
Abstract
A noise-robust approach for blind multichannel identification is proposed on the basis of Kalman filter and eigenvalue decomposition. It is proved that the state vector composed of the multichannel impulse responses is nothing but the eigenvector corresponding to the maximum eigenvalue of the filtered state-error correlation matrix. This eigenvector can be computed iteratively with the so-called ‘power method’ to reduce the complexity of the algorithm. Furthermore, it is found that the computation of the inverse of the filtered state-error correlation matrix is much easier than itself, the wanted state vector can be computed from this inverse matrix with the so-called ‘inverse power method’. Therefore, two algorithms are proposed on the basis of the eigenvalue decomposition of the filtered state-error correlation matrix and its inverse matrix, respectively. In addition, for reducing the computing complexity of the proposed algorithms, matrix factorization such as QR-, LU- and Cholesky-factorizations are exploited to accelerate the computation of the algorithms. Simulations show that the proposed algorithms perform well over a wide range of the signal-to-noise ratio of the multichannel signals.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
Blind multichannel identification is needed in many applications, including channel equalization (Xu et al. 1995; Tong and Perreau 1998), the suppression of reverberation effects in audio processing (Mei et al. 2009; Mertins et al. 2010), Speech Source Localization and Tracking (Merks et al. 2013; Dey and Ashour 2018a, b). Furthermore, the multichannel parameters can even be used to estimate the environmental scale (Shabtai et al. 2010; Filos et al. 2010). Sometimes it is impossible or undesirable to measure the channel impulse responses with known input signals, the channel identification has to be carried out blindly, which means that the channel parameters are estimated by exploiting no other information than the received signals. In this field, one of the pioneers is Godard, who proposed a family of Constant Modulus blind equalization algorithms which are widely used in blind channel equalization in cases which the sources have constant envelope magnitudes (Godard 1980).
Usually, approaches for blind channel identification are classified into higher-order statistics (HOS) and second-order statistics (SOS) based algorithms (Haykin 1996). HOS-based algorithms exploit HOS implicitly (for example, Godard’s approach) or explicitly (for example, polyspectra-based algorithms). Some SOS-based approaches exploit the cyclostationarity of the channel input signal (Tong et al. 1994). With the cyclostationarity of channel input signals and the oversampling of channel output signals, a single-input single-output (SISO) system is equivalent to a single-input multi-output (SIMO) system.
For non-minimum phase and finite impulse response (FIR) SISO systems, second-order statistics have been proved to be insufficient for blind channel identification without further assumptions on the input signal. However, the situation is different for SIMO models. For such systems, second-order statistics are sufficient for the blind identification of the channels. The channel impulse responses (CIRs) of a SIMO system can be identified by subspace decomposition (Tong et al. 1994) or by exploiting the cross relations (CR) between the SIMO output signals (Xu et al. 1995). Based on Xu’s work (Xu et al. 1995) , both adaptive (Huang and Benesty 2002a, b, 2003) and non-adaptive CR-based approaches (Moulines et al. 1995; Avendano et al. 1999; Mayyala et al. 2017) have been proposed. Adaptive algorithms are more attractive because of their inherent ability to track time-varying channels.
To minimize the cost function of a given channel-identification algorithm, multichannel least-mean-squares (MCLMS) (Huang and Benesty 2002a, b) and normalized multichannel frequency-domain LMS (NMCFLMS) (Huang and Benesty 2003; Ahmad et al. 2015) algorithms may be used. Moreover, in order to improve the noise-robustness and the convergence stability, several revised NMCFLMS algorithms, such as the direct path constrained NMCFLMS (i.e., DP-NMCFLMS), the power and direct path constrained NMCFLMS algorithms (Hasan et al. 2010; Liao et al. 2010), the robust NMCFLMS (RNMCFLMS, Haque and Hasan 2008) and the \(\ell _p\)-NMCFLMS with \(\ell _p\)-norm constraint (He et al. 2018) have been proposed. However, the above mentioned LMS-like algorithms converge very slowly and are therefore not suitable for the identification of fast time-varying channels.
Kalman filter is often used for channel identification in communication signal processing, but as we know so far, none of them is an actually blind approach (Song et al. 2003; Chen and Zhang 2004; Al-Naffouri 2007; Zhang and Wei 2002; Park et al. 2012). The additional information of communication signal such as pilots, the cyclic prefix, and the finite alphabet is more or less exploited for channel identification.
A blind frequency-domain Kalman filter approach was proposed in (Malik et al. 2012) by using the cross-relations among channels, it is more stable than those LMS-like algorithms (Huang and Benesty 2002a, b), but the disadvantage is its slow converging property as the simulation results shown in their paper.
In reference (Qu et al. 2016), the authors have proposed a fast converging multichannel identification algorithm based on the cross relations among channels and Kalman filter in time-domain. By using a different state-space model from that used in (Malik et al. 2012), it was found that the state vector (i.e. the multichannel impulse responses) is iteratively computed in the same way as that of the filtered state-error correlation matrix, so the standard Kalman filter implementation is simplified. This simplified algorithm is computationally efficient, but it is noise-sensitive. It will not work well on noisy signals.
The presented algorithms are based on the simplified algorithm in (Qu et al. 2016). It is proved in this paper that the state vector composed of the CIRs is nothing but the eigenvector corresponding to the maximum eigenvalue of the filtered state-error correlation matrix, so eigenvalue decomposition is used to extract the eigenvector from the filtered state-error correlation matrix and its inverse matrix of Kalman filter. Enormous and intensive simulations prove that this will improve the noise-robustness of the channel estimation algorithm.
The rest of the paper is organized as follows. In Sect. 2, the multichannel identification problem and the cross relations among the channel observations are described concisely; Algorithms are developed in Sect. 3; Simulation results are given in Sect. 4. Finally, conclusions are presented in Sect. 5.
2 Problem formulation
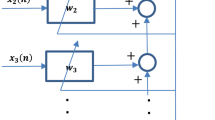
For the derivation of the algorithm, we consider a non-minimum phase time-invariant FIR SIMO system (the most common cases in practice). Let s(n) be the unknown input signal, and let \(h_i(n)\,(i=1,2,\ldots,N)\) be the N CIRs. The channel output signals, denoted by \(x_i(n)\)s, are then given by
where \(u_i(n)\) is the observation noise, and L denotes the length of the CIRs \(h_i(n)\). The task of blind multichannel identification is to estimate the impulse responses \(h_i(n)\)s from the observed signals \(x_i(n)\)s.
Whatever the multichannel impulse responses \(h_i(n)\)s are, if there is no observation noise (i.e., \(u_i(n)=0\)), the cross-relation between any pair of output signals holds as follows:
where ‘\(*\)’ is the convolution operator. In practice, the noise is always present, so that the cross relations must be reformulated as
With the abbreviation \(\theta _{ij}(n)=u_i(n)*h_j(n)-u_j(n)*h_i(n)\) for the noise-related term, Eq. (3) can be rewritten in the form
It is proved (Xu et al. 1995) that if the channel impulse responses \(h_i(n)(i=1,2,...,N)\) are coprime in z-domain (i.e., if their z-transforms do not share common zeros), blind multichannel identification is possible on the basis of the cross-relations among the outputs of different channels.
3 Algorithm development
In this section, we derive the Kalman-filter based algorithms. For this purpose, the multichannel identification problem is first expressed in state-space with process equation and measurement equation.
3.1 Simplified Kalman filter
Referring to (Qu et al. 2016), let \({\mathbf {h}}_i=[h_i(0),h_i(1),\ldots,h_i(L-1)]^\mathrm {T}\). The required state vector is defined as \({\mathbf {h}}=[{\mathbf {h}}_1^\mathrm {T},{\mathbf {h}}_2^\mathrm {T},\ldots,{\mathbf {h}}_N^\mathrm {T}]^{T}\). With this definition, the process equation is expressed mathematically as
where \({\mathbf {F}}(n+1,n)={\mathbf {I}}\) (\({\mathbf {I}}\) is an LN-by-LN identity matrix) is the state transition matrix (it is reasonable for slow-changing system.). The vector \({\mathbf {v}}_1(n)\) represents the process noise, which is modeled as a zero-mean, white-noise process with correlation matrix
where \(\mathrm {E}[\cdot ]\) is the ensemble average operator.
For the construction of the measurement equation, the cross-relation equations in (4) are rewritten in matrix form as
where the \([{N(N-1)}/{2}]\)-by-LN matrix sequence \({\mathbf {C}}(n)\) is defined in Eq. (8).
with \({\mathbf {x}}_i(n)=[x_i(n),x_i(n-1),\ldots,x_i(n-L+1)]\). The \([{N(N-1)}/{2}]\)-by-1 vector \({\mathbf {v}}_2(n)\) is given by \({\mathbf {v}}_2(n)=[\theta _{12}(n),\ldots,\theta _{1N}(n), \theta _{23}(n),\ldots,\theta _{2N}(n),\ldots,\theta _{N-1,N}(n)]^\mathrm {T}\). \({\mathbf {v}}_2(n)\) is approximately white noise vector series because the passband of a room is generally wide enough for audio signals.
According to the cross-relation equation (7), the measurement equation can be defined in state-space as
where \({\mathbf {C}}(n)\) and \({\mathbf {v}}_2(n)\) are called the measurement matrix and measurement noise process, respectively. The measurement noise process \({\mathbf {v}}_2(n)\) meets approximatively the requirements by Kalman filter theory, i.e. it is approximatively a zero-mean and temporally white noise process with correlation matrix (this holds if only the frequency band of the room is not too narrow!):
The vector \({\mathbf {y}}(n)\) in Eq. (9) is called the observation vector. How to define the observation vector \({\mathbf {y}}(n)\) is the key to solve our problem. According to the cross-relation equation (7) and the definition of the measurement matrix (8), it is straightforward to find that
where \({\mathbf {0}}\) is a zero vector of dimension \(\left(\frac{1}{2}N(N-1)\times 1\right)\). Such an observation vector allows us to simplify the computation of the Kalman filter (see Table 1).
In addition, for multichannel identification, we assume further that the process noise vector satisfies \({\mathbf {v}}_1(n) ={\mathbf {0}}\) (the process equation is free of an external force!), this leads the standard Kalman filter problem (Eqs. 5 and 9) to the so-called unforced dynamical model (Haykin 1996; Sayed and Kailath 1994):
where the observation vector is \({\mathbf {y}}(n)={\mathbf {0}}\).
According to the definitions of the process equation (12) and the measurement equation (13), \({\mathbf {F}}(n+1,n)={\mathbf {I}}\) and \({\mathbf {Q}}_1(n)={\mathbf {0}}\), so the predicted state-error correlation matrix \({\mathbf {K}}(n+1,n)\) is equal to the filtered state-error correlation matrix \({\mathbf {K}}(n)\):
so the Kalman gain \({\mathbf {G}}(n)\) can be computed as follows (see Haykin 1996, pp. 318–321),
Accordingly, the predicted estimate \(\widehat{{\mathbf {h}}}(n+1)\) of the state vector is shown in the following equation by taking Eq. (11) into account,
and the filtered state-error correlation matrix is estimated as,
From Eqs. (16) and (17), we find that the predicted estimate of the state vector \(\widehat{{\mathbf {h}}}(n+1)\) is iteratively computed in the same way of the filtered state-error correlation matrix \({\mathbf {K}}(n)\) except for the fact that \(\widehat{{\mathbf {h}}}(n+1)\) is a vector whereas \({\mathbf {K}}(n)\) is a symmetric matrix. This reminds us that \(\widehat{{\mathbf {h}}}(n+1)\) and the column vectors of \({\mathbf {K}}(n)\) will converge to the same vector if they share a common initial non-zero vector. So \(\widehat{{\mathbf {h}}}(n+1)\) is not necessarily computed in each iteration, it can be extracted directly from \({\mathbf {K}}(n)\).
This simplified Kalman filter algorithm is summarized in Table 1. Comparing with the standard Kalman filter (Haykin 1996), the computation efficiency is increased, however, because of the existence of observation noise, this algorithm is not as noise-robust as what we expect, the estimated \(\widehat{{\mathbf {h}}}(n)\) will become less and less accurate with the increasing of observation noise. From formula (16) it is easy to find that \(\widehat{{\mathbf {h}}}(n)\) is affected directly by the observation noises because matrix \({\mathbf {C}}(n)\) is composed of observed signals.
3.2 Improving the noise-robustness with eigenvalue decomposition
Although the simplified kalman filter algorithm in Table 1 is noise-robust in some degree if the matrix \({\mathbf {Q}}_2(n)\) is properly initialized. its performance will decrease with the increasing of noise level of the observed multichannel outputs. For improving the noise-robustness, we proposed the following scheme by introducing eigenvalue decomposition to the simplified kalman filter.
3.2.1 \(\widehat{{\mathbf {h}}}(n+1)\) and the eigenvector of \({\mathbf {K}}(n)\)
Let us consider the correlation matrix of the innovation process, so we can find the relations among the estimated state vector \(\widehat{{\mathbf {h}}}(n)\), the filtered state-error correlation matrix \({\mathbf {K}}(n)\) and the correlation matrix of the observation noise \({\mathbf {Q}}_2(n)\).
From the process and measurement equations (12) and (13) and taking Eq. (11) into account, on one hand, the innovation process \({\mathbf {a}}(n)\) is shown as,
where \({\widehat{\mathbf{y}}}(n)={\mathbf {C}}(n){\widehat{\mathbf{h}}}(n)\) is the one-step prediction of \({\mathbf {y}}(n)\), \({\widehat{\mathbf{h}}}(n)\) is the one-step predicted state vector at time n from the first \(n-1\) observations; on the other hand, it can also be expressed with the predicted state-error vector \({\mathbf {e}}(n,n-1)={\mathbf {h}}(n)-{\widehat{\mathbf{h}}}(n)\) as follow (to refer to Haykin 1996),
So the correlation matrix of \({\mathbf {a}}(n)\) is given in two different forms. Firstly, according to Eq. (18), we have:
where \({\mathbf {R}}_{\widehat{\mathbf{h}}}(n)=\mathrm {E}[{\widehat{\mathbf{h}}}(n){\widehat{\mathbf{h}}}^\mathrm {T}(n)]\); Secondly, according to Eq. (19), we have:
where the predicted state-error correlation matrix \({\mathbf {K}}(n,n-1)=\mathrm {E}[{\mathbf {e}}(n,n-1){\mathbf {e}}^\mathrm {T}(n,n-1)]\).
Let \({\mathbf {Q}}_2(n)={\mathbf {C}}(n){\mathbf {A}}(n){\mathbf {C}}^\mathrm {T}(n)\) (where \({\mathbf {A}}(n)\) is an observation noise-related symmetric matrix. Such a decomposition of \({\mathbf {Q}}_2(n)\) is not unique!), then Eq. (21) is rewritten as follows:
Comparing Eqs. (20) with (22), furthermore, taking into account the fact that \({\mathbf {C}}(n)\) is composed of the randomly time-changing observed signals \(x_i(n)\), so the following equation will hold:
For a determined system, \({\mathbf {R}}_{\widehat{\mathbf{h}}}(n)=\widehat{{\mathbf {h}}}(n)\widehat{{\mathbf {h}}}^\mathrm {T}(n)\) after the convergence of the algorithm, so we get from Eq. (23) for time n that:
To suppose that \({\mathbf {A}}(n+1)=\gamma {\mathbf {I}}\) (for the case \(N=2\)), it is easy to prove that \({\mathbf {K}}(n)\) has only two different nonzero eigenvalues \(\lambda _i(i=1,2)\): one is \(\lambda _1=-\gamma\), the other one is \(\lambda _2=-\gamma +\widehat{{\mathbf {h}}}^\mathrm {T}(n+1)\widehat{{\mathbf {h}}}(n+1)\) and obviously \(\lambda _2\ge \lambda _1\). The eigenvector corresponding to \(\lambda _2\) is \(\widehat{{\mathbf {h}}}(n+1)/\Vert \widehat{{\mathbf {h}}}(n+1)\Vert\). In other words, it means that the eigenvector corresponding to the bigger eigenvalue of the matrix \({\mathbf {K}}(n)\) is the true solution of \(\widehat{{\mathbf {h}}}(n+1)\) in spite of the normalization.
Generally, \({\mathbf {A}}(n+1)=\gamma {\mathbf {I}}\) does not hold and the number of the different nonzero eigenvalues of matrix \({\mathbf {K}}(n)\) is bigger than 2, but it is reasonable to deduce that the eigenvector of matrix \({\mathbf {K}}(n)\) associated with its maximum eigenvalue is a better, or in other words, a more noise-robust estimate of \(\widehat{{\mathbf {h}}}(n+1)\) than the first column of \({\mathbf {K}}(n)\) as that in the simplified Kalman filter algorithm (Table 1). This means that it is a more noise robust solution for the multichannel estimation.
3.2.2 \(\widehat{{\mathbf {h}}}(n+1)\) and the eigenvector of \({\mathbf {K}}^{-1}(n)\)
Now we will look at the problem from a different point of view.
Let us consider to emerge the computations of \({\mathbf {G}}(n)\) and \({\mathbf {K}}(n)\) in one step. Referring to (Haykin 1996), we reformulate (15) as follow:
from Eq. (17), we get
furthermore, let \({\mathbf {Q}}_2(n)=\sigma ^2{\mathbf {I}}\) and substitute the right-side of Eq. (26) into the left-side of Eq. (25), then we get the following equation:
Now eliminating \({\mathbf {G}}(n)\) between Eqs. (26) and (27), we get
The above Eq. (28) shows that the filtered state-error correlation matrix \({\mathbf {K}}(n)\) will be computed iteratively from the measurement matrix \({\mathbf {C}}(n)\).
The inverse form of Eq. (28) is as follow:
It is well known that a positive-definite symmetric matrix shares the same eigenvectors with its inverse matrix, but their eigenvalues are reciprocals. This means that the maximum eigenvalue-associated eigenvector of matrix \({\mathbf {K}}(n)\), which is the solution state vector \(\widehat{{\mathbf {h}}}(n+1)\) we wanted, is the minimum eigenvalue-associated eigenvector of matrix \({\mathbf {K}}^{-1}(n)\).
It is proven that \(\widehat{{\mathbf {h}}}(n)\) is the minimum eigenvalue-associated eigenvector of matrix \(\mathrm {E}[{\mathbf {C}}^\mathrm {T}(n){\mathbf {C}}(n)]\) (Avendano et al. 1999). \(\mathrm {E}[{\mathbf {C}}^\mathrm {T}(n){\mathbf {C}}(n)]\) is usually estimated recursively with
where \(\beta\) is a constant number, \(\lambda (0<\lambda <1)\) is the forgetting factor. Comparing (29) with (30), formula (29) is the extreme case for \(\lambda =1\) in (30). The noise-robustness is at the cost of time-tracking ability. In addition, for stability concerns, the formula (29) should be revised in practice as
where \(\gamma\) is smaller than but close to 1.
Therefore, It is clear now that the noise-robust CIRs estimation can be done following two different schemes:
The first scheme is composed of the computation of the matrix \({\mathbf {K}}(n)\) with formula (28) (the combination of formulae (15) and (17) as that in Table 1) and the estimation of the eigenvector associated with the maximum eigenvalue of the matrix \({\mathbf {K}}(n)\).
The second scheme is composed of the computation of the matrix \({\mathbf {K}}^{-1}(n)\) with formula (29) and the estimation of the eigenvector associated with the minimum eigenvalue of the matrix \({\mathbf {K}}^{-1}(n)\).
3.3 The novel algorithms based on eigenvector computation
Based on the simplified Kalman filter algorithm in Table 1, the two schemes mentioned above are implemented differently.
For the first scheme, the maximum eigenvalue-associated eigenvector of \({\mathbf {K}}(n)\) is iteratively estimated with the so-called “power method”; Similarly, the minimum eigenvalue-associated eigenvector of \({\mathbf {K}}^{-1}(n)\) is iteratively estimated with the so-called “inverse power method”. These two eigenvectors estimated with “power method” and “inverse power method” are the same eigenvector which is nothing but the noise-robust solution we wanted.
Power method and inverse power method are often used for the estimation of the eigenvector associated with the maximun and the minimum eigenvalues, respectively. The procedures are as in Tables 2 and 3.
After good enough iterations of the algorithm, \({\mathbf {u}}_{i+1}\) will converge to the eigenvector associated with the maximun/minimum eigenvalue of matrix \({\mathbf {A}}\).
It is found in simulation that the value of \(\sigma ^2\) in \({\mathbf {Q}}_2(n)\) has great influence on the convergence behavior of the novel algorithms. Although the smaller the value of \(\sigma ^2\) is, the better the convergence behavior is, the algorithm will become unstable at the initial period of the iteration if the value of \(\sigma ^2\) is too small, so we define a time-changing \(\sigma ^2\):
where n is the iteration index; \(\sigma ^2_0=10^{-5}\).
In practice, the iteration of the power method (inverse power method) is emerged into the iteration of the Kalman filtering for the sake of computation efficiency. The novel algorithms are summarized in Tables 4 and 5.
The algorithms presented in Tables 4 and 5 are not only computationally as efficient as that in Table 1, but also the most important is that it is more noise-robust than the simplified Kalman filter algorithm in Table 1.
For improving the computation efficiency, the computation of \({\mathbf {K}}(n)\) in Table 4 can be accelerated by introducing matrix factorization such as LU or QR factorization. The second step of the computation stage in Table 4 can be replaced with the computation steps in Table 6. Cholesky Factorization does not work because the matrix \({\mathbf {A}}\) in Table 6 is not guaranteed positive definite in practice.
The inverse power method in the second algorithm in Table 5 can be accelerated in a similar way [for the estimation of the minimum eigenvalue associated eigenvector of matrix \({\mathbf {K}}^{-1}(n)\)]. Cholesky factorization is the best choice for it because of the least computing complexity and the guaranteed positive definite property of matrix \({\mathbf {K}}^{-1}(n)\).
Computation complexity estimation: as the algorithm in Table 4 concerned, it mainly involves one \((LN\times LN)\) matrixes production and one \((LN\times LN)\) matrix inverse computation, so its computation complexity is approximately \(O(2(LN)^3)\); the algorithm in Table 5 mainly involves only one \((LN\times LN)\) matrix inverse computation (if \(N_{pm}=1\)), so its computation complexity is \(O((LN)^3)\), approximately half of the algorithm in Table 4.
The novel algorithms can be implemented in block way by redefining the vector \({\mathbf {x}}_i(n)\) in Eq. (8) as a Hankel matrix. We suppose that the block size is B, this means that B samples are updated in each iteration of the algorithm, therefore, the Hankel matrix is defined during the mth iteration,
where \({\mathbf {x}}_i(m)\) is a B-by-L Hankel matrix. The measurement matrix \({\mathbf {C}}(n)\) is now \(B[{N(N-1)}/{2}]\)-by-LN in dimension.
4 Simulation results
Generally, three factors, that is, the SNR of the observed channel output signals, the CIRs’ properties (including the length,the distribution of the zero points in Z-domain) and the types of source signals, have great influence on the convergence behavior of a blind multichannel identification algorithm. As the simulations concerned, three typical types of source signals are considered, they are binary valued random time series, stationary white noise of an uniform probability distribution in the interval \([-1,1]\) and speech signals. Intensive simulations show that there is no difference between binary valued random time series and stationary white noise, the proposed algorithm works well for both of them. The proposed algorithm is essentially based on second-order statistical or spectral property of the source signals. Because of the spectral non-whiteness of speech signals, the proposed algorithm does not work for speech signals as well as for the other two type of signals.
In addition, real word recorded speeches in Laboratory are also available for testing our algorithm. All of the simulation results of the proposed algoritm are compared with those of the NMCFLMS algorithm.
For evaluating the CIR’s estimation accuracy and showing the convergence properties, the normalized projection misalignment (NPM) (Hasan et al. 2010)
was computed during the iteration process, where, n is the iteration index, \({\mathbf {h}}_i(n)\) and \(\widehat{{\mathbf {h}}}_i(n)\) (\(i=1,2,\ldots,N\)) are the true and estimated CIRs, respectively. For normalized \({\mathbf {h}}_i\) and \(\widehat{{\mathbf {h}}}_i(n)\), formula (34) is simplified as,
where \(r_i(n)={\mathbf {h}}^\mathrm {T}_i(n)\widehat{{\mathbf {h}}}_i(n)\).
The total NPM is defined as
where \(r(n)={\mathbf {h}}^\mathrm {T}(n)\widehat{{\mathbf {h}}}(n)\), \({\mathbf {h}}(n)\) and \(\widehat{{\mathbf {h}}}(n)\) are the normalized known state vector and the estimated state vector, respectively. The smaller the NPM value is, the better the performance of the algorithm is.
The two algorithms have similar converging behavior, but algorithm II is computationally more efficient, so all of the simulations are done with it.
4.1 Convergence behavior against source signals
The above mentioned three types of signals are exploited for the convergence behavior exploration of the proposed algorithm. Randomly generated CIRs are used in simulations.
The first simulation is as follows.
Three randomly generated CIRs (channel number N=3) of a length of \(L=25\) are convolved with the source signals to produce the observed signals. The signal-to-noise ratio (SNR) of these observed signals are set to be 80 dB. For comparison purpose, the same CIRs are applied to the three types of source signals. The convergence behaviors of the proposed algorithm are shown in Fig. 1. The parameters used in this simulation are as follows: block size: \(B=20\) (see formula 33); \(\delta =10^{-7}\); \(\sigma _0^2=10^{-5}\); the iteration times of the power method: \(N_{pm}=1\).

Convergence behavior comparison: the convergence behaviors are different for the same channels but different sources: SNR = 80 dB; length of CIR L = 25; channel number N = 3; block size B = 20
Secondly, for intensively estimating the converging stability of the proposed algorithm, 50 Monte Carlo simulations were performed for the given three types of source signals: speech, binary time series and uniformly distributed white noise. 50 groups of CIRs of three channels (of a length of 25) are generated randomly, the CIRs are convolved with the source signals respectively to generate the observed signals for blind channel estimation with the proposed algorithm. The SNRs of the observed signals are set to be 60dB. The other parameters are the same as that in the first simulation. Simulation results are presented in Fig. 2. The averaged converging curves of the total NPM for the three types of sources prove that the proposed algorithm performs stably for different type of source signals. In Fig. 3, the 50 converging total NPM curves show that the convergence property of the proposed algorithm is quite consistent for randomly generated CIRs of the same length. In contrary, the convergence of the NMCFLMS algorithm depends closely on the CIRs, it works sometimes well, but at other time it works badly.

Convergence behavior comparison: the averaged convergence behavior of 50 Monte Carlo simulations: SNR = 60 dB; length of CIR L = 25; channel number N = 3; block size B = 20

Convergence behavior: The 50 Monte Carlo simulations show that the proposed algorithm works quite stable. SNR = 60 dB; length of CIR L = 25; channel number N = 3; block size B = 20
4.2 Performance against the length of CIRs
If the observed signals are of high SNRs, the performance of the proposed algorithm hardly depends on the length of the CIRs (see Fig. 4) as what the NMCFLMS algorithm does (see Fig. 5). The total NPM increases slowly with the increase of the length of the channel impulse response. This abstractive property is especially useful for long CIRs identification such as the situations we have to face in audio processing. Furthermore, for the situation of over-estimation of the length of CIRs, such property will ensure that the proposed algorithm does not work too bad.

Performance against the length of CIRs: The performance f the proposed algorithm is good when the length of CIRs change from 25 to 325 (SNR = 20, 40, 60 dB; channel number N = 3)

Performance against the length of CIRs: The performance f the NMCFLMS algorithm is not as good as that of our proposed algorithm when the length of CIRs change from 25 to 325 (SNR = 20, 40, 60 dB; channel number N = 3)
4.3 Noise-robustness
Blind multichannel identification algorithms are usually very sensitive to observation noises, many of them work well for only high-SNR observed signals. The noise-robustness of the proposed algorithm was investigated comparing with NMCFLMS algorithm in Monte Carlo way.
For each of the three type of sources, 50 groups of CIRs of three channels (of a length of 25) are generated randomly, the CIRs are convolved with the source signal to generate the noisy observed signals of a given level of SNR. For a given group of CIRs, it will be estimated from the noisy observed signals (of a given SNR) with both of the proposed and NMCFLMS algorithms, respectively. The averaged NPM of the last 100 iterations is computed after the convergence of the algorithms. In such a way, we get two NPM-via-SNR curves with the two algorithms for each group of CIRs. For all of the 50 groups of CIRs, The averaged NPM-via-SNR curves are shown in Figs. 6, 7 and 8 for the three types of source sigals.
These simulation results show clearly that the proposed algorithm works much more noise-robust than NMCFLMS in a wide range of SNR \((20-80\,\text {dB})\). Although both of the two algorithms do not work in the case of speech as well as the cases of binary series or uniformly distributed white noise, the proposed algorithm outperforms NMCFLMS algorithm well.

The averaged NPM against the SNR of the observed signals: speech

The averaged NPM against the SNR of the observed signals: binary series

The averaged NPM against the SNR of the observed signals: uniformly distributed white noise
4.4 Real world recordings
The observed signals are recorded in a quiet laboratory room of dimension (10m-by-5m-by-3m). Three microphones are placed at 1 m, 2 m and 3 m from a loudspeaker respectively to record the played speech signal. The microphones are placed in the front area of the loudspeaker so as to reduce the loudspeaker’s influence on CIRs. Real world noise is usually not ideally white, it has great influence on the performance of the algorithm. The source signal is a piece of 4 s long speech, it is played repeatedly. The sampling frequency is 8000 Hz, recording period is 12 s.
Firstly, The LMS algorithm is used for the CIRs identification with the known source signal and the three recorded microphone signals. The learning step used for LMS algorithm is set to be as small as possible to warrant the estimation of the CIRs as accurate as possible.
Theoretically, the residual signal will be zero after the LMS converges to its true solution if there is no noise in the microphone signals. In fact, noise is always there, the only difference is that the noise is strong or weak. The SNRs estimated from the residual signals of the LMS algorithm are about 30dB for this real world recorded signals.
The CIRs estimated with LMS and the proposed algorithms are both shown in Figs. 9, 10 and 11. The length of the CIRs is 2048, equivalently, the impulse response period is 256 ms.
The total NPM between the CIRs estimated with LMS and the proposed algorithms is shown in Fig. 12. In addition, the total NPM between the CIRs estimated with LMS and the NMCFLMS algorithms is shown in the same Figure too.
These results show that the proposed algorithm works effectively, although not perfectly, on such a case. Comparing with the NMCFLMS algorithm, the new method is obviously better.

The estimated impluse response of a Lab room: channel 1. Top panel: LMS; bottom panel: the proposed algorithm

The estimated impluse response of a Lab room: channel 2. Top panel: LMS; bottom panel: the proposed algorithm

The estimated impluse response of a Lab room: channel 3. Top panel: LMS; bottom panel: the proposed algorithm

The total NPM of three channels in a Lab room
5 Conclusions
Based on Kalman filter theory, it is proved that the multichannel impulse responses are contained in the eigenvector which is associated with the maximum eigenvalue of the filtered state-error correlation matrix of the Kalman filter. The combination of Kalman filter and eigenvalue decomposition results in a noise-robust algorithm for blind multichannel identification. Simulations and laboratory experiments show that the proposed algorithm works well over a wide range of SNR of the observed signals. our future work will focus on combining Kalman filter theory and active learning techniques to improve the robustness of multichannel identification (Bouguelia et al. 2018).
References
Ahmad, R., Khong, A. W., Hasan, M. K., Naylor, P. A. (2015). An extended normalized multichannel FLMS algorithm for blind channel identification. In Signal Processing Conference, 2006, IEEE, European, pp. 1–5.
Al-Naffouri, T. Y. (2007). An em-based forward-backward kalman filter for the estimation of time-variant channels in ofdm. IEEE Transactions on Signal Processing, 55(7), 3924–3930.
Avendano, C., Benesty, J., & Morgan, D. R. (1999). A least squares component normalization approach to blind channel identification. In IEEE International Conference on Acoustics, Speech, and Signal Processing, Proceedings, Vol. 4, pp. 1797–1800.
Bouguelia, M. R., Nowaczyk, S., Santosh, K. C., & Verikas, A. (2018). Agreeing to disagree: Active learning with noisy labels without crowdsourcing. International Journal of Machine Learning and Cybernetics, 9(8), 1307–1319.
Chen, W., Zhang, R. (2004). Kalman-filter channel estimator for OFDM system in time and frequency-selective fading envroment. In Proceedings of ICASSP, IV, pp. 377–380.
Dey, N., Ashour, A. S. (2018a). Applied examples and applications of localization and tracking problem of multiple speech sources. In Direction of Arrival Estimation and Localization of Multi-speech Sources, pp. 35–48. Cham: Springer.
Dey, N., Ashour, A. S. (2018b). Challenges and Future Perspectives in speech-sources direction of arrival estimation and localization. In Direction of Arrival Estimation and Localization of Multi-speech Sources, pp. 49–52. Cham: Springer.
Filos, J., Habets, E., Naylor, P. A. (2010). A two-step approach to blindly infer room geometries. In Proceedings of International Workshop on Acoustic Echo and Noise Control, IWAENC 2010.
Godard, D. N. (1980). Self-recovering equalization and carrier tracking in two-dimensional data communication systems. IEEE Transactions on Communications, 28(11), 1867–1875.
Haque, M. A., & Hasan, M. K. (2008). Noise robust multichannel frequencydomain LMS algorithms for blind channel identification. IEEE Signal Processing Letters, 15, 305–308.
Hasan, M. K., Benesty, J., Naylor, P. A., Ward, D. B. (2010). Improving robustness of blind adaptive multichannel identification algorithms using constraints. In Signal Processing Conference, 2010, IEEE, European, pp. 1–4.
Haykin, S. (1996). Adaptive filter theory (3rd ed.). Upper Saddle River: Prentice-Hall.
He H., Chen J., Benesty J., Yang T. (2018). Noise robust frequency-domain adaptive blind multichannel identification With \(\ell _p\)-Norm constraint. IEEE/ACM Transactions on Audio, Speech, and Language Processing. https://doi.org/10.1109/TASLP.2018.2835729.
Huang, Y., & Benesty, J. (2003). A class of frequency-domain adaptive approaches to blind multichannel identification. IEEE Transactions on Signal Processing, 51(1), 11–24.
Huang, Y., & Benesty, J. (2002a). Adaptive multi-channel least mean square and Newton algorithms for blind channel identification. Signal Processing, 82, 1127–1138.
Huang, Y., Benesty, J. (2002b). Adaptive blind channel identification: Multi-channel and least mean square and Newton algorithms. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing.
Liao, L., Khong, A. W. H., Liao, L. (2010). A noise robust multichannel algorithm for blind estimation of room impulse responses. In Proceedings of the 12th International Workshop on Acoustic Echo and Noise Control, IWAENC 2010.
Malik, S., Schmid, D., & Enzner, G. (2012). A state-space cross-relation approach to adaptive blind simo system identification. IEEE Signal Processing Letters, 19(8), 511–514.
Mayyala, Q., Abed-Meraim, K., & Zerguine, A. (2017). Structure-based subspace method for multichannel blind system identification. IEEE Signal Processing Letters, 24(8), 1183–1187.
Mei, T., Mertins, A., Kallinger, M. (2009). Room impulse response shortening with infinity-norm optimization. In Proceedings of the IEEE International Conference on Acoustics Speech and Signal Processing, pp. 3745–3748.
Merks, I., Enzner, G., Zhang, T. (2013). Sound source localization with binaural hearing aids using adaptive blind channel identification. In IEEE International Conference on Acoustics, Speech and Signal Processing, pp. 438–442.
Mertins, A., Mei, T., & Kallinger, M. (2010). Room impulse response shortening/reshaping with infinity- and \(p\)-norm optimization. IEEE Transactions on Audio, Speech, and Language Processing, 18(2), 249–259.
Moulines, E., Duhamel, P., Cardoso, J. F., & Mayrargue, S. (1995). Subspace methods for the blind identification of multichannel FIR filters. IEEE Transactions on Signal Processing, 43(2), 516–525.
Park, J., Ha, Y., & Chung, W. (2012). Kalman filtering based adaptive frequency domain channel estimation with low pilot overhead for ofdm systems. International Journal of Control and Automation, 5, 107–114.
Qu, W., Mei, T., Hu, Y., Mertins, A. (2016). Blind Identification of Multichannels with Kalman Filter. International Forum on Mechanical, Control and Automation (IFMCA 2016, Senzhen Chian), Open access: http://creativecommons.org/licenses/by-nc/4.0/. Published by Atlantis Press.
Sayed, A. H., & Kailath, T. (1994). A state-space approach to adaptive RLS filtering. IEEE Signal Processing Magazine, 11, 18–60.
Shabtai, N., Rafaely, B., Zigel, Y. (2010). Room volume classification from reverberant speech. In Proceedings of International Workshop on Acoustic Echo and Noise Control (IWAENC2010).
Song, K. J., Hong, S. K., Jung, S. Y., Park, D. J. (2003). Novel channel estimation algorithm using Kalman filter for DS-CDMA Rayleigh fading channel. In IEEE International Conference on Acoustics, Speech, and Signal Processing, Vol. 4, IV-429-32.
Tong, L., & Perreau, S. (1998). Multichannel blind identification: From subspace to maximum likelihood methods. Proceedings of the IEEE, 86(10), 1951–1968.
Tong, L., Xu, G., & Kailath, T. (1994). Blind identification and equalization based on second-order statistics: A time domain approach. IEEE Transactions on Information Theory, 40(2), 340–348.
Xu, G., Liu, H., Tong, L., & Kailath, T. (1995). A least-square approach to blind channel identification. IEEE Transactions on Signal Processing, 43(12), 2982–2992.
Zhang, X. D., & Wei, W. (2002). Blind adaptive multiuser detection based on kalman filtering. IEEE Transactions on Signal Processing, 50(1), 87–95.
Funding
The work is supported by Liaoning Educational committee (LG201601), China.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article

Cite this article
Mei, T. Blind multichannel identification based on Kalman filter and eigenvalue decomposition. Int J Speech Technol 22, 1–11 (2019). https://doi.org/10.1007/s10772-018-09562-w
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10772-018-09562-w