain et al., 2022). Secondly, applying Pre-augmentation with \(\alpha \) ratio 0.8 achieves the highest accuracy of NEU dataset about 1.8% compared to baseline.
Experiment on the combination of augmentation methods
This section evaluates whether the off-line pre-augmentation network and on-line augmentation combined improves the prediction result. In combination augmentation mechanism, we randomly perform augmentation on the new samples and original samples during training. We re-train the target network for every 10% additional samples and capture the highest accuracy. We present several different \(\alpha \) ratios for two different augmentation approaches: off-line pre-augmentation and general on-line augmentation method. Figure 9 demonstrates how the increasing number of samples affect the accuracy of target network for all datasets. The accuracy of target network constantly matches or improves from baseline and general augmentation. The performance of off-line pre-augmentation and combination methods are particularly good on the AOI dataset, the improvement occurred in the addition of new samples starting from the small ratio. In other words, these results show that our method can indeed enlarge the defect samples in target network to produce better accuracy. The new samples from pre-augmentation network are more robust than default random on-line augmentation. This phenomenon is in line with our assumption that the pre-augmentation network only distributes samples that have been correctly selected based on the boundary in the classifier so that the new generated samples are more robust and useful for the target network (Table 5).
In Fig. 9, it can be seen that not all pre-augmentation combination produces better results compared to single on-line augmentation. Result on MT dataset, the combination methods produce unstable accuracy at higher \(\alpha \) ratio. We found that the combination method produces lower than baseline at \(\alpha \) ratio (0.3, 0.4). We assume this phenomenon occurs due to lack of data in sample pool so that some samples forwarded from pre-augmentation are identical. We also found that if the original class data was too small, the pre-augmentation network required more updates to reach the expected ratio than other classes. These multiple updates affect the searching time on our pre-augmentation network.
Limitations
We next discuss limitations regarding our method. First, we note that the arbitrary image transformation is not preferred in the augmentation searching process, since the augmentation generator needs to produce a lot more samples before an acceptable sample can be found. Likewise, the time-consuming for searching boundary is heavily depending on the total input sample to classifier. As a result, when the number of transformed samples is larger than the original image, we split the input samples in batches to be fed into the SVM classifier. Furthermore, due to various transformations in augmentation generator \({\mathbb{G}}\), the preparation of new samples can be very challenging to achieve in small iterations. Since the position boundary heavily depends on the quality of features, low-quality samples can weaken the searching process or even failed to improve the decision boundary. If this happens, re-running the process for another iteration can typically resolve the issue.
Conclusion
In this work, we design the Pre-Augmentation Network (PreAugNet) for generating and screening augmented samples to improve data augmentation in training a target network. The PreAugNet iteratively retrieves CNN features from the raw samples to improve the generated samples, where the updating process is governed by an SVM classifier with decision boundary analysis. This way, the new samples produced from the PreAugNet are much more diverse and suitable for effective data augmentation. The effectiveness of this approach is evaluated on the industrial defect recognition problem over three real-world datasets. We compare our PreAugNet with multiple data augmentation approaches, and we also compare our end-to-end pipeline with multiple state-of-the-art surface defect classification methods. Extensive experiments show that the PreAugNet with a standard ResNet-18 target network can achieve 3.3% accuracy improvement on the AOI dataset, 6.25% on the MT dataset, and 2.1% on the NEU dataset. Results demonstrate the effectiveness of the PreAugNet data augmentation in improving the training of a defect classification network.
Future work
Joint training solutions have great potential in reducing training costs and time for real-world applications. Future work includes tighter integration of the proposed pre-augmentation network with the target network, such that better training performance might be obtained. Also, our approach can be deployed in other real-world applications where data scarcity remains the bottleneck.
Data availability
The datasets analysed during the current study are publicly available.
Code availability
Not applicable.
References
Abiodun, O. I., Jantan, A., Omolara, A. E., Dada, K. V., Mohamed, N. A., & Arshad, H. (2018). State-of-the-art in artificial neural network applications: a survey. Heliyon, 4(11), e00938.
Abu, M., Amir, A., Lean, Y., Zahri, N., & Azemi, S. (2021). The performance analysis of transfer learning for steel defect detection by using deep learning. Journal of Physics: Conference Series, 1755(1), 012041.
Bowles, C., Chen, L., Guerrero, R., Bentley, P., Gunn, R., Hammers, A., Dickie, D. A., Hernández, M. V., Wardlaw, J., & Rueckert, D. (2018). Gan augmentation: Augmenting training data using generative adversarial networks. Preprint retrieved from https://arxiv.org/abs/1810.10863.
Burrascano, P. (1991). Learning vector quantization for the probabilistic neural network. IEEE Transactions on Neural Networks, 2(4), 458–461.
Buslaev, A., Iglovikov, V. I., Khvedchenya, E., Parinov, A., Druzhinin, M., & Kalinin, A. A. (2020). Albumentations: Fast and flexible image augmentations. Information, 11(2), 125.
Chen, H., Pang, Y., Hu, Q., & Liu, K. (2020). Solar cell surface defect inspection based on multispectral convolutional neural network. Journal of Intelligent Manufacturing, 31, 453–468.
Cheon, S., Lee, H., Kim, C. O., & Lee, S. H. (2019). Convolutional neural network for wafer surface defect classification and the detection of unknown defect class. IEEE Transactions on Semiconductor Manufacturing, 32(2), 163–170.
Choe, J., Lee, S., & Shim, H. (2020). Attention-based dropout layer for weakly supervised single object localization and semantic segmentation. IEEE Transactions on Pattern Analysis and Machine Intelligence, 43(12), 4256–4271.
Czimmermann, T., Ciuti, G., Milazzo, M., Chiurazzi, M., Roccella, S., Oddo, C. M., & Dario, P. (2020). Visual-based defect detection and classification approaches for industrial applications—A survey. Sensors, 20(5), 1459.
DeVries, T., & Taylor, G. W. (2017). Improved regularization of convolutional neural networks with cutout. Preprint retrived from https://arxiv.org/abs/1708.04552.
Elleuch, M., Maalej, R., & Kherallah, M. (2016). A new design based-SVM of the CNN classifier architecture with dropout for offline Arabic handwritten recognition. Procedia Computer Science, 80, 1712–1723.
Farady, I., Lin, C. Y., Akhyar, F., Roshini, R., & Alex, J. S. R. (2021). Evaluation of data augmentation on surface defect detection. 2021 IEEE international conference on consumer electronics-Taiwan (ICCE-TW). IEEE.
Farady, I., Sarkar, M. D., Chang, W. T., & Lin, C. Y. (2022). Evaluation of additional augmented images for steel surface defect detection. 2022 IEEE international conference on consumer electronics-Taiwan (pp. 1–2). IEEE.
Frid-Adar, M., Diamant, I., Klang, E., Amitai, M., Goldberger, J., & Greenspan, H. (2018). GAN-based synthetic medical image augmentation for increased CNN performance in liver lesion classification. Neurocomputing, 321, 321–331.
Ghiasi, G., Lin, T. Y., & Le, Q. V. (2018). Dropblock: A regularization method for convolutional networks. Advances in Neural Information Processing Systems, 31, 1–10.
Goodfellow, I., Pouget-Abadie, J., Mirza, M., Xu, B., Warde-Farley, D., Ozair, S., Courville, A., & Bengio, Y. (2020). Generative adversarial networks. Communications of the ACM, 63(11), 139–144.
He, K., Gkioxari, G., Dollár, P., & Girshick, R. (2017). Mask r-cnn. Proceedings of the IEEE international conference on computer vision (pp. 2961–2969). IEEE.
He, K., Zhang, X., Ren, S., & Sun, J. (2016). Deep residual learning for image recognition. Proceeding of the IEEE conference on computer vision and pattern recognition (pp. 770–778). IEEE.
He, Y., Song, K., Dong, H., & Yan, Y. (2019a). Semi-supervised defect classification of steel surface based on multi-training and generative adversarial network. Optics and Lasers in Engineering, 122, 294–302.
He, Y., Song, K., Meng, Q., & Yan, Y. (2019b). An end-to-end steel surface defect detection approach via fusing multiple hierarchical features. IEEE Transactions on Instrumentation and Measurement, 69(4), 1493–1504.
Hernández-García, A., & König, P. (2018). Data augmentation instead of explicit regularization. Preprint retrieved from https://arxiv.org/abs/1806.03852.
Huang, Y., Qiu, C., Wang, X., Wang, S., & Yuan, K. (2020a). A compact convolutional neural network for surface defect inspection. Sensors, 20(7), 1974.
Huang, Y., Qiu, C., & Yuan, K. (2020b). Surface defect saliency of magnetic tile. The Visual Computer, 36, 85–96.
Jain, S., Seth, G., Paruthi, A., Soni, U., & Kumar, G. (2022). Synthetic data augmentation for surface defect detection and classification using deep learning. Journal of Intelligent Manufacturing, 2022, 1–14.
Joshi, K. D., Chauhan, V., & Surgenor, B. (2020). A flexible machine vision system for small part inspection based on a hybrid SVM/ANN approach. Journal of Intelligent Manufacturing, 31, 103–125.
Kang, J., Park, Y. J., Lee, J., Wang, S. H., & Eom, D. S. (2017). Novel leakage detection by ensemble CNN-SVM and graph-based localization in water distribution systems. IEEE Transactions on Industrial Electronics, 65(5), 4279–4289.
Krizhevsky, A., Sutskever, I., & Hinton, G. E. (2017). Imagenet classification with deep convolutional neural networks. Communications of the ACM, 60(6), 84–90.
Kumar, A. (2008). Computer-vision-based fabric defect detection: a survey. IEEE Transactions on Industrial Electronics, 55(1), 348–363.
LeCun, Y., Bottou, L., Bengio, Y., & Haffner, P. (1998). Gradient-based learning applied to document recognition. Proceedings of the IEEE, 86(11), 2278–2324.
Li, C., Xu, T., Zhu, J., & Zhang, B. (2017). Triple generative adversarial nets. Advances in Neural Information Processing Systems, 30, 1.
Liu, W., Anguelov, D., Erhan, D., Szegedy, C., Reed, S., Fu, C.-Y., & Berg, A. C. (2016). Ssd: Single shot multibox detector. Computer Vision–ECCV 2016: 14th European Conference, The Netherlands, October 11–14, 2016.
Liu, M. Y., & Tuzel, O. (2016). Coupled generative adversarial networks. Advances in Neural Information Processing Systems, 29, 1.
Luo, Q., Fang, X., Liu, L., Yang, C., & Sun, Y. (2020). Automated visual defect detection for flat steel surface: A survey. IEEE Transactions on Instrumentation and Measurement, 69(3), 626–644.
Mao, K. Z., Tan, K. C., & Ser, W. (2000). Probabilistic neural-network structure determination for pattern classification. IEEE Transactions on Neural Networks, 11(4), 1009–1016.
Marino, S., Beauseroy, P., & Smolarz, A. (2020). Unsupervised adversarial deep domain adaptation method for potato defects classification. Computers and Electronics in Agriculture, 174, 105501.
Meireles, M. R., Almeida, P. E., & Simões, M. G. (2003). A comprehensive review for industrial applicability of artificial neural networks. IEEE Transactions on Industrial Electronics, 50(3), 585–601.
Ngan, H. Y., Pang, G. K., & Yung, N. H. (2011). Automated fabric defect detection—a review. Image and Vision Computing, 29(7), 442–458.
Niu, X. X., & Suen, C. Y. (2012). A novel hybrid CNN–SVM classifier for recognizing handwritten digits. Pattern Recognition, 45(4), 1318–1325.
Pan, H., Pang, Z., Wang, Y., Wang, Y., & Chen, L. (2020). A new image recognition and classification method combining transfer learning algorithm and mobilenet model for welding defects. Ieee Access, 8, 119951–119960.
Park, J. K., Kwon, B. K., Park, J. H., & Kang, D. J. (2016). Machine learning-based imaging system for surface defect inspection. International Journal of Precision Engineering and Manufacturing-Green Technology, 3, 303–310.
Redmon, J., Divvala, S., Girshick, R., & Farhadi, A. (2016). You only look once: unified, real-time object detection. Proceedings of the EEE conference on computer vision and pattern recognition (pp. 779–788). IEEE.
Ren, S., He, K., Girshick, R., & Sun, J. (2015). Faster r-cnn: Towards real-time object detection with region proposal networks. Advances in Neural Information Processing Systems, 28, 1.
Ronneberger, O., Fischer, P., & Brox, T. (2015). U-net: Convolutional networks for biomedical image segmentation. Medical Image Computing and Computer-Assisted Intervention–MICCAI 2015: 18th International Conference, Munich, Germany, October 5-9, 2015, Proceedings, Part III 18, 234-241
Saito, K., Kim, D., Sclaroff, S., & Saenko, K. (2020). Universal domain adaptation through self supervision. Advances in Neural Information Processing Systems, 33, 16282–16292.
Saritas, M. M., & Yasar, A. (2019). Performance analysis of ANN and Naive Bayes classification algorithm for data classification. International Journal of Intelligent Systems and Applications in Engineering, 7(2), 88–91.
Shorten, C., & Khoshgoftaar, T. M. (2019). A survey on image data augmentation for deep learning. Journal of Big Data, 6(1), 1–48.
Simonyan, K., & Zisserman, A. (2014). Very deep convolutional networks for large-scale image recognition. Preprint retrived from https://arxiv.org/abs/1409.1556.
Singh, K. K., & Lee, Y. J. (2017). Hide-and-seek: Forcing a network to be meticulous for weakly-supervised object and action localization. IEEE International Conference on Computer Vision (ICCV), 2017, 3544–3553.
Sun, X., Liu, L., Li, C., Yin, J., Zhao, J., & Si, W. (2019). Classification for remote sensing data with improved CNN-SVM method. Ieee Access, 7, 164507–164516.
Szegedy, C., Vanhoucke, V., Ioffe, S., Shlens, J., & Wojna, Z. (2016). Rethinking the inception architecture for computer vision. Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 2818–2826). IEEE.
Tan, M., & Le, Q. (2019). Efficientnet: rethinking model scaling for convolutional neural networks. International Conference on Machine Learning, 2019, 6105–6144.
Vapnik, V. N. (1999). An overview of statistical learning theory. IEEE Transactions on Neural Networks, 10(5), 988–999.
Wong, S. C., Gatt, A., Stamatescu, V., & McDonnell, M. D. (2016). Understanding data augmentation for classification: when to warp? 2016 international conference on digital image computing: techniques and applications (DICTA) (pp. 1–6). IEEE.
Xue, D. X., Zhang, R., Feng, H., & Wang, Y. L. (2016). CNN-SVM for microvascular morphological type recognition with data augmentation. Journal of Medical and Biological Engineering, 36, 755–764.
Yang, S., Wang, Y., Van De Weijer, J., Herranz, L., & Jui, S. (2021). Generalized source-free domain adaptation. Proceedings of the IEEE/CVF International Conference on Computer Vision (pp. 8978–8987). IEEE.
Yun, J. P., Shin, W. C., Koo, G., Kim, M. S., Lee, C., & Lee, S. J. (2020). Automated defect inspection system for metal surfaces based on deep learning and data augmentation. Journal of Manufacturing Systems, 55, 317–324.
Yun, S., Han, D., Oh, S. J., Chun, S., Choe, J., & Yoo, Y. (2019). Cutmix: Regularization strategy to train strong classifiers with localizable features. Proceeding of the IEEE/CVF international conference on computer vision (pp. 6023–6032). IEEE.
Zhang, H., Cisse, M., Dauphin, Y. N., & Lopez-Paz, D. (2017). mixup: Beyond empirical risk minimization. Preprint retrived from https://arxiv.org/abs/1710.09412.
Zhang, S., Zhang, Q., Gu, J., Su, L., Li, K., & Pecht, M. (2021a). Visual inspection of steel surface defects based on domain adaptation and adaptive convolutional neural network. Mechanical Systems and Signal Processing, 153, 107541.
Zhang, W., Li, X., Ma, H., Luo, Z., & Li, X. (2021b). Transfer learning using deep representation regularization in remaining useful life prediction across operating conditions. Reliability Engineering & System Safety, 211, 107556.
Zhang, W., Li, X., Ma, H., Luo, Z., & Li, X. (2021c). Universal domain adaptation in fault diagnostics with hybrid weighted deep adversarial learning. IEEE Transactions on Industrial Informatics, 17(12), 7957–7967.
Zhang, Y., Wang, Y., Jiang, Z., Zheng, L., Chen, J., & Lu, J. (2022). Tire Defect Detection by Dual-Domain Adaptation-Based Transfer Learning Strategy. IEEE Sensors Journal, 22(19), 18804–18814.
Zhong, J., Liu, X., & Hsieh, C.J. (2020a). Improving the speed and quality of gan by adversarial training. Preprint retrieved from https://arxiv.org/abs/2008.03364.
Zhong, Z., Zheng, L., Kang, G., Li, S., & Yang, Y. (2020b). Random erasing data augmentation. Proceedings of the AAAI Conference on Artificial Intelligence, 13(7), 13001–13008.
Zhu, J. Y., Park, T., Isola, P., & Efros, A. A. (2017). Unpaired image-to-image translation using cycle-consistent adversarial networks. Proceedings of the IEEE international conference on computer vision (pp. 2223–2232). IEEE.
Funding
This study was funded by Ministry of Science and Technology, Taiwan (MOST 110-2221-E-155-039-MY3).
Author information
Authors and Affiliations
Contributions
All authors contributed to the design and implementation of the research. All authors read and approved the final manuscript.
Corresponding author
Ethics declarations
Competing interest
The authors declare that they have no competing interests.
Ethical approval
This article does not contain any studies with human participants or animals performed by any of the authors.
Informed consent
Not applicable.
Consent for publication
Not applicable.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Farady, I., Lin, CY. & Chang, MC. PreAugNet: improve data augmentation for industrial defect classification with small-scale training data. J Intell Manuf 35, 1233–1246 (2024). https://doi.org/10.1007/s10845-023-02109-0
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10845-023-02109-0