
Abstract
Video modeling was used to teach children with autism spectrum disorder how to respond to taped stranger lure scenarios and in-situ stranger lures. A multiple baseline design across participants was used to assess treatment effects. Measures consisted of reported verbal and motor responses to three abduction scenarios and actual responses to stranger lures planted near the children’s therapy program and within the children’s communities. Each child displayed increases in appropriate responses to taped abduction scenarios and in-situ stranger lures post-treatment. One year following the intervention 90% of the participants maintained and generalized the skills. This study indicated that children with ASD could learn to respond to taped stranger lure scenarios and correspondingly demonstrate these skills in situ and maintain these skills for at least one year following treatment.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
Introduction
Children with autism spectrum disorder (ASD) are at risk of becoming victims of abduction (Autism & Wandering, 2012). Each year an estimated 58,200 children in the United States are abducted by a stranger (NISMART, 2015). Children who are at risk of abduction share similar characteristics such as innocence, poor social skills and social isolation. Research with abductors reveals that accessibility is the primary reason for selecting particular children (Elliot et al., 1995). Child abductors admit they search for children who appear to be innocent and trusting, otherwise stated as children who display poor reactions to social cues. They admit to looking specifically for children segregated from their peers in large group settings, such as schools and playgrounds. Alarmingly, many of these characteristics are attributed to children with autism spectrum disorder (Matson, 1984, Strain, 1984, Moran et al., 2011, Yi et al., 2003).
Children with ASD lack strong social and communication skills and do not display proper judgment in social situations (Matson, 1984). If approached by a stranger, a child with ASD may not be able to determine if the stranger’s intentions are harmful. Indeed, past research has indicated that judgment in high-functioning adults with ASD is impaired. Compared to their typically developing peers, youth with ASD struggle to distinguish intentional from accidental acts of harm (Moran et al., 2011). Although children with ASD will not blindly trust a stranger, children with ASD were more likely to believe an unfamiliar adult (Yi et al., 2013). Being too trusting and misunderstanding a stranger’s intentions can be detrimental to a child with ASD.
Children with ASD often engage in behaviors, such as withdrawal and elopement, that make them particularly vulnerable to abductors (Autism & Wandering, 2012). Compared with their typically developing peers, children with ASD are more likely to isolate themselves from others (Anderson et al., 2012). Isolation occurs because children with ASD are more likely to play alone or engage in stereotopy. Preferring to play alone places children with ASD at risk for abduction.
Another behavior that makes children with ASD a target group for abductors is elopement, which consists of running away. Forty-nine percent of children with ASD attempt to elope, and 50% of those who do elope go missing or enter dangerous situations (Anderson et al., 2002). Eloping consists of wandering or bolting from a situation without permission or notification (Perrin C et al., 2008). Elopement frequencies of children with ASD were compared with their typically developing siblings. In the Anderson et al. study (2012), 27% of children with ASD eloped, while only 1% of their non-affected siblings did. Children with ASD use elopement as a method to escape anxious situations and uncomfortable sensory stimuli (Boltz, 2006). It may also be used to explore or obtain a special interest. Autism & Wandering, (2012) indicated that children with ASD are at risk of “potential encounters with child molesters or others who would intentionally try to take advantage or harm them” when they elope or go missing. For the purpose of this study, elopement refers to fleeing or wandering away from others without notification or permission which isolates the individual and places them at risk for dangerous situations.
Teaching children with ASD how to respond to an encounter with an abductor is crucial. Several studies have taught stranger safety conduct through modeling. For example, a study involving modeling and a time delay taught preschool children with mental disabilities what to do in situations with strangers (Gast et al., 1993); however, results did not generalize to real world situations. Another study created an intervention to teach predator safety behaviors to children ages 6–8 with intellectual impairments, using fifteen discussion lessons, modeling and scenario role playing (Watson et al., 1992). Six of the seven participants were able to make improvements to the self-protective skills but did not fully master the skills. The same six children maintained the appropriate safety behaviors 14 days after the intervention.
A potential method to teach, maintain, and generalize such skills is video modeling. Video modeling is a form of observational learning in which children learn desired behaviors by watching a video demonstration and then imitating the modeled behavior. This method is often used with children with ASD because they prefer visual stimuli (Kinney et al., 2003) and they are better at processing visual than verbal information (Samson et al., 2011).
Video modeling has been used to help children reproduce a variety of desirable social behaviors (Wert & Neisworth, 2003, D'Ateno et al., 2003). Presumably, the motivation to reproduce the desired behavior would be spurred if the child encounters an abductor in his or her daily life. Video modeling has successfully taught children with ASD communication skills and social and play behaviors (Wert & Neisworth, 2003, D'Ateno et al., 2003). The aim of many video modeling studies has been to increase social skills. For example, video modeling has been used to increase play skills and comments (Sancho et al., 2010), and these skills were evident up to 2 weeks after they were modelled. In other interventions, video modeling enhanced social initiations and reciprocal play and these results were sustained for up to 3 months following treatment (Nikopoulos & Keenan, 2004). Not only has video modeling been found to be a useful tool for teaching behaviors, but it has also been found to be a useful tool for maintaining social interactions over time.
The lessons learned from video modeling have also been found to generalize across settings. Video modeling has been shown to not only increase but maintain appropriate play and pretend play for up to 2 months (Boudreau & D’Entremont, 2010; Nikopoulos & Keenan, 2004). When children are able to generalize learned behaviors to other settings, they display both mastery and application. It is essential that children with ASD learn, generalize, and maintain the social skills that will keep them safe from dangerous abductors.
Previous abduction-prevention studies combined video modeling with a variety of training methods. Gunby and Rapp (2014) used in-situation (in-situ) feedback along with video modeling, live modeling, and rehearsal. All three children in their study met the desired level of behavior with this training and maintained the behavior for 1-month. However, only one child was able to generalize the behavior across stimuli. Video modeling was also used, in combination with in-situ training, to teach high functioning children with ASD about stranger danger (Akmanoglu & Tekin-Iftar, 2011). The children were instructed to watch videos presenting the correct way to respond to a stranger. Following the video, the children were told to wait alone. While the instructor was away, a stranger approached the child. Their instructor then returned and told the child how to respond. With this approach, participants failed to apply skills learned in 54–63% of opportunities. However, all three children responded appropriately to strangers in generalization and maintenance settings. Although, these interventions were effective, repeated exposure to in-situation abduction lures can have adverse effects on children such as fear and anxiety (Johnson et al., 2006).
The past two studies featured multiple procedures (in-situ, behavioral skills training and video modeling) making it difficult to determine, without a component analysis, which of the procedures was the effective one. Since prior research on video modeling alone has yielded very successful results (D'Ateno et al., 2003; Wert & Neisworth, 2003), it is likely the video modeling component was at least in part responsible for the learning. Video modeling is a cost and personnel efficient procedure and has been associated with generalization and maintenance in prior research. Using video modeling as an alternative to in-situ behavioral skills training may avoid additional Behavior Skills Training in-situ sessions that can lead to potential emotional harm to the child.
The present study conducted a video modeling intervention to teach children with autism spectrum disorder how to appropriately respond when approached by a potential abductor. The present study extended prior research by teaching children to make a loud assertive response in addition to leaving the scene. In addition, the present study incorporated three types of common abduction scenarios to increase the likelihood of response generalization.
Method
Participants
Six children with ASD ages 6–12 years attending a weekly after-school behavior therapy program participated in this study. All children were diagnosed with autism spectrum disorder by two independent agencies according to the criteria of the American Psychiatric Association (2013). Diagnostic and statistical manual of mental disorders (5th ed.). Participants in the study regularly interacted with strangers and engaged in withdrawal and elopement. They were appropriate for video modeling interventions because they had a history of viewing videos on screen and strong attention to information on screen. Participants’ parents consented to their children’s participation.
Jessica, an 11- year -old Hispanic American female, frequently engages in preferred activities rather than group activities, thus isolating herself from her peers. Parents and therapists have reported that Jessica displays spontaneous speech and conversation bids with her peers as well as strangers. Her parents reported that Jessica does not know how to avoid strangers. Jessica’s language skills were measured by the Peabody expressive verbal test (EVT; Williams, 2007) to be 12.5 years old and her receptive language skills were measured to be 9.10 years (PPVT-4; Dunn et al., 2007).
Mason, a 10-year-old Caucasian-American male, prefers to play alone rather than with a group, which often isolates him from peers. He also elopes to avoid non-preferred activities. Mason’s language skills were measured by the Peabody expressive verbal test (EVT; Williams, 2007) to be 15.11 years old while his receptive language skills were measured to be 12.7 (PPVT-4; Dunn et al., 2007).
Brandon, an 8-year-old Caucasian male, prefers to play alone rather than with a group. He also elopes to avoid non-preferred activities. Parent reports indicate that Brandon makes conversation bids with strangers and does not know how to interact safely with strangers. Brandon’s language skills were measured by the Peabody expressive verbal test (EVT; Williams, 2007) to be 9.4 years old while his receptive languages kills were measured to be 8.5 years (PPVT-4; Dunn et al., 2007).
Adam, an 11-year-old Asian male, also prefers to play alone rather than with a group, and he too elopes to avoid non-preferred activities. Adam does not interact with strangers appropriately; parents and therapists report that he has approached or greeted individuals he does not know. Adam’s language skills were measured by the Peabody expressive verbal test (EVT; Williams, 2007) to be 8.5 years old while his receptive language skills were measured to be 7.11 years (PPVT-4; Dunn et al., 2007).
Like others, Christopher, an 8-year old Hispanic male, prefers to play alone. Parents and therapists report that he initiates conversations with strangers and does not understand how to interact with strangers. Christopher’s language skills were measured by the Peabody expressive verbal test (EVT; Williams, 2007) to be 6 years old while his receptive language skills were measured to be 6.7 years (PPVT-4; Dunn et al., 2007).
Danielle, a 7-year old Hispanic female, also isolates herself during group play, particularly during non-preferred activities. Parent reports indicate that Danielle does not understand how to safely interact with strangers. Danielle’s language skills were measured by the Peabody expressive verbal test (EVT; Williams, 2007) to be 6.11 years, and her receptive language skills were measured to be 5.7 years (PPVT-4; Dunn et al., 2007).
Materials
Skills Acquisition Assessment Session (SAAS) Video and Questions
Four short videos were created to simulate stranger lure situations. These videos consisted of three types of potential stranger encounters, each of which features undergraduate students, familiar to the participants in the study, being approached by a stranger. Unfamiliar adults are included in the videos as fictional abductors. Each video has two versions. Across these two versions, the scenarios remain the same but present different models and stimuli. The first set of videos includes a male abductor and a male child. The same videos were duplicated with a male abductor and a female child. These videos do not include modeled responses in order to give the children the opportunity to answer questions on their own prior to video modeling and after video modeling. The average length of each video is 52.5 s. Each video is coupled with an empirically tested set of four questions that assess how the child would respond to an encounter with a stranger and if the child would respond assertively (Rex, Charlop, & Spector, in press). The questions ask what the child would say and do in each situation that was modeled in the SAAS video, for example “What would you do/say if a stranger asked you to go to their car for candy?”. The participants were also asked “Would you tell your mother if anything from the movie happened to you?” (See Table 1).
Video Modeling Tapes
A video tape of three types of potential stranger encounters was created. Two familiar adults displayed desired responses to these types of situations. Unfamiliar adults were included in the videos as fictional potential abductors. Each video has two versions. Across the versions, the scenario remains the same but presents different models and stimuli. The first set of videos includes a male abductor and a male child. The same videos were duplicated with a male abductor and a female child. In a slow and exaggerated manner, the adults display the appropriate speech and action behaviors (Charlop & Milstein, 1989). In each video, the actors face the camera and give explicit direction regarding how to respond when approached by a stranger. The average length on each video is 32 s.
Settings
SAAS and video modeling videos were shown to the children during their attendance at the afterschool therapy program. In situation probes were conducted in community locations nearby. In situation probes on site took place in an outdoor seating area near the afterschool program, and in-situ probes in the community took place in local restaurants and stores. In the restaurants, participants were seated at a table waiting for their order to arrive, and in the store, participant was browsing the toy section.
Strangers
Strangers in in-situ probes consisted of undergraduate research assistants who were unfamiliar to the children. To avoid biases, the assistants were naïve to the study aims.
Side Effect Questionnaire
A side effect questionnaire created by Johnson et al. (2006) was administered to the participants’ parents or guardians. This survey determined what type of side effects, if any, followed the intervention.
Procedure
Design
A multiple baseline design across participants was used to examine the effect of video modeling on appropriate verbal responses to video stranger lure scenarios and appropriate verbal and motor responses to in-situ stranger lures in children with ASD. During baseline, the number of appropriate behaviors prior to intervention were observed and recorded. The intervention was then presented at different times in a multiple baseline design for each participant. As in multiple baseline design, the staggered staircase pattern of intervention introduction allows the experimenter to determine if the change in behavior from baseline to intervention is due to the intervention (Cooper et al., 2007; Mayer et al., 2014). Such a conclusion can be made since multiple baseline designs permit the experimenter to control for confounding variables and chance variation (Cooper et al., 2007). During baseline, the participants viewed the SAAS videos and were asked to respond to a set of corresponding question. The children also participated in in-situation probes during baseline sessions. Video modeling intervention which displayed appropriate stranger responses was introduced to each participant. Post-treatment, the children participated in SAAS and in-situ probes. The experimenter videotaped all of the sessions in the study including baseline, intervention and post-intervention.
Baseline
During baseline sessions the children were presented with three types of probes: in-situ generalization probes in the local community, in-situ generalization probes near their weekly after school program and SAAS probes.
In-situation Generalization Probe
During the first generalization probe a male stranger approached the child near his or her afterschool program. The stranger presented several pieces of candy and, stated “I have more candy in my car, come with me.” In the second generalization probe a different male stranger approached the child at a nearby restaurant. The stranger presented several pieces of candy and stated, “I have more candy in my car, come with me.”
Intervention
Following participation in the in situ generalization probes presented at baseline, each child began video modeling intervention. Each child was escorted into a therapy room and prompted to sit down in front of a computer monitor. Once the child was facing the monitor and focused, the first video was played. The experimenter instructed the child to pay attention and observe. At the end of the first scenario, the video was paused, and the experimenter asked the child a question regarding the video (See Table 1 for questions). Then the second scenario was played for the child. When the video concluded, it was paused, and the experimenter again asked the child a similar question. Finally, the third scenario was played, and the experimenter asked the child one more corresponding question, such as “What would you do or say if a stranger asked for help finding their puppy?”. At the conclusion of all three scenarios the experimenter asked the child “Would you tell your mother if anything from the videos happened to you?”. Meeting criteria means the child provided at least one appropriate verbal or motor response to each of the three video modeling scenarios and reported the event to their parent (scoring 4 out of 4) across two consecutive sessions.
Post-treatment
Follow up probes were conducted following post-intervention. Follow up probes took place 2 weeks and 3 months following the participants’ last post-intervention session. Each follow up session consisted of a SAAS probe.
Dependent Variable
The dependent variable for video modeling sessions consisted of correct responses to questions paired with the video modeling treatment. The children’s answers were used to determine if the child learned from the video. Correct responses included an assertive “No!,” “Stop!,” or “Go Away!,” stating that they would run away and stating that they would tell an adult that “A stranger bothered me!”. Responses similar to those taught such as “No way!” and “A stranger asked me to go with them” were considered correct. Incorrect responses included sayings such as “ I want candy” and “ Why can’t you pick up your own keys?”. Participants met criterion if they scored 100% (4 out of 4 opportunities) across two consecutive sessions.
Scoring
The experimenter coded videotapes of each session. In SAAS sessions, the children received a score for each of the four corresponding questions. During video modeling sessions, participants received a score for each of the four corresponding questions. Each correct answer was awarded one point. The participants could score a total of 4 points during each SAAS and video modeling sessions. The participants could score a total of 3 points during in-situ sessions. One point was awarded for each of the following behaviors: an assertive statement such as “No!,” “Go Away!,” “Stop!”, quickly leaving the dangerous situation (running away) and reporting the incident to an adult.
Inter-observer Agreement
A second rater followed the same scoring procedure and independently scored one-third of all sessions (baseline, intervention and post-intervention). The rater was trained by reviewing operational definitions of the target behaviors and viewing the first baseline session for each participant. The second raters were blind to the experiment. Agreement was calculated by dividing the total number of agreements by the total number of disagreements plus total number of agreements, and then multiplying this number by 100. Inter-observer reliability across all children was 98% for all four-response categories throughout each condition of the study.
Results
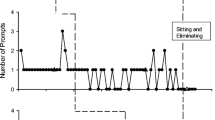
During baseline, none of the participants reached criterion on SAAS probes, nor did any demonstrate appropriate behaviors during in-situ generalization probes. All six children met criterion during video modeling treatment. Each child displayed increases in correct responses to taped stranger lure scenarios (SAAS) and in-situation sessions when comparing post-intervention generalization percentages with baselines percentages. Following is a summary of results by participant.
At baseline, Jessica did not meet criterion for any of the three SAAS sessions, nor did she meet criterion during in-situation generalization probes. During video modeling intervention, Jessica met criterion after five sessions. Following intervention, Jessica displayed 100% of the target responses to SAAS questions in 4 of 4 opportunities across two sessions. During post-intervention in-situ generalization sessions, Jessica displayed 2 out of 4 and 4 out of 4 correct responses. Jessica also displayed 2-week maintenance of the target SAAS responses in 4 of 4 opportunities. Jessica also displayed 1-year maintenance of the target in-situ responses in 3 of 3 opportunities. Jessica’s mother did not report negative side effects from the study in the parent survey.
At baseline, Alex (second panel of the results figure) did meet criterion across 4 opportunities. Alex displayed only 2 of 3 correct responses during in-situ probes. Once video modeling intervention was introduced, Alex’s correct responses increased across five sessions, reaching criterion in the last two consecutive sessions. In post-intervention SAAS sessions Alex made all of the appropriate responses across two sessions. He performed at 100% (3 out of 3) across two in-situ generalization sessions post treatment. In addition, Alex displayed maintenance in 2-week, 3-month follow up SAAS sessions performing at 100% (4 out of 4 responses) in each. Alex also displayed 1-year maintenance of the target in-situ responses in 3 of 3 opportunities. Alex’s mother did not report negative side effects from the study in the parent survey (Fig. 1).

Responses to stranger lures during baseline, intervention and post-intervention sessions
Mason (third panel) did not meet criterion for any of the five SAAS sessions, nor meet criterion during in-situation generalization probes. During video modeling treatment, Mason met criterion (100% across two consecutive sessions) in just two sessions. Following treatment, Mason made appropriate responses to SAAS probes in 1 out of 4 and 4 out of 4 opportunities. He displayed appropriate in-situ generalization probe behaviors in 2 of 3, and 3 of 3 opportunities. Mason was not available to participate in follow up data collection or the side effect questionnaire because he no longer attended the afterschool program.
Brandon (fourth panel) did not meet criterion in any baseline sessions. He did not meet criterion in SAAS or in-situ baseline sessions. Brandon attempted to leave with the actor during a baseline in-situ probe. During video modeling treatment, Brandon achieved criterion after four sessions. Post treatment, Brandon displayed target SAAS responses in 4 out of 4 opportunities. During post-intervention in-situ generalization sessions, he displayed complete accuracy in generalization (3 out of 3) and then 1 out of 3 opportunities. Brandon maintained the skills learned from video modeling treatment, 2 weeks and three months following treatment. Brandon also displayed 1-year maintenance of the target in-situ responses in 3 of 3 opportunities. Brandon’s mother did not report any side effects from the study in the parent survey.
Christopher (fifth panel) did not meet criterion for any of the seven SAAS sessions nor did meet criterion during in-situation generalization probes. During video modeling treatment, Christopher met criterion in three sessions. In post-intervention SAAS sessions, Christopher displayed appropriate responses in 3 out of 4 opportunities the first probe and 4 out of 4 opportunities for the next three probes. He also displayed correct responses to 4 out of 4 opportunities in 2-week and 3-month follow up sessions. Christopher also displayed 1-year maintenance of the target in-situ responses in 3 of 3 opportunities. Christopher’s father did not report any side effects from the study in the parent survey.
Danielle (bottom panel), did not meet criterion in baseline SAAS or in-situ sessions. During video modeling treatment, Danielle gradually met criterion across four sessions. Following treatment, Danielle performed perfectly in two SAAS sessions (4 out of 4 opportunities). She displayed appropriate in-situ generalization responses in 1 out of 3, and 2 out of 3 opportunities post treatment. In a 2-week SAAS follow-up session, she displayed the majority of the target responses (3 of 4 opportunities). In a 3-month SAAS follow-up sessions Danielle displayed 100% accuracy (4 of 4 opportunities). Danielle also displayed 1-year maintenance of the target in-situ responses in 2 of 3 opportunities. Danielle’s father did not report negative side effects from the study in the parent survey.
To determine the social validity of the SAAS and Video Modeling videos, twenty-seven undergraduate college students who were naïve to the study, rated actors’ behavior after watching an edited videotape. The videotape consisted of three scenarios depicting a child in an after-school program setting and a stranger’s lure. After each segment, the videotape was paused, and the undergraduates filled out a questionnaire regarding what they saw. The questionnaire included four items regarding how realistic the actors’ behavior appeared as well as how dangerous and threatening the stranger and situation appeared. Responses were recorded on a 1 to 5 scale. The videos were scored moderately to extremely realistic and moderately to extremely threatening.
Discussion
The results of the present study indicate that video modeling successfully promoted appropriate responses to taped and in-situ stranger lure scenarios in six children with autism spectrum disorder. All of the children in this study met criterion for acquisition (4 out of 4 opportunities, or 100% for two consecutive sessions), and all six displayed rapid acquisition of the target behaviors. Participants met criteria within 2–5 video modeling sessions. The rates of acquisition in this study resemble previous studies that implemented video modeling (Macpherson et al., 2014). The present study’s intervention may be considered “pure” as no other intervention components such as rehearsal, prompting or reinforcers such as tangible or direct praise were implemented (See Table 2).
Video modeling may have led to rapid acquisition in children with autism spectrum disorder for a number of reasons. First, video modeling uses a fun and reinforcing activity to prompt learning. Children with ASD spend the majority of their free time participating in screen based activities such as television, computer and video games (Shane & Albert, 2008). Video modeling allows children with ASD to learn skills in the setting of a preferred leisure activity. Second, children with autism spectrum disorder like visual stimuli (Kinney et al., 2003) and they are better at processing visual information than verbal information (Samson et al., 2011). Lastly, video modeling acknowledges that children with autism struggle to attend to multiple stimuli at one time. By emphasizing relevant information with visual cues, video modeling helps children with ASD focus on the relevant information (Charlop-Christy & Daneshvar, 2003).
This study demonstrates the utility of video modeling when teaching abduction safety skills. The present study establishes that video modeling can teach children with ASD the three skills needed to protect themselves from an abductor. The skills include, assertively saying one of the following: “No,” “Go Away,” or “Stop,” quickly removing oneself from the situation, and reporting the incident to an adult. All three provide optimum safety. Assertively addressing the stranger will bring attention to the predator and this should halt their actions. Leaving the area removes oneself from the danger and telling an adult allows the adult to further address the situation. Video modeling offers a cost effective intervention, and an efficient means of teaching complex behaviors. Rather than teaching each step individually, video modeling allowed children to learn all three responses simultaneously. At the end of the study, the children displayed complex combinations of behaviors needed to appropriately respond to in-situ stranger lures.
The present study indicates that video modeling can be used to safely teach abduction-prevention skills to children with ASD. Video modeling intervention prevents placing the child in a potentially fearful situation during each intervention session. Previous research combined in-situ and behavioral skills training to teach abduction-prevention skills, requiring the participant to be in a potentially frightening situation while learning the important skill. A parent survey revealed that one child was more scared, cautious and upset following in-situ/ behavioral skills training intervention, while another child’s participation was terminated by their parent (Johnson, 2006). Although video modeling was an effective treatment for those with ASD, those with more severe symptoms of a developmental disability or co-occurring disability may require additional instruction such as in-situation instruction or modeling (Akmanoglu &Tekin-Iftar, 2011; Gunby & Rapp, 2014; Johnson et al., 2006).
In the present study, video modeling intervention circumvented actual treatment during in-situ sessions to make intervention a less stressful activity. While abduction lures were viewed on the videos, the videos depicted familiar scenes and the children did not present any negative side effects during training. However, to demonstrate that appropriate response to abduction scenarios is more than just a learned response set, in-situ abduction lures were presented to the child, both in familiar and community settings not associated. These abduction stranger lures show that the children demonstrated the appropriate responses to the lures. This is an important finding of the present study. However, few in situ lures were presented to minimize any potential negative side effects that were found in other studies (Gunby & Rapp, 2014; Johnson et al., 2006) yet enough to demonstrate learning.
Previous studies did not utilize restrooms in their settings for teaching abduction prevention skills to children with ASD. As children venture into the community with an opposite sex parent, they may have to enter a public restroom alone. The present study addressed this sensitive situation. While inappropriate touching was not specifically addressed, a video-taped scenario featured a stranger in a bathroom stall who asked the child to help him tie his shoe or find his keys inside the stall. This scenario may serve a dual purpose of not only teaching an appropriate response to a potential abductor but also an appropriate response to a potential molestation incident. Several studies with effective sexual abuse prevention programs taught children to avoid the lure, escape the situation and report to an adult (Olsen-Woods et al., 1998; Miltenberger & Olsen, 1996) similar to the protocol of the present abduction prevention study. Parents of children with ASD are also concerned about their children’s safety in these situations since children with intellectual disabilities are four times more likely to be sexually abused than a typically developing child (Sullivan & Knuston, 2000). It is important to note that an in-situ restroom probe was not included in the present study because it was deemed too fearful. Given the results of the other in-situ probes, it seems likely that participants would have responded correctly in this in-situ probe as well.
In addition to generalization across people, (in-situ) setting, and stimuli, the children in the present study also displayed maintenance at follow-up. Two weeks following the study, 4 of 5 students displayed 100% accuracy in a SAAS session, and 3 months following the study 4 of 4 participants displayed 100% accuracy in a SAAS session.
A limitation of the study is the small sample size and retention rate of participants. Two participants graduated from the afterschool program and were unable to participate in some of the follow up data collection. Although addition information could not be collected, both participants met criterion and performed well in post intervention probes and one displayed maintenance in a 2 week follow up probe. Another limitation is that the focus of this study was the acquisition of a set of responses to video-taped scenarios. However, the children’s interactions with predator lures (even though they were confederates) were intentionally limited which also limited the potential for any untoward side effects. Clearly, as can be seen by the in-situ probe data, the children did learn to display appropriate responses to lures when confronted with them.
In conclusion, the present study adds to the literature by demonstrating that skills to respond to a stranger’s lure can be taught to children with ASD using video modeling. Future research should be conducted to provide a better understanding of how to increase additional safety behaviors in children with ASD such as perpetrators of theft, inappropriate sexual behavior, physical violence, and so on. Further research should also establish training methods for parents and teachers to administer video modeling intervention to their children and students. In addition, it would be interesting to determine the effectiveness of video modeling intervention to teach safety behaviors to lower functioning children with ASD.
References
Akmanoglu, N., & Tekin-Iftar, E. (2011). Teaching children with autism how to respond to the lures of strangers. Autism, 15(2), 205–222.
Anderson, C., Law, J. K., Daniels, A., Rice, C., Mandell, D. S., Hagopian, L., & Law, P. A. (2012). Occurrence and family impact of elopement in children with autism spectrum disorders. Pediatrics, 130(5), 870–877.
American Psychiatric Association. (2013). Diagnostic and statistical manual of mental disorders. (5th ed.). https://doi.org/10.1176/appi.books.9780890425596
Autism & Wandering. (2012). https://www.missingkids.org/theissues/autism
Boltz, M. (2006). Wandering and elopement: A comprehensive approach. Assisted Living Consultants, 3, 17–26.
Boudreau, E., & D’Entremont, B. (2010). Improving the pretend play skills of preschoolers with autism spectrum disorders: The effects of video modeling. Journal of Developmental and Physical Disabilities, 22(4), 415–431.
Charlop-Christy, M. H., & Daneshvar, S. (2003). Using video modeling to teach perspective taking to children with autism. Journal of Positive Behavior Interventions, 5(1), 12–21.
Cooper, J. O., Heron, T. E., & Heward, W. L. (2007). Applied behavior analysis.
D’Ateno, P., Mangiapanello, K., & Taylor, B. A. (2003). Using video modeling to teach complex play sequences to a preschooler with autism. Journal of Positive Behavior Interventions, 5(1), 5–11.
Dunn, L. M., Dunn, D. M., & Pearson Assessments. (2007). PPVT-4: Peabody picture vocabulary test. Pearson Assessments.
Elliott, M., Browne, K., & Kilcoyne, J. (1995). Child sexual abuse prevention: What offenders tell us. Child Abuse & Neglect, 19(5), 579–594.
Gast, D. L., Collins, B. C., Wolery, M., & Jones, R. (1993). Teaching preschool children with disabilities to respond to the lures of strangers. Exceptional Children, 59(4), 301–311.
Grosberg, D., & Charlop, M. (2014). Teaching persistence in social initiation bids to children with autism through a portable video modeling intervention (PVMI). Journal of Developmental and Physical Disabilities, 26(5), 527–541.
Gunby, K. V., & Rapp, J. T. (2014). The use of behavioral skills training and in situ feedback to protect children with autism from abduction lures. Journal of Applied Behavior Analysis, 47(4), 856–860.
Johnson, B. M., Miltenberger, R. G., Knudson, P., Egemo-Helm, K., Kelso, P., Jostad, C., & Langley, L. (2006). A preliminary evaluation of two behavioral skills training procedures for teaching abduction-prevention skills to schoolchildren. Journal of Applied Behavior Analysis, 39(1), 25–34.
Kanner, L. (1943). Autistic disturbances of affective contact. Nervous Child, 2(3), 217–250.
Kinney, E. M., Vedora, J., & Stromer, R. (2003). Computer-presented video models to teach generative spelling to a child with an autism spectrum disorder. Journal of Positive Behavior Interventions, 5(1), 22–29.
Macpherson, K., Charlop, M. H., & Miltenberger, C. A. (2014). Using portable video modeling technology to increase the compliment behaviors of children with autism during athletic group play. Journal of Autism and Developmental Disorders, 45(12), 3836–3845.
Mayer, G. R., Sulzer-Azaroff, B., & Wallace, M. (2014). Behavior analysis for lasting change. Sloan Publishing.
Miltenberger, R. G., & Olsen, L. A. (1996). Abduction prevention training: A review of findings and issues for future research. Education and Treatment of Children, 7, 69–82.
Moran, J. M., Young, L. L., Saxe, R., Lee, S. M., O’Young, D., Mavros, P. L., & Gabrieli, J. D. (2011). Impaired theory of mind for moral judgment in high-functioning autism. Proceedings of the National Academy of Sciences, 108(7), 2688–2692.
Nikopoulos, C. K., & Keenan, M. (2004). Effects of video modeling on social initiations by children with autism. Journal of Applied Behavior Analysis, 37(1), 93–96.
NISMART bulletin (n.d.) Nonfamily abducted children: National estimates and characteristics. Retrieved December 2, 2015, from https://www.ncjrs.gov/html/ojjdp/nismart/03/ns4.html
Olsen-Woods, L. A., Miltenberger, R. G., & Foreman, G. (1998). Effects of correspondence training in an abduction prevention training program. Child & Family Behavior Therapy, 20(1), 15–34.
Perrin, C., Perrin, S., Hill, E., & DiNovi, K. (2008). Brief functional analysis and treatment of elopement in preschoolers with autism. Behavioral Interventions, 23(2), 87–95.
Samson, F., Mottron, L., Soulieres, I., & Zeffiro, T. A. (2011). Enhanced visual functioning in autism: An ALE meta-analysis. Human Brain Mapping, 33(7), 1553–1581.
Sancho, K., Sidener, T. M., Reeve, S. A., & Sidener, D. W. (2010). Two variations of video modeling interventions for teaching play skills to children with autism. Education and Treatment of Children, 33(3), 421–442.
Shane, H., & Albert, P. (2008). Electronic screen media for persons with autism spectrum disorders: Results of a survey. Journal of Autism and Developmental Disorders, 38(80), 1499–1508.
Strain, P. S. (1984). Social behavior patterns of non-handicapped and developmentally. Analysis and Intervention in Developmental Disabilities, 4, 15–28.
Sullivan, P. M., & Knutson, J. F. (2000). Maltreatment and disabilities: A population-based epidemiological study. Child Abuse & Neglect, 24(10), 1257–1273.
Watson, M., Bain, A., & Houghton, S. (1992). A preliminary study in teaching self-protective skills to children with moderate and severe mental retardation. The Journal of Special Education, 26, 181–194.
Wert, B. Y., & Neisworth, J. T. (2003). Effects of video self-modeling on spontaneous requesting in children with autism. Journal of Positive Behavior Interventions, 5(1), 30–34.
Williams, K. T., Pearson Clinical Assessment (Firm), & PsychCorp (Firm). (2007). EVT-2: Expressive vocabulary test. (second edition). Pearson.
Yi, L., Fan, Y., Quinn, P. C., Feng, C., Huang, D., Li, J., Mao, G., & Lee, K. (2013). Abnormality in face scanning by children with autism spectrum disorder is limited to the eye region: Evidence from multi-method analyses of eye tracking data. Journal of Vision, 13(10), 5.
Funding
No funding was received to assist with the preparation of this manuscript.
Author information
Authors and Affiliations
Contributions
The author confirms sole responsibility for the following: study conception and design, data collection, analysis and interpretation of results, and manuscript preparation.
Corresponding author
Ethics declarations
Conflict of interest
The author has no relevant financial or non-financial interests to disclose.
Informed Consent
Informed consent was obtained from the parents of all participants in this study. Human subjects IRB approval was obtained for the study.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Bell, B. Using Video Modeling to Teach Abduction-Prevention Skills to Children with Autism Spectrum Disorder. J Autism Dev Disord 52, 3909–3918 (2022). https://doi.org/10.1007/s10803-021-05241-z
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10803-021-05241-z