
Abstract
In this research, a hybrid constrained permutation algorithm and genetic algorithm approach is proposed to solve the process planning problem and to facilitate the optimisation process. In this approach, the process planning problem is represented as a graph in which operations are clustered corresponding to their machine, tool, and tool access direction similarities. A constrained permutation algorithm (CPA) developed to generate a set of optimised feasible operations sequences based on the principles of minimising the number of setup changes and the number of tool changes. Due to its strong capability in global search through multiple optima, genetic algorithm (GA) is used to search for an optimal or near optimal process plan, in which the population is initialised according to the operations sequences generated by CPA. Furthermore, to prevent premature convergence to local optima, a mixed crossover operator is designed and equipped into GA. Four comparative case studies are carried out to evidence the feasibility and robustness of the proposed CPAGA approach against GA, simulated annealing, tabu search, ant colony optimisation, and particle swarm optimisation based approaches reported in the literature, and the results are promising.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
Introduction
Computer-aided process planning (CAPP) is substantial linkage between computer-aided design (CAD) and computer-aided manufacturing (CAM). It aims to transform acquired part design specification from CAD into a sequence of machining operations that are used by CAM to manufacture a part economically and competitively. Although much effort has been exerted to evolve CAPP systems, they are still lagging behind in comparison with CAD and CAM systems. One of the reasons CAPP is falling behind is due to the tremendously complex nature of its tasks (Al-wswasi et al. 2018). Generally, CAPP is concerned with maintaining three main tasks, namely, feature recognition, operation selection, and operation sequencing. Feature recognition is the act of recognising the machining features from a CAD file that a part is comprised of. Operation selection is the act of selecting the necessary operations needed to produce a part. Operation sequencing is the act of determining the sequence of operations by which a part should be produced while satisfying the precedence constraints among operations.
It is well-known that operation sequencing is regarded as an NP-hard problem, which is very difficult to solve using conventional techniques. Even though many metaheuristic-based approaches have been proposed to solve the operation sequencing optimisation problem, it is difficult to handle the precedence constraints among operations efficiently. In general, precedence constraints handling methods and strategies can be categorized into additional adjustment strategies and repairing strategies. The additional adjustment strategies, such as edge selection strategy (Su et al. 2018) and intelligent search strategy (Salehi and Bahreininejad 2011), evades infeasible solutions in initialisation. Premature convergence in some complicated precedence constraints cases is considered its main drawback (Su et al. 2018; Li et al. 2004). On the other hand, the repairing strategies, such as a penalty matrix strategy (Liu et al. 2013; Nallakumarasamy et al. 2011) and a topological storing and encoding strategy (Huang et al. 2012; Yun and Moon 2011), tries to rectify the infeasible solutions that conflict with the precedence constraints. Unreliability and low efficiency are its main drawbacks (Yun and Moon 2011; Moon et al. 2002). In this research, a novel constrained permutation algorithm has been established and combined with Genetic algorithm (GA) to solve the operations sequencing and operation selections problems simultaneously. GA effectiveness has been practically demonstrated in solving sophisticated combinatorial optimization problems. As opposite to other meta-heuristics, GA has the ability to direct the search toward relatively promising regions in the problem’s search space (Zacharia et al. 2015). The contribution of this research is as follows:
-
1.
A new graph-based representation of the process planning problem has been developed. In which, operations are clustered corresponding to their machine, tool, and tool access direction (TAD) similarities. The graph consists of a set of operations that can be machined in one setup (OSS) nodes, a set of operations that can be machined by one tool in one setup (OTS) nodes, operation (O) nodes, directed arcs, and undirected arcs. Undirected arcs represent the inclusion relationship between OSS, OTS, and O nodes, on the other hand, directed arcs represent precedence constraints between OSS nodes, OTS nodes, and O nodes.
-
2.
A novel constrained permutation algorithm has been established to generate an initial set of operations sequences. First, the algorithm is used to initiate the OSS, OTS, and O nodes. Second, several graphs depending on the part complexity are generated by applying the part precedence constraints among OSS nodes, OTS nodes, and O nodes. Finally, for each graph, a constrained permutation is performed among OSS nodes and OTS nodes, and the operations sequences are acquired by replacing OTS nodes by O nodes.
-
3.
A mixed crossover operator that comprises an order crossover operator and a new designed three strings crossover operator is developed to avoid premature convergence to local optima and to enhance the performance of GA in searching for an optimal or near optimal process plan.
The rest of this article is organised as follows. Section in “Previous related work” gives an overview of previous related work about metaheuristic-based approaches applied to the process planning problem. Section in “Problem modelling” elaborates on the process planning problem representation. Details of the proposed CPAGA approach is presented in “Hybrid CPA and GA Approach” section. Section in “Comparative case studies” illustrates the effectiveness of the proposed CPAGA approach through four comparative case studies. Section in “Conclusions” concludes the article.
Previous related work
In the past two decades, many metaheuristic-based approaches proposed to solve the process planning problem, which can be categorised as genetic algorithm (GA) based approach (Salehi and Bahreininejad 2011; Huang et al. 2012; Zhang et al. 1997; Reddy et al. 1999; Dou et al. 2018b; Salehi and Tavakkoli-Moghaddam 2009; Musharavati and Hamouda 2011; Su et al. 2015), simulated annealing (SA) based approach (Ma et al. 2000; Nallakumarasamy et al. 2011), GA-SA based approach (Li et al. 2002; Huang et al. 2017; Xu et al. 2014) , ant colony optimisation (ACO) based approach (Liu et al. 2013; Krishna and Mallikarjuna Rao 2006; Hu et al. 2017; Wang et al. 2015), particle swarm optimisation (PSO) based approach (Dou et al. 2018a; Petrović et al. 2016; Wang et al. 2012; Guo et al. 2006; Li et al. 2013), and tabu search (TS) based approach (Li et al. 2004).
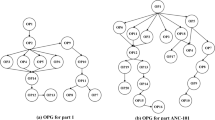
Zhang et al. (1997) presented a novel GA based approach to handle the operations sequencing and the operation resources selection of the process planning problem simultaneously. Optimal or near optimal process plans were achieved through specially designed crossover and mutation operators. Reddy et al. (1999) used GA as a global search by developing a novel chromosome representation schema for the process plan. In their approach, operation sequences were obtained quickly, and a special crossover operator to maintain them in the chromosomes was well-intended. Salehi and Tavakkoli-Moghaddam (2009) proposed an approach in which the process planning problem was handled in two stages: preliminary and secondary. In the preliminary stage, a set of feasible operation sequences was generated, while in the secondary stage, the manufacturing resources selected for each specific operation were handled. GA was used as an optimisation technique in the two stages. In the same manner, but instead, using GA in the preliminary stage, Salehi and Bahreininejad (2011) developed an intelligent search algorithm to generate a set of feasible operation sequences. The results show better computation time in comparison with the two stages of GA. Su et al. (2015) presented a hybrid approach that incorporated GA with a local search to minimise the machining cost and maximise the utilisation of the machine tools, based on a 0–1 mixed integer model. First, the feasible initial process plans were generated by using an operation precedence graph (OPG), then the hybrid GA and the local search were used to find the optimal process plan.
Moreover, Huang et al. (2012) embedded the graph theory escort with the matrix theory into GA to deal with precedence constraints and generate initial feasible operation sequences. A special crossover operator and two types of mutation operators were developed and a heuristic algorithm to modify the infeasible solutions generated by the mutation was also introduced. Furthermore, a modified GA based on a cyclic crossover operator and a neighbourhood search mutation operator were developed by Musharavati and Hamouda (2011) to obtain a near optimal process plan of multiple parts manufacturing lines. Su et al. (2018) proposed an edge selection strategy to produce feasible operation sequences in the initialisation of GA for the purpose of improving GA convergence. The operation sequences kept up through a special crossover, furthermore, a mutation operator was designed to optimise the resources selection. Dou et al. (2018b) presented an improved genetic algorithm (IGA) to minimise the cost of process plans. The feasible operation sequences were encoded by permutation. Furthermore, fragment crossover and fragment mutations were designed to maintain the operation sequences in the chromosomes. A comparison of IGA against GA, ACO, and PSO was carried out through two case studies, and a better solution was reported.
In regard to SA, Ma et al. (2000) developed SA based approach to find the optimal process plan by exploring the entire solution space. Tool cost, machine cost, tool change cost, machine change cost, and setup change cost were regarded as objective functions. Nallakumarasamy et al. (2011) used the SA algorithm to minimise machine, tool, and setup costs as an objective. A reward penalty matrix and a cost matrix were used to generate the feasible operation sequences. Their experiments showed lesser computational time and better generated operation sequences. In addition to the use of SA, Li et al. (2002) proposed a hybrid GA-SA approach to produce a set of optimal or near optimal process plans, with consideration of a dynamic job shop environment such as the unavailability of machines and tools. The GA was used as a global search, initially to explore better process plans, while SA was used as a local search to find optimal or near optimal process plans. Furthermore, Xu et al. (2014) developed genetic simulated annealing (GSA) algorithm to find a near optimal process plan with a high complexity precedence constraint cylinder block. Huang et al. (2017) proposed a hybrid GA-SA approach, in which a graph search algorithm was embedded and the precedence constraints formulated as an OPG directed graph. GA with a stochastic topologic sort algorithm was used as a global search to generate the initial feasible operation sequences, and then SA was used as a local search to find the optimal process plan.
With respect to ACO, Krishna and Mallikarjuna Rao (2006) modelled the process planning problem as a constrained travelling salesman problem (TSP) and adopted ACO for the first time to solve it. An ACO algorithm was used as a global search for finding the optimal operations sequence by considering various feasibility constraints. In a similar manner, Liu et al. (2013) used an ACO algorithm to search for the lowest cost sequence of operations. They embedded a constraint matrix and a state matrix into the ACO algorithm to show the operations state. Two study cases were investigated to show the advantage of this approach over GA, SA, and TS, and the results were promising. Hu et al. (2017) developed a novel modified ACO to solve the combinatorial optimisation problem of operation sequencing. An adaptive updating method and a local search mechanism are embedded into ACO to enhance the global search capability and to avoid the local optima. A comparison with GA, SA, TS and PSO was carried out to ensure feasibility and robustness, as well as to show the advantages of their proposed approach. In addition, Wang et al. (2015) proposed two-stage ACO algorithms (TSACO) to find the minimum total production cost. The process planning problem was modelled as a directed AND/OR graph, and one of the ACOs was used to optimise the nodes in the first stage, while the other was used to optimise the weighted arcs in the second stage.
In regard to PSO, Guo et al. (2006) developed a PSO algorithm to solve the combinatorial optimisation problem of operation sequencing. New designed crossover, mutation and shift operators were employed to avoid the local optima, and the result was satisfactory in comparison with GA and SA. Wang et al. (2012) developed a PSO with a local search strategy to avoid any unnecessary convergence that may occur in early generations. A solution scheme was offered to decode the discrete nature of the process planning problem in order to remedy the obstacle that PSO is designed for the continuous optimisation problem. Petrović et al. (2016) introduced chaos theory into PSO to prevent premature convergence and to enlarge the solution space of the AND/OR process plans network. Their approach was extensively verified through a comparison with GA, SA, GA-SA, and PSO in four experimental studies. Dou et al. (2018a) presented a novel feasible sequence discrete PSO (FSDPSO) to search for feasible operation sequences. Updating mechanism crossover, fragment mutation, and uniform greedy mutations were developed to enhance FSDPSO performance. Finally, the results showed an advantage of their approach against GA and two-stage ACO. Furthermore, efficient encoding, updating, and random search methods were developed and incorporated into PSO by Li et al. (2013). A comparison of their approach with GA and SA in seven cases was reported, and the results were satisfactory.
In addition to GA, SA, ACO, and PSO based approaches, Wen et al. (2014) proposed honey bees mating optimisation (HBMO) for the first time to solve the process planning problem. Three experiments were reported and HBMO showed better performance in comparison with well-known metaheuristic algorithms. Li et al. (2004) modelled the process planning problem as a constraint-based optimisation problem, in which the resources selection and operation sequences were treated simultaneously. A hybrid constraint-handling method is developed and embedded in a TS algorithm to handle the operation sequencing problem and conduct the search efficiently in a large-sized constraint-based space. Lian et al. (2012) utilised a novel metaheuristic-inspired imperialist competitive algorithm (ICA) to obtain a near optimal process plan. The process planning problem was modelled considering various flexibilities, i.e., machine, tool, TAD, process, and sequence flexibilities. The proposed algorithm emphasises its efficiency in comparison with other metaheuristic algorithms. Ding et al. (2005) developed a hybrid approach that incorporates an artificial neural network (ANN), an analytical hierarchical process (AHP), and GA for optimising operation sequences. A multi-objective function was established that incorporates minimising manufacturing time and cost to evaluate candidates’ process plans.

Graphical representation of the process planning problem
Through the above analysis, it could be deduced that each approach has its own advantages and disadvantages. Nevertheless, two issues are still ongoing and necessitate more attention. The first issue is that the flexibility of machines, tools, and TADs produces a large solution space for the process planning problem. The second issue is the precedence constraints handling strategies. Repairing strategies are unreliable, inefficient, and time consuming since they try to modify infeasible solutions after the process of generating them. In comparison to repairing strategies, additional adjustment strategies try to initiate a feasible solution before the process of searching for an optimal or near optimal one. In addition to suffering from the premature convergence problem, the initiated solutions are feasible, but they are not the best in the solution space, which could result in much time spent searching for the optimal or near optimal process plan. Much effort is required to design a model for the process planning problem that minifies the initial solution space to be restricted to good solution candidates only. Furthermore, there is a critical need for a new method to handle precedence constraints more effectively and efficiently.
Problem modelling
In CAPP, a process plan is described as a set of machining features that can be machined in a specific features sequence using specific manufacturing resources. First, machining features are recognised by the topological and geometrical information gained from a CAD file, such as dimension, surface finish, and position. Then an operation (O) or several operations are assigned to each machining feature, depending on its information. An operation is comprised of a set of candidate operations (CO), which is the use of a specific tool (T) on a specific machine (M) with a specific tool access direction (TAD) to produce a feature or sub-feature. Therefore, a process plan can be presented as follows:
where PP is the process plan, \(O_{i}\) is the ith operation of the process plan, which is defined as:
Where \(CO_{i, M, T,TAD}\) is the Mth, Tth, and TADth alternative operation of the ith operation of the process plan. M, T, and TAD are the indices of the machine, tool, and TAD, respectively, by which \( CO_{i} \) is formed by its machine flexibility list (M []), tool flexibility list (T []), and TAD flexibility list (TAD []). on other hand, a setup defined as a set of operation that can be machined continuously on same machine with the same TAD (Li et al. 2004). That’s it:
Where \(OSS_{s}\) is the sth set of operations of the process plan that can be machined in one setup, s is the index of setup that indicate M and TAD similarities of operations. OSS can be defined as:
Furthermore, within OSS there are operations that may be machined using same tool, therefore:
Where OTS is the Tth set of operations of OSS that can be machined using one tool which is defined as:
Finally, according Eq. (3), Eq. (5), and Eq. (6) a process plan can be represented as follows:
In order to implement the proposed approach, the process planning problem has to be represented as a graph, as shown in Fig. 1. The graph is denoted as \(G= (N, R)\), where N is a set of OSS, OTS, and O nodes and R is a set of directed and undirected arcs.Undirected arcs represent the inclusion relationships between OSS, OTS, and O nodes. For example, \( OSS_{1} \) is a parent of \( OTS_{1} \) and \( OTS_{2} \), \( OTS_{1} \) is a parent of \( O_{1} \), and \( OTS_{2} \) is a parent of \( O_{3} \), \( O_{4} \), and \( O_{5} \), and so on. On the other hand, directed arcs represent the precedence constraints between OSS nodes, OTS nodes, and O nodes. For example, the directed arc between \( O_{3} \) and \( O_{4} \) represents a part precedence constraint between these two operations, and the directed arc between \( OTS_{1} \) and \( OTS_{2} \) of \( OSS_{2} \) represents a part precedence constraint between one (or more) of the \( OTS_{1} \) child nodes and \( O_{14} \), a child of \( OTS_{2} \).
Knowledge-based production rules established to construct OSS and OTS nodes and to analyse the precedence constraints are placed in Table 1. Rules 1 to 4 are used to maintain different cases that may occur in OSS nodes construction, while Rule 5 is used to construct the OTS nodes. Regarding the precedence constraints analysis, Rules 6 and 7 are used to handle the problem of bidirectional precedence constraints that may occur when generalising the part precedence constraints from operation level into OTS or OSS level. Finally, Rule 8 is used to handle complex precedence constraints between the OSS nodes or OTS nodes.
Hybrid CPA and GA approach
GA starts with an initial set of random solutions called population (chromosomes). Each chromosome in the population representing a solution to the problem that satisfies the problem constraints. During each iterative procedure, the chromosomes are evaluated according to the problem objective or objectives. The best chromosomes are selected from the current population to form the population of the next generation by the crossover process. A mutation process is also performed on the chromosomes to prevent premature convergence through slight deformation that is to be conducted of the chromosome structure (Zacharia et al. 2018). Generally, the GA after number of iterations converges to the best chromosome, which represents the best solution to the problem. The proposed approach is comprised of CPA and GA As shown in Fig. 2. First, CPA is used to reduce the solution space through generating an optimised feasible operation sequence based on the part database and the principles of minimising the number of machine changes, the number of setup changes, and the number of tool changes. Then GA is used to optimise the manufacturing resources for these generated sequences, with the objective of finding the optimal process plan.

Block diagram of the proposed CPAGA
Constrained permutation algorithm (CPA)
In CPA, the production rules, established “Problem modelling” in section were used to construct OSS and OTS nodes and to analyse the precedence constraints between them. Furthermore, constrained permutation was performed for both OSS and OTS nodes to explore all the operation sequences alternatives. The idea is to generate an OSS sequence (OSSS), then each OSS node in OSSS is replaced by OTS sequences (OTSS). Finally, by replacing the OTS nodes by CO, the operation sequences are obtained. The CPA algorithm steps are as follows:
-
Step 1:
Initialize OSS nodes using Rule 1, Rule 2, Rule 3, and Rule 4 respectively, and generate a POSS.
-
Step 2:
For \( POSS_{i} \), \( (i= 1, \ldots , n) \), if \( i > n \) stop, otherwise go to Step 3.
-
Step 3:
Apply the part precedence constraints between OSS nodes.
-
Step 4:
Apply Rule 6, if Rule 6 two conditions achieved go to Step 2 otherwise go to Step 3.
-
Step 5:
Apply Rule 5 to create OTS nodes, and create OTS node for each operation that doesn’t follow Rule 5.
-
Step 6:
Apply the part design precedence constraints between OTS nodes.
-
Step 7:
Apply Rule 7, and go to Step 6.
-
Step 8:
Apply Rule 8.
-
Step 9:
Initialize
-
Step 9.1:
G(OSS, R) graph.
-
Step 9.2:
Computation matrix \( A_{ij}= [OSS_{s}, s] \), ( \(OSS_{s} \) is the vector of OSS nodes in G(OSS, R) , s is the number of OSS nodes).
-
Step 9.3:
Permitted nodes vector \(OSS_{p}\) (\(OSS_{p}\) is the set of OSS predecessors’ nodes in G(OSS, R) ).
-
Step 9.1:
-
Step 10:
Generate OSS sequences (\( OSSS_{k} \)) in co-factor expression, \( OSSS_{k} = OSS_{p} + A_{ij} \), for each matched node between \( OSS_{p} \) and the first row of \( A_{ij} \).
-
Step 11:
For \( OSSS_{k} \), update G(OSS, R) by removing the matched nodes between \( OSS_{p} \) and \( A_{ij} \), and update \( OSS_{p} \) and \( A_{ij} \).
-
Step 12:
Set \( OSSS_{k} = OSSS_{k} + OSS_{p} \).
-
Step 13:
If \( A_{ij} \) is empty store \( OSSS_{k} \) and go to Step 14, otherwise go to Step 11.
-
Step 14:
For \( OSS_{i} \), \( (i= 1, \ldots , s) \), if \( i > s \) go to Step 22.
-
Step 15:
Initialize
-
Step 15.1:
G(OTS, R) graph.
-
Step 15.2:
Computation matrix \( B_{ij}= [OTS_{T} , T] \), (\( OTS_{T} \) is the vector of OTS nodes in G(OTS, R)) , T is the number of OTS nodes).
-
Step 15.3:
Permitted nodes vector \( OTS_{p} \) (\( OTS_{p} \) is the set of OTS predecessors’ nodes in G(OTS, R))
-
Step 15.1:
-
Step 16:
Generate OTS sequences \( (OTSS_{h}) \) in co-factor expression, \( OTSS_{h} = OTS_{p}+ B_{ij} \), for each matched node between \( OTS_{p} \) and the first row of \( B_{ij} \).
-
Step 17:
For \( OTSS_{h} \), updateG(OTS, R) by removing the matched nodes between \( OTS_{p} \) and \( B_{ij} \), and update \( OTS_{p} \).
-
Step 18:
Set \( OTSS_{h} = OTSS_{h} + OTS_{p} \).
-
Step 19:
If \( B_{ij} \) is empty go to Step 20, otherwise go to Step 17.
-
Step 20:
Update \( OSSS_{k} \) via permutation of \( OTSS_{h} \) into \( OSS_{i} \) of \( OSSS_{k} \).
-
Step 21:
Clear \( OTSS_{h} \), and go to Step 14.
-
Step 22:
Replace OTS nodes in \( OSSS_{k} \) by its comprising operations randomly with consideration of precedence constraints.
-
Step 23:
Generate operation sequences \( (OS_{i}) \), set \( OS_{i} = OS_{i} + OSSS_{k} \), clear \( OSSS_{k} \), and go to 2.

Part 1 with 14 manufacturing feature (Li et al. 2004)
The prismatic Part 1 in Fig. 3 reported by Li et al. (2004) is used as an example to clarify some CPA steps. The part manufacturing information and the precedence constraints are listed in Table 2. The part was reported with two types of precedence constraints: hard and soft. Hard constraints influence the manufacturing feasibility, and a process plan should be consistent with these constraints. On the other hand, soft constraints influence only the cost, quality, or efficiency of a process plan. To attain the lowest production cost, soft constraints can be violated in case they conflict with hard constraints (Li et al. 2004). In Part 1, the soft constraints 8 \( \rightarrow \) 9 and 10 \( \rightarrow \) 12 conflict with the hard constraints 9 \( \rightarrow \) 8 and 12 \( \rightarrow \) 10 respectively, and, since soft constraints can be violated, four possibilities occur for applying soft constraints to each other. The possibilities for applying the soft constraints are 9 \( \rightarrow \) 8 and 10 \( \rightarrow \) 12, 8 \( \rightarrow \) 9 and 10 \( \rightarrow \) 12, 9 \( \rightarrow \) 8 and 12 \( \rightarrow \) 10, or 8 \( \rightarrow \) 9 and 12 \( \rightarrow \) 10. The clarification of CPA confines the first possibility that implies applying constraints 9 \( \rightarrow \) 8 and 10 \( \rightarrow \) 12 and neglecting constraints 8 \( \rightarrow \) 9 and 12 \( \rightarrow \) 10.
In Step 1, Rule 1 removes TADs + z and \(-\) x from the TAD [] of operations \( O_{1} \), \( O_{6} \), \( O_{7} \), and \( O_{12} \) and the operations \( O_{2} \), \( O_{13} \) respectively. Rule 2 constructs the operation setup sets \( OSS_{1} \), \( OSS_{2} \), and \( OSS_{3} \) while \( OSS_{4} \) is constructed by Rule 3. Two operations did not follow Rules 2 and 3 (\( O_{2} \) and \( O_{3} \)) because the TADs in their TAD [] already exist in the constructed OSS nodes. Therefore, Rule 4 generates a permuted OSS set (POSS) by the permutation of \( O_{2} \) into \( OSS_{1} \), \( OSS_{2} \), and \( OSS_{3} \), and the permutation of \( O_{5} \) into \( OSS_{1} \) and \( OSS_{3} \). The result is six POSS, as shown in Table 3.
In regard to \( POSS_{1} \), Fig. 1 represents the alternative process plans graph by applying Step 3 to 8. As shown in Fig. 1, some of the part precedence constraints between operations are generalised to be between OTS nodes or OSS nodes, for example, the precedence constraints between \( OSS_{3} \) and \( OSS_{1} \) caused by the part precedence constraints between \( O_{1} \) and \( O_{2} \). Furthermore, a constrained permutation of \( POSS_{1} \) to generate OSSS is performed through Step 9 to 13, as shown in Fig. 4. The same procedure is repeated on OTS nodes through Step 15 to 19 to generate OTSS. Finally, four operation sequences, as shown in Table 4, are obtained by the permutation of OTSS into the OSS of OSSS and replacing the OTS nodes by their comprising O operations. As shown in Table 4, CPA generates 36 operation sequences. \( POSS_{2} \) and \( POSS_{5} \) are neglected because the two conditions of Rule 6 are achieved. The reason is that \( O_{2} \), which caused the bidirectional constraints between\( OSS_{2} \) and \( OSS_{3} \), has already permuted into other OSS nodes, so generating additional OSS is not considered worthwhile, since it will increase the number of setups.

The constrained permutation illustration of \(POSS_{1}\)

An example of: a 3SX crossover operator, b OX crossover operator

An example of the proposed mutation operator process

Part 2 with 9 manufacturing features Ma et al. (2000)

Part 3 with 14 manufacturing features Li et al. (2004)
Process plans initialization
The chromosome presented as four strings of integers in which each gen indicates a \( O_{i, M, T, TAD} \). Usually, the population initialised randomly in GA, in CPAGA, the population size and the i string are obtained by CPA, and the M string, the Tstring, and TAD are generated randomly. The procedure of initialising the M, T, and TAD strings are as follows:
-
Step 1:
For \( S_{i} \), \( (i=1 \ldots , m) \), if \( i > m \) stop.
-
Step 2:
For \( O_{i} \), \( (i=1 \ldots , n) \), if \( i > n \) go to 1.
-
Step 3:
Randomly select M from the operation M[] .
-
Step 4:
Randomly select T from the operation T[] .
-
Step 5:
Randomly select TAD from the operation TAD[] , and go to 1
Process plans evaluation
Total production cost and total processing time are the common evaluation criteria reported in the literature. In this research, a total weighted production cost (TWPC) that is comprised of six cost factors is used to evaluate the process plan. The cost factors are: the cost of machines (CM) (obtained from the M string), the cost of tools (CT) (obtained from the T string), the cost of machine changes (CMC) (obtained from the M string), the cost of tool changes (CTC) (obtained from the M and T strings), the cost of setup changes (CSC) (obtained from the M and TAD strings), and the cost of precedence constraints violation (CPV) (obtained from the i string). The computation of each cost factor is as follows:
-
1.
Cost of machines (CM)
$$\begin{aligned} CM=\sum _{i=1}^nCIM_{i} \end{aligned}$$(8)Where n is the total number of operations, CIM is the cost index of using machine i, which is a constant value for a specific machine.
-
2.
Cost of tools (CT)
$$\begin{aligned} CT=\sum _{i=1}^nCIT_{i} \end{aligned}$$(9)Where CIT is the cost index of using tool i, which is a constant value for a specific tool.
-
3.
Cost of machine changes (CMC)
$$\begin{aligned} CMC=CIMC\times \sum _{i=1}^{n-1}\sigma _{1}(M_{i+1}-M_{i}) \end{aligned}$$(10)Where CIMC is the cost index of machine changes, which is a constant value, \( M_{i} \) is the machine i used in operation i, \( \sigma _{1} \) is a comparison factor and it is computed as follows:
$$\begin{aligned} \sigma 1(X-Y)={\left\{ \begin{array}{ll} 0\ if\ X\ne Y \\ 1\ if\ X\equiv Y\end{array}\right. } \end{aligned}$$(11) -
4.
Cost of tool changes (CTC)
$$\begin{aligned} CTC= & {} CITC \times \sum _{i=1}^{n-1} \sigma _{2}(\sigma _{1} (M_{i+1}- M_{i})) \nonumber \\&- (\sigma _{1}(T_{i+1}-T_{i})) \end{aligned}$$(12)Where CITC is the cost index of tool changes, which is a constant value, \( T_{i} \) is the tool i used in operation i, \( \sigma _{2} \) is a comparison factor and it is computed as follows:
$$\begin{aligned} \sigma _{1}(X-Y)= {\left\{ \begin{array}{ll} 0\ if\ X= Y= 0 \\ 1\ otherwise \end{array}\right. } \end{aligned}$$(13) -
5.
Cost of setup changes (CSC)
$$\begin{aligned} \begin{aligned} CSC&=CISC \\&\quad \times \left( 1+\sum _{i=1}^{n-1}\sigma _{2} (\sigma _{1}(M_{i+1}-M_{i})) \right. \\&\quad \qquad \left. - (\sigma _{1}(TAD_{i+1}-TAD_{i}))\right) \end{aligned} \end{aligned}$$(14)Where CISC is the cost index of setup change, which is a constant value, \( TAD_{i} \) is the TAD i used in operation i.
-
6.
Cost of precedence constraints violation (CPV)
$$\begin{aligned} CPV=CIPV\times \sum _{i=1}^{n-1} \sum _{j=i+1}^{n}\sigma _{3}(O_{i}-O_{j}) \end{aligned}$$(15)Where CIPV is the cost index of precedence constraints violation, \( \sigma _{3} \) is a comparison factor and it is computed as follows:
$$\begin{aligned} \begin{aligned}&\sigma _{3}(X-Y) \\&\quad ={\left\{ \begin{array}{ll} 1\ The\ sequence\ of\ x\ and\ y\ operations\\ violates\ constraints\\ 0\ The\ sequence\ of\ x\ and\ y\ operations\\ meets\ constraints\ \end{array}\right. } \end{aligned} \end{aligned}$$(16)
Finally, based on above cost factors, TWPC is computed as follow:
Where \( w_{1} \) to \( w_{6} \) are weights.

Part 4 with 28 manufacturing features Huang et al. (2017)
Process plans optimization
Selection, crossover, and mutation operators are the key characteristics of reproducing the next generation in GA. During selection, two chromosomes are selected in order to perform the crossover process between them. A stochastic selection operator, which is an extension of a roulette wheel, is used in this research. The difference is that instead of selecting one chromosome in each wheel spinning, two chromosomes are selected in one-wheel spinning, which, in turn, increases the probability of selecting better chromosomes. On the other hand, the crossover operator performs the information exchanging process between the two selected chromosomes, with the objective of obtaining better offspring. The most used crossover operator in the operation sequencing problem is the order crossover (OX) since it maintains the precedence constraints unviolated (Dou et al. 2018b; Salehi and Tavakkoli-Moghaddam 2009; Dou et al. 2018a; Petrović et al. 2016). In this research, a mixed crossover operator involving three-string crossover (3SX) and OX is used to enhance and explore the solution space. The new developed 3SX aim to exchange the resources strings information of different CO while maintaining the operations sequence string of the chromosome as it is. Whereas, the aim of OX is to exchange the information of both the operations sequence string and the resources strings to generate chromosomes that have new operations sequence. Figure 5 is an illustration of the two crossover operators process of a 6-bit chromosome length. The mixed crossover procedure is as follows:
-
Step 1:
Select two parents’ chromosomes according to stochastic selection operator.
-
Step 2:
If the generation number is \(\le n/2 \) (n is the total number of generations).
-
Step 2.1:
Generate two child’s chromosomes with same operation sequences and operation resources of the parents.
-
Step 2.2:
Randomly generate a cutting point.
-
Step 2.3:
Replace M, T, and TAD of the operations in the right side of child 1 by M, T, and TAD of the same operations from parent 2.
-
Step 2.4:
Replace M, T, and TAD of the operations in the right side of child 2 by M, T, and TAD of the same operations from parent 1.
-
Step 2.1:
-
Step 3:
Else
-
Step 3.1:
Generate two child’s chromosomes with same operation sequences and operation resources of the parents.
-
Step 3.2:
Randomly generate two cutting points.
-
Step 3.3:
Reorder the gens between the two crossover points of child 1 according to the same gens order of parent 2.
-
Step 3.4:
Replace M, T, and TAD of the operations between the two crossover points of child 1 by M, T, and TAD of the same operations from parent 2.
-
Step 3.5:
Reorder the gens between the two crossover points of child 2 according to the same gens order of parent 1.
-
Step 3.6:
Replace M, T, and TAD of the operations between the two crossover points of child 2 by M, T, and TAD of the same operations from parent 1.
-
Step 3.1:
-
Step 4:
End.
Mutation process aims to increase the population diversity with a view of avoiding premature convergence. In this research, the mutation operator is designed to replace the operation resources randomly according to the given operation resources flexibilities. Figure 6 is an illustration of a mutation process of a 6-bit chromosome length. The proposed mutation procedure is as follows:
-
Step 1:
Select a chromosome randomly.
-
Step 2:
Select two operations randomly.
-
Step 3:
Randomly select M from the operation M [].
-
Step 4:
Randomly select T from the operation T [].
-
Step 5:
Randomly select TAD from the operation TAD [].
-
Step 6:
End.
Comparative case studies
To appraise the performance of CPAGA, four comparative case studies are carried out through Part 1 (Fig. 3), Part 2 (Fig. 7), Part 3 (Fig. 8), and Part 4 (Fig. 9). The relevant manufacturing information, including features, operations, manufacturing resource flexibilities, and precedence constraints, are placed in Tables 2, 5, 6, 7 respectively, while the cost indices of the four parts are placed in Table 8. The main GA parameters are population size, generation number, crossover probability (PC), and mutation probability (PM). The population size is predetermined by the number of operation sequences generated for the given part by CPA. A comprehensive test for the four parts is carried out to obtain the best value of the remaining parameters, and the best performance of GA in the CPAGA is gained by setting PC to 0.7 and PM to 0.3. Since the convergence of all tests occurs in the early stages, the number of generations is set as 100 generations. The CPAGA was programmed in MATLAB and executed on a Windows 10 platform by a 2.6 GHz Core i7 CPU with a 16 GB RAM computer.
In Part 1, which is reported by Li et al. (2004), CPA generated 360 sequences of operations for the four possibilities of applying the soft constraints. GA was executed 20 times for the two conditions: (1) All resources are available, and \( w_{1}-w_{6} \) in Eq. (17) are set equal to 1. (2) All resources are available, and \( w_{2} = w_{4} = 0 \), \( w_{1} = w_{3} = w_{5} = w_{6} = 1 \). The best obtained process plans for the two conditions are shown in Table 9. Results were compared against GA, SA, and TS based approaches by Li et al. (2004), the TSACO by Wang et al. (2015), and the ACO by Liu et al. (2013), and are presented in Table 10. Under condition (1), among 20 trials, the result TWPC (1328) occurs 20 times. The mean TWPC (1328) is the best result among all the six algorithms. Under condition (2), the TWPC (1170.0) occurs 20 times in 20 trials, which is better than the performances of TS, SA, and GA and is the same as the performance of ACO and TSACO. In Part 2, which is reported by Ma et al. (2000), CPA generated 208 sequences of operations, and GA was executed 60 times for the two conditions: (1) All resources are available, and \( w_{1}-w_{6} \) in Eq. (17) are set equal to 1. (2) M02 is down, and \( w_{1}-w_{6} \) are set equal to 1. The best obtained process plans for the two conditions are shown in Table 11. Comparison of the results with those of GA and SA based approaches by Ma et al. (2000) are presented in Table 9. For this part, Eq. (14) modified to be the same as Ma evaluation model, as follows: (1) All resources are available, and \( w_{1}-w_{6} \) in Eq. (17) are set equal to 1. (2) M02 is down, and and \( w_{1}-w_{6} \) in Eq. (17) are set equal to 1.
Under condition (1), among 60 trial results, TWPC (743) occurred 60 times. The mean and minimum TWPC (743) was better than the other two algorithms. Under condition (2), TWPC (1198) occurred 60 times in 60 trials, which was better than the performances of SA for both mean and minimum TWPC values.
In addition to the two conditions of Part 1, third condition is used in Part 3 that is reported the first time by Li et al. (2004) to test CPAGA, which is: (3) M02 and T07 are down, and \(w_{2} = w_{4} = 0\), \(w_{1} = w_{3} = w_{5} = w_{6} = 1\). CPA generated 470 sequence of operations, and GA was executed 20 times for the three conditions. The best obtained process plans for the three conditions are shown in Table 12. Comparison of the results was carried out against FSDPSO and DDPSO by Dou et al. (2018a), IGA by Dou et al. (2018b), ACO by Hu et al. (2017), ESGA and TSGA by Su et al. (2018), PSO by Guo et al. (2006), HGGA by Huang et al. (2012), TSACO by Wang et al. (2015), and the TS, SA, and GA by Li et al. (2004), as shown in Table 9. Under condition (1), among 20 trial results, the TWPC (2530) occurred 18 times and the TWPC (2535) occurred two times. The minimum TWPC (2530) was better than the TWPC of DPPSO, TSGA, PSO, SA, and GA, equal to the TWPC of FSDPSO, IGA, ACO, and ESGA, and less than the TWPC of HGGA, TSACO, and TS. The reason that those approaches obtained less TWPC value than CPAGA TWPC value is due to the additional T06 in T [], which gives different optimal solutions. (The reader may be referred to Table 11 of Li et al. (2004), Table 9 of Wang et al. (2015), and Table 7 of Huang et al. (2012).) The mean TWPC (2530.5) is the best result among all the 13 approaches. Under condition (2), the TWPC (2090) occurred 20 times in 20 trials. The minimum TWPC (2090) is better than those of some approaches and the same as others, while the mean TWPC (2090) was the same as the mean of FSDPSO and better than all other approaches. Under condition (3), the TWPC (2500) occurred 20 times in 20 trials, which is the best result obtained among the 13 approaches in terms of minimum and mean TWPC values.
Finally, Part 4 that is reported by Huang et al. (2017) consist of 28 features that comprise of 46 operations with 213 precedence constraints among the operations. For this complex part, CPA generates 1618 sequences of operations. GA was executed 20 times for the following two conditions: (1) All resources are available, and \( w_{1}-w_{6} \) in Eq. (17) are set equal to 1. (2) M03, M07, and T08 are down, and \( w_{1}-w_{6} \) in Eq. (17) are set equal to 1. The best obtained process plans under the two conditions accompanied by those that are obtained by GA-SA (Huang et al. 2017) are placed in Table 13. Note that the process plan generated by GA-SA under condition (1) is unfeasible because some of the precedence constraints are violated such as \( O_{8} \) came before \( O_{30} \), \( O_{31} \), and \( O_{32} \). Furthermore, \( O_{12} \) assigned to M03 which it is not given in the \( O_{12} \)’ M[]. Although the process plans generated by GA-SA are unfeasible, CPAGA generated better process plans under the two conditions. Where under condition (1) the TWPC (4299) occurred 16 times, the TWPC (4314) occurred 3 times, and the TWPC (4315) occurred 1 time, which are all better than the best TWPC value that is obtained by GA-SA. Under condition (2) the TWPC (4503) is obtained 20 times, which is better than the TWPC value that is obtained by GA-SA.
Unfortunately, all researchers mentioned in the above comparisons except Su et al. (2018) have not been taken CPU time into consideration. Therefore, the efficiency verification of the proposed approach is carried out against ESGA, and TSGA by Su et al. (2018). Table 14 shows the CPU time of the best obtained TWPC values of CPAGA for the four parts under different conditions, as well as the ESGA and TSGA CPU time when they are performed under condition (1) of Part 3. Generally, CPAGA is able to generate optimal or near-optimal solutions with reasonable CPU time. Compared with ESGA and TSGA, the proposed CPAGA is able to find a competitive solution with a lower CPU time. where, with the same TWPC values CPAGA dominates ESGA in term of the CPU time, on the other hand, CPAGA dominates TSGA in term of TWPC value and CPU time.
Conclusions
A CPAGA approach was proposed to solve the process planning problem. The process planning problem was represented as a graph of OSS, OTS, and O nodes and the CPA was used to generate an initial set of optimised operation sequences based on the principles of minimising the number of setup changes, tool changes, and machine changes, and supplying it to GA. GA, in turn, was used to obtain an optimal or near optimal process plan. Mixed OX and 3SX crossover were developed to generate better offspring to subsequently enhance the performance of GA. 3SX was used first to search within the operations sequences generated by CPA, then OX was used to explore alternative operation sequences to be evaluated. In comparing the CPAGA approach to different approaches reported in the literature for the four parts, CPAGA proved its efficiency and effectiveness. From a generated solutions quality perspective, CPAGA obtained better TWPC values for the two conditions of Part 2, the third condition of Part 3, and the two conditions of Part 4. Since the solution space was reduced by the CPA to be limited to only the optimised operation sequences. This, in turn, gives the advantage to GA in searching for an optimal or near optimal process plan. From the perspective of the repeatability of good quality of generated solutions, CPAGA obtained better TWPC means for all the conditions of the four parts, due to the good quality of operations sequences obtained by CPA, and the effectiveness of the proposed crossover operator. From the perspective of the CPAGA efficiency, a better CPU time has been accomplished against ESGA and TSGA for the first condition of Part 3. Although the proposed approach has demonstrated a good performance compared to other approaches, some issues need to be considered in future studies: first, incorporating more knowledge-based production rules to maintain different cases that may occur in OSS and OTS nodes construction; second, investigating more complex parts with difficult precedence constraints among their features, to show the effectiveness of the proposed approach; and, finally, incorporating CPA with different meta-heuristic algorithms instead of GA.
References
Al-wswasi, M., Ivanov, A., & Makatsoris, H. (2018). A survey on smart automated computer-aided process planning (ACAPP) techniques. International Journal of Advanced Manufacturing Technology, 97(1–4), 809–832.
Ding, L., Yue, Y., Ahmet, K., Jackson, M., & Parkin, R. (2005). Global optimization of a feature-based process sequence using GA and ANN techniques. International Journal of Production Research, 43(15), 3247–3272.
Dou, J., Li, J., & Su, C. (2018a). A discrete particle swarm optimisation for operation sequencing in CAPP. International Journal of Production Research, 56(11), 3795–3814.
Dou, J., Zhao, X., & Su, C. (2018b). An improved genetic algorithm for optimization of operation sequencing. In Proceedings of 2018 IEEE International Conference on Mechatronics and Automation, ICMA 2018 (pp. 695–700).
Guo, Y. W., Mileham, A. R., Owen, G. W., & Li, W. D. (2006). Operation sequencing optimization using a particle swarm optimization approach. Proceedings of the Institution of Mechanical Engineers, Part B: Journal of Engineering Manufacture, 220(12), 1945–1958.
Hu, Q., Qiao, L., & Peng, G. (2017). An ant colony approach to operation sequencing optimization in process planning. Proceedings of the Institution of Mechanical Engineers, Part B: Journal of Engineering Manufacture, 231(3), 470–489.
Huang, W., Hu, Y., & Cai, L. (2012). An effective hybrid graph and genetic algorithm approach to process planning optimization for prismatic parts. International Journal of Advanced Manufacturing Technology, 62(9–12), 1219–1232.
Huang, W., Lin, W., & Xu, S. (2017). Application of graph theory and hybrid GA-SA for operation sequencing in a dynamic workshop environment. Computer-Aided Design and Applications, 14(2), 148–159.
Krishna, A. G., & Mallikarjuna Rao, K. (2006). Optimisation of operations sequence in CAPP using an ant colony algorithm. International Journal of Advanced Manufacturing Technology, 29(1–2), 159–164.
Li, W. D., O, S. K., & N, A. Y. C. (2002). Hybrid genetic algorithm and simulated annealing approach for the optimization of process plans for prismatic parts. International Journal of Production Research, 40 1899.
Li, W. D., Ong, S. K., & Nee, A. Y. (2004). Optimization of process plans using a constraint-based tabu search approach. International Journal of Production Research, 42(10), 1955–1985.
Li, X., Gao, L., & Wen, X. (2013). Application of an efficient modified particle swarm optimization algorithm for process planning. International Journal of Advanced Manufacturing Technology, 67(5–8), 1355–1369.
Lian, K., Zhang, C., Shao, X., & Gao, L. (2012). Optimization of process planning with various flexibilities using an imperialist competitive algorithm. International Journal of Advanced Manufacturing Technology, 59(5–8), 815–828.
Liu, X. J., Yi, H., & Ni, Z. H. (2013). Application of ant colony optimization algorithm in process planning optimization. Journal of Intelligent Manufacturing, 24(1), 1–13.
Ma, G. H., Zhang, Y. F., & Nee, A. Y. (2000). A simulated annealing-based optimization algorithm for process planning. International Journal of Production Research, 38(12), 2671–2687.
Moon, C., Kim, J., Choi, G., & Seo, Y. (2002). An efficient genetic algorithm for the traveling salesman problem with precedence constraints. European Journal of Operational Research, 140(3), 606–617.
Musharavati, F., & Hamouda, A. S. M. (2011). Modified genetic algorithms for manufacturing process planning in multiple parts manufacturing lines. Expert Systems with Applications, 38(9), 10770–10779.
Nallakumarasamy, G., Srinivasan, P. S., Venkatesh Raja, K., & Malayalamurthi, R. (2011). Optimization of operation sequencing in CAPP using simulated annealing technique (SAT). International Journal of Advanced Manufacturing Technology, 54(5–8), 721–728.
Petrović, M., Mitić, M., Vuković, N., & Miljković, Z. (2016). Chaotic particle swarm optimization algorithm for flexible process planning. International Journal of Advanced Manufacturing Technology, 85(9–12), 2535–2555.
Reddy, S. V., Shunmugam, M. S., & Narendran, T. T. (1999). Operation sequencing in CAPP using genetic algorithms. International Journal of Production Research, 37(5), 1063–1074.
Salehi, M., & Bahreininejad, A. (2011). Optimization process planning using hybrid genetic algorithm and intelligent search for job shop machining. Journal of Intelligent Manufacturing, 22(4), 643–652.
Salehi, M., & Tavakkoli-Moghaddam, R. (2009). Application of genetic algorithm to computer-aided process planning in preliminary and detailed planning. Engineering Applications of Artificial Intelligence, 22(8), 1179–1187.
Su, Y., Chu, X., Chen, D., & Sun, X. (2018). A genetic algorithm for operation sequencing in CAPP using edge selection based encoding strategy. Journal of Intelligent Manufacturing, 29(2), 313–332.
Su, Y., Chu, X., Zhang, Z., & Chen, D. (2015). Process planning optimization on turning machine tool using a hybrid genetic algorithm with local search approach. Advances in Mechanical Engineering, 7(4), 1–14.
Wang, J. F., Wu, X., & Fan, X. (2015). A two-stage ant colony optimization approach based on a directed graph for process planning. International Journal of Advanced Manufacturing Technology, 80(5–8), 839–850.
Wang, Y. F., Zhang, Y. F., & Fuh, J. Y. (2012). A hybrid particle swarm based method for process planning optimisation. International Journal of Production Research, 50(1), 277–292.
Wen, X. Y., Li, X. Y., Gao, L., & Sang, H. Y. (2014). Honey bees mating optimization algorithm for process planning problem. Journal of Intelligent Manufacturing, 25(3), 459–472.
Xu, L., Deng, W., Liu, W., Ma, S., Li, A., & Matta, A. (2014). Optimization of process planning for cylinder block based on feature machining elements. In Conference Proceedings–IEEE International Conference on Systems, Man and Cybernetics (vol. 2014, pp. 2575–2580).
Yun, Y., & Moon, C. (2011). Genetic algorithm approach for precedence-constrained sequencing problems. Journal of Intelligent Manufacturing, 22, 379–388.
Zacharia, P. T., Tsirkas, S. A., Kabouridis, G., & Giannopoulos, G. I. (2015). Planning the construction process of a robotic arm using a genetic algorithm. The International Journal of Advanced Manufacturing Technology, 79(5–8), 1293–1302.
Zacharia, P. T., Tsirkas, S. A., Kabouridis, G., Yiannopoulos, A. C., & Giannopoulos, G. I. (2018). Genetic-Based Optimization of the Manufacturing Process of a Robotic Arm under Fuzziness. Mathematical Problems in Engineering, 2018, 1–12.
Zhang, F., Zhang, Y., & Nee, A. (1997). Using genetic algorithms in process planning for job shop machining. IEEE Transactions on Evolutionary Computation, 1(4), 278–289.
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Falih, A., Shammari, A.Z.M. Hybrid constrained permutation algorithm and genetic algorithm for process planning problem. J Intell Manuf 31, 1079–1099 (2020). https://doi.org/10.1007/s10845-019-01496-7
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10845-019-01496-7