
Abstract
Wireless Local Area Network (WLAN) positioning has become a popular localization system due to its low-cost installation and widespread availability of WLAN access points. Traditional grid-based radio frequency (RF) fingerprinting (GRFF) suffers from two drawbacks. First it requires costly and non-efficient data collection and updating procedure; secondly the method goes through time-consuming data pre-processing before it outputs user position. This paper proposes Cluster-based RF Fingerprinting (CRFF) to overcome these limitations by using modified Minimization of Drive Tests data which can be autonomously collected by cellular operators from their subscribers. The effect of environmental changes and device variation on positioning accuracy has been carried out. Experimental results show that even under these variations CRFF can improve positioning accuracy by 15.46 and 22.30% in 95 percentile of positioning error as compared to that of GRFF and K-nearest neighbour methods respectively.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
1 Introduction
Location systems have long been identified as an important component of a wide set of applications such as for E-911 emergency positioning, personal navigation and Location-Based Services in outdoor environments. The role of a positioning system is to estimate and report geographical location information pertaining to the user for the purposes of management, enhancement, and personalization of services. At present Global Navigation Satellite System (GNSS) is the most popular positioning system for mobile devices in outdoor environments. However, GNSS geolocation performs poorly in dense urban areas and inside buildings, where satellites are not visible by mobile user equipment (UE) [1]. With the rapid increase in Wireless Local Area Network (WLAN) access points (AP) in metropolitan areas and due to their ubiquitous coverage in large environments, outdoor location systems based on WLAN have gained recent attention in research and commercial applications [2,3,4]. WLAN positioning works better than GNSS in dense metropolitan areas, both outdoors and indoors owing to its greater received signal strength and lower attenuation [3]. WLAN received signal strength (RSS) measurements can be obtained relatively effortlessly and inexpensively without the need for additional hardware [5]. Moreover, RSS-based positioning is non-invasive, as all sensing tasks can be carried out on the mobile UE, eliminating the necessity for central processing [6]. Skyhook [7] has used Wi-Fi signals emitted from residential homes and offices to build a cost-effective location system on a global scale. Several existing WLAN methods have aimed to use theoretical path loss (PL) models whose parameters are estimated based on training data [8]. Given an RSS measurement and PL model, the distances from the UE to at least three APs are determined, and trilateration is used to obtain the UE position. The limitations of such an approach are the dependence on prior topological information and assumption of isotropic RSS contours [9]. Alternatively, the RSS-position relationship has been characterized implicitly using a training-based method known as location fingerprinting. Positioning results from urban and sub-urban areas with WCDMA and GSM networks in [10] shows that radio-frequency (RF) fingerprinting is a better method than PL model based localization. An RF fingerprint-based positioning system has two phases. First, offline training phase: RSS and corresponding location data are collected to create a ‘radio map’ with sufficient representation of spatiotemporal RSS properties of the area. Second, online location determination phase: the system uses the signal strength samples received from a test UE to ’search’ the radio map to estimate the user location.
In order to enhance WLAN RSS based indoor positioning pedestrian dead reckoning (PDR) is often used. PDR uses an inertial measurement unit (IMU) which has three-axis accelerometers and gyroscopes to detect a user direction changes between footsteps. The user heading change is computed by projecting the gyroscope measurements to the horizontal plane. Authors [42] have proposed a novel linear model for PDR and compared it to conventional nonlinear models. For this purpose they have used Kalman filter (KF), the extended Kalman filter (EKF), and the unscented Kalman filter (UKF). The evaluation shows that despite being simpler than the traditional methods, it performs especially well in situations where the initial heading and position are not known.
In this work, cluster-based RF fingerprinting (CRFF) method is used with data similar to Minimization of Drive Tests (MDT) data [11]. CRFF method divides a group of a MDT data-set into a certain number of subsets or clusters, so that the members in the same cluster are similar in terms of their RSS values. The proposed CRFF confronts the following main challenges of RF fingerprint based UE positioning:
1.1 RF Fingerprint Collection and Updating
The conventional way of creating fingerprint training data-base is to periodically conduct extensive drive test campaigns which are time-consuming and unpractical for building a metropolitan-scale radio map of the locating system [12, 41]. A major drawback of this method is to update the training radio map when new APs are deployed and existing APs are decommissioned. The accuracy of any location estimation system is highly dependent on the density of the set of collected fingerprints which is difficult to achieve through conventional drive test methods [13]. To solve this issue we have used generalized MDT (GMDT) data that allows UEs to collect location-aware radio measurements from LTE BSs as well as WLAN access networks [14]. GMDT allows cellular operators to collect and update big RF fingerprint data-base autonomously using subscribers UE without any additional hardware instalment. This is the most cost effective solution to build and maintain fine-grained radio map to increase the accuracy of UE localization.
1.2 Pre-processing of Training Data
In most cellular-communication systems the basic positioning method is based upon cell-identity (cell-ID) which reports the identity of the cell to which the terminal is connected to [15]. It has sort response time but the accuracy is low [16]. Author in [17] has proposed an adaptive enhanced cell-ID localization method which uses an offline cluster based fingerprinting to enhance the positioning performance. To reduce computational complexity and search space in WLAN positioning authors in [18] and [19] have conducted offline clustering of locations based on the training data. However the operation of these systems are hampered over time since WLAN infrastructures are highly dynamic and APs can be easily moved or discarded, in contrast to the BS counterparts in cellular systems, which generally remain intact for long periods of time. Our proposed CRFF method utilizes GMDT data to output result in sort time and does not go through time consuming training data processing phase.
1.3 AP Selection for UE Positioning
In a typical urban environment, the number of detected WLAN APs is greater than usually necessary for UE position estimation. RSS is dependent on the relative distance of the UE and each AP. It is affected by the topology of the surrounding environment in terms of obstacles causing non line-of-sight RF signal propagation; thus subsets of available APs may report correlated readings. Hence considering all available APs for position estimation increases the computational complexity of the positioning algorithm [6]. To simplify the training data collection process we have adopted the ‘Maximum RSS’ (MRSS) based selection methodology where APs are sorted in descending order based on their maximum RSS value and a certain part is chosen to create the training database [20].
1.4 Position Estimation Using New RSS Observation and Radio Map
This essentially involves a distance calculation between the RSS observation of a test UE and the training records; Euclidean distance has been used in this study [21]. UE location estimation using RSS measurements is a difficult task due to the noisy characteristics of signal propagation and absorption by surrounding structures and human bodies. Even changes in the environmental conditions, such as temperature or humidity, affect the signals to a large extent. As a consequence, the signal strength recorded from an AP at a fixed location varies with [19]. Moreover RSS values measured from WLAN APs may differ significantly with the UE’s hardware even under the same wireless conditions [22, 23]. In order to study the effect time and device variation on UE positioning we have collected GMDT data using different devices in two different times of a year.
The main goal of this research is to use four popular clustering algorithms namely: k-means, Hierarchical Clustering, Fuzzy C-Means Clustering and Self-Organizing Map based clustering in conjunction to our proposed CRFF method and also to compare these CRFF methods with GRFF and KNN in terms of positioning accuracy and computational time complexity. Thereby we can evaluate which clustering algorithm performs the best using the proposed CRFF technique. The rest of the paper is organized as follow. Section 2 describes the GMDT data collection and pre-processing steps. The conventional grid-based RF fingerprinting (GRFF) method, K-nearest neighbours (KNN) based positioning and CRFF methods are explained in Sect. 3. Section 4 presents the experiment results and their performance comparison. Finally, Section 5 concludes the paper and gives some future directions to this effort.
2 Offline Data Collections and Pre-processing
2.1 GMDT Data Measurement
The 3rd Generation Partnership Project (3GPP) has been studying solutions for enhancing the interworking between WLAN and LTE in Release 12 and 13 [24]. Authors in [14] have proposed an enhancement to the LTE MDT referred to as GMDT with minor changes to the 3GPP MDT framework which enables WLAN APs to be added to the MDT report containing LTE network measurements as well as the UE location information.
To build the GMDT data-base commercially available mobile phones installed with drive test software known as ‘Nemo Handy’ was used [25]. This enabled us to measure reference signal received power (RSRP) values of Long Term Evolution (LTE) serving and detected Base Stations (BS) and received signal strength indicator (RSSI) values of WLAN APs with corresponding GNSS locations of the UEs. Both LTE and WLAN signal strengths were recorded in dBm and GNSS latitude and longitude values were converted to Universal Transverse Mercator (UTM) coordinate system values. About 150 km of measurements were recorded by feet, bicycle and car from a residential urban area in Tampere, Finland. In order to collect enough measurement samples from the area of interest every route was repeated at least twice during the data recording period. Table 1 summarizes the parameters of two data collection campaigns.
2.2 GMDT Data Pre-processing
Our proposed positioning system is network-based system where a positioning server (GMDT server) is used to store and update the ‘radio map’ through merging multiple GMDT samples recorded from the same x–y coordinate comprising of similar LTE BS and WLAN AP IDs to form a single fingerprint of mean RSS values of the constituent GMDTs. Since the strongest APs provide good probability of coverage over time [18]; we have chosen a subset of APs with the highest observation RSS values. In indoor WLAN positioning seven WLAN RSSI values were used by authors in [20] to obtain acceptable positioning accuracies. Authors in [14] have noticed that increasing WLAN APs after ten provides little to no gain in UE positioning performance. Hence in this study we have compare the UE positioning performances of two different sets of RSS values S j,n where, j = 1 and 2 refers to different GMDT data-sets and n is the total number of GMDT samples. The first set S 1,n comprises of serving LTE RSRP and six WLAN RSSI values while the second set S 2,n contains serving LTE RSRP and ten WLAN RSSI values. We can represent a GMDT sample of a set by a row vector:
where, LW ID denotes the LTE BS IDs and WLAN AP IDs, RSS LW corresponds to RSRP and RSSI values, and P XY contains x–y coordinates of the UEs obtained from GNSS positioning information.
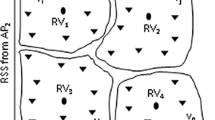
Training phase of GRFF method: We have used a conventional single grid-cell layout based fingerprinting. The whole geographical area of interest is segmented into 10 m-by-10 m square grid-cell units (GCU). As shown in Fig. 1a the GMDT samples of a given data-set S j,n are grouped in different GCUs. For any particular GCU a single training signature Train Sig is formed from all its samples. This shortens the searching time during the UE position estimation phase and reduces the computational cost. The Train Sig formed from all the GMDT samples of ith GCU can be defined by:
where, TS LW ID contains all unique LTE BS IDs and WLAN AP IDs obtained from samples of the GCU, \(RSS_{TS}^{LW}\) is a vector of the corresponding mean LTE RSRP and WLAN RSSI values, and \(P_{{\text{Re} f}}^{XY}\) is the reference x–y coordinate calculated from the mean values of x and y coordinates of the samples.

Block diagram of GRFF and CRFF positioning methods. a Training phase, b UE positioning phase
Training phase of CRFF method: The GMDT samples of a given data set S j,n are grouped according to unique LTE serving BS IDs. Hence literally it does not require any data-processing during the training phase.
3 Position Estimation Phase
The test UE first sends a positioning request to the GMDT server along with the recorded cell-IDs and associated RSS values. After matching and data processing GMDT server sends the position estimation information to the test UE.
3.1 Test Phase of GRFF Method
As shown in Fig. 1b the LW ID of test GMDT sample (Test Sam ) is compared to TS LW ID of all the training signatures of the data server to select those signatures which meet a minimum matching threshold (MT) value. In our study this minimum MT number for both GMDT sets were set to two. Therefore for MT-2 all the training signatures that contain at least two or higher number of LW ID as compared to the test GMDT are selected: a partial ID match procedure. The maximum MT numbers for S 1,n and S 2,n were four and five respectively. Euclidean distance was used to measure the statistical difference between a test sample and selected training signatures which was found to be effective in WLAN-based indoor UE positioning [26]. Here we have used a simplified Mahalanobis distance (MD) equation where the inverse covariance matrix is replaced by an identity matrix:
where, \(\varvec{u}_{{\varvec{Te}}}\) and \(\varvec{u}_{{\varvec{Tr}}}\) denotes the RSRP and RSSI values of the Test Sam and a Train Sig respectively and I is the identity matrix. Separate calculations are done to measure all the distances between a Test Sam and training signatures. The Train Sig that corresponds to the smallest Euclidean distance is chosen for UE positioning. The estimated position of the Test Sam is obtained from \(P_{{\text{Re} f}}^{XY}\) of the chosen Train Sig .
3.2 Test Phase of KNN Based Positioning
The most well-known pattern matching algorithm is K nearest neighbour (KNN) [5]. In order to satisfy the acceptable localization accuracy with low computation effort KNN has been used for WLAN UE positioning by several researchers [3, 21, 27, 28]. Here first we select the training GMDT group (Train Grp ) according to the LTE serving BS ID of the Test Sam . Then multiple GMDT samples are selected from Train Grp according to the partial ID matching. The partial matching begins with the highest MT number and until multiple partially matched training samples (GMDT PM ) are obtained MT number is sequentially lowered towards the minimum. Now according to the lowest Euclidean distance a maximum of five closest GMDTs are chosen using the following KNN equation:
where, GMDT RSS and Test RSS are vectors of LTE RSRP and WLAN RSSI values of GMDT PM and Test Sam respectively. The estimated position of a test UE is calculated from mean x–y coordinates of the selected GMDT PM samples.
3.3 Test Phase of CRFF Methods
The main steps of the proposed CRFF method is depicted in Fig. 2.

Block-diagram of CRFF based UE fingerprint positioning
3.3.1 K-means Cluster Based Positioning
The k-means method is a widely used clustering technique in scientific and industrial applications [29]. Although it offers no accuracy guarantee, its simplicity and speed are very appealing in practical RF fingerprint positioning. It has been successfully used in indoor mobile localization and also in outdoor positioning as an energy efficient RF fingerprinting method [30, 31]. Here k-means++ algorithm was used which is faster to implement and also improves the performance of Lloyd’s algorithm [32]. The methods begins with a set of x i data points where i = 1,2,…,n and a pre-defined maximum cluster number K. The task is to choose K centres c k so as to minimize the following distance function,
Here each centroid is the component-wise median of the sample points in that cluster. Assuming D(x i ) denotes the shortest distance from a data point to the already chosen cluster centre k-means++ algorithm performs the following steps:
-
1.
The first centre c 1 is chosen uniformly at random from x.
-
2.
A new centre ck is chosen from x with probability \(\frac{{D(x_{i} )^{2} }}{{\sum\limits_{i = 1}^{n - 1} {D(x_{i} )^{2} } }}.\)
-
3.
Step (2) is repeated until all k centres are chosen.
-
4.
For each c k , data points are assigned to it which are closer to it than any other c k .
-
5.
New c k is computed from the mean of all data points that belongs to the previous c k .
-
6.
Steps (4) and (5) are repeated until c no longer changes.
Depending upon number of GMDT PM samples (GMDT num PM ) different K values were assigned for k-means++ algorithm so that clustering takes place even with less GMDT num PM . K is set to 6 if GMDT num PM ≥ 20, K is 3 if 20 > GMDT num PM ≥ 10 and K is 2 if 10 > GMDT num PM ≥ 2.
3.3.2 Agglomerative Hierarchical Cluster Based Positioning
Hierarchical clustering is a technique that constructs a tree-like nested structure of clusters. In agglomerative hierarchical clustering (AHC), one starts by considering each data point as a single cluster and follows by merging two neighbouring clusters at each step of the process [33]. In this study we have used weighted-linkage based AHC clustering since it has shown good positioning performance in GSM outdoor UE localization [34]. The neighbouring clusters are chosen based on a linkage criterion where weighted average distance determines the distance between two clusters. In order to select the optimal cluster number in AHC method we have used Davies-Bouldin criterion [35]. This criterion is based on a ratio of within-cluster and between-cluster distances. Minimum Davies–Bouldin index (DB) indicates the potential number of clusters in the data:
where, K is the initial maximum number of clusters, D i,j is the within-to-between cluster distance ratio for the ith and jth clusters. D i,j is given by; D i,j = (d i ¯ + d j ¯)/d i,j , where,d i ¯ is the average distance between each point in ith cluster and centroid of the ith cluster d j ¯ is the average distance between each point in jth cluster and centroid of the jth cluster d i, j is the Euclidean distance between centroids of the ith and jth clusters. Here we have selected K = 6 if GMDT num PM > 10 and K = 2 when GMDT num PM < 10, so that clustering still takes place when there is lees number of GMDT num PM samples.
3.3.3 Fuzzy C-Means Cluster Based Positioning
Fuzzy C-means (FCM) is a data clustering technique—a dataset is partitioned into multiple clusters with every data-point in the dataset belonging to every cluster to a certain degree. Authors in [36] and [37] have used FCM in WLAN indoor localization to obtain good positioning accuracy and also to reduce the computation time as compared to a conventional GRFF method. We have assigned different initial cluster size c depending on number of GMDT PM samples: c = 6 if GMDT num PM ≥ 20; c = 3 if GMDT num PM < 20 and GMDT num PM ≥ 10; and c = 2 if GMDT num PM < 10 and GMDT num PM > 2. FCM starts with an initial guess for the cluster centres, which are intended to mark the mean location of each cluster and it also assigns every data point a membership grade for each cluster. By iteratively updating the cluster centres and the membership grades for each data point, it moves the cluster centres to the right location. This iteration is based on minimizing the objective function for subdividing the selected GMDT data-set [38]:
where, n is the number of samples in the data set, c is the number of clusters (1 ≤ c ≤ n),u i,k is the element of partition matrix U of size (c x n) containing membership function, v i is the centre of ith cluster, and m is a weighting factor that controls fuzziness of membership function. The matrix U is constrained to contain elements in the range of [0, 1] such that \(\sum\nolimits_{i = 1}^{c} {u_{ik} = 1}\) for each u ik (1 ≤ k≤n). The norm \(||D_{k} - v_{i} ||\) is the distance between the sample D k and the clusters centre v i .
3.3.4 Self-Organizing Map Based Positioning
SOM was introduced as an unsupervised competitive learning algorithm of the artificial neural networks by Finnish Professor Teuvo Kohonen in the early 1980s, SOM is also called the Kohonen map. A Self Organizing Map (SOM) is a single layer neural network, where neurons are set along an n-dimensional grid. Each neuron has as many components as the input patterns. Training a SOM requires a number of steps to be performed in a sequential way. For an input sample the SOM training phase consists of three steps: (1) to evaluate the distance between input sample and each neuron of the SOM; (2) to select the neuron (node) with the smallest distance from the sample; and (3) to correct the position of each node according to the results of step 2), in order to preserve the network topology. Steps 1–3) can be repeated more than once for each input sample until stopping criteria is reached. The SOM technique is simple yet effective in capturing the properties of the input space and it can be used for clustering input data.
In [43] and [44] authors have used SOM to compute virtual coordinates that are effective for location-aided routing in Wireless Sensor Networks (WSN). In [44] synchronous readings collected by all the sensor nodes were used to build the training set for the SOM. After training the model, the localization task was performed using new sensor readings to sort nodes on the basis of their proximity to a virtual grid of nodes. In [45] authors have used SOM to develop an indoor locating and tracking system using Wi-Fi RSS values. They have achieved good positioning accuracy by using SOM technique. In this study we have employed SOM as another CRFF method for outdoor user localization using GMDT data.
4 Experimental Results and Discussion
To evaluate the robustness of the positioning methods with changes in recording device and surrounding environment two experimental studies (ExStudy-1 and ExStudy-2) were carried out. In ExStudy-1 both training and test samples were selected from the same time period—September 2014. Here training and test data-sets comprises of randomly choosing data chunks of 20 sequentially recorded samples.
Table 2 shows the UE positioning results of ExStudy-1 obtained from 10 fold cross-validations. In this study only GMDT data-set S 1,n was used. In each of experimental studies the number of training and test GMDTs were 23,080 and 2565 respectively. Table 2 shows the 68th and 95th percentile cumulative distribution function (CDF) values of positioning error (PE) for each of the positioning methods along with the percentage of analysed Test Sam s corresponding to different MT values.
Table 3 shows results of ExStudy-2 where both S 1,n, and S 2,n datasets were used. These datasets contain 32,791 training GMDTs of September 2014 and 3574 Test Sam s of May 2015. Here each of the selected Test Sam is surround by more than ten training GMDTs within its 3 m circular radius area to ensure the presence of sufficient number of training samples in its vicinity. It is found from Tables 2, 3 and 4 that for MT-2 all the methods have analyze maximum amount of Test Sam s.
The bar plot of Fig. 3a, b shows 68th and 95th percentile PE values respectively corresponding to MT-2 of both studies using dataset S 1,n . In every study AHC based RFFP has outperformed other positioning methods in both 68%-ile and 95%-ile of PE. For MT-2 in ExStudy-1 AHC has shown an improvement of 40.52% and 21.66% in 68%-ile and 95%-ile of PE respectively as compared to that of the GRFF method. For the same MT value and using S 1,n in ExStudy-2 AHC improves positioning accuracy by 19.71% and 15.46% in 68%-ile and 95%-ile of PE respectively over that of GRFF method. In ExStudy-2 AHC outperforms KNN by 18.54% and 22.30% in 68%-ile and 95%-ile of PE respectively. However in both of the studies AHC has analyzed lower percentages of Test Sam s. From Table 3 it was found that when S 2,n is used in ExStudy-2 positioning performences of K-means and FCM does not differ significantly from that of the AHC method for MT values of 2, 3 and 4. It is also noticeable that corresponding to each of these MT values K-means and FCM have analyzed more Test Sam s than AHC based positioning.

Comparison of PE results between ExStudy-1 and ExStudy-2 for MT-2. a 68th percentile PE values (meters), b 95th percentile PE values (meters)
In Table 4 gives the PEs of SOM based RFFP for ExStudy-2 using GMDT dataset S 1,n and S 2,n . It has given better positioning accuracies when compared to GRFF, KNN, K-means and FCM based RFFP but with significant reduction of analyzed Test Sam s. For MT-2 its 68%-ile and 95%-ile results closely resemble that of AHC results. For higher MT values the analyzed percentages of Test Sam s are even less.
The average computation time taken by the GRFF and cluster based methods are shown in Table 5; where n = 3574 is the total number of GMDT data samples; N GCU = 5478 is the total number of GCUs in GRFF method, d = 2–7 for data-set S 1,n and d = 2–11 for data-set S 2,n —is the data dimension of a GMDT sample; K = 2–6 is the number of initial clusters; K n = 100 is the number of neurons in SOM and T = 1 to 6 for data-set S 1,n and T = 1–10 for data-set S 2,n —is the number of iterations taken by an algorithm to converge. The computation time of all the positioning methods other than GRFF depend upon the T. We can find from Table 5 that only the GRFF needs training time—which is very long compared to the testing time of any method. It is also found that UE position estimation time increases for all the methods when data-set S 2,n was used as compared to that of S 1,n —due to the increase in data dimension.
AHC has taken the least amount of time for UE positioning in both of the experimental Studies. But due to its high computational complexity, which is at least O (N 2) it may not be a suitable method for a large-scale data-set. Since K, d, and T are usually much less than N, the time complexity of K-means method is approximately linear; hence this algorithm scales well to large-scale data-sets [39, 40]. SOM based RFFP has taken much longer time to output position estimation as compared to rest of the methods. It is worth mentioning that depending upon the choice of the initial cluster size K both the performances and execution time of the methods might differ. Hence as a future work we intend to compare positioning accuracies of the methods with variations in K numbers. Also it worth comparing the results with less number of training samples in the vicinity of a test sample.
5 Conclusion
The conventional grid-based RF fingerprinting positioning heavily depends on training phase data-processing and also the output result varies upon the chosen grid-cell size. In this study we have used GMDT data for outdoor UE positioning in urban area using cluster-based fingerprint positioning that does not go through a training phase data processing. Proposed CRFF method can provide improved positioning accuracy with less computational cost over traditional GRFF and KNN methods. CRFF continues to perform better than GRFF and KNN even when facing recording device variation and environmental changes. For lower MT value SOM performs similar to AHC method but it fails to analyze considerable amount of test samples and also it takes the longest execution time for positioning. With data-set having eleven RSS K-means and FCM based CRFF improves positioning accuracies and analyzes 99% test data. From this study it is found that using GMDT data consisting of seven RSS values AHC based CRFF has given best positioning accuracy taking shortest time as compared to other methods. Hence using GMDT data cellular operators can utilize AHC based RF fingerprinting to provide fast and acceptable results for outdoor UE positioning.
References
E. Kaplan, C. Hegarty, Understanding GPS: Principles and Applications. Artech House, Inc., 2005.
M. Anisetti, C. A. Ardagna, V. Bellandi, E. Damiani and S. Reale, Map-based location and tracking in multipath outdoor mobile networks, IEEE Transactions on Wireless Communications, Vol. 10, No. 3, pp. 814–824, 2011.
J. H. Kim, K. S. Min, W. Y. Yeo, A design of irregular grid map for large-scale Wi-Fi LAN fingerprint positioning systems, The Scientific World Journal, Vol. 2014, ID 203419, 2014.
X. Liu, S. Zhang, J. Quan, X. Lin, The experimental analysis of outdoor positioning system based on fingerprint approach. In 12th IEEE International Conference on Communication Technology (ICCT), pages 369–372, Nanjing, China, 2010.
M. Yousief, Horus: A WLAN-Based Indoor Location Determination system, in PhD thesis, University of Maryland, 2004.
A. Kushki, K. N. Plataniotis and A. N. Venetsanopoulos, Kernel-based positioning in wireless local area networks, IEEE Transactions on Mobile Computing, Vol. 6, No. 6, pp. 689–705, 2007.
Skyhook. In Global 1st Party Location Network. http://www.skyhookwireless.com/about-skyhook. Accessed 24 Dec 2016.
K. Li, P. Jiang, E. L. Bodanese and J. Bigham, Outdoor location estimation using received signal strength feedback, IEEE Communications Letters, Vol. 16, No. 7, pp. 978–981, 2012.
R. Singh, L. Macchi, C. S. Regazzoni, K. N. Plataniotis. A statistical modelling based location determination method using fusion technique in WLAN. In International Workshop on Wireless Ad-Hoc Networks, London, UK, 2005.
J. Talvitie. Algorithms and Methods for Received Signal Strength Based Wireless Localization, in PhD thesis, Tampere University of Technology, 2016.
J. Johansson, W. A. Hapsari, S. Kelley and G. Bodog, Minimization of drive tests in 3GPP release 11, IEEE Communications Magazine, Vol. 50, No. 11, pp. 36–43, 2012.
3GPP TR 36.805. Study on minimization of drive-tests in next generation networks. Accessed Dec 2009.
M. H. A. Meniem, A. M. Hamad, E. Shaaban. Relative RSS-based GSM localization technique. In IEEE International Conference on Electro/Information Technology (EIT), pages 1–6, South Dakota, USA, 2013.
T. Hiltunen, R. U. Mondal, J. Turkka, T. Ristaniemi. Generic architecture for minimizing drive tests in heterogeneous networks. In IEEE 82nd Vehicular Technology Conference (VTC Fall), pages 1–5, Boston, USA, 2015.
M. Bshara, U. Orguner, F. Gustafsson and L. V. Biesen, Fingerprinting localization in wireless networks based on received signal-strength measurements: a case study on WiMAX networks, IEEE Transactions on Vehicular Technology, Vol. 59, No. 1, pp. 283–294, 2010.
H. Liu, Y. Zhang, X. Su, X. Li, N. Xu, Mobile localization based on received signal strength and Pearson’s correlation coefficient, International Journal of Distributed Sensor Networks, Vol. 2015, ID. 157046, 2015.
T. Wigren, Adaptive enhanced cell-ID fingerprinting localization by clustering of precise position measurements, IEEE Transactions on Vehicular Technology, Vol. 56, No. 5, pp. 3199–3209, 2007.
M. Youssef, A. Agrawala, A. U. Shankar. WLAN location determination via clustering and probability distributions. 1st IEEE International Conference on Pervasive Computing and Communication (PerCom 2003), pages 143–150, Texas USA, 2003.
Y. Chen, Q. Yang, J. Yin and X. Chai, Power-efficient access-point selection for indoor location estimation, IEEE Transactions on Knowledge and Data Engineering, Vol. 18, No. 7, pp. 877–888, 2006.
E. Laitinen, E. S. Lohan, J. Talvitie, S. Shrestha. Access point significance measures in WLAN-based location. In 9th Workshop on Positioning Navigation and Communication (WPNC), pages 24–29, Dresden, Germany 2012.
P. Bahl and V. Padmanabhan, RADAR: An in-building RF-based user location and tracking System, IEEE INFOCOM, Vol. 2, pp. 775–784, 2000.
M. H. N. Hossain, Van, Y. Jin, W. S. Soh. Indoor localization using multiple wireless technologies. In IEEE MASS, Pisa, Italy, 2007.
M. B. Kjærgaard, C. V. Munk. Hyperbolic location fingerprinting: A calibration-free solution for handling differences in signal strength. In 6th Annual IEEE International Conference on Pervasive Computing and Communications (PerCom 2008), pages 110–116, Hong Kong, 2008.
3GPP TR 37.834, Study on WLAN/3GPP radio interworking. Vol. 1.0.0, 2013.
Nemo Handy: handheld drive test software, http://www.anite.com/businesses/network-testing/products/nemo-handy-world’s-most-widely-used-handheld-drive-test-tool#.Vc8_nPmqpBd. Accessed June 2016.
C. Feng, W. S. A. Au, S. Valaee and Z. Tan, Received-signalstrength-based indoor positioning using compressive sensing, IEEE Transactions on Mobile Computing, Vol. 11, No. 12, pp. 1983–1993, 2012.
I. J. Quader, B. Li, W. Peng, A. G. Dempster. Use of fingerprinting in Wi-Fi based outdoor positioning. In International Global Navigation Satellite Systems Society IGNSS Symposium, The University of New South Wales, Sydney, Australia, 2007.
F. Yu, M. Jiang, J. Liang, X. Qin, M. Hu, T. Peng, X. Hu, 5G WiFi signal-based indoor localization system using cluster k-nearest neighbor algorithm, International Journal of Distributed Sensor Networks, Vol. 2014, ID 247525, 2014.
P. Berkhin, Survey of Clustering Data Mining Techniques, Grouping Multidimensional DataSpringer, Berlin Heidelberg, 2006. pp. 25–71.
A. Razavi, M. Valkama, E. S. Lohan. K-Means fingerprint clustering for low-complexity floor estimation in indoor mobile localization. In IEEE GLOBCOM Workshop on Localization and Tracking: Indoors, Outdoors and Emerging Networks, Washington DC, USA, 2015.
A. Arya, P. Godlewski, M. Campedel and G. Che´ne´, Radio database compression for accurate energy-efficient localization in fingerprinting systems, IEEE Transactions on Knowledge and Data Engineering, Vol. 25, No. 6, pp. 1368–1379, 2013.
A. David, S. Vassilvitskii. K-means ++: The advantages of careful seeding. In 18 th Annual ACM-SIAM Symposium on Discrete Algorithms (SODA 2007), pages 1027–1035, Louisiana, United States, 2007.
A. C. Rencher, Methods of Multivariate Analysis. Wiley, Inc., 2002.
A. Arya, P. Godlewski, P. Melle. A hierarchical clustering technique for radio map compression in location fngerprinting systems. In International Conference on Vehicular Technology, pages 1–5, Taipei, China, 2010.
D. L. Davies, D. W. Bouldin, A cluster separation measure, IEEE Transactions on Pattern Analysis and Machine Intelligence, Vol. PAMI-1, No. 2, pp. 224–227, 1979.
H. Zhou, N. N. Van. Indoor fingerprint localization based on fuzzy C-means clustering. In 6th International Conference on Measuring Technology and Mechatronics Automation, pages 337–340, China, 2014.
D. J. Suroso, P. Cherntanomwong, P. Sooraksa, J. Takada. Location fingerprint technique using Fuzzy C-Means clustering algorithm for indoor localization. In IEEE TENCON, Indonesia, 2011.
J. C. Bezdec, Pattern Recognition with Fuzzy Objective Function Algorithms, Plenum PressNew York, 1981.
R. Xu, D. C. Wunsch II, Clustering, John Wiley and Sons, Inc., 2009.
O. A. Abbas, Comparisons between data clustering algorithms, The International Arab Journal of Information Technology, Vol. 5, No. 3, pp. 320–325, 2008.
X. Liu, S. Zhang, H. Lu, X. Lin. Method for efficiently constructing and updating radio map of fingerprint positioning. In IEEE GLOBCOM 2010 Workshop on Heterogeneous, Multi-hop Wireless and Mobile Networks, pages 74–78, Florida, USA, 2010.
M. Raitoharju, H. Nurminen, R. Piché, Kalman filter with a linear state model for PDR + WLAN positioning and its application to assisting a particle filter, EURASIP Journal on Advances in Signal Processing, 2015.
E. Ertin and K. Priddy. Self-localization of wireless sensor networks using self-organizing maps. In Proceedings of SPIE, 2005.
G. Giorgetti, S. K. S. Gupta, G. Manes. Wireless localization using self-organizing maps. In Proceedings of IPSN’07, pages 25–27, Massachusetts, USA, April 2007.
T. Mantoro, M. A. Ayu, A. Nuraini, S. M. Amin. Self-organizing map approach for determining mobile user location using IEEE 802.11 signals. In Proceeding of International Symposium on Information Technology (ITSim), Kuala Lumpur, Malaysia, 2010.
Acknowledgements
The authors would like to thank colleagues from University of Jyvaskyla and European Communications Engineering, Finland for their constructive criticism, comments and support.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article

Cite this article
Mondal, R.U., Ristaniemi, T. & Turkka, J. Cluster-Based RF Fingerprint Positioning Using LTE and WLAN Signal Strengths. Int J Wireless Inf Networks 24, 413–423 (2017). https://doi.org/10.1007/s10776-017-0369-9
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10776-017-0369-9