
Abstract
Different factors have been claimed to affect the choice of repair on English words with ill-formed Cantonese phonotactics in Cantonese loanword phonology. The first half of this paper presents experimental evidence showing that variation is observed only when repairing different onset cluster types: there is vowel epenthesis for s + consonant (sC) clusters but deletion of the second consonant for other (OR) clusters. I propose that the Syllable Mapping Grammar (SMG), the syllable structure mapping component of the perception grammar, drives such variation: Cantonese speakers assign different phonological representations based on cluster well-formedness. When they perceive words with an sC cluster, their SMG assigns [s] as syllabic. A full OT grammar is also provided. I present evidence for the knowledge of cluster well-formedness from speakers of languages like Cantonese where complex onsets are absent. Potential sources of such knowledge and other alternatives to my proposal are also discussed.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
Syllable repairs occur when a borrowed word violates the phonotactics of the borrowing language. In the case of ill-formed onsets and codas, two common repair strategies found cross-linguistically are vowel epenthesis and consonant deletion. While it is common for a language to adopt one of the two repair strategies, a few languages use both (Kang 2011). An example of such a language is Cantonese. In Cantonese loanword phonology, researchers have claimed that different factors play a role in determining the choice of repair. For example, Yip (1993) finds that onset clusters are repaired differently based on their word size and cluster type and Luke and Lau (2008) claim that repair of fricative codas is sensitive to word class.
In this paper, I will address the question of whether the choice of repair is predictable, and will present experimental evidence to show that an onset cluster is the only environment that shows variation in choice of repair: Cantonese speakers delete the sonorant member of an onset cluster in a non-[s] + sonorant (OR) cluster and they preserve both segments by epenthesizing a vowel between the two members in an [s] + consonant (sC) cluster. I propose that the motivation for such variations lies in the mental representation of these two cluster types: Cantonese speakers are aware of cluster well-formedness and when perceiving a foreign word with an sC cluster, the syllable structure mapping component of their perception grammar (the Syllable Mapping Grammar, SMG) assigns a representation different from that of an OR cluster: the [s] is assigned a syllabic representation (e.g. ‘slide’ as |s̩.lɑɪd|). Two repair strategies are therefore used to resolve the two different structures: consonant deletion is used to simplify an onset cluster while epenthesis is used to avoid having a syllabic consonant in the output. I will illustrate how the SMG and production grammar work in an Optimality-Theoretic framework. I will also provide cross-linguistic evidence that even speakers of languages with no complex onsets do have knowledge about well-formedness and will give two potential explanations for the source of such knowledge.
The paper is organized as follows: a survey of factors claimed to affect phonotactic repairs in Cantonese loanword phonology is discussed in Sect. 2. Experimental results on the effects of these factors are presented in Sect. 3; Sect. 4 presents a unified model of the representation of sC, followed by an OT grammar of phonotactic repairs in Cantonese loanwords in Sect. 5. Possible explanations of how speakers of languages such as Cantonese are equipped with cluster well-formedness constraints are provided in Sect. 6. An alternative account will be reviewed in Sect. 7 followed by concluding remarks in Sect. 8.
2 Phonotactic repair
In Cantonese loanword phonology, both deletion and epenthesis are used in repairing ill-formed phonotactics. In this section, I will outline the factors that have been claimed by different researchers to determine repair of onset clusters and fricative codas.
2.1 Repairs of onset clusters
Since Cantonese allows only simplex onsets, two repair options are available for loans with an onset cluster, as shown in (1). Epenthesis is used in (1a–c) while deletion of the more sonorous consonant is used in (1d, e).
(1) | Cantonese | English | |
a. | [pow.lɐm] | ‘plum’ | |
b. | [fu.lok] | ‘fluke’ | |
c. | [kej.lim] | ‘cream’ | |
d. | [fi.sa] | ‘freezer’ | |
e. | [fɔ.sow] | ‘floor-show’ |
In addition to using the two repair strategies of epenthesis and deletion, Yip (1993) and Bauer and Benedict (1997) have reported that some speakers were able to preserve the clusters, possibly due to their higher English proficiency.
Since neither epenthesis nor deletion is productive in Cantonese phonology, it is unclear how one is chosen over the other in a specific context. Having observed that several morphological processes in Cantonese are sensitive to prosodic word size, Yip (1993) proposed that the choice of repair for onset clusters is determined by a disyllabic minimality constraint: if the word is monosyllabic (1a–c), epenthesis is used to fulfil the word size requirement; for disyllabic words (1d, e), deletion of the second consonant of the cluster is preferred.
While minimality is obeyed in many cases of loanword adaptation, there are two cases in which this constraint does not hold. The first is when the second member of an onset cluster is [r], which is absent in the Cantonese phonemic inventory. Leci and Poon (2004) report that some Cantonese speakers delete the [r] in an onset cluster environment regardless of word size. For (1c) ‘cream’, these speakers produce the deleted form [kim] instead of the expected epenthetic form. Hamann and Li (2016), however, report both deletion of [r] and insertion of a vowel in Cr onsets, attributing the variation to diachronic change: the older generation prefers the epenthetic form while the younger generation prefers the deleted form. They argue that these adaptations result from misperception of the foreign form. This means that for the same word ‘cream’, younger Cantonese speakers cannot perceive the [r] in the cluster at all, resulting in the production [kim]. Older Cantonese speakers, on the other hand, perceive an intervening vowel between the two consonants, and so they would produce the epenthetic form, [kej.lim]. Hamann and Li argue that the shift to the preference for the deleted form among the younger generation is because the younger speakers are more familiar with the prosodic structure of English and therefore want to be faithful to the English form in terms of word size.
Unlike Cr clusters, obstruent + [l] clusters are said to always respect the word size constraint, with one exception: [sl] onsets. Like other [s] + consonant (hereafter sC) clusters, [sl] is always repaired with epenthesis, as shown in (2d), below:
(2) | Cantonese | English | |
a. | [si.pak] | ‘spark’ | |
b. | [si.pa.la] | ‘spanner’ | |
c, | [si.maat] | ‘smart’ | |
d. | [si.lek] | ‘slick’ | |
e. | [si.wit] | ‘sweet’ |
Yip (1993) argued that it is the perceptual salience of [s] that makes sC clusters different than other obstruent-sonorant (hereafter OR) clusters. However, while this explains why [s] in an sC onset is never deleted, it does not account for the fact that both [s] and any consonant that follows [s] in an onset cluster is retained. Another proposal that made reference to the special status of [s] is that of Silverman (1992), who claimed that when Cantonese speakers perceive words with an sC cluster, they perceive the cluster as if a vowel, [i], was present between the two consonants. This is consistent with the fact that while the epenthetic vowels used to break up obstruent + sonorant (hereafter OR) clusters share some features of the stem vowel, [i] is the vowel used to break up an sC cluster, regardless of the quality of the stem vowel. Silverman’s proposal, however, did not explain why Cantonese speakers always perceive [s] as [si].
2.2 Repair of illegal codas
In contrast to the treatment of onset clusters, the treatment of ill-formed codas is more straightforward. Cantonese does not allow fricative codas, and loans ending in a fricative can only be repaired by epenthesis, as in (3)Footnote 1:
(3) | Cantonese | English | |
a. | [say.si] | ‘size’ | |
b. | [phau.fu] | ‘puff’ | |
c, | [tɛn.ni.si] | ‘tennis’ |
The quality of the epenthetic vowel is fully predictable: each fricative is followed by a specific default epenthetic vowel. For example, [s] is always followed by [i], as in (3a), and [f] is always followed by [u], as in (3b). Word minimality does not play a role here: regardless of word size, epenthesis is the only option for repairing fricative codas. Yip (1993) argued that deletion is ruled out because perceptual salience overrides the word size constraint: fricatives are perceptually salient and therefore likely to be retained in the process of adaptation.
Although word size does not appear to be relevant in coda repair, an experiment done by Luke and Lau (2008) revealed the possible influence of another factor: lexical category. Luke and Lau ran an experiment eliciting preference judgments on borrowed word adaptation from 20 native speakers of Cantonese. Nine monosyllabic English words that can function as either a noun or a verb were used in the experiment. All of these words ended with a fricative or a consonant cluster, all of which are phonotactically ill-formed in Cantonese. Each stimulus was presented in two forms: the monosyllabic form (the form faithful to the English input, e.g. pass) and the disyllabic form (the epenthetic one, e.g. pass-i). Each form was read in two carrier sentences: one where the nonce form occurred in a verb context and the other where the same form occurred in a noun context. Participants were asked to choose the form they preferred in each context. Results showed that participants were significantly more likely to choose the monosyllabic form when the borrowed word was used in the verb context, which Luke and Lau claimed results from a preference for bisyllabic nouns. They did not report, however, whether participants responded differently to different ill-formed codas.
2.3 Factors claimed to determine choice of repair
While the main purpose of the previous sections is to provide a summary of what has been claimed to affect choice of repair in Cantonese loanword phonology, it also highlights some discrepancies between different proposals. Luke and Lau’s (2008) results challenge Yip’s (1993) claim that fricative codas are always repaired through epenthesis regardless of word size. Even though the word size effect has been argued to play a role in repairing onset clusters, whether or not there also exists a word size effect for codas remains unclear.
What is interesting here is that in the coda position, [s] and [f] (and other fricatives) are repaired in the same way: by epenthesizing a vowel after the fricative. In the onset position, on the other hand, [f] + sonorant clusters pattern with other OR clusters in which the word minimality constraint is respected, instead of with sC clusters, where epenthesis always takes place regardless of word size. To be more specific, Cantonese speakers use different strategies to adapt forms beginning with [fl] and [sl], which are both possible onset clusters in English; [fl] onsets are adapted by following the word minimality constraint ([fu.lok] ‘fluke’ vs. [fɔ.sow] ‘floor-show’) while [sl] onsets are always adapted by epenthesizing an [i] between the two consonants. This asymmetry challenges the previously-assumed special status of [s]: if it was solely the [s] that is special, we would expect [s]-codas to behave differently than other fricative codas. However, the only environment in which [s] behaves differently than other fricatives is when it is part of an onset cluster. I will argue, therefore, that it is in fact the sC clusters that are different from other onset clusters and that this difference arises from the marked status of the sC clusters. I will first show experimental results establishing that Cantonese speakers do in fact treat [fl] and [sl] clusters differently but treat [s] and [f] codas the same, regardless of their word size. I will then present cross-linguistic evidence for a different representation of sC clusters.
3 Experiments
The goal of the two experiments described in this section is to examine the effects of the factors claimed to play a role in Cantonese loanword phonology. The first experiment focuses on repairs of onset clusters; the second experiment focuses on repairs of fricative codas.
3.1 Experiment 1: Word-class and English proficiency effects on onset clusters
The major question this experiment seeks to answer is whether or not repair of an onset cluster is subject to a word-class effect. Given different contexts, participants were asked to choose between the two repaired forms of each stimulus. Since all stimuli used in this experiment were monosyllables with an onset cluster, the two competing proposals by Yip (1993) and Luke and Lau (2008) make different predictions: Yip’s (1993) proposal predicts a preference for the epenthetic form with all monosyllables while Luke and Lau’s (2008) proposal predicts a preference for the epenthetic form for nouns but the deleted form for verbs. The findings, as will be shown, revealed a completely different story.
The second question that this experiment hopes to address is the effect of English proficiency. Since participants were asked to answer questions based on two actors with different educational levels, if English proficiency plays a role, neither the deleted nor the epenthetic form would be rated as natural for the more educated character.
3.1.1 Participants
Participants (n = 48) were recruited through social media and word of mouth. They were not paid for doing the experiment. At the beginning of the experiment, participants had the options to volunteer their background information. Of the 48 participants, 28 were females and 18 were males; two did not say. Ages ranged from 18 to 45.
3.1.2 Stimuli
The stimuli consisted of monosyllabic words with an onset cluster whose first member is an obstruent and whose second member is the lateral liquid, [l]. These words can function both as a noun and a verb.
Existing loanword corpora (Bauer and Benedict 1997; Kenstowicz 2011) were first consulted for stimuli selection, but there were not many existing loanwords that fit the above criteria (monosyllabic; start with an obstruent plus lateral onset cluster; can be both a noun and a verb). Therefore, most of the stimuli were English words that have not been reported as loanwords in Cantonese.
To avoid the influence of faithfulness to the source language, only the two repaired forms, the deleted form (which is monosyllabic) and the epenthetic form (which is disyllabic), were included in this experiment. A total of 24 words were used (Appendix 1). Each stimulus was recorded in two Cantonese sentences, one where it was used as a noun and the other where it was used as a verb. A total of 24 fillers were also included.
3.1.3 Design and procedure
The experiment was presented to the participants over the Internet. After giving consent and filling out their background information, participants were shown a 1-min clip from a sitcom where two characters were conversing in a mix of Cantonese and English. One character, a female lawyer, (hereafter referred to as “high (English) proficiency”) was teaching a male character, who was an office assistant (hereafter “low (English) proficiency”), the correct way of pronouncing some English words. The clip ended with the lawyer giving up hope on getting the right pronunciation from the office assistant. Participants then completed four practice questions before the main task.
Participants were asked to answer two questions for each stimulus. The first question was a forced-choice task: participants were shown the orthographic form of a stimulus and asked to listen to two recordings (same carrier sentence, one with the deleted form and the other with the epenthetic form). They were then asked to choose the one that either the educated or the uneducated character would most likely produce. After that, they were shown the next screen and asked to rate the naturalness, on a scale of zero (least natural) to six (most natural), of the same recordings, from the perspective of the given character. The purpose of asking participants to answer based on the two characters was to control for potential confounds due to their own English proficiency.
If a participant chose one option in the forced-choice question but rated the other more natural in the naturalness-rating question, these two responses were eliminated. Of the 1152 responses collected, 122 (10.5%) responses were eliminated for this reason. After completing the two questions on the same stimulus, participants proceeded to the next stimulus. The order of the stimuli in the experiment was pseudo-randomized.
3.1.4 Results
Figure 1 shows the participants’ responses for the two characters, with the y-axis denoting how often they chose the epenthetic form. For the low-proficiency character, the deleted form was clearly preferred (around 75% of the time). For the high-proficiency character, it seems that there was no clear preference for either form. This difference was confirmed statistically by a paired-sample t test (p < .001), suggesting that English proficiency did influence participants’ responses.

Choice of adaptation by characters. Error bars represent 95% confidence intervals
The observation made from their forced-choice response, in that there was not a clear preferred form for the high-proficiency character, was supported by the naturalness rating responses, shown in Fig. 2.

Naturalness rating of each form by characters. Error bars represent 95% confidence intervals
For the high-proficiency character, both forms were rated below 3, which I defined as the threshold of naturalness. This means that the participants did not think either the epenthetic or the deleted form sounded natural if spoken by the high-proficiency character. On the other hand, for the low-proficiency character, the deleted form was rated as more natural than the epenthetic form. These findings seem to support the influence of English proficiency on the choice of repair in that the more proficient speakers were perceived to retain the cluster in their adaptation, rendering both the deleted and epenthetic forms unnatural.
Since the only purpose of including the high-proficiency character in the experiment was to determine if English proficiency would affect preference for the adapted form, which it did, the findings reported below focus only on the low-proficiency character, whose adaptation arguably more closely reflects Cantonese native phonology.
Focusing on the low-proficiency character, what is interesting from Figs. 1 and 2 is that not only was the deleted form preferred over the epenthetic form, but the former was also rated as more natural than the latter. Figure 3, below, shows how participants were influenced by word class and cluster types.

Choice of adaptation by cluster type and word class. Error bars represent 95% confidence intervals
As can be seen in Fig. 3, regardless of word class, participants preferred the deleted form to repair both stop + liquid (hereafter Cl) and f + liquid (fl) cluster types, but the epenthetic form for the s + liquid (sl) type. To check the effect of word class and cluster type, regression analysis was done on their forced choice response. Using R (R Core Team 2013) and lme4 (Bates et al. 2015), a mixed-effects logistic regression model was created with cluster type and word class (noun vs. verb) as fixed effects, with participant and item as random effects. The predictor, word class, was deviation coded with values − .5 and .5 prior to model fitting. Since the other predictor, cluster type, is three-level, namely [sl], [fl] and [Cl], Helmert coding was used to transform this predictor into two binary predictors: [sl] versus non-[sl] (including both [fl] and [Cl]), and [fl] versus [Cl]. The effects, including the interactions between the two predictors (word class and [sl] vs. non-[sl], labeled as “word class:[sl] vs. non-[sl]”, and word class and [fl] vs. [Cl], labeled as “word class:[fl] vs. [Cl]”), are reported in Table 1.
Word class did not seem to influence the choice (p = .97), and the overwhelming preference for the deleted monosyllabic form contradicts the claimed effect of disyllabic minimality. Cluster type, on the other hand, was a significant predictor of repair choice. As shown in Fig. 3, the deleted form was preferred in the non-[sl] group, including both [fl] and [Cl] clusters, while the epenthetic form was preferred in the s + liquid (sl) group, and the difference is statistically significant (p < .001).
The results of this experiment suggest that, contrary to earlier claims (Silverman 1992; Yip 1993), the choice of repair in onset clusters in Cantonese loanword phonology seems to be completely driven by cluster type: deletion is preferred in OR clusters while epenthesis is used for sC clusters. While it can be confirmed from this experiment that [fl] and [sl] are repaired differently, it is still unclear whether it is the special status of [s] or sC clusters that contributes to this difference. The following experiment was designed to answer this question.
3.2 Experiment 2: Fricative coda repair
This experiment seeks to answer whether or not an [s] coda is repaired differently than other fricative codas. The form that is of primary interest in this experiment is the epenthetic form: if the epenthetic form is the most preferred in both [f] and [s] coda stimuli, it suggests that [s] and [f] codas are repaired in the same manner. In addition, since all the stimuli used in this experiment are nouns in which the optimal size is disyllabic, Luke and Lau’s (2008) proposal predicts the epenthetic form to be more preferred in the monosyllabic stimuli than the disyllabic ones. As it turns out, the experimental results show that the epenthetic form was the preferred form in both [s] and [f] codas regardless of word size.
3.2.1 Participants
Participants (n = 51) were recruited through social media and word of mouth. They were not paid for doing the experiment. 29 of the participants reported that they had not participated in the first experiment while 22 participants had. No significant difference was found between the results of these two groups (p < .74). At the end of the experiment, participants had the option of volunteering their background information. Of the 51 participants, 28 were females and 17 were males; 6 did not say. Ages ranged between 18 and 45.
3.2.2 Stimuli
Each stimulus was either a monosyllabic or disyllabic (trochaic or iambic) noun with a fricative coda, either [s] or [f]Footnote 2 (e.g. pass). Three forms, the deleted form (e.g. pa), the faithful form (e.g. pass) and the epenthetic form (e.g. passi), were included in this experiment. A total of 18 words (Appendix 2) were used and each stimulus was recorded in a Cantonese carrier sentence. A total of seven fillers were also included in the experiment.
3.2.3 Design and procedure
The experiment was presented to the participants over the Internet. The task orientation was the same as that in Experiment 1: participants watched the same clip and completed four practice questions before the main task.
For the experiment, participants were asked to answer two questions for each stimulus. The first question was a forced-choice task: participants were shown the written form of a stimulus and asked to listen to a recording (one of the three forms in the carrier sentence). They were then asked to decide if the pronunciation from the recording would be a possible one for the given character. They were also asked to rate the naturalness, on a scale of zero (least natural) to six (most natural), of the same recording, from the perspective of that character. After completing the two questions on the same stimulus, participants proceeded to the next stimulus. The order of the stimuli in the experiment was pseudo-randomized. A total of 918 responses were collected from this experiment.
3.2.4 Results
Figure 4 shows that the epenthetic form was preferred over the other two forms in both [f] and [s] stimuli. I collapsed the deleted and faithful forms into one category for ease of statistical comparison, for two reasons: (1) the primary interest is whether or not the epenthetic form was the preferred form in both groups, and (2) checking for word-class effect would require control of output size (both the deleted and faithful forms are of the same length as the stimuli while the epenthetic form is one syllable longer). As it turns out, the preference for the epenthetic form was also statistically supported in both groups (p < .001), as shown in Tables 2 (for the [f] stimuli) and 3 (for the [s] stimuli).

Preference for the adapted form type by fricative type. Error bars represent 95% confidence intervals
Results of this experiment suggest that epenthesis is the preferred repair strategy for both [f]-codas and [s]-codas. The findings of the two experiments support the argument made earlier that the choice of repair is highly phonotactically-driven and predictable:
-
1.
Fricative codas are very often repaired by epenthesis.
-
2.
OR onset clusters are very likely repaired by deletion of the sonorant.
-
3.
sC onset clusters, both s + obstruent and s + sonorant, are always repaired by epenthesis.
Other factors, such as word minimality and word-class effects, did not seem to play a role in the participants’ judgments of choice of repair in loans. Going back to the central claim raised in Sect. 1, it seems that instead of treating [s] differently from other fricatives, it is the sC clusters that receive special attention by Cantonese speakers. In the next section, I will argue that it is the different phonological representations of sC onsets versus other onsets that motivates the difference in repair strategies. I will also provide evidence for my proposal from both first language phonology and loanword phonology.
4 Representation of sC
In this section, I will first show how the behavior of sC clusters differs from that of other OR clusters, both in native phonology and in loanword phonology. I argue that when these clusters are transferred to second language or loanword phonology, the perception grammar of Cantonese speakers provides a different representation for them to use in the adaptation. I will first look at how sC clusters differ from other clusters in English and explain how this representational account can capture variations in loanword adaptation.
4.1 The special status of sC
Cross-linguistically, for languages that allow onset clusters, sC clusters have been shown to behave differently than other clusters. For example, Hermes et al. (2013) argued against a unified syllabification of all onset clusters in Italian by showing that the gestural timing pattern of sC clusters is different from that of other CC clusters. They compared participants’ production of CC clusters and sC clusters with a simple onset, with the second consonant in the two cluster types being identical to that in the simple onset. Their results showed that the timing of the second consonant was shortened in the CC cluster condition but remained the same in the sC cluster condition, suggesting that the [s] belongs to a separate syllable.
It has been shown in previous literature on loanword adaptation (e.g. Fleischhacker 2005; Broselow 2015) that in many languages with no onset clusters at all, sC clusters in borrowed words are adapted differently than other onset clusters. A clear example would be English loans in Farsi, as shown in (4):
(4) | Farsi (Shademan 2002, from Broselow 2015, p. 307) | ||
a. | Terafik | ‘traffic’ | |
Korom | ‘chrome’ | ||
b. | Eski | ‘ski’ | |
Eslav | ‘Slav’ | ||
Not only is the position of the epenthetic vowel different between OR and sC clusters, but the quality of the vowel is also different: a default vowel is used to repair the sC clusters but the epenthetic vowel that breaks up an OR cluster varies, depending on the adjacent stem vowel. This tendency to have a default vowel for sC clusters in loanword adaptation is in fact quite common cross-linguistically (Broselow 2015), which can best be illustrated in the Dehu data below:
(5) | Dehu (Tryon 1970, from Broselow 2015: 310) | ||
a. | Peleit | ‘plate’ | |
Gilis | ‘grease’ | ||
Balaiket | ‘blanket’ | ||
Faraig | ‘franc’ | ||
b. | Sipo | ‘spur’ | |
Sipun | ‘spoon’ | ||
Sitima | ‘steamer’ | ||
Unlike in Farsi, the position of the epenthetic vowel in Dehu is the same in resolving OR and sC clusters. The quality of the vowel, however, differs depending on cluster type: regardless of the quality of stem vowel, [i] is used to break up an sC cluster, as shown in (5b), above.
The evidence clearly shows that speakers of many borrowing languages treat sC clusters differently from other clusters in the process of adapting English loans.
In fact, the special status of sC clusters is also present in English phonology. While English tolerates consonant clusters in the onset, all non-sC clusters, and more precisely the OR clusters, respect the sonority sequencing hierarchy (SSH, Selkirk 1984), where the consonants in an onset cluster are sequenced in order of rising sonority with reference to the following sonority scale:
(6) | Stop < Fricative < Nasal < Liquid < Glide |
Most onset clusters in English also exhibit a minimal sonority distance (MSD), in which the sonority of the two consonants is at least two steps apart on the scale. This makes [fl] a good onset cluster but [fm] a bad cluster.
sC clusters in English, on the other hand, may violate both the requirement that onset clusters rise in sonority and that onset consonants obey a minimal distance in sonority. While s + liquid (SL) or s + glide (SW) onsets obey the two principles above, ST clusters violate both the sonority sequencing principle and minimal sonority distance because the second member of the cluster is less sonorous than the first. While the sequence of s + nasal (SN) is of rising sonority, such clusters violate minimal sonority distance. sC clusters can therefore be ranked in terms of their relative markedness, with ST being the most marked and SW the least, as shown in (7):
(7) | ST > SN > SL > SW |
Focusing on SL-clusters, the only productive combination of such onset clusters in English is [s] with the lateral liquid, [l]. This [sl]-cluster combination is similar to fricative + sonorant clusters, such as [fl] and [fr], in that they respect both the sonority sequencing hierarchy and minimal sonority distance. However, what makes both SL-clusters and [sn] clusters different from other OR clusters is that they blatantly violate the place identity constraint, or OCP(Place), which forbids the members in OR clusters from having the same place of articulation, ruling out [tl] clusters, for example (Goad 2011).
So far I have shown that each cluster type, namely ST, SN, SL and SW, violates one or more of the three markedness principles, namely sonority sequencing, minimal sonority distance and OCP(Place). It should be pointed out that some specific clusters within each type can be more marked than others, in terms of their violation profile. For example, [st] is more marked than other ST clusters not only because of the violation of SSH but also because [s] and [t] share the same place specification; [sn] is more marked than [sm] for the same reason. Table 4, below, sums up the violation profile of each cluster type:
As can be seen from Table 4, the only sC-cluster type that does not seem to be marked in any way is SW; all the other sC-clusters are marked in one way or another. These factors, as I will argue below, affect Cantonese speakers’ perception in loanword adaptation.
4.2 sC representation in Cantonese loanword phonology
I argue that when Cantonese speakers perceive words beginning with an sC cluster, they are aware of the marked status of these clusters compared to other OR clusters, and therefore assign to them a different phonological representation than to other onset clusters. Given the perceptual salience of fricatives, which discourages deletion, speakers syllabify [s] as the nucleus of a separate syllable from the rest of the word. The representations of sC and OR clusters are shown in Fig. 5.

Representation of sC and OR clusters
These two representations motivate different repair strategies: for OR clusters, the ill-formed onset cluster forces the deletion of the sonorant. For sC clusters, on the other hand, the ill-formed segment is the syllabic [s], which is repaired by realizing this syllable with a vowel. Deletion of the second consonant, which, in this representation, is the onset of a subsequent syllable, is not necessary, as it does not violate any Cantonese phonotactics.
This proposal assumes that when Cantonese speakers perceive words with an OR cluster, the syllable structure mapping component of the perception grammar (hereafter SMG, short for Syllable Mapping Grammar) assigns a syllabic representation in which the OR sequence is part of the syllable onset, the same representation that English speakers assign to this input. On the other hand, when Cantonese speakers encounter words with an sC cluster, the marked status of this cluster motivates a different phonological representation for this sequence: their SMG assigns a representation where the [s] is syllabic. This representation serves as the basis for adaptation.
Table 5, above, shows how the SMG can contribute to the altered phonological representation of a loanword for later adaptation. The remaining sC cluster, SW, does not seem to violate any of the three principles, but I argue that Cantonese speakers extend the generalization that [s] may constitute a syllable to this cluster type when they adapt English loans. As a result, when they encounter words like ‘sweet’, adapted as [si.wit], their perception grammar forces a representation similar to that of other sC clusters, i.e. |s̩.wit|.
5 An OT analysis
I argued in the previous section that Cantonese speakers in fact consider [s] in all sC clusters to be syllabic, which explains why sC onsets are repaired differently from OR clusters, where deletion of the second consonant takes place. I follow Pater’s (2004) claim that the same constraints are present in both the perception and production grammars. This section provides a brief sketch of what such a perception grammar looks like, followed by an analysis of how such representational differences force Cantonese speakers to adapt sC and OR clusters differently.
5.1 Syllable Mapping Grammar (SMG)
To translate how the SMG, as depicted in Table 5, works in OT, the three principles can in fact be expressed in terms of constraints. Following Pater’s (2004) proposal, I assume these constraints are present but they play a different role in perception and production: in perception, Cantonese speakers assign a phonological representation to the acoustic signals they receive based on these constraints. I will start this section by showing how each markedness principle works in SMG.
Focusing on the Sonority Sequencing Hierarchy, I follow Morelli (1999) in representing the hierarchy in terms of banning plateaus and reversals, formulated as the following constraints (Morelli 1999, p. 27):
(8) | *Plateau: sonority plateaus are disallowed |
(9) | *Reversal: sonority reversals are disallowed |
Because ST clusters violate the sonority sequencing hierarchy, in particular the reversal constraint in (9), this forces a different phonological representation of borrowed words with an ST cluster such as ‘speak’, at the expense of violating another markedness constraint that forbids any syllabic consonants:
(10) | *Peak/C: Peak must not be a consonantFootnote 3 (Hammond 1997) |

The minimal sonority distance can be captured with the following constraint:
(12) | Msd = 2: the minimal sonority distance in a cluster must be at least two steps away on the sonority scale. |
This constraint also dominates the constraint in (10) so that borrowed words with an SN cluster (e.g. ‘smoke’) are given a different phonological representation, as shown in (13), below:

The avoidance of place identity can be easily expressed as an OCP constraint:
(14) | Ocp(Place): Clusters must not share the same place of specification. |
Similarly, this OCP constraint outranks the syllabic consonant constraint:

Note that the phonological representation depicted above arises only when the acoustic form of a borrowed word perceived by Cantonese speakers is marked. The perception grammar does not assign such a phonological representation to a borrowed word with an OR cluster because of the active *Peak/C constraint:

The grammar I posit here allows listeners to interpret the syllable structure of foreign words, assigning a phonological representation, including syllable structure, to these words. These phonological representations serve as inputs to the output/production grammar of Cantonese, where adaptation of borrowed words takes place. (17), below, combines the rankings of these constraints to show how the winner of each cluster type is selected:

Since OR clusters such as [fl] do not violate any of the three higher-ranked constraints: *Reversal, Msd = 2 and Ocp(Place), their assigned phonological representation is a complex onset. On the other hand, the same phonological representation cannot be assigned to any sC clusters as this will incur violations of one of these constraints. Therefore, a different phonological representation, where the [s] is syllabic, is assigned.
5.2 Production grammar
Deletion of the second member in an OR cluster can be captured by the interaction of the following constraints: *ComplexOnset, Dep-V, Max-C. Their relative ranking is demonstrated in (18), below:

*ComplexOnset forbids the most faithful candidate (b). Dep-V has to be higher-ranked than Max-C in order for the deleted candidate, (a), to win. This constraint ranking holds to account for fricative coda epenthesis as well. Fricative codas are not allowed in Cantonese, so there is a very high-ranked markedness constraint that bans a fricative coda, *Fric/Coda. Since no fricatives are deleted in loanword adaptation, there is a more specific Max constraint that outranks Dep-V. Here, I use Max-Fricative (but in theory, Max-Obstruent also works). Incorporating this constraint into our ranking, we can correctly predict the winner, as shown in (19), below:

Returning to onset repairs, if sC is considered to be the same as other OR clusters, the ranking here would predict the wrong winner, as shown in (20):

This ranking would predict candidate (c), the deleted candidate, to win instead of the actual winner, (a). However, if we consider [s] to be a syllabic consonant, the markedness constraint that prohibits the faithful candidate from surfacing is then not *ComplexOnset but *Peak/C, which forces the underlying [s̩] to be realized with a vowel that occupies the nucleus position, as shown in (21), below:

In (21), the deleted form, candidate (c), loses because of the high-ranked Parse(syl), which is defined below:
(22) | Parse(syl): Assign a violation mark if a syllable is not parsed in the output. |
The difference between the winner, candidate (a), and the input is the segment occupying the first peak: in the output, an epenthetic vowel fills the first peak because of the *Peak/C constraint. While [s] in candidate (b) loses its syllabic status, this output form violates both Parse(syl) and *CC-Onset. The faithful output, candidate (d), violates the markedness constraint, *Peak/C. The high-ranked Onset constraint forbids the deletion of [l], which would produce an onsetless final syllable. The ranking here can correctly account for the different repairs on OR and sC clusters in Cantonese loanword phonology, as shown in (23):

Figure 6, below, visualizes this final ranking in the form of a Hasse diagram.

Hasse diagram of the final ranking
6 Source of sonority-related constraints
My proposal has made three important assumptions related to Cantonese speakers’ grammar: (1) Cantonese speakers are aware of the well-formedness of onset clusters on the basis of sonority, or sonority projection (Hayes 2011), (2) Cantonese speakers prefer segments in an onset cluster to be at least two steps away on the sonority scale, and (3) Onset clusters should not share the same place of specification. For a language that does not allow clusters, where do these constraints come from? A more general question that we can ask is how speakers can generalize unattested phonological patterns that are absent in their native language. In fact, this has been an area of interest for many phonologists (e.g. Davidson 2007; Berent et al. 2008; Hayes 2011). While it is not my intention to give a direct answer as to how these universal constraints are active in the grammar of Cantonese speakers, I will demonstrate how some of the languages with no complex onsets show sensitivity to sonority well-formedness in adapting foreign words with an onset cluster, and then provide supporting evidence for the presence of sonority projection in these speakers’ minds.
6.1 Sonority projection in loanword phonology
Recall from Sect. 4 that in some languages, where epenthesis is the repair strategy for onset clusters, the position of the inserted vowel varies depending on cluster type. The example used was data from Farsi, which are repeated below:
(4) | Farsi (Shademan 2002, from Broselow 2015, p. 307) | ||
a. | terafik | ‘traffic’ | |
korom | ‘chrome’ | ||
b. | eski | ‘ski’ | |
eslav | ‘Slav’ | ||
In Farsi, an OR cluster is repaired by inserting a vowel between the two consonants while an sC cluster is repaired by inserting a vowel before the cluster. This suggests that Farsi speakers treat OR and sC clusters differently. Compare Farsi with Central Pahari, in (24):
(24) | Central Pahari (Sharma 1980, cited from Broselow 2015, p. 296) | ||
a. | Kilip | ‘clip’ | |
b. | Silet | ‘slate’ | |
c. | Istuul | ‘stool’ | |
d. | ispit͡ʃ | ‘speech’ | |
Similar to Farsi, speakers of Central Pahari insert the epenthetic vowel between the two consonants to break up an OR cluster (24a) but place the vowel before an ST cluster (24c). What is different between the two languages is how an SL cluster is repaired: in Central Pahari, it is repaired the same way as an OR cluster (24b).
In fact, for these languages, where the position of vowel insertion varies, it is always the case that OR and ST are treated differently. What varies is the repair choice for the three SR clusters, namely SN, SL and SW (Broselow 2015). For some languages, some of the SR clusters pattern with OR clusters (e.g. Central Pahari in (24), and other languages including Bengali and Sherpa, Broselow (2015) while in other languages, other types of SR clusters pattern with the ST clusters (e.g. Farsi in (4)). This variation, however, strictly follows the markedness continuum depicted in (7), above: for example, there is no language that repairs SW and ST in the same manner but SL differently, as illustrated in the unattested language, e.g. ‘Central Pahari’ in (25), below:
(25) | Central Pahari | ||
a. | Kilip | ‘clip’ | |
b. | Islet | ‘slate’ | |
c. | Situul | ‘stool’ | |
d. | spiit͡ʃ | ‘speech’ | |
What we can generalize from these language data is that despite the absence of onset clusters in their native language, speakers of these languages are somewhat influenced by the sonority profile of different cluster types in deciding which repair strategy to use. The fact that these languages do not treat OR and ST clusters in the same manner suggests that speakers have knowledge of sonority projection: OR clusters are unmarked whereas ST clusters are marked. The cross-linguistic variation of the treatment of SR clusters seems to suggest that these languages have different degrees of tolerance for minimal sonority distance within an onset cluster: for Farsi speakers, segments in an onset cluster have to be three steps away on the sonority scale while for speakers of Central Pahari, the minimal sonority distance is two.
While this section illustrates that speakers of languages with no complex onsets do show some sensitivity to sonority projection, two questions remain:
-
1.
Where does such knowledge come from?
-
2.
Why do these languages differ in terms of minimal sonority distance?
In order to answer the above questions, we need to review different hypotheses of Universal Grammar (UG).
6.2 Sonority projection: innate or learned?
There are two different hypotheses with regards to the presence of unattested language patterns under UG: one being that these patterns are universal linguistic knowledge that is innate (the innatist hypothesis); the other being that most phonological generalizations come from our lexicon and such unattested patterns can in fact be learned implicitly from our linguistic experience (the lexicalist hypothesis, Daland et al. 2011). The focus of this section is not to argue for one over the other. Rather, I will present evidence for each of the two approaches to show how sonority projection can be present in speakers of languages like Cantonese.
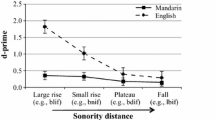
The innatist hypothesis states that universal linguistic knowledge is active in all human brains. It has been shown that speakers exhibit sensitivity to the well-formedness of a pattern that is absent from their native language. Focusing on onset cluster well-formedness, Berent et al. (2008) conducted two experiments with Korean speakers, whose language also does not allow complex onsets, on their perception of different onset clusters with varying sonority profiles, large rise (least marked): [bl], small rise: [bn], plateau: [bd] and fall (most marked): [lb]. In the syllable count experiment, participants were asked to listen to monosyllabic stimuli, each with one of these clusters, and decide if the stimuli consisted of one or two syllables. In the identity judgment experiment, two stimuli, C1C2VC3 and C1eC2VC3, where C1 and C2 were one of these clusters, were given in each question. Participants were asked to listen to the two stimuli and decide if they were identical or not. The accuracy and response time of their responses corresponded to the well-formedness of the clusters, i.e. they were more accurate and responded faster to stimuli with the least marked cluster, [bl], than the most marked cluster, [lb]. Berent et al. argue that this pattern, which mirrors the universal restrictions on onset clusters, supports their hypothesis that “adult human brains possess knowledge of universal properties of linguistic structures absent from their language” (Berent et al. 2008, p. 5324). Zhao and Berent (2017) replicated the same experiments with Mandarin speakers. While the Mandarin speakers exhibited similar patterns in experiment 2, their performance in experiment 1 was very different from the Korean group: Mandarin speakers counted all stimuli as disyllabic regardless of the sonority distance. Zhao and Berent (2017) attribute the results to phonetic factors: Mandarin speakers misinterpreted the stop burst of [b] as an epenthetic vowel.
It has been questioned, on the other hand, whether languages like Korean and Mandarin allow branching onsets at all. For example, Daland et al. (2011) argue that Korean family names such as ‘Choi’ can be syllabified as having a complex obstruent-glide onset, [tɕwæ], instead of having a diphthong, [tɕuæ]. An innatist answer to this question is that the only possible combination of this type is obstruent-glide formation and the inventory of such a formation in their lexicon is impoverished (Zhao and Berent 2017). This raises the question of whether these speakers can learn the sonority projection from such limited data. This learnability issue is indeed at the core of the lexicalist approach.
The major assumption of the lexical hypothesis is that the lexicon is the major source of phonotactic generalizations. Speakers’ knowledge of the well-formedness of unattested phonological patterns is learned from experience in speech perception and production (Daland et al. 2011). Such experience contains implicit evidence for them to make phonological generalizations beyond the lexicon. Under this assumption, the fact that speakers of a language with no onset clusters demonstrate an ability to differentiate marked clusters from unmarked ones is something learned implicitly from some (indirect) experience, rather than being innate. Hayes (2011) argues that these speakers acquire sonority projection of onset clusters based on the sonority differences of different syllabic positions: since sonority rises from the onset to the nucleus, they are able to extend this generalization to onset clusters where sonority should rise from the first consonant to the second one.
Hayes (2011) shows that onset cluster well-formedness is in fact computationally learnable by pseudo-languages which have only an obstruent-glide onset (the Bwa Language) and languages that have only a simple onset (the Ba Language). By feeding the learning program constraints that express the sonority hierarchy as features (e.g. *[-consonantal][-sonorant] = no glide-obstruent sequence) and every legal word of the two languages, both grammars are able to produce results that align with the sonority projection, i.e. the degree of penalty of a cluster sequence corresponds to the degree of its sonority violation. While the same simulation fails to work on languages with polysyllables and codas, Hayes proposes feeding more conditions (i.e. more indirect evidence) than just the feature constraints and learning data could potentially mirror learning behaviors for such languages.
To answer the first question, where do speakers acquire knowledge about principles such as the sonority projection, both hypotheses, despite their different underlying assumptions, suggest the presence of sonority projection in speakers of languages like Cantonese. If we adopt the innatist hypothesis, these speakers were born with these universal constraints. Even though consonant clusters do not exist in Cantonese, these constraints emerge when they are faced with foreign words with a cluster. The lexicalist hypothesis, on the other hand, says that it is learned by indirect evidence. When acquiring their native language, these speakers are also indirectly learning to generalize sequences based on sonority. These speakers make use of the learned knowledge to evaluate foreign words with a cluster.
It is less straightforward, however, for the innatist approach to answer the second question concerning how speakers acquire knowledge of different degrees of minimal sonority distance: if these constraints are universal, why do these languages (e.g. Farsi vs. Central Pahari) repair SR clusters differently? In order to maintain the innateness of such constraints, one innatist explanation is the influence of phonetic factors. Under the lexicalist approach, since unattested phonological patterns are learned from indirect evidence, these types of variations can be argued to be the result of the interaction between indirect evidence and the language-specific lexicon.
While the purpose of this section is not to give a definitive answer as to where this type of knowledge comes from, there seems to be some evidence showing that some such universal knowledge is inherently present. Hopefully, future experimental work and computational modeling can determine the source of such knowledge.
7 Alternative accounts
The proposal outlined here differs from Hamann and Li’s (2016) proposal based on the BiPhon model (Boersma and Hamann 2009), in which the same constraints and rankings are used in both perception and production. The BiPhon model works on loanword adaptation as follows: when perceiving a foreign word, speakers of the borrowing language map the acoustic signals to form an underlying representation based on the interaction between markedness constraints and cue constraints. These cue constraints are language specific, which drives these speakers to interpret these signals using their native language phonology, resulting in the adapted form being stored in their lexicon. This adapted form serves as the underlying representation in their loanword production. An important implication of this model is that the form that these speakers produce is in fact what they perceive.
In the case of speakers repairing an OR cluster by deleting the liquid in the cluster, Hamann and Li (2016) argue that the choice of deletion is a result of relative saliency: obstruents are salient and are therefore always perceived. Liquids, on the other hand, have weaker auditory cues in an onset cluster, so speakers who produce the deleted form fail to perceive the acoustic signal of the liquid in their perception. In constraint terms, this means that for these speakers, the cue constraint that bans the deletion of obstruents is ranked very high but the same constraint for liquids is ranked low.
One problem with Hamann and Li’s proposal is that it cannot explain why [sl] is repaired differently than other OR clusters by the same speaker. Since the cue constraints are phonetically-driven, if a speaker cannot perceive the liquid in an OR cluster, they should not be able to perceive the [l] in an [sl] cluster either. By solely referring to the cue constraints of obstruents and liquids, this proposed scenario cannot explain why a speaker perceives ‘flip’ as [fɪp] but ‘slip’ as [si.lɪp]. One possible way around this problem is to say that the [l] in [sl] is more salient than the [l] in other OR clusters. Phonetic evidence for such a difference would then be needed.
Another possibility is to go back to Yip’s (1993) and Silverman’s (1992) proposal that perceptually salient segments are syllabic. While this can explain the difference between [sl] and stop-liquid clusters, it does not really tell us why [fl] and [sl] are treated differently. For Hamann and Li’s proposal to work, they would need to posit different cue constraints, one for [s] alone and another for other fricatives. The cue constraint for [s] would have to be high enough to cause [s] to be perceived as syllabic and the cue constraint for other fricatives would not be high enough to make them perceived as syllabic but also not low enough for them not to be. But as seen in experiment 2, the preferred repair strategy for [f] and [s] codas is epenthesis. Unless we see other environments in which [s] is treated differently from other fricatives, it is more plausible to assume fricatives in general, rather than just [s] alone, are perceptually salient in Cantonese loanword phonology.
8 Residual issues and conclusion
In this paper, I presented experimental evidence showing that phonotactic repairs in Cantonese loanword phonology are mostly phonologically-driven. Factors such as word minimality and category specific effects seem to play a minimal role, but the makeup of onset clusters is crucial: sC sequences are clearly different from other onset clusters. By looking at repairs on onset clusters across the loanword paradigm, I proposed that [s] is perceived as syllabic in sC clusters and this representation is governed by the Syllable Mapping Grammar that assigns phonological representations to foreign inputs. Despite the absence of consonant clusters in Cantonese, this proposal assumes Cantonese speakers’ knowledge of sonority projection. Even though a direct answer as to where this knowledge comes from is not available, there is some evidence suggesting that the knowledge is either innate or learnable. The question of where such knowledge comes from is a task for future research.
Notes
As pointed out by a reviewer, the generalization here focuses on English words with a simplex fricative coda. For words with a coda cluster in which one member is a fricative, please refer to Kenstowicz (2011).
Since there is no voicing contrast in Cantonese, English words ending with the voiced fricatives were also used in this experiment.
It is a simplified version of a family of constraints that bans syllabic consonants with different sonority profiles (e.g. *Peak/Stop ≫ *Peak/Fricative ≫ *Peak/Nasal…).
References
Bates, Douglas, Martin Mächler, Ben Bolker, and Steve Walker. 2015. Fitting linear mixed-effects models using lme4. Journal of Statistical Software 67(1): 1–48. https://doi.org/10.18637/jss.v067.i01.
Bauer, Robert S., and Paul K. Benedict. 1997. Modern Cantonese phonology. Berlin: Mouton de Gruyter.
Berent, Iris, Tracy Lennertz, Jongho Jun, Miguel A. Moreno, and Paul Smolensky. 2008. Language universals in human brains. Proceedings of the National Academy of Sciences 105(14): 5321–5325. https://doi.org/10.1073/pnas.0801469105.
Boersma, Paul, and Silke Hamann. 2009. Loanword adaptation as first-language phonological perception. In Loan phonology (current issues in linguistic theory), ed. Andrea Calabrese and W. Leo Wetzels, 11–58. Amsterdam: Benjamins. https://doi.org/10.1075/cilt.307.02boe.
Broselow, Ellen. 2015. The typology of position-quality interactions in loanword vowel insertion. In Capturing phonological shades: Papers in theoretical phonology, ed. Yuchau E. Hsiao and Lian-Hee Wee, 292–319. Cambridge: Cambridge Scholars Press.
Daland, Robert, Bruce Hayes, James White, Marc Garellek, Andrea Davis, and Ingrid Normann. 2011. Explaining sonority projection effects. Phonology 28(2): 197–234. https://doi.org/10.1017/s0952675711000145.
Davidson, Lisa. 2007. The relationship between the perception of non-native phonotactics and loanword adaptation. Phonology 24(2): 261–286. https://doi.org/10.1017/s0952675707001200.
Fleischhacker, Heidi Anne. 2005. Similarity in phonology: Evidence from reduplication and loan adaptation. PhD dissertation, University of California Los Angeles.
Goad, Heather. 2011. The representation of sC clusters. In The Blackwell companion to phonology, ed. Marc van Oostendorp, Colin J. Ewen, Elizabeth Hume, and Karen Rice, 898–923. Wiley-Blackwell: Malden.
Hamann, Silke, and David W.L. Li. 2016. Adaptation of English onset clusters across time in Hong Kong Cantonese: The role of the perception grammar. Linguistics in Amsterdam 9(3): 56–76.
Hammond, Michael. 1997. Parsing in OT. Unpublished manuscript, typescript.
Hayes, Bruce. 2011. Interpreting sonority-projection experiments: The role of phonotactic modeling. In Proceedings of the 17th international congress of phonetic sciences, 835–838.
Hermes, Anne, Doris Mücke, and Martine Grice. 2013. Gestural coordination of Italian word-initial clusters: The case of ‘impures’. Phonology 30(1): 1–25. https://doi.org/10.1017/s095267571300002x.
Kang, Yoonjung. 2011. Loanword phonology. In The Blackwell companion to phonology, ed. Marc van Oostendorp, Colin J. Ewen, Elizabeth Hume, and Karen Rice, 2258–2282. Malden: Wiley-Blackwell.
Kenstowicz, Michael. 2011. Cantonese loanwords: Conflicting faithfulness in VC rime constraints. Catalan Journal of Linguistics 11: 65–91.
Leci, Mark, and Meoni Poon. 2004. Resolving consonant clusters: An OT analysis of English loanwords into Cantonese. University of Washington Working Papers in Linguistics 23, 103–118.
Luke, Kang-kwong, and Chaak-ming Lau. 2008. On loanword truncation in Cantonese. Journal of East Asian Linguistics 17(4): 347–362.
Morelli, Frida. 1999. The phonotactics and phonology of obstruent clusters in optimality theory. PhD dissertation, University of Maryland.
Pater, Joe. 2004. Bridging the gap between receptive and productive development with minimally violable constraints. In Constraints in phonological acquisition, ed. René Kager, Joe Pater, and Wim Zonneveld, 219–244. Cambridge: Cambridge University Press.
R Core Team. 2013. R: A language and environment for statistical computing. R Foundation for Statistical Computing. Vienna, Austria. http://www.R-project.org/.
Selkirk, Elisabeth. 1984. On the major class features and syllable theory. In Language sound structure, ed. Mark Aronoff and Richard T. Oehrle, 107–136. Cambridge: The MIT Press.
Silverman, Daniel. 1992. Multiple scansions in loanword phonology: Evidence from Cantonese. Phonology 9(2): 289–328. https://doi.org/10.1017/s0952675700001627.
Yip, Moira. 1993. Cantonese loanword phonology and optimality theory. Journal of East Asian Linguistics 2: 261–291.
Zhao, Xu, and Iris Berent. 2017. The basis of the syllable hierarchy: Articulatory pressures or universal phonological constraints? Journal of Psycholinguistic Research 45(4): 795–811. https://doi.org/10.1007/s10936-015-9375-1.
Acknowledgements
I would like to thank Ellen Broselow, Christina Bethin, Michael Becker, and the anonymous JEAL reviewers for their insightful comments and suggestions. Part of this research was presented in the 4th Workshop on innovations in Cantonese Linguistics, the 27th Annual Conference of International Association of Chinese Linguistics, and Chicago Linguistics Society 55. I thank the audiences for their questions and comments. Thanks are also due to the participants of the experiments.
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Appendices
Appendix 1: Stimuli for experiment 1
RP English | Epenthetic form | Deleted form | |
|---|---|---|---|
blank | blæŋk | peŋle:ŋ | pe:ŋ |
bleep | blip | pi:li:p | pi:p |
blink | blɪŋk | pɪŋlɪŋ | pɪŋ |
block | blɒk | pɔklɔk | pɔk |
clap | kʰlæp | khelep | khep |
click | kʰlɪk | kheklek | khek |
clip | kʰlɪp | khi:li:p | khiːp |
clog | kʰlɒg | khɔklɔk | khɔk |
flip | flɪp | fi:li:p | fi:p |
flirt | flɜːt | fɜtlɜt | fɜt |
flood | flʌd | fʌtlʌt | fʌt |
flow | fləʊ | fowlow | fow |
glare | ɡleə | ke:le: | ke: |
gleam | gli:m | ki:li:m | ki:m |
glow | gləʊ | kowlow | kow |
glue | glu: | ku:lu: | ku: |
plan | phlæn | phe:le:n | phe:n |
play | phlej | phejlej | phej |
plot | phlɒt | phɔtlɔt | phɔt |
plug | phlʌɡ | phʌklʌ:k | pʌ:k |
slam | slæm | si:lem | sem |
slap | slæp | si:lep | sep |
sleep | slip | si:lip | sip |
slide | slajd | si:lajt | sajt |
Appendix 2: Stimuli for experiment 2
RP English | Epenthetic form | Faithful form | Deleted form | |
|---|---|---|---|---|
advice | ədvaɪs | etwajsi | etwajs | etwaj |
base | bejs | pejsi | pejs | pej |
belief | bɪliːf | piliːfu | piliːf | piliː |
bonus | bəʊnəs | pownʌsi | pownʌs | pownʌ |
captive | kæptɪv | keptifu | keptif | kepti |
cave | kejv | kejfu | kejf | kej |
course | kɔːs | kɔːsi | kɔːs | kɔː |
invoice | ɪnvɔjs | inwɔ:jsi | inwɔ:js | inwɔ:j |
motif | məʊˈtiːf | mowti:fu | mowti:f | mowti: |
motive | məʊtɪv | mowtifu | mowtif | mowti |
office | ɒfɪs | ɔfʌsi | ɔfʌs | ɔfʌ |
olive | ɒlɪv | ɔli:fu | ɔli:f | ɔli: |
pass | pɑːs | pɑːsi | pɑːs | pɑː |
police | pəliːs | powliːsi | powliːs | powli: |
reserve | rɪzɜːv | wi:sɜːfu | wi:sɜːf | wi:sɜː |
serve | sɜːv | sɜːfu | sɜːf | sɜː |
service | sɜːvɪs | sɜːfʌsi | sɜːfʌs | sɜːfʌ |
wife | wajf | wajfu | wajf | waj |
Rights and permissions
About this article

Cite this article
Yeung, A.HL. Revisiting phonotactic repairs in Cantonese loanword phonology: it’s all about sC. J East Asian Linguist 29, 279–309 (2020). https://doi.org/10.1007/s10831-020-09212-w
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10831-020-09212-w