
Abstract
Long-range dependence (LRD) has been observed in a variety of phenomena in nature, and for several years also in the spiking activity of neurons. Often, this is interpreted as originating from a non-Markovian system. Here we show that a purely Markovian integrate-and-fire (IF) model, with a noisy slow adaptation term, can generate interspike intervals (ISIs) that appear as having LRD. However a proper analysis shows that this is not the case asymptotically. For comparison, we also consider a new model of individual IF neuron with fractional (non-Markovian) noise. The correlations of its spike trains are studied and proven to have LRD, unlike classical IF models. On the other hand, to correctly measure long-range dependence, it is usually necessary to know if the data are stationary. Thus, a methodology to evaluate stationarity of the ISIs is presented and applied to the various IF models. We explain that Markovian IF models may seem to have LRD because of non-stationarities.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
1 Introduction
The modeling of neuronal activity has a long and rich history whose first successes date back to the 50’s and the seminal work of Hodgkin and Huxley (1952). A few years later, a simpler probabilistic model based on the passage times of a random walk was introduced by Gerstein and Mandelbrot (1964), corresponding to a stochastic version of the Perfect Integrate-and-Fire (PIF) model.
The activity of a neuron is characterized by the electrical potential of its membrane, and more precisely by spikes whose amplitude and duration are very similar to one another. Therefore, it is rather the sequence of times at which these spikes occur which is believed to carry the neuronal information. While temporal (and spatial) correlations between interspike intervals (ISIs) have been observed for a long time (see Chacron et al. 2003 and references therein), the presence of fractal behavior (Teich 1992; Bair et al. 1994) and LRD phenomena in the spiking activity of neurons has been acknowledged for only two decades: see Teich et al. (1996, 1997), Lewis et al. (2001), Lowen et al. (2001), Bhattacharya et al. (2005), including artificially grown neuronal networks in Segev et al. (2002), etc. (see the introduction of Jackson2004 for a very comprehensive list of references). This LRD phenomenon is ubiquitous in nature, and takes the form of power-law correlations between interspike intervals rather than exponentially decaying correlations. In particular, LRD implies that the present neuronal activity is correlated with a very distant past.
Until recently in the neuroscience literature, long-range dependence, also called long memory, has been quantified mostly by the Fano factor. In Bhattacharya et al. (2005), temporal and spatial LRD of in vivo human hippocampal neurons is detected relying on statistics like the detrended fluctuation analysis (Peng et al. 1992). We shall adopt a similar approach, which has also been used to detect LRD in ion channels (de Oliveira et al. 2006). LRD may arise due to the influence of presynaptic neurons, as well as intrinsic factors such as fluctuations in ion channel activity (producing LRD in neurotransmitter exocytosis, as described by Lowen et al. 1997). Schwalger et al. (2015) also mention several possible sources of LRD: neural refractoriness, bursting and adaptation. Here, the LRD phenomenon is closely related (although not rigorously equivalent) to the power-law decay of correlations of the ISIs. The latter property has been considered as a near optimal way of encoding neuronal information (Baddeley et al. 1997).
Early attempts to replicate the LRD property of ISIs were based on point processes models and were proposed by Teich (1992), Bair et al. (1994), and more recently by Jackson (2004). Instead, we focus here on stochastic Integrate-and-Fire models, especially because they allow to preserve the aforementioned interpretation on the origin of LRD. Besides, it is commonly accepted that they provide a good compromise between biologically complex and realistic models such as the Hodgkin-Huxley model, and more simple and amenable ones to perform statistical computations with.
Brunel and Sergi (1998) and Destexhe et al. (2003) noticed that an additional differential equation for the synaptic current, coupled with the membrane potential equation of a simple IF model, introduces temporal correlations in the dynamics. Assuming that the pre-synaptic excitation is modeled by a Poisson noise, it is natural by diffusion approximation to write the synaptic equation as a stochastic differential equation driven by white noise. An interesting feature of this model is that it is simple enough to compute (or approximate) some ISI statistics: for example, Middleton et al. (2003) focused on the ISI density, power spectral density and Fano factor of the PIF, Lindner (2004) on serial correlation coefficients of the PIF, Schwalger and Schimansky-Geier (2008) on the ISI density, coefficient of variation, Fano factor of the leaky integrate-and-fire (LIF) model, etc. We also refer to Sacerdote and Giraudo (2013) for a mathematical and statistical treatment of Markovian IF models.
The purpose of this paper is to explain that a (linear) IF model with Markovian noise, even enhanced with a noisy adaptation variable, has exponentially decaying correlations which cannot produce long-range dependent ISIs. To account for different correlation patterns observed on real data, we introduce an IF model governed by a non-Markovian noise, namely a fractional Brownian noise. The fractional Brownian motion (fBm) is a stochastic process whose increments (the noise process) are long-range dependent and stationary. It naturally appears in modeling as a limit of more simple processes: For instance, the fBm appears as the limit of high-dimensional Orstein-Uhlenbeck processes (Carmona et al. 2000). However, it is non-Markovian, which makes it a challenge to study and compute all the aforementioned statistics of spike trains. We shall discuss the related idea developed by Schwalger et al. (2015), where general Gaussian processes are proxied by finite-dimensional Markov processes and serve as input in an IF model.
In addition to modeling, our contribution is also methodological: we compare several measures of LRD and stationarity. Indeed, testing stationarity is important in the attempt to measure LRD, as we shall see that non-stationary spike trains from Markovian models can give the illusion of LRD. We refer to Samorodnitsky (2016) and Beran et al. (2013) on these questions, as well as the collection of review articles edited by Rangarajan and Ding (2003) on modeling long-range dependent phenomena in various fields ranging from economy, biology, neuroscience to internet traffic. Last but not least, one is often interested in getting estimates on the distribution of the ISIs. But without the stationarity assumption, these distributions are likely to vary with time, which makes the estimation procedure either difficult or inaccurate. Hence, it is crucial to determine if these distributions vary with time, as it is desirable that the sequence of ISIs be in a stationary regime for such study. We therefore explain how to test this assumption, with a direct application to ISIs generated by integrate-and-fire models.
The remainder of the paper is organized as follows: in Section 2, we present an account of the tools and methods to measure LRD and stationarity from a single spike train. Then the stochastic Integrate-and-Fire models and some of its variations are presented in Section 3, with an emphasis on fractional noise. The results of our analysis are detailed in Section 4.1 for the PIF with Markovian noise with or without adaptation, in Section 4.2 for the PIF with fractional noise, and in Section 4.3 for variants with mixed Brownian and fractional noise. Finally, we discuss these results and compare them to previous models in Section 5.
2 Methods: statistical measurement of long-range dependence and stationarity
2.1 Long-range dependence
The terminology “long memory” or “long-range dependence” appeared in the early work of Mandelbrot and coauthors in the 60’s (Mandelbrot 1965; Mandelbrot and Wallis 1968), in an attempt to describe the phenomenon observed by Hurst on the flows of the Nile river.
If X is a random variable or a stochastic process, we say that X(ω) is a realization (or an observation) of X for the outcome ω in the probability space Ω of all possible outcomes. Let us denote by \(\mathbb {E}\) the expectation of a random variable. A sequence of random variables \(\{X_{n}\}_{n\in \mathbb {N}}\) has the long-range dependence (LRD) property if it satisfies:
Observe that the LRD property is obtained by averaging over all possible outcomes. In practical situations though, where we might have access to very few realizations (or even a single one) of the same phenomenon, at least two limitations appear: the length of the sequence is finite, and we do not know the law of the X n ’s (in fact when dealing with spike trains, we often have only one sample of the sequence). To detect long-range dependence, we will use two estimators: the detrended fluctuation analysis (DFA) and the rescaled range statistics (R/S). There exist other popular methods to measure the Hurst parameter (properly defined in Section 2.1.1), but as seen from Taqqu et al. (1995) and Weron (2002) we may not expect to get much better results than with the DFA and R/S methods. Besides, the latter is the only statistics for which it has been possible to prove convergence to the Hurst parameter rigorously in some non-trivial cases as the number of observations goes to infinity (Samorodnitsky 2016; Beran et al. 2013).
To prove convergence of the R/S statistics, it is usually required that the sequence \(\{X_{n}\}_{n\in \mathbb {N}}\) is L2-stationary, in the sense that
although there are examples of such convergence for non-stationary data (Bhattacharya et al. 1983 and Samorodnitsky2016, p.183–185). Verifying this requirement is often eluded in practical situations, although non-stationarity may have important consequences on the interpretation of statistical analysis of data. We emphasize that measuring (non-)stationarity and long-range dependence is a tricky question.
Let us insist on the type of data we shall be dealing with: these are (finite) sequences \(X_{1}, \dots , X_{N}\) (we now use this notation both for the probabilistic model and a realization of it). We aim at obtaining the Hurst parameter of the data from a single sequence (i.e. not from averaging several realizations), to cope with biological constraints.
2.1.1 The rescaled ranged statistics (R/S)
For a sequence \(\{X_{n}\}_{n\in \mathbb {N}}\) of random variables, let \(\{Y_{j} = {\sum }_{i = 1}^{j} X_{i}\}_{j\in \mathbb {N}}\) denote the sequence of the cumulated sums, and let the rescaled-range statistics be defined as:
If for some H ∈ (0,1), the law of \(\frac {1}{N^{H}} R/S(N)\) converges, as N goes to \(+\infty \), toward some positive random variable denoted by eb, we call H the Hurst parameter of the model. In the most simple example, where the X n ’s are independent and identically distributed (i.i.d.) with finite variance, the convergence occurs with H = 0.5. We consider that data have LRD when H > 0.5 (the reverse case H < 0.5 is often called anti-persistence, but we will not encounter it here).
Let us recall that N denotes the length of the sequence of data \(X_{1}, \dots , X_{N}\). A simple way to estimate H is to fit the following linear model for various values of N:
However this is not the robust way to proceed in practice, see Beran et al. (2013), Taqqu et al. (1995), Weron (2002). Instead, we divide the data into M blocks of length n (N = M × n) and compute the R/S statistics on each block \(\widetilde {R/S}(m,n)\) for \(m = 1 {\dots } M\). Then, we average over all blocks to obtain \(\widetilde {R/S}(n) = \tfrac {1}{M} {\sum }_{m = 1}^{M} \widetilde {R/S}(m,n)\). Finally we let n take integer values between 1 and N and estimate the slope of the function \(n\mapsto \widetilde {R/S}(n)\). This slope gives the estimated Hurst parameter of {X i }i≤N, frequently denoted by \(\hat {H}_{N}\) in the rest of this paper.
Let us conclude this paragraph with several insightful examples:
-
If the X n ’s are i.i.d. and \(\mathbb {E}\left ({X_{n}^{2}}\right )<\infty \), then standard convergence results imply that \(\frac {{1}}{\sqrt {N}} R/S(N)\) converges.
-
If the X n ’s are mixing and stationary, then H = 0.5 (see Section 5.2).
-
If the X n ’s are the increments of a fractional Brownian motion with scaling parameter α (fBm, see Section 3.1), then α is also the Hurst parameter, i.e. \(\frac {1}{N^{\alpha }} R/S(N)\) converges.
There are also examples of sequences of random variables with infinite variance such that \(\frac {{1}}{\sqrt {N}} R/S(N)\) converges (Samorodnitsky 2016, p.178–180), which emphasizes the robustness of the R/S method to a wide class of distribution of the X n . There are also examples of non-stationary random sequences for which the R/S statistics converges at prescribed rate \(H\in \left [0.5\right .,\left .1\right )\) (Samorodnitsky 2016, p.187).
2.1.2 The detrended fluctuation analysis (DFA)
This method was introduced by Peng et al. (1992, 1994) in genetics. We merely rephrase (Weron 2002) to present it. See also Taqqu et al. (1995) where it is called Residuals of Regression method and where it is compared to other methods.
Like in the R/S analysis, the data are divided into M blocks of length n. For \(m = 1{\dots } M\) and \(j = 1{\dots } n\), we denote the partial sum on block m by
On each block, a linear regression is applied to determine coefficients (a m , b m ) such that \(\tilde {Y}_{m,j}:= a_{m} j + b_{m}, j = 1{\dots } n\) is the least-square approximation of Ym, j. Then, the empirical standard deviation of the error is computed:
Finally, the mean of these standard deviations is \(\bar {s}_{n} := \tfrac {1}{M} {\sum }_{m = 1}^{M} s_{m}\). The analysis performed with \(\widetilde {R/S}(n)\) can now be reproduced with \(\bar {s}_{n}\) (i.e. the heuristics is that \(\bar {s}_{n}\) behaves asymptotically as a constant times nH). The slope computed from the log-log plot is again denoted by \(\hat {H}_{N}\).
2.1.3 Surrogate data
To check for the statistical significance of the R/S and DFA analyzes, we employed a bootstrapping with replacement procedure. For each simulated spike train, we produced 100 sequences of spikes by randomly shuffling the interspike intervals of the spike train. In this way, we obtain 100 new spike trains having the same interspike interval distribution, but without any correlation structure between spikes. The LRD analysis is applied to these new data to estimate \(\hat {H}_{N}\) as a function of N for each of them. The mean over all surrogate samples is plotted (see Section 4) in a black solid line, while two gray lines represent the mean ± 2 times the standard deviation. Thus, the region between gray lines will contain roughly 95% of possible H values that can be obtained by chance from a non-correlated data series. If the plot of \(\hat {H}_{N}\) of the initial spike train enters this shadow region, then it is doubtful that the data have the LRD property.
2.2 Stationarity
To compute statistics on a time series (e.g. spike trains) such as the mean, the distribution or more complex statistics aimed at determining the presence of power law or LRD, it is often necessary that the series is stationary. But it is in general a difficult problem to decide whether time series data are issued from a stationary distribution or not. Like the measurement of long-range dependence, part of the difficulty here arises from the fact that we want to decide whether biological data are stationary relying on a single observation (i.e. a single sequence of spikes).
Here we used several tests for stationarity: a simple windowed Kolmogorov-Smirnov (KS) test, the Priestley-Subba Rao (PSR) test and a wavelet-based test. Note that notion of stationarity itself must be clarified: the first test (KS) evaluates strong stationarity, i.e. whether the law of the process is invariant by any time shift. The PSR and wavelet-based tests consider a weaker form of stationarity that we shall refer to as L2-stationarity. A process X is L2-stationary if it satisfies Eq. (1). It is important to have in mind that the best test to use in a given situation depends strongly on the type of non-stationarity of the data (see for instance Table 2 in Cardinali and Nason2010). Since we do not know a priori what type of non-stationarity may appear, we are applying several tests.
Note that a frequently used test for stationarity is the KPSS test (Kwiatkowski et al. 1992), based on unit root testing. However, we found unit root tests to perform badly when used on fractional noise (which is stationary).
Like for the Hurst estimation of the previous section, these tests are designed to be run on a single realization of the process (said otherwise, no averaging is needed), which is well-suited for biological data. However, to decide whether a model yields stationary spike trains, multiple simulations can be performed. Hence the PSR and wavelet-based tests were applied to 50 simulations of the same model and a boxplot of the p-values was plotted. If the data come from a model which produces stationary ISIs, p-values must be uniformly distributed between 0 and 1. Otherwise we may conclude that the model yields data which are not stationary.
Thus, this methodology is designed to decide whether our models produce stationary ISIs. If the problem is to decide whether a single (biological or simulated) sequence is stationary, such stationarity tests will merely give a probability that the sequence is stationary.
2.2.1 The windowed Kolmogorov-Smirnov (KS) test
Based on the usual Kolmogorov-Smirnov (KS) test, we designed a windowed KS test. In this test, the ISI series are split in windows of fixed time length. Each block is tested against the others to see if they are described by the same distribution, using the non-parametric KS test. For each pair, the p-value is then represented in a two-dimensional table. The null hypothesis is that the two samples are drawn from the same distribution. Hence, small p-values indicate that the data may be non-stationary. In this way, a visual map is obtained in which one can easily detect portions of the time series that do not follow the same distribution as the others. Since this test does not return a single p-value, it is not suited to the aforementioned methodology of repeating simulations. Yet it allows for simple interpretations and we keep it for comparison with other tests.
2.2.2 The Priestley-Subba Rao (PSR) test
Let \(X = \{X_{t}\}_{t\in \mathbb {R}}\) be a centered stochastic process with finite variance. It is known that if X is L2-stationary, then
where \(Z = \{Z_{\omega }(B),\ \omega \in {\Omega }, B\in \mathcal {B}(\mathbb {R}) \}\) is a random measure on \(\mathbb {R}\) and A is the spectral density function. A natural generalization of the definition of X t is to let A depend on time. The PSR test (Priestley and Subba Rao 1969) evaluates the time dependence of A t (⋅). Thus, a test is proposed with the following null hypothesis: t↦A t (f) is constant in time. Note that the process must have zero mean (data can be centered in practice), finite variance, and be “almost” Gaussian.
A two-factor analysis of variance is performed. If the first p-value is small, then the test can stop here and the data declared to be non-stationary (Priestley and Subba Rao 1969). Otherwise, one can proceed to test the stationarity with a second p-value.
2.2.3 A wavelet-based test
This test (Cardinali and Nason 2018) is designed for a large class of processes called locally stationary wavelet processes, which can be written:
where \(\{\psi _{j,k}(t), t\in \mathbb {Z} \}\) is a wavelet basis, {ξj, k} is an array of i.i.d. random variables with mean 0 and variance 1, and {𝜃j, k} are the (deterministic) wavelet coefficients of X.
A test statistic is constructed from the data and a p-value is computed to decide whether the so-called β-spectrum (see Cardinali and Nason2018) is constant. If it is, the data are then stationary. We refer to Nason (2013), Cardinali and Nason (2018) and references therein for more details about this test.
The PSR test and this wavelet test give excellent results when applied to pure fractional noise, in the sense that they repeatedly give large p-values, as expected.
2.3 Numerical tools
To test stationarity, we relied upon Python’s function stats.ks_2samp from the scipy library for our windowed KS test, and upon the couple of R packages:
-
for the PSR test, we have used the R package fractal, and particularly the function stationarity.
-
for the wavelet-based test, we have used the function BootWPTOS from the R package BootWPTOS.
Our Python code to measure the Hurst parameter and to generate spike trains from the various models presented hereafter is available in modelDB (http://modeldb.yale.edu/235054).
3 The models
We describe a large class of noisy integrate-and-fire models with adaptation. Integrate-and-fire models have two regimes. The subthreshold regime is characterized by the stochastic differential system
The process (V t , t ≥ 0) models the membrane potential (normalized between 0 and 1) and (Z t , t ≥ 0) corresponds to an adaptation variable. We call Z the adaptation variable/process, even though in several cases we remove the adaptation mechanism. μ V , λ V , λ Z , γ, σ, \(\sigma ^{\prime }\) and α are parameters of the model. We detail the role of μZ, t in the next paragraph. μ V is the voltage offset (in ms− 1); λ V is the relaxation rate of the voltage (in ms− 1); γ is the coupling factor between the adaptation variable Z t and V t (in ms− 1); λ Z is the relaxation rate of the adaptation (in ms− 1); σ and \(\sigma ^{\prime }\) are the intensities of the noises Bα and \(\tilde {B}^{\alpha }\) (in ms−α) – random noises called fractional Brownian motions and described further in Section 3.1.
μZ, t is an offset factor for Z. We will either consider that μZ, t is constant in time (μZ, t ≡ μ Z ) or that it varies during 1 ms only after a spike (μZ, t ≡ μ Z + 𝜖Z, t). In both cases, let us remark that the law of (V t , t ≥ 0) remains invariant by the modification of parameters \((\mu _{Z},\mu _{V})\rightarrow \left (\mu _{Z} + a, \mu _{V} - \gamma \frac {a}{\lambda _{Z}}\right )\). So, to reduce the number of parameters to estimate, we assume that μ Z = 0. In the second case (adaptation), we thus have μZ, t = 𝜖Z, t, where 𝜖Z, t is equal to 1 during 1 ms after a spike and 0 otherwise. Using this form of adaptation (instead of a fixed increment of Z) puts a natural limit to Z, mimicking the behavior of a finite population of ion channels (Schwalger et al. 2010). More hidden states like Z can be added in Eq. (2) to approximate Gaussian processes which have long-range correlations (see Schwalger et al. 2015) where this idea is fully developed, and Section 4.3.2 where we test it numerically.
The firing regime is activated at the times τ when the membrane potential hits a fixed (deterministic) threshold Vth. We call such a time τ a firing time. Just after τ, the membrane potential is reset to a fixed value Vr, the rest potential. At the same time, we recall that μZ, t can be incremented due to adaptation. The sequence of firing times is formally defined for \(n = 1,2,\dots \) as
and τ0 = 0. The sequence of interspike intervals is \(\{X_{n} = \tau _{n}-\tau _{n-1}\}_{n\in \mathbb {N}}\), consistently with the notations of Section 2.
3.1 The noise
In Eq. (2), the noises \((B_{t}^{\alpha },t\geq 0)\) and \((\tilde {B}_{t}^{\alpha },t\geq 0)\) are fractional Brownian motions (fBm) of scaling parameter α ∈ (0,1). This family of processes, introduced in Mandelbrot and Van Ness (1968), is given by Gaussian centered processes with covariance function
The case α = 0.5 corresponds to the standard Brownian motion (integral of white noise). When α > 0.5, the increments of the fBm (i.e. the fractional noise) have positive correlations decaying very slowly, according to a power law:
This property will account either for a strongly correlated synaptic input to the neuron, or it could also be that the membrane acts as a fractional integrator over a noncorrelated input noise. Contrary to most noises encountered in the literature (in particular Markovian noises), the range of dependence of this noise can be said to be infinite. Mathematically, this is the long-range dependence property we shall include in our models. A complementary interpretation of α is as a scaling parameter (or power law): indeed, the fBm is statistically scale invariant of parameter α, meaning that an homothetic time change of parameter c will result in an homothetic space change of order cα.
This stochastic process has already been applied in various fields of physics and more recently, biology: in the context of biological dynamics (cell movement in crowded environment, so-called anomalous diffusions), see for instance (Metzler and Klafter 2004; Churilla et al. 1995; Rangarajan and Ding 2003). Notably, a reviewer kindly pointed to us the work of Zilany et al. (2009) that makes use of fractional Brownian motion in the modeling of auditory-nerve fibers: As a consequence, their model displays power law adaptation properties, as biologically observed several years earlier by Fairhall et al. (2001).
More generally, fractional Brownian motion provides a good, mathematically tractable, model of so-called 1/f noise, see e.g. Abry et al. (1995). 1/f noise has been successfully applied to describe many phenomena, from heartbeat (Peng et al. 1993) to internet traffic (Willinger et al. 1997), including neuronal fractal dynamics (Lowen et al. 2001; Sobie et al. 2011).
Contrary to standard Brownian motion, the fBm with α≠ 0.5 is not Markovian, which makes the computation of even basic statistics of ISIs a very difficult problem. The case α < 0.5 also yields power-law correlations, but negative, which is not used here. Very little is known on the first-passage time (i.e. spiking time) of models such as Eq. (2) driven by fractional Brownian motion: for the passage-time of fBm itself, see Delorme and Wiese (2015) for simulations and formal estimation of the density when α is close to 0.5 and Decreusefond and Nualart (2008) for inequalities on its Laplace transform, and on the general model see Richard and Talay (2016) for inequalities on Laplace transforms.
3.2 Models without the Z variable (γ = 0)
When γ = 0, Eq. (2) is a noisy Leaky Integrate-and-Fire (LIF) model. The particular case λ V = 0 corresponds to the noisy Perfect Integrate-and-Fire (PIF) model. The membrane potential is solution of a linear stochastic differential equation. In the white noise setting α = 0.5, the interspike intervals are independent and identically distributed, so in particular such sequences are stationary and do not have LRD.
Compared with multidimensional Markov models (see Section 4.3.2), this model with α > 0.5 is also more compact. This can be interesting when one needs to estimate the parameters from real data, see Sacerdote and Giraudo (2013).
We have also chosen to consider a model without any refractory period. The results seem to be interesting even in this simplified case.
3.3 Simulation tools
We simulated the subthreshold regime (2) with a simple Euler scheme. The hitting times are then recorded each time the simulated value of V reaches a value above the threshold, according to the firing regime described above. Note that there is no simple and efficient algorithm to simulate fractional Brownian motion. For our simulations, we chose the most efficient exact algorithm, namely the Davis-Harte algorithm (Coeurjolly 2000) (this algorithm has complexity \(O(n\log n)\)). All our Python code is available in modelDB and can be downloaded from http://modeldb.yale.edu/235054.
4 Study of LRD and stationarity of the simulated data
4.1 PIF model with stochastic adaptation \(\left (\alpha = 0.5\right )\)
4.1.1 Long-range dependence
We simulated a spike train using a Perfect Integrate-and-fire (PIF) model with adaptation, i.e. (2) with λ V = 0. The voltage dynamic is deterministic (σ = 0) and the slow adaptation variable (Z) has an additive white noise (i.e. α = 0.5) with \(\sigma ^{\prime }={2.5e-6}\).
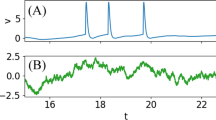
Figure 1A shows the spikes and the intervals obtained in a 500s-long realization of the model, which yielded 15,164 spikes for a firing rate of approximately 30 spikes/s (and a mean ISI of 33ms with standard deviation of 4.5). The Rescaled Range statistics and Detrended Fluctuation analyzes were first applied to a shorter sequence of intervals, the first 100s (3,023 spikes) of simulation. Figure 1B shows that the common linear regression between \(\log n\) and \(\log R/S(n)\) or \(\log DFA(n)\) yields a H value near 0.75 in both cases, suggesting a long-range dependence of the ISI sequence. However, this is a Markovian model and we do not expect it to yield LRD, as we shall prove.

R/S and DFA analysis of PIF model with noisy adaptation. A ISI sequence analyzed. parameters are μ V = 0.04, λ V = 0, γ = − 0.3, σ = 0, λ Z = 0.005, \(\sigma ^{\prime }={2.5e-6}\) (all in units of [ms− 1]). The vertical segmented line shows the limit of the data analyzed in B. Inset, ISI n /ISIn+ 1 plot. B Rescaled range (left) and Detrended Fluctuation Analysis (right) for the ISIs in the first 100 seconds of simulation (3023 spikes). H value is the slope of the best fit of \(\log n\) vs. \(\log R/S(n)\) or \(\log DFA(n)\) points to a straight line (segmented line over the data points). CR/S and DFA analysis of the full ISI sequence (15164 spikes). The H values indicated in the top left corner, and the segmented lines correspond to the fit of the full set of points to the data as in B. The shorter, continuous lines depict the best fit of a subset of the points. For clarity, not all points are shown. D Slope values calculated at different n values (with a moving window of 15 points), for the R/S (left) and DFA analysis (right). The continuous line shows the mean slope calculated with 100 surrogate series and the shadow region shows 2 Standard Deviations above and below the mean of the surrogate data slopes
Visual inspection of the plots reveals that the slope calculated is far from being the asymptotic slope, and that the curve ‘bends’ toward the right end. When we included the full sequence to the R/S and DFA analyzes (Fig. 1C), it is evident that the points are not following a linear relationship and the calculated slopes are lower. To characterize better the non-asymptotic nature of the slope, we repeated the fit to smaller subsets of 15 contiguous points, in a sliding window fashion. Three of such fits are shown as continuous lines in Fig. 1C (note that in Fig. 1C every other point has been omitted) and in Fig. 1D are plotted the slopes at different positions of the moving window. From this figure, it is clear that for both R/S and DFA the actual asymptotic behavior is a slope of 0.5. As the sequence length n increases, the slope approaches the 0.5 value and, moreover, gets into the 2*standard deviation range calculated from surrogate data (see Section 2). Thus, only the analysis of a very large sequence of data —probably discarding the shorter sequences in the analysis— will reveal that what appears to be long-range dependence has only a limited time span and that the phenomena underlying it is Markovian. Nevertheless, even on smaller sequences, we see that the Hurst estimator \(\hat {H}_{n}\) is decreasing with n in the Markovian model (Figs. 2 and 3), while it is relatively stable in the fractional case, as we shall see later (Fig. 6). In the following, the R/S analysis is no longer displayed in the plots. The reason is that we systematically observed a similar quantitative behavior between the R/S and the DFA, hence it was not necessary to keep both. We chose the DFA over the R/S for its better accuracy (see Fig. 7).

Hurst estimation depending on the different sources of noise. Detrended Fluctuation Analysis of simulations with noise only in the voltage equation (A), in both the Voltage and the Adaptation equation (B), and in the Adaptation equation (C and D) with two values of \(\sigma ^{\prime }\). Panels are as described in Fig. 1C and D (right)

Dependency of the LRD on adaptation parameters. A Effect of a larger rate for Z. B Effect of a smaller rate. C. Long-range dependence analysis in the absence of adaptation, i.e. the Z variable is not affected by the occurrence of spikes
The apparent long-range dependence of the data is largely related to the stochastic nature of the adaptation. Figure 2A shows that the apparent LRD is lost when the noise is present only in the voltage equation (σ > 0) but not in the adaptation (\(\sigma ^{\prime }= 0\)). When the noise is present in both equations, the apparent LRD is somewhat reduced for high values of σ (Fig. 2B). Also, Fig. 2B shows an interesting case where visually the straight line seems to be a good fit of the \(\log n\) versus \(\log DFA(n)\) data (and the associated r coefficient seems also good). However, the bottom plot shows that H > 0.5 is only observed at the left side of the plot (shorter sequences) while the asymptotic value actually falls within the standard deviation for the shuffled data. On the other hand, the magnitude of the noise seems not to affect much this behavior (Fig. 2C and D).
The LRD is also linked to the rate constant for slow adaptation, λ Z . Figure 3 shows that a large rate (or a small time constant τ Z = 1/λ Z ) is associated with the loss of apparent LRD (Fig. 3A), while a smaller value produces a LRD that is maintained for longer sequence lengths and also a higher H value (Fig. 3B). Further parameter explorations revealed that in order to observe the apparent LRD, the time constant for slow adaptation has to be at least twice the mean interval between spikes (not shown).
Figure 3C explores the situation where the adaptation variable Z is no longer updated at each spike (i.e., μZ, t = 0 for every t). In this case, Z t can be understood as a correlated noise (in the form of an Ornstein-Uhlenbeck process) added to the variable V. Although the adaptation effect is lost and the firing rate is increased (not shown), the apparent LRD is still present, showing that it is the correlated nature of the stochastic variable that causes this effect. This is very much in line with what has been described for other statistics of firing in the presence of different forms of correlated noise (Schwalger et al. 2010, 2015).
4.1.2 Stationarity
We base our stationarity analysis of the spike trains on the windowed KS, PSR and wavelet tests. For the PSR and wavelet tests, we apply the methodology described in Section 2, hence in each panel of Fig. 4, the left bar is a boxplot of 50 p-values from the PSR test computed from 50 independent spike trains generated by the same model; the right bar does the same with the wavelet test. On the other hand, Fig. 5 shows the results of the windowed KS test (see Section 2.2.1) for a single realization of the models indicated.

PSR and wavelet tests of stationarity on the PIF model with stochastic adaptation. The box displays the first quartile, the median and the third quartile, the whiskers extend to the most extreme data point which is no more than 1.5 times an interquartile away from the box. We observe here the effect of τ Z = 1/λ Z on the stationarity of the ISIs. We see in A, B and C that the smaller λ Z is, the further the ISIs are from being stationary. τ Z can be interpreted as a relaxation time toward a stationary regime. In D, the absence of noise in the adaptation variable yields stationary ISIs

Windowed KS test of ISI series, for the PIF model with stochastic adaptation (A) and the PIF model with fractional Gaussian noise (B). In A, the panel for λ Z = 0.005 analyzes the same data as in Fig. 1, while panels for λ Z = 0.05 and λ Z = 0.0005 use the same data as in Fig. 3A and B, respectively. The panel with σ= 0.0001, \(\sigma ^{\prime }\)= 0 corresponds to Fig. 2A. In B, three values of α are shown. At the top of each panel, a sample sequence of 60 s long (around 1800 spikes) is shown. The ISI sequence analyzed in the windowed KS test is of 300 s (9000 spikes), with 20 windows of 15 s. Blue colors (p-value < 0.05) indicate that the series compared are likely to be described by different distributions
In the PIF model with stochastic adaptation, a lower adaptation rate λ Z (longer adaptation time constant) is associated with a loss of stationarity, i.e. the data windows are no longer described by the same distribution (Figs. 4A–C and 5A). It seems that a lower adaptation rate λ Z (corresponding to a larger relaxation time 1/λ Z ) produces a sequence of ISIs farther from stationarity, and that 1/λ Z not only characterizes the speed of convergence of Z t to its stationary regime, but also the speed of convergence of the law of the ISIs to their stationary law.
Observing Figs. 4 and 5A, it seems that the spike trains for larger λ Z are stationary while they are not for smaller λ Z . A first explanation could be that the transient period to reach a stationary regime is longer for small λ Z , since the characteristic time \(\tau _{Z} = \lambda _{Z}^{-1}\) is larger. However we obtained the same result after removing a sufficiently large number of spikes at the beginning of the sequence. In fact we believe that even for small λ Z , the spike train reaches a stationary regime: First, it is likely that the stationarity tests are not robust to the very large fluctuations induced by a small λ Z (see Fig. 5A) and do not scale well; second, we performed multi-sample tests of stationarity for λ Z = 0.0005, which confirmed our intuition of a long transient period followed by stationarity (although we recall that such tests require to simulate many spike trains from the same model, which is not feasible biologically). This question has practical consequences, since non-stationary time series cannot be analyzed, in general, with the same methods as stationary time series and doing so can lead to severe mistakes.
On the other hand, adding only white noise to the dynamics of V produces stationary data (Figs. 4D and 5A).
4.2 PIF model with fractional Brownian noise
We decided to compare the behavior of the previous Markovian PIF model with or without adaptation (but with noise always in the adaptation variable) to a non-Markovian PIF model without adaptation mechanism, as this was proved to be irrelevant as far as LRD is concerned. Therefore we set γ = 0, λ V = 0 and explored values of α above 0.5. σ and μ were adjusted in order to obtain similar mean and variance of the ISIs obtained in the previous simulations.
4.2.1 Long-range dependence
Figure 6 shows that adding a fractional Gaussian noise indeed produces a long-term dependence in the series of ISIs, as evidenced by both Rescaled Range statistics and Detrended Fluctuation Analysis. In contrast to the PIF model with stochastic adaptation, however, the high slope in the \(\log n\) versus \(\log R/S(n)\) or \(\log DFA(n)\) plots is maintained and does not decay as n increases. In other words, the \(\hat {H}_{n}\) value obtained by these analyzes appears to be rapidly close to its true asymptotic value. This behavior is observed at different values of α (Fig. 6). The PIF model with fractional Brownian noise, however, shows a weaker correlation of consecutive intervals (Fig. 6A, inset, r = 0.34) than the PIF model with noisy adaptation (compare to inset of Fig. 1A, r = 0.85).

Long-range dependence behavior in a PIF model with fractional Gaussian noise. A sequence of ISIs obtained in a simulation with equation (2) and parameters μ V = 0.0303, λ V = 0, γ = 0, σ = 0.0117, α = 0.7. The Z variable was not taken into account. Inset, ISI n /ISIn+ 1 plot. B DFA analyzes for the full sequence of 14,500 spikes. The three continuous lines that depict local slopes are overlapping a segmented line that represents the best fit for all the data points. As in Fig. 1C, every other point has been omitted. Bottom, plot of best-fit slopes in moving windows of 15 points. The continuous line and the shadowed region are the mean and standard deviation, respectively, of the fits with surrogate data. C and D DFA analysis of ISI sequences obtained with α = 0.6 and α = 0.8, respectively
Furthermore, we see in Fig. 7 that estimated Hurst parameter \(\hat {H}_{n}\) is very close to the input value α. Hence we can safely assert that \(\hat {H}_{n}\) converges to α.

Measure of the Hurst parameter \(\hat {H}_{n}\) of the fractional PIF model. For each α ∈{0.5,0.6,0.7,0.8,0.85}, we simulated 50 independent sequences of ISIs from a fractional PIF with parameter α (and with μ and σ chosen so that the ISIs X n have the following moments \(\mathbb {E}[X_{n}]\approx 32.9 \text {ms}\) and Var[X n ] ≈ 20). The Hurst parameter was estimated by the R/S (blue plot) and DFA (red plot) methods for each simulation, and for each underlying α parameter, the result has been aggregated in a boxplot. We see that the estimated Hurst parameter of the ISIs is very close to the value of the scaling parameter of the fBm used in the simulations. The DFA method seems to perform better
4.2.2 Stationarity
Results concerning stationarity of this model are shown in Fig. 5B for the KS test. We conclude that the ISIs are stationary when α = 0.5 (the PSR and wavelet tests yielded the same conclusion). This agrees with the theoretical result in this simple framework. The conclusion from the cases α = 0.7 and α = 0.85 is less straightforward in view of the PSR and wavelet tests, but we performed additional tests (all not shown) which suggest stationarity as well. Even more than for the Markovian model though, proving stationarity seems mathematically challenging.
4.3 Other models
4.3.1 Leaky integrate-and-fire models
The leaky Integrate-and-Fire model corresponds to λ V > 0 in Eq. (2), instead of λ V = 0 for the PIF. We draw the same conclusions on the LRD property for the LIF (not shown).
4.3.2 Higher dimensional integrate-and-fire models with Brownian noise
Following the idea in Schwalger et al. (2015), we simulated a PIF with three noisy adaptation variables whose time constants are 200ms, 1000ms and 5000ms (Fig. 8A). The aim is to get a better approximation of long-range dependence with a Markovian model. We observe in Fig. 8A that the Hurst estimation decays more slowly in this new model, indicating that it can be a good approximation of a LRD sequence when the length is not too large. Yet it still seems to converge to 0.5, which means that it is still not LRD. To emphasize the slower convergence of the LRD estimator in the multidimensional model, we compared it to the previous PIF model (from Section 4.1) with a large time constant of 5000ms (Fig. 8B).
We observe (particularly in Fig. 8B) that the mean curve of the surrogate data can be higher than 0.5 for the DFA, although it decreases (we checked that it indeed decreases to 0.5 for longer spike trains). This is a drawback of the DFA, which is not robust to data with very large mean and/or variance. We confirmed this either by artificially removing the largest ISIs (hence reducing drastically the variance), or by simulating sequences of i.i.d. positive random variables following a Pareto law (with scale 1 and shape parameter between 1 and 2). In that situation, a strong bias appears, unlike the R/S which still returns values close to 0.5 (not shown).
4.3.3 PIF model with Brownian and fractional Brownian noise
Considering the approach of some authors (Schwalger et al. 2015) to add high-dimensional noise in the adaptation variable (see also some heuristics in Section 5.2) and the power law behavior of the adaptation often observed (Fairhall et al. 2001), one is tempted to consider the following modification of our model (2), where the scaling parameter of the noise in the voltage is 0.5 and is α > 0.5 in the adaptation variable:
This model may allow for more complex behaviors, e.g. observations from simulations on the previous model display several firing regimes:
-
if σ = 0 and for λ Z > 0, λ V = 0, μ = − 10γ, the estimated Hurst parameter of the ISIs, \(\hat {H}_{n}\), remains close to the scaling parameter α of the model.
-
if σ > 0 and \(\sigma ^{\prime } \ll \sigma \), the ISIs are almost independent and \(\hat {H}_{n}\) is close to 0.5.
-
if \(\sigma \ll \sigma ^{\prime }\) and μ ≪ 1, then similarly to the biological data, \(\hat {H}_{n}\) increases with n toward the value α and the ISI histogram seems to deviate from the inverse Gaussian distribution (figures not shown).
Furthermore, it would be interesting to see in future works if this model shares the multiple time scale adaptation observed by Fairhall et al. (2001) and modeled by Lundstrom et al. (2008), Teka et al. (2014) using fractional differentiation or cascade processes as in Drew and Abbott (2006), Pozzorini et al. (2013).

Long-range dependence in the PIF model with multidimensional noise. In A, a PIF with three-dimensional noise whose time constants are 200 ms, 1000 ms and 5000 ms is simulated and we observe a slow decay of the Hurst estimation. In B, a PIF with a single time constant (τ = 5000ms) is simulated and the Hurst parameter decreases to 0.5, even with a large time constant. This is coherent with the results of Section 4.1.1. Note that in both cases, the slope is decreasing, unlike the fractional PIF model (Fig. 6)
5 Discussion
In this paper, we have studied two approaches to model the long-range temporal correlations observed in the spike trains of certain neurons. In a first approach, the introduction of a weakly correlated input noise with a finite number of timescales into a linear Integrate-and-Fire model can produce quite large time dependencies and be a good approximation of a power law dynamics; however this is not genuine LRD nor power law behavior, as it is shown when a sufficiently large sequence is analyzed. Besides, we have shown that using multiple large time constants usually yields non-stationarities. A second approach is also of the Integrate-and-Fire type, with a stochastic input called fractional Brownian motion. To the best of our knowledge, this is the first time this stochastic process is used in an IF model, and we showed that it is very well suited to produce genuine long-range dependent spike trains. Besides, this type of stationary Gaussian noise emerges naturally as a scaling limit of discrete noises (see Sections 5.1 and 5.2) which can originate either from the fractal behavior of ion channels or from the cumulated inputs of the neuronal network.
To measure the long-range dependence of spike trains, we followed a well-established procedure (Taqqu et al. 1995). For previous examples in neuroscience, see for instance the DFA analysis of ISIs in Bhattacharya et al. (2005) or the R/S analysis for ion channels in de Oliveira et al. (2006). In the literature to date, we have identified several types of IF models aimed at producing correlated spike trains: those with colored noise input (i.e. Markov noise) (Brunel and Sergi 1998; Middleton et al. 2003; Lindner 2004; Schwalger and Schimansky-Geier 2008; Schwalger et al. 2010) and more recently PIF with high-dimensional Ornstein-Uhlenbeck noise (Schwalger et al. 2015); non-renewal point processes inputFootnote 1 (Teich 1992; Bair et al. 1994; Teich et al. 1997; Lowen et al. 1997, 2001; Jackson 2004); and models with 1/f noise input (Sobie et al. 2011). The first conclusion of our study is that the ISIs generated from Markovian integrate-and-fire models do not have LRD stricto sensu, and produce instead ISIs whose correlations are exponentially decaying. From this perspective, we must however point out Schwalger et al. (2015) whose precise goal was to replicate power-law decay of the correlations. While this goal is achieved on a reasonable band of frequency (see the power spectrum of their simulated spike trains), we have shown that such models still do not produce LRD. However, as seen in all Figs. 1 to 3, these Markovian integrate-and-fire models (whether perfect of leaky) can replicate a LRD effect for sequences of spikes with a given length (see Fig. 1), if the adaptation variable is noisy and its time constant 1/λ Z is large enough. Nonetheless, plots of the estimated Hurst parameter as a function of the sequence length are always decreasing. This contrasts with fractional integrate-and-fire models, for which this function appears constant at a value \(\hat {H}\) (see Fig. 6). This provides a simple criterion to discriminate between Markovian and fractional IF models. Moreover, we see in Fig. 7 that \(\hat {H}\), the estimated Hurst index of the spike trains, is exactly the scaling parameter α of the fractional Brownian motion injected in the model.
We also presented and compared the effectiveness of several stationarity tests suited to time series analysis. The methodology for testing stationarity we propose seems relatively new to the neuroscience literature. Stationarity is often believed to hold for ISIs (Schwalger et al. 2015), yet it produced surprising results since we observed that sequences of ISIs can look non-stationary (Figs. 4 and 5), even when generated from a simple IF model with Ornstein-Uhlenbeck noise. However, we believe that a stationary regime exists for such models. This stationarity property has important consequences: if a sequence of ISIs has a stationary regime and its correlations decay exponentially fast, then the estimated Hurst of the R/S statistic must be 0.5. Altogether the present discussion on stationarity leaves several questions unanswered and should be the purpose of future work.
A very interesting and important problem that we may also be the content of future work is calibration. Consider the following situation: given an observed spike train with measured Hurst parameter \(\hat {H}>0.5\), we want to calibrate either the parameters μ V , σ and α of a fractional PIF or the parameters \(\mu _{V}, \gamma , \sigma , \lambda _{Z}, \sigma ^{\prime }\) of a Markovian \(\left (\alpha = 0.5\right )\) PIF with an adaptation variable. In the first case, it results from Fig. 7 that we must choose \(\alpha =\hat {H}\). We only have two more parameters to fix, and the mean of the ISIs is given by \(\frac {1}{\mu _{V}}\) (assuming implicitly that the threshold is 1). We can then try to compute σ from the variance of the ISIs and \(\hat {H}\). On the other hand, we have seen from Fig. 3 that the \(\hat {H}\) value can be replicated by adjusting λ V : a larger λ V yields smaller \(\hat {H}\) parameter, but also impacts the first two moments of the ISIs. Hence it may be easier to fix first the scaling parameter of the noise, rather than having additional parameters just to replicate the correlations of the ISIs. Then we can focus on additional properties that adaptation can bring to integrate-and-fire models.
5.1 Other classes of models with fractal/LRD behavior
Despite the numerous articles emphasizing the presence of fractal and/or long-range dependence of the spiking activity of some neurons (see Section 1), we merely identified two streams of papers proposing a model reflecting these characteristics. In Jackson (2004) (see references therein from related previous works from the 90’s, including in particular (Lowen et al. 1997) and coworkers), an integrate-and-fire model is used in conjunction with various point processes modeling a random input into the neuron. If the point process is a renewal process, then it may produce long-range dependence only if it has infinite variance (Jackson 2004, Theorem 2). Infinite variance models can get far from biological observations, thus a more sophisticated point process, the fractional-Gaussian-noise-driven Poisson process, is used in Jackson (2004). This process is a doubly stochastic Poisson process, whose (stochastic) rate function is a nonlinear function of a fractional Gaussian noise. Each jump corresponds to a spike in a presynaptic neuron, and when injected in an IF model, it is successful in producing spike trains with long-range dependence (as measured with the Fano factor). However, the use of such process seems less mathematically tractable than our approach with a fractional noise. In fact, the fBm is itself the scaling limit of discrete processes (Taqqu 1975; Sottinen 2001; Hammond and Sheffield 2013), is statistically self-similar and with stationary increments, which makes it a natural candidate as input noise.
The second approach to model LRD is an Integrate-and-Fire model with 1/f noise proposed by Sobie et al. (2011), strongly related to our model. The link between fractional Brownian motion and 1/f noise is explained in Abry et al. (1995), although there is no definition of 1/f noise as clear and universally accepted as the definition of fBm can be. Besides, an advantage of using fBm is that it can be exactly simulated, which ensures that all frequencies are present in its spectrum and that LRD holds, while a simulated 1/f noise is an approximate 1/f noise with limited bandwidth. Nevertheless, the approach of Sobie et al. (2011) is complementary to ours since this study focuses on the dispersion of spike trains in time windows [0, t] for various times t (as measured by the Fano factor).
5.2 Heuristics on long-range dependence and fractional Brownian motion
In classical Markovian models (e.g. PIF model with multidimensional Ornstein-Uhlenbeck noise, α = 0.5), the correlation between interspike i and i + n decays exponentially in n, even though having high-dimensional OU process is intended to produce large time constants. We assert that the ISIs of this model are mixing, i.e. that \(\sup _{A,B} |\mathbb {P}\left (X_{i}\in A, X_{i+n}\in B\right ) -\mathbb {P}(X_{i}\in A) \mathbb {P}(X_{i+n}\in B)|\leq \phi (n)\), for some ϕ such that \({\sum }_{n} \phi (n)<\infty \). We also believe, based on mathematical arguments and some numerical evidence (see Section 4), that such model produces ISIs which converge to a stationary regime.
From Doukhan (1994), Chapter 1.5, it is known that any stationary and mixing sequence satisfies an invariance principle. This is enough to apply Theorem 4of Mandelbrot (1975), which gives the convergence of N− 1/2R/S(N) to anon-trivial random variable. Therefore we conjecture the following result that we plan to prove in aseparate work, that is:
If α = 0.5, the sequence of interspike intervals generated by the PIF/LIF model (2) has astationary regime, and \(N^{-\frac {1}{2}} R/S(N)\) converges to anon-degenerate random variable (i.e. \(\hat {H}_{N} \rightarrow 0.5\)).
Our second heuristics is about the approximation of the fractional Brownian motion by a sequence of n-dimensional Ornstein-Uhlenbeck processes, as n increases. In Schwalger et al. (2015), the general idea is that the covariance of a general Gaussian process can be approximated by an Ornstein-Uhlenbeck with sufficiently many components. In Carmona et al. (2000), it is proven that the fBm is indeed an infinite-dimensional Ornstein-Uhlenbeck process. Therefore, we can consider our model with fractional noise as a natural limit to the model proposed in Schwalger et al. (2015). Although this is not the only possible limit in their approach, the fBm is the most sensible choice to obtain long-range dependence.
Notes
A limitation of the point process approach is that it is far from the biological reality.
References
Abry, P., Gonçalvès, P., Flandrin, P. (1995). Wavelets, spectrum analysis and 1/f processes, (pp. 15–29). New York: Springer.
Baddeley, R., Abbott, L.F., Booth, M.C., Sengpiel, F., Freeman, T., Wakeman, E.A., Rolls, E.T. (1997). Responses of neurons in primary and inferior temporal visual cortices to natural scenes, (Vol. 264 pp. 1775–1783).
Bair, W., Koch, C., Newsome, W., Britten, K. (1994). Power spectrum analysis of bursting cells in area mt in the behaving monkey. Journal of Neuroscience, 14(5), 2870–2892.
Beran, J., Feng, Y., Ghosh, S., Kulik, R. (2013). Long-memory processes. Heidelberg: Springer. Probabilistic properties and statistical methods.
Bhattacharya, R.N., Gupta, V.K., Waymire, E. (1983). The Hurst effect under trends. Journal of Applied Probability, 20(3), 649–662.
Bhattacharya, J., Edwards, J., Mamelak, A., Schuman, E. (2005). Long-range temporal correlations in the spontaneous spiking of neurons in the hippocampal-amygdala complex of humans. Neuroscience, 131(2), 547–555.
Brunel, N., & Sergi, S. (1998). Firing frequency of leaky intergrate-and-fire neurons with synaptic current dynamics. Journal of Theoretical Biology, 195(1), 87–95.
Cardinali, A., & Nason, G.P. (2010). Costationarity of locally stationary time series. Journal of Time Series Econometrics, 2(2), Article 1.
Cardinali, A., & Nason, G.P. (2018). Practical powerful wavelet packet tests for second-order stationarity. Applied and Computational Harmonic Analysis 44(3), 558–583.
Carmona, P., Coutin, L., Montseny, G. (2000). Approximation of some Gaussian processes. Statistical Inference for Stochastic Processes, 3(1-2), 161–171. 19th “Rencontres Franco-Belges de Statisticiens” (Marseille, 1998).
Chacron, M.J., Pakdaman, K., Longtin, A. (2003). Interspike interval correlations, memory, adaptation, and refractoriness in a leaky integrate-and-fire model with threshold fatigue. Neural Computation, 15(2), 253–278.
Churilla, A.M., Gottschalke, W.A., Liebovitch, L.S., Selector, L.Y., Todorov, A.T., Yeandle, S. (1995). Membrane potential fluctuations of human t-lymphocytes have fractal characteristics of fractional brownian motion. Annals of Biomedical Engineering, 24(1), 99–108.
Coeurjolly, J.-F. (2000). Simulation and identification of the fractional brownian motion: a bibliographical and comparative study. Journal of Statistical Software, 5(1), 1–53.
de Oliveira, R.C., Barbosa, C., Consoni, L., Rodrigues, A., Varanda, W., Nogueira, R. (2006). Long-term correlation in single calcium-activated potassium channel kinetics. Physica A: Statistical Mechanics and its Applications, 364, 13–22.
Decreusefond, L., & Nualart, D. (2008). Hitting times for Gaussian processes. The Annals of Probability, 36 (1), 319–330.
Delorme, M., & Wiese, K.J. (2015). Maximum of a fractional Brownian motion: analytic results from perturbation theory. Physical Review Letters, 115(21), 210601, 5.
Destexhe, A., Rudolph, M., Paré, D. (2003). The high-conductance state of neocortical neurons in vivo. Nature Reviews Neuroscience, 4(9), 739–751.
Doukhan, P. (1994). Mixing, properties and examples, volume 85 of lecture notes in statistics. New York: Springer.
Drew, P.J., & Abbott, L.F. (2006). Models and properties of power-law adaptation in neural systems. Journal of Neurophysiology, 96(2), 826–833.
Fairhall, A.L., Lewen, G.D., Bialek, W., de Ruyter van Steveninck, R.R. (2001). Efficiency and ambiguity in an adaptive neural code. Nature, 412, 787–792.
Gerstein, G.L., & Mandelbrot, B. (1964). Random walk models for the spike activity of a single neuron. Biophysical Journal, 4(1), 41–68.
Hammond, A., & Sheffield, S. (2013). Power law Pólya’s urn and fractional Brownian motion. Probability Theory and Related Fields, 157(3–4), 691–719.
Hodgkin, A.L., & Huxley, A.F. (1952). A quantitative description of membrane current and its application to conduction and excitation in nerve. The Journal of Physiology, 117(4), 500–544.
Jackson, B.S. (2004). Including long-range dependence in integrate-and-fire models of the high interspike-interval variability of cortical neurons. Neural Computation, 16(10), 2125–2195.
Kwiatkowski, D., Phillips, P.C., Schmidt, P., Shin, Y. (1992). Testing the null hypothesis of stationarity against the alternative of a unit root. Journal of Econometrics, 54(1), 159–178.
Lewis, C.D., Gebber, G.L., Larsen, P.D., Barman, S.M. (2001). Long-term correlations in the spike trains of medullary sympathetic neurons. Journal of Neurophysiology, 85(4), 1614–1622.
Lindner, B. (2004). Interspike interval statistics of neurons driven by colored noise. Physical Review E, 69, 022901.
Lowen, S.B., Cash, S.S., Poo, M.-m., Teich, M.C. (1997). Quantal neurotransmitter secretion rate exhibits fractal behavior. Journal of Neuroscience, 17(15), 5666–5677.
Lowen, S.B., Ozaki, T., Kaplan, E., Saleh, B.E., Teich, M.C. (2001). Fractal features of dark, maintained, and driven neural discharges in the cat visual system. Methods, 24(4), 377–394.
Lundstrom, B.N., Higgs, M.H., Spain, W.J., Fairhall, A.L. (2008). Fractional differentiation by neocortical pyramidal neurons. Nature Neuroscience, 11(11), 1335–1342.
Mandelbrot, B.B. (1965). Une classe de processus stochastiques homothétiques à soi; application à la loi climatologique de H. E. Hurst. C. R. Acad. Sci. Paris, 260, 3274–3277.
Mandelbrot, B.B. (1975). Limit theorems on the self-normalized range for weakly and strongly dependent processes. Z. Wahrscheinlichkeitstheorie und Verw. Gebiete, 31, 271–285.
Mandelbrot, B.B., & Wallis, J.R. (1968). Noah, Joseph, and operational hydrology. Water Resources Research, 4(5), 909–918.
Mandelbrot, B.B., & Van Ness, J.W. (1968). Fractional Brownian motions, fractional noises and applications. SIAM Review, 10(4), 422–437.
Metzler, R., & Klafter, J. (2004). The restaurant at the end of the random walk: recent developments in the description of anomalous transport by fractional dynamics. Journal of Physics. A. Mathematical and General, 37 (31), R161–R208.
Middleton, J.W., Chacron, M.J., Lindner, B., Longtin, A. (2003). Firing statistics of a neuron model driven by long-range correlated noise. Physical Review E, 68, 021920.
Nason, G. (2013). A test for second-order stationarity and approximate confidence intervals for localized autocovariances for locally stationary time series. Journal of the Royal Statistical Society. Series B. Statistical Methodology, 75(5), 879–904.
Peng, C.K., Buldyrev, S.V., Goldberger, A.L., Havlin, S., Sciortino, F., Simon, M., Stanley, H.E. (1992). Long-range correlations in nucleotide sequences. Nature, 356, 168–170.
Peng, C.-K., Mietus, J., Hausdorff, J.M., Havlin, S., Stanley, H.E., Goldberger, A.L. (1993). Long-range anticorrelations and non-Gaussian behavior of the heartbeat. Physical Review Letters, 70, 1343–1346.
Peng, C.-K., Buldyrev, S.V., Havlin, S., Simons, M., Stanley, H.E., Goldberger, A.L. (1994). Mosaic organization of DNA nucleotides. Physical Review E, 49, 1685–1689.
Pozzorini, C., Naud, R., Mensi, S., Gerstner, W. (2013). Temporal whitening by power-law adaptation in neocortical neurons. Nature neuroscience, 16(7), 942–948.
Priestley, M.B., & Subba Rao, T. (1969). A test for non-stationarity of time-series. Journal of the Royal Statistical Society. Series B. Methodological, 31, 140–149.
Rangarajan, G., & Ding, M. (Eds.). (2003). Processes with long-range correlations: theory and applications, volume 621 of Lecture Notes in Physics. Berlin: Springer.
Richard, A., & Talay, D. (2016). Hölder continuity in the Hurst parameter of functionals of Stochastic Differential Equations driven by fractional Brownian motion. arXiv:1605.03475.
Sacerdote, L., & Giraudo, M.T. (2013). Stochastic integrate and fire models: a review on mathematical methods and their applications. In Stochastic biomathematical models, volume 2058 of Lecture Notes in Math. (pp. 99–148). Heidelberg: Springer.
Samorodnitsky, G. (2016). Stochastic processes and long range dependence. Springer Series in Operations Research and Financial Engineering. Cham: Springer.
Schwalger, T., & Schimansky-Geier, L. (2008). Interspike interval statistics of a leaky integrate-and-fire neuron driven by Gaussian noise with large correlation times. Physical Review E, 77, 031914.
Schwalger, T., Fisch, K., Benda, J., Lindner, B. (2010). How noisy adaptation of neurons shapes interspike interval histograms and correlations. PLoS Computational Biology, 6(12), e1001026, 25.
Schwalger, T., Droste, F., Lindner, B. (2015). Statistical structure of neural spiking under non-Poissonian or other non-white stimulation. Journal of Computational Neuroscience, 39(1), 29–51.
Segev, R., Benveniste, M., Hulata, E., Cohen, N., Palevski, A., Kapon, E., Shapira, Y., Ben-Jacob, E. (2002). Long term behavior of lithographically prepared in vitro neuronal networks. Physical Review Letters, 88, 118102.
Sobie, C., Babul, A., de Sousa, R. (2011). Neuron dynamics in the presence of 1/f noise. Physical Review E, 83, 051912.
Sottinen, T. (2001). Fractional Brownian motion, random walks and binary market models. Finance and Stochastics, 5(3), 343–355.
Taqqu, M.S. (1975). Weak convergence to fractional Brownian motion and to the Rosenblatt process. Z. Wahrscheinlichkeitstheorie und Verw. Gebiete, 31, 287–302.
Taqqu, M.S., Teverovsky, V., Willinger, W. (1995). Estimators for long-range dependence: an empirical study. Fractals, 03(04), 785–798.
Teich, M.C. (1992). Fractal neuronal firing patterns. In McKenna, T., Davis, J., Zornetzer, S. F. (Eds.), Single Neuron Computation, Neural Networks: Foundations to Applications (pp. 589–625). San Diego: Academic Press.
Teich, M.C., Turcott, R.G., Siegel, R.M. (1996). Temporal correlation in cat striate-cortex neural spike trains. IEEE Engineering in Medicine and Biology Magazine, 15(5), 79–87.
Teich, M.C., Heneghan, C., Lowen, S.B., Ozaki, T., Kaplan, E. (1997). Fractal character of the neural spike train in the visual system of the cat. Journal of the Optical Society of America A, 14(3), 529–546.
Teka, W., Marinov, T.M., Santamaria, F. (2014). Neuronal spike timing adaptation described with a fractional leaky integrate-and-fire model. PLoS Computational Biology, 10(3), e1003526.
Weron, R. (2002). Estimating long-range dependence: finite sample properties and confidence intervals. Physica A. Statistical Mechanics and its Applications, 312(1-2), 285–299.
Willinger, W., Taqqu, M.S., Sherman, R., Wilson, D.V. (1997). Self-similarity through high-variability: statistical analysis of ethernet lan traffic at the source level. IEEE/ACM Transactions on Networking, 5(1), 71–86.
Zilany, M.S., Bruce, I.C., Nelson, P.C., Carney, L.H. (2009). A phenomenological model of the synapse between the inner hair cell and auditory nerve: long-term adaptation with power-law dynamics. The Journal of the Acoustical Society of America, 126(5), 390–2412.
Acknowledgements
Part of this work was carried out while A.R. was a postdoc at Inria Sophia-Antipolis and at Ecole Polytechnique (the support from ERC 321111 Rofirm is gratefully acknowledged). A.R. and E.T. acknowledge the support from the ECOS-Sud Program Chili-France C15E05 and from the European Union’s Horizon 2020 Framework Program for Research and Innovation under Grant Agreement No. 720270 (Human Brain Project SGA1). P.O acknowledges the support from the Advanced Center for Electrical and Electronic Engineering (Basal Funding FB0008, Conicyt) and the project P09-022-F from the Millennium Scientific Initiative of the Chilean Ministry of Economy, Development, and Tourism.
We thank the reviewers for their remarks which helped to improve significantly the quality of this paper.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of Interest
The authors declare that they have no conflict of interest.
Additional information
Action Editor: A. Compte
Rights and permissions
About this article

Cite this article
Richard, A., Orio, P. & Tanré, E. An integrate-and-fire model to generate spike trains with long-range dependence. J Comput Neurosci 44, 297–312 (2018). https://doi.org/10.1007/s10827-018-0680-1
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10827-018-0680-1